Lorawan-stack: Integración básica de la estación: la condición de carrera en el manejo de la reconexión provoca una falla permanente del reenvío de enlace ascendente
Resumen
El protocolo de la estación básica se basa en TCP. Ocasionalmente puede suceder que el cliente interrumpa esta conexión sin ejecutar una secuencia de cierre de conexión TCP limpia. Esto puede ocurrir si la conectividad de la capa de enlace / red desaparece repentinamente y hace que la capa de TCP se reinicie y vuelva a intentarlo (por ejemplo, una puerta de enlace está cambiando de la red de retorno de Ethernet a la red de retorno de 3G porque ethernet desapareció; o la puerta de enlace está experimentando un ciclo de energía inesperado y se inicia rápidamente - a escenario común de desconexión / complemento para TTIG). Si Basic Station establece una nueva conexión dentro de un cierto tiempo después de que se reenvió el último enlace ascendente para la conexión anterior, el LNS deja de procesar enlaces ascendentes desde esta puerta de enlace de forma permanente. Parece que este tiempo de espera es de unos 60 segundos. Dados los síntomas y el hecho de que esto no sucede en la pila v3, parece que este problema está relacionado con # 1729.
Este problema también se ha discutido en los foros de TTN.
Pasos para reproducir
- Para simular una terminación de conexión TCP no limpia, introduzca una regla de iptables que bloquee los paquetes FIN de TCP:
iptables -A OUTPUT -d 52.169.76.203 --protocol tcp --tcp-flags FIN FIN -j DROP - Inicie Basic en la máquina donde está activa la regla iptables. Asegúrese de estar en un entorno de enlaces ascendentes regulares (cada 10 segundos aproximadamente). Observe
https://console.thethingsnetwork.org/gateways/<GATEWAYID>/trafficpara el tráfico entrante. - Después de que se reenvíen algunos enlaces ascendentes, detenga el proceso de la estación con CTRL + C (el servidor verá una terminación TCP no limpia, debido a que falta el paquete FIN). Definamos la hora
Tcomo la hora a la que se reenvió el último mensaje de enlace ascendente antes de que se matara el proceso de la estación. - Poco después, vuelva a iniciar el proceso de la estación (la estación básica se conectará y reenviará los enlaces ascendentes).
- En el momento
T + 60 s, se activa la condición de error.
¿Qué ves ahora?
La condición de error: La consola de puerta de enlace https://console.thethingsnetwork.org/gateways/<GATEWAYID>/traffic dejará de mostrar enlaces ascendentes mientras la conexión entre la Estación Básica y el Servidor se mantiene activa (se intercambian mensajes de mantenimiento de vida de TCP) y la Estación Básica continúa recibiendo enlaces ascendentes. Una captura de paquetes TCP / IP muestra que los enlaces ascendentes se transfieren realmente a través del websocket y el servidor reconoce los paquetes TCP, es decir, el servidor definitivamente recibe los mensajes del enlace ascendente pero no los muestra en la consola de la puerta de enlace.
¿Qué quieres ver en su lugar?
Los mensajes de enlace ascendente deben seguir siendo procesados por el LNS.
Ambiente
Basic Station (última versión), red comunitaria TTN.
(En la pila v3 esto no sucede, de ahí la sospecha de que tiene algo que ver con la heurística de terminación de conexión inactiva).
¿Cómo se propone implementar esto?
Esto es difícil de juzgar sin tener acceso al código. Por los síntomas, parece que este problema está relacionado con la heurística de terminación de conexión inactiva, como se discutió en el número 1729. Probablemente el servidor esté viendo dos conexiones porque se establece una nueva antes de que la anterior se cierre limpiamente. Tal vez, la heurística de terminación de conexión detecta una conexión inactiva en la conexión 'muerta' y destruye el contexto relacionado con la puerta de enlace sin considerar que una segunda conexión requiere este contexto para reenviar enlaces ascendentes en la pila. Obviamente, esto es una suposición, pero podría explicar los síntomas.
 beitler
beitler
Todos 16 comentarios
Con la última actualización, el tiempo de espera aparentemente se ha cambiado de 60 sa 600 s. Pero el problema subyacente permanece y se puede reproducir de manera confiable con los pasos anteriores.
beitler
en 6 feb. 2020
Intentaré simular esto y ajustar la configuración de Proxy para ver dónde está el problema. Pero debe tenerse en cuenta que esto solo parece afectar a un porcentaje de las pasarelas.
En el siguiente gráfico, el borde ascendente del pico en los mensajes de estado corresponde a la ventana inactiva de 600 segundos. Cada vez que la puerta de enlace se vuelve a conectar, registramos un solo mensaje de estado (que explica este pico). Pero si ve el tráfico, la caída es leve pero no lo suficientemente drástica como para indicar un problema con todas las puertas de enlace: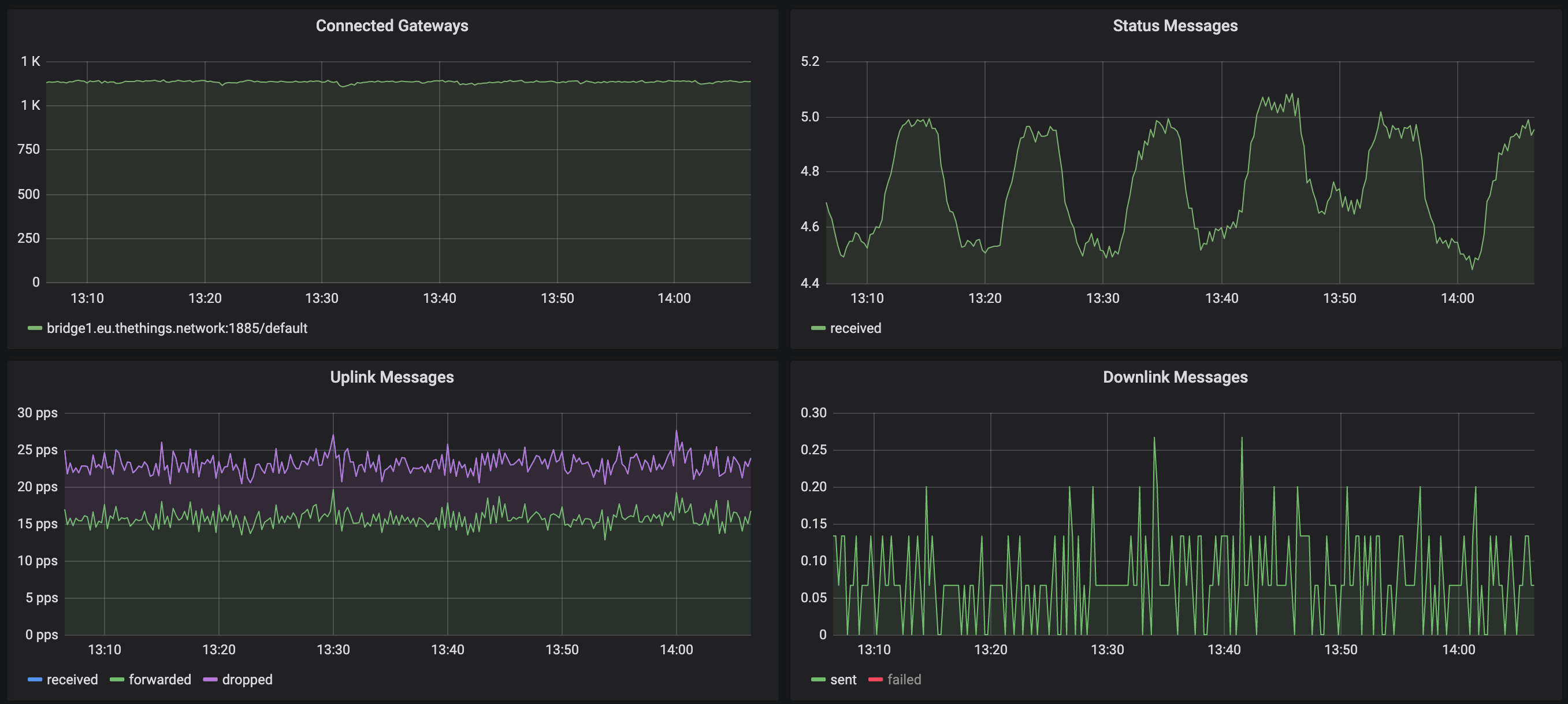
 KrishnaIyer
en 8 feb. 2020
KrishnaIyer
en 8 feb. 2020
Hola Krishna, el problema no está relacionado con las desconexiones del lado del servidor, sino con la forma en que el servidor maneja las desconexiones no limpias del lado del cliente con reconexiones inmediatas. El problema afecta a todas las puertas de enlace basadas en Basic Station y se puede reproducir de forma fiable con las instrucciones anteriores.
El patrón de error es así:
- El dispositivo termina la conexión de manera no limpia (ciclo de energía, reinicio completo, caída de WiFi, desconexión / complemento de TTIG, etc.)
- El dispositivo se vuelve a conectar inmediatamente
- Durante 600 segundos después de la desconexión (este número solía ser 60), los paquetes reenviados se ven en el LNS.
- Después de 600 segundos y más después de la desconexión, los paquetes reenviados NO se ven en el LNS
Aumentar el tiempo de espera de 60 a 600 hizo que el problema fuera más severo: con 60 segundos, el usuario, que desconecta su TTIG, solo tenía que esperar 60 segundos antes de volver a enchufarlo para evitar encontrarse con el problema. Esto puede haber sucedido con bastante frecuencia, especialmente cuando las personas hacen un restablecimiento de fábrica. Ahora, con 600, un porcentaje mayor se encontrará con el problema, que también es lo que se puede observar.
¿Sería doloroso desactivar este tiempo de espera por completo? Basic Station mantiene activo TCP de forma predeterminada (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). ¿No es suficiente para comprobar la vitalidad de la conexión?
beitler
en 8 feb. 2020
Para mí, parece que el error también se ha producido, cuando el proveedor desconecta su conexión a Internet y obtiene una nueva IP en la reconexión :(
En este momento, todos los días, mi TTIG Gateway ya no funciona, y cuando aparezco en los registros de mi aplicación, el último valor que recibí es corto antes de que la conexión se desconectara y luego se volviera a conectar.
Para que la puerta de enlace vuelva a funcionar, tengo que desenchufarla, esperar un poco y luego volver a enchufarla.
Pero este comportamiento ocurre solo desde el 29.01, antes de que esto nunca fuera un problema.
 JackGruber
en 9 feb. 2020
JackGruber
en 9 feb. 2020
@JackGruber, ¿ puede confirmar que también puede recibir enlaces ascendentes sin problemas durante los primeros 600 segundos después de que se desconectó la conexión a Internet? (Para ser exactos: 600 segundos, menos el tiempo que tarda el módem y la puerta de enlace en volver a conectarse por completo).
O si no ve ningún enlace ascendente en esos 600 segundos: ¿con qué frecuencia transmiten sus dispositivos? (En otras palabras: ¿esperaría recibir algunos enlaces ascendentes durante esos 600 segundos?)
 avbentem
en 9 feb. 2020
avbentem
en 9 feb. 2020
El dispositivo que estoy monitoreando transmite cada 5 minutos.
02:42 Cuadro RX
02:47 Cuadro RX
02:53 Cuadro RX
02:56 Reconectar
02:58 Cuadro RX
sin marcos
07:30 Desenchufe / vuelva a enchufar TTIG
07:36 Cuadro RX
JackGruber
en 9 feb. 2020
Teniendo en cuenta 600 segundos después de la reconexión 2:56, supongo que después del enlace ascendente 2:58 uno también podría esperar un enlace ascendente 3:03 (que todavía está antes de 2:56 más 600 segundos = 3:06). Pero tal vez el tiempo de espera de 600 segundos se restablezca después del enlace ascendente 2:53 (en lugar de después de algún mensaje de estado / mantenimiento posterior), lo que hace que TTN borre erróneamente el contexto / estado justo cuando se debería recibir el enlace ascendente 3:03. (Y, por supuesto, es posible que los enlaces ascendentes no se reciban también por otras razones).
Además, todo está bien al reiniciar el TTIG a las 7:30, y luego no tener problemas nuevamente 600 segundos después de eso, parece confirmar el ( excelente ) análisis de @beitler , que asume que TTN borra erróneamente algún contexto / estado compartido en alrededor de las 3:03 o 3:06.
avbentem
en 9 feb. 2020
Hoy eché un vistazo más de cerca a los tiempos
También he adjuntado un archivo de registro del TTIG.
Desafortunadamente, no desde el momento de la reconexión del ISP.
Si lo desea, creo un registro a largo plazo, para que también se incluya la reconexión
TTIG.log
Horario (UTC + 1)
02:46 Mensajes RX
02:51 Mensajes RX
02:56 Mensajes RX
02:58 Mensajes RX
02:58 Reconexión de ISP
03:01 Mensajes RX
03:03 Mensajes RX
03:06 Mensajes RX
no más mensajes recibidos
Consola TTN
Estado: no conectado
Visto por última vez: 2/11/2020 03:05:04
06:46 TTIG corto de desconexión / reconexión (sin energía durante 10 segundos)
Consola TTN
Estado: conectado
Visto por última vez: 2/11/2020 06:47:12
06:48 Mensajes RX
....
Encontré un error en mi regla de firewall y la conexión primaria CUPS (rjs.sm.tc) no estaba permitida, solo CUPS-BACKUP (mh.sm.tc).
JackGruber
en 11 feb. 2020
Gracias por informarnos, hemos identificado el problema y lo estamos solucionando. Este problema vive en nuestra base de código propietario, pero se cerrará aquí.
 johanstokking
en 12 feb. 2020
johanstokking
en 12 feb. 2020
¿Ha cambiado algo en el backend desde las +/- 18h de esta tarde?
Ahora es casi imposible ejecutar TTN Indoor Gateway durante más de 10 minutos, mientras que, hasta donde yo sé, funcionó bien durante meses.
El cambio de dirección IP a través del servidor DHCP proporciona 10 minutos de conectividad a la red TTN, pero luego se pierde nuevamente. (volver a enchufar también funciona durante 10 minutos)
 TD-er
en 13 feb. 2020
TD-er
en 13 feb. 2020
@ TD-er, ¿lo dejaste desconectado durante más de 10 minutos (600 segundos)?
Como se explicó anteriormente, eso ha sido necesario desde el cambio del 6 de febrero. Antes del 7 de febrero, era necesario dejarlo desenchufado durante 60 segundos. No tengo claro si la solución combinada de hoy también se ha implementado.
avbentem
en 13 feb. 2020
No, no desconectado por tanto tiempo.
Una vez desenchufado, solo estuvo desenchufado durante unos segundos.
Con el cambio de DHCP de la dirección IP, la unidad ni siquiera se apagó y volvió a encender, simplemente recibió una nueva IP del servidor DHCP y, por lo tanto, reconstruyó su conexión de red. Esto hizo que funcionara durante casi exactamente 10 minutos hasta que no estuvo disponible nuevamente.
Ahora lo desconectaré por un tiempo y luego veré qué sucede después de volver a conectarlo.
TD-er
en 13 feb. 2020
Lo tenía apagado durante aproximadamente 25 minutos y ahora enchufado durante aproximadamente 15 minutos y todavía está funcionando :) Veré si todavía funciona mañana por la mañana.
TD-er
en 14 feb. 2020
Lanzamos v3.5.3 hoy que contiene la solución, y es probable que podamos implementarla en los servidores a los que se conecta TTIG. Con suerte, eso se resolverá muy pronto.
johanstokking
en 14 feb. 2020
Esperemos que aún no se haya implementado, ya que mi puerta de enlace interior ahora está nuevamente fuera de línea durante aproximadamente 3 horas.
TD-er
en 14 feb. 2020
No hemos escuchado este problema después de la implementación de las últimas correcciones. No dude en volver a abrir si se observa de nuevo.
KrishnaIyer
en 24 feb. 2020
Temas relacionados
 bafonins
·
5Comentarios
johanstokking
·
8Comentarios
bafonins
·
5Comentarios
johanstokking
·
8Comentarios
 ecities
·
5Comentarios
ecities
·
5Comentarios
 thinkOfaNumber
·
4Comentarios
thinkOfaNumber
·
4Comentarios
 htdvisser
·
4Comentarios
htdvisser
·
4Comentarios
Comentario más útil
Hola Krishna, el problema no está relacionado con las desconexiones del lado del servidor, sino con la forma en que el servidor maneja las desconexiones no limpias del lado del cliente con reconexiones inmediatas. El problema afecta a todas las puertas de enlace basadas en Basic Station y se puede reproducir de forma fiable con las instrucciones anteriores.
El patrón de error es así:
Aumentar el tiempo de espera de 60 a 600 hizo que el problema fuera más severo: con 60 segundos, el usuario, que desconecta su TTIG, solo tenía que esperar 60 segundos antes de volver a enchufarlo para evitar encontrarse con el problema. Esto puede haber sucedido con bastante frecuencia, especialmente cuando las personas hacen un restablecimiento de fábrica. Ahora, con 600, un porcentaje mayor se encontrará con el problema, que también es lo que se puede observar.
¿Sería doloroso desactivar este tiempo de espera por completo? Basic Station mantiene activo TCP de forma predeterminada (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). ¿No es suficiente para comprobar la vitalidad de la conexión?