Pytorch: kemungkinan kebuntuan di dataloader
bug dijelaskan di pytorch/examples#148. Saya hanya ingin tahu apakah ini bug di PyTorch itu sendiri, karena kode contoh terlihat bersih bagi saya. Juga, saya ingin tahu apakah ini terkait dengan #1120.
 zym1010
zym1010
Semua 189 komentar
Berapa banyak memori bebas yang Anda miliki saat loader berhenti?
 apaszke
pada 25 Apr 2017
apaszke
pada 25 Apr 2017
@apaszke jika saya memeriksa top , memori yang tersisa (mem cache juga dihitung seperti yang digunakan) biasanya 2GB. Tetapi jika Anda tidak menghitung cache seperti yang digunakan, selalu banyak, katakanlah 30GB+.
zym1010
pada 25 Apr 2017
Saya juga tidak mengerti mengapa itu selalu berhenti di awal validasi, tetapi tidak di tempat lain.
zym1010
pada 25 Apr 2017
Mungkin karena untuk validasi, pemuat terpisah digunakan yang mendorong penggunaan memori bersama melampaui batas.
 ngimel
pada 25 Apr 2017
ngimel
pada 25 Apr 2017
@ngimel
Saya baru saja menjalankan program lagi. Dan terjebak.
Keluaran dari top :
~~~
atas - 17:51:18 hingga 2 hari, 21:05, 2 pengguna, rata-rata memuat: 0,49, 3,00, 5,41
Tugas: total 357, 2 berlari, 355 tidur, 0 berhenti, 0 zombie
%Cpu(s): 1.9 us, 0.1 sy, 0.7 ni, 97,3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 65863816 total, 60115084 digunakan, 5748732 gratis, 1372688 buffer
KiB Swap: 5917692 total, 620 digunakan, 5917072 gratis. 51154784 Mem-cache
PID PENGGUNA PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3067 aalreja 20 0 143332 101816 21300 R 46.1 0.2 1631:44 Xvnc
16613 aalreja 30 10 32836 4880 3912 S 16.9 0.0 1:06.92 fiberlamp 3221 aalreja 20 0 8882348 1.017g 110120 S 1.3 1.6 579:06.87 MATLAB
1285 root 20 0 1404848 48252 25580 S 0.3 0.1 6:00.12 buruh pelabuhan 16597 yimengz+ 20 0 25084 3252 2572 R 0.3 0.0 0:04.56 atas
1 root 20 0 33616 4008 2624 S 0.0 0.0 0:01.43 init
~~~
Keluaran free
~yimengzh_everyday@yimengzh :~$ gratistotal buffer bersama gratis yang digunakan di-cacheMem: 65863816 60122060 5741756 9954628 1372688 51154916-/+ buffer/cache: 7594456 58269360Tukar: 5917692 620 5917072~
Keluaran nvidia-smi
~~~
yimengzh_everyday@yimengzh :~$ nvidia-smi
Sel 25 Apr 17:52:38 2017
+------------------------------------------------- ----------------------------+
| NVIDIA-SMI 375.39 Versi Driver: 375.39 |
|----------------------------+------------------ -----+----------------------+
| Nama GPU Kegigihan-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Penggunaan/Cap | Penggunaan Memori | GPU-Util Compute M. |
|==================================================== =====+========================|
| 0 GeForce GTX TIT... Mati | 0000:03:00.0 Diskon | T/A |
| 30% 42C P8 14W / 250W | 3986MiB / 6082MiB | 0% Bawaan |
+-------------------------------+----------------- -----+----------------------+
| 1 Tesla K40c Mati | 0000:81:00.0 Diskon | Mati |
| 0% 46C P0 57W / 235W | 0MiB / 12205MiB | 0% Bawaan |
+-------------------------------+----------------- -----+----------------------+
+------------------------------------------------- ----------------------------+
| Proses: Memori GPU |
| Jenis PID GPU Nama proses Penggunaan |
|================================================== ==============================|
| 0 16509 C python 3970MiB |
+------------------------------------------------- ----------------------------+
~~~
Saya tidak berpikir itu masalah memori.
zym1010
pada 25 Apr 2017
Ada batasan terpisah untuk memori bersama. Bisakah Anda mencoba ipcs -lm atau cat /proc/sys/kernel/shmall dan cat /proc/sys/kernel/shmmax ? Juga, apakah akan menemui jalan buntu jika Anda menggunakan lebih sedikit pekerja (misalnya tes dengan kasus ekstrim 1 pekerja)?
apaszke
pada 26 Apr 2017
@paszke
~~~
yimengzh_everyday@yimengzh :~$ ipcs -lm
------ Batas Memori Bersama --------
jumlah segmen maksimum = 4096
ukuran seg maks (kbytes) = 18014398509465599
total memori bersama maksimum (kbytes) = 18446744073642442748
ukuran seg min (byte) = 1
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmall
18446744073692774399
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmmax
18446744073692774399
~~~
bagaimana mereka mencarimu?
untuk pekerja yang lebih sedikit, saya yakin itu tidak akan sering terjadi. (Saya bisa mencoba sekarang). Tetapi saya pikir dalam praktiknya saya membutuhkan banyak pekerja.
zym1010
pada 26 Apr 2017
Anda memiliki maksimal 4096 segmen memori bersama yang diizinkan, mungkin itu masalah. Anda dapat mencoba meningkatkannya dengan menulis ke /proc/sys/kernel/shmmni (mungkin coba 8192). Anda mungkin memerlukan hak pengguna super.
apaszke
pada 26 Apr 2017
@apaszke baik ini adalah nilai default oleh Ubuntu dan CentOS 6... Apakah itu benar-benar masalah?
zym1010
pada 26 Apr 2017
@apaszke saat menjalankan program pelatihan, ipcs -a sebenarnya menunjukkan tidak ada memori bersama yang digunakan. Apakah itu yang diharapkan?
zym1010
pada 26 Apr 2017
@apaszke mencoba menjalankan program (masih 22 pekerja) dengan pengaturan berikut pada mem bersama, dan macet lagi.
~~~
yimengzh_everyday@yimengzh :~$ ipcs -lm
------ Batas Memori Bersama --------
jumlah maksimum segmen = 8192
ukuran seg maks (kbytes) = 18014398509465599
total memori bersama maksimum (kbytes) = 18446744073642442748
ukuran seg min (byte) = 1
~~~
tidak mencoba satu pekerja. pertama, itu akan lambat; kedua, jika masalahnya benar-benar dead lock, maka pasti akan hilang.
zym1010
pada 26 Apr 2017
@zym1010 pengaturan default tidak harus dibuat dengan beban kerja seperti itu, jadi ya itu mungkin menjadi masalah. ipcs adalah untuk memori bersama Sistem V yang tidak kami gunakan, tetapi saya ingin memastikan batas yang sama tidak berlaku untuk memori bersama POSIX.
Itu tidak akan pasti hilang , karena jika masalahnya benar-benar ada, maka kemungkinan besar terjadi kebuntuan antara pekerja dan proses utama, dan satu pekerja mungkin cukup untuk memicu ini. Bagaimanapun, saya tidak dapat memperbaiki masalah sampai saya dapat mereproduksinya. Apa parameter yang Anda gunakan untuk menjalankan contoh dan apakah Anda memodifikasi kode dengan cara apa pun? Juga, berapa nilainya torch.__version__ ? Apakah Anda berjalan di buruh pelabuhan?
apaszke
pada 26 Apr 2017
@apaszke Terima kasih. Saya memahami analisis Anda jauh lebih baik sekarang.
Semua hasil lain yang ditunjukkan kepada Anda hingga bagaimana kinerjanya pada mesin Ubuntu 14.04 dengan RAM 64GB, dual Xeon, dan Titan Black (ada juga K40, tetapi saya tidak menggunakannya).
Perintah untuk menghasilkan masalah adalah CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 20 --lr 0.01 --workers 22 --batch-size 256 /mnt/temp_drive_3/cv_datasets/ILSVRC2015/Data/CLS-LOC . Saya tidak mengubah kode sama sekali.
Saya menginstal pytorch melalui pip, pada Python 3.5. versi pytorch adalah 0.1.11_5 . Tidak berjalan di Docker.
BTW, saya juga mencoba menggunakan 1 pekerja. Tapi saya melakukannya di komputer lain (RAM 128GB, dual Xeon, 4 Pascal Titan X, CentOS 6). Saya menjalankannya menggunakan CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 1 --lr 0.01 --workers 1 --batch-size 256 /ssd/cv_datasets/ILSVRC2015/Data/CLS-LOC , dan log kesalahannya adalah sebagai berikut.
Epoch: [0][5003/5005] Time 2.463 (2.955) Data 2.414 (2.903) Loss 5.9677 (6.6311) Prec<strong i="14">@1</strong> 3.516 (0.545) Prec<strong i="15">@5</strong> 8.594 (2.262)
Epoch: [0][5004/5005] Time 1.977 (2.955) Data 1.303 (2.903) Loss 5.9529 (6.6310) Prec<strong i="16">@1</strong> 1.399 (0.545) Prec<strong i="17">@5</strong> 7.692 (2.262)
^CTraceback (most recent call last):
File "main.py", line 292, in <module>
main()
File "main.py", line 137, in main
prec1 = validate(val_loader, model, criterion)
File "main.py", line 210, in validate
for i, (input, target) in enumerate(val_loader):
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 168, in __next__
idx, batch = self.data_queue.get()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/queue.py", line 164, in get
self.not_empty.wait()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/threading.py", line 293, in wait
waiter.acquire()
top menunjukkan hal berikut ketika terjebak dengan 1 pekerja.
~atas - 08:34:33 hingga 15 hari, 20:03, 0 pengguna, rata-rata memuat: 0,37, 0,39, 0,36Tugas: 894 total, 1 lari, 892 tidur, 0 berhenti, 1 zombieCPU: 7.2%us, 2.8%sy, 0.0%ni, 89.7%id, 0.3%wa, 0.0%hi, 0.0%si, 0.0%stMem: 132196824k total, 131461528k digunakan, 735296k gratis, 347448k bufferTukar: 2047996k total, 22656k digunakan, 2025340k gratis, 125226796k di-cache~
zym1010
pada 26 Apr 2017
hal lain yang saya temukan adalah, jika saya memodifikasi kode pelatihan, sehingga tidak akan melalui semua batch, katakanlah, hanya melatih 50 batch
if i >= 50:
break
maka kebuntuan tampaknya hilang.
zym1010
pada 26 Apr 2017
pengujian lebih lanjut tampaknya menunjukkan bahwa, pembekuan ini lebih sering terjadi jika saya menjalankan program tepat setelah me-reboot komputer. Setelah ada beberapa cache di komputer, sepertinya frekuensi pembekuan ini lebih sedikit.
zym1010
pada 27 Apr 2017
Saya mencoba, tetapi saya tidak dapat mereproduksi bug ini dengan cara apa pun.
apaszke
pada 4 Mei 2017
Saya menemui masalah serupa: pemuat data berhenti ketika saya menyelesaikan suatu zaman dan akan memulai zaman baru.
 tiancheng-zhi
pada 4 Mei 2017
tiancheng-zhi
pada 4 Mei 2017
Pengaturan num_workers = 0 bekerja. Tapi programnya melambat.
tiancheng-zhi
pada 4 Mei 2017
@apaszke sudahkah Anda mencoba me-reboot komputer terlebih dahulu dan kemudian menjalankan program? Bagi saya, ini menjamin pembekuan. Saya baru saja mencoba versi 0.12, dan masih sama.
Satu hal yang ingin saya tunjukkan adalah bahwa saya menginstal pytorch menggunakan pip , karena saya telah menginstal numpy terkait-OpenBLAS dan MKL dari anaconda cloud @soumith tidak akan memainkannya dengan baik.
Jadi pada dasarnya pytorch menggunakan MKL dan numpy menggunakan OpenBLAS. Ini mungkin tidak ideal, tetapi saya pikir ini seharusnya tidak ada hubungannya dengan masalah di sini.
zym1010
pada 9 Mei 2017
Saya melihat ke dalamnya, tetapi saya tidak pernah bisa mereproduksinya. MKL/OpenBLAS seharusnya tidak terkait dengan masalah ini. Mungkin ada masalah dengan konfigurasi sistem
apaszke
pada 9 Mei 2017
@apaszke terima kasih. Saya baru saja mencoba python dari repo resmi anaconda dan pytorch berbasis MKL. Masih masalah yang sama.
zym1010
pada 9 Mei 2017
mencoba menjalankan kode di Docker. Masih macet.
zym1010
pada 11 Mei 2017
Kami memiliki masalah yang sama, menjalankan contoh pelatihan pytorch/examples imagenet (resnet18, 4 pekerja) di dalam nvidia-docker menggunakan 1 GPU dari 4. Saya akan mencoba mengumpulkan gdb backtrace, jika saya berhasil sampai ke proses .
Setidaknya OpenBLAS diketahui memiliki masalah kebuntuan dalam perkalian matriks, yang relatif jarang terjadi: https://github.com/xianyi/OpenBLAS/issues/937. Bug ini hadir setidaknya dalam OpenBLAS yang dikemas dalam numpy 1.12.0.
 jsainio
pada 7 Jun 2017
jsainio
pada 7 Jun 2017
@jsainio Saya juga mencoba PyTorch berbasis MKL murni (numpy juga terkait dengan MKL), dan masalah yang sama.
Juga, masalah ini terpecahkan (setidaknya untuk saya), jika saya mengaktifkan pin_memory untuk pemuat data.
zym1010
pada 7 Jun 2017
Sepertinya dua pekerja mati.
Selama operasi normal:
root<strong i="7">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 33.2 4.7 91492324 3098288 ? Ssl 10:51 1:10 python -m runne
user+ 58 76.8 2.3 91079060 1547512 ? Rl 10:54 1:03 python -m runne
user+ 59 76.0 2.2 91006896 1484536 ? Rl 10:54 1:02 python -m runne
user+ 60 76.4 2.3 91099448 1559992 ? Rl 10:54 1:02 python -m runne
user+ 61 79.4 2.2 91008344 1465292 ? Rl 10:54 1:05 python -m runne
setelah mengunci:
root<strong i="11">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 24.8 4.4 91509728 2919744 ? Ssl 14:25 13:01 python -m runne
user+ 58 51.7 0.0 0 0 ? Z 14:27 26:20 [python] <defun
user+ 59 52.1 0.0 0 0 ? Z 14:27 26:34 [python] <defun
user+ 60 52.0 2.4 91147008 1604628 ? Sl 14:27 26:31 python -m runne
user+ 61 52.0 2.3 91128424 1532088 ? Sl 14:27 26:29 python -m runne
Untuk satu pekerja yang masih tersisa, awal dari stacktrace gdb terlihat seperti:
root<strong i="15">@b06f896d5c1d</strong>:~/mnt# gdb --pid 60
GNU gdb (GDB) 8.0
Attaching to process 60
[New LWP 65]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb) bt
#0 0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f36f52af8d4 in __new_sem_wait_slow.constprop.0 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#2 0x00007f36f52af97a in sem_wait@@GLIBC_2.2.5 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#3 0x00007f36f157efb1 in semlock_acquire (self=0x7f3656296458,
args=<optimized out>, kwds=<optimized out>)
at /home/ilan/minonda/conda-bld/work/Python-3.5.2/Modules/_multiprocessing/semaphore.c:307
#4 0x00007f36f5579621 in PyCFunction_Call (func=
<built-in method __enter__ of _multiprocessing.SemLock object at remote 0x7f3656296458>, args=(), kwds=<optimized out>) at Objects/methodobject.c:98
#5 0x00007f36f5600bd5 in call_function (oparg=<optimized out>,
pp_stack=0x7f36c7ffbdb8) at Python/ceval.c:4705
#6 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#7 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=1, kws=0x0, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0,
closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#8 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#9 0x00007f36f5557542 in function_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/funcobject.c:627
#10 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36561c7d08>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#11 0x00007f36f554077c in method_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/classobject.c:330
#12 0x00007f36f5524236 in PyObject_Call (
func=<method at remote 0x7f36556f9248>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#13 0x00007f36f55277d9 in PyObject_CallFunctionObjArgs (
callable=<method at remote 0x7f36556f9248>) at Objects/abstract.c:2445
#14 0x00007f36f55fc3a9 in PyEval_EvalFrameEx (f=<optimized out>,
throwflag=<optimized out>) at Python/ceval.c:3107
#15 0x00007f36f5601166 in fast_function (nk=<optimized out>, na=1,
n=<optimized out>, pp_stack=0x7f36c7ffc418,
func=<function at remote 0x7f36561c78c8>) at Python/ceval.c:4803
#16 call_function (oparg=<optimized out>, pp_stack=0x7f36c7ffc418)
at Python/ceval.c:4730
#17 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#18 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=4, kws=0x7f36f5b85060, kwcount=0, defs=0x0, defcount=0,
kwdefs=0x0, closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#19 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#20 0x00007f36f5557661 in function_call (
func=<function at remote 0x7f36e14170d0>,
arg=(<ImageFolder(class_to_idx={'n04153751': 783, 'n02051845': 144, 'n03461385': 582, 'n04350905': 834, 'n02105056': 224, 'n02112137': 260, 'n03938244': 721, 'n01739381': 59, 'n01797886': 82, 'n04286575': 818, 'n02113978': 268, 'n03998194': 741, 'n15075141': 999, 'n03594945': 609, 'n04099969': 765, 'n02002724': 128, 'n03131574': 520, 'n07697537': 934, 'n04380533': 846, 'n02114712': 271, 'n01631663': 27, 'n04259630': 808, 'n04326547': 825, 'n02480855': 366, 'n02099429': 206, 'n03590841': 607, 'n02497673': 383, 'n09332890': 975, 'n02643566': 396, 'n03658185': 623, 'n04090263': 764, 'n03404251': 568, 'n03627232': 616, 'n01534433': 13, 'n04476259': 868, 'n03495258': 594, 'n04579145': 901, 'n04266014': 812, 'n01665541': 34, 'n09472597': 980, 'n02095570': 189, 'n02089867': 166, 'n02009229': 131, 'n02094433': 187, 'n04154565': 784, 'n02107312': 237, 'n04372370': 844, 'n02489166': 376, 'n03482405': 588, 'n04040759': 753, 'n01774750': 76, 'n01614925': 22, 'n01855032': 98, 'n03903868': 708, 'n02422699': 352, 'n01560419': 1...(truncated), kw={}) at Objects/funcobject.c:627
#21 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36e14170d0>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#22 0x00007f36f55fe234 in ext_do_call (nk=1444355432, na=0,
flags=<optimized out>, pp_stack=0x7f36c7ffc768,
func=<function at remote 0x7f36e14170d0>) at Python/ceval.c:5034
#23 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3275
--snip--
Saya memiliki log kesalahan serupa, dengan proses utama macet: self.data_queue.get()
Bagi saya masalahnya adalah saya menggunakan opencv sebagai pemuat gambar. Dan fungsi cv2.imread tergantung tanpa batas tanpa kesalahan pada gambar imagenet tertentu ("n01630670/n01630670_1010.jpeg")
Jika Anda mengatakan itu bekerja untuk Anda dengan num_workers = 0 bukan itu. Tapi saya pikir itu mungkin membantu beberapa orang dengan jejak kesalahan serupa.
 M-Eng
pada 9 Jun 2017
M-Eng
pada 9 Jun 2017
Saya sedang menjalankan tes dengan num_workers = 0 saat ini, belum ada hang. Saya menjalankan kode contoh dari https://github.com/pytorch/examples/blob/master/imagenet/main.py . pytorch/vision ImageFolder tampaknya menggunakan PIL atau pytorch/accimage internal untuk memuat gambar, jadi tidak ada OpenCV yang terlibat.
Dengan num_workers = 4 , saya kadang-kadang bisa mendapatkan kereta epoch pertama dan memvalidasi sepenuhnya, dan terkunci di tengah epoch kedua. Jadi, sepertinya tidak ada masalah dalam fungsi dataset/loading.
Ini terlihat seperti kondisi balapan di ImageLoader yang mungkin relatif jarang dipicu oleh kombinasi perangkat keras/perangkat lunak tertentu.
jsainio
pada 9 Jun 2017
@zym1010 terima kasih atas penunjuknya, saya akan mencoba mengatur pin_memory = False juga untuk DataLoader.
jsainio
pada 9 Jun 2017
Menarik. Pada pengaturan saya, pengaturan pin_memory = False dan num_workers = 4 contoh imagenet segera hang dan tiga pekerja berakhir sebagai proses zombie:
root<strong i="8">@034c4212d022</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 6.7 2.8 92167056 1876612 ? Ssl 13:50 0:36 python -m runner
user+ 38 1.9 0.0 0 0 ? Z 13:51 0:08 [python] <defunct>
user+ 39 4.3 2.3 91069804 1550736 ? Sl 13:51 0:19 python -m runner
user+ 40 2.0 0.0 0 0 ? Z 13:51 0:09 [python] <defunct>
user+ 41 4.1 0.0 0 0 ? Z 13:51 0:18 [python] <defunct>
Dalam pengaturan saya, kumpulan data terletak pada disk jaringan yang dibaca melalui NFS. Dengan pin_memory = False dan num_workers = 4 saya bisa membuat sistem gagal dengan cukup cepat.
=> creating model 'resnet18'
- training epoch 0
Epoch: [0][0/5005] Time 10.713 (10.713) Data 4.619 (4.619) Loss 6.9555 (6.9555) Prec<strong i="8">@1</strong> 0.000 (0.000) Prec<strong i="9">@5</strong> 0.000 (0.000)
Traceback (most recent call last):
--snip--
imagenet_pytorch.main.main([data_dir, "--transient_dir", context.transient_dir])
File "/home/user/mnt/imagenet_pytorch/main.py", line 140, in main
train(train_loader, model, criterion, optimizer, epoch, args)
File "/home/user/mnt/imagenet_pytorch/main.py", line 168, in train
for i, (input, target) in enumerate(train_loader):
File "/home/user/anaconda/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 206, in __next__
idx, batch = self.data_queue.get()
File "/home/user/anaconda/lib/python3.5/multiprocessing/queues.py", line 345, in get
return ForkingPickler.loads(res)
File "/home/user/anaconda/lib/python3.5/site-packages/torch/multiprocessing/reductions.py", line 70, in rebuild_storage_fd
fd = df.detach()
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError
:
[Errno 104] Connection reset by peer
@zym1010 apakah Anda kebetulan memiliki disk jaringan atau disk pemintalan tradisional yang mungkin lebih lambat dalam latensi/dll.?
jsainio
pada 9 Jun 2017
@jsainio
Saya menggunakan SSD lokal pada node komputasi cluster. Kodenya ada di drive NFS, tetapi datanya ada di SSD lokal, untuk kecepatan pemuatan maksimal. Tidak pernah mencoba memuat data pada drive NFS.
zym1010
pada 9 Jun 2017
@zym1010 Terima kasih atas infonya. Saya menjalankan ini juga pada node komputasi dari sebuah cluster.
Sebenarnya, saya menjalankan eksperimen num_workers = 0 pada node yang sama secara bersamaan saat mencoba variasi num_workers = 4 . Mungkin eksperimen pertama menghasilkan beban yang cukup sehingga kondisi balapan yang mungkin muncul lebih cepat di eksperimen terakhir.
jsainio
pada 9 Jun 2017
@apaszke Ketika Anda mencoba mereproduksi ini sebelumnya, apakah Anda mencoba menjalankan dua instance secara berdampingan atau dengan beban lain yang signifikan pada sistem?
jsainio
pada 9 Jun 2017
@jsainio Terima kasih telah menyelidiki ini! Itu aneh, pekerja hanya harus keluar bersama, dan setelah proses utama selesai membaca data. Bisakah Anda mencoba memeriksa mengapa mereka keluar sebelum waktunya? Mungkin periksa log kernel ( dmesg )?
apaszke
pada 9 Jun 2017
Tidak, saya belum mencobanya, tetapi sepertinya itu muncul bahkan ketika bukan itu masalahnya IIRC
apaszke
pada 9 Jun 2017
@apaszke Ok, senang mengetahui bahwa para pekerja seharusnya tidak keluar.
Saya sudah mencoba tetapi saya tidak tahu cara yang baik untuk memeriksa mengapa mereka keluar. dmesg tidak menunjukkan sesuatu yang relevan. (Saya menjalankan Docker yang diturunkan dari Ubuntu 16.04, menggunakan paket Anaconda)
jsainio
pada 9 Jun 2017
Salah satu caranya adalah dengan menambahkan sejumlah cetakan di dalam loop pekerja . Saya tidak tahu mengapa mereka diam-diam keluar. Ini mungkin bukan pengecualian, karena itu akan dicetak ke stderr, jadi mereka keluar dari loop, atau terbunuh oleh OS (mungkin oleh sinyal?)
apaszke
pada 9 Jun 2017
@jsainio , hanya untuk memastikan, apakah Anda menjalankan buruh pelabuhan dengan --ipc=Host (Anda tidak menyebutkan ini)? Bisakah Anda memeriksa ukuran segmen memori bersama Anda (df -h | grep shm)?
ngimel
pada 9 Jun 2017
@ngimel Saya menggunakan --shm-size=1024m . df -h | grep shm melaporkan sesuai:
root<strong i="9">@db92462e8c19</strong>:~/mnt# df -h | grep shm
shm 1.0G 883M 142M 87% /dev/shm
Penggunaan itu tampaknya agak sulit. Ini ada di buruh pelabuhan dengan dua pekerja zombie.
jsainio
pada 12 Jun 2017
Bisakah Anda mencoba meningkatkan ukuran shm? Saya baru saja memeriksa dan di server tempat saya mencoba mereproduksi masalah itu adalah 16GB. Anda dapat mengubah bendera buruh pelabuhan atau menjalankan
mount -o remount,size=8G /dev/shm
Saya baru saja mencoba mengurangi ukurannya menjadi 512MB, tetapi saya mendapatkan kesalahan yang jelas alih-alih kebuntuan. Masih tidak bisa mereproduksi
apaszke
pada 14 Jun 2017
Dengan buruh pelabuhan kita cenderung mendapatkan kebuntuan ketika shm tidak cukup, daripada menghapus pesan kesalahan, tidak tahu mengapa. Tetapi biasanya disembuhkan dengan meningkatkan shm (dan saya memang mendapatkan kebuntuan dengan 1G).
ngimel
pada 14 Jun 2017
Oke, sepertinya dengan 10 pekerja muncul kesalahan, tetapi ketika saya menggunakan 4 pekerja saya mendapatkan jalan buntu di 58% dari penggunaan /dev/shm! Saya akhirnya mereproduksinya
apaszke
pada 14 Jun 2017
Itu bagus bahwa Anda dapat mereproduksi bentuk masalah ini. Saya memposting skrip yang memicu hang di #1579, dan Anda menjawab bahwa skrip tersebut tidak hang di sistem Anda. Saya sebenarnya hanya mengujinya di MacBook saya. Saya baru saja mencoba di Linux, dan tidak hang. Jadi, jika Anda hanya mencoba di Linux, mungkin juga layak untuk dicoba di Mac.
 greaber
pada 14 Jun 2017
greaber
pada 14 Jun 2017
Ok, jadi setelah menyelidiki masalahnya, sepertinya ini adalah masalah yang aneh. Bahkan ketika saya membatasi /dev/shm menjadi hanya 128MB besar, Linux dengan senang hati mengizinkan kami membuat file 147MB di sana, mmap mereka sepenuhnya dalam memori, tetapi akan mengirimkan SIGBUS mematikan ke pekerja setelah benar-benar mencoba mengakses halaman ... Saya tidak dapat memikirkan mekanisme apa pun yang memungkinkan kami memeriksa validitas halaman kecuali untuk mengulanginya, dan menyentuh masing-masing, dengan penangan SIGBUS terdaftar...
Solusi untuk saat ini adalah memperluas /dev/shm dengan perintah mount seperti yang saya tunjukkan di atas. Coba dengan 16GB (ofc jika Anda memiliki cukup RAM).
apaszke
pada 15 Jun 2017
Sulit untuk menemukan penyebutan ini, tetapi ini satu .
apaszke
pada 15 Jun 2017
Terima kasih atas waktu Anda tentang masalah ini, itu telah membuat saya gila untuk waktu yang lama! Jika saya mengerti dengan benar, saya perlu memperluas /dev/shm menjadi 16G, bukan 8G. Itu masuk akal tetapi ketika ketika di try df -h , saya dapat melihat bahwa semua ram saya sebenarnya dialokasikan seperti itu: (Saya punya 16G)
tmpfs 7,8G 393M 7,4G 5% /dev/shm
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,8G 0 7,8G 0% /sys/fs/cgroup
tmpfs 1,6G 60K 1,6G 1% /run/user/1001
Ini adalah output dari df -h selama kebuntuan. Sejauh yang saya mengerti, Jika saya memiliki partisi SWAP 16G, saya dapat me-mount tmpfs hingga 32G, jadi seharusnya tidak menjadi masalah untuk memperluas /dev/shm , bukan?
Lebih penting lagi, saya bingung tentang partisi cgroup dan tujuannya karena membutuhkan hampir setengah dari RAM saya. Rupanya itu dirancang untuk mengelola tugas multi-prosesor yang efisien, tetapi saya benar-benar tidak terbiasa dengan apa yang dilakukannya dan mengapa kami membutuhkannya, apakah itu akan mengubah sesuatu untuk mengalokasikan semua RAM fisik ke shm (karena kami mengatur ukurannya ke 16G) dan taruh di SWAP (walaupun saya yakin keduanya akan sebagian di RAM dan SWAP secara bersamaan)
 ClementPinard
pada 15 Jun 2017
ClementPinard
pada 15 Jun 2017
@apaszke Terima kasih! Bagus bahwa Anda menemukan penyebab yang mendasarinya. Saya kadang-kadang mendapatkan berbagai kesalahan "ConnectionReset" dan kebuntuan dengan buruh pelabuhan --shm-size=1024m tergantung apa beban lain ada satu mesin. Pengujian sekarang dengan --shm-size=16384m dan 4 pekerja.
jsainio
pada 15 Jun 2017
@jsainio ConnectionReset mungkin disebabkan oleh hal yang sama. Proses mulai bertukar beberapa data, tetapi begitu shm kehabisan ruang, SIGBUS dikirim ke pekerja dan mematikannya.
@ClementPinard sejauh yang saya mengerti Anda dapat membuatnya sebesar yang Anda inginkan, kecuali bahwa itu kemungkinan akan membekukan mesin Anda setelah Anda kehabisan RAM (karena bahkan kernel tidak dapat membebaskan memori ini). Anda mungkin tidak perlu repot tentang /sys/fs/cgroup . Partisi tmpfs mengalokasikan memori dengan malas, jadi selama penggunaan tetap pada 0B, Anda tidak dikenakan biaya apa pun (termasuk batasan). Saya tidak berpikir menggunakan swap adalah ide yang baik, karena itu akan membuat pemuatan data menjadi lebih lambat, jadi Anda dapat mencoba meningkatkan ukuran shm menjadi 12GB, dan membatasi jumlah pekerja (seperti yang saya katakan, jangan gunakan semua RAM Anda untuk shm!). Berikut ini adalah artikel bagus tentang tmpfs dari dokumentasi kernel.
Saya tidak tahu mengapa kebuntuan terjadi bahkan ketika penggunaan /dev/shm sangat kecil (terjadi pada 20kB di mesin saya). Mungkin kernel terlalu optimis, tetapi tidak menunggu sampai Anda mengisi semuanya, dan menghentikan proses setelah mulai menggunakan apa pun dari wilayah ini.
apaszke
pada 15 Jun 2017
Menguji sekarang dengan 12G dan setengah pekerja yang saya miliki, dan gagal :(
Itu bekerja seperti pesona dalam versi lua torch (kecepatan yang sama, jumlah pekerja yang sama), yang membuat saya bertanya-tanya apakah masalahnya hanya terkait /dev/shm dan tidak lebih dekat dengan python multiprocessing...
Hal yang aneh tentang itu (seperti yang Anda sebutkan) adalah bahwa /dev/shm tidak pernah hampir penuh. Selama periode pelatihan pertama, tidak pernah melebihi 500Mo. Dan itu juga tidak pernah mengunci selama zaman pertama, dan jika saya mematikan pengujian, trainloader tidak pernah gagal di semua zaman. Kebuntuan tampaknya hanya muncul saat memulai uji coba. Saya harus melacak /dev/shm saat beralih dari kereta ke pengujian, mungkin ada penggunaan puncak selama perubahan pemuat data.
ClementPinard
pada 15 Jun 2017
@ClementPinard bahkan dengan memori bersama yang lebih tinggi, dan tanpa Docker, itu masih bisa gagal.
zym1010
pada 15 Jun 2017
Jika versi obor == Lua Torch, maka itu mungkin masih terkait dengan /dev/shm . Lua Torch dapat menggunakan utas (tidak ada GIL), jadi tidak perlu melalui mem bersama (mereka semua berbagi satu ruang alamat).
apaszke
pada 15 Jun 2017
Saya memiliki masalah yang sama ketika pemuat data mogok setelah mengeluh bahwa itu tidak dapat mengalokasikan memori di awal pelatihan atau periode validasi baru. Solusi di atas tidak bekerja untuk saya (i) /dev/shm adalah 32GB dan tidak pernah digunakan lebih dari 2.5GB, dan (ii) pengaturan pin_memory=False tidak berfungsi.
Ini mungkin ada hubungannya dengan pengumpulan sampah? Kode saya kira-kira terlihat seperti berikut ini. Saya membutuhkan iterator tak terbatas dan karenanya saya mencoba / kecuali sekitar next() bawah :-)
def train():
train_iter = train_loader.__iter__()
for i in xrange(max_batches):
try:
x, y = next(train_iter)
except StopIteration:
train_iter = train_loader.__iter__()
...
del train_iter
train_loader adalah objek DataLoader . Tanpa garis del train_iter eksplisit di akhir fungsi, proses selalu macet setelah 2-3 epoch ( /dev/shm masih menunjukkan 2,5 GB). Semoga ini membantu!
Saya menggunakan 4 pekerja (versi 0.1.12_2 dengan CUDA 8.0 di Ubuntu 16.04).
 pratikac
pada 7 Jul 2017
pratikac
pada 7 Jul 2017
Saya juga menemui jalan buntu, terutama ketika work_number besar. Apakah ada solusi yang mungkin untuk masalah ini? Ukuran /dev/shm saya adalah 32GB, dengan cuda 7.5, pytorch 0.1.12 dan python 2.7.13. Berikut info terkait setelah kematian. Tampaknya terkait dengan memori. @paszke

 zhengyunqq
pada 4 Agu 2017
zhengyunqq
pada 4 Agu 2017
@zhengyunqq coba pin_memory=False jika Anda mengaturnya ke True . Kalau tidak, saya tidak mengetahui solusi apa pun.
zym1010
pada 4 Agu 2017
Saya juga menemui jalan buntu ketika num_workers besar.
 hendrycks
pada 11 Agu 2017
hendrycks
pada 11 Agu 2017
Bagi saya, masalahnya adalah jika utas pekerja mati karena alasan apa pun, maka index_queue.put hang selamanya. Salah satu alasan utas yang berfungsi mati adalah kegagalan unpickler selama inisialisasi. Dalam hal ini, hingga perbaikan bug Python di master pada Mei 2017, utas pekerja akan mati dan menyebabkan hang tanpa akhir. Dalam kasus saya, hang terjadi dalam tahap priming pra-pengambilan batch.
Mungkin penggantian SimpleQueue digunakan di DataLoaderIter oleh Queue yang memungkinkan timeout dengan pesan pengecualian yang anggun.
UPD: Saya salah, perbaikan bug ini menambal Queue , bukan SimpleQueue . Masih benar bahwa SimpleQueue akan mengunci jika tidak ada utas pekerja yang online. Cara mudah untuk memeriksanya adalah dengan mengganti baris ini dengan self.workers = [] .
 vadimkantorov
pada 16 Agu 2017
vadimkantorov
pada 16 Agu 2017
saya memiliki masalah yang sama, dan saya tidak dapat mengubah shm (tanpa izin), mungkin lebih baik menggunakan Antrian atau yang lainnya?
 xfanplus
pada 8 Sep 2017
xfanplus
pada 8 Sep 2017
Saya memiliki masalah serupa.
Kode ini akan membeku dan tidak pernah mencetak apa pun. Jika saya mengatur num_workers=0 itu akan berhasil
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
model.cuda()
for i, batch in enumerate(dataloader):
print(i)
Jika saya meletakkan model.cuda() di belakang loop, semuanya akan berjalan dengan baik.
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
for i, batch in enumerate(dataloader):
print(i)
model.cuda()
Apakah ada yang punya solusi untuk masalah itu?
 anDoer
pada 13 Sep 2017
anDoer
pada 13 Sep 2017
Saya juga mengalami masalah serupa saat melatih ImageNet. Itu akan hang pada iterasi pertama evaluasi secara konsisten pada server tertentu dengan arsitektur tertentu (dan tidak pada server lain dengan arsitektur yang sama atau server yang sama dengan arsitektur yang berbeda), tetapi selalu pada iter pertama selama evaluasi pada validasi. Ketika saya menggunakan Torch, kami menemukan nccl dapat menyebabkan kebuntuan seperti ini, apakah ada cara untuk mematikannya?
 WendyShang
pada 20 Sep 2017
WendyShang
pada 20 Sep 2017
Saya menghadapi masalah yang sama, secara acak macet di awal zaman ke-1. Semua solusi yang disebutkan di atas tidak berfungsi untuk saya. Ketika Ctrl-C ditekan, ia mencetak ini:
Traceback (most recent call last):
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 249, in _bootstrap
self.run()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 44, in _worker_loop
data_queue.put((idx, samples))
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/queues.py", line 354, in put
self._writer.send_bytes(obj)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 200, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 398, in _send_bytes
self._send(buf)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
KeyboardInterrupt
Traceback (most recent call last):
File "scripts/train_model.py", line 640, in <module>
main(args)
File "scripts/train_model.py", line 193, in main
train_loop(args, train_loader, val_loader)
File "scripts/train_model.py", line 341, in train_loop
ee_optimizer.step()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/optim/adam.py", line 74, in step
p.data.addcdiv_(-step_size, exp_avg, denom)
KeyboardInterrupt
 zoharli
pada 23 Okt 2017
zoharli
pada 23 Okt 2017
Saya memiliki masalah yang sama mengalami kebuntuan dengan satu pekerja di dalam buruh pelabuhan dan saya dapat mengonfirmasi bahwa itu adalah masalah memori bersama dalam kasus saya. Secara default buruh pelabuhan tampaknya hanya mengalokasikan 64MB memori bersama, namun saya membutuhkan 440MB untuk 1 pekerja, yang mungkin menyebabkan perilaku yang dijelaskan oleh @apaszke.
 paulguerrero
pada 23 Okt 2017
paulguerrero
pada 23 Okt 2017
Saya bermasalah dengan masalah yang sama, namun saya berada di lingkungan yang berbeda dari kebanyakan orang lain di utas ini, jadi mungkin masukan saya dapat membantu menemukan penyebab yang mendasarinya. Pytorch saya diinstal menggunakan paket conda luar biasa yang dibuat oleh peterjc123 di bawah Windows10.
Saya menjalankan beberapa cnn pada dataset cifar10. Untuk pemuat data, num_workers disetel ke 1. Meskipun memiliki num_workers > 0 diketahui menyebabkan BrokenPipeError dan disarankan untuk tidak melakukannya di #494, apa yang saya alami bukanlah BrokenPipeError tetapi beberapa kesalahan alokasi memori. Kesalahan selalu terjadi di sekitar 50 epoch, tepat setelah validasi epoch terakhir dan sebelum dimulainya pelatihan untuk epoch berikutnya. 90% dari waktu tepatnya 50 epoch, di lain waktu akan mati 1 atau 2 epoch. Selain itu segala sesuatu yang lain cukup konsisten. Pengaturan num_workers=0 akan menghilangkan masalah ini.
 berzjackson
pada 24 Okt 2017
berzjackson
pada 24 Okt 2017
@paulguerrero benar. Saya memecahkan masalah ini dengan meningkatkan memori bersama dari 64M ke 2G. Mungkin ini berguna untuk pengguna buruh pelabuhan.
 yjzhux
pada 24 Okt 2017
yjzhux
pada 24 Okt 2017
@berzjackson Itu bug yang diketahui dalam paket conda. Diperbaiki di build CI terbaru.
 peterjc123
pada 25 Okt 2017
peterjc123
pada 25 Okt 2017
Kami memiliki ~600 orang yang memulai kursus baru yang menggunakan Pytorch pada hari Senin. Banyak orang di forum kami melaporkan masalah ini. Beberapa di AWS P2, beberapa di sistem mereka sendiri (terutama GTX 1070, beberapa Titan X).
Saat mereka menginterupsi pelatihan, akhir pelacakan tumpukan menunjukkan:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv_bytes(self, maxsize)
405
406 def _recv_bytes(self, maxsize=None):
--> 407 buf = self._recv(4)
408 size, = struct.unpack("!i", buf.getvalue())
409 if maxsize is not None and size > maxsize:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv(self, size, read)
377 remaining = size
378 while remaining > 0:
--> 379 chunk = read(handle, remaining)
380 n = len(chunk)
381 if n == 0:
Kami memiliki num_workers=4, pin_memory=False. Saya telah meminta mereka untuk memeriksa pengaturan memori bersama mereka - tetapi apakah ada yang bisa saya lakukan (atau bisa kita lakukan di Pytorch) untuk menghilangkan masalah ini? (Selain mengurangi num_workers, karena itu akan memperlambat segalanya.)
 jph00
pada 1 Nov 2017
jph00
pada 1 Nov 2017
Saya di kelas @jph00 (terima kasih Jeremy! :)) dimaksud. Saya mencoba menggunakan "num_workers=0" juga. Masih mendapatkan kesalahan yang sama di mana resnet34 memuat sangat lambat. Pemasangannya juga sangat lambat. Tapi hal yang aneh: ini hanya terjadi sekali seumur hidup dari sesi notebook.
Dengan kata lain, setelah data dimuat, dan pemasangan dijalankan sekali, saya dapat bergerak dan terus mengulangi langkah-langkahnya... bahkan dengan 4 num_workers, dan semuanya tampak bekerja cepat seperti yang diharapkan di GPU.
Saya menggunakan PyTorch 0.2.0_4, Python 3.6.2, Torchvision 0.1.9, Ubuntu 16.04 LTS. Melakukan "df -h" di terminal saya mengatakan bahwa saya memiliki 16GB di /dev/shm, meskipun pemanfaatannya sangat rendah.
Berikut tangkapan layar di mana pemuatan gagal (perhatikan saya telah menggunakan num_workers=0 untuk datanya)
(maaf tentang huruf kecil. Saya harus memperkecil untuk menangkap semuanya...)

 apiltamang
pada 1 Nov 2017
apiltamang
pada 1 Nov 2017
@apiltaman Saya tidak yakin itu masalah yang sama - tidak terdengar seperti gejala yang sama sama sekali. Sebaiknya kami mendiagnosisnya di forum fast.ai, bukan di sini.
jph00
pada 1 Nov 2017
melihat ke dalam ini ASAP!
 soumith
pada 1 Nov 2017
soumith
pada 1 Nov 2017
@soumith Saya telah memberikan @apaszke akses ke forum pribadi kursus dan saya telah meminta siswa yang bermasalah untuk memberi kami akses untuk masuk ke kotak mereka.
jph00
pada 1 Nov 2017
@jph00 Hai Jeremy, apakah ada siswa yang mencoba meningkatkan shm seperti @apaszke yang disebutkan di atas? Apakah itu membantu?
 SsnL
pada 1 Nov 2017
SsnL
pada 1 Nov 2017
@SsnL salah satu siswa telah mengkonfirmasi bahwa mereka telah meningkatkan memori bersama, dan masih memiliki masalah. Saya telah meminta beberapa orang lain untuk mengkonfirmasi juga.
jph00
pada 1 Nov 2017
@jph00 Terima kasih! Saya berhasil mereproduksi hang karena memori bersama yang rendah. Jika masalahnya ada di tempat lain, saya harus menggali lebih dalam! Apakah Anda keberatan berbagi skrip dengan saya?
SsnL
pada 1 Nov 2017
Tentu - ini buku catatan yang kami gunakan: https://github.com/fastai/fastai/blob/master/courses/dl1/lesson1.ipynb . Para siswa telah memperhatikan bahwa masalah hanya terjadi ketika mereka menjalankan semua sel sesuai urutan yang ada di buku catatan. Semoga notebook ini cukup jelas, tetapi beri tahu saya jika Anda mengalami kesulitan menjalankannya - ini termasuk tautan untuk mengunduh data yang diperlukan.
Berdasarkan masalah memori bersama yang dapat Anda tiru, apakah ada solusi apa pun yang dapat saya tambahkan ke perpustakaan atau buku catatan kami yang akan menghindarinya?
jph00
pada 1 Nov 2017
@jph00 Menyelam ke dalam kode sekarang. Saya akan mencoba mencari cara untuk mengurangi penggunaan memori bersama. Tampaknya skrip tidak harus menggunakan shm dalam jumlah besar, jadi ada harapan!
Saya juga akan mengirimkan PR untuk menunjukkan pesan kesalahan yang bagus saat mencapai batas shm daripada membiarkannya menggantung.
SsnL
pada 1 Nov 2017
Oke, saya telah mereplikasi masalah pada instans AWS P2 baru menggunakan AMI CUDA 9 mereka dengan instalasi Pytorch conda terbaru. Jika Anda memberikan kunci publik Anda, saya dapat memberi Anda akses untuk mencobanya secara langsung. Email saya adalah huruf pertama dari nama depan saya di fast.ai
jph00
pada 1 Nov 2017
@jph00 Baru saja mengirimi Anda email :) terima kasih!
SsnL
pada 1 Nov 2017
@jph00 Dan untuk diketahui, skrip mengambil memori bersama 400MB di kotak saya. Jadi alangkah baiknya bagi siswa yang memiliki masalah ini untuk memeriksa apakah mereka memiliki cukup shm gratis.
SsnL
pada 1 Nov 2017
Oke, jadi saya telah menemukan masalah dasarnya, yaitu bahwa opencv dan multiprosesor Pytorch kadang-kadang tidak berjalan dengan baik. Tidak ada masalah pada kotak kami di universitas, tetapi banyak masalah pada AWS (pada pembelajaran mendalam baru CUDA 9 AMI dengan instans P2). Menambahkan penguncian di sekitar semua panggilan cv2 tidak memperbaikinya, dan menambahkan cv2.setNumThreads(0) tidak memperbaikinya. Ini sepertinya memperbaikinya:
from multiprocessing import set_start_method
set_start_method('spawn')
Namun itu berdampak pada kinerja sekitar 15%. Rekomendasi dalam masalah github opencv adalah menggunakan https://github.com/tomMoral/loky . Saya telah menggunakan modul itu sebelumnya dan ternyata sangat kokoh. Tidak mendesak, karena kami memiliki solusi yang berfungsi cukup baik untuk saat ini - tetapi mungkin perlu dipertimbangkan untuk menggunakan Loky untuk Dataloader?
Mungkin yang lebih penting, alangkah baiknya jika setidaknya ada semacam batas waktu dalam antrian pytorch sehingga hang yang tak terbatas ini akan tertangkap.
jph00
pada 2 Nov 2017
FYI, saya baru saja mencoba perbaikan yang berbeda, karena 'spawn' membuat beberapa bagian 2-3x lebih lambat - yaitu saya menambahkan beberapa tidur acak di bagian yang beralih melalui pemuat data dengan cepat. Itu juga memperbaiki masalah - meskipun mungkin tidak ideal!
jph00
pada 2 Nov 2017
Terima kasih telah menggali ini! Senang mengetahui bahwa Anda telah menemukan dua solusi. Memang akan lebih baik untuk menambahkan batas waktu pada pengindeksan ke dalam kumpulan data. Kami akan membahas dan menghubungi Anda kembali pada rute itu besok.
cc @soumith apakah ada sesuatu yang ingin kami selidiki?
SsnL
pada 2 Nov 2017
Untuk orang-orang yang datang ke utas ini untuk diskusi di atas, masalah opencv dibahas secara lebih mendalam di https://github.com/opencv/opencv/issues/5150
SsnL
pada 2 Nov 2017
Oke, sepertinya saya memiliki perbaikan yang tepat untuk ini sekarang - Saya telah menulis ulang Dataloader ke pengguna ProcessPoolExecutor.map() dan memindahkan pembuatan tensor ke proses induk. Hasilnya lebih cepat daripada yang saya lihat dengan Dataloader asli, dan stabil di semua komputer yang saya coba. Kodenya juga jauh lebih sederhana.
Jika ada yang tertarik untuk menggunakannya, Anda bisa mendapatkannya dari https://github.com/fastai/fastai/blob/master/fastai/dataloader.py .
API sama dengan versi standar, kecuali bahwa Dataset Anda tidak boleh mengembalikan tensor Pytorch - ia harus mengembalikan array numpy atau daftar python. Saya belum melakukan upaya apa pun untuk membuatnya berfungsi pada Python yang lebih lama, jadi saya tidak akan terkejut jika ada beberapa masalah di sana.
(Alasan saya menempuh jalur ini adalah karena saya menemukan ketika melakukan banyak pemrosesan gambar/augmentasi pada GPU terbaru bahwa saya tidak dapat menyelesaikan pemrosesan dengan cukup cepat untuk membuat GPU sibuk, jika saya melakukan pra-pemrosesan menggunakan CPU Pytorch operasi; namun menggunakan opencv jauh lebih cepat, dan sebagai hasilnya saya dapat sepenuhnya memanfaatkan GPU.)
jph00
pada 2 Nov 2017
Oh jika ini adalah masalah opencv maka tidak banyak yang bisa kita lakukan untuk itu. Memang benar bahwa forking berbahaya bila Anda memiliki kumpulan benang. Saya tidak berpikir kami ingin menambahkan ketergantungan runtime (saat ini kami tidak memilikinya), terutama karena itu tidak akan menangani tensor PyTorch dengan baik. Akan lebih baik untuk mencari tahu apa yang menyebabkan kebuntuan dan @SsnL ada di dalamnya.
@jph00 sudahkah Anda mencoba Bantal-SIMD? Ini harus bekerja dengan torchvision di luar kotak dan saya telah mendengar banyak hal baik tentangnya.
apaszke
pada 2 Nov 2017
Ya saya tahu bantal-SIMD dengan baik. Ini hanya mempercepat pengubahan ukuran, blur, dan konversi RGB.
Saya tidak setuju tidak banyak yang dapat Anda lakukan di sini. Ini bukan masalah opencv (mereka tidak mengklaim mendukung jenis multiprosesor python ini secara lebih umum, apalagi modul multi-pemrosesan khusus pytorch) dan juga bukan masalah Pytorch. Tetapi fakta bahwa Pytorch diam-diam menunggu selamanya tanpa memberikan kesalahan apa pun adalah (IMO) sesuatu yang dapat Anda perbaiki, dan secara umum banyak orang pintar telah bekerja keras selama beberapa tahun terakhir untuk menciptakan pendekatan multiprosesor yang ditingkatkan yang menghindari masalah hanya Seperti yang ini. Anda dapat meminjam dari pendekatan yang mereka gunakan tanpa menimbulkan ketergantungan eksternal.
Olivier Grisel, yang merupakan salah satu orang di belakang Loky, memiliki dek slide hebat yang merangkum keadaan multiprosesor dengan Python: http://ogrisel.github.io/decks/2017_euroscipy_parallelism/
Saya tidak keberatan, karena sekarang saya telah menulis Dataloader baru yang tidak memiliki masalah. Tapi saya, FWIW, curiga bahwa interaksi antara multiprosesor pytorch dan sistem lain akan menjadi masalah bagi orang lain juga di masa depan.
jph00
pada 2 Nov 2017
Untuk apa nilainya, saya mengalami masalah ini pada Python 2.7 di ubuntu 14.04. Pemuat data saya membaca dari database sqlite dan bekerja sempurna dengan num_workers=0 , terkadang tampak OK dengan num_workers=1 , dan sangat cepat menemui jalan buntu untuk nilai yang lebih tinggi. Jejak tumpukan menunjukkan proses digantung di recv_bytes .
Hal-hal yang tidak berhasil:
- Melewati
--shm-size 8Gatau--ipc=hostsaat meluncurkan buruh pelabuhan - Menjalankan
echo 16834 | sudo tee /proc/sys/kernel/shmmniuntuk menambah jumlah segmen memori bersama (defaultnya adalah 4096 pada mesin saya) - Mengatur
pin_memory=Trueataupin_memory=False, tidak ada yang membantu
Hal yang secara andal memperbaiki masalah saya adalah mem-porting kode saya ke Python 3. Meluncurkan versi Torch yang sama di dalam instance Python 3.6 (dari Anaconda) sepenuhnya memperbaiki masalah saya dan sekarang pemuatan data tidak lagi macet.
 gcr
pada 16 Nov 2017
gcr
pada 16 Nov 2017
@apaszke inilah mengapa bekerja dengan baik dengan opencv itu penting, FYI (dan mengapa torchsample bukan pilihan yang bagus - ini dapat menangani rotasi <200 gambar/dtk!):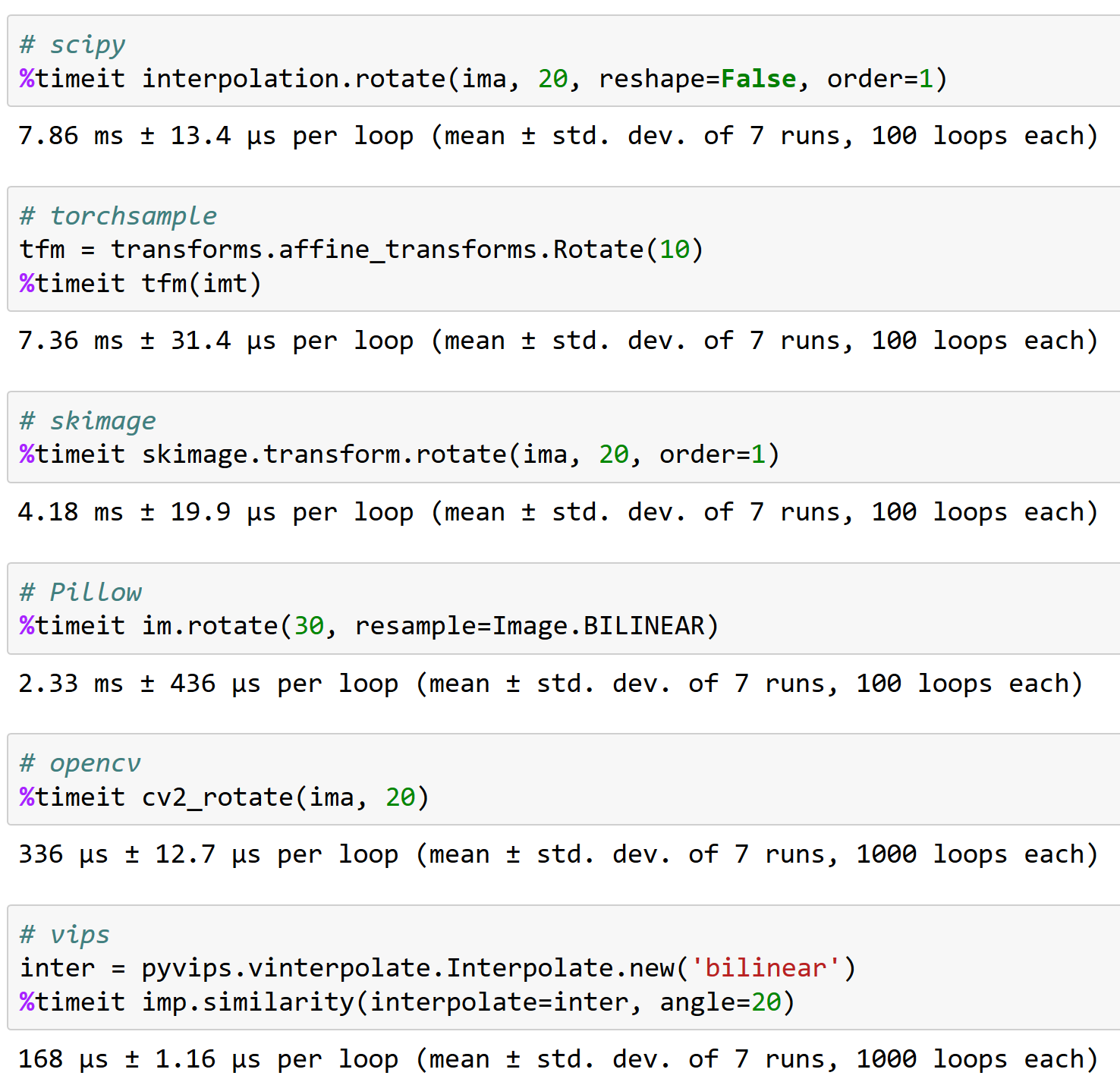
jph00
pada 18 Nov 2017
Apakah ada yang menemukan solusi untuk masalah ini?
 iqbalu
pada 9 Des 2017
iqbalu
pada 9 Des 2017
@iqbalu Coba script di atas: https://github.com/fastai/fastai/blob/master/fastai/dataloader.py
Itu memecahkan masalah saya tetapi tidak mendukung num_workers=0 .
 elbaro
pada 14 Des 2017
elbaro
pada 14 Des 2017
@elbaro sebenarnya saya mencobanya dan dalam kasus saya itu tidak menggunakan banyak pekerja sama sekali. Apakah Anda mengubah sesuatu di sana?
iqbalu
pada 14 Des 2017
@iqbalu fast.ai data loader tidak pernah memunculkan proses pekerja. Itu hanya menggunakan utas, jadi mungkin tidak muncul di beberapa alat
apaszke
pada 14 Des 2017
@apaszke @elbaro @jph00 Pemuat data dari fast.ai memperlambat pembacaan data lebih dari 10x. Saya menggunakan num_workers=8. Adakah petunjuk apa yang bisa menjadi alasannya?
iqbalu
pada 15 Des 2017
Sepertinya pemuat data menggunakan paket yang tidak melepaskan GIL
apaszke
pada 15 Des 2017
@apaszke tahu mengapa penggunaan memori bersama terus meningkat setelah beberapa zaman. Dalam kasus saya, ini dimulai dengan 400MB dan kemudian setiap ~20th meningkat sebesar 400MB. Terima kasih!
iqbalu
pada 28 Des 2017
@iqbalu tidak juga. Itu seharusnya tidak terjadi
apaszke
pada 28 Des 2017
Saya mencoba banyak hal dan cv2.setNumThreads(0) akhirnya menyelesaikan masalah saya.
Terima kasih @jph00
 Cadene
pada 19 Jan 2018
Cadene
pada 19 Jan 2018
Saya telah terganggu oleh masalah ini baru-baru ini. cv2.setNumThreads(0) tidak bekerja untuk saya. Saya bahkan mengubah semua kode cv2 untuk menggunakan scikit-image sebagai gantinya, tetapi masalahnya masih ada. Selain itu, saya memiliki 16G untuk /dev/shm . Saya hanya memiliki masalah ini saat menggunakan banyak GPU. Semuanya berfungsi dengan baik pada satu GPU. Apakah ada yang punya pemikiran baru tentang solusinya?
 roytseng-tw
pada 25 Jan 2018
roytseng-tw
pada 25 Jan 2018
Kesalahan yang sama. Saya memiliki masalah ini saat menggunakan GPU tunggal.
 Jiankai-Sun
pada 27 Jan 2018
Jiankai-Sun
pada 27 Jan 2018
Bagi saya menonaktifkan utas opencv memecahkan masalah:
cv2.setNumThreads(0)
 shacharf
pada 28 Jan 2018
shacharf
pada 28 Jan 2018
tekan juga dengan pytorch 0.3, cuda 8.0, ubuntu 16.04
tidak ada opencv yang digunakan.
 tianq01
pada 1 Feb 2018
tianq01
pada 1 Feb 2018
Saya menggunakan pytorch 0.3, cuda 8.0, ubuntu 14.04. Mengamati hang ini setelah saya mulai menggunakan cv2.resize()
cv2.setNumThreads(0) memecahkan masalah saya.
 mathmanu
pada 9 Feb 2018
mathmanu
pada 9 Feb 2018
Saya menggunakan python 3.6, pytorch 0.3.0, cuda 8.0 dan ubuntu 17.04 pada sistem dengan dua 1080Ti dan 32GB RAM.
Ketika saya menggunakan 8 pekerja untuk dataset saya sendiri, saya sering melihat kebuntuan (itu terjadi di zaman pertama). Ketika saya mengurangi pekerja menjadi 4, itu menghilang (saya menjalankan 80 zaman).
Ketika kebuntuan terjadi, saya masih memiliki ~ 10GB kosong di RAM.
 milani
pada 2 Mar 2018
milani
pada 2 Mar 2018
Di sini Anda dapat melihat log setelah menghentikan skrip: https://Gist.github.com/milani/42f50c023cdca407115b309237d29c70
PEMBARUAN: Saya mengonfirmasi bahwa saya dapat menyelesaikan masalah dengan meningkatkan SHMMNI . Di Ubuntu 17.04, saya menambahkan kernel.shmmni=8192 ke /etc/sysctl.conf .
milani
pada 2 Mar 2018
Juga mengalami masalah ini, Ubuntu 17.10, Python 3.6, Pytorch 0.3.1, CUDA 8.0. Ada banyak RAM yang tersisa ketika kebuntuan terjadi dan waktu tampaknya tidak konsisten - dapat terjadi setelah epoch ke-1, atau setelah ke-200.
Kombinasi kernel.shmmni=8192 dan cv2.setNumThreads(0) tampaknya telah memperbaikinya, sedangkan mereka tidak bekerja secara individual.
 inoryy
pada 8 Mar 2018
inoryy
pada 8 Mar 2018
Sama dalam kasus saya. Saya mengalami kebuntuan jika saya mengatur num_workers=4. Saya menggunakan Ubuntu 17.10, Pytorch 0.3.1, CUDA 9.1, python 3.6. Diamati bahwa ada 4 utas python, yang masing-masing menempati memori 1,6 GB sementara CPU (4 core) tetap menganggur. Pengaturan num_workers=0 membantu menyelesaikan masalah ini.
 AlenUbuntu
pada 27 Mar 2018
AlenUbuntu
pada 27 Mar 2018
Saya memiliki masalah yang sama, membeku setelah tepat satu zaman, tetapi tidak benar-benar dapat direproduksi untuk kumpulan data yang lebih kecil. Saya menggunakan CUDA 9.1, Pytorch 0.3.1, Python 3.6 di lingkungan Docker.
Saya mencoba Dataloader @ jph00 , namun saya merasa jauh lebih lambat untuk usecase saya. Solusi saya saat ini adalah membuat ulang Pytorch DataLoader sebelum setiap Zaman. Ini tampaknya berhasil, tetapi sangat jelek.
 tfriedel
pada 11 Apr 2018
tfriedel
pada 11 Apr 2018
Saya memiliki masalah yang persis sama di Ubuntu 17.10, CUDA 9.1, master Pytorch (dikompilasi 19/04 pagi). Juga menggunakan OpenCV di subkelas Dataset saya.
Kemudian saya dapat menghindari kebuntuan dengan mengubah metode mulai multiproses dari 'forkserver' menjadi 'spawn':
# Set multiprocessing start method - deadlock
set_start_method(forkserver')
# Set multiprocessing start method - runs fine
set_start_method('spawn')
 mfuntowicz
pada 19 Apr 2018
mfuntowicz
pada 19 Apr 2018
Saya hampir mencoba semua pendekatan di atas! Tak satu pun dari mereka bekerja!
Masalah ini mungkin terkait dengan beberapa ketidakcocokan dengan arsitektur perangkat keras dan saya tidak tahu bagaimana Pytorch dapat memprovokasinya! Ini mungkin atau mungkin bukan masalah Pytorch!
Jadi, inilah cara masalah saya diselesaikan:
_Saya memperbarui BIOS!
Cobalah. Setidaknya itu menyelesaikan masalahku.
 astorfi
pada 21 Apr 2018
astorfi
pada 21 Apr 2018
Sama disini. Ubuntu PyTorch 0.4, python3.6.
 Shuailong
pada 30 Apr 2018
Shuailong
pada 30 Apr 2018
Sepertinya masalahnya masih ada di pytorch 0.4 dan python 3.6. Tidak yakin apakah itu masalah pytorch. Saya menggunakan opencv dan mengatur num_workers=8 , pin_memory=True . Saya mencoba semua trik yang disebutkan di atas dan menyetel cv2.setNumThreads(0) menyelesaikan masalah saya.
 JasonQSY
pada 10 Mei 2018
JasonQSY
pada 10 Mei 2018
(1) Mengatur num_workers=0 dalam pemuatan data PyTorch memecahkan masalah (lihat di atas) ATAU
(2) cv2.setNumThreads(0) memecahkan masalah bahkan dengan num_workers yang cukup besar
Ini terlihat seperti masalah penguncian utas.
Saya mengatur cv2.setNumThreads(0) di suatu tempat menuju awal file python utama saya dan saya tidak pernah mengalami masalah ini sejak saat itu.
mathmanu
pada 10 Mei 2018
Ya, banyak dari masalah itu karena perpustakaan pihak ketiga tidak aman untuk fork. Salah satu resolusi alternatif mungkin menggunakan metode spawn start.
apaszke
pada 10 Mei 2018
Bagi saya, masalah kebuntuan muncul ketika saya membungkus model saya dengan nn.DataParallel dan menggunakan num_workers > 0 di dataloader. Dengan menghapus pembungkus nn.DataParallel, saya dapat menjalankan skrip saya tanpa penguncian apa pun.
CUDA_VISIBLE_DEVICES=0 python myscript.py --split 1
CUDA_VISIBLE_DEVICES=1 python myscript.py --split 2
Tanpa banyak GPU, skrip saya berjalan lebih lambat tetapi saya dapat menjalankan beberapa eksperimen pada saat yang sama pada pemisahan dataset yang berbeda.
 euwern
pada 15 Jun 2018
euwern
pada 15 Jun 2018
Saya memiliki masalah yang sama pada Python 3.6.2 / Pytorch 0.4.0.
dan saya mencoba di atas semua pendekatan switching pin_memory, mengubah ukuran memori bersama, dan saya menggunakan perpustakaan skiamge (saya tidak menggunakan cv2!!), tapi saya masih punya masalah.
masalah ini meningkat secara acak. mengendalikan masalah ini hanya dengan menonton konsol dan memulai kembali pelatihan.
 slaysd
pada 19 Jun 2018
slaysd
pada 19 Jun 2018
@ jinh574 Saya baru saja mengatur jumlah pekerja pemuat data ke 0, dan berhasil.
Shuailong
pada 19 Jun 2018
@Shuailong Saya harus menggunakan gambar ukuran besar, jadi saya tidak dapat menggunakan parameter itu karena kecepatan. saya perlu lebih memeriksa tentang masalah ini
slaysd
pada 19 Jun 2018
Saya memiliki masalah yang sama pada Python 3.6 / Pytorch 0.4.0. Apakah opsi pin_memory mempengaruhi sesuatu?
 ein-farbe
pada 26 Jun 2018
ein-farbe
pada 26 Jun 2018
Jika Anda menggunakan collate_fn, dan num_workers>0 dengan versi PyTorch < 0.4:
PASTIKAN ANDA TIDAK MENGEMBALIKAN NOL DIM TENSOR DARI FUNGSI __getitem__() ANDA.
ATAU KEMBALI SEBAGAI ARRAY NUMPY.
 pyaf
pada 12 Jul 2018
pyaf
pada 12 Jul 2018
Saya memiliki masalah itu bahkan setelah menyetel num_workers=0 atau cv2.setNumThreads(0).
Gagal dengan salah satu dari dua masalah ini. Adakah orang lain yang menghadapi hal yang sama?
Traceback (panggilan terakhir terakhir):
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", baris 193, di _run_module_as_main
"__main__", mod_spec)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", baris 85, di _run_code
exec(kode, run_globals)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", baris 209, di
utama()
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", baris 205, di main
proses.tunggu()
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", baris 1457, menunggu
(pid, sts) = self._try_wait(0)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", baris 1404, di _try_wait
(pid, sts) = os.waitpid(self.pid, wait_flags)
Interupsi Keyboard
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", baris 258, di _bootstrap
diri.run()
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", baris 93, sedang dijalankan
self._target( self._args, * self._kwargs)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/utils/data/dataloader.py", baris 96, di _worker_loop
r = index_queue.get(batas waktu=MANAGER_STATUS_CHECK_INTERVAL)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/queues.py", baris 104, di get
jika bukan self._poll(batas waktu):
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", baris 257, dalam polling
kembalikan self._poll(batas waktu)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", baris 414, di _poll
r = tunggu([mandiri], batas waktu)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", baris 911, menunggu
siap = pemilih.pilih(batas waktu)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/selectors.py", baris 376, di pilih
fd_event_list = self._poll.poll(batas waktu)
Interupsi Keyboard
 swethmandava
pada 25 Agu 2018
swethmandava
pada 25 Agu 2018
Saya menggunakan versi '0.5.0a0+f57e4ce' dan memiliki masalah yang sama. Membatalkan pemuat data paralel (num_workers=0) atau menyetel cv2.setNumThreads(0) berfungsi.
 omersumer
pada 5 Okt 2018
omersumer
pada 5 Okt 2018
Saya cukup yakin bahwa #11985 akan menghilangkan semua gangguan (kecuali jika Anda menyela pada waktu yang tidak menguntungkan yang tidak dapat kami kendalikan). Sekarang setelah digabungkan, saya menutup ini.
Masalah dengan cv2 juga di luar kendali kami karena cv2 tidak berfungsi dengan baik dengan multiprosesor.
SsnL
pada 9 Okt 2018
Masih mengalami ini pada torch_nightly-1.0.0.dev20181029 , PRnya belum digabung di sana?
 Evpok
pada 30 Okt 2018
Evpok
pada 30 Okt 2018
@Evpok ini telah digabungkan di sana. Anda harus memiliki tambalan ini dengan pasti. Ingin tahu apakah ada kemungkinan kebuntuan lagi. Apakah Anda memiliki repro mudah yang bisa kami coba lihat?
soumith
pada 30 Okt 2018
Saya benar-benar melacaknya ke kekacauan multiprosesor yang tidak terkait di pihak saya, maaf atas ketidaknyamanan ini.
Evpok
pada 30 Okt 2018
hai @Evpok
saya menggunakan torch_nightly-1.0.0 , dan menemui masalah ini. apakah kamu sudah memecahkan masalah ini?
 zimenglan-sysu-512
pada 14 Nov 2018
zimenglan-sysu-512
pada 14 Nov 2018
Jika Anda menggunakan collate_fn, dan num_workers>0 dengan versi PyTorch < 0.4:
PASTIKAN ANDA TIDAK MENGEMBALIKAN NOL DIM TENSOR DARI FUNGSI
__getitem__()ANDA.
ATAU KEMBALI SEBAGAI ARRAY NUMPY.
Saya memperbaiki bug saya untuk mengembalikan nol tensor redup dan masalahnya masih ada.
 liluxuan1997
pada 14 Nov 2018
liluxuan1997
pada 14 Nov 2018
@zimenglan-sysu-512 Masalah utamanya adalah dengan keterbatasan multiprocessing : saat menggunakan spawn atau forkserver (yang diperlukan untuk komunikasi CPU-GPU) berbagi objek antar proses agak terbatas dan tidak cocok untuk jenis objek yang harus saya manipulasi.
Evpok
pada 14 Nov 2018
Tak satu pun dari ini bekerja untuk saya. Namun, opencv terbaru berfungsi ( 3.4.0.12 hingga 3.4.3.18 tidak ada lagi yang berubah):
sudo pip3 install --upgrade opencv-python
 see--
pada 17 Nov 2018
see--
pada 17 Nov 2018
@lihat-- senang mengetahui bahwa opencv memperbaiki masalah mereka :)
SsnL
pada 17 Nov 2018
Saya menggunakan OpenCV 3.4.3.18 dengan python2.7, dan saya masih melihat kebuntuan terjadi. :/
 SreenivasVRao
pada 3 Des 2018
SreenivasVRao
pada 3 Des 2018
Silakan coba yang berikut ini:
from torch.utils.data.dataloader import DataLoader
dari pada
from torch.utils.data import DataLoader
Saya pikir ada masalah dengan pemeriksaan tipe di sini:
https://github.com/pytorch/pytorch/blob/656b565a0f53d9f24547b060bd27aa67ebb89b88/torch/utils/data/dataloader.py#L816
 jewfro-cuban
pada 16 Des 2018
jewfro-cuban
pada 16 Des 2018
Silakan coba yang berikut ini:
from torch.utils.data.dataloader import DataLoaderdari pada
from torch.utils.data import DataLoaderSaya pikir ada masalah dengan pemeriksaan tipe di sini:
pytorch/torch/utils/data/dataloader.py
Jalur 816 di 656b565
super(DataLoader, self).__setattr__(attr, val)
Apakah ini bukan hanya sebuah alias? di torch.utils.data.__init__ mereka mengimpor dataloader.DataLoader
 simonhessner
pada 8 Jan 2019
simonhessner
pada 8 Jan 2019
Saya juga memiliki num_workers > 0. Kode saya tidak memiliki opencv, dan penggunaan memori /dev/shm tidak menjadi masalah. Tidak ada saran di atas yang berhasil untuk saya. Perbaikan saya adalah memperbarui numpy dari 1.14.1 ke 1.14.5:
conda install numpy=1.14.5
Semoga bermanfaat.
 daniyar-niantic
pada 8 Jan 2019
daniyar-niantic
pada 8 Jan 2019
Hmm, versi numpy saya adalah 1.15.4, jadi lebih baru dari 1.14.5... Seharusnya tidak apa-apa?
simonhessner
pada 8 Jan 2019
Hmm, versi numpy saya adalah 1.15.4, jadi lebih baru dari 1.14.5... Seharusnya tidak apa-apa?
Idk, pembaruan numpy saya juga memperbarui mkl.
daniyar-niantic
pada 8 Jan 2019
Versi mkl yang Anda miliki? Milik saya adalah 2019.1 (build 144) dan paket lain yang menyertakan mkl dalam namanya adalah:
mkl-service 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
simonhessner
pada 8 Jan 2019
Versi mkl yang Anda miliki? Milik saya adalah 2019.1 (build 144) dan paket lain yang menyertakan mkl dalam namanya adalah:
mkl-service 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
conda list | grep mkl
mkl 2018.0.1 h19d6760_4
mkl-service 1.1.2 py36h17a0993_4
Jika Anda masih melihat hang di pytorch terbaru, akan sangat membantu jika Anda dapat memberikan skrip pendek yang mereproduksi masalah tersebut. Terima kasih!
SsnL
pada 9 Jan 2019
Saya masih melihat kebuntuan ini, saya akan melihat apakah saya dapat membuat skrip yang mereproduksi.
 dtmoodie
pada 15 Jan 2019
dtmoodie
pada 15 Jan 2019
pin_memory=True memecahkan masalah untuk saya.
pyaf
pada 30 Jan 2019
Tampaknya tidak berfungsi untuk saya dengan pin_memory=True , masih macet setelah 70 zaman. Satu-satunya hal yang berhasil bagi saya sejauh ini adalah menyetel num_workers=0 , tetapi terasa lebih lambat.
 jclevesque
pada 14 Feb 2019
jclevesque
pada 14 Feb 2019
Saya juga mengalami kebuntuan (terjadi secara acak). Mencoba pin_memory dan memperbarui Numpy. Saya akan mencoba menjalankannya di mesin lain.
 Avsecz
pada 14 Feb 2019
Avsecz
pada 14 Feb 2019
Jika Anda menggunakan beberapa utas dengan pemuat data di dalamnya, coba gunakan multiprosesor alih-alih multithreading. Ini benar-benar menyelesaikan masalah bagi saya (dan omong-omong, ini juga lebih baik untuk tugas-tugas komputasi intensif dengan Python karena GIL)
simonhessner
pada 14 Feb 2019
kesalahan yang sama di Pytorch1.0, Pillow5.0.0 numpy1.16.1 python3.6
 jianlong-yuan
pada 15 Feb 2019
jianlong-yuan
pada 15 Feb 2019
Saya juga mendapatkan kesalahan yang sama. Saya telah menetapkan pin_memory=True dan num_workers=0 . Meskipun satu hal yang saya perhatikan bahwa ketika saya menggunakan sebagian kecil dari dataset, kesalahan ini tidak terjadi. Hanya menggunakan seluruh kumpulan data yang menyebabkan kesalahan ini.
Sunting: Hanya restart sederhana dari sistem yang memperbaikinya untuk saya.
 Venka97
pada 6 Mar 2019
Venka97
pada 6 Mar 2019
Saya memiliki masalah serupa. Dalam beberapa kode, fungsi ini (hampir selalu) bertahan di d_iter.next():
def get_next_batch(d_iter, loader):
try:
data, label = d_iter.next()
except StopIteration:
d_iter = iter(loader)
data, label = d_iter.next()
return data, label
Retasan yang berhasil bagi saya adalah menambahkan sedikit penundaan setelah memanggil fungsi ini
trn_X, trn_y = get_next_batch(train_data_iter, train_loader)
time.sleep(0.003)
val_X, val_y = get_next_batch(valid_data_iter, valid_loader)
Saya kira penundaan membantu menghindari kebuntuan?
 enoonIT
pada 20 Mar 2019
enoonIT
pada 20 Mar 2019
Saya masih menemui masalah ini. Menggunakan pytorch 1.0 dan python 3.7. Ketika saya menggunakan banyak data_loader, bug ini akan muncul. Jika saya menggunakan kurang dari 3 data_loader atau menggunakan satu GPU, bug ini tidak akan muncul. Dicoba:
- waktu.tidur(0.003)
- pin_memory=Benar/Salah
- jumlah_pekerja=0/1
- dari torch.utils.data.dataloader impor DataLoader
- menulis 8192 ke /proc/sys/kernel/shmmni
Tak satu pun dari mereka bekerja. Tidak tahu apakah ada solusi?
 xuw080
pada 16 Apr 2019
xuw080
pada 16 Apr 2019
solusi saya tambahkan cv2.setNumThreads(0) di program praproses
Saya memiliki 2 dataloader, yaitu untuk kereta dan val
Saya hanya bisa menjalankan penilai sekali.
 lightningsoon
pada 10 Mei 2019
lightningsoon
pada 10 Mei 2019
Saya baru saja menemukan bug ini dengan pytorch 1.1. Sama terjebak dua kali di tempat yang sama: akhir zaman ke-99. pin_memory disetel ke False .
 Randl
pada 17 Mei 2019
Randl
pada 17 Mei 2019
Masalah yang sama saat menggunakan pekerja> 0, memori pin tidak menyelesaikan masalah.
 nicolasCruzW21
pada 20 Mei 2019
nicolasCruzW21
pada 20 Mei 2019
solusi saya tambahkan cv2.setNumThreads(0) di program praproses
Saya memiliki 2 dataloader, yaitu untuk kereta dan val
Saya hanya bisa menjalankan penilai sekali.
Solusi ini bekerja untuk saya, terima kasih
 zxhr2793
pada 3 Jun 2019
zxhr2793
pada 3 Jun 2019
pemuat data berhenti ketika saya menyelesaikan suatu zaman dan akan memulai zaman baru.
menemui masalah yang sama. Dalam kasus saya, masalah muncul ketika saya menginstal opencv-python (saya telah menginstal opencv3 sebelumnya). Setelah pindah opencv-python, pelatihan tidak akan berhenti.
 hongzhenwang
pada 20 Jun 2019
hongzhenwang
pada 20 Jun 2019
itu ide yang bagus juga
Pada 20-06-2019 10:51:02, "hongzhenwang" [email protected] menulis:
pemuat data berhenti ketika saya menyelesaikan suatu zaman dan akan memulai zaman baru.
menemui masalah yang sama. Dalam kasus saya, masalah muncul ketika saya menginstal opencv-python (saya telah menginstal opencv3 sebelumnya). Setelah pindah opencv-python, pelatihan tidak akan berhenti.
—
Anda menerima ini karena Anda berkomentar.
Balas email ini secara langsung, lihat di GitHub, atau matikan utasnya.
lightningsoon
pada 27 Jun 2019
Saya masih menemui masalah ini. Menggunakan pytorch 1.0 dan python 3.7. Ketika saya menggunakan banyak data_loader, bug ini akan muncul. Jika saya menggunakan kurang dari 3 data_loader atau menggunakan satu GPU, bug ini tidak akan muncul. Dicoba:
1. time.sleep(0.003) 2. pin_memory=True/False 3. num_workers=0/1 4. from torch.utils.data.dataloader import DataLoader 5. writing 8192 to /proc/sys/kernel/shmmni None of them works. Don't know whether there is any solutions?
Masih berusaha mencari solusi. Saya setuju bahwa saya sepertinya hanya memiliki masalah ini ketika saya menjalankan 2 proses paralel pada GPU yang berbeda secara bersamaan. Yang satu terus berjalan sementara yang lain berhenti.
 ArturoDeza
pada 3 Jul 2019
ArturoDeza
pada 3 Jul 2019
Ketika saya mengatur num_workers=4, program macet selama beberapa detik (atau beberapa menit) setiap 4 batch., Yang membuang banyak waktu. Adakah ide tentang cara menyelesaikannya?
 huangchaoxing
pada 27 Jul 2019
huangchaoxing
pada 27 Jul 2019
menambahkan flag: pin_memory=True dan num_workers=0 di pemuat data adalah solusinya!
ArturoDeza
pada 27 Jul 2019
menambahkan flag: pin_memory=True dan num_workers=0 di pemuat data adalah solusinya!
@ArturoDeza
Ini mungkin solusi. Namun, pengaturan num_workers=0 memperlambat pengambilan seluruh data dari cpu dan tingkat penggunaan GPU akan sangat rendah.
huangchaoxing
pada 28 Jul 2019
Bagi saya, alasannya adalah tidak ada cukup CPU di sistem saya atau tidak cukup num_workers ditentukan dalam Dataloader. Sebaiknya nonaktifkan threading di pekerja Dataloader jika metode __get_item__ di dataloader menggunakan pustaka berulir seperti numpy , librosa atau opencv (silakan lihat di bawah mengapa ini penting). Ini dapat dicapai dengan menjalankan skrip pelatihan Anda dengan OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . Sebagai klarifikasi untuk diskusi di bawah ini, harap perhatikan bahwa setiap kumpulan Dataloader ditangani oleh satu pekerja: setiap pekerja menangani sampel batch_size untuk menyelesaikan satu kumpulan, dan kemudian mulai memproses kumpulan data baru.
Anda perlu menyetel num_workers lebih rendah dari jumlah CPU di mesin (atau pod jika Anda menggunakan Kubernetes), tetapi cukup tinggi sehingga data selalu siap untuk iterasi berikutnya. Jika GPU menjalankan setiap iterasi dalam t detik, dan setiap pekerja pemuat data membutuhkan N*t detik untuk memuat/memproses satu kumpulan, maka Anda harus menyetel num_workers ke setidaknya N , untuk menghindari gangguan GPU. Tentu saja, Anda harus memiliki setidaknya N CPU dalam sistem.
Sayangnya, jika Dataloader menggunakan pustaka apa pun yang menggunakan utas K , maka jumlah proses yang dihasilkan menjadi num_workers*K = N*K . Ini bisa jauh lebih tinggi daripada jumlah CPU di mesin. Ini mencekik pod, dan Dataloader menjadi sangat lambat. Hal ini dapat menyebabkan Dataloader tidak mengembalikan batch setiap t detik, menyebabkan GPU terhenti.
Salah satu cara untuk menghindari utas K adalah dengan memanggil skrip utama dengan OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . Ini membatasi setiap pekerja Dataloader untuk menggunakan satu utas, dan menghindari membebani mesin. Anda masih harus memiliki cukup num_workers untuk menjaga agar GPU tetap diumpankan.
Anda juga harus mengoptimalkan kode Anda di __get_item__ sehingga setiap pekerja menyelesaikan batch-nya dalam waktu singkat. Harap pastikan waktu untuk menyelesaikan pra-pemrosesan batch oleh pekerja tidak terhalang oleh waktu untuk membaca data pelatihan dari disk (terutama jika Anda membaca dari penyimpanan jaringan), atau bandwidth jaringan (jika Anda membaca dari jaringan disk). Jika dataset Anda kecil dan Anda memiliki RAM yang cukup, pertimbangkan untuk memindahkan dataset ke RAM (atau /tmpfs ) dan baca dari sana untuk akses cepat. Untuk Kubernetes, Anda dapat membuat disk RAM (cari emptyDir di Kubernetes).
Jika Anda telah mengoptimalkan kode __get_item__ , dan memastikan bahwa akses disk/akses jaringan bukan penyebabnya, tetapi masih melihat kemacetan, Anda perlu meminta lebih banyak CPU (untuk pod Kubernetes) atau memindahkan GPU Anda ke mesin dengan lebih banyak CPU.
Pilihan lain adalah mengurangi batch_size sehingga setiap worker memiliki lebih sedikit pekerjaan yang harus dilakukan, dan akan menyelesaikan pra-pemrosesan lebih cepat. Opsi terakhir tidak diinginkan dalam beberapa kasus, karena akan ada memori GPU yang tidak digunakan yang tidak digunakan.
Anda juga dapat mempertimbangkan untuk melakukan beberapa pra-pemrosesan secara offline, dan mengurangi beban setiap pekerja. Misalnya, jika setiap pekerja membaca dalam file wav dan menghitung spektogram untuk file audio, Anda dapat mempertimbangkan untuk menghitung spektogram secara offline dan hanya membaca spektogram yang dihitung dari disk di pekerja. Ini akan mengurangi jumlah pekerjaan yang harus dilakukan setiap pekerja.
 gkeskin07
pada 3 Agu 2019
gkeskin07
pada 3 Agu 2019
temui masalah yang sama dengan horovod
 jinhou
pada 12 Agu 2019
jinhou
pada 12 Agu 2019
Temui masalah serupa... Kebuntuan saat baru saja menyelesaikan sebuah Epoch dan mulai memuat data untuk validasi...
 jackroos
pada 20 Agu 2019
jackroos
pada 20 Agu 2019
@jinhou @jackroos Hal yang sama, secara acak macet di awal validasi dengan horovod. Apa yang saat ini saya lakukan sebagai solusinya adalah mengatur batas waktu dan melewati validasi. Apakah Anda punya solusi?
 lzljzys
pada 28 Agu 2019
lzljzys
pada 28 Agu 2019
@jinhou @jackroos Hal yang sama, secara acak macet di awal validasi dengan horovod. Apa yang saat ini saya lakukan sebagai solusinya adalah mengatur batas waktu dan melewati validasi. Apakah Anda punya solusi?
Tidak. Saya hanya mematikan pelatihan terdistribusi dalam kasus itu.
jackroos
pada 29 Agu 2019
Saya menemui masalah serupa: pemuat data berhenti ketika saya menyelesaikan suatu zaman dan akan memulai zaman baru.
kenapa banyak zan?
 foocker
pada 22 Okt 2019
foocker
pada 22 Okt 2019
Saya masih menemui masalah ini. Menggunakan pytorch 1.0 dan python 3.7. Ketika saya menggunakan banyak data_loader, bug ini akan muncul. Jika saya menggunakan kurang dari 3 data_loader atau menggunakan satu GPU, bug ini tidak akan muncul. Dicoba:
- waktu.tidur(0.003)
- pin_memory=Benar/Salah
- jumlah_pekerja=0/1
- dari torch.utils.data.dataloader impor DataLoader
- menulis 8192 ke /proc/sys/kernel/shmmni
Tak satu pun dari mereka bekerja. Tidak tahu apakah ada solusi?
num_workers diatur ke 0 bekerja untuk saya. Anda harus memastikannya pada 0 di mana pun Anda menggunakannya.
Beberapa solusi potensial lainnya:
- dari multiprocessing impor set_start_method
set_start_method('spawn') - cv2.setNumThreads(0)
Tampaknya 3 atau 7 adalah cara untuk pergi.
 the7threvival
pada 18 Nov 2019
the7threvival
pada 18 Nov 2019
Saya mengalami masalah ini dengan pytorch 1.3, ubuntu16, semua saran di atas tidak berfungsi kecuali pekerja=0 yang memperlambat eksekusi. Ini hanya terjadi ketika menjalankan dari terminal, dalam notebook Jupyter semuanya baik-baik saja, bahkan dengan pekerja=32.
Masalahnya sepertinya tidak terpecahkan, haruskah dibuka kembali? Saya juga melihat banyak orang lain melaporkan masalah yang sama...
 skariel
pada 2 Des 2019
skariel
pada 2 Des 2019
Saya masih menemui masalah ini. Menggunakan pytorch 1.0 dan python 3.7. Ketika saya menggunakan banyak data_loader, bug ini akan muncul. Jika saya menggunakan kurang dari 3 data_loader atau menggunakan satu GPU, bug ini tidak akan muncul. Dicoba:
- waktu.tidur(0.003)
- pin_memory=Benar/Salah
- jumlah_pekerja=0/1
- dari torch.utils.data.dataloader impor DataLoader
- menulis 8192 ke /proc/sys/kernel/shmmni
Tak satu pun dari mereka bekerja. Tidak tahu apakah ada solusi?num_workers diatur ke 0 bekerja untuk saya. Anda harus memastikannya pada 0 di mana pun Anda menggunakannya.
Beberapa solusi potensial lainnya:
- dari multiprocessing impor set_start_method
set_start_method('spawn')- cv2.setNumThreads(0)
Tampaknya 3 atau 7 adalah cara untuk pergi.
Saya memodifikasi train.py seperti ini:
from __future__ import division
import cv2
cv2.setNumThreads(0)
import argparse
...
Dan itu bekerja untuk saya.
 DHZS
pada 10 Des 2019
DHZS
pada 10 Des 2019
Hai teman-teman jika saya bisa membantu,
Saya juga punya masalah ini mirip dengan ini, tapi itu akan terjadi setiap 100 atau lebih zaman.
Saya perhatikan itu hanya terjadi dengan CUDA diaktifkan, juga dmesg memiliki entri log ini setiap kali macet.
python[11240]: segfault at 10 ip 00007fabdd6c37d8 sp 00007ffddcd64fd0 error 4 in libcudart.so.10.1.243[7fabdd699000+77000]
Ini omong kosong bagi saya, tetapi itu memberi tahu saya bahwa CUDA dan python multithreading tidak berfungsi dengan baik.
Perbaikan saya adalah menonaktifkan cuda di datathreads, berikut adalah cuplikan file entri python saya.
from multiprocessing import set_start_method
import os
if __name__ == "__main__":
set_start_method('spawn')
else:
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import torch
import application
Semoga itu bisa membantu siapa saja yang mendarat di sini seperti yang saya butuhkan saat itu.
 roderickObrist
pada 24 Mar 2020
roderickObrist
pada 24 Mar 2020
@jinhou @jackroos Hal yang sama, secara acak macet di awal validasi dengan horovod. Apa yang saat ini saya lakukan sebagai solusinya adalah mengatur batas waktu dan melewati validasi. Apakah Anda punya solusi?
Tidak. Saya hanya mematikan pelatihan terdistribusi dalam kasus itu.
Saya menemui masalah serupa dalam pelatihan terdistribusi tanpa menggunakan OpenCV setelah memperbarui ke PyTorch 1.4.
Sekarang saya harus menjalankan validasi sekali sebelum pelatihan dan loop validasi.
 wizardk
pada 9 Jun 2020
wizardk
pada 9 Jun 2020
Aku punya banyak masalah dengan ini. Tampaknya bertahan di seluruh versi pytorch, versi python dan juga mesin fisik yang berbeda (yang kemungkinan akan diatur secara identik).
Setiap kali itu adalah kesalahan yang sama:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/bicep/loops.py", line 73, in __call__
for data, target in self.dataloader:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 830, in _next_data
self._shutdown_workers()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 942, in _shutdown_workers
w.join()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/process.py", line 149, in join
res = self._popen.wait(timeout)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 47, in wait
return self.poll(os.WNOHANG if timeout == 0.0 else 0)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll
pid, sts = os.waitpid(self.pid, flag)
Jelas ada beberapa masalah dalam cara menangani proses pada mesin yang saya gunakan. Tak satu pun dari solusi di atas tampaknya berfungsi, selain dari pengaturan num_workers=0.
Saya benar-benar ingin dapat menyelesaikan ini, apakah ada yang tahu harus mulai dari mana atau bagaimana menginterogasi ini?
 brynhayder
pada 9 Jun 2020
brynhayder
pada 9 Jun 2020
Saya juga di sini.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 480, in _try_get_batch
data = self.data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 65, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 95106) is killed by signal: Segmentation fault.
Satu hal yang menarik adalah
ketika saya hanya mengurai data baris demi baris, saya tidak memiliki masalah ini:
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
tetapi jika saya menambahkan logika parse JSON setelah membaca baris demi baris, itu akan melaporkan kesalahan ini
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
Saya mengerti akan ada beberapa overhead memori JSON, tetapi bahkan saya mengurangi jumlah pekerja menjadi 2, dan kumpulan data sangat kecil, masih memiliki masalah yang sama. Saya agak ragu itu terkait shm. ada petunjuk?
 zhangruiskyline
pada 16 Jun 2020
zhangruiskyline
pada 16 Jun 2020
Haruskah kita membuka kembali masalah ini?
 takatosp1
pada 18 Jun 2020
takatosp1
pada 18 Jun 2020
Saya pikir kita harus. BTW, saya melakukan beberapa debug GDB dan tidak ada yang ditemukan di sana. jadi saya tidak begitu yakin apakah ini masalah memori bersama,
(gdb) run
Starting program: /home/miniconda/bin/python performance.py
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7fffa60a6700 (LWP 61963)]
[New Thread 0x7fffa58a5700 (LWP 61964)]
[New Thread 0x7fffa10a4700 (LWP 61965)]
[New Thread 0x7fff9e8a3700 (LWP 61966)]
[New Thread 0x7fff9c0a2700 (LWP 61967)]
[New Thread 0x7fff998a1700 (LWP 61968)]
[New Thread 0x7fff970a0700 (LWP 61969)]
[New Thread 0x7fff9489f700 (LWP 61970)]
[New Thread 0x7fff9409e700 (LWP 61971)]
[New Thread 0x7fff8f89d700 (LWP 61972)]
[New Thread 0x7fff8d09c700 (LWP 61973)]
[New Thread 0x7fff8a89b700 (LWP 61974)]
[New Thread 0x7fff8809a700 (LWP 61975)]
[New Thread 0x7fff85899700 (LWP 61976)]
[New Thread 0x7fff83098700 (LWP 61977)]
[New Thread 0x7fff80897700 (LWP 61978)]
[New Thread 0x7fff7e096700 (LWP 61979)]
[New Thread 0x7fff7d895700 (LWP 61980)]
[New Thread 0x7fff7b094700 (LWP 61981)]
[New Thread 0x7fff78893700 (LWP 61982)]
[New Thread 0x7fff74092700 (LWP 61983)]
[New Thread 0x7fff71891700 (LWP 61984)]
[New Thread 0x7fff6f090700 (LWP 61985)]
[Thread 0x7fff7e096700 (LWP 61979) exited]
[Thread 0x7fff6f090700 (LWP 61985) exited]
[Thread 0x7fff74092700 (LWP 61983) exited]
[Thread 0x7fff7b094700 (LWP 61981) exited]
[Thread 0x7fff80897700 (LWP 61978) exited]
[Thread 0x7fff83098700 (LWP 61977) exited]
[Thread 0x7fff85899700 (LWP 61976) exited]
[Thread 0x7fff8809a700 (LWP 61975) exited]
[Thread 0x7fff8a89b700 (LWP 61974) exited]
[Thread 0x7fff8d09c700 (LWP 61973) exited]
[Thread 0x7fff8f89d700 (LWP 61972) exited]
[Thread 0x7fff9409e700 (LWP 61971) exited]
[Thread 0x7fff9489f700 (LWP 61970) exited]
[Thread 0x7fff970a0700 (LWP 61969) exited]
[Thread 0x7fff998a1700 (LWP 61968) exited]
[Thread 0x7fff9c0a2700 (LWP 61967) exited]
[Thread 0x7fff9e8a3700 (LWP 61966) exited]
[Thread 0x7fffa10a4700 (LWP 61965) exited]
[Thread 0x7fffa58a5700 (LWP 61964) exited]
[Thread 0x7fffa60a6700 (LWP 61963) exited]
[Thread 0x7fff71891700 (LWP 61984) exited]
[Thread 0x7fff78893700 (LWP 61982) exited]
[Thread 0x7fff7d895700 (LWP 61980) exited]
total_files = 5040. //customer comments
[New Thread 0x7fff6f090700 (LWP 62006)]
[New Thread 0x7fff71891700 (LWP 62007)]
[New Thread 0x7fff74092700 (LWP 62008)]
[New Thread 0x7fff78893700 (LWP 62009)]
ERROR: Unexpected segmentation fault encountered in worker.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 62005) is killed by signal: Segmentation fault.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "performance.py", line 62, in <module>
main()
File "performance.py", line 48, in main
for i,batch in enumerate(rl_data_loader):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 841, in _next_data
idx, data = self._get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 808, in _get_data
success, data = self._try_get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 774, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 62005) exited unexpectedly
[Thread 0x7fff78893700 (LWP 62009) exited]
[Thread 0x7fff74092700 (LWP 62008) exited]
[Thread 0x7fff71891700 (LWP 62007) exited]
[Thread 0x7fff6f090700 (LWP 62006) exited]
[Inferior 1 (process 61952) exited with code 01]
(gdb) backtrace
No stack.
Dan saya pikir saya memiliki memori bersama yang cukup, setidaknya saya berharap memori bersama cukup baik untuk waktu yang cukup lama hingga segfault, tetapi kesalahan segmen terjadi segera setelah saya meluncurkan pekerjaan pemuat data
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18014398509481980
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
Hai @soumith @apaszke , bisakah kita membuka kembali masalah ini, saya mencoba semua solusi yang diusulkan seperti meningkatkan ukuran dan segmen shm, tidak ada yang berhasil, saya tidak menggunakan opencv atau lebih, hanya parsing JSON sederhana. tapi masalah masih ada. dan saya tidak berpikir itu terkait dengan shm sejak dicentang saya membuka semua memori sebagai memori bersama. Jejak tumpukan juga tidak menunjukkan apa pun di sana seperti yang diposting di atas.
@apaszke , mengenai saran Anda untuk
"Ya, banyak dari masalah itu karena perpustakaan pihak ketiga tidak aman untuk fork. Salah satu resolusi alternatif mungkin menggunakan metode spawn start."
Saya menggunakan multi pekerja dataloader, bagaimana saya bisa mengubah metodenya? Saya menyetel set_start_method('spawn') ke main.py saya tetapi dosis sepertinya tidak membantu
Saya juga punya pertanyaan umum di sini, jika saya mengaktifkan pemuat data multi pekerja (multi proses), dan dalam pelatihan utama saya juga memulai multi proses seperti yang disarankan di https://pytorch.org/docs/stable/notes/multiprocessing.html #multiprocessing -praktik terbaik
bagaimana pytorch mengelola multi-proses pemuat data dan pelatihan utama? apakah mereka akan membagikan semua kemungkinan proses/threading pada GPU multi core? juga memori bersama untuk multi proses "dibagi" oleh pemuat data dan proses pelatihan utama? juga jika saya memiliki beberapa pekerjaan memasak data seperti penguraian JSON, penguraian CSV, ekstraksi fitur panda. dll, di mana cara terbaik untuk meletakkan? di dataloader untuk menghasilkan data yang sempurna untuk siap atau cukup gunakan pelatihan utama untuk melakukannya seperti yang disarankan di atas untuk menjaga pemuat data __get_item__ sesederhana mungkin
zhangruiskyline
pada 19 Jun 2020
@zhangruiskyline Masalah Anda sebenarnya bukan jalan buntu. Ini tentang para pekerja yang dibunuh oleh segfault. sigbus adalah yang menyarankan masalah shm. Anda harus memeriksa kode dataset Anda dan melakukan debug di sana.
Untuk menjawab pertanyaan Anda yang lain,
- gunakan kwarg
multiproessing_context='spawn'di DataLoader akan mengatur spawn.set_start_methodjuga melakukan itu. - biasanya dalam pelatihan multiproses, setiap proses memiliki DataLoader sendiri, dan dengan demikian pekerja DataLoader. Tidak ada yang dibagikan di antara proses kecuali secara eksplisit melakukannya.
SsnL
pada 20 Jun 2020
Terima kasih @SsnL , saya menambahkan multiproessing_context='spawn' tetapi kegagalan yang sama.
Saya tunjukkan di utas sebelumnya, kode saya sangat sederhana,
- potongan kode ini berfungsi
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
- tetapi jika saya menambahkan logika parse JSON setelah membaca baris demi baris, itu akan melaporkan kesalahan ini
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
jadi saya ragu ini adalah masalah kode saya, saya juga mencoba untuk tidak menggunakan parsing JSON, tetapi langsung memisahkan string, masalah yang sama. sepertinya selama saya memiliki logika yang memakan waktu untuk proses data di pemuat data, masalah ini terjadi
Juga tentang
pelatihan multiproses, setiap proses memiliki DataLoader sendiri, dan dengan demikian pekerja DataLoader Tidak ada yang dibagikan di antara proses kecuali secara eksplisit melakukannya.
Jadi mari kita lihat saya memiliki 4 proses untuk pelatihan, masing-masing dengan 8 pemuat data pekerja, jadi total 32 proses di bawahnya?
zhangruiskyline
pada 20 Jun 2020
@zhangruiskyline Tanpa skrip mandiri untuk mereproduksi masalah, kami tidak dapat membantu Anda. Ya akan ada 32 proses
SsnL
pada 20 Jun 2020
Terima kasih, saya juga melihat masalah serupa di
https://github.com/pytorch/pytorch/issues/4969
https://github.com/pytorch/pytorch/issues/5040
keduanya ditutup tetapi saya tidak melihat solusi atau perbaikan yang jelas, apakah ini masih merupakan masalah yang ada?
Saya akan melihat apakah saya dapat menyediakan skrip reproduksi mandiri tetapi sangat terintegrasi dengan platform dan sumber data kami, jadi akan dicoba
zhangruiskyline
pada 20 Jun 2020
@zhangruiskyline Masalah Anda tidak mirip dengan masalah terkait apa pun, jika Anda membacanya. mereka ditutup karena masalah asli/paling umum yang dilaporkan pada utas tersebut sudah ditangani.
SsnL
pada 20 Jun 2020
Terima kasih @SsnL , saya tidak begitu akrab dengan Pytorch jadi saya bisa saja salah, tetapi saya telah melewati semua itu, dan sepertinya beberapa di antaranya tampaknya diselesaikan oleh
kurangi jumlah pekerja menjadi 0, ini tidak dapat diterima bagi kami karena terlalu lambat,
menambah ukuran shm, tetapi kami memiliki cukup shm, saya percaya, dan masalah terjadi segera setelah kami mulai, dan saya mencoba dengan kumpulan data yang jauh lebih kecil, masalahnya sama
beberapa lib seperti dosis opencv tidak berfungsi dengan baik dalam multi-proses, kami hanya menggunakan JSON/CSV, jadi bukan barang yang terlalu mewah
kode kami cukup sederhana, kumpulan data pelatihan memiliki 10.000+ file, setiap file adalah beberapa baris string JSON. di dataloader, kami mendefinisikan __get_item__ untuk mengeluarkan setiap file dari 10K+ file dan membaca semua konten dalam file itu.
dalam solusi 1, pertama-tama kita membaca dan membagi baris demi baris ke dalam daftar string JSON, jika kita segera kembali, itu berfungsi, kinerjanya bagus
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
return all_data
sekarang karena nilai yang dikembalikan masih berupa string JSON, kami ingin memanfaatkan pemuat data multi proses untuk mempercepat, jadi letakkan logika penguraian JSON di sini dan gagal
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
kami kemudian berpikir parsing JSON terlalu berat dan juga JSON memiliki terlalu banyak jejak memori, kemudian kami memilih untuk mengurai string JSON dan secara manual mengonversi ke daftar fitur, kegagalan yang sama. melakukan beberapa analisis jejak tumpukan dan tidak ada apa-apa di sana
BTW, kami menjalankan kode kami di Linux Docker Env, CPU 24 core dan 1 V100.
Saya tidak yakin di mana saya harus mulai menyelidiki selanjutnya. Apakah kamu punya ide?
zhangruiskyline
pada 20 Jun 2020
Hai,
Saya menemukan komentar menarik di https://github.com/open-mmlab/mmcv , yang digunakan di https://github.com/open-mmlab/mmdetection :
Kode berikut digunakan di awal zaman kereta dan zaman val.
time.sleep(2) # Mencegah kemungkinan kebuntuan selama transisi zaman
Mungkin Anda bisa mencobanya.
mathmanu
pada 20 Jun 2020
BTW, jika saya pergi ke multi proses dan setiap proses dengan pemuat data multi pekerja, bagaimana proses yang berbeda dapat memastikan pemuat data yang sesuai tidak akan membaca data yang sama dengan pemuat data proses lain? apakah saya sudah ditangani oleh pytorch dataloader __get_item__ ?
zhangruiskyline
pada 20 Jun 2020
Hai @SsnL , Terima kasih atas bantuan Anda. hanya ingin menindaklanjuti utas ini sedikit, saya refactor kode pelatihan menggunakan pytorch multi processing untuk mempercepat beberapa pemrosesan data di sisi CPU (agar memberi makan ke GPU lebih cepat), https://pytorch.org/docs/stable /notes/multiprocessing.html#multiprocessing -praktik terbaik
Di setiap fungsi pemrosesan, saya juga menggunakan pemuat data multi-pekerja untuk mempercepat waktu pemrosesan pemuatan data. https://pytorch.org/docs/stable/data.html
Saya meletakkan penguraian JSON CPU yang naik-turun bukan di dataloader, tetapi dalam proses pelatihan utama, dan masalahnya sepertinya hilang, saya tidak tahu mengapa tetapi sepertinya berhasil. tetapi ada pertanyaan lanjutan: misalkan saya memiliki N pemrosesan, masing-masing memiliki M pekerja pemuat data, jadi total NxM bawah threading di sana.
Jika di dataloader saya, saya ingin mendapatkan semua data dengan cara indeks, yang berarti __get_item__(self, idx) di M pemuat data di N pemrosesan yang berbeda dapat bekerja sama untuk memproses indeks yang berbeda, bagaimana saya bisa memastikan mereka tidak memproses duplikat atau ketinggalan proses beberapa?
zhangruiskyline
pada 23 Jun 2020
Saya memiliki masalah yang sama ketika pemuat data mogok setelah mengeluh bahwa itu tidak dapat mengalokasikan memori di awal pelatihan atau periode validasi baru. Solusi di atas tidak bekerja untuk saya (i)
/dev/shmadalah 32GB dan tidak pernah digunakan lebih dari 2.5GB, dan (ii) pengaturan pin_memory=False tidak berfungsi.Ini mungkin ada hubungannya dengan pengumpulan sampah? Kode saya kira-kira terlihat seperti berikut ini. Saya membutuhkan iterator tak terbatas dan karenanya saya mencoba / kecuali sekitar
next()bawah :-)def train(): train_iter = train_loader.__iter__() for i in xrange(max_batches): try: x, y = next(train_iter) except StopIteration: train_iter = train_loader.__iter__() ... del train_iter
train_loaderadalah objekDataLoader. Tanpa garisdel train_itereksplisit di akhir fungsi, proses selalu macet setelah 2-3 epoch (/dev/shmmasih menunjukkan 2,5 GB). Semoga ini membantu!Saya menggunakan
4pekerja (versi0.1.12_2dengan CUDA 8.0 di Ubuntu 16.04).
Ini memecahkan masalah bagi saya setelah berminggu-minggu berjuang. Saya harus secara eksplisit menggunakan iterator pemuat alih-alih mengulang pemuat secara langsung dan menggunakan del loader_iterator di akhir Zaman akhirnya menghapus kebuntuan
 kennyFF92
pada 15 Jul 2020
kennyFF92
pada 15 Jul 2020
Saya pikir saya menghadapi masalah yang sama. Mencoba menggunakan 8 pemuat data (MNIST, MNISTM, SVHN, USPS, masing-masing untuk melatih dan menguji). Menggunakan 6 (ada 6) berfungsi dengan baik. Menggunakan 8 selalu blok saat memuat yang ke-6, uji MNIST-M. Itu terjebak dalam beberapa loop tak berujung mencoba untuk mengambil gambar, gagal, menunggu sebentar dan kemudian mencoba lagi. Kesalahan tetap ada untuk batch_size apa pun, saya memiliki banyak memori kosong yang tersisa, dan itu hanya hilang jika saya mengatur num_workers ke 0. Jumlah lain yang menyebabkan masalah
 pmirallesr
pada 21 Jul 2020
pmirallesr
pada 21 Jul 2020
Saya mendapat beberapa petunjuk dari https://stackoverflow.com/questions/54013846/pytorch-dataloader-stucked-if-using-opencv-resize-method
Ketika saya meletakkan cv2.setNumThreads(0) , itu berfungsi dengan baik dengan saya.
 LifeBeyondExpectations
pada 17 Agu 2020
LifeBeyondExpectations
pada 17 Agu 2020
Halo, saya memiliki masalah yang sama. Dan itu ada hubungannya dengan ulimit -n, cukup tingkatkan dan masalahnya selesai, saya menggunakan ulimit -n 500000
 SebastienEske
pada 18 Agu 2020
SebastienEske
pada 18 Agu 2020
@SebastienEske ulimit -n memperbaiki ini untuk saya juga, di Ubuntu 20.04
 david-waterworth
pada 24 Sep 2020
david-waterworth
pada 24 Sep 2020
Mungkin set ulimit -n adalah cara yang tepat, Dengan bertambahnya model, kebuntuan menjadi semakin sering, saya juga menguji cv2.setNumThreads(0) , Tetapi tidak berhasil.
 BLING-1994
pada 27 Sep 2020
BLING-1994
pada 27 Sep 2020
Sebagai catatan, cv2.setNumThreads(0) bekerja untuk saya.
 franchesoni
pada 18 Nov 2020
franchesoni
pada 18 Nov 2020
Masalah terkait
 dzhulgakov
·
68Komentar
dzhulgakov
·
68Komentar
 JamesOwers
·
61Komentar
JamesOwers
·
61Komentar
 chausies
·
67Komentar
chausies
·
67Komentar
 HarshneetBhatia
·
172Komentar
HarshneetBhatia
·
172Komentar
 hameerabbasi
·
74Komentar
hameerabbasi
·
74Komentar
Komentar yang paling membantu
Saya menemui masalah serupa: pemuat data berhenti ketika saya menyelesaikan suatu zaman dan akan memulai zaman baru.