Pytorch: الجمود المحتمل في أداة تحميل البيانات
تم وصف الخطأ في pytorch / أمثلة # 148. أنا فقط أتساءل عما إذا كان هذا خطأ في PyTorch نفسها ، حيث يبدو رمز المثال نظيفًا بالنسبة لي. أيضًا ، أتساءل عما إذا كان هذا مرتبطًا بالرقم 1120.
 zym1010
zym1010
ال 189 كومينتر
ما مقدار الذاكرة الخالية لديك عند توقف اللودر؟
 apaszke
في ٢٥ أبريل ٢٠١٧
apaszke
في ٢٥ أبريل ٢٠١٧
apaszke إذا top ، فإن الذاكرة المتبقية (تُحسب أيضًا الذاكرة المخبأة على أنها مستخدمة) عادة ما تكون 2 غيغابايت. ولكن إذا لم تحسب ذاكرة التخزين المؤقت على أنها مستخدمة ، فهي دائمًا كثيرة ، لنقل 30 غيغابايت +.
zym1010
في ٢٥ أبريل ٢٠١٧
كما أنني لا أفهم سبب توقفها دائمًا عند بداية التحقق ، ولكن ليس في أي مكان آخر.
zym1010
في ٢٥ أبريل ٢٠١٧
ربما لأنه من أجل التحقق من الصحة ، يتم استخدام محمل منفصل يدفع استخدام الذاكرة المشتركة إلى تجاوز الحد.
 ngimel
في ٢٥ أبريل ٢٠١٧
ngimel
في ٢٥ أبريل ٢٠١٧
تضمين التغريدة
لقد قمت بتشغيل البرنامج مرة أخرى. وتعثرت.
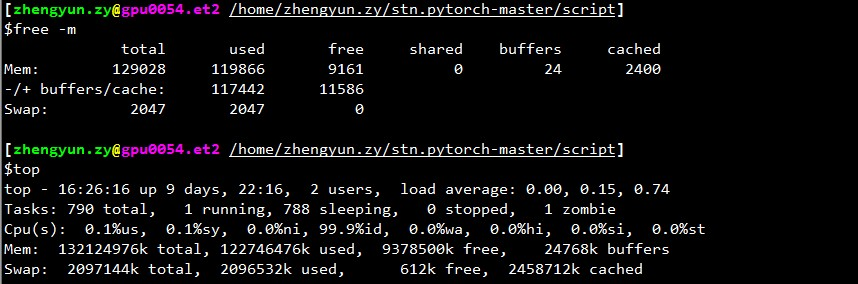
ناتج top :
~~~
أعلى - 17:51:18 حتى يومين ، 21:05 ، مستخدمان ، متوسط التحميل: 0.49 ، 3.00 ، 5.41
المهام: 357 مجموع ، 2 جري ، 355 نائم ، 0 توقف ، 0 زومبي
٪ وحدة المعالجة المركزية (وحدات المعالجة المركزية): 1.9 الولايات المتحدة ، 0.1 سي ، 0.7 ني ، 97.3 معرف ، 0.0 وات ، 0.0 مرحبا ، 0.0 سي ، 0.0 ست
KiB Mem: إجمالي 65863816 ، 60115084 مستخدم ، 5748732 مجاني ، 1372688 مخازن مؤقتة
KiB Swap: إجمالي 5917692 ، 620 مستخدمًا ، 5917072 مجانًا. 51154784 ذاكرة مخبأة
PID USER PR NI VIRT RES SHR S٪ CPU٪ MEM TIME + COMMAND 3067 aalreja 20 0 143332 101816 21300 R 46.1 0.2 1631: 44 Xvnc
16613 aalreja 30 10 32836 4880 3912 S 16.9 0.0 1: 06.92 مصباح ليفي 3221 aalreja 20 0 8882348 1.017g 110120 S 1.3 1.6 579: 06.87 MATLAB
1285 الجذر 20 01404848 48252 25580 S 0.3 0.1 6: 00.12 dockerd 16597 yimengz + 20 025084 3252 2572 R 0.3 0.0 0: 04.56 top
1 جذر 20 0 33616 4008 2624 S 0.0 0.0 0: 01.43 init
~~~
ناتج free
~yimengzh_everyday @ yimengzh : ~ $ مجانًاإجمالي المخازن المؤقتة المشتركة المجانية المستخدمة مؤقتًاMem: 65863816 60122060 5741756 9954628 1372688 51154916- / + المخازن المؤقتة / الكاش: 7594456 58269360السواب: 5917692620 5917072~
ناتج nvidia-smi
~~~
yimengzh_everyday @ yimengzh : ~ $ nvidia-smi
الثلاثاء 25 أبريل 17:52:38 2017
+ ------------------------------------------------- ---------------------------- +
| NVIDIA-SMI 375.39 إصدار برنامج التشغيل: 375.39 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| استمرار اسم وحدة معالجة الرسومات- M | Bus-Id Disp.A | متقلب Uncorr. ECC |
| أداء درجة حرارة المروحة : الاستخدام / الغطاء | استخدام الذاكرة | GPU-Util Compute M. |
| ================================ + ================= ===== + ======================= |
| 0 GeForce GTX TIT ... إيقاف | 0000: 03: 00.0 إيقاف | غير متاح |
| 30٪ 42C P8 14 واط / 250 واط | 3986 ميغا بايت / 6082 ميغا بايت | 0٪ افتراضي |
+ ------------------------------- + ----------------- ----- + ---------------------- +
| 1 تسلا K40c أوف | 0000: 81: 00.0 إيقاف | متوقف |
| 0٪ 46C P0 57W / 235 واط | 0 ميغا بايت / 12205 ميغا بايت | 0٪ افتراضي |
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| العمليات: ذاكرة وحدة معالجة الرسومات |
| GPU PID اكتب اسم العملية الاستخدام |
| =================================================== ============================== |
| 0 16509 C بيثون 3970 ميغا بايت |
+ ------------------------------------------------- ---------------------------- +
~~~
لا أعتقد أنها مشكلة في الذاكرة.
zym1010
في ٢٥ أبريل ٢٠١٧
هناك حدود منفصلة للذاكرة المشتركة. هل يمكنك تجربة ipcs -lm أو cat /proc/sys/kernel/shmall و cat /proc/sys/kernel/shmmax ؟ أيضًا ، هل هو طريق مسدود إذا كنت تستخدم عددًا أقل من العمال (على سبيل المثال ، الاختبار مع الحالة القصوى لعامل واحد)؟
apaszke
في ٢٦ أبريل ٢٠١٧
تضمين التغريدة
~~~
yimengzh_everyday @ yimengzh : ~ $ ipcs -lm
------ حدود الذاكرة المشتركة --------
أقصى عدد من المقاطع = 4096
الحد الأقصى لحجم المقطع (كيلو بايت) = 18014398509465599
إجمالي الذاكرة المشتركة القصوى (كيلو بايت) = 18446744073642442748
الحد الأدنى لحجم المقطع (بايت) = 1
yimengzh_everyday @ yimengzh : ~ $ cat / proc / sys / kernel / shmall
18446744073692774399
yimengzh_everyday @ yimengzh : ~ $ cat / proc / sys / kernel / shmmax
18446744073692774399
~~~
كيف يبحثون عنك
بالنسبة لعدد أقل من العمال ، أعتقد أن هذا لن يحدث كثيرًا. (يمكنني المحاولة الآن). لكنني أعتقد عمليًا أنني بحاجة إلى العديد من العمال.
zym1010
في ٢٦ أبريل ٢٠١٧
لديك بحد أقصى 4096 شريحة ذاكرة مشتركة مسموح بها ، ربما تكون هذه مشكلة. يمكنك محاولة زيادة ذلك عن طريق الكتابة إلى /proc/sys/kernel/shmmni (ربما جرب 8192). قد تحتاج إلى امتيازات المستخدم المتميز.
apaszke
في ٢٦ أبريل ٢٠١٧
apaszke حسنًا ، هذه قيم افتراضية بواسطة كل من Ubuntu و CentOS 6 ... هل هذه مشكلة حقًا؟
zym1010
في ٢٦ أبريل ٢٠١٧
apaszke عند تشغيل برنامج تدريبي ، يظهر ipcs -a الواقع عدم استخدام ذاكرة مشتركة. هل هذا متوقع؟
zym1010
في ٢٦ أبريل ٢٠١٧
حاول apaszke تشغيل البرنامج (لا يزال 22 عاملاً)
~~~
yimengzh_everyday @ yimengzh : ~ $ ipcs -lm
------ حدود الذاكرة المشتركة --------
أقصى عدد للقطع = 8192
الحد الأقصى لحجم المقطع (كيلو بايت) = 18014398509465599
إجمالي الذاكرة المشتركة القصوى (كيلو بايت) = 18446744073642442748
الحد الأدنى لحجم المقطع (بايت) = 1
~~~
لم يجرب عامل واحد. أولاً ، سيكون ذلك بطيئًا ؛ ثانيًا ، إذا كانت المشكلة هي قفل ميت حقًا ، فستختفي بالتأكيد.
zym1010
في ٢٦ أبريل ٢٠١٧
لا يلزم إنشاء الإعدادات الافتراضية @ zym1010 مع وضع أحمال العمل هذه في الاعتبار ، لذلك نعم ربما كانت مشكلة. ipcs مخصص للذاكرة المشتركة System V التي لا نستخدمها ، لكنني أردت التأكد من عدم تطبيق نفس الحدود على ذاكرة POSIX المشتركة.
لن تختفي بالتأكيد ، لأنه إذا كانت المشكلة موجودة بالفعل ، فمن المحتمل أن يكون هناك طريق مسدود بين العامل والعملية الرئيسية ، وقد يكون عامل واحد كافيًا لبدء هذا. على أي حال ، لا يمكنني إصلاح المشكلة حتى أتمكن من إعادة إنتاجها. ما هي المعلمات التي تستخدمها لتشغيل المثال وهل قمت بتعديل الكود بأي شكل من الأشكال؟ أيضًا ، ما هي قيمة torch.__version__ ؟ هل تعمل في عامل ميناء؟
apaszke
في ٢٦ أبريل ٢٠١٧
apaszke شكرا. أنا أفهم تحليلك بشكل أفضل الآن.
تم عرض جميع النتائج الأخرى لك على جهاز Ubuntu 14.04 مع ذاكرة وصول عشوائي بسعة 64 جيجابايت و Xeon مزدوج و Titan Black (هناك أيضًا K40 ، لكنني لم أستخدمه).
أمر إنشاء المشكلة هو CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 20 --lr 0.01 --workers 22 --batch-size 256 /mnt/temp_drive_3/cv_datasets/ILSVRC2015/Data/CLS-LOC . أنا لم أقوم بتعديل الكود على الإطلاق.
لقد قمت بتثبيت pytorch through pip على Python 3.5. إصدار pytorch هو 0.1.11_5 . لا يعمل في Docker.
راجع للشغل ، حاولت أيضًا استخدام عامل واحد. لكنني فعلت ذلك على جهاز آخر (ذاكرة وصول عشوائي (RAM) سعة 128 جيجابايت ، و Xeon مزدوج ، و 4 Pascal Titan X ، و CentOS 6). قمت بتشغيله باستخدام CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 1 --lr 0.01 --workers 1 --batch-size 256 /ssd/cv_datasets/ILSVRC2015/Data/CLS-LOC ، وسجل الأخطاء كما يلي.
Epoch: [0][5003/5005] Time 2.463 (2.955) Data 2.414 (2.903) Loss 5.9677 (6.6311) Prec<strong i="14">@1</strong> 3.516 (0.545) Prec<strong i="15">@5</strong> 8.594 (2.262)
Epoch: [0][5004/5005] Time 1.977 (2.955) Data 1.303 (2.903) Loss 5.9529 (6.6310) Prec<strong i="16">@1</strong> 1.399 (0.545) Prec<strong i="17">@5</strong> 7.692 (2.262)
^CTraceback (most recent call last):
File "main.py", line 292, in <module>
main()
File "main.py", line 137, in main
prec1 = validate(val_loader, model, criterion)
File "main.py", line 210, in validate
for i, (input, target) in enumerate(val_loader):
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 168, in __next__
idx, batch = self.data_queue.get()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/queue.py", line 164, in get
self.not_empty.wait()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/threading.py", line 293, in wait
waiter.acquire()
أظهر top ما يلي عندما تمسك بعامل واحد.
~أعلى - 08:34:33 حتى 15 يومًا ، 20:03 ، 0 مستخدمين ، متوسط التحميل: 0.37 ، 0.39 ، 0.36المهام: 894 مجموع ، 1 جري ، 892 نائم ، 0 توقف ، 1 زومبيوحدة المعالجة المركزية (وحدات المعالجة المركزية): 7.2٪ us ، 2.8٪ sy ، 0.0٪ ni ، 89.7٪ id ، 0.3٪ wa ، 0.0٪ hi ، 0.0٪ si ، 0.0٪ stMem: إجمالي 132196824k ، 131461528k مستخدم ، 735296k مجاني ، 347448k مخازن مؤقتةالسواب: إجمالي 2047996 ألف ، مستخدم 22656 ألف ، مجاني 2025340 ألف ، مخبأ 125226796 ألف~
zym1010
في ٢٦ أبريل ٢٠١٧
شيء آخر وجدته هو أنه إذا قمت بتعديل رمز التدريب ، بحيث لا يمر عبر جميع الدُفعات ، دعنا نقول ، قم فقط بتدريب 50 دفعة
if i >= 50:
break
ثم يبدو أن المأزق قد اختفى.
zym1010
في ٢٦ أبريل ٢٠١٧
يبدو أن المزيد من الاختبارات تشير إلى أن هذا التجميد يحدث كثيرًا إذا قمت بتشغيل البرنامج بعد إعادة تشغيل الكمبيوتر مباشرة. بعد وجود بعض ذاكرة التخزين المؤقت في الكمبيوتر ، يبدو أن تكرار الحصول على هذا التجميد أقل.
zym1010
في ٢٧ أبريل ٢٠١٧
حاولت ، لكن لا يمكنني إعادة إنتاج هذا الخطأ بأي شكل من الأشكال.
apaszke
في ٤ مايو ٢٠١٧
واجهت مشكلة مماثلة: توقف أداة تحميل البيانات عندما أنتهي من حقبة ما وأبدأ حقبة جديدة.
 tiancheng-zhi
في ٤ مايو ٢٠١٧
tiancheng-zhi
في ٤ مايو ٢٠١٧
تحديد عدد العمال = 0 أعمال. لكن البرنامج يتباطأ.
tiancheng-zhi
في ٤ مايو ٢٠١٧
apaszke هل حاولت أولاً إعادة تشغيل الكمبيوتر ثم تشغيل البرامج؟ بالنسبة لي ، هذا يضمن التجميد. لقد جربت للتو إصدار 0.12 ، وما زال كما هو.
هناك شيء واحد أود أن أشير إليه هو أنني قمت بتثبيت pytorch باستخدام pip ، حيث أن لدي numpy مرتبط بـ OpenBLAS مثبتًا وأن MKL من سحابة anaconda الخاصة بـ soumith لن يلعب معها بشكل جيد.
لذلك يستخدم pytorch بشكل أساسي MKL ويستخدم Numpy OpenBLAS. قد لا يكون هذا مثاليًا ، لكنني أعتقد أن هذا لا علاقة له بالمشكلة هنا.
zym1010
في ٩ مايو ٢٠١٧
نظرت في الأمر ، لكنني لم أتمكن من إعادة إنتاجه أبدًا. يجب ألا تكون MKL / OpenBLAS ذات صلة بهذه المشكلة. من المحتمل أن تكون هناك مشكلة ما في تكوين النظام
apaszke
في ٩ مايو ٢٠١٧
تضمين التغريدة لقد جربت للتو الثعبان من الريبو الرسمي الأناكوندا و pytorch القائم على MKL. لا تزال نفس المشكلة.
zym1010
في ٩ مايو ٢٠١٧
حاول تشغيل الكود في Docker. لا يزال عالقا.
zym1010
في ١١ مايو ٢٠١٧
لدينا نفس المشكلة ، تشغيل مثال تدريب pytorch / أمثلة imagenet (resnet18 ، 4 عمال) داخل عامل إرساء nvidia باستخدام 1 GPU من أصل 4. سأحاول جمع gdb backtrace ، إذا تمكنت من الوصول إلى العملية .
من المعروف على الأقل أن OpenBLAS لديه مشكلة توقف تام في مضاعفة المصفوفة ، والتي تحدث نادرًا نسبيًا: https://github.com/xianyi/OpenBLAS/issues/937. كان هذا الخطأ موجودًا على الأقل في OpenBLAS المعبأ في numpy 1.12.0.
 jsainio
في ٧ يونيو ٢٠١٧
jsainio
في ٧ يونيو ٢٠١٧
jsainio لقد جربت أيضًا
أيضًا ، تم حل هذه المشكلة (على الأقل بالنسبة لي) ، إذا قمت بتشغيل pin_memory لأداة تحميل البيانات.
zym1010
في ٧ يونيو ٢٠١٧
يبدو كما لو أن اثنين من العمال ماتوا.
أثناء التشغيل العادي:
root<strong i="7">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 33.2 4.7 91492324 3098288 ? Ssl 10:51 1:10 python -m runne
user+ 58 76.8 2.3 91079060 1547512 ? Rl 10:54 1:03 python -m runne
user+ 59 76.0 2.2 91006896 1484536 ? Rl 10:54 1:02 python -m runne
user+ 60 76.4 2.3 91099448 1559992 ? Rl 10:54 1:02 python -m runne
user+ 61 79.4 2.2 91008344 1465292 ? Rl 10:54 1:05 python -m runne
بعد الإغلاق:
root<strong i="11">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 24.8 4.4 91509728 2919744 ? Ssl 14:25 13:01 python -m runne
user+ 58 51.7 0.0 0 0 ? Z 14:27 26:20 [python] <defun
user+ 59 52.1 0.0 0 0 ? Z 14:27 26:34 [python] <defun
user+ 60 52.0 2.4 91147008 1604628 ? Sl 14:27 26:31 python -m runne
user+ 61 52.0 2.3 91128424 1532088 ? Sl 14:27 26:29 python -m runne
بالنسبة إلى عامل واحد متبقٍ ، تبدو بداية gdb stacktrace كما يلي:
root<strong i="15">@b06f896d5c1d</strong>:~/mnt# gdb --pid 60
GNU gdb (GDB) 8.0
Attaching to process 60
[New LWP 65]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb) bt
#0 0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f36f52af8d4 in __new_sem_wait_slow.constprop.0 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#2 0x00007f36f52af97a in sem_wait@@GLIBC_2.2.5 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#3 0x00007f36f157efb1 in semlock_acquire (self=0x7f3656296458,
args=<optimized out>, kwds=<optimized out>)
at /home/ilan/minonda/conda-bld/work/Python-3.5.2/Modules/_multiprocessing/semaphore.c:307
#4 0x00007f36f5579621 in PyCFunction_Call (func=
<built-in method __enter__ of _multiprocessing.SemLock object at remote 0x7f3656296458>, args=(), kwds=<optimized out>) at Objects/methodobject.c:98
#5 0x00007f36f5600bd5 in call_function (oparg=<optimized out>,
pp_stack=0x7f36c7ffbdb8) at Python/ceval.c:4705
#6 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#7 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=1, kws=0x0, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0,
closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#8 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#9 0x00007f36f5557542 in function_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/funcobject.c:627
#10 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36561c7d08>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#11 0x00007f36f554077c in method_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/classobject.c:330
#12 0x00007f36f5524236 in PyObject_Call (
func=<method at remote 0x7f36556f9248>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#13 0x00007f36f55277d9 in PyObject_CallFunctionObjArgs (
callable=<method at remote 0x7f36556f9248>) at Objects/abstract.c:2445
#14 0x00007f36f55fc3a9 in PyEval_EvalFrameEx (f=<optimized out>,
throwflag=<optimized out>) at Python/ceval.c:3107
#15 0x00007f36f5601166 in fast_function (nk=<optimized out>, na=1,
n=<optimized out>, pp_stack=0x7f36c7ffc418,
func=<function at remote 0x7f36561c78c8>) at Python/ceval.c:4803
#16 call_function (oparg=<optimized out>, pp_stack=0x7f36c7ffc418)
at Python/ceval.c:4730
#17 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#18 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=4, kws=0x7f36f5b85060, kwcount=0, defs=0x0, defcount=0,
kwdefs=0x0, closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#19 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#20 0x00007f36f5557661 in function_call (
func=<function at remote 0x7f36e14170d0>,
arg=(<ImageFolder(class_to_idx={'n04153751': 783, 'n02051845': 144, 'n03461385': 582, 'n04350905': 834, 'n02105056': 224, 'n02112137': 260, 'n03938244': 721, 'n01739381': 59, 'n01797886': 82, 'n04286575': 818, 'n02113978': 268, 'n03998194': 741, 'n15075141': 999, 'n03594945': 609, 'n04099969': 765, 'n02002724': 128, 'n03131574': 520, 'n07697537': 934, 'n04380533': 846, 'n02114712': 271, 'n01631663': 27, 'n04259630': 808, 'n04326547': 825, 'n02480855': 366, 'n02099429': 206, 'n03590841': 607, 'n02497673': 383, 'n09332890': 975, 'n02643566': 396, 'n03658185': 623, 'n04090263': 764, 'n03404251': 568, 'n03627232': 616, 'n01534433': 13, 'n04476259': 868, 'n03495258': 594, 'n04579145': 901, 'n04266014': 812, 'n01665541': 34, 'n09472597': 980, 'n02095570': 189, 'n02089867': 166, 'n02009229': 131, 'n02094433': 187, 'n04154565': 784, 'n02107312': 237, 'n04372370': 844, 'n02489166': 376, 'n03482405': 588, 'n04040759': 753, 'n01774750': 76, 'n01614925': 22, 'n01855032': 98, 'n03903868': 708, 'n02422699': 352, 'n01560419': 1...(truncated), kw={}) at Objects/funcobject.c:627
#21 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36e14170d0>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#22 0x00007f36f55fe234 in ext_do_call (nk=1444355432, na=0,
flags=<optimized out>, pp_stack=0x7f36c7ffc768,
func=<function at remote 0x7f36e14170d0>) at Python/ceval.c:5034
#23 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3275
--snip--
كان لدي سجل أخطاء مشابه ، مع توقف العملية الرئيسية: self.data_queue.get ()
بالنسبة لي كانت المشكلة أنني استخدمت opencv كمحمل للصور. وكانت وظيفة cv2.imread معلقة إلى أجل غير مسمى بدون أخطاء في صورة معينة من imagenet ("n01630670 / n01630670_1010.jpeg")
إذا قلت أنها تعمل من أجلك مع num_workers = 0 ، فهذا ليس كذلك. لكنني اعتقدت أنه قد يساعد بعض الأشخاص الذين لديهم تتبع خطأ مشابه.
 M-Eng
في ٩ يونيو ٢٠١٧
M-Eng
في ٩ يونيو ٢٠١٧
أنا أجري اختبارًا مع num_workers = 0 حاليًا ، ولم تتوقف حتى الآن. أقوم بتشغيل مثال الكود من https://github.com/pytorch/examples/blob/master/imagenet/main.py. يبدو أن ImageFolder pytorch/vision يستخدم PIL أو pytorch/accimage داخليًا لتحميل الصور ، لذلك لا يوجد OpenCV متضمن.
باستخدام num_workers = 4 ، يمكنني أحيانًا الحصول على أول قطار من وقت لآخر والتحقق من صحته بشكل كامل ، ويتم قفله في منتصف الحقبة الثانية. لذلك ، فمن غير المحتمل وجود مشكلة في وظيفة مجموعة البيانات / التحميل.
يبدو وكأنه حالة سباق في ImageLoader والتي قد يتم تشغيلها بشكل نادر نسبيًا بواسطة مجموعة معينة من الأجهزة / البرامج.
jsainio
في ٩ يونيو ٢٠١٧
@ zym1010 شكرًا للمؤشر ، سأحاول تعيين pin_memory = False أيضًا لـ DataLoader.
jsainio
في ٩ يونيو ٢٠١٧
مثير للاهتمام. عند الإعداد الخاص بي ، فإن إعداد pin_memory = False و num_workers = 4 ، يتوقف مثال الصور على الفور تقريبًا وينتهي الأمر بثلاثة من العمال كعمليات زومبي:
root<strong i="8">@034c4212d022</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 6.7 2.8 92167056 1876612 ? Ssl 13:50 0:36 python -m runner
user+ 38 1.9 0.0 0 0 ? Z 13:51 0:08 [python] <defunct>
user+ 39 4.3 2.3 91069804 1550736 ? Sl 13:51 0:19 python -m runner
user+ 40 2.0 0.0 0 0 ? Z 13:51 0:09 [python] <defunct>
user+ 41 4.1 0.0 0 0 ? Z 13:51 0:18 [python] <defunct>
في الإعداد الخاص بي ، تقع مجموعة البيانات على قرص متصل بالشبكة يتم قراءته عبر NFS. باستخدام pin_memory = False و num_workers = 4 يمكنني الحصول على النظام يفشل بسرعة إلى حد ما.
=> creating model 'resnet18'
- training epoch 0
Epoch: [0][0/5005] Time 10.713 (10.713) Data 4.619 (4.619) Loss 6.9555 (6.9555) Prec<strong i="8">@1</strong> 0.000 (0.000) Prec<strong i="9">@5</strong> 0.000 (0.000)
Traceback (most recent call last):
--snip--
imagenet_pytorch.main.main([data_dir, "--transient_dir", context.transient_dir])
File "/home/user/mnt/imagenet_pytorch/main.py", line 140, in main
train(train_loader, model, criterion, optimizer, epoch, args)
File "/home/user/mnt/imagenet_pytorch/main.py", line 168, in train
for i, (input, target) in enumerate(train_loader):
File "/home/user/anaconda/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 206, in __next__
idx, batch = self.data_queue.get()
File "/home/user/anaconda/lib/python3.5/multiprocessing/queues.py", line 345, in get
return ForkingPickler.loads(res)
File "/home/user/anaconda/lib/python3.5/site-packages/torch/multiprocessing/reductions.py", line 70, in rebuild_storage_fd
fd = df.detach()
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError
:
[Errno 104] Connection reset by peer
@ zym1010 هل
jsainio
في ٩ يونيو ٢٠١٧
تضمين التغريدة
أنا أستخدم SSD محلي على عقدة حساب الكتلة ، الكود موجود على محرك NFS ، لكن البيانات موجودة على SSD المحلي ، لسرعة التحميل القصوى. لم أحاول مطلقًا تحميل البيانات على محركات أقراص NFS.
zym1010
في ٩ يونيو ٢٠١٧
@ zym1010 شكرا للمعلومات. أنا أقوم بتشغيل هذا أيضًا على عقدة حسابية لمجموعة.
في الواقع ، أقوم بتشغيل تجربة num_workers = 0 على نفس العقدة في نفس الوقت أثناء تجربة أشكال num_workers = 4 . قد تكون التجربة الأولى تولد حمولة كافية بحيث تظهر ظروف السباق المحتملة نفسها بشكل أسرع في الأخير.
jsainio
في ٩ يونيو ٢٠١٧
apaszke عندما حاولت إعادة إنتاج هذا سابقًا ، هل حاولت تشغيل مثيلين جنبًا إلى جنب أو مع بعض الأحمال المهمة الأخرى على النظام؟
jsainio
في ٩ يونيو ٢٠١٧
jsainio شكرا على التحقيق في هذا! هذا غريب ، يجب على العمال الخروج معًا فقط ، وبمجرد الانتهاء من العملية الرئيسية قراءة البيانات. هل يمكنك محاولة فحص سبب خروجهم قبل الأوان؟ ربما تحقق من سجل النواة ( dmesg )؟
apaszke
في ٩ يونيو ٢٠١٧
لا ، لم أحاول ذلك ، ولكن يبدو أنه يظهر حتى عندما لم يكن هذا هو الحال IIRC
apaszke
في ٩ يونيو ٢٠١٧
apaszke حسنًا ، من الجيد معرفة أنه لا ينبغي أن
لقد حاولت ولكني لا أعرف طريقة جيدة للتحقق من سبب خروجهم. لا يُظهر dmesg أي شيء ذي صلة. (أنا أعمل في Docker مشتق من Ubuntu 16.04 ، باستخدام حزم Anaconda)
jsainio
في ٩ يونيو ٢٠١٧
تتمثل إحدى الطرق في إضافة عدد من المطبوعات داخل حلقة العامل . ليس لدي أي فكرة لماذا يخرجون بصمت. ربما لا يكون استثناءً ، لأنه كان من الممكن طباعته على stderr ، لذلك إما أن يخرجوا من الحلقة ، أو يتم قتلهم بواسطة نظام التشغيل (ربما بواسطة إشارة؟)
apaszke
في ٩ يونيو ٢٠١٧
jsainio ، فقط للتأكد ، هل تقوم بتشغيل عامل الإرساء باستخدام --ipc = host (لم تذكر هذا)؟ هل يمكنك التحقق من حجم شريحة الذاكرة المشتركة (df -h | grep shm)؟
ngimel
في ٩ يونيو ٢٠١٧
ngimel أستخدم --shm-size=1024m . تقارير df -h | grep shm وفقًا لذلك:
root<strong i="9">@db92462e8c19</strong>:~/mnt# df -h | grep shm
shm 1.0G 883M 142M 87% /dev/shm
يبدو أن هذا الاستخدام صعب إلى حد ما. هذا على رصيف مع اثنين من عمال الزومبي.
jsainio
في ١٢ يونيو ٢٠١٧
هل يمكنك محاولة زيادة حجم shm؟ لقد تحققت للتو وعلى الخادم حيث حاولت إعادة إنتاج المشاكل ، كان 16 غيغابايت. يمكنك إما تغيير علامة عامل الإرساء أو الجري
mount -o remount,size=8G /dev/shm
لقد حاولت فقط تقليل الحجم إلى 512 ميغا بايت ، لكنني حصلت على خطأ واضح بدلاً من الجمود. ما زلت لا تستطيع التكاثر 😕
apaszke
في ١٤ يونيو ٢٠١٧
مع عامل الإرساء ، نميل إلى الوصول إلى طريق مسدود عندما لا يكون shm كافيًا ، بدلاً من رسائل الخطأ الواضحة ، لا أعرف السبب. ولكن عادة ما يتم علاجه عن طريق زيادة shm (وقد حصلت بالفعل على طريق مسدود مع 1G).
ngimel
في ١٤ يونيو ٢٠١٧
حسنًا ، يبدو أنه حدث خطأ مع 10 عمال ، ولكن عندما أستخدم 4 عمال أحصل على طريق مسدود بنسبة 58٪ من استخدام / dev / shm! أنا في النهاية أعدت إنتاجه
apaszke
في ١٤ يونيو ٢٠١٧
إنه لأمر رائع أنه يمكنك إعادة إنتاج شكل من أشكال هذه المشكلة. لقد نشرت نصًا يؤدي إلى تعليق في # 1579 ، وأجبت أنه لم يعلق على نظامك. لقد اختبرته بالفعل على جهاز MacBook الخاص بي فقط. لقد جربت للتو نظام Linux ، ولم يتعطل. لذلك إذا جربت نظام Linux فقط ، فقد يكون الأمر يستحق المحاولة أيضًا على جهاز Mac.
 greaber
في ١٤ يونيو ٢٠١٧
greaber
في ١٤ يونيو ٢٠١٧
حسنًا ، بعد التحقيق في المشكلة يبدو أنها مشكلة غريبة. حتى عندما أقوم بتحديد /dev/shm ليكون حجمه 128 ميغا بايت فقط ، يسعد Linux للسماح لنا بإنشاء ملفات 147 ميجا بايت هناك ، ووضعها بالكامل في الذاكرة ، ولكنها سترسل SIGBUS مميتًا إلى العامل بمجرد أن يحاول بالفعل الوصول إلى الصفحات ... لا يمكنني التفكير في أي آلية تسمح لنا بالتحقق من صلاحية الصفحات باستثناء تكرارها ولمس كل واحدة باستخدام معالج SIGBUS مسجل ...
الحل الآن هو توسيع /dev/shm باستخدام الأمر mount كما هو موضح أعلاه. جرب بسعة 16 جيجا بايت (ofc إذا كان لديك ذاكرة RAM كافية).
apaszke
في ١٥ يونيو ٢٠١٧
من الصعب العثور على أي إشارة إلى هذا ، ولكن هذا واحد .
apaszke
في ١٥ يونيو ٢٠١٧
شكرًا على وقتك بشأن هذه المشكلة ، لقد كان يقودني إلى الجنون لفترة طويلة! إذا فهمت بشكل صحيح ، فأنا بحاجة إلى توسيع /dev/shm ليصبح 16G بدلاً من 8G. إنه أمر منطقي ولكن عند تجربة df -h ، يمكنني أن أرى أن كل ذاكرة الوصول العشوائي الخاصة بي مخصصة بالفعل على هذا النحو: (لدي 16 جيجا)
tmpfs 7,8G 393M 7,4G 5% /dev/shm
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,8G 0 7,8G 0% /sys/fs/cgroup
tmpfs 1,6G 60K 1,6G 1% /run/user/1001
هذا هو ناتج df -h أثناء الجمود. بقدر ما أفهم ، إذا كان لدي قسم SWAP من 16 جيجا ، يمكنني تحميل tmpfs حتى 32 جيجا ، لذلك لا ينبغي أن تكون مشكلة لتوسيع /dev/shm ، أليس كذلك؟
الأهم من ذلك ، أنا في حيرة من قسم cgroup والغرض منه لأنه يأخذ ما يقرب من نصف ذاكرة الوصول العشوائي الخاصة بي. يبدو أنه مصمم لإدارة المهام متعددة المعالجات بكفاءة ، لكنني لست على دراية بما يفعله ولماذا نحتاج إليه ، هل سيغير شيئًا ما لتخصيص كل ذاكرة الوصول العشوائي الفعلية (لأننا حددنا حجمها على 16 جيجا) و ضعه في SWAP (على الرغم من أنني أعتقد أن كليهما سيكون جزئيًا في ذاكرة الوصول العشوائي و SWAP في وقت واحد)
 ClementPinard
في ١٥ يونيو ٢٠١٧
ClementPinard
في ١٥ يونيو ٢٠١٧
apaszke شكرا! عظيم أنك وجدت السبب الأساسي. كنت أتلقى أحيانًا أخطاء "إعادة تعيين الاتصال" المختلفة وحالات توقف تام مع عامل الإرساء --shm-size=1024m اعتمادًا على الحمولة الأخرى الموجودة في الجهاز. الاختبار الآن مع --shm-size=16384m و 4 عمال.
jsainio
في ١٥ يونيو ٢٠١٧
jsainio ConnectionReset ربما نتج عن نفس الشيء. بدأت العمليات في تبادل بعض البيانات ، ولكن بمجرد نفاد مساحة shm تم إرسال SIGBUS إلى العامل وقتلها.
ClementPinard بقدر ما أفهم ، يمكنك جعله كبيرًا كما تريد ، باستثناء أنه من المحتمل أن يتجمد جهازك بمجرد نفاد ذاكرة الوصول العشوائي (لأنه حتى kernel لا يمكنه تحرير هذه الذاكرة). ربما لا تحتاج إلى القلق بشأن /sys/fs/cgroup . تخصص أقسام tmpfs الذاكرة بتكاسل ، وطالما ظل الاستخدام عند 0B ، فلن يكلفك أي شيء (بما في ذلك الحدود). لا أعتقد أن استخدام المبادلة فكرة جيدة ، لأنه سيجعل تحميل البيانات أبطأ بكثير ، لذا يمكنك محاولة زيادة الحجم shm ليقول 12 غيغابايت ، والحد من عدد العمال (كما قلت ، لا تستخدم كل ما تبذلونه من ذاكرة الوصول العشوائي ل shm!). إليك كتابة لطيفة على tmpfs من وثائق kernel.
لا أعرف سبب حدوث الجمود حتى عندما يكون استخدام /dev/shm صغيرًا جدًا (يحدث عند 20 كيلوبايت على جهازي). ربما تكون النواة مفرطة في التفاؤل ، لكنها لا تنتظر حتى تملأ كل شيء ، وتقتل العملية بمجرد أن تبدأ في استخدام أي شيء من هذه المنطقة.
apaszke
في ١٥ يونيو ٢٠١٧
جربت الآن مع 12G ونصف العمال الذين كنت أملك ، وفشلت:
لقد كان يعمل مثل السحر في إصدار lua torch (نفس السرعة ، نفس العدد من العمال) ، مما يجعلني أتساءل عما إذا كانت المشكلة مرتبطة فقط بـ /dev/shm وليست أقرب إلى معالجة بيثون المتعددة ...
الشيء الغريب في الأمر (كما أشرت) هو أن /dev/shm لم يقترب أبدًا من الامتلاء. خلال حقبة التدريب الأولى ، لم تتجاوز 500Mo أبدًا. كما أنه لا يتم قفله أبدًا خلال الحقبة الأولى ، وإذا أغلقت اختبار أداة التحميل ، فلن يفشل أبدًا في جميع العصور. يبدو أن المأزق لا يظهر إلا عند بداية فترة الاختبار. يجب أن أتتبع /dev/shm عند الانتقال من قطار إلى آخر ، ربما يكون هناك ذروة استخدام أثناء تغيير محمل البيانات.
ClementPinard
في ١٥ يونيو ٢٠١٧
ClementPinard حتى مع وجود ذاكرة مشتركة أعلى ، وبدون Docker ، لا يزال من الممكن أن تفشل.
zym1010
في ١٥ يونيو ٢٠١٧
إذا كان إصدار الشعلة == Lua Torch ، فربما لا يزال مرتبطًا بـ /dev/shm . يمكن لـ Lua Torch استخدام سلاسل الرسائل (لا يوجد GIL) ، لذلك لا تحتاج إلى المرور عبر mem المشتركة (يشتركون جميعًا في مساحة عنوان واحدة).
apaszke
في ١٥ يونيو ٢٠١٧
واجهت نفس المشكلة حيث يتعطل أداة تحميل البيانات بعد الشكوى من عدم قدرتها على تخصيص الذاكرة في بداية فترة تدريب أو تحقق جديدة. لم تنجح الحلول المذكورة أعلاه بالنسبة لي (1) بلدي /dev/shm هو 32 جيجا بايت ولم يتم استخدامه مطلقًا أكثر من 2.5 جيجا بايت ، و (2) إعداد pin_memory = False لم يعمل.
ربما هذا شيء له علاقة بجمع القمامة؟ الكود الخاص بي يشبه ما يلي تقريبًا. أحتاج إلى مكرر لانهائي ، ومن ثم أقوم بتجربة / باستثناء ما يقرب من next() أدناه :-)
def train():
train_iter = train_loader.__iter__()
for i in xrange(max_batches):
try:
x, y = next(train_iter)
except StopIteration:
train_iter = train_loader.__iter__()
...
del train_iter
train_loader هو كائن DataLoader . بدون السطر الصريح del train_iter في نهاية الوظيفة ، تتعطل العملية دائمًا بعد 2-3 فترات (لا يزال يظهر 2.5 جيجابايت من /dev/shm ). أتمنى أن يساعدك هذا!
أنا أستخدم عمال 4 (الإصدار 0.1.12_2 مع CUDA 8.0 على Ubuntu 16.04).
 pratikac
في ٧ يوليو ٢٠١٧
pratikac
في ٧ يوليو ٢٠١٧
لقد واجهت أيضًا حالة الجمود ، خاصة عندما يكون رقم work_number كبيرًا. هل هناك أي حل ممكن لهذه المشكلة؟ الحجم الخاص بي / dev / shm هو 32 جيجابايت ، مع cuda 7.5 و pytorch 0.1.12 و python 2.7.13. فيما يلي معلومات ذات صلة بعد الموت. يبدو مرتبطًا بالذاكرة. تضمين التغريدة

 zhengyunqq
في ٤ أغسطس ٢٠١٧
zhengyunqq
في ٤ أغسطس ٢٠١٧
zhengyunqq جرب pin_memory=False إذا قمت بتعيينه على True . خلاف ذلك ، لست على علم بأي حل.
zym1010
في ٤ أغسطس ٢٠١٧
لقد واجهت أيضًا طريق مسدود عندما يكون عدد العمال كبيرًا.
 hendrycks
في ١١ أغسطس ٢٠١٧
hendrycks
في ١١ أغسطس ٢٠١٧
بالنسبة لي ، كانت المشكلة أنه إذا مات مؤشر ترابط عامل لأي سبب من الأسباب ، فإن index_queue.put سيتوقف إلى الأبد. أحد أسباب موت خيوط العمل هو فشل unpickler أثناء التهيئة. في هذه الحالة ، حتى يتم إصلاح خطأ Python هذا في مايو 2017 ، سيموت مؤشر ترابط العامل
ربما يكون استبدال SimpleQueue المستخدم في DataLoaderIter بواسطة Queue مما يسمح بانتهاء المهلة مع رسالة استثناء رشيقة.
محدث: لقد كنت مخطئًا ، هذا التصحيح الخطأ Queue ، وليس SimpleQueue . لا يزال صحيحًا أن SimpleQueue سيتم قفله إذا لم تكن هناك سلاسل عمليات متصلة بالإنترنت. طريقة سهلة للتحقق من استبدال هذه الأسطر بـ self.workers = [] .
 vadimkantorov
في ١٦ أغسطس ٢٠١٧
vadimkantorov
في ١٦ أغسطس ٢٠١٧
لدي نفس المشكلة ، ولا يمكنني تغيير shm (بدون إذن) ، فربما يكون من الأفضل استخدام قائمة الانتظار أو أي شيء آخر؟
 xfanplus
في ٨ سبتمبر ٢٠١٧
xfanplus
في ٨ سبتمبر ٢٠١٧
لدي مشكلة مماثلة.
سيتجمد هذا الرمز ولن يطبع أي شيء أبدًا. إذا قمت بتعيين num_workers = 0 فسوف يعمل بالرغم من ذلك
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
model.cuda()
for i, batch in enumerate(dataloader):
print(i)
إذا وضعت model.cuda () خلف الحلقة ، فسيعمل كل شيء على ما يرام.
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
for i, batch in enumerate(dataloader):
print(i)
model.cuda()
هل لدى أي شخص حل لهذه المشكلة؟
 anDoer
في ١٣ سبتمبر ٢٠١٧
anDoer
في ١٣ سبتمبر ٢٠١٧
لقد واجهت مشكلات مماثلة أيضًا أثناء تدريب ImageNet. سيتوقف عند التكرار الأول للتقييم باستمرار على خوادم معينة ببنية معينة (وليس على خوادم أخرى لها نفس البنية أو نفس الخادم بهندسة مختلفة) ، ولكن دائمًا أول مكرر أثناء التقييم عند التحقق من الصحة. عندما كنت أستخدم Torch ، وجدنا أن nccl يمكن أن يتسبب في حالة من الجمود مثل هذا ، فهل هناك طريقة لإيقاف تشغيله؟
 WendyShang
في ٢٠ سبتمبر ٢٠١٧
WendyShang
في ٢٠ سبتمبر ٢٠١٧
أواجه نفس المشكلة ، حيث أعلق بشكل عشوائي في بداية العصر الأول. جميع الحلول المذكورة أعلاه لا تعمل بالنسبة لي ، عند الضغط على Ctrl-C ، فإنه يطبع ما يلي:
Traceback (most recent call last):
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 249, in _bootstrap
self.run()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 44, in _worker_loop
data_queue.put((idx, samples))
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/queues.py", line 354, in put
self._writer.send_bytes(obj)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 200, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 398, in _send_bytes
self._send(buf)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
KeyboardInterrupt
Traceback (most recent call last):
File "scripts/train_model.py", line 640, in <module>
main(args)
File "scripts/train_model.py", line 193, in main
train_loop(args, train_loader, val_loader)
File "scripts/train_model.py", line 341, in train_loop
ee_optimizer.step()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/optim/adam.py", line 74, in step
p.data.addcdiv_(-step_size, exp_avg, denom)
KeyboardInterrupt
 zoharli
في ٢٣ أكتوبر ٢٠١٧
zoharli
في ٢٣ أكتوبر ٢٠١٧
واجهت مشكلة مماثلة تتمثل في حدوث مأزق مع عامل واحد داخل عامل الرصيف ويمكنني أن أؤكد أنها كانت مشكلة الذاكرة المشتركة في حالتي. بشكل افتراضي ، يبدو أن عامل الإرساء يخصص 64 ميغا بايت فقط من الذاكرة المشتركة ، لكنني كنت بحاجة إلى 440 ميغا بايت لعامل واحد ، وهو ما تسبب على الأرجح في السلوك الذي وصفهapaszke.
 paulguerrero
في ٢٣ أكتوبر ٢٠١٧
paulguerrero
في ٢٣ أكتوبر ٢٠١٧
أنا منزعج من نفس المشكلة ، ومع ذلك فأنا أعيش في بيئة مختلفة عن معظم الآخرين في هذا الموضوع ، لذلك ربما يمكن أن تساعد مدخلاتي في تحديد السبب الأساسي. تم تثبيت pytorch الخاص بي باستخدام حزمة conda الممتازة التي صممها peterjc123 ضمن Windows10.
أقوم بتشغيل بعض cnn على مجموعة بيانات cifar10. بالنسبة لأدوات تحميل البيانات ، يتم تعيين num_workers إلى 1. على الرغم من أنه من المعروف أن وجود num_workers> 0 يتسبب في حدوث BrokenPipeError ونصائح ضده في # 494 ، إلا أن ما أواجهه ليس خطأ BrokenPipeError ولكن بعض أخطاء تخصيص الذاكرة. حدث الخطأ دائمًا في حوالي 50 حقبة ، مباشرة بعد التحقق من صحة الحقبة الأخيرة وقبل بدء التدريب للحقبة التالية. 90٪ من الوقت هي على وجه التحديد 50 حقبة ، وفي أحيان أخرى ستتوقف بفترتين أو حقبتين. بخلاف ذلك ، كل شيء آخر متسق جدًا. تحديد عدد العمال = 0 سيقضي على هذه المشكلة.
 berzjackson
في ٢٤ أكتوبر ٢٠١٧
berzjackson
في ٢٤ أكتوبر ٢٠١٧
paulguerrero صحيح. لقد قمت بحل هذه المشكلة عن طريق زيادة الذاكرة المشتركة من 64 ميجا إلى 2 جيجا. ربما يكون مفيدًا لرسو المستخدمين.
 yjzhux
في ٢٤ أكتوبر ٢٠١٧
yjzhux
في ٢٤ أكتوبر ٢٠١٧
berzjackson هذا خطأ معروف في حزمة Conda. ثابت في أحدث بنيات CI.
 peterjc123
في ٢٥ أكتوبر ٢٠١٧
peterjc123
في ٢٥ أكتوبر ٢٠١٧
لدينا حوالي 600 شخص بدأوا دورة جديدة تستخدم Pytorch يوم الاثنين. يقوم الكثير من الأشخاص في منتدانا بالإبلاغ عن هذه المشكلة. بعضها على AWS P2 ، وبعضها على أنظمتها الخاصة (بشكل رئيسي GTX 1070 ، وبعض Titan X).
عندما يقطعون التدريب ، تظهر نهاية تتبع المكدس:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv_bytes(self, maxsize)
405
406 def _recv_bytes(self, maxsize=None):
--> 407 buf = self._recv(4)
408 size, = struct.unpack("!i", buf.getvalue())
409 if maxsize is not None and size > maxsize:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv(self, size, read)
377 remaining = size
378 while remaining > 0:
--> 379 chunk = read(handle, remaining)
380 n = len(chunk)
381 if n == 0:
لدينا عدد العمال = 4 ، pin_memory = خطأ. لقد طلبت منهم التحقق من إعدادات الذاكرة المشتركة - ولكن هل هناك أي شيء يمكنني القيام به (أو يمكننا القيام به في Pytorch) لإزالة هذه المشكلة؟ (بخلاف تقليل عدد العمال ، لأن ذلك سيؤدي إلى إبطاء الأمور قليلاً.)
 jph00
في ١ نوفمبر ٢٠١٧
jph00
في ١ نوفمبر ٢٠١٧
أنا في الفصل @ jph00 (شكرًا جيريمي! :)) المشار إليه. حاولت أيضًا استخدام "num_workers = 0". لا يزال لديك نفس الخطأ حيث يتم تحميل resnet34 ببطء شديد. كما أن التركيب بطيء جدًا. لكن شيئًا غريبًا: هذا يحدث مرة واحدة فقط في عمر جلسة الكمبيوتر المحمول.
بمعنى آخر ، بمجرد تحميل البيانات وتشغيل التركيب مرة واحدة ، يمكنني التنقل ومواصلة تكرار الخطوات ... حتى مع وجود 4 عدد من العمال ، ويبدو أن كل شيء يعمل بسرعة كما هو متوقع في وحدة معالجة الرسومات.
أنا على PyTorch 0.2.0_4 ، Python 3.6.2 ، Torchvision 0.1.9 ، Ubuntu 16.04 LTS. يشير إجراء "df -h" على الجهاز الطرفي إلى أن لديّ 16 غيغابايت على / dev / shm ، على الرغم من أن الاستخدام كان منخفضًا للغاية.
إليك لقطة شاشة توضح مكان فشل التحميل (لاحظ أنني استخدمت num_workers = 0 للبيانات)
(آسف على الأحرف الصغيرة. اضطررت إلى التصغير لالتقاط كل شيء ...)

 apiltamang
في ١ نوفمبر ٢٠١٧
apiltamang
في ١ نوفمبر ٢٠١٧
apiltamang لست متأكدًا من أن هذه هي نفس المشكلة - لا يبدو أنها نفس الأعراض على الإطلاق. الأفضل بالنسبة لنا لتشخيص ذلك في منتدى fast.ai ، وليس هنا.
jph00
في ١ نوفمبر ٢٠١٧
النظر في هذا في اسرع وقت ممكن!
 soumith
في ١ نوفمبر ٢٠١٧
soumith
في ١ نوفمبر ٢٠١٧
soumith لقد منحت apaszke حق الوصول إلى المنتدى الخاص بالدورة التدريبية وطلبت من الطلاب الذين يعانون من المشكلة منحنا إمكانية الوصول لتسجيل الدخول إلى
jph00
في ١ نوفمبر ٢٠١٧
@ jph00 مرحبًا جيريمي ، هل حاول أي من الطلاب زيادة shm كما ذكر apaszke أعلاه؟ هل كان ذلك مفيدًا؟
 SsnL
في ١ نوفمبر ٢٠١٧
SsnL
في ١ نوفمبر ٢٠١٧
SsnL أكد أحد الطلاب أنه زاد من الذاكرة المشتركة ، ولا تزال المشكلة قائمة. لقد طلبت من بعض الآخرين التأكيد أيضًا.
jph00
في ١ نوفمبر ٢٠١٧
@ jph00 شكرا! لقد نجحت في إعادة إنتاج التعليق بسبب انخفاض الذاكرة المشتركة. إذا كانت المشكلة تكمن في مكان آخر ، فسوف يتعين علي البحث بشكل أعمق! هل تمانع في مشاركة السيناريو معي؟
SsnL
في ١ نوفمبر ٢٠١٧
بالتأكيد - إليك دفتر الملاحظات الذي نستخدمه: https://github.com/fastai/fastai/blob/master/courses/dl1/lesson1.ipynb . لاحظ الطلاب أن المشكلة تحدث فقط عندما يقومون بتشغيل كل الخلايا بالترتيب الموجود في دفتر الملاحظات. نأمل أن يكون الكمبيوتر الدفتري لا يحتاج إلى شرح ، ولكن أعلمني إذا كان لديك أي مشكلة في تشغيله - فهو يتضمن رابطًا لتنزيل البيانات الضرورية.
استنادًا إلى مشكلة الذاكرة المشتركة التي يمكنك تكرارها ، هل هناك أي حل بديل يمكنني إضافته إلى مكتبتنا أو دفتر ملاحظاتنا لتجنب ذلك؟
jph00
في ١ نوفمبر ٢٠١٧
@ jph00 الغوص في الشفرة الآن. سأحاول اكتشاف طرق لتقليل استخدام الذاكرة المشتركة. لا يبدو أن النص يجب أن يستخدم كمية كبيرة من shm ، لذلك هناك أمل!
سأرسل أيضًا PR لإظهار رسالة خطأ لطيفة عند الوصول إلى حد shm بدلاً من تركه معلقًا.
SsnL
في ١ نوفمبر ٢٠١٧
حسنًا ، لقد قمت بتكرار المشكلة في مثيل AWS P2 جديد باستخدام CUDA 9 AMI مع أحدث تثبيت Pytorch conda. إذا قدمت مفتاحك العمومي ، يمكنني منحك حق الوصول لتجربته مباشرةً. بريدي الإلكتروني هو الحرف الأول من اسمي الأول في fast.ai
jph00
في ١ نوفمبر ٢٠١٧
@ jph00 أرسل لك بريدًا إلكترونيًا :) شكرًا!
SsnL
في ١ نوفمبر ٢٠١٧
@ jph00 و FYI ، أخذ النص 400
SsnL
في ١ نوفمبر ٢٠١٧
حسنًا ، لقد اكتشفت المشكلة الأساسية ، وهي أن المعالجة المتعددة opencv و Pytorch لا تعمل بشكل جيد معًا ، في بعض الأحيان. لا توجد مشاكل في صندوقنا في الجامعة ، ولكن هناك الكثير من المشكلات على AWS (في التعلم العميق الجديد CUDA 9 AMI مع مثيل P2). لا تؤدي إضافة قفل حول جميع استدعاءات cv2 إلى إصلاحه ، كما أن إضافة cv2.setNumThreads(0) لا يصلح. يبدو أن هذا لإصلاحه:
from multiprocessing import set_start_method
set_start_method('spawn')
ومع ذلك ، فإن ذلك يؤثر على الأداء بنحو 15٪. التوصية في قضية جيثب opencv هي استخدام https://github.com/tomMoral/loky . لقد استخدمت هذه الوحدة من قبل ووجدتها صلبة للغاية. ليس عاجلاً ، نظرًا لأن لدينا حلًا يعمل جيدًا بما يكفي في الوقت الحالي - ولكن قد يكون من المفيد التفكير في استخدام Loky لـ Dataloader؟
ربما الأهم من ذلك ، سيكون من الجيد أن يكون هناك على الأقل نوع من المهلة في قائمة انتظار pytorch حتى يتم القبض على هذه التعليقات اللانهائية.
jph00
في ٢ نوفمبر ٢٠١٧
لمعلوماتك ، لقد جربت للتو إصلاحًا مختلفًا ، نظرًا لأن "النشر" كان يجعل بعض الأجزاء أبطأ بمقدار 2-3x - وهو أنني أضفت عددًا قليلاً من فترات النوم العشوائية في الأقسام التي تتكرر عبر أداة تحميل البيانات بسرعة. وقد أدى ذلك أيضًا إلى حل المشكلة - على الرغم من أنها قد لا تكون مثالية!
jph00
في ٢ نوفمبر ٢٠١٧
شكرا للتعمق في هذا! يسعدني معرفة أنك وجدت حلين. في الواقع سيكون من الجيد إضافة مهلات للفهرسة في مجموعات البيانات. سنناقش ونعود إليك على هذا الطريق غدًا.
ccsoumith هل loky شيء نريد التحقيق فيه؟
SsnL
في ٢ نوفمبر ٢٠١٧
بالنسبة للأشخاص الذين يأتون إلى هذا الموضوع للمناقشة أعلاه ، تتم مناقشة قضية opencv بعمق أكبر على https://github.com/opencv/opencv/issues/5150
SsnL
في ٢ نوفمبر ٢٠١٧
حسنًا ، يبدو أن لدي إصلاحًا مناسبًا لهذا الآن - لقد أعدت كتابة Dataloader للمستخدم ProcessPoolExecutor.map() وقمت بنقل إنشاء الموتر إلى العملية الأم. كانت النتيجة أسرع مما كنت أراه مع Dataloader الأصلي ، وكان مستقرًا على جميع أجهزة الكمبيوتر التي جربتها عليها. الكود أيضًا أبسط كثيرًا.
إذا كان أي شخص مهتمًا باستخدامه ، فيمكنك الحصول عليه من https://github.com/fastai/fastai/blob/master/fastai/dataloader.py .
واجهة برمجة التطبيقات هي نفس الإصدار القياسي ، باستثناء أن مجموعة البيانات الخاصة بك يجب ألا تُرجع موتر Pytorch - يجب أن تُرجع المصفوفات المعقدة أو قوائم بايثون. لم أقم بأي محاولة لجعلها تعمل على Pythons الأقدم ، لذلك لن أتفاجأ إذا كانت هناك بعض المشكلات هناك.
(السبب الذي دفعني إلى السير في هذا المسار هو أنني وجدت عند إجراء الكثير من معالجة / زيادة الصور على وحدات معالجة الرسومات الحديثة أنه لم أتمكن من إكمال المعالجة بالسرعة الكافية لإبقاء وحدة معالجة الرسومات مشغولة ، إذا أجريت المعالجة المسبقة باستخدام Pytorch CPU العمليات ؛ ومع ذلك ، كان استخدام opencv أسرع بكثير ، وكنت قادرًا على الاستفادة الكاملة من وحدة معالجة الرسومات (GPU) كنتيجة لذلك.)
jph00
في ٢ نوفمبر ٢٠١٧
أوه ، إذا كانت مشكلة opencv ، فليس هناك الكثير مما يمكننا القيام به حيال ذلك. صحيح أن التفرع يكون خطيرًا عندما يكون لديك برك من الخيوط. لا أعتقد أننا نريد إضافة تبعية وقت التشغيل (ليس لدينا حاليًا أي تبعية) ، خاصةً أنها لن تتعامل مع موترات PyTorch بشكل جيد. سيكون من الأفضل فقط معرفة سبب الجمود و SsnL موجود فيه.
@ jph00 هل جربت Pillow-SIMD؟ يجب أن يعمل مع torchvision خارج الصندوق وقد سمعت الكثير من الأشياء الجيدة عنه.
apaszke
في ٢ نوفمبر ٢٠١٧
نعم أعرف وسادة SIMD جيدا. إنه يسرع فقط تغيير الحجم والتشويش وتحويل RGB.
لا أوافق على أنه ليس هناك الكثير مما يمكنك القيام به هنا. إنها ليست مشكلة opencv بالضبط (لا يزعمون أنهم يدعمون هذا النوع من معالجات البايثون المتعددة بشكل عام ، ناهيك عن وحدة المعالجة المتعددة ذات الغلاف الخاص من pytorch) وليست بالضبط مشكلة Pytorch أيضًا. لكن حقيقة أن Pytorch تنتظر بصمت إلى الأبد دون إعطاء أي نوع من الخطأ هي (IMO) شيء يمكنك إصلاحه ، وبشكل عام ، عمل الكثير من الأشخاص الأذكياء بجد خلال السنوات القليلة الماضية لإنشاء أساليب معالجة متعددة محسنة تتجنب المشاكل فقط مثل هذه. يمكنك الاقتراض من الأساليب التي يستخدمونها دون جلب تبعية خارجية.
Olivier Grisel ، أحد الأشخاص الذين يقفون وراء Loky ، لديه مجموعة شرائح كبيرة تلخص حالة المعالجة المتعددة في Python: http://ogrisel.github.io/decks/2017_euroscipy_parallelism/
لا أمانع في كلتا الحالتين ، لأنني كتبت الآن Dataloader جديدًا ليس لديه مشكلة. لكنني أظن ، FWIW ، أن التفاعلات بين المعالجة المتعددة لـ pytorch والأنظمة الأخرى ستكون مشكلة لأشخاص آخرين أيضًا في المستقبل.
jph00
في ٢ نوفمبر ٢٠١٧
لما يستحق ، واجهت هذه المشكلة في Python 2.7 في ubuntu 14.04. تمت قراءة أداة تحميل البيانات الخاصة بي من قاعدة بيانات sqlite وعملت بشكل مثالي مع num_workers=0 ، ويبدو أحيانًا على ما يرام مع num_workers=1 ، وسرعان ما وصلت إلى طريق مسدود لأي قيمة أعلى. أظهرت تتبعات التكديس أن العملية معلقة في recv_bytes .
الأشياء التي لم تنجح:
- تمرير
--shm-size 8Gأو--ipc=hostعند بدء تشغيل عامل الإرساء - تشغيل
echo 16834 | sudo tee /proc/sys/kernel/shmmniلزيادة عدد أجزاء الذاكرة المشتركة (الافتراضي هو 4096 على جهازي) - تعيين
pin_memory=Trueأوpin_memory=False، لم يساعد أحد
الشيء الذي أصلح مشكلتي بشكل موثوق هو نقل الكود الخاص بي إلى Python 3. تشغيل نفس الإصدار من Torch داخل مثيل Python 3.6 (من Anaconda) أدى إلى إصلاح مشكلتي تمامًا والآن لم يعد تحميل البيانات معطلاً.
 gcr
في ١٦ نوفمبر ٢٠١٧
gcr
في ١٦ نوفمبر ٢٠١٧
apaszke هنا سبب أهمية العمل بشكل جيد مع opencv ، FYI (ولماذا لا يعد torchsample خيارًا رائعًا - يمكنه التعامل مع تدوير أقل من 200 صورة / ثانية!):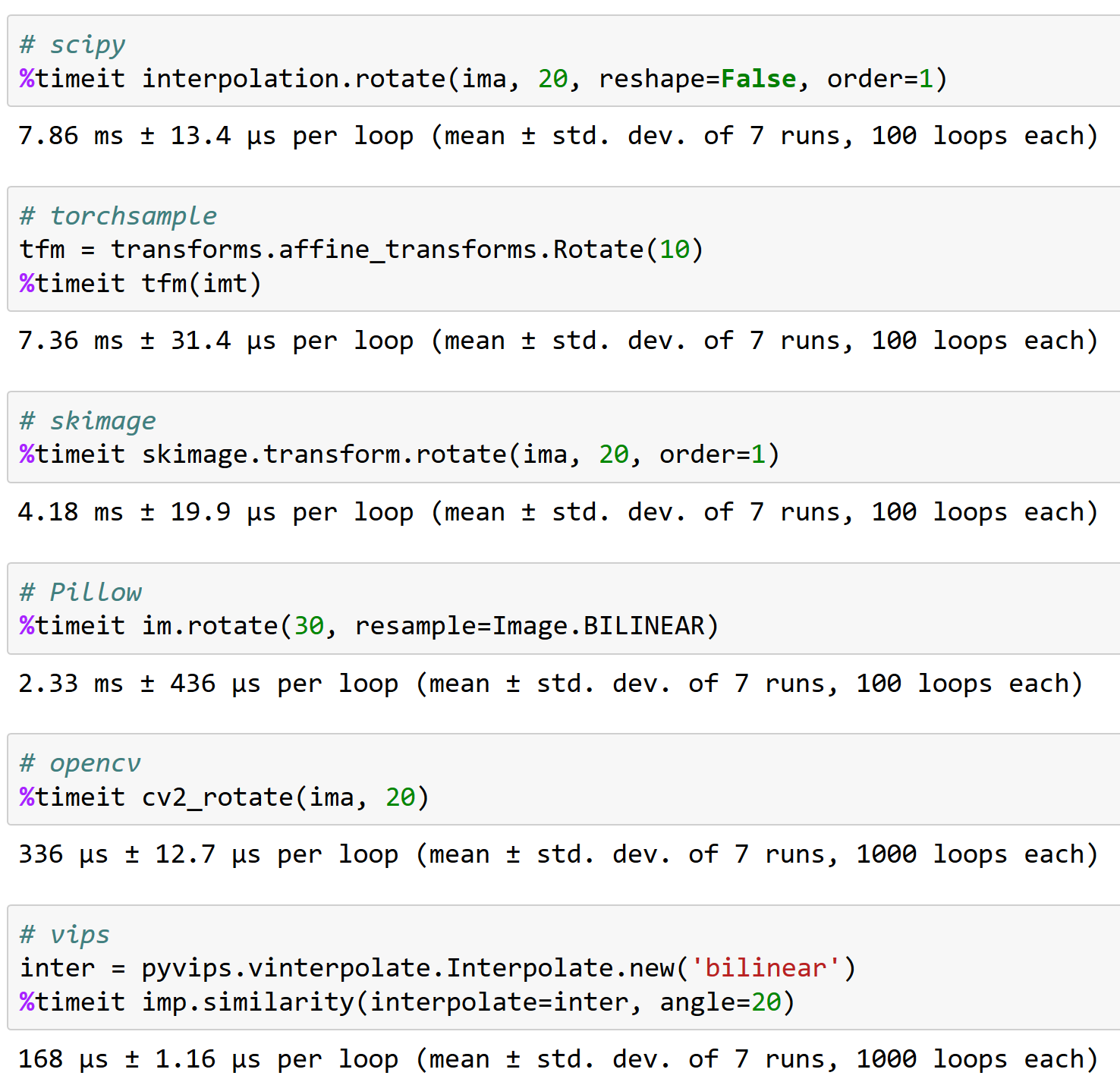
jph00
في ١٨ نوفمبر ٢٠١٧
هل وجد أي شخص حلا لهذه المشكلة؟
 iqbalu
في ٩ ديسمبر ٢٠١٧
iqbalu
في ٩ ديسمبر ٢٠١٧
iqbalu جرب البرنامج النصي أعلاه: https://github.com/fastai/fastai/blob/master/fastai/dataloader.py
لقد تم حل مشكلتي ولكنها لا تدعم num_workers=0 .
 elbaro
في ١٤ ديسمبر ٢٠١٧
elbaro
في ١٤ ديسمبر ٢٠١٧
elbaro في الواقع لقد جربته وفي حالتي لم يكن يستخدم عدة عمال على الإطلاق. هل قمت بتغيير أي شيء هناك؟
iqbalu
في ١٤ ديسمبر ٢٠١٧
iqbalu أداة تحميل البيانات fast.ai لا تفرز أبدًا عمليات العمال. يستخدم فقط الخيوط ، لذلك قد لا تظهر في بعض الأدوات
apaszke
في ١٤ ديسمبر ٢٠١٧
apaszkeelbaro @ jph00 تباطأت المحمل البيانات من fast.ai أسفل قراءة البيانات من أكثر من 10X. أنا أستخدم عدد العمال = 8. أي تلميح يمكن أن يكون السبب؟
iqbalu
في ١٥ ديسمبر ٢٠١٧
من المحتمل أن يستخدم برنامج تحميل البيانات حزمًا لا تتخلى عن GIL
apaszke
في ١٥ ديسمبر ٢٠١٧
apaszke ، أي فكرة عن سبب استمرار زيادة استخدام الذاكرة المشتركة بعد بعض العصور. في حالتي ، يبدأ بـ 400 ميغا بايت ثم يزداد كل عشرين حقبة بمقدار 400 ميغا بايت. شكرا!
iqbalu
في ٢٨ ديسمبر ٢٠١٧
iqbalu ليس حقا. لا ينبغي أن يحدث هذا
apaszke
في ٢٨ ديسمبر ٢٠١٧
لقد جربت العديد من الأشياء وحل مشكلتي أخيرًا cv2.setNumThreads(0) .
شكرا @ jph00
 Cadene
في ١٩ يناير ٢٠١٨
Cadene
في ١٩ يناير ٢٠١٨
لقد أزعجتني هذه المشكلة مؤخرًا. cv2.setNumThreads(0) لا يصلح لي. حتى أنني قمت بتغيير كل أكواد cv2 لاستخدام scikit-image بدلاً من ذلك ، لكن المشكلة لا تزال قائمة. بالإضافة إلى ذلك ، لدي 16 جيجا مقابل /dev/shm . لدي هذه المشكلة فقط عند استخدام gpus متعددة. كل شيء يعمل بشكل جيد على وحدة معالجة مركزية واحدة. هل لدى أي شخص أي أفكار جديدة حول الحل؟
 roytseng-tw
في ٢٥ يناير ٢٠١٨
roytseng-tw
في ٢٥ يناير ٢٠١٨
نفس الخطأ. لدي هذه المشكلة عند استخدام وحدة معالجة الرسومات (gpu) واحدة.
 Jiankai-Sun
في ٢٧ يناير ٢٠١٨
Jiankai-Sun
في ٢٧ يناير ٢٠١٨
بالنسبة لي ، أدى تعطيل مؤشرات ترابط opencv إلى حل المشكلة:
cv2.setNumThreads (0)
 shacharf
في ٢٨ يناير ٢٠١٨
shacharf
في ٢٨ يناير ٢٠١٨
اضربها أيضًا باستخدام pytorch 0.3 ، cuda 8.0 ، ubuntu 16.04
لا تستخدم opencv.
 tianq01
في ١ فبراير ٢٠١٨
tianq01
في ١ فبراير ٢٠١٨
أنا أستخدم pytorch 0.3 ، cuda 8.0 ، ubuntu 14.04. لاحظت هذا التعليق بعد أن بدأت في استخدام cv2.resize ()
cv2.setNumThreads (0) حل مشكلتي.
 mathmanu
في ٩ فبراير ٢٠١٨
mathmanu
في ٩ فبراير ٢٠١٨
أنا أستخدم python 3.6 و pytorch 0.3.0 و cuda 8.0 و ubuntu 17.04 على نظام مزود بذاكرة الوصول العشوائي 1080Ti و 32GB.
عندما أستخدم 8 عمال لمجموعة البيانات الخاصة بي ، كثيرًا ما أرى المأزق (يحدث في الحقبة الأولى). عندما اختزلت عدد العمال إلى 4 ، فإنها تختفي (أدرت 80 حقبة).
عندما يحدث طريق مسدود ، لا يزال لدي حوالي 10 غيغابايت من ذاكرة الوصول العشوائي.
 milani
في ٢ مارس ٢٠١٨
milani
في ٢ مارس ٢٠١٨
هنا يمكنك رؤية السجل بعد إنهاء البرنامج النصي: https://gist.github.com/milani/42f50c023cdca407115b309237d29c70
تحديث: أؤكد أنه يمكنني حل المشكلة بزيادة SHMMNI. في Ubuntu 17.04 ، أضفت kernel.shmmni=8192 إلى /etc/sysctl.conf .
milani
في ٢ مارس ٢٠١٨
تواجه أيضًا هذه المشكلة ، Ubuntu 17.10 ، Python 3.6 ، Pytorch 0.3.1 ، CUDA 8.0. يتبقى الكثير من ذاكرة الوصول العشوائي عند حدوث الجمود ويبدو أن الوقت غير متسق - يمكن أن يحدث بعد العصر الأول أو بعد العصر 200.
يبدو أن الجمع بين kernel.shmmni=8192 و cv2.setNumThreads(0) قد أصلحه ، بينما لم يعملوا بشكل فردي.
 inoryy
في ٨ مارس ٢٠١٨
inoryy
في ٨ مارس ٢٠١٨
نفس الشيء في حالتي. لقد واجهت طريقًا مسدودًا إذا قمت بإعداد عدد العمال = 4. أستخدم Ubuntu 17.10 و Pytorch 0.3.1 و CUDA 9.1 و python 3.6. ويلاحظ أن هناك 4 خيوط من نوع python ، يشغل كل منها 1.6 جيجا بايت من الذاكرة بينما تظل وحدة المعالجة المركزية (4 مراكز) خامدة. يساعد تعيين num_workers = 0 في حل هذه المشكلة.
 AlenUbuntu
في ٢٧ مارس ٢٠١٨
AlenUbuntu
في ٢٧ مارس ٢٠١٨
لدي نفس المشكلة ، إنها تتجمد بعد حقبة واحدة بالضبط ، ولكنها غير قابلة للتكرار حقًا لمجموعات البيانات الأصغر. أنا أستخدم CUDA 9.1 و Pytorch 0.3.1 و Python 3.6 في بيئة Docker.
لقد جربت Dataloader @ jph00 ، لكنني وجدت أنه أبطأ كثيرًا بالنسبة لحالة الاستخدام الخاصة بي. يتمثل الحل البديل حاليًا في إعادة إنشاء Pytorch DataLoader قبل كل عصر. يبدو أن هذا يعمل ، لكنه قبيح حقًا.
 tfriedel
في ١١ أبريل ٢٠١٨
tfriedel
في ١١ أبريل ٢٠١٨
كان لدي نفس المشكلة بالضبط في Ubuntu 17.10 ، CUDA 9.1 ، Pytorch master (تم تجميعه في 19/04 صباحًا). أيضًا استخدام OpenCV في الفئة الفرعية لمجموعة البيانات الخاصة بي.
ثم تمكنت من تجنب المأزق عن طريق تغيير طريقة بدء المعالجة المتعددة من "forkserver" إلى "spawn":
# Set multiprocessing start method - deadlock
set_start_method(forkserver')
# Set multiprocessing start method - runs fine
set_start_method('spawn')
 mfuntowicz
في ١٩ أبريل ٢٠١٨
mfuntowicz
في ١٩ أبريل ٢٠١٨
لقد جربت كل الطرق المذكورة أعلاه تقريبًا! لا أحد منهم يعمل!
قد تكون هذه المشكلة مرتبطة ببعض حالات عدم التوافق مع بنية الأجهزة ولا أعرف كيف قد يثيرها Pytorch! قد تكون مشكلة Pytorch وقد لا تكون كذلك!
إذن إليك كيف تم حل مشكلتي:
_أقوم بتحديث BIOS!
أعطها فرصة. على الأقل هذا يحل مشكلتي.
 astorfi
في ٢١ أبريل ٢٠١٨
astorfi
في ٢١ أبريل ٢٠١٨
كذلك هنا. أوبونتو PyTorch 0.4 ، بيثون 3.6.
 Shuailong
في ٣٠ أبريل ٢٠١٨
Shuailong
في ٣٠ أبريل ٢٠١٨
يبدو أن المشكلة لا تزال موجودة في pytorch 0.4 و python 3.6. لست متأكدا ما إذا كانت مشكلة pytorch. أستخدم opencv وقم بتعيين num_workers=8 ، pin_memory=True . لقد جربت جميع الحيل المذكورة أعلاه وإعداد cv2.setNumThreads(0) يحل مشكلتي.
 JasonQSY
في ١٠ مايو ٢٠١٨
JasonQSY
في ١٠ مايو ٢٠١٨
(1) يؤدي ضبط num_workers = 0 في تحميل بيانات PyTorch إلى حل المشكلة (انظر أعلاه) أو
(2) تحل cv2.setNumThreads (0) المشكلة حتى مع وجود عدد كبير من العمال بشكل معقول
هذا يبدو وكأنه نوع من مشكلة قفل الخيط.
لقد قمت بتعيين cv2.setNumThreads (0) في مكان ما في بداية ملف python الرئيسي ولم أواجه هذه المشكلة مطلقًا منذ ذلك الحين.
mathmanu
في ١٠ مايو ٢٠١٨
نعم ، يرجع سبب الكثير من هذه المشكلات إلى عدم أمان مكتبات الجهات الخارجية. قد يكون أحد الحلول البديلة هو استخدام طريقة بدء النشر.
apaszke
في ١٠ مايو ٢٠١٨
بالنسبة لي ، تنشأ مشكلة الجمود عندما أقوم بلف نموذجي باستخدام nn.DataParallel واستخدم num_workers> 0 في أداة تحميل البيانات. بإزالة مغلف nn.DataParallel ، يمكنني تشغيل البرنامج النصي الخاص بي دون أي قفل.
CUDA_VISIBLE_DEVICES = 0 python myscript.py - تقسيم 1
CUDA_VISIBLE_DEVICES = 1 python myscript.py - تقسيم 2
بدون وحدة معالجة رسومات متعددة ، يعمل البرنامج النصي الخاص بي بشكل أبطأ ولكن يمكنني إجراء تجارب متعددة في نفس الوقت على تقسيم مختلف لمجموعة البيانات.
 euwern
في ١٥ يونيو ٢٠١٨
euwern
في ١٥ يونيو ٢٠١٨
لدي نفس المشكلة في Python 3.6.2 / Pytorch 0.4.0.
وحاولت قبل كل شيء تبديل pin_memory ، وتغيير حجم الذاكرة المشتركة ، واستخدام مكتبة skiamge (أنا لا أستخدم cv2 !!) ، ولكن لا يزال لدي مشكلة.
تثير هذه المشكلة بشكل عشوائي. التحكم في هذه المشكلة هو مجرد مشاهدة وحدة التحكم وإعادة التدريب.
 slaysd
في ١٩ يونيو ٢٠١٨
slaysd
في ١٩ يونيو ٢٠١٨
@ jinh574 لقد قمت للتو بتعيين عدد عمال محمل البيانات على 0 ، وهو يعمل.
Shuailong
في ١٩ يونيو ٢٠١٨
Shuailong لا بد لي من استخدام صورة كبيرة الحجم ، لذلك لا يمكنني استخدام هذه المعلمات بسبب السرعة. أنا بحاجة لمزيد من التفتيش حول هذه المشكلة
slaysd
في ١٩ يونيو ٢٠١٨
لدي نفس المشكلة في Python 3.6 / Pytorch 0.4.0. هل يؤثر الخيار pin_memory على شيء ما؟
 ein-farbe
في ٢٦ يونيو ٢٠١٨
ein-farbe
في ٢٦ يونيو ٢٠١٨
إذا كنت تستخدم collate_fn و num_workers> 0 مع إصدار PyTorch <0.4:
تأكد من أنك لا تسترجع موترات خافتة الصفر من وظيفة __getitem__() .
أو قم بإعادتها كمصفوفات رقمية.
 pyaf
في ١٢ يوليو ٢٠١٨
pyaf
في ١٢ يوليو ٢٠١٨
لدي هذه المشكلة حتى بعد تعيين num_workers = 0 أو cv2.setNumThreads (0).
فشل مع أي من هاتين المسألتين. أي شخص آخر يواجه نفس الشيء؟
Traceback (آخر مكالمة أخيرة):
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py" ، السطر 193 ، في _run_module_as_main
"__main__" ، mod_spec)
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py" ، السطر 85 ، في _run_code
exec (كود ، run_globals)
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py" ، السطر 209 ، في
الأساسية()
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py" ، السطر 205 ، بشكل رئيسي
عملية الانتظار ()
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py" ، السطر 1457 ، قيد الانتظار
(pid، sts) = self._try_wait (0)
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py" ، السطر 1404 ، في _try_wait
(pid، sts) = os.waitpid (self.pid، wait_flags)
لوحة المفاتيح المقاطعة
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py" ، السطر 258 ، في _bootstrap
self.run ()
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py" ، السطر 93 ، قيد التشغيل
self._arget ( self._args، * self._kwargs)
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/utils/data/dataloader.py" ، السطر 96 ، في _worker_loop
r = index_queue.get (المهلة = MANAGER_STATUS_CHECK_INTERVAL)
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/queues.py" ، السطر 104 ، في get
إن لم يكن self._poll (timeout):
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py" ، السطر 257 ، في الاستطلاع
عودة self._poll (مهلة)
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py" ، السطر 414 ، في _poll
r = انتظر ([ذاتي] ، مهلة)
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py" ، السطر 911 ، قيد الانتظار
جاهز = selector.select (timeout)
ملف "/opt/conda/envs/pytorch-py3.6/lib/python3.6/selectors.py" ، السطر 376 ، في التحديد
fd_event_list = self._poll.poll (مهلة)
لوحة المفاتيح المقاطعة
 swethmandava
في ٢٥ أغسطس ٢٠١٨
swethmandava
في ٢٥ أغسطس ٢٠١٨
أنا أستخدم الإصدار "0.5.0a0 + f57e4ce" ولدي نفس المشكلة. يعمل إما إلغاء أداة تحميل البيانات المتوازية (num_workers = 0) أو إعداد cv2.setNumThreads (0).
 omersumer
في ٥ أكتوبر ٢٠١٨
omersumer
في ٥ أكتوبر ٢٠١٨
أنا واثق تمامًا من أن الرقم 11985 يجب أن يزيل جميع حالات التعليق (إلا إذا قاطعت في الأوقات المؤسفة التي لا يمكننا التحكم فيها). الآن بعد أن تم دمجه ، أقوم بإغلاق هذا.
تعليق مع cv2 خارج عن سيطرتنا أيضًا لأن cv2 لا يلعب بشكل جيد مع المعالجة المتعددة.
SsnL
في ٩ أكتوبر ٢٠١٨
لا تزال تواجه هذا اعتبارًا من torch_nightly-1.0.0.dev20181029 ، ألم يتم دمج العلاقات العامة هناك حتى الآن؟
 Evpok
في ٣٠ أكتوبر ٢٠١٨
Evpok
في ٣٠ أكتوبر ٢٠١٨
Evpok تم دمج هذا هناك. يجب أن يكون لديك هذا التصحيح بالتأكيد. أتساءل عما إذا كان هناك المزيد من المآزق المحتملة. هل لديك نسخة سهلة يمكن أن نحاول إلقاء نظرة عليها؟
soumith
في ٣٠ أكتوبر ٢٠١٨
لقد تتبعت ذلك في الواقع إلى فوضى متعددة المعالجات غير ذات صلة من جانبي ، آسف للإزعاج.
Evpok
في ٣٠ أكتوبر ٢٠١٨
مرحباEvpok
أستخدم torch_nightly-1.0.0 وأواجه هذه المشكلة. هل حلت هذه المشكلة؟
 zimenglan-sysu-512
في ١٤ نوفمبر ٢٠١٨
zimenglan-sysu-512
في ١٤ نوفمبر ٢٠١٨
إذا كنت تستخدم collate_fn و num_workers> 0 مع إصدار PyTorch <0.4:
تأكد من أنك لا تسترجع موترات خافتة الصفر من وظيفة
__getitem__().
أو قم بإعادتها كمصفوفات رقمية.
لقد أصلحت خطأ إرجاع الأصفار الخافتة ولا تزال المشكلة قائمة.
 liluxuan1997
في ١٤ نوفمبر ٢٠١٨
liluxuan1997
في ١٤ نوفمبر ٢٠١٨
@ zimenglan-sysu-512 كانت المشكلة الرئيسية مع قيود المعالجة المتعددة: عند استخدام spawn أو forkserver (وهو أمر ضروري لاتصال CPU-GPU) تكون مشاركة الكائنات بين العملية محدودة إلى حد ما وليس مناسب لنوع الأشياء التي يجب أن أتعامل معها.
Evpok
في ١٤ نوفمبر ٢٠١٨
لا شيء من هذا يعمل بالنسبة لي. ومع ذلك ، فإن أحدث نسخة مفتوحة تعمل ( 3.4.0.12 إلى 3.4.3.18 لا شيء آخر لتغييره):
sudo pip3 install --upgrade opencv-python
 see--
في ١٧ نوفمبر ٢٠١٨
see--
في ١٧ نوفمبر ٢٠١٨
@ see - يسعدني معرفة أن opencv أصلحت الشيء :)
SsnL
في ١٧ نوفمبر ٢٠١٨
أنا على OpenCV 3.4.3.18 مع python2.7 ، وما زلت أرى المأزق يحدث. : /
 SreenivasVRao
في ٣ ديسمبر ٢٠١٨
SreenivasVRao
في ٣ ديسمبر ٢٠١٨
الرجاء محاولة ما يلي:
from torch.utils.data.dataloader import DataLoader
بدلا من
from torch.utils.data import DataLoader
أعتقد أن هناك مشكلة في التحقق من النوع هنا:
https://github.com/pytorch/pytorch/blob/656b565a0f53d9f24547b060bd27aa67ebb89b88/torch/utils/data/dataloader.py#L816
 jewfro-cuban
في ١٦ ديسمبر ٢٠١٨
jewfro-cuban
في ١٦ ديسمبر ٢٠١٨
الرجاء محاولة ما يلي:
from torch.utils.data.dataloader import DataLoaderبدلا من
from torch.utils.data import DataLoaderأعتقد أن هناك مشكلة في التحقق من النوع هنا:
pytorch / torch / utils / data / dataloader.py
خط 816 في 656b565
سوبر (DataLoader ، self) .__ setattr __ (attr ، val)
أليس هذا مجرد اسم مستعار؟ في torch.utils.data .__ init__ يقومون باستيراد dataloader.DataLoader
 simonhessner
في ٨ يناير ٢٠١٩
simonhessner
في ٨ يناير ٢٠١٩
كان لدي أيضًا تعليق مع num_workers> 0. لا يحتوي الكود الخاص بي على opencv ، ولا يمثل استخدام الذاكرة /dev/shm مشكلة. لا توجد اقتراحات أعلاه عملت بالنسبة لي. كان الإصلاح الذي أجريته هو تحديث numpy من 1.14.1 إلى 1.14.5:
conda install numpy=1.14.5
اتمنى ان تكون مفيدة
 daniyar-niantic
في ٨ يناير ٢٠١٩
daniyar-niantic
في ٨ يناير ٢٠١٩
حسنًا ، الإصدار الخاص بي هو 1.15.4 ، لذا فهو أحدث من 1.14.5 ... هل يجب أن يكون على ما يرام إذن؟
simonhessner
في ٨ يناير ٢٠١٩
حسنًا ، الإصدار الخاص بي هو 1.15.4 ، لذا فهو أحدث من 1.14.5 ... هل يجب أن يكون على ما يرام إذن؟
Idk ، تحديثي لـ numpy قام أيضًا بتحديث mkl.
daniyar-niantic
في ٨ يناير ٢٠١٩
ما هو إصدار MKL لديك؟ المنجم هو 2019.1 (الإصدار 144) والحزم الأخرى التي تتضمن mkl في أسمائها هي:
خدمة mkl 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 pe37hd81dba3_0
mkl_random 1.0.2 pe37hd81dba3_0
simonhessner
في ٨ يناير ٢٠١٩
ما هو إصدار MKL لديك؟ المنجم هو 2019.1 (الإصدار 144) والحزم الأخرى التي تتضمن mkl في أسمائها هي:
خدمة mkl 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 pe37hd81dba3_0
mkl_random 1.0.2 pe37hd81dba3_0
conda list | grep mkl
mkl 2018.0.1 h19d6760_4
mkl-service 1.1.2 py36h17a0993_4
إذا كنت لا تزال ترى تعليقًا في أحدث pytorch ، فسيكون من المفيد جدًا تقديم نص قصير يعيد إنتاج المشكلة. شكرا!
SsnL
في ٩ يناير ٢٠١٩
ما زلت أرى هذا المأزق ، سأرى ما إذا كان بإمكاني إنشاء نص برمجي يعيد إنتاجه.
 dtmoodie
في ١٥ يناير ٢٠١٩
dtmoodie
في ١٥ يناير ٢٠١٩
pin_memory=True حل المشكلة بالنسبة لي.
pyaf
في ٣٠ يناير ٢٠١٩
لا يبدو أنه يعمل بالنسبة لي مع pin_memory=True ، ما زلت عالقًا بعد 70 حقبة. الشيء الوحيد الذي نجح معي حتى الآن هو تعيين num_workers=0 ، لكنه أبطأ بشكل ملحوظ.
 jclevesque
في ١٤ فبراير ٢٠١٩
jclevesque
في ١٤ فبراير ٢٠١٩
أنا أيضًا أعاني من الجمود (يحدث بشكل عشوائي جدًا). حاولت pin_memory وتحديث Numpy. سأحاول تشغيله على جهاز مختلف.
 Avsecz
في ١٤ فبراير ٢٠١٩
Avsecz
في ١٤ فبراير ٢٠١٩
إذا كنت تستخدم سلاسل رسائل متعددة مع محمل بيانات ، فحاول استخدام المعالجة المتعددة بدلاً من تعدد مؤشرات الترابط. أدى هذا إلى حل المشكلة تمامًا بالنسبة لي (وبالمناسبة ، من الأفضل أيضًا المهام المكثفة حسابيًا في Python بسبب GIL)
simonhessner
في ١٤ فبراير ٢٠١٩
نفس الخطأ في Pytorch1.0 ، Pillow5.0.0 numpy 1.16.1 python3.6
 jianlong-yuan
في ١٥ فبراير ٢٠١٩
jianlong-yuan
في ١٥ فبراير ٢٠١٩
أنا أيضا أحصل على نفس الخطأ. لقد قمت بتعيين pin_memory=True و num_workers=0 . على الرغم من أن هناك شيئًا واحدًا لاحظت أنه عندما أستخدم جزءًا صغيرًا من مجموعة البيانات ، فإن هذا الخطأ لا يحدث. يؤدي استخدام مجموعة البيانات بأكملها فقط إلى حدوث هذا الخطأ.
تحرير: مجرد إعادة تشغيل بسيطة للنظام تم إصلاحه لي.
 Venka97
في ٦ مارس ٢٠١٩
Venka97
في ٦ مارس ٢٠١٩
لدي مشكلة مماثلة. في بعض التعليمات البرمجية ، ستتوقف هذه الوظيفة (دائمًا تقريبًا) على d_iter.next ():
def get_next_batch(d_iter, loader):
try:
data, label = d_iter.next()
except StopIteration:
d_iter = iter(loader)
data, label = d_iter.next()
return data, label
كان الاختراق الذي نجح معي هو إضافة تأخير بسيط بعد استدعاء هذه الوظيفة
trn_X, trn_y = get_next_batch(train_data_iter, train_loader)
time.sleep(0.003)
val_X, val_y = get_next_batch(valid_data_iter, valid_loader)
أعتقد أن التأخير ساعد في تجنب بعض الجمود؟
 enoonIT
في ٢٠ مارس ٢٠١٩
enoonIT
في ٢٠ مارس ٢٠١٩
ما زلت أقابل هذه المشكلة. باستخدام pytorch 1.0 و python 3.7. عندما كنت أستخدم محمل بيانات متعددة ، سيظهر هذا الخطأ. إذا استخدمت أقل من 3 محمل بيانات أو استخدمت وحدة معالجة رسومات واحدة ، فلن يظهر هذا الخطأ. حاول:
- time.sleep (0.003)
- pin_memory = صح / خطأ
- عدد_العمال = 0/1
- من torch.utils.data.dataloader استيراد DataLoader
- كتابة 8192 إلى / proc / sys / kernel / shmmni
لا أحد منهم يعمل. لا أعرف ما إذا كان هناك أي حلول؟
 xuw080
في ١٦ أبريل ٢٠١٩
xuw080
في ١٦ أبريل ٢٠١٩
إضافة الحلول الخاصة بي cv2.setNumThreads (0) في برنامج preprocess
لدي 2 dataloader ، وهما القطار و val
يمكنني تشغيل برنامج التقييم مرة واحدة فقط.
 lightningsoon
في ١٠ مايو ٢٠١٩
lightningsoon
في ١٠ مايو ٢٠١٩
لقد واجهت للتو هذا الخطأ مع pytorch 1.1. لقد علق نفسه مرتين في نفس المكان: نهاية الحقبة التاسعة والتسعين. تم تعيين pin_memory على False .
 Randl
في ١٧ مايو ٢٠١٩
Randl
في ١٧ مايو ٢٠١٩
نفس المشكلة عند استخدام العمال> 0 ، ذاكرة الدبوس لم تحل المشكلة.
 nicolasCruzW21
في ٢٠ مايو ٢٠١٩
nicolasCruzW21
في ٢٠ مايو ٢٠١٩
إضافة الحلول الخاصة بي cv2.setNumThreads (0) في برنامج preprocess
لدي 2 dataloader ، وهما القطار و val
يمكنني تشغيل برنامج التقييم مرة واحدة فقط.
هذا الحل يناسبني ، شكرا
 zxhr2793
في ٣ يونيو ٢٠١٩
zxhr2793
في ٣ يونيو ٢٠١٩
يتوقف برنامج تحميل البيانات عندما أنهي حقبة ما ويبدأ حقبة جديدة.
تواجه نفس المشكلة. في حالتي ، تظهر المشكلة عندما أقوم بتثبيت opencv-python (لقد قمت بتثبيت opencv3 من قبل). بعد نقل opencv-python ، لن يتوقف التدريب.
 hongzhenwang
في ٢٠ يونيو ٢٠١٩
hongzhenwang
في ٢٠ يونيو ٢٠١٩
إنها فكرة جيدة أيضًا
في 2019-06-20 10:51:02 ، كتب "hongzhenwang" [email protected] :
يتوقف برنامج تحميل البيانات عندما أنهي حقبة ما ويبدأ حقبة جديدة.
تواجه نفس المشكلة. في حالتي ، تظهر المشكلة عندما أقوم بتثبيت opencv-python (لقد قمت بتثبيت opencv3 من قبل). بعد نقل opencv-python ، لن يتوقف التدريب.
-
أنت تتلقى هذا لأنك علقت.
قم بالرد على هذه الرسالة الإلكترونية مباشرةً ، أو اعرضها على GitHub ، أو قم بكتم صوت الموضوع.
lightningsoon
في ٢٧ يونيو ٢٠١٩
ما زلت أقابل هذه المشكلة. باستخدام pytorch 1.0 و python 3.7. عندما كنت أستخدم محمل بيانات متعددة ، سيظهر هذا الخطأ. إذا استخدمت أقل من 3 محمل بيانات أو استخدمت وحدة معالجة رسومات واحدة ، فلن يظهر هذا الخطأ. حاول:
1. time.sleep(0.003) 2. pin_memory=True/False 3. num_workers=0/1 4. from torch.utils.data.dataloader import DataLoader 5. writing 8192 to /proc/sys/kernel/shmmni None of them works. Don't know whether there is any solutions?
ما زلت أحاول إيجاد حل بديل. أوافق على أنني أواجه هذه المشكلة فقط عندما أقوم بتشغيل عمليتين متوازيتين على وحدات معالجة رسومات مختلفة في نفس الوقت. واحد يستمر بينما الآخر يتوقف.
 ArturoDeza
في ٣ يوليو ٢٠١٩
ArturoDeza
في ٣ يوليو ٢٠١٩
عندما أقوم بتعيين عدد العمال = 4 ، توقف البرنامج لبضع ثوان (أو دقائق) كل 4 دفعات ، مما يضيع الكثير من الوقت. أي فكرة عن كيفية حلها؟
 huangchaoxing
في ٢٧ يوليو ٢٠١٩
huangchaoxing
في ٢٧ يوليو ٢٠١٩
إضافة العلامات: pin_memory = True و num_workers = 0 في أداة تحميل البيانات هو الحل!
ArturoDeza
في ٢٧ يوليو ٢٠١٩
إضافة العلامات: pin_memory = True و num_workers = 0 في أداة تحميل البيانات هو الحل!
تضمين التغريدة
قد يكون هذا حلاً ، ومع ذلك ، يؤدي تعيين num_workers = 0 إلى إبطاء جلب البيانات بالكامل لوحدة المعالجة المركزية وسيكون معدل استخدام GPU منخفضًا للغاية.
huangchaoxing
في ٢٨ يوليو ٢٠١٩
بالنسبة لي ، كان السبب هو عدم وجود وحدات معالجة مركزية كافية في نظامي أو عدم وجود ما يكفي من num_workers المحدد في Dataloader. قد يكون من الجيد أيضًا تعطيل الترابط في عمال Dataloader في حالة استخدام طريقة __get_item__ في أداة تحميل البيانات مكتبة مترابطة مثل numpy أو librosa أو opencv (يُرجى الاطلاع أدناه على سبب أهمية ذلك). يمكن تحقيق ذلك عن طريق تشغيل البرنامج النصي التدريبي الخاص بك بـ OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . كتوضيح للمناقشة أدناه ، يرجى ملاحظة أن كل دفعة Dataloader يتم التعامل معها بواسطة عامل واحد: يتعامل كل عامل مع عينات batch_size لإكمال دفعة واحدة ، ثم يبدأ في معالجة دفعة جديدة من البيانات.
تحتاج إلى تعيين num_workers أقل من عدد وحدات المعالجة المركزية في الجهاز (أو pod إذا كنت تستخدم Kubernetes) ، ولكن عالية بما يكفي لتكون البيانات جاهزة دائمًا للتكرار التالي. إذا قامت وحدة معالجة الرسومات بتشغيل كل عملية تكرار في t ثانية ، ويستغرق كل عامل تحميل بيانات N*t ثانية لتحميل / معالجة دفعة واحدة ، فيجب عليك تعيين num_workers على الأقل N لتجنب توقف وحدة معالجة الجرافيكس. بالطبع ، يجب أن يكون لديك وحدات معالجة مركزية على الأقل N في النظام.
لسوء الحظ ، إذا كان Dataloader يستخدم أي مكتبة تستخدم خيوط K ، فإن عدد العمليات التي تم إنتاجها يصبح num_workers*K = N*K . قد يكون هذا أعلى بكثير من عدد وحدات المعالجة المركزية في الجهاز. هذا يخنق الكبسولة ، ويصبح Dataloader بطيئًا جدًا. يمكن أن يتسبب هذا في عدم قيام Dataloader بإرجاع دفعة كل ثانية ، مما يتسبب في توقف وحدة معالجة الرسومات.
تتمثل إحدى طرق تجنب سلاسل عمليات K في استدعاء النص الرئيسي بواسطة OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . هذا يقيد كل عامل Dataloader لاستخدام خيط واحد ، وتجنب إرباك الجهاز. لا يزال يتعين عليك الحصول على ما يكفي من num_workers للحفاظ على تغذية وحدة معالجة الرسومات.
يجب أيضًا تحسين الكود الخاص بك في __get_item__ بحيث يكمل كل عامل مجموعته في فترة زمنية قصيرة. يرجى التأكد من أن الوقت لإكمال المعالجة المسبقة لمجموعة من قبل العامل لا يعوقه الوقت لقراءة بيانات التدريب من القرص (خاصة إذا كنت تقرأ من وحدة تخزين شبكة) ، أو عرض النطاق الترددي للشبكة (إذا كنت تقرأ من شبكة القرص). إذا كانت مجموعة البيانات الخاصة بك صغيرة ولديك ذاكرة وصول عشوائي كافية ، ففكر في نقل مجموعة البيانات إلى ذاكرة الوصول العشوائي (أو /tmpfs ) واقرأ من هناك للوصول السريع. بالنسبة إلى Kubernetes ، يمكنك إنشاء قرص RAM (ابحث عن emptyDir في Kubernetes).
إذا قمت بتحسين كود __get_item__ الخاص بك ، وتأكدت من أن الوصول إلى القرص / الوصول إلى الشبكة ليسوا المذنبين ، ولكنك لا تزال ترى الأكشاك ، فستحتاج إلى طلب المزيد من وحدات المعالجة المركزية (لحجرة Kubernetes) أو نقل وحدة معالجة الرسومات الخاصة بك إلى الجهاز مع المزيد من وحدات المعالجة المركزية.
خيار آخر هو تقليل batch_size بحيث يكون لكل worker عمل أقل للقيام به ، وسيتم إنهاء المعالجة المسبقة بشكل أسرع. الخيار الأخير غير مرغوب فيه في بعض الحالات ، لأنه لن يتم استخدام ذاكرة GPU خاملة.
يمكنك أيضًا التفكير في إجراء بعض عمليات المعالجة المسبقة في وضع عدم الاتصال ، والتخلص من ثقل كل عامل. على سبيل المثال ، إذا كان كل عامل يقرأ في ملف wav ويقوم بحساب مخططات طيفية لملف الصوت ، فيمكنك التفكير مسبقًا في حساب مخططات الطيف في وضع عدم الاتصال وقراءة المخطط الطيفي المحسوب من القرص في العامل. سيؤدي ذلك إلى تقليل حجم العمل الذي يتعين على كل عامل القيام به.
 gkeskin07
في ٣ أغسطس ٢٠١٩
gkeskin07
في ٣ أغسطس ٢٠١٩
تواجه نفس المشكلة مع Horovod
 jinhou
في ١٢ أغسطس ٢٠١٩
jinhou
في ١٢ أغسطس ٢٠١٩
واجه مشكلة مماثلة ... حالة الجمود أثناء الانتهاء من حقبة ما والبدء في تحميل البيانات للتحقق من صحتها ...
 jackroos
في ٢٠ أغسطس ٢٠١٩
jackroos
في ٢٠ أغسطس ٢٠١٩
jinhoujackroos نفس الشيء، تمسك بشكل عشوائي في بداية التحقق مع horovod. ما أفعله حاليًا كحل بديل هو تعيين مهلة وتخطي التحقق من الصحة. هل لديك حل؟
 lzljzys
في ٢٨ أغسطس ٢٠١٩
lzljzys
في ٢٨ أغسطس ٢٠١٩
jinhoujackroos نفس الشيء، تمسك بشكل عشوائي في بداية التحقق مع horovod. ما أفعله حاليًا كحل بديل هو تعيين مهلة وتخطي التحقق من الصحة. هل لديك حل؟
لا ، لقد قمت للتو بإيقاف التدريب الموزع في هذه الحالة.
jackroos
في ٢٩ أغسطس ٢٠١٩
واجهت مشكلة مماثلة: توقف أداة تحميل البيانات عندما أنتهي من حقبة ما وأبدأ حقبة جديدة.
لماذا زان كثيرا؟
 foocker
في ٢٢ أكتوبر ٢٠١٩
foocker
في ٢٢ أكتوبر ٢٠١٩
ما زلت أقابل هذه المشكلة. باستخدام pytorch 1.0 و python 3.7. عندما كنت أستخدم محمل بيانات متعددة ، سيظهر هذا الخطأ. إذا استخدمت أقل من 3 محمل بيانات أو استخدمت وحدة معالجة رسومات واحدة ، فلن يظهر هذا الخطأ. حاول:
- time.sleep (0.003)
- pin_memory = صح / خطأ
- عدد_العمال = 0/1
- من torch.utils.data.dataloader استيراد DataLoader
- كتابة 8192 إلى / proc / sys / kernel / shmmni
لا أحد منهم يعمل. لا أعرف ما إذا كان هناك أي حلول؟
تم تعيين عدد العمال على 0 بالنسبة لي. يجب عليك التأكد من أنه عند 0 في كل مكان تستخدمه فيه.
بعض الحلول المحتملة الأخرى:
- من استيراد مجموعة المعالجة المتعددة set_start_method
set_start_method ("تفرخ") - cv2.setNumThreads (0)
يبدو أن 3 أو 7 هي السبيل للذهاب.
 the7threvival
في ١٨ نوفمبر ٢٠١٩
the7threvival
في ١٨ نوفمبر ٢٠١٩
واجهت هذه المشكلة مع pytorch 1.3 ، ubuntu16 ، لم تنجح جميع الاقتراحات المذكورة أعلاه باستثناء العمال = 0 مما يؤدي إلى إبطاء التنفيذ. يحدث هذا فقط عند الركض من المحطة ، كل شيء على ما يرام داخل دفتر Jupyter ، حتى مع العمال = 32.
لا يبدو أن القضية قد تم حلها ، فهل يجب إعادة فتحها؟ أرى أيضًا العديد من الأشخاص الآخرين يبلغون عن نفس المشكلة ...
 skariel
في ٢ ديسمبر ٢٠١٩
skariel
في ٢ ديسمبر ٢٠١٩
ما زلت أقابل هذه المشكلة. باستخدام pytorch 1.0 و python 3.7. عندما كنت أستخدم محمل بيانات متعددة ، سيظهر هذا الخطأ. إذا استخدمت أقل من 3 محمل بيانات أو استخدمت وحدة معالجة رسومات واحدة ، فلن يظهر هذا الخطأ. حاول:
- time.sleep (0.003)
- pin_memory = صح / خطأ
- عدد_العمال = 0/1
- من torch.utils.data.dataloader استيراد DataLoader
- كتابة 8192 إلى / proc / sys / kernel / shmmni
لا أحد منهم يعمل. لا أعرف ما إذا كان هناك أي حلول؟تم تعيين عدد العمال على 0 بالنسبة لي. يجب عليك التأكد من أنه عند 0 في كل مكان تستخدمه فيه.
بعض الحلول المحتملة الأخرى:
- من استيراد مجموعة المعالجة المتعددة set_start_method
set_start_method ("تفرخ")- cv2.setNumThreads (0)
يبدو أن 3 أو 7 هي السبيل للذهاب.
قمت بتعديل train.py مثل هذا:
from __future__ import division
import cv2
cv2.setNumThreads(0)
import argparse
...
ويعمل بالنسبة لي.
 DHZS
في ١٠ ديسمبر ٢٠١٩
DHZS
في ١٠ ديسمبر ٢٠١٩
مرحبًا يا رفاق ، إذا كان بإمكاني المساعدة ،
لدي أيضًا مشكلة مشابهة لهذه ، لكنها ستحدث كل 100 حقبة أو نحو ذلك.
لقد لاحظت أنه حدث فقط مع تمكين CUDA ، كما أن dmesg لديه إدخال السجل هذا كلما تعطل.
python[11240]: segfault at 10 ip 00007fabdd6c37d8 sp 00007ffddcd64fd0 error 4 in libcudart.so.10.1.243[7fabdd699000+77000]
إنها رطانة بالنسبة لي ، لكنها أخبرتني أن CUDA و python multithreading لا يلعبان بشكل جيد.
كان الإصلاح الذي أجريته هو تعطيل cuda في خيوط البيانات ، وهنا مقتطف من ملف إدخال Python الخاص بي.
from multiprocessing import set_start_method
import os
if __name__ == "__main__":
set_start_method('spawn')
else:
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import torch
import application
آمل أن يساعد ذلك أي شخص يهبط هنا مثلما كنت بحاجة إليه في ذلك الوقت.
 roderickObrist
في ٢٤ مارس ٢٠٢٠
roderickObrist
في ٢٤ مارس ٢٠٢٠
jinhoujackroos نفس الشيء، تمسك بشكل عشوائي في بداية التحقق مع horovod. ما أفعله حاليًا كحل بديل هو تعيين مهلة وتخطي التحقق من الصحة. هل لديك حل؟
لا ، لقد قمت للتو بإيقاف التدريب الموزع في هذه الحالة.
واجهت مشكلة مماثلة في التدريب الموزع دون استخدام OpenCV بعد التحديث إلى PyTorch 1.4.
الآن عليّ تشغيل عملية التحقق مرة واحدة قبل حلقة التدريب والتحقق من الصحة.
 wizardk
في ٩ يونيو ٢٠٢٠
wizardk
في ٩ يونيو ٢٠٢٠
لقد واجهت الكثير من المشاكل مع هذا. يبدو أنه يستمر عبر إصدارات من pytorch ، وإصدارات من Python وأيضًا آلات فيزيائية مختلفة (من المحتمل أن تكون قد تم إعدادها بشكل متماثل).
في كل مرة يحدث نفس الخطأ:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/bicep/loops.py", line 73, in __call__
for data, target in self.dataloader:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 830, in _next_data
self._shutdown_workers()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 942, in _shutdown_workers
w.join()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/process.py", line 149, in join
res = self._popen.wait(timeout)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 47, in wait
return self.poll(os.WNOHANG if timeout == 0.0 else 0)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll
pid, sts = os.waitpid(self.pid, flag)
من الواضح أن هناك بعض المشكلات في طريقة معالجة العمليات على الجهاز الذي أستخدمه. لا يبدو أن أيًا من الحلول المذكورة أعلاه يعمل ، بصرف النظر عن تعيين عدد العمال = 0.
أود حقًا أن أكون قادرًا على الوصول إلى جوهر هذا ، هل لدى أي شخص أي فكرة من أين يبدأ أو كيف يستجوب هذا؟
 brynhayder
في ٩ يونيو ٢٠٢٠
brynhayder
في ٩ يونيو ٢٠٢٠
أنا أيضًا هنا.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 480, in _try_get_batch
data = self.data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 65, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 95106) is killed by signal: Segmentation fault.
شيء واحد الفائدة هو
عندما أقوم فقط بتحليل البيانات سطرًا بسطر ، لا أواجه هذه المشكلة:
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
ولكن إذا أضفت منطق تحليل JSON بعد قراءة سطر بسطر ، فسيتم الإبلاغ عن هذا الخطأ
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
أتفهم أنه سيكون هناك بعض الحمل على ذاكرة JSON ، ولكن حتى أقوم بتقليل عدد العاملين إلى 2 ، ومجموعة البيانات صغيرة جدًا ، ولا تزال تواجه نفس المشكلة. أنا أشك في أنها مرتبطة بجمهورية مصر العربية. أي فكرة؟
 zhangruiskyline
في ١٦ يونيو ٢٠٢٠
zhangruiskyline
في ١٦ يونيو ٢٠٢٠
هل يجب علينا إعادة فتح هذه القضية؟
 takatosp1
في ١٨ يونيو ٢٠٢٠
takatosp1
في ١٨ يونيو ٢٠٢٠
أعتقد أننا يجب أن. راجع للشغل ، لقد قمت ببعض تصحيح أخطاء GDB ولم يتم العثور على شيء هناك. لذلك لست متأكدًا مما إذا كانت مشكلة الذاكرة المشتركة ،
(gdb) run
Starting program: /home/miniconda/bin/python performance.py
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7fffa60a6700 (LWP 61963)]
[New Thread 0x7fffa58a5700 (LWP 61964)]
[New Thread 0x7fffa10a4700 (LWP 61965)]
[New Thread 0x7fff9e8a3700 (LWP 61966)]
[New Thread 0x7fff9c0a2700 (LWP 61967)]
[New Thread 0x7fff998a1700 (LWP 61968)]
[New Thread 0x7fff970a0700 (LWP 61969)]
[New Thread 0x7fff9489f700 (LWP 61970)]
[New Thread 0x7fff9409e700 (LWP 61971)]
[New Thread 0x7fff8f89d700 (LWP 61972)]
[New Thread 0x7fff8d09c700 (LWP 61973)]
[New Thread 0x7fff8a89b700 (LWP 61974)]
[New Thread 0x7fff8809a700 (LWP 61975)]
[New Thread 0x7fff85899700 (LWP 61976)]
[New Thread 0x7fff83098700 (LWP 61977)]
[New Thread 0x7fff80897700 (LWP 61978)]
[New Thread 0x7fff7e096700 (LWP 61979)]
[New Thread 0x7fff7d895700 (LWP 61980)]
[New Thread 0x7fff7b094700 (LWP 61981)]
[New Thread 0x7fff78893700 (LWP 61982)]
[New Thread 0x7fff74092700 (LWP 61983)]
[New Thread 0x7fff71891700 (LWP 61984)]
[New Thread 0x7fff6f090700 (LWP 61985)]
[Thread 0x7fff7e096700 (LWP 61979) exited]
[Thread 0x7fff6f090700 (LWP 61985) exited]
[Thread 0x7fff74092700 (LWP 61983) exited]
[Thread 0x7fff7b094700 (LWP 61981) exited]
[Thread 0x7fff80897700 (LWP 61978) exited]
[Thread 0x7fff83098700 (LWP 61977) exited]
[Thread 0x7fff85899700 (LWP 61976) exited]
[Thread 0x7fff8809a700 (LWP 61975) exited]
[Thread 0x7fff8a89b700 (LWP 61974) exited]
[Thread 0x7fff8d09c700 (LWP 61973) exited]
[Thread 0x7fff8f89d700 (LWP 61972) exited]
[Thread 0x7fff9409e700 (LWP 61971) exited]
[Thread 0x7fff9489f700 (LWP 61970) exited]
[Thread 0x7fff970a0700 (LWP 61969) exited]
[Thread 0x7fff998a1700 (LWP 61968) exited]
[Thread 0x7fff9c0a2700 (LWP 61967) exited]
[Thread 0x7fff9e8a3700 (LWP 61966) exited]
[Thread 0x7fffa10a4700 (LWP 61965) exited]
[Thread 0x7fffa58a5700 (LWP 61964) exited]
[Thread 0x7fffa60a6700 (LWP 61963) exited]
[Thread 0x7fff71891700 (LWP 61984) exited]
[Thread 0x7fff78893700 (LWP 61982) exited]
[Thread 0x7fff7d895700 (LWP 61980) exited]
total_files = 5040. //customer comments
[New Thread 0x7fff6f090700 (LWP 62006)]
[New Thread 0x7fff71891700 (LWP 62007)]
[New Thread 0x7fff74092700 (LWP 62008)]
[New Thread 0x7fff78893700 (LWP 62009)]
ERROR: Unexpected segmentation fault encountered in worker.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 62005) is killed by signal: Segmentation fault.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "performance.py", line 62, in <module>
main()
File "performance.py", line 48, in main
for i,batch in enumerate(rl_data_loader):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 841, in _next_data
idx, data = self._get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 808, in _get_data
success, data = self._try_get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 774, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 62005) exited unexpectedly
[Thread 0x7fff78893700 (LWP 62009) exited]
[Thread 0x7fff74092700 (LWP 62008) exited]
[Thread 0x7fff71891700 (LWP 62007) exited]
[Thread 0x7fff6f090700 (LWP 62006) exited]
[Inferior 1 (process 61952) exited with code 01]
(gdb) backtrace
No stack.
وأعتقد أن لدي ما يكفي من الذاكرة المشتركة ، على الأقل أتوقع أن تكون الذاكرة المشتركة جيدة بما يكفي لفترة طويلة جدًا حتى segfault ، ولكن يحدث خطأ في المقطع على الفور تقريبًا بعد أن أقوم بتشغيل وظيفة أداة تحميل البيانات
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18014398509481980
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
مرحباsoumithapaszke، يمكننا إعادة فتح هذه المسألة، حاولت كل الحلول المقترحة مثل زيادة حجم SHM والقطاع، ويعمل أي شيء، وأنا لا تستخدم مكتبة برمجية مفتوحة للرؤية الحاسوبية أو نحو ذلك، مجرد بسيطة تحليل JSON. لكن القضية لا تزال هناك. ولا أعتقد أنها مرتبطة بـ shm منذ أن تحققت من فتح كل الذاكرة كذاكرة مشتركة. يظهر تتبع المكدس أيضًا أي شيء هناك كما تم نشره أعلاه.
apaszke ، بخصوص اقتراحك لـ
"نعم ، يرجع سبب الكثير من هذه المشكلات إلى عدم أمان مكتبات الجهات الخارجية. قد يكون أحد الحلول البديلة هو استخدام طريقة بدء النشر."
أنا أستخدم أداة تحميل البيانات متعددة العمال ، كيف يمكنني تغيير الطريقة؟ أقوم بتعيين set_start_method('spawn') في main.py الخاصة بي ولكن لا يبدو أن جرعة الدواء تساعد
لدي أيضًا سؤال عام هنا ، إذا قمت بتمكين أداة تحميل بيانات متعددة العمال (عمليات متعددة) ، وفي التدريب الرئيسي ، أبدأ أيضًا عملية متعددة كما هو مقترح في https://pytorch.org/docs/stable/notes/multiprocessing.html #multiprocessing- أفضل الممارسات
كيف pytorch إدارة كل من dataloader والتدريب الرئيسي متعدد العمليات؟ هل سيشاركون كل العمليات الممكنة / خيوط المعالجة على وحدة معالجة الرسومات متعددة النواة؟ هل يتم "مشاركة" الذاكرة المشتركة لعمليات متعددة بواسطة أداة تحميل البيانات وعملية التدريب الرئيسية؟ أيضًا إذا كان لدي بعض وظائف طهي البيانات مثل تحليل JSON وتحليل CSV واستخراج ميزة الباندا. إلخ ، أين أفضل طريقة لوضعها؟ في أداة تحميل البيانات لإنشاء بيانات مثالية لتكون جاهزة أو مجرد استخدام التدريب الرئيسي للقيام بذلك كما اقترح البعض أعلاه للحفاظ على أداة تحميل البيانات __get_item__ بسيطة قدر الإمكان
zhangruiskyline
في ١٩ يونيو ٢٠٢٠
zhangruiskyline مشكلتك ليست حقًا طريق مسدود. إنه يتعلق بقتل العمال بواسطة segfault. sigbus هو الذي يقترح مشكلات shm. يجب عليك التحقق من رمز مجموعة البيانات وتصحيح الأخطاء هناك.
للإجابة على أسئلتك الأخرى ،
- استخدام kwarg
multiproessing_context='spawn'في DataLoader سيحدد تفرخًا.set_start_methodيفعل ذلك أيضًا. - عادة في التدريب متعدد العمليات ، كل عملية لها DataLoader الخاص بها ، وبالتالي عمال DataLoader. لا يتم تقاسم أي شيء بين العمليات ما لم يتم ذلك صراحة.
SsnL
في ٢٠ يونيو ٢٠٢٠
شكرًا SsnL ، أضفت multiproessing_context='spawn' لكن نفس الفشل.
أشرت في الموضوع السابق ، الكود الخاص بي بسيط للغاية ،
- هذا الجزء من التعليمات البرمجية يعمل
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
- ولكن إذا أضفت منطق تحليل JSON بعد قراءة سطر بسطر ، فسيتم الإبلاغ عن هذا الخطأ
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
لذلك أشك في أنها مشكلة التعليمات البرمجية الخاصة بي ، كما أنني أحاول عدم استخدام تحليل JSON ، ولكن تقسيم السلسلة مباشرة ، نفس المشكلة. يبدو أنه طالما لدي بعض المنطق الذي يستغرق وقتًا طويلاً لمعالجة البيانات في أداة تحميل البيانات ، تحدث هذه المشكلة
أيضا بخصوص
التدريب متعدد العمليات ، كل عملية لها DataLoader الخاص بها ، وبالتالي عمال DataLoader لا يتم مشاركة أي شيء بين العمليات ما لم يتم ذلك صراحة.
لذلك دعونا نرى أن لدي 4 عمليات للتدريب ، كل واحدة بها 8 محمل بيانات عمال ، إذن إجمالي 32 عملية تحتها؟
zhangruiskyline
في ٢٠ يونيو ٢٠٢٠
zhangruiskyline بدون برنامج نصي
SsnL
في ٢٠ يونيو ٢٠٢٠
شكرًا ، لقد رأيت أيضًا مشكلة مماثلة في
https://github.com/pytorch/pytorch/issues/4969
https://github.com/pytorch/pytorch/issues/5040
كلاهما مغلق ولكني لا أرى حلًا أو إصلاحًا واضحًا ، فهل لا تزال هذه مشكلة قائمة؟
سأرى ما إذا كان بإمكاني تقديم برنامج نصي مكتمل ذاتيًا ولكنه متكامل بشكل كبير مع نظامنا الأساسي ومصدر البيانات ، لذا سأحاول
zhangruiskyline
في ٢٠ يونيو ٢٠٢٠
zhangruiskyline مشكلتك ليست مشابهة لأي من المشاكل المرتبطة ، إذا قرأتها. تم إغلاقها لأن المشكلة الأصلية / الأكثر شيوعًا التي تم الإبلاغ عنها في سلاسل الرسائل هذه تمت معالجتها بالفعل.
SsnL
في ٢٠ يونيو ٢٠٢٠
شكرًا SsnL ، لست على دراية بـ Pytorch لذا قد أكون مخطئًا ، لكنني مررت بكل هذه الأمور ، ويبدو أن بعضها قد تم حله من خلال
قلل عدد العمال إلى 0 ، فهذا غير مقبول بالنسبة لنا لأنه بطيء للغاية ،
زيادة حجم shm ، لكن لدينا ما يكفي من shm على ما أعتقد ، وحدثت المشكلة على الفور تقريبًا بعد أن نبدأ ، وحاولت مع مشكلة مجموعة بيانات أصغر بكثير هي نفسها
بعض جرعة lib مثل opencv لا تعمل في عمليات متعددة بشكل جيد ، فنحن نستخدم JSON / CSV فقط ، لذلك لا توجد أشياء رائعة حقًا
الكود الخاص بنا بسيط إلى حد ما ، مجموعة بيانات التدريب تحتوي على أكثر من 10000 ملف ، كل ملف عبارة عن أسطر متعددة من سلاسل JSON. في أداة تحميل البيانات ، نحدد __get_item__ لإخراج كل ملف من أكثر من 10 آلاف ملف وقراءة كل المحتوى في هذا الملف.
في الحل 1 ، نقرأ الأسطر أولاً ونقسمها إلى سطر إلى قائمة سلسلة JSON ، إذا عدنا على الفور ، فهذا يعمل ، والأداء جيد
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
return all_data
الآن بما أن القيمة المرتجعة لا تزال عبارة عن سلسلة JSON ، نريد الاستفادة من أداة تحميل البيانات متعددة العمليات للإسراع ، لذلك ضع منطق تحليل JSON هنا وفشل
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
اعتقدنا لاحقًا أن تحليل JSON ثقيل جدًا وأيضًا يحتوي JSON على مساحة ذاكرة كبيرة جدًا ، ثم اخترنا تحليل سلسلة JSON والتحويل يدويًا إلى قائمة الميزات ، نفس الفشل. قام ببعض تحليل تتبع المكدس ولا شيء هناك
راجع للشغل ، نحن نقوم بتشغيل الكود الخاص بنا في Linux Docker Env ، 24 نواة وحدة المعالجة المركزية و 1 V100.
لست متأكدًا من أين يجب أن أبدأ في التحقيق بعد ذلك. هل لديك أي فكرة؟
zhangruiskyline
في ٢٠ يونيو ٢٠٢٠
مرحبا،
لقد وجدت تعليقًا مثيرًا للاهتمام في https://github.com/open-mmlab/mmcv ، والذي يُستخدم في https://github.com/open-mmlab/mmdetection :
يتم استخدام الكود التالي في بداية كل من حقبة القطار وعهد فال.
time.sleep (2) # منع الجمود المحتمل أثناء انتقال الحقبة
قد يكون يمكنك تجربته.
mathmanu
في ٢٠ يونيو ٢٠٢٠
راجع للشغل ، إذا ذهبت إلى عملية متعددة وكل عملية باستخدام أداة تحميل بيانات متعددة العمال ، فكيف يمكن للعملية المختلفة أن تضمن أن أداة تحميل البيانات المقابلة لن تقرأ نفس البيانات مثل أداة تحميل البيانات الخاصة بالعملية الأخرى؟ يتم التعامل مع ti بالفعل بواسطة أداة تحميل البيانات pytorch __get_item__ ؟
zhangruiskyline
في ٢٠ يونيو ٢٠٢٠
مرحبًا SsnL ، شكرًا على مساعدتك. أريد فقط متابعة هذا الموضوع قليلاً ، فأنا أعد تشكيل رمز التدريب باستخدام معالجة متعددة pytorch لتسريع بعض معالجة البيانات في جانب وحدة المعالجة المركزية (من أجل التغذية إلى وحدة معالجة الرسومات بشكل أسرع) ، https://pytorch.org/docs/stable /notes/multiprocessing.html#multiprocessing -best -
في كل وظيفة معالجة ، أستخدم أيضًا أداة تحميل بيانات متعددة العمال لتسريع وقت معالجة تحميل البيانات. https://pytorch.org/docs/stable/data.html
لقد وضعت تحليل JSON لوحدة المعالجة المركزية (CPU) الخاصة بي في أداة تحميل البيانات ، ولكن في عملية التدريب الرئيسية ، ويبدو أن المشكلة قد ولت ، لا أعرف لماذا ولكن على أي حال يبدو أنها تعمل. ولكن لديك سؤال متابعة: لنفترض أن لديّ معالجة N ، كل منها لديه M عامل تحميل البيانات ، لذلك إجمالي NxM تحت سلسلة الترابط هناك.
إذا كنت أرغب في أداة تحميل البيانات الخاصة بي في الحصول على جميع البيانات بطريقة فهرسة ، مما يعني أن أداة تحميل البيانات M __get_item__(self, idx) في مُحمل بيانات N يمكن أن تعمل معًا لمعالجة فهرس مختلف ، فكيف يمكنني التأكد من أنها لا تقوم بمعالجة التكرار أو تفوت عملية بعض؟
zhangruiskyline
في ٢٣ يونيو ٢٠٢٠
واجهت نفس المشكلة حيث يتعطل أداة تحميل البيانات بعد الشكوى من عدم قدرتها على تخصيص الذاكرة في بداية فترة تدريب أو تحقق جديدة. لم تنجح الحلول المذكورة أعلاه بالنسبة لي (1) بلدي
/dev/shmهو 32 جيجا بايت ولم يتم استخدامه مطلقًا أكثر من 2.5 جيجا بايت ، و (2) إعداد pin_memory = False لم يعمل.ربما هذا شيء له علاقة بجمع القمامة؟ الكود الخاص بي يشبه ما يلي تقريبًا. أحتاج إلى مكرر لانهائي ، ومن ثم أقوم بتجربة / باستثناء ما يقرب من
next()أدناه :-)def train(): train_iter = train_loader.__iter__() for i in xrange(max_batches): try: x, y = next(train_iter) except StopIteration: train_iter = train_loader.__iter__() ... del train_iter
train_loaderهو كائنDataLoader. بدون السطر الصريحdel train_iterفي نهاية الوظيفة ، تتعطل العملية دائمًا بعد 2-3 فترات (لا يزال يظهر 2.5 جيجابايت من/dev/shm). أتمنى أن يساعدك هذا!أنا أستخدم عمال
4(الإصدار0.1.12_2مع CUDA 8.0 على Ubuntu 16.04).
هذا حل المشكلة بالنسبة لي بعد أسابيع من الكفاح. يجب أن أستخدم مكرر اللودر بشكل صريح بدلاً من تكرار اللودر مباشرة واستخدام del loader_iterator في نهاية الحقبة أخيرًا أزالت المآزق
 kennyFF92
في ١٥ يوليو ٢٠٢٠
kennyFF92
في ١٥ يوليو ٢٠٢٠
أعتقد أنني أواجه نفس المشكلة. محاولة استخدام 8 برامج تحميل بيانات (MNIST ، MNISTM ، SVHN ، USPS ، للتدريب واختبار كل منها). استخدام 6 (أي 6) يعمل بشكل جيد. باستخدام 8 كتل دائمًا عند تحميل السادس ، اختبار MNIST-M. إنه عالق في حلقة لا نهاية لها لمحاولة استرداد الصورة ، والفشل ، والانتظار قليلاً ثم المحاولة مرة أخرى. يستمر الخطأ في أي حجم للدفعة ، ولدي الكثير من الذاكرة الخالية المتبقية ، ولا يختفي إلا إذا قمت بتعيين عدد العمال على 0. أي مبلغ آخر يسبب المشكلة
 pmirallesr
في ٢١ يوليو ٢٠٢٠
pmirallesr
في ٢١ يوليو ٢٠٢٠
تلقيت بعض التلميحات من https://stackoverflow.com/questions/54013846/pytorch-dataloader-stucked-if-using-opencv-resize-method
عندما أضع cv2.setNumThreads(0) ، فإنه يعمل بشكل جيد معي.
 LifeBeyondExpectations
في ١٧ أغسطس ٢٠٢٠
LifeBeyondExpectations
في ١٧ أغسطس ٢٠٢٠
مرحبا ، لدي نفس المشكلة. وكان له علاقة بـ ulimit -n ، ببساطة قم بزيادته وتم حل المشكلة ، لقد استخدمت ulimit -n 500000
 SebastienEske
في ١٨ أغسطس ٢٠٢٠
SebastienEske
في ١٨ أغسطس ٢٠٢٠
SebastienEske ulimit -n أصلح هذا لي أيضًا ، على Ubuntu 20.04
 david-waterworth
في ٢٤ سبتمبر ٢٠٢٠
david-waterworth
في ٢٤ سبتمبر ٢٠٢٠
ربما تكون set ulimit -n هي الطريقة الصحيحة ، مع زيادة النموذج ، يصبح الجمود أكثر وأكثر تكرارًا ، أقوم أيضًا باختبار cv2.setNumThreads(0) ، لكنه لا يعمل.
 BLING-1994
في ٢٧ سبتمبر ٢٠٢٠
BLING-1994
في ٢٧ سبتمبر ٢٠٢٠
للتسجيل ، عملت معي cv2.setNumThreads(0) .
 franchesoni
في ١٨ نوفمبر ٢٠٢٠
franchesoni
في ١٨ نوفمبر ٢٠٢٠
القضايا ذات الصلة
 PhilippPelz
·
128تعليقات
PhilippPelz
·
128تعليقات
 HarshneetBhatia
·
172تعليقات
HarshneetBhatia
·
172تعليقات
 JamesOwers
·
61تعليقات
JamesOwers
·
61تعليقات
 elbamos
·
61تعليقات
elbamos
·
61تعليقات
 xiaoxiangyeyuwangye
·
103تعليقات
xiaoxiangyeyuwangye
·
103تعليقات
التعليق الأكثر فائدة
واجهت مشكلة مماثلة: توقف أداة تحميل البيانات عندما أنتهي من حقبة ما وأبدأ حقبة جديدة.