Pytorch: posible interbloqueo en el cargador de datos
el error se describe en pytorch/examples#148. Solo me pregunto si esto es un error en PyTorch, ya que el código de ejemplo me parece limpio. Además, me pregunto si esto está relacionado con el #1120.
 zym1010
zym1010
Todos 189 comentarios
¿Cuánta memoria libre tienes cuando el cargador se detiene?
 apaszke
en 25 abr. 2017
apaszke
en 25 abr. 2017
@apaszke si top , la memoria restante (la memoria en caché también cuenta como usada) suele ser de 2 GB. Pero si no cuenta el almacenamiento en caché como usado, siempre es mucho, digamos más de 30 GB.
zym1010
en 25 abr. 2017
Además, no entiendo por qué siempre se detiene al comienzo de la validación, pero no en todos los demás lugares.
zym1010
en 25 abr. 2017
Posiblemente porque para la validación se usa un cargador separado que empuja el uso de la memoria compartida por encima del límite.
 ngimel
en 25 abr. 2017
ngimel
en 25 abr. 2017
@ngimel
Acabo de ejecutar el programa de nuevo. Y se quedó atascado.
Salida de top :
~~~
arriba - 17:51:18 hasta 2 días, 21:05, 2 usuarios, promedio de carga: 0.49, 3.00, 5.41
Tareas: 357 en total, 2 en ejecución, 355 durmiendo, 0 detenido, 0 zombi
%Cpu(s): 1,9 us, 0,1 sy, 0,7 ni, 97,3 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st
KiB Mem: 65863816 total, 60115084 usado, 5748732 libre, 1372688 búfer
Intercambio de KiB: 5917692 en total, 620 usados, 5917072 gratis. 51154784 memoria caché
PID USUARIO PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3067 aalreja 20 0 143332 101816 21300 R 46.1 0.2 1631:44 Xvnc
16613 aalreja 30 10 32836 4880 3912 S 16,9 0,0 1:06,92 lámpara de fibra 3221 aalreja 20 0 8882348 1,017g 110120 S 1,3 1,6 579:06,87 MATLAB
1285 raíz 20 0 1404848 48252 25580 S 0.3 0.1 6:00.12 dockerd 16597 yimengz+ 20 0 25084 3252 2572 R 0.3 0.0 0:04.56 arriba
1 raíz 20 0 33616 4008 2624 S 0.0 0.0 0:01.43 inicio
~~~
Salida de free
~yimengzh_everyday@yimengzh :~$ gratistotal de búferes compartidos libres utilizados almacenados en cachéMem: 65863816 60122060 5741756 9954628 1372688 51154916-/+ búfer/caché: 7594456 58269360Permuta: 5917692 620 5917072~
Salida de nvidia-smi
~~~
yimengzh_everyday@yimengzh :~$ nvidia-smi
Mar 25 Abr 17:52:38 2017
+------------------------------------------------- ----------------------------+
| Versión del controlador NVIDIA-SMI 375.39: 375.39 |
|-----------------------------------------------+----------------- -----+-------------------------------------+
| Nombre de GPU Persistencia-M| Bus-Id Disp.A | Descorr. volátil ECC |
| Fan Temp Perf Pwr:Uso/Cap | Uso de memoria | GPU-Util Cómputo M. |
|===============================+================= =====+======================|
| 0 GeForce GTX TIT... Apagado | 0000:03:00.0 Desactivado | N/D |
| 30% 42C P8 14W / 250W | 3986MiB / 6082MiB | 0% Predeterminado |
+----------------------------------------+----------------- -----+-------------------------------------+
| 1 Tesla K40c de descuento | 0000:81:00.0 Desactivado | Apagado |
| 0% 46C P0 57W / 235W | 0MiB / 12205MiB | 0% Predeterminado |
+----------------------------------------+----------------- -----+-------------------------------------+
+------------------------------------------------- ----------------------------+
| Procesos: Memoria GPU |
| GPU PID Tipo Nombre del proceso Uso |
|================================================ ============================|
| 0 16509 C pitón 3970MiB |
+------------------------------------------------- ----------------------------+
~~~
No creo que sea un problema de memoria.
zym1010
en 25 abr. 2017
Hay límites separados para la memoria compartida. ¿Puedes probar ipcs -lm o cat /proc/sys/kernel/shmall y cat /proc/sys/kernel/shmmax ? Además, ¿se bloquea si usa menos trabajadores (por ejemplo, pruebe con el caso extremo de 1 trabajador)?
apaszke
en 26 abr. 2017
@apaszke
~~~
yimengzh_todos los dias@yimengzh :~$ ipcs -lm
------ Límites de memoria compartida --------
número máximo de segmentos = 4096
tamaño máximo de segmento (kbytes) = 18014398509465599
memoria compartida total máxima (kbytes) = 18446744073642442748
tamaño de segmento mínimo (bytes) = 1
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmall
18446744073692774399
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmmax
18446744073692774399
~~~
como te buscan
en cuanto a menos trabajadores, creo que no sucederá tan a menudo. (Puedo probar ahora). Pero creo que en la práctica necesito tantos trabajadores.
zym1010
en 26 abr. 2017
Tiene un máximo de 4096 segmentos de memoria compartida permitidos, tal vez eso sea un problema. Puede intentar aumentar eso escribiendo a /proc/sys/kernel/shmmni (tal vez intente 8192). Es posible que necesite privilegios de superusuario.
apaszke
en 26 abr. 2017
@apaszke bueno, estos son valores predeterminados tanto para Ubuntu como para CentOS 6... ¿Es realmente un problema?
zym1010
en 26 abr. 2017
@apaszke cuando ejecuta el programa de entrenamiento, ipcs -a realidad no muestra que se esté usando memoria compartida. ¿Es eso lo esperado?
zym1010
en 26 abr. 2017
@apaszke intentó ejecutar el programa (todavía 22 trabajadores) con la siguiente configuración en la memoria compartida y volvió a bloquearse.
~~~
yimengzh_todos los dias@yimengzh :~$ ipcs -lm
------ Límites de memoria compartida --------
número máximo de segmentos = 8192
tamaño máximo de segmento (kbytes) = 18014398509465599
memoria compartida total máxima (kbytes) = 18446744073642442748
tamaño de segmento mínimo (bytes) = 1
~~~
no probé un trabajador. primero, eso sería lento; segundo, si el problema es realmente un bloqueo total, definitivamente desaparecería.
zym1010
en 26 abr. 2017
La configuración predeterminada de ipcs es para la memoria compartida System V que no estamos usando, pero quería asegurarme de que los mismos límites no se aplican a la memoria compartida POSIX.
Definitivamente no torch.__version__ ? ¿Estás ejecutando en la ventana acoplable?
apaszke
en 26 abr. 2017
@apaszke Gracias. Ahora entiendo mucho mejor tu análisis.
Todos los demás resultados que se le muestran hasta cómo se realizan en una máquina Ubuntu 14.04 con 64 GB de RAM, dual Xeon y Titan Black (también hay un K40, pero no lo usé).
El comando para generar el problema es CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 20 --lr 0.01 --workers 22 --batch-size 256 /mnt/temp_drive_3/cv_datasets/ILSVRC2015/Data/CLS-LOC . No modifiqué el código en absoluto.
Instalé pytorch a través de pip, en Python 3.5. La versión de pytorch es 0.1.11_5 . No se ejecuta en Docker.
Por cierto, también intenté usar 1 trabajador. Pero lo hice en otra máquina (128 GB de RAM, dual Xeon, 4 Pascal Titan X, CentOS 6). Lo ejecuté usando CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 1 --lr 0.01 --workers 1 --batch-size 256 /ssd/cv_datasets/ILSVRC2015/Data/CLS-LOC y el registro de errores es el siguiente.
Epoch: [0][5003/5005] Time 2.463 (2.955) Data 2.414 (2.903) Loss 5.9677 (6.6311) Prec<strong i="14">@1</strong> 3.516 (0.545) Prec<strong i="15">@5</strong> 8.594 (2.262)
Epoch: [0][5004/5005] Time 1.977 (2.955) Data 1.303 (2.903) Loss 5.9529 (6.6310) Prec<strong i="16">@1</strong> 1.399 (0.545) Prec<strong i="17">@5</strong> 7.692 (2.262)
^CTraceback (most recent call last):
File "main.py", line 292, in <module>
main()
File "main.py", line 137, in main
prec1 = validate(val_loader, model, criterion)
File "main.py", line 210, in validate
for i, (input, target) in enumerate(val_loader):
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 168, in __next__
idx, batch = self.data_queue.get()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/queue.py", line 164, in get
self.not_empty.wait()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/threading.py", line 293, in wait
waiter.acquire()
el top mostró lo siguiente cuando se quedó con 1 trabajador.
~arriba - 08:34:33 hasta 15 días, 20:03, 0 usuarios, promedio de carga: 0.37, 0.39, 0.36Tareas: 894 en total, 1 en ejecución, 892 durmiendo, 0 detenido, 1 zombiCPU(s): 7.2%us, 2.8%sy, 0.0%ni, 89.7%id, 0.3%wa, 0.0%hi, 0.0%si, 0.0%stMem: 132196824k total, 131461528k usado, 735296k gratis, 347448k buffersIntercambio: 2047996k total, 22656k usado, 2025340k gratis, 125226796k en caché~
zym1010
en 26 abr. 2017
otra cosa que encontré es que, si modifiqué el código de entrenamiento, para que no pase por todos los lotes, digamos, solo entrene 50 lotes
if i >= 50:
break
entonces el interbloqueo parece desaparecer.
zym1010
en 26 abr. 2017
Pruebas adicionales parecen sugerir que este congelamiento ocurre con mucha más frecuencia si ejecuto el programa justo después de reiniciar la computadora. Después de que haya algo de caché en la computadora, parece que la frecuencia de este congelamiento es menor.
zym1010
en 27 abr. 2017
Lo intenté, pero no puedo reproducir este error de ninguna manera.
apaszke
en 4 may. 2017
Encontré un problema similar: el cargador de datos se detiene cuando termino una época y comenzará una nueva época.
 tiancheng-zhi
en 4 may. 2017
tiancheng-zhi
en 4 may. 2017
Establecer num_workers = 0 funciona. Pero el programa se ralentiza.
tiancheng-zhi
en 4 may. 2017
@apaszke, ¿ ha intentado primero reiniciar la computadora y luego ejecutar los programas? Para mí, esto garantiza la congelación. Acabo de probar la versión 0.12 y sigue igual.
Una cosa que me gustaría señalar es que instalé pytorch usando pip , ya que tengo un numpy vinculado a OpenBLAS instalado y el MKL de la nube anaconda de @soumith no funcionaría bien con él.
Básicamente, pytorch usa MKL y numpy usa OpenBLAS. Esto puede no ser ideal, pero creo que esto no debería tener nada que ver con el problema aquí.
zym1010
en 9 may. 2017
Lo investigué, pero nunca pude reproducirlo. MKL/OpenBLAS no debería estar relacionado con este problema. Probablemente sea algún problema con una configuración del sistema.
apaszke
en 9 may. 2017
@apaszke gracias. Acabo de probar python del repositorio oficial de anaconda y pytorch basado en MKL. Sigue siendo el mismo problema.
zym1010
en 9 may. 2017
Intenté ejecutar el código en Docker. Todavía atascado.
zym1010
en 11 may. 2017
Tenemos el mismo problema, ejecutando el ejemplo de entrenamiento pytorch/examples imagenet (resnet18, 4 trabajadores) dentro de un nvidia-docker usando 1 GPU de 4. Intentaré recopilar un seguimiento de gdb, si logro llegar al proceso .
Al menos se sabe que OpenBLAS tiene un problema de interbloqueo en la multiplicación de matrices, que ocurre relativamente raramente: https://github.com/xianyi/OpenBLAS/issues/937. Este error estaba presente al menos en OpenBLAS empaquetado en numpy 1.12.0.
 jsainio
en 7 jun. 2017
jsainio
en 7 jun. 2017
@jsainio También probé
Además, este problema se resuelve (al menos para mí), si apago pin_memory para el cargador de datos.
zym1010
en 7 jun. 2017
Parece que dos de los trabajadores mueren.
Durante el funcionamiento normal:
root<strong i="7">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 33.2 4.7 91492324 3098288 ? Ssl 10:51 1:10 python -m runne
user+ 58 76.8 2.3 91079060 1547512 ? Rl 10:54 1:03 python -m runne
user+ 59 76.0 2.2 91006896 1484536 ? Rl 10:54 1:02 python -m runne
user+ 60 76.4 2.3 91099448 1559992 ? Rl 10:54 1:02 python -m runne
user+ 61 79.4 2.2 91008344 1465292 ? Rl 10:54 1:05 python -m runne
después de encerrar:
root<strong i="11">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 24.8 4.4 91509728 2919744 ? Ssl 14:25 13:01 python -m runne
user+ 58 51.7 0.0 0 0 ? Z 14:27 26:20 [python] <defun
user+ 59 52.1 0.0 0 0 ? Z 14:27 26:34 [python] <defun
user+ 60 52.0 2.4 91147008 1604628 ? Sl 14:27 26:31 python -m runne
user+ 61 52.0 2.3 91128424 1532088 ? Sl 14:27 26:29 python -m runne
Para uno de los trabajadores que aún quedan, el comienzo de gdb stacktrace se ve así:
root<strong i="15">@b06f896d5c1d</strong>:~/mnt# gdb --pid 60
GNU gdb (GDB) 8.0
Attaching to process 60
[New LWP 65]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb) bt
#0 0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f36f52af8d4 in __new_sem_wait_slow.constprop.0 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#2 0x00007f36f52af97a in sem_wait@@GLIBC_2.2.5 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#3 0x00007f36f157efb1 in semlock_acquire (self=0x7f3656296458,
args=<optimized out>, kwds=<optimized out>)
at /home/ilan/minonda/conda-bld/work/Python-3.5.2/Modules/_multiprocessing/semaphore.c:307
#4 0x00007f36f5579621 in PyCFunction_Call (func=
<built-in method __enter__ of _multiprocessing.SemLock object at remote 0x7f3656296458>, args=(), kwds=<optimized out>) at Objects/methodobject.c:98
#5 0x00007f36f5600bd5 in call_function (oparg=<optimized out>,
pp_stack=0x7f36c7ffbdb8) at Python/ceval.c:4705
#6 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#7 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=1, kws=0x0, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0,
closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#8 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#9 0x00007f36f5557542 in function_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/funcobject.c:627
#10 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36561c7d08>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#11 0x00007f36f554077c in method_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/classobject.c:330
#12 0x00007f36f5524236 in PyObject_Call (
func=<method at remote 0x7f36556f9248>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#13 0x00007f36f55277d9 in PyObject_CallFunctionObjArgs (
callable=<method at remote 0x7f36556f9248>) at Objects/abstract.c:2445
#14 0x00007f36f55fc3a9 in PyEval_EvalFrameEx (f=<optimized out>,
throwflag=<optimized out>) at Python/ceval.c:3107
#15 0x00007f36f5601166 in fast_function (nk=<optimized out>, na=1,
n=<optimized out>, pp_stack=0x7f36c7ffc418,
func=<function at remote 0x7f36561c78c8>) at Python/ceval.c:4803
#16 call_function (oparg=<optimized out>, pp_stack=0x7f36c7ffc418)
at Python/ceval.c:4730
#17 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#18 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=4, kws=0x7f36f5b85060, kwcount=0, defs=0x0, defcount=0,
kwdefs=0x0, closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#19 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#20 0x00007f36f5557661 in function_call (
func=<function at remote 0x7f36e14170d0>,
arg=(<ImageFolder(class_to_idx={'n04153751': 783, 'n02051845': 144, 'n03461385': 582, 'n04350905': 834, 'n02105056': 224, 'n02112137': 260, 'n03938244': 721, 'n01739381': 59, 'n01797886': 82, 'n04286575': 818, 'n02113978': 268, 'n03998194': 741, 'n15075141': 999, 'n03594945': 609, 'n04099969': 765, 'n02002724': 128, 'n03131574': 520, 'n07697537': 934, 'n04380533': 846, 'n02114712': 271, 'n01631663': 27, 'n04259630': 808, 'n04326547': 825, 'n02480855': 366, 'n02099429': 206, 'n03590841': 607, 'n02497673': 383, 'n09332890': 975, 'n02643566': 396, 'n03658185': 623, 'n04090263': 764, 'n03404251': 568, 'n03627232': 616, 'n01534433': 13, 'n04476259': 868, 'n03495258': 594, 'n04579145': 901, 'n04266014': 812, 'n01665541': 34, 'n09472597': 980, 'n02095570': 189, 'n02089867': 166, 'n02009229': 131, 'n02094433': 187, 'n04154565': 784, 'n02107312': 237, 'n04372370': 844, 'n02489166': 376, 'n03482405': 588, 'n04040759': 753, 'n01774750': 76, 'n01614925': 22, 'n01855032': 98, 'n03903868': 708, 'n02422699': 352, 'n01560419': 1...(truncated), kw={}) at Objects/funcobject.c:627
#21 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36e14170d0>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#22 0x00007f36f55fe234 in ext_do_call (nk=1444355432, na=0,
flags=<optimized out>, pp_stack=0x7f36c7ffc768,
func=<function at remote 0x7f36e14170d0>) at Python/ceval.c:5034
#23 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3275
--snip--
Tuve un registro de errores similar, con el proceso principal atascado en: self.data_queue.get()
Para mí, el problema fue que usé opencv como cargador de imágenes. Y la función cv2.imread se colgaba indefinidamente sin error en una imagen particular de imagenet ("n01630670/n01630670_1010.jpeg")
Si dijiste que te funciona con num_workers = 0, no es eso. Pero pensé que podría ayudar a algunas personas con un seguimiento de error similar.
 M-Eng
en 9 jun. 2017
M-Eng
en 9 jun. 2017
Estoy ejecutando una prueba con num_workers = 0 actualmente, todavía no se bloquea. Estoy ejecutando el código de ejemplo de https://github.com/pytorch/examples/blob/master/imagenet/main.py. pytorch/vision ImageFolder parece usar PIL o pytorch/accimage internamente para cargar las imágenes, por lo que no hay OpenCV involucrado.
Con num_workers = 4 , ocasionalmente puedo obtener el tren de la primera época y validarlo por completo, y se bloquea a la mitad de la segunda época. Por lo tanto, es poco probable que haya un problema en la función de conjunto de datos/carga.
Parece algo así como una condición de carrera en ImageLoader que podría activarse relativamente raramente por una cierta combinación de hardware/software.
jsainio
en 9 jun. 2017
@ zym1010 gracias por el puntero, intentaré configurar pin_memory = False también para DataLoader.
jsainio
en 9 jun. 2017
Interesante. En mi configuración, configurando pin_memory = False y num_workers = 4 el ejemplo de imagenet se bloquea casi de inmediato y tres de los trabajadores terminan como procesos zombis:
root<strong i="8">@034c4212d022</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 6.7 2.8 92167056 1876612 ? Ssl 13:50 0:36 python -m runner
user+ 38 1.9 0.0 0 0 ? Z 13:51 0:08 [python] <defunct>
user+ 39 4.3 2.3 91069804 1550736 ? Sl 13:51 0:19 python -m runner
user+ 40 2.0 0.0 0 0 ? Z 13:51 0:09 [python] <defunct>
user+ 41 4.1 0.0 0 0 ? Z 13:51 0:18 [python] <defunct>
En mi configuración, el conjunto de datos se encuentra en un disco en red que se lee a través de NFS. Con pin_memory = False y num_workers = 4 puedo hacer que el sistema falle bastante rápido.
=> creating model 'resnet18'
- training epoch 0
Epoch: [0][0/5005] Time 10.713 (10.713) Data 4.619 (4.619) Loss 6.9555 (6.9555) Prec<strong i="8">@1</strong> 0.000 (0.000) Prec<strong i="9">@5</strong> 0.000 (0.000)
Traceback (most recent call last):
--snip--
imagenet_pytorch.main.main([data_dir, "--transient_dir", context.transient_dir])
File "/home/user/mnt/imagenet_pytorch/main.py", line 140, in main
train(train_loader, model, criterion, optimizer, epoch, args)
File "/home/user/mnt/imagenet_pytorch/main.py", line 168, in train
for i, (input, target) in enumerate(train_loader):
File "/home/user/anaconda/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 206, in __next__
idx, batch = self.data_queue.get()
File "/home/user/anaconda/lib/python3.5/multiprocessing/queues.py", line 345, in get
return ForkingPickler.loads(res)
File "/home/user/anaconda/lib/python3.5/site-packages/torch/multiprocessing/reductions.py", line 70, in rebuild_storage_fd
fd = df.detach()
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError
:
[Errno 104] Connection reset by peer
@ zym1010 , ¿tiene un disco en red o un disco giratorio tradicional que podría tener una latencia más lenta, etc.?
jsainio
en 9 jun. 2017
@jsainio
Estoy usando un SSD local en el nodo de cómputo del clúster. El código está en una unidad NFS, pero los datos están en el SSD local, para una velocidad de carga máxima. Nunca intenté cargar datos en unidades NFS.
zym1010
en 9 jun. 2017
@ zym1010 Gracias por la información. También estoy ejecutando esto en un nodo de cómputo de un clúster.
En realidad, estoy ejecutando el experimento num_workers = 0 en el mismo nodo al mismo tiempo mientras pruebo las variaciones de num_workers = 4 . Puede ser que el primer experimento esté generando suficiente carga para que las posibles condiciones de carrera se manifiesten más rápido en el segundo.
jsainio
en 9 jun. 2017
@apaszke Cuando intentó reproducir esto anteriormente, ¿intentó ejecutar dos instancias una al lado de la otra o con alguna otra carga significativa en el sistema?
jsainio
en 9 jun. 2017
@jsainio ¡ Gracias por investigar esto! Eso es extraño, los trabajadores solo deben salir juntos, y una vez que el proceso principal haya terminado, lea los datos. ¿Puedes intentar inspeccionar por qué salen prematuramente? ¿Tal vez verifique el registro del kernel ( dmesg )?
apaszke
en 9 jun. 2017
No, no lo he probado, pero parecía aparecer incluso cuando ese no era el caso IIRC
apaszke
en 9 jun. 2017
@apaszke Ok, es bueno saber que los trabajadores no deberían haber salido.
Lo he intentado pero no conozco una buena manera de comprobar por qué salen. dmesg no muestra nada relevante. (Estoy ejecutando en un Docker derivado de Ubuntu 16.04, usando paquetes de Anaconda)
jsainio
en 9 jun. 2017
Una forma sería agregar una cantidad de impresiones dentro del ciclo de trabajo . No tengo idea de por qué salen en silencio. Probablemente no sea una excepción, porque se habría impreso en stderr, por lo que se salen del bucle o el sistema operativo los elimina (¿quizás por una señal?)
apaszke
en 9 jun. 2017
@jsainio , solo para asegurarse, ¿está ejecutando docker con --ipc=host (no menciona esto)? ¿Puede verificar el tamaño de su segmento de memoria compartida (df -h | grep shm)?
ngimel
en 9 jun. 2017
@ngimel estoy usando --shm-size=1024m . df -h | grep shm informa en consecuencia:
root<strong i="9">@db92462e8c19</strong>:~/mnt# df -h | grep shm
shm 1.0G 883M 142M 87% /dev/shm
Ese uso parece bastante difícil. Esto está en una ventana acoplable con dos trabajadores zombis.
jsainio
en 12 jun. 2017
¿Puedes intentar aumentar el tamaño de shm? Acabo de comprobar y en el servidor donde traté de reproducir los problemas eran 16 GB. O cambias la bandera de la ventana acoplable o ejecutas
mount -o remount,size=8G /dev/shm
Intenté disminuir el tamaño a 512 MB, pero obtuve un error claro en lugar de un punto muerto. Todavía no puedo reproducirme 😕
apaszke
en 14 jun. 2017
Con la ventana acoplable, tendemos a tener interbloqueos cuando shm no es suficiente, en lugar de borrar mensajes de error, no sé por qué. Pero generalmente se cura aumentando shm (y obtuve interbloqueos con 1G).
ngimel
en 14 jun. 2017
Ok, parece que con 10 trabajadores aparece un error, pero cuando uso 4 trabajadores obtengo un interbloqueo en el 58% del uso de /dev/shm. por fin lo reproduje
apaszke
en 14 jun. 2017
Es genial que puedas reproducir una forma de este problema. Publiqué una secuencia de comandos que provoca un bloqueo en el n.º 1579 y usted respondió que no se bloqueó en su sistema. De hecho, solo lo había probado en mi MacBook. Acabo de probar en Linux, y no se bloqueó. Entonces, si solo probó en Linux, también podría valer la pena probar en una Mac.
 greaber
en 14 jun. 2017
greaber
en 14 jun. 2017
Ok, después de investigar el problema, parece ser un problema extraño. Incluso cuando limito /dev/shm a solo 128 MB de tamaño, Linux se complace en permitirnos crear archivos de 147 MB allí, asignarlos completamente en la memoria, pero enviará un SIGBUS mortal al trabajador una vez que realmente intente acceder a las páginas. ... No puedo pensar en ningún mecanismo que nos permita verificar la validez de las páginas, excepto iterar sobre ellas y tocar cada una, con un controlador SIGBUS registrado ...
Una solución por ahora es expandir /dev/shm con el comando mount como se muestra arriba. Pruebe con 16 GB (ofc si tiene suficiente RAM).
apaszke
en 15 jun. 2017
Es difícil encontrar alguna mención de esto, pero aquí hay uno .
apaszke
en 15 jun. 2017
Gracias por su tiempo sobre este tema, ¡me ha estado volviendo loco durante mucho tiempo! Si entiendo correctamente, necesito expandir /dev/shm para que sea 16G en lugar de 8G. Tiene sentido, pero cuando intento df -h , puedo ver que toda mi memoria RAM está realmente asignada como tal: (tengo 16G)
tmpfs 7,8G 393M 7,4G 5% /dev/shm
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,8G 0 7,8G 0% /sys/fs/cgroup
tmpfs 1,6G 60K 1,6G 1% /run/user/1001
Esta es la salida de df -h durante un interbloqueo. Según tengo entendido, si tengo una partición SWAP de 16G, puedo montar tmpfs hasta 32G, por lo que no debería ser un problema expandir /dev/shm , ¿verdad?
Más importante aún, estoy desconcertado acerca de la partición cgroup y su propósito, ya que ocupa casi la mitad de mi RAM. Aparentemente, está diseñado para administrar de manera eficiente tareas de múltiples procesadores, pero realmente no estoy familiarizado con lo que hace y por qué lo necesitamos, ¿cambiaría algo para asignar toda la RAM física a shm (porque configuramos su tamaño en 16G) y ponerlo en SWAP (aunque creo que ambos estarán en parte en la RAM y SWAP simultáneamente)
 ClementPinard
en 15 jun. 2017
ClementPinard
en 15 jun. 2017
@apaszke Gracias! Genial que hayas encontrado la causa subyacente. Ocasionalmente recibía varios errores de "Reinicio de conexión" y puntos muertos con la ventana acoplable --shm-size=1024m dependiendo de qué otra carga había en la máquina. Probando ahora con --shm-size=16384m y 4 trabajadores.
jsainio
en 15 jun. 2017
@jsainio ConnectionReset podría haber sido causado por lo mismo. Los procesos comenzaron a intercambiar algunos datos, pero una vez que shm se quedó sin espacio, se envió un SIGBUS al trabajador y lo eliminó.
@ClementPinard , según tengo entendido, puede hacerlo tan grande como desee, excepto que probablemente congelará su máquina una vez que se quede sin RAM (porque incluso el kernel no puede liberar esta memoria). Probablemente no necesite preocuparse por /sys/fs/cgroup . tmpfs particiones shm para decir 12 GB y limitar la cantidad de trabajadores (como dije, ¡No uses toda tu RAM para shm!). Aquí hay un buen artículo sobre tmpfs de la documentación del kernel.
No sé por qué ocurre el interbloqueo incluso cuando el uso de /dev/shm es muy pequeño (ocurre a 20kB en mi máquina). Tal vez el núcleo es demasiado optimista, pero no espera hasta que lo llene todo y termina el proceso una vez que comienza a usar algo de esta región.
apaszke
en 15 jun. 2017
Probando ahora con 12G y la mitad de los trabajadores que tenía, y falló :(
Estaba funcionando de maravilla en la versión lua torch (misma velocidad, mismo número de trabajadores), lo que me hace preguntarme si el problema solo está relacionado con /dev/shm y no está más cerca del multiprocesamiento de Python...
Lo extraño de esto (como mencionaste) es que /dev/shm nunca está cerca de estar lleno. Durante la primera época de entrenamiento, nunca superó los 500Mo. Y tampoco se bloquea durante la primera época, y si cierro la prueba, el cargador de trenes nunca falla en todas las épocas. El interbloqueo parece aparecer solo cuando comienza la época de prueba. Debería hacer un seguimiento de /dev/shm cuando vaya del tren a la prueba, tal vez haya un uso máximo durante el cambio de los cargadores de datos.
ClementPinard
en 15 jun. 2017
@ClementPinard, incluso con una memoria compartida más alta y sin Docker, aún puede fallar.
zym1010
en 15 jun. 2017
Si la versión de la antorcha == Lua Torch, entonces aún podría estar relacionado con /dev/shm . Lua Torch puede usar subprocesos (no hay GIL), por lo que no necesita pasar por una memoria compartida (todos comparten un solo espacio de direcciones).
apaszke
en 15 jun. 2017
Tuve el mismo problema en el que el cargador de datos falla después de quejarse de que no podía asignar memoria al comienzo de una nueva época de capacitación o validación. Las soluciones anteriores no me funcionaron (i) mi /dev/shm tiene 32 GB y nunca se usó más de 2,5 GB, y (ii) configurar pin_memory=False no funcionó.
¿Quizás esto tenga algo que ver con la recolección de basura? Mi código se ve más o menos como el siguiente. Necesito un iterador infinito y, por lo tanto, pruebo / excepto alrededor del next() continuación :-)
def train():
train_iter = train_loader.__iter__()
for i in xrange(max_batches):
try:
x, y = next(train_iter)
except StopIteration:
train_iter = train_loader.__iter__()
...
del train_iter
train_loader es un objeto DataLoader . Sin la línea explícita del train_iter al final de la función, el proceso siempre falla después de 2 o 3 épocas ( /dev/shm todavía muestra 2,5 GB). ¡Espero que esto ayude!
Estoy usando 4 trabajadores (versión 0.1.12_2 con CUDA 8.0 en Ubuntu 16.04).
 pratikac
en 7 jul. 2017
pratikac
en 7 jul. 2017
También encontré el interbloqueo, especialmente cuando el número de trabajo es grande. ¿Hay alguna solución posible para este problema? Mi tamaño de /dev/shm es de 32 GB, con cuda 7.5, pytorch 0.1.12 y python 2.7.13. La siguiente es información relacionada después de la muerte. Parece relacionado con la memoria. @apaszke

 zhengyunqq
en 4 ago. 2017
zhengyunqq
en 4 ago. 2017
@zhengyunqq prueba pin_memory=False si lo configuras en True . De lo contrario, no estoy al tanto de ninguna solución.
zym1010
en 4 ago. 2017
También encontré el punto muerto cuando num_workers es grande.
 hendrycks
en 11 ago. 2017
hendrycks
en 11 ago. 2017
Para mí, el problema era que si un subproceso de trabajo muere por cualquier motivo, entonces index_queue.put bloquea para siempre. Una de las razones por las que los subprocesos de trabajo mueren es que el despickler falla durante la inicialización. En ese caso, hasta esta corrección de
Tal vez un reemplazo de SimpleQueue usado en DataLoaderIter por Queue que permite un tiempo de espera con un mensaje de excepción correcto.
UPD: Me equivoqué, esta corrección de errores parchea Queue , no SimpleQueue . Todavía es cierto que SimpleQueue se bloqueará si no hay subprocesos de trabajo en línea. Una manera fácil de verificar eso es reemplazar estas líneas con self.workers = [] .
 vadimkantorov
en 16 ago. 2017
vadimkantorov
en 16 ago. 2017
tengo el mismo problema y no puedo cambiar shm (sin permiso), ¿tal vez sea mejor usar Queue o algo más?
 xfanplus
en 8 sept. 2017
xfanplus
en 8 sept. 2017
Tengo un problema similar.
Este código se congelará y nunca imprimirá nada. Sin embargo, si configuro num_workers = 0, funcionará
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
model.cuda()
for i, batch in enumerate(dataloader):
print(i)
Si pongo model.cuda() detrás del bucle, todo funcionará bien.
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
for i, batch in enumerate(dataloader):
print(i)
model.cuda()
¿Alguien tiene una solución para ese problema?
 anDoer
en 13 sept. 2017
anDoer
en 13 sept. 2017
También me he encontrado con problemas similares mientras entrenaba ImageNet. Se colgará en la primera iteración de la evaluación de manera consistente en ciertos servidores con cierta arquitectura (y no en otros servidores con la misma arquitectura o el mismo servidor con una arquitectura diferente), pero siempre en la primera iteración durante la evaluación en la validación. Cuando estaba usando Torch, descubrimos que nccl puede causar un punto muerto como este, ¿hay alguna forma de apagarlo?
 WendyShang
en 20 sept. 2017
WendyShang
en 20 sept. 2017
Estoy enfrentando el mismo problema, me quedo atascado aleatoriamente al comienzo de la primera época. Todas las soluciones mencionadas anteriormente no funcionan para mí. Cuando se presiona Ctrl-C, imprime esto:
Traceback (most recent call last):
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 249, in _bootstrap
self.run()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 44, in _worker_loop
data_queue.put((idx, samples))
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/queues.py", line 354, in put
self._writer.send_bytes(obj)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 200, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 398, in _send_bytes
self._send(buf)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
KeyboardInterrupt
Traceback (most recent call last):
File "scripts/train_model.py", line 640, in <module>
main(args)
File "scripts/train_model.py", line 193, in main
train_loop(args, train_loader, val_loader)
File "scripts/train_model.py", line 341, in train_loop
ee_optimizer.step()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/optim/adam.py", line 74, in step
p.data.addcdiv_(-step_size, exp_avg, denom)
KeyboardInterrupt
 zoharli
en 23 oct. 2017
zoharli
en 23 oct. 2017
Tuve un problema similar al tener un interbloqueo con un solo trabajador dentro de la ventana acoplable y puedo confirmar que en mi caso fue el problema de la memoria compartida. Por defecto, la ventana acoplable solo parece asignar 64 MB de memoria compartida; sin embargo, necesitaba 440 MB para 1 trabajador, lo que probablemente causó el comportamiento descrito por @apaszke.
 paulguerrero
en 23 oct. 2017
paulguerrero
en 23 oct. 2017
Me preocupa el mismo problema, pero estoy en un entorno diferente al de la mayoría de los demás en este hilo, por lo que tal vez mis entradas puedan ayudar a localizar la causa subyacente. Mi pytorch está instalado usando el excelente paquete conda construido por peterjc123 bajo Windows10.
Estoy ejecutando algunos cnn en el conjunto de datos cifar10. Para los cargadores de datos, num_workers se establece en 1. Aunque se sabe que tener num_workers > 0 causa BrokenPipeError y se desaconseja en #494, lo que estoy experimentando no es BrokenPipeError sino algún error de asignación de memoria. El error siempre ocurría alrededor de 50 épocas, justo después de la validación de la última época y antes del inicio del entrenamiento para la próxima época. El 90% de las veces son precisamente 50 épocas, otras veces estará desfasado por 1 o 2 épocas. Aparte de eso, todo lo demás es bastante consistente. Establecer num_workers=0 eliminará este problema.
 berzjackson
en 24 oct. 2017
berzjackson
en 24 oct. 2017
@paulguerrero tiene razón. Resolví este problema aumentando la memoria compartida de 64M a 2G. Tal vez sea útil para los usuarios de Docker.
 yjzhux
en 24 oct. 2017
yjzhux
en 24 oct. 2017
@berzjackson Ese es un error conocido en el paquete conda. Solucionado en las últimas compilaciones de CI.
 peterjc123
en 25 oct. 2017
peterjc123
en 25 oct. 2017
Tenemos ~600 personas que comenzaron un nuevo curso que usa Pytorch el lunes. Mucha gente en nuestro foro está reportando este problema. Algunos en AWS P2, otros en sus propios sistemas (principalmente GTX 1070, algunos Titan X).
Cuando interrumpen el entrenamiento, el final del seguimiento de la pila muestra:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv_bytes(self, maxsize)
405
406 def _recv_bytes(self, maxsize=None):
--> 407 buf = self._recv(4)
408 size, = struct.unpack("!i", buf.getvalue())
409 if maxsize is not None and size > maxsize:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv(self, size, read)
377 remaining = size
378 while remaining > 0:
--> 379 chunk = read(handle, remaining)
380 n = len(chunk)
381 if n == 0:
Tenemos num_workers=4, pin_memory=False. Les pedí que verifiquen la configuración de su memoria compartida, pero ¿hay algo que pueda hacer (o que podamos hacer en Pytorch) para que este problema desaparezca? (Aparte de reducir num_workers, ya que eso ralentizaría bastante las cosas).
 jph00
en 1 nov. 2017
jph00
en 1 nov. 2017
Estoy en la clase @ jph00 (¡gracias Jeremy! :)) a la que se hace referencia. Intenté usar "num_workers=0" también. Sigo recibiendo el mismo error donde resnet34 se carga muy lentamente. El montaje también es muy lento. Pero algo extraño: esto solo sucede una vez en la vida útil de una sesión de cuaderno.
En otras palabras, una vez que se cargan los datos y se ejecuta la adaptación una vez, puedo moverme y seguir repitiendo los pasos... incluso con 4 num_workers, y todo parece funcionar tan rápido como se esperaba en una GPU.
Estoy en PyTorch 0.2.0_4, Python 3.6.2, Torchvision 0.1.9, Ubuntu 16.04 LTS. Hacer "df -h" en mi terminal dice que tengo 16 GB en /dev/shm, aunque la utilización fue muy baja.
Aquí hay una captura de pantalla de donde falla la carga (nota que he usado num_workers=0 para los datos)
(Perdón por las letras pequeñas. Tuve que alejar el zoom para capturar todo...)

 apiltamang
en 1 nov. 2017
apiltamang
en 1 nov. 2017
@apiltamang No estoy seguro de que sea el mismo problema, no parece tener los mismos síntomas. Es mejor que lo diagnostiquemos en el foro fast.ai, no aquí.
jph00
en 1 nov. 2017
investigando esto lo antes posible!
 soumith
en 1 nov. 2017
soumith
en 1 nov. 2017
@soumith Le he dado acceso a @apaszke al foro privado del curso y le he pedido a los estudiantes con el problema que nos den acceso para iniciar sesión en su casilla.
jph00
en 1 nov. 2017
@jph00 Hola, Jeremy, ¿alguno de los estudiantes intentó aumentar shm como @apaszke mencionó anteriormente? ¿Fue útil?
 SsnL
en 1 nov. 2017
SsnL
en 1 nov. 2017
@SsnL, uno de los estudiantes ha confirmado que ha aumentado la memoria compartida y aún tiene el problema. Le he pedido a otros que confirmen también.
jph00
en 1 nov. 2017
@jph00 ¡Gracias! Reproduje con éxito el bloqueo debido a la poca memoria compartida. Si el problema está en otra parte, ¡tendré que profundizar más! ¿Te importaría compartir el guión conmigo?
SsnL
en 1 nov. 2017
Claro, aquí está el cuaderno que estamos usando: https://github.com/fastai/fastai/blob/master/courses/dl1/lesson1.ipynb . Los estudiantes notaron que el problema solo ocurre cuando ejecutan todas las celdas en el orden en que están en el cuaderno. Con suerte, el cuaderno se explica por sí mismo, pero avíseme si tiene algún problema para ejecutarlo; incluye un enlace para descargar los datos necesarios.
Según el problema de la memoria compartida que podría replicar, ¿hay algún tipo de solución alternativa que pueda agregar a nuestra biblioteca o cuaderno que lo evite?
jph00
en 1 nov. 2017
@ jph00 Profundizando en el código ahora mismo. Intentaré encontrar formas de reducir el uso de la memoria compartida. No parece que el script deba usar una gran cantidad de shm, ¡así que hay esperanza!
También enviaré un PR para mostrar un buen mensaje de error al alcanzar el límite de shm en lugar de simplemente dejarlo colgado.
SsnL
en 1 nov. 2017
Bien, he replicado el problema en una nueva instancia de AWS P2 utilizando su CUDA 9 AMI con la última instalación de Pytorch conda. Si proporciona su clave pública, puedo darle acceso para probarlo directamente. Mi correo electrónico es la primera letra de mi nombre en fast.ai
jph00
en 1 nov. 2017
@ jph00 Acabo de
SsnL
en 1 nov. 2017
@ jph00 Y para su información, el script tomó 400 MB de memoria compartida en mi caja. Por lo tanto, sería genial que los estudiantes que tuvieron este problema comprobaran que tienen suficiente shm libre.
SsnL
en 1 nov. 2017
Bien, he descubierto el problema básico, que es que el multiprocesamiento de opencv y Pytorch no funcionan bien juntos, a veces. No hubo problemas en nuestra caja en la universidad, pero sí muchos problemas en AWS (en la nueva AMI CUDA 9 de aprendizaje profundo con instancia P2). Agregar bloqueo alrededor de todas las llamadas cv2 no lo soluciona, y agregar cv2.setNumThreads(0) no lo soluciona. Esto parece solucionarlo:
from multiprocessing import set_start_method
set_start_method('spawn')
Sin embargo, eso afecta el rendimiento en aproximadamente un 15%. La recomendación en el problema de opencv github es usar https://github.com/tomMoral/loky . He usado ese módulo antes y lo encontré sólido como una roca. No es urgente, ya que tenemos una solución que funciona lo suficientemente bien por ahora, pero ¿podría valer la pena considerar usar Loky para Dataloader?
Quizás lo más importante, sería bueno si al menos hubiera algún tipo de tiempo de espera en la cola de pytorch para que estos bloqueos infinitos quedaran atrapados.
jph00
en 2 nov. 2017
Para su información, probé una solución diferente, ya que 'spawn' estaba haciendo algunas partes 2-3 veces más lentas, que es que agregué algunas pausas aleatorias en secciones que iteran rápidamente a través del cargador de datos. Eso también solucionó el problema, ¡aunque quizás no sea lo ideal!
jph00
en 2 nov. 2017
¡Gracias por profundizar en esto! Me alegra saber que ha encontrado dos soluciones. De hecho, sería bueno agregar tiempos de espera en la indexación en conjuntos de datos. Hablaremos y nos pondremos en contacto con usted en esa ruta mañana.
cc @soumith es loky algo que queremos investigar?
SsnL
en 2 nov. 2017
Para las personas que acuden a este hilo para la discusión anterior, el problema de opencv se analiza con mayor profundidad en https://github.com/opencv/opencv/issues/5150
SsnL
en 2 nov. 2017
Bien, parece que tengo una solución adecuada para esto ahora: reescribí Dataloader para el usuario ProcessPoolExecutor.map() y moví la creación del tensor al proceso principal. El resultado es más rápido de lo que estaba viendo con el Dataloader original, y ha sido estable en todas las computadoras en las que lo probé. El código también es mucho más simple.
Si alguien está interesado en usarlo, puede obtenerlo en https://github.com/fastai/fastai/blob/master/fastai/dataloader.py .
La API es la misma que la versión estándar, excepto que su conjunto de datos no debe devolver un tensor de Pytorch; debe devolver matrices numpy o listas de python. No he hecho ningún intento de hacer que funcione en Pythons más antiguos, por lo que no me sorprendería si hay algunos problemas allí.
(La razón por la que he seguido este camino es que al hacer mucho procesamiento/aumento de imágenes en GPU recientes, descubrí que no podía completar el procesamiento lo suficientemente rápido como para mantener ocupada la GPU, si hacía el preprocesamiento usando la CPU Pytorch operaciones; sin embargo, usar opencv fue mucho más rápido y, como resultado, pude utilizar completamente la GPU).
jph00
en 2 nov. 2017
Oh, si es un problema de OpenCV, entonces no hay mucho que podamos hacer al respecto. Es cierto que la bifurcación es peligrosa cuando tienes grupos de subprocesos. No creo que queramos agregar una dependencia de tiempo de ejecución (actualmente no tenemos ninguna), especialmente porque no manejará bien los tensores de PyTorch. Sería mejor averiguar qué está causando los interbloqueos y @SsnL está en ello.
@ jph00 ¿Has probado Pillow-SIMD? Debería funcionar con torchvision desde el primer momento y he oído muchas cosas buenas al respecto.
apaszke
en 2 nov. 2017
Sí, conozco bien la almohada SIMD. Solo acelera el cambio de tamaño, el desenfoque y la conversión RGB.
No estoy de acuerdo, no hay mucho que puedas hacer aquí. No es exactamente un problema de opencv (no afirman admitir este tipo de multiprocesamiento de python de manera más general, y mucho menos el módulo de multiprocesamiento de carcasa especial de pytorch) y tampoco es exactamente un problema de Pytorch. Pero el hecho de que Pytorch espere en silencio para siempre sin dar ningún tipo de error es (en mi opinión) algo que se puede arreglar y, en general, mucha gente inteligente ha estado trabajando duro durante los últimos años para crear enfoques mejorados de multiprocesamiento que eviten problemas simplemente como éste. Puede tomar prestado de los enfoques que utilizan sin generar una dependencia externa.
Olivier Grisel, quien es una de las personas detrás de Loky, tiene una excelente plataforma de diapositivas que resume el estado del multiprocesamiento en Python: http://ogrisel.github.io/decks/2017_euroscipy_parallelism/
No me importa de ninguna manera, ya que ahora he escrito un nuevo Dataloader que no tiene el problema. Pero sí, FWIW, sospecho que las interacciones entre el multiprocesamiento de pytorch y otros sistemas también serán un problema para otras personas en el futuro.
jph00
en 2 nov. 2017
Por lo que vale, tuve este problema en Python 2.7 en ubuntu 14.04. Mi cargador de datos leyó de una base de datos sqlite y funcionó perfectamente con num_workers=0 , a veces parecía estar bien con num_workers=1 , y se bloqueaba muy rápidamente para cualquier valor más alto. Los seguimientos de la pila mostraron que el proceso se colgó en recv_bytes .
Cosas que no funcionaron:
- Pasar
--shm-size 8Go--ipc=hostal iniciar la ventana acoplable - Ejecutar
echo 16834 | sudo tee /proc/sys/kernel/shmmnipara aumentar la cantidad de segmentos de memoria compartida (el valor predeterminado era 4096 en mi máquina) - Configurando
pin_memory=Trueopin_memory=False, ninguno ayudó
Lo que solucionó mi problema de manera confiable fue transferir mi código a Python 3. Lanzar la misma versión de Torch dentro de una instancia de Python 3.6 (de Anaconda) solucionó completamente mi problema y ahora la carga de datos ya no se bloquea.
 gcr
en 16 nov. 2017
gcr
en 16 nov. 2017
@apaszke he aquí por qué es importante trabajar bien con opencv, FYI (y por qué torchsample no es una gran opción, ¡puede manejar una rotación de <200 imágenes/seg!):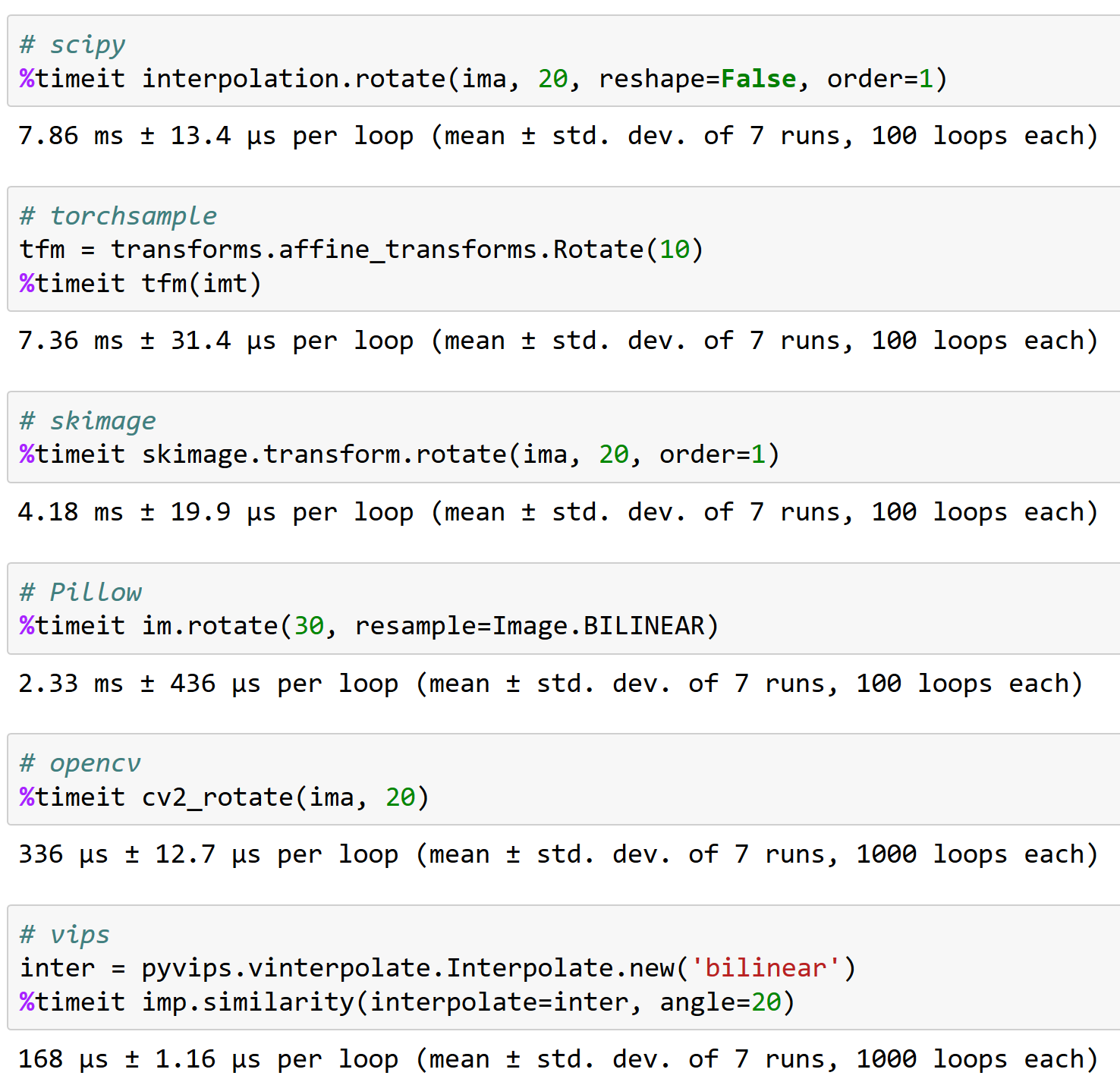
jph00
en 18 nov. 2017
¿Alguien encontró una solución a este problema?
 iqbalu
en 9 dic. 2017
iqbalu
en 9 dic. 2017
@iqbalu Prueba el script anterior: https://github.com/fastai/fastai/blob/master/fastai/dataloader.py
Resolvió mi problema pero no es compatible con num_workers=0 .
 elbaro
en 14 dic. 2017
elbaro
en 14 dic. 2017
@elbaro en realidad lo probé y en mi caso no estaba usando varios trabajadores en absoluto. ¿Cambiaste algo ahí?
iqbalu
en 14 dic. 2017
El cargador de datos
apaszke
en 14 dic. 2017
@apaszke @elbaro @jph00 El cargador de datos de fast.ai ralentizó la lectura de datos en más de 10 veces. Estoy usando num_workers=8. ¿Alguna pista de cuál podría ser la razón?
iqbalu
en 15 dic. 2017
Es probable que el cargador de datos use paquetes que no renuncian al GIL
apaszke
en 15 dic. 2017
@apaszke alguna idea de por qué el uso de la memoria compartida sigue aumentando después de algunas épocas. En mi caso, comienza con 400 MB y luego cada ~ 20 épocas aumenta en 400 MB. ¡Gracias!
iqbalu
en 28 dic. 2017
@iqbalu no realmente. Eso no debería estar pasando
apaszke
en 28 dic. 2017
Probé muchas cosas y cv2.setNumThreads(0) finalmente resolvió mi problema.
Gracias @jph00
 Cadene
en 19 ene. 2018
Cadene
en 19 ene. 2018
He estado preocupado por este problema recientemente. cv2.setNumThreads(0) no funciona para mí. Incluso cambio todo el código cv2 para usar scikit-image en su lugar, pero el problema persiste. Además, tengo 16G por /dev/shm . Solo tengo este problema cuando uso múltiples gpus. Todo funciona bien en una sola gpu. ¿Alguien tiene alguna idea nueva sobre la solución?
 roytseng-tw
en 25 ene. 2018
roytseng-tw
en 25 ene. 2018
Mismo error. Tengo este problema cuando uso solo gpu.
 Jiankai-Sun
en 27 ene. 2018
Jiankai-Sun
en 27 ene. 2018
Para mí, deshabilitar los hilos de OpenCV resolvió el problema:
cv2.setNumHilos(0)
 shacharf
en 28 ene. 2018
shacharf
en 28 ene. 2018
golpéalo también con pytorch 0.3, cuda 8.0, ubuntu 16.04
no se utiliza opencv.
 tianq01
en 1 feb. 2018
tianq01
en 1 feb. 2018
Estoy usando pytorch 0.3, cuda 8.0, ubuntu 14.04. Observé este bloqueo después de que comencé a usar cv2.resize()
cv2.setNumThreads(0) resolvió mi problema.
 mathmanu
en 9 feb. 2018
mathmanu
en 9 feb. 2018
Estoy usando python 3.6, pytorch 0.3.0, cuda 8.0 y ubuntu 17.04 en un sistema con dos 1080Ti y 32 GB de RAM.
Cuando uso 8 trabajadores para mi propio conjunto de datos, con frecuencia veo el punto muerto (sucede en la primera época). Cuando reduzco los trabajadores a 4, desaparece (corrí 80 épocas).
Cuando ocurre un interbloqueo, todavía tengo ~ 10 GB libres en RAM.
 milani
en 2 mar. 2018
milani
en 2 mar. 2018
Aquí puede ver el registro después de finalizar el script: https://gist.github.com/milani/42f50c023cdca407115b309237d29c70
ACTUALIZACIÓN: confirmo que pude resolver el problema aumentando SHMMNI. En Ubuntu 17.04, agregué kernel.shmmni=8192 a /etc/sysctl.conf .
milani
en 2 mar. 2018
También experimentan este problema Ubuntu 17.10, Python 3.6, Pytorch 0.3.1, CUDA 8.0. Queda mucha RAM cuando se produce el interbloqueo y el tiempo parece ser inconsistente; puede ocurrir después de la 1.ª época o después de la 200.ª.
La combinación de kernel.shmmni=8192 y cv2.setNumThreads(0) parece haberlo solucionado, mientras que no funcionaron individualmente.
 inoryy
en 8 mar. 2018
inoryy
en 8 mar. 2018
Lo mismo en mi caso. Experimenté un punto muerto si configuré num_workers=4. Uso Ubuntu 17.10, Pytorch 0.3.1, CUDA 9.1, Python 3.6. Se observa que hay 4 hilos de python, cada uno de los cuales ocupa 1,6 GB de memoria mientras la CPU (4 núcleos) permanece inactiva. Establecer num_workers=0 ayuda a resolver este problema.
 AlenUbuntu
en 27 mar. 2018
AlenUbuntu
en 27 mar. 2018
Tengo el mismo problema, se congela después de exactamente una época, pero no es realmente reproducible para conjuntos de datos más pequeños. Estoy usando CUDA 9.1, Pytorch 0.3.1, Python 3.6 en un entorno Docker.
Probé el
 tfriedel
en 11 abr. 2018
tfriedel
en 11 abr. 2018
Tuve exactamente el mismo problema en Ubuntu 17.10, CUDA 9.1, Pytorch master (compilado el 19/04 por la mañana). También uso OpenCV en mi subclase Dataset.
Luego pude evitar el interbloqueo cambiando el método de inicio de multiprocesamiento de 'forkserver' a 'spawn':
# Set multiprocessing start method - deadlock
set_start_method(forkserver')
# Set multiprocessing start method - runs fine
set_start_method('spawn')
 mfuntowicz
en 19 abr. 2018
mfuntowicz
en 19 abr. 2018
¡Casi probé todos los enfoques anteriores! ¡Ninguno de ellos funcionó!
¡Este problema podría estar relacionado con algunas incompatibilidades con la arquitectura del hardware y no sé cómo Pytorch puede provocarlo! ¡Puede o no ser el problema de Pytorch!
Así que así es como se ha resuelto mi problema:
_¡Actualizo la BIOS!
Dale un tiro. Al menos eso resuelve mi problema.
 astorfi
en 21 abr. 2018
astorfi
en 21 abr. 2018
Aquí igual. Ubuntu PyTorch 0.4, python3.6.
 Shuailong
en 30 abr. 2018
Shuailong
en 30 abr. 2018
Parece que el problema aún existe en pytorch 0.4 y python 3.6. No estoy seguro si es un problema de pytorch. Uso opencv y configuro num_workers=8 , pin_memory=True . Pruebo todos los trucos mencionados anteriormente y establecer cv2.setNumThreads(0) resuelve mi problema.
 JasonQSY
en 10 may. 2018
JasonQSY
en 10 may. 2018
(1) Establecer num_workers=0 en la carga de datos de PyTorch resuelve el problema (ver arriba) O
(2) cv2.setNumThreads(0) resuelve el problema incluso con un número razonablemente grande de trabajadores
Esto parece algún tipo de problema de bloqueo de subprocesos.
Establecí cv2.setNumThreads(0) en algún lugar hacia el comienzo de mi archivo principal de python y nunca he tenido este problema desde entonces.
mathmanu
en 10 may. 2018
Sí, muchos de esos problemas se deben a que las bibliotecas de terceros no son seguras para las bifurcaciones. Una resolución alternativa podría ser utilizar el método de inicio de generación.
apaszke
en 10 may. 2018
Para mí, el problema del interbloqueo surge cuando envuelvo mi modelo con nn.DataParallel y uso num_workers > 0 en el cargador de datos. Al eliminar el contenedor nn.DataParallel, puedo ejecutar mi script sin ningún tipo de bloqueo.
CUDA_VISIBLE_DEVICES=0 python myscript.py --dividir 1
CUDA_VISIBLE_DEVICES=1 python myscript.py --dividir 2
Sin múltiples gpu, mi secuencia de comandos se ejecuta más lentamente, pero puedo ejecutar varios experimentos al mismo tiempo en diferentes divisiones del conjunto de datos.
 euwern
en 15 jun. 2018
euwern
en 15 jun. 2018
Tengo el mismo problema en Python 3.6.2/Pytorch 0.4.0.
e intenté, sobre todo, acercarme a cambiar pin_memory, cambiar el tamaño de la memoria compartida, y uso la biblioteca skiamge (¡no estoy usando cv2!), Pero todavía tengo un problema.
este problema plantea aleatoriamente. controlar este problema es solo mirar la consola y reiniciar el entrenamiento.
 slaysd
en 19 jun. 2018
slaysd
en 19 jun. 2018
@ jinh574 Acabo de establecer la cantidad de trabajadores del cargador de datos en 0 y funciona.
Shuailong
en 19 jun. 2018
@Shuailong Tengo que usar una imagen de gran tamaño, por lo que no puedo usar esos parámetros debido a la velocidad. necesito más inspección sobre este problema
slaysd
en 19 jun. 2018
Tengo el mismo problema en Python 3.6/Pytorch 0.4.0. ¿La opción pin_memory afecta algo?
 ein-farbe
en 26 jun. 2018
ein-farbe
en 26 jun. 2018
Si está utilizando collate_fn y num_workers>0 con PyTorch versión < 0.4:
ASEGÚRESE DE NO DEVOLVER TENSORES DIM CERO DE SU FUNCIÓN __getitem__() .
O DEVOLVERLOS COMO MATRICES NUMPY.
 pyaf
en 12 jul. 2018
pyaf
en 12 jul. 2018
Tengo ese problema incluso después de configurar num_workers=0 o cv2.setNumThreads(0).
Falla con cualquiera de estos dos problemas. ¿Alguien más enfrenta lo mismo?
Rastreo (llamadas recientes más última):
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", línea 193, en _run_module_as_main
"__principal__", mod_spec)
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", línea 85, en _run_code
exec(código, run_globals)
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", línea 209, en
principal()
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", línea 205, en main
proceso.esperar()
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", línea 1457, en espera
(pid, puntos) = self._try_wait(0)
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", línea 1404, en _try_wait
(pid, sts) = os.waitpid(self.pid, wait_flags)
Interrupción del teclado
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", línea 258, en _bootstrap
auto.ejecutar()
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", línea 93, en ejecución
self._objetivo( self._args, * self._kwargs)
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/utils/data/dataloader.py", línea 96, en _worker_loop
r = index_queue.get(timeout=MANAGER_STATUS_CHECK_INTERVAL)
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/queues.py", línea 104, en get
si no self._poll (tiempo de espera):
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", línea 257, en encuesta
devolver self._poll(tiempo de espera)
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", línea 414, en _poll
r = esperar ([auto], tiempo de espera)
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", línea 911, en espera
listo = selector.select(tiempo de espera)
Archivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/selectors.py", línea 376, en select
fd_event_list = self._poll.poll(tiempo de espera)
Interrupción del teclado
 swethmandava
en 25 ago. 2018
swethmandava
en 25 ago. 2018
Estoy usando la versión '0.5.0a0+f57e4ce' y tuve el mismo problema. Ya sea cancelando el cargador de datos paralelo (num_workers=0) o configurando cv2.setNumThreads(0) funciona.
 omersumer
en 5 oct. 2018
omersumer
en 5 oct. 2018
Estoy bastante seguro de que #11985 debería eliminar todos los bloqueos (a menos que interrumpa en momentos desafortunados que no podemos controlar). Ahora que está fusionado, estoy cerrando esto.
El bloqueo con cv2 también está fuera de nuestro control, ya que cv2 simplemente no funciona bien con el multiprocesamiento.
SsnL
en 9 oct. 2018
Todavía experimenta esto a partir de torch_nightly-1.0.0.dev20181029 , ¿no se ha fusionado el PR allí todavía?
 Evpok
en 30 oct. 2018
Evpok
en 30 oct. 2018
@Evpok esto se ha fusionado allí. Deberías tener este parche seguro. Me pregunto si es posible que haya más estancamientos persistentes. ¿Tienes una reproducción fácil que podamos intentar mirar?
soumith
en 30 oct. 2018
De hecho, lo rastreé hasta un problema de multiprocesamiento no relacionado de mi parte, disculpe las molestias.
Evpok
en 30 oct. 2018
hola @Evpok
Uso torch_nightly-1.0.0 y me encuentro con este problema. has solucionado este problema?
 zimenglan-sysu-512
en 14 nov. 2018
zimenglan-sysu-512
en 14 nov. 2018
Si está utilizando collate_fn y num_workers>0 con PyTorch versión < 0.4:
ASEGÚRESE DE NO DEVOLVER TENSORES DIM CERO DE SU FUNCIÓN
__getitem__().
O DEVOLVERLOS COMO MATRICES NUMPY.
Arreglé mi error de devolver ceros tensores tenues y el problema aún existe.
 liluxuan1997
en 14 nov. 2018
liluxuan1997
en 14 nov. 2018
@ zimenglan-sysu-512 El problema principal fue con las limitaciones del multiprocesamiento: cuando se usa spawn o forkserver (que se necesita para la comunicación CPU-GPU), compartir objetos entre procesos es bastante limitado y no adecuado para el tipo de objetos que tengo que manipular.
Evpok
en 14 nov. 2018
Nada de esto funcionó para mí. Sin embargo, la última versión de opencv funciona ( 3.4.0.12 a 3.4.3.18 nada más que cambiar):
sudo pip3 install --upgrade opencv-python
 see--
en 17 nov. 2018
see--
en 17 nov. 2018
@see-- me alegra saber que opencv arregló lo suyo :)
SsnL
en 17 nov. 2018
Estoy en OpenCV 3.4.3.18 con python2.7, y todavía veo que ocurre el interbloqueo. :/
 SreenivasVRao
en 3 dic. 2018
SreenivasVRao
en 3 dic. 2018
Por favor intenta lo siguiente:
from torch.utils.data.dataloader import DataLoader
en vez de
from torch.utils.data import DataLoader
Creo que hay un problema con la verificación de tipo aquí:
https://github.com/pytorch/pytorch/blob/656b565a0f53d9f24547b060bd27aa67ebb89b88/torch/utils/data/dataloader.py#L816
 jewfro-cuban
en 16 dic. 2018
jewfro-cuban
en 16 dic. 2018
Por favor intenta lo siguiente:
from torch.utils.data.dataloader import DataLoaderen vez de
from torch.utils.data import DataLoaderCreo que hay un problema con la verificación de tipo aquí:
pytorch/torch/utils/data/dataloader.py
Línea 816 en 656b565
super(Cargador de datos, propio).__setattr__(atributo, valor)
¿No es esto solo un alias? en torch.utils.data.__init__ importan dataloader.DataLoader
 simonhessner
en 8 ene. 2019
simonhessner
en 8 ene. 2019
También tuve problemas con num_workers> 0. Mi código no tiene opencv, y el uso de memoria de /dev/shm no es un problema. Ninguna de las sugerencias anteriores funcionó para mí. Mi solución fue actualizar numpy de 1.14.1 a 1.14.5:
conda install numpy=1.14.5
Espero que sea útil.
 daniyar-niantic
en 8 ene. 2019
daniyar-niantic
en 8 ene. 2019
Hmm, mi versión numpy es 1.15.4, por lo que es más reciente que 1.14.5... ¿Debería estar bien entonces?
simonhessner
en 8 ene. 2019
Hmm, mi versión numpy es 1.15.4, por lo que es más reciente que 1.14.5... ¿Debería estar bien entonces?
Idk, mi actualización de numpy también actualizó mkl.
daniyar-niantic
en 8 ene. 2019
¿Qué versión de mkl tienes? El mío es 2019.1 (build 144) y otros paquetes que incluyen mkl en su nombre son:
mkl-servicio 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
simonhessner
en 8 ene. 2019
¿Qué versión de mkl tienes? El mío es 2019.1 (build 144) y otros paquetes que incluyen mkl en su nombre son:
mkl-servicio 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
conda list | grep mkl
mkl 2018.0.1 h19d6760_4
mkl-service 1.1.2 py36h17a0993_4
Si aún ve bloqueos en el pytorch más nuevo, sería de gran ayuda si puede proporcionar una secuencia de comandos breve que reproduzca el problema. ¡Gracias!
SsnL
en 9 ene. 2019
Todavía estoy viendo este punto muerto, veré si puedo crear una secuencia de comandos que se reproduzca.
 dtmoodie
en 15 ene. 2019
dtmoodie
en 15 ene. 2019
pin_memory=True resolvió el problema por mí.
pyaf
en 30 ene. 2019
No parece funcionar para mí con pin_memory=True , todavía se atascó después de 70 épocas. Lo único que me ha funcionado hasta ahora es configurar num_workers=0 , pero es notablemente más lento.
 jclevesque
en 14 feb. 2019
jclevesque
en 14 feb. 2019
También estoy experimentando el punto muerto (ocurre bastante al azar). Intenté pin_memory y actualicé Numpy. Intentaré ejecutarlo en una máquina diferente.
 Avsecz
en 14 feb. 2019
Avsecz
en 14 feb. 2019
Si está utilizando varios subprocesos con cargadores de datos, intente utilizar multiprocesamiento en lugar de subprocesos múltiples. Esto resolvió el problema por completo para mí (y, por cierto, también es mejor para tareas computacionalmente intensivas en Python debido a GIL)
simonhessner
en 14 feb. 2019
mismo error en Pytorch1.0, Pillow5.0.0 numpy1.16.1 python3.6
 jianlong-yuan
en 15 feb. 2019
jianlong-yuan
en 15 feb. 2019
También recibo el mismo error. He configurado pin_memory=True y num_workers=0 . Aunque una cosa que noté es que cuando uso una pequeña porción del conjunto de datos, este error no ocurre. Solo el uso de todo el conjunto de datos provoca este error.
Editar: solo un simple reinicio del sistema lo arregló para mí.
 Venka97
en 6 mar. 2019
Venka97
en 6 mar. 2019
Tuve un problema similar. En algún código, esta función colgaría (casi siempre) en d_iter.next():
def get_next_batch(d_iter, loader):
try:
data, label = d_iter.next()
except StopIteration:
d_iter = iter(loader)
data, label = d_iter.next()
return data, label
El truco que funcionó para mí fue agregar un pequeño retraso después de llamar a esta función
trn_X, trn_y = get_next_batch(train_data_iter, train_loader)
time.sleep(0.003)
val_X, val_y = get_next_batch(valid_data_iter, valid_loader)
¿Supongo que la demora ayudó a evitar un punto muerto?
 enoonIT
en 20 mar. 2019
enoonIT
en 20 mar. 2019
Todavía me encuentro con este problema. Usando pytorch 1.0 y python 3.7. Cuando estaba usando múltiples data_loader, aparecerá este error. Si uso menos de 3 data_loader o uso una sola GPU, este error no aparecerá. Intentado:
- tiempo.dormir(0.003)
- pin_memory=Verdadero/Falso
- núm_trabajadores=0/1
- desde torch.utils.data.dataloader importar DataLoader
- escribiendo 8192 en /proc/sys/kernel/shmmni
Ninguno de ellos funciona. ¿No sabes si hay alguna solución?
 xuw080
en 16 abr. 2019
xuw080
en 16 abr. 2019
mis soluciones agregan cv2.setNumThreads(0) en el programa de preprocesamiento
Tengo 2 cargadores de datos, que son para tren y val.
Solo pude ejecutar el evaluador una vez.
 lightningsoon
en 10 may. 2019
lightningsoon
en 10 may. 2019
Acabo de encontrar este error con pytorch 1.1. Lo mismo se quedó atascado dos veces en el mismo lugar: final de la época 99. pin_memory se estableció en False .
 Randl
en 17 may. 2019
Randl
en 17 may. 2019
El mismo problema cuando se usan trabajadores> 0, la memoria pin no resolvió el problema.
 nicolasCruzW21
en 20 may. 2019
nicolasCruzW21
en 20 may. 2019
mis soluciones agregan cv2.setNumThreads(0) en el programa de preprocesamiento
Tengo 2 cargadores de datos, que son para tren y val.
Solo pude ejecutar el evaluador una vez.
Esta solucion me funciono, gracias
 zxhr2793
en 3 jun. 2019
zxhr2793
en 3 jun. 2019
el cargador de datos se detiene cuando termino una época y comenzará una nueva época.
cumplir con el mismo problema. En mi caso, el problema surge cuando instalo opencv-python (he instalado opencv3 antes). Después de mover opencv-python, el entrenamiento no se detendrá.
 hongzhenwang
en 20 jun. 2019
hongzhenwang
en 20 jun. 2019
es una buena idea también
En 2019-06-20 10:51:02, "hongzhenwang" [email protected] escribió:
el cargador de datos se detiene cuando termino una época y comenzará una nueva época.
cumplir con el mismo problema. En mi caso, el problema surge cuando instalo opencv-python (he instalado opencv3 antes). Después de mover opencv-python, el entrenamiento no se detendrá.
—
Estás recibiendo esto porque comentaste.
Responda a este correo electrónico directamente, véalo en GitHub o silencie el hilo.
lightningsoon
en 27 jun. 2019
Todavía me encuentro con este problema. Usando pytorch 1.0 y python 3.7. Cuando estaba usando múltiples data_loader, aparecerá este error. Si uso menos de 3 data_loader o uso una sola GPU, este error no aparecerá. Intentado:
1. time.sleep(0.003) 2. pin_memory=True/False 3. num_workers=0/1 4. from torch.utils.data.dataloader import DataLoader 5. writing 8192 to /proc/sys/kernel/shmmni None of them works. Don't know whether there is any solutions?
Todavía estoy tratando de encontrar una solución. Estoy de acuerdo en que solo parece que tengo este problema cuando ejecuto 2 procesos paralelos en diferentes GPU al mismo tiempo. Uno continúa mientras el otro se detiene.
 ArturoDeza
en 3 jul. 2019
ArturoDeza
en 3 jul. 2019
Cuando establecí num_workers=4, el programa se atascó durante unos segundos (o minutos) cada 4 lotes, lo que desperdicia mucho tiempo. ¿Alguna idea de cómo solucionarlo?
 huangchaoxing
en 27 jul. 2019
huangchaoxing
en 27 jul. 2019
agregar las banderas: pin_memory=True y num_workers=0 en el cargador de datos es la solución.
ArturoDeza
en 27 jul. 2019
agregar las banderas: pin_memory=True y num_workers=0 en el cargador de datos es la solución.
@arturodeza
Esta podría ser una solución. Sin embargo, configurar num_workers=0 ralentiza toda la obtención de datos de la CPU y la tasa de uso de la GPU será muy baja.
huangchaoxing
en 28 jul. 2019
Para mí, la razón era que no había suficientes CPU en mi sistema o no había suficientes num_workers especificados en el cargador de datos. También podría ser una buena idea deshabilitar los subprocesos en los trabajadores del cargador de datos en caso de que el método __get_item__ en el cargador de datos use una biblioteca de subprocesos como numpy , librosa o opencv (consulte a continuación por qué esto podría ser importante). Esto se puede lograr ejecutando su script de entrenamiento con OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . Como aclaración para la discusión a continuación, tenga en cuenta que cada lote de Dataloader es manejado por un solo trabajador: cada trabajador maneja batch_size muestras para completar un solo lote y luego comienza a procesar un nuevo lote de datos.
Debe establecer num_workers más bajo que la cantidad de CPU en la máquina (o pod si está usando Kubernetes), pero lo suficientemente alto como para que los datos estén siempre listos para la siguiente iteración. Si la GPU ejecuta cada iteración en t segundos, y cada trabajador del cargador de datos tarda N*t segundos en cargar/procesar un solo lote, entonces debe establecer num_workers en al menos N , para evitar paradas de GPU. Por supuesto, debe tener al menos N CPU en el sistema.
Desafortunadamente, si Dataloader usa cualquier biblioteca que use subprocesos K , entonces la cantidad de procesos generados se convierte en num_workers*K = N*K . Esto podría ser significativamente mayor que la cantidad de CPU en la máquina. Esto acelera el módulo y el cargador de datos se vuelve muy lento. Esto puede hacer que el cargador de datos no devuelva un lote cada t segundos, lo que provoca que la GPU se detenga.
Una forma de evitar hilos K es llamar al script principal por OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . Esto restringe que cada trabajador de Dataloader use un solo subproceso y evita sobrecargar la máquina. Aún debe tener suficientes num_workers para mantener alimentada la GPU.
También debe optimizar su código en __get_item__ para que cada trabajador complete su lote en una pequeña cantidad de tiempo. Asegúrese de que el tiempo para completar el preprocesamiento de un lote por parte del trabajador no se vea obstaculizado por el tiempo para leer los datos de entrenamiento del disco (especialmente si está leyendo desde un almacenamiento en red) o el ancho de banda de la red (si está leyendo desde una red). disco). Si su conjunto de datos es pequeño y tiene suficiente RAM, considere mover el conjunto de datos a la RAM (o /tmpfs ) y lea desde allí para un acceso rápido. Para Kubernetes, puede crear un disco RAM (busque emptyDir en Kubernetes).
Si optimizó su código de __get_item__ y se aseguró de que el acceso al disco o a la red no sean los culpables, pero aún observa bloqueos, deberá solicitar más CPU (para un pod de Kubernetes) o mover su GPU a un máquina con más CPU.
Otra opción es reducir los batch_size para que cada worker tenga menos trabajo por hacer y termine el preprocesamiento más rápido. La última opción no es deseable en algunos casos, porque no se utilizará la memoria GPU inactiva.
También podría considerar hacer parte del preprocesamiento fuera de línea y quitarle el peso de encima a cada trabajador. Por ejemplo, si cada trabajador está leyendo un archivo wav y calculando espectrogramas para el archivo de audio, podría considerar calcular previamente los espectrogramas fuera de línea y simplemente leer el espectrograma calculado del disco en el trabajador. Esto reducirá la cantidad de trabajo que cada trabajador tiene que hacer.
 gkeskin07
en 3 ago. 2019
gkeskin07
en 3 ago. 2019
encontrar el mismo problema con horovod
 jinhou
en 12 ago. 2019
jinhou
en 12 ago. 2019
Conozca un problema similar... Interbloqueo mientras acaba de terminar una época y comienza a cargar datos para la validación...
 jackroos
en 20 ago. 2019
jackroos
en 20 ago. 2019
@jinhou @jackroos Lo mismo, atascado aleatoriamente al comienzo de la validación con horovod. Lo que hago actualmente como solución es establecer un tiempo de espera y omitir la validación. tienes una solución?
 lzljzys
en 28 ago. 2019
lzljzys
en 28 ago. 2019
@jinhou @jackroos Lo mismo, atascado aleatoriamente al comienzo de la validación con horovod. Lo que hago actualmente como solución es establecer un tiempo de espera y omitir la validación. tienes una solución?
No. Simplemente desactivo el entrenamiento distribuido en ese caso.
jackroos
en 29 ago. 2019
Encontré un problema similar: el cargador de datos se detiene cuando termino una época y comenzará una nueva época.
¿Por qué tanto zan?
 foocker
en 22 oct. 2019
foocker
en 22 oct. 2019
Todavía me encuentro con este problema. Usando pytorch 1.0 y python 3.7. Cuando estaba usando múltiples data_loader, aparecerá este error. Si uso menos de 3 data_loader o uso una sola GPU, este error no aparecerá. Intentado:
- tiempo.dormir(0.003)
- pin_memory=Verdadero/Falso
- núm_trabajadores=0/1
- desde torch.utils.data.dataloader importar DataLoader
- escribiendo 8192 en /proc/sys/kernel/shmmni
Ninguno de ellos funciona. ¿No sabes si hay alguna solución?
num_workers establecido en 0 funcionó para mí. Debe asegurarse de que esté en 0 en todos los lugares donde lo esté usando.
Algunas otras posibles soluciones:
- desde la importación de multiprocesamiento set_start_method
set_start_method('spawn') - cv2.setNumHilos(0)
Parece que 3 o 7 son el camino a seguir.
 the7threvival
en 18 nov. 2019
the7threvival
en 18 nov. 2019
Experimento este problema con pytorch 1.3, ubuntu16, todas las sugerencias anteriores no funcionaron, excepto los trabajadores = 0, lo que ralentiza la ejecución. Esto solo sucede cuando se ejecuta desde la terminal, dentro del cuaderno Jupyter todo está bien, incluso con trabajadores = 32.
El problema no parece resuelto, ¿debería reabrirse? También veo a muchas otras personas reportando el mismo problema...
 skariel
en 2 dic. 2019
skariel
en 2 dic. 2019
Todavía me encuentro con este problema. Usando pytorch 1.0 y python 3.7. Cuando estaba usando múltiples data_loader, aparecerá este error. Si uso menos de 3 data_loader o uso una sola GPU, este error no aparecerá. Intentado:
- tiempo.dormir(0.003)
- pin_memory=Verdadero/Falso
- núm_trabajadores=0/1
- desde torch.utils.data.dataloader importar DataLoader
- escribiendo 8192 en /proc/sys/kernel/shmmni
Ninguno de ellos funciona. ¿No sabes si hay alguna solución?num_workers establecido en 0 funcionó para mí. Debe asegurarse de que esté en 0 en todos los lugares donde lo esté usando.
Algunas otras posibles soluciones:
- desde la importación de multiprocesamiento set_start_method
set_start_method('spawn')- cv2.setNumHilos(0)
Parece que 3 o 7 son el camino a seguir.
Modifiqué train.py así:
from __future__ import division
import cv2
cv2.setNumThreads(0)
import argparse
...
Y funciona para mi.
 DHZS
en 10 dic. 2019
DHZS
en 10 dic. 2019
Hola chicos, si puedo ayudar,
También tuve este problema similar a este, pero sucedería cada 100 épocas más o menos.
Noté que solo sucedió con CUDA habilitado, también dmesg tiene esta entrada de registro cada vez que falla.
python[11240]: segfault at 10 ip 00007fabdd6c37d8 sp 00007ffddcd64fd0 error 4 in libcudart.so.10.1.243[7fabdd699000+77000]
Es un galimatías para mí, pero me dijo que CUDA y python multithreading no estaban jugando bien.
Mi solución fue deshabilitar cuda en los subprocesos de datos, aquí hay un fragmento de mi archivo de entrada de python.
from multiprocessing import set_start_method
import os
if __name__ == "__main__":
set_start_method('spawn')
else:
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import torch
import application
Con suerte, eso puede ayudar a cualquiera que aterrice aquí como lo necesitaba en ese momento.
 roderickObrist
en 24 mar. 2020
roderickObrist
en 24 mar. 2020
@jinhou @jackroos Lo mismo, atascado aleatoriamente al comienzo de la validación con horovod. Lo que hago actualmente como solución es establecer un tiempo de espera y omitir la validación. tienes una solución?
No. Simplemente desactivo el entrenamiento distribuido en ese caso.
Encuentro un problema similar en el entrenamiento distribuido sin usar OpenCV después de actualizar a PyTorch 1.4.
Ahora tengo que ejecutar la validación una vez antes del ciclo de entrenamiento y validación.
 wizardk
en 9 jun. 2020
wizardk
en 9 jun. 2020
He tenido muchos problemas con esto. Parece persistir en las versiones de pytorch, versiones de python y también en diferentes máquinas físicas (que probablemente se hayan configurado de manera idéntica).
Cada vez que es el mismo error:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/bicep/loops.py", line 73, in __call__
for data, target in self.dataloader:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 830, in _next_data
self._shutdown_workers()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 942, in _shutdown_workers
w.join()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/process.py", line 149, in join
res = self._popen.wait(timeout)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 47, in wait
return self.poll(os.WNOHANG if timeout == 0.0 else 0)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll
pid, sts = os.waitpid(self.pid, flag)
Claramente, hay algún problema en la forma en que se manejan los procesos en la máquina que estoy usando. Ninguna de las soluciones anteriores parece funcionar, aparte de establecer num_workers=0.
Realmente me gustaría poder llegar al fondo de esto, ¿alguien tiene alguna idea de por dónde empezar o cómo interrogar esto?
 brynhayder
en 9 jun. 2020
brynhayder
en 9 jun. 2020
Yo también aquí.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 480, in _try_get_batch
data = self.data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 65, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 95106) is killed by signal: Segmentation fault.
Una cosa de interés es
cuando solo analizo los datos línea por línea, no tengo este problema:
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
pero si agrego una lógica de análisis JSON después de leer línea por línea, informará este error
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
Entiendo que habrá algo de sobrecarga de memoria JSON, pero incluso reduzco la cantidad de trabajadores a 2, y el conjunto de datos es muy pequeño, todavía tiene el mismo problema. Dudo que esté relacionado con shm. ¿Cualquier pista?
 zhangruiskyline
en 16 jun. 2020
zhangruiskyline
en 16 jun. 2020
¿Reabrimos este tema?
 takatosp1
en 18 jun. 2020
takatosp1
en 18 jun. 2020
Pienso que deberíamos. Por cierto, hice una depuración de GDB y no encontré nada allí. así que no estoy muy seguro de si se trata de un problema de memoria compartida,
(gdb) run
Starting program: /home/miniconda/bin/python performance.py
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7fffa60a6700 (LWP 61963)]
[New Thread 0x7fffa58a5700 (LWP 61964)]
[New Thread 0x7fffa10a4700 (LWP 61965)]
[New Thread 0x7fff9e8a3700 (LWP 61966)]
[New Thread 0x7fff9c0a2700 (LWP 61967)]
[New Thread 0x7fff998a1700 (LWP 61968)]
[New Thread 0x7fff970a0700 (LWP 61969)]
[New Thread 0x7fff9489f700 (LWP 61970)]
[New Thread 0x7fff9409e700 (LWP 61971)]
[New Thread 0x7fff8f89d700 (LWP 61972)]
[New Thread 0x7fff8d09c700 (LWP 61973)]
[New Thread 0x7fff8a89b700 (LWP 61974)]
[New Thread 0x7fff8809a700 (LWP 61975)]
[New Thread 0x7fff85899700 (LWP 61976)]
[New Thread 0x7fff83098700 (LWP 61977)]
[New Thread 0x7fff80897700 (LWP 61978)]
[New Thread 0x7fff7e096700 (LWP 61979)]
[New Thread 0x7fff7d895700 (LWP 61980)]
[New Thread 0x7fff7b094700 (LWP 61981)]
[New Thread 0x7fff78893700 (LWP 61982)]
[New Thread 0x7fff74092700 (LWP 61983)]
[New Thread 0x7fff71891700 (LWP 61984)]
[New Thread 0x7fff6f090700 (LWP 61985)]
[Thread 0x7fff7e096700 (LWP 61979) exited]
[Thread 0x7fff6f090700 (LWP 61985) exited]
[Thread 0x7fff74092700 (LWP 61983) exited]
[Thread 0x7fff7b094700 (LWP 61981) exited]
[Thread 0x7fff80897700 (LWP 61978) exited]
[Thread 0x7fff83098700 (LWP 61977) exited]
[Thread 0x7fff85899700 (LWP 61976) exited]
[Thread 0x7fff8809a700 (LWP 61975) exited]
[Thread 0x7fff8a89b700 (LWP 61974) exited]
[Thread 0x7fff8d09c700 (LWP 61973) exited]
[Thread 0x7fff8f89d700 (LWP 61972) exited]
[Thread 0x7fff9409e700 (LWP 61971) exited]
[Thread 0x7fff9489f700 (LWP 61970) exited]
[Thread 0x7fff970a0700 (LWP 61969) exited]
[Thread 0x7fff998a1700 (LWP 61968) exited]
[Thread 0x7fff9c0a2700 (LWP 61967) exited]
[Thread 0x7fff9e8a3700 (LWP 61966) exited]
[Thread 0x7fffa10a4700 (LWP 61965) exited]
[Thread 0x7fffa58a5700 (LWP 61964) exited]
[Thread 0x7fffa60a6700 (LWP 61963) exited]
[Thread 0x7fff71891700 (LWP 61984) exited]
[Thread 0x7fff78893700 (LWP 61982) exited]
[Thread 0x7fff7d895700 (LWP 61980) exited]
total_files = 5040. //customer comments
[New Thread 0x7fff6f090700 (LWP 62006)]
[New Thread 0x7fff71891700 (LWP 62007)]
[New Thread 0x7fff74092700 (LWP 62008)]
[New Thread 0x7fff78893700 (LWP 62009)]
ERROR: Unexpected segmentation fault encountered in worker.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 62005) is killed by signal: Segmentation fault.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "performance.py", line 62, in <module>
main()
File "performance.py", line 48, in main
for i,batch in enumerate(rl_data_loader):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 841, in _next_data
idx, data = self._get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 808, in _get_data
success, data = self._try_get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 774, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 62005) exited unexpectedly
[Thread 0x7fff78893700 (LWP 62009) exited]
[Thread 0x7fff74092700 (LWP 62008) exited]
[Thread 0x7fff71891700 (LWP 62007) exited]
[Thread 0x7fff6f090700 (LWP 62006) exited]
[Inferior 1 (process 61952) exited with code 01]
(gdb) backtrace
No stack.
Y creo que tengo suficiente memoria compartida, al menos espero que la memoria compartida sea lo suficientemente buena durante bastante tiempo hasta que se produce una falla de segmento, pero la falla del segmento ocurre casi inmediatamente después de iniciar el trabajo del cargador de datos.
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18014398509481980
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
Hola @soumith @apaszke , ¿podemos volver a abrir este problema ? Probé todas las soluciones propuestas, como aumentar el tamaño y el segmento de shm, nada funciona, no estoy usando opencv más o menos, solo un simple análisis de JSON. pero el problema sigue ahí. y no creo que esté relacionado con shm ya que verifiqué que abro toda la memoria como memoria compartida. El seguimiento de la pila tampoco muestra nada allí como se publicó anteriormente.
@apaszke , con respecto a su sugerencia de
"Sí, muchos de esos problemas se deben a que las bibliotecas de terceros no son seguras para las bifurcaciones. Una solución alternativa podría ser usar el método de inicio de generación".
Estoy usando el cargador de datos para múltiples trabajadores, ¿cómo puedo cambiar el método? Estoy configurando set_start_method('spawn') en mi main.py pero la dosis no parece ayudar
También tengo una pregunta general aquí, si habilito el cargador de datos de múltiples trabajadores (multiproceso), y en el entrenamiento principal también comienzo el multiproceso como se sugiere en https://pytorch.org/docs/stable/notes/multiprocessing.html #multiprocesamiento - mejores prácticas
¿Cómo pytorch gestiona tanto el cargador de datos como el multiproceso de entrenamiento principal? ¿Compartirán todos los procesos/subprocesos posibles en GPU multinúcleo? ¿También la memoria compartida para procesos múltiples es "compartida" por el cargador de datos y el proceso de entrenamiento principal? también si tengo algún trabajo de preparación de datos como el análisis de JSON, el análisis de CSV, la extracción de funciones de pandas. etc, ¿dónde está la mejor manera de poner? en el cargador de datos para generar datos perfectos para estar listos o simplemente use el entrenamiento principal para hacerlo como algunos sugirieron anteriormente para mantener el cargador de datos __get_item__ más simple posible
zhangruiskyline
en 19 jun. 2020
@zhangruiskyline Su problema no es realmente un punto muerto. Se trata de que los trabajadores sean asesinados por segfault. sigbus es el que sugiere problemas de shm. Debe verificar su código de conjunto de datos y depurar allí.
Para responder a sus otras preguntas,
- use kwarg
multiproessing_context='spawn'en DataLoader establecerá la generación.set_start_methodtambién hace eso. - por lo general, en el entrenamiento multiproceso, cada proceso tiene su propio DataLoader y, por lo tanto, los trabajadores de DataLoader. Nada se comparte entre los procesos a menos que se haga explícitamente.
SsnL
en 20 jun. 2020
Gracias @SsnL , agregué multiproessing_context='spawn' pero el mismo error.
Señalé en el hilo anterior, mi código es muy simple,
- esta pieza de código funciona
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
- pero si agrego una lógica de análisis JSON después de leer línea por línea, informará este error
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
así que dudo que sea mi problema de código, también trato de no usar el análisis JSON, sino directamente la división de cadenas, el mismo problema. parece que mientras tenga algo de lógica que consuma mucho tiempo para el proceso de datos en el cargador de datos, este problema sucederá
También con respecto a
entrenamiento multiproceso, cada proceso tiene su propio DataLoader y, por lo tanto, los trabajadores de DataLoader No se comparte nada entre los procesos a menos que se haga explícitamente.
Entonces, veamos que tengo 4 procesos para la capacitación, cada uno con un cargador de datos de 8 trabajadores, por lo que hay un total de 32 procesos debajo.
zhangruiskyline
en 20 jun. 2020
@zhangruiskyline Sin un script independiente para reproducir el problema, no podemos ayudarlo. Sí habrá 32 procesos
SsnL
en 20 jun. 2020
Gracias, también vi un problema similar en
https://github.com/pytorch/pytorch/issues/4969
https://github.com/pytorch/pytorch/issues/5040
ambos cerrados pero no veo una solución o solución clara, ¿sigue siendo un problema amplio?
Veré si puedo proporcionar un script de reproducción autónomo, pero está altamente integrado a nuestra plataforma y fuente de datos, así que intentaré
zhangruiskyline
en 20 jun. 2020
@zhangruiskyline Su problema no es similar a ninguno de los problemas vinculados, si los lee. están cerrados porque el problema original/más común informado en esos hilos ya se ha abordado.
SsnL
en 20 jun. 2020
Gracias @SsnL , no estoy tan familiarizado con Pytorch, así que podría estar equivocado, pero revisé todos esos, y parece que algunos de ellos parecen resueltos por
reducir el número de trabajadores a 0, esto es inaceptable para nosotros ya que es demasiado lento,
aumente el tamaño de shm, pero creo que tenemos suficiente shm, y el problema ocurrió casi inmediatamente después de que comenzamos, y lo intenté con un conjunto de datos mucho más pequeño, el mismo problema
algunas lib como la dosis de opencv no funcionan bien en multiproceso, solo estamos usando JSON/CSV, por lo que no son cosas realmente sofisticadas
nuestro código es bastante simple, el conjunto de datos de entrenamiento tiene más de 10000 archivos, cada archivo tiene varias líneas de cadenas JSON. en el cargador de datos, definimos __get_item__ para obtener cada archivo de más de 10
en la solución 1, primero leemos y dividimos línea por línea en la lista de cadenas JSON, si regresamos inmediatamente, funciona, el rendimiento es bueno
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
return all_data
ahora que el valor devuelto sigue siendo una cadena JSON, queremos aprovechar el cargador de datos de procesos múltiples para acelerar, así que coloque la lógica de análisis JSON aquí y falla
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
Más tarde pensamos que el análisis JSON es demasiado pesado y también JSON tiene demasiada huella de memoria, luego elegimos analizar la cadena JSON y convertirla manualmente a la lista de funciones, el mismo error. hizo un análisis de seguimiento de pila y nada allí
Por cierto, estamos ejecutando nuestro código en Linux Docker Env, CPU de 24 núcleos y 1 V100.
No estoy seguro de dónde debo comenzar a investigar a continuación. ¿Tienes alguna idea?
zhangruiskyline
en 20 jun. 2020
Hola,
Encontré un comentario interesante en https://github.com/open-mmlab/mmcv , que se usa en https://github.com/open-mmlab/mmdetection :
El siguiente código se usa al comienzo de la época del tren y de la época del valor.
time.sleep(2) # Previene un posible interbloqueo durante la transición de época
Puede ser que puedas intentarlo.
mathmanu
en 20 jun. 2020
Por cierto, si voy a multiproceso y cada proceso con un cargador de datos de varios trabajadores, ¿cómo diferentes procesos pueden garantizar que su cargador de datos correspondiente no lea los mismos datos que el cargador de datos de otro proceso? ¿ya lo maneja pytorch dataloader __get_item__ ?
zhangruiskyline
en 20 jun. 2020
Hola @SsnL , gracias por tu ayuda. solo quiero seguir un poco este hilo, refactoricé el código de entrenamiento usando el procesamiento múltiple de pytorch para acelerar el procesamiento de algunos datos en el lado de la CPU (para alimentar a la GPU más rápido), https://pytorch.org/docs/stable /notes/multiprocessing.html#multiprocessing -mejores prácticas
En cada función de procesamiento, también uso el cargador de datos de varios trabajadores para acelerar el tiempo de procesamiento de la carga de datos. https://pytorch.org/docs/stable/data.html
Puse mi análisis JSON de CPU agitado no en el cargador de datos, sino en el proceso de entrenamiento principal, y el problema parece haber desaparecido, no sé por qué, pero de todos modos parece funcionar. pero tengo una pregunta de seguimiento: supongamos que tengo N procesamiento de M trabajador de cargador de datos de NxM debajo del subprocesamiento allí.
Si en mi cargador de datos, quiero obtener todos los datos en forma de índice, lo que significa que __get_item__(self, idx) en M cargador de datos en N procesos diferentes pueden trabajar juntos para procesar índices diferentes, ¿cómo puedo asegurarme de que no procesen duplicados o perder el proceso de algunos?
zhangruiskyline
en 23 jun. 2020
Tuve el mismo problema en el que el cargador de datos falla después de quejarse de que no podía asignar memoria al comienzo de una nueva época de capacitación o validación. Las soluciones anteriores no me funcionaron (i) mi
/dev/shmtiene 32 GB y nunca se usó más de 2,5 GB, y (ii) configurar pin_memory=False no funcionó.¿Quizás esto tenga algo que ver con la recolección de basura? Mi código se ve más o menos como el siguiente. Necesito un iterador infinito y, por lo tanto, pruebo / excepto alrededor del
next()continuación :-)def train(): train_iter = train_loader.__iter__() for i in xrange(max_batches): try: x, y = next(train_iter) except StopIteration: train_iter = train_loader.__iter__() ... del train_iter
train_loaderes un objetoDataLoader. Sin la línea explícitadel train_iteral final de la función, el proceso siempre falla después de 2 o 3 épocas (/dev/shmtodavía muestra 2,5 GB). ¡Espero que esto ayude!Estoy usando
4trabajadores (versión0.1.12_2con CUDA 8.0 en Ubuntu 16.04).
Esto resolvió el problema para mí después de semanas de lucha. Tengo que usar explícitamente el iterador del cargador en lugar de hacer un bucle en el cargador directamente y usar del loader_iterator al final de la época finalmente eliminó los interbloqueos
 kennyFF92
en 15 jul. 2020
kennyFF92
en 15 jul. 2020
Creo que me estoy encontrando con el mismo problema. Tratando de usar 8 cargadores de datos (MNIST, MNISTM, SVHN, USPS, para entrenar y probar cada uno). Usar 6 (cualquier 6) funciona bien. Usando 8 bloques siempre al cargar el 6º, prueba MNIST-M. Está atascado en un bucle sin fin de intentar recuperar la imagen, fallar, esperar un poco y luego volver a intentarlo. El error persiste para cualquier tamaño de lote, me queda mucha memoria libre y solo desaparece si configuro num_workers en 0. Cualquier otra cantidad causa el problema
 pmirallesr
en 21 jul. 2020
pmirallesr
en 21 jul. 2020
Recibí una pista de https://stackoverflow.com/questions/54013846/pytorch-dataloader-stucked-if-using-opencv-resize-method
Cuando pongo cv2.setNumThreads(0) , funciona bien conmigo.
 LifeBeyondExpectations
en 17 ago. 2020
LifeBeyondExpectations
en 17 ago. 2020
Hola, tuve el mismo problema. Y tenía que ver con ulimit -n, simplemente auméntalo y se soluciona el problema, usé ulimit -n 500000
 SebastienEske
en 18 ago. 2020
SebastienEske
en 18 ago. 2020
@SebastienEske ulimit -n también me solucionó esto, en Ubuntu 20.04
 david-waterworth
en 24 sept. 2020
david-waterworth
en 24 sept. 2020
Tal vez establecer ulimit -n sea una forma correcta. Con el aumento del modelo, el interbloqueo se vuelve cada vez más frecuente. También pruebo cv2.setNumThreads(0) , pero no funciona.
 BLING-1994
en 27 sept. 2020
BLING-1994
en 27 sept. 2020
Para que conste, cv2.setNumThreads(0) funcionó para mí.
 franchesoni
en 18 nov. 2020
franchesoni
en 18 nov. 2020
Temas relacionados
 dablyo
·
3Comentarios
soumith
·
3Comentarios
dablyo
·
3Comentarios
soumith
·
3Comentarios
 NgPDat
·
3Comentarios
NgPDat
·
3Comentarios
 mishraswapnil
·
3Comentarios
mishraswapnil
·
3Comentarios
 ikostrikov
·
3Comentarios
ikostrikov
·
3Comentarios
Comentario más útil
Encontré un problema similar: el cargador de datos se detiene cuando termino una época y comenzará una nueva época.