无法阻止发布的套件:
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
这三间套房最近都剥落了,介意分类吗?
/ sig可伸缩性
/优先级失败测试
/种类错误
/ status-for-里程碑
cc @jdumars @jberkus
/分配@shyamjvs @
 krzyzacy
krzyzacy
所有164条评论
- 正确性工作失败主要是由于超时(需要相应地调整我们的日程表),因为最近有大量e2es被添加到套件中(例如https://github.com/kubernetes/kubernetes/pull/59391)
- 对于100节点的薄片,我们有https://github.com/kubernetes/kubernetes/issues/60500 (我相信这是相关的。需要检查)。
- 对于性能工作,我认为这是一种回归(最近几次运行似乎与pod-startup延迟有关)。 也许还有更多。
我将在本周的某个时间尝试联系他们(缺少免费的自动取款机)。
 shyamjvs
于 2018-02-28
shyamjvs
于 2018-02-28
@shyamjvs是否有此问题的任何更新?
krzyzacy
于 2018-03-02
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
我对此进行了简要介绍。 而且某些测试非常缓慢,或者有些悬挂。 最近一次运行的日志数:
62571 I0301 23:01:31.360] Mar 1 23:01:31.348: INFO: Running AfterSuite actions on all node
62572 I0301 23:01:31.360]
62573 W0302 07:32:00.441] 2018/03/02 07:32:00 process.go:191: Abort after 9h30m0s timeout during ./hack/ginkgo-e2e.sh --ginkgo.flakeAttempts=2 --ginkgo.skip=\[Serial\]|\[Disruptive \]|\[Flaky\]|\[Feature:.+\]|\[DisabledForLargeClusters\] --allowed-not-ready-nodes=50 --node-schedulable-timeout=90m --minStartupPods=8 --gather-resource-usage=master --gathe r-metrics-at-teardown=master --logexporter-gcs-path=gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-correctness/80/artifacts --report-dir=/workspace/_artifacts --dis able-log-dump=true --cluster-ip-range=10.64.0.0/11. Will terminate in another 15m
62574 W0302 07:32:00.445] SIGABRT: abort
8h30m内未完成测试
 wojtek-t
于 2018-03-02
wojtek-t
于 2018-03-02
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
确实看起来像是回归。 我认为回归发生在运行之间的某个地方:
105(还是可以的)
108(启动时间明显更长)
我们可以尝试查看kubemark-5000,以查看它是否也可见。
wojtek-t
于 2018-03-02
Kubemark-5000非常稳定。 该图上的第99个百分位(也许回归甚至发生在以前,但我认为它在105到108之间):

wojtek-t
于 2018-03-02
关于正确性测试-gce-large-correctity也失败。
也许当时添加了一些测试时间过长?
wojtek-t
于 2018-03-02
非常感谢您寻找@ wojtek-t。 Wrt的绩效工作-我也强烈地感觉到存在一种回归(尽管我无法正确地研究它们)。
也许当时添加了一些测试时间过长?
我前一段时间正在研究这个问题。 我发现了2个可疑的更改:
- #59391-这在本地存储周围添加了一系列测试(此更改开始超时后的运行)
- StatefulSet与荚反关联性应该使用卷分布在节点(此测试似乎运行3.5 - 5小时) - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e -gce-scale-correctity / 79
shyamjvs
于 2018-03-02
cc @ kubernetes / sig-storage-bugs
shyamjvs
于 2018-03-02
/分配
一些本地存储测试将尝试使用群集中的每个节点,以为群集的大小并不大。 我将添加一个修复程序来限制最大节点数。
 msau42
于 2018-03-02
msau42
于 2018-03-02
一些本地存储测试将尝试使用群集中的每个节点,以为群集的大小并不大。 我将添加一个修复程序来限制最大节点数。
谢谢@ msau42-太好了。
wojtek-t
于 2018-03-02
回到https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance套件
我仔细研究了运行到105和108之后的情况。
与pod启动时间最大的不同似乎出现在以下步骤:
10% worst watch latencies:
[其名称具有误导性-将在下面说明]
最多运行105次,通常如下所示:
I0129 21:17:43.450] Jan 29 21:17:43.356: INFO: perc50: 1.041233793s, perc90: 1.685463015s, perc99: 2.350747103s
从108运行开始,它看起来更像:
Feb 12 10:08:57.123: INFO: perc50: 1.122693874s, perc90: 1.934670461s, perc99: 3.195883331s
这基本上意味着〜0.85s的增加,这大约是我们最终观察到的结果。
现在-什么是“观看滞后”。
基本上是从“ Kubelet观察到容器正在运行”到“测试观察到的容器更新将其状态设置为运行”之间的时间。
我们有两种可能退步的可能性:
- kubelet的报告状态变慢
- kubelet饿死了(因此报告状态变慢)
- apiserver较慢(例如,CPU饥饿),因此处理请求的速度较慢(写入,监视或同时执行)
- 测试缺乏CPU,因此处理传入事件的速度较慢
由于我们并未真正观察到Pod的“时间表->开始”之间的差异,因此表明它很可能不是apiserver(因为处理请求和监视也在该路径上),并且它很可能不是慢速kubelet也是如此(因为它启动了广告连播)。
所以我认为最可能的假设是:
- kubelet饿死了(或者阻止它快速发送状态更新的某物)
- 测试缺乏CPU(或类似的东西)
在那段时间,测试完全没有改变。 所以我认为这很可能是第一个。
就是说,我经历了105到108次运行之间合并的PR,到目前为止,没有发现任何有用的信息。
wojtek-t
于 2018-03-02
我认为下一步是:
- 查看最慢的Pod(最慢的Pod之间似乎也有O(1s)的差异),并查看差异是否在发送更新状态请求的“之前”或“之后”
wojtek-t
于 2018-03-02
因此,我研究了示例豆荚。 而且我已经看到了:
I0209 10:01:19.960823 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.615907ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
...
I0209 10:01:22.464046 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (279.153µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:23.468353 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (218.216µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:24.470944 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.42987ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 09:57:01.559125 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (1.836423ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
...
I0209 09:57:04.452830 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (231.2µs) 429 [[kubelet/v1.10.0 (linu x/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:05.454274 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (213.872µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:06.458831 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (2.13295ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 10:01:53.063575 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (1.410064ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:3391
...
I0209 10:01:55.259949 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (10.4894ms) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:56.266377 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (233.931µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:57.269427 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (182.035µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:58.290456 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (13.44863ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
因此,很显然该问题与“ 429”有关。
wojtek-t
于 2018-03-02
那些受限制的API调用是否归因于所有者帐户的配额?
 jdumars
于 2018-03-02
jdumars
于 2018-03-02
那些受限制的API调用是否归因于所有者帐户的配额?
这并不像我最初想的那样节流。 这些是apiserver上的429s(原因可能是由于某些原因导致apiserver速度变慢,或者是有更多请求发送到apiserver)。
wojtek-t
于 2018-03-02
哦好的。 那不是好消息。
jdumars
于 2018-03-02
/里程碑清除
krzyzacy
于 2018-03-02
/里程碑v1.10
krzyzacy
于 2018-03-02
/里程碑清除
 cjwagner
于 2018-03-02
cjwagner
于 2018-03-02
@cjwagner :您必须是kubernetes-milestone-maintainers github团队的成员才能设置里程碑。
针对此:
/里程碑清除
可在此处获得使用PR注释与我互动的说明。 如果您对我的行为有任何疑问或建议,请针对kubernetes / test-infra存储库提出问题。
 k8s-ci-robot
于 2018-03-02
k8s-ci-robot
于 2018-03-02
/里程碑v1.9
cjwagner
于 2018-03-02
@cjwagner :您必须是kubernetes-milestone-maintainers github团队的成员才能设置里程碑。
针对此:
/里程碑v1.9
可在此处获得使用PR注释与我互动的说明。 如果您对我的行为有任何疑问或建议,请针对kubernetes / test-infra存储库提出问题。
k8s-ci-robot
于 2018-03-02
好像PR https://github.com/kubernetes/kubernetes/pull/60740修复了超时问题-感谢@ msau42的快速响应。
我们的正确性工作(2k和5k)现在又恢复了绿色:
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -large-correctness
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -scale-correctness
因此,我对那些体积测试的
shyamjvs
于 2018-03-05
确认进行中
预计到达时间:9/3/2018
风险:对k8s性能的潜在影响
shyamjvs
于 2018-03-05
因此,我对此进行了深入研究,从5k节点测试的pod-startup延迟图表中,我感觉到回归也可以是黑白运行108和109(请参见99%ile):

shyamjvs
于 2018-03-05
我迅速扫过了差异,以下更改对我来说似乎是可疑的:
“允许从NewRequest一直传递请求超时”#51042
该PR允许将客户端的超时作为查询参数传播到API调用。 我确实看到这两次运行之间的PATCH node/status调用存在以下差异(来自apiserver日志):
运行108:
I0207 22:01:06.450385 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-2rn2/status: (11.81392ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.227.96.23:47270]
I0207 22:01:03.857892 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-9659/status: (8.570809ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.196.85.108:43532]
I0207 22:01:03.857972 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc4w/status: (8.287643ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.229.110.22:50530]
运行109:
I0209 21:01:08.551289 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-89f2/status?timeout=10s: (71.351634ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.229.77.215:51070]
I0209 21:01:08.551310 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-3ms3/status?timeout=10s: (70.705466ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.227.84.87:49936]
I0209 21:01:08.551394 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc02/status?timeout=10s: (70.847605ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.196.125.143:53662]
我的假设是,由于PATCH调用增加了10s的超时,因此这些调用现在在服务器端持续更长的时间(IIUC正确此注释)。 这意味着它们现在处于飞行队列中的时间更长。 结合这些PATCH调用在如此大的集群中大量发生的事实,导致PUT pod/status调用无法在机上队列中获得足够的带宽,因此返回429s。 结果,更新吊舱状态的kubelet侧延迟增加了。 这个故事也与@ wojtek-t的上述观察非常吻合。
我将尝试收集更多证据以验证这一假设。
shyamjvs
于 2018-03-05
因此,我检查了PATCH node-status延迟在测试运行过程中如何变化,确实似乎在那段时间第99个百分位数(请参阅第一行)有所增加。 但是,尚不清楚它是否发生了黑白运行108和109(尽管我认为是这样):
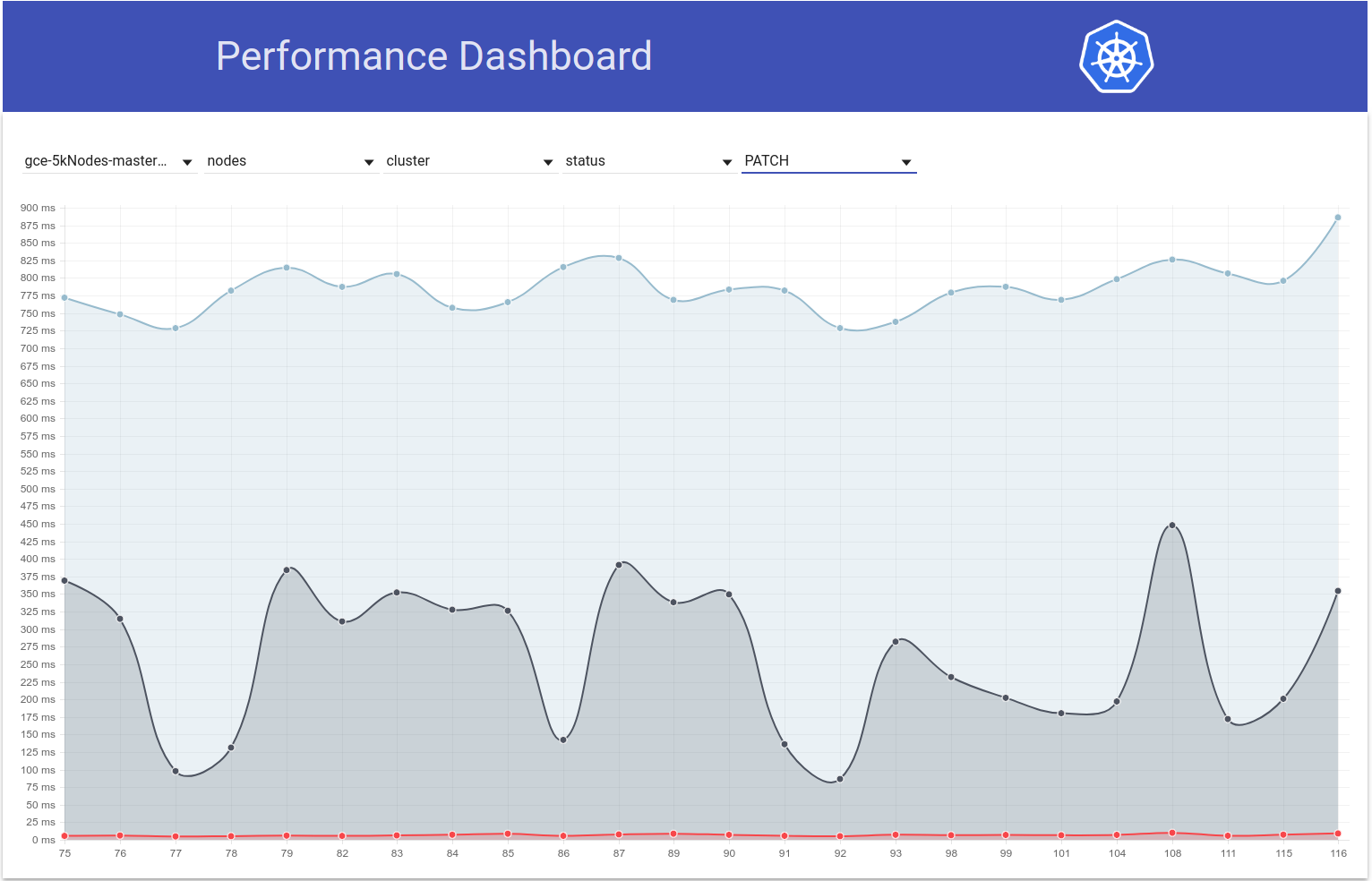
shyamjvs
于 2018-03-05
[编辑:我之前的评论错误地提到了这429秒的计数(客户端为npd,而不是kubelet)]
我现在有更多支持证据:
在run-108中,我们有〜479k PATCH node/status调用得到429:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"479181"
]
},
在109行中,我们大约有757k:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"757318"
]
},
还有...看这个:
在运行108中:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"28594"
]
},
在运行109中:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"33224"
]
},
我检查了其他几个相邻运行的编号:
-PR合并了-
虽然看起来有些变化,但总体看来还是没有。 的429秒增加了大约25%。
shyamjvs
于 2018-03-05
对于来自接收到429s的kubelet的PATCH node-status ,数字如下所示:
- 运行104 = 313348
- 运行105 = 309136
- 运行108 = 479181
-PR合并了-
- 运行109 = 757318
- 110运行= 752062
- 运行111 = 296368
这也有所不同,但通常似乎有所增加。
shyamjvs
于 2018-03-05
PATCH node-status呼叫延迟的第99%ile似乎也普遍增加了(正如我在https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370573938中所预测的那样):
run-104 (798ms), run-105 (783ms), run-108 (826ms)
run-109 (878ms), run-110 (869ms), run-111 (806ms)
顺便说一句-以上所有指标,108似乎比正常情况差,而111似乎比正常情况好。
shyamjvs
于 2018-03-05
明天我将尝试通过手动运行大型5k集群来验证这一点。
shyamjvs
于 2018-03-05
感谢分流@shyamjvs
krzyzacy
于 2018-03-05
因此,我针对〜HEAD对5k集群进行了两次密度测试,结果令人惊讶地通过了两次测试,两次测试的启动延迟分别为4.510015461s和4.623276837s 。 但是,``等待时间''确实显示了@ wojtek-t在https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -369951288中指出的增加
在第一次运行中,它是:
INFO: perc50: 1.123056294s, perc90: 1.932503347s, perc99: 3.061238209s
第二次运行是:
INFO: perc50: 1.121218293s, perc90: 1.996638787s, perc99: 3.137325187s
我现在尝试检查情况如何。
shyamjvs
于 2018-03-06
https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938-我不确定我遵循的是-我们添加了超时时间,但是默认超时时间大于10s IIRC-因此它仅对您有所帮助不会使事情变得更糟。
我认为我们仍然不明白为什么我们会观察到更多429s(事实与我在https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370036377中已经提到的429s相关的事实)
wojtek-t
于 2018-03-06
关于您的数字-我不认为回归是在109中进行的-可能会有两次回归-一个在105到108之间,另一个在109中。
wojtek-t
于 2018-03-06
嗯...我不否认您提到的可能性(以上只是我的假设)。
我目前正在进行二等分(现在针对108的提交)进行验证。
shyamjvs
于 2018-03-06
我觉得回归在运行108之前越来越强烈。
例如,在108次运行中,api调用的等待时间已经增加。
修补程序节点状态:
90%:198毫秒(105)447毫秒(108)444毫秒(109)
放置广告连播状态:
99%:83ms(105)657ms(108)728ms(109)
wojtek-t
于 2018-03-06
我想我想说的是:
- 429秒的数量是一个结果,我们不应该在此上花费太多时间
- 根本原因是API调用速度变慢或其中调用次数增加
很明显,我们似乎看到108中的api调用速度变慢。问题是我们是否也看到了更多的API调用。
wojtek-t
于 2018-03-06
所以我认为为什么要求明显变慢-有三种主要可能性
明显有更多的请求(乍一看似乎并非如此)
我们在处理路径(例如附加处理)上添加了一些内容,或者对象本身更大
主计算机(例如调度程序)上的其他东西消耗更多的cpu,从而使apiserver更加饥饿
wojtek-t
于 2018-03-06
因此,我和@ wojtek-t进行了离线讨论,我们俩现在都同意,在108之前很可能存在回归。添加一些要点:
明显有更多的请求(乍一看似乎并非如此)
对我来说似乎也不是这样
我们在处理路径(例如附加处理)上添加了一些内容,或者对象本身更大
我的感觉是,与apiserver相比,它在kubelet中的可能性更高(因为我们在kubemark-5000上未看到补丁/放置延迟的任何可见变化)
主计算机(例如调度程序)上的其他东西消耗更多的cpu,从而使apiserver更加饥饿
IMO并非如此,因为我们的主服务器上有一些CPU /内存松弛。 同样,perf-dash并不表示对主组件的使用有任何显着增加。
就是说,我进行了一点挖掘,“幸运的是”似乎我们注意到即使对于2k节点的群集,监视延迟也有所增加:
INFO: perc50: 1.024377533s, perc90: 1.589770858s, perc99: 1.934099611s
INFO: perc50: 1.03503718s, perc90: 1.624451701s, perc99: 2.348645755s
应该使二等分容易一些。
shyamjvs
于 2018-03-06
不幸的是,这些手表等待时间的变化似乎是一次性的(否则大致相同)。 幸运的是,我们有PUT pod-status延迟作为回归的可靠指标。 昨天我进行了两轮对分,然后缩小到这个差异(约80次提交)。 我浏览了一下它们,并对以下内容产生了强烈的怀疑:
- #58990-在pod-status中添加了一个新字段(尽管我不确定是否会在我们的测试中填写该字段,因为IIUC抢占没有发生-但需要检查)
- #58645-将etcd服务器版本更新为3.2.14
shyamjvs
于 2018-03-07
我真的怀疑#58990是否与此处相关-NominatedNodeName是包含单个节点名称的字符串。 即使将其始终填充,对象大小的变化也应忽略不计。
wojtek-t
于 2018-03-07
@ wojtek-t-正如您建议的脱机建议一样,确实似乎我们在kubemark(https://github.com/kubernetes/kubernetes/blob/master/test/kubemark/中使用了其他版本(3.2.16) start-kubemark.sh#L62),这是在那里看不到此回归的潜在原因:)
cc @jpbetz
shyamjvs
于 2018-03-07
我们现在到处都在使用3.2.16。
wojtek-t
于 2018-03-07
糟糕,事后看来很抱歉-我正在查看错误的提交组合。
shyamjvs
于 2018-03-07
顺便说一句-在大型真实集群中的负载测试中,PUT pod /状态等待时间的增加也是显而易见的。
wojtek-t
于 2018-03-07
因此,我进行了更多研究,似乎我们开始在那段时间开始观察到一般而言对写入请求的更大延迟(这使我怀疑etcd的变化更大):
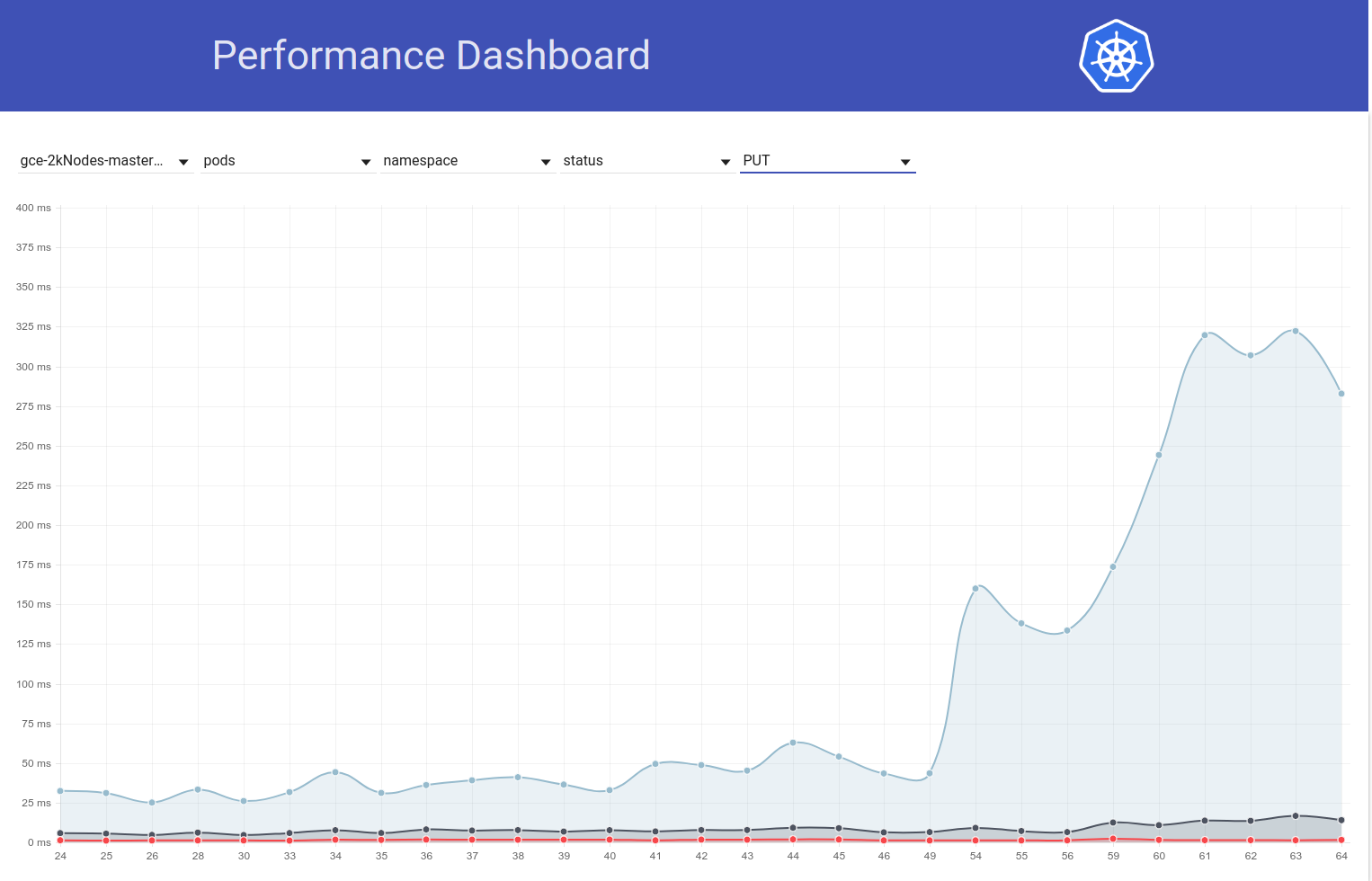
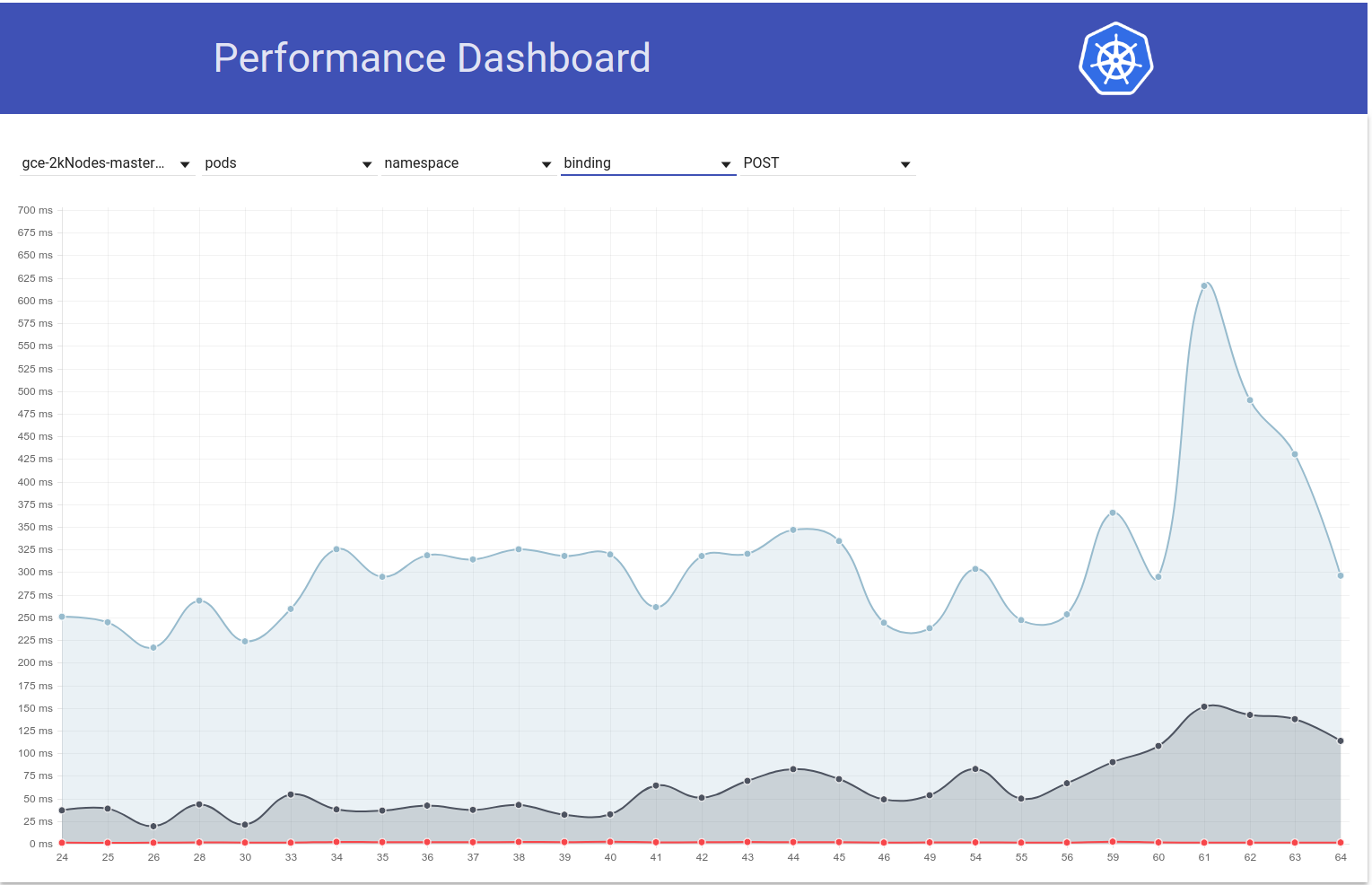

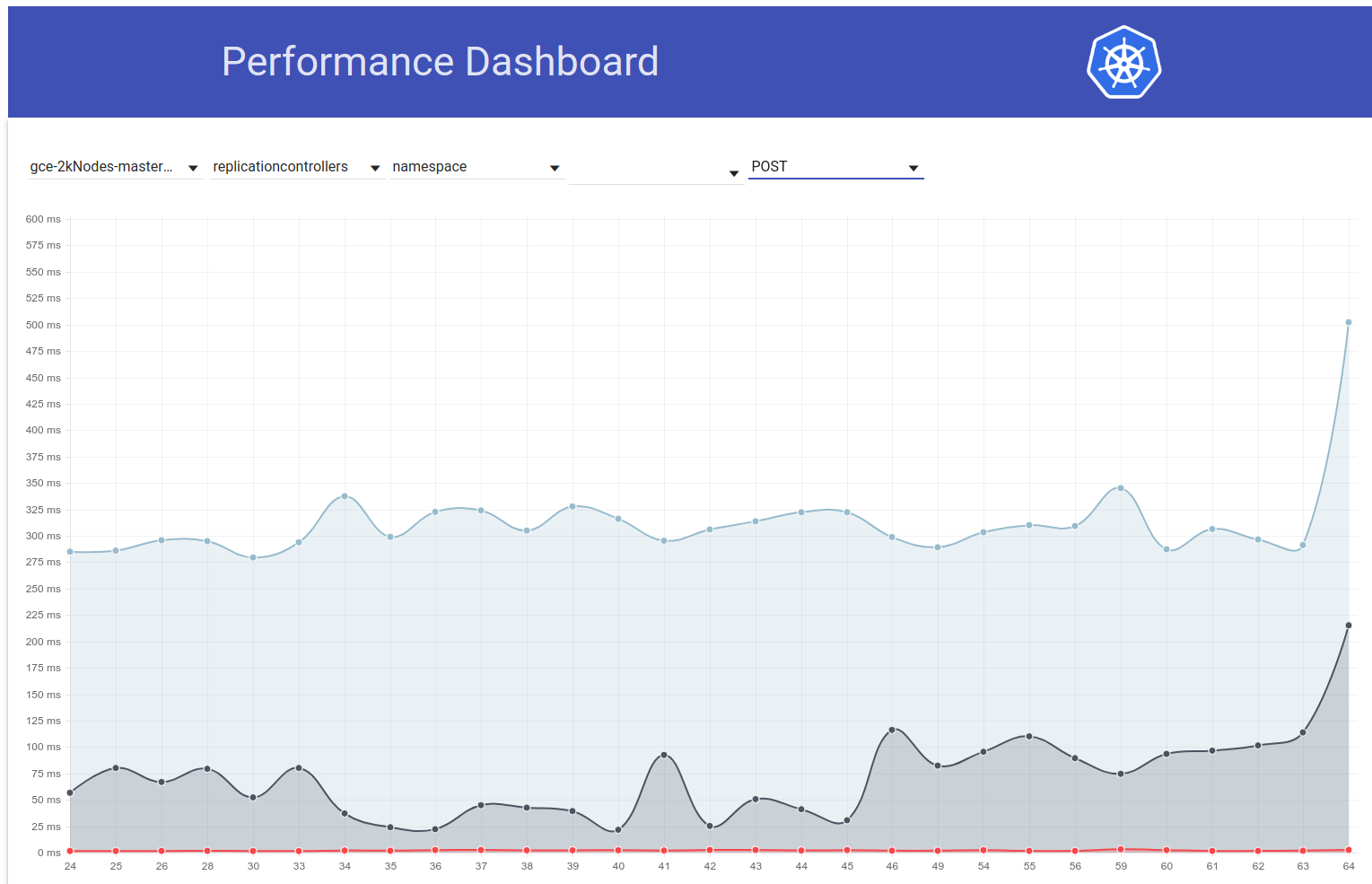
shyamjvs
于 2018-03-07
实际上,我投票认为问题的至少一部分在这里:
https://github.com/kubernetes/kubernetes/pull/58990/commits/384a86caa92bdb7cf9ac96b10a6ef333d2d60519#diff -c73f80ad83608f18657d22a06950d929R240
如果这将是整个问题,我会感到惊讶,但它可能会助长整个问题。
将发送PR在一秒钟内更改。
wojtek-t
于 2018-03-07
仅供参考-当我遇到在etcd 3.2.14更改之前但在pod-status API更改之后的提交时,put节点-状态延迟似乎完全正常(即99%ile = 39ms)。
shyamjvs
于 2018-03-07
因此,我验证了它确实是由etcd升至3.2.14引起的。 这是放置pod状态延迟的样子:
针对该公关:
{
"data": {
"Perc50": 1.479,
"Perc90": 10.959,
"Perc99": 163.095
},
"unit": "ms",
"labels": {
"Count": "344494",
"Resource": "pods",
"Scope": "namespace",
"Subresource": "status",
"Verb": "PUT"
}
},
还原到PR的〜HEAD(自3月5日起)(测试仍在运行,但即将完成):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.5"} 1669
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.9"} 9597
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.99"} 63392
63ms似乎与以前很像。
我们应该还原该版本并尝试了解:
- 为什么我们在etcd 3.2.14中看到这种增加?
- 为什么我们没有在kubemark中抓住这个?
cc @jpbetz @ kubernetes / sig-api-machinery-bugs
shyamjvs
于 2018-03-07
一个假设(为什么我们没有在kubemark中抓住它-尽管仍然是一个猜测)是我们可能已将那里的证书更改为其他证书。
当我比较来自kubemark和真实集群的etcd日志时,仅在后者中,我看到以下行:
2018-03-05 08:06:56.389648 I | embed: peerTLS: cert = /etc/srv/kubernetes/etcd-peer.crt, key = /etc/srv/kubernetes/etcd-peer.key, ca = , trusted-ca = /etc/srv/kubernetes/etcd-ca.crt, client-cert-auth = true
从公关本身来看,我看不到任何变化,但是我也不知道为什么我们只应该在真实集群中看到那条线...
@jpbetz的想法
wojtek-t
于 2018-03-07
确认进行中
预计到达时间:9/3/2018
风险:问题根源(主要是)
shyamjvs
于 2018-03-07
关于peerTLS-以前也是如此(3.1.11版),所以我认为这是一条红鲱鱼
wojtek-t
于 2018-03-07
cc @gyuho @wenjiaswe
 jpbetz
于 2018-03-07
jpbetz
于 2018-03-07
63ms似乎与
我们从哪里得到这些数字? apiserver_request_latencies_summary实际上测量的是etcd写入的延迟吗? 另外,来自etcd的指标也将有所帮助。
 gyuho
于 2018-03-07
gyuho
于 2018-03-07
嵌入:peerTLS:证书...
如果配置了对等TLS(与3.1相同),将显示此信息。
gyuho
于 2018-03-07
我们从哪里得到这些数字? apiserver_request_latencies_summary是否实际测量etcd写入的延迟? 另外,来自etcd的指标也将有所帮助。
这将测量无形的延迟,该延迟(至少在写调用的情况下)包括etcd的延迟。
我们仍然不太了解发生了什么,但是恢复到以前的etcd版本(3.1)可以修复回归问题。 显然问题出在etcd中。
wojtek-t
于 2018-03-07
@shyamjvs
您正在运行什么版本的Kubemark和Kubernetes? 我们针对etcd 3.2 vs 3.3(500节点工作负载)测试了Kubemark 1.10,但没有观察到这一点。 要重现此节点需要多少个节点?
gyuho
于 2018-03-07
您正在运行什么版本的Kubemark和Kubernetes? 我们针对etcd 3.2 vs 3.3(500节点工作负载)测试了Kubemark 1.10,但没有观察到这一点。 要重现此节点需要多少个节点?
即使使用5k节点,我们也无法使用kubemark复制它-请参阅https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -371171837的底部
仅在实际集群中,这似乎是一个问题。
这是一个悬而未决的问题,为什么会这样。
wojtek-t
于 2018-03-07
由于我们已经回滚到etcd 3.1。 用于kubernetes。 我们还发布了etcd 3.1.12,它具有针对kubernetes的唯一出色的关键修复程序: mvcc“未同步”的watcher恢复操作。 找到并解决了本期中发现的性能下降的根本原因后,我们可以草拟一个计划,以将kubernetes使用的etcd服务器升级回3.2。
jpbetz
于 2018-03-08
看起来像https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100从今天早上开始就一直失败
krzyzacy
于 2018-03-09
从diff出发,唯一的变化是https://github.com/kubernetes/kubernetes/pull/60421 ,默认情况下,这会在我们的性能测试中启用配额。 我们看到的错误是:
Container kube-controller-manager-e2e-big-master/kube-controller-manager is using 0.531144723/0.5 CPU
not to have occurred
@gmarek-似乎启用配额正在影响我们的可伸缩性:)您能否对此进行更深入的了解-也许是认真的?
让我提出另一个问题,以使这一问题步入正轨。
shyamjvs
于 2018-03-09
@ wojtek -t @gyuho @timothysc我发现etcd版本更改确实很有趣,这表明从etcd 3.1.11迁移到3.2.16的显着效果。
当作业从k8s版本1.9移至1.10时,请看下我们的100节点集群中的etcd内存使用情况的下图(它增加了约2倍):
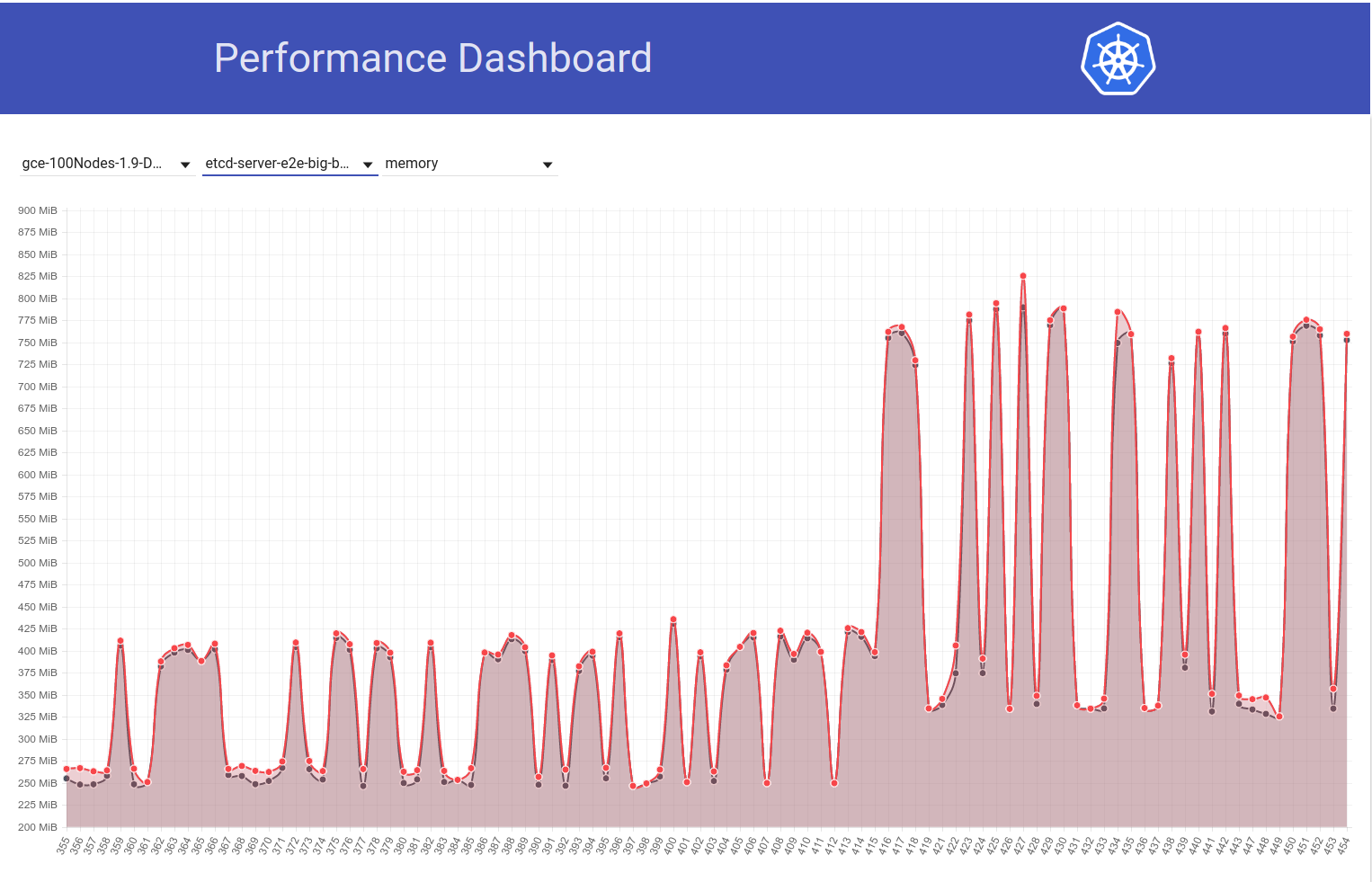
接下来看一下我们的100个节点的作业(针对HEAD运行)如何在我从etcd 3.2.16-> 3.1.11还原后看到内存使用率下降到一半:
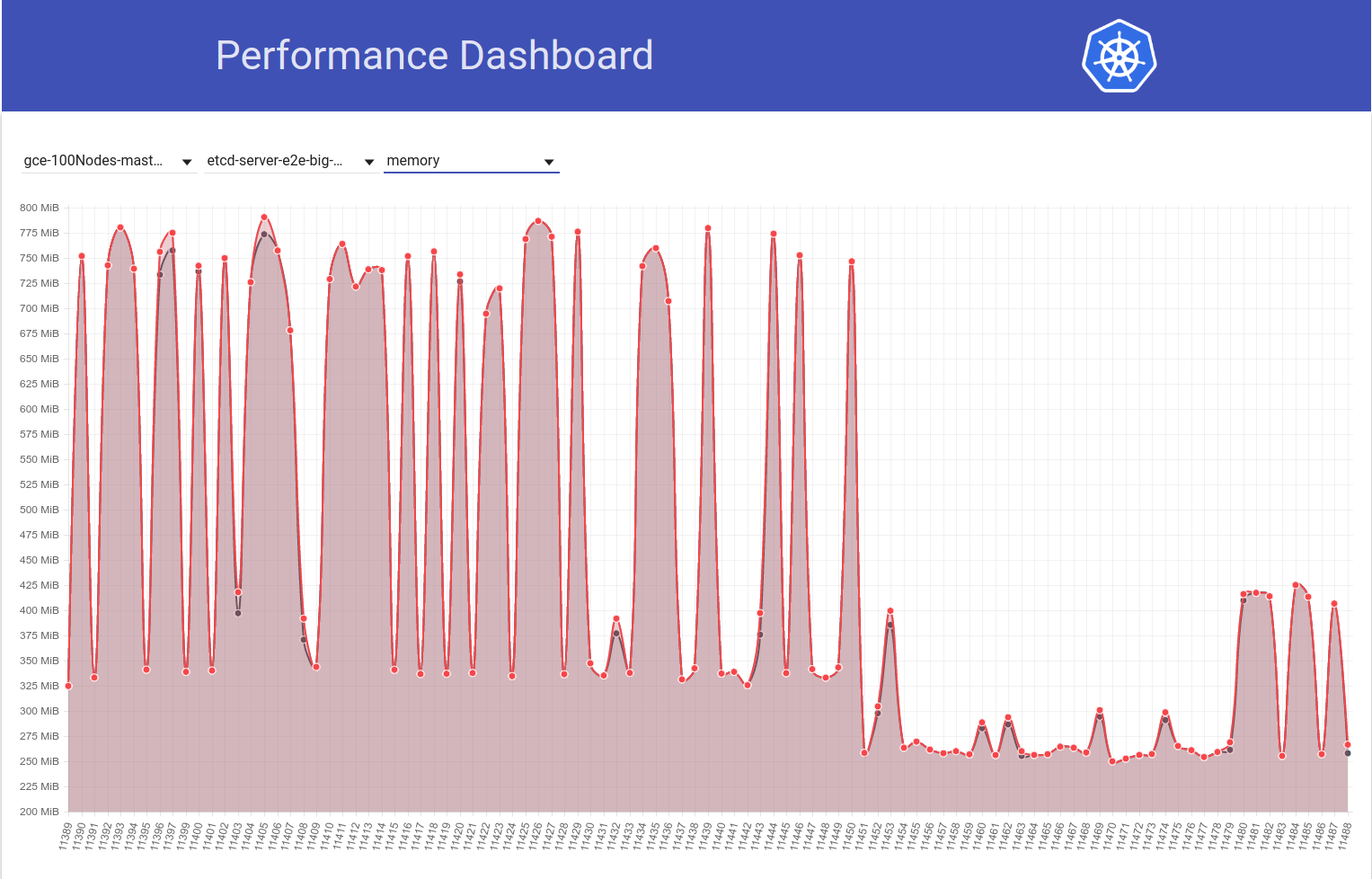
因此,etcd 3.2服务器版本显然显示了受影响的性能(所有其他变量保持相同):)
shyamjvs
于 2018-03-10
我从etcd 3.2.16-> 3.2.11恢复:
我们的意思是3.1.11吗?
gyuho
于 2018-03-10
是的..对不起。 编辑了我的评论。
shyamjvs
于 2018-03-10
@shyamjvs如何配置etcd? 我们在v3.2中将默认值--snapshot-count从10000增加到100000 。 因此,如果快照计数不同,则具有较大快照计数的快照将更长时间地保存Raft条目,从而需要更多的驻留内存,然后再丢弃旧日志。
gyuho
于 2018-03-10
啊! 确实,这似乎是一个可疑的变化。 WRT标志,我认为k8s方面的标志没有任何变化。 因为,如您在我上面的第二张图中看到的, diff b / w运行11450,而11451主要只是我的etcd还原更改(似乎不涉及任何标志)。
我们将默认值-快照计数从10000增加到了100000
您能否确定这是内存使用量增加的根本原因? 如果是这样,我们可能要:
- 用原始值修补etcd,或者
- 在k8s中将其设置为10000
切换回3.2之前
shyamjvs
于 2018-03-10
啊! 确实,这似乎是一个可疑的变化。
是的,应该在etcd方面突出显示此更改(将改进我们的更改日志和升级指南)。
您能否确定这是内存使用量增加的根本原因?
我不确定这是否是根本原因。 较低的快照数量无疑将有助于减轻尖峰的内存使用。 如果两个etcd版本使用相同的快照计数,但是一个etcd仍然显示更高的内存使用率,则应该有其他内容。
gyuho
于 2018-03-10
更新:我确认etcd mem使用量的增加确实是由于--snapshot-count默认值较高所致。 更多详细信息-https : //github.com/kubernetes/kubernetes/pull/61037#issuecomment -372457843
如果我们不希望增加内存使用量,则在考虑到etcd 3.2.16时,应该考虑将其设置为10,000。
cc @gyuho @ xiang90 @jpbetz
shyamjvs
于 2018-03-12
更新:修复了etcd之后,pod启动延迟99%似乎仍接近违反5s SLO。 至少还有另外一种回归,并且我已经收集了证据,表明它最有可能在我们的5k节点性能工作的黑白运行中运行111和112(请参见我粘贴在https:/ /github.com/kubernetes/kubernetes/issues/60589#issuecomment-370568929)。 目前,我将diff分为两部分(大约有50次提交),并且每次迭代测试需要约4-5个小时。
我上面提到的证据如下:
手表等待时间为111:
Feb 14 21:36:05.531: INFO: perc50: 1.070980786s, perc90: 1.743347483s, perc99: 2.629721166s
而总的Pod启动延迟为111:
Feb 14 21:36:05.671: INFO: perc50: 2.416307575s, perc90: 3.24553118s, perc99: 4.092430858s
虽然在112处相同:
Feb 16 10:07:43.222: INFO: perc50: 1.131108849s, perc90: 2.18487651s, perc99: 3.570548412s
和
Feb 16 10:07:43.353: INFO: perc50: 2.56160248s, perc90: 3.754024568s, perc99: 4.967573867s
同时,如果有人支持下注游戏-您可以看一下我上面提到的提交差异,并猜出有问题的:)
shyamjvs
于 2018-03-12
确认进行中
预计到达时间:13/03/2018
风险:如果未提前调试,则可以推迟发布日期
shyamjvs
于 2018-03-12
@shyamjvs toooooooo许多承诺下注:)
 dims
于 2018-03-13
dims
于 2018-03-13
@dims我想这会增加更多的乐趣;)
更新:因此,我对两部分进行了几次迭代,这是相关度量在提交中的外观(按时间顺序排列)的方式。 注意,对于我手动运行的那些,我将它们还原为较早的回归(即3.2。-> 3.1.11)。
| 提交| 99%的观看延迟| 99%的Pod启动延迟| 好坏? |
| ------------- | ------------- | ----- | ------- |
| a042ecde36(来自运行111)| 2.629721166s | 4.092430858s | 好(手动再次确认)|
| 5f7b530d87(手动)| 3.150616856s | 4.683392706s | 坏(可能)|
| a8060ab0a1(手动)| 3.11319985s | 4.710277511s | 坏(可能)|
| 430c1a68c8(来自运行112)| 3.570548412s | 4.967573867s | 不好
| 430c1a68c8(手动)| 3.63505091s | 4.96697776s | 不好
从上面看,似乎这里可能有2个回归(因为它不是从2.6s-> 3.6s直线上升)-一个黑白“ a042ecde36-5f7b530d87”和另一个黑白“ a8060ab0a1-430c1a68c8”。 叹!
shyamjvs
于 2018-03-13
表示为范围以获取比较链接:
a042ecde36 ... 5f7b530
a8060ab0a1 ... 430c1a6
 liggitt
于 2018-03-13
liggitt
于 2018-03-13
刚获得针对a042ecde36进行手动运行的结果,这只会使工作变得更加艰难:
3.269330734s (watch), 4.939237532s (pod-startup)
因为这可能意味着它可能是片状回归。
shyamjvs
于 2018-03-13
我目前正在针对a042ecde36再次进行测试,以验证是否在回归之前进行了回归。
shyamjvs
于 2018-03-13
因此,这是再次针对a042ecd运行的结果:
2.645592996s (watch), 5.026010032s (pod-startup)
这可能意味着甚至在111号运行之前就进入了回归(好消息是,现在该等分线有一个正确的终点)。
我现在尝试追求左端。 Run-108(commit 11104d75f)是一个潜在的候选者,当我较早运行它(使用etcd 3.1.11)时,它具有以下结果:
2.593628224s (watch), 4.321942836s (pod-startup)
我针对提交11104d7的重新运行似乎确实是一个不错的选择:
2.663456162s (watch), 4.288927203s (pod-startup)
我将在这里等分11104d7 ... a042ecd
shyamjvs
于 2018-03-13
更新:我需要测试097efb71a315提交三次,以获取信心。 它显示出一些差异,但似乎是一个不错的承诺:
2.578970061s (watch), 4.129003596s (pod-startup)
2.315561531s (watch), 4.70792639s (pod-startup)
2.303510957s (watch), 3.88150234s (pod-startup)
我将继续二等分。
就是说,几天前Pod启动延迟似乎又出现了一个高峰(〜1秒)。 而这一步将99%提升至将近6秒:
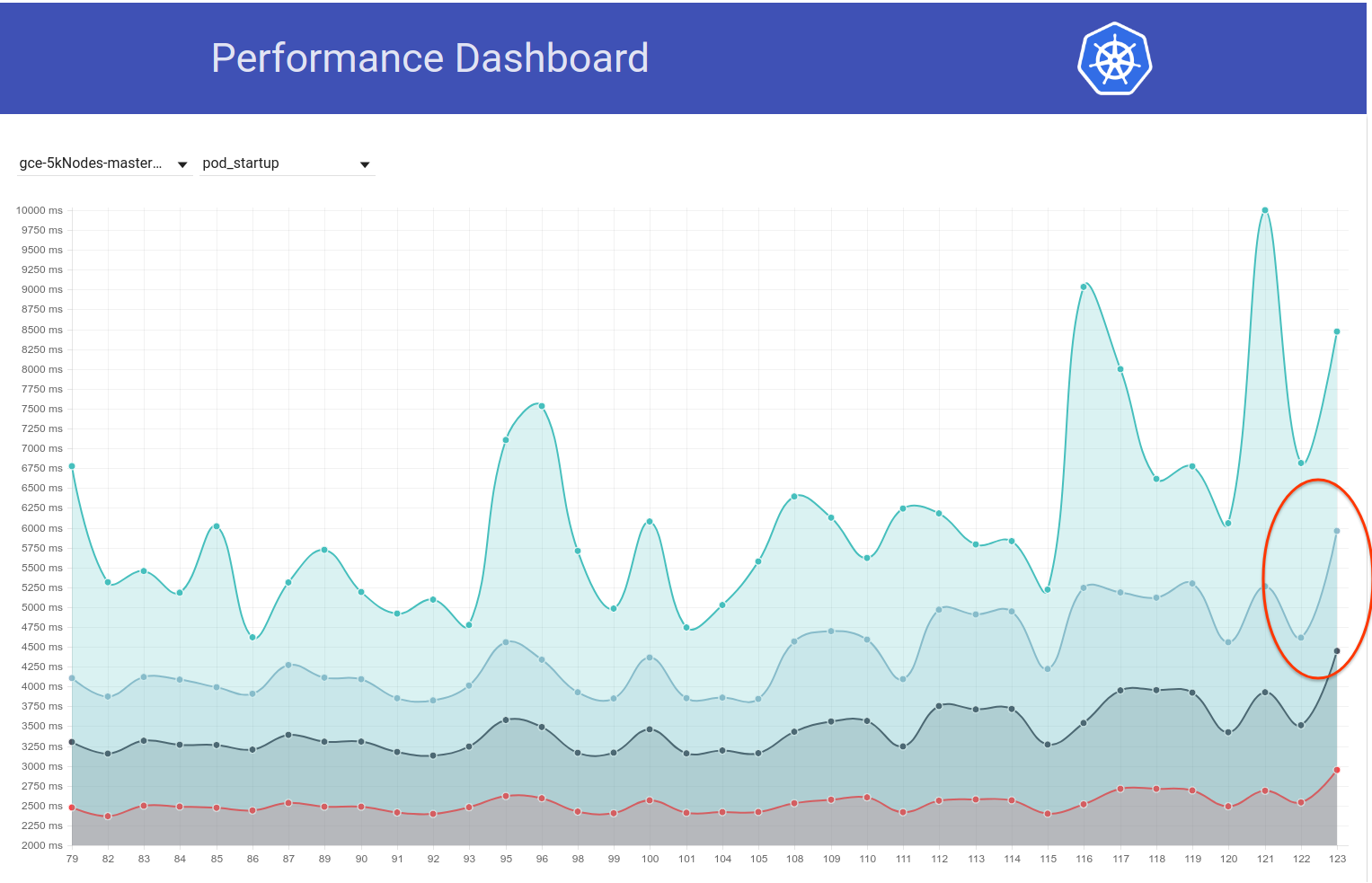
我从提交差异中主要怀疑的是从3.1.11-> 3.1.12(https://github.com/kubernetes/kubernetes/pull/60998)更改的etcd。 我将等待下一次运行(当前正在进行中)以确认它不是一次过的-但我们确实需要了解这一点。
cc @jpbetz @gyuho
shyamjvs
于 2018-03-14
由于本周我将在星期四休假,因此我粘贴了针对5k节点群集运行密度测试的说明(这样,有权访问该项目的人可以继续二等分):
# Start with a clean shell.
# Checkout to the right commit.
make quick-release
# Set the project:
gcloud config set project k8s-scale-testing
# Set some configs for creating/testing 5k-node cluster:
export CLOUDSDK_CORE_PRINT_UNHANDLED_TRACEBACKS=1
export KUBE_GCE_ZONE=us-east1-a
export NUM_NODES=5000
export NODE_SIZE=n1-standard-1
export NODE_DISK_SIZE=50GB
export MASTER_MIN_CPU_ARCHITECTURE=Intel\ Broadwell
export ENABLE_BIG_CLUSTER_SUBNETS=true
export LOGROTATE_MAX_SIZE=5G
export KUBE_ENABLE_CLUSTER_MONITORING=none
export ALLOWED_NOTREADY_NODES=50
export KUBE_GCE_ENABLE_IP_ALIASES=true
export TEST_CLUSTER_LOG_LEVEL=--v=1
export SCHEDULER_TEST_ARGS=--kube-api-qps=100
export CONTROLLER_MANAGER_TEST_ARGS=--kube-api-qps=100\ --kube-api-burst=100
export APISERVER_TEST_ARGS=--max-requests-inflight=3000\ --max-mutating-requests-inflight=1000
export TEST_CLUSTER_RESYNC_PERIOD=--min-resync-period=12h
export TEST_CLUSTER_DELETE_COLLECTION_WORKERS=--delete-collection-workers=16
export PREPULL_E2E_IMAGES=false
export ENABLE_APISERVER_ADVANCED_AUDIT=false
# Bring up the cluster (this brings down pre-existing one if present, so you don't have to explicitly '--down' the previous one) and run density test:
go run hack/e2e.go \
--up \
--test \
--test_args='--ginkgo.focus=\[sig\-scalability\]\sDensity\s\[Feature\:Performance\]\sshould\sallow\sstarting\s30\spods\sper\snode\susing\s\{\sReplicationController\}\swith\s0\ssecrets\,\s0\sconfigmaps\sand\s0\sdaemons$ --allowed-not-ready-nodes=30 --node-schedulable-timeout=30m --minStartupPods=8 --gather-resource-usage=master --gather-metrics-at-teardown=master' \
> somepath/build-log.txt 2>&1
# To re-run the test on same cluster (without re-creating) just omit '--up' in the above.
重要笔记:
- 当前怀疑的提交范围是ff7918d ... a042ecde3(我们将其一分为二,让它保持更新)
- 我们需要使用etcd-3.1.11而不是3.2.14(以避免包括更早的回归)。 更改以下文件中的版本,以最小程度地实现该目的:
- cluster / gce / manifests / etcd.manifest
- 群集/图像/ etcd / Makefile
- hack / lib / etcd.sh
shyamjvs
于 2018-03-14
抄送:@ wojtek-t
jdumars
于 2018-03-14
etcd v3.1.12修复了恢复时观看事件丢失的问题。 这是我们对v3.1.11所做的唯一更改。 性能测试是否涉及etcd重新启动或多节点可能触发领导者快照的任何事情?
gyuho
于 2018-03-14
shyamjvs
于 2018-03-14
我懂了。 然后,v3.1.11和v3.1.12应该没有不同的:0
如果第二次运行还显示出更高的延迟,则需要另外看看。
gyuho
于 2018-03-14
抄送: @jpbetz
jdumars
于 2018-03-14
同意@gyuho ,鉴于隔离到etcd的唯一代码更改被隔离以重新启动/恢复代码,因此我们应该尝试对此发出更强的信号。
唯一的其他更改是将etcd从go1.8.5升级到go1.8.7,但是我怀疑我们是否会看到性能显着下降。
jpbetz
于 2018-03-14
因此,继续对分,ff7918d1f似乎不错:
2.246719086s (watch), 3.916350274s (pod-startup)
我将在https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -373051051中相应地更新提交范围。
shyamjvs
于 2018-03-14
接下来,提交aa19a1726似乎是一个不错的选择,尽管我建议再次重试以确认:
2.715156606s (watch), 4.382527095s (pod-startup)
在这一点上,我将暂停二等分并开始我的假期:)
我关闭了集群,为下一次运行腾出空间。
shyamjvs
于 2018-03-15
谢谢Shyam。 我正在重试aa19a172693a4ad60d5a08e9b93557267d259c37。
 wasylkowski-a
于 2018-03-15
wasylkowski-a
于 2018-03-15
对于提交aa19a172693a4ad60d5a08e9b93557267d259c37,我得到以下结果:
2.47655243s (watch), 4.174016696s (pod-startup)
因此,这看起来不错。 连续二等分。
怀疑当前提交范围:aa19a172693a4ad60d5a08e9b93557267d259c37 ... a042ecde362000e51f1e7bdbbda5bf9d81116f84
wasylkowski-a
于 2018-03-15
@ wasylkowski-a您可以参加太平洋标准时间UTC / 1PM / 1PM Eastern / 10AM Pacific的发布会议吗? 这是一次Zoom会议: https :
jdumars
于 2018-03-15
我会参加。
wasylkowski-a
于 2018-03-15
提交cca7ccbff161255292f72c2d18459cdface62122看起来不清楚,结果如下:
2.984185673s (watch), 4.568914929s (pod-startup)
我将再运行一次,以确保我不会输入错误的二等分。
wasylkowski-a
于 2018-03-15
好的,所以我现在非常有信心cca7ccbff161255292f72c2d18459cdface62122不好:
3.285168535s (watch), 4.783986141s (pod-startup)
将范围缩小到aa19a172693a4ad60d5a08e9b93557267d259c37 ... cca7ccbff161255292f72c2d18459cdface62122并尝试92e4d3da0076f923a45d54d69c84e91ac6a61a55。
wasylkowski-a
于 2018-03-16
提交92e4d3da0076f923a45d54d69c84e91ac6a61a55看起来不错:
2.522438984s (watch), 4.21739985s (pod-startup)
新的可疑提交范围是92e4d3da0076f923a45d54d69c84e91ac6a61a55 ... cca7ccbff161255292f72c2d18459cdface62122,尝试603ebe466d335a37392315d491782ed18d1bae11
wasylkowski-a
于 2018-03-16
@wasylkowski请注意,其中一项提交即https://github.com/kubernetes/kubernetes/commit/4c289014a05669c376994868d8d91f7565a204b5已在https://github.com/kubernetes/kubernetes/commit/493f33583053bb4ce9f7d348c5bac39975883
dims
于 2018-03-16
重述@dims注释会更清楚,我们可能会在本节中追逐一个信号鬼。 如果问题出在4c28901上,并且由于看似无关的原因已经在493f335上恢复了,那么针对1.10分支头的可伸缩性测试是否显示绿色信号?
我们能否优先针对1.10分支头重新测试一次,而不是继续进行二等分?
 tpepper
于 2018-03-16
tpepper
于 2018-03-16
@wasylkowski / @ wasylkowski-a ^^^^
tpepper
于 2018-03-16
@ wojtek-t PTAL尽快
jdumars
于 2018-03-16
谢谢@dims和@tpepper。 让我尝试使用1.10分支头,看看会发生什么。
wasylkowski-a
于 2018-03-16
谢谢@wasylkowski最糟糕的情况是我们回到之前平分的东西。 对?
dims
于 2018-03-16
1.10头有回归:
3.522924087s (watch), 4.946431238s (pod-startup)
这是在etcd 3.1.12上,而不是etcd 3.1.11上,但是如果我正确理解的话,这应该不会有太大的区别。
另外,603ebe466d335a37392315d491782ed18d1bae11看起来不错:
2.744654024s (watch), 4.284582476s (pod-startup)
2.76287483s (watch), 4.326409841s (pod-startup)
2.560703844s (watch), 4.213785531s (pod-startup)
这使我们的范围为603ebe466d335a37392315d491782ed18d1bae11 ... cca7ccbff161255292f72c2d18459cdface62122,那里只有3个提交。 让我看看我发现了什么。
确实有可能4c289014a05669c376994868d8d91f7565a204b5是这里的罪魁祸首,但是这意味着我们还有另一个回归的迹象。
wasylkowski-a
于 2018-03-16
好的,因此显然提交6590ea6d5d50700d34255b1e037b2702ad26b7fc是好的:
2.553170576s (watch), 4.22516704s (pod-startup)
而提交7b678dc4035c61a1991b5e1442edb13f40deae72是错误的:
3.498855918s (watch), 4.886599251s (pod-startup)
错误的提交是@dims提到的已还原提交的合并,因此我们必须观察到另一个回归。
让我尝试重新运行etcd 3.1.11而不是3.1.12,看看会发生什么。
wasylkowski-a
于 2018-03-17
@ wasylkowski-a啊经典的好消息坏消息:)感谢您继续这样做。
@wojtek -t还有其他建议吗?
dims
于 2018-03-17
直面etcd 3.1.11也很糟糕; 我的下一个尝试将是在还原之后直接尝试(因此,在提交cdecea545553eff09e280d389a3aef69e2f32bf1时),但是使用etcd 3.1.11而不是3.2.14。
wasylkowski-a
于 2018-03-17
听起来不错Andrzej
-昏暗
2018年3月17日,下午1:19,Andrzej Wasylkowski [email protected]写道:
直面etcd 3.1.11也很糟糕; 我的下一个尝试将是在还原后直接尝试(因此,在提交cdecea5时),但是使用etcd 3.1.11而不是3.2.14。
-
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看,或使该线程静音。
dims
于 2018-03-17
提交cdecea545553eff09e280d389a3aef69e2f32bf1很好,因此我们进行了以下回归:
2.66454307s (watch), 4.308091589s (pod-startup)
提交2a373ace6eda6a9cf050ce70a6cf99183c5e5b37显然很糟糕:
3.656979569s (watch), 6.746987916s (pod-startup)
@ wasylkowski-a因此,我们基本上是在查看https://github.com/kubernetes/kubernetes/compare/cdecea5...2a373ac范围内的提交,看看有什么问题呢? (在这两个之间等分)?
dims
于 2018-03-17
是。 不幸的是,这是一个很大的范围。 我现在正在调查aded0d922592fdff0137c70443caf2a9502c7580。
wasylkowski-a
于 2018-03-17
谢谢@wasylkowski ,当前范围是多少? (所以我可以去看看公关)。
dims
于 2018-03-18
提交aded0d922592fdff0137c70443caf2a9502c7580不好:
3.626257043s (watch), 5.00754503s (pod-startup)
提交f8298702ffe644a4f021e23a616ad6a8790a5537也很糟糕:
3.747051371s (watch), 6.126914967s (pod-startup)
提交20a6749c3f86c7cb9e98442046532380fb5f6e36也是如此:
3.641172882s (watch), 5.100922237s (pod-startup)
0e81651e77e0be7e75179e5986ef2c76601f4bd6也是如此:
3.687028394s (watch), 5.208157763s (pod-startup)
当前范围是cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6。 我们(我,@ wojtek-t,@ shyamjvs)开始怀疑cdecea545553eff09e280d389a3aef69e2f32bf1实际上是易碎通行证,因此我们需要一个不同的左端。
wasylkowski-a
于 2018-03-19
/ me下注https://github.com/kubernetes/kubernetes/commit/b259543985b10875f4a010ed0285ac43e335c8e0作为罪魁祸首
cc @ wasylkowski-a
dims
于 2018-03-19
事实证明,0e81651e77e0be7e75179e5986ef2c76601f4bd6不好,所以b259543985b10875f4a010ed0285ac43e335c8e0(合并为244549f02afabc5be23fc56e86a60e5b36838828)
wasylkowski-a
于 2018-03-19
对于@ wojtek -t和
wasylkowski-a
于 2018-03-19
根据我观察到的以下结果,我将假定cdecea545553eff09e280d389a3aef69e2f32bf1实际上是好的:
2.66454307s (watch), 4.308091589s (pod-startup)
2.695629257s (watch), 4.194027608s (pod-startup)
2.660956347s (watch), 3m36.62259323s (pod-startup) <-- looks like an outlier
2.865445137s (watch), 4.594671099s (pod-startup)
2.412093606s (watch), 4.070130529s (pod-startup)
当前可疑范围:cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6
目前正在测试99c87cf679e9cbd9647786bf7e81f0a2d771084f
wasylkowski-a
于 2018-03-20
感谢@wasylkowski继续进行这项工作。
jdumars
于 2018-03-20
根据今天的讨论:fluentd-scaler仍然存在问题: https :
 jberkus
于 2018-03-20
jberkus
于 2018-03-20
与流利的https://github.com/kubernetes/kubernetes/commit/a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2相关的PR之一处于最新范围
dims
于 2018-03-20
根据今天的讨论:流利的缩放器仍然存在问题:#61190,PR尚未解决。 这种回归是否可能是由于流利引起的?
TBH,如果是流利的问题,我会感到非常惊讶。 但是我不能肯定地排除这个假设。
我个人的感觉是Kubelet会有一些变化,但我也查看了该范围内的PR,似乎没有什么可疑的...
希望明天范围会缩小4倍,这意味着只有几个PR。
wojtek-t
于 2018-03-20
好的,所以99c87cf679e9cbd9647786bf7e81f0a2d771084f看起来不错,但是我需要运行三遍以确保它不是薄片:
2.901624657s (watch), 4.418169754s (pod-startup)
2.938653965s (watch), 4.423465198s (pod-startup)
3.047455619s (watch), 4.455485098s (pod-startup)
接下来,a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2不好:
3.769747695s (watch), 5.338517616s (pod-startup)
当前范围是99c87cf679e9cbd9647786bf7e81f0a2d771084f ... a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 ... 正在分析c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd。
wasylkowski-a
于 2018-03-20
我查看了上面提到的范围-那里只有9个PR。
https://github.com/kubernetes/kubernetes/pull/59944-100%不-仅更改所有者文件
https://github.com/kubernetes/kubernetes/pull/59953-可能
https://github.com/kubernetes/kubernetes/pull/59809-仅触摸kubectl代码,因此在这种情况下无关紧要
https://github.com/kubernetes/kubernetes/pull/59955-100%不-仅涉及不相关的e2e测试
https://github.com/kubernetes/kubernetes/pull/59808-可能(更改集群设置)
https://github.com/kubernetes/kubernetes/pull/59913-100%不-仅涉及不相关的e2e测试
https://github.com/kubernetes/kubernetes/pull/59917-它正在更改测试,但未启用更改,因此不太可能
https://github.com/kubernetes/kubernetes/pull/59668-100%不是-仅接触AWS代码
https://github.com/kubernetes/kubernetes/pull/59909-100%不是-仅接触所有者文件
所以我认为我们这里有两个候选人: https : https://github.com/kubernetes/kubernetes/pull/59808
我将尝试更深入地了解它们。
wojtek-t
于 2018-03-21
c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd看起来很糟糕:
3.428891786s (watch), 4.909251611s (pod-startup)
鉴于这是Wojtek的嫌疑人之一#59953的合并,因此我现在将在此之前执行一次提交,因此f60083549a43f152b3142e01756e25611d911770。
但是,该提交是OWNERS_ALIASES更改,并且在此范围内没有任何内容,因此c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd必须是问题所在。 无论如何,我都会出于安全考虑进行测试。
wasylkowski-a
于 2018-03-21
脱机讨论-我们将首先在本地进行还原此提交的情况下运行测试。
wojtek-t
于 2018-03-21
哇! 一只班轮造成很大麻烦。 谢谢@wasylkowski @
dims
于 2018-03-21
@dims单线确实会导致可伸缩性的破坏。 另一个过去的例子-https://github.com/kubernetes/kubernetes/pull/53720#issue-145949976
总的来说,您可能想看一下https://github.com/kubernetes/community/blob/master/sig-scalability/blogs/scalability-regressions-case-studies.md以获取更多信息:)
shyamjvs
于 2018-03-21
更新重新。 全面测试:首次运行时,提交已本地还原。 不过,这可能是片状,因此我将其重新运行。
wasylkowski-a
于 2018-03-21
liggitt
于 2018-03-21
@ Random-Liu谁能更好地向我们解释这种改变的影响:)
shyamjvs
于 2018-03-21
看着#59953中的提交...不是在修复错误吗? 似乎已修复了将“预定”状态放入错误对象的错误。 kubelet可能已经报告了在该修复程序之前安排豆荚的时间太早了吗?
是的-我知道这是一个错误修复。 我只是不完全理解。
似乎已将Pod报告的问题解决为“计划的”。 但是,直到kubelet将其报告为“ StartedAt”时,我们才发现问题。
问题是,在Kubelet报告为“ StartedAt”的时间与测试报告和监视窗格状态更新之间的时间之间,我们看到显着增加。
因此,我认为“计划的”位在这里是一个红鲱鱼。
我的猜测(但这仍然仅仅是猜测)是由于此更改,我们发送了更多的Pod状态更新,从而导致更多的429s之类的东西。 最后,Kubelet需要花费更多时间来报告广告连播状态。 但这是我们仍然需要确认的事情。
wojtek-t
于 2018-03-21
经过两次运行,我非常有信心恢复#59953可以解决此问题:
3.052567319s (watch), 4.489142104s (pod-startup)
2.799364978s (watch), 4.385999497s (pod-startup)
我们将发送更多的Pod状态更新,从而导致更多的429秒。 最后,Kubelet需要花费更多时间来报告广告连播状态。
这几乎是我在https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938中假设的效果(尽管我猜错了原因):)
另外,我们的IIRC确实确实看到429个看跌期权的增加(请参阅我的https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370582634),但这是我认为的更早范围围绕etcd更改)。
shyamjvs
于 2018-03-21
经过两次运行,我非常有信心恢复#59953可以解决此问题:
我的直觉(https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370874602)关于在线程中尽早出现在kubelet方面的问题毕竟是正确的:)
shyamjvs
于 2018-03-21
/ sig节点
@ kubernetes / sig-node-bugs发行团队可以真正在#59953提交与还原以及此处的性能问题上使用审查
tpepper
于 2018-03-21
看着#59953中的提交...不是在修复错误吗? 似乎已修复了将“预定”状态放入错误对象的错误。 基于该PR中引用的问题,看起来kubelet可能会错过报告未计划该pod的pod的报告?
@liggitt感谢您为我解释。 是的,那个公关正在修复一个错误。 以前,kubelet并不总是设置PodScheduled 。 使用#59953,kubelet将正确执行此操作。
@shyamjvs我不确定它是否可以引入更多pod状态更新。
如果我理解正确,将在第一个状态更新中设置PodScheduled条件,然后它将始终存在且从未更改。 我不明白为什么它会生成更多状态更新。
如果确实确实引入了更多状态更新,则这是2年前推出的一个问题https://github.com/kubernetes/kubernetes/pull/24459但存在错误,并且#59953只是修复了错误...
@ wasylkowski-a是否在https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -374982422和https://github.com/kubernetes/kubernetes/issues/60589#中有2次测试运行的日志
 Random-Liu
于 2018-03-21
Random-Liu
于 2018-03-21
@yujuhong和我发现,#59953暴露了一个问题,即静态pod的PodScheduled条件会不断更新。
Kubelet为没有它的pod生成一个新的PodScheduled条件。 静态窗格没有它,并且它的状态从不更新(预期行为)。 因此,kubelet将继续为静态Pod生成新的PodScheduled条件。
该问题是在#24459中引入的,但存在错误。 #59953解决了该错误,并暴露了原始问题。
有2个选项可以快速解决此问题:
- 选项1:不要让kubelet添加
PodScheduled条件,kubelet应该只保留调度程序设置的PodScheduled条件。- 优点:简单。
- 缺点:静态Pod和绕过调度程序的Pod(直接分配节点名称)将没有
PodScheduled条件。 实际上没有#59953,尽管kubelet最终会为这些吊舱设置此条件,但是由于存在错误,可能会花费很长时间。
- 选项2:当kubelet最初看到它时,为静态Pod生成
PodScheduled条件。
选项2可能会引入较少的面向用户的更改。
但是,我们确实要问PodScheduled对于未由调度程序调度的Pod意味着什么? 这些果荚真的需要这种条件吗? / cc @ kubernetes / sig-autoscaling-bugs因为@yujuhong告诉我PodScheduled现在用于自动缩放。
/ cc @ kubernetes / sig-node-bugs @ kubernetes / sig-scheduling-bugs
Random-Liu
于 2018-03-21
@ Random-Liu very long time for kubelet to eventually set this condition什么? 最终用户会注意到什么问题/面部(在测试线束脆弱性之外)? (来自选项1)
dims
于 2018-03-21
@dims用户很长时间不会看到PodScheduled条件。
Random-Liu
于 2018-03-21
我有一个修复#61504,它在https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979中实现了选项2。
如果人们认为这是更好的解决方法,则可以将其更改为选项1。 :)
Random-Liu
于 2018-03-21
你最好问那些从内到外都知道这件事的人! (不是发布团队😄!)
ping @dashpole @ dchen1107 @derekwaynecarr
dims
于 2018-03-21
@ Random-Liu IIRC在我们的测试中,在节点上运行的唯一静态pod是kube-proxy。 您能否说出kubelet多久进行一次这些“连续更新”? (要求以估计由错误引入的额外qps)
shyamjvs
于 2018-03-21
@ Random-Liu IIRC在我们的测试中,在节点上运行的唯一静态pod是kube-proxy。 您能否说出kubelet多久进行一次这些“连续更新”? (要求以估计由错误引入的额外qps)
@shyamjvs是的, kube-proxy是现在节点上唯一的一个。
我认为这取决于pod同步频率https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/kubeletconfig/v1beta1/defaults.go#L47 ,即1分钟。 因此,kubelet每1分钟生成一次额外的pod状态更新。
Random-Liu
于 2018-03-22
谢谢。 因此,这意味着5000/60 =〜83 qps增加了额外的额外费用,原因是发出了pod-status呼叫。 似乎可以解释该错误前面提到的增加的429s。
shyamjvs
于 2018-03-22
@ Random-Liu非常感谢您帮助我们进行了排序。
jdumars
于 2018-03-22
@jdumars np〜@ yujuhong帮助了我很多!
Random-Liu
于 2018-03-22
但是我们确实想问一下PodScheduled对未由调度程序调度的Pod意味着什么? 这些果荚真的需要这种条件吗? / cc @ kubernetes / sig-autoscaling-bugs因为@yujuhong告诉我,现在自动缩放使用PodScheduled。
我仍然认为让kubelet设置PodScheduled条件有些奇怪(正如我在原始PR中所指出的)。 即使kubelet没有设置此条件,它也不会影响群集自动缩放器,因为自动缩放器会忽略没有特定条件的Pod。 无论如何,我们最终提出的解决方案占用的资源很小,并且可以维持当前行为(即始终设置PodScheduled条件),因此我们继续进行。
 yujuhong
于 2018-03-22
yujuhong
于 2018-03-22
此外,恢复了为稳态Pod更新速率添加测试的真正老问题#14391
yujuhong
于 2018-03-22
无论如何,我们最终提出的解决方案占用的资源很小,并且可以维持当前行为(即始终设置PodScheduled条件),因此我们继续进行。
@yujuhong-您是否在谈论这个问题:#61504(还是我误会了)?
@wasylkowski @ shyamjvs-您能否在本地进行补丁(在我们合并之前)运行5000个节点的测试,以确保这确实有帮助?
wojtek-t
于 2018-03-22
我针对1.10 HEAD +#61504运行了测试,并且pod-startup延迟似乎很好:
INFO: perc50: 2.594635536s, perc90: 3.483550118s, perc99: 4.327417676s
将再次运行以确认。
shyamjvs
于 2018-03-22
@shyamjvs-非常感谢!
wojtek-t
于 2018-03-22
第二次运行似乎也不错:
INFO: perc50: 2.583489146s, perc90: 3.466873901s, perc99: 4.380595534s
现在相当有信心此修复程序成功了。 让我们尽快进入1.10。
shyamjvs
于 2018-03-22
谢谢@shyamjvs
在我们离线讨论时-我认为上个月左右我们又进行了一次回归,但那不应该阻止发布。
wojtek-t
于 2018-03-22
@yujuhong-您是否在谈论这个问题:#61504(还是我误会了)?
是的 PR中的当前修复不在https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979最初建议的选项中
yujuhong
于 2018-03-22
重新打开,直到我们获得良好的性能测试结果。
jberkus
于 2018-03-25
@yujuhong @krzyzacy @shyamjvs @ wojtek -t @ Random-Liu @ wasylkowski-a对此有任何更新吗? 目前,它仍在阻止1.10。
jdumars
于 2018-03-26
因此,此错误中唯一阻止发布的部分是5k节点性能工作。 不幸的是,由于其他原因,我们从今天起失去了运行(参考:https://github.com/kubernetes/kubernetes/issues/61190#issuecomment-376150569)
话虽如此,我们对我的手动运行修复工作很有信心(结果粘贴在https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-375350217中)。 因此,恕我直言,我们不需要阻止其发布(下一轮将在星期三进行)。
shyamjvs
于 2018-03-26
+1
@jdumars-我认为我们可以将其视为
wojtek-t
于 2018-03-26
抱歉,我在上面编辑了我的帖子。 我的意思是我们应该将其视为“无障碍”。
wojtek-t
于 2018-03-26
好的,非常感谢。 这个结论代表您已经投入了大量的时间,对于您所做的工作,我可能无法表示全部的感谢。 当我们抽象地谈论“社区”和“贡献者”时,您以及其他处理此问题的人都用具体的术语来表示。 您是这个项目的灵魂所在,当我说与这样的热情,奉献精神和敬业精神一起工作是一种荣幸时,我知道我会为参与其中的每个人发言。
jdumars
于 2018-03-26
[MILESTONENOTIFIER]里程碑问题:流程最新
@krzyzacy @ msau42 @shyamjvs @ WOJTEK叔
发行标签
sig/api-machinerysig/autoscalingsig/nodesig/scalabilitysig/schedulingsig/storage:如果需要,问题将升级为这些SIG。priority/critical-urgent:从不自动将问题移出发行里程碑; 通过所有可用渠道不断升级为贡献者和SIG。kind/bug:修复了当前版本中发现的错误。救命
 k8s-github-robot
于 2018-04-11
k8s-github-robot
于 2018-04-11
此问题已通过1.10中的相关修复得到解决。
对于1.11,我们在-https: //github.com/kubernetes/kubernetes/issues/63030下跟踪故障
/关
shyamjvs
于 2018-05-25
相关问题
 montanaflynn
·
3评论
montanaflynn
·
3评论
 pwittrock
·
3评论
pwittrock
·
3评论
 sanjana-bhat
·
3评论
sanjana-bhat
·
3评论
 mml
·
3评论
mml
·
3评论
 zetaab
·
3评论
zetaab
·
3评论
最有用的评论
我针对1.10 HEAD +#61504运行了测试,并且pod-startup延迟似乎很好:
将再次运行以确认。