Kubernetes: [uji serpih] suite skalabilitas utama
Rangkaian pemblokir rilis yang gagal:
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
ketiga suite banyak mengelupas akhir-akhir ini, pikiran triase?
/ sig skalabilitas
/ prioritas gagal-tes
/ jenis bug
/ status disetujui untuk pencapaian
CC @jumars
/ tetapkan @shyamjvs @ wojtek-t
 krzyzacy
krzyzacy
Semua 164 komentar
- Pekerjaan kebenaran gagal sebagian besar karena waktu tunggu (perlu menyesuaikan jadwal kami secara bersamaan) karena ada banyak e2es yang ditambahkan ke suite baru-baru ini (misalnya https://github.com/kubernetes/kubernetes/pull/59391)
- Untuk serpihan 100 node, kami memiliki https://github.com/kubernetes/kubernetes/issues/60500 (dan saya yakin itu terkait .. perlu diperiksa).
- Untuk pekerjaan kinerja, saya percaya ada regresi (tampaknya dari beberapa berjalan terakhir seperti itu di sekitar latensi pod-startup). Mungkin lebih juga.
Saya akan mencoba mendapatkan mereka kapan-kapan selama minggu ini (memiliki kelangkaan siklus gratis atm).
 shyamjvs
pada 28 Feb 2018
shyamjvs
pada 28 Feb 2018
@shyamjvs apakah ada pembaruan untuk masalah ini?
krzyzacy
pada 2 Mar 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
Saya melihat sekilas tentang itu. Dan entah beberapa tes sangat lambat atau ada yang menggantung. Par log dari operasi terakhir:
62571 I0301 23:01:31.360] Mar 1 23:01:31.348: INFO: Running AfterSuite actions on all node
62572 I0301 23:01:31.360]
62573 W0302 07:32:00.441] 2018/03/02 07:32:00 process.go:191: Abort after 9h30m0s timeout during ./hack/ginkgo-e2e.sh --ginkgo.flakeAttempts=2 --ginkgo.skip=\[Serial\]|\[Disruptive \]|\[Flaky\]|\[Feature:.+\]|\[DisabledForLargeClusters\] --allowed-not-ready-nodes=50 --node-schedulable-timeout=90m --minStartupPods=8 --gather-resource-usage=master --gathe r-metrics-at-teardown=master --logexporter-gcs-path=gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-correctness/80/artifacts --report-dir=/workspace/_artifacts --dis able-log-dump=true --cluster-ip-range=10.64.0.0/11. Will terminate in another 15m
62574 W0302 07:32:00.445] SIGABRT: abort
Tidak ada tes yang selesai dalam 8h30m
 wojtek-t
pada 2 Mar 2018
wojtek-t
pada 2 Mar 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
Memang tampak seperti regresi. Saya pikir regresi terjadi di suatu tempat di antara proses:
105 (yang masih ok)
108 (yang memiliki waktu startup yang jauh lebih tinggi)
Kita dapat mencoba melihat kubemark-5000 untuk melihat apakah itu juga terlihat di sana.
wojtek-t
pada 2 Mar 2018
Kubemark-5000 cukup stabil. Persentil ke-99 pada grafik ini (mungkin regresi terjadi bahkan sebelumnya, tetapi menurut saya ini berada di antara 105 dan 108):

wojtek-t
pada 2 Mar 2018
Mengenai uji ketepatan - gce-large-correctness juga gagal.
Mungkinkah beberapa tes yang sangat lama ditambahkan pada saat itu?
wojtek-t
pada 2 Mar 2018
Terima kasih banyak telah mencari @ wojtek-t. Pekerjaan kinerja tertulis - Saya juga merasa yakin ada kemunduran (meskipun saya tidak bisa memeriksanya dengan benar).
Mungkinkah beberapa tes yang sangat lama ditambahkan pada saat itu?
Saya melihat ini beberapa waktu yang lalu. Dan ada 2 perubahan mencurigakan yang saya temukan:
- # 59391 - Ini menambahkan banyak tes di sekitar penyimpanan lokal (berjalan setelah perubahan ini mulai waktu habis)
- StatefulSet dengan pod anti-afinitas harus menggunakan volume yang tersebar di seluruh node (pengujian ini tampaknya berjalan selama 3,5 - 5 jam) - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e -gce-scale-correctness / 79
shyamjvs
pada 2 Mar 2018
cc @ kubernetes / sig-storage-bugs
shyamjvs
pada 2 Mar 2018
/menetapkan
Beberapa pengujian penyimpanan lokal akan mencoba menggunakan setiap node di cluster, berpikir bahwa ukuran cluster tidak terlalu besar. Saya akan menambahkan perbaikan untuk membatasi jumlah node maksimal.
 msau42
pada 2 Mar 2018
msau42
pada 2 Mar 2018
Beberapa pengujian penyimpanan lokal akan mencoba menggunakan setiap node di cluster, berpikir bahwa ukuran cluster tidak terlalu besar. Saya akan menambahkan perbaikan untuk membatasi jumlah node maksimal.
Terima kasih @ msau42 - itu akan bagus.
wojtek-t
pada 2 Mar 2018
Kembali ke https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance suite
Saya melihat lebih dekat lari ke 105 dan lari 108 dan setelah itu.
Perbedaan terbesar waktu startup wrt ke pod tampaknya muncul pada langkah:
10% worst watch latencies:
[namanya menyesatkan - akan dijelaskan di bawah]
Hingga 105 run, umumnya terlihat seperti ini:
I0129 21:17:43.450] Jan 29 21:17:43.356: INFO: perc50: 1.041233793s, perc90: 1.685463015s, perc99: 2.350747103s
Dimulai dengan 108 run, tampilannya lebih seperti:
Feb 12 10:08:57.123: INFO: perc50: 1.122693874s, perc90: 1.934670461s, perc99: 3.195883331s
Itu pada dasarnya berarti peningkatan ~ 0,85 dan ini kira-kira apa yang kita amati pada hasil akhirnya.
Sekarang - apa itu "watch lag".
Ini pada dasarnya adalah waktu antara "Kubelet mengamati bahwa pod sedang berjalan" hingga "saat menguji pembaruan pod yang diamati menyetel statusnya menjadi berjalan".
Ada beberapa kemungkinan di mana kami bisa mengalami kemunduran:
- kubelet melambat dalam status pelaporan
- kubelet adalah qps-starved (dan dengan demikian lebih lambat dalam status pelaporan)
- apiserver lebih lambat (mis. cpu-kelaparan) dan dengan demikian memproses permintaan lebih lambat (baik menulis, menonton, atau keduanya)
- tes kekurangan cpu dan dengan demikian memproses acara masuk lebih lambat
Karena kita tidak benar-benar mengamati perbedaan antara "schedule -> start" dari sebuah pod, hal itu menunjukkan bahwa pod tersebut kemungkinan besar bukan apiserver (karena memproses permintaan dan watch juga ada di jalur itu), dan kemungkinan besar tidak memperlambat kubelet juga (karena itu memulai pod).
Jadi menurut saya hipotesis yang paling mungkin adalah:
- kubelet adalah qps-starved (atau sth yang mencegahnya mengirim pembaruan status dengan cepat)
- uji cpu-haus (atau sth seperti itu)
Tes tidak berubah sama sekali pada waktu itu. Jadi saya pikir itu kemungkinan besar yang pertama.
Yang mengatakan, saya melalui PR gabungan antara 105 dan 108 berjalan dan tidak menemukan sesuatu yang berguna sejauh ini.
wojtek-t
pada 2 Mar 2018
Saya pikir langkah selanjutnya adalah:
- lihat ke pod paling lambat (tampaknya ada perbedaan O (1) antara yang paling lambat juga) dan lihat apakah perbedaannya adalah "sebelum" dari "setelah" permintaan status pembaruan dikirim
wojtek-t
pada 2 Mar 2018
Jadi saya melihat contoh pod. Dan saya sudah melihat ini:
I0209 10:01:19.960823 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.615907ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
...
I0209 10:01:22.464046 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (279.153µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:23.468353 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (218.216µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:24.470944 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.42987ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 09:57:01.559125 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (1.836423ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
...
I0209 09:57:04.452830 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (231.2µs) 429 [[kubelet/v1.10.0 (linu x/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:05.454274 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (213.872µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:06.458831 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (2.13295ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 10:01:53.063575 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (1.410064ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:3391
...
I0209 10:01:55.259949 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (10.4894ms) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:56.266377 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (233.931µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:57.269427 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (182.035µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:58.290456 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (13.44863ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
Jadi tampaknya cukup jelas bahwa masalahnya terkait dengan "429".
wojtek-t
pada 2 Mar 2018
Apakah panggilan API yang dibatasi karena kuota di akun pemilik?
 jdumars
pada 2 Mar 2018
jdumars
pada 2 Mar 2018
Apakah panggilan API yang dibatasi karena kuota di akun pemilik?
Ini tidak membatasi seperti yang saya pikirkan pada awalnya. Ini adalah 429 di apiserver (alasannya mungkin apiserver lebih lambat karena beberapa alasan, atau lebih banyak permintaan datang ke apiserver).
wojtek-t
pada 2 Mar 2018
Oh oke. Itu bukan berita bagus.
jdumars
pada 2 Mar 2018
/ tonggak jelas
krzyzacy
pada 2 Mar 2018
/ milestone v1.10
krzyzacy
pada 2 Mar 2018
/ tonggak jelas
 cjwagner
pada 2 Mar 2018
cjwagner
pada 2 Mar 2018
@cjwagner : Anda harus menjadi anggota tim github kubernetes-milestone-maintainers untuk menetapkan pencapaian.
Menanggapi ini :
/ tonggak jelas
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, harap ajukan masalah ke kubernetes / test-infra repository.
 k8s-ci-robot
pada 2 Mar 2018
k8s-ci-robot
pada 2 Mar 2018
/ tonggak v1.9
cjwagner
pada 2 Mar 2018
@cjwagner : Anda harus menjadi anggota tim github kubernetes-milestone-maintainers untuk menetapkan pencapaian.
Menanggapi ini :
/ tonggak v1.9
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, harap ajukan masalah ke kubernetes / test-infra repository.
k8s-ci-robot
pada 2 Mar 2018
Sepertinya PR https://github.com/kubernetes/kubernetes/pull/60740 memperbaiki masalah batas waktu - terima kasih @ msau42 untuk tanggapan cepat.
Pekerjaan kebenaran kami (baik 2k dan 5k) kembali hijau sekarang:
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -large-correctness
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -scale-correctness
Jadi kecurigaan saya tentang tes volume itu memang benar :)
shyamjvs
pada 5 Mar 2018
ACK. Sedang berlangsung
ETA: 9/3/2018
Risiko: Potensi dampak pada kinerja k8s
shyamjvs
pada 5 Mar 2018
Jadi saya menggali sedikit tentang ini dan dari grafik latensi pod-startup untuk pengujian 5k-node kami, saya merasa bahwa regresi juga bisa dalam b / w berjalan 108 dan 109 (lihat 99% ile):

shyamjvs
pada 5 Mar 2018
Saya menyapu dengan cepat perbedaan dan perubahan berikut tampaknya mencurigakan bagi saya:
"Izinkan penerusan waktu tunggu permintaan dari NewRequest hingga ke bawah" # 51042
PR itu memungkinkan penyebaran waktu tunggu klien sebagai parameter kueri ke panggilan API. Dan saya memang melihat perbedaan berikut dalam panggilan PATCH node/status di 2 proses tersebut (dari log apiserver):
run-108:
I0207 22:01:06.450385 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-2rn2/status: (11.81392ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.227.96.23:47270]
I0207 22:01:03.857892 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-9659/status: (8.570809ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.196.85.108:43532]
I0207 22:01:03.857972 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc4w/status: (8.287643ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.229.110.22:50530]
run-109:
I0209 21:01:08.551289 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-89f2/status?timeout=10s: (71.351634ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.229.77.215:51070]
I0209 21:01:08.551310 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-3ms3/status?timeout=10s: (70.705466ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.227.84.87:49936]
I0209 21:01:08.551394 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc02/status?timeout=10s: (70.847605ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.196.125.143:53662]
Hipotesis saya adalah, karena waktu tunggu tambahan 10 detik ke panggilan PATCH, panggilan tersebut sekarang berlangsung lebih lama di sisi server (IIUC komentar ini dengan benar). Artinya, mereka sekarang berada dalam antrian dalam penerbangan untuk durasi yang lebih lama. Hal itu, dikombinasikan dengan fakta bahwa panggilan PATCH tersebut terjadi dalam jumlah besar di cluster besar seperti itu, menyebabkan panggilan PUT pod/status tidak dapat memperoleh bandwidth yang cukup dalam antrian dalam penerbangan dan karenanya dikembalikan dengan 429 detik. Akibatnya, penundaan sisi kubelet dalam memperbarui status pod telah meningkat. Cerita ini juga cocok dengan pengamatan @ wojtek-t di atas.
Saya akan mencoba mengumpulkan lebih banyak bukti untuk memverifikasi hipotesis ini.
shyamjvs
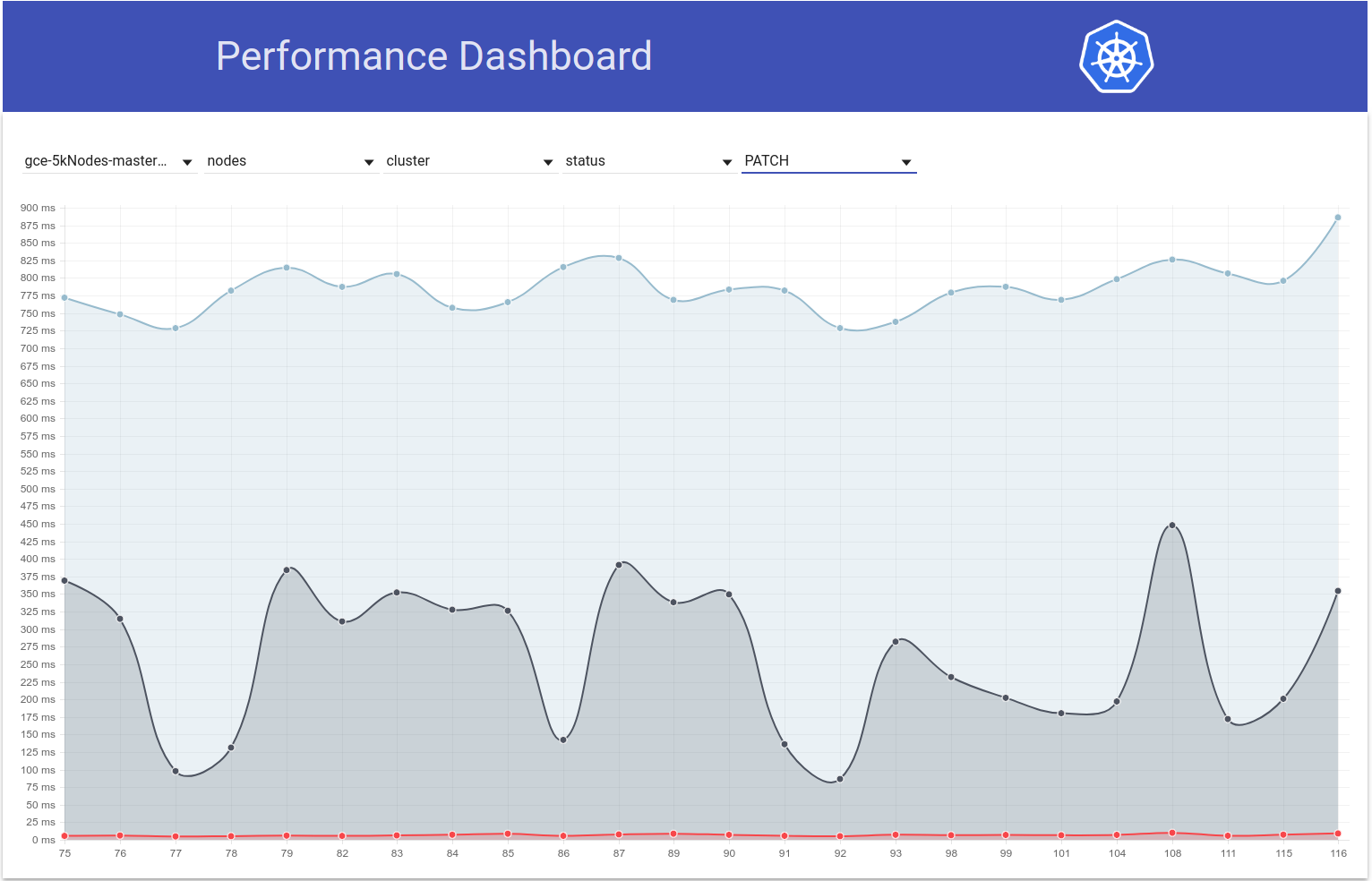
pada 5 Mar 2018
Jadi saya memeriksa bagaimana latensi PATCH node-status bervariasi selama pengujian berjalan, dan sepertinya memang ada kenaikan dalam persentil ke-99 (lihat baris teratas) sekitar waktu itu. Namun tidak terlalu jelas bahwa itu terjadi b / w berjalan 108 dan 109 (meskipun saya yakin itu masalahnya):
shyamjvs
pada 5 Mar 2018
[EDIT: Komentar saya sebelumnya salah menyebutkan jumlah 429 itu (klien adalah npd, bukan kubelet)]
Saya memiliki lebih banyak bukti pendukung sekarang:
di run-108 , kami memiliki ~ 479k PATCH node/status panggilan yang mendapat 429:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"479181"
]
},
dan dalam run-109 , kami memiliki ~ 757k di antaranya:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"757318"
]
},
Dan ... Lihat ini:
di run-108:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"28594"
]
},
dan dalam run-109:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"33224"
]
},
Saya memeriksa nomor untuk beberapa lari berdekatan lainnya:
- PR itu digabungkan -
Meskipun tampaknya sedikit berbeda, secara keseluruhan sepertinya tidak. dari 429 meningkat sekitar 25%.
shyamjvs
pada 5 Mar 2018
Dan untuk PATCH node-status berasal dari kubelet yang menerima 429s, berikut ini bagaimana angkanya terlihat:
- run-104 = 313348
- run-105 = 309136
- run-108 = 479181
- PR itu digabungkan -
- run-109 = 757318
- run-110 = 752062
- run-111 = 296368
Ini juga bervariasi, tetapi secara umum tampaknya meningkat.
shyamjvs
pada 5 Mar 2018
File% ke-99 dari PATCH node-status latensi panggilan juga tampaknya telah meningkat secara umum (seperti yang saya prediksi di https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370573938):
run-104 (798ms), run-105 (783ms), run-108 (826ms)
run-109 (878ms), run-110 (869ms), run-111 (806ms)
Btw - Catat semua metrik di atas, 108 tampaknya berjalan lebih buruk dari normal dan 111 tampaknya lebih baik dari lari normal.
shyamjvs
pada 5 Mar 2018
Saya akan mencoba memverifikasi ini besok dengan menjalankan cluster 5k besar secara manual.
shyamjvs
pada 5 Mar 2018
terima kasih untuk triase @shyamjvs
krzyzacy
pada 5 Mar 2018
Jadi saya menjalankan uji kepadatan dua kali terhadap 5k cluster terhadap ~ HEAD, dan pengujian secara mengejutkan lulus kedua kali dengan 99% latensi startup ile pod sebagai 4.510015461s dan 4.623276837s . Namun, 'latensi jam tangan', memang menunjukkan peningkatan yang ditunjukkan @ wojtek-t di https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -369951288
Yang pertama dijalankan adalah:
INFO: perc50: 1.123056294s, perc90: 1.932503347s, perc99: 3.061238209s
dan proses kedua adalah:
INFO: perc50: 1.121218293s, perc90: 1.996638787s, perc99: 3.137325187s
Sekarang saya akan mencoba memeriksa apa yang terjadi sebelumnya.
shyamjvs
pada 6 Mar 2018
https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 - Saya tidak yakin saya mengikuti ini Ya - kami menambahkan waktu tunggu, tetapi waktu tunggu default lebih besar dari 10 detik IIRC - jadi itu hanya membantu tidak memperburuk keadaan.
Saya pikir kami masih tidak mengerti mengapa kami mengamati lebih banyak 429 (fakta bahwa ini terkait dengan 429 yang sudah saya sebutkan di https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370036377)
wojtek-t
pada 6 Mar 2018
Dan mengenai angka Anda - saya tidak yakin bahwa regresi berjalan 109 - mungkin ada dua regresi - satu di antara 105 dan 108 dan yang lainnya di 109.
wojtek-t
pada 6 Mar 2018
Hmm ... Saya tidak menyangkal kemungkinan yang Anda sebutkan (di atas hanyalah hipotesis saya).
Saat ini saya melakukan pembagian (sekarang terhadap komit 108) untuk memverifikasi.
shyamjvs
pada 6 Mar 2018
Perasaan saya bahwa regresi sebelum menjalankan 108 lebih kuat dan lebih kuat.
Sebagai contoh, latensi panggilan api sudah meningkat dalam 108 run.
status node patch:
90%: 198ms (105) 447ms (108) 444ms (109)
taruh status pod:
99%: 83ms (105) 657ms (108) 728ms (109)
wojtek-t
pada 6 Mar 2018
Saya rasa yang ingin saya katakan adalah:
- jumlah 429 adalah konsekuensi dan kita tidak boleh menghabiskan terlalu banyak waktu untuk itu
- akar penyebabnya adalah panggilan api yang lebih lambat atau jumlah yang lebih besar
Kami jelas melihat panggilan api yang lebih lambat di 108. Pertanyaannya adalah apakah kami juga melihat jumlah yang lebih besar dari itu.
wojtek-t
pada 6 Mar 2018
Jadi saya pikir mengapa permintaan terlihat lebih lambat - ada tiga kemungkinan utama
ada lebih banyak permintaan secara signifikan (dari pandangan pertama sepertinya tidak demikian)
kami menambahkan sesuatu di jalur pemrosesan (misalnya pemrosesan tambahan) atau objek itu sendiri lebih besar
sesuatu yang lain pada mesin master (misalnya scheduler) memakan lebih banyak cpu dan dengan demikian membuat apiserver lebih kelaparan
wojtek-t
pada 6 Mar 2018
Jadi saya dan @ wojtek-t berdiskusi secara offline dan kami berdua setuju sekarang karena kemungkinan besar ada regresi sebelum 108. Menambahkan beberapa poin:
ada lebih banyak permintaan secara signifikan (dari pandangan pertama sepertinya tidak demikian)
Bagi saya sepertinya tidak demikian
kami menambahkan sesuatu di jalur pemrosesan (misalnya pemrosesan tambahan) atau objek itu sendiri lebih besar
Perasaan saya adalah sth lebih mungkin di kubelet dibandingkan dengan apiserver (karena kami tidak melihat perubahan yang terlihat pada patch / latency put pada kubemark-5000)
sesuatu yang lain pada mesin master (misalnya scheduler) memakan lebih banyak cpu dan dengan demikian membuat apiserver lebih kelaparan
IMO ini tidak terjadi karena kami memiliki cukup banyak CPU / mem slack pada master kami. Juga perf-dash tidak menunjukkan peningkatan yang berarti dalam penggunaan komponen utama.
Karena itu, saya menggali sedikit dan "untungnya" sepertinya kami memperhatikan peningkatan latensi jam bahkan untuk cluster 2k-node:
INFO: perc50: 1.024377533s, perc90: 1.589770858s, perc99: 1.934099611s
INFO: perc50: 1.03503718s, perc90: 1.624451701s, perc99: 2.348645755s
Harus membuat membagi dua sedikit lebih mudah.
shyamjvs
pada 6 Mar 2018
Sayangnya, variasi dalam latensi arloji tersebut tampak seperti satu kali saja (jika tidak kira-kira sama). Untungnya, kami memiliki latensi PUT pod-status sebagai indikator regresi yang andal. Saya menjalankan 2 putaran pembagian kemarin dan mempersempit ke perbedaan ini (~ 80 komit). Saya membaca sekilas dan memiliki kecurigaan yang kuat pada:
- # 58990 - menambahkan bidang baru ke status pod (meskipun saya tidak yakin apakah itu akan diisi dalam pengujian kami, di mana preemption IIUC tidak terjadi - tetapi perlu diperiksa)
- # 58645 - memperbarui versi server etcd ke 3.2.14
shyamjvs
pada 7 Mar 2018
Saya benar-benar ragu bahwa # 58990 terkait di sini - NominatedNodeName adalah string yang berisi satu nama node. Bahkan jika itu akan terisi sepanjang waktu, perubahan ukuran objek seharusnya dapat diabaikan.
wojtek-t
pada 7 Mar 2018
@ wojtek-t - Seperti yang Anda sarankan secara offline, sepertinya kami menggunakan versi yang berbeda (3.2.16) di kubemark (https://github.com/kubernetes/kubernetes/blob/master/test/kubemark/ start-kubemark.sh # L62) yang merupakan alasan potensial untuk tidak melihat regresi ini di sana :)
cc @jpbetz
shyamjvs
pada 7 Mar 2018
Kami menggunakan 3.2.16 di mana-mana sekarang.
wojtek-t
pada 7 Mar 2018
Ups .. Maaf melihat ke belakang - Saya melihat kombinasi komit yang salah.
shyamjvs
pada 7 Mar 2018
BTW - peningkatan dalam pod PUT / latensi status terlihat juga dalam uji beban di cluster nyata yang besar.
wojtek-t
pada 7 Mar 2018
Jadi saya menggali sedikit lebih banyak dan sepertinya kami mulai mengamati latensi yang lebih besar sekitar waktu itu untuk permintaan tulis secara umum (yang membuat saya curiga etcd berubah lebih banyak):
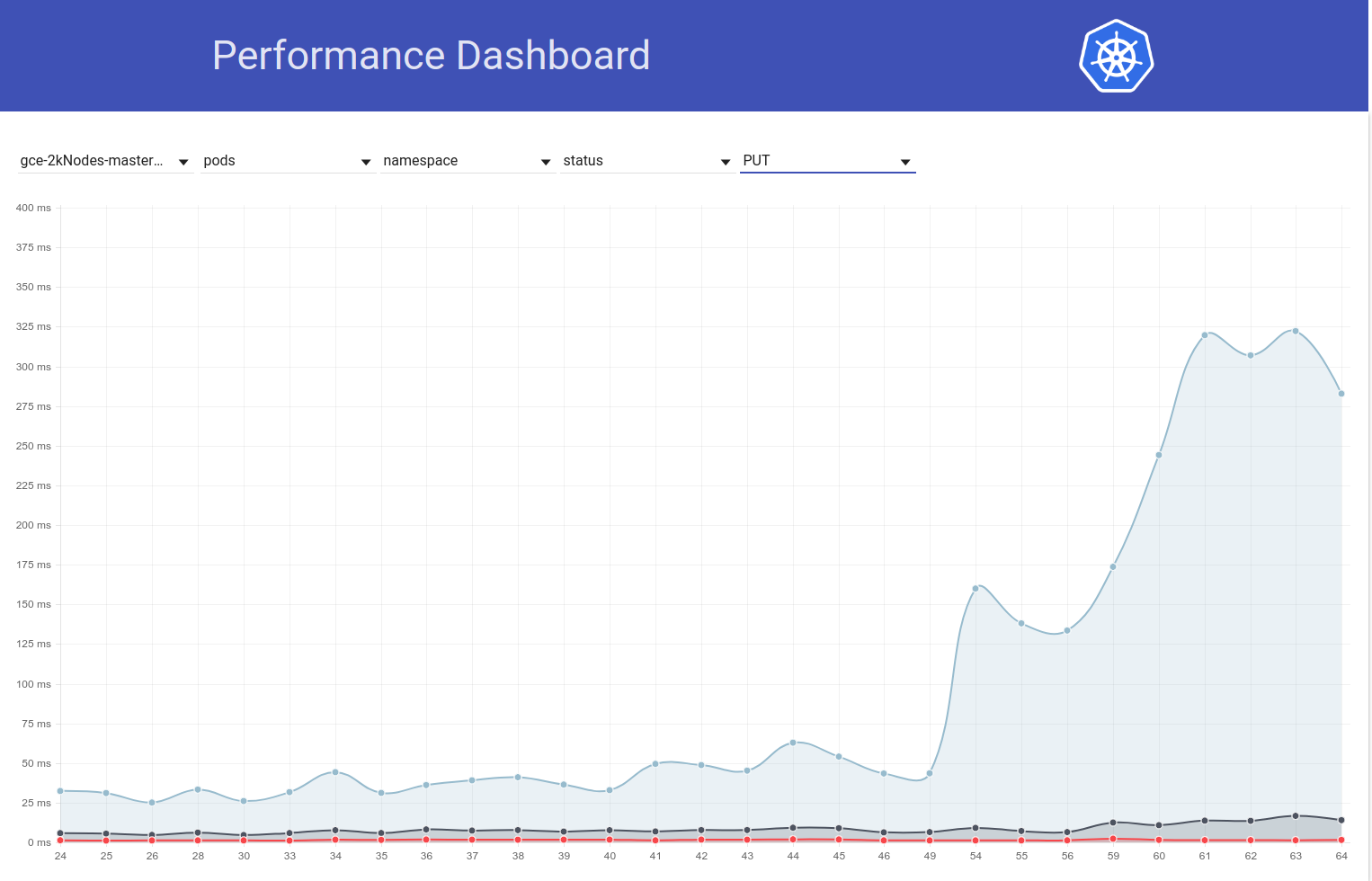
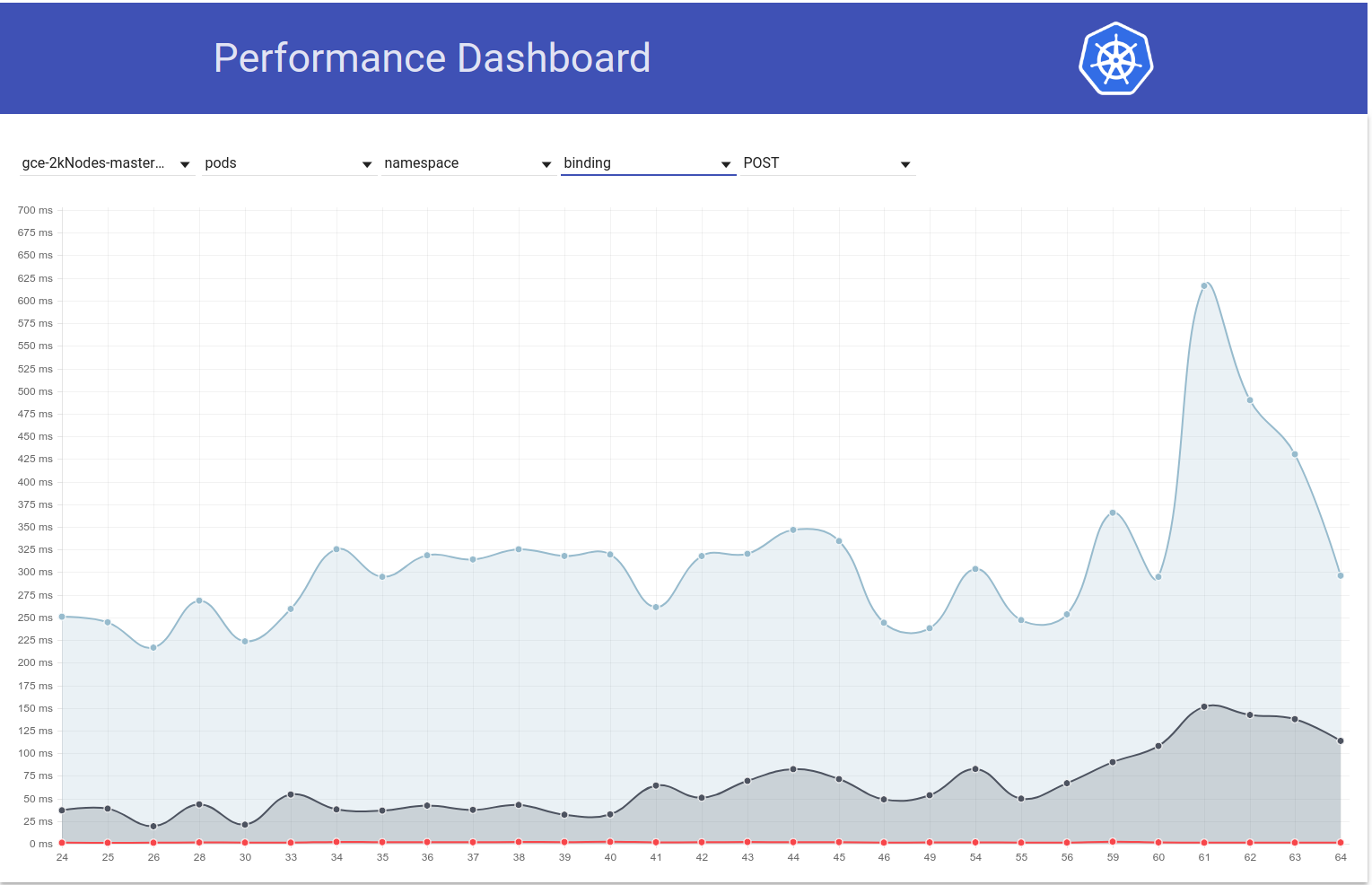

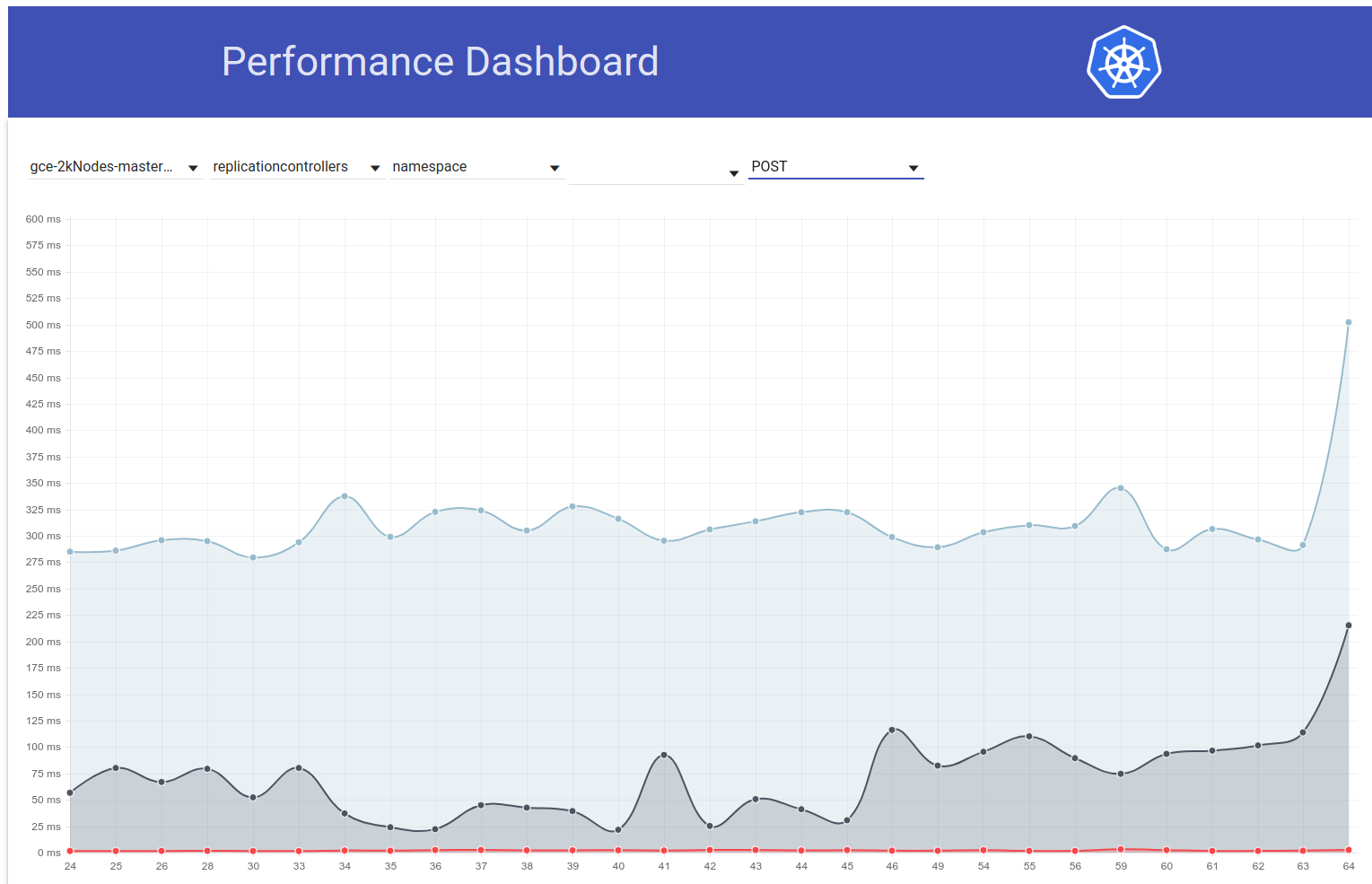
shyamjvs
pada 7 Mar 2018
Sebenarnya, saya memilih bahwa setidaknya sebagian dari masalahnya ada di sini:
https://github.com/kubernetes/kubernetes/pull/58990/commits/384a86caa92bdb7cf9ac96b10a6ef333d2d60519#diff -c73f80ad83608f18657d22a06950d929R240
Saya akan terkejut jika itu akan menjadi masalah keseluruhan, tetapi mungkin berkontribusi padanya.
Akan mengirim PR mengubahnya dalam satu detik.
wojtek-t
pada 7 Mar 2018
FYI - Ketika saya menjalankan komit sebelum perubahan etcd 3.2.14 tetapi setelah perubahan API status-pod, latensi status node put tampaknya baik-baik saja (yaitu 99% ile = 39ms).
shyamjvs
pada 7 Mar 2018
Jadi saya memverifikasi bahwa itu memang disebabkan oleh benjolan etcd ke 3.2.14. Beginilah tampilan latensi status pod:
terhadap PR itu :
{
"data": {
"Perc50": 1.479,
"Perc90": 10.959,
"Perc99": 163.095
},
"unit": "ms",
"labels": {
"Count": "344494",
"Resource": "pods",
"Scope": "namespace",
"Subresource": "status",
"Verb": "PUT"
}
},
terhadap ~ HEAD (dari 5 Maret) dengan PR tersebut dikembalikan (tes masih berjalan, tetapi akan segera selesai):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.5"} 1669
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.9"} 9597
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.99"} 63392
63ms sepertinya sangat mirip dengan sebelumnya .
Kami harus mengembalikan versinya dan mencoba memahami:
- Mengapa kami melihat peningkatan ini di etcd 3.2.14?
- Mengapa kami tidak menangkap ini di kubemark?
cc @jpbetz @ kubernetes / sig-api-mesin-bugs
shyamjvs
pada 7 Mar 2018
Satu hipotesis (mengapa kami tidak menangkapnya di kubemark - meskipun masih tebakan) adalah bahwa kami mungkin telah mengubah sth wrt menjadi sertifikat di sana.
Ketika saya membandingkan log etcd dari kubemark dan real cluster, hanya di cluster terakhir saya melihat baris berikut:
2018-03-05 08:06:56.389648 I | embed: peerTLS: cert = /etc/srv/kubernetes/etcd-peer.crt, key = /etc/srv/kubernetes/etcd-peer.key, ca = , trusted-ca = /etc/srv/kubernetes/etcd-ca.crt, client-cert-auth = true
Melihat PR itu sendiri, saya tidak melihat ada perubahan di sekitarnya, tetapi saya juga tidak tahu mengapa kami harus melihat garis itu hanya di cluster nyata ...
@jpbet untuk pemikiran
wojtek-t
pada 7 Mar 2018
ACK. Sedang berlangsung
ETA: 9/3/2018
Risiko: Masalah yang disebabkan oleh akar (kebanyakan)
shyamjvs
pada 7 Mar 2018
Re peerTLS - tampaknya juga terjadi sebelumnya (dengan 3.1.11) jadi saya pikir itu adalah red herring
wojtek-t
pada 7 Mar 2018
cc @gyuho @wenjias
 jpbetz
pada 7 Mar 2018
jpbetz
pada 7 Mar 2018
63ms sepertinya sangat mirip dengan apa
Dari mana kita mendapatkan angka-angka itu? Apakah apiserver_request_latencies_summary sebenarnya mengukur latensi penulisan etcd? Juga, metrik dari etcd akan membantu.
 gyuho
pada 7 Mar 2018
gyuho
pada 7 Mar 2018
embed: peerTLS: cert ...
Ini mencetak, jika peer TLS dikonfigurasi (sama di 3.1).
gyuho
pada 7 Mar 2018
Dari mana kita mendapatkan angka-angka itu? Apakah apiserver_request_latencies_summary sebenarnya mengukur latensi penulisan etcd? Juga, metrik dari etcd akan membantu.
Ini mengukur latensi apicalls yang (setidaknya dalam kasus panggilan tulis) termasuk latensi etcd.
Kami masih belum benar-benar memahami apa yang terjadi, tetapi kembali ke versi etcd sebelumnya (3.1) memperbaiki regresi. Jadi jelas masalahnya ada di suatu tempat di etcd.
wojtek-t
pada 7 Mar 2018
@yusuf
Versi Kubemark dan Kubernetes apa yang Anda jalankan? Kami menguji Kubemark 1.10 terhadap etcd 3.2 vs 3.3 (beban kerja 500-node), dan tidak mengamati ini. Berapa banyak node yang dibutuhkan untuk mereproduksi ini?
gyuho
pada 7 Mar 2018
Versi Kubemark dan Kubernetes apa yang Anda jalankan? Kami menguji Kubemark 1.10 terhadap etcd 3.2 vs 3.3 (beban kerja 500-node), dan tidak mengamati ini. Berapa banyak node yang dibutuhkan untuk mereproduksi ini?
Kami tidak dapat mereproduksinya dengan kubemark, bahkan dengan 5k-node one - lihat bagian bawah https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -371171837
Ini tampaknya menjadi masalah hanya di cluster nyata.
Ini adalah pertanyaan terbuka mengapa demikian.
wojtek-t
pada 7 Mar 2018
Karena kita telah kembali ke etcd 3.1. untuk kubernetes. Kami juga merilis etcd 3.1.12 dengan satu-satunya perbaikan kritis yang luar biasa untuk kubernetes: mvcc "unsynced" watcher restore operation . Setelah kami menemukan dan memperbaiki akar penyebab dari regresi kinerja yang ditemukan dalam masalah ini, kami dapat membuat sketsa rencana untuk memutakhirkan server etcd yang digunakan oleh kubernetes kembali ke 3.2.
jpbetz
pada 8 Mar 2018
Sepertinya https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100 mulai gagal secara konsisten sejak pagi ini
krzyzacy
pada 9 Mar 2018
Dari perbedaan tersebut , satu-satunya perubahan adalah https://github.com/kubernetes/kubernetes/pull/60421 yang mengaktifkan kuota dalam pengujian kinerja kami secara default. Kesalahan yang kami lihat adalah:
Container kube-controller-manager-e2e-big-master/kube-controller-manager is using 0.531144723/0.5 CPU
not to have occurred
@gmarek - Sepertinya mengaktifkan kuota mempengaruhi skalabilitas kami :) Bisakah Anda melihat lebih dalam - mungkin serius?
Izinkan saya mengajukan masalah lain agar masalah ini tetap berjalan.
shyamjvs
pada 9 Mar 2018
@ wojtek-t @jpbetz @gyuho @timothysc Saya menemukan sesuatu yang sangat menarik dengan perubahan versi etcd, menunjukkan efek yang signifikan dari perpindahan dari etcd 3.1.11 ke 3.2.16.
Lihatlah grafik penggunaan memori etcd berikut di cluster 100-node kami (telah meningkat ~ 2x) ketika pekerjaan dipindahkan dari k8s rilis 1.9 ke 1.10:
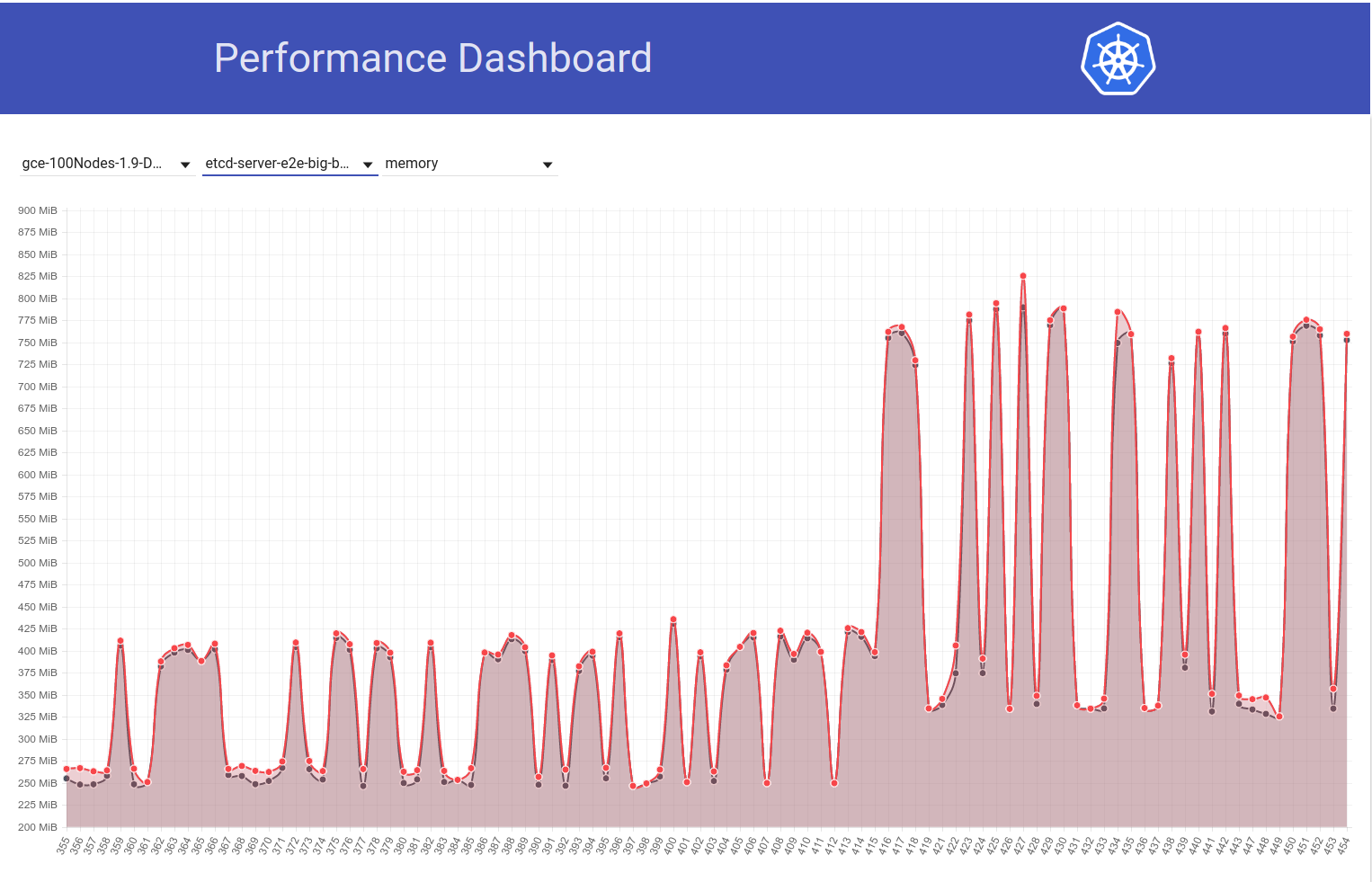
Dan selanjutnya lihat bagaimana pekerjaan 100-node kami (berjalan melawan HEAD) melihat penurunan dalam penggunaan mem menjadi setengah tepat setelah saya kembali dari etcd 3.2.16 -> 3.1.11:
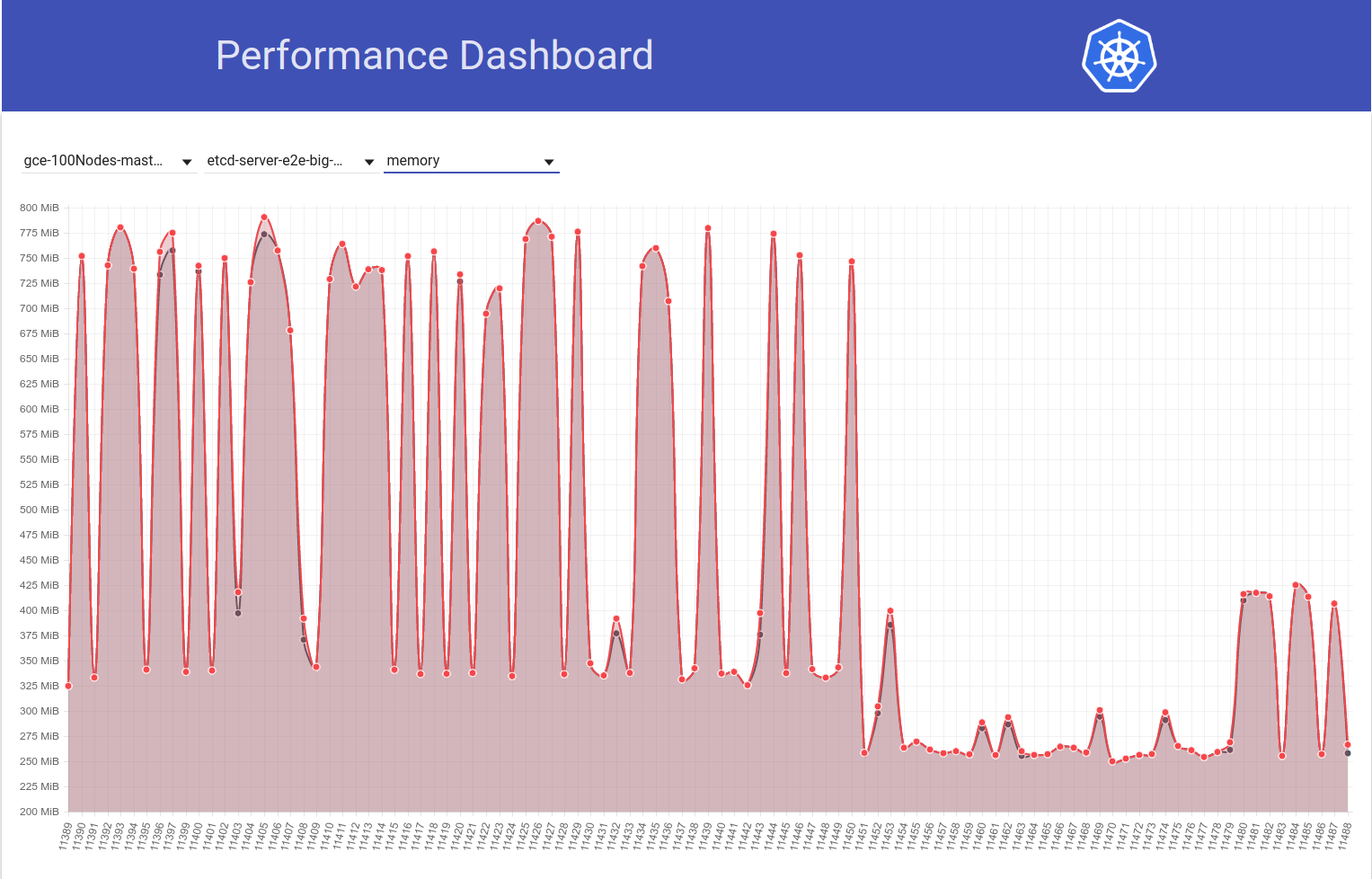
Jadi etcd 3.2 versi server JELAS menunjukkan kinerja yang terpengaruh (dengan semua variabel lain tetap sama) :)
shyamjvs
pada 10 Mar 2018
pengembalian saya dari etcd 3.2.16 -> 3.2.11:
Apakah yang kami maksud 3.1.11?
gyuho
pada 10 Mar 2018
Benar .. maaf. Mengedit komentar saya.
shyamjvs
pada 10 Mar 2018
@shyamjvs Bagaimana etcd dikonfigurasi? Kami telah meningkatkan nilai default --snapshot-count dari 10000 menjadi 100000 , di v3.2. Jadi jika jumlah snapshot berbeda, snapshot dengan jumlah snapshot lebih besar akan menahan entri Raft lebih lama, sehingga membutuhkan lebih banyak memori penduduk, sebelum membuang log lama.
gyuho
pada 10 Mar 2018
Aah! Itu memang tampak seperti perubahan yang mencurigakan. Wrt flags, saya rasa tidak ada perubahan apapun dari sisi k8s. Karena, seperti yang Anda lihat pada grafik kedua saya di atas, diff b / w berjalan 11450 dan 11451 terutama hanya perubahan pengembalian etcd saya (yang tampaknya tidak menyentuh bendera apa pun).
Kami telah meningkatkan nilai default --snapshot-count dari 10000 menjadi 100000
Bisakah Anda memastikan apakah itu penyebab utama peningkatan penggunaan mem ini? Jika ya, kami mungkin ingin:
- patch etcd kembali dengan nilai aslinya, atau
- setel ke 10000 dalam k8s
sebelum beralih kembali ke 3.2
shyamjvs
pada 10 Mar 2018
Aah! Itu memang tampak seperti perubahan yang mencurigakan.
Ya, perubahan ini seharusnya disorot dari sisi etcd (akan meningkatkan log perubahan dan panduan peningkatan kami).
Bisakah Anda memastikan apakah itu penyebab utama peningkatan penggunaan mem ini?
Saya tidak yakin apakah itu akan menjadi akar masalahnya. Jumlah snapshot yang lebih rendah pasti akan membantu mengurangi penggunaan memori yang tajam. Jika kedua versi etcd menggunakan jumlah snapshot yang sama, tetapi satu etcd masih menunjukkan penggunaan memori yang jauh lebih tinggi, seharusnya ada sesuatu yang lain.
gyuho
pada 10 Mar 2018
Pembaruan: Saya memverifikasi bahwa peningkatan penggunaan mem etcd memang disebabkan karena nilai default --snapshot-count yang lebih tinggi. Lihat detail selengkapnya di sini - https://github.com/kubernetes/kubernetes/pull/61037#issuecomment -372457843
Kita harus mempertimbangkan untuk mengaturnya menjadi 10.000 saat kita bertemu etcd 3.2.16, jika kita tidak ingin penggunaan mem meningkat.
cc @gyuho @ xiang90 @jpbetz
shyamjvs
pada 12 Mar 2018
Pembaruan: Dengan perbaikan etcd, latensi startup pod 99% tampaknya masih hampir melanggar SLO 5s. Setidaknya ada satu regresi lain dan saya telah mengumpulkan bukti bahwa kemungkinan besar dalam b / w berjalan 111 dan 112 dari pekerjaan kinerja 5k-node kami (lihat tonjolan b / w yang berjalan di grafik yang saya tempel di https: / /github.com/kubernetes/kubernetes/issues/60589#issuecomment-370568929). Saat ini saya membagi dua perbedaan (yang memiliki sekitar 50 komit) dan pengujian membutuhkan ~ 4-5 jam per iterasi.
Bukti yang saya maksudkan di atas adalah sebagai berikut:
Tonton latensi di 111 adalah:
Feb 14 21:36:05.531: INFO: perc50: 1.070980786s, perc90: 1.743347483s, perc99: 2.629721166s
Dan keseluruhan latensi pod-startup pada 111 adalah:
Feb 14 21:36:05.671: INFO: perc50: 2.416307575s, perc90: 3.24553118s, perc99: 4.092430858s
Sedangkan yang sama di 112 adalah:
Feb 16 10:07:43.222: INFO: perc50: 1.131108849s, perc90: 2.18487651s, perc99: 3.570548412s
dan
Feb 16 10:07:43.353: INFO: perc50: 2.56160248s, perc90: 3.754024568s, perc99: 4.967573867s
Sementara itu, jika seseorang siap untuk permainan taruhan - Anda dapat melihat perbedaan komit yang saya sebutkan di atas dan tebak yang salah :)
shyamjvs
pada 12 Mar 2018
ACK. Sedang berlangsung
ETA: 13/03/2018
Risiko: Dapat mendorong tanggal rilis jika tidak di-debug sebelum itu
shyamjvs
pada 12 Mar 2018
@shyamjvs toooooooo banyak komit untuk memasang taruhan :)
 dims
pada 13 Mar 2018
dims
pada 13 Mar 2018
@dims Itu akan menambah lebih banyak kesenangan, kurasa;)
Pembaruan: Jadi saya menjalankan beberapa iterasi dari dua bagian dan berikut ini tampilan metrik yang relevan di seluruh komit (diurutkan secara kronologis). Perhatikan bahwa untuk yang saya jalankan secara manual, saya menjalankannya dengan regresi sebelumnya dikembalikan (yaitu 3.2. -> 3.1.11).
| Komit | 99% latensi jam tangan | 99% latensi pod-startup | Baik / buruk? |
| ------------- | ------------- | ----- | ------- |
| a042ecde36 (dari run-111) | 2.629721166d | 4.092430858s | Bagus (konfirmasi lagi secara manual) |
| 5f7b530d87 (manual) | 3.150616856s | 4.683392706s | Buruk (mungkin) |
| a8060ab0a1 (manual) | 3.11319985s | 4.710277511s | Buruk (mungkin) |
| 430c1a68c8 (dari run-112) | 3.570548412d | 4.967573867s | Buruk |
| 430c1a68c8 (manual) | 3.63505091s | 4.96697776s | Buruk |
Dari penjelasan di atas, sepertinya ada 2 regresi di sini (karena ini bukan lompatan langsung dari 2.6s -> 3.6s) - satu b / w "a042ecde36 - 5f7b530d87" dan b / w lainnya "a8060ab0a1 - 430c1a68c8". Mendesah!
shyamjvs
pada 13 Mar 2018
mengekspresikan sebagai rentang untuk mendapatkan tautan perbandingan:
a042ecde36 ... 5f7b530
a8060ab0a1 ... 430c1a6
 liggitt
pada 13 Mar 2018
liggitt
pada 13 Mar 2018
Baru saja memperoleh hasil untuk menjalankan manual melawan a042ecde36 dan itu hanya membuat hidup lebih sulit:
3.269330734s (watch), 4.939237532s (pod-startup)
karena ini mungkin berarti regresi tidak stabil.
shyamjvs
pada 13 Mar 2018
Saat ini saya menjalankan pengujian terhadap a042ecde36 sekali lagi untuk memverifikasi kemungkinan bahwa regresi datang bahkan sebelum itu.
shyamjvs
pada 13 Mar 2018
Jadi, inilah hasil dari menjalankan melawan a042ecd lagi:
2.645592996s (watch), 5.026010032s (pod-startup)
Ini mungkin berarti regresi masuk bahkan sebelum run-111 (kabar baik bahwa kita memiliki ujung yang tepat untuk pembagian dua sekarang).
Sekarang saya akan mencoba mengejar ujung kiri. Run-108 (commit 11104d75f) adalah kandidat potensial, yang memiliki hasil sebagai berikut ketika saya menjalankannya sebelumnya (dengan etcd 3.1.11):
2.593628224s (watch), 4.321942836s (pod-startup)
Pengulangan saya terhadap komit 11104d7 sepertinya mengatakan itu bagus:
2.663456162s (watch), 4.288927203s (pod-startup)
Saya akan mencoba membagi dua di kisaran 11104d7 ... a042ecd
shyamjvs
pada 13 Mar 2018
Pembaruan: Saya perlu menguji komit 097efb71a315 tiga kali untuk mendapatkan kepercayaan. Ini menunjukkan beberapa variasi, tetapi sepertinya komit yang bagus:
2.578970061s (watch), 4.129003596s (pod-startup)
2.315561531s (watch), 4.70792639s (pod-startup)
2.303510957s (watch), 3.88150234s (pod-startup)
Saya akan terus membelah dua.
Meskipun demikian, tampaknya ada lonjakan lain (~ 1 detik) dalam latensi pod-startup beberapa hari yang lalu. Dan yang ini mendorong 99% menjadi hampir 6 d:
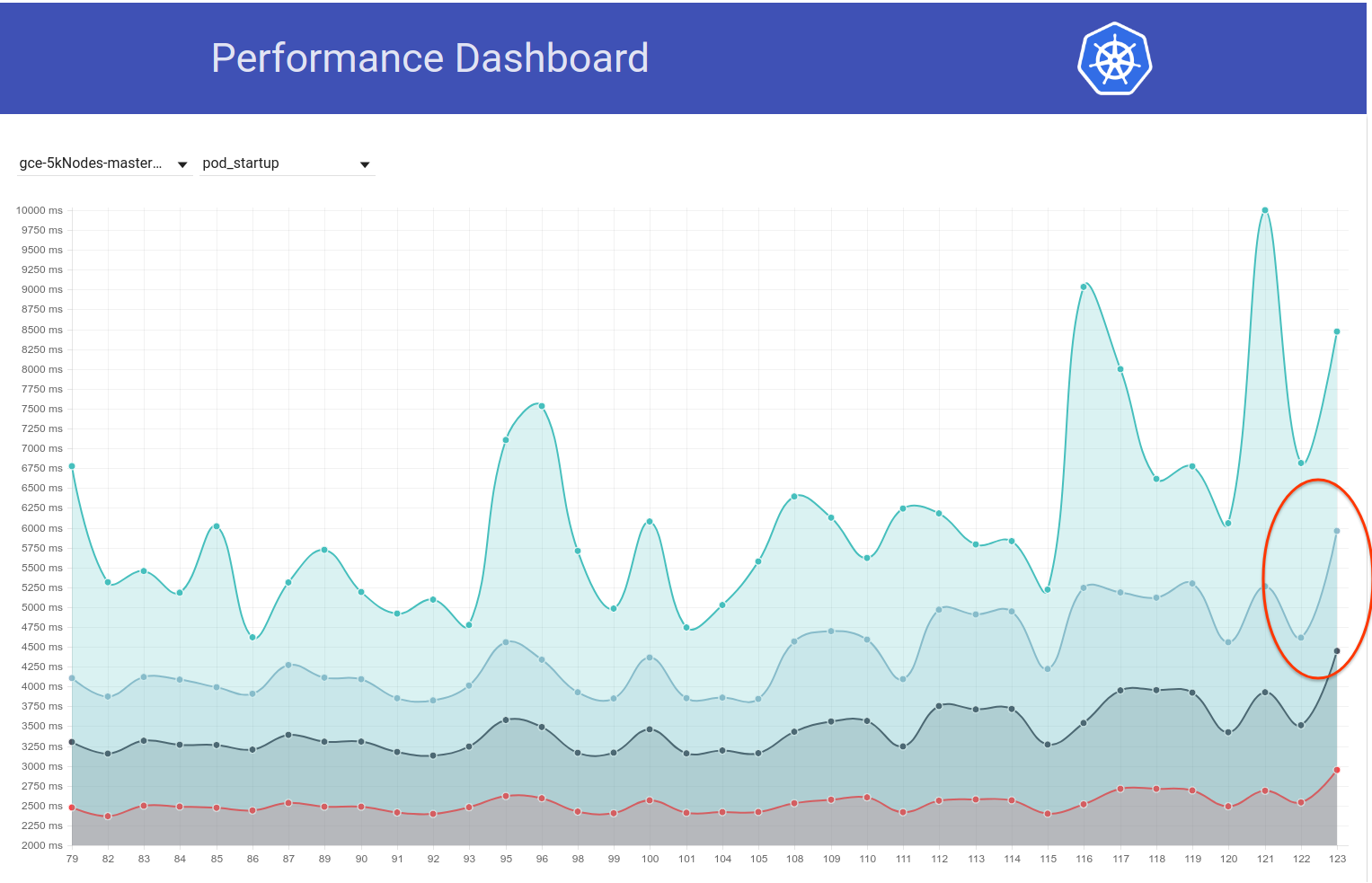
Tersangka utama saya dari commit diff adalah perubahan etcd dari 3.1.11 -> 3.1.12 (https://github.com/kubernetes/kubernetes/pull/60998). Saya akan menunggu putaran berikutnya (sedang dalam proses) untuk mengonfirmasi bahwa ini bukan satu kali saja - tetapi kami benar-benar perlu memahami ini.
cc @jpbetz @gyuho
shyamjvs
pada 14 Mar 2018
Karena saya akan berlibur Kamis-Jumat minggu ini, saya menempelkan instruksi untuk menjalankan uji kepadatan terhadap 5k-node cluster (sehingga seseorang dengan akses ke proyek dapat melanjutkan membagi dua):
# Start with a clean shell.
# Checkout to the right commit.
make quick-release
# Set the project:
gcloud config set project k8s-scale-testing
# Set some configs for creating/testing 5k-node cluster:
export CLOUDSDK_CORE_PRINT_UNHANDLED_TRACEBACKS=1
export KUBE_GCE_ZONE=us-east1-a
export NUM_NODES=5000
export NODE_SIZE=n1-standard-1
export NODE_DISK_SIZE=50GB
export MASTER_MIN_CPU_ARCHITECTURE=Intel\ Broadwell
export ENABLE_BIG_CLUSTER_SUBNETS=true
export LOGROTATE_MAX_SIZE=5G
export KUBE_ENABLE_CLUSTER_MONITORING=none
export ALLOWED_NOTREADY_NODES=50
export KUBE_GCE_ENABLE_IP_ALIASES=true
export TEST_CLUSTER_LOG_LEVEL=--v=1
export SCHEDULER_TEST_ARGS=--kube-api-qps=100
export CONTROLLER_MANAGER_TEST_ARGS=--kube-api-qps=100\ --kube-api-burst=100
export APISERVER_TEST_ARGS=--max-requests-inflight=3000\ --max-mutating-requests-inflight=1000
export TEST_CLUSTER_RESYNC_PERIOD=--min-resync-period=12h
export TEST_CLUSTER_DELETE_COLLECTION_WORKERS=--delete-collection-workers=16
export PREPULL_E2E_IMAGES=false
export ENABLE_APISERVER_ADVANCED_AUDIT=false
# Bring up the cluster (this brings down pre-existing one if present, so you don't have to explicitly '--down' the previous one) and run density test:
go run hack/e2e.go \
--up \
--test \
--test_args='--ginkgo.focus=\[sig\-scalability\]\sDensity\s\[Feature\:Performance\]\sshould\sallow\sstarting\s30\spods\sper\snode\susing\s\{\sReplicationController\}\swith\s0\ssecrets\,\s0\sconfigmaps\sand\s0\sdaemons$ --allowed-not-ready-nodes=30 --node-schedulable-timeout=30m --minStartupPods=8 --gather-resource-usage=master --gather-metrics-at-teardown=master' \
> somepath/build-log.txt 2>&1
# To re-run the test on same cluster (without re-creating) just omit '--up' in the above.
CATATAN PENTING:
- Rentang komit saat ini yang dicurigai adalah ff7918d ... a042ecde3 (mari terus perbarui ini saat kita membagi dua)
- Kita perlu menggunakan etcd-3.1.11 daripada 3.2.14 (untuk menghindari menyertakan regresi sebelumnya). Ubah versi di file berikut untuk mencapai itu minimal:
- cluster / gce / manifests / etcd.manifest
- cluster / gambar / etcd / Makefile
- hack / lib / etcd.sh
shyamjvs
pada 14 Mar 2018
cc: @ wojtek-t
jdumars
pada 14 Mar 2018
etcd v3.1.12 perbaikan acara menonton gagal pada pemulihan. Dan ini adalah satu-satunya perubahan yang kami buat dari v3.1.11. Apakah uji kinerja melibatkan sesuatu dengan restart etcd atau multi-node yang dapat memicu snapshot dari pemimpin?
gyuho
pada 14 Mar 2018
Apakah tes kinerja melibatkan apa pun dengan restart etcd
Dari log etcd , sepertinya tidak ada restart apapun.
multi-node
Kami hanya menggunakan single-node etcd dalam pengaturan kami (dengan asumsi itu yang Anda minta).
shyamjvs
pada 14 Mar 2018
Saya melihat. Kemudian, v3.1.11 dan v3.1.12 seharusnya tidak berbeda: 0
Akan melihat lagi jika run kedua juga menunjukkan latensi yang lebih tinggi.
gyuho
pada 14 Mar 2018
cc: @jpbetz
jdumars
pada 14 Mar 2018
Setuju dengan @gyuho bahwa kami harus mencoba untuk mendapatkan sinyal yang lebih kuat untuk yang satu ini mengingat bahwa satu-satunya perubahan kode ke etcd diisolasi untuk memulai ulang / memulihkan kode.
Satu-satunya perubahan lain adalah peningkatan etcd dari go1.8.5 ke go1.8.7, tetapi saya ragu bahwa kami akan melihat regresi kinerja yang signifikan dengan itu.
jpbetz
pada 14 Mar 2018
Jadi melanjutkan dengan pembagian dua, ff7918d1f tampaknya bagus:
2.246719086s (watch), 3.916350274s (pod-startup)
Saya akan memperbarui rentang komit di https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -373051051 sebagaimana mestinya.
shyamjvs
pada 14 Mar 2018
Selanjutnya, commit aa19a1726 sepertinya bagus, meskipun saya menyarankan untuk mencoba lagi sekali lagi untuk mengonfirmasi:
2.715156606s (watch), 4.382527095s (pod-startup)
Pada titik ini saya akan menghentikan bisection dan memulai liburan saya :)
Saya telah menurunkan cluster saya untuk memberi ruang untuk run berikutnya.
shyamjvs
pada 15 Mar 2018
Terima kasih Shyam. Saya mencoba kembali aa19a172693a4ad60d5a08e9b93557267d259c37.
 wasylkowski-a
pada 15 Mar 2018
wasylkowski-a
pada 15 Mar 2018
Untuk commit aa19a172693a4ad60d5a08e9b93557267d259c37 saya mendapatkan hasil sebagai berikut:
2.47655243s (watch), 4.174016696s (pod-startup)
Jadi ini terlihat bagus. Pembagian lanjutan.
Rentang komit saat ini dicurigai: aa19a172693a4ad60d5a08e9b93557267d259c37 ... a042ecde362000e51f1e7bdbbda5bf9d81116f84
wasylkowski-a
pada 15 Mar 2018
@ wasylkowski-a Bisakah Anda menghadiri pertemuan rilis kami pada pukul 17:00 UTC / 13:00 Timur / 10:00 Pasifik? Ini adalah pertemuan Zoom: https://zoom.us/j/2018742972
jdumars
pada 15 Mar 2018
Saya akan hadir.
wasylkowski-a
pada 15 Mar 2018
Commit cca7ccbff161255292f72c2d18459cdface62122 terlihat tidak jelas dengan hasil berikut:
2.984185673s (watch), 4.568914929s (pod-startup)
Saya akan menjalankan ini sekali lagi untuk mendapatkan keyakinan bahwa saya tidak memasuki setengah bagian yang salah.
wasylkowski-a
pada 15 Mar 2018
Oke, jadi saya cukup yakin sekarang bahwa cca7ccbff161255292f72c2d18459cdface62122 itu buruk:
3.285168535s (watch), 4.783986141s (pod-startup)
Memangkas rentang hingga aa19a172693a4ad60d5a08e9b93557267d259c37 ... cca7ccbff161255292f72c2d18459cdface62122 dan mencoba 92e4d3da0076f923a45d54d69c84e91ac6a61a55.
wasylkowski-a
pada 16 Mar 2018
Commit 92e4d3da0076f923a45d54d69c84e91ac6a61a55 terlihat bagus:
2.522438984s (watch), 4.21739985s (pod-startup)
Rentang komit tersangka baru adalah 92e4d3da0076f923a45d54d69c84e91ac6a61a55 ... cca7ccbff161255292f72c2d18459cdface62122, mencoba 603ebe466d335a37392315d491782ed18d1bae11
wasylkowski-a
pada 16 Mar 2018
@wasylkowski harap dicatat bahwa salah satu komit yaitu https://github.com/kubernetes/kubernetes/commit/4c289014a05669c376994868d8d91f7565a204b5 telah dikembalikan di https://github.com/kubernetes/kubernetes/commit/493bac33583053bb4ce9f7dac33583053bb4ce9f7c348
dims
pada 16 Mar 2018
Mengembalikan komentar @dims dengan lebih jelas, kami mungkin mengejar hantu sinyal di sini di dua bagian. Jika 4c28901 adalah masalahnya, dan dikembalikan pada 493f335 karena alasan yang tampaknya tidak terkait, lalu apakah uji skalabilitas terhadap 1,10 kepala cabang menunjukkan sinyal hijau?
Bisakah kita memprioritaskan pengujian ulang sekali terhadap 1,10 kepala cabang, daripada melanjutkan pembagian dua?
 tpepper
pada 16 Mar 2018
tpepper
pada 16 Mar 2018
@wasylkowski / @ wasylkowski-a ^^^^
tpepper
pada 16 Mar 2018
@ wojtek-t PTAL ASAP
jdumars
pada 16 Mar 2018
Terima kasih @dims dan @tpepper. Biarkan saya mencoba melawan 1.10 kepala cabang dan lihat apa yang terjadi.
wasylkowski-a
pada 16 Mar 2018
terima kasih @wasylkowski kasus terburuk kami kembali ke apa yang kami membagi dua sebelumnya. Baik?
dims
pada 16 Mar 2018
1.10 kepala memiliki regresi:
3.522924087s (watch), 4.946431238s (pod-startup)
Ini ada di etcd 3.1.12, bukan etcd 3.1.11, tetapi jika saya memahaminya dengan benar, ini seharusnya tidak membuat banyak perbedaan.
Selain itu, 603ebe466d335a37392315d491782ed18d1bae11 terlihat bagus:
2.744654024s (watch), 4.284582476s (pod-startup)
2.76287483s (watch), 4.326409841s (pod-startup)
2.560703844s (watch), 4.213785531s (pod-startup)
Ini menyisakan rentang 603ebe466d335a37392315d491782ed18d1bae11 ... cca7ccbff161255292f72c2d18459cdface62122 dan hanya ada 3 komit di sana. Biarkan saya melihat apa yang saya temukan.
Ada kemungkinan juga bahwa memang 4c289014a05669c376994868d8d91f7565a204b5 adalah penyebabnya di sini, tetapi itu berarti bahwa kami memiliki regresi lain yang memanifestasikan dirinya sendiri.
wasylkowski-a
pada 16 Mar 2018
Oke, jadi jelas komit 6590ea6d5d50700d34255b1e037b2702ad26b7fc bagus:
2.553170576s (watch), 4.22516704s (pod-startup)
sementara commit 7b678dc4035c61a1991b5e1442edb13f40deae72 buruk:
3.498855918s (watch), 4.886599251s (pod-startup)
Komit buruk adalah gabungan dari komit yang dikembalikan yang disebutkan oleh @dims , jadi kita harus mengamati regresi lain sebelumnya.
Izinkan saya mencoba menjalankan ulang head pada etcd 3.1.11 daripada 3.1.12 dan lihat apa yang terjadi.
wasylkowski-a
pada 17 Mar 2018
@ wasylkowski-a ah kabar baik klasik kabar buruk :) terima kasih telah menjaga ini terus berjalan.
@ wojtek-t ada saran lain?
dims
pada 17 Mar 2018
Kepala di etcd 3.1.11 juga buruk; percobaan saya selanjutnya adalah mencoba langsung setelah pengembalian (jadi, di komit cdecea545553eff09e280d389a3aef69e2f32bf1), tetapi dengan etcd 3.1.11 daripada 3.2.14.
wasylkowski-a
pada 17 Mar 2018
Kedengarannya bagus Andrzej
- meredup
Pada 17 Mar 2018, pukul 13.19, Andrzej Wasylkowski [email protected] menulis:
Kepala di etcd 3.1.11 juga buruk; percobaan saya selanjutnya adalah mencoba langsung setelah pengembalian (jadi, di komit cdecea5), tetapi dengan etcd 3.1.11 bukan 3.2.14.
-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub, atau nonaktifkan utasnya.
dims
pada 17 Mar 2018
Komit cdecea545553eff09e280d389a3aef69e2f32bf1 bagus, jadi kami memiliki regresi selanjutnya:
2.66454307s (watch), 4.308091589s (pod-startup)
Commit 2a373ace6eda6a9cf050ce70a6cf99183c5e5b37 jelas buruk:
3.656979569s (watch), 6.746987916s (pod-startup)
@ wasylkowski-a Jadi pada dasarnya kita melihat komit dalam rentang https://github.com/kubernetes/kubernetes/compare/cdecea5...2a373ac untuk melihat apa yang salah? (menjadi dua di antara keduanya)?
dims
pada 17 Mar 2018
Iya. Sayangnya, ini adalah rentang yang sangat besar. Saya sekarang menyelidiki aded0d922592fdff0137c70443caf2a9502c7580.
wasylkowski-a
pada 17 Mar 2018
Terima kasih @wasylkowski berapa kisaran saat ini? (jadi saya bisa melihat PR).
dims
pada 18 Mar 2018
Commit aded0d922592fdff0137c70443caf2a9502c7580 buruk:
3.626257043s (watch), 5.00754503s (pod-startup)
Commit f8298702ffe644a4f021e23a616ad6a8790a5537 juga buruk:
3.747051371s (watch), 6.126914967s (pod-startup)
Begitu juga commit 20a6749c3f86c7cb9e98442046532380fb5f6e36:
3.641172882s (watch), 5.100922237s (pod-startup)
Begitu juga dengan 0e81651e77e0be7e75179e5986ef2c76601f4bd6:
3.687028394s (watch), 5.208157763s (pod-startup)
Rentang saat ini adalah cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6. Kami (saya, @ wojtek-t, @shyamjvs) mulai mencurigai bahwa cdecea545553eff09e280d389a3aef69e2f32bf1 sebenarnya adalah umpan yang tidak stabil, jadi kami memerlukan ujung kiri yang berbeda.
wasylkowski-a
pada 19 Mar 2018
/ saya memasang taruhan di https://github.com/kubernetes/kubernetes/commit/b259543985b10875f4a010ed0285ac43e335c8e0 sebagai pelakunya
cc @ wasylowski-a
dims
pada 19 Mar 2018
0e81651e77e0be7e75179e5986ef2c76601f4bd6 adalah, ternyata, buruk, jadi b259543985b10875f4a010ed0285ac43e335c8e0 (bergabung sebagai 244549f02afabc5be23fc56e86a60e5b36838828, setelah 0e81651e77e0be7e75179e5986ef2c76601f4bd6) tidak dapat menjadi penyebab awal (meskipun bukan tidak mungkin bahwa hal itu telah memperkenalkan belum regresi lain kita akan mengamati setelah kami mengguncang keluar satu ini)
wasylkowski-a
pada 19 Mar 2018
Untuk @ wojtek-t dan @shyamjvs, saya menjalankan kembali cdecea545553eff09e280d389a3aef69e2f32bf1, karena kami curiga ini mungkin "barang bersisik"
wasylkowski-a
pada 19 Mar 2018
Saya akan berasumsi bahwa cdecea545553eff09e280d389a3aef69e2f32bf1 sebenarnya bagus berdasarkan hasil berikut yang saya amati:
2.66454307s (watch), 4.308091589s (pod-startup)
2.695629257s (watch), 4.194027608s (pod-startup)
2.660956347s (watch), 3m36.62259323s (pod-startup) <-- looks like an outlier
2.865445137s (watch), 4.594671099s (pod-startup)
2.412093606s (watch), 4.070130529s (pod-startup)
Rentang yang dicurigai saat ini: cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6
Saat ini menguji 99c87cf679e9cbd9647786bf7e81f0a2d771084f
wasylkowski-a
pada 20 Mar 2018
Terima kasih @wasylkowski untuk melanjutkan pekerjaan ini.
jdumars
pada 20 Mar 2018
per diskusi hari ini: fluentd-scaler masih memiliki masalah: https://github.com/kubernetes/kubernetes/issues/61190 , yang belum diperbaiki oleh PR. Mungkinkah regresi ini disebabkan oleh fluentd?
 jberkus
pada 20 Mar 2018
jberkus
pada 20 Mar 2018
salah satu PR yang berkaitan dengan fluentd https://github.com/kubernetes/kubernetes/commit/a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 ada di kisaran terbaru
dims
pada 20 Mar 2018
per diskusi hari ini: fluentd-scaler masih memiliki masalah: # 61190, yang belum diperbaiki oleh PR. Mungkinkah regresi ini disebabkan oleh fluentd?
TBH, saya akan sangat terkejut jika itu karena masalah lancar. Tapi saya tidak bisa mengecualikan hipotesis ini dengan pasti.
Perasaan pribadi saya akan menjadi beberapa perubahan di Kubelet, tetapi saya juga melihat PR dalam kisaran itu dan tidak ada yang tampak benar-benar mencurigakan ...
Mudah-mudahan kisarannya akan menjadi 4x lebih kecil besok, yang berarti hanya beberapa PR.
wojtek-t
pada 20 Mar 2018
Oke, jadi 99c87cf679e9cbd9647786bf7e81f0a2d771084f terlihat bagus, tapi saya perlu tiga kali berjalan untuk memastikan ini bukan serpihan:
2.901624657s (watch), 4.418169754s (pod-startup)
2.938653965s (watch), 4.423465198s (pod-startup)
3.047455619s (watch), 4.455485098s (pod-startup)
Selanjutnya, a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 buruk:
3.769747695s (watch), 5.338517616s (pod-startup)
Rentang saat ini adalah 99c87cf679e9cbd9647786bf7e81f0a2d771084f ... a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2. Menganalisis c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd.
wasylkowski-a
pada 20 Mar 2018
Saya melihat ke kisaran yang disebutkan di atas - hanya ada 9 PR di sana.
https://github.com/kubernetes/kubernetes/pull/59944 - 100% TIDAK - hanya mengubah file pemilik
https://github.com/kubernetes/kubernetes/pull/59953 - berpotensi
https://github.com/kubernetes/kubernetes/pull/59809 - hanya menyentuh kode kubectl, jadi tidak masalah untuk kasus ini
https://github.com/kubernetes/kubernetes/pull/59955 - 100% TIDAK - hanya menyentuh tes e2e yang tidak terkait
https://github.com/kubernetes/kubernetes/pull/59808 - berpotensi (mengubah penyiapan cluster)
https://github.com/kubernetes/kubernetes/pull/59913 - 100% TIDAK - hanya menyentuh tes e2e yang tidak terkait
https://github.com/kubernetes/kubernetes/pull/59917 - ini mengubah pengujian, tetapi tidak mengaktifkan perubahan, jadi tidak mungkin
https://github.com/kubernetes/kubernetes/pull/59668 - 100% TIDAK - hanya menyentuh kode AWS
https://github.com/kubernetes/kubernetes/pull/59909 - 100% TIDAK - hanya menyentuh file pemilik
Jadi saya pikir kami memiliki dua kandidat di sini: https://github.com/kubernetes/kubernetes/pull/59953 dan https://github.com/kubernetes/kubernetes/pull/59808
Saya akan mencoba menggali lebih dalam untuk memahami mereka.
wojtek-t
pada 21 Mar 2018
c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd terlihat agak buruk:
3.428891786s (watch), 4.909251611s (pod-startup)
Mengingat bahwa ini adalah gabungan dari # 59953, salah satu tersangka Wojtek, sekarang saya akan menjalankan satu komit sebelumnya, jadi f60083549a43f152b3142e01756e25611d911770.
Komitmen itu, bagaimanapun, adalah OWNERS_ALIASES perubahan, dan tidak ada yang tersisa dalam rentang itu sebelumnya, jadi c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd pasti menjadi masalah. Saya akan menjalankan tes hanya untuk keamanan.
wasylkowski-a
pada 21 Mar 2018
Dibahas secara offline - kami akan menjalankan tes di awal dengan komit ini dikembalikan secara lokal.
wojtek-t
pada 21 Mar 2018
Wow! satu garis menyebabkan begitu banyak masalah. terima kasih @wasylkowski @ wojtek-t
dims
pada 21 Mar 2018
@dims One-liners memang dapat menyebabkan kerusakan dengan skalabilitas. Contoh lain dari masa lalu - https://github.com/kubernetes/kubernetes/pull/53720#issue-145949976
Secara umum, Anda mungkin ingin melihat https://github.com/kubernetes/community/blob/master/sig-scalability/blogs/scalability-regressions-case-studies.md untuk membaca dengan baik :)
shyamjvs
pada 21 Mar 2018
Perbarui ulang. test at head: jalankan pertama dengan komit yang dikembalikan secara lokal lulus. Ini mungkin serpihan, jadi saya menjalankannya kembali.
wasylkowski-a
pada 21 Mar 2018
Melihat komit di https: //github.com/kubernetes/kubernetes/pull/59953 ... bukankah itu memperbaiki bug? Tampaknya telah memperbaiki bug yang menempatkan status "dijadwalkan" ke objek yang salah. Berdasarkan masalah yang direferensikan dalam PR itu, sepertinya kubelet dapat melewatkan pelaporan pod yang dijadwalkan tanpa perbaikan itu?
liggitt
pada 21 Mar 2018
@ Random-Liu Siapa yang mungkin dapat menjelaskan kepada kami dengan lebih baik apa efek dari perubahan itu :)
shyamjvs
pada 21 Mar 2018
Melihat komit di # 59953 ... bukankah itu memperbaiki bug? Tampaknya telah memperbaiki bug yang menempatkan status "dijadwalkan" ke objek yang salah. Mungkinkah kubelet melaporkan bahwa pod dijadwalkan terlalu dini sebelum perbaikan itu?
Ya - Saya tahu itu perbaikan bug. Saya hanya tidak sepenuhnya mengerti itu.
Tampaknya untuk memperbaiki masalah pelaporan pod sebagai "Terjadwal". Tetapi kami tidak melihat masalah bahkan sampai waktu yang dilaporkan oleh kubelet sebagai "StartedAt".
Masalahnya adalah kita melihat peningkatan yang signifikan antara waktu yang dilaporkan sebagai "StartedAt" oleh Kubelet dan ketika pembaruan status pod dilaporkan dan dipantau oleh pengujian.
Jadi saya pikir bit "Terjadwal" adalah masalah besar di sini.
Dugaan saya (tapi ini masih hanya tebakan) adalah karena perubahan ini kami mengirimkan lebih banyak update status Pod, yang pada gilirannya menghasilkan lebih banyak 429s atau atau sth seperti itu. Dan pada akhirnya dibutuhkan lebih banyak waktu bagi Kubelet untuk melaporkan status pod. Tapi itu adalah sesuatu yang masih perlu kami konfirmasi.
wojtek-t
pada 21 Mar 2018
Setelah dua kali berjalan, saya cukup yakin bahwa mengembalikan # 59953 akan memperbaiki masalah:
3.052567319s (watch), 4.489142104s (pod-startup)
2.799364978s (watch), 4.385999497s (pod-startup)
kami mengirimkan lebih banyak pembaruan status Pod, yang pada gilirannya menghasilkan lebih banyak 429s atau atau sth seperti itu. Dan pada akhirnya dibutuhkan lebih banyak waktu bagi Kubelet untuk melaporkan status pod.
Ini adalah efek yang saya hipotesiskan di https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 (meskipun penyebab yang saya duga salah) :)
Juga, kami IIRC tampaknya melihat peningkatan # dari 429s untuk panggilan put (lihat https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370582634 saya) tetapi itu dari rentang sebelumnya saya pikir ( sekitar perubahan etcd).
shyamjvs
pada 21 Mar 2018
Setelah dua kali berjalan, saya cukup yakin bahwa mengembalikan # 59953 akan memperbaiki masalah:
Intuisi saya (https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370874602) tentang masalah yang berada di sisi kubelet cukup awal di utas ternyata benar :)
shyamjvs
pada 21 Mar 2018
/ sig node
@ kubernetes / sig-node-bugs tim rilis benar-benar dapat menggunakan ulasan tentang # 59953 commit versus revert dan masalah kinerja di sini
tpepper
pada 21 Mar 2018
Melihat komit di # 59953 ... bukankah itu memperbaiki bug? Tampaknya telah memperbaiki bug yang menempatkan status "dijadwalkan" ke objek yang salah. Berdasarkan masalah yang direferensikan dalam PR itu, sepertinya kubelet dapat melewatkan pelaporan pod yang dijadwalkan tanpa perbaikan itu?
@ liggitt Terima kasih telah menjelaskan ini untuk saya. Ya, PR itu memperbaiki bug. Sebelumnya, kubelet tidak selalu menetapkan PodScheduled . Dengan # 59953, kubelet akan melakukannya dengan benar.
@shyamjvs Saya tidak yakin apakah itu dapat memperkenalkan lebih banyak pembaruan status pod.
Jika saya mengerti dengan benar, PodScheduled kondisi akan diset pada pembaruan status pertama dan kemudian akan selalu ada dan tidak pernah berubah. Saya tidak mengerti mengapa itu menghasilkan lebih banyak pembaruan status.
Jika itu benar-benar memperkenalkan lebih banyak pembaruan status, itu adalah masalah yang diperkenalkan 2 tahun yang lalu https://github.com/kubernetes/kubernetes/pull/24459 tetapi tercakup oleh bug, dan # 59953 hanya memperbaiki bug ...
@ wasylkowski-a Apakah Anda memiliki log untuk 2 pengujian yang dijalankan di https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -374982422 dan https://github.com/kubernetes/kubernetes/issues/60589# penerbitan -374871490? Pada dasarnya yang baik dan yang buruk. Kubelet.log akan sangat membantu.
 Random-Liu
pada 21 Mar 2018
Random-Liu
pada 21 Mar 2018
@yujuhong dan saya menemukan bahwa # 59953 mengungkapkan masalah bahwa kondisi PodScheduled dari pod statis akan terus diperbarui.
Kubelet menghasilkan kondisi PodScheduled untuk pod yang tidak memilikinya. Pod statis tidak memilikinya, dan statusnya tidak pernah diperbarui (perilaku yang diharapkan). Jadi kubelet akan terus menghasilkan kondisi PodScheduled untuk pod statis.
Masalah ini diperkenalkan di # 24459, tetapi tercakup oleh bug. # 59953 memperbaiki bug tersebut, dan mengekspos masalah aslinya.
Ada 2 opsi untuk memperbaikinya dengan cepat:
- Opsi 1: Jangan biarkan kubelet menambahkan
PodScheduledkondisi, kubelet seharusnya hanya menyimpanPodScheduledkondisi yang ditetapkan oleh penjadwal.- Kelebihan: Sederhana.
- Kekurangan: Pod dan pod statis yang melewati penjadwal (menetapkan nama node secara langsung) tidak akan memiliki kondisi
PodScheduled. Sebenarnya tanpa # 59953, meskipun kubelet pada akhirnya akan menetapkan kondisi ini untuk pod-pod tersebut, tetapi mungkin membutuhkan waktu yang sangat lama karena adanya bug.
- Opsi 2: Buat kondisi
PodScheduleduntuk pod statis ketika kubelet melihatnya pada awalnya.
Opsi 2 mungkin menyebabkan lebih sedikit perubahan yang dihadapi pengguna.
Tetapi kami ingin bertanya apa arti PodScheduled bagi pod yang tidak dijadwalkan oleh penjadwal? Apakah kita benar-benar membutuhkan kondisi ini untuk pod tersebut? / cc @ kubernetes / sig-autoscaling-bugs Karena @yujuhong memberi tahu saya bahwa PodScheduled digunakan oleh penskalaan otomatis sekarang.
/ cc @ kubernetes / sig-node-bugs @ kubernetes / sig-scheduling-bugs
Random-Liu
pada 21 Mar 2018
@ Random-Liu Apa efek dari very long time for kubelet to eventually set this condition ? Masalah apa yang akan dilihat / dihadapi oleh pengguna akhir (di luar kelemahan harness test)? (dari Opsi # 1)
dims
pada 21 Mar 2018
@dims Pengguna tidak akan melihat kondisi PodScheduled untuk waktu yang lama.
Random-Liu
pada 21 Mar 2018
Saya punya perbaikan # 61504 yang mengimplementasikan opsi 2 di https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979.
Saya dapat mengubahnya ke opsi 1 jika orang berpikir itu adalah perbaikan yang lebih baik. :)
Random-Liu
pada 21 Mar 2018
Anda sebaiknya bertanya kepada orang-orang yang mengetahui hal ini luar dalam! (BUKAN tim rilis 😄!)
ping @dashpole @ dchenekr
dims
pada 21 Mar 2018
@ Random-Liu IIRC satu-satunya pod statis yang berjalan pada node dalam pengujian kami adalah kube-proxy. Bisakah Anda mengetahui seberapa sering 'update berkelanjutan' ini dilakukan oleh kubelet? (meminta untuk memperkirakan qps tambahan yang diperkenalkan oleh bug)
shyamjvs
pada 21 Mar 2018
@ Random-Liu IIRC satu-satunya pod statis yang berjalan pada node dalam pengujian kami adalah kube-proxy. Bisakah Anda mengetahui seberapa sering 'update berkelanjutan' ini dilakukan oleh kubelet? (meminta untuk memperkirakan qps tambahan yang diperkenalkan oleh bug)
@shyamjvs Ya, kube-proxy adalah satu-satunya di node sekarang.
Saya pikir itu tergantung pada frekuensi sinkronisasi pod https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/kubeletconfig/v1beta1/defaults.go#L47 , yaitu 1 menit. Jadi kubelet menghasilkan satu pembaruan status pod tambahan setiap 1 menit.
Random-Liu
pada 22 Mar 2018
Terima kasih. Jadi itu berarti 5000/60 = ~ 83 qps ditambahkan ekstra karena mereka menempatkan panggilan status pod. Tampaknya menjelaskan peningkatan 429 yang dicatat sebelumnya dalam bug.
shyamjvs
pada 22 Mar 2018
@ Random-Liu terima kasih banyak telah membantu kami menyelesaikan masalah ini.
jdumars
pada 22 Mar 2018
@jdumars np ~ @yujuhong banyak membantu saya!
Random-Liu
pada 22 Mar 2018
Tapi kami ingin bertanya apa arti PodScheduled untuk pod yang tidak dijadwalkan oleh penjadwal? Apakah kita benar-benar membutuhkan kondisi ini untuk pod tersebut? / cc @ kubernetes / sig-autoscaling-bugs Karena @yujuhong memberi tahu saya bahwa PodScheduled digunakan oleh autoscaling sekarang.
Saya masih berpikir membiarkan kubelet mengatur kondisi PodScheduled agak aneh (seperti yang saya catat di PR asli). Walaupun kubelet tidak menyetel kondisi ini, itu tidak akan mempengaruhi autoscaler cluster karena autoscaler mengabaikan pod tanpa kondisi spesifik. Bagaimanapun, perbaikan yang akhirnya kami temukan memiliki jejak yang sangat kecil, dan akan mempertahankan perilaku saat ini (yaitu, selalu mengatur kondisi PodScheduled), jadi kami akan melakukannya.
 yujuhong
pada 22 Mar 2018
yujuhong
pada 22 Mar 2018
Juga, menghidupkan kembali masalah yang sangat lama untuk menambahkan pengujian untuk tingkat pembaruan pod kondisi-mapan # 14391
yujuhong
pada 22 Mar 2018
Bagaimanapun, perbaikan yang akhirnya kami temukan memiliki jejak yang sangat kecil, dan akan mempertahankan perilaku saat ini (yaitu, selalu mengatur kondisi PodScheduled), jadi kami akan melakukannya.
@yujuhong - apakah anda membicarakan yang ini: # 61504 (atau saya salah paham)?
@wasylkowski @shyamjvs - dapatkah Anda menjalankan pengujian 5000-node dengan PR yang ditambal secara lokal (sebelum kami menggabungkannya) untuk memastikan bahwa ini benar-benar membantu?
wojtek-t
pada 22 Mar 2018
Saya menjalankan pengujian terhadap 1,10 HEAD + # 61504, dan latensi pengaktifan pod tampaknya baik-baik saja:
INFO: perc50: 2.594635536s, perc90: 3.483550118s, perc99: 4.327417676s
Akan dijalankan kembali sekali lagi untuk mengonfirmasi.
shyamjvs
pada 22 Mar 2018
@shyamjvs - terima kasih banyak!
wojtek-t
pada 22 Mar 2018
Proses kedua juga tampaknya bagus:
INFO: perc50: 2.583489146s, perc90: 3.466873901s, perc99: 4.380595534s
Cukup yakin sekarang perbaikan itu berhasil. Mari kita membuatnya menjadi 1,10 secepatnya.
shyamjvs
pada 22 Mar 2018
Terima kasih @shyamjvs
Saat kita berbicara secara offline - Saya pikir kita memiliki satu kemunduran lagi dalam sebulan terakhir ini, tetapi yang itu seharusnya tidak memblokir rilis.
wojtek-t
pada 22 Mar 2018
@yujuhong - apakah anda membicarakan yang ini: # 61504 (atau saya salah paham)?
Ya. Perbaikan saat ini pada PR tersebut tidak ada dalam opsi yang awalnya diusulkan di https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979
yujuhong
pada 22 Mar 2018
membuka kembali sampai kami memiliki hasil tes kinerja yang baik.
jberkus
pada 25 Mar 2018
@yujuhong @krzyzacy @shyamjvs @ wojtek-t @ Random-Liu @ wasylkowski-a ada pembaruan tentang ini? Ini masih memblokir 1,10 saat ini.
jdumars
pada 26 Mar 2018
Jadi satu-satunya bagian dari bug ini yang memblokir rilis adalah pekerjaan kinerja 5k-node. Sayangnya, kami kehilangan kecepatan mulai hari ini karena alasan yang berbeda (ref: https://github.com/kubernetes/kubernetes/issues/61190#issuecomment-376150569)
Karena itu, kami cukup yakin bahwa perbaikan berfungsi berdasarkan proses manual saya (hasil ditempel di https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-375350217). Jadi IMHO kita tidak perlu memblokir rilis di atasnya (proses selanjutnya akan dilakukan pada hari pernikahan).
shyamjvs
pada 26 Mar 2018
+1
@jdumars - Saya rasa kita bisa memperlakukan ini sebagai non-blocker.
wojtek-t
pada 26 Mar 2018
Maaf, saya mengedit posting saya di atas. Maksud saya, kita harus memperlakukannya sebagai "non-blocker".
wojtek-t
pada 26 Mar 2018
OK, terima kasih banyak. Kesimpulan ini mewakili banyak sekali waktu yang telah Anda investasikan, dan saya tidak mungkin cukup berterima kasih atas pekerjaan yang telah Anda lakukan. Sementara kami berbicara secara abstrak tentang "komunitas" dan "kontributor" Anda, dan orang lain yang telah bekerja, masalah ini merepresentasikannya secara konkret. Anda adalah jantung dan jiwa dari proyek ini, dan saya tahu saya berbicara untuk semua orang yang terlibat ketika saya mengatakan ini adalah suatu kehormatan untuk bekerja bersama semangat, komitmen, dan profesionalisme seperti itu.
jdumars
pada 26 Mar 2018
[MILESTONENOTIFIER] Masalah Tonggak Sejarah: Mutakhir untuk diproses
@krzyzacy @ msau42 @shyamjvs @ Wojtek-t
Label Masalah
sig/api-machinerysig/autoscalingsig/nodesig/scalabilitysig/schedulingsig/storage: Masalah akan diteruskan ke SIG ini jika diperlukan.priority/critical-urgent: Tidak pernah secara otomatis memindahkan masalah dari tonggak rilis; terus meningkat menjadi kontributor dan SIG melalui semua saluran yang tersedia.kind/bug: Memperbaiki bug yang ditemukan selama rilis saat ini.Tolong
 k8s-github-robot
pada 11 Apr 2018
k8s-github-robot
pada 11 Apr 2018
Masalah ini telah diatasi dengan perbaikan yang relevan untuk 1.10.
Untuk 1.11, kami melacak kegagalan di - https://github.com/kubernetes/kubernetes/issues/63030.
/Menutup
shyamjvs
pada 25 Mei 2018
Masalah terkait
 ttripp
·
3Komentar
ttripp
·
3Komentar
 zetaab
·
3Komentar
zetaab
·
3Komentar
 jadhavnitind
·
3Komentar
jadhavnitind
·
3Komentar
 sanjana-bhat
·
3Komentar
sanjana-bhat
·
3Komentar
 theothermike
·
3Komentar
theothermike
·
3Komentar
Komentar yang paling membantu
Saya menjalankan pengujian terhadap 1,10 HEAD + # 61504, dan latensi pengaktifan pod tampaknya baik-baik saja:
Akan dijalankan kembali sekali lagi untuk mengonfirmasi.