Pytorch: возможный тупик в загрузчике данных
ошибка описана в pytorch/examples#148. Мне просто интересно, является ли это ошибкой в самом PyTorch, поскольку код примера выглядит для меня чистым. Кроме того, мне интересно, связано ли это с # 1120.
 zym1010
zym1010
Все 189 Комментарий
Сколько у вас свободной памяти при остановке загрузчика?
 apaszke
25 апр. 2017
apaszke
25 апр. 2017
@apaszke, если я проверю top , оставшаяся память (кэшированная память также считается использованной) обычно составляет 2 ГБ. Но если вы не считаете кеширование использованным, это всегда много, скажем, 30 ГБ+.
zym1010
25 апр. 2017
Также я не понимаю, почему он всегда останавливается в начале проверки, но не везде.
zym1010
25 апр. 2017
Возможно, потому что для проверки используется отдельный загрузчик, который увеличивает использование общей памяти сверх лимита.
 ngimel
25 апр. 2017
ngimel
25 апр. 2017
@нгимель
Я только что снова запустил программу. И застрял.
Вывод top :
~~~
топ - 17:51:18 вверх 2 дня, 21:05, 2 пользователя, средняя загрузка: 0,49, 3,00, 5,41
Задания: 357 всего, 2 бегущих, 355 спящих, 0 остановленных, 0 зомби
%Cpu(s): 1,9 мкс, 0,1 си, 0,7 ни, 97,3 ид, 0,0 ва, 0,0 привет, 0,0 си, 0,0 ст
KiB Mem: всего 65863816, 60115084 использовано, 5748732 свободно, 1372688 буферов
KiB Swap: всего 5917692, 620 использовано, 5917072 бесплатно. 51154784 кэшированная память
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3067 aalreja 20 0 143332 101816 21300 R 46.1 0.2 1631:44 Xvnc
16613 аальрея 30 10 32836 4880 3912 S 16,9 0,0 1:06,92 волоконная лампа 3221 аальрея 20 0 8882348 1,017 г 110120 S 1,3 1,6 579:06,87 MATLAB
1285 root 20 0 1404848 48252 25580 S 0.3 0.1 6:00.12 dockerd 16597 yimengz+ 20 0 25084 3252 2572 R 0.3 0.0 0:04.56 верх
1 корень 20 0 33616 4008 2624 S 0,0 0,0 0:01,43 инициализация
~~~
Вывод free
~yimengzh_everyday@yimengzh :~$ бесплатнообщее количество использованных свободных общих буферов в кэшеМем: 65863816 60122060 5741756 9954628 1372688 51154916-/+ буферы/кэш: 7594456 58269360Обмен: 5917692 620 5917072~
Вывод nvidia-smi
~~~
yimengzh_everyday@yimengzh :~$ nvidia-smi
Вт 25 апр 17:52:38 2017
+------------------------------------------------- ----------------------------+
| NVIDIA-SMI 375.39 Версия драйвера: 375.39 |
|-------------------------------+---------------- -----+----------------------+
| Имя GPU Persistence-M| Bus-Id Disp.A | Летучий некорр. ЕСК |
| Fan Temp Perf Pwr:Usage/Cap | Использование памяти | GPU-Util Compute M. |
|==============================+================== =====+======================|
| 0 GeForce GTX TIT... Выкл. | 0000:03:00.0 Выкл | Н/Д |
| 30% 42C P8 14 Вт / 250 Вт | 3986 МБ / 6082 МБ | 0% По умолчанию |
+----------------------------------------------+---------------- -----+----------------------+
| 1 Тесла K40c Off | 0000:81:00.0 Выкл | Выкл. |
| 0% 46C P0 57 Вт / 235 Вт | 0МиБ / 12205МиБ | 0% По умолчанию |
+----------------------------------------------+---------------- -----+----------------------+
+------------------------------------------------- ----------------------------+
| Процессы: Память графического процессора |
| Тип PID графического процессора Имя процесса Использование |
|================================================ =============================|
| 0 16509 C питон 3970МиБ |
+------------------------------------------------- ----------------------------+
~~~
Я не думаю, что это проблема с памятью.
zym1010
25 апр. 2017
Существуют отдельные ограничения для общей памяти. Можете попробовать ipcs -lm или cat /proc/sys/kernel/shmall и cat /proc/sys/kernel/shmmax ? Кроме того, не блокируется ли он, если вы используете меньше воркеров (например, тест с крайним случаем 1 воркер)?
apaszke
26 апр. 2017
@apaszke
~~~
yimengzh_everyday@yimengzh :~$ ipcs -lm
------ Пределы общей памяти --------
максимальное количество сегментов = 4096
максимальный размер сегмента (кбайт) = 18014398509465599
максимальная общая общая память (кбайт) = 18446744073642442748
минимальный размер сегмента (байты) = 1
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmall
18446744073692774399
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmmax
18446744073692774399
~~~
как они тебя ищут?
что касается меньшего количества рабочих, я думаю, что это будет происходить не так часто. (сейчас могу попробовать). Но я думаю, что на практике мне нужно столько рабочих.
zym1010
26 апр. 2017
У вас разрешено не более 4096 сегментов общей памяти, возможно, это проблема. Вы можете попробовать увеличить это, написав в /proc/sys/kernel/shmmni (возможно, попробуйте 8192). Вам могут понадобиться привилегии суперпользователя.
apaszke
26 апр. 2017
@apaszke, ну, это значения по умолчанию как для Ubuntu, так и для CentOS 6 ... Это действительно проблема?
zym1010
26 апр. 2017
@apaszke при запуске программы обучения ipcs -a фактически показывает, что общая память не используется. Это ожидается?
zym1010
26 апр. 2017
@apaszke попытался запустить программу (все еще 22 рабочих) со следующими настройками в общей памяти и снова застрял.
~~~
yimengzh_everyday@yimengzh :~$ ipcs -lm
------ Пределы общей памяти --------
максимальное количество сегментов = 8192
максимальный размер сегмента (кбайт) = 18014398509465599
максимальная общая общая память (кбайт) = 18446744073642442748
минимальный размер сегмента (байты) = 1
~~~
не пробовал один рабочий. во-первых, это было бы медленно; во-вторых, если проблема действительно в мертвой блокировке, то она точно исчезнет.
zym1010
26 апр. 2017
Настройки по умолчанию ipcs предназначен для разделяемой памяти System V, которую мы не используем, но я хотел убедиться, что те же ограничения не применяются к разделяемой памяти POSIX.
Он определенно не torch.__version__ ? Вы работаете в докере?
apaszke
26 апр. 2017
@apaszke Спасибо. Теперь я намного лучше понимаю ваш анализ.
Все остальные результаты, показанные вам вплоть до того, как выполняются на машине Ubuntu 14.04 с 64 ГБ ОЗУ, двойным Xeon и Titan Black (есть еще K40, но я им не пользовался).
Команда для создания проблемы CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 20 --lr 0.01 --workers 22 --batch-size 256 /mnt/temp_drive_3/cv_datasets/ILSVRC2015/Data/CLS-LOC . Я вообще не менял код.
Я установил pytorch через pip на Python 3.5. версия pytorch 0.1.11_5 . Не работает в Докере.
Кстати, я также пытался использовать 1 работника. Но я сделал это на другой машине (128 ГБ ОЗУ, двойной Xeon, 4 Pascal Titan X, CentOS 6). Я запустил его, используя CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 1 --lr 0.01 --workers 1 --batch-size 256 /ssd/cv_datasets/ILSVRC2015/Data/CLS-LOC , и журнал ошибок выглядит следующим образом.
Epoch: [0][5003/5005] Time 2.463 (2.955) Data 2.414 (2.903) Loss 5.9677 (6.6311) Prec<strong i="14">@1</strong> 3.516 (0.545) Prec<strong i="15">@5</strong> 8.594 (2.262)
Epoch: [0][5004/5005] Time 1.977 (2.955) Data 1.303 (2.903) Loss 5.9529 (6.6310) Prec<strong i="16">@1</strong> 1.399 (0.545) Prec<strong i="17">@5</strong> 7.692 (2.262)
^CTraceback (most recent call last):
File "main.py", line 292, in <module>
main()
File "main.py", line 137, in main
prec1 = validate(val_loader, model, criterion)
File "main.py", line 210, in validate
for i, (input, target) in enumerate(val_loader):
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 168, in __next__
idx, batch = self.data_queue.get()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/queue.py", line 164, in get
self.not_empty.wait()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/threading.py", line 293, in wait
waiter.acquire()
top показал следующее, когда застрял с 1 рабочим.
~топ - 08:34:33 вверх 15 дней, 20:03, 0 пользователей, средняя загрузка: 0,37, 0,39, 0,36Задания: всего 894, 1 бег, 892 сон, 0 остановлено, 1 зомбиЦП: 7,2% us, 2,8% sy, 0,0% ni, 89,7% id, 0,3% wa, 0,0% hi, 0,0% si, 0,0% stПамять: 132196824k всего, 131461528k использовано, 735296k свободно, 347448k буферовПодкачка: 2047996k всего, 22656k использовано, 2025340k свободно, 125226796k кэшировано~
zym1010
26 апр. 2017
еще одна вещь, которую я обнаружил, заключается в том, что если я изменю код обучения, чтобы он не проходил через все пакеты, скажем, только для обучения 50 пакетов.
if i >= 50:
break
затем тупик, кажется, исчезает.
zym1010
26 апр. 2017
дальнейшее тестирование, кажется, предполагает, что это зависание происходит гораздо чаще, если я запускаю программу сразу после перезагрузки компьютера. После того, как в компе есть кэш, кажется, что частота получения этого зависания меньше.
zym1010
27 апр. 2017
Я пытался, но никак не могу воспроизвести этот баг.
apaszke
4 мая 2017
Я столкнулся с похожей проблемой: загрузчик данных останавливается, когда я заканчиваю эпоху, и начинаю новую эпоху.
 tiancheng-zhi
4 мая 2017
tiancheng-zhi
4 мая 2017
Установка num_workers = 0 работает. Но программа тормозит.
tiancheng-zhi
4 мая 2017
@apaszke вы пробовали сначала перезагрузить компьютер, а затем запустить программы? Для меня это гарантия заморозки. Я только что попробовал версию 0.12, и она все та же.
Я хотел бы отметить одну вещь: я установил pytorch, используя pip , так как у меня установлен numpy, связанный с OpenBLAS, и MKL из @soumith не будет
Таким образом, pytorch использует MKL, а numpy использует OpenBLAS. Это может быть не идеально, но я думаю, что это не должно иметь ничего общего с проблемой здесь.
zym1010
9 мая 2017
Я смотрел в него, но я никогда не мог воспроизвести его. MKL/OpenBLAS не должен быть связан с этой проблемой. Вероятно, это какая-то проблема с конфигурацией системы.
apaszke
9 мая 2017
@apaszke спасибо. Я только что попробовал python из официального репозитория anaconda и pytorch на основе MKL. Все та же проблема.
zym1010
9 мая 2017
попробовал запустить код в Docker. Все еще застряли.
zym1010
11 мая 2017
У нас та же проблема, запуск обучающего примера pytorch/examples imagenet (resnet18, 4 работника) внутри nvidia-docker с использованием 1 GPU из 4. Я попытаюсь собрать обратную трассировку gdb, если мне удастся добраться до процесса .
По крайней мере, известно, что OpenBLAS имеет проблему взаимоблокировки при умножении матриц, что происходит относительно редко: https://github.com/xianyi/OpenBLAS/issues/937. Эта ошибка присутствовала, по крайней мере, в OpenBLAS, упакованном в numpy 1.12.0.
 jsainio
7 июн. 2017
jsainio
7 июн. 2017
@jsainio Я также пробовал чистый PyTorch на основе MKL (numpy также связан с MKL) и та же проблема.
Также эта проблема решается (по крайней мере для меня), если я включаю pin_memory для даталоадера.
zym1010
7 июн. 2017
Похоже, двое рабочих вымирают.
При нормальной работе:
root<strong i="7">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 33.2 4.7 91492324 3098288 ? Ssl 10:51 1:10 python -m runne
user+ 58 76.8 2.3 91079060 1547512 ? Rl 10:54 1:03 python -m runne
user+ 59 76.0 2.2 91006896 1484536 ? Rl 10:54 1:02 python -m runne
user+ 60 76.4 2.3 91099448 1559992 ? Rl 10:54 1:02 python -m runne
user+ 61 79.4 2.2 91008344 1465292 ? Rl 10:54 1:05 python -m runne
после блокировки:
root<strong i="11">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 24.8 4.4 91509728 2919744 ? Ssl 14:25 13:01 python -m runne
user+ 58 51.7 0.0 0 0 ? Z 14:27 26:20 [python] <defun
user+ 59 52.1 0.0 0 0 ? Z 14:27 26:34 [python] <defun
user+ 60 52.0 2.4 91147008 1604628 ? Sl 14:27 26:31 python -m runne
user+ 61 52.0 2.3 91128424 1532088 ? Sl 14:27 26:29 python -m runne
Для одного еще оставшегося воркера начало трассировки стека gdb выглядит так:
root<strong i="15">@b06f896d5c1d</strong>:~/mnt# gdb --pid 60
GNU gdb (GDB) 8.0
Attaching to process 60
[New LWP 65]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb) bt
#0 0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f36f52af8d4 in __new_sem_wait_slow.constprop.0 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#2 0x00007f36f52af97a in sem_wait@@GLIBC_2.2.5 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#3 0x00007f36f157efb1 in semlock_acquire (self=0x7f3656296458,
args=<optimized out>, kwds=<optimized out>)
at /home/ilan/minonda/conda-bld/work/Python-3.5.2/Modules/_multiprocessing/semaphore.c:307
#4 0x00007f36f5579621 in PyCFunction_Call (func=
<built-in method __enter__ of _multiprocessing.SemLock object at remote 0x7f3656296458>, args=(), kwds=<optimized out>) at Objects/methodobject.c:98
#5 0x00007f36f5600bd5 in call_function (oparg=<optimized out>,
pp_stack=0x7f36c7ffbdb8) at Python/ceval.c:4705
#6 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#7 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=1, kws=0x0, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0,
closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#8 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#9 0x00007f36f5557542 in function_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/funcobject.c:627
#10 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36561c7d08>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#11 0x00007f36f554077c in method_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/classobject.c:330
#12 0x00007f36f5524236 in PyObject_Call (
func=<method at remote 0x7f36556f9248>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#13 0x00007f36f55277d9 in PyObject_CallFunctionObjArgs (
callable=<method at remote 0x7f36556f9248>) at Objects/abstract.c:2445
#14 0x00007f36f55fc3a9 in PyEval_EvalFrameEx (f=<optimized out>,
throwflag=<optimized out>) at Python/ceval.c:3107
#15 0x00007f36f5601166 in fast_function (nk=<optimized out>, na=1,
n=<optimized out>, pp_stack=0x7f36c7ffc418,
func=<function at remote 0x7f36561c78c8>) at Python/ceval.c:4803
#16 call_function (oparg=<optimized out>, pp_stack=0x7f36c7ffc418)
at Python/ceval.c:4730
#17 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#18 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=4, kws=0x7f36f5b85060, kwcount=0, defs=0x0, defcount=0,
kwdefs=0x0, closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#19 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#20 0x00007f36f5557661 in function_call (
func=<function at remote 0x7f36e14170d0>,
arg=(<ImageFolder(class_to_idx={'n04153751': 783, 'n02051845': 144, 'n03461385': 582, 'n04350905': 834, 'n02105056': 224, 'n02112137': 260, 'n03938244': 721, 'n01739381': 59, 'n01797886': 82, 'n04286575': 818, 'n02113978': 268, 'n03998194': 741, 'n15075141': 999, 'n03594945': 609, 'n04099969': 765, 'n02002724': 128, 'n03131574': 520, 'n07697537': 934, 'n04380533': 846, 'n02114712': 271, 'n01631663': 27, 'n04259630': 808, 'n04326547': 825, 'n02480855': 366, 'n02099429': 206, 'n03590841': 607, 'n02497673': 383, 'n09332890': 975, 'n02643566': 396, 'n03658185': 623, 'n04090263': 764, 'n03404251': 568, 'n03627232': 616, 'n01534433': 13, 'n04476259': 868, 'n03495258': 594, 'n04579145': 901, 'n04266014': 812, 'n01665541': 34, 'n09472597': 980, 'n02095570': 189, 'n02089867': 166, 'n02009229': 131, 'n02094433': 187, 'n04154565': 784, 'n02107312': 237, 'n04372370': 844, 'n02489166': 376, 'n03482405': 588, 'n04040759': 753, 'n01774750': 76, 'n01614925': 22, 'n01855032': 98, 'n03903868': 708, 'n02422699': 352, 'n01560419': 1...(truncated), kw={}) at Objects/funcobject.c:627
#21 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36e14170d0>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#22 0x00007f36f55fe234 in ext_do_call (nk=1444355432, na=0,
flags=<optimized out>, pp_stack=0x7f36c7ffc768,
func=<function at remote 0x7f36e14170d0>) at Python/ceval.c:5034
#23 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3275
--snip--
У меня был аналогичный журнал ошибок с зависанием основного процесса: self.data_queue.get()
Для меня проблема заключалась в том, что я использовал opencv в качестве загрузчика изображений. А функция cv2.imread безошибочно зависала на неопределенный срок на конкретном изображении imagenet ("n01630670/n01630670_1010.jpeg")
Если вы сказали, что это работает для вас с num_workers = 0, это не так. Но я подумал, что это может помочь некоторым людям с похожей трассировкой ошибок.
 M-Eng
9 июн. 2017
M-Eng
9 июн. 2017
В настоящее время я запускаю тест с num_workers = 0 , пока нет зависаний. Я запускаю пример кода с https://github.com/pytorch/examples/blob/master/imagenet/main.py. pytorch/vision ImageFolder, кажется, использует PIL или pytorch/accimage внутри для загрузки изображений, поэтому OpenCV не задействован.
С num_workers = 4 я могу иногда получить поезд первой эпохи и полностью проверить его, и он блокируется в середине второй эпохи. Так что вряд ли проблема в наборе данных/функции загрузки.
Это похоже на состояние гонки в ImageLoader, которое может запускаться относительно редко определенной комбинацией аппаратного и программного обеспечения.
jsainio
9 июн. 2017
@ zym1010 zym1010 спасибо за указатель, я попробую установить pin_memory = False и для DataLoader.
jsainio
9 июн. 2017
Интересный. В моей настройке при установке pin_memory = False и num_workers = 4 пример imagenet зависает почти сразу, и три рабочих процесса становятся процессами-зомби:
root<strong i="8">@034c4212d022</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 6.7 2.8 92167056 1876612 ? Ssl 13:50 0:36 python -m runner
user+ 38 1.9 0.0 0 0 ? Z 13:51 0:08 [python] <defunct>
user+ 39 4.3 2.3 91069804 1550736 ? Sl 13:51 0:19 python -m runner
user+ 40 2.0 0.0 0 0 ? Z 13:51 0:09 [python] <defunct>
user+ 41 4.1 0.0 0 0 ? Z 13:51 0:18 [python] <defunct>
В моей настройке набор данных лежит на сетевом диске, который читается по NFS. С pin_memory = False и num_workers = 4 я могу довольно быстро вывести систему из строя.
=> creating model 'resnet18'
- training epoch 0
Epoch: [0][0/5005] Time 10.713 (10.713) Data 4.619 (4.619) Loss 6.9555 (6.9555) Prec<strong i="8">@1</strong> 0.000 (0.000) Prec<strong i="9">@5</strong> 0.000 (0.000)
Traceback (most recent call last):
--snip--
imagenet_pytorch.main.main([data_dir, "--transient_dir", context.transient_dir])
File "/home/user/mnt/imagenet_pytorch/main.py", line 140, in main
train(train_loader, model, criterion, optimizer, epoch, args)
File "/home/user/mnt/imagenet_pytorch/main.py", line 168, in train
for i, (input, target) in enumerate(train_loader):
File "/home/user/anaconda/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 206, in __next__
idx, batch = self.data_queue.get()
File "/home/user/anaconda/lib/python3.5/multiprocessing/queues.py", line 345, in get
return ForkingPickler.loads(res)
File "/home/user/anaconda/lib/python3.5/site-packages/torch/multiprocessing/reductions.py", line 70, in rebuild_storage_fd
fd = df.detach()
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError
:
[Errno 104] Connection reset by peer
@ zym1010 zym1010 у вас есть сетевой диск или традиционный вращающийся диск, который может быть медленнее по задержке и т. д.?
jsainio
9 июн. 2017
@jsainio
Я использую локальный SSD на вычислительном узле кластера. Код находится на диске NFS, но данные находятся на локальном SSD для максимальной скорости загрузки. Никогда не пробовал загружать данные на диски NFS.
zym1010
9 июн. 2017
@ zym1010 Спасибо за информацию. Я тоже запускаю это на вычислительном узле кластера.
На самом деле, я одновременно провожу эксперимент num_workers = 0 на том же узле и пробую варианты num_workers = 4 . Может случиться так, что первый эксперимент генерирует достаточную нагрузку, чтобы возможные условия гонки проявлялись быстрее во втором.
jsainio
9 июн. 2017
@apaszke Когда вы пытались воспроизвести это ранее, вы пытались запустить два экземпляра бок о бок или с какой-то другой значительной нагрузкой на систему?
jsainio
9 июн. 2017
@jsainio Спасибо за расследование! Это странно, воркеры должны завершаться только вместе, и как только основной процесс завершится чтением данных. Можете ли вы попытаться проверить, почему они выходят преждевременно? Может быть, проверить журнал ядра ( dmesg )?
apaszke
9 июн. 2017
Нет, я этого не пробовал, но казалось, что это появляется, даже когда это не так IIRC
apaszke
9 июн. 2017
@apaszke Хорошо, приятно знать, что рабочие не должны были выходить.
Я пробовал, но не знаю, как проверить, почему они выходят. dmesg не показывает ничего важного. (Я работаю в Docker, производном от Ubuntu 16.04, используя пакеты Anaconda)
jsainio
9 июн. 2017
Одним из способов было бы добавить несколько отпечатков внутри рабочего цикла . Я понятия не имею, почему они молча уходят. Это, вероятно, не исключение, потому что это было бы напечатано в stderr, поэтому они либо вырываются из цикла, либо убиваются ОС (возможно, по сигналу?)
apaszke
9 июн. 2017
@jsainio , просто чтобы убедиться, что вы используете докер с --ipc=host (вы не упоминаете об этом)? Можете ли вы проверить размер вашего сегмента общей памяти (df -h | grep shm)?
ngimel
9 июн. 2017
@ngimel Я использую --shm-size=1024m . df -h | grep shm сообщает соответственно:
root<strong i="9">@db92462e8c19</strong>:~/mnt# df -h | grep shm
shm 1.0G 883M 142M 87% /dev/shm
Это использование кажется довольно жестким. Это на докере с двумя рабочими-зомби.
jsainio
12 июн. 2017
Можете ли вы попробовать увеличить размер shm? Я только что проверил, и на сервере, где я пытался воспроизвести проблемы, было 16 ГБ. Вы либо меняете флаг докера, либо запускаете
mount -o remount,size=8G /dev/shm
Я только что попытался уменьшить размер до 512 МБ, но вместо взаимоблокировки получил явную ошибку. До сих пор не могу воспроизвести 😕
apaszke
14 июн. 2017
С докером мы склонны к взаимоблокировкам, когда shm недостаточно, а не к четким сообщениям об ошибках, не знаю почему. Но это обычно лечится увеличением shm (а у меня тупики были с 1G).
ngimel
14 июн. 2017
Хорошо, кажется, что с 10 воркерами возникает ошибка, но когда я использую 4 воркера, я получаю тупик при 58% использования /dev/shm! наконец-то я его воспроизвел
apaszke
14 июн. 2017
Это здорово, что вы можете воспроизвести форму этой проблемы. Я выложил скрипт, вызывающий зависание в #1579, а вы ответили, что в вашей системе он не зависал. На самом деле я тестировал его только на своем MacBook. Я только что попробовал на Linux, и он не завис. Так что, если вы пробовали только на Linux, возможно, стоит попробовать и на Mac.
 greaber
14 июн. 2017
greaber
14 июн. 2017
Итак, после изучения проблемы это кажется странным. Даже когда я ограничиваю размер /dev/shm всего 128 МБ, Linux с радостью позволяет нам создавать там файлы размером 147 МБ, полностью отображать их в памяти, но отправит смертельный SIGBUS рабочему процессу, как только он действительно попытается получить доступ к страницам. ... Я не могу придумать никакого механизма, который позволил бы нам проверять достоверность страниц, кроме как перебирать их и касаться каждой из них с зарегистрированным обработчиком SIGBUS...
Обходной путь на данный момент — расширить /dev/shm с помощью команды mount как показано выше. Попробуйте с 16 ГБ (если у вас достаточно оперативной памяти).
apaszke
15 июн. 2017
Трудно найти какие-либо упоминания об этом, но вот одно .
apaszke
15 июн. 2017
Спасибо, что уделили время этой проблеме, она давно сводила меня с ума! Если я правильно понимаю, мне нужно расширить /dev/shm до 16G вместо 8G. Это имеет смысл, но когда я пытаюсь df -h , я вижу, что вся моя оперативная память фактически выделена как таковая: (у меня 16 ГБ)
tmpfs 7,8G 393M 7,4G 5% /dev/shm
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,8G 0 7,8G 0% /sys/fs/cgroup
tmpfs 1,6G 60K 1,6G 1% /run/user/1001
Это вывод df -h во время взаимоблокировки. Насколько я понимаю, если у меня есть раздел подкачки 16 ГБ, я могу смонтировать tmpfs до 32 ГБ, поэтому расширение /dev/shm не должно быть проблемой, верно?
Что еще более важно, я озадачен разделом cgroup и его назначением, поскольку он занимает почти половину моей оперативной памяти. По-видимому, он предназначен для эффективного управления многопроцессорными задачами, но я действительно не знаком с тем, что он делает и зачем он нам нужен, изменит ли он что-то, чтобы выделить всю физическую оперативную память для shm (потому что мы устанавливаем его размер 16G) и поместите его в SWAP (хотя я считаю, что оба будут частично в ОЗУ и в SWAP одновременно)
 ClementPinard
15 июн. 2017
ClementPinard
15 июн. 2017
@apaszke Спасибо! Хорошо, что вы нашли основную причину. Время от времени я получал как различные ошибки «ConnectionReset», так и взаимоблокировки с докером --shm-size=1024m зависимости от того, какая еще нагрузка была на одну машину. Тестирование сейчас с --shm-size=16384m и 4 работниками.
jsainio
15 июн. 2017
@jsainio ConnectionReset мог быть вызван тем же самым. Процессы начали обмениваться некоторыми данными, но как только shm закончилось место, SIGBUS был отправлен на рабочий процесс и убил его.
@ClementPinard, насколько я понимаю, вы можете сделать его настолько большим, насколько хотите, за исключением того, что он, скорее всего, заморозит вашу машину, когда у вас закончится ОЗУ (потому что даже ядро не может освободить эту память). Вам, вероятно, не нужно беспокоиться о /sys/fs/cgroup . tmpfs выделяют память лениво, поэтому, пока использование остается на уровне 0B, это ничего вам не стоит (включая ограничения). Я не думаю, что использование подкачки — хорошая идея, так как это сделает загрузку данных намного медленнее, поэтому вы можете попробовать увеличить размер shm скажем, до 12 ГБ, и ограничить количество рабочих процессов (как я уже сказал, не используйте всю оперативную память для shm!). Вот хорошая статья о tmpfs из документации ядра.
Я не знаю, почему возникает взаимоблокировка, даже когда использование /dev/shm очень мало (на моей машине происходит при 20 КБ). Возможно, ядро слишком оптимистично, но не ждет, пока вы все заполните, и убивает процесс, как только он начинает использовать что-либо из этого региона.
apaszke
15 июн. 2017
Тестирую сейчас с 12G и половиной рабочих, которые у меня были, и это не удалось :(
Он работал как шарм в версии lua torch (такая же скорость, такое же количество рабочих), что заставляет меня задаться вопросом, связана ли проблема только с /dev/shm а не ближе к многопроцессорной обработке python...
Странная вещь в этом (как вы упомянули) заключается в том, что /dev/shm никогда не бывает близок к заполнению. Во время первой тренировочной эпохи оно никогда не превышало 500Mo. И он также никогда не блокируется в течение первой эпохи, и если я отключу тестовый загрузчик, он никогда не выйдет из строя во все эпохи. Тупик появляется только в начале тестовой эпохи. Я должен отслеживать /dev/shm при переходе от поезда к тесту, возможно, пиковое использование происходит во время смены загрузчиков данных.
ClementPinard
15 июн. 2017
@ClementPinard, даже с более высокой общей памятью и без Docker, он все равно может выйти из строя.
zym1010
15 июн. 2017
Если версия факела == Lua Torch, то это все равно может быть связано с /dev/shm . Lua Torch может использовать потоки (нет GIL), поэтому ему не нужно проходить через общую память (все они используют одно адресное пространство).
apaszke
15 июн. 2017
У меня была та же проблема, когда загрузчик данных давал сбой после жалобы на то, что он не может выделить память в начале новой эпохи обучения или проверки. Приведенные выше решения не сработали для меня (i) мой /dev/shm составляет 32 ГБ, и он никогда не использовался более 2,5 ГБ, и (ii) настройка pin_memory = False не работала.
Возможно, это как-то связано со сборкой мусора? Мой код выглядит примерно следующим образом. Мне нужен бесконечный итератор, и поэтому я делаю попытку / кроме next() ниже :-)
def train():
train_iter = train_loader.__iter__()
for i in xrange(max_batches):
try:
x, y = next(train_iter)
except StopIteration:
train_iter = train_loader.__iter__()
...
del train_iter
train_loader — это объект DataLoader . Без явной строки del train_iter в конце функции процесс всегда падает через 2-3 эпохи ( /dev/shm прежнему показывает 2,5 ГБ). Надеюсь это поможет!
Я использую рабочих 4 (версия 0.1.12_2 с CUDA 8.0 на Ubuntu 16.04).
 pratikac
7 июл. 2017
pratikac
7 июл. 2017
Я также встретил тупик, особенно когда work_number большой. Есть ли возможное решение этой проблемы? Мой размер /dev/shm составляет 32 ГБ, с cuda 7.5, pytorch 0.1.12 и python 2.7.13. Ниже приводится связанная информация после смерти. Кажется, это связано с памятью. @apaszke

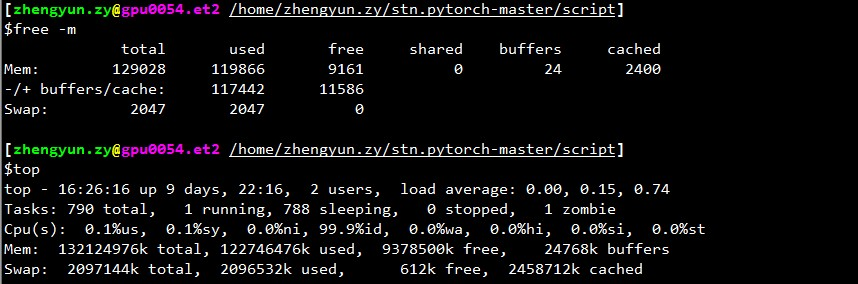
 zhengyunqq
4 авг. 2017
zhengyunqq
4 авг. 2017
@zhengyunqq попробуйте pin_memory=False если вы установите его на True . В противном случае я не знаю никакого решения.
zym1010
4 авг. 2017
Я также столкнулся с тупиком, когда num_workers велико.
 hendrycks
11 авг. 2017
hendrycks
11 авг. 2017
Для меня проблема заключалась в том, что если рабочий поток умирает по какой-либо причине, то index_queue.put зависает навсегда. Одной из причин смерти рабочих потоков является сбой unpickler во время инициализации. В этом случае до исправления ошибки Python в мастере в мае 2017 года рабочий поток умирал и вызывал бесконечное зависание. В моем случае зависание происходило на этапе подготовки к пакетной предварительной выборке.
Возможно, замена SimpleQueue используемая в DataLoaderIter на Queue которая допускает тайм-аут с изящным сообщением об исключении.
UPD: ошибся, этот багфикс исправляет Queue , а не SimpleQueue . Верно и то, что SimpleQueue заблокируется, если рабочие потоки не подключены к сети. Простой способ проверить это — заменить эти строки на self.workers = [] .
 vadimkantorov
16 авг. 2017
vadimkantorov
16 авг. 2017
у меня такая же проблема, и я не могу изменить shm (без разрешения), может быть, лучше использовать Queue или что-то еще?
 xfanplus
8 сент. 2017
xfanplus
8 сент. 2017
У меня похожая проблема.
Этот код зависнет и никогда ничего не напечатает. Если я установлю num_workers=0, это сработает.
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
model.cuda()
for i, batch in enumerate(dataloader):
print(i)
Если я поставлю model.cuda() за цикл, все будет работать нормально.
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
for i, batch in enumerate(dataloader):
print(i)
model.cuda()
У кого-нибудь есть решение этой проблемы?
 anDoer
13 сент. 2017
anDoer
13 сент. 2017
Я тоже сталкивался с подобными проблемами во время обучения ImageNet. Он будет постоянно зависать на 1-й итерации оценки на определенных серверах с определенной архитектурой (а не на других серверах с той же архитектурой или на том же сервере с другой архитектурой), но всегда на 1-й итерации во время оценки при проверке. Когда я использовал Torch, мы обнаружили, что nccl может вызвать взаимоблокировку, как это, есть ли способ отключить это?
 WendyShang
20 сент. 2017
WendyShang
20 сент. 2017
Я столкнулся с той же проблемой, случайно застряв в начале 1-й эпохи. Все обходные пути, упомянутые выше, не работают для меня. При нажатии Ctrl-C он печатает это:
Traceback (most recent call last):
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 249, in _bootstrap
self.run()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 44, in _worker_loop
data_queue.put((idx, samples))
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/queues.py", line 354, in put
self._writer.send_bytes(obj)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 200, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 398, in _send_bytes
self._send(buf)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
KeyboardInterrupt
Traceback (most recent call last):
File "scripts/train_model.py", line 640, in <module>
main(args)
File "scripts/train_model.py", line 193, in main
train_loop(args, train_loader, val_loader)
File "scripts/train_model.py", line 341, in train_loop
ee_optimizer.step()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/optim/adam.py", line 74, in step
p.data.addcdiv_(-step_size, exp_avg, denom)
KeyboardInterrupt
 zoharli
23 окт. 2017
zoharli
23 окт. 2017
У меня была аналогичная проблема с тупиком с одним рабочим внутри докера, и я могу подтвердить, что в моем случае это была проблема с общей памятью. По умолчанию докер выделяет только 64 МБ общей памяти, однако мне нужно было 440 МБ для 1 работника, что, вероятно, вызвало поведение, описанное @apaszke.
 paulguerrero
23 окт. 2017
paulguerrero
23 окт. 2017
Меня беспокоит та же проблема, но я нахожусь в другой среде, чем большинство других в этой ветке, поэтому, возможно, мой вклад может помочь определить основную причину. Мой pytorch установлен с помощью отличного пакета conda, созданного peterjc123 под Windows10.
Я запускаю cnn в наборе данных cifar10. Для загрузчиков данных num_workers устанавливается равным 1. Хотя известно, что num_workers > 0 вызывает BrokenPipeError и не рекомендуется в #494, я испытываю не BrokenPipeError, а некоторую ошибку выделения памяти. Ошибка всегда возникала примерно на 50-й эпохе, сразу после проверки последней эпохи и перед началом обучения следующей эпохи. В 90% случаев это ровно 50 эпох, в других случаях они будут отличаться на 1 или 2 эпохи. В остальном все довольно стабильно. Установка num_workers=0 устранит эту проблему.
 berzjackson
24 окт. 2017
berzjackson
24 окт. 2017
@paulguerrero прав. Я решил эту проблему, увеличив общую память с 64M до 2G. Может быть, это полезно для пользователей докеров.
 yjzhux
24 окт. 2017
yjzhux
24 окт. 2017
@berzjackson Это известная ошибка в пакете conda. Исправлено в последних сборках CI.
 peterjc123
25 окт. 2017
peterjc123
25 окт. 2017
У нас около 600 человек, которые в понедельник начали новый курс с использованием Pytorch. Многие люди на нашем форуме сообщают об этой проблеме. Некоторые на AWS P2, некоторые на своих собственных системах (в основном GTX 1070, некоторые Titan X).
Когда они прерывают обучение, конец трассировки стека показывает:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv_bytes(self, maxsize)
405
406 def _recv_bytes(self, maxsize=None):
--> 407 buf = self._recv(4)
408 size, = struct.unpack("!i", buf.getvalue())
409 if maxsize is not None and size > maxsize:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv(self, size, read)
377 remaining = size
378 while remaining > 0:
--> 379 chunk = read(handle, remaining)
380 n = len(chunk)
381 if n == 0:
У нас num_workers=4, pin_memory=False. Я попросил их проверить настройки общей памяти, но могу ли я что-нибудь сделать (или мы могли бы сделать в Pytorch), чтобы решить эту проблему? (Кроме сокращения num_workers, так как это немного замедлит работу.)
 jph00
1 нояб. 2017
jph00
1 нояб. 2017
Я учусь в классе @jph00 (спасибо, Джереми! :) ). Я также пытался использовать «num_workers = 0». Все еще получаю ту же ошибку, когда resnet34 загружается очень медленно. Подгонка тоже очень медленная. Но странная вещь: это происходит только один раз за всю жизнь сеанса ноутбука.
Другими словами, как только данные загружены и подгонка запущена один раз, я могу перемещаться и продолжать повторять шаги... даже с 4 num_workers, и кажется, что все работает быстро, как и ожидалось в графическом процессоре.
Я использую PyTorch 0.2.0_4, Python 3.6.2, Torchvision 0.1.9, Ubuntu 16.04 LTS. Выполнение «df -h» на моем терминале говорит, что у меня есть 16 ГБ на /dev/shm, хотя использование было очень низким.
Вот скриншот, на котором происходит сбой загрузки (обратите внимание, что я использовал num_workers=0 для данных)
(извините за маленькие буквы. Мне пришлось уменьшить масштаб, чтобы запечатлеть все...)

 apiltamang
1 нояб. 2017
apiltamang
1 нояб. 2017
@apiltamang Я не уверен, что это та же проблема - это совсем не похоже на те же симптомы. Лучше всего диагностировать это на форуме fast.ai, а не здесь.
jph00
1 нояб. 2017
изучая это как можно скорее!
 soumith
1 нояб. 2017
soumith
1 нояб. 2017
@soumith Я предоставил @apaszke доступ к закрытому форуму курса и попросил студентов,
jph00
1 нояб. 2017
@ jph00 Привет, Джереми, слов, как
 SsnL
1 нояб. 2017
SsnL
1 нояб. 2017
@SsnL один из студентов подтвердил, что они увеличили общую память, но проблема все еще существует. Я попросил некоторых других подтвердить тоже.
jph00
1 нояб. 2017
@jph00 Спасибо! Я успешно воспроизвел зависание из-за нехватки общей памяти. Если проблема в другом, придется копать глубже! Не поделитесь со мной сценарием?
SsnL
1 нояб. 2017
Конечно, вот блокнот, который мы используем: https://github.com/fastai/fastai/blob/master/courses/dl1/lesson1.ipynb . Учащиеся заметили, что проблема возникает только тогда, когда они запускают все ячейки в том порядке, в котором они находятся в записной книжке. Надеюсь, блокнот не требует пояснений, но дайте мне знать, если у вас возникнут проблемы с его запуском — он содержит ссылку для загрузки необходимых данных.
Основываясь на проблеме с общей памятью, которую вы могли воспроизвести, есть ли какой-либо обходной путь, который я мог бы добавить в нашу библиотеку или блокнот, чтобы избежать этого?
jph00
1 нояб. 2017
@ jph00 Прямо сейчас
Я также отправлю PR, чтобы показать хорошее сообщение об ошибке при достижении лимита shm, а не просто позволить ему зависнуть.
SsnL
1 нояб. 2017
ОК, я воспроизвел проблему на новом экземпляре AWS P2, используя их CUDA 9 AMI с последней установкой Pytorch conda. Если вы предоставите свой открытый ключ, я могу дать вам доступ, чтобы попробовать его напрямую. Моя электронная почта — это первая буква моего имени на fast.ai
jph00
1 нояб. 2017
@jph00 Только что отправил вам письмо :) спасибо!
SsnL
1 нояб. 2017
@jph00 jph00 И к вашему сведению, сценарий занял
SsnL
1 нояб. 2017
Итак, я понял основную проблему, заключающуюся в том, что многопроцессорность opencv и Pytorch иногда плохо сочетается друг с другом. Никаких проблем с нашей коробкой в университете, но много проблем с AWS (на новом глубоком обучении CUDA 9 AMI с экземпляром P2). Добавление блокировки ко всем вызовам cv2 не исправляет это, и добавление cv2.setNumThreads(0) не исправляет. Это, кажется, исправить это:
from multiprocessing import set_start_method
set_start_method('spawn')
Однако это влияет на производительность примерно на 15%. В выпуске opencv github рекомендуется использовать https://github.com/tomMoral/loky . Я использовал этот модуль раньше и нашел его надежным. Не срочно, так как у нас есть решение, которое на данный момент работает достаточно хорошо, но, возможно, стоит подумать об использовании Loky для Dataloader?
Возможно, что еще более важно, было бы неплохо, если бы в очереди pytorch был хотя бы какой-то тайм-аут, чтобы эти бесконечные зависания отлавливались.
jph00
2 нояб. 2017
К вашему сведению, я только что попробовал другое исправление, так как «порождение» делало некоторые части в 2-3 раза медленнее, а именно, я добавил несколько случайных засыпаний в разделах, которые быстро проходят через загрузчик данных. Это также решило проблему - хотя, возможно, не идеально!
jph00
2 нояб. 2017
Спасибо, что копаетесь в этом! Рад узнать, что вы нашли два обходных пути. Действительно, было бы неплохо добавить тайм-ауты при индексации наборов данных. Мы обсудим и свяжемся с вами по этому маршруту завтра.
cc @soumith — это то, что мы хотим исследовать?
SsnL
2 нояб. 2017
Для людей, которые приходят в эту тему для обсуждения выше, проблема opencv обсуждается более подробно на https://github.com/opencv/opencv/issues/5150.
SsnL
2 нояб. 2017
ОК, похоже, теперь у меня есть правильное решение для этого - я переписал Dataloader для пользователя ProcessPoolExecutor.map() и перенес создание тензора в родительский процесс. Результат быстрее, чем я видел с оригинальным загрузчиком данных, и он был стабильным на всех компьютерах, на которых я его пробовал. Код также намного проще.
Если кто-то заинтересован в его использовании, вы можете получить его с https://github.com/fastai/fastai/blob/master/fastai/dataloader.py .
API такой же, как и в стандартной версии, за исключением того, что ваш набор данных не должен возвращать тензор Pytorch — он должен возвращать массивы numpy или списки python. Я не пытался заставить его работать на старых Python, поэтому не удивлюсь, если там возникнут какие-то проблемы.
(Причина, по которой я пошел по этому пути, заключается в том, что я обнаружил, что при выполнении большого количества обработки/увеличения изображений на последних графических процессорах я не мог завершить обработку достаточно быстро, чтобы сохранить загруженность графического процессора, если бы я выполнял предварительную обработку с использованием процессора Pytorch. операции; однако использование opencv было намного быстрее, и в результате я смог полностью использовать графический процессор.)
jph00
2 нояб. 2017
О, если это проблема opencv, то мы мало что можем с этим поделать. Это правда, что разветвление опасно, когда у вас есть пулы потоков. Я не думаю, что мы хотим добавить зависимость времени выполнения (в настоящее время у нас ее нет), особенно потому, что она не будет хорошо обрабатывать тензоры PyTorch. Было бы лучше просто выяснить, что вызывает взаимоблокировки, и @SsnL на этом.
@ jph00 ты пробовал Pillow-SIMD? Он должен работать с torchvision из коробки, и я слышал о нем много хороших отзывов.
apaszke
2 нояб. 2017
Да, я хорошо знаю подушку SIMD. Это только ускоряет изменение размера, размытие и преобразование RGB.
Я не согласен, что здесь мало что можно сделать. Это не совсем проблема opencv (они не утверждают, что поддерживают этот тип многопроцессорной обработки python в целом, не говоря уже о модуле многопроцессорной обработки pytorch в специальном корпусе), и не совсем проблема Pytorch. Но тот факт, что Pytorch молча ждет вечно, не выдавая никаких ошибок, — это (IMO) то, что вы можете исправить, и в целом многие умные люди усердно работали в течение последних нескольких лет, чтобы создать улучшенные подходы к многопроцессорной обработке, которые просто избегают проблем. как этот. Вы можете позаимствовать подходы, которые они используют, не прибегая к внешней зависимости.
У Оливье Гризеля, одного из авторов Loky, есть отличная презентация, обобщающая состояние многопроцессорности в Python: http://ogrisel.github.io/decks/2017_euroscipy_parallelism/
Я не возражаю в любом случае, так как я написал новый загрузчик данных, у которого нет этой проблемы. Но я, FWIW, подозреваю, что взаимодействие между многопроцессорной обработкой pytorch и другими системами станет проблемой и для других людей в будущем.
jph00
2 нояб. 2017
Как бы то ни было, у меня была эта проблема на Python 2.7 в Ubuntu 14.04. Мой загрузчик данных читал из базы данных sqlite и отлично работал с num_workers=0 , иногда казалось, что все в порядке с num_workers=1 , и очень быстро блокировался для любого более высокого значения. Трассировка стека показала, что процесс завис в recv_bytes .
Что не сработало:
- Передача
--shm-size 8Gили--ipc=hostпри запуске докера - Запуск
echo 16834 | sudo tee /proc/sys/kernel/shmmniдля увеличения количества сегментов общей памяти (по умолчанию на моей машине было 4096) - Установка
pin_memory=Trueилиpin_memory=Falseни одна не помогла
Что надежно решило мою проблему, так это перенос моего кода на Python 3. Запуск той же версии Torch внутри экземпляра Python 3.6 (от Anaconda) полностью устранил мою проблему, и теперь загрузка данных больше не зависает.
 gcr
16 нояб. 2017
gcr
16 нояб. 2017
@apaszke, вот почему важно хорошо работать с opencv, к вашему сведению (и почему torchsample не лучший вариант - он может обрабатывать вращение <200 изображений в секунду!):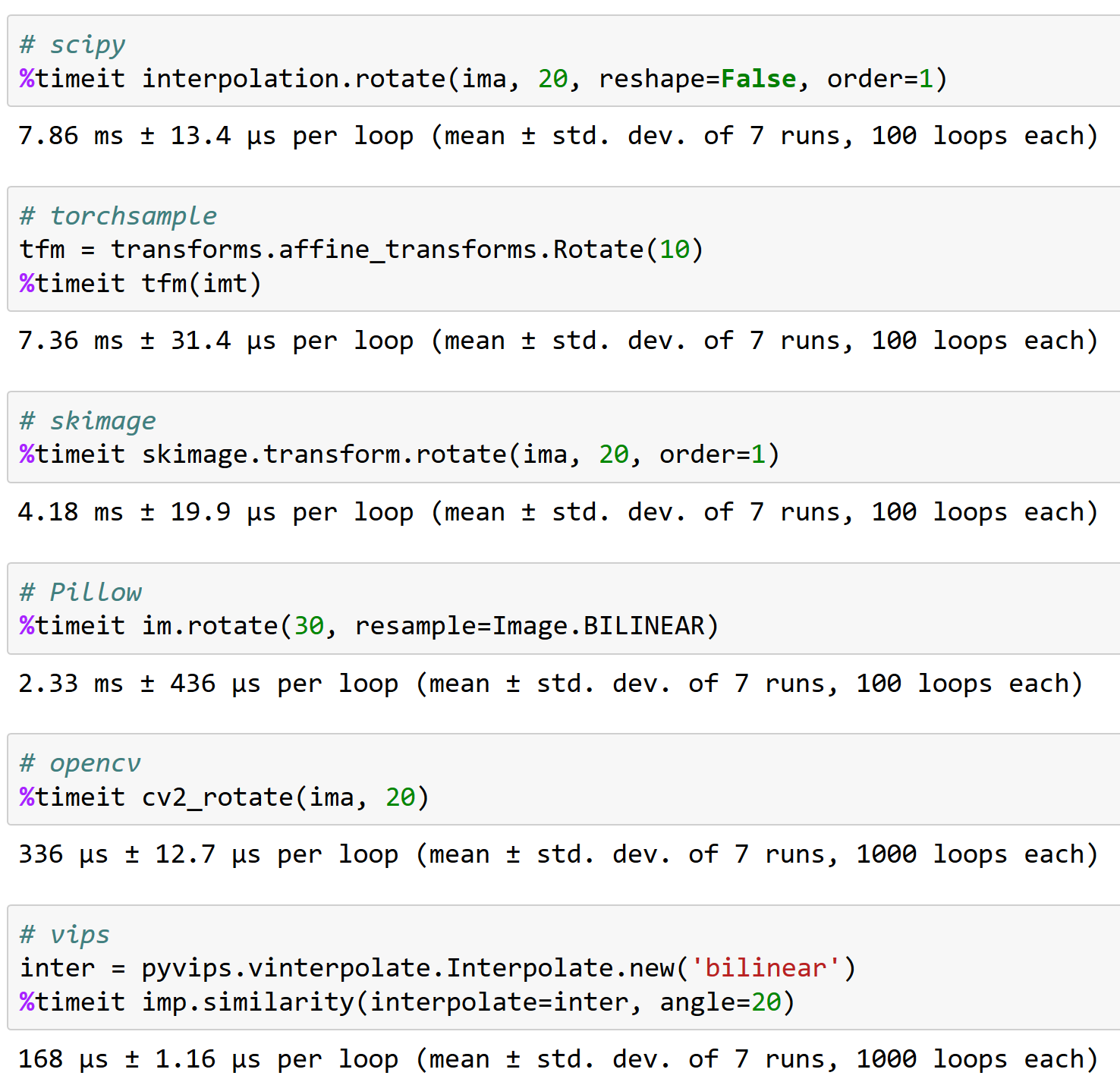
jph00
18 нояб. 2017
Кто-нибудь нашел решение этой проблемы?
 iqbalu
9 дек. 2017
iqbalu
9 дек. 2017
@iqbalu Попробуйте скрипт выше: https://github.com/fastai/fastai/blob/master/fastai/dataloader.py
Это решило мою проблему, но не поддерживает num_workers=0 .
 elbaro
14 дек. 2017
elbaro
14 дек. 2017
@elbaro на самом деле я пробовал, и в моем случае он вообще не использовал несколько рабочих. Вы там что-то меняли?
iqbalu
14 дек. 2017
Загрузчик данных
apaszke
14 дек. 2017
@apaszke @elbaro @jph00 Загрузчик данных из fast.ai замедлил чтение данных более чем в 10 раз. Я использую num_workers=8. Любая подсказка, в чем может быть причина?
iqbalu
15 дек. 2017
Вероятно, загрузчик данных использует пакеты, которые не отказываются от GIL.
apaszke
15 дек. 2017
@apaszke есть идеи, почему использование общей памяти продолжает расти через несколько эпох. В моем случае он начинается с 400 МБ, а затем каждые ~ 20-е эпохи увеличивается на 400 МБ. Спасибо!
iqbalu
28 дек. 2017
@iqbalu не совсем так. Этого не должно быть
apaszke
28 дек. 2017
Я пробовал много вещей, и cv2.setNumThreads(0) наконец решил мою проблему.
Спасибо @jph00
 Cadene
19 янв. 2018
Cadene
19 янв. 2018
Недавно меня беспокоила эта проблема. cv2.setNumThreads(0) у меня не работает. Я даже изменил весь код cv2, чтобы вместо этого использовать scikit-image, но проблема все еще существует. Кроме того, у меня есть 16G за /dev/shm . У меня такая проблема только при использовании нескольких gpus. Все работает нормально на одном GPU. Есть у кого новые мысли по поводу решения?
 roytseng-tw
25 янв. 2018
roytseng-tw
25 янв. 2018
Та же ошибка. У меня есть эта проблема при использовании одного GPU.
 Jiankai-Sun
27 янв. 2018
Jiankai-Sun
27 янв. 2018
Для меня отключение потоков opencv решило проблему:
cv2.setNumThreads (0)
 shacharf
28 янв. 2018
shacharf
28 янв. 2018
ударьте его тоже с pytorch 0.3, cuda 8.0, ubuntu 16.04
не используется opencv.
 tianq01
1 февр. 2018
tianq01
1 февр. 2018
Я использую pytorch 0.3, cuda 8.0, ubuntu 14.04. Наблюдал это зависание после того, как начал использовать cv2.resize()
cv2.setNumThreads(0) решил мою проблему.
 mathmanu
9 февр. 2018
mathmanu
9 февр. 2018
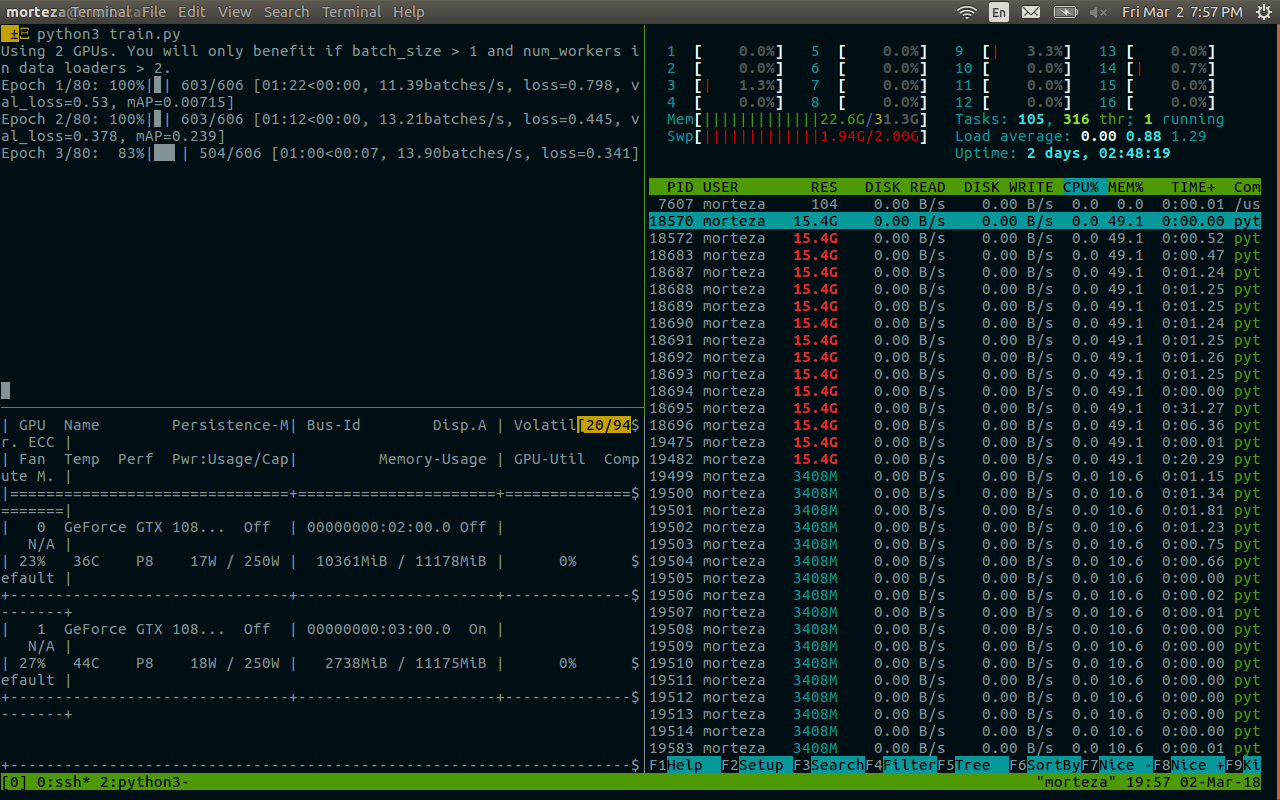
Я использую python 3.6, pytorch 0.3.0, cuda 8.0 и ubuntu 17.04 в системе с двумя 1080Ti и 32 ГБ ОЗУ.
Когда я использую 8 воркеров для своего собственного набора данных, я часто вижу взаимоблокировку (это происходит в первой эпохе). Когда я уменьшаю рабочих до 4, он исчезает (я пробежал 80 эпох).
Когда происходит взаимоблокировка, у меня все еще есть около 10 ГБ свободной оперативной памяти.
 milani
2 мар. 2018
milani
2 мар. 2018
Здесь вы можете увидеть лог после завершения скрипта: https://gist.github.com/milani/42f50c023cdca407115b309237d29c70
ОБНОВЛЕНИЕ: я подтверждаю, что смог решить проблему с увеличением SHMMNI . В Ubuntu 17.04 я добавил kernel.shmmni=8192 к /etc/sysctl.conf .
milani
2 мар. 2018
Также возникает эта проблема, Ubuntu 17.10, Python 3.6, Pytorch 0.3.1, CUDA 8.0. Остается много оперативной памяти, когда происходит взаимоблокировка и время кажется несогласованным - может произойти после 1-й эпохи или после 200-й.
Комбинация kernel.shmmni=8192 и cv2.setNumThreads(0) кажется, исправила ситуацию, тогда как по отдельности они не работали.
 inoryy
8 мар. 2018
inoryy
8 мар. 2018
То же самое в моем случае. Я столкнулся с тупиковой ситуацией, если установил num_workers=4. Я использую Ubuntu 17.10, Pytorch 0.3.1, CUDA 9.1, Python 3.6. Замечено, что существует 4 потока Python, каждый из которых занимает 1,6 ГБ памяти, в то время как ЦП (4 ядра) остается бездействующим. Установка num_workers=0 помогает решить эту проблему.
 AlenUbuntu
27 мар. 2018
AlenUbuntu
27 мар. 2018
У меня та же проблема, зависает ровно через одну эпоху, но не воспроизводится для небольших наборов данных. Я использую CUDA 9.1, Pytorch 0.3.1, Python 3.6 в среде Docker.
Я попробовал Dataloader @jph00 , однако обнаружил, что он намного медленнее для моего варианта использования. Мой обходной путь в настоящее время заключается в воссоздании Pytorch DataLoader перед каждой эпохой. Кажется, это работает, но это действительно уродливо.
 tfriedel
11 апр. 2018
tfriedel
11 апр. 2018
У меня была точно такая же проблема с Ubuntu 17.10, CUDA 9.1, Pytorch master (скомпилировано 19/04 утром). Также использую OpenCV в моем подклассе набора данных.
Затем мне удалось избежать взаимоблокировки, изменив метод запуска многопроцессорной обработки с «forkserver» на «spawn»:
# Set multiprocessing start method - deadlock
set_start_method(forkserver')
# Set multiprocessing start method - runs fine
set_start_method('spawn')
 mfuntowicz
19 апр. 2018
mfuntowicz
19 апр. 2018
Я почти пробовал все вышеперечисленные подходы! Ни один из них не работал!
Эта проблема может быть связана с некоторыми несовместимостями аппаратной архитектуры, и я не знаю, как Pytorch может ее спровоцировать! Это может быть или не быть проблемой Pytorch!
Итак, как решилась моя проблема:
_Обновляю БИОС!
Дать ему шанс. По крайней мере, это решит мою проблему.
 astorfi
21 апр. 2018
astorfi
21 апр. 2018
То же самое. Убунту ПиТорч 0.4, питон3.6.
 Shuailong
30 апр. 2018
Shuailong
30 апр. 2018
Похоже, проблема все еще существует в pytorch 0.4 и python 3.6. Не уверен, что это проблема pytorch. Я использую opencv и устанавливаю num_workers=8 , pin_memory=True . Я пробую все приемы, упомянутые выше, и установка cv2.setNumThreads(0) решает мою проблему.
 JasonQSY
10 мая 2018
JasonQSY
10 мая 2018
(1) Установка num_workers=0 при загрузке данных PyTorch решает проблему (см. выше) ИЛИ
(2) cv2.setNumThreads(0) решает проблему даже при достаточно больших num_workers
Это похоже на какую-то проблему с блокировкой потока.
Я установил cv2.setNumThreads(0) где-то в начале моего основного файла Python, и с тех пор у меня никогда не было этой проблемы.
mathmanu
10 мая 2018
Да, многие из этих проблем связаны с тем, что сторонние библиотеки не являются безопасными для форка. Одним из альтернативных решений может быть использование метода запуска спавна.
apaszke
10 мая 2018
Для меня проблема взаимоблокировки возникает, когда я оборачиваю свою модель в nn.DataParallel и использую num_workers > 0 в загрузчике данных. Удалив оболочку nn.DataParallel, я могу запустить свой скрипт без каких-либо блокировок.
CUDA_VISIBLE_DEVICES=0 python myscript.py --split 1
CUDA_VISIBLE_DEVICES=1 python myscript.py --split 2
Без нескольких графических процессоров мой скрипт работает медленнее, но я могу одновременно запускать несколько экспериментов с разными частями набора данных.
 euwern
15 июн. 2018
euwern
15 июн. 2018
У меня такая же проблема на Python 3.6.2/Pytorch 0.4.0.
и я попытался прежде всего подойти к переключению pin_memory, изменению размера общей памяти и использовать библиотеку skiamge (я не использую cv2 !!), но у меня все еще есть проблема.
эта проблема возникает случайно. управлять этой проблемой можно просто наблюдая за консолью и перезапуская тренировку.
 slaysd
19 июн. 2018
slaysd
19 июн. 2018
@ jinh574 jinh574 Я просто установил количество рабочих загрузчиков данных
Shuailong
19 июн. 2018
@Shuailong Мне нужно использовать изображение большого размера, поэтому я не могу использовать эти параметры из-за скорости. мне нужно больше узнать об этой проблеме
slaysd
19 июн. 2018
У меня такая же проблема с Python 3.6/Pytorch 0.4.0. Влияет ли опция pin_memory на что-то?
 ein-farbe
26 июн. 2018
ein-farbe
26 июн. 2018
Если вы используете collate_fn и num_workers>0 с версией PyTorch <0.4:
УБЕДИТЕСЬ, ЧТО ВЫ НЕ ВОЗВРАЩАЕТЕ ZERO DIM TENSORS ИЗ ВАШЕЙ ФУНКЦИИ __getitem__() .
ИЛИ ВЕРНИТЕ ИХ КАК МАССИВЫ NUMPY.
 pyaf
12 июл. 2018
pyaf
12 июл. 2018
У меня есть эта проблема даже после установки num_workers=0 или cv2.setNumThreads(0).
Это терпит неудачу с любой из этих двух проблем. Кто-нибудь еще сталкивается с тем же?
Traceback (последний последний вызов):
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", строка 193, в _run_module_as_main
"__main__", mod_spec)
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", строка 85, в _run_code
exec(код, run_globals)
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", строка 209, в
главный()
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", строка 205, в основном
процесс.ждите()
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", строка 1457, в ожидании
(pid, sts) = self._try_wait(0)
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", строка 1404, в _try_wait
(pid, sts) = os.waitpid(self.pid, wait_flags)
КлавиатураПрерывание
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", строка 258, в _bootstrap
самозапуск()
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", строка 93, выполняется
self._target( self._args, * self._kwargs)
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/utils/data/dataloader.py", строка 96, в _worker_loop
r = index_queue.get (время ожидания = MANAGER_STATUS_CHECK_INTERVAL)
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/queues.py", строка 104, в get
если не self._poll(время ожидания):
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", строка 257, в опросе
вернуть self._poll(время ожидания)
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", строка 414, в _poll
r = ждать([я], тайм-аут)
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", строка 911, в ожидании
готов = selector.select (тайм-аут)
Файл "/opt/conda/envs/pytorch-py3.6/lib/python3.6/selectors.py", строка 376, при выборе
fd_event_list = self._poll.poll(время ожидания)
КлавиатураПрерывание
 swethmandava
25 авг. 2018
swethmandava
25 авг. 2018
Я использую версию «0.5.0a0+f57e4ce» и столкнулся с той же проблемой. Работает либо отмена параллельного загрузчика данных (num_workers=0), либо установка cv2.setNumThreads(0).
 omersumer
5 окт. 2018
omersumer
5 окт. 2018
Я совершенно уверен, что #11985 должен устранить все зависания (если только вы не прерываете работу в неподходящий момент, который мы не можем контролировать). Теперь, когда он объединен, я закрываю это.
Зависание с cv2 также находится вне нашего контроля, поскольку cv2 просто не очень хорошо работает с многопроцессорной обработкой.
SsnL
9 окт. 2018
Это все еще происходит с torch_nightly-1.0.0.dev20181029 , разве PR еще не объединен?
 Evpok
30 окт. 2018
Evpok
30 окт. 2018
@Evpok это было объединено там. У вас обязательно должен быть этот патч. Интересно, есть ли еще затяжные тупики. У вас есть простая копия, которую мы можем попробовать посмотреть?
soumith
30 окт. 2018
На самом деле я проследил это до несвязанного беспорядка многопроцессорности на моей стороне, извините за неудобства.
Evpok
30 окт. 2018
привет @Evpok
я использую torch_nightly-1.0.0 и сталкиваюсь с этой проблемой. ты решил эту проблему?
 zimenglan-sysu-512
14 нояб. 2018
zimenglan-sysu-512
14 нояб. 2018
Если вы используете collate_fn и num_workers>0 с версией PyTorch <0.4:
УБЕДИТЕСЬ, ЧТО ВЫ НЕ ВОЗВРАЩАЕТЕ ZERO DIM TENSORS ИЗ ВАШЕЙ ФУНКЦИИ
__getitem__().
ИЛИ ВЕРНИТЕ ИХ КАК МАССИВЫ NUMPY.
Я исправил свою ошибку возврата нулей тусклых тензоров, и проблема все еще существует.
 liluxuan1997
14 нояб. 2018
liluxuan1997
14 нояб. 2018
@ zimenglan-sysu-512 Основная проблема заключалась в ограничениях многопроцессорности: при использовании spawn или forkserver (что необходимо для связи CPU-GPU) совместное использование объектов между процессами довольно ограничено, а не подходит для тех объектов, которыми мне приходится манипулировать.
Evpok
14 нояб. 2018
Ничто из этого не сработало для меня. Однако последняя версия opencv работает (от 3.4.0.12 до 3.4.3.18 больше ничего не менять):
sudo pip3 install --upgrade opencv-python
 see--
17 нояб. 2018
see--
17 нояб. 2018
@see-- рад узнать, что opencv все исправила :)
SsnL
17 нояб. 2018
Я на OpenCV 3.4.3.18 с python2.7, и я все еще вижу тупик. :/
 SreenivasVRao
3 дек. 2018
SreenivasVRao
3 дек. 2018
Пожалуйста, попробуйте следующее:
from torch.utils.data.dataloader import DataLoader
вместо
from torch.utils.data import DataLoader
Я думаю, что здесь проблема с проверкой типа:
https://github.com/pytorch/pytorch/blob/656b565a0f53d9f24547b060bd27aa67ebb89b88/torch/utils/data/dataloader.py#L816
 jewfro-cuban
16 дек. 2018
jewfro-cuban
16 дек. 2018
Пожалуйста, попробуйте следующее:
from torch.utils.data.dataloader import DataLoaderвместо
from torch.utils.data import DataLoaderЯ думаю, что здесь проблема с проверкой типа:
pytorch/torch/utils/data/dataloader.py
Строка 816 в 656b565
super(DataLoader, self).__setattr__(attr, val)
Это не просто псевдоним? в torch.utils.data.__init__ они импортируют dataloader.DataLoader
 simonhessner
8 янв. 2019
simonhessner
8 янв. 2019
У меня также было зависание с num_workers> 0. В моем коде нет opencv, и использование памяти /dev/shm не является проблемой. Никакие предложения выше не работали для меня. Мое исправление состояло в том, чтобы обновить numpy с 1.14.1 до 1.14.5:
conda install numpy=1.14.5
Надеюсь, это полезно.
 daniyar-niantic
8 янв. 2019
daniyar-niantic
8 янв. 2019
Хм, моя пустая версия 1.15.4, то есть новее 1.14.5... Тогда все в порядке?
simonhessner
8 янв. 2019
Хм, моя пустая версия 1.15.4, то есть новее 1.14.5... Тогда все в порядке?
Idk, мое обновление numpy также обновило mkl.
daniyar-niantic
8 янв. 2019
Какая у вас версия мкл? У меня 2019.1 (сборка 144), а другие пакеты, в названии которых есть mkl:
mkl-сервис 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
simonhessner
8 янв. 2019
Какая у вас версия мкл? У меня 2019.1 (сборка 144), а другие пакеты, в названии которых есть mkl:
mkl-сервис 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
conda list | grep mkl
mkl 2018.0.1 h19d6760_4
mkl-service 1.1.2 py36h17a0993_4
Если вы все еще видите зависание в новейшем pytorch, было бы очень полезно, если бы вы могли предоставить короткий сценарий, который воспроизводит проблему. Спасибо!
SsnL
9 янв. 2019
Я все еще вижу этот тупик, я посмотрю, смогу ли я создать сценарий, который воспроизводится.
 dtmoodie
15 янв. 2019
dtmoodie
15 янв. 2019
pin_memory=True решил проблему для меня.
pyaf
30 янв. 2019
Кажется, у меня не работает с pin_memory=True , все еще застрял после 70 эпох. Единственное, что у меня сработало до сих пор, это установка num_workers=0 , но это заметно медленнее.
 jclevesque
14 февр. 2019
jclevesque
14 февр. 2019
Я также испытываю тупик (происходит довольно случайно). Пробовал pin_memory и обновлял Numpy. Попробую запустить на другой машине.
 Avsecz
14 февр. 2019
Avsecz
14 февр. 2019
Если вы используете несколько потоков с загрузчиками данных, попробуйте использовать многопроцессорность вместо многопоточности. Это полностью решило проблему для меня (и, кстати, это также лучше для задач с интенсивными вычислениями в Python из-за GIL).
simonhessner
14 февр. 2019
такая же ошибка в Pytorch1.0, Pillow5.0.0 numpy1.16.1 python3.6
 jianlong-yuan
15 февр. 2019
jianlong-yuan
15 февр. 2019
Я также получаю ту же ошибку. Я установил pin_memory=True и num_workers=0 . Хотя я заметил одну вещь: когда я использую небольшую часть набора данных, этой ошибки не возникает. Эта ошибка возникает только при использовании всего набора данных.
Редактировать: Простой перезапуск системы исправил это для меня.
 Venka97
6 мар. 2019
Venka97
6 мар. 2019
У меня была аналогичная проблема. В каком-то коде эта функция (почти всегда) зависала бы на d_iter.next():
def get_next_batch(d_iter, loader):
try:
data, label = d_iter.next()
except StopIteration:
d_iter = iter(loader)
data, label = d_iter.next()
return data, label
Хак, который сработал для меня, состоял в том, чтобы добавить небольшую задержку после вызова этой функции.
trn_X, trn_y = get_next_batch(train_data_iter, train_loader)
time.sleep(0.003)
val_X, val_y = get_next_batch(valid_data_iter, valid_loader)
Я предполагаю, что задержка помогла избежать тупика?
 enoonIT
20 мар. 2019
enoonIT
20 мар. 2019
Я все еще встречаюсь с этой проблемой. Использование pytorch 1.0 и python 3.7. Когда я использовал несколько data_loader, эта ошибка появится. Если я использую менее 3 data_loader или использую один GPU, эта ошибка не появится. Пытался:
- время сна (0,003)
- pin_memory = Истина/Ложь
- количество_работников=0/1
- из torch.utils.data.dataloader импортировать DataLoader
- запись 8192 в /proc/sys/kernel/shmmni
Ни один из них не работает. Не знаете, есть ли решения?
 xuw080
16 апр. 2019
xuw080
16 апр. 2019
мои решения добавляют cv2.setNumThreads(0) в программу предварительной обработки
У меня есть 2 загрузчика данных, которые предназначены для поездов и валов.
Я смог запустить оценщик только один раз.
 lightningsoon
10 мая 2019
lightningsoon
10 мая 2019
Я только что столкнулся с этой ошибкой с pytorch 1.1. Один и тот же дважды застрял на одном и том же месте: конец 99-й эпохи. pin_memory установлено значение False .
 Randl
17 мая 2019
Randl
17 мая 2019
Та же проблема при использовании worker>0, память контактов не решила проблему.
 nicolasCruzW21
20 мая 2019
nicolasCruzW21
20 мая 2019
мои решения добавляют cv2.setNumThreads(0) в программу предварительной обработки
У меня есть 2 загрузчика данных, которые предназначены для поездов и валов.
Я смог запустить оценщик только один раз.
Это решение работает для меня, спасибо
 zxhr2793
3 июн. 2019
zxhr2793
3 июн. 2019
загрузчик данных останавливается, когда я заканчиваю эпоху, и начинаю новую эпоху.
столкнуться с той же проблемой. В моем случае проблема возникает, когда я устанавливаю opencv-python (раньше я устанавливал opencv3). После переноса opencv-python обучение не остановится.
 hongzhenwang
20 июн. 2019
hongzhenwang
20 июн. 2019
это тоже хорошая идея
В 20.06.2019 10:51:02 «hongzhenwang» [email protected] написал:
загрузчик данных останавливается, когда я заканчиваю эпоху, и начинаю новую эпоху.
столкнуться с той же проблемой. В моем случае проблема возникает, когда я устанавливаю opencv-python (раньше я устанавливал opencv3). После переноса opencv-python обучение не остановится.
—
Вы получаете это, потому что вы прокомментировали.
Ответьте на это письмо напрямую, просмотрите его на GitHub или отключите ветку.
lightningsoon
27 июн. 2019
Я все еще встречаюсь с этой проблемой. Использование pytorch 1.0 и python 3.7. Когда я использовал несколько data_loader, эта ошибка появится. Если я использую менее 3 data_loader или использую один GPU, эта ошибка не появится. Пытался:
1. time.sleep(0.003) 2. pin_memory=True/False 3. num_workers=0/1 4. from torch.utils.data.dataloader import DataLoader 5. writing 8192 to /proc/sys/kernel/shmmni None of them works. Don't know whether there is any solutions?
Все еще пытаюсь найти обходной путь. Я согласен с тем, что эта проблема возникает только тогда, когда я одновременно запускаю 2 параллельных процесса на разных графических процессорах. Один продолжает движение, а другой останавливается.
 ArturoDeza
3 июл. 2019
ArturoDeza
3 июл. 2019
Когда я установил num_workers = 4, программа зависала на несколько секунд (или минут) каждые 4 пакета, что тратит много времени. Любая идея о том, как это решить?
 huangchaoxing
27 июл. 2019
huangchaoxing
27 июл. 2019
добавление флагов: pin_memory=True и num_workers=0 в загрузчик данных - это решение!
ArturoDeza
27 июл. 2019
добавление флагов: pin_memory=True и num_workers=0 в загрузчик данных - это решение!
@АртуроДеза
Это может быть решением. Однако установка num_workers=0 замедляет получение всех данных процессором, и скорость использования графического процессора будет очень низкой.
huangchaoxing
28 июл. 2019
Для меня причина заключалась в том, что в моей системе было недостаточно процессоров или недостаточно num_workers указанных в загрузчике данных. Также может быть хорошей идеей отключить многопоточность в рабочих процессах загрузчика данных, если метод __get_item__ в загрузчике данных использует потоковую библиотеку, например numpy , librosa или opencv (см. ниже, почему это может быть важно). Этого можно добиться, запустив обучающий скрипт с OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . В качестве пояснения к приведенному ниже обсуждению обратите внимание, что каждый пакет Dataloader обрабатывается одним рабочим процессом: каждый рабочий процесс обрабатывает образцы batch_size для завершения одного пакета, а затем начинает обработку нового пакета данных.
Вам нужно установить num_workers ниже, чем количество процессоров в машине (или поде, если вы используете Kubernetes), но достаточно высоко, чтобы данные всегда были готовы к следующей итерации. Если GPU выполняет каждую итерацию за t секунд, а каждому рабочему загрузчику данных требуется N*t секунд для загрузки/обработки одного пакета, тогда вы должны установить для num_workers не менее N , чтобы избежать зависаний графического процессора. Конечно, в системе должно быть не менее N процессоров.
К сожалению, если Dataloader использует какую-либо библиотеку, использующую потоки K , то количество порожденных процессов становится равным num_workers*K = N*K . Это может быть значительно больше, чем количество процессоров в машине. Это тормозит модуль, и загрузчик данных становится очень медленным. Это может привести к тому, что загрузчик данных не будет возвращать пакет каждые t секунд, что приведет к зависанию графического процессора.
Один из способов избежать потоков K — это вызвать основной скрипт с помощью OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . Это ограничивает использование каждым работником Dataloader одного потока и позволяет избежать перегрузки машины. У вас все еще должно быть достаточно num_workers чтобы поддерживать работу графического процессора.
Вы также должны оптимизировать свой код в __get_item__ чтобы каждый рабочий процесс выполнял свой пакет за небольшой промежуток времени. Пожалуйста, убедитесь, что время для завершения предварительной обработки пакета рабочим процессом не ограничено временем чтения обучающих данных с диска (особенно если вы читаете из сетевого хранилища) или пропускной способностью сети (если вы читаете из сети). диск). Если ваш набор данных небольшой и у вас достаточно оперативной памяти, рассмотрите возможность перемещения набора данных в оперативную память (или /tmpfs ) и читайте оттуда для быстрого доступа. Для Kubernetes вы можете создать RAM-диск (ищите emptyDir в Kubernetes).
Если вы оптимизировали свой код __get_item__ и убедились, что доступ к диску или доступ к сети не являются виновниками, но по-прежнему видите зависания, вам нужно будет запросить больше ЦП (для модуля Kubernetes) или переместить свой GPU на машина с большим количеством процессоров.
Другой вариант — уменьшить batch_size чтобы каждый worker выполнял меньше работы и быстрее завершал предварительную обработку. Последний вариант в некоторых случаях нежелателен, так как неиспользуемая память графического процессора будет простаивать.
Вы также можете рассмотреть возможность выполнения некоторой предварительной обработки в автономном режиме и снять нагрузку с каждого работника. Например, если каждый рабочий поток читает wav-файл и вычисляет спектрограммы для аудиофайла, вы можете предварительно вычислить спектрограммы в автономном режиме и просто прочитать вычисленную спектрограмму с диска в рабочем потоке. Это уменьшит объем работы, которую должен выполнять каждый работник.
 gkeskin07
3 авг. 2019
gkeskin07
3 авг. 2019
столкнуться с той же проблемой с horovod
 jinhou
12 авг. 2019
jinhou
12 авг. 2019
Познакомьтесь с похожей проблемой... Тупик при завершении эпохи и начале загрузки данных для проверки...
 jackroos
20 авг. 2019
jackroos
20 авг. 2019
@jinhou @jackroos То же самое, случайным образом застрял в начале проверки хороводом. Что я сейчас делаю в качестве обходного пути, так это устанавливаю тайм-аут и пропускаю проверку. У тебя есть решение?
 lzljzys
28 авг. 2019
lzljzys
28 авг. 2019
@jinhou @jackroos То же самое, случайным образом застрял в начале проверки хороводом. Что я сейчас делаю в качестве обходного пути, так это устанавливаю тайм-аут и пропускаю проверку. У тебя есть решение?
Нет. В таком случае я просто отключу распределенное обучение.
jackroos
29 авг. 2019
Я столкнулся с похожей проблемой: загрузчик данных останавливается, когда я заканчиваю эпоху, и начинаю новую эпоху.
зачем столько зана?
 foocker
22 окт. 2019
foocker
22 окт. 2019
Я все еще встречаюсь с этой проблемой. Использование pytorch 1.0 и python 3.7. Когда я использовал несколько data_loader, эта ошибка появится. Если я использую менее 3 data_loader или использую один GPU, эта ошибка не появится. Пытался:
- время сна (0,003)
- pin_memory = Истина/Ложь
- количество_работников=0/1
- из torch.utils.data.dataloader импортировать DataLoader
- запись 8192 в /proc/sys/kernel/shmmni
Ни один из них не работает. Не знаете, есть ли решения?
num_workers, установленный на 0, у меня сработал. Вы должны убедиться, что он равен 0 везде, где вы его используете.
Некоторые другие возможные решения:
- из многопроцессорного импорта set_start_method
set_start_method('порождение') - cv2.setNumThreads (0)
Кажется, 3 или 7 - это путь.
 the7threvival
18 нояб. 2019
the7threvival
18 нояб. 2019
У меня возникла эта проблема с pytorch 1.3, ubuntu16, все вышеперечисленные предложения не сработали, кроме worker=0, что замедляет выполнение. Это происходит только при запуске из терминала, в блокноте Jupyter все в порядке, даже с worker=32.
Проблема не кажется решенной, следует ли ее снова открыть? Я также вижу, что многие другие люди сообщают о той же проблеме...
 skariel
2 дек. 2019
skariel
2 дек. 2019
Я все еще встречаюсь с этой проблемой. Использование pytorch 1.0 и python 3.7. Когда я использовал несколько data_loader, эта ошибка появится. Если я использую менее 3 data_loader или использую один GPU, эта ошибка не появится. Пытался:
- время сна (0,003)
- pin_memory = Истина/Ложь
- количество_работников=0/1
- из torch.utils.data.dataloader импортировать DataLoader
- запись 8192 в /proc/sys/kernel/shmmni
Ни один из них не работает. Не знаете, есть ли решения?num_workers, установленный на 0, у меня сработал. Вы должны убедиться, что он равен 0 везде, где вы его используете.
Некоторые другие возможные решения:
- из многопроцессорного импорта set_start_method
set_start_method('порождение')- cv2.setNumThreads (0)
Кажется, 3 или 7 - это путь.
Я изменил train.py следующим образом:
from __future__ import division
import cv2
cv2.setNumThreads(0)
import argparse
...
И это работает для меня.
 DHZS
10 дек. 2019
DHZS
10 дек. 2019
Эй, ребята, если я могу помочь,
У меня также была эта проблема, похожая на эту, но это происходило каждые 100 или около того эпох.
Я заметил, что это происходит только при включенном CUDA, также в dmesg есть эта запись в журнале всякий раз, когда он аварийно завершает работу.
python[11240]: segfault at 10 ip 00007fabdd6c37d8 sp 00007ffddcd64fd0 error 4 in libcudart.so.10.1.243[7fabdd699000+77000]
Для меня это тарабарщина, но мне сказали, что многопоточность CUDA и python не очень хороша.
Мое исправление состояло в том, чтобы отключить cuda в потоках данных, вот фрагмент моего файла записи python.
from multiprocessing import set_start_method
import os
if __name__ == "__main__":
set_start_method('spawn')
else:
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import torch
import application
Надеюсь, это может помочь любому, кто приземлится здесь, как мне было нужно в то время.
 roderickObrist
24 мар. 2020
roderickObrist
24 мар. 2020
@jinhou @jackroos То же самое, случайным образом застрял в начале проверки хороводом. Что я сейчас делаю в качестве обходного пути, так это устанавливаю тайм-аут и пропускаю проверку. У тебя есть решение?
Нет. В таком случае я просто отключу распределенное обучение.
Я встречаю аналогичную проблему в распределенном обучении без использования OpenCV после обновления до PyTorch 1.4.
Теперь мне нужно запустить проверку один раз перед циклом обучения и проверки.
 wizardk
9 июн. 2020
wizardk
9 июн. 2020
У меня было много проблем с этим. Кажется, что он сохраняется в версиях pytorch, версиях python, а также на разных физических машинах (которые, вероятно, будут настроены одинаково).
Каждый раз одна и та же ошибка:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/bicep/loops.py", line 73, in __call__
for data, target in self.dataloader:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 830, in _next_data
self._shutdown_workers()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 942, in _shutdown_workers
w.join()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/process.py", line 149, in join
res = self._popen.wait(timeout)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 47, in wait
return self.poll(os.WNOHANG if timeout == 0.0 else 0)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll
pid, sts = os.waitpid(self.pid, flag)
Очевидно, есть какая-то проблема в том, как обрабатываются процессы на машине, которую я использую. Ни одно из вышеперечисленных решений не работает, кроме установки num_workers=0.
Я действительно хотел бы добраться до сути этого, есть ли у кого-нибудь идеи, с чего начать или как допросить это?
 brynhayder
9 июн. 2020
brynhayder
9 июн. 2020
Я тоже здесь.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 480, in _try_get_batch
data = self.data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 65, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 95106) is killed by signal: Segmentation fault.
Одна интересная вещь
когда я просто анализирую данные построчно, у меня нет этой проблемы:
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
но если я добавлю логику синтаксического анализа JSON после чтения построчно, он сообщит об этой ошибке
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
Я понимаю, что будут некоторые накладные расходы памяти JSON, но даже я уменьшу количество рабочих до 2, а набор данных очень мал, у него все еще будет та же проблема. Я немного сомневаюсь, что это связано с ШМ. любая подсказка?
 zhangruiskyline
16 июн. 2020
zhangruiskyline
16 июн. 2020
Давайте снова откроем этот вопрос?
 takatosp1
18 июн. 2020
takatosp1
18 июн. 2020
Я думаю, нам следует. Кстати, я отлаживал GDB и ничего там не нашел. поэтому я не совсем уверен, является ли это проблемой общей памяти,
(gdb) run
Starting program: /home/miniconda/bin/python performance.py
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7fffa60a6700 (LWP 61963)]
[New Thread 0x7fffa58a5700 (LWP 61964)]
[New Thread 0x7fffa10a4700 (LWP 61965)]
[New Thread 0x7fff9e8a3700 (LWP 61966)]
[New Thread 0x7fff9c0a2700 (LWP 61967)]
[New Thread 0x7fff998a1700 (LWP 61968)]
[New Thread 0x7fff970a0700 (LWP 61969)]
[New Thread 0x7fff9489f700 (LWP 61970)]
[New Thread 0x7fff9409e700 (LWP 61971)]
[New Thread 0x7fff8f89d700 (LWP 61972)]
[New Thread 0x7fff8d09c700 (LWP 61973)]
[New Thread 0x7fff8a89b700 (LWP 61974)]
[New Thread 0x7fff8809a700 (LWP 61975)]
[New Thread 0x7fff85899700 (LWP 61976)]
[New Thread 0x7fff83098700 (LWP 61977)]
[New Thread 0x7fff80897700 (LWP 61978)]
[New Thread 0x7fff7e096700 (LWP 61979)]
[New Thread 0x7fff7d895700 (LWP 61980)]
[New Thread 0x7fff7b094700 (LWP 61981)]
[New Thread 0x7fff78893700 (LWP 61982)]
[New Thread 0x7fff74092700 (LWP 61983)]
[New Thread 0x7fff71891700 (LWP 61984)]
[New Thread 0x7fff6f090700 (LWP 61985)]
[Thread 0x7fff7e096700 (LWP 61979) exited]
[Thread 0x7fff6f090700 (LWP 61985) exited]
[Thread 0x7fff74092700 (LWP 61983) exited]
[Thread 0x7fff7b094700 (LWP 61981) exited]
[Thread 0x7fff80897700 (LWP 61978) exited]
[Thread 0x7fff83098700 (LWP 61977) exited]
[Thread 0x7fff85899700 (LWP 61976) exited]
[Thread 0x7fff8809a700 (LWP 61975) exited]
[Thread 0x7fff8a89b700 (LWP 61974) exited]
[Thread 0x7fff8d09c700 (LWP 61973) exited]
[Thread 0x7fff8f89d700 (LWP 61972) exited]
[Thread 0x7fff9409e700 (LWP 61971) exited]
[Thread 0x7fff9489f700 (LWP 61970) exited]
[Thread 0x7fff970a0700 (LWP 61969) exited]
[Thread 0x7fff998a1700 (LWP 61968) exited]
[Thread 0x7fff9c0a2700 (LWP 61967) exited]
[Thread 0x7fff9e8a3700 (LWP 61966) exited]
[Thread 0x7fffa10a4700 (LWP 61965) exited]
[Thread 0x7fffa58a5700 (LWP 61964) exited]
[Thread 0x7fffa60a6700 (LWP 61963) exited]
[Thread 0x7fff71891700 (LWP 61984) exited]
[Thread 0x7fff78893700 (LWP 61982) exited]
[Thread 0x7fff7d895700 (LWP 61980) exited]
total_files = 5040. //customer comments
[New Thread 0x7fff6f090700 (LWP 62006)]
[New Thread 0x7fff71891700 (LWP 62007)]
[New Thread 0x7fff74092700 (LWP 62008)]
[New Thread 0x7fff78893700 (LWP 62009)]
ERROR: Unexpected segmentation fault encountered in worker.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 62005) is killed by signal: Segmentation fault.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "performance.py", line 62, in <module>
main()
File "performance.py", line 48, in main
for i,batch in enumerate(rl_data_loader):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 841, in _next_data
idx, data = self._get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 808, in _get_data
success, data = self._try_get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 774, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 62005) exited unexpectedly
[Thread 0x7fff78893700 (LWP 62009) exited]
[Thread 0x7fff74092700 (LWP 62008) exited]
[Thread 0x7fff71891700 (LWP 62007) exited]
[Thread 0x7fff6f090700 (LWP 62006) exited]
[Inferior 1 (process 61952) exited with code 01]
(gdb) backtrace
No stack.
И я действительно думаю, что у меня достаточно общей памяти, по крайней мере, я ожидаю, что общей памяти хватит на довольно долгое время до segfault, но сбой сегмента происходит почти сразу после запуска задания загрузчика данных.
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18014398509481980
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
Привет @soumith @apaszke , можем ли мы снова открыть эту проблему, я попробовал все предложенные решения, такие как увеличение размера и сегмента shm, ничего не работает, я не использую opencv или что-то в этом роде, просто анализ JSON. но проблема все еще там. и я не думаю, что это связано с shm, так как проверил, что я открываю всю память как общую память. Трассировка стека также ничего не показывает, как указано выше.
@apaszke относительно вашего предложения
«Да, многие из этих проблем возникают из-за того, что сторонние библиотеки не являются безопасными для форка. Одним из альтернативных решений может быть использование метода запуска порождения».
Я использую многофункциональный загрузчик данных, как я могу изменить метод? Я устанавливаю set_start_method('spawn') в свой main.py, но это не помогает
Также у меня есть общий вопрос, если я включу многофункциональный (многопроцессный) загрузчик данных, а в основном обучении я также запущу многопроцессорный процесс, как это предлагается в https://pytorch.org/docs/stable/notes/multiprocessing.html. #multiprocessing — лучшие практики
как pytorch управляет как загрузчиком данных, так и основным многопроцессорным процессом обучения? будут ли они совместно использовать все возможные процессы/потоки на многоядерном графическом процессоре? также общая память для нескольких процессов «разделяется» загрузчиком данных и основным процессом обучения? также, если у меня есть какая-то работа по подготовке данных, такая как анализ JSON, анализ CSV, извлечение функций панд. и т.д., куда лучше поставить? в загрузчике данных, чтобы сгенерировать идеальные, чтобы быть готовыми данные, или просто использовать основное обучение, чтобы сделать это, как некоторые предлагали выше, чтобы сделать загрузчик данных __get_item__ как можно более простым
zhangruiskyline
19 июн. 2020
@zhangruiskyline Ваша проблема на самом деле не тупиковая. Речь идет о рабочих, убитых из-за segfault. sigbus предлагает проблемы с shm. Вы должны проверить свой код набора данных и выполнить его отладку.
Чтобы ответить на другие ваши вопросы,
- используйте kwarg
multiproessing_context='spawn'в DataLoader, чтобы установить спавн.set_start_methodтакже делает это. - обычно при многопроцессном обучении каждый процесс имеет свой собственный DataLoader и, следовательно, рабочие процессы DataLoader. Ничто не является общим для процессов, если это не сделано явно.
SsnL
20 июн. 2020
Спасибо @SsnL , я добавил multiproessing_context='spawn' но та же ошибка.
Я указал в предыдущем потоке, мой код очень прост,
- этот кусок кода работает
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
- но если я добавлю логику синтаксического анализа JSON после чтения построчно, он сообщит об этой ошибке
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
поэтому я сомневаюсь, что это проблема моего кода, также я стараюсь не использовать синтаксический анализ JSON, а напрямую разбивать строки, та же проблема. кажется, пока у меня есть какая-то трудоемкая логика для обработки данных в загрузчике данных, эта проблема возникает
Также относительно
многопроцессное обучение, каждый процесс имеет свой собственный DataLoader, и, таким образом, рабочие процессы DataLoader Ничто не разделяется между процессами, если это не указано явно.
Итак, давайте посмотрим, что у меня есть 4 процесса для обучения, каждый с 8 рабочими загрузчиками данных, так что всего 32 процесса внизу?
zhangruiskyline
20 июн. 2020
@zhangruiskyline Без автономного сценария для воспроизведения проблемы мы не сможем вам помочь. Да будет 32 процесса
SsnL
20 июн. 2020
Спасибо, я тоже видел похожую проблему в
https://github.com/pytorch/pytorch/issues/4969
https://github.com/pytorch/pytorch/issues/5040
оба закрыты, но я не вижу четкого решения или исправления, это все еще серьезная проблема?
Я посмотрю, смогу ли я предоставить автономный сценарий воспроизведения, но он тесно интегрирован с нашей платформой и источником данных, поэтому постараюсь
zhangruiskyline
20 июн. 2020
@zhangruiskyline Ваша проблема не похожа ни на одну из связанных проблем, если вы их читали. они закрыты, потому что исходная / наиболее распространенная проблема, о которой сообщалось в этих темах, уже решена.
SsnL
20 июн. 2020
Спасибо @SsnL , я не очень хорошо знаком с Pytorch, поэтому могу ошибаться, но я прошел через все это, и похоже, что некоторые из них решены
уменьшить число рабочих до 0, это неприемлемо для нас, так как это слишком медленно,
увеличьте размер shm, но я считаю, что у нас достаточно shm, и проблема возникла почти сразу после того, как мы начали, и я пробовал с гораздо меньшим набором данных, проблема такая же
некоторые библиотеки, такие как opencv, не работают в многопроцессорном режиме, мы просто используем JSON/CSV, так что это не очень модно
наш код довольно прост, набор обучающих данных содержит более 10000 файлов, каждый файл представляет собой несколько строк строк JSON. в загрузчике данных мы определяем __get_item__ чтобы получить каждый файл из более чем 10 000 файлов и прочитать все содержимое этого файла.
в решении 1 мы сначала читаем и разбиваем построчно в список строк JSON, если сразу возвращаемся, работает, производительность хорошая
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
return all_data
теперь, поскольку возвращаемое значение по-прежнему является строкой JSON, мы хотим использовать многопроцессорный загрузчик данных для ускорения, поэтому поместите здесь логику синтаксического анализа JSON, и это не удастся
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
позже мы подумали, что синтаксический анализ JSON слишком тяжел, а также JSON занимает слишком много памяти, затем мы решили проанализировать строку JSON и вручную преобразовать в список функций, та же ошибка. сделал некоторый анализ трассировки стека и ничего там
Кстати, мы запускаем наш код в Linux Docker Env, 24-ядерном процессоре и 1 V100.
Я не уверен, где я должен начать расследование дальше. у тебя есть идеи?
zhangruiskyline
20 июн. 2020
Привет,
Я нашел интересный комментарий в https://github.com/open-mmlab/mmcv , который используется в https://github.com/open-mmlab/mmdetection :
Следующий код используется в начале как эпохи поезда, так и эпохи val.
time.sleep(2) # Предотвращает возможный тупик при переходе между эпохами
Может быть, вы можете попробовать.
mathmanu
20 июн. 2020
Кстати, если я перейду к нескольким процессам и каждому процессу с многофункциональным загрузчиком данных, как другой процесс может гарантировать, что их соответствующий загрузчик данных не будет считывать те же данные, что и загрузчик данных другого процесса? это уже обрабатывается загрузчиком данных pytorch __get_item__ ?
zhangruiskyline
20 июн. 2020
Привет @SsnL , спасибо за вашу помощь. просто хочу немного продолжить эту тему, я рефакторинг обучающего кода с использованием многопроцессорной обработки pytorch, чтобы ускорить обработку некоторых данных на стороне процессора (чтобы быстрее передавать их на графический процессор), https://pytorch.org/docs/stable /notes/multiprocessing.html#multiprocessing -best -practices
В каждой функции обработки я также использую многофункциональный загрузчик данных, чтобы ускорить время обработки загрузки данных. https://pytorch.org/docs/stable/data.html
Я поместил свой парсинг процессора JSON не в загрузчик данных, а в основной процесс обучения, и проблема, кажется, исчезла, я не знаю почему, но в любом случае это работает. но у меня есть дополнительный вопрос: предположим, у меня есть обработка N , у каждого есть M работник загрузчика данных, поэтому всего NxM под потоками там.
Если в моем загрузчике данных я хочу получить все данные в виде индекса, что означает, что __get_item__(self, idx) в загрузчике данных M в N различные обработки могут работать вместе для обработки разных индексов, как я могу гарантировать, что они не обрабатывают дубликаты или пропустить процесс некоторые?
zhangruiskyline
23 июн. 2020
У меня была та же проблема, когда загрузчик данных давал сбой после жалобы на то, что он не может выделить память в начале новой эпохи обучения или проверки. Приведенные выше решения не сработали для меня (i) мой
/dev/shmсоставляет 32 ГБ, и он никогда не использовался более 2,5 ГБ, и (ii) настройка pin_memory = False не работала.Возможно, это как-то связано со сборкой мусора? Мой код выглядит примерно следующим образом. Мне нужен бесконечный итератор, и поэтому я делаю попытку / кроме
next()ниже :-)def train(): train_iter = train_loader.__iter__() for i in xrange(max_batches): try: x, y = next(train_iter) except StopIteration: train_iter = train_loader.__iter__() ... del train_iter
train_loader— это объектDataLoader. Без явной строкиdel train_iterв конце функции процесс всегда падает через 2-3 эпохи (/dev/shmпрежнему показывает 2,5 ГБ). Надеюсь это поможет!Я использую рабочих
4(версия0.1.12_2с CUDA 8.0 на Ubuntu 16.04).
Это решило проблему для меня после нескольких недель борьбы. Я должен явно использовать итератор загрузчика вместо того, чтобы напрямую зацикливать загрузчик и использовать del loader_iterator в конце эпохи, наконец, устранив взаимоблокировки
 kennyFF92
15 июл. 2020
kennyFF92
15 июл. 2020
Я думаю, что сталкиваюсь с той же проблемой. Попытка использовать 8 загрузчиков данных (MNIST, MNISTM, SVHN, USPS, для обучения и тестирования каждого). Использование 6 (любых 6) работает нормально. Использование 8 всегда блокирует при загрузке 6-го, тест MNIST-M. Он застрял в каком-то бесконечном цикле попыток получить изображение, терпит неудачу, немного ждет, а затем пытается снова. Ошибка сохраняется для любого размера batch_size, у меня осталось много свободной памяти, и она исчезает, только если я устанавливаю num_workers равным 0. Любое другое количество вызывает проблему.
 pmirallesr
21 июл. 2020
pmirallesr
21 июл. 2020
Я получил подсказку от https://stackoverflow.com/questions/54013846/pytorch-dataloader-stucked-if-using-opencv-resize-method
Когда я ставлю cv2.setNumThreads(0) , у меня все работает нормально.
 LifeBeyondExpectations
17 авг. 2020
LifeBeyondExpectations
17 авг. 2020
Здравствуйте, у меня была такая же проблема. И это было связано с ulimit -n, просто увеличьте его и проблема решена, я использовал ulimit -n 500000
 SebastienEske
18 авг. 2020
SebastienEske
18 авг. 2020
@SebastienEske ulimit -n исправил это и для меня в Ubuntu 20.04
 david-waterworth
24 сент. 2020
david-waterworth
24 сент. 2020
Возможно, set ulimit -n - это правильный путь. С увеличением модели взаимоблокировка становится все более и более частой, я также тестирую cv2.setNumThreads(0) , но это не работает.
 BLING-1994
27 сент. 2020
BLING-1994
27 сент. 2020
К слову, у меня сработало cv2.setNumThreads(0) .
 franchesoni
18 нояб. 2020
franchesoni
18 нояб. 2020
Смежные вопросы
 eliabruni
·
3Комментарии
eliabruni
·
3Комментарии
 negrinho
·
3Комментарии
negrinho
·
3Комментарии
 NgPDat
·
3Комментарии
NgPDat
·
3Комментарии
 bartvm
·
3Комментарии
bartvm
·
3Комментарии
 ikostrikov
·
3Комментарии
ikostrikov
·
3Комментарии
Самый полезный комментарий
Я столкнулся с похожей проблемой: загрузчик данных останавливается, когда я заканчиваю эпоху, и начинаю новую эпоху.