バグはpytorch / examples#148で説明されています。 サンプルコードは私にはきれいに見えるので、これはPyTorch自体のバグかどうか疑問に思います。 また、これは#1120に関連しているのだろうか。
 zym1010
zym1010
全てのコメント189件
ローダーが停止したときに、どのくらいの空きメモリがありますか?
 apaszke
2017年04月25日
apaszke
2017年04月25日
@apaszke topをチェックすると、残りのメモリ(キャッシュされたメモリも使用済みとしてカウントされます)は通常2GBです。 ただし、キャッシュされたものを使用済みとしてカウントしない場合は、常に多く、たとえば30GB以上になります。
zym1010
2017年04月25日
また、検証の開始時に常に停止する理由はわかりませんが、それ以外の場所では停止しません。
zym1010
2017年04月25日
おそらく、検証のために、共有メモリの使用を制限を超えてプッシュする別のローダーが使用されているためです。
 ngimel
2017年04月25日
ngimel
2017年04月25日
@ngimel
プログラムをもう一度実行しました。 そして行き詰まりました。
top出力:
~~~
トップ-17:51:182日間、21:05、2ユーザー、平均負荷:0.49、3.00、5.41
タスク:合計357、実行中2、睡眠中355、停止中0、ゾンビ0
%Cpu(s):1.9 us、0.1 sy、0.7 ni、97.3 id、0.0 wa、0.0 hi、0.0 si、0.0 st
KiB Mem:合計65863816、使用済み60115084、無料5748732、バッファー1372688
KiBスワップ:合計5917692、使用済み620、無料5917072。 51154784キャッシュされたMem
PIDユーザーPRNI VIRT RES SHR S%CPU%MEM TIME + COMMAND 3067 aalreja 20 0 143332 101816 21300 R 46.1 0.2 1631:44 Xvnc
16613 aalreja 30 10 32836 4880 3912 S 16.9 0.0 1:06.92ファイバーランプ3221 aalreja 20 0 8882348 1.017g 110120 S 1.3 1.6 579:06.87 MATLAB
1285ルート200 1404848 48252 25580 S 0.3 0.1 6:00.12 dockerd 16597 yimengz + 20 0 25084 3252 2572 R 0.3 0.0 0:04.56 top
1ルート200 33616 4008 2624 S 0.0 0.0 0:01.43 init
~~~
free出力
〜yimengzh_everyday @ yimengzh :〜$無料キャッシュされた使用済み空き共有バッファの合計Mem:65863816 60122060 5741756 9954628 1372688 51154916-/ +バッファ/キャッシュ:7594465 58269360スワップ:5917692 620 5917072〜
nvidia-smi出力
~~~
yimengzh_everyday @ yimengzh :〜$ nvidia-smi
2017年4月25日火曜日17:52:38
+ ------------------------------------------------- ---------------------------- +
| NVIDIA-SMI 375.39ドライバーバージョン:375.39 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| GPU名の永続性-M | Bus-Id Disp.A | 揮発性のUncorr。 ECC |
| Fan Temp Perf Pwr:Usage / Cap | メモリ-使用法| GPU-Util Compute M. |
| =============================== + ================= ===== + ====================== |
| 0 GeForce GTX TIT ...オフ| 0000:03:00.0オフ| 該当なし|
| 30%42C P8 14W / 250W | 3986MiB / 6082MiB | 0%デフォルト|
+ ------------------------------- + ----------------- ----- + ---------------------- +
| 1テスラK40cオフ| 0000:81:00.0オフ| オフ|
| 0%46C P0 57W / 235W | 0MiB / 12205MiB | 0%デフォルト|
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| プロセス:GPUメモリ|
| GPUPIDタイププロセス名使用法|
| ================================================= ============================ |
| 0 16509 C python 3970MiB |
+ ------------------------------------------------- ---------------------------- +
~~~
記憶の問題ではないと思います。
zym1010
2017年04月25日
共有メモリには個別の制限があります。 ipcs -lmまたはcat /proc/sys/kernel/shmallとcat /proc/sys/kernel/shmmaxを試すことができますか? また、使用するワーカーが少ない場合(たとえば、1人のワーカーの極端なケースでテストする場合)、デッドロックが発生しますか?
apaszke
2017年04月26日
@apaszke
~~~
yimengzh_everyday @ yimengzh :〜$ ipcs -lm
------共有メモリの制限--------
セグメントの最大数= 4096
最大セグメントサイズ(キロバイト)= 18014398509465599
最大合計共有メモリ(キロバイト)= 18446744073642442748
最小セグメントサイズ(バイト)= 1
yimengzh_everyday @ yimengzh :〜$ cat / proc / sys / kernel / shmall
18446744073692774399
yimengzh_everyday @ yimengzh :〜$ cat / proc / sys / kernel / shmmax
18446744073692774399
~~~
彼らはどのようにあなたを探しますか?
労働者の数が少ないということに関しては、それほど頻繁には起こらないと思います。 (私は今試すことができます)。 しかし、実際には、その多くの労働者が必要だと思います。
zym1010
2017年04月26日
最大4096の共有メモリセグメントが許可されています。これが問題である可能性があります。 /proc/sys/kernel/shmmni書き込むことで、それを増やすことができます(おそらく8192を試してください)。 スーパーユーザー権限が必要な場合があります。
apaszke
2017年04月26日
@apaszkeまあこれらはUbuntuと
zym1010
2017年04月26日
トレーニングプログラムを実行しているときの@apaszke 、 ipcs -a実際には共有メモリが使用されていないことを示しています。 それは期待されていますか?
zym1010
2017年04月26日
@apaszkeは、
~~~
yimengzh_everyday @ yimengzh :〜$ ipcs -lm
------共有メモリの制限--------
セグメントの最大数= 8192
最大セグメントサイズ(キロバイト)= 18014398509465599
最大合計共有メモリ(キロバイト)= 18446744073642442748
最小セグメントサイズ(バイト)= 1
~~~
1人の労働者を試しませんでした。 まず、それは遅いでしょう。 第二に、問題が本当にデッドロックである場合、それは間違いなく消えます。
zym1010
2017年04月26日
@ zym1010のデフォルト設定は、そのようなワークロードを念頭に置いて作成する必要はないので、そうです、それは問題であった可能性があります。 ipcsは、使用していないSystem V共有メモリ用ですが、同じ制限がPOSIX共有メモリに適用されないようにしたかったのです。
問題が実際に存在する場合は、ワーカーとメインプロセスの間でデッドロックが発生している可能性があり、1人のワーカーでこれをトリガーできる可能性があるため、確実に消えることはありません。 とにかく、私はそれを再現することができるまで問題を修正することはできません。 例を実行するために使用しているパラメーターは何ですか?また、コードを何らかの方法で変更しましたか? また、 torch.__version__の値は何ですか? Dockerで実行していますか?
apaszke
2017年04月26日
@apaszkeありがとう。 私はあなたの分析を今よりよく理解しています。
64GB RAM、デュアルXeon、TitanBlackを搭載したUbuntu14.04マシンで実行されるまでに示された他のすべての結果(K40もありますが、私は使用しませんでした)。
問題を生成するコマンドはCUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 20 --lr 0.01 --workers 22 --batch-size 256 /mnt/temp_drive_3/cv_datasets/ILSVRC2015/Data/CLS-LOCです。 コードはまったく変更しませんでした。
Python3.5にpipを介してpytorchをインストールしました。 pytorchのバージョンは0.1.11_5です。 Dockerで実行されていません。
ところで、私も1人のワーカーを使ってみました。 しかし、私は別のマシン(128GB RAM、デュアルXeon、4 Pascal Titan X、CentOS 6)でそれを行いました。 CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 1 --lr 0.01 --workers 1 --batch-size 256 /ssd/cv_datasets/ILSVRC2015/Data/CLS-LOCを使用して実行しましたが、エラーログは次のとおりです。
Epoch: [0][5003/5005] Time 2.463 (2.955) Data 2.414 (2.903) Loss 5.9677 (6.6311) Prec<strong i="14">@1</strong> 3.516 (0.545) Prec<strong i="15">@5</strong> 8.594 (2.262)
Epoch: [0][5004/5005] Time 1.977 (2.955) Data 1.303 (2.903) Loss 5.9529 (6.6310) Prec<strong i="16">@1</strong> 1.399 (0.545) Prec<strong i="17">@5</strong> 7.692 (2.262)
^CTraceback (most recent call last):
File "main.py", line 292, in <module>
main()
File "main.py", line 137, in main
prec1 = validate(val_loader, model, criterion)
File "main.py", line 210, in validate
for i, (input, target) in enumerate(val_loader):
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 168, in __next__
idx, batch = self.data_queue.get()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/queue.py", line 164, in get
self.not_empty.wait()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/threading.py", line 293, in wait
waiter.acquire()
topは、1人のワーカーでスタックしたときに次のことを示しました。
〜トップ-08:34:33アップ15日、20:03、0ユーザー、平均負荷:0.37、0.39、0.36タスク:合計894、実行中1、睡眠中892、停止中0、ゾンビ1CPU:7.2%us、2.8%sy、0.0%ni、89.7%id、0.3%wa、0.0%hi、0.0%si、0.0%stMem:合計132196824k、使用済み131461528k、空き735296k、バッファー347448kスワップ:合計2047996k、使用22656k、無料2025340k、キャッシュ125226796k〜
zym1010
2017年04月26日
私が見つけたもう1つのことは、トレーニングコードを変更して、すべてのバッチを通過しないようにした場合、たとえば、50バッチのみをトレーニングすることです。
if i >= 50:
break
その後、デッドロックは解消されたようです。
zym1010
2017年04月26日
さらなるテストは、コンピュータを再起動した直後にプログラムを実行した場合、このフリーズがはるかに頻繁に発生することを示唆しているようです。 コンピュータにキャッシュがあった後、このフリーズが発生する頻度は少ないようです。
zym1010
2017年04月27日
試しましたが、このバグを再現することはできません。
apaszke
2017年05月04日
同様の問題が発生しました。エポックを終了するとデータローダーが停止し、新しいエポックを開始します。
 tiancheng-zhi
2017年05月04日
tiancheng-zhi
2017年05月04日
num_workers = 0に設定すると機能します。 しかし、プログラムは遅くなります。
tiancheng-zhi
2017年05月04日
@apaszke最初にコンピューターを再起動してから、プログラムを実行してみましたか? 私にとって、これは凍結を保証します。 0.12バージョンを試しましたが、それでも同じです。
私が指摘したいのは、OpenBLASにリンクされたnumpyがインストールされていて、 @ soumithのanacondaクラウドのMKLがpipを使用してpytorchをインストールしたことです。
つまり、基本的にpytorchはMKLを使用し、numpyはOpenBLASを使用しています。 これは理想的ではないかもしれませんが、これはここでの問題とは何の関係もないはずだと思います。
zym1010
2017年05月09日
調べてみましたが、再現できませんでした。 MKL / OpenBLASはこの問題とは無関係である必要があります。システム構成に問題がある可能性があります
apaszke
2017年05月09日
@apaszkeありがとう。 anacondaの公式リポジトリとMKLベースのpytorchからPythonを試しました。 それでも同じ問題。
zym1010
2017年05月09日
Dockerでコードを実行してみました。 まだ立ち往生。
zym1010
2017年05月11日
同じ問題があり、4つのうち1つのGPUを使用してnvidia-docker内でpytorch / examples imagenetトレーニングの例(resnet18、4人のワーカー)を実行します。プロセスに到達できたら、gdbバックトレースを収集しようとします。 。
少なくともOpenBLASには、行列の乗算でデッドロックの問題があることが知られていますが、これは比較的まれにしか発生しません: https :
 jsainio
2017年06月07日
jsainio
2017年06月07日
@jsainio純粋なMKLベースのPyTorch(numpyはMKLにもリンクされています)も試しましたが、同じ問題が発生しました。
また、データローダーにpin_memoryを使用すると、この問題は解決されます(少なくとも私にとっては)。
zym1010
2017年06月07日
2人の労働者が死んだように見えます。
通常の操作中:
root<strong i="7">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 33.2 4.7 91492324 3098288 ? Ssl 10:51 1:10 python -m runne
user+ 58 76.8 2.3 91079060 1547512 ? Rl 10:54 1:03 python -m runne
user+ 59 76.0 2.2 91006896 1484536 ? Rl 10:54 1:02 python -m runne
user+ 60 76.4 2.3 91099448 1559992 ? Rl 10:54 1:02 python -m runne
user+ 61 79.4 2.2 91008344 1465292 ? Rl 10:54 1:05 python -m runne
ロックアップ後:
root<strong i="11">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 24.8 4.4 91509728 2919744 ? Ssl 14:25 13:01 python -m runne
user+ 58 51.7 0.0 0 0 ? Z 14:27 26:20 [python] <defun
user+ 59 52.1 0.0 0 0 ? Z 14:27 26:34 [python] <defun
user+ 60 52.0 2.4 91147008 1604628 ? Sl 14:27 26:31 python -m runne
user+ 61 52.0 2.3 91128424 1532088 ? Sl 14:27 26:29 python -m runne
まだ残っている1つのワーカーの場合、gdbスタックトレースの先頭は次のようになります。
root<strong i="15">@b06f896d5c1d</strong>:~/mnt# gdb --pid 60
GNU gdb (GDB) 8.0
Attaching to process 60
[New LWP 65]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb) bt
#0 0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f36f52af8d4 in __new_sem_wait_slow.constprop.0 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#2 0x00007f36f52af97a in sem_wait@@GLIBC_2.2.5 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#3 0x00007f36f157efb1 in semlock_acquire (self=0x7f3656296458,
args=<optimized out>, kwds=<optimized out>)
at /home/ilan/minonda/conda-bld/work/Python-3.5.2/Modules/_multiprocessing/semaphore.c:307
#4 0x00007f36f5579621 in PyCFunction_Call (func=
<built-in method __enter__ of _multiprocessing.SemLock object at remote 0x7f3656296458>, args=(), kwds=<optimized out>) at Objects/methodobject.c:98
#5 0x00007f36f5600bd5 in call_function (oparg=<optimized out>,
pp_stack=0x7f36c7ffbdb8) at Python/ceval.c:4705
#6 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#7 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=1, kws=0x0, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0,
closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#8 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#9 0x00007f36f5557542 in function_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/funcobject.c:627
#10 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36561c7d08>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#11 0x00007f36f554077c in method_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/classobject.c:330
#12 0x00007f36f5524236 in PyObject_Call (
func=<method at remote 0x7f36556f9248>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#13 0x00007f36f55277d9 in PyObject_CallFunctionObjArgs (
callable=<method at remote 0x7f36556f9248>) at Objects/abstract.c:2445
#14 0x00007f36f55fc3a9 in PyEval_EvalFrameEx (f=<optimized out>,
throwflag=<optimized out>) at Python/ceval.c:3107
#15 0x00007f36f5601166 in fast_function (nk=<optimized out>, na=1,
n=<optimized out>, pp_stack=0x7f36c7ffc418,
func=<function at remote 0x7f36561c78c8>) at Python/ceval.c:4803
#16 call_function (oparg=<optimized out>, pp_stack=0x7f36c7ffc418)
at Python/ceval.c:4730
#17 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#18 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=4, kws=0x7f36f5b85060, kwcount=0, defs=0x0, defcount=0,
kwdefs=0x0, closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#19 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#20 0x00007f36f5557661 in function_call (
func=<function at remote 0x7f36e14170d0>,
arg=(<ImageFolder(class_to_idx={'n04153751': 783, 'n02051845': 144, 'n03461385': 582, 'n04350905': 834, 'n02105056': 224, 'n02112137': 260, 'n03938244': 721, 'n01739381': 59, 'n01797886': 82, 'n04286575': 818, 'n02113978': 268, 'n03998194': 741, 'n15075141': 999, 'n03594945': 609, 'n04099969': 765, 'n02002724': 128, 'n03131574': 520, 'n07697537': 934, 'n04380533': 846, 'n02114712': 271, 'n01631663': 27, 'n04259630': 808, 'n04326547': 825, 'n02480855': 366, 'n02099429': 206, 'n03590841': 607, 'n02497673': 383, 'n09332890': 975, 'n02643566': 396, 'n03658185': 623, 'n04090263': 764, 'n03404251': 568, 'n03627232': 616, 'n01534433': 13, 'n04476259': 868, 'n03495258': 594, 'n04579145': 901, 'n04266014': 812, 'n01665541': 34, 'n09472597': 980, 'n02095570': 189, 'n02089867': 166, 'n02009229': 131, 'n02094433': 187, 'n04154565': 784, 'n02107312': 237, 'n04372370': 844, 'n02489166': 376, 'n03482405': 588, 'n04040759': 753, 'n01774750': 76, 'n01614925': 22, 'n01855032': 98, 'n03903868': 708, 'n02422699': 352, 'n01560419': 1...(truncated), kw={}) at Objects/funcobject.c:627
#21 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36e14170d0>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#22 0x00007f36f55fe234 in ext_do_call (nk=1444355432, na=0,
flags=<optimized out>, pp_stack=0x7f36c7ffc768,
func=<function at remote 0x7f36e14170d0>) at Python/ceval.c:5034
#23 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3275
--snip--
同様のエラーログがあり、メインプロセスがスタックしています:self.data_queue.get()
私にとっての問題は、画像ローダーとしてopencvを使用したことでした。 また、cv2.imread関数は、imagenetの特定のイメージ( "n01630670 / n01630670_1010.jpeg")でエラーなしで無期限にハングしていました。
num_workers = 0で機能していると言った場合は、そうではありません。 しかし、私はそれが同様のエラートレースを持つ一部の人々を助けるかもしれないと思いました。
 M-Eng
2017年06月09日
M-Eng
2017年06月09日
現在num_workers = 0テストを実行していますが、まだハングしていません。 https://github.com/pytorch/examples/blob/master/imagenet/main.pyからサンプルコードを実行していpytorch/vision ImageFolderは内部でPILまたはpytorch/accimageを使用して画像をロードしているようであるため、OpenCVは関与していません。
num_workers = 4を使用すると、最初のエポックトレインを取得して完全に検証できる場合があり、2番目のエポックの途中でロックされます。 したがって、データセット/読み込み関数で問題が発生する可能性はほとんどありません。
これは、特定のハードウェア/ソフトウェアの組み合わせによって比較的まれにトリガーされる可能性のあるImageLoaderの競合状態のように見えます。
jsainio
2017年06月09日
@ zym1010ポインターをありがとう、 pin_memory = False設定してみます。
jsainio
2017年06月09日
面白い。 私のセットアップでは、 pin_memory = Falseとnum_workers = 4すると、imagenetの例がほぼすぐにハングし、3人のワーカーがゾンビプロセスとして終了します。
root<strong i="8">@034c4212d022</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 6.7 2.8 92167056 1876612 ? Ssl 13:50 0:36 python -m runner
user+ 38 1.9 0.0 0 0 ? Z 13:51 0:08 [python] <defunct>
user+ 39 4.3 2.3 91069804 1550736 ? Sl 13:51 0:19 python -m runner
user+ 40 2.0 0.0 0 0 ? Z 13:51 0:09 [python] <defunct>
user+ 41 4.1 0.0 0 0 ? Z 13:51 0:18 [python] <defunct>
私の設定では、データセットはNFSを介して読み取られるネットワークディスク上にあります。 pin_memory = Falseとnum_workers = 4を使用すると、システムの障害をかなり早く発生させることができます。
=> creating model 'resnet18'
- training epoch 0
Epoch: [0][0/5005] Time 10.713 (10.713) Data 4.619 (4.619) Loss 6.9555 (6.9555) Prec<strong i="8">@1</strong> 0.000 (0.000) Prec<strong i="9">@5</strong> 0.000 (0.000)
Traceback (most recent call last):
--snip--
imagenet_pytorch.main.main([data_dir, "--transient_dir", context.transient_dir])
File "/home/user/mnt/imagenet_pytorch/main.py", line 140, in main
train(train_loader, model, criterion, optimizer, epoch, args)
File "/home/user/mnt/imagenet_pytorch/main.py", line 168, in train
for i, (input, target) in enumerate(train_loader):
File "/home/user/anaconda/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 206, in __next__
idx, batch = self.data_queue.get()
File "/home/user/anaconda/lib/python3.5/multiprocessing/queues.py", line 345, in get
return ForkingPickler.loads(res)
File "/home/user/anaconda/lib/python3.5/site-packages/torch/multiprocessing/reductions.py", line 70, in rebuild_storage_fd
fd = df.detach()
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError
:
[Errno 104] Connection reset by peer
@ zym1010ネットワークディスクまたは従来の回転ディスクもありますが、レイテンシーなどが遅くなる可能性がありますか?
jsainio
2017年06月09日
@jsainio
クラスターの計算ノードでローカルSSDを使用しています。コードはNFSドライブにありますが、データはローカルSSDにあり、最大の読み込み速度を実現しています。 NFSドライブにデータをロードしようとしたことはありません。
zym1010
2017年06月09日
@ zym1010情報をありがとう。 これもクラスターの計算ノードで実行しています。
実際、 num_workers = 4バリエーションを試している間、同じノードで同時にnum_workers = 0実験を実行しています。 最初の実験は十分な負荷を生成しているため、後者では競合状態がより早く現れる可能性があります。
jsainio
2017年06月09日
@apaszke以前にこれを再現しようとしたとき、2つのインスタンスを並べて実行したり、システムに他の重要な負荷をかけたりして実行しようとしましたか?
jsainio
2017年06月09日
@jsainioこれを調査してくれてありがとう! これは奇妙なことです。ワーカーは一緒に終了する必要があり、メインプロセスが完了したらデータの読み取りを行います。 なぜそれらが時期尚早に終了するのかを調べてみることができますか? たぶんカーネルログ( dmesg )をチェックしますか?
apaszke
2017年06月09日
いいえ、試したことはありませんが、IIRCではない場合でも表示されているようです。
apaszke
2017年06月09日
@apaszkeわかりました、労働者が退出するべきではなかったことを知っておくとよいでしょう。
試しましたが、なぜ終了するのかを確認する良い方法がわかりません。 dmesgは、関連するものは何も表示されません。 (私は、Anacondaパッケージを使用してUbuntu 16.04から派生したDockerで実行しています)
jsainio
2017年06月09日
1つの方法は、ワーカーループ内に多数の印刷を追加することです。 なぜ彼らが黙って出るのか私には分かりません。 stderrに出力されるため、おそらく例外ではありません。ループから抜け出すか、OSによって(おそらくシグナルによって)強制終了されます。
apaszke
2017年06月09日
@jsainio 、念のために言っておきますが、-ipc = hostを使用してdockerを実行していますか(これについては言及していません)? 共有メモリセグメントのサイズ(df -h | grep shm)を確認できますか?
ngimel
2017年06月09日
@ngimel私は--shm-size=1024mます。 df -h | grep shmはそれに応じて報告します:
root<strong i="9">@db92462e8c19</strong>:~/mnt# df -h | grep shm
shm 1.0G 883M 142M 87% /dev/shm
その使用法はかなり難しいようです。 これは、2人のゾンビワーカーがいる港湾労働者です。
jsainio
2017年06月12日
shmのサイズを大きくしてみてください。 確認したところ、問題を再現しようとしたサーバーでは16GBでした。 Dockerフラグを変更するか、実行します
mount -o remount,size=8G /dev/shm
サイズを512MBに減らしてみましたが、デッドロックではなく明確なエラーが発生しました。 まだ再現できません😕
apaszke
2017年06月14日
dockerを使用すると、明確なエラーメッセージではなく、shmが十分でない場合にデッドロックが発生する傾向があり、理由がわかりません。 しかし、通常はshmを増やすことで解決します(1Gでデッドロックが発生しました)。
ngimel
2017年06月14日
わかりました。10人のワーカーでエラーが発生したようですが、4人のワーカーを使用すると、/ dev / shmの使用量の58%でデッドロックが発生します。 やっと再現しました
apaszke
2017年06月14日
この問題の形を再現できるのは素晴らしいことです。 #1579でハングをトリガーするスクリプトを投稿しましたが、システムでハングしなかったとの返信がありました。 私は実際にMacBookでしかテストしていませんでした。 Linuxを試してみましたが、ハングしませんでした。 したがって、Linuxでのみ試した場合は、Macでも試す価値があるかもしれません。
 greaber
2017年06月14日
greaber
2017年06月14日
さて、問題を調査した後、それは奇妙な問題のようです。 /dev/shmサイズを128MBに制限した場合でも、Linuxはそこで147MBのファイルを作成し、それらを完全にメモリにmmapさせますが、実際にページにアクセスしようとすると、致命的なSIGBUSをワーカーに送信します。 ... SIGBUSハンドラーを登録して、ページを繰り返し処理し、各ページにアクセスする以外に、ページの有効性を確認できるメカニズムは考えられません...
今のところ回避策は、上に示したようにmountコマンドを使用して/dev/shmを展開することです。 16GBで試してください(十分なRAMがある場合はよくあります)。
apaszke
2017年06月15日
これについての言及を見つけるのは難しいですが、ここに1つあります。
apaszke
2017年06月15日
この問題についてお時間をいただきありがとうございます、それは長い間私を狂わせてきました! 正しく理解できれば、 /dev/shmを8Gではなく16Gに拡張する必要があります。 それは意味がありますが、 df -hを試してみると、すべてのRAMが実際にそのように割り当てられていることがわかります:(私は16Gを持っています)
tmpfs 7,8G 393M 7,4G 5% /dev/shm
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,8G 0 7,8G 0% /sys/fs/cgroup
tmpfs 1,6G 60K 1,6G 1% /run/user/1001
これは、デッドロック中のdf -hの出力です。 私が理解している限り、16GのSWAPパーティションがある場合、最大32Gのtmpfsをマウントできるので、 /dev/shmを拡張することは問題ありませんよね?
さらに重要なことに、RAMの半分近くを占めるため、cgroupパーティションとその目的に戸惑っています。 どうやらそれは効率的にマルチプロセッサタスクを管理するように設計されていますが、私はそれが何をするのか、そしてなぜそれが必要なのかよくわかりません、それはすべての物理RAMをshmに割り当てるために何かを変更しますか(サイズを16Gに設定したため)そしてそれをSWAPに入れます(ただし、両方が部分的にRAMとSWAPに同時に含まれると思います)
 ClementPinard
2017年06月15日
ClementPinard
2017年06月15日
@apaszkeありがとう! 根本的な原因を見つけたのは素晴らしいことです。 マシンに他にどのような負荷がかかっているかに応じて、さまざまな「ConnectionReset」エラーとdocker --shm-size=1024mデッドロックの両方が発生することがありました。 --shm-size=16384mと4人のワーカーで今すぐテストします。
jsainio
2017年06月15日
@jsainioConnectionResetは同じことが原因である可能性があります。 プロセスは一部のデータの交換を開始しましたが、shmがスペースを使い果たすと、SIGBUSがワーカーに送信され、強制終了されました。
@ClementPinardは、RAMが不足するとマシンがフリーズする可能性があることを除いて、必要なだけ大きくすることができます(カーネルでさえこのメモリを解放できないため)。 おそらく/sys/fs/cgroupについて気にする必要はありません。 tmpfsパーティションはメモリを遅延的に割り当てます。使用量が0Bのままである限り、コストはかかりません(制限を含む)。 スワップを使用するとデータの読み込みが非常に遅くなるため、スワップを使用するのは良い考えではないと思います。そのため、 shmサイズを12GBに増やし、ワーカーの数を制限してみてください(私が言ったように、すべてのRAMをshmに使用しないでください!)。 これは、カーネルのドキュメントからの
/dev/shm使用量が非常に少ない場合でもデッドロックが発生する理由はわかりません(私のマシンでは20kBで発生します)。 おそらく、カーネルは過度に楽観的ですが、すべてが満たされるまで待機せず、この領域から何かを使用し始めるとプロセスを強制終了します。
apaszke
2017年06月15日
今12Gと私が持っていた半分の労働者でテストしました、そしてそれは失敗しました:(
それはluaトーチバージョン(同じ速度、同じ数のワーカー)の魅力のように機能していました。これは、問題が/dev/shm関連していて、Pythonマルチプロセッシングに近くないのではないかと思います...
(あなたが言ったように)それについての奇妙なことは、 /dev/shmが満杯に近づくことは決してないということです。 最初のトレーニングエポックでは、500Moを超えることはありませんでした。 また、最初のエポックでロックされることはなく、テストをシャットダウンしても、trainloaderがすべてのエポックで失敗することはありません。 デッドロックは、テストエポックを開始したときにのみ表示されるようです。 電車からテストに行くときは/dev/shm追跡する必要があります。おそらく、データローダーの変更中にピーク使用量が発生する可能性があります。
ClementPinard
2017年06月15日
@ClementPinardは、共有メモリが高くても、Dockerがなくても、失敗する可能性があります。
zym1010
2017年06月15日
トーチバージョン== Lua Torchの場合でも、 /dev/shm関連している可能性があります。 Lua Torchはスレッドを使用できるため(GILはありません)、共有メモリを経由する必要はありません(すべてが単一のアドレス空間を共有します)。
apaszke
2017年06月15日
新しいトレーニングまたは検証エポックの開始時にメモリを割り当てることができないと文句を言った後、データローダーがクラッシュするという同じ問題がありました。 上記の解決策は私には機能しませんでした(i)私の/dev/shmは32GBであり、2.5GBを超えて使用されることはなく、(ii)pin_memory = Falseの設定は機能しませんでした。
これはおそらくガベージコレクションと関係がありますか? 私のコードはおおよそ次のようになります。 無限のイテレータが必要なので、以下のnext()を除いて/を試してみます:-)
def train():
train_iter = train_loader.__iter__()
for i in xrange(max_batches):
try:
x, y = next(train_iter)
except StopIteration:
train_iter = train_loader.__iter__()
...
del train_iter
train_loaderはDataLoaderオブジェクトです。 関数の最後に明示的なdel train_iter行がないと、プロセスは常に2〜3エポック後にクラッシュします( /dev/shm引き続き2.5 GBを示します)。 お役に立てれば!
私は4ワーカーを使用しています(Ubuntu16.04のCUDA8.0でバージョン0.1.12_2 )。
 pratikac
2017年07月07日
pratikac
2017年07月07日
また、特にwork_numberが大きい場合、デッドロックに遭遇しました。 この問題の可能な解決策はありますか? 私の/ dev / shmサイズは32GBで、cuda 7.5、pytorch 0.1.12、python2.7.13です。 以下は死亡後の関連情報です。 それは記憶に関係しているようです。 @apaszke

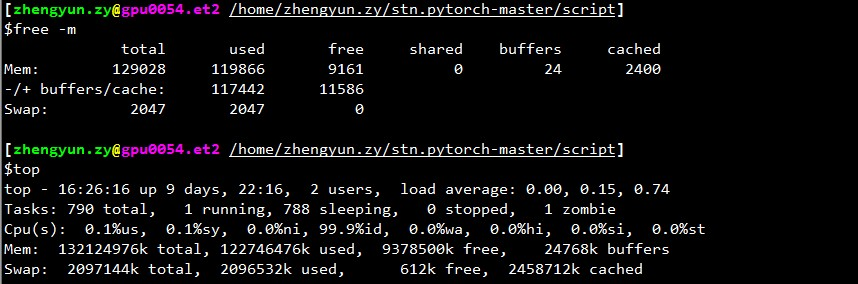
 zhengyunqq
2017年08月04日
zhengyunqq
2017年08月04日
@zhengyunqqをTrue設定した場合は、 pin_memory=False試してください。 そうでなければ、私は解決策を知りません。
zym1010
2017年08月04日
num_workersが大きいときにもデッドロックに遭遇しました。
 hendrycks
2017年08月11日
hendrycks
2017年08月11日
私にとっての問題は、何らかの理由でワーカースレッドが停止した場合、 index_queue.putが永久にハングすることでした。 動作中のスレッドが停止する理由の1つは、初期化中にアンピッカーが失敗することです。 その場合、2017年5月にマスターでこのPythonのバグ修正が行われるまで、ワーカースレッドが停止し、無限のハングが発生していました。 私の場合、ハングはバッチプリフェッチプライミング段階で発生していました。
たぶん、 SimpleQueue使用されているDataLoaderIterをQueue置き換えると、適切な例外メッセージでタイムアウトが可能になります。
UPD:私は間違っていました、このバグ修正はSimpleQueueではなくQueueにパッチを当てます。 オンラインのワーカースレッドがない場合、 SimpleQueueがロックされるのは事実です。 これらの行をself.workers = []置き換えることを確認する簡単な方法です。
 vadimkantorov
2017年08月16日
vadimkantorov
2017年08月16日
私は同じ問題を抱えています、そして私は(許可なしに)shmを変更することはできません、多分キューか何か他のものを使うほうが良いですか?
 xfanplus
2017年09月08日
xfanplus
2017年09月08日
同様の問題があります。
このコードはフリーズし、何も出力しません。 num_workers = 0に設定すると、機能しますが
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
model.cuda()
for i, batch in enumerate(dataloader):
print(i)
model.cuda()をループの後ろに置くと、すべてが正常に実行されます。
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
for i, batch in enumerate(dataloader):
print(i)
model.cuda()
誰かがその問題の解決策を持っていますか?
 anDoer
2017年09月13日
anDoer
2017年09月13日
ImageNetのトレーニング中にも同様の問題が発生しました。 これは、特定のアーキテクチャを備えた特定のサーバーで一貫して評価の最初の反復でハングします(同じアーキテクチャを備えた他のサーバー、または異なるアーキテクチャを備えた同じサーバーではハングしません)が、検証の評価中は常に最初の反復です。 Torchを使用していたときに、ncclがこのようなデッドロックを引き起こす可能性があることがわかりました。これをオフにする方法はありますか?
 WendyShang
2017年09月20日
WendyShang
2017年09月20日
私は同じ問題に直面しており、最初のエポックの開始時にランダムにスタックします。上記のすべての回避策は私には機能しません。Ctrl-Cを押すと、次のように出力されます。
Traceback (most recent call last):
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 249, in _bootstrap
self.run()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 44, in _worker_loop
data_queue.put((idx, samples))
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/queues.py", line 354, in put
self._writer.send_bytes(obj)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 200, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 398, in _send_bytes
self._send(buf)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
KeyboardInterrupt
Traceback (most recent call last):
File "scripts/train_model.py", line 640, in <module>
main(args)
File "scripts/train_model.py", line 193, in main
train_loop(args, train_loader, val_loader)
File "scripts/train_model.py", line 341, in train_loop
ee_optimizer.step()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/optim/adam.py", line 74, in step
p.data.addcdiv_(-step_size, exp_avg, denom)
KeyboardInterrupt
 zoharli
2017年10月23日
zoharli
2017年10月23日
Docker内の1人のワーカーでデッドロックが発生するという同様の問題があり、私の場合は共有メモリの問題であることが確認できます。 デフォルトでは、dockerは64MBの共有メモリしか割り当てていないようですが、1人のワーカーに440MBが必要でした。これにより、@ apaszkeで説明されている動作が発生した可能性があります。
 paulguerrero
2017年10月23日
paulguerrero
2017年10月23日
私は同じ問題に悩まされていますが、このスレッドの他のほとんどの環境とは異なる環境にいるので、私の入力が根本的な原因を特定するのに役立つ可能性があります。 私のpytorchは、Windows10でpeterjc123によって構築された優れたcondaパッケージを使用してインストールされます。
cifar10データセットでcnnを実行しています。 データローダーの場合、num_workersは1に設定されます。num_workersが0より大きいと、BrokenPipeErrorが発生することがわかっており、#494でアドバイスされていますが、私が経験しているのはBrokenPipeErrorではなく、メモリ割り当てエラーです。 エラーは常に、最後のエポックの検証直後で、次のエポックのトレーニングの開始前の約50エポックで発生しました。 90%の確率で正確に50エポックですが、それ以外の場合は1または2エポックずれます。 それ以外はすべてかなり一貫しています。 num_workers = 0に設定すると、この問題が解消されます。
 berzjackson
2017年10月24日
berzjackson
2017年10月24日
@paulguerreroは正しいです。 共有メモリを64Mから2Gに増やすことで、この問題を解決しました。 Dockerユーザーにとっては便利かもしれません。
 yjzhux
2017年10月24日
yjzhux
2017年10月24日
@berzjacksonこれはcondaパッケージの既知のバグです。 最新のCIビルドで修正されました。
 peterjc123
2017年10月25日
peterjc123
2017年10月25日
月曜日にPytorchを使用する新しいコースを開始した人は約600人です。 私たちのフォーラムの多くの人々がこの問題を報告しています。 一部はAWSP2にあり、一部は独自のシステム(主にGTX 1070、一部はTitan X)にあります。
トレーニングを中断すると、スタックトレースの最後に次のように表示されます。
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv_bytes(self, maxsize)
405
406 def _recv_bytes(self, maxsize=None):
--> 407 buf = self._recv(4)
408 size, = struct.unpack("!i", buf.getvalue())
409 if maxsize is not None and size > maxsize:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv(self, size, read)
377 remaining = size
378 while remaining > 0:
--> 379 chunk = read(handle, remaining)
380 n = len(chunk)
381 if n == 0:
num_workers = 4、pin_memory = Falseがあります。 共有メモリの設定を確認するように依頼しましたが、この問題を解決するためにできること(またはPytorchでできること)はありますか? (num_workersを減らす以外は、かなり遅くなるためです。)
 jph00
2017年11月01日
jph00
2017年11月01日
私は@ jph00のクラスにい1回だけ発生します。
つまり、データが読み込まれ、フィッティングが1回実行されると、移動して手順を繰り返し続けることができます... 4 num_workersを使用しても、GPUではすべてが期待どおりに高速に動作するようです。
私はPyTorch0.2.0_4、Python 3.6.2、Torchvision 0.1.9、Ubuntu 16.04LTSを使用しています。 ターミナルで「df-h」を実行すると、使用率は非常に低いものの、/ dev / shmに16GBあることがわかります。
これは、ロードが失敗した場所のスクリーンショットです(データにnum_workers = 0を使用したことに注意してください)
(小さな文字については申し訳ありません。すべてをキャプチャするにはズームアウトする必要がありました...)

 apiltamang
2017年11月01日
apiltamang
2017年11月01日
@apiltamangそれが同じ問題かどうかは
jph00
2017年11月01日
このできるだけ早く調べてください!
 soumith
2017年11月01日
soumith
2017年11月01日
私はもちろんのプライベートフォーラムへのアクセス@apaszke与えてくれたと私は彼らのボックスに私達のログインへのアクセス権を与える問題を学生に求めてきました@soumith。
jph00
2017年11月01日
@ jph00こんにちはジェレミー、学生のいずれかが@apaszkeは前述したようにSHMを増やしてみたのですか? 役に立ちましたか?
 SsnL
2017年11月01日
SsnL
2017年11月01日
@SsnLの学生の一人は、共有メモリを増やしたが、まだ問題があることを確認しました。 他の人にも確認してもらいました。
jph00
2017年11月01日
@ jph00ありがとう! 共有メモリが少ないため、ハングを正常に再現できました。 問題が他の場所にある場合は、さらに深く掘り下げる必要があります。 スクリプトを私と共有してもよろしいですか?
SsnL
2017年11月01日
確かに-これが私たちが使用しているノートブックです: https :
複製できる共有メモリの問題に基づいて、ライブラリまたはノートブックに追加して回避できる回避策はありますか?
jph00
2017年11月01日
@ jph00今すぐコードに飛び込みます。 共有メモリの使用量を減らす方法を見つけようとします。 スクリプトで大量のshmを使用する必要はないようですので、希望があります。
また、PRを送信して、shm制限に達したときに、単にハングさせるのではなく、適切なエラーメッセージを表示します。
SsnL
2017年11月01日
OK最新のPytorchcondaインストールを備えたCUDA9 AMIを使用して、新しいAWSP2インスタンスで問題を再現しました。 公開鍵を提供していただければ、直接試してみることができます。 私のメールアドレスはfast.aiでの私の名の最初の文字です
jph00
2017年11月01日
@ jph00あなたにメールを送りました:)ありがとう!
SsnL
2017年11月01日
@ jph00そして
SsnL
2017年11月01日
さて、私は基本的な問題を理解しました。それは、opencvとPytorchマルチプロセッシングが一緒にうまく機能しない場合があるということです。 大学のボックスには問題はありませんが、AWSには多くの問題があります(P2インスタンスを使用した新しいディープラーニングCUDA 9 AMI)。 すべてのcv2呼び出しの周りにロックを追加しても修正されません。また、 cv2.setNumThreads(0)を追加しても修正されません。 これはそれを修正するようです:
from multiprocessing import set_start_method
set_start_method('spawn')
ただし、これはパフォーマンスに約15%影響します。 opencv githubの問題で推奨されているのは、 https://github.com/tomMoral/lokyを使用することです。 私は以前にそのモジュールを使用したことがあり、それが堅実であることがわかりました。 今のところ十分に機能するソリューションがあるので、緊急ではありませんが、データローダーにLokyを使用することを検討する価値があるかもしれません。
おそらくもっと重要なのは、少なくともpytorchのキューに何らかのタイムアウトがあり、これらの無限のハングがキャッチされるようにすると便利です。
jph00
2017年11月02日
参考までに、「spawn」によって一部のパーツが2〜3倍遅くなったため、別の修正を試しました。つまり、データローダーをすばやく反復するセクションにランダムなスリープをいくつか追加しました。 それはまた問題を修正しました-おそらく理想的ではありませんが!
jph00
2017年11月02日
これを掘り下げてくれてありがとう! 2つの回避策が見つかったことを知ってうれしいです。 実際、データセットへのインデックス作成にタイムアウトを追加するとよいでしょう。 明日、そのルートについて話し合い、折り返しご連絡いたします。
cc @soumithは、私たちが調査したい何かがおかしいですか?
SsnL
2017年11月02日
上記の議論のためにこのスレッドに来る人々のために、opencvの問題はhttps://github.com/opencv/opencv/issues/5150でより深く議論されてい
SsnL
2017年11月02日
OK私は今これを適切に修正しているようです-DataloaderをユーザーProcessPoolExecutor.map()書き直し、テンソルの作成を親プロセスに移動しました。 結果は、元のデータローダーで見たよりも速く、試してみたすべてのコンピューターで安定しています。 コードも非常に単純です。
誰かがそれを使用することに興味があるなら、あなたはそれをhttps://github.com/fastai/fastai/blob/master/fastai/dataloader.pyから得ることができ
APIは標準バージョンと同じですが、データセットがPytorchテンソルを返さないようにする必要があります。つまり、numpy配列またはpythonリストを返す必要があります。 私はそれを古いPythonで動作させる試みをしていませんので、そこにいくつかの問題があったとしても驚かないでしょう。
(私がこの道を進んだ理由は、最近のGPUで多くの画像処理/拡張を行ったときに、Pytorch CPUを使用して前処理を行った場合、GPUをビジー状態に保つのに十分な速度で処理を完了できないことがわかったためです。操作;ただし、opencvの使用ははるかに高速であり、結果としてGPUを十分に活用することができました。)
jph00
2017年11月02日
ああ、それがopencvの問題であるなら、それについて私たちができることはあまりありません。 スレッドプールがある場合、フォークは危険です。 ランタイム依存関係を追加したくないと思います(現在はありません)。特に、PyTorchテンソルを適切に処理できないためです。 デッドロックの原因を突き止め、
@ jph00 Pillow-SIMDを試しましたか? それは箱から出してトーチビジョンで動作するはずです、そして私はそれについて多くの良いことを聞いたことがあります。
apaszke
2017年11月02日
はい、私は枕を知っています-SIMDはよく知っています。 サイズ変更、ぼかし、RGB変換のみを高速化します。
ここでできることがたくさんないことに同意しません。 これは、opencvの問題ではなく(pytorchの特殊なケースのマルチプロセッシングモジュールは言うまでもなく、このタイプのpythonマルチプロセッシングをより一般的にサポートするとは主張していません)、Pytorchの問題でもありません。 しかし、Pytorchがエラーを発生させずに静かに待機するという事実は、(IMO)修正できるものであり、より一般的には、多くの賢い人々が過去数年間、問題を回避する改善されたマルチプロセッシングアプローチを作成するために懸命に取り組んできました。このように。 外部の依存関係を持ち込むことなく、彼らが使用するアプローチから借りることができます。
Lokyの背後にいる人々の1人であるOlivierGriselは、Pythonでのマルチプロセッシングの状態を要約した素晴らしいスライドデッキを持っています: http :
問題のない新しいデータローダーを作成したので、どちらの方法でもかまいません。 しかし、FWIWは、pytorchのマルチプロセッシングと他のシステムとの相互作用が、将来的には他の人々にとっても問題になると考えています。
jph00
2017年11月02日
その価値については、ubuntu14.04のPython2.7でこの問題が発生しました。 マイデータローダはsqliteのデータベースから読み込まれて完全に働いたnum_workers=0で、時々見えたOKをnum_workers=1 、そして非常に迅速に任意のより高い値のためのデッドロック。 スタックトレースは、プロセスがrecv_bytesハングしていることを示しています。
うまくいかなかったこと:
- Dockerの起動時に
--shm-size 8Gまたは--ipc=host渡す echo 16834 | sudo tee /proc/sys/kernel/shmmniを実行して共有メモリセグメントの数を増やします(私のマシンではデフォルトは4096でした)pin_memory=Trueまたはpin_memory=False、どちらも役に立ちませんでした
私の問題を確実に修正したのは、コードをPython 3に移植することでした。Python3.6インスタンス(Anacondaから)内で同じバージョンのTorchを起動すると、問題が完全に修正され、データの読み込みがハングしなくなりました。
 gcr
2017年11月16日
gcr
2017年11月16日
@apaszkeは、opencvでうまく機能することが重要である理由です、参考までに(そして、torchsampleが優れたオプションではない理由-<200画像/秒の回転を処理できます!):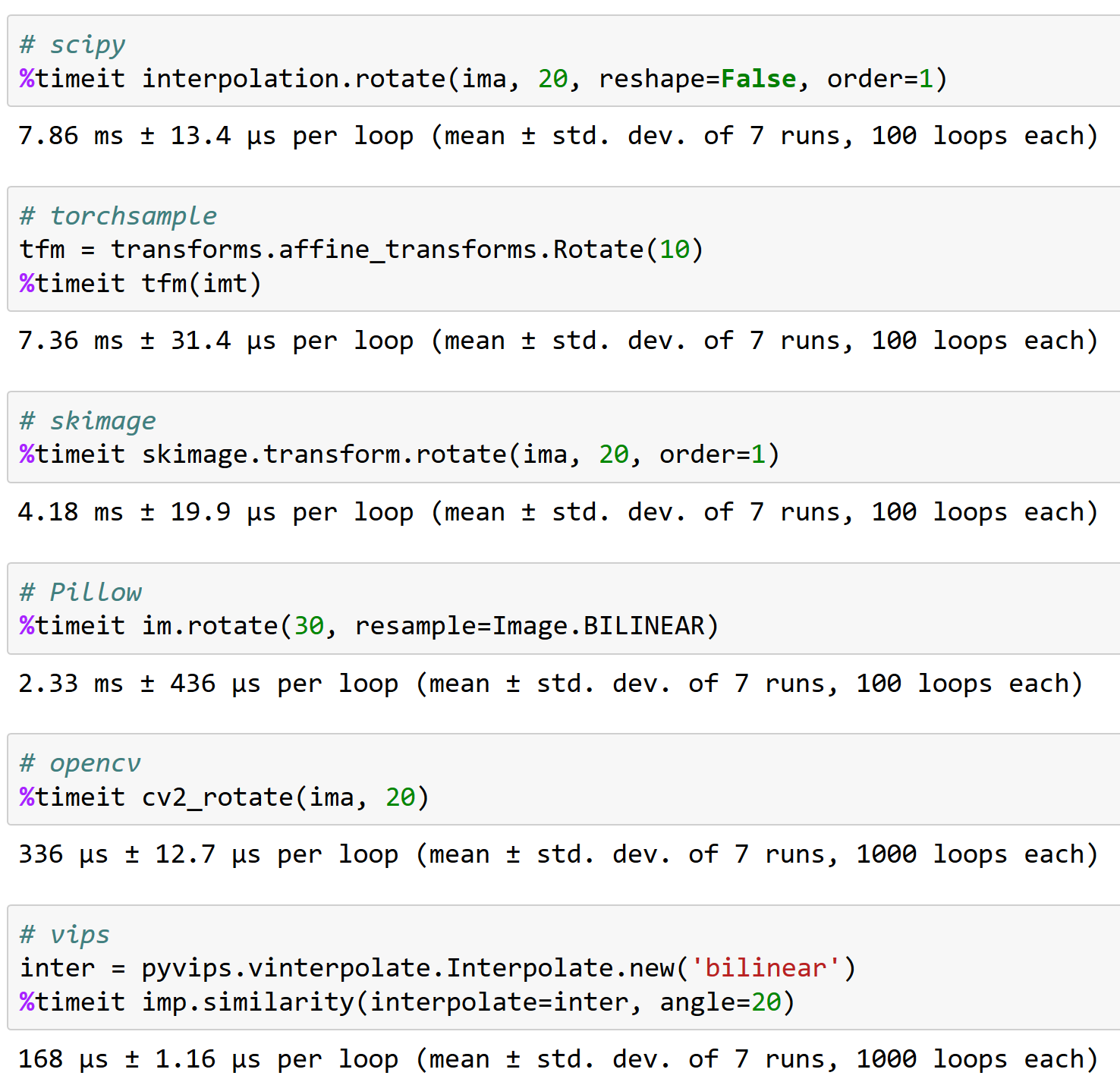
jph00
2017年11月18日
誰かがこの問題の解決策を見つけましたか?
 iqbalu
2017年12月09日
iqbalu
2017年12月09日
@iqbalu上記のスクリプトを試してください: https :
それは私の問題を解決しましたが、 num_workers=0サポートしていません。
 elbaro
2017年12月14日
elbaro
2017年12月14日
@elbaro実際に試してみましたが、私の場合は複数のワーカーをまったく使用していませんでした。 そこで何か変更しましたか?
iqbalu
2017年12月14日
@iqbalu fast.aiデータローダーは、ワーカープロセスを生成しません。 スレッドのみを使用するため、一部のツールでは表示されない場合があります
apaszke
2017年12月14日
@apaszke @elbaro @ jph00 fast.aiのデータローダーは、データの読み取りを10倍以上遅くしました。 num_workers = 8を使用しています。 理由は何でしょうか?
iqbalu
2017年12月15日
データローダーがGILを放棄しないパッケージを使用している可能性があります
apaszke
2017年12月15日
@apaszkeいくつかのエポックの後、共有メモリの使用量が増え続ける理由についての考え。 私の場合、それは400MBから始まり、その後、約20エポックごとに400MBずつ増加します。 ありがとう!
iqbalu
2017年12月28日
@iqbaluはそうではありません。 それは起こってはならない
apaszke
2017年12月28日
私は多くのことを試しましたが、 cv2.setNumThreads(0)ついに私の問題を解決しました。
ありがとう@ jph00
 Cadene
2018年01月19日
Cadene
2018年01月19日
私は最近この問題に悩まされています。 cv2.setNumThreads(0)は私には機能しません。 すべてのcv2コードを変更して、代わりにscikit-imageを使用することもできますが、問題は依然として存在します。 その上、私は/dev/shm 16Gを持っています。 この問題は、複数のGPUを使用している場合にのみ発生します。 すべてが単一のGPUで正常に機能します。 誰かが解決策について何か新しい考えを持っていますか?
 roytseng-tw
2018年01月25日
roytseng-tw
2018年01月25日
同じエラー。 単一のGPUを使用すると、この問題が発生します。
 Jiankai-Sun
2018年01月27日
Jiankai-Sun
2018年01月27日
私にとって、opencvスレッドを無効にすると、問題が解決しました。
cv2.setNumThreads(0)
 shacharf
2018年01月28日
shacharf
2018年01月28日
pytorch 0.3、cuda 8.0、ubuntu16.04でもヒットします
opencvは使用されていません。
 tianq01
2018年02月01日
tianq01
2018年02月01日
私はpytorch0.3、cuda 8.0、ubuntu14.04を使用しています。 cv2.resize()を使い始めた後、このハングを観察しました
cv2.setNumThreads(0)で問題が解決しました。
 mathmanu
2018年02月09日
mathmanu
2018年02月09日
2つの1080Tiと32GBのRAMを搭載したシステムで、python 3.6、pytorch 0.3.0、cuda 8.0、ubuntu17.04を使用しています。
自分のデータセットに8つのワーカーを使用すると、デッドロックが頻繁に発生します(最初のエポックで発生します)。 ワーカーを4に減らすと、それは消えます(80エポックを実行しました)。
デッドロックが発生した場合でも、RAMに最大10GBの空き容量があります。
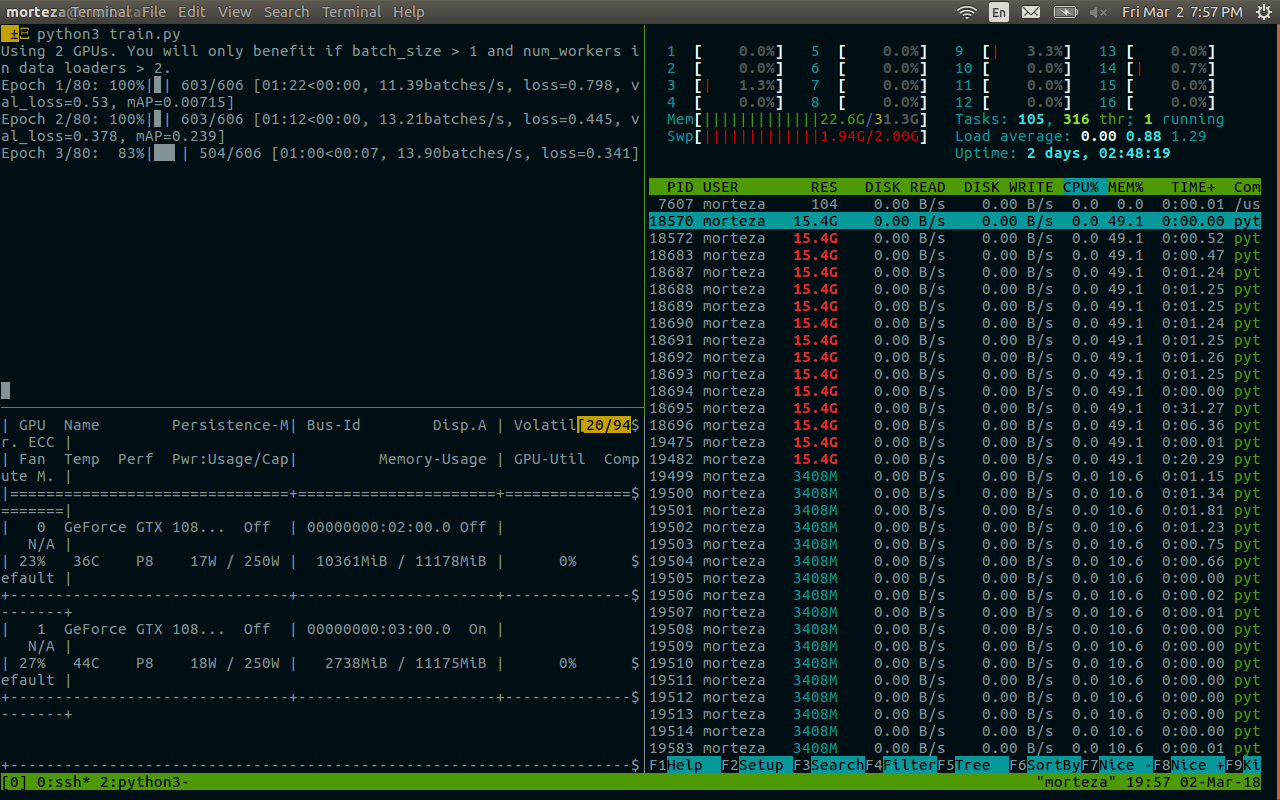
 milani
2018年03月02日
milani
2018年03月02日
ここでは、スクリプトを終了した後のログを確認できます: https :
更新:SHMMNIを増やすことで問題を解決できることを確認しました。 Ubuntu 17.04では、 kernel.shmmni=8192を/etc/sysctl.confに追加しました。
milani
2018年03月02日
この問題も発生しています。Ubuntu17.10、Python 3.6、Pytorch 0.3.1、CUDA8.0。 デッドロックが発生し、時間が一貫していないように見える場合は、RAMが十分に残っています。これは、第1エポック後または200日後に発生する可能性があります。
kernel.shmmni=8192とcv2.setNumThreads(0)組み合わせはそれを改善したようですが、個別には機能しませんでした。
 inoryy
2018年03月08日
inoryy
2018年03月08日
私の場合も同じです。 num_workers = 4を設定すると、デッドロックが発生しました。 私はUbuntu17.10、Pytorch 0.3.1、CUDA 9.1、python3.6を使用しています。 4つのPythonスレッドがあり、CPU(4コア)がアイドル状態のままである間、それぞれが1.6GBのメモリを占有することが観察されます。 num_workers = 0に設定すると、この問題を解決するのに役立ちます。
 AlenUbuntu
2018年03月27日
AlenUbuntu
2018年03月27日
同じ問題が発生し、ちょうど1つのエポックの後でフリーズしますが、小さいデータセットでは実際には再現できません。 Docker環境でCUDA9.1、Pytorch 0.3.1、Python3.6を使用しています。
@ jph00のデータローダーを試しましたが、ユースケースではかなり遅いことがわかりました。 現在の私の回避策は、すべてのエポックの前にPytorchDataLoaderを再作成することです。 これはうまくいくようですが、本当に醜いです。
 tfriedel
2018年04月11日
tfriedel
2018年04月11日
Ubuntu 17.10、CUDA 9.1、Pytorchマスター(19/04の朝にコンパイル)でもまったく同じ問題が発生しました。 また、データセットサブクラスでOpenCVを使用しています。
次に、マルチプロセッシングの開始メソッドを「forkserver」から「spawn」に変更することで、デッドロックを回避することができました。
# Set multiprocessing start method - deadlock
set_start_method(forkserver')
# Set multiprocessing start method - runs fine
set_start_method('spawn')
 mfuntowicz
2018年04月19日
mfuntowicz
2018年04月19日
私は上記のアプローチのほとんどすべてを試しました! それらのどれも機能しませんでした!
この問題は、ハードウェアアーキテクチャとの非互換性に関連している可能性があり、Pytorchがどのように問題を引き起こすのかわかりません。 Pytorchの問題である場合とそうでない場合があります。
これが私の問題がどのように解決されたかです:
_BIOSを更新します!
試してみます。 少なくともそれは私の問題を解決します。
 astorfi
2018年04月21日
astorfi
2018年04月21日
こっちも一緒。 Ubuntu PyTorch 0.4、python3.6。
 Shuailong
2018年04月30日
Shuailong
2018年04月30日
問題はpytorch0.4とpython3.6にまだ存在しているようです。 それがpytorchの問題であるかどうかはわかりません。 私はopencvを使用し、 num_workers=8 、 pin_memory=Trueます。 上記のすべてのトリックを試し、 cv2.setNumThreads(0)を設定すると問題が解決します。
 JasonQSY
2018年05月10日
JasonQSY
2018年05月10日
(1)PyTorchデータロードでnum_workers = 0を設定すると、問題が解決します(上記を参照)または
(2)cv2.setNumThreads(0)は、num_workersが適度に大きい場合でも問題を解決します。
これは、ある種のスレッドロックの問題のように見えます。
メインのPythonファイルの先頭に向かってcv2.setNumThreads(0)を設定しましたが、それ以降、この問題が発生したことはありません。
mathmanu
2018年05月10日
はい、これらの問題の多くは、サードパーティのライブラリがフォークセーフではないことが原因です。 代替の解決策の1つは、spawnstartメソッドを使用することです。
apaszke
2018年05月10日
私の場合、モデルをnn.DataParallelでラップし、データローダーでnum_workers> 0を使用すると、デッドロックの問題が発生します。 nn.DataParallelラッパーを削除することで、ロックせずにスクリプトを実行できます。
CUDA_VISIBLE_DEVICES = 0 python myscript.py --split 1
CUDA_VISIBLE_DEVICES = 1 python myscript.py --split 2
複数のGPUがないと、スクリプトの実行速度は遅くなりますが、データセットの異なる分割で同時に複数の実験を実行できます。
 euwern
2018年06月15日
euwern
2018年06月15日
Python 3.6.2 / Pytorch0.4.0でも同じ問題が発生します。
そして何よりもpin_memoryの切り替え、共有メモリのサイズの変更に取り組み、skiamgeライブラリを使用しています(cv2を使用していません!!)が、それでも問題があります。
この問題はランダムに発生します。 この問題を制御するには、コンソールを監視してトレーニングを再開するだけです。
 slaysd
2018年06月19日
slaysd
2018年06月19日
@ jinh574データローダーワーカーの数を0に設定しただけで、機能します。
Shuailong
2018年06月19日
@Shuailong大きなサイズの画像を使用する必要があるため、速度が原因でそのパラメーターを使用できません。 私はこの問題についてもっと調べる必要があります
slaysd
2018年06月19日
Python 3.6 / Pytorch0.4.0でも同じ問題が発生します。 pin_memoryオプションは何かに影響しますか?
 ein-farbe
2018年06月26日
ein-farbe
2018年06月26日
collate_fnを使用していて、num_workers> 0をPyTorchバージョン<0.4で使用している場合:
__getitem__()関数から
または、それらをNumpy配列として返します。
 pyaf
2018年07月12日
pyaf
2018年07月12日
num_workers = 0またはcv2.setNumThreads(0)を設定した後でも、この問題が発生します。
これらの2つの問題のいずれかで失敗します。 同じことに直面している他の誰か?
トレースバック(最後の最後の呼び出し):
_run_module_as_mainのファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py"、行193
"__main __"、mod_spec)
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py"、85行目、_run_code
exec(code、run_globals)
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py"、行209、
主要()
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py"、行205、メイン
process.wait()
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py"、1457行目、待機中
(pid、sts)= self._try_wait(0)
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py"、1404行目、_try_wait
(pid、sts)= os.waitpid(self.pid、wait_flags)
KeyboardInterrupt
_bootstrapのファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py"、行258
self.run()
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py"、行93、実行中
self._target( self._args、* self._kwargs)
_worker_loopのファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/utils/data/dataloader.py"、行96
r = index_queue.get(timeout = MANAGER_STATUS_CHECK_INTERVAL)
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/queues.py"、104行目、get
self._poll(timeout)でない場合:
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py"、257行目、投票
self._poll(timeout)を返します
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py"、行414、_poll
r = wait([self]、timeout)
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py"、行911、待機中
準備完了= selector.select(timeout)
ファイル "/opt/conda/envs/pytorch-py3.6/lib/python3.6/selectors.py"、376行目、select
fd_event_list = self._poll.poll(timeout)
KeyboardInterrupt
 swethmandava
2018年08月25日
swethmandava
2018年08月25日
バージョン「0.5.0a0 + f57e4ce」を使用していますが、同じ問題が発生しました。 パラレルデータローダーのキャンセル(num_workers = 0)またはcv2.setNumThreads(0)の設定のいずれかが機能します。
 omersumer
2018年10月05日
omersumer
2018年10月05日
#11985は、すべてのハングを解消するはずだと私はかなり確信しています(私たちが制御できない不幸な時間に中断しない限り)。 マージされたので、これを閉じます。
cv2はマルチプロセッシングでうまく機能しないため、cv2でのハングも制御できません。
SsnL
2018年10月09日
torch_nightly-1.0.0.dev20181029時点でまだこれを経験していますが、PRはまだそこにマージされていませんか?
 Evpok
2018年10月30日
Evpok
2018年10月30日
@Evpokこれはそこでマージされました。 確かにこのパッチが必要です。 これ以上の長引くデッドロックが発生する可能性があるかどうか疑問に思います。 私たちが見てみることができる簡単な再現はありますか?
soumith
2018年10月30日
ご不便をおかけして申し訳ありませんが、私は実際にそれを私の側の無関係なマルチプロセッシングの混乱にたどりました。
Evpok
2018年10月30日
こんにちは@Evpok
私はtorch_nightly-1.0.0 、この問題に対処します。 あなたはこの問題を解決しましたか?
 zimenglan-sysu-512
2018年11月14日
zimenglan-sysu-512
2018年11月14日
collate_fnを使用していて、num_workers> 0をPyTorchバージョン<0.4で使用している場合:
__getitem__()関数から
または、それらをNumpy配列として返します。
ゼロの薄暗いテンソルを返すバグを修正しましたが、問題はまだ存在します。
 liluxuan1997
2018年11月14日
liluxuan1997
2018年11月14日
@ zimenglan-sysu-512主な問題は、マルチプロセッシングの制限にありました。 spawnまたはforkserver (CPU-GPU通信に必要)を使用する場合、プロセス間でオブジェクトを共有することはかなり制限されており、私が操作しなければならない種類のオブジェクトに適しています。
Evpok
2018年11月14日
これはどれも私にはうまくいきませんでした。 ただし、最新のopencvは機能します( 3.4.0.12から3.4.3.18まで変更する必要はありません)。
sudo pip3 install --upgrade opencv-python
 see--
2018年11月17日
see--
2018年11月17日
@ see--opencvが彼らのことを修正したことを知ってうれしいです:)
SsnL
2018年11月17日
python2.7を使用してOpenCV3.4.3.18を使用していますが、デッドロックが発生しているのがわかります。 :/
 SreenivasVRao
2018年12月03日
SreenivasVRao
2018年12月03日
次のことを試してください。
from torch.utils.data.dataloader import DataLoader
それ以外の
from torch.utils.data import DataLoader
ここでの型チェックに問題があると思います。
https://github.com/pytorch/pytorch/blob/656b565a0f53d9f24547b060bd27aa67ebb89b88/torch/utils/data/dataloader.py#L816
 jewfro-cuban
2018年12月16日
jewfro-cuban
2018年12月16日
次のことを試してください。
from torch.utils.data.dataloader import DataLoaderそれ以外の
from torch.utils.data import DataLoaderここでの型チェックに問題があると思います。
pytorch / torch / utils / data / dataloader.py
656b565の行816
super(DataLoader、self).__ setattr __(attr、val)
これは単なるエイリアスではありませんか? torch.utils.data .__ init__では、dataloader.DataLoaderをインポートします
 simonhessner
2019年01月08日
simonhessner
2019年01月08日
また、num_workers> 0でハングしていました。私のコードにはopencvがなく、 /dev/shmのメモリ使用量は問題ではありません。 上記の提案は私にはうまくいきませんでした。 私の修正は、numpyを1.14.1から1.14.5に更新することでした:
conda install numpy=1.14.5
お役に立てば幸いです。
 daniyar-niantic
2019年01月08日
daniyar-niantic
2019年01月08日
うーん、私のnumpyバージョンは1.15.4なので、1.14.5よりも新しいです...それなら大丈夫ですか?
simonhessner
2019年01月08日
うーん、私のnumpyバージョンは1.15.4なので、1.14.5よりも新しいです...それなら大丈夫ですか?
Idk、numpyのアップデートでmklもアップデートされました。
daniyar-niantic
2019年01月08日
どのmklバージョンがありますか? 私のは2019.1(ビルド144)で、名前にmklが含まれている他のパッケージは次のとおりです。
mkl-service 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
simonhessner
2019年01月08日
どのmklバージョンがありますか? 私のは2019.1(ビルド144)で、名前にmklが含まれている他のパッケージは次のとおりです。
mkl-service 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
conda list | grep mkl
mkl 2018.0.1 h19d6760_4
mkl-service 1.1.2 py36h17a0993_4
それでも最新のpytorchでハングが発生する場合は、問題を再現する短いスクリプトを提供できると非常に役立ちます。 ありがとう!
SsnL
2019年01月09日
このデッドロックはまだ発生しています。再現するスクリプトを作成できるかどうかを確認します。
 dtmoodie
2019年01月15日
dtmoodie
2019年01月15日
pin_memory=True問題が解決しました。
pyaf
2019年01月30日
pin_memory=Trueではうまくいかないようですが、70エポックを過ぎてもスタックします。 これまで私のために働いたのはnum_workers=0設定することだけですが、それは著しく遅くなります。
 jclevesque
2019年02月14日
jclevesque
2019年02月14日
また、デッドロックが発生しています(かなりランダムに発生します)。 pin_memoryを試し、Numpyを更新しました。 別のマシンで実行してみます。
 Avsecz
2019年02月14日
Avsecz
2019年02月14日
データローダーを含む複数のスレッドを使用している場合は、マルチスレッドの代わりにマルチプロセッシングを使用してみてください。 これで問題は完全に解決しました(ちなみに、GILがあるため、Pythonでの計算量の多いタスクにも適しています)
simonhessner
2019年02月14日
Pytorch1.0、Pillow5.0.0 numpy1.16.1python3.6でも同じエラー
 jianlong-yuan
2019年02月15日
jianlong-yuan
2019年02月15日
同じエラーが発生します。 pin_memory=Trueとnum_workers=0 。 データセットのごく一部を使用すると、このエラーは発生しないことに気づきました。 データセット全体を使用するだけでこのエラーが発生します。
編集:システムを再起動するだけで修正されました。
 Venka97
2019年03月06日
Venka97
2019年03月06日
私も同様の問題を抱えていました。 一部のコードでは、この関数は(ほとんどの場合)d_iter.next()でハングします。
def get_next_batch(d_iter, loader):
try:
data, label = d_iter.next()
except StopIteration:
d_iter = iter(loader)
data, label = d_iter.next()
return data, label
私のために働いたハックは、この関数を呼び出した後に少し遅延を追加することでした
trn_X, trn_y = get_next_batch(train_data_iter, train_loader)
time.sleep(0.003)
val_X, val_y = get_next_batch(valid_data_iter, valid_loader)
遅延はデッドロックを回避するのに役立ったと思いますか?
 enoonIT
2019年03月20日
enoonIT
2019年03月20日
私はまだこの問題に直面しています。 pytorch1.0とpython3.7を使用します。 複数のdata_loaderを使用していた場合、このバグが発生します。 3つ未満のdata_loaderを使用するか、単一のGPUを使用する場合、このバグは発生しません。 試した:
- time.sleep(0.003)
- pin_memory = True / False
- num_workers = 0/1
- torch.utils.data.dataloaderからimportDataLoader
- / proc / sys / kernel / shmmniに8192を書き込みます
それらのどれも動作しません。 解決策があるかどうかわかりませんか?
 xuw080
2019年04月16日
xuw080
2019年04月16日
私のソリューションは、前処理プログラムでcv2.setNumThreads(0)を追加します
私は電車とヴァル用の2つのデータローダーを持っています
評価者を実行できるのは1回だけです。
 lightningsoon
2019年05月10日
lightningsoon
2019年05月10日
pytorch1.1でこのバグに遭遇しました。 同じ場所で2回スタックしました:99エポックの終わり。 pin_memoryはFalseに設定されました。
 Randl
2019年05月17日
Randl
2019年05月17日
ワーカー> 0を使用する場合の同じ問題、ピンメモリは問題を解決しませんでした。
 nicolasCruzW21
2019年05月20日
nicolasCruzW21
2019年05月20日
私のソリューションは、前処理プログラムでcv2.setNumThreads(0)を追加します
私は電車とヴァル用の2つのデータローダーを持っています
評価者を実行できるのは1回だけです。
この解決策は私のために働きます、ありがとう
 zxhr2793
2019年06月03日
zxhr2793
2019年06月03日
エポックが終了するとデータローダーが停止し、新しいエポックが開始されます。
同じ問題に対応します。 私の場合、opencv-pythonをインストールすると問題が発生します(以前にopencv3をインストールしました)。 opencv-pythonを移動した後、トレーニングは停止しません。
 hongzhenwang
2019年06月20日
hongzhenwang
2019年06月20日
それも良い考えです
2019-06-20 10:51:02に、「hongzhenwang」 [email protected]は次のように書いています。
エポックが終了するとデータローダーが停止し、新しいエポックが開始されます。
同じ問題に対応します。 私の場合、opencv-pythonをインストールすると問題が発生します(以前にopencv3をインストールしました)。 opencv-pythonを移動した後、トレーニングは停止しません。
—
コメントしたのでこれを受け取っています。
このメールに直接返信するか、GitHubで表示するか、スレッドをミュートしてください。
lightningsoon
2019年06月27日
私はまだこの問題に直面しています。 pytorch1.0とpython3.7を使用します。 複数のdata_loaderを使用していた場合、このバグが発生します。 3つ未満のdata_loaderを使用するか、単一のGPUを使用する場合、このバグは発生しません。 試した:
1. time.sleep(0.003) 2. pin_memory=True/False 3. num_workers=0/1 4. from torch.utils.data.dataloader import DataLoader 5. writing 8192 to /proc/sys/kernel/shmmni None of them works. Don't know whether there is any solutions?
まだ回避策を見つけようとしています。 異なるGPUで2つの並列プロセスを同時に実行している場合にのみ、この問題が発生するように思われることに同意します。 一方は停止し、もう一方は停止します。
 ArturoDeza
2019年07月03日
ArturoDeza
2019年07月03日
num_workers = 4に設定すると、プログラムは4バッチごとに数秒(または数分)スタックし、多くの時間を浪費します。 それを解決する方法について何かアイデアはありますか?
 huangchaoxing
2019年07月27日
huangchaoxing
2019年07月27日
フラグを追加する:データローダーのpin_memory = Trueおよびnum_workers = 0が解決策です!
ArturoDeza
2019年07月27日
フラグを追加する:データローダーのpin_memory = Trueおよびnum_workers = 0が解決策です!
@ArturoDeza
これは解決策かもしれませんが、num_workers = 0に設定すると、CPUのデータフェッチ全体が遅くなり、GPUの使用率が非常に低くなります。
huangchaoxing
2019年07月28日
私の場合、その理由は、システムに十分なCPUがないか、データローダーで指定されたnum_workers不足しているためです。 データローダーの__get_item__メソッドがnumpy 、 librosa 、 opencvなどのスレッドライブラリを使用する場合は、データローダーワーカーのスレッドを無効にすることもお勧めします。 OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.pyしてトレーニングスクリプトを実行することで実現できます。 以下の説明を明確にするために、各データローダーバッチは単一のワーカーによって処理されることに注意してください。各ワーカーはbatch_sizeサンプルを処理して単一のバッチを完了し、データの新しいバッチの処理を開始します。
num_workersマシン(またはKubernetesを使用している場合はポッド)のCPU数よりも低く設定する必要がありますが、データが常に次の反復に備えられるように十分に高く設定する必要があります。 GPUが各反復をt秒で実行し、各データローダーワーカーが単一のバッチのロード/処理にN*t秒かかる場合は、 num_workersを少なくともN設定する必要がありますN CPUが必要です。
残念ながら、DataloaderがKスレッドを使用するライブラリを使用する場合、生成されるプロセスの数はnum_workers*K = N*Kます。 これは、マシンのCPUの数よりも大幅に多い可能性があります。 これによりポッドが抑制され、データローダーが非常に遅くなります。 これにより、データローダーがt秒ごとにバッチを返さず、GPUが停止する可能性があります。
Kスレッドを回避する1つの方法は、メインスクリプトをOMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py呼び出すことです。 これにより、各Dataloaderワーカーが単一のスレッドを使用するように制限され、マシンを圧倒することを回避できます。 GPUに給電し続けるには、まだ十分なnum_workersが必要です。
また、各ワーカーが短時間でバッチを完了するように、コードを__get_item__で最適化する必要があります。 ワーカーによるバッチの前処理を完了する時間は、ディスクからトレーニングデータを読み取る時間(特にネットワークストレージから読み取る場合)またはネットワーク帯域幅(ネットワークから読み取る場合)によって妨げられないようにしてください。ディスク)。 データセットが小さく、十分なRAMがある場合は、データセットをRAM(または/tmpfs )に移動し、そこから読み取ってすばやくアクセスすることを検討してください。 Kubernetesの場合、RAMディスクを作成できます(KubernetesでemptyDirを検索してください)。
__get_item__コードを最適化し、ディスクアクセス/ネットワークアクセスが原因ではないことを確認したが、それでもストールが発生する場合は、より多くのCPUをリクエストするか(Kubernetesポッドの場合)、GPUをより多くのCPUを搭載したマシン。
もう1つのオプションは、 batch_sizeを減らして、各worker作業が少なくなり、前処理がより速く完了するようにすることです。 後者のオプションは、アイドル状態のGPUメモリが使用されていないため、望ましくない場合があります。
また、前処理の一部をオフラインで実行し、各ワーカーの重みを取り除くことを検討することもできます。 たとえば、各ワーカーがwavファイルを読み込んで、オーディオファイルのスペクトログラムを計算している場合、スペクトログラムをオフラインで事前に計算し、計算されたスペクトログラムをワーカーのディスクから読み取ることを検討できます。 これにより、各作業者が行う必要のある作業量が削減されます。
 gkeskin07
2019年08月03日
gkeskin07
2019年08月03日
horovodで同じ問題に対応
 jinhou
2019年08月12日
jinhou
2019年08月12日
同様の問題に対処します...エポックを終了し、検証のためにデータのロードを開始しているときにデッドロックが発生します...
 jackroos
2019年08月20日
jackroos
2019年08月20日
@jinhou @jackroos同じことですが、
 lzljzys
2019年08月28日
lzljzys
2019年08月28日
@jinhou @jackroos同じことですが、
いいえ。その場合は、分散トレーニングをオフにします。
jackroos
2019年08月29日
同様の問題が発生しました。エポックを終了するとデータローダーが停止し、新しいエポックを開始します。
なんでそんなにザン?
 foocker
2019年10月22日
foocker
2019年10月22日
私はまだこの問題に直面しています。 pytorch1.0とpython3.7を使用します。 複数のdata_loaderを使用していた場合、このバグが発生します。 3つ未満のdata_loaderを使用するか、単一のGPUを使用する場合、このバグは発生しません。 試した:
- time.sleep(0.003)
- pin_memory = True / False
- num_workers = 0/1
- torch.utils.data.dataloaderからimportDataLoader
- / proc / sys / kernel / shmmniに8192を書き込みます
それらのどれも動作しません。 解決策があるかどうかわかりませんか?
0に設定されたnum_workersは私のために働いた。 使用しているすべての場所で0になっていることを確認する必要があります。
他のいくつかの潜在的な解決策:
- マルチプロセッシングからインポートset_start_method
set_start_method( 'spawn') - cv2.setNumThreads(0)
3か7が行く方法のようです。
 the7threvival
2019年11月18日
the7threvival
2019年11月18日
私はpytorch1.3、ubuntu16でこの問題を経験しますが、実行を遅くするworkers = 0を除いて、上記のすべての提案は機能しませんでした。 これは、ターミナルから実行している場合にのみ発生します。Jupyterノートブック内では、workers = 32の場合でもすべて問題ありません。
問題は解決されていないようですが、再開する必要がありますか? 同じ問題を報告している他の多くの人々も見ています...
 skariel
2019年12月02日
skariel
2019年12月02日
私はまだこの問題に直面しています。 pytorch1.0とpython3.7を使用します。 複数のdata_loaderを使用していた場合、このバグが発生します。 3つ未満のdata_loaderを使用するか、単一のGPUを使用する場合、このバグは発生しません。 試した:
- time.sleep(0.003)
- pin_memory = True / False
- num_workers = 0/1
- torch.utils.data.dataloaderからimportDataLoader
- / proc / sys / kernel / shmmniに8192を書き込みます
それらのどれも動作しません。 解決策があるかどうかわかりませんか?0に設定されたnum_workersは私のために働いた。 使用しているすべての場所で0になっていることを確認する必要があります。
他のいくつかの潜在的な解決策:
- マルチプロセッシングからインポートset_start_method
set_start_method( 'spawn')- cv2.setNumThreads(0)
3か7が行く方法のようです。
train.pyように変更しました:
from __future__ import division
import cv2
cv2.setNumThreads(0)
import argparse
...
そしてそれは私のために働きます。
 DHZS
2019年12月10日
DHZS
2019年12月10日
私が助けることができればねえみんな、
私もこれと同様の問題を抱えていましたが、100エポックごとに発生します。
CUDAが有効になっている場合にのみ発生することに気付きました。また、dmesgには、クラッシュするたびにこのログエントリがあります。
python[11240]: segfault at 10 ip 00007fabdd6c37d8 sp 00007ffddcd64fd0 error 4 in libcudart.so.10.1.243[7fabdd699000+77000]
それは私にはぎこちないですが、CUDAとPythonマルチスレッドがうまく機能していないことを教えてくれました。
私の修正は、データスレッドでcudaを無効にすることでした。これは、私のpythonエントリファイルのスニペットです。
from multiprocessing import set_start_method
import os
if __name__ == "__main__":
set_start_method('spawn')
else:
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import torch
import application
うまくいけば、それは私がその時に必要としていたようにここに着陸する人を助けるかもしれません。
 roderickObrist
2020年03月24日
roderickObrist
2020年03月24日
@jinhou @jackroos同じことですが、
いいえ。その場合は、分散トレーニングをオフにします。
PyTorch 1.4にアップデートした後、OpenCVを使用せずに分散トレーニングで同様の問題が発生します。
ここで、トレーニングと検証のループの前に、検証を1回実行する必要があります。
 wizardk
2020年06月09日
wizardk
2020年06月09日
私はこれで多くの問題を抱えています。 これは、pytorchのバージョン、pythonのバージョン、および異なる物理マシン(おそらく同じようにセットアップされている)間で持続するようです。
毎回同じエラーです:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/bicep/loops.py", line 73, in __call__
for data, target in self.dataloader:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 830, in _next_data
self._shutdown_workers()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 942, in _shutdown_workers
w.join()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/process.py", line 149, in join
res = self._popen.wait(timeout)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 47, in wait
return self.poll(os.WNOHANG if timeout == 0.0 else 0)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll
pid, sts = os.waitpid(self.pid, flag)
私が使用しているマシンでプロセスが処理される方法には、明らかにいくつかの問題があります。 num_workers = 0を設定することを除けば、上記の解決策はどれも機能しないようです。
私は本当にこれの底に到達できるようにしたいと思います、誰かがこれをどこから始めるべきか、またはこれをどのように尋問するかについて何か考えがありますか?
 brynhayder
2020年06月09日
brynhayder
2020年06月09日
私もここにいます。
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 480, in _try_get_batch
data = self.data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 65, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 95106) is killed by signal: Segmentation fault.
1つの興味深いことは
データを1行ずつ解析するだけでは、次の問題は発生しません。
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
しかし、行ごとに読み取った後にJSON解析ロジックを追加すると、このエラーが報告されます
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
JSONメモリのオーバーヘッドが発生することは理解していますが、ワーカーの数を2に減らしても、データセットが非常に小さいため、同じ問題が発生します。 私はそれがshmに関連しているのではないかと疑っています。 どんな手掛かり?
 zhangruiskyline
2020年06月16日
zhangruiskyline
2020年06月16日
この号を再開しませんか?
 takatosp1
2020年06月18日
takatosp1
2020年06月18日
私たちはすべきだと思います。 ところで、私はいくつかのGDBデバッグを行いましたが、何も見つかりませんでした。 ですから、それが共有メモリの問題であるかどうかはよくわかりません。
(gdb) run
Starting program: /home/miniconda/bin/python performance.py
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7fffa60a6700 (LWP 61963)]
[New Thread 0x7fffa58a5700 (LWP 61964)]
[New Thread 0x7fffa10a4700 (LWP 61965)]
[New Thread 0x7fff9e8a3700 (LWP 61966)]
[New Thread 0x7fff9c0a2700 (LWP 61967)]
[New Thread 0x7fff998a1700 (LWP 61968)]
[New Thread 0x7fff970a0700 (LWP 61969)]
[New Thread 0x7fff9489f700 (LWP 61970)]
[New Thread 0x7fff9409e700 (LWP 61971)]
[New Thread 0x7fff8f89d700 (LWP 61972)]
[New Thread 0x7fff8d09c700 (LWP 61973)]
[New Thread 0x7fff8a89b700 (LWP 61974)]
[New Thread 0x7fff8809a700 (LWP 61975)]
[New Thread 0x7fff85899700 (LWP 61976)]
[New Thread 0x7fff83098700 (LWP 61977)]
[New Thread 0x7fff80897700 (LWP 61978)]
[New Thread 0x7fff7e096700 (LWP 61979)]
[New Thread 0x7fff7d895700 (LWP 61980)]
[New Thread 0x7fff7b094700 (LWP 61981)]
[New Thread 0x7fff78893700 (LWP 61982)]
[New Thread 0x7fff74092700 (LWP 61983)]
[New Thread 0x7fff71891700 (LWP 61984)]
[New Thread 0x7fff6f090700 (LWP 61985)]
[Thread 0x7fff7e096700 (LWP 61979) exited]
[Thread 0x7fff6f090700 (LWP 61985) exited]
[Thread 0x7fff74092700 (LWP 61983) exited]
[Thread 0x7fff7b094700 (LWP 61981) exited]
[Thread 0x7fff80897700 (LWP 61978) exited]
[Thread 0x7fff83098700 (LWP 61977) exited]
[Thread 0x7fff85899700 (LWP 61976) exited]
[Thread 0x7fff8809a700 (LWP 61975) exited]
[Thread 0x7fff8a89b700 (LWP 61974) exited]
[Thread 0x7fff8d09c700 (LWP 61973) exited]
[Thread 0x7fff8f89d700 (LWP 61972) exited]
[Thread 0x7fff9409e700 (LWP 61971) exited]
[Thread 0x7fff9489f700 (LWP 61970) exited]
[Thread 0x7fff970a0700 (LWP 61969) exited]
[Thread 0x7fff998a1700 (LWP 61968) exited]
[Thread 0x7fff9c0a2700 (LWP 61967) exited]
[Thread 0x7fff9e8a3700 (LWP 61966) exited]
[Thread 0x7fffa10a4700 (LWP 61965) exited]
[Thread 0x7fffa58a5700 (LWP 61964) exited]
[Thread 0x7fffa60a6700 (LWP 61963) exited]
[Thread 0x7fff71891700 (LWP 61984) exited]
[Thread 0x7fff78893700 (LWP 61982) exited]
[Thread 0x7fff7d895700 (LWP 61980) exited]
total_files = 5040. //customer comments
[New Thread 0x7fff6f090700 (LWP 62006)]
[New Thread 0x7fff71891700 (LWP 62007)]
[New Thread 0x7fff74092700 (LWP 62008)]
[New Thread 0x7fff78893700 (LWP 62009)]
ERROR: Unexpected segmentation fault encountered in worker.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 62005) is killed by signal: Segmentation fault.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "performance.py", line 62, in <module>
main()
File "performance.py", line 48, in main
for i,batch in enumerate(rl_data_loader):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 841, in _next_data
idx, data = self._get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 808, in _get_data
success, data = self._try_get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 774, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 62005) exited unexpectedly
[Thread 0x7fff78893700 (LWP 62009) exited]
[Thread 0x7fff74092700 (LWP 62008) exited]
[Thread 0x7fff71891700 (LWP 62007) exited]
[Thread 0x7fff6f090700 (LWP 62006) exited]
[Inferior 1 (process 61952) exited with code 01]
(gdb) backtrace
No stack.
そして、私は十分な共有メモリを持っていると思います、少なくとも私は共有メモリがsegfaultまでかなり長い間十分であると期待していますが、セグメント障害はデータローダージョブを起動した直後に発生します
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18014398509481980
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
こんにちは@ soumith @ apaszke 、この問題を再度開くことができますか? shmのサイズとセグメントを増やすなど、提案されたすべてのソリューションを試しましたが、何も機能しません。opencvなどを使用していません。単純なJSON解析だけです。 しかし、まだそこに問題があります。 チェックしたので、すべてのメモリを共有メモリとして開いているので、shmに関連しているとは思いません。 スタックトレースにも、上記のように何も表示されません。
@apaszke 、あなたの提案に関して
「はい、これらの問題の多くは、サードパーティのライブラリがフォークセーフではないことが原因です。別の解決策の1つは、spawnstartメソッドを使用することです。」
データローダーマルチワーカーを使用していますが、方法を変更するにはどうすればよいですか? main.pyにset_start_method('spawn')を設定していますが、役に立たないようです
また、ここで一般的な質問があります。マルチワーカー(マルチプロセス)データローダーを有効にした場合、メイントレーニングでは、 https://pytorch.org/docs/stable/notes/multiprocessing.htmlで提案されているようにマルチプロセスも開始し
pytorchはデータローダーとメイントレーニングマルチプロセスの両方をどのように管理しますか? マルチコアGPUで可能なすべてのプロセス/スレッドを共有しますか? また、マルチプロセスの共有メモリは、データローダーとメイントレーニングプロセスによって「共有」されますか? また、JSON解析、CSV解析、パンダの特徴抽出などのデータクックジョブがある場合もあります。 など、どこに置くのが最善の方法ですか? データローダーで、準備が整った完璧なデータを生成するか、メイントレーニングを使用して、データローダー__get_item__を可能な限りシンプルに保つために上記で提案したようにします。
zhangruiskyline
2020年06月19日
@zhangruiskylineあなたの問題は実際にはデッドロックではありません。 それは、セグメンテーション違反によって殺された労働者についてです。 sigbusは、shmの問題を示唆するものです。 データセットコードを確認し、そこでデバッグする必要があります。
他の質問に答えるには、
- DataLoaderでkwarg
multiproessing_context='spawn'を使用すると、スポーンが設定されます。set_start_methodもそれを行います。 - 通常、マルチプロセストレーニングでは、各プロセスに独自のDataLoaderがあり、したがってDataLoaderワーカーがあります。 明示的に行われない限り、プロセス間で共有されるものはありません。
SsnL
2020年06月20日
@SsnLに感謝しmultiproessing_context='spawn'を追加しましたが、同じ失敗です。
前のスレッドで指摘しましたが、私のコードは非常に単純ですが、
- このコードは機能します
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
- しかし、行ごとに読み取った後にJSON解析ロジックを追加すると、このエラーが報告されます
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
したがって、これが私のコードの問題であるとは思えません。また、JSON解析を使用せずに、直接文字列分割を使用しようとしています。同じ問題です。 データローダーのデータ処理に時間のかかるロジックがある限り、この問題が発生するようです
またについて
マルチプロセストレーニングでは、各プロセスに独自のDataLoaderがあるため、DataLoaderワーカー明示的に行われない限り、プロセス間で共有されるものはありません。
では、トレーニング用のプロセスが4つあり、それぞれに8つのワーカーデータローダーがあるので、その下に合計32のプロセスがあるとしましょう。
zhangruiskyline
2020年06月20日
@zhangruiskyline問題を再現するための自己完結型のスクリプトがなければ、私たちはあなたを助けることができません。 はい、32のプロセスがあります
SsnL
2020年06月20日
おかげで、私も同様の問題を見ました
https://github.com/pytorch/pytorch/issues/4969
https://github.com/pytorch/pytorch/issues/5040
両方とも閉じていますが、明確な解決策や修正が見当たりません。これはまだ幅広い既存の問題ですか?
自己完結型の複製スクリプトを提供できるかどうかを確認しますが、プラットフォームとデータソースに高度に統合されているため、試してみます
zhangruiskyline
2020年06月20日
@zhangruiskylineあなたがそれらを読んだ場合、あなたの問題はリンクされた問題のいずれにも似ていません。 それらのスレッドで報告された元の/最も一般的な問題はすでに対処されているため、それらは閉じられています。
SsnL
2020年06月20日
@SsnLに感謝しPytorchにあまり精通していないので、間違っている可能性がありますが、私はそれらすべてを実行しました、そしてそれらのいくつかはによって解決されたようです
ワーカーの数を0に減らします。これは遅すぎるため、受け入れられません。
shmのサイズを大きくしますが、十分なshmがあると思います。問題は開始直後に発生し、はるかに小さいデータセットで試しました。問題は同じです。
opencvのようないくつかのlibは、マルチプロセスではうまく機能しません。JSON/ CSVを使用しているだけなので、それほど派手なものではありません。
コードはかなり単純で、トレーニングデータセットには10000以上のファイルがあり、各ファイルは複数行のJSON文字列です。 データローダーでは、 __get_item__を定義して、
ソリューション1では、最初に1行ずつ読み取り、JSON文字列リストに分割します。すぐに戻ると、機能し、パフォーマンスは良好です。
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
return all_data
戻り値はまだJSON文字列であるため、マルチプロセスデータローダーを利用して速度を上げたいので、ここにJSON解析ロジックを配置すると失敗します
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
後で、JSONの解析が重すぎ、JSONのメモリフットプリントが多すぎると考えたため、JSON文字列を解析し、手動で機能リストに変換することを選択しました。同じ失敗です。 スタックトレース分析を行いましたが、何もしませんでした
ところで、Linux Docker Env、24コアCPU、1V100でコードを実行しています。
次にどこから調査を始めればいいのかわかりません。 何か考えがありますか?
zhangruiskyline
2020年06月20日
こんにちは、
https://github.com/open-mmlab/mmdetectionで使用されているhttps://github.com/open-mmlab/mmcvで興味深いコメントを見つけました:
次のコードは、trainepochとvalepochの両方の先頭で使用されます。
time.sleep(2)#エポック移行中に発生する可能性のあるデッドロックを防止します
たぶんあなたはそれを試すことができます。
mathmanu
2020年06月20日
ところで、マルチプロセスとマルチワーカーデータローダーを使用する各プロセスに移動した場合、対応するデータローダーが他のプロセスのデータローダーと同じデータを読み取らないようにするには、どのように異なるプロセスを使用できますか? tiはすでにpytorchデータローダー__get_item__によって処理されていますか?
zhangruiskyline
2020年06月20日
こんにちは@SsnL 、あなたの助けをありがとう。 このスレッドを少しフォローアップしたいのですが、pytorchマルチプロセッシングを使用してトレーニングコードをリファクタリングし、CPU側でのデータ処理を高速化します(GPUへのフィードを高速化するため)、 https: //pytorch.org/docs/stable
各処理機能では、マルチワーカーデータローダーを使用して、データの読み込み処理時間を短縮しています。 https://pytorch.org/docs/stable/data.html
ヒービングCPUのJSON解析をデータローダーではなく、メインのトレーニングプロセスに配置しましたが、問題が解決したようです。理由はわかりませんが、とにかく機能しているようです。 ただし、フォローアップの質問があります。 N処理があり、それぞれにMローダーワーカーがあるとすると、スレッドの下に合計NxMがあります。
データローダーですべてのデータをインデックス方式で取得したい場合、つまり、N個の異なる処理のMデータローダーの__get_item__(self, idx)が連携して異なるインデックスを処理できる場合、重複して処理されないようにするにはどうすればよいですか?いくつかのプロセスを逃しますか?
zhangruiskyline
2020年06月23日
新しいトレーニングまたは検証エポックの開始時にメモリを割り当てることができないと文句を言った後、データローダーがクラッシュするという同じ問題がありました。 上記の解決策は私には機能しませんでした(i)私の
/dev/shmは32GBであり、2.5GBを超えて使用されることはなく、(ii)pin_memory = Falseの設定は機能しませんでした。これはおそらくガベージコレクションと関係がありますか? 私のコードはおおよそ次のようになります。 無限のイテレータが必要なので、以下の
next()を除いて/を試してみます:-)def train(): train_iter = train_loader.__iter__() for i in xrange(max_batches): try: x, y = next(train_iter) except StopIteration: train_iter = train_loader.__iter__() ... del train_iter
train_loaderはDataLoaderオブジェクトです。 関数の最後に明示的なdel train_iter行がないと、プロセスは常に2〜3エポック後にクラッシュします(/dev/shm引き続き2.5 GBを示します)。 お役に立てれば!私は
4ワーカーを使用しています(Ubuntu16.04のCUDA8.0でバージョン0.1.12_2)。
これは、何週間も苦労した後、私にとって問題を解決しました。 ローダーを直接ループするのではなく、ローダーイテレーターを明示的に使用する必要があります。エポックの最後にdel loader_iteratorを使用すると、最終的にデッドロックが解消されます。
 kennyFF92
2020年07月15日
kennyFF92
2020年07月15日
私は同じ問題に直面していると思います。 8つのデータローダー(MNIST、MNISTM、SVHN、USPS、それぞれのトレーニングとテストに使用)を使用しようとしています。 6(任意の6)を使用すると問題なく動作します。 6番目のMNIST-Mテストをロードするときに8を使用すると常にブロックされます。 それは、画像を取得しようとし、失敗し、少し待ってから再試行するという無限のループで立ち往生しています。 エラーはどのbatch_sizeでも持続し、十分な空きメモリが残っています。num_workersを0に設定した場合にのみ、エラーは解消されます。その他の量を指定すると、問題が発生します。
 pmirallesr
2020年07月21日
pmirallesr
2020年07月21日
https://stackoverflow.com/questions/54013846/pytorch-dataloader-stucked-if-using-opencv-resize-methodからヒントを得ました
cv2.setNumThreads(0)を入れると、問題なく動作します。
 LifeBeyondExpectations
2020年08月17日
LifeBeyondExpectations
2020年08月17日
こんにちは、私は同じ問題を抱えていました。 そしてそれはulimit-nと関係があり、単にそれを増やすと問題は解決しました、私はulimit -n500000を使用しました
 SebastienEske
2020年08月18日
SebastienEske
2020年08月18日
@SebastienEske ulimit -nは、
 david-waterworth
2020年09月24日
david-waterworth
2020年09月24日
たぶん、 ulimit -nを設定するのが正しい方法です。モデルの増加に伴い、デッドロックがますます頻繁になります。 cv2.setNumThreads(0)もテストしますが、機能しません。
 BLING-1994
2020年09月27日
BLING-1994
2020年09月27日
記録のために、 cv2.setNumThreads(0)は私のために働いた。
 franchesoni
2020年11月18日
franchesoni
2020年11月18日
関連する問題
 Coderx7
·
3コメント
Coderx7
·
3コメント
 a1363901216
·
3コメント
a1363901216
·
3コメント
 szagoruyko
·
3コメント
szagoruyko
·
3コメント
 bartolsthoorn
·
3コメント
bartolsthoorn
·
3コメント
 NgPDat
·
3コメント
NgPDat
·
3コメント
最も参考になるコメント
同様の問題が発生しました。エポックを終了するとデータローダーが停止し、新しいエポックを開始します。