Kubernetes: [prueba de escamas] suites de escalabilidad maestra
Suites de bloqueo de versiones fallidas:
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
las tres suites se están descascarando mucho recientemente, ¿me importa la clasificación?
/ sig escalabilidad
/ prueba fallida de prioridad
/ tipo error
/ status aprobado-para-hito
cc @jdumars @jberkus
/ asignar @shyamjvs @ wojtek-t
 krzyzacy
krzyzacy
Todos 164 comentarios
- El trabajo de corrección está fallando principalmente debido al tiempo de espera (es necesario ajustar nuestro horario en consecuencia), ya que recientemente se agregaron un montón de e2 a la suite (por ejemplo, https://github.com/kubernetes/kubernetes/pull/59391)
- Para los copos de 100 nodos, tenemos https://github.com/kubernetes/kubernetes/issues/60500 (y creo que eso está relacionado ... necesito verificar).
- Para el trabajo de rendimiento, creo que hay una regresión (parece que en las últimas ejecuciones se trata de la latencia de inicio de pod). Quizás algo más también.
Intentaré llegar a ellos en algún momento de esta semana (hay escasez de cajeros automáticos de ciclos gratuitos).
 shyamjvs
en 28 feb. 2018
shyamjvs
en 28 feb. 2018
@shyamjvs ¿hay alguna actualización para este problema?
krzyzacy
en 2 mar. 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
Eché un breve vistazo a eso. Y algunas pruebas son extremadamente lentas o algo está colgando en algún lugar. Par de registros de la última ejecución:
62571 I0301 23:01:31.360] Mar 1 23:01:31.348: INFO: Running AfterSuite actions on all node
62572 I0301 23:01:31.360]
62573 W0302 07:32:00.441] 2018/03/02 07:32:00 process.go:191: Abort after 9h30m0s timeout during ./hack/ginkgo-e2e.sh --ginkgo.flakeAttempts=2 --ginkgo.skip=\[Serial\]|\[Disruptive \]|\[Flaky\]|\[Feature:.+\]|\[DisabledForLargeClusters\] --allowed-not-ready-nodes=50 --node-schedulable-timeout=90m --minStartupPods=8 --gather-resource-usage=master --gathe r-metrics-at-teardown=master --logexporter-gcs-path=gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-correctness/80/artifacts --report-dir=/workspace/_artifacts --dis able-log-dump=true --cluster-ip-range=10.64.0.0/11. Will terminate in another 15m
62574 W0302 07:32:00.445] SIGABRT: abort
Ninguna prueba terminó en 8h30m
 wojtek-t
en 2 mar. 2018
wojtek-t
en 2 mar. 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
De hecho, parece una regresión. Creo que la regresión ocurrió en algún lugar entre ejecuciones:
105 (que todavía estaba bien)
108 (que tuvo un tiempo de inicio visiblemente más alto)
Podemos intentar buscar en kubemark-5000 para ver si también es visible allí.
wojtek-t
en 2 mar. 2018
Kubemark-5000 es bastante estable. Percentil 99 en este gráfico (tal vez la regresión ocurrió incluso antes, pero creo que está entre 105 y 108):

wojtek-t
en 2 mar. 2018
En cuanto a las pruebas de corrección, gce-large-correctness también está fallando.
¿Quizás se agregó alguna prueba que es extremadamente larga en ese momento?
wojtek-t
en 2 mar. 2018
Muchas gracias por mirar a @ wojtek-t. Trabajo de rendimiento de Wrt: yo también siento firmemente que hay una regresión (aunque no pude verlos correctamente).
¿Quizás se agregó alguna prueba que es extremadamente larga en ese momento?
Estuve investigando esto hace un tiempo. Y hubo 2 cambios sospechosos que encontré:
- # 59391 - Esto agregó un montón de pruebas sobre el almacenamiento local (las ejecuciones después de este cambio comenzaron a agotarse)
- StatefulSet con antiafinidad de pod debe usar volúmenes repartidos entre los nodos (esta prueba parece ejecutarse durante 3,5 a 5 horas): https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e -gce-scale-correctness / 79
shyamjvs
en 2 mar. 2018
cc @ kubernetes / sig-storage-bugs
shyamjvs
en 2 mar. 2018
/asignar
Algunas de las pruebas de almacenamiento local intentarán utilizar todos los nodos del clúster, pensando que los tamaños del clúster no son tan grandes. Agregaré una solución para limitar el número máximo de nodos.
 msau42
en 2 mar. 2018
msau42
en 2 mar. 2018
Algunas de las pruebas de almacenamiento local intentarán utilizar todos los nodos del clúster, pensando que los tamaños del clúster no son tan grandes. Agregaré una solución para limitar el número máximo de nodos.
Gracias @ msau42 , eso sería genial.
wojtek-t
en 2 mar. 2018
Volviendo a https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance suite
Eché un vistazo más de cerca a las carreras hasta 105 y 108 y después de eso.
La mayor diferencia entre el tiempo de inicio y el tiempo de inicio del pod parece aparecer en el paso:
10% worst watch latencies:
[el nombre es engañoso - se explica a continuación]
Hasta 105 ejecuciones, generalmente se veía así:
I0129 21:17:43.450] Jan 29 21:17:43.356: INFO: perc50: 1.041233793s, perc90: 1.685463015s, perc99: 2.350747103s
Comenzando con 108 run, se parece más a:
Feb 12 10:08:57.123: INFO: perc50: 1.122693874s, perc90: 1.934670461s, perc99: 3.195883331s
Eso básicamente significa un aumento de ~ 0.85s y esto es aproximadamente lo que observamos en el resultado final.
Ahora, qué es ese "retraso del reloj".
Básicamente es un tiempo entre "Kubelet observó que el pod se está ejecutando" y "cuando la prueba observó la actualización del pod estableciendo su estado en ejecución".
Hay un par de posibilidades en las que podríamos haber retrocedido:
- kubelet se ralentiza en el estado de informes
- kubelet tiene hambre de qps (y, por lo tanto, es más lento en el estado de informes)
- apiserver es más lento (por ejemplo, sin cpu) y, por lo tanto, procesa las solicitudes más lentamente (ya sea para escribir, mirar o ambos)
- la prueba no tiene CPU y, por lo tanto, procesa los eventos entrantes más lentamente
Dado que realmente no observamos una diferencia entre "programar -> inicio" de un pod, eso sugiere que probablemente no sea un servidor (porque el procesamiento de solicitudes y la observación también están en ese camino), y probablemente no sea lento kubelet también (porque inicia la vaina).
Entonces creo que la hipótesis más probable es:
- kubelet tiene hambre de qps (o algo que le impide enviar rápidamente una actualización de estado)
- la prueba no tiene CPU (o algo así)
La prueba no cambió en absoluto en ese momento. Así que creo que probablemente sea el primero.
Dicho esto, revisé PR fusionados entre 105 y 108 carreras y no encontré nada útil hasta ahora.
wojtek-t
en 2 mar. 2018
Creo que el siguiente paso es:
- busque en los pods más lentos (parece haber una diferencia de O (1s) entre los más lentos también) y vea si la diferencia es "antes" de "después" de que se envió la solicitud de estado de actualización
wojtek-t
en 2 mar. 2018
Así que busqué cápsulas de ejemplo. Y ya estoy viendo esto:
I0209 10:01:19.960823 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.615907ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
...
I0209 10:01:22.464046 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (279.153µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:23.468353 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (218.216µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:24.470944 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.42987ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 09:57:01.559125 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (1.836423ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
...
I0209 09:57:04.452830 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (231.2µs) 429 [[kubelet/v1.10.0 (linu x/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:05.454274 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (213.872µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:06.458831 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (2.13295ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 10:01:53.063575 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (1.410064ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:3391
...
I0209 10:01:55.259949 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (10.4894ms) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:56.266377 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (233.931µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:57.269427 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (182.035µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:58.290456 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (13.44863ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
Así que parece bastante claro que el problema está relacionado con "429".
wojtek-t
en 2 mar. 2018
¿Esas llamadas de API limitadas se deben a una cuota en la cuenta del propietario?
 jdumars
en 2 mar. 2018
jdumars
en 2 mar. 2018
¿Esas llamadas de API limitadas se deben a una cuota en la cuenta del propietario?
Esto no es un estrangulamiento como pensé inicialmente. Estos son 429 en apiserver (la razón puede ser apiserver más lento debido a alguna razón, o más solicitudes que llegan a apiserver).
wojtek-t
en 2 mar. 2018
Oh, ok. Eso no es una gran noticia.
jdumars
en 2 mar. 2018
/ hito claro
krzyzacy
en 2 mar. 2018
/ hito v1.10
krzyzacy
en 2 mar. 2018
/ hito claro
 cjwagner
en 2 mar. 2018
cjwagner
en 2 mar. 2018
@cjwagner : debes ser miembro del equipo de github de kubernetes-milestone- maintenanceers para establecer el hito.
En respuesta a esto :
/ hito claro
Las instrucciones para interactuar conmigo usando comentarios de relaciones públicas están disponibles aquí . Si tiene preguntas o sugerencias relacionadas con mi comportamiento, presente un problema en el repositorio de kubernetes / test-infra .
 k8s-ci-robot
en 2 mar. 2018
k8s-ci-robot
en 2 mar. 2018
/ hito v1.9
cjwagner
en 2 mar. 2018
@cjwagner : debes ser miembro del equipo de github de kubernetes-milestone- maintenanceers para establecer el hito.
En respuesta a esto :
/ hito v1.9
Las instrucciones para interactuar conmigo usando comentarios de relaciones públicas están disponibles aquí . Si tiene preguntas o sugerencias relacionadas con mi comportamiento, presente un problema en el repositorio de kubernetes / test-infra .
k8s-ci-robot
en 2 mar. 2018
Parece que PR https://github.com/kubernetes/kubernetes/pull/60740 solucionó los problemas de tiempo de espera; gracias @ msau42 por una respuesta rápida.
Nuestros trabajos de corrección (tanto 2k como 5k) han vuelto a ser ecológicos ahora:
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -large-correctness
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -scale-correctness
Entonces, mi sospecha sobre esas pruebas de volumen era correcta :)
shyamjvs
en 5 mar. 2018
ACK. En progreso
ETA: 03/09/2018
Riesgos: impacto potencial en el rendimiento de k8s
shyamjvs
en 5 mar. 2018
Así que indagué un poco en esto y, a partir del gráfico de latencia de inicio de pod para nuestra prueba de 5k nodos, tengo la sensación de que la regresión también podría estar en b / w ejecuciones 108 y 109 (ver 99% ile):

shyamjvs
en 5 mar. 2018
Pasé rápidamente por el diff y el siguiente cambio me parece sospechoso:
"Permitir pasar el tiempo de espera de solicitud de NewRequest completamente hacia abajo" # 51042
Ese PR habilita la propagación del tiempo de espera del cliente como un parámetro de consulta para la llamada a la API. Y, de hecho, veo la siguiente diferencia en las llamadas PATCH node/status en esas 2 ejecuciones (de los registros de apiserver):
ejecutar-108:
I0207 22:01:06.450385 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-2rn2/status: (11.81392ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.227.96.23:47270]
I0207 22:01:03.857892 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-9659/status: (8.570809ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.196.85.108:43532]
I0207 22:01:03.857972 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc4w/status: (8.287643ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.229.110.22:50530]
ejecutar-109:
I0209 21:01:08.551289 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-89f2/status?timeout=10s: (71.351634ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.229.77.215:51070]
I0209 21:01:08.551310 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-3ms3/status?timeout=10s: (70.705466ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.227.84.87:49936]
I0209 21:01:08.551394 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc02/status?timeout=10s: (70.847605ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.196.125.143:53662]
Mi hipótesis es que, debido a ese tiempo de espera agregado de 10 segundos a las llamadas PATCH, esas llamadas ahora duran más tiempo en el lado del servidor (IIUC este comentario correctamente). Esto significa que ahora están en la cola en vuelo durante más tiempo. Eso, combinado con el hecho de que esas llamadas PATCH ocurren en grandes cantidades en grupos tan grandes, está provocando que las llamadas PUT pod/status no puedan obtener suficiente ancho de banda en la cola de vuelo y, por lo tanto, se devuelvan con 429. Como resultado, el retraso del lado de kubelet en la actualización del estado del pod ha aumentado. Esta historia también encaja bien con las observaciones anteriores de @ wojtek-t.
Intentaré reunir más evidencia para verificar esta hipótesis.
shyamjvs
en 5 mar. 2018
Así que verifiqué cómo varían las latencias de PATCH node-status durante las ejecuciones de prueba y, de hecho, parece que hay un aumento en el percentil 99 (ver la línea superior) en ese momento. Sin embargo, no está muy claro que sucedió en las ejecuciones 108 y 109 (aunque creo que ese es el caso):
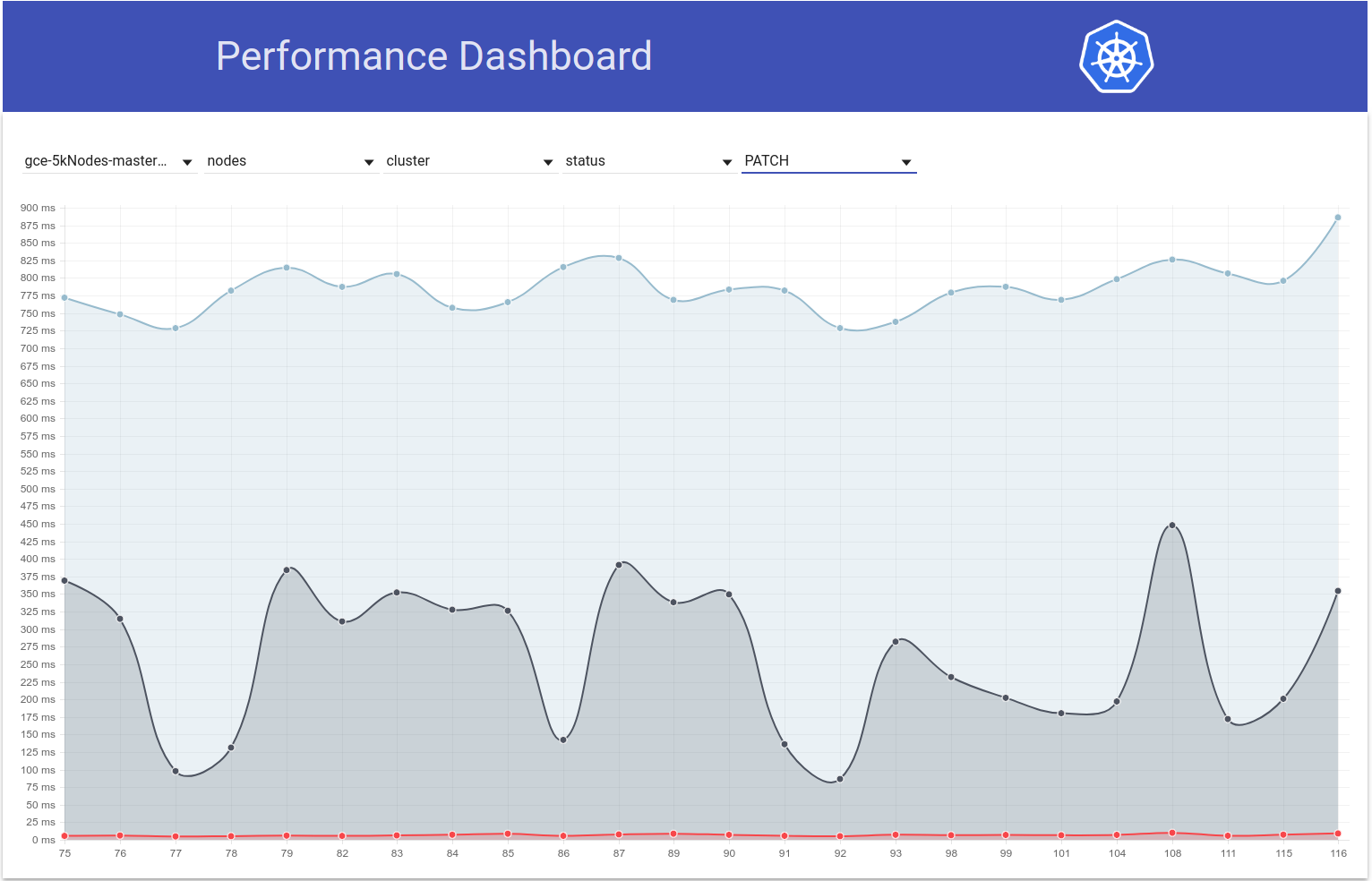
shyamjvs
en 5 mar. 2018
[EDITAR: Mi comentario anterior mencionó erróneamente el recuento de esos 429 (el cliente era npd, no kubelet)]
Ahora tengo más evidencia de apoyo:
en la ejecución 108 , tuvimos ~ 479k PATCH node/status llamadas que obtuvieron un 429:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"479181"
]
},
y en la ejecución 109 , tenemos ~ 757k de esos:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"757318"
]
},
Y ... mira esto:
en la carrera 108:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"28594"
]
},
y en la ejecución-109:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"33224"
]
},
Verifiqué el número de algunas otras ejecuciones adyacentes:
- que PR se fusionó -
Si bien parece un poco variable, en general parece que no. de 429 aumentó en aproximadamente un 25%.
shyamjvs
en 5 mar. 2018
Y por PATCH node-status provenientes de kubelets que recibieron 429, así es como se ven los números:
- correr-104 = 313348
- ejecutar-105 = 309136
- correr-108 = 479181
- que PR se fusionó -
- ejecutar-109 = 757318
- ejecutar-110 = 752062
- correr-111 = 296368
Esto también varía, pero en general parece aumentar.
shyamjvs
en 5 mar. 2018
El 99% de ile de PATCH node-status latencias de llamada también parece haber aumentado en general (como estaba prediciendo en https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370573938):
run-104 (798ms), run-105 (783ms), run-108 (826ms)
run-109 (878ms), run-110 (869ms), run-111 (806ms)
Por cierto: con todas las métricas anteriores, 108 parece ser una ejecución peor de lo normal y 111 parece ser una ejecución mejor de lo normal.
shyamjvs
en 5 mar. 2018
Intentaré verificar esto mañana ejecutando manualmente un gran clúster de 5k.
shyamjvs
en 5 mar. 2018
gracias por la clasificación @shyamjvs
krzyzacy
en 5 mar. 2018
Así que ejecuté la prueba de densidad dos veces contra el clúster de 5k contra ~ HEAD, y la prueba pasó sorprendentemente en ambas ocasiones con una latencia de inicio del pod de 99% ile como 4.510015461s y 4.623276837s . Sin embargo, las 'latencias de reloj', sí mostraron el aumento que @ wojtek-t señaló en https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -369951288
En la primera ejecución fue:
INFO: perc50: 1.123056294s, perc90: 1.932503347s, perc99: 3.061238209s
y la segunda corrida fue:
INFO: perc50: 1.121218293s, perc90: 1.996638787s, perc99: 3.137325187s
Ahora intentaré comprobar cuál fue el caso antes.
shyamjvs
en 6 mar. 2018
https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 - No estoy seguro de estar siguiendo esto Sí, agregamos tiempo de espera, pero el tiempo de espera predeterminado es mayor que 10 s IIRC, por lo que solo debería ayudar no empeorar las cosas.
Creo que todavía no entendemos por qué observamos más 429 (el hecho de que esto está relacionado de alguna manera con 429 ya lo mencioné en https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370036377)
wojtek-t
en 6 mar. 2018
Y con respecto a sus números, no estoy convencido de que la regresión estuviera en la ejecución 109, podría haber habido dos regresiones, una en algún lugar entre 105 y 108 y la otra en 109.
wojtek-t
en 6 mar. 2018
Hmm ... No niego las posibilidades que mencionaste (lo anterior fue solo mi hipótesis).
Actualmente estoy haciendo una bisección (ahora mismo contra el compromiso de 108) para verificar.
shyamjvs
en 6 mar. 2018
Mi sensación de que la regresión es antes de la carrera 108 es cada vez más fuerte.
Como ejemplo, las latencias de las llamadas a la API ya aumentaron en 108 ejecuciones.
estado del nodo de parche:
90%: 198 ms (105) 447 ms (108) 444 ms (109)
poner estado de la vaina:
99%: 83 ms (105) 657 ms (108) 728 ms (109)
wojtek-t
en 6 mar. 2018
Supongo que lo que intento decir es:
- el número de 429 es una consecuencia y no deberíamos dedicar demasiado tiempo a eso
- la causa raíz son llamadas api más lentas o una mayor cantidad de esas
Claramente, parece que vemos llamadas de API más lentas en 108. La pregunta es si también vemos un mayor número de ellas.
wojtek-t
en 6 mar. 2018
Entonces, creo que por qué las solicitudes son visiblemente más lentas: hay tres posibilidades principales
hay muchas más solicitudes (a primera vista no parece ser el caso)
agregamos algo en la ruta de procesamiento (por ejemplo, procesamiento adicional) o los objetos en sí son más grandes
algo más en la máquina maestra (por ejemplo, el programador) consume más cpu y, por lo tanto, muere de hambre a un servidor más
wojtek-t
en 6 mar. 2018
Entonces yo y @ wojtek-t discutimos sin conexión y ambos estamos de acuerdo ahora en que es muy probable que haya una regresión antes de 108. Agregando algunos puntos:
hay muchas más solicitudes (a primera vista no parece ser el caso)
A mí tampoco me parece que sea el caso
agregamos algo en la ruta de procesamiento (por ejemplo, procesamiento adicional) o los objetos en sí son más grandes
Mi sensación es que es algo más probable en kubelet que en apiserver (ya que no estamos viendo ningún cambio visible en las latencias de parche / colocación en kubemark-5000)
algo más en la máquina maestra (por ejemplo, el programador) consume más cpu y, por lo tanto, muere de hambre a un servidor más
En mi opinión, este no es el caso, ya que estamos teniendo bastante holgura de CPU / memoria en nuestro maestro. Además, perf-dash no sugiere ningún aumento considerable en el uso de componentes maestros.
Dicho esto, investigué un poco y, "afortunadamente", parece que estamos notando este aumento en las latencias de observación incluso para los clústeres de 2k nodos:
INFO: perc50: 1.024377533s, perc90: 1.589770858s, perc99: 1.934099611s
INFO: perc50: 1.03503718s, perc90: 1.624451701s, perc99: 2.348645755s
Debería hacer que la bisección sea un poco más fácil.
shyamjvs
en 6 mar. 2018
Desafortunadamente, la variación en esas latencias de reloj parece única (por lo demás, es aproximadamente la misma). Afortunadamente, tenemos una latencia de PUT pod-status como indicador confiable de la regresión. Ejecuté 2 rondas de bisección ayer y reduje a esta diferencia (~ 80 confirmaciones). Los hojeé y tengo fuertes sospechas sobre:
- # 58990: agrega un nuevo campo al estado de la vaina (aunque no estoy seguro de si se completará en nuestras pruebas, donde las apropiaciones de IIUC no están sucediendo, pero es necesario verificar)
- # 58645 - Actualiza la versión del servidor etcd a 3.2.14
shyamjvs
en 7 mar. 2018
Realmente dudo que el # 58990 esté relacionado aquí: NominatedNodeName es una cadena que contiene un solo nombre de nodo. Incluso si estuviera lleno todo el tiempo, el cambio en el tamaño del objeto debería ser insignificante.
wojtek-t
en 7 mar. 2018
@ wojtek-t: como sugieres sin conexión, de hecho parece que estamos usando una versión diferente (3.2.16) en kubemark (https://github.com/kubernetes/kubernetes/blob/master/test/kubemark/ start-kubemark.sh # L62) que es la razón potencial para no ver esta regresión allí :)
cc @jpbetz
shyamjvs
en 7 mar. 2018
Estamos usando 3.2.16 en todas partes ahora.
wojtek-t
en 7 mar. 2018
Vaya ... Lo siento por la retrospectiva, estaba buscando una combinación incorrecta de confirmaciones.
shyamjvs
en 7 mar. 2018
Por cierto, ese aumento en la latencia de estado / pods PUT es visible también en la prueba de carga en grandes clústeres reales.
wojtek-t
en 7 mar. 2018
Así que indagué un poco más y parece que comenzamos a observar mayores latencias en ese momento para las solicitudes de escritura en general (lo que me hace sospechar que etcd cambiará aún más):
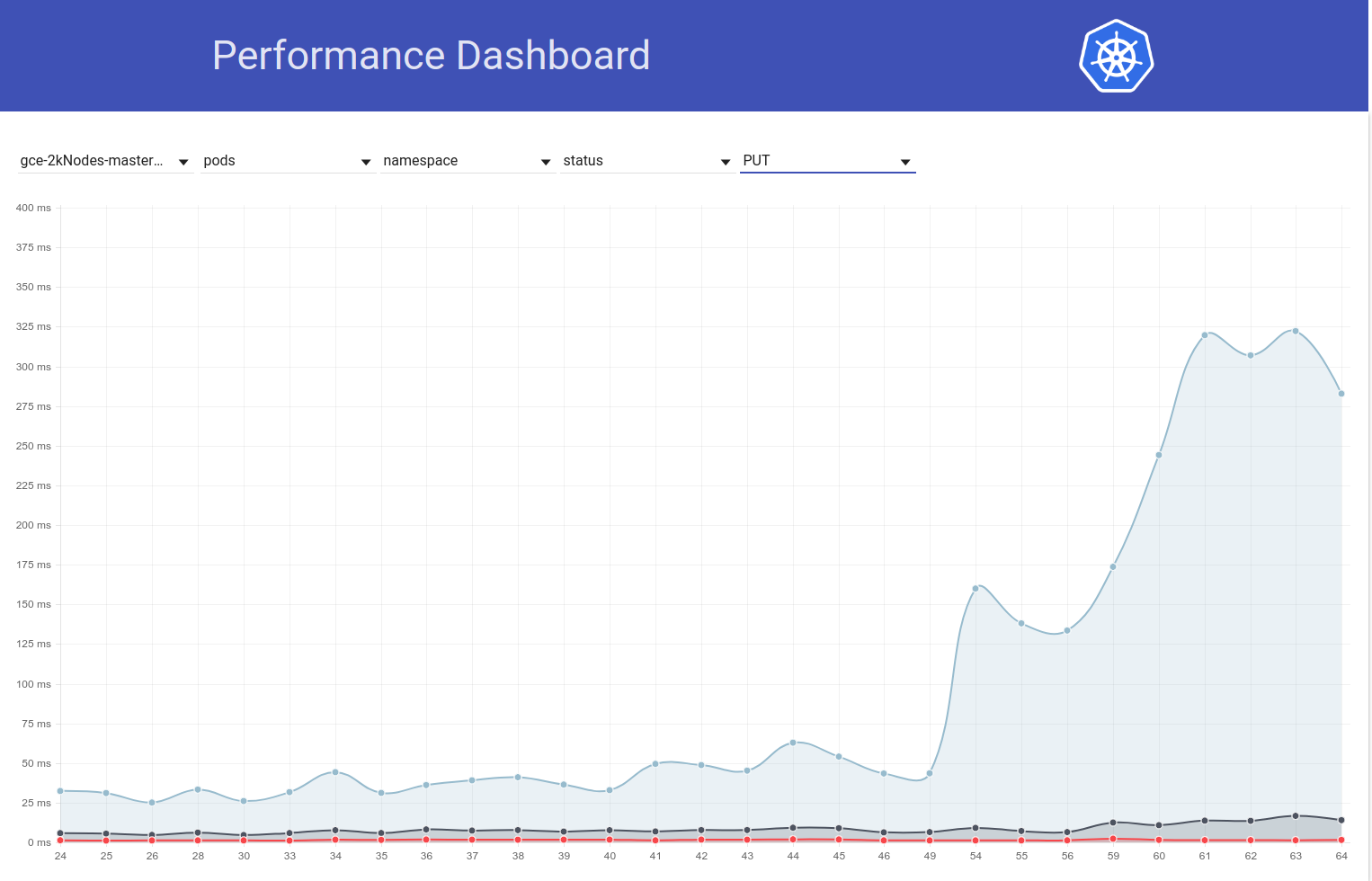
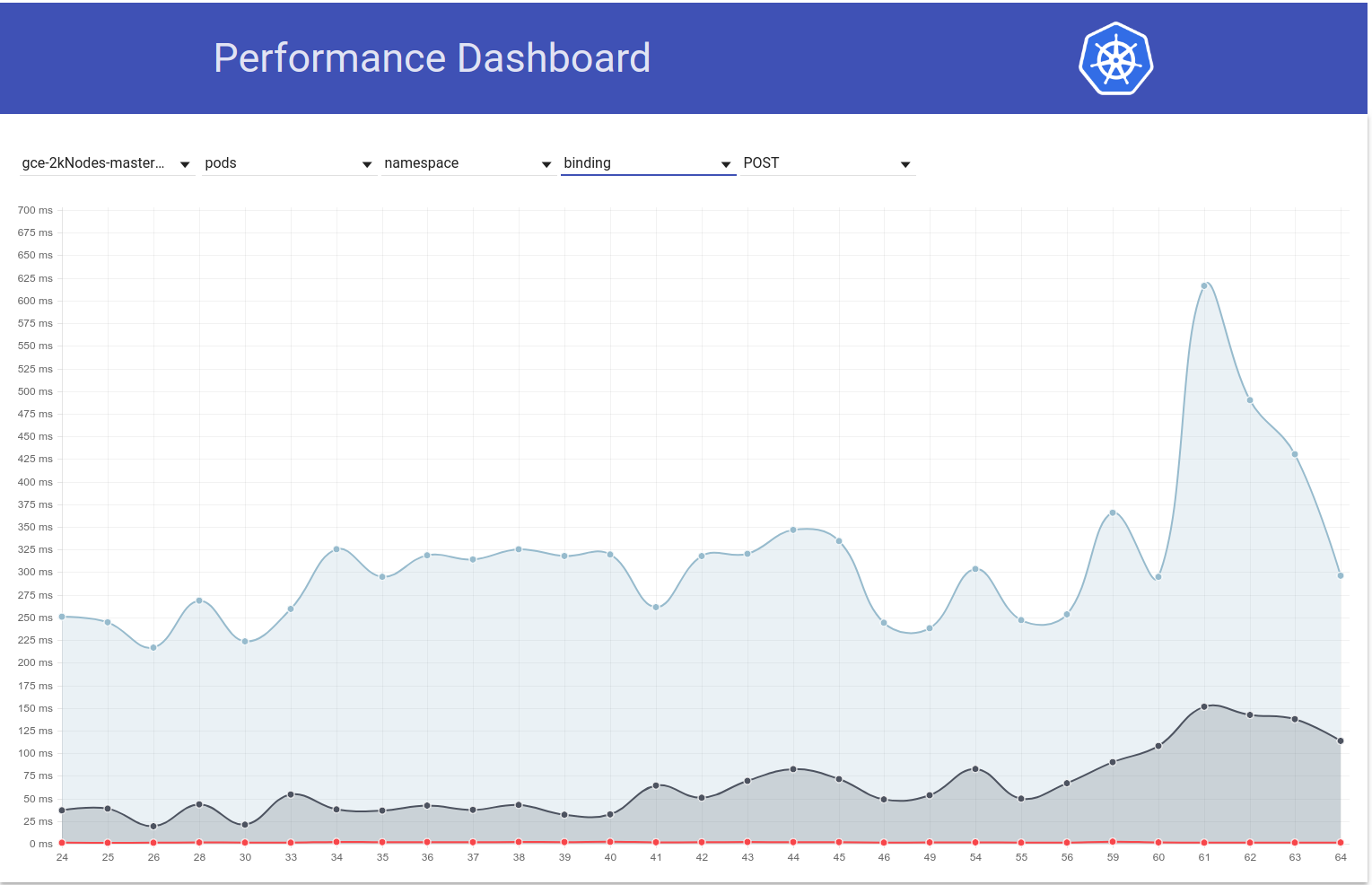

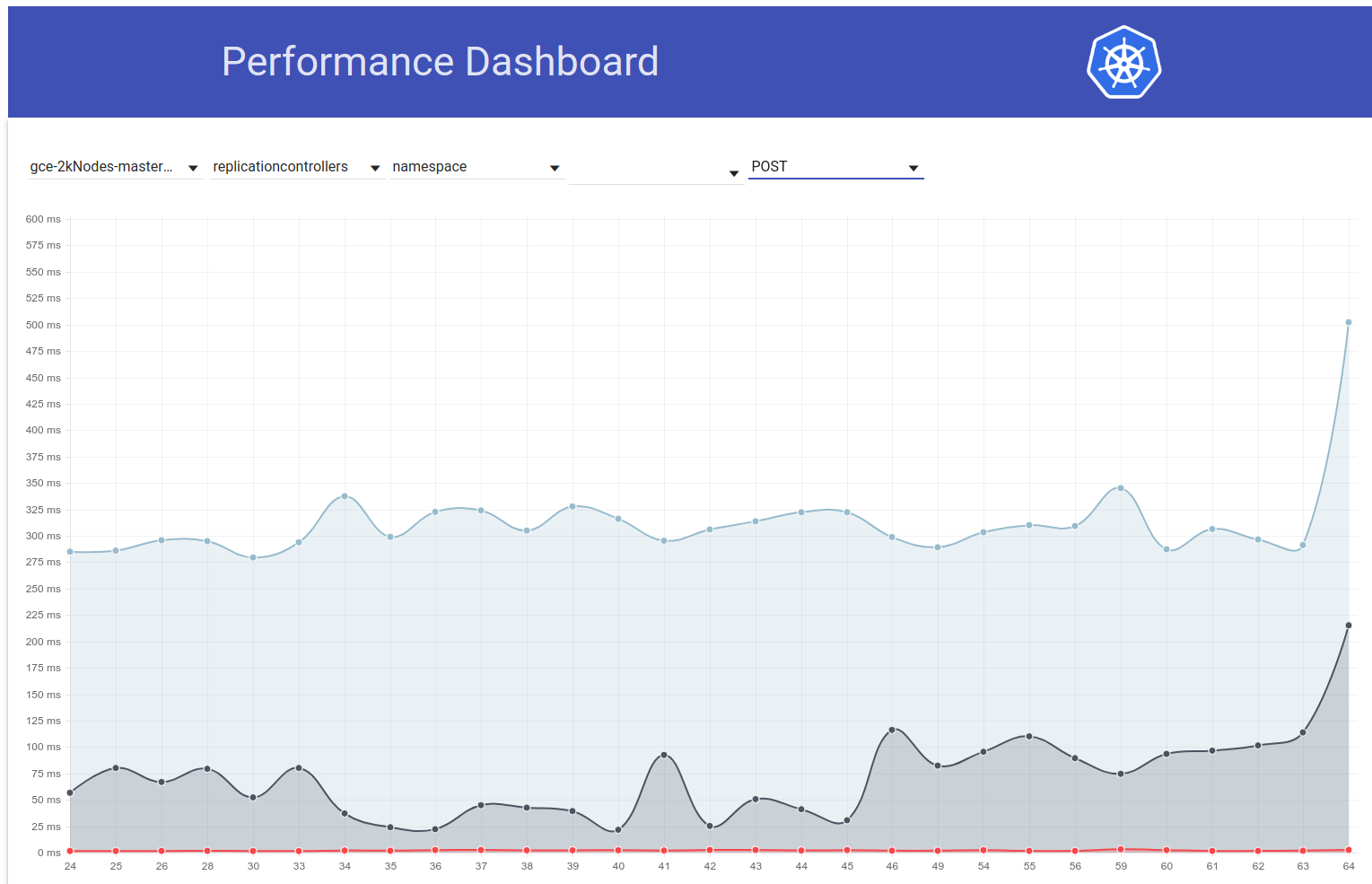
shyamjvs
en 7 mar. 2018
En realidad, voto que al menos parte del problema está aquí:
https://github.com/kubernetes/kubernetes/pull/58990/commits/384a86caa92bdb7cf9ac96b10a6ef333d2d60519#diff -c73f80ad83608f18657d22a06950d929R240
Me sorprendería que fuera todo el problema, pero puede contribuir a ello.
Enviará un PR cambiando eso en un segundo.
wojtek-t
en 7 mar. 2018
Para su información: cuando me encontré con una confirmación anterior al cambio etcd 3.2.14, pero después del cambio de la API de estado de pod, la latencia de estado de nodo de colocación parece totalmente correcta (es decir, 99% ile = 39ms).
shyamjvs
en 7 mar. 2018
Así que verifiqué que de hecho es causado por el salto etcd a 3.2.14. Así es como se ve la latencia de estado del pod de colocación:
contra ese PR :
{
"data": {
"Perc50": 1.479,
"Perc90": 10.959,
"Perc99": 163.095
},
"unit": "ms",
"labels": {
"Count": "344494",
"Resource": "pods",
"Scope": "namespace",
"Subresource": "status",
"Verb": "PUT"
}
},
contra ~ HEAD (desde el 5 de marzo) con ese PR revertido (la prueba aún se está ejecutando, pero está a punto de terminar pronto):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.5"} 1669
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.9"} 9597
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.99"} 63392
63ms parece bastante similar a lo que era antes .
Deberíamos revertir la versión e intentar comprender:
- ¿Por qué estamos viendo este aumento en etcd 3.2.14?
- ¿Por qué no detectamos esto en kubemark?
cc @jpbetz @ kubernetes / sig-api-machinery-bugs
shyamjvs
en 7 mar. 2018
Una hipótesis (por qué no captamos eso en kubemark, aunque todavía es una suposición) es que es posible que hayamos cambiado sth wrt a certificados allí.
Cuando comparo el registro de etcd de kubemark y el clúster real, solo en este último veo la siguiente línea:
2018-03-05 08:06:56.389648 I | embed: peerTLS: cert = /etc/srv/kubernetes/etcd-peer.crt, key = /etc/srv/kubernetes/etcd-peer.key, ca = , trusted-ca = /etc/srv/kubernetes/etcd-ca.crt, client-cert-auth = true
En cuanto a las relaciones públicas en sí, no veo ningún cambio en torno a eso, pero tampoco sé por qué deberíamos haber visto esa línea solo en grupos reales ...
@jpbetz para pensamientos
wojtek-t
en 7 mar. 2018
ACK. En progreso
ETA: 03/09/2018
Riesgos: problema causado por la raíz (principalmente)
shyamjvs
en 7 mar. 2018
Re peerTLS: parece ser el caso también antes (con 3.1.11), así que creo que es una pista falsa
wojtek-t
en 7 mar. 2018
cc @gyuho @wenjiaswe
 jpbetz
en 7 mar. 2018
jpbetz
en 7 mar. 2018
63ms parece bastante similar a lo que
¿De dónde sacamos esos números? ¿ apiserver_request_latencies_summary mide realmente las latencias de las escrituras etcd? Además, las métricas de etcd ayudarían.
 gyuho
en 7 mar. 2018
gyuho
en 7 mar. 2018
embed: peerTLS: cert ...
Esto se imprime, si se configura TLS del mismo nivel (lo mismo en 3.1).
gyuho
en 7 mar. 2018
¿De dónde sacamos esos números? ¿Apiserver_request_latencies_summary mide realmente las latencias de las escrituras etcd? Además, las métricas de etcd ayudarían.
Esto mide la latencia de una llamada que (al menos en el caso de llamadas de escritura) incluye la latencia de etcd.
Todavía no entendemos realmente lo que está sucediendo, pero volver a la versión anterior de etcd (3.1) corrige la regresión. Así que claramente el problema está en algún lugar de etcd.
wojtek-t
en 7 mar. 2018
@shyamjvs
¿Qué versiones de Kubemark y Kubernetes está ejecutando? Probamos Kubemark 1.10 contra etcd 3.2 vs 3.3 (cargas de trabajo de 500 nodos), y no observamos esto. ¿Cuántos nodos se necesitan para reproducir esto?
gyuho
en 7 mar. 2018
¿Qué versiones de Kubemark y Kubernetes está ejecutando? Probamos Kubemark 1.10 contra etcd 3.2 vs 3.3 (cargas de trabajo de 500 nodos), y no observamos esto. ¿Cuántos nodos se necesitan para reproducir esto?
No podemos reproducirlo con kubemark, incluso con 5k-nodo uno; consulte la parte inferior de https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -371171837
Esto parece ser un problema solo en clusters reales.
Esta es una pregunta abierta por qué es así.
wojtek-t
en 7 mar. 2018
Desde que volvimos a etcd 3.1. para kubernetes. También lanzamos etcd 3.1.12 con la única corrección crítica pendiente para kubernetes: la operación de restauración del observador mvcc "unsynced" . Una vez que hayamos encontrado y solucionado la causa raíz de la regresión del rendimiento encontrada en este problema, podemos esbozar un plan para actualizar el servidor etcd utilizado por kubernetes a la versión 3.2.
jpbetz
en 8 mar. 2018
parece que https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100 comienza a fallar constantemente desde esta mañana
krzyzacy
en 9 mar. 2018
Desde el diferencial , el único cambio es https://github.com/kubernetes/kubernetes/pull/60421, que habilita cuotas en nuestras pruebas de rendimiento de forma predeterminada. El error que estamos viendo es:
Container kube-controller-manager-e2e-big-master/kube-controller-manager is using 0.531144723/0.5 CPU
not to have occurred
@gmarek : parece que habilitar las cuotas está afectando nuestra escalabilidad :) ¿Podrías profundizar en esto?
Permítanme presentar otro problema para mantener este en curso.
shyamjvs
en 9 mar. 2018
@ wojtek-t @jpbetz @gyuho @timothysc Encontré algo realmente interesante con el cambio de versión de etcd, lo que sugiere un efecto significativo de pasar de etcd 3.1.11 a 3.2.16.
Mire el siguiente gráfico del uso de memoria etcd en nuestro clúster de 100 nodos (ha aumentado ~ 2x) cuando el trabajo se movió de la versión 1.9 de k8s a la 1.10:
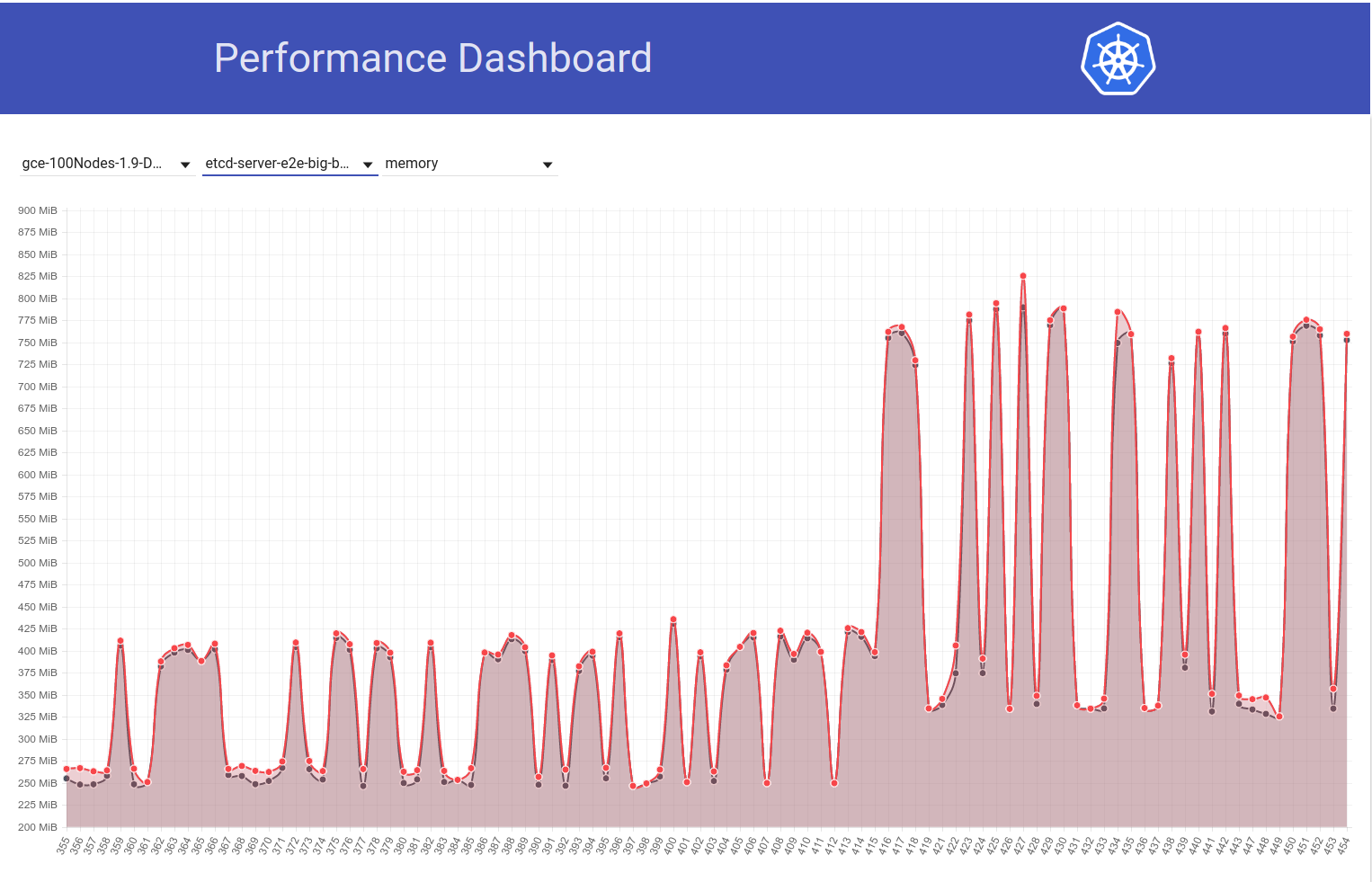
Y a continuación, observe cómo nuestro trabajo de 100 nodos (que se ejecuta contra HEAD) ve una caída en el uso de mem a la mitad justo después de mi reversión de etcd 3.2.16 -> 3.1.11:
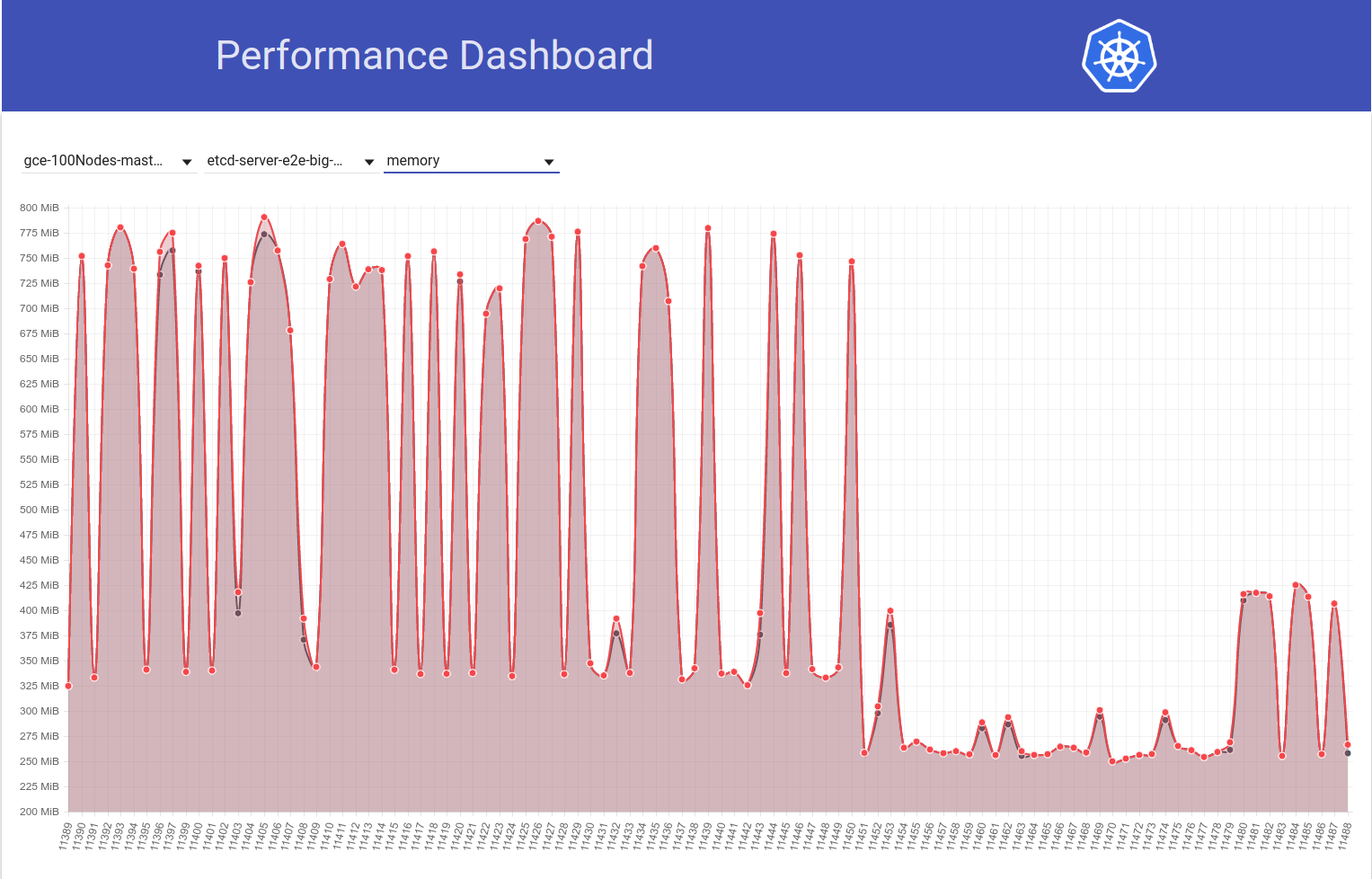
Entonces, la versión del servidor etcd 3.2 CLARAMENTE muestra el rendimiento afectado (con todas las demás variables mantenidas igual) :)
shyamjvs
en 10 mar. 2018
mi reversión de etcd 3.2.16 -> 3.2.11:
¿Quisimos decir 3.1.11?
gyuho
en 10 mar. 2018
Eso es ... lo siento. Editó mi comentario.
shyamjvs
en 10 mar. 2018
@shyamjvs ¿Cómo se configura etcd? Hemos aumentado el valor predeterminado --snapshot-count de 10000 a 100000 , en v3.2. Entonces, si el recuento de instantáneas es diferente, el que tiene un mayor recuento de instantáneas retiene las entradas de Raft durante más tiempo, por lo que requiere más memoria residente, antes de descartar los registros antiguos.
gyuho
en 10 mar. 2018
¡Aah! Eso de hecho parece un cambio sospechoso. Wrt flags, no creo que haya ningún cambio en las del lado de los k8. Porque, como puede ver en mi segundo gráfico anterior, la diferencia en blanco y negro se ejecuta 11450 y 11451 es principalmente mi cambio de reversión de etcd (que no parece tocar ninguna marca).
Hemos aumentado el valor predeterminado: recuento de instantáneas de 10000 a 100000
¿Podría confirmar si esa es la causa principal de este aumento en el uso de mem? Si es así, es posible que deseemos:
- parche etcd de nuevo con el valor original, o
- configúrelo en 10000 en k8s
antes de volver a 3.2
shyamjvs
en 10 mar. 2018
¡Aah! Eso de hecho parece un cambio sospechoso.
Sí, este cambio debería haberse resaltado desde el lado de etcd (mejorará nuestros registros de cambios y guías de actualización).
¿Podría confirmar si esa es la causa principal de este aumento en el uso de mem?
No estoy seguro de si esa sería la causa principal. Un recuento de instantáneas más bajo definitivamente ayudará a aliviar el uso de memoria con picos. Si ambas versiones de etcd usan el mismo recuento de instantáneas, pero una etcd aún muestra un uso de memoria mucho mayor, debería haber algo más.
gyuho
en 10 mar. 2018
Actualización: verifiqué que el aumento en el uso de etcd mem se debe a un valor predeterminado más alto de --snapshot-count. Más detalles aquí: https://github.com/kubernetes/kubernetes/pull/61037#issuecomment -372457843
Deberíamos considerar establecerlo en 10,000 cuando estemos pasando a etcd 3.2.16, si no queremos un mayor uso de mem.
cc @gyuho @ xiang90 @jpbetz
shyamjvs
en 12 mar. 2018
Actualización: con la corrección de etcd, la latencia de inicio del pod del 99% todavía parece estar cerca de violar el SLO de 5 segundos. Hay al menos otra regresión y he reunido evidencia de que es más probable que sea en las ejecuciones en b / n 111 y 112 de nuestro trabajo de rendimiento de 5k nodos (vea el aumento en b / w de esas ejecuciones en el gráfico que pegué en https: / /github.com/kubernetes/kubernetes/issues/60589#issuecomment-370568929). Actualmente estoy dividiendo la diferencia (que tiene alrededor de 50 confirmaciones) y la prueba toma ~ 4-5 horas por iteración.
La evidencia a la que me refería anteriormente es la siguiente:
Las latencias de reloj en 111 fueron:
Feb 14 21:36:05.531: INFO: perc50: 1.070980786s, perc90: 1.743347483s, perc99: 2.629721166s
Y las latencias generales de inicio de pods en 111 fueron:
Feb 14 21:36:05.671: INFO: perc50: 2.416307575s, perc90: 3.24553118s, perc99: 4.092430858s
Mientras que los mismos en el 112 fueron:
Feb 16 10:07:43.222: INFO: perc50: 1.131108849s, perc90: 2.18487651s, perc99: 3.570548412s
y
Feb 16 10:07:43.353: INFO: perc50: 2.56160248s, perc90: 3.754024568s, perc99: 4.967573867s
Mientras tanto, si alguien está listo para el juego de apuestas, puede echar un vistazo a la diferencia de compromiso que mencioné anteriormente y adivinar la defectuosa :)
shyamjvs
en 12 mar. 2018
ACK. En progreso
ETA: 13/03/2018
Riesgos: puede retrasar la fecha de lanzamiento si no se depura antes de eso
shyamjvs
en 12 mar. 2018
@shyamjvs toooooooo muchos se comprometen a hacer apuestas :)
 dims
en 13 mar. 2018
dims
en 13 mar. 2018
@dims Eso agregaría más diversión, supongo;)
Actualización: ejecuté algunas iteraciones de la bisección y así es como se veían las métricas relevantes en las confirmaciones (ordenadas cronológicamente). Tenga en cuenta que para los que ejecuté manualmente, los ejecuté con la regresión anterior revertida (es decir, 3.2. -> 3.1.11).
| Comprometerse | 99% de latencia de reloj | 99% de latencia de inicio de pod | ¿Bueno malo? |
| ------------- | ------------- | ----- | ------- |
| a042ecde36 (desde run-111) | 2.629721166s | 4.092430858s | Bueno (confirmando de nuevo manualmente) |
| 5f7b530d87 (manual) | 3.150616856s | 4.683392706s | Malo (probable) |
| a8060ab0a1 (manual) | 3.11319985s | 4.710277511s | Malo (probable) |
| 430c1a68c8 (desde run-112) | 3.570548412s | 4.967573867s | Malo |
| 430c1a68c8 (manual) | 3.63505091s | 4.96697776s | Malo |
De lo anterior, parece que puede haber 2 regresiones aquí (ya que no es un salto directo de 2.6s -> 3.6s) - una b / n "a042ecde36 - 5f7b530d87" y otra b / n "a8060ab0a1 - 430c1a68c8". ¡Suspiro!
shyamjvs
en 13 mar. 2018
expresando como rangos para obtener enlaces de comparación:
a042ecde36 ... 5f7b530
a8060ab0a1 ... 430c1a6
 liggitt
en 13 mar. 2018
liggitt
en 13 mar. 2018
Acabo de obtener los resultados para la ejecución manual contra a042ecde36 y solo hace la vida más difícil:
3.269330734s (watch), 4.939237532s (pod-startup)
ya que esto probablemente significa que podría ser una regresión inestable.
shyamjvs
en 13 mar. 2018
Actualmente estoy ejecutando la prueba contra a042ecde36 una vez más para verificar la posibilidad de que la regresión se produjera incluso antes.
shyamjvs
en 13 mar. 2018
Así que aquí está el resultado de ejecutar nuevamente contra a042ecd:
2.645592996s (watch), 5.026010032s (pod-startup)
Esto probablemente significa que la regresión ingresó incluso antes de la ejecución-111 (buenas noticias de que ahora tenemos un final correcto para la bisección).
Ahora intentaré seguir por un extremo izquierdo. Run-108 (commit 11104d75f) es un candidato potencial, que tuvo los siguientes resultados cuando lo ejecuté anteriormente (con etcd 3.1.11):
2.593628224s (watch), 4.321942836s (pod-startup)
Mi repetición contra el compromiso 11104d7 parece decir que es bueno:
2.663456162s (watch), 4.288927203s (pod-startup)
Intentaré bisecar aquí en el rango 11104d7 ... a042ecd
shyamjvs
en 13 mar. 2018
Actualización: necesitaba probar el compromiso 097efb71a315 tres veces para ganar confianza. Muestra bastante variación, pero parece un buen compromiso:
2.578970061s (watch), 4.129003596s (pod-startup)
2.315561531s (watch), 4.70792639s (pod-startup)
2.303510957s (watch), 3.88150234s (pod-startup)
Continuaré dividiéndome más.
Dicho esto, parece haber habido otro pico (de ~ 1s) en la latencia de inicio de pod hace solo un par de días. Y este está empujando el 99% a casi 6 segundos:
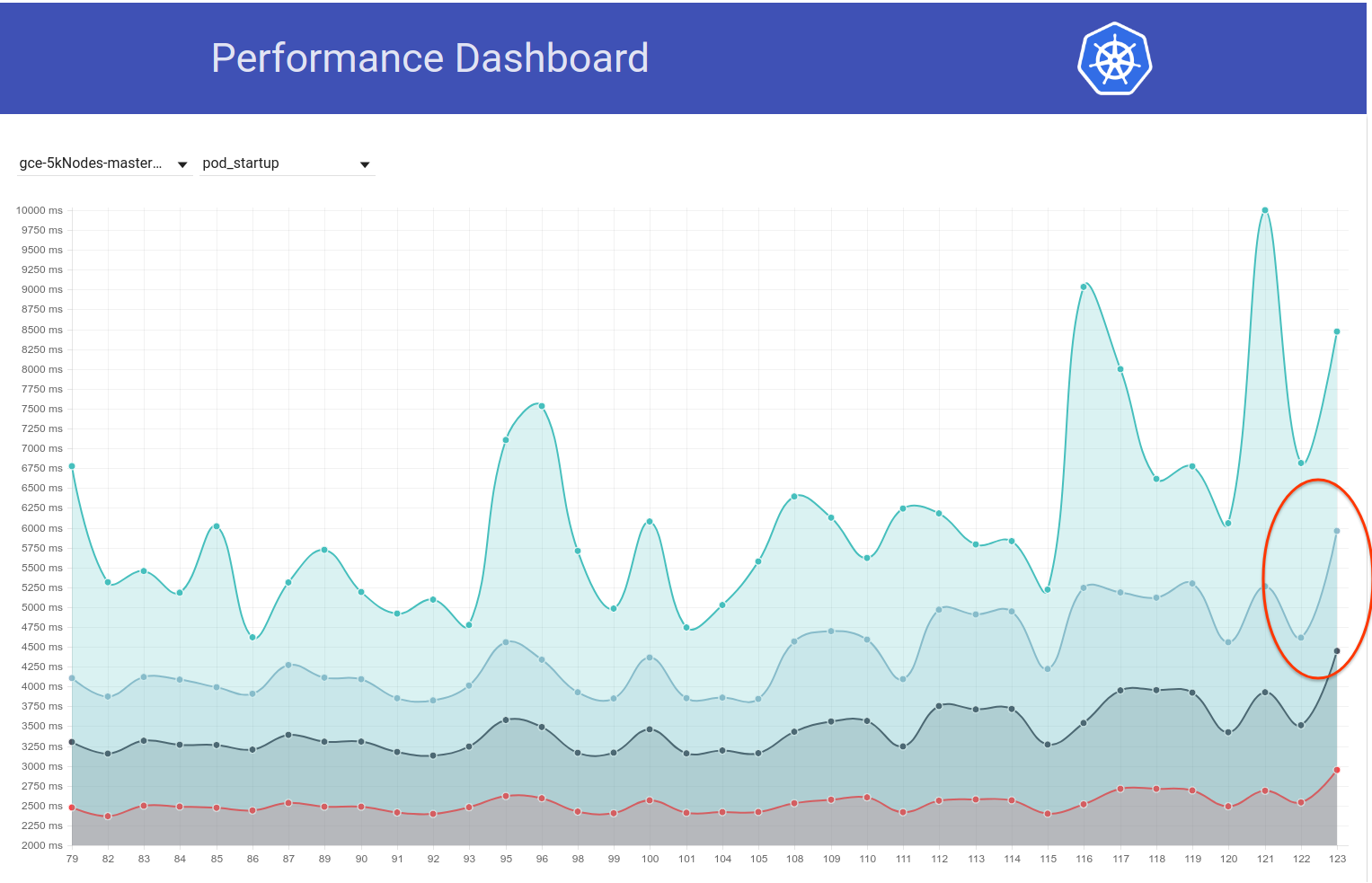
Mi principal sospechoso de la diferencia de confirmación es el cambio de etcd de 3.1.11 -> 3.1.12 (https://github.com/kubernetes/kubernetes/pull/60998). Esperaría a la próxima ejecución (actualmente en progreso) para confirmar que no fue una única vez, pero realmente necesitamos entender esto.
cc @jpbetz @gyuho
shyamjvs
en 14 mar. 2018
Como estaría de vacaciones de jueves a viernes esta semana, estoy pegando instrucciones para ejecutar la prueba de densidad en un clúster de 5k nodos (para que alguien con acceso al proyecto pueda continuar con la bisección):
# Start with a clean shell.
# Checkout to the right commit.
make quick-release
# Set the project:
gcloud config set project k8s-scale-testing
# Set some configs for creating/testing 5k-node cluster:
export CLOUDSDK_CORE_PRINT_UNHANDLED_TRACEBACKS=1
export KUBE_GCE_ZONE=us-east1-a
export NUM_NODES=5000
export NODE_SIZE=n1-standard-1
export NODE_DISK_SIZE=50GB
export MASTER_MIN_CPU_ARCHITECTURE=Intel\ Broadwell
export ENABLE_BIG_CLUSTER_SUBNETS=true
export LOGROTATE_MAX_SIZE=5G
export KUBE_ENABLE_CLUSTER_MONITORING=none
export ALLOWED_NOTREADY_NODES=50
export KUBE_GCE_ENABLE_IP_ALIASES=true
export TEST_CLUSTER_LOG_LEVEL=--v=1
export SCHEDULER_TEST_ARGS=--kube-api-qps=100
export CONTROLLER_MANAGER_TEST_ARGS=--kube-api-qps=100\ --kube-api-burst=100
export APISERVER_TEST_ARGS=--max-requests-inflight=3000\ --max-mutating-requests-inflight=1000
export TEST_CLUSTER_RESYNC_PERIOD=--min-resync-period=12h
export TEST_CLUSTER_DELETE_COLLECTION_WORKERS=--delete-collection-workers=16
export PREPULL_E2E_IMAGES=false
export ENABLE_APISERVER_ADVANCED_AUDIT=false
# Bring up the cluster (this brings down pre-existing one if present, so you don't have to explicitly '--down' the previous one) and run density test:
go run hack/e2e.go \
--up \
--test \
--test_args='--ginkgo.focus=\[sig\-scalability\]\sDensity\s\[Feature\:Performance\]\sshould\sallow\sstarting\s30\spods\sper\snode\susing\s\{\sReplicationController\}\swith\s0\ssecrets\,\s0\sconfigmaps\sand\s0\sdaemons$ --allowed-not-ready-nodes=30 --node-schedulable-timeout=30m --minStartupPods=8 --gather-resource-usage=master --gather-metrics-at-teardown=master' \
> somepath/build-log.txt 2>&1
# To re-run the test on same cluster (without re-creating) just omit '--up' in the above.
NOTAS IMPORTANTES:
- Se sospecha que el rango de confirmación actual es ff7918d ... a042ecde3 (mantengamos esto actualizado mientras bisecamos)
- Necesitamos usar etcd-3.1.11 en lugar de 3.2.14 (para evitar incluir una regresión anterior). Cambie la versión en los siguientes archivos para lograrlo mínimamente:
- cluster / gce / manifiestos / etcd.manifest
- cluster / images / etcd / Makefile
- hack / lib / etcd.sh
shyamjvs
en 14 mar. 2018
cc: @ wojtek-t
jdumars
en 14 mar. 2018
etcd v3.1.12 corrige fallas de eventos de reloj en la restauración. Y este es el único cambio que hemos realizado desde la v3.1.11. ¿La prueba de rendimiento implica algo con reinicio de etcd o multinodo que pueda activar una instantánea del líder?
gyuho
en 14 mar. 2018
¿La prueba de rendimiento implica algo con el reinicio de etcd?
De los registros de etcd , no parece que haya ningún reinicio.
multinodo
Estamos usando solo un solo nodo etcd en nuestra configuración (asumiendo que eso es lo que preguntaste).
shyamjvs
en 14 mar. 2018
Veo. Entonces, v3.1.11 y v3.1.12 no deberían ser diferentes: 0
Echaremos otro vistazo si la segunda ejecución también muestra latencias más altas.
gyuho
en 14 mar. 2018
cc: @jpbetz
jdumars
en 14 mar. 2018
De acuerdo con @gyuho en que deberíamos tratar de obtener una señal más fuerte en este caso dado que el único cambio de código en etcd es aislado para reiniciar / recuperar código.
El único otro cambio es la actualización de etcd de go1.8.5 a go1.8.7, pero dudo que veamos una regresión de rendimiento significativa con eso.
jpbetz
en 14 mar. 2018
Entonces, continuando con la bisección, ff7918d1f parece ser bueno:
2.246719086s (watch), 3.916350274s (pod-startup)
Actualizaré el rango de confirmación en https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -373051051 en consecuencia.
shyamjvs
en 14 mar. 2018
A continuación, la confirmación aa19a1726 parece buena, aunque sugeriría volver a intentarlo una vez más para confirmar:
2.715156606s (watch), 4.382527095s (pod-startup)
En este punto voy a pausar la bisección y comenzar mis vacaciones :)
Bajé mi clúster para hacer espacio para la próxima ejecución.
shyamjvs
en 15 mar. 2018
Gracias Shyam. Estoy volviendo a intentar aa19a172693a4ad60d5a08e9b93557267d259c37.
 wasylkowski-a
en 15 mar. 2018
wasylkowski-a
en 15 mar. 2018
Para confirmar aa19a172693a4ad60d5a08e9b93557267d259c37 obtuve los siguientes resultados:
2.47655243s (watch), 4.174016696s (pod-startup)
Entonces esto se ve bien. Continuando con la bisección.
Se sospecha del rango de confirmación actual: aa19a172693a4ad60d5a08e9b93557267d259c37 ... a042ecde362000e51f1e7bdbbda5bf9d81116f84
wasylkowski-a
en 15 mar. 2018
@ wasylkowski-a, ¿podría asistir a nuestra reunión de lanzamiento a las 5 p.m. UTC / 1 p.m. Este / 10 a.m. Pacífico? Es una reunión de Zoom: https://zoom.us/j/2018742972
jdumars
en 15 mar. 2018
Asistiré.
wasylkowski-a
en 15 mar. 2018
La confirmación cca7ccbff161255292f72c2d18459cdface62122 parece poco clara con los siguientes resultados:
2.984185673s (watch), 4.568914929s (pod-startup)
Ejecutaré esto una vez más para tener confianza en que no ingresé la mitad incorrecta de la bisección.
wasylkowski-a
en 15 mar. 2018
Bien, ahora estoy bastante seguro de que cca7ccbff161255292f72c2d18459cdface62122 es malo:
3.285168535s (watch), 4.783986141s (pod-startup)
Reduciendo el rango hasta aa19a172693a4ad60d5a08e9b93557267d259c37 ... cca7ccbff161255292f72c2d18459cdface62122 y probando 92e4d3da0076f923a45d54d69c84e91ac6a61a55.
wasylkowski-a
en 16 mar. 2018
Commit 92e4d3da0076f923a45d54d69c84e91ac6a61a55 se ve bien:
2.522438984s (watch), 4.21739985s (pod-startup)
El nuevo rango de confirmación sospechosa es 92e4d3da0076f923a45d54d69c84e91ac6a61a55 ... cca7ccbff161255292f72c2d18459cdface62122, probando 603ebe466d335a37392315d491782ed18d1bae11
wasylkowski-a
en 16 mar. 2018
@wasylkowski, tenga en cuenta que una de las confirmaciones, a saber, https://github.com/kubernetes/kubernetes/commit/4c289014a05669c376994868d8d91f7565a204b5, se revirtió en https://github.com/kubernetes/kubernetes/commit/493f335830c53bb4ce988
dims
en 16 mar. 2018
Reiterando el comentario de
¿Podemos priorizar la repetición de pruebas una vez contra el cabezal de rama 1.10, en lugar de continuar con la bisección?
 tpepper
en 16 mar. 2018
tpepper
en 16 mar. 2018
@wasylkowski / @ wasylkowski-a ^^^^
tpepper
en 16 mar. 2018
@ wojtek-t PTAL lo antes posible
jdumars
en 16 mar. 2018
Gracias @dims y @tpepper. Deje que lo intente contra la cabeza de la rama 1.10 y vea qué sucede.
wasylkowski-a
en 16 mar. 2018
gracias @wasylkowski en el peor de los casos volvemos a lo que estábamos dividiendo antes. ¿derecho?
dims
en 16 mar. 2018
1.10 cabeza tiene una regresión:
3.522924087s (watch), 4.946431238s (pod-startup)
Esto está en etcd 3.1.12, no en etcd 3.1.11, pero si lo entiendo correctamente, esto no debería hacer mucha diferencia.
Además, 603ebe466d335a37392315d491782ed18d1bae11 se ve bien:
2.744654024s (watch), 4.284582476s (pod-startup)
2.76287483s (watch), 4.326409841s (pod-startup)
2.560703844s (watch), 4.213785531s (pod-startup)
Esto nos deja con el rango 603ebe466d335a37392315d491782ed18d1bae11 ... cca7ccbff161255292f72c2d18459cdface62122 y solo hay 3 confirmaciones allí. Déjame ver lo que averiguo.
También es posible que de hecho 4c289014a05669c376994868d8d91f7565a204b5 sea el culpable aquí, pero luego significa que tenemos otra regresión que se manifiesta en la cabeza.
wasylkowski-a
en 16 mar. 2018
OK, entonces evidentemente el compromiso 6590ea6d5d50700d34255b1e037b2702ad26b7fc es bueno:
2.553170576s (watch), 4.22516704s (pod-startup)
mientras que la confirmación 7b678dc4035c61a1991b5e1442edb13f40deae72 es incorrecta:
3.498855918s (watch), 4.886599251s (pod-startup)
La confirmación incorrecta es la fusión de la confirmación revertida mencionada por @dims , por lo que debemos estar observando otra regresión en la cabeza.
Permítanme volver a ejecutar la cabeza en etcd 3.1.11 en lugar de 3.1.12 y ver qué sucede.
wasylkowski-a
en 17 mar. 2018
@ wasylkowski-a ah clásico buenas noticias malas noticias :) gracias por mantener esto en marcha.
@ wojtek-t ¿alguna otra sugerencia?
dims
en 17 mar. 2018
Head on etcd 3.1.11 también es malo; mi próximo intento será intentarlo directamente después de la reversión (entonces, en la confirmación cdecea545553eff09e280d389a3aef69e2f32bf1), pero con etcd 3.1.11 en lugar de 3.2.14.
wasylkowski-a
en 17 mar. 2018
Suena bien Andrzej
- atenúa
El 17 de marzo de 2018, a las 1:19 p.m., Andrzej Wasylkowski [email protected] escribió:
Head on etcd 3.1.11 también es malo; mi próximo intento será intentarlo directamente después de la reversión (por lo tanto, en la confirmación cdecea5), pero con etcd 3.1.11 en lugar de 3.2.14.
-
Estás recibiendo esto porque te mencionaron.
Responda a este correo electrónico directamente, véalo en GitHub o silencia el hilo.
dims
en 17 mar. 2018
Confirmar cdecea545553eff09e280d389a3aef69e2f32bf1 es bueno, por lo que tenemos una regresión posterior:
2.66454307s (watch), 4.308091589s (pod-startup)
La confirmación 2a373ace6eda6a9cf050ce70a6cf99183c5e5b37 es claramente incorrecta:
3.656979569s (watch), 6.746987916s (pod-startup)
@ wasylkowski-a Entonces, básicamente estamos mirando confirmaciones en el rango https://github.com/kubernetes/kubernetes/compare/cdecea5...2a373ac para ver qué pasa entonces. (ejecutar bisectriz entre estos dos)?
dims
en 17 mar. 2018
Si. Este es un rango enorme, desafortunadamente. Ahora mismo estoy investigando aded0d922592fdff0137c70443caf2a9502c7580.
wasylkowski-a
en 17 mar. 2018
Gracias @wasylkowski ¿cuál es el rango actual? (para que pueda ir a ver las relaciones públicas).
dims
en 18 mar. 2018
La confirmación aded0d922592fdff0137c70443caf2a9502c7580 es incorrecta:
3.626257043s (watch), 5.00754503s (pod-startup)
La confirmación f8298702ffe644a4f021e23a616ad6a8790a5537 también es mala:
3.747051371s (watch), 6.126914967s (pod-startup)
También lo es el compromiso 20a6749c3f86c7cb9e98442046532380fb5f6e36:
3.641172882s (watch), 5.100922237s (pod-startup)
Y también lo es 0e81651e77e0be7e75179e5986ef2c76601f4bd6:
3.687028394s (watch), 5.208157763s (pod-startup)
El rango actual es cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6. Nosotros (yo, @ wojtek-t, @shyamjvs) estamos empezando a sospechar que cdecea545553eff09e280d389a3aef69e2f32bf1 es de hecho un pase inestable, por lo que necesitamos un extremo izquierdo diferente.
wasylkowski-a
en 19 mar. 2018
/ me apuesta por https://github.com/kubernetes/kubernetes/commit/b259543985b10875f4a010ed0285ac43e335c8e0 como culpable
cc @ wasylkowski-a
dims
en 19 mar. 2018
0e81651e77e0be7e75179e5986ef2c76601f4bd6 es, resulta que, mal, así b259543985b10875f4a010ed0285ac43e335c8e0 (como se fusionó 244549f02afabc5be23fc56e86a60e5b36838828, después 0e81651e77e0be7e75179e5986ef2c76601f4bd6) no puede ser el primer culpable (aunque no es imposible que se ha introducido una nueva regresión observaremos una vez que nos damos a cabo éste)
wasylkowski-a
en 19 mar. 2018
Per @ wojtek-t y @shyamjvs Estoy volviendo a ejecutar cdecea545553eff09e280d389a3aef69e2f32bf1, porque sospechamos que esto podría haber sido un "bien inestable"
wasylkowski-a
en 19 mar. 2018
Asumiré que cdecea545553eff09e280d389a3aef69e2f32bf1 es realmente bueno según los siguientes resultados que he observado:
2.66454307s (watch), 4.308091589s (pod-startup)
2.695629257s (watch), 4.194027608s (pod-startup)
2.660956347s (watch), 3m36.62259323s (pod-startup) <-- looks like an outlier
2.865445137s (watch), 4.594671099s (pod-startup)
2.412093606s (watch), 4.070130529s (pod-startup)
Rango actualmente sospechoso: cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6
Actualmente probando 99c87cf679e9cbd9647786bf7e81f0a2d771084f
wasylkowski-a
en 20 mar. 2018
Gracias @wasylkowski por continuar con este trabajo.
jdumars
en 20 mar. 2018
por discusión hoy: fluentd-scaler todavía tiene problemas: https://github.com/kubernetes/kubernetes/issues/61190 , que no han sido solucionados por los RP. ¿Es posible que esta regresión sea causada por fluentd?
 jberkus
en 20 mar. 2018
jberkus
en 20 mar. 2018
uno de los RP relacionados con fluentd https://github.com/kubernetes/kubernetes/commit/a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 está en el rango más reciente
dims
en 20 mar. 2018
por discusión de hoy: fluentd-scaler todavía tiene problemas: # 61190, que no han sido corregidos por los RP. ¿Es posible que esta regresión sea causada por fluentd?
TBH, me sorprendería mucho que se debiera a problemas de fluidez. Pero no puedo excluir esta hipótesis con seguridad.
Mi sentimiento personal sería algún cambio en Kubelet, pero también busqué relaciones públicas en ese rango y nada parece realmente sospechoso ...
Con suerte, el rango será 4 veces más pequeño mañana, lo que significaría solo un par de RP.
wojtek-t
en 20 mar. 2018
Bien, entonces 99c87cf679e9cbd9647786bf7e81f0a2d771084f se ve bien, pero necesitaba tres ejecuciones para asegurarme de que esto no sea una escama:
2.901624657s (watch), 4.418169754s (pod-startup)
2.938653965s (watch), 4.423465198s (pod-startup)
3.047455619s (watch), 4.455485098s (pod-startup)
A continuación, a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 es malo:
3.769747695s (watch), 5.338517616s (pod-startup)
El rango actual es 99c87cf679e9cbd9647786bf7e81f0a2d771084f ... a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2. Analizando c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd.
wasylkowski-a
en 20 mar. 2018
Miré el rango mencionado anteriormente: solo hay 9 RP allí.
https://github.com/kubernetes/kubernetes/pull/59944 - 100% NO - solo cambia el archivo de propietarios
https://github.com/kubernetes/kubernetes/pull/59953 - potencialmente
https://github.com/kubernetes/kubernetes/pull/59809 : solo toca el código kubectl, por lo que no debería importar en este caso
https://github.com/kubernetes/kubernetes/pull/59955 - 100% NO - solo tocando pruebas e2e no relacionadas
https://github.com/kubernetes/kubernetes/pull/59808 - potencialmente (cambia la configuración del clúster)
https://github.com/kubernetes/kubernetes/pull/59913 - 100% NO - solo tocando pruebas e2e no relacionadas
https://github.com/kubernetes/kubernetes/pull/59917 : está cambiando la prueba, pero no activa los cambios, por lo que es poco probable
https://github.com/kubernetes/kubernetes/pull/59668 - 100% NO - solo tocando el código AWS
https://github.com/kubernetes/kubernetes/pull/59909 - 100% NO - solo tocando archivos de propietarios
Entonces creo que tenemos dos candidatos aquí: https://github.com/kubernetes/kubernetes/pull/59953 y https://github.com/kubernetes/kubernetes/pull/59808
Intentaré profundizar en ellos para comprenderlos.
wojtek-t
en 21 mar. 2018
c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd se ve bastante mal:
3.428891786s (watch), 4.909251611s (pod-startup)
Dado que esta es la combinación de # 59953, uno de los sospechosos de Wojtek, ahora ejecutaré una confirmación antes de eso, por lo que f60083549a43f152b3142e01756e25611d911770.
Sin embargo, esa confirmación es un cambio de OWNERS_ALIASES, y no queda nada en ese rango antes, por lo que c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd debe ser el problema. De todos modos, haré la prueba solo por seguridad.
wasylkowski-a
en 21 mar. 2018
Discutido fuera de línea: ejecutaremos pruebas al principio con esta confirmación revertida localmente.
wojtek-t
en 21 mar. 2018
¡Guauu! una sola línea que causa tantos problemas. gracias @wasylkowski @ wojtek-t
dims
en 21 mar. 2018
@dims One-liners puede causar devastación con la escalabilidad. Otro, por ejemplo, del pasado: https://github.com/kubernetes/kubernetes/pull/53720#issue-145949976
En general, es posible que desee ver https://github.com/kubernetes/community/blob/master/sig-scalability/blogs/scalability-regressions-case-studies.md para una buena lectura :)
shyamjvs
en 21 mar. 2018
Actualizar re. prueba en la cabecera: primera ejecución con la confirmación revertida localmente aprobada. Sin embargo, esto podría ser un error, así que lo volveré a ejecutar.
wasylkowski-a
en 21 mar. 2018
Mirando la confirmación en https: //github.com/kubernetes/kubernetes/pull/59953 ... ¿ no estaba arreglando un error? Parece haber estado arreglando un error que coloca el estado "programado" en el objeto incorrecto. Según el problema al que se hace referencia en ese PR, parece que el kubelet podría no informar que se programó un pod sin esa solución
liggitt
en 21 mar. 2018
@ Random-Liu ¿Quién podría explicarnos mejor cuál es el efecto de ese cambio :)
shyamjvs
en 21 mar. 2018
Mirando la confirmación en # 59953 ... ¿no estaba arreglando un error? Parece haber estado arreglando un error que coloca el estado "programado" en el objeto incorrecto. ¿Podría el kubelet haber informado que se programó un pod demasiado pronto antes de esa solución?
Sí, sé que fue una corrección de errores. Simplemente no lo entiendo completamente.
Parece que se soluciona el problema de los informes de grupos como "Programado". Pero no vemos el problema incluso hasta el momento en que kubelet informa como "StartedAt".
El problema es que vemos un aumento signifcativo entre el tiempo informado como "StartedAt" por Kubelet y cuando la prueba informa y observa la actualización del estado del pod.
Así que creo que la parte "Programada" es una pista falsa aquí.
Mi suposición (pero esto sigue siendo solo una suposición) es que debido a este cambio estamos enviando más actualizaciones de estado de Pod, lo que a su vez está dando como resultado más 429 o algo así. Y al final, un Kubelet necesita más tiempo para informar el estado del pod. Pero eso es algo que aún debemos confirmar.
wojtek-t
en 21 mar. 2018
Después de dos ejecuciones, estoy bastante seguro de que revertir # 59953 soluciona el problema:
3.052567319s (watch), 4.489142104s (pod-startup)
2.799364978s (watch), 4.385999497s (pod-startup)
estamos enviando más actualizaciones de estado de Pod, lo que a su vez resulta en más 429 o algo así. Y al final, un Kubelet necesita más tiempo para informar el estado del pod.
Este es más o menos el efecto que estaba hipotetizando en https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 (aunque la causa que supuse era incorrecta) :)
Además, el IIRC pareció ver un aumento en el número de 429 para llamadas put (consulte mi https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370582634) pero eso fue de un rango anterior, creo ( alrededor de etcd change).
shyamjvs
en 21 mar. 2018
Después de dos ejecuciones, estoy bastante seguro de que revertir # 59953 soluciona el problema:
Mi intuición (https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370874602) sobre el problema de estar en el lado de kubelet bastante temprano en el hilo fue correcta después de todo :)
shyamjvs
en 21 mar. 2018
/ sig nodo
@ kubernetes / sig-node-bugs, el equipo de lanzamiento realmente podría usar la revisión de # 59953 commit versus revert y el problema de rendimiento aquí
tpepper
en 21 mar. 2018
Mirando la confirmación en # 59953 ... ¿no estaba arreglando un error? Parece haber estado arreglando un error que coloca el estado "programado" en el objeto incorrecto. Según el problema al que se hace referencia en ese PR, parece que el kubelet podría no informar que se programó un pod sin esa solución
@liggitt Gracias por explicarme esto. Sí, ese PR está arreglando un error. Anteriormente, kubelet no siempre establecía PodScheduled . Con # 59953, kubelet lo hará correctamente.
@shyamjvs No estoy seguro de si podría introducir más actualizaciones de estado de pod.
Si entiendo correctamente, la condición PodScheduled se establecerá en la primera actualización de estado y luego siempre estará allí y nunca se cambiará. No entiendo por qué genera más actualizaciones de estado.
Si realmente introduce más actualizaciones de estado, es un problema introducido hace 2 años https://github.com/kubernetes/kubernetes/pull/24459 pero cubierto por un error, y # 59953 simplemente corrige el error ...
@ wasylkowski-a ¿Tiene registros para la ejecución de 2 pruebas en https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -374982422 y https://github.com/kubernetes/kubernetes/issues/60589# problemacomentar -374871490? Básicamente uno bueno y uno malo. El kubelet.log será muy útil.
 Random-Liu
en 21 mar. 2018
Random-Liu
en 21 mar. 2018
@yujuhong y yo encontramos que # 59953 expuso un problema de que la condición PodScheduled del pod estático seguirá actualizándose.
Kubelet genera una nueva condición PodScheduled para el pod que no la tiene. El pod estático no lo tiene y su estado nunca se actualiza (comportamiento esperado). Por lo tanto, kubelet seguirá generando una nueva condición PodScheduled para el pod estático.
El problema se introdujo en el # 24459, pero cubierto por un error. # 59953 corrigió el error y expuso el problema original.
Hay 2 opciones para solucionar este problema rápidamente:
- Opción 1: No permita que kubelet agregue la condición
PodScheduled, kubelet solo debe conservar la condiciónPodScheduledestablecida por el programador.- Ventajas: Simple.
- Contras: el módulo estático y el módulo que omite el programador (asignar el nombre del nodo directamente) no tendrán la condición
PodScheduled. En realidad sin # 59953, aunque kubelet eventualmente establecerá esta condición para esos pods, pero puede llevar mucho tiempo debido a un error.
- Opción 2: Genere una condición
PodScheduledpara el pod estático cuando kubelet lo vea inicialmente.
La opción 2 podría introducir menos cambios de cara al usuario.
Pero queremos preguntar qué significa PodScheduled para los pods que no están programados por el programador. ¿Realmente necesitamos esta condición para esas vainas? / cc @ kubernetes / sig-autoscaling-bugs Porque @yujuhong me dijo que ahora el autoescalado usa PodScheduled .
/ cc @ kubernetes / sig-node-bugs @ kubernetes / sig-scheduling-bugs
Random-Liu
en 21 mar. 2018
@ Random-Liu ¿Cuál es el efecto del very long time for kubelet to eventually set this condition ? ¿Qué problema notará / enfrentará un usuario final (fuera de la descamación del arnés de prueba)? (de la Opción # 1)
dims
en 21 mar. 2018
@dims El usuario no verá la condición PodScheduled durante mucho tiempo.
Random-Liu
en 21 mar. 2018
Tengo una solución # 61504 que implementa la opción 2 en https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979.
Puedo cambiarlo a la opción 1 si la gente piensa que es una mejor solución. :)
Random-Liu
en 21 mar. 2018
¡Será mejor que pregunte a las personas que conocen esto de adentro hacia afuera! (¡NO el equipo de lanzamiento 😄!)
ping @dashpole @ dchen1107 @derekwaynecarr
dims
en 21 mar. 2018
@ Random-Liu IIRC, el único pod estático que se ejecuta en nodos en nuestras pruebas es kube-proxy. ¿Podría decirnos con qué frecuencia kubelet realiza estas "actualizaciones continuas"? (preguntando para estimar qps adicionales introducidos por el error)
shyamjvs
en 21 mar. 2018
@ Random-Liu IIRC, el único pod estático que se ejecuta en nodos en nuestras pruebas es kube-proxy. ¿Podría decirnos con qué frecuencia kubelet realiza estas "actualizaciones continuas"? (preguntando para estimar qps adicionales introducidos por el error)
@shyamjvs Sí, kube-proxy es el único en el nodo ahora.
Creo que depende de la frecuencia de sincronización de pod https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/kubeletconfig/v1beta1/defaults.go#L47 , que es de 1 minuto. Entonces, kubelet genera una actualización de estado de pod adicional cada 1 minuto.
Random-Liu
en 22 mar. 2018
Gracias. Eso significa que 5000/60 = ~ 83 qps se agregaron extra debido a las llamadas de estado de pods. Parece explicar el aumento de 429 señalado anteriormente en el error.
shyamjvs
en 22 mar. 2018
@ Random-Liu muchas gracias por ayudarnos a solucionar este problema.
jdumars
en 22 mar. 2018
@jdumars np ~ ¡ @yujuhong me ayudó mucho!
Random-Liu
en 22 mar. 2018
Pero queremos preguntar qué significa PodScheduled para los pods que no están programados por el programador. ¿Realmente necesitamos esta condición para esas vainas? / cc @ kubernetes / sig-autoscaling-bugs Porque @yujuhong me dijo que el autoescalado usa PodScheduled ahora.
Sigo pensando que dejar que kubelet establezca la condición PodScheduled es algo extraño (como señalé en el PR original). Incluso si kubelet no establece esta condición, no afectará al escalador automático del clúster, ya que el escalador automático ignora los pods sin la condición específica. De todos modos, la solución que finalmente encontramos tiene una huella muy pequeña y mantendría el comportamiento actual (es decir, siempre configurando la condición PodScheduled), así que seguiremos con eso.
 yujuhong
en 22 mar. 2018
yujuhong
en 22 mar. 2018
Además, revivió el problema realmente antiguo para agregar pruebas para la tasa de actualización de pod de estado estable # 14391
yujuhong
en 22 mar. 2018
De todos modos, la solución que finalmente encontramos tiene una huella muy pequeña y mantendría el comportamiento actual (es decir, siempre configurando la condición PodScheduled), así que seguiremos con eso.
@yujuhong - ¿estás hablando de este: # 61504 (o lo entiendo mal)?
@wasylkowski @shyamjvs : ¿puede ejecutar pruebas de 5000 nodos con ese PR parcheado localmente (antes de fusionarlo) para asegurarse de que esto realmente ayude?
wojtek-t
en 22 mar. 2018
Ejecuté la prueba contra 1.10 HEAD + # 61504, y la latencia de inicio del pod parece estar bien:
INFO: perc50: 2.594635536s, perc90: 3.483550118s, perc99: 4.327417676s
Se volverá a ejecutar una vez más para confirmar.
shyamjvs
en 22 mar. 2018
@shyamjvs - ¡muchas gracias!
wojtek-t
en 22 mar. 2018
La segunda ejecución también parece buena:
INFO: perc50: 2.583489146s, perc90: 3.466873901s, perc99: 4.380595534s
Bastante seguro ahora que la solución funcionó. Vamos a ponerlo en 1.10 lo antes posible.
shyamjvs
en 22 mar. 2018
Gracias @shyamjvs
Mientras hablamos sin conexión, creo que tuvimos una regresión más en el último mes, pero esa no debería bloquear el lanzamiento.
wojtek-t
en 22 mar. 2018
@yujuhong - ¿estás hablando de este: # 61504 (o lo entiendo mal)?
Sí. La solución actual en ese PR no está en las opciones propuestas inicialmente en https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979
yujuhong
en 22 mar. 2018
reabrir hasta que tengamos un buen resultado de la prueba de rendimiento.
jberkus
en 25 mar. 2018
@yujuhong @krzyzacy @shyamjvs @ wojtek-t @ Random-Liu @ wasylkowski-a ¿alguna actualización sobre esto? Esto todavía está bloqueando 1.10 en este momento.
jdumars
en 26 mar. 2018
Entonces, la única parte de este error que estaba bloqueando el lanzamiento es el trabajo de rendimiento de 5k nodos. Desafortunadamente, perdimos nuestra carrera a partir de hoy debido a una razón diferente (ref: https://github.com/kubernetes/kubernetes/issues/61190#issuecomment-376150569)
Dicho esto, estamos bastante seguros de que la solución funciona según mis ejecuciones manuales (los resultados se pegan en https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-375350217). Así que, en mi humilde opinión, no necesitamos bloquear el lanzamiento (la próxima ejecución será el miércoles).
shyamjvs
en 26 mar. 2018
+1
@jdumars : creo que podemos tratar esto como un no bloqueador.
wojtek-t
en 26 mar. 2018
Lo siento, edité mi publicación anterior. Quise decir que deberíamos tratarlo como "no bloqueador".
wojtek-t
en 26 mar. 2018
Vale, muchas gracias. Esta conclusión representa una tremenda cantidad de horas que han invertido y no puedo agradecerles lo suficiente por el trabajo que han realizado. Si bien hablamos en abstracto de "comunidad" y "contribuyentes", usted y los demás que han trabajado este tema lo representan en términos concretos. Ustedes son el corazón y el alma de este proyecto, y sé que hablo en nombre de todos los involucrados cuando digo que es un honor trabajar junto con tanta pasión, compromiso y profesionalismo.
jdumars
en 26 mar. 2018
[MILESTONENOTIFIER] Problema de hito: actualizado para el proceso
@krzyzacy @ msau42 @shyamjvs @ wojtek-t
Emitir etiquetas
sig/api-machinerysig/autoscalingsig/nodesig/scalabilitysig/schedulingsig/storage: El problema se escalará a estos SIG si es necesario.priority/critical-urgent: Nunca mueva el problema automáticamente fuera de un hito de lanzamiento; escalar continuamente a colaborador y SIG a través de todos los canales disponibles.kind/bug: corrige un error descubierto durante la versión actual.Ayuda
 k8s-github-robot
en 11 abr. 2018
k8s-github-robot
en 11 abr. 2018
Este problema se resolvió con las correcciones pertinentes en la versión 1.10.
Para la versión 1.11, estamos rastreando las fallas en: https://github.com/kubernetes/kubernetes/issues/63030.
/cerca
shyamjvs
en 25 may. 2018
Temas relacionados
 sanjana-bhat
·
3Comentarios
sanjana-bhat
·
3Comentarios
 chowyu08
·
3Comentarios
chowyu08
·
3Comentarios
 rhohubbuild
·
3Comentarios
rhohubbuild
·
3Comentarios
 pwittrock
·
3Comentarios
pwittrock
·
3Comentarios
 ddysher
·
3Comentarios
ddysher
·
3Comentarios
Comentario más útil
Ejecuté la prueba contra 1.10 HEAD + # 61504, y la latencia de inicio del pod parece estar bien:
Se volverá a ejecutar una vez más para confirmar.