Lorawan-stack: Базовая интеграция станции: состояние гонки при обработке повторного подключения вызывает постоянный сбой пересылки по восходящей линии связи.
Резюме
Протокол базовой станции основан на TCP. Иногда может случиться так, что клиент разорвет это соединение, не выполнив чистую последовательность закрытия TCP-соединения. Это может произойти, если соединение уровня канала / сети внезапно пропадает и вызывает сброс уровня TCP и повторную попытку (например, шлюз переключается с транзитного рейса Ethernet на транзитное соединение 3G, потому что Ethernet отключился; или шлюз видит неожиданный цикл питания и быстро загружается - a распространенный сценарий отключения / подключения для TTIG). Если базовая станция устанавливает новое соединение в течение определенного времени после перенаправления последнего восходящего канала для старого соединения, LNS прекращает обработку восходящих каналов от этого шлюза навсегда. Похоже, этот тайм-аут составляет около 60 секунд. Учитывая симптомы и тот факт, что этого не происходит в стеке v3, похоже, что эта проблема связана с # 1729.
Этот вопрос также обсуждался на форумах TTN.
Действия по воспроизведению
- Чтобы имитировать нечистое завершение TCP-соединения, введите правило iptables, которое блокирует TCP-пакеты FIN:
iptables -A OUTPUT -d 52.169.76.203 --protocol tcp --tcp-flags FIN FIN -j DROP - Запустите Basic на машине, где действует правило iptables. Убедитесь, что вы находитесь в среде регулярных аплинков (каждые 10 секунд или около того). Обратите внимание на входящий трафик
https://console.thethingsnetwork.org/gateways/<GATEWAYID>/traffic. - После перенаправления нескольких восходящих каналов остановите процесс станции с помощью CTRL + C (сервер увидит нечистое завершение TCP из-за отсутствия пакета FIN). Давайте определим время
Tкак время, когда было перенаправлено последнее сообщение восходящей линии связи до того, как процесс станции был остановлен. - Вскоре после этого снова запустите процесс станции (базовая станция подключится и переадресует восходящие каналы).
- В момент
T + 60 sвозникает ошибка.
Что ты сейчас видишь?
Состояние ошибки: консоль шлюза https://console.thethingsnetwork.org/gateways/<GATEWAYID>/traffic перестанет отображать восходящие каналы, пока соединение между базовой станцией и сервером остается активным (происходит обмен сообщениями TCP keep alive), а базовая станция продолжает получать восходящие каналы. Захват пакетов TCP / IP показывает, что восходящие каналы фактически передаются через веб-сокет, а пакеты TCP подтверждаются сервером, т. Е. Сервер определенно получает сообщения восходящего канала, но не отображает их в консоли шлюза.
Что вы хотите увидеть вместо этого?
Сообщения восходящей линии связи должны продолжать обрабатываться LNS.
Среда
Базовая станция (последняя версия), сеть сообщества TTN.
(В стеке v3 этого не происходит - отсюда и подозрение, что это как-то связано с эвристикой завершения неактивного соединения).
Как вы предлагаете это реализовать?
Об этом сложно судить, не имея доступа к коду. Судя по симптомам, похоже, что эта проблема связана с эвристикой завершения неактивного соединения, как обсуждалось в проблеме № 1729. Вероятно, сервер видит два соединения, потому что новое соединение устанавливается до того, как старое полностью закрывается. Возможно, эвристика завершения соединения обнаруживает неактивное соединение на «мертвом» соединении и уничтожает контекст, связанный со шлюзом, без учета того, что второе соединение требует этого контекста для пересылки восходящих каналов вверх по стеку. Очевидно, это предположение, но оно может объяснить симптомы.
 beitler
beitler
Все 16 Комментарий
В последнем обновлении время ожидания было изменено с 60 до 600 с. Но основная проблема остается, и ее можно надежно воспроизвести с помощью описанных выше шагов.
beitler
6 февр. 2020
Я попытаюсь смоделировать это и настроить параметры прокси, чтобы увидеть, в чем проблема. Но следует отметить, что это влияет только на определенный процент шлюзов.
На следующем графике нарастающий фронт всплеска сообщений о состоянии соответствует окну ожидания 600 с. Каждый раз, когда шлюз повторно подключается, мы регистрируем одно сообщение о состоянии (которое учитывает этот всплеск). Но если вы видите трафик, то падение незначительное, но не настолько сильное, чтобы указывать на проблему со всеми шлюзами: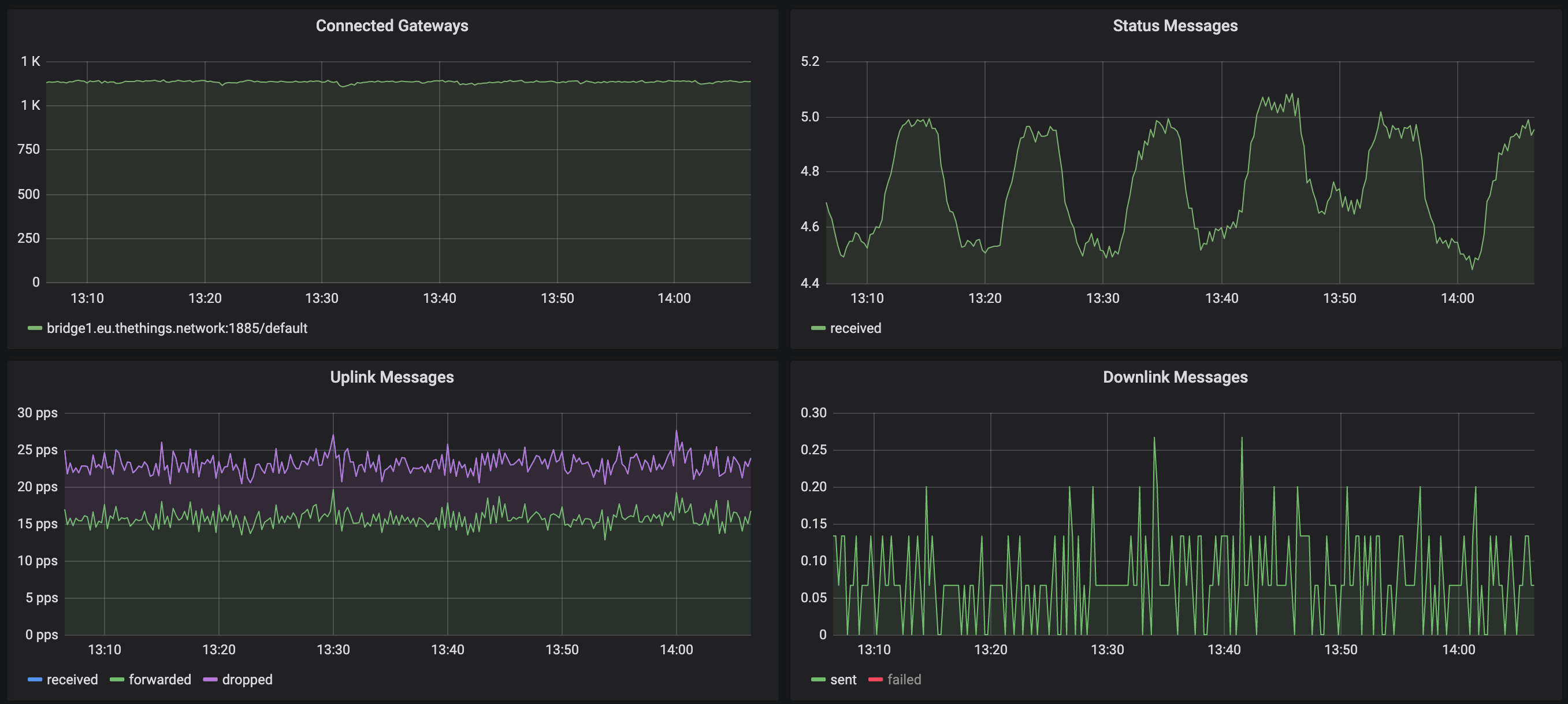
 KrishnaIyer
8 февр. 2020
KrishnaIyer
8 февр. 2020
Привет, Кришна, проблема связана не с отключениями на стороне сервера, а с тем, как сервер обрабатывает нечистые отключения на стороне клиента с немедленным повторным подключением. Проблема действительно затрагивает все шлюзы на базе базовой станции и может быть надежно воспроизведена с помощью приведенных выше инструкций.
Схема ошибки выглядит так:
- Устройство некорректно прерывает соединение (цикл питания, аппаратный сброс, отключение Wi-Fi, отключение / подключение TTIG и т. Д.)
- Устройство немедленно повторно подключается
- В течение 600 секунд после отключения (это число было 60 секунд) переадресованные пакеты видны в LNS.
- Через 600 с и более после отключения перенаправленные пакеты НЕ видны в LNS.
Увеличение тайм-аута с 60 до 600 сделало проблему более серьезной: при 60 секундах пользователю, отключающему свой TTIG, просто приходилось ждать 60 секунд, прежде чем снова подключать его, чтобы не столкнуться с проблемой. Это могло происходить достаточно часто, особенно когда люди выполняли сброс настроек до заводских. Теперь с 600s, больший процент столкнется с проблемой, что также можно наблюдать.
Больно ли вообще отключить этот тайм-аут? Базовая станция поддерживает TCP по умолчанию (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Разве этого не достаточно для проверки работоспособности соединения?
beitler
8 февр. 2020
Для меня похоже, что ошибка также возникает, если провайдер отключит ваше интернет-соединение, и вы получите новый IP-адрес при повторном подключении :(
В настоящий момент каждый день мой шлюз TTIG больше не работает, и когда я показываю в журналах своего приложения, последнее полученное мной значение является коротким до того, как соединение было отключено, а затем снова подключено.
Чтобы шлюз снова заработал, мне нужно отключить его, немного подождать, а затем снова подключить.
Но такое поведение происходит только с 29.01, раньше это никогда не было проблемой.
 JackGruber
9 февр. 2020
JackGruber
9 февр. 2020
@JackGruber, можете ли вы подтвердить, что вы также можете нормально получать аплинки в течение первых 600 секунд после отключения интернет-соединения? (Если быть точным: 600 секунд, минус время, необходимое для полного переподключения модема и шлюза.)
Или, если вы не видите никаких исходящих соединений в течение этих 600 секунд: как часто ваши устройства передают данные? (Другими словами: ожидаете ли вы получить несколько аплинков в течение этих 600 секунд?)
 avbentem
9 февр. 2020
avbentem
9 февр. 2020
Контролируемое мной устройство передает данные каждые 5 минут.
02:42 Кадр RX
02:47 Кадр RX
02:53 Кадр RX
02:56 Подключиться
02:58 Кадр RX
без рамок
07:30 Отключить / снова подключить TTIG
07:36 Кадр RX
JackGruber
9 февр. 2020
Учитывая 600 секунд после повторного подключения 2:56, я предполагаю, что после восходящего канала 2:58 можно также ожидать восходящего канала 3:03 (который все еще до 2:56 плюс 600 секунд = 3:06). Но, возможно, тайм-аут в 600 секунд сбрасывается после восходящего канала 2:53 (а не после некоторого более позднего сообщения keep-alive / status), заставляя TTN ошибочно стирать контекст / состояние только тогда, когда должен быть получен восходящий канал 3:03. (И, конечно, аплинки могут не быть получены и по другим причинам.)
Кроме того, все в порядке при перезапуске TTIG в 7:30, а затем отсутствии проблем снова через 600 секунд после этого, похоже, подтверждает ( отличный ) анализ @beitler , который предполагает, что TTN ошибочно стирает некоторый общий контекст / состояние в примерно 3:03 или 3:06.
avbentem
9 февр. 2020
Сегодня я внимательно посмотрел на время
Я также прикрепил файл журнала из TTIG.
К сожалению, не с момента переподключения провайдера.
При желании я создаю долгосрочный журнал, чтобы также было включено повторное подключение
TTIG.log
Расписание (UTC + 1)
02:46 Сообщения RX
02:51 RX сообщения
02:56 RX сообщения
02:58 RX сообщения
02:58 переподключение ISP
03:01 RX сообщения
03:03 RX сообщения
03:06 RX сообщения
сообщений больше не получено
Консоль TTN
Статус: не подключен
Последний визит: 11.02.2020 03:05:04
06:46 Короткое отключение / повторное включение TTIG (нет питания в течение 10 секунд)
Консоль TTN
Статус: подключен
Последний визит: 11.02.2020 06:47:12
06:48 Сообщения RX
....
Я обнаружил ошибку в своем правиле брандмауэра: основное соединение CUPS (rjs.sm.tc) было запрещено, только CUPS-BACKUP (mh.sm.tc).
JackGruber
11 февр. 2020
Благодарим за сообщение, проблема обнаружена и мы ее исправляем. Эта проблема существует в нашей собственной кодовой базе, но здесь будет закрыта.
 johanstokking
12 февр. 2020
johanstokking
12 февр. 2020
Что-то изменилось в серверной части с +/- 18 часов сегодня днем?
Сейчас почти невозможно запустить TTN Indoor Gateway дольше 10 минут, хотя, насколько я знаю, он работал нормально в течение нескольких месяцев.
Смена IP-адреса через DHCP-сервер дает 10 минут подключения к сети TTN, но затем снова теряется. (replug тоже работает 10 минут)
 TD-er
13 февр. 2020
TD-er
13 февр. 2020
@ TD-er, вы оставляли его отключенным более 10 минут (600 секунд)?
Как объяснялось выше, это было необходимо после изменения 6 февраля. До 7 февраля его нужно было отключить от сети на 60 секунд. Мне неясно, было ли развернуто сегодняшнее объединенное исправление.
avbentem
13 февр. 2020
Нет, не отключили так долго.
В отключенном состоянии он был отключен всего на несколько секунд.
С изменением IP-адреса DHCP устройство даже никогда не выключало и снова включало питание, оно просто получило новый IP-адрес от DHCP-сервера и, таким образом, восстановило свое сетевое соединение. Это заставило его работать почти ровно 10 минут, пока он снова не стал недоступен.
Сейчас я отключу его от сети на некоторое время, а затем посмотрю, что произойдет после того, как я его снова подключу.
TD-er
13 февр. 2020
Если бы он был выключен примерно на 25 минут, а теперь подключен примерно на 15 минут, он все еще работает :) Посмотрим, будет ли он работать завтра утром.
TD-er
14 февр. 2020
Сегодня мы выпускаем v3.5.3, содержащую исправление, и, вероятно, сможем развернуть его на серверах, к которым подключается TTIG. Надеюсь, это скоро решится.
johanstokking
14 февр. 2020
Будем надеяться, что он еще не развернут, так как мой внутренний шлюз снова отключен примерно на 3 часа.
TD-er
14 февр. 2020
Мы не слышали об этой проблеме после установки последних исправлений. Пожалуйста, не стесняйтесь открывать снова, если снова заметите.
KrishnaIyer
24 февр. 2020
Смежные вопросы
 thinkOfaNumber
·
4Комментарии
thinkOfaNumber
·
4Комментарии
 kschiffer
·
6Комментарии
johanstokking
·
6Комментарии
johanstokking
·
8Комментарии
kschiffer
·
6Комментарии
johanstokking
·
6Комментарии
johanstokking
·
8Комментарии
 adriansmares
·
8Комментарии
adriansmares
·
8Комментарии
Самый полезный комментарий
Привет, Кришна, проблема связана не с отключениями на стороне сервера, а с тем, как сервер обрабатывает нечистые отключения на стороне клиента с немедленным повторным подключением. Проблема действительно затрагивает все шлюзы на базе базовой станции и может быть надежно воспроизведена с помощью приведенных выше инструкций.
Схема ошибки выглядит так:
Увеличение тайм-аута с 60 до 600 сделало проблему более серьезной: при 60 секундах пользователю, отключающему свой TTIG, просто приходилось ждать 60 секунд, прежде чем снова подключать его, чтобы не столкнуться с проблемой. Это могло происходить достаточно часто, особенно когда люди выполняли сброс настроек до заводских. Теперь с 600s, больший процент столкнется с проблемой, что также можно наблюдать.
Больно ли вообще отключить этот тайм-аут? Базовая станция поддерживает TCP по умолчанию (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Разве этого не достаточно для проверки работоспособности соединения?