Lorawan-stack: تكامل المحطة الأساسي: تؤدي حالة السباق في معالجة إعادة الاتصال إلى فشل دائم في إعادة توجيه الوصلة الصاعدة
ملخص
يعتمد بروتوكول المحطة الأساسية على TCP. قد يحدث أحيانًا أن يسقط العميل هذا الاتصال دون تنفيذ تسلسل إغلاق اتصال TCP نظيف. قد يحدث هذا في حالة اختفاء اتصال طبقة الارتباط / الشبكة فجأة وتسبب في إعادة تعيين طبقة TCP وإعادة المحاولة (على سبيل المثال ، تقوم البوابة بالتبديل من وصلة إيثرنت إلى شبكة الجيل الثالث لأن شبكة إيثرنت قد اختفت ؛ أو ترى البوابة دورة طاقة غير متوقعة ويتم التمهيد بسرعة - a سيناريو unplug / plugin الشائع لـ TTIG). إذا أنشأت المحطة الأساسية اتصالاً جديدًا في غضون فترة زمنية معينة بعد إعادة توجيه الوصلة الصاعدة الأخيرة للاتصال القديم ، يتوقف LNS عن معالجة الارتباطات الصاعدة من هذه البوابة بشكل دائم. يبدو أن هذه المهلة حوالي 60 ثانية. نظرًا للأعراض وحقيقة أن هذا لا يحدث على مكدس v3 ، يبدو أن هذه المشكلة مرتبطة بـ # 1729.
تمت مناقشة هذه المشكلة أيضًا في منتديات TTN
خطوات التكاثر
- لمحاكاة إنهاء اتصال TCP غير النظيف ، أدخل قاعدة iptables التي تحظر حزم TCP FIN:
iptables -A OUTPUT -d 52.169.76.203 --protocol tcp --tcp-flags FIN FIN -j DROP - ابدأ Basic على الجهاز حيث تكون قاعدة iptables نشطة. تأكد من أنك في بيئة ذات روابط صاعدة منتظمة (كل 10 ثوانٍ أو نحو ذلك). لاحظ
https://console.thethingsnetwork.org/gateways/<GATEWAYID>/trafficلحركة المرور الواردة. - بعد إعادة توجيه عدد قليل من الارتباطات الصاعدة ، أوقف عملية المحطة باستخدام CTRL + C (سيرى الخادم إنهاء TCP غير نظيف ، بسبب فقدان حزمة FIN). لنحدد الوقت
Tأنه الوقت الذي تم فيه إعادة توجيه آخر رسالة للوصلة الصاعدة قبل إيقاف عملية المحطة. - بعد فترة وجيزة ، ابدأ عملية المحطة مرة أخرى (ستتصل المحطة الأساسية بالارتباطات الصاعدة وتعيد توجيهها).
- في الوقت
T + 60 s، تبدأ حالة الخطأ.
ماذا ترى الآن؟
حالة الخطأ: ستتوقف وحدة تحكم البوابة https://console.thethingsnetwork.org/gateways/<GATEWAYID>/traffic عن إظهار الارتباطات الصاعدة أثناء بقاء الاتصال بين المحطة الأساسية والخادم على قيد الحياة (يتم تبادل رسائل TCP باستمرار) وتستمر المحطة الأساسية في تلقي الارتباطات الصاعدة. يُظهر التقاط حزمة TCP / IP أن الوصلات الصاعدة يتم نقلها بالفعل عبر مقبس الويب ويتم التعرف على حزم TCP من قبل الخادم - أي أن الخادم يستقبل بالتأكيد رسائل الوصلة الصاعدة ولكنه لا يعرضها في وحدة تحكم البوابة.
ماذا تريد ان ترى بدلا من ذلك؟
يجب أن تستمر معالجة رسائل الارتباط الصاعد بواسطة LNS.
بيئة
المحطة الأساسية (أحدث إصدار) ، شبكة مجتمع TTN.
(في المكدس v3 ، لا يحدث هذا - ومن هنا يأتي الشك في أن له علاقة بإرشاد إنهاء الاتصال غير النشط).
كيف تقترح تنفيذ ذلك؟
من الصعب الحكم على هذا دون الوصول إلى المدونة. من الأعراض ، يبدو أن هذه المشكلة مرتبطة بإرشاد إنهاء الاتصال غير النشط كما تمت مناقشته في الإصدار رقم 1729. ربما يرى الخادم اتصالين لأنه تم إنشاء اتصال جديد قبل إغلاق الاتصال القديم تمامًا. ربما ، يكتشف دليل إنهاء الاتصال اتصالاً غير نشط على اتصال "ميت" ويدمر السياق المرتبط بالبوابة دون اعتبار أن الاتصال الثاني يتطلب هذا السياق لإعادة توجيه الروابط الصاعدة إلى المكدس. من الواضح أن هذا تخمين ، لكنه قد يفسر الأعراض.
 beitler
beitler
ال 16 كومينتر
مع التحديث الأخير ، يبدو أنه تم تغيير المهلة من 60 ثانية إلى 600 ثانية. لكن المشكلة الأساسية لا تزال قائمة ويمكن إعادة إنتاجها بشكل موثوق بالخطوات المذكورة أعلاه.
beitler
في ٦ فبراير ٢٠٢٠
سأحاول محاكاة هذا وتعديل إعدادات الوكيل لمعرفة مكان المشكلة. لكن تجدر الإشارة إلى أن هذا يبدو أنه يؤثر فقط على نسبة مئوية من البوابات.
في الرسم البياني التالي ، تتوافق الحافة الصاعدة لارتفاع رسائل الحالة مع نافذة الخمول 600 ثانية. في كل مرة تعيد البوابة الاتصال ، نسجل رسالة حالة واحدة (والتي تمثل هذا الارتفاع المفاجئ). ولكن إذا رأيت حركة المرور ، فإن الانخفاض طفيف ولكنه ليس حادًا بدرجة كافية للإشارة إلى وجود مشكلة في جميع البوابات: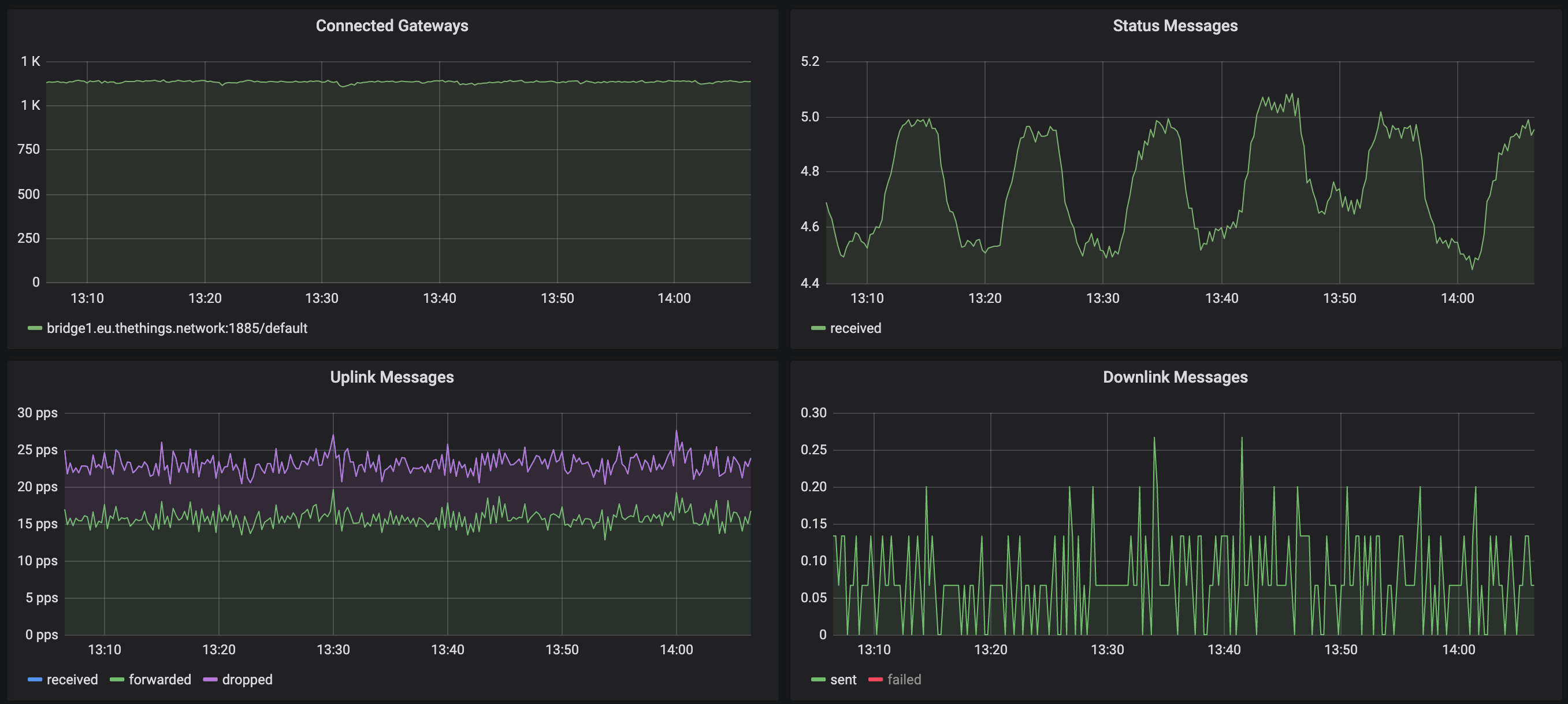
 KrishnaIyer
في ٨ فبراير ٢٠٢٠
KrishnaIyer
في ٨ فبراير ٢٠٢٠
مرحبًا كريشنا ، لا تتعلق المشكلة بقطع الاتصال من جانب الخادم ولكن بالطريقة التي يتعامل بها الخادم مع قطع اتصال جانب العميل غير النظيف مع عمليات إعادة الاتصال الفورية. لا تؤثر المشكلة على جميع البوابات المستندة إلى المحطة الأساسية ويمكن إعادة إنتاجها بشكل موثوق باستخدام الإرشادات المذكورة أعلاه.
نمط الخطأ كالتالي:
- يقوم الجهاز بإنهاء الاتصال بشكل غير نظيف (دورة الطاقة ، إعادة الضبط الثابت ، إسقاط WiFi ، فصل TTIG / المكون الإضافي ، إلخ)
- يعيد الجهاز الاتصال على الفور
- لمدة 600 ثانية بعد قطع الاتصال (كان هذا الرقم 60 ثانية) ، تظهر الحزم المعاد توجيهها في LNS
- بعد 600 ثانية وما بعدها بعد قطع الاتصال ، لا تظهر الحزم المُعاد توجيهها في LNS
زيادة المهلة من الستينيات إلى الستينيات جعلت المشكلة أكثر خطورة: مع الستينيات ، كان على المستخدم ، الذي فصل TTIG الخاص به ، الانتظار لمدة 60 ثانية قبل إعادة توصيله لتجنب الوقوع في المشكلة. قد يحدث هذا كثيرًا بشكل كافٍ خاصةً عندما يقوم الأشخاص بإعادة ضبط المصنع. الآن مع 600s ، ستواجه نسبة أكبر المشكلة ، وهذا أيضًا ما يمكن ملاحظته.
هل سيضر إلغاء تنشيط هذه المهلة تمامًا؟ تحافظ المحطة الأساسية على بقاء TCP على قيد الحياة افتراضيًا (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). ألا يكفي هذا للتحقق من الاتصال الحي؟
beitler
في ٨ فبراير ٢٠٢٠
بالنسبة لي ، يبدو أن الخطأ هابينز أيضًا ، عندما قام المزود بقطع اتصالك بالإنترنت وتحصل على عنوان IP جديد عند إعادة الاتصال :(
في الوقت الحالي ، كل يوم لا تعمل بوابة TTIG الخاصة بي ، وعندما أعرض في سجلات تطبيقي ، تكون القيمة الأخيرة التي تلقيتها قصيرة قبل قطع الاتصال ثم إعادة الاتصال.
لتشغيل البوابة مرة أخرى ، لا بد لي من فصلها ، والانتظار قليلاً ثم توصيلها مرة أخرى.
لكن هذا السلوك يحدث فقط منذ 29.01 ، قبل أن يكون هذا مشكلة على الإطلاق.
 JackGruber
في ٩ فبراير ٢٠٢٠
JackGruber
في ٩ فبراير ٢٠٢٠
JackGruber ، هل يمكنك تأكيد أنه يمكنك أيضًا تلقي ارتباطات صاعدة على ما يرام خلال أول 600 ثانية بعد قطع الاتصال بالإنترنت؟ (على وجه الدقة: 600 ثانية ، مطروحًا منه الوقت المستغرق لإعادة توصيل المودم والبوابة بالكامل.)
أو إذا كنت لا ترى أي روابط صاعدة في تلك الـ 600 ثانية: كم مرة تقوم أجهزتك بالإرسال؟ (بمعنى آخر: هل تتوقع أن تتلقى بعض الروابط الصاعدة خلال تلك الـ 600 ثانية؟)
 avbentem
في ٩ فبراير ٢٠٢٠
avbentem
في ٩ فبراير ٢٠٢٠
الجهاز الذي أراقبه يرسل كل 5 دقائق.
02:42 إطار RX
02:47 إطار RX
02:53 إطار RX
02:56 أعد الاتصال
02:58 إطار RX
لا توجد إطارات
07:30 افصل / أعِد توصيل TTIG
07:36 إطار RX
JackGruber
في ٩ فبراير ٢٠٢٠
بالنظر إلى 600 ثانية بعد إعادة الاتصال 2:56 ، أعتقد أنه بعد 2:58 الوصلة الصاعدة ، قد يتوقع المرء أيضًا ارتباطًا صاعدًا 3:03 (والذي لا يزال قبل 2:56 بالإضافة إلى 600 ثانية = 3:06). ولكن ربما تتم إعادة تعيين مهلة 600 ثانية بعد الوصلة الصاعدة 2:53 (بدلاً من بعض رسائل الحالة / البقاء لاحقًا) ، مما يجعل TTN تمسح السياق / الحالة بشكل خاطئ عند استلام الوصلة الصاعدة 3:03 (وبالطبع ، قد لا يتم تلقي الروابط الصاعدة لأسباب أخرى أيضًا.)
أيضًا ، يبدو أن كل شيء على ما يرام عند إعادة تشغيل TTIG في الساعة 7:30 ، ثم عدم مواجهة المشاكل مرة أخرى بعد 600 ثانية من ذلك ، يؤكد التحليل ( الرائع ) بواسطة beitler ، والذي يفترض أن TTN تمسح عن طريق الخطأ بعض السياق / الحالة المشتركة في حوالي 3:03 أو 3:06.
avbentem
في ٩ فبراير ٢٠٢٠
ألقيت اليوم نظرة فاحصة على الأوقات
لقد أرفقت أيضًا ملف سجل من TTIG.
للأسف ليس من وقت إعادة الاتصال ISP.
إذا رغبت في ذلك ، أقوم بإنشاء سجل طويل الأجل ، بحيث يتم أيضًا تضمين إعادة الاتصال
TTIG.log
الجدول الزمني (UTC + 1)
02:46 رسائل RX
02:51 رسائل RX
02:56 رسائل RX
02:58 رسائل RX
02:58 إعادة الاتصال بـ ISP
03:01 رسائل RX
03:03 رسائل RX
03:06 رسائل RX
لا مزيد من الرسائل المتلقاة
وحدة تحكم TTN
الحالة: غير متصل
آخر ظهور: 2/11/2020 03:05:04
06:46 قصير Un- / Replug TTIG (لا توجد طاقة لمدة 10 ثوانٍ)
وحدة تحكم TTN
الحالة: متصل
آخر ظهور: 2/11/2020 06:47:12
06:48 رسائل RX
....
لقد وجدت خطأ في قاعدة جدار الحماية الخاص بي ، حيث لم يُسمح بالاتصال الأساسي CUPS (rjs.sm.tc) ، فقط CUPS-BACKUP (mh.sm.tc).
JackGruber
في ١١ فبراير ٢٠٢٠
نشكرك على الإبلاغ ، لقد حددنا المشكلة ونعمل على إصلاحها. هذه المشكلة موجودة في قاعدة التعليمات البرمجية الخاصة بنا ولكن سيتم إغلاقها هنا.
 johanstokking
في ١٢ فبراير ٢٠٢٠
johanstokking
في ١٢ فبراير ٢٠٢٠
هل تغير شيء ما على الواجهة الخلفية منذ +/- 18 ساعة بعد ظهر اليوم؟
أصبح الآن من المستحيل تشغيل TTN Indoor Gateway لمدة تزيد عن 10 دقائق ، بينما كانت تعمل بشكل جيد بقدر ما أعرف منذ شهور.
يؤدي تغيير عنوان IP عبر خادم DHCP إلى توفير 10 دقائق من الاتصال بشبكة TTN ، ولكن يتم فقدها مرة أخرى. (تعمل إعادة التشغيل أيضًا لمدة 10 دقائق)
 TD-er
في ١٣ فبراير ٢٠٢٠
TD-er
في ١٣ فبراير ٢٠٢٠
@ TD-er ، هل تركته غير موصول لأكثر من 10 دقائق (600 ثانية)؟
كما هو موضح أعلاه ، كان ذلك مطلوبًا منذ تغيير 6 فبراير. قبل السابع من فبراير ، احتاج المرء إلى تركه غير متصل لمدة 60 ثانية. ليس من الواضح بالنسبة لي ما إذا تم نشر الإصلاح المدمج اليوم أيضًا.
avbentem
في ١٣ فبراير ٢٠٢٠
لا ، لم يتم فصله لفترة طويلة.
عند فصله ، تم فصله لبضع ثوانٍ فقط.
مع تغيير DHCP لعنوان IP ، لم يتم تدوير الطاقة أبدًا للوحدة ، فقد تلقت للتو عنوان IP جديدًا من خادم DHCP وبالتالي أعادت بناء اتصال الشبكة الخاص بها. جعل هذا الأمر يعمل لمدة 10 دقائق تقريبًا حتى لم يعد متاحًا مرة أخرى.
سأفصله الآن لفترة ثم أرى ما سيحدث بعد إعادة توصيله.
TD-er
في ١٣ فبراير ٢٠٢٠
لو تم إيقاف تشغيله لمدة 25 دقيقة تقريبًا وتم توصيله الآن لمدة 15 دقيقة تقريبًا وما زال يعمل :) هل ستعرف ما إذا كان لا يزال يعمل صباح الغد.
TD-er
في ١٤ فبراير ٢٠٢٠
نحن نصدر اليوم الإصدار 3.5.3 الذي يحتوي على الإصلاح ، ومن المحتمل أن نكون قادرين على نشره على الخوادم التي يتصل بها TTIG. نأمل أن يتم حل ذلك قريبًا جدًا.
johanstokking
في ١٤ فبراير ٢٠٢٠
دعونا نأمل أنه لم يتم نشره بعد ، حيث أن بوابتي الداخلية أصبحت الآن غير متصلة بالإنترنت مرة أخرى لمدة 3 ساعات بالفعل.
TD-er
في ١٤ فبراير ٢٠٢٠
لم نسمع هذه المشكلة بعد نشر أحدث الإصلاحات. لا تتردد في إعادة الفتح إذا تمت ملاحظته مرة أخرى.
KrishnaIyer
في ٢٤ فبراير ٢٠٢٠
القضايا ذات الصلة
johanstokking
·
6تعليقات
 kschiffer
·
7تعليقات
kschiffer
·
6تعليقات
kschiffer
·
7تعليقات
kschiffer
·
6تعليقات
 adriansmares
·
8تعليقات
adriansmares
·
8تعليقات
 adamsondelacruz
·
7تعليقات
adamsondelacruz
·
7تعليقات
التعليق الأكثر فائدة
مرحبًا كريشنا ، لا تتعلق المشكلة بقطع الاتصال من جانب الخادم ولكن بالطريقة التي يتعامل بها الخادم مع قطع اتصال جانب العميل غير النظيف مع عمليات إعادة الاتصال الفورية. لا تؤثر المشكلة على جميع البوابات المستندة إلى المحطة الأساسية ويمكن إعادة إنتاجها بشكل موثوق باستخدام الإرشادات المذكورة أعلاه.
نمط الخطأ كالتالي:
زيادة المهلة من الستينيات إلى الستينيات جعلت المشكلة أكثر خطورة: مع الستينيات ، كان على المستخدم ، الذي فصل TTIG الخاص به ، الانتظار لمدة 60 ثانية قبل إعادة توصيله لتجنب الوقوع في المشكلة. قد يحدث هذا كثيرًا بشكل كافٍ خاصةً عندما يقوم الأشخاص بإعادة ضبط المصنع. الآن مع 600s ، ستواجه نسبة أكبر المشكلة ، وهذا أيضًا ما يمكن ملاحظته.
هل سيضر إلغاء تنشيط هذه المهلة تمامًا؟ تحافظ المحطة الأساسية على بقاء TCP على قيد الحياة افتراضيًا (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). ألا يكفي هذا للتحقق من الاتصال الحي؟