Pytorch: blocage possible dans le chargeur de données
le bogue est décrit dans pytorch/examples#148. Je me demande simplement s'il s'agit d'un bogue dans PyTorch lui-même, car l'exemple de code me semble propre. Aussi, je me demande si cela est lié à #1120.
 zym1010
zym1010
Tous les 189 commentaires
De combien de mémoire libre disposez-vous lorsque le chargeur s'arrête ?
 apaszke
le 25 avr. 2017
apaszke
le 25 avr. 2017
@apaszke si je vérifie top , la mémoire restante (la mémoire mise en cache compte également comme utilisée) est généralement de 2 Go. Mais si vous ne comptez pas le cache comme utilisé, c'est toujours beaucoup, disons 30 Go+.
zym1010
le 25 avr. 2017
Aussi je ne comprends pas pourquoi ça s'arrête toujours en début de validation, mais pas partout ailleurs.
zym1010
le 25 avr. 2017
Peut-être parce que pour la validation, un chargeur séparé est utilisé qui pousse l'utilisation de la mémoire partagée au-delà de la limite.
 ngimel
le 25 avr. 2017
ngimel
le 25 avr. 2017
@ngimel
Je viens de relancer le programme. Et s'est coincé.
Sortie de top :
~~~
top - 17:51:18 jusqu'à 2 jours, 21:05, 2 utilisateurs, charge moyenne : 0,49, 3,00, 5,41
Tâches : 357 au total, 2 en cours d'exécution, 355 en sommeil, 0 arrêtée, 0 zombie
%Cpu(s): 1,9 us, 0,1 sy, 0,7 ni, 97,3 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st
KiB Mem : 65863816 au total, 60115084 utilisé, 5748732 libre, 1372688 tampons
Échange de KiB : 5917692 au total, 620 utilisés, 5917072 gratuit. 51154784 mémoire cache
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3067 aalreja 20 0 143332 101816 21300 R 46,1 0,2 1631:44 Xvnc
16613 aalreja 30 10 32836 4880 3912 S 16.9 0.0 1:06.92 fiberlamp 3221 aalreja 20 0 8882348 1.017g 110120 S 1.3 1.6 579:06.87 MATLAB
1285 racine 20 0 1404848 48252 25580 S 0.3 0.1 6:00.12 dockerd 16597 yimengz+ 20 0 25084 3252 2572 R 0.3 0.0 0:04.56 top
1 racine 20 0 33616 4008 2624 S 0.0 0.0 0:01.43 init
~~~
Sortie de free
~yimengzh_everyday@yimengzh :~$ gratuittotal des tampons partagés libres utilisés mis en cacheMémoire : 65863816 60122060 5741756 9954628 1372688 51154916-/+ tampons/cache : 7594456 58269360Échange : 5917692 620 5917072~
Sortie de nvidia-smi
~~~
yimengzh_everyday@yimengzh :~$ nvidia-smi
mar 25 avr. 17:52:38 2017
+---------------------------------------------------------------- ----------------------------+
| Version du pilote NVIDIA-SMI 375.39 : 375.39 |
|----------------------------------------------+----------------- -----+----------------------+
| Nom du GPU Persistance-M| Bus-Id Disp.A | Uncorr volatil. CEC |
| Fan Temp Perf Pwr:Usage/Cap | Utilisation de la mémoire | GPU-Util Compute M. |
|===============================+================= =====+======================|
| 0 GeForce GTX TIT... Désactivé | 0000:03:00.0 Désactivé | S/O |
| 30% 42C P8 14W / 250W | 3986 Mio / 6082 Mio | 0% par défaut |
+--------------------------------+----------------- -----+----------------------+
| 1 Tesla K40c éteint | 0000:81:00.0 Désactivé | Désactivé |
| 0% 46C P0 57W / 235W | 0 Mio / 12205 Mio | 0% par défaut |
+--------------------------------+----------------- -----+----------------------+
+---------------------------------------------------------------- ----------------------------+
| Processus : Mémoire GPU |
| Type de PID GPU Nom du processus Utilisation |
|================================================= ============================|
| 0 16509 C python 3970MiB |
+---------------------------------------------------------------- ----------------------------+
~~~
Je ne pense pas que ce soit un problème de mémoire.
zym1010
le 25 avr. 2017
Il existe des limites distinctes pour la mémoire partagée. Pouvez-vous essayer ipcs -lm ou cat /proc/sys/kernel/shmall et cat /proc/sys/kernel/shmmax ? De plus, cela se bloque-t-il si vous utilisez moins de travailleurs (par exemple, test avec le cas extrême de 1 travailleur) ?
apaszke
le 26 avr. 2017
@apaszke
~~~
yimengzh_everyday@yimengzh :~$ ipcs -lm
------ Limites de la mémoire partagée --------
nombre maximum de segments = 4096
taille de segment maximale (ko) = 18014398509465599
mémoire partagée totale maximale (koctets) = 18446744073642442748
taille de segment min (octets) = 1
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmall
18446744073692774399
yimengzh_everyday@yimengzh :~$ cat /proc/sys/kernel/shmmax
18446744073692774399
~~~
comment te cherchent-ils ?
quant à moins de travailleurs, je pense que cela n'arrivera pas si souvent. (je peux essayer maintenant). Mais je pense qu'en pratique j'ai besoin d'autant de travailleurs.
zym1010
le 26 avr. 2017
Vous avez un maximum de 4096 segments de mémoire partagée autorisés, c'est peut-être un problème. Vous pouvez essayer d'augmenter cela en écrivant à /proc/sys/kernel/shmmni (peut-être essayer 8192). Vous aurez peut-être besoin de privilèges de superutilisateur.
apaszke
le 26 avr. 2017
@apaszke eh bien, ce sont les valeurs par défaut d'Ubuntu et de CentOS 6... Est-ce vraiment un problème ?
zym1010
le 26 avr. 2017
@apaszke lors de l'exécution d'un programme d'entraînement, ipcs -a n'affiche en fait aucune mémoire partagée utilisée. C'est prévu ?
zym1010
le 26 avr. 2017
@apaszke a essayé d'exécuter le programme (toujours 22 travailleurs) avec le paramètre suivant sur la mémoire partagée, et s'est à nouveau bloqué.
~~~
yimengzh_everyday@yimengzh :~$ ipcs -lm
------ Limites de la mémoire partagée --------
nombre maximum de segments = 8192
taille de segment maximale (ko) = 18014398509465599
mémoire partagée totale maximale (koctets) = 18446744073642442748
taille de segment min (octets) = 1
~~~
n'a pas essayé un seul travailleur. d'abord, ce serait lent; Deuxièmement, si le problème est vraiment un blocage, il disparaîtra définitivement.
zym1010
le 26 avr. 2017
Les paramètres par défaut de ipcs est pour la mémoire partagée System V que nous n'utilisons pas, mais je voulais m'assurer que les mêmes limites ne s'appliquent pas à la mémoire partagée POSIX.
Cela ne disparaîtrait pas torch.__version__ ? Courez-vous dans docker?
apaszke
le 26 avr. 2017
@apaszke Merci. Je comprends beaucoup mieux votre analyse maintenant.
Tous les autres résultats vous sont montrés jusqu'à comment sont exécutés sur une machine Ubuntu 14.04 avec 64 Go de RAM, double Xeon et Titan Black (il y a aussi un K40, mais je ne l'ai pas utilisé).
La commande pour générer le problème est CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 20 --lr 0.01 --workers 22 --batch-size 256 /mnt/temp_drive_3/cv_datasets/ILSVRC2015/Data/CLS-LOC . Je n'ai pas du tout modifié le code.
J'ai installé pytorch via pip, sur Python 3.5. la version pytorch est 0.1.11_5 . Ne fonctionne pas dans Docker.
BTW, j'ai également essayé d'utiliser 1 travailleur. Mais je l'ai fait sur une autre machine (128 Go de RAM, dual Xeon, 4 Pascal Titan X, CentOS 6). Je l'ai exécuté en utilisant CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 1 --lr 0.01 --workers 1 --batch-size 256 /ssd/cv_datasets/ILSVRC2015/Data/CLS-LOC , et le journal des erreurs est le suivant.
Epoch: [0][5003/5005] Time 2.463 (2.955) Data 2.414 (2.903) Loss 5.9677 (6.6311) Prec<strong i="14">@1</strong> 3.516 (0.545) Prec<strong i="15">@5</strong> 8.594 (2.262)
Epoch: [0][5004/5005] Time 1.977 (2.955) Data 1.303 (2.903) Loss 5.9529 (6.6310) Prec<strong i="16">@1</strong> 1.399 (0.545) Prec<strong i="17">@5</strong> 7.692 (2.262)
^CTraceback (most recent call last):
File "main.py", line 292, in <module>
main()
File "main.py", line 137, in main
prec1 = validate(val_loader, model, criterion)
File "main.py", line 210, in validate
for i, (input, target) in enumerate(val_loader):
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 168, in __next__
idx, batch = self.data_queue.get()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/queue.py", line 164, in get
self.not_empty.wait()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/threading.py", line 293, in wait
waiter.acquire()
le top montré ce qui suit lorsqu'il est coincé avec 1 ouvrier.
~top - 08:34:33 jusqu'à 15 jours, 20:03, 0 utilisateurs, charge moyenne : 0,37, 0,39, 0,36Tâches : 894 au total, 1 en cours d'exécution, 892 en sommeil, 0 arrêtée, 1 zombieProcesseur(s) : 7,2%us, 2,8%sy, 0,0%ni, 89,7%id, 0,3%wa, 0,0%hi, 0,0%si, 0,0%stMémoire : 132196824k au total, 131461528k utilisé, 735296k gratuit, 347448k tamponsÉchange : total 2047996k, 22656k utilisé, 2025340k gratuit, 125226796k mis en cache~
zym1010
le 26 avr. 2017
une autre chose que j'ai trouvée est que, si je modifie le code d'entraînement, afin qu'il ne passe pas par tous les lots, disons, n'entraîne que 50 lots
if i >= 50:
break
puis l'impasse semble disparaître.
zym1010
le 26 avr. 2017
des tests supplémentaires semblent suggérer que ce blocage se produit beaucoup plus fréquemment si j'exécute le programme juste après le redémarrage de l'ordinateur. Une fois qu'il y a du cache dans l'ordinateur, il semble que la fréquence d'obtention de ce gel soit moindre.
zym1010
le 27 avr. 2017
J'ai essayé, mais je ne peux en aucun cas reproduire ce bug.
apaszke
le 4 mai 2017
J'ai rencontré un problème similaire : le chargeur de données s'arrête lorsque je termine une époque et démarre une nouvelle époque.
 tiancheng-zhi
le 4 mai 2017
tiancheng-zhi
le 4 mai 2017
La définition de num_workers = 0 fonctionne. Mais le programme ralentit.
tiancheng-zhi
le 4 mai 2017
@apaszke avez-vous d'abord essayé de redémarrer l'ordinateur, puis d'exécuter les programmes ? Pour moi, cela garantit la congélation. Je viens d'essayer la version 0.12, et c'est toujours pareil.
Une chose que je voudrais souligner est que j'ai installé le pytorch en utilisant pip , car j'ai un numpy lié à OpenBLAS installé et le MKL du nuage anaconda de @soumith ne jouerait pas bien avec.
Donc, essentiellement, pytorch utilise MKL et numpy utilise OpenBLAS. Ce n'est peut-être pas l'idéal, mais je pense que cela ne devrait rien avoir avec le problème ici.
zym1010
le 9 mai 2017
Je l'ai examiné, mais je n'ai jamais pu le reproduire. MKL/OpenBLAS ne devrait pas être lié à ce problème. C'est probablement un problème avec une configuration système
apaszke
le 9 mai 2017
@apaszke merci. Je viens d'essayer le python du référentiel officiel d'anaconda et le pytorch basé sur MKL. Toujours le même problème.
zym1010
le 9 mai 2017
essayé d'exécuter le code dans Docker. Toujours coincé.
zym1010
le 11 mai 2017
Nous avons le même problème, en exécutant l'exemple de formation imagenet pytorch/examples (resnet18, 4 travailleurs) dans un nvidia-docker utilisant 1 GPU sur 4. J'essaierai de rassembler un backtrace gdb, si j'arrive à accéder au processus .
Au moins, OpenBLAS est connu pour avoir un problème de blocage dans la multiplication matricielle, ce qui se produit relativement rarement : https://github.com/xianyi/OpenBLAS/issues/937. Ce bogue était présent au moins dans OpenBLAS emballé dans numpy 1.12.0.
 jsainio
le 7 juin 2017
jsainio
le 7 juin 2017
@jsainio J'ai également essayé PyTorch basé sur MKL pur (numpy est également lié à MKL), et même problème.
De plus, ce problème est résolu (au moins pour moi), si je désactive pin_memory pour le chargeur de données.
zym1010
le 7 juin 2017
On dirait que deux des ouvriers meurent.
En fonctionnement normal :
root<strong i="7">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 33.2 4.7 91492324 3098288 ? Ssl 10:51 1:10 python -m runne
user+ 58 76.8 2.3 91079060 1547512 ? Rl 10:54 1:03 python -m runne
user+ 59 76.0 2.2 91006896 1484536 ? Rl 10:54 1:02 python -m runne
user+ 60 76.4 2.3 91099448 1559992 ? Rl 10:54 1:02 python -m runne
user+ 61 79.4 2.2 91008344 1465292 ? Rl 10:54 1:05 python -m runne
après verrouillage :
root<strong i="11">@b06f896d5c1d</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 24.8 4.4 91509728 2919744 ? Ssl 14:25 13:01 python -m runne
user+ 58 51.7 0.0 0 0 ? Z 14:27 26:20 [python] <defun
user+ 59 52.1 0.0 0 0 ? Z 14:27 26:34 [python] <defun
user+ 60 52.0 2.4 91147008 1604628 ? Sl 14:27 26:31 python -m runne
user+ 61 52.0 2.3 91128424 1532088 ? Sl 14:27 26:29 python -m runne
Pour un travailleur restant, le début de la trace de la pile gdb ressemble à :
root<strong i="15">@b06f896d5c1d</strong>:~/mnt# gdb --pid 60
GNU gdb (GDB) 8.0
Attaching to process 60
[New LWP 65]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb) bt
#0 0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f36f52af8d4 in __new_sem_wait_slow.constprop.0 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#2 0x00007f36f52af97a in sem_wait@@GLIBC_2.2.5 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#3 0x00007f36f157efb1 in semlock_acquire (self=0x7f3656296458,
args=<optimized out>, kwds=<optimized out>)
at /home/ilan/minonda/conda-bld/work/Python-3.5.2/Modules/_multiprocessing/semaphore.c:307
#4 0x00007f36f5579621 in PyCFunction_Call (func=
<built-in method __enter__ of _multiprocessing.SemLock object at remote 0x7f3656296458>, args=(), kwds=<optimized out>) at Objects/methodobject.c:98
#5 0x00007f36f5600bd5 in call_function (oparg=<optimized out>,
pp_stack=0x7f36c7ffbdb8) at Python/ceval.c:4705
#6 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#7 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=1, kws=0x0, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0,
closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#8 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#9 0x00007f36f5557542 in function_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/funcobject.c:627
#10 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36561c7d08>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#11 0x00007f36f554077c in method_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/classobject.c:330
#12 0x00007f36f5524236 in PyObject_Call (
func=<method at remote 0x7f36556f9248>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#13 0x00007f36f55277d9 in PyObject_CallFunctionObjArgs (
callable=<method at remote 0x7f36556f9248>) at Objects/abstract.c:2445
#14 0x00007f36f55fc3a9 in PyEval_EvalFrameEx (f=<optimized out>,
throwflag=<optimized out>) at Python/ceval.c:3107
#15 0x00007f36f5601166 in fast_function (nk=<optimized out>, na=1,
n=<optimized out>, pp_stack=0x7f36c7ffc418,
func=<function at remote 0x7f36561c78c8>) at Python/ceval.c:4803
#16 call_function (oparg=<optimized out>, pp_stack=0x7f36c7ffc418)
at Python/ceval.c:4730
#17 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#18 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=4, kws=0x7f36f5b85060, kwcount=0, defs=0x0, defcount=0,
kwdefs=0x0, closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#19 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#20 0x00007f36f5557661 in function_call (
func=<function at remote 0x7f36e14170d0>,
arg=(<ImageFolder(class_to_idx={'n04153751': 783, 'n02051845': 144, 'n03461385': 582, 'n04350905': 834, 'n02105056': 224, 'n02112137': 260, 'n03938244': 721, 'n01739381': 59, 'n01797886': 82, 'n04286575': 818, 'n02113978': 268, 'n03998194': 741, 'n15075141': 999, 'n03594945': 609, 'n04099969': 765, 'n02002724': 128, 'n03131574': 520, 'n07697537': 934, 'n04380533': 846, 'n02114712': 271, 'n01631663': 27, 'n04259630': 808, 'n04326547': 825, 'n02480855': 366, 'n02099429': 206, 'n03590841': 607, 'n02497673': 383, 'n09332890': 975, 'n02643566': 396, 'n03658185': 623, 'n04090263': 764, 'n03404251': 568, 'n03627232': 616, 'n01534433': 13, 'n04476259': 868, 'n03495258': 594, 'n04579145': 901, 'n04266014': 812, 'n01665541': 34, 'n09472597': 980, 'n02095570': 189, 'n02089867': 166, 'n02009229': 131, 'n02094433': 187, 'n04154565': 784, 'n02107312': 237, 'n04372370': 844, 'n02489166': 376, 'n03482405': 588, 'n04040759': 753, 'n01774750': 76, 'n01614925': 22, 'n01855032': 98, 'n03903868': 708, 'n02422699': 352, 'n01560419': 1...(truncated), kw={}) at Objects/funcobject.c:627
#21 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36e14170d0>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#22 0x00007f36f55fe234 in ext_do_call (nk=1444355432, na=0,
flags=<optimized out>, pp_stack=0x7f36c7ffc768,
func=<function at remote 0x7f36e14170d0>) at Python/ceval.c:5034
#23 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3275
--snip--
J'ai eu un journal d'erreurs similaire, avec le processus principal bloqué : self.data_queue.get()
Pour moi, le problème était que j'utilisais opencv comme chargeur d'images. Et la fonction cv2.imread était suspendue indéfiniment sans erreur sur une image particulière d'imagenet ("n01630670/n01630670_1010.jpeg")
Si vous avez dit que cela fonctionne pour vous avec num_workers = 0, ce n'est pas cela. Mais j'ai pensé que cela pourrait aider certaines personnes avec une trace d'erreur similaire.
 M-Eng
le 9 juin 2017
M-Eng
le 9 juin 2017
J'exécute actuellement un test avec num_workers = 0 , aucun blocage pour le moment. J'exécute l'exemple de code de https://github.com/pytorch/examples/blob/master/imagenet/main.py. pytorch/vision ImageFolder semble utiliser PIL ou pytorch/accimage interne pour charger les images, donc il n'y a pas d'OpenCV impliqué.
Avec num_workers = 4 , je peux occasionnellement obtenir le train de la première époque et le valider complètement, et il se bloque au milieu de la deuxième époque. Il est donc peu probable qu'il y ait un problème dans la fonction de jeu de données/chargement.
Cela ressemble à une condition de concurrence dans ImageLoader qui peut être déclenchée relativement rarement par une certaine combinaison matériel/logiciel.
jsainio
le 9 juin 2017
@zym1010 merci pour le pointeur, je vais essayer de définir aussi pin_memory = False pour le DataLoader.
jsainio
le 9 juin 2017
Intéressant. Sur ma configuration, en définissant pin_memory = False et num_workers = 4 l'exemple imagenet se bloque presque immédiatement et trois des travailleurs finissent en tant que processus zombies :
root<strong i="8">@034c4212d022</strong>:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 6.7 2.8 92167056 1876612 ? Ssl 13:50 0:36 python -m runner
user+ 38 1.9 0.0 0 0 ? Z 13:51 0:08 [python] <defunct>
user+ 39 4.3 2.3 91069804 1550736 ? Sl 13:51 0:19 python -m runner
user+ 40 2.0 0.0 0 0 ? Z 13:51 0:09 [python] <defunct>
user+ 41 4.1 0.0 0 0 ? Z 13:51 0:18 [python] <defunct>
Dans ma configuration, l'ensemble de données se trouve sur un disque en réseau qui est lu via NFS. Avec pin_memory = False et num_workers = 4 je peux faire échouer le système assez rapidement.
=> creating model 'resnet18'
- training epoch 0
Epoch: [0][0/5005] Time 10.713 (10.713) Data 4.619 (4.619) Loss 6.9555 (6.9555) Prec<strong i="8">@1</strong> 0.000 (0.000) Prec<strong i="9">@5</strong> 0.000 (0.000)
Traceback (most recent call last):
--snip--
imagenet_pytorch.main.main([data_dir, "--transient_dir", context.transient_dir])
File "/home/user/mnt/imagenet_pytorch/main.py", line 140, in main
train(train_loader, model, criterion, optimizer, epoch, args)
File "/home/user/mnt/imagenet_pytorch/main.py", line 168, in train
for i, (input, target) in enumerate(train_loader):
File "/home/user/anaconda/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 206, in __next__
idx, batch = self.data_queue.get()
File "/home/user/anaconda/lib/python3.5/multiprocessing/queues.py", line 345, in get
return ForkingPickler.loads(res)
File "/home/user/anaconda/lib/python3.5/site-packages/torch/multiprocessing/reductions.py", line 70, in rebuild_storage_fd
fd = df.detach()
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError
:
[Errno 104] Connection reset by peer
@zym1010 avez-vous un disque en réseau ou un disque tournant traditionnel qui pourrait être plus lent en latence/etc.?
jsainio
le 9 juin 2017
@jsainio
J'utilise un SSD local sur le nœud de calcul du cluster. Le code est sur un lecteur NFS, mais les données sont sur le SSD local, pour une vitesse de chargement maximale. Jamais essayé de charger des données sur des lecteurs NFS.
zym1010
le 9 juin 2017
@zym1010 Merci pour l'info. Je l'exécute également sur un nœud de calcul d'un cluster.
En fait, j'exécute l'expérience num_workers = 0 sur le même nœud en même temps tout en essayant les variantes num_workers = 4 . Il se peut que la première expérience génère suffisamment de charge pour que d'éventuelles conditions de course se manifestent plus rapidement dans la seconde.
jsainio
le 9 juin 2017
@apaszke Lorsque vous avez essayé de reproduire cela précédemment, avez-vous essayé d'exécuter deux instances côte à côte ou avec une autre charge importante sur le système ?
jsainio
le 9 juin 2017
@jsainio Merci d'avoir enquêté là- dmesg ) ?
apaszke
le 9 juin 2017
Non, je n'ai pas essayé ça, mais ça semblait apparaître même quand ce n'était pas le cas IIRC
apaszke
le 9 juin 2017
@apaszke Ok, bon à savoir que les travailleurs n'auraient pas dû sortir.
J'ai essayé mais je ne connais pas un bon moyen de vérifier pourquoi ils sortent. dmesg n'affiche rien de pertinent. (Je fonctionne dans un Docker dérivé d'Ubuntu 16.04, en utilisant des packages Anaconda)
jsainio
le 9 juin 2017
Une façon serait d'ajouter un certain nombre d'impressions à l'intérieur de la boucle de travail . Je n'ai aucune idée de pourquoi ils sortent silencieusement. Ce n'est probablement pas une exception, car il aurait été imprimé sur stderr, donc ils sortent de la boucle ou sont tués par le système d'exploitation (peut-être par un signal ?)
apaszke
le 9 juin 2017
@jsainio , juste pour être sûr, utilisez-vous docker avec --ipc=host (vous ne le mentionnez pas) ? Pouvez-vous vérifier la taille de votre segment de mémoire partagée (df -h | grep shm) ?
ngimel
le 9 juin 2017
@ngimel J'utilise --shm-size=1024m . df -h | grep shm rapporte en conséquence :
root<strong i="9">@db92462e8c19</strong>:~/mnt# df -h | grep shm
shm 1.0G 883M 142M 87% /dev/shm
Cette utilisation semble assez difficile. C'est sur un docker avec deux ouvriers zombies.
jsainio
le 12 juin 2017
Pouvez-vous essayer d'augmenter la taille du shm ? Je viens de vérifier et sur le serveur où j'ai essayé de reproduire les problèmes c'était 16Go. Vous changez le drapeau docker ou exécutez
mount -o remount,size=8G /dev/shm
J'ai juste essayé de réduire la taille à 512 Mo, mais j'ai eu une erreur claire au lieu d'un blocage. Je ne peux toujours pas reproduire
apaszke
le 14 juin 2017
Avec docker, nous avons tendance à avoir des blocages lorsque shm ne suffit pas, plutôt que des messages d'erreur clairs, je ne sais pas pourquoi. Mais il est généralement résolu en augmentant shm (et j'ai eu des blocages avec 1G).
ngimel
le 14 juin 2017
Ok, il semble qu'avec 10 travailleurs, une erreur soit générée, mais lorsque j'utilise 4 travailleurs, j'obtiens un blocage à 58% d'utilisation de /dev/shm ! je l'ai enfin reproduit
apaszke
le 14 juin 2017
C'est super que vous puissiez reproduire une forme de ce problème. J'ai posté un script qui déclenche un blocage dans #1579, et vous avez répondu qu'il ne s'est pas bloqué sur votre système. En fait, je ne l'avais testé que sur mon MacBook. Je viens d'essayer sous Linux et ça ne s'est pas bloqué. Donc, si vous n'avez essayé que sous Linux, cela peut également valoir la peine d'essayer sur un Mac.
 greaber
le 14 juin 2017
greaber
le 14 juin 2017
Ok, donc après avoir enquêté sur le problème, cela semble être un problème étrange. Même lorsque je limite /dev/shm à seulement 128 Mo, Linux est heureux de nous permettre de créer des fichiers de 147 Mo là-bas, de les mettre entièrement en mémoire, mais enverra un SIGBUS mortel au travailleur une fois qu'il essaiera réellement d'accéder aux pages ... Je ne vois aucun mécanisme qui nous permettrait de vérifier la validité des pages, sauf pour les itérer et les toucher chacune, avec un gestionnaire SIGBUS enregistré...
Une solution de contournement pour l'instant consiste à développer /dev/shm avec la commande mount comme je l'ai montré ci-dessus. Essayez avec 16 Go (ofc si vous avez assez de RAM).
apaszke
le 15 juin 2017
Il est difficile de trouver des mentions à ce sujet, mais en voici une .
apaszke
le 15 juin 2017
Merci pour votre temps sur ce problème, cela me rend dingue depuis longtemps! Si je comprends bien, je dois étendre /dev/shm à 16G au lieu de 8G. C'est logique mais quand j'essaye df -h , je peux voir que toute ma RAM est en fait allouée en tant que telle : (j'ai 16G)
tmpfs 7,8G 393M 7,4G 5% /dev/shm
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,8G 0 7,8G 0% /sys/fs/cgroup
tmpfs 1,6G 60K 1,6G 1% /run/user/1001
C'est la sortie de df -h lors d'un blocage. Autant que je sache, si j'ai une partition SWAP de 16G, je peux monter des tmpfs jusqu'à 32G, donc ça ne devrait pas poser de problème d'étendre /dev/shm , non ?
Plus important encore, je suis perplexe quant à la partition cgroup et à son objectif car elle prend près de la moitié de ma RAM. Apparemment, il est conçu pour gérer efficacement les tâches multiprocesseurs, mais je ne sais vraiment pas ce qu'il fait et pourquoi nous en avons besoin, cela changerait-il quelque chose d'allouer toute la RAM physique à shm (car nous avons défini sa taille sur 16G) et mettez-le dans SWAP (bien que je pense que les deux seront en partie dans la RAM et SWAP simultanément)
 ClementPinard
le 15 juin 2017
ClementPinard
le 15 juin 2017
@apaszke Merci ! Super que vous ayez trouvé la cause sous-jacente. Je recevais occasionnellement à la fois diverses erreurs "ConnectionReset" et des blocages avec docker --shm-size=1024m fonction de l'autre charge qu'il y avait sur la machine. Test maintenant avec --shm-size=16384m et 4 travailleurs.
jsainio
le 15 juin 2017
@jsainio ConnectionReset peut avoir été causé par la même chose. Les processus ont commencé à échanger des données, mais une fois que shm a manqué d'espace, un SIGBUS a été envoyé au travailleur et l'a tué.
@ClementPinard, pour autant que je /sys/fs/cgroup . tmpfs partitions shm pour dire 12 Go, et de limiter le nombre de travailleurs (comme je l'ai dit, n'utilisez pas toute votre RAM pour shm !). Voici un bon article sur tmpfs à partir de la documentation du noyau.
Je ne sais pas pourquoi le blocage se produit même lorsque l'utilisation de /dev/shm est très faible (se produit à 20 Ko sur ma machine). Peut-être que le noyau est trop optimiste, mais n'attend pas que vous ayez tout rempli et tue le processus une fois qu'il commence à utiliser quoi que ce soit de cette région.
apaszke
le 15 juin 2017
Test maintenant avec 12G et la moitié des travailleurs que j'avais, et cela a échoué :(
Cela fonctionnait comme un charme dans la version lua torch (même vitesse, même nombre de travailleurs), ce qui me fait me demander si le problème n'est lié qu'à /dev/shm et non plus au multitraitement python...
La chose étrange à ce sujet (comme vous l'avez mentionné) est que /dev/shm n'est jamais près d'être plein. Lors de la première période d'entraînement, il n'a jamais dépassé 500Mo. Et il ne se verrouille jamais non plus pendant la première époque, et si j'arrête, le test de trainloader n'échoue jamais à toutes les époques. L'impasse semble n'apparaître qu'au début de l'époque de test. Je devrais garder une trace de /dev/shm lors du passage d'un train à un test, il y a peut-être un pic d'utilisation lors du changement des chargeurs de données.
ClementPinard
le 15 juin 2017
@ClementPinard même avec une mémoire partagée plus élevée, et sans Docker, cela peut toujours échouer.
zym1010
le 15 juin 2017
Si la version torche == Lua Torch, cela pourrait toujours être lié à /dev/shm . Lua Torch peut utiliser des threads (il n'y a pas de GIL), il n'a donc pas besoin de passer par une mémoire partagée (ils partagent tous un seul espace d'adressage).
apaszke
le 15 juin 2017
J'ai eu le même problème où le chargeur de données se bloque après s'être plaint qu'il ne pouvait pas allouer de mémoire au début d'une nouvelle période d'entraînement ou de validation. Les solutions ci-dessus n'ont pas fonctionné pour moi (i) mon /dev/shm est de 32 Go et il n'a jamais été utilisé plus de 2,5 Go, et (ii) le paramètre pin_memory=False n'a pas fonctionné.
C'est peut-être quelque chose à voir avec la collecte des ordures? Mon code ressemble à peu près à ce qui suit. J'ai besoin d'un itérateur infini et donc je fais un essai / sauf autour du next() ci-dessous :-)
def train():
train_iter = train_loader.__iter__()
for i in xrange(max_batches):
try:
x, y = next(train_iter)
except StopIteration:
train_iter = train_loader.__iter__()
...
del train_iter
train_loader est un objet DataLoader . Sans la ligne explicite del train_iter à la fin de la fonction, le processus plante toujours après 2-3 époques ( /dev/shm affiche toujours 2,5 Go). J'espère que cela t'aides!
J'utilise des travailleurs 4 (version 0.1.12_2 avec CUDA 8.0 sur Ubuntu 16.04).
 pratikac
le 7 juil. 2017
pratikac
le 7 juil. 2017
J'ai également rencontré l'impasse, surtout lorsque le work_number est grand. Existe-t-il une solution possible à ce problème ? Ma taille /dev/shm est de 32 Go, avec cuda 7.5, pytorch 0.1.12 et python 2.7.13. Ce qui suit est des informations liées après la mort. Cela semble lié à la mémoire. @apaszke

 zhengyunqq
le 4 août 2017
zhengyunqq
le 4 août 2017
@zhengyunqq essayez pin_memory=False si vous le définissez sur True . Sinon, je ne connais aucune solution.
zym1010
le 4 août 2017
J'ai également rencontré le blocage lorsque num_workers est grand.
 hendrycks
le 11 août 2017
hendrycks
le 11 août 2017
Pour moi, le problème était que si un thread de travail meurt pour une raison quelconque, alors index_queue.put bloque pour toujours. L'une des raisons de la mort des threads de travail est l'échec du décapant lors de l'initialisation. Dans ce cas, jusqu'à cette correction de
Peut-être un remplacement de SimpleQueue utilisé dans DataLoaderIter par Queue qui permet un délai d'attente avec un message d'exception gracieux.
UPD : Je me suis trompé, cette correction de bogue corrige Queue , pas SimpleQueue . Il est toujours vrai que SimpleQueue se verrouillera si aucun thread de travail n'est en ligne. Un moyen simple de vérifier cela consiste à remplacer ces lignes par self.workers = [] .
 vadimkantorov
le 16 août 2017
vadimkantorov
le 16 août 2017
j'ai le même problème et je ne peux pas changer shm (sans autorisation), peut-être vaut-il mieux utiliser la file d'attente ou autre chose?
 xfanplus
le 8 sept. 2017
xfanplus
le 8 sept. 2017
J'ai le même problème.
Ce code se figera et n'imprimera jamais rien. Si je définis num_workers=0, cela fonctionnera cependant
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
model.cuda()
for i, batch in enumerate(dataloader):
print(i)
Si je mets model.cuda() derrière la boucle, tout ira bien.
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
for i, batch in enumerate(dataloader):
print(i)
model.cuda()
Quelqu'un a-t-il une solution à ce problème ?
 anDoer
le 13 sept. 2017
anDoer
le 13 sept. 2017
J'ai également rencontré des problèmes similaires lors de la formation d'ImageNet. Il se bloquera à la 1ère itération de l'évaluation de manière cohérente sur certains serveurs avec une certaine architecture (et pas sur d'autres serveurs avec la même architecture ou le même serveur avec une architecture différente), mais toujours au 1er iter lors de l'évaluation à la validation. Lorsque j'utilisais Torch, nous avons découvert que nccl peut provoquer un blocage comme celui-ci, existe-t-il un moyen de le désactiver ?
 WendyShang
le 20 sept. 2017
WendyShang
le 20 sept. 2017
Je suis confronté au même problème, je reste bloqué au hasard au début de la 1ère époque. Toutes les solutions de contournement mentionnées ci-dessus ne fonctionnent pas pour moi. Lorsque Ctrl-C est enfoncé, il imprime celles-ci :
Traceback (most recent call last):
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 249, in _bootstrap
self.run()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 44, in _worker_loop
data_queue.put((idx, samples))
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/queues.py", line 354, in put
self._writer.send_bytes(obj)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 200, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 398, in _send_bytes
self._send(buf)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
KeyboardInterrupt
Traceback (most recent call last):
File "scripts/train_model.py", line 640, in <module>
main(args)
File "scripts/train_model.py", line 193, in main
train_loop(args, train_loader, val_loader)
File "scripts/train_model.py", line 341, in train_loop
ee_optimizer.step()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/optim/adam.py", line 74, in step
p.data.addcdiv_(-step_size, exp_avg, denom)
KeyboardInterrupt
 zoharli
le 23 oct. 2017
zoharli
le 23 oct. 2017
J'ai eu un problème similaire d'avoir un blocage avec un seul travailleur à l'intérieur de docker et je peux confirmer qu'il s'agissait d'un problème de mémoire partagée dans mon cas. Par défaut, docker ne semble allouer que 64 Mo de mémoire partagée, mais j'avais besoin de 440 Mo pour 1 travailleur, ce qui a probablement causé le comportement décrit par @apaszke.
 paulguerrero
le 23 oct. 2017
paulguerrero
le 23 oct. 2017
Je suis troublé par le même problème, mais je suis dans un environnement différent de la plupart des autres dans ce fil, alors peut-être que mes entrées peuvent aider à localiser la cause sous-jacente. Mon pytorch est installé à l'aide de l'excellent package conda construit par peterjc123 sous Windows10.
J'exécute du cnn sur l'ensemble de données cifar10. Pour les chargeurs de données, num_workers est défini sur 1. Bien qu'avoir num_workers > 0 soit connu pour provoquer BrokenPipeError et déconseillé dans #494, ce que je rencontre n'est pas BrokenPipeError mais une erreur d'allocation de mémoire. L'erreur se produisait toujours vers 50 époques, juste après la validation de la dernière époque et avant le début de l'entraînement pour la prochaine époque. 90% du temps, c'est précisément 50 époques, d'autres fois, il sera décalé de 1 ou 2 époques. A part ça, tout le reste est assez cohérent. La définition de num_workers=0 éliminera ce problème.
 berzjackson
le 24 oct. 2017
berzjackson
le 24 oct. 2017
@paulguerrero a raison. J'ai résolu ce problème en augmentant la mémoire partagée de 64M à 2G. C'est peut-être utile pour les utilisateurs de docker.
 yjzhux
le 24 oct. 2017
yjzhux
le 24 oct. 2017
@berzjackson C'est un bogue connu dans le package conda. Corrigé dans les dernières versions de CI.
 peterjc123
le 25 oct. 2017
peterjc123
le 25 oct. 2017
Nous avons environ 600 personnes qui ont commencé un nouveau cours utilisant Pytorch lundi. De nombreuses personnes sur notre forum signalent ce problème. Certains sur AWS P2, certains sur leurs propres systèmes (principalement GTX 1070, certains Titan X).
Lorsqu'ils interrompent l'entraînement, la fin de la trace de la pile affiche :
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv_bytes(self, maxsize)
405
406 def _recv_bytes(self, maxsize=None):
--> 407 buf = self._recv(4)
408 size, = struct.unpack("!i", buf.getvalue())
409 if maxsize is not None and size > maxsize:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv(self, size, read)
377 remaining = size
378 while remaining > 0:
--> 379 chunk = read(handle, remaining)
380 n = len(chunk)
381 if n == 0:
Nous avons num_workers=4, pin_memory=False. Je leur ai demandé de vérifier leurs paramètres de mémoire partagée - mais y a-t-il quelque chose que je puisse faire (ou que nous puissions faire dans Pytorch) pour résoudre ce problème ? (À part la réduction de num_workers, car cela ralentirait un peu les choses.)
 jph00
le 1 nov. 2017
jph00
le 1 nov. 2017
Je suis dans la classe @jph00 (merci Jeremy ! :) ) en référence. J'ai également essayé d'utiliser "num_workers=0". Obtenez toujours la même erreur où resnet34 se charge très lentement. Le montage est également très lent. Mais chose étrange : cela n'arrive qu'une fois dans la vie d'une session de notebook.
En d'autres termes, une fois les données chargées et l'ajustement exécuté une fois, je peux me déplacer et continuer à répéter les étapes... même avec 4 num_workers, et tout semble fonctionner rapidement comme prévu dans un GPU.
Je suis sur PyTorch 0.2.0_4, Python 3.6.2, Torchvision 0.1.9, Ubuntu 16.04 LTS. Faire "df -h" sur mon terminal indique que j'ai 16 Go sur /dev/shm, bien que l'utilisation soit très faible.
Voici une capture d'écran de l'échec du chargement (notez que j'ai utilisé num_workers=0 pour les données)
(désolé pour les petites lettres. J'ai dû faire un zoom arrière pour tout capturer...)

 apiltamang
le 1 nov. 2017
apiltamang
le 1 nov. 2017
@apiltamang Je ne suis pas sûr que ce soit le même problème - cela ne ressemble pas du tout aux mêmes symptômes. Le mieux pour nous de diagnostiquer cela sur le forum fast.ai, pas ici.
jph00
le 1 nov. 2017
regarde ça au plus vite !
 soumith
le 1 nov. 2017
soumith
le 1 nov. 2017
@soumith J'ai donné à @apaszke l' accès au forum privé du cours et j'ai demandé aux étudiants ayant le problème de nous donner accès pour se connecter à leur box.
jph00
le 1 nov. 2017
@jph00 Salut Jeremy, l'un des étudiants a-t-il essayé d'augmenter shm comme @apaszke mentionné ci-dessus ? Cela a-t-il été utile ?
 SsnL
le 1 nov. 2017
SsnL
le 1 nov. 2017
@SsnL, l' un des étudiants a confirmé qu'il avait augmenté la mémoire partagée et qu'il avait toujours le problème. J'ai demandé à d'autres de confirmer aussi.
jph00
le 1 nov. 2017
@jph00 Merci ! J'ai réussi à reproduire le blocage en raison d'une faible mémoire partagée. Si le problème est ailleurs, je vais devoir creuser plus profondément ! Cela vous dérange-t-il de partager le script avec moi ?
SsnL
le 1 nov. 2017
Bien sûr, voici le bloc-notes que nous utilisons : https://github.com/fastai/fastai/blob/master/courses/dl1/lesson1.ipynb . Les étudiants ont remarqué que le problème ne se produit que lorsqu'ils exécutent toutes les cellules dans l'ordre où elles se trouvent dans le cahier. J'espère que le bloc-notes est explicite, mais faites-moi savoir si vous rencontrez des problèmes pour l'exécuter - il comprend un lien pour télécharger les données nécessaires.
Sur la base du problème de mémoire partagée que vous pourriez reproduire, existe-t-il une solution de contournement que je pourrais ajouter à notre bibliothèque ou à notre bloc-notes pour l'éviter ?
jph00
le 1 nov. 2017
@jph00 Plonger dans le code dès maintenant. Je vais essayer de trouver des moyens de réduire l'utilisation de la mémoire partagée. Il ne semble pas que le script doive utiliser une grande quantité de shm, donc il y a de l'espoir !
J'enverrai également un PR pour afficher un joli message d'erreur lorsque j'atteint la limite de shm plutôt que de simplement le laisser pendre.
SsnL
le 1 nov. 2017
OK, j'ai répliqué le problème sur une nouvelle instance AWS P2 à l'aide de leur AMI CUDA 9 avec la dernière installation de Pytorch conda. Si vous fournissez votre clé publique, je peux vous donner accès pour l'essayer directement. Mon email est la première lettre de mon prénom sur fast.ai
jph00
le 1 nov. 2017
@jph00 Je
SsnL
le 1 nov. 2017
@jph00 Et pour
SsnL
le 1 nov. 2017
OK, j'ai donc compris le problème de base, à savoir que le multitraitement opencv et Pytorch ne fonctionne pas bien ensemble, parfois. Aucun problème sur notre box à l'université, mais beaucoup de problèmes sur AWS (sur la nouvelle AMI de deep learning CUDA 9 avec instance P2). L'ajout du verrouillage autour de tous les appels cv2 ne résout pas le problème, et l'ajout de cv2.setNumThreads(0) ne résout pas le problème. Cela semble régler le problème :
from multiprocessing import set_start_method
set_start_method('spawn')
Cependant, cela a un impact sur les performances d'environ 15 %. La recommandation dans le problème opencv github est d'utiliser https://github.com/tomMoral/loky . J'ai déjà utilisé ce module et je l'ai trouvé très solide. Pas urgent, puisque nous avons une solution qui fonctionne assez bien pour l'instant - mais cela pourrait valoir la peine d'envisager d'utiliser Loky pour Dataloader ?
Peut-être plus important encore, ce serait bien s'il y avait au moins une sorte de délai d'attente dans la file d'attente de Pytorch afin que ces blocages infinis soient détectés.
jph00
le 2 nov. 2017
Pour info, je viens d'essayer un correctif différent, car 'spawn' rendait certaines parties 2-3 fois plus lentes - c'est-à-dire que j'ai ajouté quelques sommeils aléatoires dans des sections qui parcourent rapidement le chargeur de données. Cela a également résolu le problème - bien que peut-être pas idéal !
jph00
le 2 nov. 2017
Merci d'avoir creusé ça ! Heureux de savoir que vous avez trouvé deux solutions de contournement. En effet, il serait bon d'ajouter des délais d'attente sur l'indexation dans les jeux de données. Nous discuterons et reviendrons vers vous sur cet itinéraire demain.
cc @soumith est-il quelque chose que nous voulons étudier ?
SsnL
le 2 nov. 2017
Pour les personnes qui viennent sur ce fil pour la discussion ci-dessus, la question opencv est discutée plus en profondeur à https://github.com/opencv/opencv/issues/5150
SsnL
le 2 nov. 2017
OK, il me semble avoir une solution appropriée pour cela maintenant - j'ai réécrit Dataloader pour l'utilisateur ProcessPoolExecutor.map() et déplacé la création du tenseur dans le processus parent. Le résultat est plus rapide que ce que je voyais avec le Dataloader d'origine, et il a été stable sur tous les ordinateurs sur lesquels je l'ai essayé. Le code est aussi beaucoup plus simple.
Si quelqu'un est intéressé à l'utiliser, vous pouvez l'obtenir sur https://github.com/fastai/fastai/blob/master/fastai/dataloader.py .
L'API est la même que la version standard, sauf que votre ensemble de données ne doit pas renvoyer un tenseur Pytorch - il doit renvoyer des tableaux numpy ou des listes python. Je n'ai fait aucune tentative pour que cela fonctionne sur les anciens Pythons, donc je ne serais pas surpris s'il y avait des problèmes là-bas.
(La raison pour laquelle j'ai choisi cette voie est que j'ai découvert en faisant beaucoup de traitement/augmentation d'image sur des GPU récents que je ne pouvais pas terminer le traitement assez rapidement pour garder le GPU occupé, si je faisais le prétraitement à l'aide du processeur Pytorch opérations ; cependant, l'utilisation d'opencv était beaucoup plus rapide et j'ai ainsi pu utiliser pleinement le GPU.)
jph00
le 2 nov. 2017
Oh, s'il s'agit d'un problème opencv, nous ne pouvons pas y faire grand-chose. Il est vrai que le forking est dangereux lorsque vous avez des pools de threads. Je ne pense pas que nous souhaitions ajouter une dépendance d'exécution (nous n'en avons actuellement aucune), en particulier qu'elle ne gérera pas bien les tenseurs PyTorch. Il serait préférable de simplement comprendre ce qui cause les blocages et @SsnL est dessus.
@jph00 avez-vous essayé Pillow-SIMD ? Cela devrait fonctionner avec la vision au flambeau et j'en ai entendu beaucoup de bonnes choses.
apaszke
le 2 nov. 2017
Oui je connais bien l'oreiller SIMD. Il accélère uniquement le redimensionnement, le flou et la conversion RVB.
Je ne suis pas d'accord, vous ne pouvez pas faire grand-chose ici. Ce n'est pas exactement un problème opencv (ils ne prétendent pas prendre en charge ce type de multitraitement python de manière plus générale, sans parler du module de multitraitement à boîtier spécial de pytorch) et pas exactement un problème Pytorch non plus. Mais le fait que Pytorch attende en silence pour toujours sans donner aucune sorte d'erreur est (IMO) quelque chose que vous pouvez corriger, et plus généralement, beaucoup de gens intelligents ont travaillé dur au cours des dernières années pour créer des approches de multitraitement améliorées qui évitent simplement les problèmes. comme celui-ci. Vous pouvez emprunter aux approches qu'ils utilisent sans introduire de dépendance externe.
Olivier Grisel, qui est l'une des personnes derrière Loky, a un excellent diaporama résumant l'état du multitraitement en Python : http://ogrisel.github.io/decks/2017_euroscipy_parallelism/
Cela ne me dérange pas de toute façon, puisque j'ai maintenant écrit un nouveau Dataloader qui n'a pas le problème. Mais je pense, FWIW, que les interactions entre le multitraitement de Pytorch et d'autres systèmes seront également un problème pour d'autres personnes à l'avenir.
jph00
le 2 nov. 2017
Pour ce que ça vaut, j'ai eu ce problème sur Python 2.7 sur ubuntu 14.04. Mon chargeur de données lisait à partir d'une base de données sqlite et fonctionnait parfaitement avec num_workers=0 , semblait parfois OK avec num_workers=1 , et très rapidement bloqué pour toute valeur supérieure. Les traces de la pile ont montré que le processus s'était bloqué dans recv_bytes .
Choses qui n'ont pas fonctionné :
- Passer
--shm-size 8Gou--ipc=hostlors du lancement de docker - Exécuter
echo 16834 | sudo tee /proc/sys/kernel/shmmnipour augmenter le nombre de segments de mémoire partagée (la valeur par défaut était 4096 sur ma machine) - Réglage
pin_memory=Trueoupin_memory=False, ni l'un ni l'autre n'a aidé
La chose qui a résolu mon problème de manière fiable était le portage de mon code vers Python 3. Le lancement de la même version de Torch dans une instance Python 3.6 (à partir d'Anaconda) a complètement résolu mon problème et maintenant le chargement des données ne se bloque plus.
 gcr
le 16 nov. 2017
gcr
le 16 nov. 2017
@apaszke voici pourquoi il est important de bien travailler avec opencv, pour votre information (et pourquoi l'échantillon de torche n'est pas une excellente option - il peut gérer une rotation de <200 images/sec !) :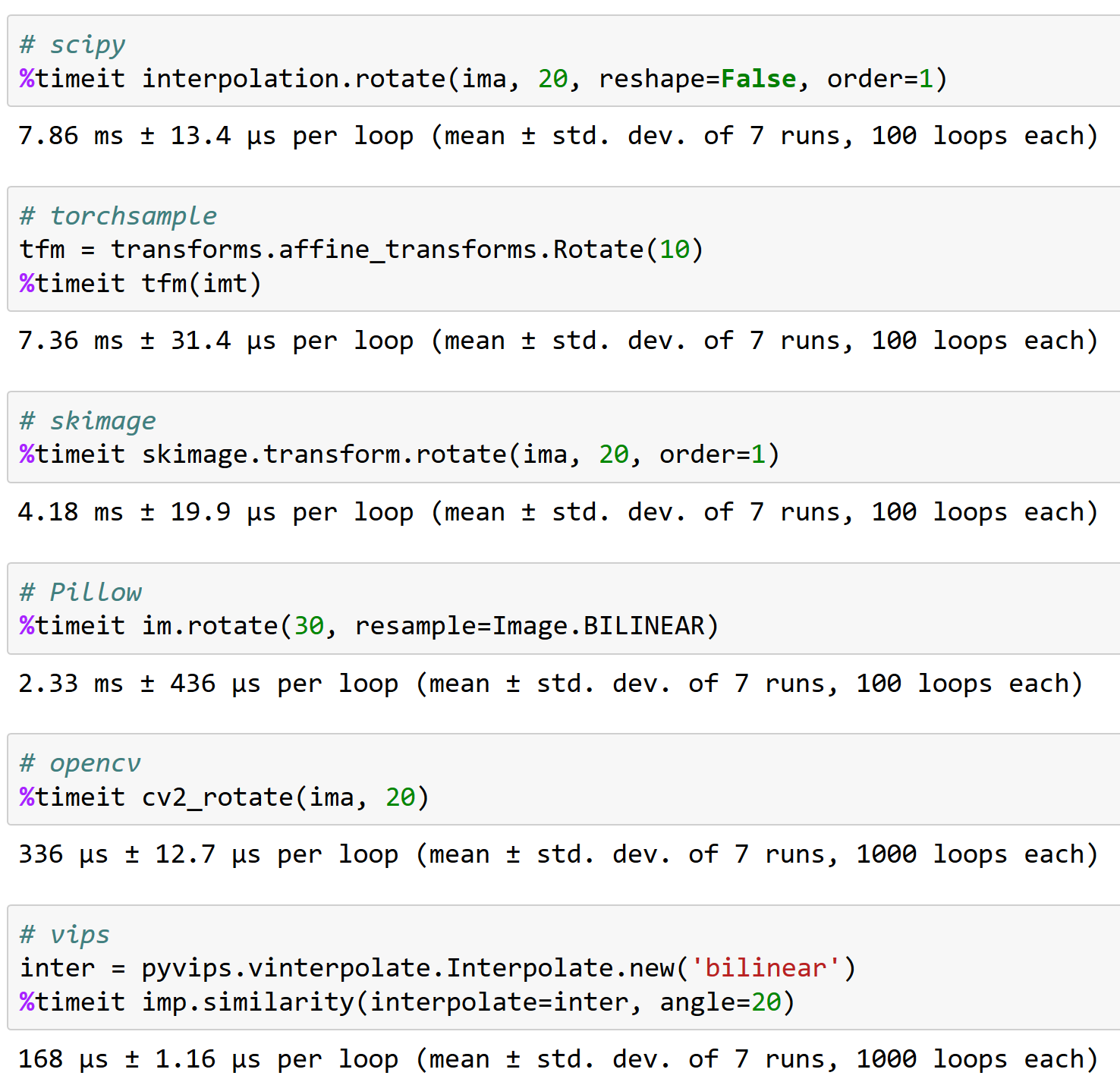
jph00
le 18 nov. 2017
Quelqu'un a-t-il trouvé une solution à ce problème ?
 iqbalu
le 9 déc. 2017
iqbalu
le 9 déc. 2017
@iqbalu Essayez le script ci-dessus : https://github.com/fastai/fastai/blob/master/fastai/dataloader.py
Cela a résolu mon problème mais il ne prend pas en charge num_workers=0 .
 elbaro
le 14 déc. 2017
elbaro
le 14 déc. 2017
@elbaro en fait, je l'ai essayé et dans mon cas, il n'utilisait pas du tout plusieurs travailleurs. Avez-vous changé quelque chose là-bas?
iqbalu
le 14 déc. 2017
Le chargeur de données @iqbalu
apaszke
le 14 déc. 2017
@apaszke @elbaro @jph00 Le chargeur de données de fast.ai a ralenti la lecture des données de plus de 10 fois. J'utilise num_workers=8. Un indice quelle pourrait être la raison?
iqbalu
le 15 déc. 2017
Il est probable que le chargeur de données utilise des packages qui n'abandonnent pas le GIL
apaszke
le 15 déc. 2017
@apaszke une idée de la raison pour laquelle l'utilisation de la mémoire partagée continue d'augmenter après certaines époques. Dans mon cas, cela commence avec 400 Mo, puis chaque ~ 20e époque augmente de 400 Mo. Merci!
iqbalu
le 28 déc. 2017
@iqbalu pas vraiment. Cela ne devrait pas arriver
apaszke
le 28 déc. 2017
J'ai essayé beaucoup de choses et cv2.setNumThreads(0) finalement résolu mon problème.
Merci @jph00
 Cadene
le 19 janv. 2018
Cadene
le 19 janv. 2018
J'ai été troublé par ce problème récemment. cv2.setNumThreads(0) ne fonctionne pas pour moi. J'ai même modifié tout le code cv2 pour utiliser scikit-image à la place, mais le problème persiste. En plus, j'ai 16G pour /dev/shm . Je n'ai ce problème que lorsque j'utilise plusieurs gpus. Tout fonctionne bien sur un seul GPU. Quelqu'un a-t-il de nouvelles idées sur la solution?
 roytseng-tw
le 25 janv. 2018
roytseng-tw
le 25 janv. 2018
Même erreur. J'ai ce problème lorsque j'utilise un seul GPU.
 Jiankai-Sun
le 27 janv. 2018
Jiankai-Sun
le 27 janv. 2018
Pour moi, la désactivation des threads opencv a résolu le problème :
cv2.setNumThreads(0)
 shacharf
le 28 janv. 2018
shacharf
le 28 janv. 2018
frappez-le aussi avec pytorch 0.3, cuda 8.0, ubuntu 16.04
aucun opencv utilisé.
 tianq01
le 1 févr. 2018
tianq01
le 1 févr. 2018
J'utilise pytorch 0.3, cuda 8.0, ubuntu 14.04. J'ai observé ce blocage après avoir commencé à utiliser cv2.resize()
cv2.setNumThreads(0) a résolu mon problème.
 mathmanu
le 9 févr. 2018
mathmanu
le 9 févr. 2018
J'utilise python 3.6, pytorch 0.3.0, cuda 8.0 et ubuntu 17.04 sur un système avec deux 1080Ti et 32 Go de RAM.
Lorsque j'utilise 8 travailleurs pour mon propre ensemble de données, je vois fréquemment l'impasse (cela se produit dans la première époque). Quand je réduis les ouvriers à 4, il disparaît (j'ai couru 80 époques).
En cas de blocage, il me reste environ 10 Go de RAM libre.
 milani
le 2 mars 2018
milani
le 2 mars 2018
Ici, vous pouvez voir le journal après avoir terminé le script : https://gist.github.com/milani/42f50c023cdca407115b309237d29c70
MISE À JOUR : je confirme que je pourrais résoudre le problème en augmentant SHMMNI . Sur Ubuntu 17.04, j'ai ajouté kernel.shmmni=8192 à /etc/sysctl.conf .
milani
le 2 mars 2018
Connaissant également ce problème, Ubuntu 17.10, Python 3.6, Pytorch 0.3.1, CUDA 8.0. Il reste beaucoup de RAM lorsque l'impasse se produit et que le temps semble être incohérent - peut se produire après la 1ère époque ou après la 200ème.
La combinaison de kernel.shmmni=8192 et cv2.setNumThreads(0) semble y avoir remédié, alors qu'ils ne fonctionnaient pas individuellement.
 inoryy
le 8 mars 2018
inoryy
le 8 mars 2018
Idem dans mon cas. J'ai rencontré un blocage si j'ai configuré le num_workers=4. J'utilise Ubuntu 17.10, Pytorch 0.3.1, CUDA 9.1, python 3.6. On observe qu'il existe 4 threads python, dont chacun occupe 1,6 Go de mémoire tandis que le CPU (4 cœurs) reste inactif. La définition de num_workers=0 aide à résoudre ce problème.
 AlenUbuntu
le 27 mars 2018
AlenUbuntu
le 27 mars 2018
J'ai le même problème, se fige après exactement une époque, mais pas vraiment reproductible pour des ensembles de données plus petits. J'utilise CUDA 9.1, Pytorch 0.3.1, Python 3.6 dans un environnement Docker.
J'ai essayé le Dataloader de @jph00 , mais j'ai trouvé qu'il était beaucoup plus lent pour mon cas d'utilisation. Ma solution de contournement consiste actuellement à recréer le Pytorch DataLoader avant chaque époque. Cela semble fonctionner, mais c'est vraiment moche.
 tfriedel
le 11 avr. 2018
tfriedel
le 11 avr. 2018
J'ai eu exactement le même problème sur Ubuntu 17.10, CUDA 9.1, maître Pytorch (compilé le matin du 19/04). J'utilise également OpenCV dans ma sous-classe Dataset.
Ensuite, j'ai pu éviter l'impasse en modifiant la méthode de démarrage du multitraitement de 'forkserver' en 'spawn' :
# Set multiprocessing start method - deadlock
set_start_method(forkserver')
# Set multiprocessing start method - runs fine
set_start_method('spawn')
 mfuntowicz
le 19 avr. 2018
mfuntowicz
le 19 avr. 2018
J'ai presque essayé toutes les approches ci-dessus! Aucun d'eux n'a fonctionné !
Ce problème peut être lié à certaines incompatibilités avec l'architecture matérielle et je ne sais pas comment Pytorch peut le provoquer ! Cela peut être ou non le problème de Pytorch !
Voici donc comment mon problème a été résolu :
_Je mets à jour le BIOS !
Donner un coup de feu. Au moins ça résout mon problème.
 astorfi
le 21 avr. 2018
astorfi
le 21 avr. 2018
Pareil ici. Ubuntu PyTorch 0.4, python3.6.
 Shuailong
le 30 avr. 2018
Shuailong
le 30 avr. 2018
Il semble que le problème existe toujours dans pytorch 0.4 et python 3.6. Je ne sais pas si c'est un problème de pytorch. J'utilise opencv et mets num_workers=8 , pin_memory=True . J'essaie toutes les astuces mentionnées ci-dessus et le réglage cv2.setNumThreads(0) résout mon problème.
 JasonQSY
le 10 mai 2018
JasonQSY
le 10 mai 2018
(1) La définition de num_workers=0 dans le chargement des données PyTorch résout le problème (voir ci-dessus) OU
(2) cv2.setNumThreads(0) résout le problème même avec un nombre raisonnablement important de num_workers
Cela ressemble à une sorte de problème de verrouillage de thread.
J'ai défini cv2.setNumThreads(0) quelque part vers le début de mon fichier python principal et je n'ai jamais eu ce problème depuis lors.
mathmanu
le 10 mai 2018
Oui, beaucoup de ces problèmes sont dus au fait que les bibliothèques tierces ne sont pas sécurisées. Une solution alternative pourrait être d'utiliser la méthode de démarrage spawn.
apaszke
le 10 mai 2018
Pour moi, le problème de blocage se pose lorsque j'enveloppe mon modèle avec nn.DataParallel et que j'utilise num_workers > 0 dans le chargeur de données. En supprimant le wrapper nn.DataParallel, je peux exécuter mon script sans aucun verrouillage.
CUDA_VISIBLE_DEVICES=0 python monscript.py --split 1
CUDA_VISIBLE_DEVICES=1 python monscript.py --split 2
Sans plusieurs GPU, mon script s'exécute plus lentement, mais je peux exécuter plusieurs expériences en même temps sur différentes parties de l'ensemble de données.
 euwern
le 15 juin 2018
euwern
le 15 juin 2018
J'ai le même problème sur Python 3.6.2 / Pytorch 0.4.0.
et j'ai surtout essayé d'aborder le changement de pin_memory, la modification de la taille de la mémoire partagée, et j'utilise la bibliothèque skiamge (je n'utilise pas cv2 !!), mais j'ai toujours un problème.
ce problème se pose au hasard. contrôler ce problème consiste simplement à regarder la console et à redémarrer l'entraînement.
 slaysd
le 19 juin 2018
slaysd
le 19 juin 2018
@ jinh574 Je viens de définir le nombre de travailleurs du chargeur de données sur 0, et cela fonctionne.
Shuailong
le 19 juin 2018
@Shuailong Je dois utiliser une image de grande taille, donc je ne peux pas utiliser ces paramètres à cause de la vitesse. j'ai besoin de plus d'inspection sur ce problème
slaysd
le 19 juin 2018
J'ai le même problème sur Python 3.6 / Pytorch 0.4.0. L'option pin_memory affecte-t-elle quelque chose ?
 ein-farbe
le 26 juin 2018
ein-farbe
le 26 juin 2018
Si vous utilisez collate_fn et num_workers>0 avec la version PyTorch < 0.4 :
ASSUREZ-VOUS DE NE PAS RETOURNER DES TENSEURS À DIM ZÉRO DE VOTRE FONCTION __getitem__() .
OU RETOURNEZ-LES SOUS FORME DE TABLEAUX NUMPY.
 pyaf
le 12 juil. 2018
pyaf
le 12 juil. 2018
J'ai ce problème même après avoir défini num_workers=0 ou cv2.setNumThreads(0).
Il échoue avec l'un ou l'autre de ces deux problèmes. Quelqu'un d'autre fait face à la même chose ?
Traceback (appel le plus récent en dernier) :
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", ligne 193, dans _run_module_as_main
"__main__", mod_spec)
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/runpy.py", ligne 85, dans _run_code
exec(code, run_globals)
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", ligne 209, dans
principale()
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/distributed/launch.py", ligne 205, dans main
process.wait()
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", ligne 1457, en attente
(pid, sts) = self._try_wait(0)
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/subprocess.py", ligne 1404, dans _try_wait
(pid, sts) = os.waitpid(self.pid, wait_flags)
ClavierInterruption
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", ligne 258, dans _bootstrap
self.run()
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/process.py", ligne 93, en cours d'exécution
self._target( self._args, * self._kwargs)
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/utils/data/dataloader.py", ligne 96, dans _worker_loop
r = index_queue.get(timeout=MANAGER_STATUS_CHECK_INTERVAL)
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/queues.py", ligne 104, dans get
sinon self._poll(timeout):
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", ligne 257, dans le sondage
return self._poll(timeout)
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", ligne 414, dans _poll
r = wait([self], timeout)
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", ligne 911, en attente
prêt = selector.select(timeout)
Fichier "/opt/conda/envs/pytorch-py3.6/lib/python3.6/selectors.py", ligne 376, dans select
fd_event_list = self._poll.poll(timeout)
ClavierInterruption
 swethmandava
le 25 août 2018
swethmandava
le 25 août 2018
J'utilise la version '0.5.0a0+f57e4ce' et j'ai eu le même problème. L'annulation du chargeur de données parallèle (num_workers=0) ou la définition de cv2.setNumThreads(0) fonctionne.
 omersumer
le 5 oct. 2018
omersumer
le 5 oct. 2018
Je suis assez confiant que #11985 devrait éliminer tous les blocages (sauf si vous interrompez à des moments malheureux que nous ne pouvons pas contrôler). Maintenant qu'il est fusionné, je ferme ceci.
Le blocage avec cv2 est également hors de notre contrôle car cv2 ne fonctionne tout simplement pas bien avec le multitraitement.
SsnL
le 9 oct. 2018
Toujours en train de vivre cela à partir de torch_nightly-1.0.0.dev20181029 , le PR n'a-t-il pas encore été fusionné là-bas ?
 Evpok
le 30 oct. 2018
Evpok
le 30 oct. 2018
@Evpok cela a été fusionné là. Vous devriez avoir ce patch à coup sûr. Je me demande s'il y a d'autres blocages persistants possibles. Avez-vous une reproduction facile que nous pouvons essayer de regarder ?
soumith
le 30 oct. 2018
En fait, je l'ai retracé à un gâchis de multitraitement sans rapport de mon côté, désolé pour le désagrément.
Evpok
le 30 oct. 2018
salut @Evpok
j'utilise torch_nightly-1.0.0 , et rencontre ce problème. as-tu résolu ce problème ?
 zimenglan-sysu-512
le 14 nov. 2018
zimenglan-sysu-512
le 14 nov. 2018
Si vous utilisez collate_fn et num_workers>0 avec la version PyTorch < 0.4 :
ASSUREZ-VOUS DE NE PAS RETOURNER DES TENSEURS À DIM ZÉRO DE VOTRE FONCTION
__getitem__().
OU RETOURNEZ-LES SOUS FORME DE TABLEAUX NUMPY.
J'ai corrigé mon bug de retour des tenseurs dim zéros et le problème persiste.
 liluxuan1997
le 14 nov. 2018
liluxuan1997
le 14 nov. 2018
@zimenglan-sysu-512 Le problème principal était les limitations du multitraitement : lors de l'utilisation de spawn ou forkserver (ce qui est nécessaire pour la communication CPU-GPU), le partage d'objets entre processus est plutôt limité et non adapté au type d'objets que je dois manipuler.
Evpok
le 14 nov. 2018
Rien de tout cela n'a fonctionné pour moi. Cependant, le dernier opencv fonctionne ( 3.4.0.12 à 3.4.3.18 rien d'autre à changer):
sudo pip3 install --upgrade opencv-python
 see--
le 17 nov. 2018
see--
le 17 nov. 2018
@see-- heureux de savoir qu'opencv a corrigé leur problème :)
SsnL
le 17 nov. 2018
Je suis sur OpenCV 3.4.3.18 avec python2.7, et je vois toujours le blocage se produire. :/
 SreenivasVRao
le 3 déc. 2018
SreenivasVRao
le 3 déc. 2018
S'il vous plaît essayez ce qui suit:
from torch.utils.data.dataloader import DataLoader
à la place de
from torch.utils.data import DataLoader
Je pense qu'il y a un problème avec la vérification de type ici :
https://github.com/pytorch/pytorch/blob/656b565a0f53d9f24547b060bd27aa67ebb89b88/torch/utils/data/dataloader.py#L816
 jewfro-cuban
le 16 déc. 2018
jewfro-cuban
le 16 déc. 2018
S'il vous plaît essayez ce qui suit:
from torch.utils.data.dataloader import DataLoaderà la place de
from torch.utils.data import DataLoaderJe pense qu'il y a un problème avec la vérification de type ici :
pytorch/torch/utils/data/dataloader.py
Ligne 816 dans 656b565
super(DataLoader, self).__setattr__(attr, val)
N'est-ce pas qu'un pseudonyme ? dans torch.utils.data.__init__ ils importent dataloader.DataLoader
 simonhessner
le 8 janv. 2019
simonhessner
le 8 janv. 2019
J'ai également eu des problèmes avec num_workers > 0. Mon code n'a pas d'opencv et l'utilisation de la mémoire de /dev/shm n'est pas un problème. Aucune des suggestions ci-dessus n'a fonctionné pour moi. Mon correctif consistait à mettre à jour numpy de 1.14.1 à 1.14.5 :
conda install numpy=1.14.5
J'espère que c'est utile.
 daniyar-niantic
le 8 janv. 2019
daniyar-niantic
le 8 janv. 2019
Hmm, ma version numpy est 1.15.4, donc plus récente que 1.14.5... Ça devrait aller alors ?
simonhessner
le 8 janv. 2019
Hmm, ma version numpy est 1.15.4, donc plus récente que 1.14.5... Ça devrait aller alors ?
Idk, ma mise à jour de numpy a également mis à jour mkl.
daniyar-niantic
le 8 janv. 2019
Quelle version de mkl as-tu ? Le mien est 2019.1 (build 144) et les autres packages qui incluent mkl dans leur nom sont :
mkl-service 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
simonhessner
le 8 janv. 2019
Quelle version de mkl as-tu ? Le mien est 2019.1 (build 144) et les autres packages qui incluent mkl dans leur nom sont :
mkl-service 1.1.2 py37he904b0f_5
mkl_fft 1.0.6 py37hd81dba3_0
mkl_random 1.0.2 py37hd81dba3_0
conda list | grep mkl
mkl 2018.0.1 h19d6760_4
mkl-service 1.1.2 py36h17a0993_4
Si vous voyez toujours se bloquer dans le dernier pytorch, il serait très utile que vous fournissiez un court script qui reproduise le problème. Merci!
SsnL
le 9 janv. 2019
Je vois toujours cette impasse, je vais voir si je peux créer un script qui se reproduise.
 dtmoodie
le 15 janv. 2019
dtmoodie
le 15 janv. 2019
pin_memory=True résolu le problème pour moi.
pyaf
le 30 janv. 2019
Ne semble pas fonctionner pour moi avec pin_memory=True , toujours bloqué après 70 époques. La seule chose qui a fonctionné pour moi jusqu'à présent est de définir num_workers=0 , mais c'est nettement plus lent.
 jclevesque
le 14 févr. 2019
jclevesque
le 14 févr. 2019
Je rencontre également l'impasse (se produit assez aléatoirement). J'ai essayé pin_memory et mis à jour Numpy. Je vais essayer de l'exécuter sur une autre machine.
 Avsecz
le 14 févr. 2019
Avsecz
le 14 févr. 2019
Si vous utilisez plusieurs threads avec des chargeurs de données, essayez d'utiliser le multitraitement au lieu du multithreading. Cela a complètement résolu le problème pour moi (et en passant, c'est aussi mieux pour les tâches de calcul intensives en Python à cause du GIL)
simonhessner
le 14 févr. 2019
même erreur dans Pytorch1.0, Pillow5.0.0 numpy1.16.1 python3.6
 jianlong-yuan
le 15 févr. 2019
jianlong-yuan
le 15 févr. 2019
J'obtiens également la même erreur. J'ai défini pin_memory=True et num_workers=0 . Bien qu'une chose que j'ai remarquée est que lorsque j'utilise une petite partie de l'ensemble de données, cette erreur ne se produit pas. Seule l'utilisation de l'ensemble de données entier provoque cette erreur.
Edit: Juste un simple redémarrage du système l'a corrigé pour moi.
 Venka97
le 6 mars 2019
Venka97
le 6 mars 2019
J'avais un problème similaire. Dans certains codes, cette fonction se bloque (presque toujours) sur d_iter.next() :
def get_next_batch(d_iter, loader):
try:
data, label = d_iter.next()
except StopIteration:
d_iter = iter(loader)
data, label = d_iter.next()
return data, label
Le hack qui a fonctionné pour moi était d'ajouter un petit délai après avoir appelé cette fonction
trn_X, trn_y = get_next_batch(train_data_iter, train_loader)
time.sleep(0.003)
val_X, val_y = get_next_batch(valid_data_iter, valid_loader)
Je suppose que le retard a permis d'éviter une impasse?
 enoonIT
le 20 mars 2019
enoonIT
le 20 mars 2019
Je rencontre toujours ce problème. Utiliser pytorch 1.0 et python 3.7. Lorsque j'utilisais plusieurs data_loader, ce bogue apparaît. Si j'utilise moins de 3 data_loader ou que j'utilise un seul GPU, ce bogue n'apparaîtra pas. A essayé:
- temps.sommeil(0.003)
- pin_memory=Vrai/Faux
- nombre_travailleurs=0/1
- de torch.utils.data.dataloader importer DataLoader
- écrire 8192 dans /proc/sys/kernel/shmmni
Aucun d'eux ne fonctionne. Vous ne savez pas s'il existe des solutions ?
 xuw080
le 16 avr. 2019
xuw080
le 16 avr. 2019
mes solutions ajoutent cv2.setNumThreads(0) au programme de prétraitement
J'ai 2 chargeurs de données, qui sont pour train et val
Je n'ai pu exécuter l'évaluateur qu'une seule fois.
 lightningsoon
le 10 mai 2019
lightningsoon
le 10 mai 2019
Je viens de rencontrer ce bug avec pytorch 1.1. Same s'est coincé deux fois au même endroit : fin de la 99ème époque. pin_memory été défini sur False .
 Randl
le 17 mai 2019
Randl
le 17 mai 2019
Même problème lors de l'utilisation de workers>0, la mémoire des broches n'a pas résolu le problème.
 nicolasCruzW21
le 20 mai 2019
nicolasCruzW21
le 20 mai 2019
mes solutions ajoutent cv2.setNumThreads(0) au programme de prétraitement
J'ai 2 chargeurs de données, qui sont pour train et val
Je n'ai pu exécuter l'évaluateur qu'une seule fois.
Cette solution fonctionne pour moi, merci
 zxhr2793
le 3 juin 2019
zxhr2793
le 3 juin 2019
le chargeur de données s'arrête lorsque je termine une époque et commence une nouvelle époque.
rencontrer le même problème. Dans mon cas, le problème se pose lorsque j'installe opencv-python (j'ai déjà installé opencv3 auparavant). Après le déplacement opencv-python, l'entraînement ne s'arrêtera pas.
 hongzhenwang
le 20 juin 2019
hongzhenwang
le 20 juin 2019
c'est une bonne idée aussi
Au 20/06/2019 à 10:51:02, "hongzhenwang" [email protected] a écrit :
le chargeur de données s'arrête lorsque je termine une époque et commence une nouvelle époque.
rencontrer le même problème. Dans mon cas, le problème se pose lorsque j'installe opencv-python (j'ai déjà installé opencv3 auparavant). Après le déplacement opencv-python, l'entraînement ne s'arrêtera pas.
-
Vous recevez ceci parce que vous avez commenté.
Répondez directement à cet e-mail, affichez-le sur GitHub ou coupez le fil de discussion.
lightningsoon
le 27 juin 2019
Je rencontre toujours ce problème. Utiliser pytorch 1.0 et python 3.7. Lorsque j'utilisais plusieurs data_loader, ce bogue apparaît. Si j'utilise moins de 3 data_loader ou que j'utilise un seul GPU, ce bogue n'apparaîtra pas. A essayé:
1. time.sleep(0.003) 2. pin_memory=True/False 3. num_workers=0/1 4. from torch.utils.data.dataloader import DataLoader 5. writing 8192 to /proc/sys/kernel/shmmni None of them works. Don't know whether there is any solutions?
J'essaye toujours de trouver une solution de contournement. Je suis d'accord pour dire que je ne semble avoir ce problème que lorsque j'exécute 2 processus parallèles sur différents GPU en même temps. L'un continue tandis que l'autre s'arrête.
 ArturoDeza
le 3 juil. 2019
ArturoDeza
le 3 juil. 2019
Lorsque j'ai défini num_workers=4, le programme est resté bloqué pendant quelques secondes (ou minutes) tous les 4 lots, ce qui fait perdre beaucoup de temps. Une idée sur la façon de le résoudre?
 huangchaoxing
le 27 juil. 2019
huangchaoxing
le 27 juil. 2019
l'ajout des drapeaux : pin_memory=True et num_workers=0 dans le chargeur de données est la solution !
ArturoDeza
le 27 juil. 2019
l'ajout des drapeaux : pin_memory=True et num_workers=0 dans le chargeur de données est la solution !
@ArturoDeza
Cela pourrait être une solution. Cependant, la définition de num_workers=0 ralentit l'ensemble de la récupération des données du processeur et le taux d'utilisation du GPU sera très faible.
huangchaoxing
le 28 juil. 2019
Pour moi, la raison était qu'il n'y avait pas assez de processeurs dans mon système ou pas assez de num_workers spécifiés dans le Dataloader. Il peut également être judicieux de désactiver les threads dans les travailleurs du chargeur de données au cas où la méthode __get_item__ dans le chargeur de données utilise une bibliothèque de threads telle que numpy , librosa ou opencv (veuillez voir ci-dessous pourquoi cela peut être important). Ceci peut être réalisé en exécutant votre script d'entraînement avec OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . Pour clarifier la discussion ci-dessous, veuillez noter que chaque lot de Dataloader est géré par un seul opérateur : chaque opérateur gère des échantillons de batch_size pour terminer un seul lot, puis commence à traiter un nouveau lot de données.
Vous devez définir num_workers inférieur au nombre de processeurs de la machine (ou du pod si vous utilisez Kubernetes), mais suffisamment élevé pour que les données soient toujours prêtes pour la prochaine itération. Si le GPU exécute chaque itération en t secondes et que chaque travailleur du chargeur de données prend N*t secondes pour charger/traiter un seul lot, alors vous devez définir num_workers sur au moins N , pour éviter les décrochages GPU. Bien sûr, vous devez avoir au moins N CPU dans le système.
Malheureusement, si Dataloader utilise une bibliothèque qui utilise des threads K , alors le nombre de processus générés devient num_workers*K = N*K . Cela pourrait être considérablement plus élevé que le nombre de processeurs dans la machine. Cela étrangle le pod et le chargeur de données devient très lent. Cela peut empêcher le chargeur de données de renvoyer un lot toutes les t secondes, provoquant des blocages du GPU.
Une façon d'éviter les threads K est d'appeler le script principal par OMP_NUM_THREADS=1 MKL_NUM_THREADS=1 python train.py . Cela restreint chaque travailleur Dataloader à utiliser un seul thread et évite de surcharger la machine. Vous devez toujours avoir suffisamment de num_workers pour alimenter le GPU.
Vous devez également optimiser votre code en __get_item__ afin que chaque travailleur termine son lot en peu de temps. Veuillez vous assurer que le temps nécessaire pour terminer le pré-traitement d'un lot par le travailleur n'est pas gêné par le temps de lire les données d'entraînement à partir du disque (surtout si vous lisez à partir d'un stockage réseau), ou la bande passante du réseau (si vous lisez à partir d'un réseau disque). Si votre ensemble de données est petit et que vous disposez de suffisamment de RAM, envisagez de déplacer l'ensemble de données vers la RAM (ou /tmpfs ) et lisez à partir de là pour un accès rapide. Pour Kubernetes, vous pouvez créer un disque RAM (recherchez emptyDir dans Kubernetes).
Si vous avez optimisé votre code __get_item__ et vous êtes assuré que l'accès au disque/l'accès au réseau ne sont pas les coupables, mais que vous voyez toujours des blocages, vous devrez demander plus de processeurs (pour un pod Kubernetes) ou déplacer votre GPU vers un machine avec plus de processeurs.
Une autre option consiste à réduire les batch_size afin que chaque worker ait moins de travail à faire et termine le pré-traitement plus rapidement. Cette dernière option n'est pas souhaitable dans certains cas, car la mémoire GPU inactive n'est pas utilisée.
Vous pouvez également envisager d'effectuer une partie du prétraitement hors ligne et d'alléger le poids de chaque travailleur. Par exemple, si chaque travailleur lit dans un fichier wav et calcule des spectrogrammes pour le fichier audio, vous pouvez envisager de précalculer les spectrogrammes hors ligne et simplement lire le spectrogramme calculé à partir du disque dans le travailleur. Cela réduira la quantité de travail que chaque travailleur doit faire.
 gkeskin07
le 3 août 2019
gkeskin07
le 3 août 2019
rencontrer le même problème avec horovod
 jinhou
le 12 août 2019
jinhou
le 12 août 2019
Rencontrez un problème similaire... Blocage en finissant juste une époque et en commençant à charger des données pour validation...
 jackroos
le 20 août 2019
jackroos
le 20 août 2019
@jinhou @jackroos Même chose, bloqué au hasard au début de la validation avec horovod. Ce que je fais actuellement comme solution de contournement, c'est de définir un délai d'attente et d'ignorer la validation. Avez-vous une solution?
 lzljzys
le 28 août 2019
lzljzys
le 28 août 2019
@jinhou @jackroos Même chose, bloqué au hasard au début de la validation avec horovod. Ce que je fais actuellement comme solution de contournement, c'est de définir un délai d'attente et d'ignorer la validation. Avez-vous une solution?
Non. Je désactive simplement la formation distribuée dans ce cas.
jackroos
le 29 août 2019
J'ai rencontré un problème similaire : le chargeur de données s'arrête lorsque je termine une époque et démarre une nouvelle époque.
pourquoi tant de zan ?
 foocker
le 22 oct. 2019
foocker
le 22 oct. 2019
Je rencontre toujours ce problème. Utiliser pytorch 1.0 et python 3.7. Lorsque j'utilisais plusieurs data_loader, ce bogue apparaît. Si j'utilise moins de 3 data_loader ou que j'utilise un seul GPU, ce bogue n'apparaîtra pas. A essayé:
- temps.sommeil(0.003)
- pin_memory=Vrai/Faux
- nombre_travailleurs=0/1
- de torch.utils.data.dataloader importer DataLoader
- écrire 8192 dans /proc/sys/kernel/shmmni
Aucun d'eux ne fonctionne. Vous ne savez pas s'il existe des solutions ?
num_workers défini sur 0 a fonctionné pour moi. Vous devez vous assurer qu'il est à 0 partout où vous l'utilisez.
Quelques autres solutions potentielles :
- à partir de l'import multitraitement set_start_method
set_start_method('spawn') - cv2.setNumThreads(0)
Il semble que 3 ou 7 soient la voie à suivre.
 the7threvival
le 18 nov. 2019
the7threvival
le 18 nov. 2019
Je rencontre ce problème avec pytorch 1.3, ubuntu16, toutes les suggestions ci-dessus n'ont pas fonctionné, à l'exception de workers=0 qui ralentit l'exécution. Cela ne se produit que lors de l'exécution à partir du terminal, dans le bloc-notes Jupyter, tout va bien, même avec workers=32.
Le problème ne semble pas résolu, faut-il le rouvrir ? Je vois aussi beaucoup d'autres personnes signaler le même problème...
 skariel
le 2 déc. 2019
skariel
le 2 déc. 2019
Je rencontre toujours ce problème. Utiliser pytorch 1.0 et python 3.7. Lorsque j'utilisais plusieurs data_loader, ce bogue apparaît. Si j'utilise moins de 3 data_loader ou que j'utilise un seul GPU, ce bogue n'apparaîtra pas. A essayé:
- temps.sommeil(0.003)
- pin_memory=Vrai/Faux
- nombre_travailleurs=0/1
- de torch.utils.data.dataloader importer DataLoader
- écrire 8192 dans /proc/sys/kernel/shmmni
Aucun d'eux ne fonctionne. Vous ne savez pas s'il existe des solutions ?num_workers défini sur 0 a fonctionné pour moi. Vous devez vous assurer qu'il est à 0 partout où vous l'utilisez.
Quelques autres solutions potentielles :
- à partir de l'import multitraitement set_start_method
set_start_method('spawn')- cv2.setNumThreads(0)
Il semble que 3 ou 7 soient la voie à suivre.
J'ai modifié train.py comme ceci :
from __future__ import division
import cv2
cv2.setNumThreads(0)
import argparse
...
Et cela fonctionne pour moi.
 DHZS
le 10 déc. 2019
DHZS
le 10 déc. 2019
Hé les gars si je peux aider,
J'ai également eu ce problème similaire à celui-ci, mais cela se produirait toutes les 100 époques environ.
J'ai remarqué que cela ne se produisait qu'avec CUDA activé, dmesg a également cette entrée de journal chaque fois qu'il se bloque.
python[11240]: segfault at 10 ip 00007fabdd6c37d8 sp 00007ffddcd64fd0 error 4 in libcudart.so.10.1.243[7fabdd699000+77000]
C'est du charabia pour moi, mais cela m'a dit que CUDA et le multithreading python ne jouaient pas bien.
Mon correctif consistait à désactiver cuda dans les datathreads, voici un extrait de mon fichier d'entrée python.
from multiprocessing import set_start_method
import os
if __name__ == "__main__":
set_start_method('spawn')
else:
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import torch
import application
J'espère que cela pourra aider tous ceux qui atterrissent ici comme j'en avais besoin à l'époque.
 roderickObrist
le 24 mars 2020
roderickObrist
le 24 mars 2020
@jinhou @jackroos Même chose, bloqué au hasard au début de la validation avec horovod. Ce que je fais actuellement comme solution de contournement, c'est de définir un délai d'attente et d'ignorer la validation. Avez-vous une solution?
Non. Je désactive simplement la formation distribuée dans ce cas.
Je rencontre un problème similaire dans la formation distribuée sans utiliser OpenCV après la mise à jour vers PyTorch 1.4.
Maintenant, je dois exécuter la validation une fois avant la boucle d'entraînement et de validation.
 wizardk
le 9 juin 2020
wizardk
le 9 juin 2020
J'ai eu beaucoup de mal avec ça. Il semble persister entre les versions de pytorch, les versions de python et également différentes machines physiques (qui auront probablement été configurées à l'identique).
A chaque fois c'est la même erreur :
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/bicep/loops.py", line 73, in __call__
for data, target in self.dataloader:
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 830, in _next_data
self._shutdown_workers()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 942, in _shutdown_workers
w.join()
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/process.py", line 149, in join
res = self._popen.wait(timeout)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 47, in wait
return self.poll(os.WNOHANG if timeout == 0.0 else 0)
File "/home/<me>/miniconda2/envs/<my-module>/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll
pid, sts = os.waitpid(self.pid, flag)
Il y a clairement un problème dans la façon dont les processus sont gérés sur la machine que j'utilise. Aucune des solutions ci-dessus ne semble fonctionner, à part la définition de num_workers=0.
J'aimerais vraiment pouvoir aller au fond de cela, est-ce que quelqu'un a une idée par où commencer ou comment interroger cela?
 brynhayder
le 9 juin 2020
brynhayder
le 9 juin 2020
Moi aussi ici.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 480, in _try_get_batch
data = self.data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/miniconda/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 65, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 95106) is killed by signal: Segmentation fault.
Une chose intéressante est
lorsque je viens d'analyser les données ligne par ligne, je n'ai pas ce problème :
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
mais si j'ajoute une logique d'analyse JSON après avoir lu ligne par ligne, il signalera cette erreur
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
Je comprends qu'il y aura une surcharge de mémoire JSON, mais même si je réduis le nombre de travailleurs en 2, et que l'ensemble de données est très petit, il a toujours le même problème. Je doute que ce soit lié au shm. une idée ?
 zhangruiskyline
le 16 juin 2020
zhangruiskyline
le 16 juin 2020
Allons-nous rouvrir ce problème?
 takatosp1
le 18 juin 2020
takatosp1
le 18 juin 2020
Je pense que nous devrions. BTW, j'ai fait du débogage GDB et rien n'y a trouvé. donc je ne suis pas vraiment sûr qu'il s'agisse d'un problème de mémoire partagée,
(gdb) run
Starting program: /home/miniconda/bin/python performance.py
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7fffa60a6700 (LWP 61963)]
[New Thread 0x7fffa58a5700 (LWP 61964)]
[New Thread 0x7fffa10a4700 (LWP 61965)]
[New Thread 0x7fff9e8a3700 (LWP 61966)]
[New Thread 0x7fff9c0a2700 (LWP 61967)]
[New Thread 0x7fff998a1700 (LWP 61968)]
[New Thread 0x7fff970a0700 (LWP 61969)]
[New Thread 0x7fff9489f700 (LWP 61970)]
[New Thread 0x7fff9409e700 (LWP 61971)]
[New Thread 0x7fff8f89d700 (LWP 61972)]
[New Thread 0x7fff8d09c700 (LWP 61973)]
[New Thread 0x7fff8a89b700 (LWP 61974)]
[New Thread 0x7fff8809a700 (LWP 61975)]
[New Thread 0x7fff85899700 (LWP 61976)]
[New Thread 0x7fff83098700 (LWP 61977)]
[New Thread 0x7fff80897700 (LWP 61978)]
[New Thread 0x7fff7e096700 (LWP 61979)]
[New Thread 0x7fff7d895700 (LWP 61980)]
[New Thread 0x7fff7b094700 (LWP 61981)]
[New Thread 0x7fff78893700 (LWP 61982)]
[New Thread 0x7fff74092700 (LWP 61983)]
[New Thread 0x7fff71891700 (LWP 61984)]
[New Thread 0x7fff6f090700 (LWP 61985)]
[Thread 0x7fff7e096700 (LWP 61979) exited]
[Thread 0x7fff6f090700 (LWP 61985) exited]
[Thread 0x7fff74092700 (LWP 61983) exited]
[Thread 0x7fff7b094700 (LWP 61981) exited]
[Thread 0x7fff80897700 (LWP 61978) exited]
[Thread 0x7fff83098700 (LWP 61977) exited]
[Thread 0x7fff85899700 (LWP 61976) exited]
[Thread 0x7fff8809a700 (LWP 61975) exited]
[Thread 0x7fff8a89b700 (LWP 61974) exited]
[Thread 0x7fff8d09c700 (LWP 61973) exited]
[Thread 0x7fff8f89d700 (LWP 61972) exited]
[Thread 0x7fff9409e700 (LWP 61971) exited]
[Thread 0x7fff9489f700 (LWP 61970) exited]
[Thread 0x7fff970a0700 (LWP 61969) exited]
[Thread 0x7fff998a1700 (LWP 61968) exited]
[Thread 0x7fff9c0a2700 (LWP 61967) exited]
[Thread 0x7fff9e8a3700 (LWP 61966) exited]
[Thread 0x7fffa10a4700 (LWP 61965) exited]
[Thread 0x7fffa58a5700 (LWP 61964) exited]
[Thread 0x7fffa60a6700 (LWP 61963) exited]
[Thread 0x7fff71891700 (LWP 61984) exited]
[Thread 0x7fff78893700 (LWP 61982) exited]
[Thread 0x7fff7d895700 (LWP 61980) exited]
total_files = 5040. //customer comments
[New Thread 0x7fff6f090700 (LWP 62006)]
[New Thread 0x7fff71891700 (LWP 62007)]
[New Thread 0x7fff74092700 (LWP 62008)]
[New Thread 0x7fff78893700 (LWP 62009)]
ERROR: Unexpected segmentation fault encountered in worker.
ERROR: Unexpected segmentation fault encountered in worker.
Traceback (most recent call last):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/home/miniconda/lib/python3.6/multiprocessing/connection.py", line 911, in wait
ready = selector.select(timeout)
File "/home/miniconda/lib/python3.6/selectors.py", line 376, in select
fd_event_list = self._poll.poll(timeout)
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 62005) is killed by signal: Segmentation fault.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "performance.py", line 62, in <module>
main()
File "performance.py", line 48, in main
for i,batch in enumerate(rl_data_loader):
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 841, in _next_data
idx, data = self._get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 808, in _get_data
success, data = self._try_get_data()
File "/home/zhrui/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 774, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str))
RuntimeError: DataLoader worker (pid(s) 62005) exited unexpectedly
[Thread 0x7fff78893700 (LWP 62009) exited]
[Thread 0x7fff74092700 (LWP 62008) exited]
[Thread 0x7fff71891700 (LWP 62007) exited]
[Thread 0x7fff6f090700 (LWP 62006) exited]
[Inferior 1 (process 61952) exited with code 01]
(gdb) backtrace
No stack.
Et je pense que j'ai assez de mémoire partagée, au moins je m'attends à ce que la mémoire partagée soit assez bonne pendant assez longtemps jusqu'à ce qu'une erreur de segmentation se produise, mais une erreur de segment se produit presque immédiatement après le lancement du travail de chargeur de données
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18014398509481980
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 32000
max semaphores per array = 32000
max semaphores system wide = 1024000000
max ops per semop call = 500
semaphore max value = 32767
Salut @soumith @apaszke , pouvons-nous rouvrir ce problème, j'ai essayé toutes les solutions proposées comme augmenter la taille et le segment de shm, rien ne fonctionne, je n'utilise pas opencv ou autre, juste une simple analyse JSON. mais problème toujours là. et je ne pense pas que ce soit lié à shm puisque j'ai vérifié que j'ouvre toute la mémoire en tant que mémoire partagée. La trace de la pile n'affiche également rien comme indiqué ci-dessus.
@apaszke , concernant votre suggestion de
« Oui, beaucoup de ces problèmes sont dus au fait que les bibliothèques tierces ne sont pas sécurisées pour les fourches. Une solution alternative pourrait consister à utiliser la méthode de démarrage spawn. »
J'utilise dataloader multi worker, comment puis-je changer de méthode ? Je mets set_start_method('spawn') dans mon main.py mais la dose ne semble pas aider
J'ai également une question générale ici, si j'active le chargeur de données multi-travailleurs (multi-processus), et dans la formation principale, je démarre également multi-processus comme suggéré dans https://pytorch.org/docs/stable/notes/multiprocessing.html #multitraitement -meilleures-pratiques
comment pytorch gère à la fois le chargeur de données et le multi-processus d'entraînement principal ? partageront-ils tous les processus/threading possibles sur un GPU multicœur ? la mémoire partagée pour le multi-processus est également "partagée" par le chargeur de données et le processus d'entraînement principal ? aussi si j'ai un travail de cuisinier de données comme l'analyse JSON, l'analyse CSV, l'extraction de fonctionnalités pandas. etc, où est la meilleure façon de mettre? dans le chargeur de données pour générer des données parfaites pour être prêtes ou utilisez simplement la formation principale pour le faire comme certains l'ont suggéré ci-dessus pour garder le chargeur de données __get_item__ aussi simple que possible
zhangruiskyline
le 19 juin 2020
@zhangruiskyline Votre problème n'est pas vraiment une impasse. Il s'agit des travailleurs tués par segfault. sigbus est celui qui suggère des problèmes de shm. Vous devriez vérifier le code de votre ensemble de données et y déboguer.
Pour répondre à vos autres questions,
- utiliser kwarg
multiproessing_context='spawn'dans DataLoader définira le spawn.set_start_methodaussi ça. - généralement dans la formation multiprocessus, chaque processus a son propre DataLoader, et donc des travailleurs DataLoader. Rien n'est partagé entre les processus à moins que cela ne soit explicitement fait.
SsnL
le 20 juin 2020
Merci @SsnL , j'ai ajouté multiproessing_context='spawn' mais même échec.
Je l'ai signalé dans le fil précédent, mon code est très simple,
- ce bout de code fonctionne
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
- mais si j'ajoute une logique d'analyse JSON après avoir lu ligne par ligne, il signalera cette erreur
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
donc je doute que ce soit mon problème de code, j'essaie également de ne pas utiliser l'analyse JSON, mais directement la division de la chaîne, même problème. il semble que tant que j'ai une logique chronophage pour le traitement des données dans le chargeur de données, ce problème se produit
Concernant aussi
formation multiprocessus, chaque processus a son propre DataLoader, et donc les travailleurs DataLoader Rien n'est partagé entre les processus à moins que cela ne soit explicitement fait.
Voyons donc que j'ai 4 processus pour la formation, chacun avec un chargeur de données de 8 travailleurs, donc un total de 32 processus en dessous ?
zhangruiskyline
le 20 juin 2020
@zhangruiskyline Sans script autonome pour reproduire le problème, nous ne pouvons pas vous aider. Oui il y aura 32 processus
SsnL
le 20 juin 2020
Merci, j'ai aussi vu un problème similaire dans
https://github.com/pytorch/pytorch/issues/4969
https://github.com/pytorch/pytorch/issues/5040
les deux sont fermés mais je ne vois pas de solution ou de solution claire, est-ce toujours un problème existant ?
Je vais voir si je peux fournir un script de reproduction autonome, mais il est hautement intégré à notre plate-forme et à notre source de données, alors j'essaierai
zhangruiskyline
le 20 juin 2020
@zhangruiskyline Votre problème ne ressemble à aucun des problèmes liés, si vous les lisez. ils sont fermés car le problème d'origine / le plus courant signalé sur ces threads est déjà résolu.
SsnL
le 20 juin 2020
Merci @SsnL , je ne connais pas si bien Pytorch, donc je peux me tromper, mais j'ai parcouru tous ceux-ci, et il semble que certains d'entre eux semblent résolus par
réduire le nombre de travailleur à 0, c'est inacceptable pour nous car c'est trop lent,
augmenter la taille de shm, mais nous avons assez de shm je crois, et le problème s'est produit presque immédiatement après le démarrage, et j'ai essayé avec un ensemble de données beaucoup plus petit, le problème est le même
certaines lib comme opencv dose ne fonctionnent pas bien en multi-processus, nous utilisons juste JSON/CSV, donc pas vraiment de trucs fantaisistes
notre code est assez simple, l'ensemble de données d'entraînement contient plus de 10 000 fichiers, chaque fichier contient plusieurs lignes de chaînes JSON. dans dataloader, nous définissons __get_item__ pour obtenir chaque fichier parmi plus de 10K fichiers et lire tout le contenu de ce fichier.
dans la solution 1, nous lisons d'abord et divisons ligne par ligne dans la liste de chaînes JSON, si nous revenons immédiatement, cela fonctionne, les performances sont bonnes
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
return all_data
maintenant, puisque la valeur renvoyée est toujours une chaîne JSON, nous voulons tirer parti du chargeur de données multi-processus pour accélérer, alors mettez la logique d'analyse JSON ici et cela échoue
with open(current_file, mode='rb') as f:
text = f.read().decode('utf-8')
all_data.extend(text.split('\n'))
json_data = []
for line in all_data:
try:
json_data.append(json.loads(line))
except:
break
return json_data
nous avons ensuite pensé que l'analyse JSON était trop lourde et que JSON avait trop d'empreinte mémoire, puis nous avons choisi d'analyser la chaîne JSON et de la convertir manuellement en liste de fonctionnalités, même échec. fait une analyse de trace de pile et rien là-bas
BTW, nous exécutons notre code sous Linux Docker Env, CPU 24 cœurs et 1 V100.
Je ne sais pas par où commencer pour enquêter ensuite. avez-vous une idée?
zhangruiskyline
le 20 juin 2020
Salut,
J'ai trouvé un commentaire intéressant dans https://github.com/open-mmlab/mmcv , qui est utilisé dans https://github.com/open-mmlab/mmdetection :
Le code suivant est utilisé au début de l'époque du train et de l'époque val.
time.sleep(2) # Empêche les blocages possibles pendant la transition d'époque
Peut-être que vous pouvez l'essayer.
mathmanu
le 20 juin 2020
BTW, si je passe à plusieurs processus et à chaque processus avec un chargeur de données multi-travailleurs, comment des processus différents peuvent-ils garantir que leur chargeur de données correspondant ne lira pas les mêmes données que le chargeur de données d'un autre processus ? est-il déjà géré par pytorch dataloader __get_item__ ?
zhangruiskyline
le 20 juin 2020
Salut @SsnL , Merci pour votre aide. Je veux juste suivre un peu ce fil, je refactorise le code d'entraînement à l'aide du multitraitement pytorch pour accélérer le traitement des données côté CPU (afin d'alimenter le GPU plus rapidement), https://pytorch.org/docs/stable /notes/multiprocessing.html#multiprocessing -best-practices
Dans chaque fonction de traitement, j'utilise également un chargeur de données multi-travailleurs pour accélérer le temps de traitement du chargement des données. https://pytorch.org/docs/stable/data.html
J'ai mis mon analyse JSON CPU lourde non dans le chargeur de données, mais dans le processus d'entraînement principal, et le problème semble avoir disparu, je ne sais pas pourquoi, mais de toute façon, cela semble fonctionner. mais j'ai une question de suivi : supposons que j'ai N traitement M travailleur de chargeur NxM sous le threading là-bas.
Si dans mon chargeur de données, je souhaite obtenir toutes les données sous forme d'index, ce qui signifie que __get_item__(self, idx) dans M chargeur de données dans N traitements différents peuvent fonctionner ensemble pour traiter différents index, comment puis-je m'assurer qu'ils ne traitent pas les doublons ou manquer de traiter certains?
zhangruiskyline
le 23 juin 2020
J'ai eu le même problème où le chargeur de données se bloque après s'être plaint qu'il ne pouvait pas allouer de mémoire au début d'une nouvelle période d'entraînement ou de validation. Les solutions ci-dessus n'ont pas fonctionné pour moi (i) mon
/dev/shmest de 32 Go et il n'a jamais été utilisé plus de 2,5 Go, et (ii) le paramètre pin_memory=False n'a pas fonctionné.C'est peut-être quelque chose à voir avec la collecte des ordures? Mon code ressemble à peu près à ce qui suit. J'ai besoin d'un itérateur infini et donc je fais un essai / sauf autour du
next()ci-dessous :-)def train(): train_iter = train_loader.__iter__() for i in xrange(max_batches): try: x, y = next(train_iter) except StopIteration: train_iter = train_loader.__iter__() ... del train_iter
train_loaderest un objetDataLoader. Sans la ligne explicitedel train_iterà la fin de la fonction, le processus plante toujours après 2-3 époques (/dev/shmaffiche toujours 2,5 Go). J'espère que cela t'aides!J'utilise des travailleurs
4(version0.1.12_2avec CUDA 8.0 sur Ubuntu 16.04).
Cela a résolu le problème pour moi après des semaines de lutte. Je dois explicitement utiliser l'itérateur du chargeur au lieu de boucler le chargeur directement et utiliser le del loader_iterator à la fin de l'époque a finalement supprimé les blocages
 kennyFF92
le 15 juil. 2020
kennyFF92
le 15 juil. 2020
Je pense que je rencontre le même problème. Essayer d'utiliser 8 chargeurs de données (MNIST, MNISTM, SVHN, USPS, pour former et tester chacun). L'utilisation de 6 (n'importe quel 6) fonctionne très bien. L'utilisation de 8 blocs toujours lors du chargement du 6ème, test MNIST-M. Il est coincé dans une boucle sans fin d'essayer de récupérer l'image, d'échouer, d'attendre un peu puis d'essayer à nouveau. L'erreur persiste pour tout batch_size, il me reste beaucoup de mémoire libre et elle ne disparaît que si je définis num_workers sur 0. Tout autre montant provoque le problème
 pmirallesr
le 21 juil. 2020
pmirallesr
le 21 juil. 2020
J'ai eu un indice de https://stackoverflow.com/questions/54013846/pytorch-dataloader-stucked-if-using-opencv-resize-method
Quand je mets cv2.setNumThreads(0) , ça marche bien avec moi.
 LifeBeyondExpectations
le 17 août 2020
LifeBeyondExpectations
le 17 août 2020
Bonjour, j'ai eu le même problème. Et cela avait à voir avec ulimit -n, augmentez-le simplement et le problème est résolu, j'ai utilisé ulimit -n 500000
 SebastienEske
le 18 août 2020
SebastienEske
le 18 août 2020
@SebastienEske ulimit -n a également corrigé cela pour moi, sur Ubuntu 20.04
 david-waterworth
le 24 sept. 2020
david-waterworth
le 24 sept. 2020
Peut-être que set ulimit -n est une bonne méthode, Avec l'augmentation du modèle, les blocages deviennent de plus en plus fréquents, je teste aussi cv2.setNumThreads(0) , Mais ça ne marche pas.
 BLING-1994
le 27 sept. 2020
BLING-1994
le 27 sept. 2020
Pour mémoire, cv2.setNumThreads(0) fonctionné pour moi.
 franchesoni
le 18 nov. 2020
franchesoni
le 18 nov. 2020
Questions connexes
 bartvm
·
3Commentaires
bartvm
·
3Commentaires
 a1363901216
·
3Commentaires
a1363901216
·
3Commentaires
 ikostrikov
·
3Commentaires
ikostrikov
·
3Commentaires
 Coderx7
·
3Commentaires
Coderx7
·
3Commentaires
 eliabruni
·
3Commentaires
eliabruni
·
3Commentaires
Commentaire le plus utile
J'ai rencontré un problème similaire : le chargeur de données s'arrête lorsque je termine une époque et démarre une nouvelle époque.