Pytorch: possível deadlock no dataloader
o bug é descrito em pytorch/examples#148. Eu só me pergunto se isso é um bug no próprio PyTorch, pois o código de exemplo parece limpo para mim. Além disso, gostaria de saber se isso está relacionado ao #1120.
 zym1010
zym1010
Todos 189 comentários
Quanta memória livre você tem quando o carregador para?
 apaszke
em 25 abr. 2017
apaszke
em 25 abr. 2017
@apaszke se eu verificar top , a memória restante (mem em cache também conta como usada) geralmente é de 2 GB. Mas se você não contar em cache como usado, é sempre muito, digamos 30 GB +.
zym1010
em 25 abr. 2017
Também não entendo por que sempre para no início da validação, mas não em todos os outros lugares.
zym1010
em 25 abr. 2017
Possivelmente porque para validação é usado um carregador separado que empurra o uso da memória compartilhada acima do limite.
 ngimel
em 25 abr. 2017
ngimel
em 25 abr. 2017
@ngimel
Acabei de executar o programa novamente. E ficou preso.
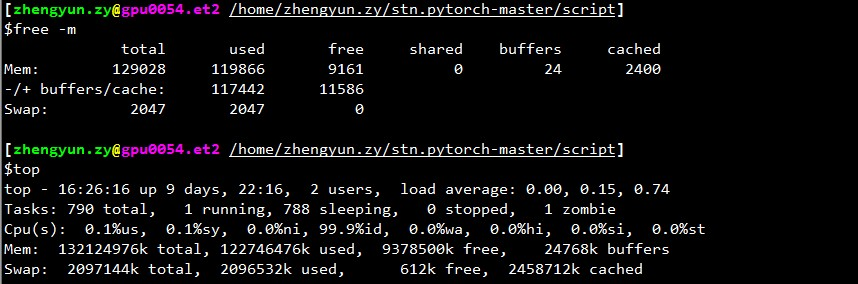
Saída de top :
~~~
início - 17:51:18 até 2 dias, 21:05, 2 usuários, carga média: 0,49, 3,00, 5,41
Tarefas: 357 no total, 2 em execução, 355 dormindo, 0 paradas, 0 zumbis
%Cpu(s): 1,9 us, 0,1 sy, 0,7 ni, 97,3 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st
KiB Mem: 65863816 total, 60115084 usado, 5748732 livre, 1372688 buffers
Troca de KiB: 5917692 no total, 620 usados, 5917072 gratuitos. 51154784 memória em cache
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3067 aalreja 20 0 143332 101816 21300 R 46,1 0,2 1631:44 Xvnc
16613 aalreja 30 10 32836 4880 3912 S 16,9 0,0 1:06,92 fibra 3221 aalreja 20 0 8882348 1,017g 110120 S 1,3 1,6 579:06,87 MATLAB
1285 root 20 0 1404848 48252 25580 S 0,3 0,1 6:00,12 dockerd 16597 yimengz+ 20 0 25084 3252 2572 R 0,3 0,0 0:04,56 top
1 raiz 20 0 33616 4008 2624 S 0,0 0,0 0:01,43 init
~~~
Saída de free
~yimengzh_everyday@yimengzh :~$ grátistotal de buffers compartilhados gratuitos usados em cacheMem: 65863816 60122060 5741756 9954628 1372688 51154916-/+ buffers/cache: 7594456 58269360Trocar: 5917692 620 5917072~
Saída de nvidia-smi
~~~
yimengzh_everyday@yimengzh :~$ nvidia-smi
Ter, 25 de abril 17:52:38 2017
+------------------------------------------------- ----------------------------+
| Versão do driver NVIDIA-SMI 375.39: 375.39 |
|------------------------------------------+----------------- -----+----------------------+
| Persistência do nome da GPU-M| Bus-Id Disp.A | Volátil Descorr. ECC |
| Fan Temp Perf Pwr:Uso/Cap | Uso de memória | GPU-Util Compute M. |
|===============================+================= =====+=======================|
| 0 GeForce GTX TIT... Desligado | 0000:03:00.0 Desligado | N/A |
| 30% 42C P8 14W / 250W | 3986MiB / 6082MiB | 0% Padrão |
+-------------------------------+----------------- -----+----------------------+
| 1 Tesla K40c desligado | 0000:81:00.0 Desligado | Desligado |
| 0% 46C P0 57W / 235W | 0MiB / 12205MiB | 0% Padrão |
+-------------------------------+----------------- -----+----------------------+
+------------------------------------------------- ----------------------------+
| Processos: Memória GPU |
| Tipo de PID de GPU Nome do processo Uso |
|================================================= =============================|
| 0 16509 C python 3970MiB |
+------------------------------------------------- ----------------------------+
~~~
Não acho que seja um problema de memória.
zym1010
em 25 abr. 2017
Existem limites separados para memória compartilhada. Você pode tentar ipcs -lm ou cat /proc/sys/kernel/shmall e cat /proc/sys/kernel/shmmax ? Além disso, ele trava se você usar menos trabalhadores (por exemplo, teste com o caso extremo de 1 trabalhador)?
apaszke
em 26 abr. 2017
@apaszke
~~~
yimengzh_everyday@yimengzh :~$ ipcs -lm
------ Limites de memória compartilhada --------
número máximo de segmentos = 4096
tamanho máximo de segmento (kbytes) = 18014398509465599
memória compartilhada total máxima (kbytes) = 18446744073642442748
tamanho mínimo de seg (bytes) = 1
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmall
18446744073692774399
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmmax
18446744073692774399
~~~
como eles te procuram?
quanto a menos trabalhadores, acredito que não aconteça com tanta frequência. (eu posso tentar agora). Mas acho que na prática preciso de tantos trabalhadores.
zym1010
em 26 abr. 2017
Você tem um máximo de 4096 segmentos de memória compartilhada permitidos, talvez isso seja um problema. Você pode tentar aumentar isso escrevendo para /proc/sys/kernel/shmmni (talvez tente 8192). Você pode precisar de privilégios de superusuário.
apaszke
em 26 abr. 2017
@apaszke bem, esses são os valores padrão do Ubuntu e do CentOS 6 ... Isso é realmente um problema?
zym1010
em 26 abr. 2017
@apaszke ao executar o programa de treinamento, ipcs -a na verdade não mostra nenhuma memória compartilhada sendo usada. Isso é esperado?
zym1010
em 26 abr. 2017
@apaszke tentou executar o programa (ainda com 22 trabalhadores) com a seguinte configuração no mem compartilhado e travou novamente.
~~~
yimengzh_everyday@yimengzh :~$ ipcs -lm
------ Limites de memória compartilhada --------
número máximo de segmentos = 8192
tamanho máximo de segmento (kbytes) = 18014398509465599
memória compartilhada total máxima (kbytes) = 18446744073642442748
tamanho mínimo de seg (bytes) = 1
~~~
não tentou um trabalhador. primeiro, isso seria lento; segundo, se o problema for realmente um bloqueio morto, ele definitivamente desaparecerá.
zym1010
em 26 abr. 2017
As configurações padrão do ipcs é para memória compartilhada do System V que não estamos usando, mas eu queria ter certeza de que os mesmos limites não se aplicam à memória compartilhada POSIX.
Ele definitivamente não torch.__version__ ? Você está rodando no docker?
apaszke
em 26 abr. 2017
@apaszke Obrigado. Agora entendo muito melhor sua análise.
Todos os outros resultados mostrados a você até como são executados em uma máquina Ubuntu 14.04 com 64 GB de RAM, dual Xeon e Titan Black (há também um K40, mas eu não o usei).
O comando para gerar o problema é CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 20 --lr 0.01 --workers 22 --batch-size 256 /mnt/temp_drive_3/cv_datasets/ILSVRC2015/Data/CLS-LOC . Eu não modifiquei nenhum código.
Eu instalei o pytorch através do pip, no Python 3.5. versão pytorch é 0.1.11_5 . Não rodando no Docker.
BTW, eu também tentei usar 1 trabalhador. Mas fiz isso em outra máquina (128 GB de RAM, dual Xeon, 4 Pascal Titan X, CentOS 6). Eu o executei usando CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 1 --lr 0.01 --workers 1 --batch-size 256 /ssd/cv_datasets/ILSVRC2015/Data/CLS-LOC e o log de erros é o seguinte.
Epoch: [0][5003/5005] Time 2.463 (2.955) Data 2.414 (2.903) Loss 5.9677 (6.6311) Prec<strong i="14">@1</strong> 3.516 (0.545) Prec<strong i="15">@5</strong> 8.594 (2.262)
Epoch: [0][5004/5005] Time 1.977 (2.955) Data 1.303 (2.903) Loss 5.9529 (6.6310) Prec<strong i="16">@1</strong> 1.399 (0.545) Prec<strong i="17">@5</strong> 7.692 (2.262)
^CTraceback (most recent call last):
File "main.py", line 292, in <module>
main()
File "main.py", line 137, in main
prec1 = validate(val_loader, model, criterion)
File "main.py", line 210, in validate
for i, (input, target) in enumerate(val_loader):
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 168, in __next__
idx, batch = self.data_queue.get()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/queue.py", line 164, in get
self.not_empty.wait()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/threading.py", line 293, in wait
waiter.acquire()
o top mostrou o seguinte quando preso com 1 trabalhador.
~início - 08:34:33 até 15 dias, 20:03, 0 usuários, carga média: 0,37, 0,39, 0,36Tarefas: 894 no total, 1 em execução, 892 dormindo, 0 parado, 1 zumbiCPU(s): 7,2%us, 2,8%sy, 0,0%ni, 89,7%id, 0,3%wa, 0,0%hi, 0,0%si, 0,0%stMem: 132196824k total, 131461528k usado, 735296k livre, 347448k buffersTroca: total de 2047996k, 22656k usados, 2025340k gratuitos, 125226796k em cache~
zym1010
em 26 abr. 2017
outra coisa que descobri é que, se eu modifiquei o código de treinamento, para que ele não passe por todos os lotes, digamos, apenas treine 50 lotes
if i >= 50:
break
então o impasse parece desaparecer.
zym1010
em 26 abr. 2017
testes adicionais parecem sugerir que esse congelamento ocorre com muito mais frequência se eu executar o programa logo após a reinicialização do computador. Depois que há algum cache no computador, parece que a frequência de obter esse congelamento é menor.
zym1010
em 27 abr. 2017
Eu tentei, mas não consigo reproduzir esse bug de forma alguma.
apaszke
em 4 mai. 2017
Encontrei um problema semelhante: o carregador de dados para quando termino uma época e inicia uma nova época.
 tiancheng-zhi
em 4 mai. 2017
tiancheng-zhi
em 4 mai. 2017
Definir num_workers = 0 funciona. Mas o programa fica mais lento.
tiancheng-zhi
em 4 mai. 2017
@apaszke você tentou primeiro reiniciar o computador e depois executar os programas? Para mim, isso garante o congelamento. Acabei de tentar a versão 0.12, e ainda é o mesmo.
Uma coisa que gostaria de salientar é que instalei o pytorch usando pip , pois tenho um numpy vinculado ao OpenBLAS instalado e o MKL da nuvem anaconda de @soumith não funcionaria bem com ele.
Então, essencialmente, pytorch está usando MKL e numpy está usando OpenBLAS. Isso pode não ser o ideal, mas acho que isso não deve ter nada a ver com o problema aqui.
zym1010
em 9 mai. 2017
Eu olhei para ele, mas eu nunca poderia reproduzi-lo. MKL/OpenBLAS não deve estar relacionado a este problema. Provavelmente é algum problema com uma configuração do sistema
apaszke
em 9 mai. 2017
@apaszke obrigado. Acabei de tentar o python do repositório oficial do anaconda e o pytorch baseado em MKL. Continua o mesmo problema.
zym1010
em 9 mai. 2017
tentei executar o código no Docker. Ainda preso.
zym1010
em 11 mai. 2017
Temos o mesmo problema, executando o exemplo de treinamento pytorch/examples imagenet (resnet18, 4 workers) dentro de um nvidia-docker usando 1 GPU de 4. Vou tentar reunir um backtrace gdb, se conseguir chegar ao processo .
Pelo menos o OpenBLAS é conhecido por ter um problema de impasse na multiplicação de matrizes, que ocorre relativamente raramente: https://github.com/xianyi/OpenBLAS/issues/937. Este bug estava presente pelo menos no OpenBLAS empacotado no numpy 1.12.0.
 jsainio
em 7 jun. 2017
jsainio
em 7 jun. 2017
@jsainio Eu também tentei o PyTorch baseado em MKL puro (numpy também está vinculado ao MKL) e o mesmo problema.
Além disso, esse problema é resolvido (pelo menos para mim), se eu desligar pin_memory para o dataloader.
zym1010
em 7 jun. 2017
Parece que dois dos trabalhadores morrem.
Durante a operação normal:
root<strong i="7">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 33.2 4.7 91492324 3098288 ? Ssl 10:51 1:10 python -m runne
user+ 58 76.8 2.3 91079060 1547512 ? Rl 10:54 1:03 python -m runne
user+ 59 76.0 2.2 91006896 1484536 ? Rl 10:54 1:02 python -m runne
user+ 60 76.4 2.3 91099448 1559992 ? Rl 10:54 1:02 python -m runne
user+ 61 79.4 2.2 91008344 1465292 ? Rl 10:54 1:05 python -m runne
após o bloqueio:
root<strong i="11">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 24.8 4.4 91509728 2919744 ? Ssl 14:25 13:01 python -m runne
user+ 58 51.7 0.0 0 0 ? Z 14:27 26:20 [python] <defun
user+ 59 52.1 0.0 0 0 ? Z 14:27 26:34 [python] <defun
user+ 60 52.0 2.4 91147008 1604628 ? Sl 14:27 26:31 python -m runne
user+ 61 52.0 2.3 91128424 1532088 ? Sl 14:27 26:29 python -m runne
Para um trabalhador ainda restante, o início do stacktrace do gdb se parece com:
root<strong i="15">@b06f896d5c1d</strong>:~/mnt# gdb --pid 60
GNU gdb (GDB) 8.0
Attaching to process 60
[New LWP 65]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb) bt
#0 0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f36f52af8d4 in __new_sem_wait_slow.constprop.0 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#2 0x00007f36f52af97a in sem_wait@@GLIBC_2.2.5 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#3 0x00007f36f157efb1 in semlock_acquire (self=0x7f3656296458,
args=<optimized out>, kwds=<optimized out>)
at /home/ilan/minonda/conda-bld/work/Python-3.5.2/Modules/_multiprocessing/semaphore.c:307
#4 0x00007f36f5579621 in PyCFunction_Call (func=
<built-in method __enter__ of _multiprocessing.SemLock object at remote 0x7f3656296458>, args=(), kwds=<optimized out>) at Objects/methodobject.c:98
#5 0x00007f36f5600bd5 in call_function (oparg=<optimized out>,
pp_stack=0x7f36c7ffbdb8) at Python/ceval.c:4705
#6 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#7 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=1, kws=0x0, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0,
closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#8 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#9 0x00007f36f5557542 in function_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/funcobject.c:627
#10 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36561c7d08>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#11 0x00007f36f554077c in method_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/classobject.c:330
#12 0x00007f36f5524236 in PyObject_Call (
func=<method at remote 0x7f36556f9248>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#13 0x00007f36f55277d9 in PyObject_CallFunctionObjArgs (
callable=<method at remote 0x7f36556f9248>) at Objects/abstract.c:2445
#14 0x00007f36f55fc3a9 in PyEval_EvalFrameEx (f=<optimized out>,
throwflag=<optimized out>) at Python/ceval.c:3107
#15 0x00007f36f5601166 in fast_function (nk=<optimized out>, na=1,
n=<optimized out>, pp_stack=0x7f36c7ffc418,
func=<function at remote 0x7f36561c78c8>) at Python/ceval.c:4803
#16 call_function (oparg=<optimized out>, pp_stack=0x7f36c7ffc418)
at Python/ceval.c:4730
#17 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#18 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=4, kws=0x7f36f5b85060, kwcount=0, defs=0x0, defcount=0,
kwdefs=0x0, closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#19 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#20 0x00007f36f5557661 in function_call (
func=<function at remote 0x7f36e14170d0>,
arg=(<ImageFolder(class_to_idx={'n04153751': 783, 'n02051845': 144, 'n03461385': 582, 'n04350905': 834, 'n02105056': 224, 'n02112137': 260, 'n03938244': 721, 'n01739381': 59, 'n01797886': 82, 'n04286575': 818, 'n02113978': 268, 'n03998194': 741, 'n15075141': 999, 'n03594945': 609, 'n04099969': 765, 'n02002724': 128, 'n03131574': 520, 'n07697537': 934, 'n04380533': 846, 'n02114712': 271, 'n01631663': 27, 'n04259630': 808, 'n04326547': 825, 'n02480855': 366, 'n02099429': 206, 'n03590841': 607, 'n02497673': 383, 'n09332890': 975, 'n02643566': 396, 'n03658185': 623, 'n04090263': 764, 'n03404251': 568, 'n03627232': 616, 'n01534433': 13, 'n04476259': 868, 'n03495258': 594, 'n04579145': 901, 'n04266014': 812, 'n01665541': 34, 'n09472597': 980, 'n02095570': 189, 'n02089867': 166, 'n02009229': 131, 'n02094433': 187, 'n04154565': 784, 'n02107312': 237, 'n04372370': 844, 'n02489166': 376, 'n03482405': 588, 'n04040759': 753, 'n01774750': 76, 'n01614925': 22, 'n01855032': 98, 'n03903868': 708, 'n02422699': 352, 'n01560419': 1...(truncated), kw={}) at Objects/funcobject.c:627
#21 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36e14170d0>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#22 0x00007f36f55fe234 in ext_do_call (nk=1444355432, na=0,
flags=<optimized out>, pp_stack=0x7f36c7ffc768,
func=<function at remote 0x7f36e14170d0>) at Python/ceval.c:5034
#23 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3275
--snip--
Eu tive um log de erros semelhante, com o processo principal preso em: self.data_queue.get()
Para mim, o problema foi que usei o opencv como carregador de imagens. E a função cv2.imread estava travando indefinidamente sem erro em uma imagem específica do imagenet ("n01630670/n01630670_1010.jpeg")
Se você disse que está funcionando para você com num_workers = 0, não é isso. Mas pensei que poderia ajudar algumas pessoas com rastreamento de erro semelhante.
 M-Eng
em 9 jun. 2017
M-Eng
em 9 jun. 2017
Estou executando um teste com num_workers = 0 atualmente, sem travamentos ainda. Estou executando o código de exemplo de https://github.com/pytorch/examples/blob/master/imagenet/main.py. pytorch/vision ImageFolder parece usar PIL ou pytorch/accimage internamente para carregar as imagens, então não há OpenCV envolvido.
Com num_workers = 4 , posso ocasionalmente pegar o primeiro trem de época e validar totalmente, e ele trava no meio da segunda época. Portanto, é improvável um problema na função de carregamento/conjunto de dados.
Parece algo como uma condição de corrida no ImageLoader que pode ser acionada relativamente raramente por uma certa combinação de hardware/software.
jsainio
em 9 jun. 2017
@zym1010 obrigado pelo ponteiro, tentarei definir pin_memory = False também para o DataLoader.
jsainio
em 9 jun. 2017
Interessante. Na minha configuração, definindo pin_memory = False e num_workers = 4 o exemplo imagenet trava quase imediatamente e três dos trabalhadores acabam como processos zumbis:
root<strong i="8">@034c4212d022</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 6.7 2.8 92167056 1876612 ? Ssl 13:50 0:36 python -m runner
user+ 38 1.9 0.0 0 0 ? Z 13:51 0:08 [python] <defunct>
user+ 39 4.3 2.3 91069804 1550736 ? Sl 13:51 0:19 python -m runner
user+ 40 2.0 0.0 0 0 ? Z 13:51 0:09 [python] <defunct>
user+ 41 4.1 0.0 0 0 ? Z 13:51 0:18 [python] <defunct>
Na minha configuração, o conjunto de dados está em um disco em rede que é lido por NFS. Com pin_memory = False e num_workers = 4 posso fazer com que o sistema falhe bem rápido.
=> creating model 'resnet18'
- training epoch 0
Epoch: [0][0/5005] Time 10.713 (10.713) Data 4.619 (4.619) Loss 6.9555 (6.9555) Prec<strong i="8">@1</strong> 0.000 (0.000) Prec<strong i="9">@5</strong> 0.000 (0.000)
Traceback (most recent call last):
--snip--
imagenet_pytorch.main.main([data_dir, "--transient_dir", context.transient_dir])
File "/home/user/mnt/imagenet_pytorch/main.py", line 140, in main
train(train_loader, model, criterion, optimizer, epoch, args)
File "/home/user/mnt/imagenet_pytorch/main.py", line 168, in train
for i, (input, target) in enumerate(train_loader):
File "/home/user/anaconda/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 206, in __next__
idx, batch = self.data_queue.get()
File "/home/user/anaconda/lib/python3.5/multiprocessing/queues.py", line 345, in get
return ForkingPickler.loads(res)
File "/home/user/anaconda/lib/python3.5/site-packages/torch/multiprocessing/reductions.py", line 70, in rebuild_storage_fd
fd = df.detach()
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError
:
[Errno 104] Connection reset by peer
@ zym1010 você tem um disco em rede ou um disco giratório tradicional também que pode ser mais lento em latência/etc.?
jsainio
em 9 jun. 2017
@jsainio
Estou usando um SSD local no nó de computação do cluster. O código está em uma unidade NFS, mas os dados estão no SSD local, para velocidade máxima de carregamento. Nunca tentei carregar dados em unidades NFS.
zym1010
em 9 jun. 2017
@zym1010 Obrigado pela informação. Estou executando isso também em um nó de computação de um cluster.
Na verdade, estou executando o experimento num_workers = 0 no mesmo nó ao mesmo tempo enquanto tento as variações num_workers = 4 . Pode ser que o primeiro experimento esteja gerando carga suficiente para que possíveis condições de corrida se manifestem mais rapidamente no último.
jsainio
em 9 jun. 2017
@apaszke Quando você tentou reproduzir isso anteriormente, você tentou executar duas instâncias lado a lado ou com alguma outra carga significativa no sistema?
jsainio
em 9 jun. 2017
@jsainio Obrigado por investigar isso! Isso é estranho, os trabalhadores só devem sair juntos e quando o processo principal terminar de ler os dados. Você pode tentar inspecionar por que eles saem prematuramente? Talvez verifique o log do kernel ( dmesg )?
apaszke
em 9 jun. 2017
Não, eu não tentei isso, mas parecia aparecer mesmo quando não era o caso IIRC
apaszke
em 9 jun. 2017
@apaszke Ok, bom saber que os trabalhadores não deveriam ter saído.
Eu tentei, mas não conheço uma boa maneira de verificar por que eles saem. dmesg não mostra nada relevante. (Estou executando em um Docker derivado do Ubuntu 16.04, usando pacotes Anaconda)
jsainio
em 9 jun. 2017
Uma maneira seria adicionar um número de impressões dentro do loop de trabalho . Eu não tenho idéia por que eles saem silenciosamente. Provavelmente não é uma exceção, porque teria sido impresso em stderr, então eles saem do loop ou são mortos pelo sistema operacional (talvez por um sinal?)
apaszke
em 9 jun. 2017
@jsainio , só para ter certeza, você está executando o docker com --ipc=host (você não menciona isso)? Você pode verificar o tamanho do seu segmento de memória compartilhada (df -h | grep shm)?
ngimel
em 9 jun. 2017
@ngimel estou usando --shm-size=1024m . df -h | grep shm informa de acordo:
root<strong i="9">@db92462e8c19</strong>:~/mnt# df -h | grep shm
shm 1.0G 883M 142M 87% /dev/shm
Esse uso parece bastante difícil. Isso está em um docker com dois trabalhadores zumbis.
jsainio
em 12 jun. 2017
Você pode tentar aumentar o tamanho do shm? Acabei de verificar e no servidor onde tentei reproduzir os problemas eram 16GB. Você altera o sinalizador do docker ou executa
mount -o remount,size=8G /dev/shm
Acabei de tentar diminuir o tamanho para 512 MB, mas recebi um erro claro em vez de um impasse. Ainda não consigo reproduzir 😕
apaszke
em 14 jun. 2017
Com o docker, tendemos a obter deadlocks quando shm não é suficiente, em vez de limpar mensagens de erro, não sei por quê. Mas geralmente é curado aumentando o shm (e eu obtive impasses com 1G).
ngimel
em 14 jun. 2017
Ok, parece que com 10 trabalhadores um erro é gerado, mas quando eu uso 4 trabalhadores eu recebo um impasse em 58% do uso de /dev/shm! Eu finalmente o reproduzi
apaszke
em 14 jun. 2017
Que bom que você pode reproduzir uma forma desse problema. Eu postei um script que aciona um travamento em #1579, e você respondeu que não travava em seu sistema. Na verdade, eu só testei no meu MacBook. Acabei de tentar no Linux e não travou. Portanto, se você tentou apenas no Linux, também pode valer a pena tentar em um Mac.
 greaber
em 14 jun. 2017
greaber
em 14 jun. 2017
Ok, então depois de investigar o problema, parece ser um problema estranho. Mesmo quando eu limito /dev/shm a ter apenas 128 MB, o Linux fica feliz em nos deixar criar arquivos de 147 MB lá, mapeá-los totalmente na memória, mas enviará um SIGBUS mortal para o trabalhador quando ele realmente tentar acessar as páginas ... Não consigo pensar em nenhum mecanismo que nos permita verificar a validade das páginas, exceto iterar sobre elas e tocar cada uma delas, com um manipulador SIGBUS registrado ...
Uma solução alternativa por enquanto é expandir /dev/shm com o comando mount como mostrei acima. Tente com 16 GB (ofc se você tiver RAM suficiente).
apaszke
em 15 jun. 2017
É difícil encontrar qualquer menção a isso, mas aqui está um .
apaszke
em 15 jun. 2017
Obrigado pelo seu tempo sobre este problema, ele está me deixando louco há muito tempo! Se bem entendi, preciso expandir /dev/shm para 16G em vez de 8G. Faz sentido, mas quando tento df -h , posso ver que toda a minha ram está realmente alocada como tal: (tenho 16G)
tmpfs 7,8G 393M 7,4G 5% /dev/shm
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,8G 0 7,8G 0% /sys/fs/cgroup
tmpfs 1,6G 60K 1,6G 1% /run/user/1001
Esta é a saída de df -h durante um impasse. Pelo que entendi, se eu tiver uma partição SWAP de 16G, posso montar tmpfs até 32G, então não deve ser um problema expandir /dev/shm , certo?
Mais importante, estou intrigado com a partição cgroup e seu propósito, pois ocupa quase metade da minha RAM. Aparentemente, ele foi projetado para gerenciar tarefas de vários processadores com eficiência, mas eu realmente não estou familiarizado com o que ele faz e por que precisamos dele, mudaria algo para alocar toda a RAM física para shm (porque definimos seu tamanho para 16G) e coloque-o em SWAP (embora eu acredite que ambos estarão parcialmente na RAM e SWAP simultaneamente)
 ClementPinard
em 15 jun. 2017
ClementPinard
em 15 jun. 2017
@apaszke Obrigado! Ótimo que você encontrou a causa subjacente. Ocasionalmente, eu estava recebendo vários erros de "ConnectionReset" e deadlocks com o docker --shm-size=1024m dependendo de qual outra carga havia na máquina. Testando agora com --shm-size=16384m e 4 trabalhadores.
jsainio
em 15 jun. 2017
@jsainio ConnectionReset pode ter sido causado pela mesma coisa. Os processos começaram a trocar alguns dados, mas quando o shm ficou sem espaço, um SIGBUS foi enviado ao trabalhador e o matou.
@ClementPinard , tanto quanto eu entendo, você pode torná-lo tão grande quanto quiser, exceto que provavelmente congelará sua máquina quando você ficar sem RAM (porque mesmo o kernel não pode liberar essa memória). Você provavelmente não precisa se preocupar com /sys/fs/cgroup . tmpfs partições shm para dizer 12 GB e limitar o número de trabalhadores (como eu disse, não use toda a sua RAM para shm!). Aqui está um bom artigo sobre tmpfs da documentação do kernel.
Não sei por que o deadlock acontece mesmo quando o uso de /dev/shm é muito pequeno (acontece a 20kB na minha máquina). Talvez o kernel seja excessivamente otimista, mas não espera até que você preencha tudo, e mata o processo quando ele começa a usar qualquer coisa dessa região.
apaszke
em 15 jun. 2017
Testando agora com 12G e metade dos workers que eu tinha, e falhou :(
Ele estava funcionando como um encanto na versão lua torch (mesma velocidade, mesmo número de trabalhadores), o que me faz pensar se o problema está apenas relacionado a /dev/shm e não mais próximo ao multiprocessamento python ...
A coisa estranha sobre isso (como você mencionou) é que /dev/shm nunca está perto de estar cheio. Durante a primeira época de treinamento, nunca passou de 500Mo. E também nunca trava durante a primeira época, e se eu desligar o trainloader de teste nunca falha em todas as épocas. O impasse parece aparecer apenas no início da época de teste. Eu deveria acompanhar /dev/shm ao passar do trem para o teste, talvez haja um pico de uso durante a mudança dos carregadores de dados.
ClementPinard
em 15 jun. 2017
@ClementPinard mesmo com memória compartilhada mais alta e sem o Docker, ainda pode falhar.
zym1010
em 15 jun. 2017
Se versão da tocha == Lua Torch, então ela ainda pode estar relacionada a /dev/shm . Lua Torch pode usar threads (não há GIL), então não precisa passar por mem compartilhado (todos eles compartilham um único espaço de endereço).
apaszke
em 15 jun. 2017
Eu tive o mesmo problema em que o dataloader trava depois de reclamar que não podia alocar memória no início de uma nova época de treinamento ou validação. As soluções acima não funcionaram para mim (i) meu /dev/shm é de 32 GB e nunca foi usado mais de 2,5 GB e (ii) a configuração pin_memory=False não funcionou.
Isso é talvez algo a ver com a coleta de lixo? Meu código se parece mais ou menos com o seguinte. Eu preciso de um iterador infinito e, portanto, faço uma tentativa / exceto em torno do next() abaixo :-)
def train():
train_iter = train_loader.__iter__()
for i in xrange(max_batches):
try:
x, y = next(train_iter)
except StopIteration:
train_iter = train_loader.__iter__()
...
del train_iter
train_loader é um objeto DataLoader . Sem a linha del train_iter explícita no final da função, o processo sempre trava após 2-3 épocas ( /dev/shm ainda mostra 2,5 GB). Espero que isto ajude!
Estou usando 4 workers (versão 0.1.12_2 com CUDA 8.0 no Ubuntu 16.04).
 pratikac
em 7 jul. 2017
pratikac
em 7 jul. 2017
Também encontrei o impasse, principalmente quando o work_number é grande. Existe alguma solução possível para este problema? Meu tamanho /dev/shm é de 32 GB, com cuda 7.5, pytorch 0.1.12 e python 2.7.13. A seguir estão informações relacionadas após a morte. Parece relacionado à memória. @apaszke

 zhengyunqq
em 4 ago. 2017
zhengyunqq
em 4 ago. 2017
@zhengyunqq tente pin_memory=False se você definir para True . Caso contrário, não tenho conhecimento de nenhuma solução.
zym1010
em 4 ago. 2017
Eu também encontrei o impasse quando num_workers é grande.
 hendrycks
em 11 ago. 2017
hendrycks
em 11 ago. 2017
Para mim, o problema era que, se um thread de trabalho morresse por qualquer motivo, index_queue.put travaria para sempre. Um dos motivos da morte de threads de trabalho é a falha do unpickler durante a inicialização. Nesse caso, até essa correção de bug do Python no mestre em maio de 2017, o thread de trabalho morreria e causaria o travamento sem fim. No meu caso, o travamento estava acontecendo no estágio de preparação de pré-busca em lote.
Talvez uma substituição de SimpleQueue usado em DataLoaderIter por Queue que permite um tempo limite com uma mensagem de exceção graciosa.
UPD: eu estava enganado, esta correção de bug corrigiu Queue , não SimpleQueue . Ainda é verdade que SimpleQueue será bloqueado se nenhum thread de trabalho estiver online. Uma maneira fácil de verificar isso é substituir essas linhas por self.workers = [] .
 vadimkantorov
em 16 ago. 2017
vadimkantorov
em 16 ago. 2017
eu tenho o mesmo problema e não consigo alterar o shm (sem permissão), talvez seja melhor usar o Queue ou outra coisa?
 xfanplus
em 8 set. 2017
xfanplus
em 8 set. 2017
Eu tenho um problema similar.
Este código irá congelar e nunca imprimir nada. Se eu definir num_workers = 0, funcionará
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
model.cuda()
for i, batch in enumerate(dataloader):
print(i)
Se eu colocar model.cuda() atrás do loop, tudo funcionará bem.
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
for i, batch in enumerate(dataloader):
print(i)
model.cuda()
Alguém tem uma solução para esse problema?
 anDoer
em 13 set. 2017
anDoer
em 13 set. 2017
Eu também tive problemas semelhantes durante o treinamento do ImageNet. Ele irá travar na 1ª iteração de avaliação consistentemente em certos servidores com certa arquitetura (e não em outros servidores com a mesma arquitetura ou no mesmo servidor com arquitetura diferente), mas sempre no 1º iter durante a avaliação na validação. Quando eu estava usando o Torch, descobrimos que nccl pode causar deadlock como este, existe uma maneira de desativá-lo?
 WendyShang
em 20 set. 2017
WendyShang
em 20 set. 2017
Estou enfrentando o mesmo problema, ficando preso aleatoriamente no início da 1ª época. Todas as soluções alternativas mencionadas acima não funcionam para mim. Quando Ctrl-C é pressionado, ele imprime estas:
Traceback (most recent call last):
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 249, in _bootstrap
self.run()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 44, in _worker_loop
data_queue.put((idx, samples))
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/queues.py", line 354, in put
self._writer.send_bytes(obj)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 200, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 398, in _send_bytes
self._send(buf)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
KeyboardInterrupt
Traceback (most recent call last):
File "scripts/train_model.py", line 640, in <module>
main(args)
File "scripts/train_model.py", line 193, in main
train_loop(args, train_loader, val_loader)
File "scripts/train_model.py", line 341, in train_loop
ee_optimizer.step()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/optim/adam.py", line 74, in step
p.data.addcdiv_(-step_size, exp_avg, denom)
KeyboardInterrupt
 zoharli
em 23 out. 2017
zoharli
em 23 out. 2017
Eu tive um problema semelhante de ter um impasse com um único trabalhador dentro do docker e posso confirmar que era o problema de memória compartilhada no meu caso. Por padrão, o docker parece alocar apenas 64 MB de memória compartilhada, no entanto, eu precisava de 440 MB para 1 trabalhador, o que provavelmente causou o comportamento descrito por @apaszke.
 paulguerrero
em 23 out. 2017
paulguerrero
em 23 out. 2017
Estou sendo incomodado pelo mesmo problema, mas estou em um ambiente diferente da maioria dos outros neste tópico, então talvez minhas entradas possam ajudar a localizar a causa subjacente. Meu pytorch é instalado usando o excelente pacote conda construído por peterjc123 no Windows10.
Estou executando alguns cnn no conjunto de dados cifar10. Para os carregadores de dados, num_workers é definido como 1. Embora ter num_workers > 0 seja conhecido por causar BrokenPipeError e desaconselhado em #494, o que estou enfrentando não é BrokenPipeError, mas algum erro de alocação de memória. O erro sempre ocorreu em torno de 50 épocas, logo após a validação da última época e antes do início do treinamento para a próxima época. 90% das vezes são precisamente 50 épocas, outras vezes será desligado por 1 ou 2 épocas. Fora isso, todo o resto é bastante consistente. Definir num_workers=0 eliminará esse problema.
 berzjackson
em 24 out. 2017
berzjackson
em 24 out. 2017
@paulguerrero está certo. Resolvi esse problema aumentando a memória compartilhada de 64M para 2G. Talvez seja útil para usuários do docker.
 yjzhux
em 24 out. 2017
yjzhux
em 24 out. 2017
@berzjackson Esse é um bug conhecido no pacote conda. Corrigido nas compilações de CI mais recentes.
 peterjc123
em 25 out. 2017
peterjc123
em 25 out. 2017
Temos cerca de 600 pessoas que iniciaram um novo curso que usa o Pytorch na segunda-feira. Muitas pessoas em nosso fórum estão relatando esse problema. Alguns no AWS P2, alguns em seus próprios sistemas (principalmente GTX 1070, alguns Titan X).
Quando eles interrompem o treinamento, o final do rastreamento de pilha mostra:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv_bytes(self, maxsize)
405
406 def _recv_bytes(self, maxsize=None):
--> 407 buf = self._recv(4)
408 size, = struct.unpack("!i", buf.getvalue())
409 if maxsize is not None and size > maxsize:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv(self, size, read)
377 remaining = size
378 while remaining > 0:
--> 379 chunk = read(handle, remaining)
380 n = len(chunk)
381 if n == 0:
Temos num_workers=4, pin_memory=False. Eu pedi a eles para verificar suas configurações de memória compartilhada - mas há algo que eu possa fazer (ou podemos fazer no Pytorch) para que esse problema desapareça? (Além de reduzir num_workers, já que isso atrasaria um pouco as coisas.)
 jph00
em 1 nov. 2017
jph00
em 1 nov. 2017
Estou na classe @jph00 (obrigado Jeremy! :)) referido. Eu tentei usar "num_workers = 0" também. Ainda recebo o mesmo erro onde o resnet34 carrega muito lentamente. A montagem também é muito lenta. Mas coisa estranha: isso só acontece uma vez na vida de uma sessão de notebook.
Em outras palavras, uma vez que os dados são carregados e o ajuste é executado uma vez, posso me mover e continuar repetindo os passos... mesmo com 4 num_workers, e tudo parece funcionar rápido como esperado em uma GPU.
Estou no PyTorch 0.2.0_4, Python 3.6.2, Torchvision 0.1.9, Ubuntu 16.04 LTS. Fazer "df -h" no meu terminal diz que tenho 16 GBs em /dev/shm, embora a utilização tenha sido muito baixa.
Aqui está uma captura de tela de onde o carregamento falha (observe que usei num_workers=0 para os dados)
(desculpe pelas letras pequenas. Tive que diminuir o zoom para capturar tudo...)

 apiltamang
em 1 nov. 2017
apiltamang
em 1 nov. 2017
@apiltamang Não tenho certeza se é o mesmo problema - não parece os mesmos sintomas. Melhor para nós diagnosticar isso no fórum fast.ai, não aqui.
jph00
em 1 nov. 2017
olhando para isso o mais rápido possível!
 soumith
em 1 nov. 2017
soumith
em 1 nov. 2017
@soumith Dei a @apaszke acesso ao fórum privado do curso e pedi aos alunos com o problema que nos dessem acesso para fazer login em sua caixa.
jph00
em 1 nov. 2017
@jph00 Oi Jeremy, algum dos alunos tentou aumentar o shm como @apaszke mencionado acima? Isso foi útil?
 SsnL
em 1 nov. 2017
SsnL
em 1 nov. 2017
@SsnL um dos alunos confirmou que aumentou a memória compartilhada e ainda tem o problema. Eu pedi a alguns outros para confirmar também.
jph00
em 1 nov. 2017
@jph00 Obrigado! Reproduzi com sucesso o travamento devido à baixa memória compartilhada. Se o problema estiver em outro lugar, terei que cavar mais fundo! Você se importa de compartilhar o roteiro comigo?
SsnL
em 1 nov. 2017
Claro - aqui está o notebook que estamos usando: https://github.com/fastai/fastai/blob/master/courses/dl1/lesson1.ipynb . Os alunos perceberam que o problema só ocorre quando eles executam todas as células na ordem em que estão no caderno. Espero que o notebook seja autoexplicativo, mas avise-me se tiver algum problema para executá-lo - ele inclui um link para baixar os dados necessários.
Com base no problema de memória compartilhada que você pode replicar, existe algum tipo de solução alternativa que eu possa adicionar à nossa biblioteca ou notebook que evite isso?
jph00
em 1 nov. 2017
@jph00 Mergulhando no código agora. Vou tentar identificar maneiras de reduzir o uso de memória compartilhada. Não parece que o script deva usar grande quantidade de shm, então há esperança!
Também enviarei um PR para mostrar uma boa mensagem de erro ao atingir o limite shm, em vez de apenas deixá-lo travar.
SsnL
em 1 nov. 2017
OK, eu repliquei o problema em uma nova instância P2 da AWS usando sua AMI CUDA 9 com a instalação mais recente do Pytorch conda. Se você fornecer sua chave pública, posso dar a você acesso para experimentá-la diretamente. Meu e-mail é a primeira letra do meu primeiro nome em fast.ai
jph00
em 1 nov. 2017
@jph00 Acabei de enviar um e-mail :) obrigado!
SsnL
em 1 nov. 2017
@jph00 E para sua informação, o script levou 400 MB de memória compartilhada na minha caixa. Portanto, seria ótimo para os alunos que tiveram esse problema verificar se têm shm livre suficiente.
SsnL
em 1 nov. 2017
OK, então eu descobri o problema básico, que é que o multiprocessamento opencv e Pytorch não funcionam bem juntos, às vezes. Sem problemas em nossa caixa na universidade, mas muitos problemas na AWS (no novo deep learning CUDA 9 AMI com instância P2). Adicionar bloqueio em todas as chamadas cv2 não resolve, e adicionar cv2.setNumThreads(0) não resolve. Isso parece corrigi-lo:
from multiprocessing import set_start_method
set_start_method('spawn')
No entanto, isso afeta o desempenho em cerca de 15%. A recomendação na questão do github opencv é usar https://github.com/tomMoral/loky . Eu usei esse módulo antes e achei sólido como uma rocha. Não é urgente, já que temos uma solução que funciona bem o suficiente por enquanto - mas pode valer a pena considerar o uso do Loky for Dataloader?
Talvez mais importante, seria bom se pelo menos houvesse algum tipo de tempo limite na fila do pytorch para que esses travamentos infinitos fossem capturados.
jph00
em 2 nov. 2017
Para sua informação, acabei de tentar uma correção diferente, já que o 'spawn' estava deixando algumas partes 2-3x mais lentas - que é que adicionei alguns sleeps aleatórios em seções que iteram rapidamente pelo dataloader. Isso também resolveu o problema - embora talvez não seja o ideal!
jph00
em 2 nov. 2017
Obrigado por se aprofundar nisso! Fico feliz em saber que você encontrou duas soluções alternativas. Na verdade, seria bom adicionar tempos limite na indexação em conjuntos de dados. Vamos discutir e voltar para você nessa rota amanhã.
cc @soumith é algo que queremos investigar?
SsnL
em 2 nov. 2017
Para as pessoas que vêm a este tópico para a discussão acima, a questão do opencv é discutida em maior profundidade em https://github.com/opencv/opencv/issues/5150
SsnL
em 2 nov. 2017
OK, parece que tenho uma correção adequada para isso agora - reescrevi o Dataloader para o usuário ProcessPoolExecutor.map() e movi a criação do tensor para o processo pai. O resultado é mais rápido do que eu estava vendo com o Dataloader original e ficou estável em todos os computadores em que testei. O código também é muito mais simples.
Se alguém estiver interessado em usá-lo, você pode obtê-lo em https://github.com/fastai/fastai/blob/master/fastai/dataloader.py .
A API é a mesma da versão padrão, exceto que seu Dataset não deve retornar um tensor Pytorch - ele deve retornar matrizes numpy ou listas python. Eu não fiz nenhuma tentativa de fazê-lo funcionar em Pythons mais antigos, então não ficaria surpreso se houvesse alguns problemas lá.
(A razão pela qual eu segui esse caminho é que descobri ao fazer muito processamento / aumento de imagem em GPUs recentes que não conseguia concluir o processamento rápido o suficiente para manter a GPU ocupada, se eu fizesse o pré-processamento usando a CPU Pytorch operações; no entanto, o uso do opencv foi muito mais rápido e, como resultado, pude utilizar totalmente a GPU.)
jph00
em 2 nov. 2017
Ah, se é um problema do opencv, não há muito o que fazer sobre isso. É verdade que a bifurcação é perigosa quando você tem pools de threads. Eu não acho que queremos adicionar uma dependência de tempo de execução (atualmente não temos nenhuma), especialmente porque ela não lidará bem com os tensores do PyTorch. Seria melhor apenas descobrir o que está causando os impasses e o @SsnL está nele.
@jph00 você já tentou Pillow-SIMD? Deve funcionar com torchvision fora da caixa e ouvi muitas coisas boas sobre isso.
apaszke
em 2 nov. 2017
Sim, eu conheço bem o travesseiro SIMD. Ele apenas acelera o redimensionamento, o desfoque e a conversão RGB.
Eu não concordo que não há muito que você possa fazer aqui. Não é exatamente um problema do opencv (eles não afirmam suportar esse tipo de multiprocessamento python de forma mais geral, muito menos o módulo de multiprocessamento com caixa especial do pytorch) e também não é exatamente um problema do Pytorch. Mas o fato de Pytorch esperar silenciosamente para sempre sem dar nenhum tipo de erro é (IMO) algo que você pode consertar e, de maneira mais geral, muitas pessoas inteligentes têm trabalhado duro nos últimos anos para criar abordagens de multiprocessamento aprimoradas que evitam problemas apenas como este. Você pode pegar emprestado das abordagens que eles usam sem trazer uma dependência externa.
Olivier Grisel, que é uma das pessoas por trás do Loky, tem um ótimo conjunto de slides resumindo o estado do multiprocessamento em Python: http://ogrisel.github.io/decks/2017_euroscipy_parallelism/
Eu não me importo de qualquer maneira, já que agora escrevi um novo Dataloader que não tem o problema. Mas eu, FWIW, suspeito que as interações entre o multiprocessamento do pytorch e outros sistemas também serão um problema para outras pessoas no futuro.
jph00
em 2 nov. 2017
Por que vale a pena, eu tive esse problema no Python 2.7 no Ubuntu 14.04. Meu carregador de dados lia de um banco de dados sqlite e funcionava perfeitamente com num_workers=0 , às vezes parecia bom com num_workers=1 e rapidamente travava para qualquer valor mais alto. Os rastreamentos de pilha mostraram o processo suspenso em recv_bytes .
Coisas que não funcionaram:
- Passando
--shm-size 8Gou--ipc=hostao iniciar o docker - Executando
echo 16834 | sudo tee /proc/sys/kernel/shmmnipara aumentar o número de segmentos de memória compartilhada (o padrão era 4096 na minha máquina) - Configurando
pin_memory=Trueoupin_memory=False, nenhum dos dois ajudou
O que resolveu meu problema de maneira confiável foi portar meu código para o Python 3. Iniciar a mesma versão do Torch dentro de uma instância do Python 3.6 (do Anaconda) corrigiu completamente meu problema e agora o carregamento de dados não trava mais.
 gcr
em 16 nov. 2017
gcr
em 16 nov. 2017
@apaszke eis por que trabalhar bem com opencv é importante, FYI (e por que torchsample não é uma ótima opção - ele pode lidar com rotação de <200 imagens/s!):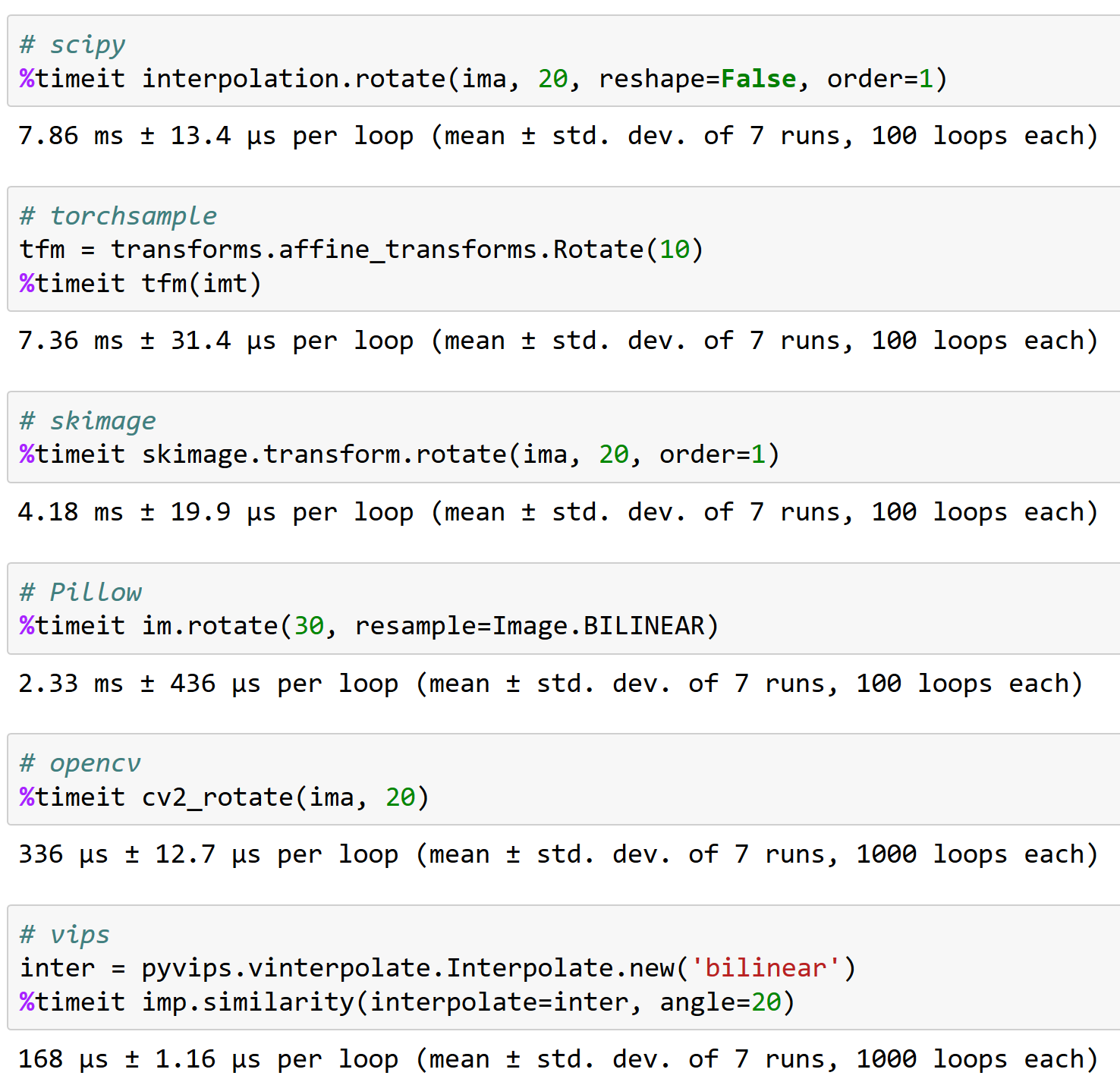
jph00
em 18 nov. 2017
Alguém encontrou uma solução para este problema?
 iqbalu
em 9 dez. 2017
iqbalu
em 9 dez. 2017
@iqbalu Experimente o script acima: https://github.com/fastai/fastai/blob/master/fastai/dataloader.py
Ele resolveu meu problema, mas não suporta num_workers=0 .
 elbaro
em 14 dez. 2017
elbaro
em 14 dez. 2017
@elbaro, na verdade, eu tentei e, no meu caso, não estava usando vários trabalhadores. Você mudou alguma coisa aí?
iqbalu
em 14 dez. 2017
O carregador de dados
apaszke
em 14 dez. 2017
@apaszke @elbaro @jph00 O carregador de dados do fast.ai desacelerou a leitura de dados em mais de 10x. Estou usando num_workers=8. Alguma dica do que pode ser o motivo?
iqbalu
em 15 dez. 2017
É provável que o data loader use pacotes que não abrem mão do GIL
apaszke
em 15 dez. 2017
@apaszke qualquer ideia de por que o uso de memória compartilhada continua aumentando após algumas épocas. No meu caso, ele começa com 400 MB e, em seguida, a cada 20ª época aumenta em 400 MB. Obrigado!
iqbalu
em 28 dez. 2017
@iqbalu não realmente. Isso não deveria estar acontecendo
apaszke
em 28 dez. 2017
Eu tentei muitas coisas e cv2.setNumThreads(0) finalmente resolveu meu problema.
Obrigado @jph00
 Cadene
em 19 jan. 2018
Cadene
em 19 jan. 2018
Eu tenho sido incomodado por este problema recentemente. cv2.setNumThreads(0) não funciona para mim. Eu até altero todo o código cv2 para usar scikit-image, mas o problema ainda existe. Além disso, tenho 16G por /dev/shm . Eu só tenho esse problema ao usar várias gpus. Tudo funciona bem em uma única gpu. Alguém tem alguma opinião nova sobre a solução?
 roytseng-tw
em 25 jan. 2018
roytseng-tw
em 25 jan. 2018
Mesmo Erro. Eu tenho esse problema ao usar gpu única.
 Jiankai-Sun
em 27 jan. 2018
Jiankai-Sun
em 27 jan. 2018
Para mim, desabilitar os threads do opencv resolveu o problema:
cv2.setNumThreads(0)
 shacharf
em 28 jan. 2018
shacharf
em 28 jan. 2018
acerte também com pytorch 0.3, cuda 8.0, ubuntu 16.04
nenhum opencv usado.
 tianq01
em 1 fev. 2018
tianq01
em 1 fev. 2018
Estou usando pytorch 0.3, cuda 8.0, Ubuntu 14.04. Observei esse travamento depois que comecei a usar cv2.resize()
cv2.setNumThreads(0) resolveu meu problema.
 mathmanu
em 9 fev. 2018
mathmanu
em 9 fev. 2018
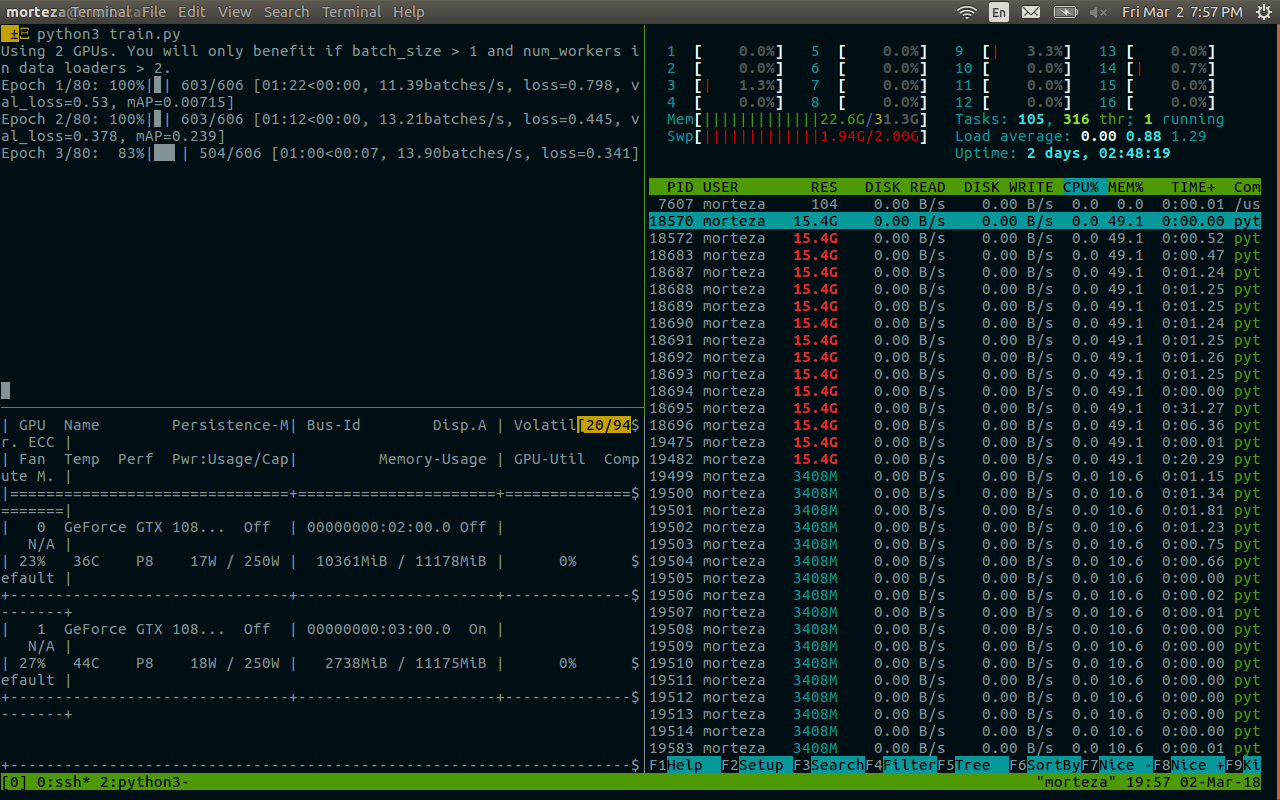
Estou usando python 3.6, pytorch 0.3.0, cuda 8.0 e ubuntu 17.04 em um sistema com dois 1080Ti e 32GB de RAM.
Quando uso 8 trabalhadores para meu próprio conjunto de dados, frequentemente vejo o impasse (acontece na primeira época). Quando reduzo os trabalhadores para 4, ele desaparece (executei 80 épocas).
Quando o impasse acontece, ainda tenho ~ 10 GB livres na RAM.
 milani
em 2 mar. 2018
milani
em 2 mar. 2018
Aqui você pode ver o log após encerrar o script: https://gist.github.com/milani/42f50c023cdca407115b309237d29c70
ATUALIZAÇÃO: confirmo que consegui resolver o problema com o aumento de SHMMNI . No Ubuntu 17.04, adicionei kernel.shmmni=8192 a /etc/sysctl.conf .
milani
em 2 mar. 2018
Também enfrentando esse problema, Ubuntu 17.10, Python 3.6, Pytorch 0.3.1, CUDA 8.0. Há muita RAM sobrando quando o impasse ocorre e o tempo parece ser inconsistente - pode acontecer após a 1ª época ou após a 200ª.
A combinação de kernel.shmmni=8192 e cv2.setNumThreads(0) parece ter remediado isso, enquanto eles não funcionaram individualmente.
 inoryy
em 8 mar. 2018
inoryy
em 8 mar. 2018
Igual no meu caso. Eu experimentei um impasse se eu configurasse o num_workers=4. Eu uso Ubuntu 17.10, Pytorch 0.3.1, CUDA 9.1, python 3.6. Observa-se que existem 4 threads python, cada uma delas ocupando 1,6 GB de memória enquanto a CPU (4 núcleos) permanece ociosa. Definir num_workers=0 ajuda a resolver esse problema.
 AlenUbuntu
em 27 mar. 2018
AlenUbuntu
em 27 mar. 2018
Eu tenho o mesmo problema, congela após exatamente uma época, mas não é realmente reproduzível para conjuntos de dados menores. Estou usando CUDA 9.1, Pytorch 0.3.1, Python 3.6 em um ambiente Docker.
Eu tentei o Dataloader do @jph00 , mas descobri que era muito mais lento para o meu caso de uso. Minha solução atualmente é recriar o Pytorch DataLoader antes de cada época. Isso parece funcionar, mas é muito feio.
 tfriedel
em 11 abr. 2018
tfriedel
em 11 abr. 2018
Eu tive exatamente o mesmo problema no Ubuntu 17.10, CUDA 9.1, Pytorch master (compilado em 19/04 de manhã). Também usando OpenCV na minha subclasse Dataset.
Então consegui evitar o impasse alterando o método de início de multiprocessamento de 'forkserver' para 'spawn':
# Set multiprocessing start method - deadlock
set_start_method(forkserver')
# Set multiprocessing start method - runs fine
set_start_method('spawn')
 mfuntowicz
em 19 abr. 2018
mfuntowicz
em 19 abr. 2018
Eu quase tentei todas as abordagens acima! Nenhum deles funcionou!
Esse problema pode estar relacionado a algumas incompatibilidades com a arquitetura de hardware e não sei como o Pytorch pode provocá-lo! Pode ou não ser o problema do Pytorch!
Então veja como meu problema foi resolvido:
_Eu atualizo a BIOS!
Dê-lhe um tiro. Pelo menos isso resolve meu problema.
 astorfi
em 21 abr. 2018
astorfi
em 21 abr. 2018
Mesmo aqui. Ubuntu PyTorch 0.4, python3.6.
 Shuailong
em 30 abr. 2018
Shuailong
em 30 abr. 2018
Parece que o problema ainda existe no pytorch 0.4 e no python 3.6. Não tenho certeza se é um problema de pytorch. Eu uso opencv e defino num_workers=8 , pin_memory=True . Eu tento todos os truques mencionados acima e definir cv2.setNumThreads(0) resolve meu problema.
 JasonQSY
em 10 mai. 2018
JasonQSY
em 10 mai. 2018
(1) Definir num_workers=0 no carregamento de dados do PyTorch resolve o problema (veja acima) OU
(2) cv2.setNumThreads(0) resolve o problema mesmo com num_workers razoavelmente grande
Isso parece algum tipo de problema de travamento de thread.
Eu configurei cv2.setNumThreads(0) em algum lugar no início do meu arquivo python principal e nunca tive esse problema desde então.
mathmanu
em 10 mai. 2018
Sim, muitos desses problemas são por causa de bibliotecas de terceiros não serem seguras para fork. Uma resolução alternativa pode ser usar o método spawn start.
apaszke
em 10 mai. 2018
Para mim, o problema de deadlock surge quando eu envolvo meu modelo com nn.DataParallel e uso num_workers > 0 no dataloader. Ao remover o wrapper nn.DataParallel, posso executar meu script sem nenhum bloqueio.
CUDA_VISIBLE_DEVICES=0 python myscript.py --split 1
CUDA_VISIBLE_DEVICES=1 python myscript.py --split 2
Sem várias GPUs, meu script é executado mais lentamente, mas posso executar vários experimentos ao mesmo tempo em diferentes divisões do conjunto de dados.
 euwern
em 15 jun. 2018
euwern
em 15 jun. 2018
Eu tenho o mesmo problema no Python 3.6.2 / Pytorch 0.4.0.
e tentei, acima de tudo, abordar a troca de pin_memory, alterando o tamanho da memória compartilhada e uso a biblioteca skiamge (não estou usando cv2 !!), mas ainda tenho problema.
este problema levantar aleatoriamente. controlar esse problema é apenas observar o console e reiniciar o treino.
 slaysd
em 19 jun. 2018
slaysd
em 19 jun. 2018
@jinh574 Acabei de definir o número de trabalhadores do carregador de dados como 0 e funciona.
Shuailong
em 19 jun. 2018
@Shuailong Eu tenho que usar uma imagem de tamanho grande, então não posso usar esses parâmetros por causa da velocidade. eu preciso inspecionar mais sobre este problema
slaysd
em 19 jun. 2018
Eu tenho o mesmo problema no Python 3.6 / Pytorch 0.4.0. A opção pin_memory afeta alguma coisa?
 ein-farbe
em 26 jun. 2018
ein-farbe
em 26 jun. 2018
Se você estiver usando collate_fn e num_workers>0 com PyTorch versão < 0.4:
CERTIFIQUE-SE DE NÃO RETORNAR ZERO TENSORES DA SUA FUNÇÃO __getitem__() .
OU DEVOLVA-OS COMO NUMPY ARRAYS.
 pyaf
em 12 jul. 2018
pyaf
em 12 jul. 2018
Eu tenho esse problema mesmo depois de definir num_workers=0 ou cv2.setNumThreads(0).
Ele falha com qualquer um desses dois problemas. Mais alguém enfrentando a mesma coisa?
Traceback (última chamada mais recente):
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", linha 193, em _run_module_as_main
"__main__", mod_spec)
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", linha 85, em _run_code
exec(código, run_globals)
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", linha 209, em
a Principal()
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", linha 205, em main
process.wait()
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", linha 1457, em espera
(pid, sts) = self._try_wait(0)
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", linha 1404, em _try_wait
(pid, sts) = os.waitpid(self.pid, wait_flags)
Interrupção do teclado
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", linha 258, em _bootstrap
self.run()
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", linha 93, em execução
self._target( self._args, * self._kwargs)
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/utils/data/dataloader.py", linha 96, em _worker_loop
r = index_queue.get(timeout=MANAGER_STATUS_CHECK_INTERVAL)
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/queues.py", linha 104, em get
se não for self._poll(timeout):
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", linha 257, na pesquisa
return self._poll(timeout)
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", linha 414, em _poll
r = wait([self], timeout)
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", linha 911, em espera
pronto = selector.select(tempo limite)
Arquivo "/opt/conda/envs/pytorch-py3.6/lib/python3.6/selectors.py", linha 376, em select
fd_event_list = self._poll.poll(timeout)
Interrupção do teclado
 swethmandava
em 25 ago. 2018
swethmandava
em 25 ago. 2018
Estou usando a versão '0.5.0a0+f57e4ce' e tive o mesmo problema. Cancelar o carregador de dados paralelo (num_workers=0) ou configurar cv2.setNumThreads(0) funciona.
 omersumer
em 5 out. 2018
omersumer
em 5 out. 2018
Estou bastante confiante de que #11985 deve eliminar todos os travamentos (a menos que você interrompa em momentos infelizes que não podemos controlar). Agora que está mesclado, estou fechando isso.
O travamento com o cv2 também está fora de nosso controle, pois o cv2 simplesmente não funciona bem com multiprocessamento.
SsnL
em 9 out. 2018
Ainda experimentando isso a partir de torch_nightly-1.0.0.dev20181029 , o PR ainda não foi mesclado?
 Evpok
em 30 out. 2018
Evpok
em 30 out. 2018
@Evpok isso foi mesclado lá. Você deve ter este patch com certeza. Querendo saber se há mais impasses persistentes possíveis. Você tem uma reprodução fácil que podemos tentar olhar?
soumith
em 30 out. 2018
Na verdade, eu rastreei isso para uma bagunça de multiprocessamento não relacionada do meu lado, desculpe pelo inconveniente.
Evpok
em 30 out. 2018
oi @Evpok
eu uso torch_nightly-1.0.0 , e encontro este problema. vc resolveu esse problema?
 zimenglan-sysu-512
em 14 nov. 2018
zimenglan-sysu-512
em 14 nov. 2018
Se você estiver usando collate_fn e num_workers>0 com PyTorch versão < 0.4:
CERTIFIQUE-SE DE NÃO RETORNAR ZERO TENSORES DA SUA FUNÇÃO
__getitem__().
OU DEVOLVA-OS COMO NUMPY ARRAYS.
Eu consertei meu bug de retornar zeros dim tensores e o problema ainda existe.
 liluxuan1997
em 14 nov. 2018
liluxuan1997
em 14 nov. 2018
@zimenglan-sysu-512 O principal problema foi com as limitações do multiprocessamento: ao usar spawn ou forkserver (o que é necessário para comunicação CPU-GPU) o compartilhamento de objetos entre o processo é bastante limitado e não adequado para o tipo de objetos que tenho que manipular.
Evpok
em 14 nov. 2018
Nada disso funcionou para mim. No entanto, o opencv mais recente funciona ( 3.4.0.12 to 3.4.3.18 nada mais para mudar):
sudo pip3 install --upgrade opencv-python
 see--
em 17 nov. 2018
see--
em 17 nov. 2018
@see-- fico feliz em saber que o opencv corrigiu a coisa :)
SsnL
em 17 nov. 2018
Estou no OpenCV 3.4.3.18 com python2.7 e ainda vejo o impasse acontecendo. :/
 SreenivasVRao
em 3 dez. 2018
SreenivasVRao
em 3 dez. 2018
Por favor, tente o seguinte:
from torch.utils.data.dataloader import DataLoader
em vez de
from torch.utils.data import DataLoader
Eu acho que há um problema com a verificação de tipo aqui:
https://github.com/pytorch/pytorch/blob/656b565a0f53d9f24547b060bd27aa67ebb89b88/torch/utils/data/dataloader.py#L816
 jewfro-cuban
em 16 dez. 2018
jewfro-cuban
em 16 dez. 2018
Por favor, tente o seguinte:
from torch.utils.data.dataloader import DataLoaderem vez de
from torch.utils.data import DataLoaderEu acho que há um problema com a verificação de tipo aqui:
pytorch/torch/utils/data/dataloader.py
Linha 816 em 656b565
super(DataLoader, self).__setattr__(attr, val)
Isso não é apenas um apelido? em torch.utils.data.__init__ eles importam dataloader.DataLoader
 simonhessner
em 8 jan. 2019
simonhessner
em 8 jan. 2019
Eu também tinha pendurado com num_workers > 0. Meu código não tem opencv, e o uso de memória de /dev/shm não é um problema. Nenhuma sugestão acima funcionou para mim. Minha correção foi atualizar o numpy de 1.14.1 para 1.14.5:
conda install numpy=1.14.5
Espero que seja útil.
 daniyar-niantic
em 8 jan. 2019
daniyar-niantic
em 8 jan. 2019
Hmm, minha versão numpy é 1.15.4, então mais recente que 1.14.5... Deve estar tudo bem então?
simonhessner
em 8 jan. 2019
Hmm, minha versão numpy é 1.15.4, então mais recente que 1.14.5... Deve estar tudo bem então?
Idk, minha atualização do numpy também atualizou o mkl.
daniyar-niantic
em 8 jan. 2019
Qual versão do mkl você tem? O meu é 2019.1 (build 144) e outros pacotes que incluem mkl em seu nome são:
mkl-service 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
simonhessner
em 8 jan. 2019
Qual versão do mkl você tem? O meu é 2019.1 (build 144) e outros pacotes que incluem mkl em seu nome são:
mkl-service 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
conda list | grep mkl
mkl 2018.0.1 h19d6760_4
mkl-service 1.1.2 py36h17a0993_4
Se você ainda vir travar no pytorch mais recente, seria muito útil fornecer um script curto que reproduza o problema. Obrigado!
SsnL
em 9 jan. 2019
Ainda estou vendo esse impasse, vou ver se consigo criar um script que reproduza.
 dtmoodie
em 15 jan. 2019
dtmoodie
em 15 jan. 2019
pin_memory=True resolveu o problema para mim.
pyaf
em 30 jan. 2019
Não parece funcionar para mim com pin_memory=True , ainda ficou preso depois de 70 épocas. A única coisa que funcionou para mim até agora é definir num_workers=0 , mas é visivelmente mais lento.
 jclevesque
em 14 fev. 2019
jclevesque
em 14 fev. 2019
Também estou enfrentando o impasse (ocorre de forma bastante aleatória). Tentei pin_memory e atualizei o Numpy. Vou tentar rodar em outra máquina.
 Avsecz
em 14 fev. 2019
Avsecz
em 14 fev. 2019
Se você estiver usando vários threads com carregadores de dados, tente usar multiprocessamento em vez de multithreading. Isso resolveu completamente o problema para mim (e, a propósito, também é melhor para tarefas computacionalmente intensivas em Python por causa do GIL)
simonhessner
em 14 fev. 2019
mesmo erro em Pytorch1.0, Pillow5.0.0 numpy1.16.1 python3.6
 jianlong-yuan
em 15 fev. 2019
jianlong-yuan
em 15 fev. 2019
Também recebo o mesmo erro. Eu configurei pin_memory=True e num_workers=0 . Apesar de uma coisa que notei que quando utilizo uma pequena parte do dataset, esse erro não ocorre. Somente o uso de todo o conjunto de dados causa esse erro.
Edit: Apenas uma simples reinicialização do sistema corrigiu para mim.
 Venka97
em 6 mar. 2019
Venka97
em 6 mar. 2019
Eu tive um problema parecido. Em algum código esta função (quase sempre) trava em d_iter.next():
def get_next_batch(d_iter, loader):
try:
data, label = d_iter.next()
except StopIteration:
d_iter = iter(loader)
data, label = d_iter.next()
return data, label
O hack que funcionou para mim foi adicionar um pequeno atraso depois de chamar essa função
trn_X, trn_y = get_next_batch(train_data_iter, train_loader)
time.sleep(0.003)
val_X, val_y = get_next_batch(valid_data_iter, valid_loader)
Acho que o atraso ajudou a evitar algum impasse?
 enoonIT
em 20 mar. 2019
enoonIT
em 20 mar. 2019
Ainda estou enfrentando esse problema. Usando pytorch 1.0 e python 3.7. Quando eu estava usando vários data_loader, esse bug aparecerá. Se eu usar menos de 3 data_loader ou usar uma única GPU, esse bug não aparecerá. Testado:
- tempo.sono(0,003)
- pin_memory=Verdadeiro/Falso
- num_workers=0/1
- de torch.utils.data.dataloader importar DataLoader
- escrevendo 8192 para /proc/sys/kernel/shmmni
Nenhum deles funciona. Não sabe se existe alguma solução?
 xuw080
em 16 abr. 2019
xuw080
em 16 abr. 2019
minhas soluções adicionam cv2.setNumThreads(0) no programa de pré-processamento
Eu tenho 2 dataloader, que são para train e val
Eu só poderia executar o avaliador uma vez.
 lightningsoon
em 10 mai. 2019
lightningsoon
em 10 mai. 2019
Acabei de encontrar esse bug com o pytorch 1.1. O mesmo ficou preso duas vezes no mesmo lugar: final da 99ª época. pin_memory foi definido como False .
 Randl
em 17 mai. 2019
Randl
em 17 mai. 2019
Mesmo problema ao usar workers>0, a memória dos pinos não resolveu o problema.
 nicolasCruzW21
em 20 mai. 2019
nicolasCruzW21
em 20 mai. 2019
minhas soluções adicionam cv2.setNumThreads(0) no programa de pré-processamento
Eu tenho 2 dataloader, que são para train e val
Eu só poderia executar o avaliador uma vez.
Esta solução funciona para mim, obrigado
 zxhr2793
em 3 jun. 2019
zxhr2793
em 3 jun. 2019
o carregador de dados para quando eu termino uma época e inicia uma nova época.
enfrentar o mesmo problema. No meu caso, o problema surge quando instalo o opencv-python (já instalei o opencv3 antes). Após mover o opencv-python, o treinamento não será interrompido.
 hongzhenwang
em 20 jun. 2019
hongzhenwang
em 20 jun. 2019
é uma boa ideia também
Em 20/06/2019 10:51:02, "hongzhenwang" [email protected] escreveu:
o carregador de dados para quando eu termino uma época e inicia uma nova época.
enfrentar o mesmo problema. No meu caso, o problema surge quando instalo o opencv-python (já instalei o opencv3 antes). Após mover o opencv-python, o treinamento não será interrompido.
—
Você está recebendo isso porque comentou.
Responda a este e-mail diretamente, visualize-o no GitHub ou silencie a conversa.
lightningsoon
em 27 jun. 2019
Ainda estou enfrentando esse problema. Usando pytorch 1.0 e python 3.7. Quando eu estava usando vários data_loader, esse bug aparecerá. Se eu usar menos de 3 data_loader ou usar uma única GPU, esse bug não aparecerá. Testado:
1. time.sleep(0.003) 2. pin_memory=True/False 3. num_workers=0/1 4. from torch.utils.data.dataloader import DataLoader 5. writing 8192 to /proc/sys/kernel/shmmni None of them works. Don't know whether there is any solutions?
Ainda tentando encontrar uma solução alternativa. Concordo que só pareço ter esse problema quando estou executando 2 processos paralelos em diferentes GPUs ao mesmo tempo. Um continua indo enquanto o outro pára.
 ArturoDeza
em 3 jul. 2019
ArturoDeza
em 3 jul. 2019
Quando configurei o num_workers=4, o programa travou por alguns segundos (ou minutos) a cada 4 lotes., o que desperdiça muito tempo. Alguma ideia de como resolver?
 huangchaoxing
em 27 jul. 2019
huangchaoxing
em 27 jul. 2019
adicionando os sinalizadores: pin_memory=True e num_workers=0 no carregador de dados é a solução!
ArturoDeza
em 27 jul. 2019
adicionando os sinalizadores: pin_memory=True e num_workers=0 no carregador de dados é a solução!
@ArturoDeza
Esta pode ser uma solução. No entanto, definir num_workers=0 retardará toda a busca de dados da CPU e a taxa de uso da GPU será muito baixa.
huangchaoxing
em 28 jul. 2019
Para mim, o motivo foi que não havia CPUs suficientes no meu sistema ou num_workers especificados no Dataloader. Também pode ser uma boa ideia desabilitar o encadeamento nos trabalhadores do Dataloader caso o método __get_item__ no carregador de dados use uma biblioteca encadeada como numpy , librosa ou opencv (veja abaixo por que isso pode ser importante). Isso pode ser feito executando seu script de treinamento com OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . Como um esclarecimento para a discussão abaixo, observe que cada lote do Dataloader é tratado por um único trabalhador: cada trabalhador manipula batch_size amostras para concluir um único lote e, em seguida, inicia o processamento de um novo lote de dados.
Você precisa definir num_workers abaixo do número de CPUs na máquina (ou pod se estiver usando Kubernetes), mas alto o suficiente para que os dados estejam sempre prontos para a próxima iteração. Se a GPU executar cada iteração em t segundos e cada trabalhador do carregador de dados levar N*t segundos para carregar/processar um único lote, você deverá definir num_workers para pelo menos N , para evitar travamentos da GPU. Claro, você precisa ter pelo menos N CPUs no sistema.
Infelizmente, se o Dataloader usar qualquer biblioteca que use K threads, o número de processos gerados se tornará num_workers*K = N*K . Isso pode ser significativamente maior do que o número de CPUs na máquina. Isso estrangula o pod e o Dataloader fica muito lento. Isso pode fazer com que o Dataloader não retorne um lote a cada t segundos, causando travamentos da GPU.
Uma maneira de evitar threads K é chamar o script principal por OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . Isso restringe cada trabalhador do Dataloader a usar um único thread e evita sobrecarregar a máquina. Você ainda precisa ter num_workers suficiente para manter a GPU alimentada.
Você também deve otimizar seu código em __get_item__ para que cada trabalhador conclua seu lote em pouco tempo. Certifique-se de que o tempo para concluir o pré-processamento de um lote pelo trabalhador não seja prejudicado pelo tempo de leitura dos dados de treinamento do disco (especialmente se você estiver lendo de um armazenamento de rede) ou da largura de banda da rede (se estiver lendo de uma rede disco). Se seu conjunto de dados for pequeno e você tiver RAM suficiente, considere mover o conjunto de dados para a RAM (ou /tmpfs ) e leia a partir daí para acesso rápido. Para Kubernetes, você pode criar um disco RAM (procure por emptyDir no Kubernetes).
Se você otimizou seu código __get_item__ e garantiu que o acesso ao disco/acesso à rede não são os culpados, mas ainda vê travamentos, você precisará solicitar mais CPUs (para um pod do Kubernetes) ou mover sua GPU para um máquina com mais CPUs.
Outra opção é reduzir os batch_size para que cada worker tenha menos trabalho a fazer e termine o pré-processamento mais rapidamente. A última opção não é desejável em alguns casos, porque haverá memória GPU ociosa não sendo utilizada.
Você também pode considerar fazer parte do pré-processamento offline e tirar o peso de cada trabalhador. Por exemplo, se cada trabalhador estiver lendo em um arquivo wav e computando espectrogramas para o arquivo de áudio, você pode considerar pré-computar os espectrogramas offline e apenas ler o espectrograma computado do disco no trabalhador. Isso reduzirá a quantidade de trabalho que cada trabalhador tem que fazer.
 gkeskin07
em 3 ago. 2019
gkeskin07
em 3 ago. 2019
encontrar o mesmo problema com horovod
 jinhou
em 12 ago. 2019
jinhou
em 12 ago. 2019
Encontre um problema semelhante... Deadlock enquanto terminava uma época e começava a carregar dados para validação...
 jackroos
em 20 ago. 2019
jackroos
em 20 ago. 2019
@jinhou @jackroos Mesma coisa, preso aleatoriamente no início da validação com horovod. O que faço atualmente como solução alternativa é definir um tempo limite e pular a validação. Você tem uma solução?
 lzljzys
em 28 ago. 2019
lzljzys
em 28 ago. 2019
@jinhou @jackroos Mesma coisa, preso aleatoriamente no início da validação com horovod. O que faço atualmente como solução alternativa é definir um tempo limite e pular a validação. Você tem uma solução?
Não. Eu apenas desativo o treinamento distribuído nesse caso.
jackroos
em 29 ago. 2019
Encontrei um problema semelhante: o carregador de dados para quando termino uma época e inicia uma nova época.
por que tanto zan?
 foocker
em 22 out. 2019
foocker
em 22 out. 2019
Ainda estou enfrentando esse problema. Usando pytorch 1.0 e python 3.7. Quando eu estava usando vários data_loader, esse bug aparecerá. Se eu usar menos de 3 data_loader ou usar uma única GPU, esse bug não aparecerá. Testado:
- tempo.sono(0,003)
- pin_memory=Verdadeiro/Falso
- num_workers=0/1
- de torch.utils.data.dataloader importar DataLoader
- escrevendo 8192 para /proc/sys/kernel/shmmni
Nenhum deles funciona. Não sabe se existe alguma solução?
num_workers definido como 0 funcionou para mim. Você deve certificar-se de que esteja em 0 em todos os lugares em que estiver usando.
Algumas outras soluções potenciais:
- de importação de multiprocessamento set_start_method
set_start_method('spawn') - cv2.setNumThreads(0)
Parece que 3 ou 7 são o caminho a percorrer.
 the7threvival
em 18 nov. 2019
the7threvival
em 18 nov. 2019
Eu experimentei esse problema com pytorch 1.3, ubuntu16, todas as sugestões acima não funcionaram, exceto workers = 0, que retarda a execução. Isso só acontece quando executado a partir do terminal, no notebook Jupyter está tudo bem, mesmo com workers=32.
O problema não parece resolvido, deve ser reaberto? Vejo também muitas outras pessoas relatando o mesmo problema...
 skariel
em 2 dez. 2019
skariel
em 2 dez. 2019
Ainda estou enfrentando esse problema. Usando pytorch 1.0 e python 3.7. Quando eu estava usando vários data_loader, esse bug aparecerá. Se eu usar menos de 3 data_loader ou usar uma única GPU, esse bug não aparecerá. Testado:
- tempo.sono(0,003)
- pin_memory=Verdadeiro/Falso
- num_workers=0/1
- de torch.utils.data.dataloader importar DataLoader
- escrevendo 8192 para /proc/sys/kernel/shmmni
Nenhum deles funciona. Não sabe se existe alguma solução?num_workers definido como 0 funcionou para mim. Você deve certificar-se de que esteja em 0 em todos os lugares em que estiver usando.
Algumas outras soluções potenciais:
- de importação de multiprocessamento set_start_method
set_start_method('spawn')- cv2.setNumThreads(0)
Parece que 3 ou 7 são o caminho a percorrer.
Modifiquei train.py assim:
from __future__ import division
import cv2
cv2.setNumThreads(0)
import argparse
...
E funciona para mim.
 DHZS
em 10 dez. 2019
DHZS
em 10 dez. 2019
Oi pessoal se eu puder ajudar,
Eu também tive esse problema semelhante a este, mas acontecia a cada 100 ou mais épocas.
Percebi que isso só acontecia com o CUDA ativado, também o dmesg tem essa entrada de log sempre que trava.
python[11240]: segfault at 10 ip 00007fabdd6c37d8 sp 00007ffddcd64fd0 error 4 in libcudart.so.10.1.243[7fabdd699000+77000]
É sem sentido para mim, mas me disse que CUDA e python multithreading não estavam jogando bem.
Minha correção foi desabilitar o cuda nos datathreads, aqui está um trecho do meu arquivo de entrada python.
from multiprocessing import set_start_method
import os
if __name__ == "__main__":
set_start_method('spawn')
else:
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import torch
import application
Espero que isso possa ajudar qualquer um que pousar aqui como eu precisava no momento.
 roderickObrist
em 24 mar. 2020
roderickObrist
em 24 mar. 2020
@jinhou @jackroos Mesma coisa, preso aleatoriamente no início da validação com horovod. O que faço atualmente como solução alternativa é definir um tempo limite e pular a validação. Você tem uma solução?
Não. Eu apenas desativo o treinamento distribuído nesse caso.
Encontro um problema semelhante no treinamento distribuído sem usar o OpenCV após a atualização para o PyTorch 1.4.
Agora eu tenho que executar a validação uma vez antes do loop de treinamento e validação.
 wizardk
em 9 jun. 2020
wizardk
em 9 jun. 2020
Já tive muitos problemas com isso. Parece persistir nas versões do pytorch, versões do python e também em diferentes máquinas físicas (que provavelmente terão sido configuradas de forma idêntica).
Toda vez é o mesmo erro:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/bicep/loops.py", line 73, in __call__
for data, target in self.dataloader:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 830, in _next_data
self._shutdown_workers()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 942, in _shutdown_workers
w.join()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/process.py", line 149, in join
res = self._popen.wait(timeout)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 47, in wait
return self.poll(os.WNOHANG if timeout == 0.0 else 0)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll
pid, sts = os.waitpid(self.pid, flag)
Há claramente algum problema na maneira como os processos estão sendo tratados na máquina que estou usando. Nenhuma das soluções acima parece funcionar, além de definir num_workers=0.
Eu realmente gostaria de poder chegar ao fundo disso, alguém tem alguma idéia por onde começar ou como interrogar isso?
 brynhayder
em 9 jun. 2020
brynhayder
em 9 jun. 2020
Eu também aqui.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 480, in _try_get_batch
data = self.data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 65, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 95106) is killed by signal: Segmentation fault.
Uma coisa interessante é
quando eu apenas analiso os dados linha por linha, não tenho esse problema:
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
mas se eu adicionar uma lógica de análise JSON depois de ler linha por linha, ele relatará esse erro
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
Eu entendo que haverá alguma sobrecarga de memória JSON, mas mesmo eu diminuo o número de trabalhadores para 2, e o conjunto de dados é muito pequeno, ainda tem o mesmo problema. Eu meio que duvido que seja relacionado ao shm. qualquer pista?
 zhangruiskyline
em 16 jun. 2020
zhangruiskyline
em 16 jun. 2020
Vamos reabrir este assunto?
 takatosp1
em 18 jun. 2020
takatosp1
em 18 jun. 2020
Eu acho que devemos. BTW, eu fiz alguns depuração GDB e nada encontrado lá. então não tenho certeza se é um problema de memória compartilhada,
(gdb) run
Starting program: /home/miniconda/bin/python performance.py
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7fffa60a6700 (LWP 61963)]
[New Thread 0x7fffa58a5700 (LWP 61964)]
[New Thread 0x7fffa10a4700 (LWP 61965)]
[New Thread 0x7fff9e8a3700 (LWP 61966)]
[New Thread 0x7fff9c0a2700 (LWP 61967)]
[New Thread 0x7fff998a1700 (LWP 61968)]
[New Thread 0x7fff970a0700 (LWP 61969)]
[New Thread 0x7fff9489f700 (LWP 61970)]
[New Thread 0x7fff9409e700 (LWP 61971)]
[New Thread 0x7fff8f89d700 (LWP 61972)]
[New Thread 0x7fff8d09c700 (LWP 61973)]
[New Thread 0x7fff8a89b700 (LWP 61974)]
[New Thread 0x7fff8809a700 (LWP 61975)]
[New Thread 0x7fff85899700 (LWP 61976)]
[New Thread 0x7fff83098700 (LWP 61977)]
[New Thread 0x7fff80897700 (LWP 61978)]
[New Thread 0x7fff7e096700 (LWP 61979)]
[New Thread 0x7fff7d895700 (LWP 61980)]
[New Thread 0x7fff7b094700 (LWP 61981)]
[New Thread 0x7fff78893700 (LWP 61982)]
[New Thread 0x7fff74092700 (LWP 61983)]
[New Thread 0x7fff71891700 (LWP 61984)]
[New Thread 0x7fff6f090700 (LWP 61985)]
[Thread 0x7fff7e096700 (LWP 61979) exited]
[Thread 0x7fff6f090700 (LWP 61985) exited]
[Thread 0x7fff74092700 (LWP 61983) exited]
[Thread 0x7fff7b094700 (LWP 61981) exited]
[Thread 0x7fff80897700 (LWP 61978) exited]
[Thread 0x7fff83098700 (LWP 61977) exited]
[Thread 0x7fff85899700 (LWP 61976) exited]
[Thread 0x7fff8809a700 (LWP 61975) exited]
[Thread 0x7fff8a89b700 (LWP 61974) exited]
[Thread 0x7fff8d09c700 (LWP 61973) exited]
[Thread 0x7fff8f89d700 (LWP 61972) exited]
[Thread 0x7fff9409e700 (LWP 61971) exited]
[Thread 0x7fff9489f700 (LWP 61970) exited]
[Thread 0x7fff970a0700 (LWP 61969) exited]
[Thread 0x7fff998a1700 (LWP 61968) exited]
[Thread 0x7fff9c0a2700 (LWP 61967) exited]
[Thread 0x7fff9e8a3700 (LWP 61966) exited]
[Thread 0x7fffa10a4700 (LWP 61965) exited]
[Thread 0x7fffa58a5700 (LWP 61964) exited]
[Thread 0x7fffa60a6700 (LWP 61963) exited]
[Thread 0x7fff71891700 (LWP 61984) exited]
[Thread 0x7fff78893700 (LWP 61982) exited]
[Thread 0x7fff7d895700 (LWP 61980) exited]
total_files = 5040. //customer comments
[New Thread 0x7fff6f090700 (LWP 62006)]
[New Thread 0x7fff71891700 (LWP 62007)]
[New Thread 0x7fff74092700 (LWP 62008)]
[New Thread 0x7fff78893700 (LWP 62009)]
ERROR: Unexpected segmentation fault encountered in worker.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 62005) is killed by signal: Segmentation fault.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "performance.py", line 62, in <module>
main()
File "performance.py", line 48, in main
for i,batch in enumerate(rl_data_loader):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 841, in _next_data
idx, data = self._get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 808, in _get_data
success, data = self._try_get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 774, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 62005) exited unexpectedly
[Thread 0x7fff78893700 (LWP 62009) exited]
[Thread 0x7fff74092700 (LWP 62008) exited]
[Thread 0x7fff71891700 (LWP 62007) exited]
[Thread 0x7fff6f090700 (LWP 62006) exited]
[Inferior 1 (process 61952) exited with code 01]
(gdb) backtrace
No stack.
E eu acho que tenho memória compartilhada suficiente, pelo menos espero que a memória compartilhada seja boa o suficiente por um bom tempo até segfault, mas a falha de segmento acontece quase imediatamente após eu iniciar o trabalho do carregador de dados
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18014398509481980
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
Oi @soumith @apaszke , podemos abrir este problema, tentei todas as soluções propostas, como aumentar o tamanho e o segmento do shm, nada funciona, não estou usando opencv ou algo assim, apenas análise JSON simples. mas questão ainda está lá. e não acho que seja relacionado ao shm, pois abro toda a memória como memória compartilhada. O rastreamento de pilha também não mostra nada, conforme postado acima.
@apaszke , sobre sua sugestão de
"Sim, muitos desses problemas são por causa de bibliotecas de terceiros não serem seguras para fork. Uma solução alternativa pode ser usar o método spawn start."
Estou usando o dataloader multi worker, como posso alterar o método? Estou configurando set_start_method('spawn') no meu main.py, mas não parece ajudar
Também tenho uma pergunta geral aqui, se eu habilitar o carregador de dados multi worker (multi process) e, no treinamento principal, também iniciar o multiprocess conforme sugerido em https://pytorch.org/docs/stable/notes/multiprocessing.html #multiprocessamento -melhores práticas
como o pytorch gerencia o dataloader e o multiprocesso de treinamento principal? eles compartilharão todos os processos/threading possíveis na GPU multicore? também a memória compartilhada para vários processos é "compartilhada" pelo carregador de dados e pelo processo de treinamento principal? também se eu tiver algum trabalho de cozimento de dados, como análise de JSON, análise de CSV, extração de recursos de pandas. etc, onde é a melhor maneira de colocar? no dataloader para gerar dados perfeitos para estarem prontos ou apenas usar o treinamento principal para fazer isso como sugerido acima para manter o carregador de dados __get_item__ mais simples possível
zhangruiskyline
em 19 jun. 2020
@zhangruiskyline Seu problema não é realmente um impasse. É sobre os trabalhadores sendo mortos por segfault. sigbus é aquele que sugere problemas de shm. Você deve verificar o código do conjunto de dados e depurar lá.
Para responder suas outras perguntas,
- use kwarg
multiproessing_context='spawn'no DataLoader para definir o spawn.set_start_methodtambém faz isso. - geralmente no treinamento multiprocesso, cada processo tem seu próprio DataLoader e, portanto, trabalhadores do DataLoader. Nada é compartilhado entre os processos, a menos que seja feito explicitamente.
SsnL
em 20 jun. 2020
Obrigado @SsnL , adicionei multiproessing_context='spawn' mas a mesma falha.
Eu apontei no tópico anterior, meu código é muito simples,
- este pedaço de código funciona
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
- mas se eu adicionar uma lógica de análise JSON depois de ler linha por linha, ele relatará esse erro
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
então duvido que seja meu problema de código, também tento não usar a análise JSON, mas diretamente a divisão de strings, mesmo problema. parece que desde que eu tenha alguma lógica demorada para o processo de dados no carregador de dados, esse problema acontece
Também em relação
treinamento multiprocesso, cada processo tem seu próprio DataLoader e, portanto, trabalhadores do DataLoader. Nada é compartilhado entre os processos, a menos que seja feito explicitamente.
Então, vamos ver que tenho 4 processos para treinamento, cada um com um carregador de dados de 8 trabalhadores, totalizando 32 processos por baixo?
zhangruiskyline
em 20 jun. 2020
@zhangruiskyline Sem um script independente para reproduzir o problema, não podemos ajudá-lo. Sim, serão 32 processos
SsnL
em 20 jun. 2020
Obrigado, também vi um problema semelhante em
https://github.com/pytorch/pytorch/issues/4969
https://github.com/pytorch/pytorch/issues/5040
ambos fechados, mas não vejo uma solução ou correção clara, esse ainda é um grande problema existente?
Verei se posso fornecer script de reprodução independente, mas é altamente integrado à nossa plataforma e fonte de dados, então tentarei
zhangruiskyline
em 20 jun. 2020
@zhangruiskyline Seu problema não é semelhante a nenhum dos problemas vinculados, se você os ler. eles estão fechados porque o problema original / mais comum relatado nesses tópicos já foi resolvido.
SsnL
em 20 jun. 2020
Obrigado @SsnL , não estou tão familiarizado com o Pytorch, então posso estar errado, mas passei por todos eles e parece que alguns deles parecem resolvidos por
reduzir o número de trabalhadores para 0, isso é inaceitável para nós, pois é muito lento,
aumentar o tamanho do shm, mas temos shm suficiente, acredito, e o problema aconteceu quase imediatamente após o início, e tentei com um conjunto de dados muito menor.
algumas lib como a dose opencv não funcionam bem em multiprocessos, estamos apenas usando JSON/CSV, então não são coisas realmente sofisticadas
nosso código é bastante simples, o conjunto de dados de treinamento tem mais de 10.000 arquivos, cada arquivo é várias linhas de strings JSON. no dataloader, definimos __get_item__ para obter cada arquivo de mais de 10 mil arquivos e ler todo o conteúdo desse arquivo.
na solução 1, primeiro lemos e dividimos linhas por linha na lista de strings JSON, se retornarmos imediatamente, funciona, o desempenho é bom
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
return all_data
agora, como o valor retornado ainda é uma string JSON, queremos aproveitar o carregador de dados de vários processos para acelerar, então coloque a lógica de análise JSON aqui e ela falha
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
mais tarde, pensamos que a análise JSON é muito pesada e também JSON tem muito espaço de memória, então optamos por analisar a string JSON e converter manualmente para a lista de recursos, a mesma falha. fiz alguma análise de rastreamento de pilha e nada lá
BTW, estamos executando nosso código no Linux Docker Env, CPU de 24 núcleos e 1 V100.
Não tenho certeza por onde devo começar a investigar a seguir. você tem alguma ideia?
zhangruiskyline
em 20 jun. 2020
Oi,
Encontrei um comentário interessante em https://github.com/open-mmlab/mmcv , que é usado em https://github.com/open-mmlab/mmdetection :
O código a seguir é usado no início de train epoch e val epoch.
time.sleep(2) # Evita um possível deadlock durante a transição de época
Pode ser que você pode tentar.
mathmanu
em 20 jun. 2020
BTW, se eu for para vários processos e cada processo com carregador de dados de vários trabalhadores, como diferentes processos podem garantir que seu carregador de dados correspondente não leia os mesmos dados que o carregador de dados de outro processo? ti já é tratado pelo pytorch dataloader __get_item__ ?
zhangruiskyline
em 20 jun. 2020
Oi @SsnL , Obrigado pela sua ajuda. só quero acompanhar um pouco este segmento, refatoro o código de treinamento usando o multiprocessamento pytorch para acelerar algum processamento de dados no lado da CPU (para alimentar a GPU mais rapidamente), https://pytorch.org/docs/stable /notes/multiprocessing.html#multiprocessing -melhores práticas
Em cada função de processamento, também uso o carregador de dados de vários trabalhadores para acelerar o tempo de processamento de carregamento de dados. https://pytorch.org/docs/stable/data.html
Eu coloquei minha análise JSON da CPU pesada não no carregador de dados, mas no processo de treinamento principal, e o problema parece ter desaparecido, não sei por que, mas de qualquer maneira parece funcionar. mas tenho uma pergunta de acompanhamento: suponha que eu tenha N processamento, cada um tem M trabalhador do carregador de dados, então totalize NxM abaixo do encadeamento lá.
Se no meu dataloader, eu quiser obter todos os dados de forma indexada, o que significa que __get_item__(self, idx) em M data loader em N diferentes processamentos podem trabalhar juntos para processar diferentes índices, como posso garantir que eles não processem duplicatas ou perder algum processo?
zhangruiskyline
em 23 jun. 2020
Eu tive o mesmo problema em que o dataloader trava depois de reclamar que não podia alocar memória no início de uma nova época de treinamento ou validação. As soluções acima não funcionaram para mim (i) meu
/dev/shmé de 32 GB e nunca foi usado mais de 2,5 GB e (ii) a configuração pin_memory=False não funcionou.Isso é talvez algo a ver com a coleta de lixo? Meu código se parece mais ou menos com o seguinte. Eu preciso de um iterador infinito e, portanto, faço uma tentativa / exceto em torno do
next()abaixo :-)def train(): train_iter = train_loader.__iter__() for i in xrange(max_batches): try: x, y = next(train_iter) except StopIteration: train_iter = train_loader.__iter__() ... del train_iter
train_loaderé um objetoDataLoader. Sem a linhadel train_iterexplícita no final da função, o processo sempre trava após 2-3 épocas (/dev/shmainda mostra 2,5 GB). Espero que isto ajude!Estou usando
4workers (versão0.1.12_2com CUDA 8.0 no Ubuntu 16.04).
Isso resolveu o problema para mim depois de semanas de luta. Eu tenho que usar explicitamente o iterador do carregador em vez de fazer o loop do carregador diretamente e usar o del loader_iterator no final da época finalmente removeu os impasses
 kennyFF92
em 15 jul. 2020
kennyFF92
em 15 jul. 2020
Acho que estou enfrentando o mesmo problema. Tentando usar 8 carregadores de dados (MNIST, MNISM, SVHN, USPS, para treinar e testar cada um). Usar 6 (qualquer 6) funciona bem. Usando 8 sempre bloqueia ao carregar o 6º, teste MNIST-M. Ele está preso em um loop infinito de tentar recuperar a imagem, falhando, esperando um pouco e tentando novamente. O erro persiste para qualquer batch_size, tenho bastante memória livre e só desaparece se eu definir num_workers como 0. Qualquer outro valor causa o problema
 pmirallesr
em 21 jul. 2020
pmirallesr
em 21 jul. 2020
Eu tenho algumas dicas de https://stackoverflow.com/questions/54013846/pytorch-dataloader-stucked-if-using-opencv-resize-method
Quando coloco cv2.setNumThreads(0) , funciona bem comigo.
 LifeBeyondExpectations
em 17 ago. 2020
LifeBeyondExpectations
em 17 ago. 2020
Olá, tive o mesmo problema. E tinha a ver com ulimit -n, basta aumentar e o problema está resolvido, usei ulimit -n 500000
 SebastienEske
em 18 ago. 2020
SebastienEske
em 18 ago. 2020
@SebastienEske ulimit -n corrigiu isso para mim também, no Ubuntu 20.04
 david-waterworth
em 24 set. 2020
david-waterworth
em 24 set. 2020
Talvez definir ulimit -n seja o caminho certo, com o aumento do modelo, o deadlock se torna cada vez mais frequente, também testo cv2.setNumThreads(0) , mas não funciona.
 BLING-1994
em 27 set. 2020
BLING-1994
em 27 set. 2020
Para constar, cv2.setNumThreads(0) funcionou para mim.
 franchesoni
em 18 nov. 2020
franchesoni
em 18 nov. 2020
Questões relacionadas
 rajarshd
·
3Comentários
rajarshd
·
3Comentários
 mishraswapnil
·
3Comentários
mishraswapnil
·
3Comentários
 kdexd
·
3Comentários
kdexd
·
3Comentários
 dablyo
·
3Comentários
dablyo
·
3Comentários
 ikostrikov
·
3Comentários
ikostrikov
·
3Comentários
Comentários muito úteis
Encontrei um problema semelhante: o carregador de dados para quando termino uma época e inicia uma nova época.