Lorawan-stack: Intégration de base de la station: la condition de concurrence dans la gestion de la reconnexion provoque une défaillance permanente du transfert de liaison montante
Résumé
Le protocole de la station de base est basé sur TCP. Parfois, il peut arriver que le client abandonne cette connexion sans exécuter une séquence de fermeture de connexion TCP propre. Cela peut se produire si la connectivité liaison / couche réseau disparaît soudainement et entraîne la réinitialisation et une nouvelle tentative de la couche TCP (par exemple, une passerelle passe de la liaison Ethernet à la liaison 3G car Ethernet a disparu; ou la passerelle voit un cycle d'alimentation inattendu et démarre rapidement - un scénario de débranchement / plugin courant pour TTIG). Si la station de base établit une nouvelle connexion dans un certain délai après le transfert de la dernière liaison montante de l'ancienne connexion, le LNS arrête définitivement le traitement des liaisons montantes de cette passerelle. Il semble que ce délai d'attente soit d'environ 60 secondes. Compte tenu des symptômes et du fait que cela ne se produit pas sur la pile v3, il semble que ce problème soit lié à # 1729.
Cette question a également été abordée dans les forums TTN
Étapes à suivre pour reproduire
- Pour simuler une terminaison de connexion TCP impure, introduisez une règle iptables qui bloque les paquets TCP FIN:
iptables -A OUTPUT -d 52.169.76.203 --protocol tcp --tcp-flags FIN FIN -j DROP - Démarrez Basic sur la machine sur laquelle la règle iptables est active. Assurez-vous que vous êtes dans un environnement de liaisons montantes régulières (toutes les 10 secondes environ). Observez
https://console.thethingsnetwork.org/gateways/<GATEWAYID>/trafficpour le trafic entrant. - Après quelques liaisons montantes, arrêtez le processus de la station avec CTRL + C (le serveur verra une terminaison TCP impure, à cause du paquet FIN manquant). Définissons l'heure
Tcomme l'heure à laquelle le dernier message de liaison montante a été transmis avant que le processus de la station ne soit tué. - Peu de temps après, redémarrez le processus de la station (la station de base se connectera et transmettra les liaisons montantes).
- Au temps
T + 60 s, la condition d'erreur se déclenche.
Que voyez-vous maintenant?
La condition d'erreur: La console de passerelle https://console.thethingsnetwork.org/gateways/<GATEWAYID>/traffic cessera d'afficher les liaisons montantes pendant que la connexion entre Basic Station et le serveur est maintenue active (les messages TCP keep alive sont échangés) et que Basic Station continue de recevoir des liaisons montantes. Une capture de paquets TCP / IP montre que les liaisons montantes sont effectivement transférées sur le websocket et que les paquets TCP sont reconnus par le serveur - c'est-à-dire que le serveur reçoit définitivement les messages de liaison montante mais ne les affiche pas dans la console de passerelle.
Que voulez-vous voir à la place?
Les messages de liaison montante doivent continuer à être traités par le LNS.
Environnement
Basic Station (dernière version), réseau communautaire TTN.
(Sur la pile v3, cela ne se produit pas - d'où le soupçon que cela a quelque chose à voir avec l'heuristique de terminaison de connexion inactive).
Comment proposez-vous de mettre en œuvre cela?
C'est difficile à juger sans avoir accès au code. D'après les symptômes, il semble que ce problème soit lié à l'heuristique de terminaison de connexion inactive, comme indiqué dans le numéro 1729. Le serveur voit probablement deux connexions car une nouvelle connexion est établie avant que l'ancienne ne soit correctement fermée. Peut-être que l'heuristique de terminaison de connexion détecte une connexion inactive sur la connexion «morte» et détruit le contexte lié à la passerelle sans considérer qu'une deuxième connexion nécessite ce contexte pour transmettre les liaisons montantes vers le haut de la pile. Évidemment, c'est une supposition, mais cela pourrait expliquer les symptômes.
 beitler
beitler
Tous les 16 commentaires
Avec la dernière mise à jour, le délai d'expiration est apparemment passé de 60 s à 600 s. Mais le problème sous-jacent demeure et peut être reproduit de manière fiable avec les étapes ci-dessus.
beitler
le 6 févr. 2020
Je vais essayer de simuler cela et d'ajuster les paramètres du proxy pour voir où se situe le problème. Mais il faut noter que cela ne semble affecter qu'un pourcentage des passerelles.
Dans le graphique suivant, le front montant du pic dans les messages d'état correspond à la fenêtre de repos des 600s. Chaque fois que la passerelle se reconnecte, nous enregistrons un seul message d'état (qui explique ce pic). Mais si vous voyez le trafic, la baisse est légère mais pas assez drastique pour indiquer un problème avec toutes les passerelles: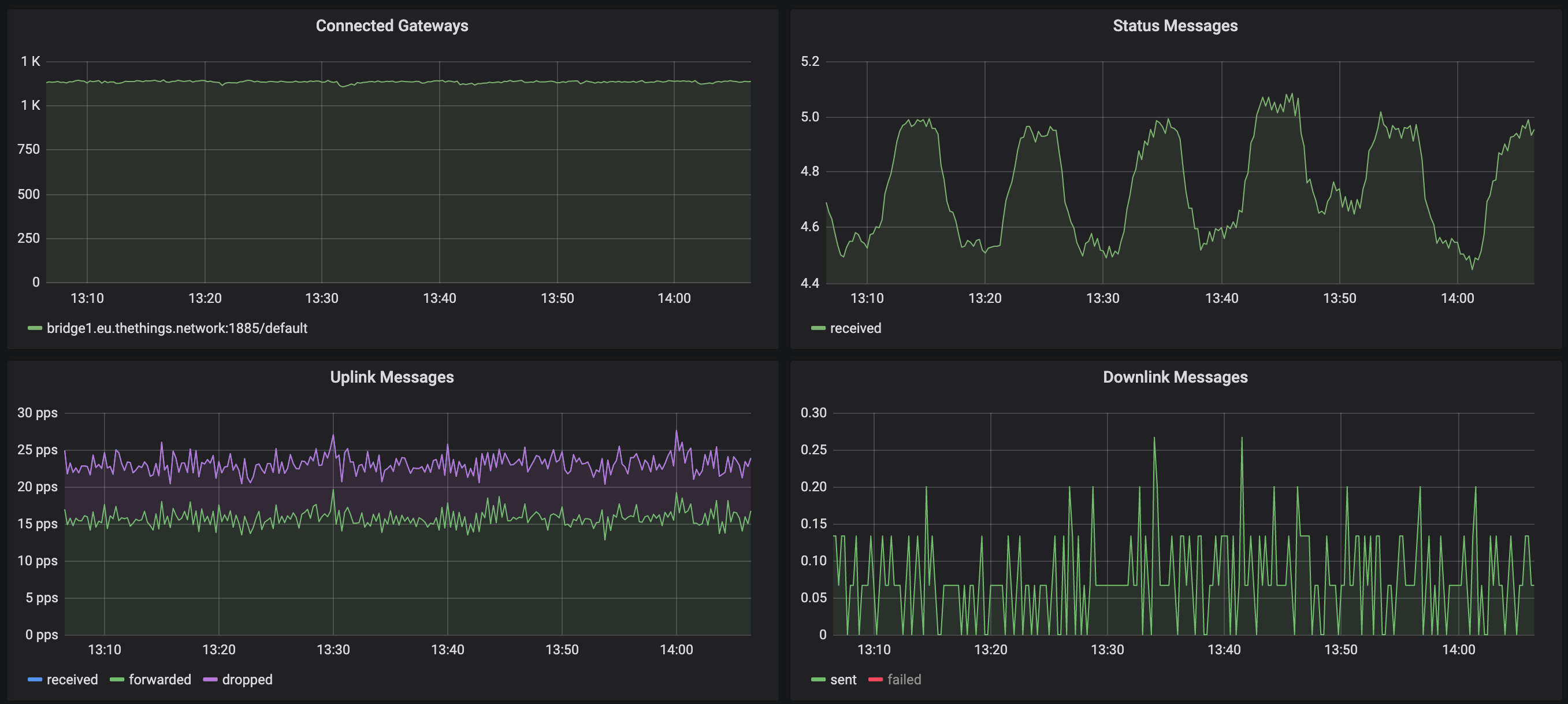
 KrishnaIyer
le 8 févr. 2020
KrishnaIyer
le 8 févr. 2020
Salut Krishna, le problème n'est pas lié aux déconnexions côté serveur mais à la façon dont le serveur gère les déconnexions côté client impur avec des reconnexions immédiates. Le problème affecte toutes les passerelles basées sur la station de base et peut être reproduit de manière fiable avec les instructions ci-dessus.
Le modèle d'erreur est comme ceci:
- L'appareil met fin à la connexion de manière malpropre (cycle d'alimentation, réinitialisation matérielle, interruption du WiFi, débranchement / plugin TTIG, etc.)
- L'appareil se reconnecte immédiatement
- Pendant 600 s après la déconnexion (ce nombre était auparavant de 60 s), les paquets transmis sont vus dans le LNS
- Après 600 s et au-delà après la déconnexion, les paquets transmis ne sont PAS vus dans le LNS
L'augmentation du délai d'attente de 60 à 600 a rendu le problème plus grave: avec les années 60, l'utilisateur, qui débranche son TTIG, devait juste attendre 60 secondes avant de le rebrancher pour éviter de se heurter au problème. Cela peut s'être produit assez souvent, en particulier lorsque les utilisateurs effectuent une réinitialisation d'usine. Désormais, avec les 600, un pourcentage plus important se heurtera au problème, ce qui est également ce que l'on peut observer.
Cela ferait-il mal de désactiver complètement ce délai? Basic Station maintient TCP en vie par défaut (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Cela ne suffit-il pas pour vérifier la vitalité de la connexion?
beitler
le 8 févr. 2020
Pour moi, cela ressemble à l'erreur habbens également, lorsque le fournisseur déconnecte votre connexion Internet et que vous obtenez une nouvelle adresse IP à la reconnexion :(
En ce moment, chaque jour, ma passerelle TTIG ne fonctionne plus, et lorsque je ne montre plus dans les journaux de mon application, la dernière valeur que j'ai reçue est courte avant que la connexion ne soit déconnectée puis reconnectée.
Pour remettre la passerelle en marche, je dois la débrancher, attendre un peu, puis la rebrancher.
Mais ce problème ne se produit que depuis le 29.01, avant que cela ne pose jamais de problème.
 JackGruber
le 9 févr. 2020
JackGruber
le 9 févr. 2020
@JackGruber pouvez-vous confirmer que vous pouvez également recevoir des liaisons montantes très bien pendant les 600 premières secondes après la déconnexion de la connexion Internet? (Pour être exact: 600 secondes, moins le temps nécessaire pour que le modem et la passerelle soient entièrement reconnectés.)
Ou si vous ne voyez aucune liaison montante pendant ces 600 secondes: à quelle fréquence vos appareils transmettent-ils? (En d'autres termes: vous attendez-vous à recevoir des liaisons montantes pendant ces 600 secondes?)
 avbentem
le 9 févr. 2020
avbentem
le 9 févr. 2020
L'appareil que je surveille émet toutes les 5 minutes.
02:42 Cadre RX
02:47 Cadre RX
02:53 Cadre RX
02:56 Reconnecter
02:58 Cadre RX
pas de cadres
07:30 Débrancher / rebrancher TTIG
07:36 Cadre RX
JackGruber
le 9 févr. 2020
Compte tenu de 600 secondes après la reconnexion de 2:56, je suppose qu'après la liaison montante de 2:58, on peut également s'attendre à une liaison montante de 3:03 (ce qui est toujours avant 2:56 plus 600 secondes = 3:06). Mais peut-être que le délai d'expiration de 600 secondes est réinitialisé après la liaison montante de 2:53 (plutôt qu'après un message de maintien en vie / état ultérieur), ce qui fait que TTN efface par erreur le contexte / l'état juste au moment où la liaison montante 3:03 doit être reçue. (Et bien sûr, les liaisons montantes peuvent ne pas être reçues pour d'autres raisons également.)
De plus, tout va bien lors du redémarrage du TTIG à 7h30, puis de ne plus rencontrer de problèmes 600 secondes après cela, semble confirmer la ( excellente ) analyse de @beitler , qui suppose que TTN efface par erreur un contexte / état partagé à vers 3h03 ou 3h06.
avbentem
le 9 févr. 2020
Aujourd'hui j'ai regardé de plus près les temps
J'ai également joint un fichier journal du TTIG.
Malheureusement pas depuis la reconnexion du FAI.
Si vous le souhaitez, je crée un journal à long terme, de sorte que la reconnexion soit également incluse
TTIG.log
Calendrier horaire (UTC + 1)
02:46 Messages RX
02:51 Messages RX
02:56 Messages RX
02:58 Messages RX
02:58 Reconnexion du FAI
03:01 Messages RX
03:03 Messages RX
03:06 Messages RX
plus de messages reçus
Console TTN
Statut: non connecté
Vu pour la dernière fois: 2/11/2020 03:05:04
06:46 Short Un- / Replug TTIG (pas d'alimentation pendant 10 s)
Console TTN
Statut: connecté
Vu pour la dernière fois: 11/02/2020 06:47:12
06:48 Messages RX
....
J'ai trouvé une erreur dans ma règle de pare-feu et la connexion principale CUPS (rjs.sm.tc) n'était pas autorisée, seulement CUPS-BACKUP (mh.sm.tc).
JackGruber
le 11 févr. 2020
Merci de nous avoir signalé, nous avons identifié le problème et sommes en train de le résoudre. Ce problème réside dans notre base de code propriétaire mais sera clos ici.
 johanstokking
le 12 févr. 2020
johanstokking
le 12 févr. 2020
Quelque chose a changé sur le backend depuis +/- 18h cet après-midi?
Il est maintenant quasiment impossible d'exécuter la passerelle intérieure TTN pendant plus de 10 minutes, alors qu'elle fonctionnait bien à ma connaissance pendant des mois.
Le changement d'adresse IP via le serveur DHCP donne 10 minutes de connectivité au réseau TTN, mais il est à nouveau perdu. (le rebranchement fonctionne également pendant 10 minutes)
 TD-er
le 13 févr. 2020
TD-er
le 13 févr. 2020
@ TD-euh, l'avez-vous laissé débranché pendant plus de 10 minutes (600 secondes)?
Comme expliqué ci-dessus, cela est nécessaire depuis le changement du 6 février. Avant le 7 février, il fallait le laisser débranché pendant 60 secondes. Je ne sais pas si le correctif fusionné d'aujourd'hui a également été déployé.
avbentem
le 13 févr. 2020
Non, pas débranché depuis si longtemps.
Une fois débranché, il n'a été débranché que pendant quelques secondes.
Avec le changement DHCP de l'adresse IP, l'unité n'a même jamais été mise hors tension, elle a juste reçu une nouvelle adresse IP du serveur DHCP et a ainsi reconstruit sa connexion réseau. Cela l'a fait fonctionner pendant presque exactement 10 minutes jusqu'à ce qu'il ne soit plus disponible.
Je vais maintenant le débrancher pendant un moment, puis voir ce qui se passe après l'avoir rebranché.
TD-er
le 13 févr. 2020
Avait-il éteint pendant environ 25 minutes et maintenant branché pendant environ 15 minutes et il fonctionne toujours :) Je verrai s'il fonctionne toujours demain matin.
TD-er
le 14 févr. 2020
Nous publions aujourd'hui la v3.5.3 contenant le correctif, et nous pourrons probablement le déployer sur les serveurs auxquels TTIG se connecte. Espérons que cela sera résolu très bientôt.
johanstokking
le 14 févr. 2020
Espérons qu'il n'a pas encore été déployé, car ma passerelle intérieure est à nouveau hors ligne depuis environ 3 heures déjà.
TD-er
le 14 févr. 2020
Nous n'avons pas entendu ce problème après le déploiement des derniers correctifs. N'hésitez pas à rouvrir si observé à nouveau.
KrishnaIyer
le 24 févr. 2020
Questions connexes
 adriansmares
·
9Commentaires
johanstokking
·
8Commentaires
adriansmares
·
9Commentaires
johanstokking
·
8Commentaires
 kschiffer
·
4Commentaires
kschiffer
·
4Commentaires
 w4tsn
·
6Commentaires
w4tsn
·
6Commentaires
 htdvisser
·
9Commentaires
htdvisser
·
9Commentaires
Commentaire le plus utile
Salut Krishna, le problème n'est pas lié aux déconnexions côté serveur mais à la façon dont le serveur gère les déconnexions côté client impur avec des reconnexions immédiates. Le problème affecte toutes les passerelles basées sur la station de base et peut être reproduit de manière fiable avec les instructions ci-dessus.
Le modèle d'erreur est comme ceci:
L'augmentation du délai d'attente de 60 à 600 a rendu le problème plus grave: avec les années 60, l'utilisateur, qui débranche son TTIG, devait juste attendre 60 secondes avant de le rebrancher pour éviter de se heurter au problème. Cela peut s'être produit assez souvent, en particulier lorsque les utilisateurs effectuent une réinitialisation d'usine. Désormais, avec les 600, un pourcentage plus important se heurtera au problème, ce qui est également ce que l'on peut observer.
Cela ferait-il mal de désactiver complètement ce délai? Basic Station maintient TCP en vie par défaut (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Cela ne suffit-il pas pour vérifier la vitalité de la connexion?