Lorawan-stack: 基本的なステーション統合:再接続処理の競合状態により、アップリンク転送が永続的に失敗します
概要
BasicStationプロトコルはTCPに基づいています。 場合によっては、クライアントがクリーンなTCP接続クローズシーケンスを実行せずにこの接続をドロップすることがあります。 これは、リンク/ネットレイヤーの接続が突然失われ、TCPレイヤーがリセットされて再試行される場合に発生する可能性があります(たとえば、イーサネットがなくなったためにゲートウェイがイーサネットバックホールから3Gバックホールに切り替わっている、またはゲートウェイが予期しない電源の再投入を認識してすぐに起動する- TTIGの一般的なアンプラグ/プラグインシナリオ)。 古い接続の最後のアップリンクが転送されてから一定時間内にBasicStationが新しい接続を確立すると、LNSはこのゲートウェイからのアップリンクの処理を永続的に停止します。 このタイムアウトは約60秒のようです。 症状とこれがv3スタックでは発生しないという事実を考えると、この問題は#1729に関連しているようです。
この問題はTTNフォーラムでも議論されてい
再現する手順
- クリーンでないTCP接続の終了をシミュレートするには、TCP FINパケットをブロックするiptablesルールを導入します:
iptables -A OUTPUT -d 52.169.76.203 --protocol tcp --tcp-flags FIN FIN -j DROP - iptablesルールがアクティブなマシンでBasicを起動します。 通常のアップリンク(10秒ごと)の環境にいることを確認してください。 着信トラフィックの
https://console.thethingsnetwork.org/gateways/<GATEWAYID>/trafficを観察します。 - いくつかのアップリンクが転送された後、CTRL + Cでステーションプロセスを停止します(FINパケットが欠落しているため、サーバーにはクリーンでないTCP終端が表示されます)。 時間
Tを、ステーションプロセスが強制終了される前に最後のアップリンクメッセージが転送された時間として定義しましょう。 - その後すぐに、ステーションプロセスを再開します(基本ステーションが接続してアップリンクを転送します)。
- 時間
T + 60 sで、エラー状態が発生します。
あなたは今何を見ていますか?
エラー状態:ゲートウェイコンソールhttps://console.thethingsnetwork.org/gateways/<GATEWAYID>/trafficは、Basic Stationとサーバー間の接続が維持されている間(TCPキープアライブメッセージが交換されている間)、アップリンクの表示を停止し、BasicStationは引き続きアップリンクを受信します。 TCP / IPパケットキャプチャは、アップリンクが実際にWebSocketを介して転送され、TCPパケットがサーバーによって確認応答されることを示します。つまり、サーバーはアップリンクメッセージを確実に受信しますが、ゲートウェイコンソールには表示しません。
代わりに何を見たいですか?
アップリンクメッセージは、引き続きLNSによって処理される必要があります。
環境
ベーシックステーション(最新バージョン)、TTNコミュニティネットワーク。
(v3スタックでは、これは発生しません。したがって、非アクティブな接続終了ヒューリスティックと関係があるという疑いがあります)。
これをどのように実装することを提案しますか?
これは、コードにアクセスできなければ判断するのが困難です。 症状から、この問題は、問題#1729で説明されているように、非アクティブな接続終了ヒューリスティックに関連しているように見えます。 古い接続が完全に閉じられる前に新しい接続が確立されたため、サーバーは2つの接続を認識している可能性があります。 おそらく、接続終了ヒューリスティックは、「デッド」接続で非アクティブな接続を検出し、2番目の接続がアップリンクをスタックに転送するためにこのコンテキストを必要とすることを考慮せずに、ゲートウェイに関連するコンテキストを破棄します。 明らかにこれは推測ですが、症状を説明することができます。
 beitler
beitler
全てのコメント16件
最新のアップデートでは、タイムアウトが60秒から600秒に変更されたようです。 しかし、根本的な問題は残っており、上記の手順で確実に再現できます。
beitler
2020年02月06日
これをシミュレートし、プロキシ設定を微調整して、問題がどこにあるかを確認します。 ただし、これはゲートウェイの一部にのみ影響するように見えることに注意する必要があります。
次のグラフでは、ステータスメッセージのスパイクの立ち上がりエッジが600秒のアイドルウィンドウに対応しています。 ゲートウェイが再接続するたびに、単一のステータスメッセージをログに記録します(これがこのスパイクの原因です)。 ただし、トラフィックが表示される場合、低下はわずかですが、すべてのゲートウェイに問題があることを示すほど劇的ではありません。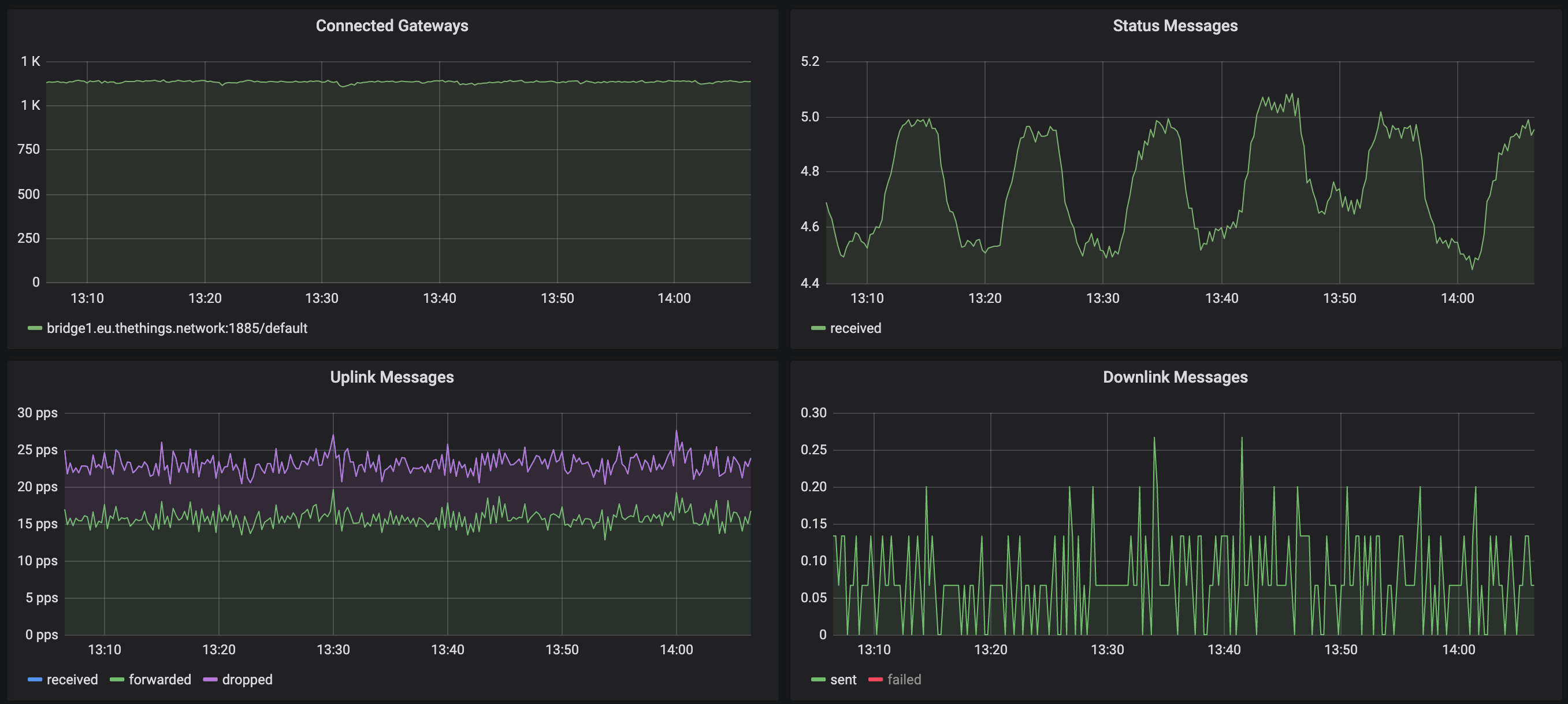
 KrishnaIyer
2020年02月08日
KrishnaIyer
2020年02月08日
こんにちはクリシュナ、問題はサーバー側の切断に関連しているのではなく、サーバーが汚れたクライアント側の切断を処理して即座に再接続する方法に関連しています。 この問題は、すべてのBasic Stationベースのゲートウェイに影響し、上記の手順で確実に再現できます。
エラーパターンは次のようになります。
- デバイスが接続を不正に終了します(電源の入れ直し、ハードリセット、WiFiドロップ、TTIGのプラグイン/プラグインなど)
- デバイスはすぐに再接続します
- 切断後600秒間(この数は60秒間でした)、転送されたパケットはLNSに表示されます。
- 600秒以降、切断後、転送されたパケットはLNSに表示されません。
タイムアウトを60秒から600秒に増やすと、問題がさらに深刻になりました。60秒の場合、TTIGのプラグを抜いたユーザーは、問題が発生しないように、プラグを差し込む前に60秒待つ必要がありました。 これは、特に出荷時設定へのリセットを行う場合に、十分な頻度で発生した可能性があります。 600が増えると、より多くの割合で問題が発生します。これも観察される可能性があります。
このタイムアウトを完全に無効にするのは害がありますか? Basic StationはデフォルトでTCPを維持します(https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637)。 接続の活性をチェックするにはそれで十分ではありませんか?
beitler
2020年02月08日
私にとっては、エラーが発生しているように見えます。プロバイダーがインターネット接続を切断し、再接続時に新しいIPを取得します:(
現時点では、毎日TTIGゲートウェイが機能していません。アプリからログに表示すると、接続が切断されてから再接続されるため、最後に受け取った値が短くなります。
ゲートウェイを再び実行するには、ゲートウェイを取り外し、少し待ってから再度接続する必要があります。
しかし、この動作は29.01以降にのみ発生し、これが問題になることはありませんでした。
 JackGruber
2020年02月09日
JackGruber
2020年02月09日
@JackGruberあなた後、あなたも最初の600秒の間にうまくアップリンク受信できることを確認することができますか? (正確には、600秒から、モデムとゲートウェイが完全に再接続されるまでにかかる時間を差し引いたものです。)
または、600秒以内にアップリンクが表示されない場合:デバイスはどのくらいの頻度で送信しますか? (言い換えれば、600秒の間にいくつかのアップリンクを受信することを期待しますか?)
 avbentem
2020年02月09日
avbentem
2020年02月09日
私が監視しているデバイスは5分ごとに送信します。
02:42RXフレーム
02:47RXフレーム
02:53RXフレーム
02:56再接続
02:58RXフレーム
フレームなし
07:30TTIGのプラグを抜く/再度差し込む
07:36RXフレーム
JackGruber
2020年02月09日
2:56の再接続後600秒を考えると、2:58のアップリンクの後も3:03のアップリンクが予想されると思います(2:56プラス600秒= 3:06の前です)。 ただし、600秒のタイムアウトは2:53アップリンクの後でリセットされ(後でキープアライブ/ステータスメッセージが表示された後ではなく)、3:03アップリンクを受信する必要があるときにTTNが誤ってコンテキスト/状態をワイプする可能性があります。 (もちろん、他の理由でもアップリンクが受信されない場合があります。)
また、7:30にTTIGを再起動し、その後600秒後に再び問題が発生しない場合はすべて問題が@ beitlerによる(すばらしい)分析が確認されたようです。約3:03または3:06。
avbentem
2020年02月09日
今日は時代を詳しく見てみました
TTIGからのログファイルも添付しました。
残念ながら、ISPの再接続時からではありません。
必要に応じて、長期ログを作成し、再接続も含まれるようにします
TTIG.log
タイムスケジュール(UTC + 1)
02:46RXメッセージ
02:51RXメッセージ
02:56RXメッセージ
02:58RXメッセージ
02:58ISPの再接続
03:01RXメッセージ
03:03RXメッセージ
03:06RXメッセージ
これ以上メッセージを受信しません
TTNコンソール
ステータス:接続されていません
最終確認日:2020年2月11日03:05:04
06:46 TTIGのショートアン/再プラグ(10秒間電源が入らない)
TTNコンソール
ステータス:接続済み
最終確認日:2020年2月11日06:47:12
06:48RXメッセージ
...。
ファイアウォールルールにエラーが見つかりました。CUPS(rjs.sm.tc)プライマリ接続は許可されておらず、CUPS-BACKUP(mh.sm.tc)のみが許可されていました。
JackGruber
2020年02月11日
ご報告いただきありがとうございます。問題を特定し、修正中です。 この問題はプロプライエタリコードベースにありますが、ここでクローズされます。
 johanstokking
2020年02月12日
johanstokking
2020年02月12日
今日の午後+/- 18時間以降、バックエンドで何か変更がありましたか?
TTN Indoor Gatewayを10分以上実行することはほぼ不可能ですが、私が知る限り、数か月間は正常に機能していました。
DHCPサーバーを介してIPアドレスを変更すると、TTNネットワークに10分間接続できますが、その後再び失われます。 (再プラグも10分間機能します)
 TD-er
2020年02月13日
TD-er
2020年02月13日
@ TD-er、10分(600秒)以上プラグを抜いたままにしましたか?
上で説明したように、それは2月6日の変更以来必要とされています。 2月7日までに、60秒間プラグを抜いたままにする必要がありました。 今日のマージされた修正も展開されているかどうかは私にはわかりません。
avbentem
2020年02月13日
いいえ、それほど長くプラグを抜いてはいけません。
プラグを抜くと、数秒間しかプラグが抜かれませんでした。
IPアドレスのDHCP変更により、ユニットの電源を入れ直すことはなく、DHCPサーバーから新しいIPを受信しただけで、ネットワーク接続が再構築されました。 これにより、再び使用できなくなるまで、ほぼ正確に10分間動作しました。
しばらくプラグを抜いてから、再度プラグを差し込んだ後に何が起こるかを確認します。
TD-er
2020年02月13日
約25分間電源を切り、約15分間接続しても、まだ機能しています:)明日の朝も実行されるかどうかを確認します。
TD-er
2020年02月14日
本日、修正を含むv3.5.3をリリースし、TTIGが接続するサーバーにそれを展開できる可能性があります。 うまくいけば、それはすぐに解決されるでしょう。
johanstokking
2020年02月14日
私の屋内ゲートウェイはすでに約3時間オフラインになっているので、まだ展開されていないことを期待しましょう。
TD-er
2020年02月14日
最新の修正プログラムの展開後、この問題は発生していません。 再度観察された場合は、お気軽に再開してください。
KrishnaIyer
2020年02月24日
関連する問題
 ecities
·
5コメント
ecities
·
5コメント
 kschiffer
·
7コメント
kschiffer
·
7コメント
 adriansmares
·
9コメント
adriansmares
·
9コメント
 bafonins
·
5コメント
johanstokking
·
6コメント
bafonins
·
5コメント
johanstokking
·
6コメント
最も参考になるコメント
こんにちはクリシュナ、問題はサーバー側の切断に関連しているのではなく、サーバーが汚れたクライアント側の切断を処理して即座に再接続する方法に関連しています。 この問題は、すべてのBasic Stationベースのゲートウェイに影響し、上記の手順で確実に再現できます。
エラーパターンは次のようになります。
タイムアウトを60秒から600秒に増やすと、問題がさらに深刻になりました。60秒の場合、TTIGのプラグを抜いたユーザーは、問題が発生しないように、プラグを差し込む前に60秒待つ必要がありました。 これは、特に出荷時設定へのリセットを行う場合に、十分な頻度で発生した可能性があります。 600が増えると、より多くの割合で問題が発生します。これも観察される可能性があります。
このタイムアウトを完全に無効にするのは害がありますか? Basic StationはデフォルトでTCPを維持します(https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637)。 接続の活性をチェックするにはそれで十分ではありませんか?