Kubernetes: [رقائق الاختبار] مجموعات قابلية التوسع الرئيسية
مجموعات فشل تحرير حظر:
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-rightness
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
جميع الأجنحة الثلاثة تتساقط كثيرًا مؤخرًا ، هل تريد الفرز؟
/ سيج قابلية التوسع
/ أولوية فشل الاختبار
/ نوع الخطأ
/ حالة الموافقة على المعالم
سم مكعبjdumarsjberkus
/ تعيين shyamjvs @ wojtek-t
 krzyzacy
krzyzacy
ال 164 كومينتر
- تفشل وظيفة الصحة في الغالب بسبب انتهاء المهلة (تحتاج إلى تعديل جدولنا في المقابل) حيث كانت هناك مجموعة من e2es تمت إضافتها إلى المجموعة مؤخرًا (على سبيل المثال https://github.com/kubernetes/kubernetes/pull/59391)
- بالنسبة إلى رقائق 100 عقدة ، لدينا https://github.com/kubernetes/kubernetes/issues/60500 (وأعتقد أن هذا مرتبط .. بحاجة إلى التحقق).
- بالنسبة لوظيفة الأداء ، أعتقد أن هناك انحدارًا (يبدو من الدورات القليلة الماضية كما لو كان حول زمن انتقال بدء التشغيل) ربما شيء أكثر أيضًا.
سأحاول الوصول إليهم في وقت ما خلال هذا الأسبوع (مع ندرة الدورات المجانية لأجهزة الصراف الآلي).
 shyamjvs
في ٢٨ فبراير ٢٠١٨
shyamjvs
في ٢٨ فبراير ٢٠١٨
shyamjvs هل هناك أي تحديث لهذه المشكلة؟
krzyzacy
في ٢ مارس ٢٠١٨
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-rightness
لقد ألقيت نظرة سريعة على ذلك. وإما أن تكون بعض الاختبارات بطيئة للغاية أو أن هناك شيئًا ما معلقًا في مكان ما. الاسمية للسجلات من آخر تشغيل:
62571 I0301 23:01:31.360] Mar 1 23:01:31.348: INFO: Running AfterSuite actions on all node
62572 I0301 23:01:31.360]
62573 W0302 07:32:00.441] 2018/03/02 07:32:00 process.go:191: Abort after 9h30m0s timeout during ./hack/ginkgo-e2e.sh --ginkgo.flakeAttempts=2 --ginkgo.skip=\[Serial\]|\[Disruptive \]|\[Flaky\]|\[Feature:.+\]|\[DisabledForLargeClusters\] --allowed-not-ready-nodes=50 --node-schedulable-timeout=90m --minStartupPods=8 --gather-resource-usage=master --gathe r-metrics-at-teardown=master --logexporter-gcs-path=gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-correctness/80/artifacts --report-dir=/workspace/_artifacts --dis able-log-dump=true --cluster-ip-range=10.64.0.0/11. Will terminate in another 15m
62574 W0302 07:32:00.445] SIGABRT: abort
لم ينته أي اختبار في غضون 8h30m
 wojtek-t
في ٢ مارس ٢٠١٨
wojtek-t
في ٢ مارس ٢٠١٨
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
في الواقع يبدو وكأنه تراجع. أعتقد أن الانحدار حدث في مكان ما بين الأشواط:
105 (التي كانت لا تزال على ما يرام)
108 (والتي شهدت وقت بدء تشغيل أعلى بشكل واضح)
يمكننا محاولة البحث في kubemark-5000 لمعرفة ما إذا كان مرئيًا هناك أيضًا.
wojtek-t
في ٢ مارس ٢٠١٨
Kubemark-5000 مستقر جدًا. النسبة المئوية 99 في هذا الرسم البياني (ربما حدث الانحدار حتى من قبل ، لكنني أعتقد أنه يقع في مكان ما بين 105 و 108):

wojtek-t
في ٢ مارس ٢٠١٨
فيما يتعلق باختبارات التماسك - فشل تصحيح gce-Large -ح أيضًا.
ربما تمت إضافة اختبار طويل للغاية في ذلك الوقت؟
wojtek-t
في ٢ مارس ٢٠١٨
شكرا جزيلا للبحث @ wojtek-t. وظيفة أداء Wrt - أشعر أيضًا بقوة أن هناك تراجعًا (على الرغم من أنني لم أتمكن من النظر إليها بشكل صحيح).
ربما تمت إضافة اختبار طويل للغاية في ذلك الوقت؟
كنت أبحث في هذا منذ فترة. وكان هناك تغييران مشبوهان وجدتهما:
- # 59391 - أضاف هذا مجموعة من الاختبارات حول التخزين المحلي (بدأت المهلة بعد هذا التغيير)
- يجب أن تستخدم StatefulSet مع pod anti-affinity وحدات تخزين موزعة عبر العقد (يبدو أن هذا الاختبار يعمل لمدة 3.5 - 5 ساعات) - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e -صحة-مقياس-gce / 79
shyamjvs
في ٢ مارس ٢٠١٨
cc @ kubernetes / sig-storage-bugs
shyamjvs
في ٢ مارس ٢٠١٨
/تعيين
ستحاول بعض اختبارات التخزين المحلية استخدام كل عقدة في الكتلة ، معتقدين أن أحجام الكتلة ليست كبيرة. سأضيف إصلاحًا لتحديد الحد الأقصى لعدد العقد.
 msau42
في ٢ مارس ٢٠١٨
msau42
في ٢ مارس ٢٠١٨
ستحاول بعض اختبارات التخزين المحلية استخدام كل عقدة في الكتلة ، معتقدين أن أحجام الكتلة ليست كبيرة. سأضيف إصلاحًا لتحديد الحد الأقصى لعدد العقد.
شكرًا @ msau42 - سيكون ذلك رائعًا.
wojtek-t
في ٢ مارس ٢٠١٨
العودة إلى https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance suite
ألقيت نظرة فاحصة على دورات تصل إلى 105 و 108 وبعد ذلك.
يبدو أن الاختلاف الأكبر في وقت بدء التشغيل يظهر في الخطوة:
10% worst watch latencies:
[الاسم مضلل - سنشرح أدناه]
حتى 105 ركض ، بدا الأمر بشكل عام كما يلي:
I0129 21:17:43.450] Jan 29 21:17:43.356: INFO: perc50: 1.041233793s, perc90: 1.685463015s, perc99: 2.350747103s
بدءًا من 108 Run ، يبدو الأمر أكثر مثل:
Feb 12 10:08:57.123: INFO: perc50: 1.122693874s, perc90: 1.934670461s, perc99: 3.195883331s
هذا يعني في الأساس زيادة بمقدار 0.85 ثانية وهذا تقريبًا ما نلاحظه في النتيجة النهائية.
الآن - ما هو "تأخر المشاهدة".
إنه في الأساس وقت بين "لاحظ Kubelet أن البود يعمل" إلى "عند اختبار تحديث البود الملحوظ ويضبط حالته على التشغيل".
هناك احتمالان يمكن أن نتراجع فيه:
- kubelet أبطأ في حالة الإبلاغ
- kubelet متعطش لـ qps (وبالتالي أبطأ في حالة الإبلاغ)
- apiserver أبطأ (مثل توقف وحدة المعالجة المركزية) وبالتالي معالجة الطلبات أبطأ (إما الكتابة أو المشاهدة أو كليهما)
- اختبار نقص وحدة المعالجة المركزية وبالتالي معالجة الأحداث الواردة بشكل أبطأ
نظرًا لأننا لا نلاحظ حقًا اختلافًا بين "جدول -> بدء" للحجرة ، فإن هذا يشير إلى أنها على الأرجح ليست خادمًا (لأن معالجة الطلبات والمشاهدة تسير على هذا المسار أيضًا) ، ومن المحتمل ألا تكون kubelet بطيئة أيضًا (لأنه يبدأ الكبسولة).
لذلك أعتقد أن الفرضية الأكثر احتمالاً هي:
- kubelet متعطش لـ qps (أو شيء يمنعه من إرسال تحديث الحالة بسرعة)
- الاختبار متعطش لوحدة المعالجة المركزية (أو شيء من هذا القبيل)
لم يتغير الاختبار على الإطلاق في ذلك الوقت. لذلك أعتقد أنه على الأرجح الأول.
بعد قولي هذا ، مررت بعلاقات عامة مدمجة بين 105 و 108 أشواط ولم أجد أي شيء مفيد حتى الآن.
wojtek-t
في ٢ مارس ٢٠١٨
أعتقد أن الخطوة التالية هي:
- انظر في أبطأ البودات (يبدو أن هناك فرق O (1) بين الأبطأ أيضًا) ومعرفة ما إذا كان الاختلاف "قبل" من "بعد" إرسال طلب حالة التحديث
wojtek-t
في ٢ مارس ٢٠١٨
لذلك نظرت إلى أمثلة القرون. وأنا أرى هذا بالفعل:
I0209 10:01:19.960823 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.615907ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
...
I0209 10:01:22.464046 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (279.153µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:23.468353 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (218.216µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:24.470944 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.42987ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 09:57:01.559125 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (1.836423ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
...
I0209 09:57:04.452830 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (231.2µs) 429 [[kubelet/v1.10.0 (linu x/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:05.454274 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (213.872µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:06.458831 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (2.13295ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 10:01:53.063575 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (1.410064ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:3391
...
I0209 10:01:55.259949 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (10.4894ms) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:56.266377 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (233.931µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:57.269427 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (182.035µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:58.290456 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (13.44863ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
لذلك يبدو واضحًا أن المشكلة مرتبطة بـ "429" ثانية.
wojtek-t
في ٢ مارس ٢٠١٨
هل هذه الاستدعاءات المقيدة لواجهة برمجة التطبيقات بسبب حصة في حساب المالك؟
 jdumars
في ٢ مارس ٢٠١٨
jdumars
في ٢ مارس ٢٠١٨
هل هذه الاستدعاءات المقيدة لواجهة برمجة التطبيقات بسبب حصة في حساب المالك؟
هذا ليس اختناق كما اعتقدت في البداية. هذه 429s على apiserver (قد يكون السبب إما أبطأ apiserver لسبب ما ، أو المزيد من الطلبات القادمة إلى apiserver).
wojtek-t
في ٢ مارس ٢٠١٨
حسنا. هذه ليست أخبار جيدة.
jdumars
في ٢ مارس ٢٠١٨
/ معلم واضح
krzyzacy
في ٢ مارس ٢٠١٨
/ معلم v1.10
krzyzacy
في ٢ مارس ٢٠١٨
/ معلم واضح
 cjwagner
في ٢ مارس ٢٠١٨
cjwagner
في ٢ مارس ٢٠١٨
cjwagner : يجب أن تكون عضوًا في فريق جيثب kubernetes-milestone -keepers لتعيين هذا الإنجاز.
ردًا على هذا :
/ معلم واضح
تعليمات للتفاعل معي باستخدام تعليقات العلاقات العامة متوفرة هنا . إذا كانت لديك أسئلة أو اقتراحات تتعلق بسلوكي ، فالرجاء رفع قضية ضد
 k8s-ci-robot
في ٢ مارس ٢٠١٨
k8s-ci-robot
في ٢ مارس ٢٠١٨
/ معلم v1.9
cjwagner
في ٢ مارس ٢٠١٨
cjwagner : يجب أن تكون عضوًا في فريق جيثب kubernetes-milestone -keepers لتعيين هذا الإنجاز.
ردًا على هذا :
/ معلم v1.9
تعليمات للتفاعل معي باستخدام تعليقات العلاقات العامة متوفرة هنا . إذا كانت لديك أسئلة أو اقتراحات تتعلق بسلوكي ، فالرجاء رفع قضية ضد
k8s-ci-robot
في ٢ مارس ٢٠١٨
يبدو أن العلاقات العامة https://github.com/kubernetes/kubernetes/pull/60740 أصلحت مشكلات المهلة - شكرًا @ msau42 للاستجابة السريعة.
وظائف التصحيح لدينا (2k و 5k) عادت إلى اللون الأخضر الآن:
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce- تكبير-صحة
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -scale-rightness
لذا فإن شكوكي بشأن اختبارات الحجم تلك كانت صحيحة حقًا :)
shyamjvs
في ٥ مارس ٢٠١٨
ACK. في تقدم
الوقت المتوقع للسفر: 9/3/2018
المخاطر: التأثير المحتمل على أداء k8s
shyamjvs
في ٥ مارس ٢٠١٨
لذلك بحثت قليلاً في هذا ومن الرسم البياني لزمن انتقال pod-startup لاختبار 5k-node ، لدي شعور بأن الانحدار يمكن أن يكون أيضًا في b / w تشغيل 108 و 109 (انظر 99٪ ile):

shyamjvs
في ٥ مارس ٢٠١٨
اكتسحت الفرق بسرعة ويبدو التغيير التالي مريبًا بالنسبة لي:
"السماح بتمرير مهلة الطلب من NewRequest إلى أسفل" # 51042
يعمل هذا PR على تمكين نشر مهلة العميل كمعامل استعلام لاستدعاء API. وأرى بالفعل الاختلاف التالي في مكالمات PATCH node/status عبر هاتين الجريتين (من سجلات apiserver):
رن 108:
I0207 22:01:06.450385 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-2rn2/status: (11.81392ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.227.96.23:47270]
I0207 22:01:03.857892 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-9659/status: (8.570809ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.196.85.108:43532]
I0207 22:01:03.857972 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc4w/status: (8.287643ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.229.110.22:50530]
رن 109:
I0209 21:01:08.551289 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-89f2/status?timeout=10s: (71.351634ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.229.77.215:51070]
I0209 21:01:08.551310 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-3ms3/status?timeout=10s: (70.705466ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.227.84.87:49936]
I0209 21:01:08.551394 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc02/status?timeout=10s: (70.847605ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.196.125.143:53662]
فرضيتي هي أنه بسبب هذه المهلة المضافة البالغة 10 ثوانٍ إلى مكالمات PATCH ، فإن هذه المكالمات تدوم الآن لفترة أطول على جانب الخادم (IIUC هذا التعليق بشكل صحيح). هذا يعني أنهم الآن في قائمة انتظار الرحلات لمدة أطول. هذا ، جنبًا إلى جنب مع حقيقة أن مكالمات PATCH هذه تحدث بكميات ضخمة في مثل هذه المجموعات الكبيرة ، يؤدي إلى مكالمات PUT pod/status غير قادرة على الحصول على عرض نطاق ترددي كافٍ في قائمة انتظار الرحلات وبالتالي يتم إرجاعها بـ 429s. نتيجة لذلك ، زاد التأخير من جانب kubelet في تحديث حالة البود. تتلاءم هذه القصة أيضًا مع ملاحظات @ wojtek-t أعلاه.
سأحاول جمع المزيد من الأدلة للتحقق من هذه الفرضية.
shyamjvs
في ٥ مارس ٢٠١٨
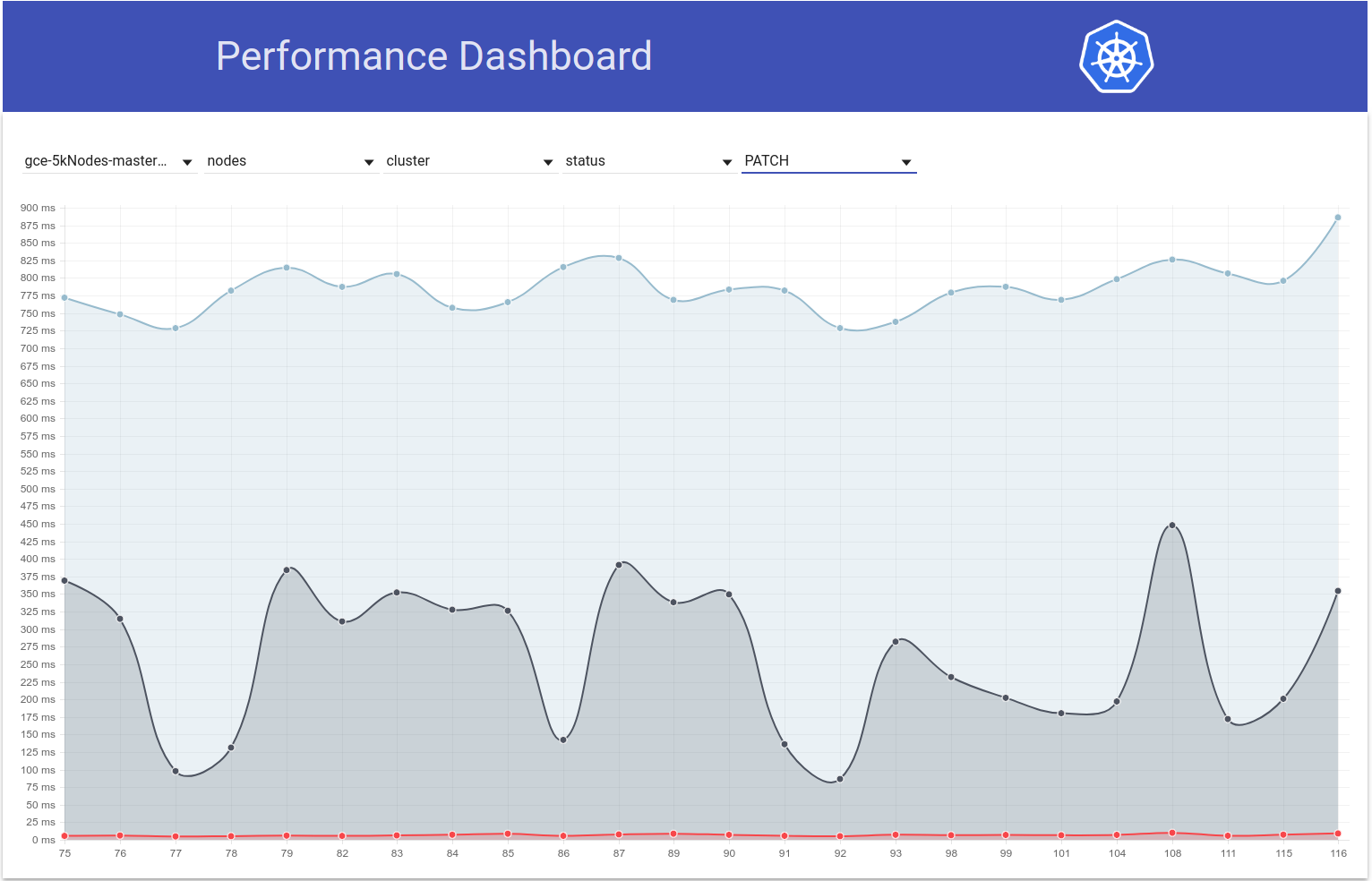
لذا فقد تحققت من كيفية اختلاف زمن الوصول إلى PATCH node-status خلال عمليات الاختبار ، ويبدو بالفعل أن هناك ارتفاعًا في النسبة المئوية 99 (انظر السطر العلوي) في ذلك الوقت تقريبًا. ومع ذلك ، فليس من الواضح تمامًا أنه حدث بين 108 و 109 (على الرغم من اعتقادي أن هذا هو الحال):
shyamjvs
في ٥ مارس ٢٠١٨
[تعديل: أشار تعليقي السابق بشكل خاطئ إلى عدد الـ 429 ثانية (العميل كان npd ، وليس kubelet)]
لدي المزيد من الأدلة الداعمة الآن:
في التشغيل 108 ، كان لدينا 479 PATCH node/status مكالمات حصلت على 429:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"479181"
]
},
وفي التشغيل 109 ، لدينا 757 ألفًا من هؤلاء:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"757318"
]
},
و ... انظر إلى هذا:
في التشغيل -108:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"28594"
]
},
وفي التشغيل 109:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"33224"
]
},
لقد تحققت من الرقم لبعض الأشواط المجاورة الأخرى:
- تم دمج العلاقات العامة -
- للجري 109 هو 33224
- للجري 110 30977
- للتشغيل 111 هو 25615
على الرغم من أن الأمر يبدو متباينًا بعض الشيء ، إلا أنه يبدو بشكل عام لا. من 429s زادت بنحو 25٪.
shyamjvs
في ٥ مارس ٢٠١٨
وبالنسبة إلى PATCH node-status القادمة من kubelets استقبلت 429s ، فإليك شكل الأرقام:
- تشغيل 104 = 313348
- تشغيل 105 = 309136
- تشغيل 108 = 479181
- تم دمج العلاقات العامة -
- تشغيل 109 = 757318
- المدى 110 = 752062
- تشغيل 111 = 296368
هذا متفاوت أيضًا ، لكن يبدو أنه يزداد بشكل عام.
shyamjvs
في ٥ مارس ٢٠١٨
يبدو أن زمن انتقال الاتصال 99٪ من PATCH node-status قد زاد بشكل عام (كما كنت أتوقع في https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370573938):
run-104 (798ms), run-105 (783ms), run-108 (826ms)
run-109 (878ms), run-110 (869ms), run-111 (806ms)
راجع للشغل - بالنظر إلى جميع المقاييس المذكورة أعلاه ، يبدو أن 108 كان تشغيلًا أسوأ من المعتاد ويبدو أن 111 أفضل من المعتاد.
shyamjvs
في ٥ مارس ٢٠١٨
سأحاول التحقق من ذلك غدًا عن طريق تشغيل مجموعة كبيرة بحجم 5 كيلو بايت يدويًا.
shyamjvs
في ٥ مارس ٢٠١٨
شكرا لفرز shyamjvs
krzyzacy
في ٥ مارس ٢٠١٨
لذلك قمت بإجراء اختبار الكثافة مرتين مقابل مجموعة 5k مقابل ~ HEAD ، وتم اجتياز الاختبار بشكل مفاجئ في المرتين مع زمن انتقال 99٪ لبدء تشغيل البود مثل 4.510015461s و 4.623276837s . ومع ذلك ، فقد أظهرت "فترات الاستجابة للساعة" الزيادة التي أشار إليها @ wojtek-t في https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -369951288
في الجولة الأولى كان:
INFO: perc50: 1.123056294s, perc90: 1.932503347s, perc99: 3.061238209s
والشوط الثاني كان:
INFO: perc50: 1.121218293s, perc90: 1.996638787s, perc99: 3.137325187s
سأحاول الآن التحقق مما كان عليه الحال في وقت سابق.
shyamjvs
في ٦ مارس ٢٠١٨
https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 - لست متأكدًا من أنني أتبع هذا نعم - أضفنا مهلة ، لكن المهلة الافتراضية أكبر من 10 ثوانٍ IIRC - لذا يجب أن تساعد فقط لا تجعل الأمور أسوأ.
أعتقد أننا ما زلنا لا نفهم لماذا نلاحظ المزيد من 429s (حقيقة أن هذا مرتبط بطريقة ما بـ 429s التي ذكرتها بالفعل في https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370036377)
wojtek-t
في ٦ مارس ٢٠١٨
وفيما يتعلق بأرقامك - لست مقتنعًا بأن الانحدار كان قيد التشغيل 109 - ربما كان هناك انحداران - أحدهما في مكان ما بين 105 و 108 والآخر في 109.
wojtek-t
في ٦ مارس ٢٠١٨
حسنًا ... لا أنكر الاحتمالات التي ذكرتها (ما سبق كان مجرد فرضيتي).
أقوم حاليًا بتقسيم (الآن مقابل التزام 108) للتحقق.
shyamjvs
في ٦ مارس ٢٠١٨
شعوري أن الانحدار كان قبل تشغيل 108 أقوى وأقوى.
على سبيل المثال ، تم زيادة زمن انتقال مكالمات api بالفعل في 108 تشغيل.
حالة عقدة التصحيح:
90٪: 198 مللي ثانية (105) 447 مللي ثانية (108) 444 مللي ثانية (109)
ضع حالة الجراب:
99٪: 83 مللي ثانية (105) 657 مللي ثانية (108) 728 مللي ثانية (109)
wojtek-t
في ٦ مارس ٢٠١٨
أعتقد أن ما أحاول قوله هو:
- عدد 429 هو نتيجة لذلك ولا ينبغي لنا أن نقضي الكثير من الوقت في ذلك
- السبب الرئيسي هو إما بطء مكالمات api أو عدد أكبر منها
من الواضح أننا نرى مكالمات أبطأ في 108. السؤال هو ما إذا كنا نرى أيضًا عددًا أكبر منها.
wojtek-t
في ٦ مارس ٢٠١٨
لذلك أعتقد لماذا الطلبات أبطأ بشكل واضح - هناك ثلاثة احتمالات رئيسية
هناك طلبات أكثر بكثير (من النظرة الأولى لا يبدو الأمر كذلك)
أضفنا شيئًا ما على مسار المعالجة (مثل المعالجة الإضافية) أو أن الكائنات نفسها أكبر
شيء آخر على الجهاز الرئيسي (على سبيل المثال ، المجدول) يستهلك المزيد من وحدة المعالجة المركزية وبالتالي يجوع الخادم أكثر
wojtek-t
في ٦ مارس ٢٠١٨
لذلك ناقشت أنا و @ wojtek-t دون اتصال بالإنترنت ونتفق الآن على أنه من المحتمل جدًا حدوث تراجع قبل 108. إضافة بعض النقاط:
هناك طلبات أكثر بكثير (من النظرة الأولى لا يبدو الأمر كذلك)
لا يبدو أن هذا هو الحال بالنسبة لي أيضًا
أضفنا شيئًا ما على مسار المعالجة (مثل المعالجة الإضافية) أو أن الكائنات نفسها أكبر
شعوري هو أنه من المحتمل جدًا في kubelet بدلاً من apiserver (لأننا لا نرى أي تغيير مرئي في التصحيح / وضع الكمون على kubemark-5000)
شيء آخر على الجهاز الرئيسي (على سبيل المثال ، المجدول) يستهلك المزيد من وحدة المعالجة المركزية وبالتالي يجوع الخادم أكثر
ليس هذا هو الحال IMO لأن لدينا بعض الركود CPU / mem على سيدنا. كما لا تشير لوحة perf-dash إلى أي زيادة كبيرة في استخدامات المكونات الرئيسية.
ومع ذلك ، فقد بحثت قليلاً و "لحسن الحظ" يبدو أننا نلاحظ هذه الزيادة في زمن انتقال المشاهدة حتى بالنسبة لمجموعات 2k node:
INFO: perc50: 1.024377533s, perc90: 1.589770858s, perc99: 1.934099611s
INFO: perc50: 1.03503718s, perc90: 1.624451701s, perc99: 2.348645755s
يجب أن يجعل التنصيف أسهل قليلاً.
shyamjvs
في ٦ مارس ٢٠١٨
لسوء الحظ ، يبدو التباين في فترات انتقال المشاهدة هذه وكأنه حدث لمرة واحدة (بخلاف ذلك تقريبًا هو نفسه). لحسن الحظ ، لدينا زمن انتقال PUT pod-status كمؤشر موثوق للانحدار. ركضت جولتين من التنصيف بالأمس وقلصت إلى هذا الاختلاف (حوالي 80 مرة). بحثت عنهم ولدي شك قوي في:
- # 58990 - يضيف حقلاً جديدًا إلى حالة البود (على الرغم من أنني لست متأكدًا مما إذا كان سيتم ملؤه في اختباراتنا ، حيث لا تحدث إجراءات استباقية IIUC - ولكن يلزم التحقق)
- # 58645 - تحديث إصدار خادم الخ إلى 3.2.14
shyamjvs
في ٧ مارس ٢٠١٨
أشك حقًا في أن # 58990 مرتبط هنا - NominatedNodeName هي سلسلة تحتوي على اسم عقدة واحدة. حتى لو تم ملؤه طوال الوقت ، فإن التغيير في حجم الكائن يجب أن يكون ضئيلًا.
wojtek-t
في ٧ مارس ٢٠١٨
@ wojtek-t - كما كنت تقترح وضع عدم الاتصال ، يبدو بالفعل أننا نستخدم إصدارًا مختلفًا (3.2.16) في kubemark (https://github.com/kubernetes/kubernetes/blob/master/test/kubemark/ start-kubemark.sh # L62) وهو السبب المحتمل لعدم رؤية هذا الانحدار هناك :)
cc jpbetz
shyamjvs
في ٧ مارس ٢٠١٨
نحن نستخدم 3.2.16 في كل مكان الآن.
wojtek-t
في ٧ مارس ٢٠١٨
عفوًا .. آسف للإدراك المتأخر - كنت أبحث في مجموعة خاطئة من الالتزامات.
shyamjvs
في ٧ مارس ٢٠١٨
راجع للشغل - هذه الزيادة في PUT pods / زمن انتقال الحالة مرئية أيضًا في اختبار الحمل في مجموعات حقيقية كبيرة.
wojtek-t
في ٧ مارس ٢٠١٨
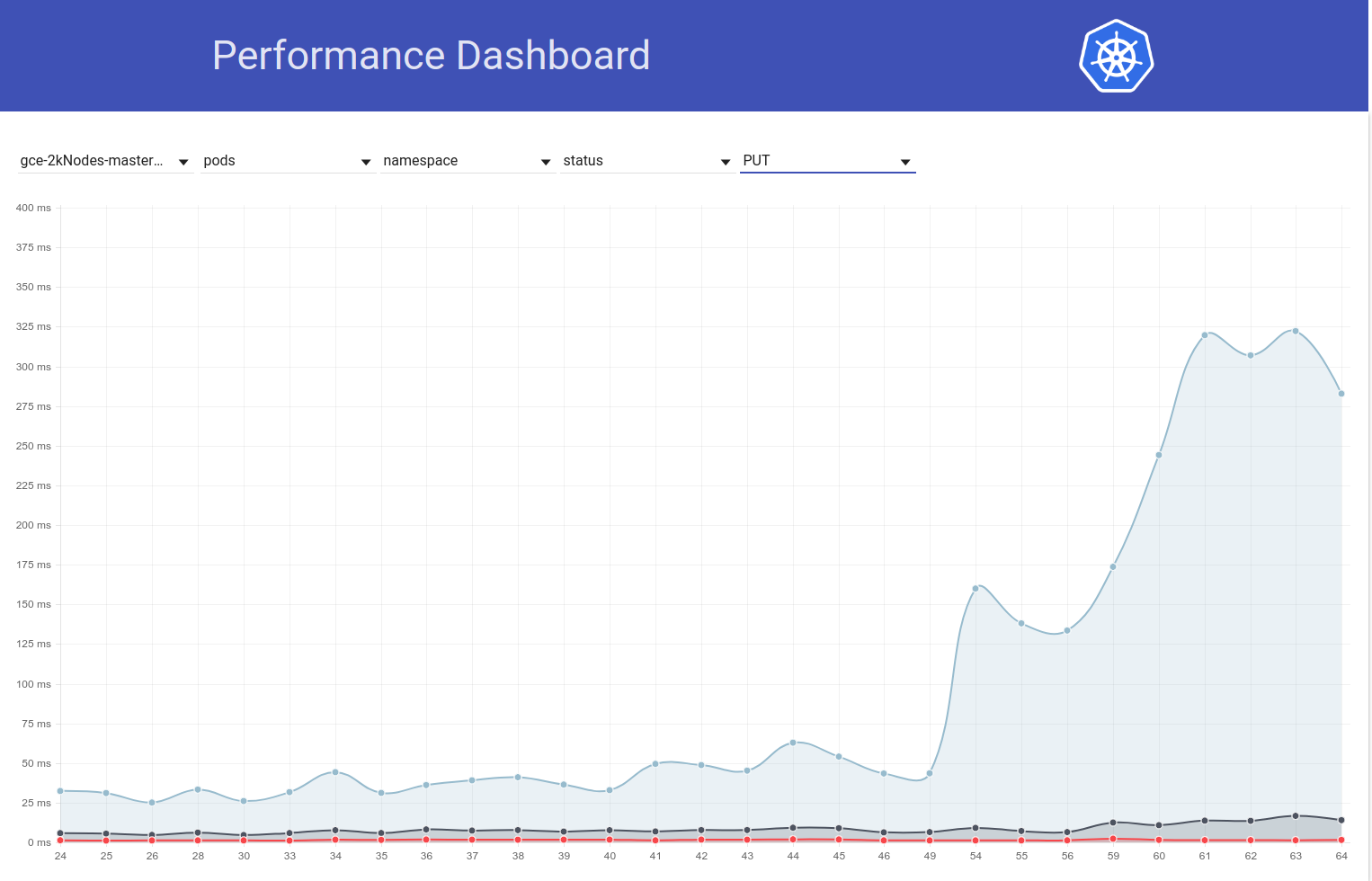
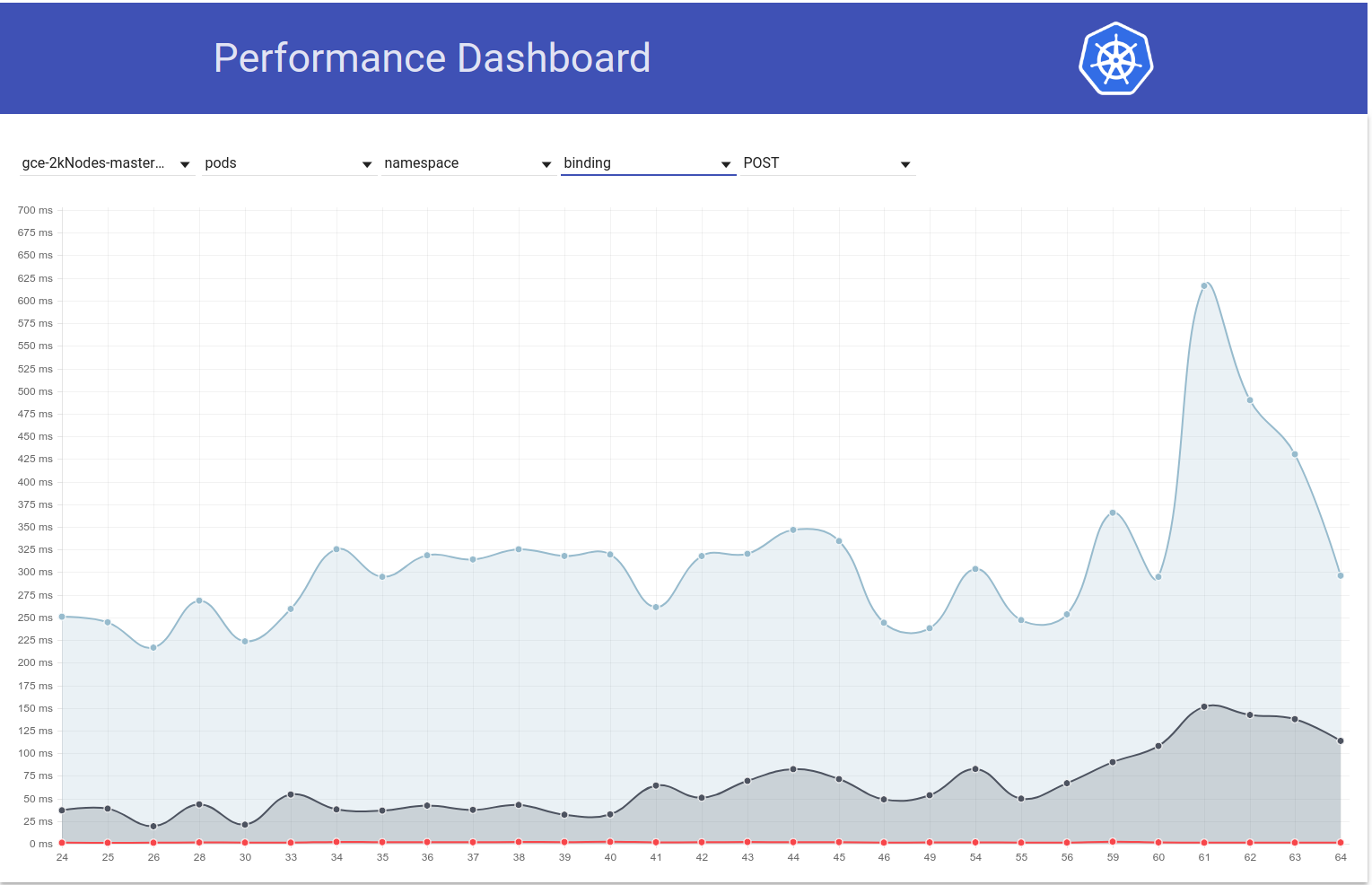
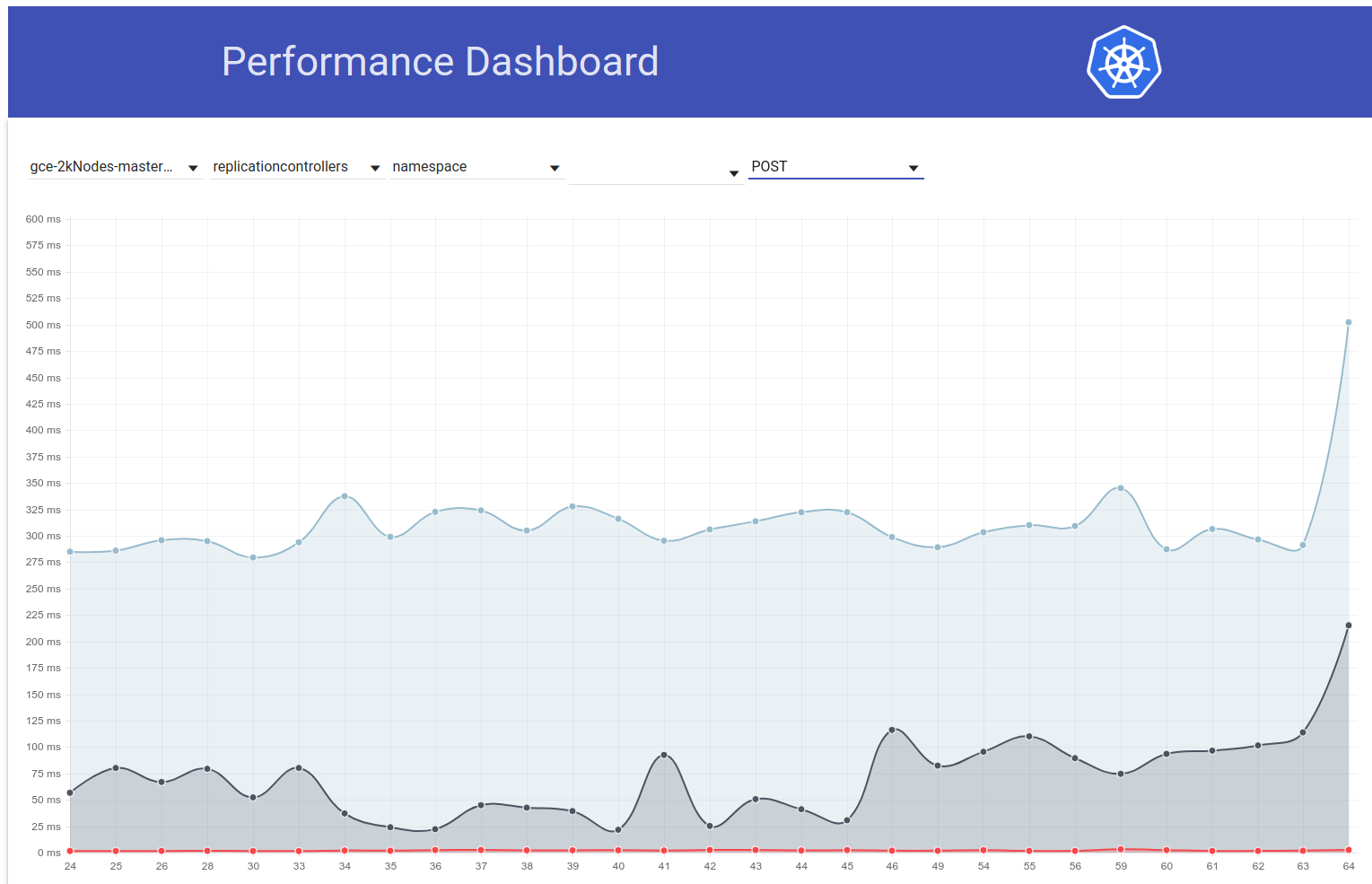
لذلك بحثت أكثر قليلاً ويبدو أننا بدأنا في مراقبة فترات انتقال أكبر في ذلك الوقت لطلبات الكتابة بشكل عام (مما يجعلني أشك في تغيير إلخ أكثر):

shyamjvs
في ٧ مارس ٢٠١٨
في الواقع ، أنا أصوت أن جزءًا على الأقل من المشكلة موجود هنا:
https://github.com/kubernetes/kubernetes/pull/58990/commits/384a86caa92bdb7cf9ac96b10a6ef333d2d60519#diff -c73f80ad83608f18657d22a06950d929R240
سأندهش إذا كانت ستكون المشكلة برمتها ، لكنها قد تساهم في ذلك.
سيرسل PR يغير ذلك في ثانية.
wojtek-t
في ٧ مارس ٢٠١٨
لمعلوماتك - عندما ركضت مقابل التزام كان قبل تغيير 3.2.14 ، ولكن بعد تغيير واجهة برمجة تطبيقات حالة البود ، يبدو زمن انتقال حالة عقدة الوضع جيدًا تمامًا (أي 99٪ ملف = 39 مللي ثانية).
shyamjvs
في ٧ مارس ٢٠١٨
لذا فقد تحققت من أنه بالفعل ناتج عن ارتداد الخ إلى 3.2.14. إليك كيف يبدو وقت الاستجابة لحالة البود:
ضد هذا العلاقات العامة :
{
"data": {
"Perc50": 1.479,
"Perc90": 10.959,
"Perc99": 163.095
},
"unit": "ms",
"labels": {
"Count": "344494",
"Resource": "pods",
"Scope": "namespace",
"Subresource": "status",
"Verb": "PUT"
}
},
ضد ~ HEAD (من 5 مارس) مع عودة العلاقات العامة (الاختبار لا يزال قيد التشغيل ، ولكن على وشك الانتهاء قريبًا):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.5"} 1669
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.9"} 9597
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.99"} 63392
63 مللي ثانية تبدو مشابهة تمامًا لما كانت عليه من قبل .
يجب إعادة الإصدار ومحاولة فهم:
- لماذا نشهد هذه الزيادة في 3.2.14 الخ؟
- لماذا لم نلتقط هذا في kubemark؟
ccjpbetz @ kubernetes / sig-api-machinery-bugs
shyamjvs
في ٧ مارس ٢٠١٨
إحدى الفرضيات (لماذا لم نكتشف ذلك في kubemark - على الرغم من أنها لا تزال تخمينًا) هي أننا ربما قمنا بتغيير شيء ما إلى شهادات هناك.
عندما أقوم بمقارنة سجل etcd من kubemark والكتلة الحقيقية ، فقط في الأخير أرى السطر التالي:
2018-03-05 08:06:56.389648 I | embed: peerTLS: cert = /etc/srv/kubernetes/etcd-peer.crt, key = /etc/srv/kubernetes/etcd-peer.key, ca = , trusted-ca = /etc/srv/kubernetes/etcd-ca.crt, client-cert-auth = true
بالنظر إلى العلاقات العامة نفسها ، لا أرى أي تغييرات حول ذلك ، لكنني أيضًا لا أعرف لماذا يجب أن نرى هذا الخط فقط في مجموعات حقيقية ...
jpbetz للأفكار
wojtek-t
في ٧ مارس ٢٠١٨
ACK. في تقدم
الوقت المتوقع للسفر: 9/3/2018
المخاطر: سبب المشكلة من جذورها (في الغالب)
shyamjvs
في ٧ مارس ٢٠١٨
Re peerTLS - يبدو أن هذا هو الحال أيضًا من قبل (مع 3.1.11) لذا أعتقد أن هذا أمر محبط
wojtek-t
في ٧ مارس ٢٠١٨
تضمين التغريدة
 jpbetz
في ٧ مارس ٢٠١٨
jpbetz
في ٧ مارس ٢٠١٨
63 مللي ثانية تبدو مشابهة تمامًا لما
من أين نحصل على هذه الأرقام؟ هل يقوم apiserver_request_latencies_summary بقياس زمن الوصول إلى عمليات الكتابة الأخرى؟ أيضا ، سوف تساعد المقاييس من الخ.
 gyuho
في ٧ مارس ٢٠١٨
gyuho
في ٧ مارس ٢٠١٨
تضمين: peerTLS: شهادة ...
هذا يطبع ، إذا تم تكوين نظير TLS (نفس الشيء في 3.1).
gyuho
في ٧ مارس ٢٠١٨
من أين نحصل على هذه الأرقام؟ هل apiserver_request_latencies_summary يقيس فعليًا اختفاء عمليات الكتابة وغيرها؟ أيضا ، سوف تساعد المقاييس من الخ.
هذا يقيس زمن انتقال المكالمات والذي (على الأقل في حالة مكالمات الكتابة) يتضمن زمن انتقال الخ.
ما زلنا لا نفهم ما يحدث بالفعل ، لكن العودة إلى الإصدار السابق (3.1) يُصلح الانحدار. من الواضح أن المشكلة في مكان ما في الخ.
wojtek-t
في ٧ مارس ٢٠١٨
تضمين التغريدة
ما هي إصدارات Kubemark و Kubernetes التي تستخدمها؟ اختبرنا Kubemark 1.10 مقابل 3.2 إلى 3.2 مقابل 3.3 (أحمال عمل 500 عقدة) ، ولم نلاحظ ذلك. كم عدد العقد اللازمة لإعادة إنتاج هذا؟
gyuho
في ٧ مارس ٢٠١٨
ما هي إصدارات Kubemark و Kubernetes التي تستخدمها؟ اختبرنا Kubemark 1.10 مقابل 3.2 إلى 3.2 مقابل 3.3 (أحمال عمل 500 عقدة) ، ولم نلاحظ ذلك. كم عدد العقد اللازمة لإعادة إنتاج هذا؟
لا يمكننا إعادة إنتاجه باستخدام kubemark ، حتى مع 5k-node one - انظر أسفل https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -371171837
يبدو أن هذه مشكلة فقط في مجموعات حقيقية.
هذا سؤال مفتوح لماذا هذا هو الحال.
wojtek-t
في ٧ مارس ٢٠١٨
منذ أن عدنا إلى الخ 3.1. ل kubernetes. قمنا أيضًا بإصدار 3.1.12 etcd مع الإصلاح المهم الوحيد المتميز لـ kubernetes: عملية استعادة مراقب mvcc "غير المزامنة" . بمجرد العثور على السبب الجذري لانحدار الأداء الموجود في هذه المشكلة وإصلاحه ، يمكننا رسم خطة لترقية الخادم إلخ الذي يستخدمه kubernetes احتياطيًا حتى 3.2.
jpbetz
في ٨ مارس ٢٠١٨
يبدو أن https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100 يبدأ بالفشل باستمرار منذ هذا الصباح
krzyzacy
في ٩ مارس ٢٠١٨
من الفرق ، فإن التغيير الوحيد هو https://github.com/kubernetes/kubernetes/pull/60421 والذي يُمكّن الحصص في اختبارات الأداء الخاصة بنا افتراضيًا. الخطأ الذي نراه هو:
Container kube-controller-manager-e2e-big-master/kube-controller-manager is using 0.531144723/0.5 CPU
not to have occurred
gmarek - يبدو أن تمكين الحصص يؤثر على
اسمحوا لي أن أقدم مشكلة أخرى لإبقاء هذه المشكلة على المسار الصحيح.
shyamjvs
في ٩ مارس ٢٠١٨
@ فويتك تيjpbetzgyuhotimothysc وجدت شيئا للاهتمام حقا مع تغيير إصدار etcd، مما يشير إلى تأثير كبير الانتقال من etcd 3.1.11 إلى 3.2.16.
انظر إلى الرسم البياني التالي لاستخدام الذاكرة etcd في مجموعة 100 عقدة (زادت بمقدار 2x تقريبًا) عندما تم نقل المهمة من إصدار k8s 1.9 إلى 1.10:
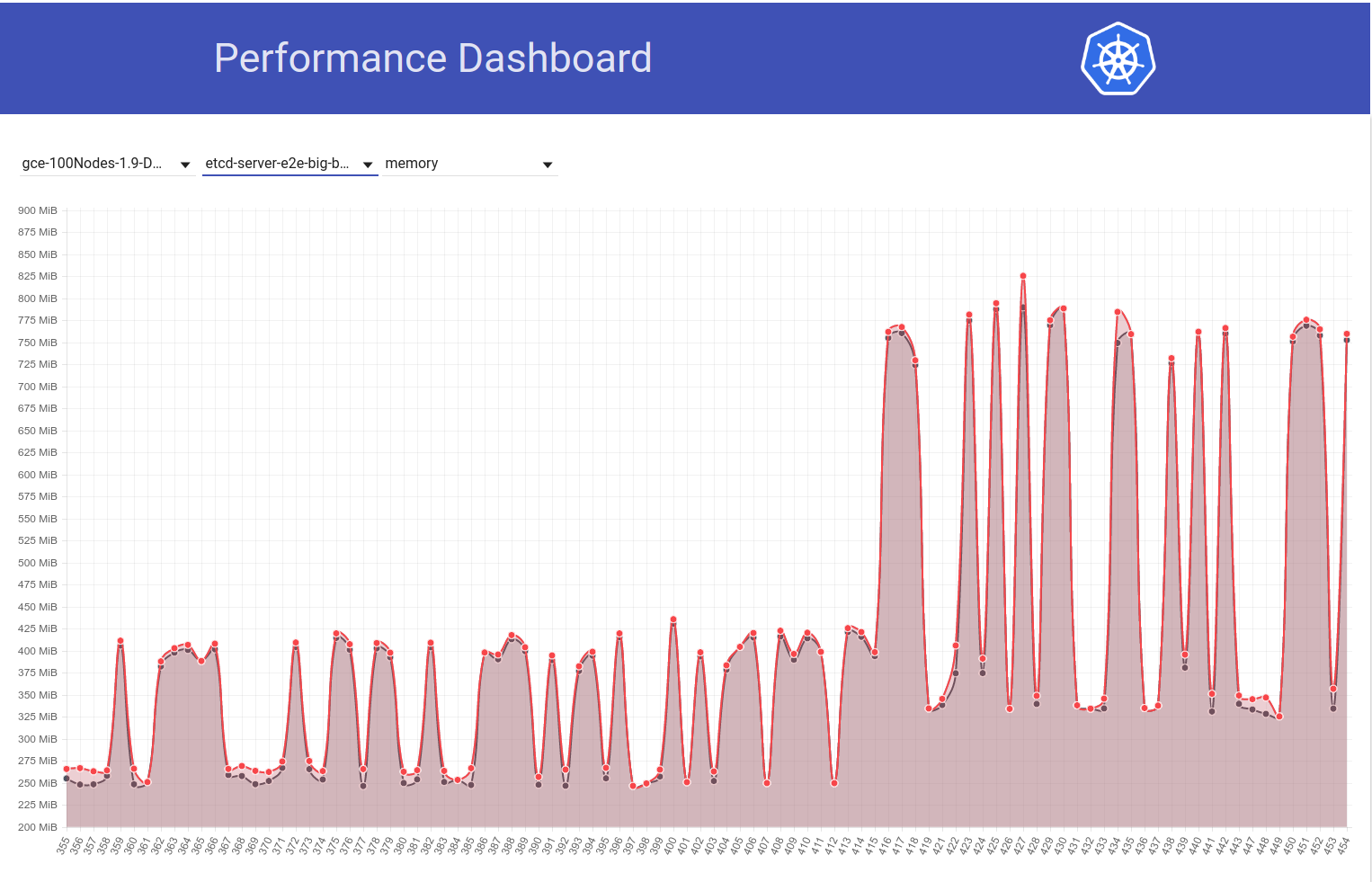
وإلقاء نظرة بعد ذلك على كيف أن وظيفتنا المكونة من 100 عقدة (التي تعمل ضد HEAD) ترى انخفاضًا في استخدام الذاكرة إلى النصف مباشرة بعد عودتي من 3.2.16 -> 3.1.11:
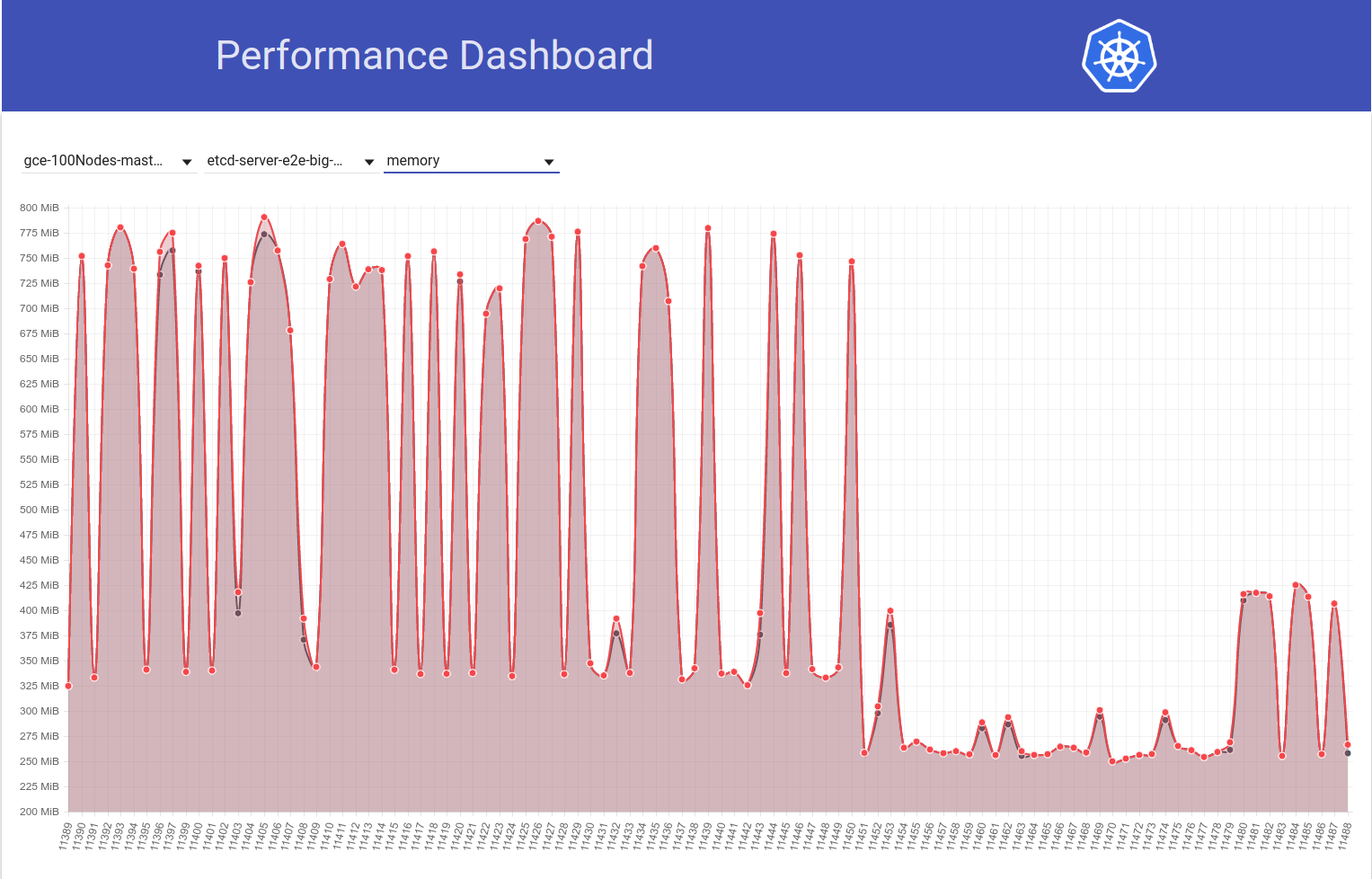
لذا فإن الإصدار 3.2 من الخادوم يُظهر بوضوح الأداء المتأثر (مع الاحتفاظ بجميع المتغيرات الأخرى كما هي) :)
shyamjvs
في ١٠ مارس ٢٠١٨
عودتي من الخ 3.2.16 -> 3.2.11:
هل نعني 3.1.11؟
gyuho
في ١٠ مارس ٢٠١٨
هذا صحيح .. آسف. تحرير تعليقي.
shyamjvs
في ١٠ مارس ٢٠١٨
shyamjvs كيف يتم تكوين الخد؟ لقد قمنا بزيادة القيمة الافتراضية --snapshot-count من 10000 إلى 100000 ، في الإصدار 3.2. لذلك إذا كان عدد اللقطات مختلفًا ، فإن الشخص الذي يحتوي على عدد أكبر من اللقطات يحتفظ بإدخالات Raft لفترة أطول ، وبالتالي يتطلب المزيد من الذاكرة المقيمة ، قبل تجاهل السجلات القديمة.
gyuho
في ١٠ مارس ٢٠١٨
آه! يبدو أن هذا بالفعل تغيير مشبوه. Wrt flags ، لا أعتقد أن هناك أي تغيير في تلك من جانب k8s. لأنه ، كما ترون في الرسم البياني الثاني أعلاه ، فإن الفرق b / w يعمل 11450 و 11451 هو في الأساس مجرد تغيير العودة وما إلى ذلك (والذي لا يبدو أنه يلامس أي علامات).
لقد قمنا بزيادة القيمة الافتراضية - عدد اللقطات من 10000 إلى 100000
هل يمكنك تأكيد ما إذا كان هذا هو السبب الجذري لهذا الاستخدام المتزايد للذاكرة؟ إذا كان الأمر كذلك ، فقد نرغب في:
- إعادة التصحيح بالقيمة الأصلية ، أو
- اضبطه على 10000 في k8s
قبل العودة إلى الإصدار 3.2
shyamjvs
في ١٠ مارس ٢٠١٨
آه! يبدو أن هذا بالفعل تغيير مشبوه.
نعم ، كان يجب إبراز هذا التغيير من جانب آخر (سيؤدي إلى تحسين سجلات التغيير لدينا وأدلة الترقية).
هل يمكنك تأكيد ما إذا كان هذا هو السبب الجذري لهذا الاستخدام المتزايد للذاكرة؟
لست متأكدًا مما إذا كان هذا هو السبب الجذري. سيساعد عدد اللقطات الأقل بالتأكيد في التخفيف من استخدام الذاكرة الشائك. إذا كان كلا الإصدارين etcd يستخدمان نفس عدد اللقطات ، لكن لا يزال أحدهما يعرض استخدامًا أعلى للذاكرة ، فيجب أن يكون هناك شيء آخر.
gyuho
في ١٠ مارس ٢٠١٨
تحديث: لقد تحققت من أن الزيادة في استخدام meme etcd ناتجة بالفعل عن ارتفاع القيمة الافتراضية لعدد اللقطة. مزيد من التفاصيل هنا - https://github.com/kubernetes/kubernetes/pull/61037#issuecomment -372457843
يجب أن نفكر في تعيينه على 10000 عندما ننتقل إلى 3.2.16 ، إذا كنا لا نريد زيادة استخدام الذاكرة.
سم مكعبgyuho @ xiang90jpbetz
shyamjvs
في ١٢ مارس ٢٠١٨
تحديث: مع إصلاح etcd ، لا يزال وقت استجابة بدء تشغيل pod 99٪ قريبًا من انتهاك SLO 5s. يوجد انحدار واحد آخر على الأقل وقد جمعت دليلًا على أنه من المرجح أن يكون في b / w تشغيل 111 و 112 من وظيفة أداء 5k node (انظر النتوء b / w الذي يعمل في الرسم البياني الذي قمت بلصقه في https: / /github.com/kubernetes/kubernetes/issues/60589#issuecomment-370568929). أقوم حاليًا بتقسيم الفرق (الذي يحتوي على حوالي 50 التزامًا) ويستغرق الاختبار حوالي 4-5 ساعات لكل تكرار.
الدليل الذي كنت أشير إليه أعلاه هو ما يلي:
مشاهدة الكمون في 111 كانت:
Feb 14 21:36:05.531: INFO: perc50: 1.070980786s, perc90: 1.743347483s, perc99: 2.629721166s
وكانت فترات الاستجابة الإجمالية لبدء تشغيل البودات عند 111 هي:
Feb 14 21:36:05.671: INFO: perc50: 2.416307575s, perc90: 3.24553118s, perc99: 4.092430858s
في حين أن نفس الرقم 112 كان:
Feb 16 10:07:43.222: INFO: perc50: 1.131108849s, perc90: 2.18487651s, perc99: 3.570548412s
و
Feb 16 10:07:43.353: INFO: perc50: 2.56160248s, perc90: 3.754024568s, perc99: 4.967573867s
في هذه الأثناء ، إذا كان شخص ما جاهزًا للعبة الرهان - يمكنك إلقاء نظرة على فرق الالتزام الذي ذكرته أعلاه وتخمين العنصر المعيب :)
shyamjvs
في ١٢ مارس ٢٠١٨
ACK. في تقدم
الوقت المتوقع: 13/03/2018
المخاطر: يمكن دفع تاريخ الإصدار إذا لم يتم تصحيحه قبل ذلك
shyamjvs
في ١٢ مارس ٢٠١٨
shyamjvs toooooooo العديد من الالتزامات لوضع الرهانات :)
 dims
في ١٣ مارس ٢٠١٨
dims
في ١٣ مارس ٢٠١٨
dims من شأنه أن يضيف المزيد من المرح على ما أعتقد ؛)
تحديث: لذلك قمت بإجراء عدد قليل من التكرارات للتقسيم وإليك كيف بدت المقاييس ذات الصلة عبر الالتزامات (مرتبة ترتيبًا زمنيًا). لاحظ أنه بالنسبة لتلك التي قمت بتشغيلها يدويًا ، قمت بتشغيلها مع رجوع الانحدار السابق (أي 3.2. -> 3.1.11).
| الالتزام | 99٪ مشاهدة الكمون | 99٪ زمن انتقال جراب بدء التشغيل | جيد سيئ؟ |
| ------------- | ------------- | ----- | ------- |
| a042ecde36 (من Run-111) | 2.629721166s | 4.092430858s | جيد (التأكيد مرة أخرى يدويًا) |
| 5f7b530d87 (يدوي) | 3.150616856s | 4.683392706s | سيء (محتمل) |
| a8060ab0a1 (يدوي) | 3.11319985s | 4.710277511s | سيء (محتمل) |
| 430c1a68c8 (من تشغيل 112) | 3.570548412s | 4.967573867s | سيء |
| 430c1a68c8 (يدوي) | 3.63505091 ثانية | 4.96697776 ثانية | سيء |
مما سبق ، يبدو أنه قد يكون هناك انحداران هنا (لأنه ليس قفزة مباشرة من 2.6 ثانية -> 3.6 ثانية) - واحد ب / ث "a042ecde36 - 5f7b530d87" وآخر ب / ث "a8060ab0a1 - 430c1a68c8" تنهد!
shyamjvs
في ١٣ مارس ٢٠١٨
التعبير عن النطاقات للحصول على روابط مقارنة:
ارجوكم ...
أ8060ab0a1 ... 430c1a6
 liggitt
في ١٣ مارس ٢٠١٨
liggitt
في ١٣ مارس ٢٠١٨
لقد حصلت للتو على نتائج التشغيل اليدوي مقابل a042ecde36 وهذا يجعل الحياة أكثر صعوبة:
3.269330734s (watch), 4.939237532s (pod-startup)
لأن هذا ربما يعني أنه قد يكون انحدارًا غير مستقر.
shyamjvs
في ١٣ مارس ٢٠١٨
أقوم حاليًا بإجراء الاختبار مقابل a042ecde36 مرة أخرى للتحقق من احتمالية حدوث الانحدار حتى قبل ذلك.
shyamjvs
في ١٣ مارس ٢٠١٨
إذن ها هي نتيجة الجري ضد a042ecd مرة أخرى:
2.645592996s (watch), 5.026010032s (pod-startup)
ربما يعني هذا أن الانحدار دخل حتى قبل تشغيل 111 (خبر جيد أن لدينا نهاية صحيحة للتقسيم الآن).
سأحاول الآن السعي إلى النهاية اليسرى. Run-108 (الالتزام 11104d75f) هو مرشح محتمل ، والذي كان له النتائج التالية عندما قمت بتشغيله مسبقًا (مع إلخ 3.1.11):
2.593628224s (watch), 4.321942836s (pod-startup)
يبدو أن إعادة التشغيل الخاصة بي ضد الالتزام 11104d7 تقول إنها جيدة:
2.663456162s (watch), 4.288927203s (pod-startup)
سآخذ طعنة هنا في التشريح في النطاق 11104d7 ... a042ecd
shyamjvs
في ١٣ مارس ٢٠١٨
تحديث: كنت بحاجة لاختبار الالتزام 097efb71a315 ثلاث مرات من أجل اكتساب الثقة. يظهر بعض التباين ، لكنه يبدو التزامًا جيدًا:
2.578970061s (watch), 4.129003596s (pod-startup)
2.315561531s (watch), 4.70792639s (pod-startup)
2.303510957s (watch), 3.88150234s (pod-startup)
سأستمر في التقسيم أكثر.
ومع ذلك ، يبدو أنه كان هناك ارتفاع آخر (~ 1 ثانية) في زمن انتقال pod-startup منذ يومين فقط. وهذا يدفع 99٪ إلى ما يقرب من 6 ثوانٍ:
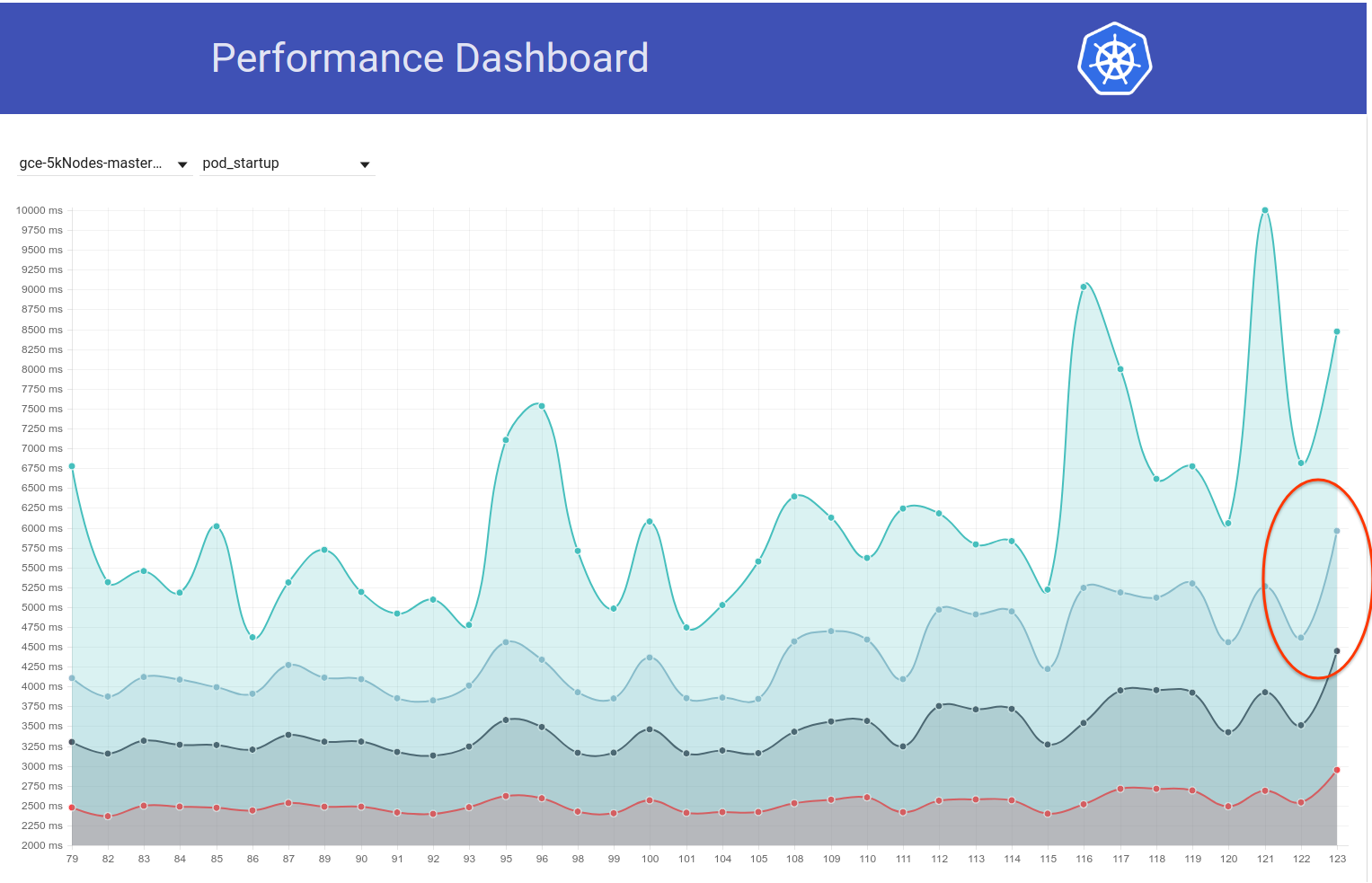
المشتبه فيه الأساسي من فرق الالتزام هو تغيير الخ من 3.1.11 -> 3.1.12 (https://github.com/kubernetes/kubernetes/pull/60998). كنت أنتظر الجولة التالية (قيد التقدم حاليًا) لأؤكد أنها لم تكن لمرة واحدة - لكننا نحتاج حقًا إلى فهم ذلك.
تضمين التغريدة
shyamjvs
في ١٤ مارس ٢٠١٨
نظرًا لأنني سأكون في إجازة يوم الخميس والجمعة هذا الأسبوع ، فأنا ألصق تعليمات لإجراء اختبار الكثافة مقابل مجموعة عقدة 5k (بحيث يمكن لأي شخص لديه حق الوصول إلى المشروع متابعة التقسيم):
# Start with a clean shell.
# Checkout to the right commit.
make quick-release
# Set the project:
gcloud config set project k8s-scale-testing
# Set some configs for creating/testing 5k-node cluster:
export CLOUDSDK_CORE_PRINT_UNHANDLED_TRACEBACKS=1
export KUBE_GCE_ZONE=us-east1-a
export NUM_NODES=5000
export NODE_SIZE=n1-standard-1
export NODE_DISK_SIZE=50GB
export MASTER_MIN_CPU_ARCHITECTURE=Intel\ Broadwell
export ENABLE_BIG_CLUSTER_SUBNETS=true
export LOGROTATE_MAX_SIZE=5G
export KUBE_ENABLE_CLUSTER_MONITORING=none
export ALLOWED_NOTREADY_NODES=50
export KUBE_GCE_ENABLE_IP_ALIASES=true
export TEST_CLUSTER_LOG_LEVEL=--v=1
export SCHEDULER_TEST_ARGS=--kube-api-qps=100
export CONTROLLER_MANAGER_TEST_ARGS=--kube-api-qps=100\ --kube-api-burst=100
export APISERVER_TEST_ARGS=--max-requests-inflight=3000\ --max-mutating-requests-inflight=1000
export TEST_CLUSTER_RESYNC_PERIOD=--min-resync-period=12h
export TEST_CLUSTER_DELETE_COLLECTION_WORKERS=--delete-collection-workers=16
export PREPULL_E2E_IMAGES=false
export ENABLE_APISERVER_ADVANCED_AUDIT=false
# Bring up the cluster (this brings down pre-existing one if present, so you don't have to explicitly '--down' the previous one) and run density test:
go run hack/e2e.go \
--up \
--test \
--test_args='--ginkgo.focus=\[sig\-scalability\]\sDensity\s\[Feature\:Performance\]\sshould\sallow\sstarting\s30\spods\sper\snode\susing\s\{\sReplicationController\}\swith\s0\ssecrets\,\s0\sconfigmaps\sand\s0\sdaemons$ --allowed-not-ready-nodes=30 --node-schedulable-timeout=30m --minStartupPods=8 --gather-resource-usage=master --gather-metrics-at-teardown=master' \
> somepath/build-log.txt 2>&1
# To re-run the test on same cluster (without re-creating) just omit '--up' in the above.
ملاحظات هامة:
- نطاق الالتزام الحالي المشتبه به هو ff7918d ... a042ecde3 (دعنا نحافظ على تحديث هذا بينما ننصف)
- نحتاج إلى استخدام etcd-3.1.11 بدلاً من 3.2.14 (لتجنب تضمين الانحدار السابق). قم بتغيير الإصدار في الملفات التالية لتحقيق ذلك الحد الأدنى:
- الكتلة / gce / manifests / etcd
- الكتلة / الصور / etcd / Makefile
- hack / lib / etcd.sh
shyamjvs
في ١٤ مارس ٢٠١٨
نسخة إلى: @ wojtek-t
jdumars
في ١٤ مارس ٢٠١٨
etcd v3.1.12 يعمل على إصلاح أخطاء حدث المشاهدة عند الاستعادة. وهذا هو التغيير الوحيد الذي أجريناه من الإصدار 3.1.11. هل يتضمن اختبار الأداء أي شيء مع إعادة تشغيل إلخ أو متعدد العقد قد يؤدي إلى لقطة من القائد؟
gyuho
في ١٤ مارس ٢٠١٨
هل يتضمن اختبار الأداء أي شيء مع إعادة تشغيل الخ
من سجلات الخ ، لا يبدو أنه كان هناك أي إعادة تشغيل.
متعدد العقدة
نحن نستخدم فقط عقدة واحدة وما إلى ذلك في إعدادنا (على افتراض أن هذا ما طلبته).
shyamjvs
في ١٤ مارس ٢٠١٨
أنا أرى. بعد ذلك ، يجب ألا يكون الإصدار 3.1.11 و v3.1.12 مختلفين: 0
سيتم إلقاء نظرة أخرى إذا كان التشغيل الثاني يظهر أيضًا زمن انتقال أعلى.
gyuho
في ١٤ مارس ٢٠١٨
نسخة إلى :
jdumars
في ١٤ مارس ٢٠١٨
اتفق مع gyuho على أننا يجب أن نحاول الحصول على إشارة أقوى على هذه الإشارة نظرًا لأن تغيير الكود الوحيد إلى etcd معزول لإعادة تشغيل / استرداد الكود.
التغيير الآخر الوحيد هو ترقية etcd من go1.8.5 إلى go1.8.7 ، لكنني أشك في أننا سنرى تراجعًا كبيرًا في الأداء مع ذلك.
jpbetz
في ١٤ مارس ٢٠١٨
لذا ، بالاستمرار في التقسيم ، يبدو أن ff7918d1f جيد:
2.246719086s (watch), 3.916350274s (pod-startup)
سوف أقوم بتحديث نطاق الالتزام في https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -373051051 وفقًا لذلك.
shyamjvs
في ١٤ مارس ٢٠١٨
بعد ذلك ، يبدو الالتزام aa19a1726 جيدًا ، على الرغم من أنني أقترح إعادة المحاولة مرة أخرى للتأكيد:
2.715156606s (watch), 4.382527095s (pod-startup)
في هذه المرحلة ، سأوقف التنصيف وأبدأ عطلتي :)
لقد أسقطت مجموعتي لإفساح المجال للجولة التالية.
shyamjvs
في ١٥ مارس ٢٠١٨
شكرا شيام. أنا أحاول إعادة المحاولة aa19a172693a4ad60d5a08e9b93557267d259c37.
 wasylkowski-a
في ١٥ مارس ٢٠١٨
wasylkowski-a
في ١٥ مارس ٢٠١٨
للالتزام aa19a172693a4ad60d5a08e9b93557267d259c37 حصلت على النتائج التالية:
2.47655243s (watch), 4.174016696s (pod-startup)
لذا يبدو هذا جيدًا. التنصيف المستمر.
نطاق الالتزام الحالي المشتبه به: aa19a172693a4ad60d5a08e9b93557267d259c37 ... a042ecde362000e51f1e7bdbbda5bf9d81116f84
wasylkowski-a
في ١٥ مارس ٢٠١٨
@ wasylkowski-a هل يمكنك حضور اجتماع الإصدار الخاص بنا في 5PM UTC / 1PM Eastern / 10AM Pacific؟ إنه اجتماع Zoom: https://zoom.us/j/2018742972
jdumars
في ١٥ مارس ٢٠١٨
سأحضر.
wasylkowski-a
في ١٥ مارس ٢٠١٨
يبدو الالتزام cca7ccbff161255292f72c2d18459cdface62122 غير واضح مع النتائج التالية:
2.984185673s (watch), 4.568914929s (pod-startup)
سأجري هذا مرة أخرى للحصول على الثقة أنني لا أدخل النصف الخطأ من التنصيف.
wasylkowski-a
في ١٥ مارس ٢٠١٨
حسنًا ، أنا واثق تمامًا الآن من أن cca7ccbff161255292f72c2d18459cdface62122 سيء:
3.285168535s (watch), 4.783986141s (pod-startup)
قص النطاق وصولاً إلى aa19a172693a4ad60d5a08e9b93557267d259c37 ... cca7ccbff161255292f72c2d18459cdface62122 وتجربة 92e4d3da0076f923a45d54d69c84e91ac6a61a55.
wasylkowski-a
في ١٦ مارس ٢٠١٨
الالتزام 92e4d3da0076f923a45d54d69c84e91ac6a61a55 يبدو جيدًا:
2.522438984s (watch), 4.21739985s (pod-startup)
نطاق الالتزام الجديد المشتبه به هو 92e4d3da0076f923a45d54d69c84e91ac6a61a55 ... cca7ccbff161255292f72c2d18459cdface62122 ، تجربة 603ebe466d335a37392315d491782ed18d1bae11
wasylkowski-a
في ١٦ مارس ٢٠١٨
wasylkowski ، يرجى ملاحظة أنه تم https://github.com/kubernetes/kubernetes/commit/4c289014a05669c376994868d8d91f7565a204b5 في https://github.com/kubernetes/kubernetes/commit/493f3358307b3998
dims
في ١٦ مارس ٢٠١٨
إعادة صياغة تعليق نلاحق شبح إشارة هنا في القسم. إذا كانت المشكلة 4c28901 ، وتم إرجاعها عند 493f335 بالفعل لأسباب تبدو غير ذات صلة ، فهل يُظهر اختبار قابلية التوسع مقابل رأس الفرع 1.10 إشارة خضراء؟
هل يمكننا إعطاء الأولوية لإعادة الاختبار مرة واحدة مقابل 1.10 رأس فرع ، بدلاً من استمرار التقسيم؟
 tpepper
في ١٦ مارس ٢٠١٨
tpepper
في ١٦ مارس ٢٠١٨
wasylkowski / @ wasylkowski- ا ^ ^ ^ ^
tpepper
في ١٦ مارس ٢٠١٨
@ wojtek-t PTAL في اسرع وقت ممكن
jdumars
في ١٦ مارس ٢٠١٨
شكرا dims وtpepper. دعنا نحاول ضد رأس الفرع 1.10 ونرى ما سيحدث.
wasylkowski-a
في ١٦ مارس ٢٠١٨
شكرا wasylkowski أسوأ حالة نعود إلى ما كنا نصفه من قبل. حق؟
dims
في ١٦ مارس ٢٠١٨
1.10 الرأس لديه انحدار:
3.522924087s (watch), 4.946431238s (pod-startup)
هذا في 3.1.12 ، وليس إلخ 3.1.11 ، ولكن إذا فهمته بشكل صحيح ، فلن يحدث هذا فرقًا كبيرًا.
أيضا ، 603ebe466d335a37392315d491782ed18d1bae11 تبدو جيدة:
2.744654024s (watch), 4.284582476s (pod-startup)
2.76287483s (watch), 4.326409841s (pod-startup)
2.560703844s (watch), 4.213785531s (pod-startup)
هذا يتركنا مع النطاق 603ebe466d335a37392315d491782ed18d1bae11 ... cca7ccbff161255292f72c2d18459cdface62122 وهناك 3 التزامات فقط هناك. اسمحوا لي أن أرى ما اكتشفت.
من الممكن أيضًا أن يكون 4c289014a05669c376994868d8d91f7565a204b5 هو الجاني بالفعل ، ولكن هذا يعني أن لدينا انحدارًا آخر يتجلى بشكل رأسي.
wasylkowski-a
في ١٦ مارس ٢٠١٨
حسنًا ، من الواضح أن الالتزام بـ 6590ea6d5d50700d34255b1e037b2702ad26b7fc أمر جيد:
2.553170576s (watch), 4.22516704s (pod-startup)
بينما الالتزام 7b678dc4035c61a1991b5e1442edb13f40deae72 سيء:
3.498855918s (watch), 4.886599251s (pod-startup)
الالتزام السيئ هو دمج الالتزام المراجع الذي ذكره
اسمحوا لي أن أحاول إعادة تشغيل 3.1.11 بشكل مباشر بدلاً من 3.1.12 ونرى ما سيحدث.
wasylkowski-a
في ١٧ مارس ٢٠١٨
@ wasylkowski- آه كلاسيك الأخبار الجيدة الأخبار السيئة :) شكرا لاستمرار هذا.
@ wojtek- تي أي اقتراحات أخرى؟
dims
في ١٧ مارس ٢٠١٨
Head on etcd 3.1.11 سيئ أيضًا ؛ ستكون محاولتي التالية هي المحاولة مباشرة بعد العودة (لذلك ، عند الالتزام cdecea545553eff09e280d389a3aef69e2f32bf1) ، ولكن مع إلخ 3.1.11 بدلاً من 3.2.14.
wasylkowski-a
في ١٧ مارس ٢٠١٨
يبدو اندرزيج جيد
- يخفت
في 17 مارس 2018 ، الساعة 1:19 مساءً ، كتب Andrzej Wasylkowski [email protected] :
Head on etcd 3.1.11 سيئ أيضًا ؛ ستكون محاولتي التالية هي المحاولة مباشرة بعد العودة (لذلك ، عند الالتزام cdecea5) ، ولكن مع إلخ 3.1.11 بدلاً من 3.2.14.
-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذه الرسالة الإلكترونية مباشرةً ، أو اعرضها على GitHub ، أو قم بكتم صوت الموضوع.
dims
في ١٧ مارس ٢٠١٨
الالتزام cdecea545553eff09e280d389a3aef69e2f32bf1 جيد ، لذلك لدينا انحدار لاحق:
2.66454307s (watch), 4.308091589s (pod-startup)
الالتزام 2a373ace6eda6a9cf050ce70a6cf99183c5e5b37 سيء بشكل واضح:
3.656979569s (watch), 6.746987916s (pod-startup)
@ wasylkowski-a لذا فنحن ننظر أساسًا إلى الالتزامات في النطاق https://github.com/kubernetes/kubernetes/compare/cdecea5...2a373ac لمعرفة ما هو الخطأ إذن؟ (تشغيل شطر بين هذين)؟
dims
في ١٧ مارس ٢٠١٨
نعم. هذا نطاق ضخم ، للأسف. أنا الآن أحقق في aded0d922592fdff0137c70443caf2a9502c7580.
wasylkowski-a
في ١٧ مارس ٢٠١٨
شكرا wasylkowski ما هو النطاق الحالي؟ (حتى أتمكن من إلقاء نظرة على العلاقات العامة).
dims
في ١٨ مارس ٢٠١٨
تنفيذ aded0d922592fdff0137c70443caf2a9502c7580 سيء:
3.626257043s (watch), 5.00754503s (pod-startup)
الالتزام f8298702ffe644a4f021e23a616ad6a8790a5537 سيء أيضًا:
3.747051371s (watch), 6.126914967s (pod-startup)
لذلك هو الالتزام 20a6749c3f86c7cb9e98442046532380fb5f6e36:
3.641172882s (watch), 5.100922237s (pod-startup)
وكذلك هو 0e81651e77e0be7e75179e5986ef2c76601f4bd6:
3.687028394s (watch), 5.208157763s (pod-startup)
النطاق الحالي هو cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6. لقد بدأنا (me، @ wojtek-t،shyamjvs) في الشك في أن cdecea545553eff09e280d389a3aef69e2f32bf1 هو في الواقع تمريرة غير مستقرة ، لذلك نحتاج إلى نهاية يسرى مختلفة
wasylkowski-a
في ١٩ مارس ٢٠١٨
/ me تراهن على https://github.com/kubernetes/kubernetes/commit/b259543985b10875f4a010ed0285ac43e335c8e0 باعتباره الجاني
cc @ wasylkowski-a
dims
في ١٩ مارس ٢٠١٨
0e81651e77e0be7e75179e5986ef2c76601f4bd6 هو، تبين، سيئة، لذلك b259543985b10875f4a010ed0285ac43e335c8e0 (دمج كما 244549f02afabc5be23fc56e86a60e5b36838828، بعد 0e81651e77e0be7e75179e5986ef2c76601f4bd6) لا يمكن أن يكون أقرب الجاني (على الرغم من أنه ليس من المستحيل أن أدخلت بعد الانحدار آخر ونحن سوف نلاحظ بمجرد أن نفض هذا واحد)
wasylkowski-a
في ١٩ مارس ٢٠١٨
لكل @ فويتك تي وshyamjvs أنا rerunning cdecea545553eff09e280d389a3aef69e2f32bf1، لأننا أظن أن هذا قد يكون "جيدة قشاري"
wasylkowski-a
في ١٩ مارس ٢٠١٨
سأفترض أن cdecea545553eff09e280d389a3aef69e2f32bf1 جيد بالفعل بناءً على النتائج التالية التي لاحظتها:
2.66454307s (watch), 4.308091589s (pod-startup)
2.695629257s (watch), 4.194027608s (pod-startup)
2.660956347s (watch), 3m36.62259323s (pod-startup) <-- looks like an outlier
2.865445137s (watch), 4.594671099s (pod-startup)
2.412093606s (watch), 4.070130529s (pod-startup)
النطاق المشتبه به حاليًا: cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6
اختبار 99c87cf679e9cbd9647786bf7e81f0a2d771084f حاليًا
wasylkowski-a
في ٢٠ مارس ٢٠١٨
شكرا لك wasylkowski على مواصلة هذا العمل.
jdumars
في ٢٠ مارس ٢٠١٨
لكل مناقشة اليوم: لا يزال fluentd-scaler يواجه مشكلات: https://github.com/kubernetes/kubernetes/issues/61190 ، والتي لم يتم إصلاحها بواسطة العلاقات العامة. هل من الممكن أن يكون هذا الانحدار سببه بطلاقة؟
 jberkus
في ٢٠ مارس ٢٠١٨
jberkus
في ٢٠ مارس ٢٠١٨
أحد العلاقات العامة المتعلقة بطلاقة https://github.com/kubernetes/kubernetes/commit/a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 هو في أحدث نطاق
dims
في ٢٠ مارس ٢٠١٨
في كل مناقشة اليوم: ما زال المتسلل بطلاقة يواجه مشكلات: # 61190 ، والتي لم يتم إصلاحها بواسطة العلاقات العامة. هل من الممكن أن يكون هذا الانحدار سببه بطلاقة؟
TBH ، سأكون مندهشًا حقًا إذا كان ذلك بسبب مشكلات بطلاقة. لكن لا يمكنني استبعاد هذه الفرضية بالتأكيد.
سيكون شعوري الشخصي هو بعض التغيير في Kubelet ، لكنني نظرت أيضًا في العلاقات العامة في هذا النطاق ولا يبدو أي شيء مريبًا حقًا ...
نأمل أن يكون النطاق أصغر 4 مرات غدًا ، مما يعني مجرد زوجين من العلاقات العامة.
wojtek-t
في ٢٠ مارس ٢٠١٨
حسنًا ، حسنًا ، يبدو 99c87cf679e9cbd9647786bf7e81f0a2d771084f جيدًا ، لكنني كنت بحاجة إلى ثلاثة أشواط للتأكد من أن هذا ليس تقشرًا:
2.901624657s (watch), 4.418169754s (pod-startup)
2.938653965s (watch), 4.423465198s (pod-startup)
3.047455619s (watch), 4.455485098s (pod-startup)
التالي ، a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 سيء:
3.769747695s (watch), 5.338517616s (pod-startup)
النطاق الحالي هو 99c87cf679e9cbd9647786bf7e81f0a2d771084f ... a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2. تحليل c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd.
wasylkowski-a
في ٢٠ مارس ٢٠١٨
لقد بحثت في النطاق المذكور أعلاه - لا يوجد سوى 9 علاقات عامة هناك.
https://github.com/kubernetes/kubernetes/pull/59944 - 100٪ NOT - فقط يغير ملف المالكين
https://github.com/kubernetes/kubernetes/pull/59953 - يحتمل
https://github.com/kubernetes/kubernetes/pull/59809 - لمس رمز kubectl فقط ، لذلك لا يهم في هذه الحالة
https://github.com/kubernetes/kubernetes/pull/59955 - 100٪ NOT - فقط لمس اختبارات e2e غير ذات الصلة
https://github.com/kubernetes/kubernetes/pull/59808 - من المحتمل (يغير إعداد المجموعة)
https://github.com/kubernetes/kubernetes/pull/59913 - 100٪ NOT - فقط لمس اختبارات e2e غير ذات الصلة
https://github.com/kubernetes/kubernetes/pull/59917 - إنه يغير الاختبار ، لكن لا يشغل التغييرات ، لذا من غير المحتمل
https://github.com/kubernetes/kubernetes/pull/59668 - 100٪ ليس - فقط لمس رمز AWS
https://github.com/kubernetes/kubernetes/pull/59909 - 100٪ NOT - فقط لمس ملفات المالكين
لذلك أعتقد أن لدينا مرشحان هنا: https://github.com/kubernetes/kubernetes/pull/59953 و https://github.com/kubernetes/kubernetes/pull/59808
سأحاول التعمق في هؤلاء لفهمهم.
wojtek-t
في ٢١ مارس ٢٠١٨
c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd تبدو سيئة إلى حد ما:
3.428891786s (watch), 4.909251611s (pod-startup)
بالنظر إلى أن هذا هو دمج # 59953 ، أحد المشتبه بهم في Wojtek ، سأعمل الآن على التزام واحد قبل ذلك ، لذا f60083549a43f152b3142e01756e25611d911770.
ومع ذلك ، فإن هذا الالتزام هو تغيير OWNERS_ALIASES ، ولم يتبق شيء في هذا النطاق قبله ، لذلك يجب أن تكون المشكلة c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd. سأجري الاختبار فقط من أجل السلامة ، على أي حال.
wasylkowski-a
في ٢١ مارس ٢٠١٨
تمت مناقشته في وضع عدم الاتصال - سنجري اختبارات في الرأس مع عودة الالتزام محليًا بدلاً من ذلك.
wojtek-t
في ٢١ مارس ٢٠١٨
نجاح باهر! بطانة واحدة تسبب الكثير من المتاعب. شكرا wasylkowski @ wojtek-t
dims
في ٢١ مارس ٢٠١٨
dims يمكن
بشكل عام ، قد ترغب في الاطلاع على https://github.com/kubernetes/community/blob/master/sig-scalability/blogs/scalability-regressions-case-studies.md للحصول على قراءة جيدة :)
shyamjvs
في ٢١ مارس ٢٠١٨
إعادة التحديث. اختبار في الرأس: أول تشغيل مع تم إرجاع الالتزام محليًا. قد يكون هذا تقشرًا ، لذلك أنا أعيد تشغيله.
wasylkowski-a
في ٢١ مارس ٢٠١٨
بالنظر إلى الالتزام في https: //github.com/kubernetes/kubernetes/pull/59953 ... ألم يكن
liggitt
في ٢١ مارس ٢٠١٨
@ Random-Liu الذي قد يكون قادرًا على شرح لنا بشكل أفضل ما هو تأثير هذا التغيير :)
shyamjvs
في ٢١ مارس ٢٠١٨
بالنظر إلى الالتزام في # 59953 ... ألم يكن إصلاحًا لخلل؟ يبدو أنه تم إصلاح خطأ بوضع الحالة "المجدولة" في الكائن الخطأ. هل يمكن أن يكون kubelet قد أبلغ عن جدول زمني مبكر جدًا للقرن قبل ذلك الإصلاح؟
نعم - أعلم أنه كان إصلاحًا للأخطاء. أنا فقط لا أفهم ذلك تمامًا.
يبدو أن إصلاح مشكلة الإبلاغ عن البودات على أنها "مجدولة". لكننا لا نرى المشكلة حتى الوقت الذي يتم الإبلاغ عنه بواسطة kubelet على أنه "StartedAt".
تكمن المشكلة في أننا نرى زيادة كبيرة بين الوقت الذي تم الإبلاغ عنه كـ "StartedAt" بواسطة Kubelet وعند الإبلاغ عن تحديث حالة pod ومشاهدته بواسطة الاختبار.
لذلك أعتقد أن الجزء "المجدول" يعد بمثابة رد فعل هنا.
تخميني (ولكن هذا لا يزال مجرد تخمين) هو أنه بسبب هذا التغيير ، فإننا نرسل المزيد من تحديثات حالة Pod ، مما يؤدي بدوره إلى المزيد من 429s أو شيء من هذا القبيل. وفي النهاية ، يستغرق الأمر وقتًا أطول حتى يقوم Kubelet بالإبلاغ عن حالة البود. لكن هذا شيء ما زلنا بحاجة إلى تأكيده.
wojtek-t
في ٢١ مارس ٢٠١٨
بعد جولتين ، أنا على ثقة تامة من أن الرجوع إلى # 59953 يحل المشكلة:
3.052567319s (watch), 4.489142104s (pod-startup)
2.799364978s (watch), 4.385999497s (pod-startup)
نحن نرسل المزيد من تحديثات حالة Pod ، والتي بدورها تؤدي إلى المزيد من 429 أو شيء من هذا القبيل. وفي النهاية ، يستغرق الأمر وقتًا أطول حتى يقوم Kubelet بالإبلاغ عن حالة البود.
هذا هو التأثير الذي كنت أفترضه إلى حد كبير في https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 (على الرغم من أن السبب الذي توقعته كان خاطئًا) :)
أيضًا ، يبدو أننا في IIRC شهدنا زيادة في # 429 ثانية لمكالمات الوضع (راجع https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370582634) ولكن كان ذلك من نطاق سابق على ما أعتقد ( حول تغيير الخ).
shyamjvs
في ٢١ مارس ٢٠١٨
بعد جولتين ، أنا على ثقة تامة من أن الرجوع إلى # 59953 يحل المشكلة:
كان حدسي (https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370874602) حول كون المشكلة على جانب kubelet مبكرًا جدًا في الموضوع صحيحًا بعد كل شيء :)
shyamjvs
في ٢١ مارس ٢٠١٨
/ عقدة سيج
@ kubernetes / sig-node-bugs يمكن لفريق الإصدار حقًا استخدام المراجعة على # 59953 الالتزام مقابل التراجع ومشكلة الأداء هنا
tpepper
في ٢١ مارس ٢٠١٨
بالنظر إلى الالتزام في # 59953 ... ألم يكن إصلاحًا لخلل؟ يبدو أنه تم إصلاح خطأ بوضع الحالة "المجدولة" في الكائن الخطأ. استنادًا إلى المشكلة المشار إليها في تلك العلاقات العامة ، يبدو أن kubelet قد يفوت الإبلاغ عن جدول زمني للقرص بدون هذا الإصلاح؟
liggitt شكرا لشرح هذا بالنسبة لي. نعم ، هذا العلاقات العامة يعمل على إصلاح الخلل. في السابق ، لم يقم kubelet دائمًا بتعيين PodScheduled . مع # 59953 ، سيفعل kubelet ذلك بشكل صحيح.
shyamjvs لست متأكدًا مما إذا كان يمكن أن يقدم المزيد من تحديث حالة البود.
إذا فهمت بشكل صحيح ، فسيتم تعيين حالة PodScheduled في أول تحديث للحالة ، وبعد ذلك سيكون هناك دائمًا ولن يتغير أبدًا. لا أفهم سبب إنشاء المزيد من تحديثات الحالة.
إذا كانت تقدم بالفعل مزيدًا من تحديث الحالة ، فهذه مشكلة تم تقديمها منذ عامين https://github.com/kubernetes/kubernetes/pull/24459 لكنها مغطاة بخلل ، و # 59953 فقط أصلح الخطأ ...
@ wasylkowski-a هل لديك سجلات للتشغيل التجريبي الثاني في https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -374982422 و https://github.com/kubernetes/kubernetes/issues/60589# إصدار -374871490؟ أساسا جيدة وسيئة. سيكون kubelet.log مفيدًا جدًا.
 Random-Liu
في ٢١ مارس ٢٠١٨
Random-Liu
في ٢١ مارس ٢٠١٨
yujuhong ووجدت أن # 59953 كشف عن مشكلة أن حالة البود الثابت PodScheduled ستستمر في التحديث.
ينشئ Kubelet حالة PodScheduled جديدة للقرص الذي لا يحتوي عليه. لا يحتوي البود الثابت عليه ، ولا يتم تحديث حالته أبدًا (السلوك المتوقع). وبالتالي ، سيستمر kubelet في إنشاء حالة PodScheduled جديدة للقرص الثابت.
تم تقديم المشكلة في # 24459 ، لكن تمت تغطيتها بواسطة خطأ. # 59953 أصلح الخلل ، وكشف المشكلة الأصلية.
هناك خياران لإصلاح هذا بسرعة:
- الخيار 1: لا تدع kubelet يضيف حالة
PodScheduled، يجب أن يحتفظ kubelet فقط بالشرطPodScheduledتعيينه بواسطة المجدول.- الايجابيات: بسيط.
- السلبيات: لن يكون للجراب الثابت والقرن الذي يمر عبر المجدول (تعيين اسم العقدة مباشرة) حالة
PodScheduled. في الواقع بدون # 59953 ، على الرغم من أن kubelet سيحدد هذا الشرط في النهاية لتلك القرون ، إلا أن الأمر قد يستغرق وقتًا طويلاً جدًا بسبب خطأ.
- الخيار 2: قم بإنشاء حالة
PodScheduledللقرن الثابت عندما يراه kubelet في البداية.
قد يقدم الخيار 2 تغييرات أقل تواجه المستخدم.
لكننا نريد أن نسأل ماذا يعني PodScheduled للبودات التي لم يتم جدولتها بواسطة المجدول؟ هل نحن حقا بحاجة إلى هذا الشرط لتلك القرون؟ / cc @ kubernetes / sig-autoscaling-bugs لأن yujuhong أخبرني أن PodScheduled يُستخدم بواسطة القياس التلقائي الآن.
/ cc @ kubernetes / sig-node-bugs @ kubernetes / sig-Scheduling-bugs
Random-Liu
في ٢١ مارس ٢٠١٨
@ Random-Liu ما هو تأثير very long time for kubelet to eventually set this condition ؟ ما المشكلة التي سيلاحظها / يواجهها المستخدم النهائي (خارج الاختبار يسخر التقلب)؟ (من الخيار رقم 1)
dims
في ٢١ مارس ٢٠١٨
dims لن يرى المستخدم حالة PodScheduled لفترة طويلة.
Random-Liu
في ٢١ مارس ٢٠١٨
لدي إصلاح # 61504 الذي ينفذ الخيار 2 في https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979.
يمكنني تغييره إلى الخيار 1 إذا اعتقد الناس أن هذا حل أفضل. :)
Random-Liu
في ٢١ مارس ٢٠١٨
من الأفضل أن تسأل الأشخاص الذين يعرفون هذا من الداخل إلى الخارج! (ليس فريق الإصدار 😄!)
pingdashpole @ dchen1107derekwaynecarr
dims
في ٢١ مارس ٢٠١٨
@ Random-Liu IIRC ، البود الثابت الوحيد الذي يعمل على العقد في اختباراتنا هو kube-proxy. هل يمكنك معرفة عدد المرات التي يتم فيها إجراء هذه "التحديثات المستمرة" بواسطة kubelet؟ (يسأل من أجل تقدير qps الإضافية التي قدمها الخطأ)
shyamjvs
في ٢١ مارس ٢٠١٨
@ Random-Liu IIRC ، البود الثابت الوحيد الذي يعمل على العقد في اختباراتنا هو kube-proxy. هل يمكنك معرفة عدد المرات التي يتم فيها إجراء هذه "التحديثات المستمرة" بواسطة kubelet؟ (يسأل من أجل تقدير qps الإضافية التي قدمها الخطأ)
shyamjvs نعم ، kube-proxy هو الوحيد على العقدة الآن.
أعتقد أن ذلك يعتمد على تردد مزامنة pod https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/kubeletconfig/v1beta1/defaults.go#L47 ، وهي دقيقة واحدة. لذا يقوم kubelet بإنشاء تحديث إضافي لحالة البود كل دقيقة واحدة.
Random-Liu
في ٢٢ مارس ٢٠١٨
شكر. هذا يعني أن 5000/60 = ~ 83 qps مضافة إضافية بسبب مكالمات حالة pod. يبدو أنه يفسر زيادة 429s التي لوحظت سابقًا في الخطأ.
shyamjvs
في ٢٢ مارس ٢٠١٨
@ Random-Liu شكرًا جزيلاً لك على مساعدتنا في حل هذه المشكلة.
jdumars
في ٢٢ مارس ٢٠١٨
jdumars np ~ yujuhong ساعدني كثيرًا!
Random-Liu
في ٢٢ مارس ٢٠١٨
لكننا نريد أن نسأل ماذا يعني PodScheduled للبودات التي لم يتم جدولتها بواسطة المجدول؟ هل نحن حقا بحاجة إلى هذا الشرط لتلك القرون؟ / cc @ kubernetes / sig-autoscaling-bugs لأن yujuhong أخبرني أن PodScheduled يستخدم عن طريق القياس التلقائي الآن.
ما زلت أعتقد أن السماح لـ kubelet بتعيين الحالة PodScheduled أمر غريب إلى حد ما (كما أشرت في PR الأصلي). حتى إذا لم يضبط kubelet هذا الشرط ، فإنه لن يؤثر على مقياس الكتلة التلقائي لأن جهاز القياس التلقائي يتجاهل القرون بدون الحالة المحددة. على أي حال ، فإن الإصلاح الذي توصلنا إليه أخيرًا له بصمة طفيفة جدًا ، وسيحافظ على السلوك الحالي (على سبيل المثال ، دائمًا إعداد شرط PodScheduled) ، لذلك سنذهب مع ذلك.
 yujuhong
في ٢٢ مارس ٢٠١٨
yujuhong
في ٢٢ مارس ٢٠١٨
أيضًا ، تم إحياء المشكلة القديمة حقًا لإضافة اختبارات لمعدل تحديث البود ذي الحالة المستقرة # 14391
yujuhong
في ٢٢ مارس ٢٠١٨
على أي حال ، فإن الإصلاح الذي توصلنا إليه أخيرًا له بصمة طفيفة جدًا ، وسيحافظ على السلوك الحالي (على سبيل المثال ، دائمًا إعداد شرط PodScheduled) ، لذلك سنذهب مع ذلك.
yujuhong - هل تتحدث عن هذا: # 61504 (أو هل أسيء فهمه)؟
wasylkowskishyamjvs - يمكنك الرجاء تشغيل الاختبارات 5000 عقدة مع أن PR مصححة محليا (قبل أن دمج ذلك) للتأكد من أن هذا يساعد حقا؟
wojtek-t
في ٢٢ مارس ٢٠١٨
أجريت الاختبار مقابل 1.10 HEAD + # 61504 ، ويبدو أن زمن انتقال بدء تشغيل البود على ما يرام:
INFO: perc50: 2.594635536s, perc90: 3.483550118s, perc99: 4.327417676s
سيعاد تشغيله مرة أخرى للتأكيد.
shyamjvs
في ٢٢ مارس ٢٠١٨
shyamjvs - شكرا جزيلا!
wojtek-t
في ٢٢ مارس ٢٠١٨
يبدو التشغيل الثاني جيدًا أيضًا:
INFO: perc50: 2.583489146s, perc90: 3.466873901s, perc99: 4.380595534s
واثق إلى حد ما من أن الإصلاح أدى إلى الحيلة. دعنا ندخل 1.10 في أسرع وقت ممكن.
shyamjvs
في ٢٢ مارس ٢٠١٨
shyamjvs
كما تحدثنا في وضع عدم الاتصال - أعتقد أننا شهدنا تراجعًا آخر في الشهر الماضي أو نحو ذلك ، ولكن لا ينبغي أن يمنع ذلك الإصدار.
wojtek-t
في ٢٢ مارس ٢٠١٨
yujuhong - هل تتحدث عن هذا: # 61504 (أو هل أسيء فهمه)؟
نعم. الإصلاح الحالي في ذلك PR ليس في الخيارات المقترحة مبدئيًا في https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979
yujuhong
في ٢٢ مارس ٢٠١٨
إعادة الفتح حتى نحصل على نتيجة اختبار أداء جيدة.
jberkus
في ٢٥ مارس ٢٠١٨
yujuhong krzyzacy @ shyamjvs @ wojtek-t @ Random-Liu @ wasylkowski- أي تحديثات على هذا؟ لا يزال هذا يحجب 1.10 في الوقت الحالي.
jdumars
في ٢٦ مارس ٢٠١٨
لذا فإن الجزء الوحيد من هذا الخطأ الذي كان يمنع الإصدار هو وظيفة أداء 5k node. للأسف ، فقدنا شوطنا من اليوم لسبب مختلف (المرجع: https://github.com/kubernetes/kubernetes/issues/61190#issuecomment-376150569)
ومع ذلك ، نحن واثقون تمامًا من أن الإصلاح يعمل بناءً على عمليات التشغيل اليدوية الخاصة بي (تم لصق النتائج في https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-375350217). لذا IMHO ، لسنا بحاجة إلى حظر الإصدار عليه (ستكون الجولة التالية يوم الأربعاء).
shyamjvs
في ٢٦ مارس ٢٠١٨
+1
jdumars - أعتقد أنه يمكننا التعامل مع هذا على أنه غير مانع.
wojtek-t
في ٢٦ مارس ٢٠١٨
آسف ، لقد قمت بتعديل رسالتي أعلاه. قصدت أنه يجب علينا التعامل معها على أنها "غير مانعة".
wojtek-t
في ٢٦ مارس ٢٠١٨
حسنا شكرا جزيلا. يمثل هذا الاستنتاج قدرًا هائلاً من الساعات التي استثمرتها ، ولا يمكنني أن أشكرك جميعًا بما يكفي على العمل الذي قمت به. بينما نتحدث في الملخص عن "المجتمع" و "المساهمين" ، أنت والآخرون الذين عملوا في هذه القضية تمثلونها بشكل ملموس. أنت قلب وروح هذا المشروع ، وأنا أعلم أنني أتحدث نيابة عن جميع المعنيين عندما أقول إنه لشرف لي أن أعمل جنبًا إلى جنب مع هذا الشغف والالتزام والاحتراف.
jdumars
في ٢٦ مارس ٢٠١٨
[MILESTONENOTIFIER] المشكلة الرئيسية: محدثة للعملية
MustafaHosny اللهم امين يارب
تسميات العدد
sig/api-machinerysig/autoscalingsig/nodesig/scalabilitysig/schedulingsig/storage: سيتم تصعيد المشكلة إلى SIGs إذا لزم الأمر.priority/critical-urgent: لا تقم مطلقًا بنقل الإصدار تلقائيًا من أحد مراحل الإصدار ؛ التصعيد باستمرار للمساهم و SIG من خلال جميع القنوات المتاحة.kind/bug: إصلاح خطأ تم اكتشافه أثناء الإصدار الحالي.مساعدة
 k8s-github-robot
في ١١ أبريل ٢٠١٨
k8s-github-robot
في ١١ أبريل ٢٠١٨
تم حل هذه المشكلة مع الإصلاحات ذات الصلة في 1.10.
بالنسبة إلى الإصدار 1.11 ، نتتبع حالات الفشل ضمن - https://github.com/kubernetes/kubernetes/issues/63030.
/أغلق
shyamjvs
في ٢٥ مايو ٢٠١٨
القضايا ذات الصلة
 broady
·
3تعليقات
broady
·
3تعليقات
 Seb-Solon
·
3تعليقات
Seb-Solon
·
3تعليقات
 tbchj
·
3تعليقات
tbchj
·
3تعليقات
 alexferl
·
3تعليقات
alexferl
·
3تعليقات
 theothermike
·
3تعليقات
theothermike
·
3تعليقات
التعليق الأكثر فائدة
أجريت الاختبار مقابل 1.10 HEAD + # 61504 ، ويبدو أن زمن انتقال بدء تشغيل البود على ما يرام:
سيعاد تشغيله مرة أخرى للتأكيد.