Kubernetes: [test flakes] suítes master-scalability
Pacotes com falha de bloqueio de liberação:
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
todas as três suítes estão descascando muito recentemente, triagem mental?
escalabilidade / sig
/ prioridade-teste de falha
/ tipo bug
/ status aprovado para marco
cc @jdumars @jberkus
/ assign @shyamjvs @ wojtek-t
 krzyzacy
krzyzacy
Todos 164 comentários
- O trabalho de correção está falhando principalmente devido ao tempo limite (é necessário ajustar nossa programação de forma correspondente), pois vários e2es foram adicionados ao pacote recentemente (por exemplo, https://github.com/kubernetes/kubernetes/pull/59391)
- Para os flocos de 100 nós, temos https://github.com/kubernetes/kubernetes/issues/60500 (e acredito que esteja relacionado ... é preciso verificar).
- Para o trabalho de desempenho, acredito que haja uma regressão (parece que nas últimas execuções é em torno da latência de inicialização do pod). Talvez mais também.
Vou tentar chegar até eles em algum momento durante esta semana (havendo escassez de ciclos livres atm).
 shyamjvs
em 28 fev. 2018
shyamjvs
em 28 fev. 2018
@shyamjvs existe alguma atualização para este problema?
krzyzacy
em 2 mar. 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
Eu dei uma breve olhada nisso. E ou alguns teste (s) estão extremamente lentos ou algo está pendurado em algum lugar. Par de registros da última execução:
62571 I0301 23:01:31.360] Mar 1 23:01:31.348: INFO: Running AfterSuite actions on all node
62572 I0301 23:01:31.360]
62573 W0302 07:32:00.441] 2018/03/02 07:32:00 process.go:191: Abort after 9h30m0s timeout during ./hack/ginkgo-e2e.sh --ginkgo.flakeAttempts=2 --ginkgo.skip=\[Serial\]|\[Disruptive \]|\[Flaky\]|\[Feature:.+\]|\[DisabledForLargeClusters\] --allowed-not-ready-nodes=50 --node-schedulable-timeout=90m --minStartupPods=8 --gather-resource-usage=master --gathe r-metrics-at-teardown=master --logexporter-gcs-path=gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-correctness/80/artifacts --report-dir=/workspace/_artifacts --dis able-log-dump=true --cluster-ip-range=10.64.0.0/11. Will terminate in another 15m
62574 W0302 07:32:00.445] SIGABRT: abort
Nenhum teste terminou em 8h30m
 wojtek-t
em 2 mar. 2018
wojtek-t
em 2 mar. 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
Na verdade, parece uma regressão. Acho que a regressão aconteceu em algum lugar entre as execuções:
105 (que ainda estava ok)
108 (que teve um tempo de inicialização visivelmente maior)
Podemos tentar examinar o kubemark-5000 para ver se ele também está visível.
wojtek-t
em 2 mar. 2018
Kubemark-5000 é bastante estável. 99º percentil neste gráfico (talvez a regressão tenha acontecido antes, mas acho que está em algum lugar entre 105 e 108):

wojtek-t
em 2 mar. 2018
Com relação aos testes de correção - gce-large-corretividade também está falhando.
Talvez algum teste extremamente longo tenha sido adicionado naquela época?
wojtek-t
em 2 mar. 2018
Muito obrigado por procurar @ wojtek-t. Trabalho de desempenho errado - eu também sinto fortemente que há uma regressão (embora eu não conseguisse examiná-los adequadamente).
Talvez algum teste extremamente longo tenha sido adicionado naquela época?
Eu estava investigando isso há um tempo. E encontrei 2 alterações suspeitas:
- # 59391 - Isso adicionou uma série de testes em torno do armazenamento local (as execuções após essa mudança iniciaram o tempo limite)
- StatefulSet com antiafinidade de pod deve usar volumes espalhados por nós (este teste parece estar sendo executado por 3,5 - 5 horas) - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e -gce-scale-correctness / 79
shyamjvs
em 2 mar. 2018
cc @ kubernetes / sig-storage-bugs
shyamjvs
em 2 mar. 2018
/atribuir
Alguns dos testes de armazenamento local tentarão usar todos os nós do cluster, pensando que os tamanhos do cluster não são tão grandes. Vou adicionar uma correção para limitar o número máximo de nós.
 msau42
em 2 mar. 2018
msau42
em 2 mar. 2018
Alguns dos testes de armazenamento local tentarão usar todos os nós do cluster, pensando que os tamanhos do cluster não são tão grandes. Vou adicionar uma correção para limitar o número máximo de nós.
Obrigado @ msau42 - isso seria ótimo.
wojtek-t
em 2 mar. 2018
Voltando para https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance suite
Dei uma olhada mais de perto nas corridas até 105 e 108 e depois disso.
A maior diferença em relação ao tempo de inicialização do pod parece aparecer na etapa:
10% worst watch latencies:
[o nome dele é enganoso - explicarei abaixo]
Até 105 execuções, geralmente parecia assim:
I0129 21:17:43.450] Jan 29 21:17:43.356: INFO: perc50: 1.041233793s, perc90: 1.685463015s, perc99: 2.350747103s
Começando com 108 execuções, parece mais com:
Feb 12 10:08:57.123: INFO: perc50: 1.122693874s, perc90: 1.934670461s, perc99: 3.195883331s
Isso basicamente significa um aumento de ~ 0,85s e é mais ou menos o que observamos no resultado final.
Agora - o que é esse "lag do relógio".
É basicamente um tempo entre "Kubelet observou que o pod está em execução" e "quando o teste observou a atualização do pod configurando seu estado para execução".
Existem algumas possibilidades em que poderíamos ter regredido:
- kubelet está lento no status de relatório
- kubelet está carente de qps (e, portanto, mais lento no status de relatórios)
- apiserver é mais lento (por exemplo, cpu-starved) e, portanto, processamento de solicitações mais lento (seja escrever, assistir ou ambos)
- teste está com falta de CPU e, portanto, o processamento de eventos de entrada é mais lento
Como não observamos realmente uma diferença entre "cronograma -> início" de um pod, isso sugere que provavelmente não é um apiserver (porque o processamento de solicitações e observação também está nesse caminho) e muito provavelmente não é um kubelet lento também (porque inicia o pod).
Então, acho que a hipótese mais provável é:
- kubelet é carente de qps (ou sth que o impede de enviar atualizações de status rapidamente)
- teste está com falta de CPU (ou algo parecido)
O teste não mudou nessa época. Então eu acho que provavelmente é o primeiro.
Dito isso, analisei PRs mesclados entre 105 e 108 execuções e não encontrei nada útil até agora.
wojtek-t
em 2 mar. 2018
Acho que o próximo passo é:
- observe os pods mais lentos (parece haver uma diferença de O (1s) entre os mais lentos também) e veja se a diferença é "antes" ou "depois" do envio da solicitação de status de atualização
wojtek-t
em 2 mar. 2018
Então, eu procurei exemplos de pods. E já estou vendo isso:
I0209 10:01:19.960823 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.615907ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
...
I0209 10:01:22.464046 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (279.153µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:23.468353 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (218.216µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:24.470944 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.42987ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 09:57:01.559125 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (1.836423ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
...
I0209 09:57:04.452830 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (231.2µs) 429 [[kubelet/v1.10.0 (linu x/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:05.454274 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (213.872µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:06.458831 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (2.13295ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 10:01:53.063575 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (1.410064ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:3391
...
I0209 10:01:55.259949 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (10.4894ms) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:56.266377 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (233.931µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:57.269427 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (182.035µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:58.290456 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (13.44863ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
Portanto, parece bastante claro que o problema está relacionado aos "429" s.
wojtek-t
em 2 mar. 2018
Essas chamadas de API limitadas são devido a uma cota na conta do proprietário?
 jdumars
em 2 mar. 2018
jdumars
em 2 mar. 2018
Essas chamadas de API limitadas são devido a uma cota na conta do proprietário?
Isso não está estrangulando como pensei inicialmente. São 429s no apiserver (o motivo pode ser um apiserver mais lento por algum motivo ou mais solicitações chegando ao apiserver).
wojtek-t
em 2 mar. 2018
Ah ok. Isso não é uma boa notícia.
jdumars
em 2 mar. 2018
/ marco claro
krzyzacy
em 2 mar. 2018
/ milestone v1.10
krzyzacy
em 2 mar. 2018
/ marco claro
 cjwagner
em 2 mar. 2018
cjwagner
em 2 mar. 2018
@cjwagner : você deve ser membro da equipe do github kubernetes-milestone -keepers para definir o marco.
Em resposta a isso :
/ marco claro
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
 k8s-ci-robot
em 2 mar. 2018
k8s-ci-robot
em 2 mar. 2018
/ milestone v1.9
cjwagner
em 2 mar. 2018
@cjwagner : você deve ser membro da equipe do github kubernetes-milestone -keepers para definir o marco.
Em resposta a isso :
/ milestone v1.9
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 2 mar. 2018
Parece que PR https://github.com/kubernetes/kubernetes/pull/60740 corrigiu os problemas de tempo limite - obrigado @ msau42 pela resposta rápida.
Nossos trabalhos de correção (2k e 5k) estão de volta ao verde agora:
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -large-correctness
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -scale-correctness
Então, minha suspeita sobre os testes de volume estava certa :)
shyamjvs
em 5 mar. 2018
ACK. Em progresso
ETA: 03/09/2018
Riscos: Potencial impacto no desempenho do k8s
shyamjvs
em 5 mar. 2018
Então, descobri um pouco sobre isso e, a partir do gráfico de latência de inicialização do pod para nosso teste de 5k nós, tenho a sensação de que a regressão também poderia estar nas execuções p / b 108 e 109 (ver 99% ile):

shyamjvs
em 5 mar. 2018
Eu varri rapidamente o diff e a seguinte mudança parece suspeita para mim:
"Permitir passar o tempo limite de solicitação de NewRequest até o fim" # 51042
Esse PR está permitindo a propagação do tempo limite do cliente como um parâmetro de consulta para a chamada API. E eu realmente vejo a seguinte diferença nas chamadas de PATCH node/status entre essas 2 execuções (dos logs do apiserver):
run-108:
I0207 22:01:06.450385 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-2rn2/status: (11.81392ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.227.96.23:47270]
I0207 22:01:03.857892 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-9659/status: (8.570809ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.196.85.108:43532]
I0207 22:01:03.857972 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc4w/status: (8.287643ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.229.110.22:50530]
run-109:
I0209 21:01:08.551289 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-89f2/status?timeout=10s: (71.351634ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.229.77.215:51070]
I0209 21:01:08.551310 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-3ms3/status?timeout=10s: (70.705466ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.227.84.87:49936]
I0209 21:01:08.551394 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc02/status?timeout=10s: (70.847605ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.196.125.143:53662]
Minha hipótese é que, por causa do tempo limite adicionado de 10s às chamadas PATCH, essas chamadas agora estão durando mais tempo no lado do servidor (IIUC este comentário corretamente). Isso significa que agora eles estão na fila de vôo por mais tempo. Isso, combinado com o fato de que essas chamadas PATCH ocorrem em grandes quantidades em tais grandes clusters, está levando a PUT pod/status chamadas incapazes de obter largura de banda suficiente na fila de vôo e, portanto, são retornadas com 429s. Como resultado, o atraso do lado do kubelet na atualização do status do pod aumentou. Esta história também se encaixa bem com as observações de @ wojtek-t acima.
Vou tentar reunir mais evidências para verificar essa hipótese.
shyamjvs
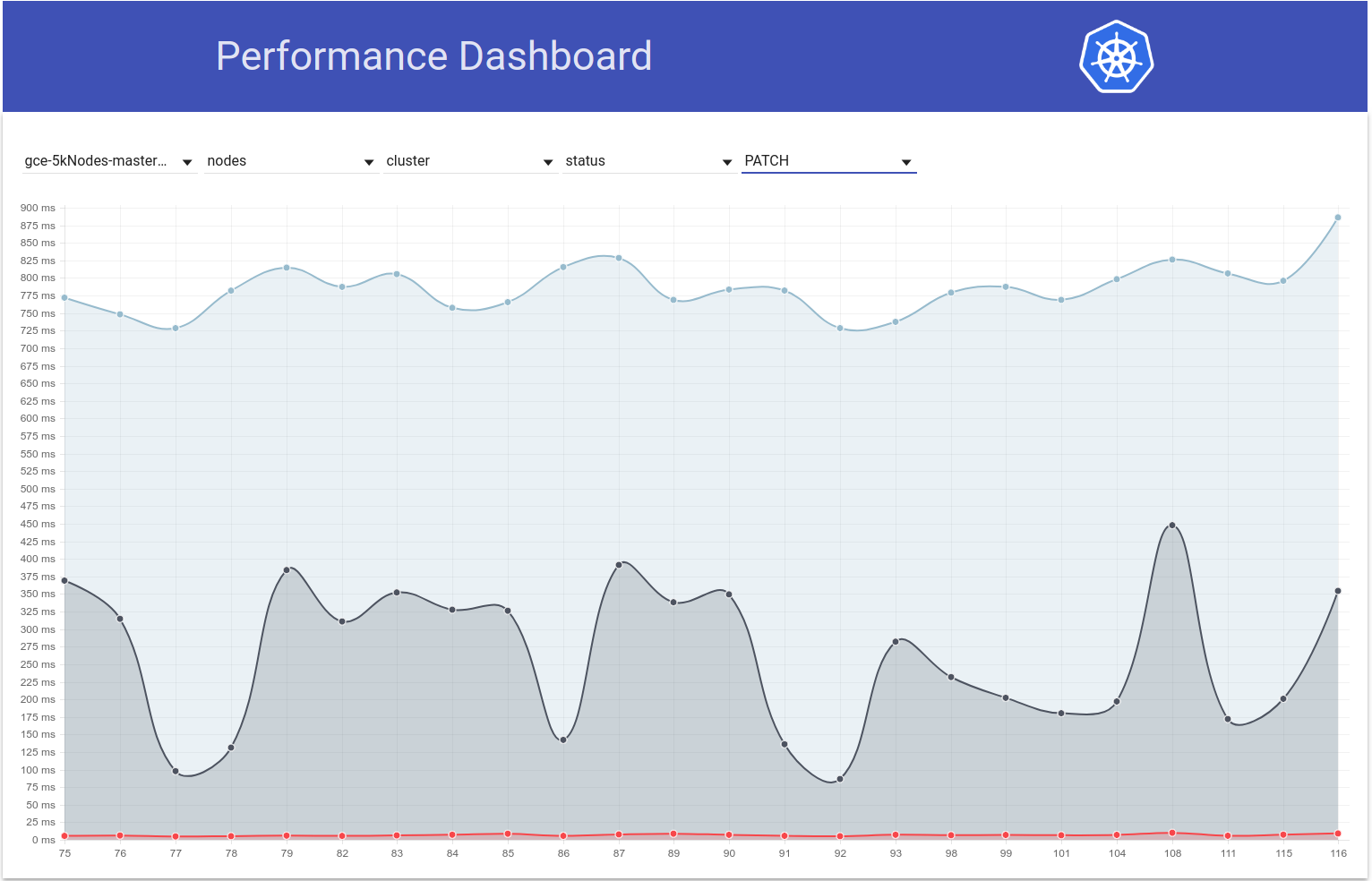
em 5 mar. 2018
Portanto, verifiquei como as latências de PATCH node-status variam ao longo das execuções de teste e, de fato, parece que há um aumento no 99º percentil (consulte a linha superior) nessa época. No entanto, não está muito claro que isso aconteceu nas corridas 108 e 109 (embora eu acredite que seja esse o caso):
shyamjvs
em 5 mar. 2018
[EDITAR: Meu comentário anterior mencionou incorretamente a contagem desses 429s (o cliente era npd, não kubelet)]
Tenho mais evidências de apoio agora:
na run-108 , tivemos ~ 479k PATCH node/status chamadas que obtiveram 429:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"479181"
]
},
e na execução 109 , temos ~ 757k desses:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"757318"
]
},
E ... olhe isso:
na execução-108:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"28594"
]
},
e na execução-109:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"33224"
]
},
Eu verifiquei o número para algumas outras execuções adjacentes:
- aquele PR fundiu -
Embora pareça um pouco diferente, no geral parece que o não. de 429s aumentou cerca de 25%.
shyamjvs
em 5 mar. 2018
E para PATCH node-status provenientes de kubelets que receberam 429s, veja como os números se parecem:
- run-104 = 313348
- run-105 = 309136
- run-108 = 479181
- aquele PR fundiu -
- run-109 = 757318
- run-110 = 752062
- run-111 = 296368
Isso também varia, mas geralmente parece aumentar.
shyamjvs
em 5 mar. 2018
O 99º% ile das latências de chamada de PATCH node-status também parece ter geralmente aumentado (como eu estava prevendo em https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370573938):
run-104 (798ms), run-105 (783ms), run-108 (826ms)
run-109 (878ms), run-110 (869ms), run-111 (806ms)
Btw - Com base em todas as métricas acima, 108 parece ser uma execução pior do que o normal e 111 parece ser uma execução melhor do que o normal.
shyamjvs
em 5 mar. 2018
Vou tentar verificar isso amanhã executando manualmente um grande cluster de 5k.
shyamjvs
em 5 mar. 2018
obrigado pela triagem @shyamjvs
krzyzacy
em 5 mar. 2018
Então, executei o teste de densidade duas vezes em um cluster de 5k em ~ HEAD, e o teste foi surpreendentemente aprovado nas duas vezes com latência de inicialização do pod de 99% ile como 4.510015461s e 4.623276837s . No entanto, as 'latências de observação' mostraram o aumento que @ wojtek-t apontou em https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -369951288
Na primeira execução foi:
INFO: perc50: 1.123056294s, perc90: 1.932503347s, perc99: 3.061238209s
e a segunda corrida foi:
INFO: perc50: 1.121218293s, perc90: 1.996638787s, perc99: 3.137325187s
Agora tentarei verificar qual era o caso antes.
shyamjvs
em 6 mar. 2018
https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 - Não tenho certeza se estou seguindo isso Sim - adicionamos o tempo limite, mas o tempo limite padrão é maior do que 10s IIRC - então só deve ajudar não piorar as coisas.
Acho que ainda não entendemos por que observamos mais 429s (o fato de que isso está de alguma forma relacionado aos 429s que já mencionei em https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370036377)
wojtek-t
em 6 mar. 2018
E em relação aos seus números - não estou convencido de que a regressão estava na corrida 109 - pode ter havido duas regressões - uma em algum lugar entre 105 e 108 e a outra em 109.
wojtek-t
em 6 mar. 2018
Hmm ... Eu não nego as possibilidades que você mencionou (o acima foi apenas minha hipótese).
No momento, estou fazendo a bissecção (agora contra o commit de 108) para verificar.
shyamjvs
em 6 mar. 2018
Minha sensação de que a regressão é anterior à corrida 108 é cada vez mais forte.
Por exemplo, as latências das chamadas de API já aumentaram em 108 execuções.
status do nó do patch:
90%: 198ms (105) 447ms (108) 444ms (109)
colocar status do pod:
99%: 83ms (105) 657ms (108) 728ms (109)
wojtek-t
em 6 mar. 2018
Acho que o que estou tentando dizer é:
- o número de 429s é uma consequência e não devemos gastar muito tempo com isso
- a causa raiz são chamadas de API mais lentas ou um número maior delas
Parece que vemos chamadas de API mais lentas em 108. A questão é se também vemos um número maior delas.
wojtek-t
em 6 mar. 2018
Então eu acho que por que as solicitações são visivelmente mais lentas - existem três possibilidades principais
há muito mais solicitações (à primeira vista, não parece ser o caso)
adicionamos algo no caminho de processamento (por exemplo, processamento adicional) ou os próprios objetos são maiores
algo mais na máquina mestre (por exemplo, planejador) está consumindo mais cpu e, assim, deixando o apiserver mais
wojtek-t
em 6 mar. 2018
Então eu e @ wojtek-t discutimos offline e ambos concordamos agora que é muito provável que haja uma regressão antes de 108. Adicionando alguns pontos:
há muito mais solicitações (à primeira vista, não parece ser o caso)
Não parece ser o caso para mim também
adicionamos algo no caminho de processamento (por exemplo, processamento adicional) ou os próprios objetos são maiores
Minha sensação é que é mais provável que seja sth no kubelet do que no apiserver (já que não estamos vendo nenhuma mudança visível no patch / colocar latências no kubemark-5000)
algo mais na máquina mestre (por exemplo, planejador) está consumindo mais cpu e, assim, deixando o apiserver mais
IMO, este não é o caso, pois estamos tendo alguma folga de CPU / memória em nosso mestre. Além disso, o perf-dash não sugere nenhum aumento considerável no uso de componentes principais.
Dito isso, descobri um pouco e, "felizmente", parece que estamos percebendo esse aumento nas latências de observação, mesmo para clusters de 2k nós:
INFO: perc50: 1.024377533s, perc90: 1.589770858s, perc99: 1.934099611s
INFO: perc50: 1.03503718s, perc90: 1.624451701s, perc99: 2.348645755s
Deve tornar a divisão ao meio um pouco mais fácil.
shyamjvs
em 6 mar. 2018
Infelizmente, a variação nessas latências de relógio parece única (caso contrário, é praticamente a mesma). Felizmente, temos PUT pod-status latência como um indicador confiável da regressão. Corri 2 rodadas de bissecção ontem e reduzi a esta diferença (~ 80 confirmações). Eu os folheei e tenho fortes suspeitas sobre:
- # 58990 - adiciona um novo campo ao pod-status (embora eu não tenha certeza se isso seria preenchido em nossos testes, onde as preempções IIUC não estão acontecendo - mas é preciso verificar)
- # 58645 - atualiza a versão do servidor etcd para 3.2.14
shyamjvs
em 7 mar. 2018
Eu realmente duvido que # 58990 esteja relacionado aqui - NominatedNodeName é uma string que contém um único nome de nó. Mesmo que ele seja preenchido o tempo todo, a alteração no tamanho do objeto deve ser insignificante.
wojtek-t
em 7 mar. 2018
@ wojtek-t - Como você estava sugerindo off-line, realmente parece que estamos usando uma versão diferente (3.2.16) no kubemark (https://github.com/kubernetes/kubernetes/blob/master/test/kubemark/ start-kubemark.sh # L62) que é o motivo potencial para não ver essa regressão lá :)
cc @jpbetz
shyamjvs
em 7 mar. 2018
Estamos usando 3.2.16 em todos os lugares agora.
wojtek-t
em 7 mar. 2018
Oops .. Desculpe pelo retrospecto - eu estava vendo uma combinação errada de commits.
shyamjvs
em 7 mar. 2018
BTW - esse aumento em pods PUT / latência de status é visível também no teste de carga em grandes clusters reais.
wojtek-t
em 7 mar. 2018
Então eu cavei um pouco mais e parece que começamos a observar latências maiores naquela época para solicitações de gravação em geral (o que me faz suspeitar que o etcd mude ainda mais):
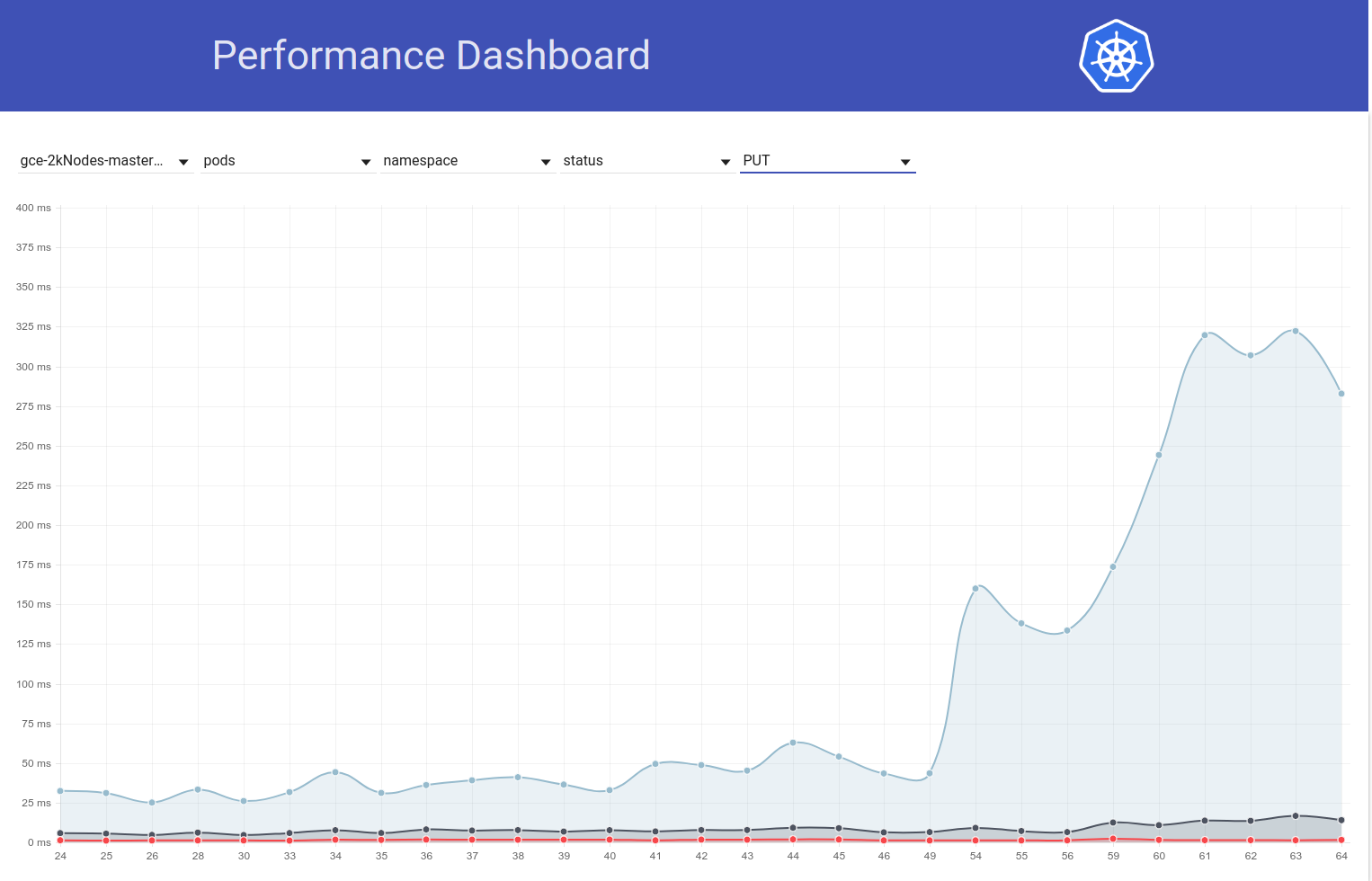
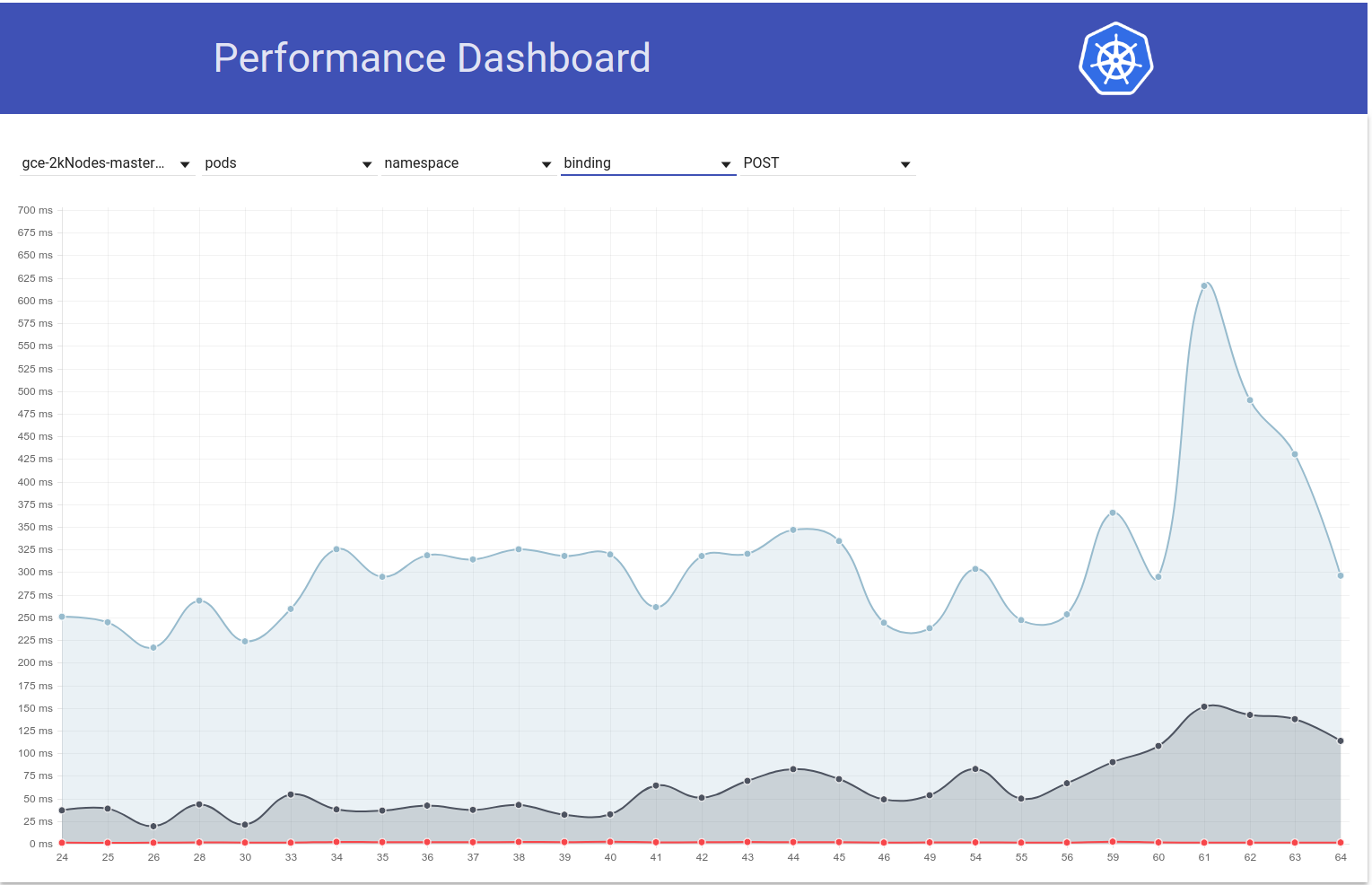

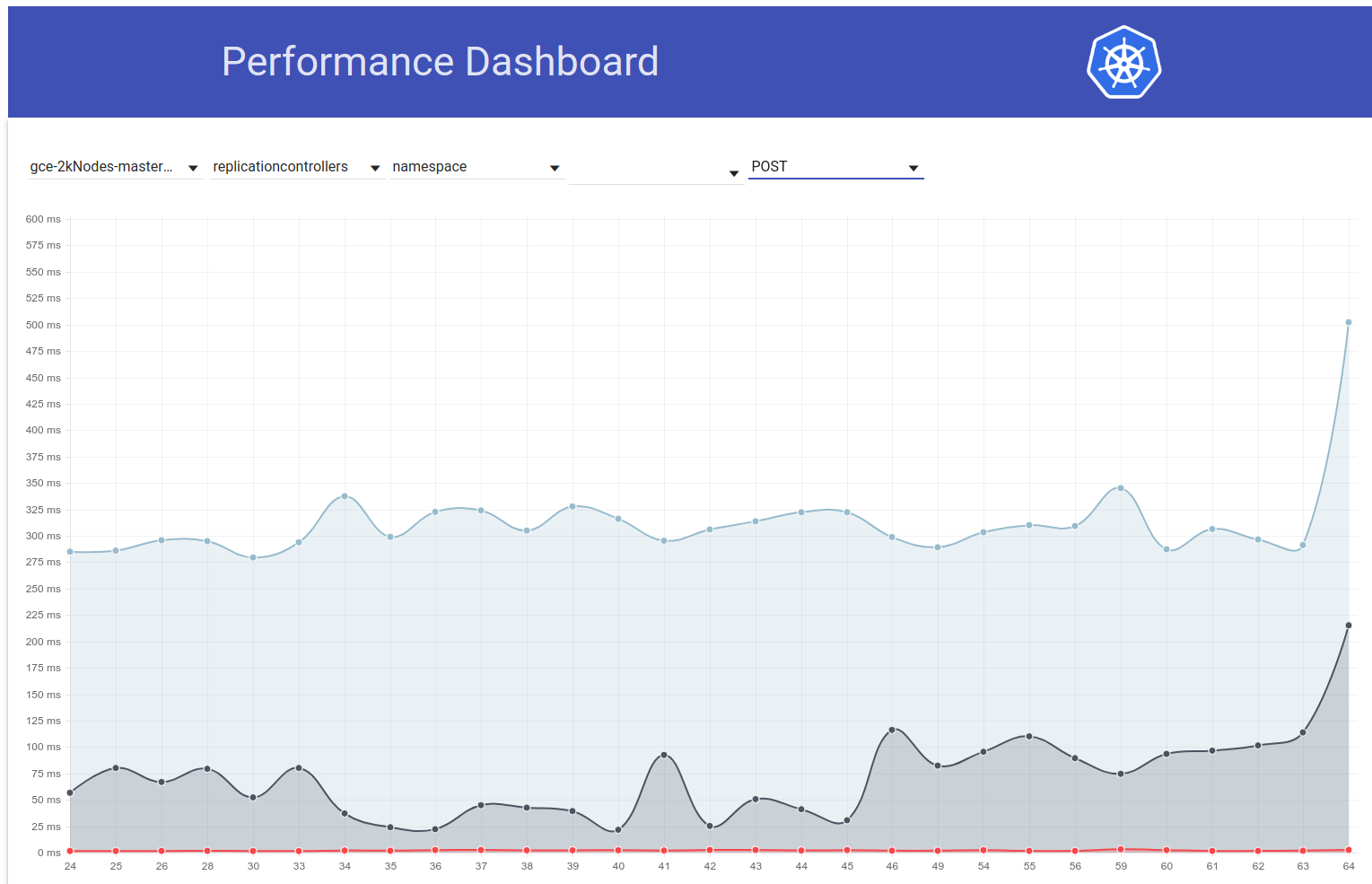
shyamjvs
em 7 mar. 2018
Na verdade, eu voto que pelo menos parte do problema está aqui:
https://github.com/kubernetes/kubernetes/pull/58990/commits/384a86caa92bdb7cf9ac96b10a6ef333d2d60519#diff -c73f80ad83608f18657d22a06950d929R240
Eu ficaria surpreso se fosse todo o problema, mas pode contribuir para isso.
Vou enviar um PR mudando isso em um segundo.
wojtek-t
em 7 mar. 2018
Para sua informação - quando eu executei contra um commit anterior à alteração do etcd 3.2.14, mas após a alteração da API do pod-status, a latência do status do nó put parece totalmente boa (ou seja, 99% ile = 39ms).
shyamjvs
em 7 mar. 2018
Portanto, verifiquei que realmente é causado pelo aumento do etcd no 3.2.14. Esta é a aparência da latência put pod-status:
contra aquele PR :
{
"data": {
"Perc50": 1.479,
"Perc90": 10.959,
"Perc99": 163.095
},
"unit": "ms",
"labels": {
"Count": "344494",
"Resource": "pods",
"Scope": "namespace",
"Subresource": "status",
"Verb": "PUT"
}
},
contra ~ HEAD (a partir de 5 de março) com esse PR revertido (o teste ainda está em execução, mas prestes a terminar):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.5"} 1669
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.9"} 9597
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.99"} 63392
63ms parece bastante semelhante ao que era antes .
Devemos reverter a versão e tentar entender:
- Por que estamos vendo esse aumento no etcd 3.2.14?
- Por que não pegamos isso no kubemark?
cc @jpbetz @ kubernetes / sig-api-machines-bugs
shyamjvs
em 7 mar. 2018
Uma hipótese (por que não pegamos isso no kubemark - embora ainda seja uma suposição) é que podemos ter alterado o sth em relação aos certificados lá.
Quando estou comparando o log etcd do kubemark e o cluster real, apenas neste último estou vendo a seguinte linha:
2018-03-05 08:06:56.389648 I | embed: peerTLS: cert = /etc/srv/kubernetes/etcd-peer.crt, key = /etc/srv/kubernetes/etcd-peer.key, ca = , trusted-ca = /etc/srv/kubernetes/etcd-ca.crt, client-cert-auth = true
Olhando para o PR em si, não vejo nenhuma mudança em torno disso, mas também não sei por que deveríamos ver essa linha apenas em clusters reais ...
@jpbetz para pensamentos
wojtek-t
em 7 mar. 2018
ACK. Em progresso
ETA: 03/09/2018
Riscos: problema causado pela raiz (principalmente)
shyamjvs
em 7 mar. 2018
Re peerTLS - parece ser o caso também antes (com 3.1.11), então acho que é uma pista falsa
wojtek-t
em 7 mar. 2018
cc @gyuho @wenjiaswe
 jpbetz
em 7 mar. 2018
jpbetz
em 7 mar. 2018
63ms parece bastante semelhante ao que
Onde podemos obter esses números? apiserver_request_latencies_summary realmente medindo as latências das gravações do etcd? Além disso, as métricas do etcd ajudariam.
 gyuho
em 7 mar. 2018
gyuho
em 7 mar. 2018
embed: peerTLS: cert ...
Isso imprime, se o par TLS estiver configurado (o mesmo em 3.1).
gyuho
em 7 mar. 2018
Onde podemos obter esses números? O apiserver_request_latencies_summary está realmente medindo as latências das gravações do etcd? Além disso, as métricas do etcd ajudariam.
Isso mede a latência de apicalls, que (pelo menos no caso de chamadas de gravação) inclui a latência de etcd.
Ainda não entendemos realmente o que está acontecendo, mas reverter para a versão anterior do etcd (3.1) corrige a regressão. Claramente, o problema está em algum lugar no etcd.
wojtek-t
em 7 mar. 2018
@shyamjvs
Quais versões do Kubemark e do Kubernetes você está executando? Testamos o Kubemark 1.10 em relação ao etcd 3.2 vs 3.3 (cargas de trabalho de 500 nós) e não observamos isso. Quantos nós são necessários para reproduzir isso?
gyuho
em 7 mar. 2018
Quais versões do Kubemark e do Kubernetes você está executando? Testamos o Kubemark 1.10 em relação ao etcd 3.2 vs 3.3 (cargas de trabalho de 500 nós) e não observamos isso. Quantos nós são necessários para reproduzir isso?
Não podemos reproduzi-lo com o kubemark, mesmo com um nó de 5k - veja o final de https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -371171837
Isso parece ser um problema apenas em clusters reais.
Esta é uma questão em aberto porque é esse o caso.
wojtek-t
em 7 mar. 2018
Já que voltamos para o etcd 3.1. para kubernetes. Também lançamos o etcd 3.1.12 com a única correção crítica pendente para kubernetes: operação de restauração do inspetor
jpbetz
em 8 mar. 2018
parece que https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100 começa a falhar de forma consistente desde esta manhã
krzyzacy
em 9 mar. 2018
Do diff , a única mudança é https://github.com/kubernetes/kubernetes/pull/60421 que está habilitando cotas em nossos testes de desempenho por padrão. O erro que estamos vendo é:
Container kube-controller-manager-e2e-big-master/kube-controller-manager is using 0.531144723/0.5 CPU
not to have occurred
@gmarek - Parece que habilitar cotas está afetando nossa escalabilidade :) Você poderia olhar mais a fundo - talvez seja sério?
Deixe-me registrar outro problema para mantê-lo sob controle.
shyamjvs
em 9 mar. 2018
@ wojtek-t @jpbetz @gyuho @timothysc Achei algo realmente interessante com a mudança de versão do etcd, sugerindo um efeito significativo da mudança do etcd 3.1.11 para 3.2.16.
Observe o gráfico a seguir do uso de memória etcd em nosso cluster de 100 nós (aumentou ~ 2x) quando o trabalho foi movido da versão 1.9 para 1.10 do k8s:
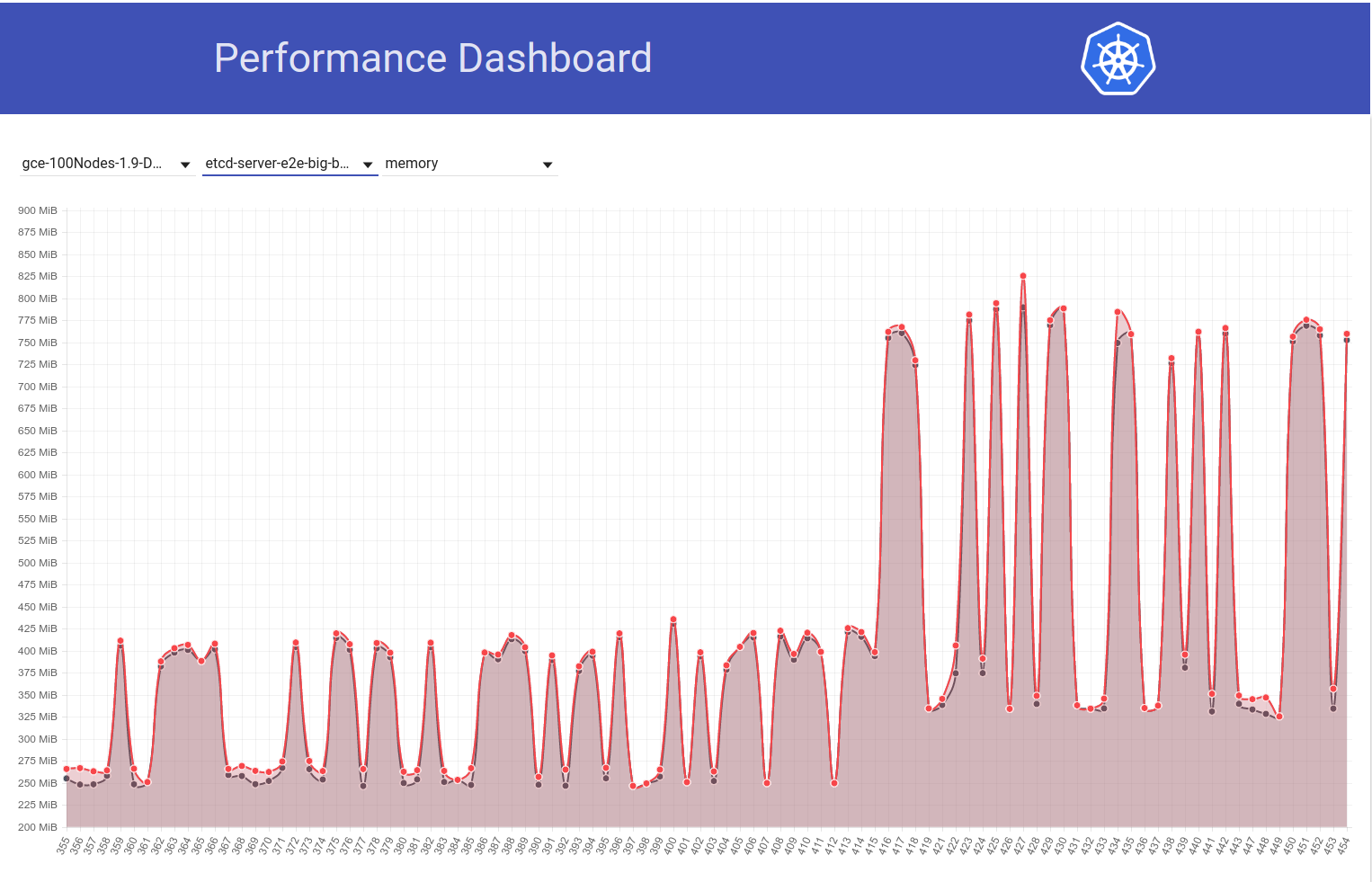
E a seguir, observe como nosso trabalho de 100 nós (em execução no HEAD) reduz o uso de mem pela metade logo após minha reversão do etcd 3.2.16 -> 3.1.11:
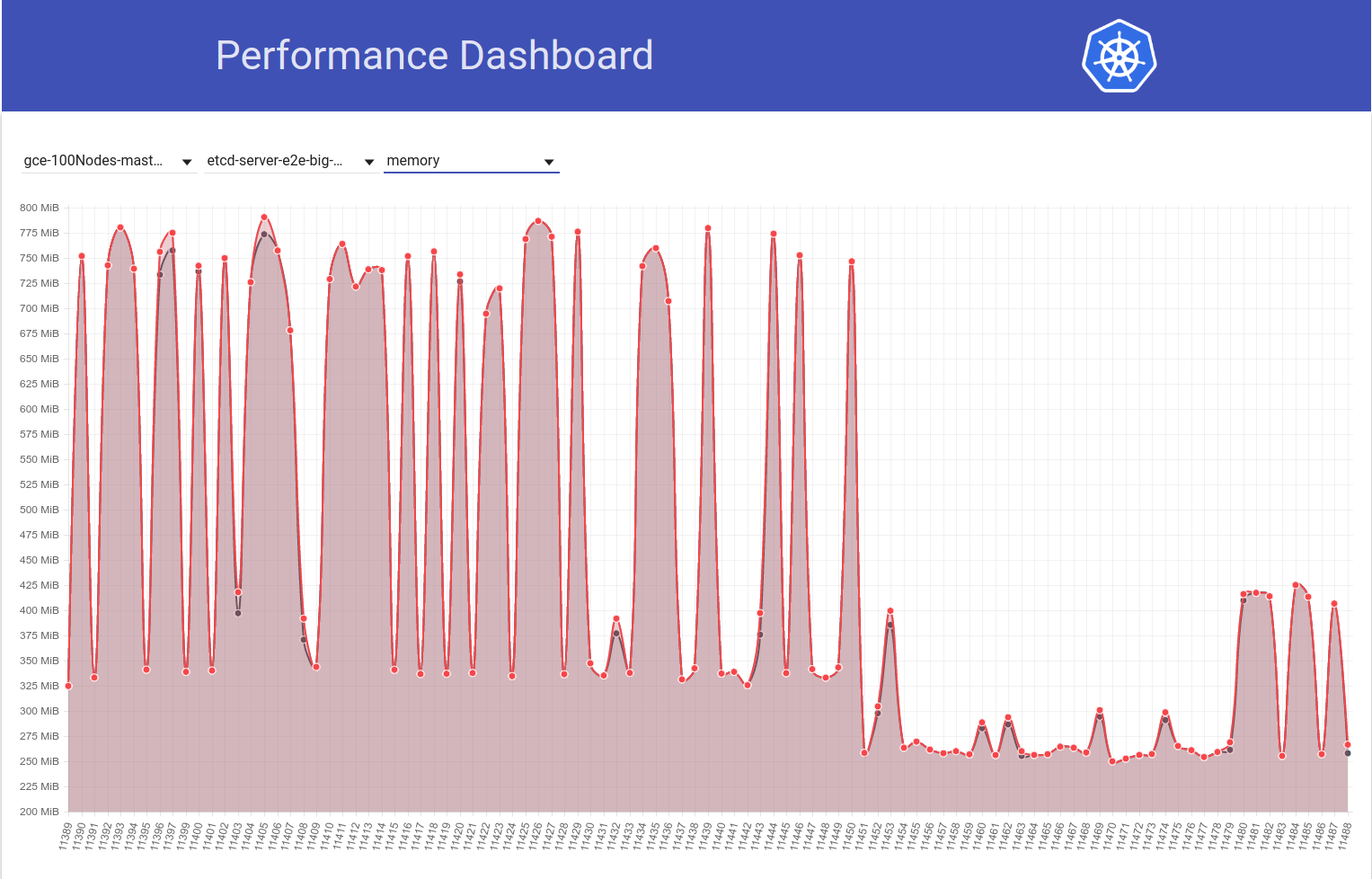
Portanto, a versão do servidor etcd 3.2 CLEARLY está mostrando o desempenho afetado (com todas as outras variáveis mantidas as mesmas) :)
shyamjvs
em 10 mar. 2018
minha reversão do etcd 3.2.16 -> 3.2.11:
Queríamos dizer 3.1.11?
gyuho
em 10 mar. 2018
Isso mesmo .. desculpe. Editou meu comentário.
shyamjvs
em 10 mar. 2018
@shyamjvs Como o etcd é configurado? Aumentamos o valor padrão --snapshot-count de 10000 para 100000 , na v3.2. Portanto, se a contagem de instantâneos for diferente, aquele com maior contagem de instantâneos mantém as entradas do Raft por mais tempo, portanto, requer mais memória residente, antes de descartar os registros antigos.
gyuho
em 10 mar. 2018
Aah! Isso realmente parece uma mudança suspeita. Sinalizadores errados, eu não acho que haja qualquer mudança naqueles do lado do k8. Porque, como você pode ver no meu segundo gráfico acima, o diff b / w executa 11450 e 11451 é principalmente apenas minha mudança de reversão do etcd (que parece não tocar em nenhuma sinalização).
Aumentamos o valor padrão --snapshot-count de 10000 para 100000
Você poderia confirmar se essa é a causa raiz desse aumento no uso de mem? Em caso afirmativo, podemos desejar:
- remendar o etcd de volta com o valor original ou
- defina-o para 10000 em k8s
antes de voltar para 3.2
shyamjvs
em 10 mar. 2018
Aah! Isso realmente parece uma mudança suspeita.
Sim, esta mudança deveria ter sido destacada do lado do etcd (irá melhorar nossos logs de mudanças e guias de atualização).
Você poderia confirmar se essa é a causa raiz desse aumento no uso de mem?
Não tenho certeza se essa seria a causa raiz. A contagem de instantâneos mais baixa definitivamente ajudará a aliviar o uso de memória intermitente. Se as duas versões do etcd usarem a mesma contagem de instantâneos, mas um etcd ainda mostrar um uso de memória muito maior, deve haver outra coisa.
gyuho
em 10 mar. 2018
Atualização: eu verifiquei que o aumento no uso de mem do etcd é causado devido ao valor padrão de --snapshot-count mais alto. Mais detalhes aqui - https://github.com/kubernetes/kubernetes/pull/61037#issuecomment -372457843
Devemos considerar configurá-lo para 10.000 quando estivermos passando para o etcd 3.2.16, se não quisermos aumentar o uso de mem.
cc @gyuho @ xiang90 @jpbetz
shyamjvs
em 12 mar. 2018
Atualização: com a correção do etcd ativada, a latência de inicialização do pod de 99% ainda parece estar perto de violar o SLO 5s. Há pelo menos uma outra regressão e reuni evidências de que é mais provável nas execuções p / b 111 e 112 de nosso trabalho de desempenho de 5k nós (veja o aumento p / b dessas execuções no gráfico que colei em https: / /github.com/kubernetes/kubernetes/issues/60589#issuecomment-370568929). Atualmente estou dividindo o diff (que tem cerca de 50 commits) e o teste leva cerca de 4-5 horas por iteração.
A evidência a que me referi acima é a seguinte:
As latências do relógio em 111 foram:
Feb 14 21:36:05.531: INFO: perc50: 1.070980786s, perc90: 1.743347483s, perc99: 2.629721166s
E as latências gerais de inicialização do pod em 111 foram:
Feb 14 21:36:05.671: INFO: perc50: 2.416307575s, perc90: 3.24553118s, perc99: 4.092430858s
Enquanto os mesmos em 112 eram:
Feb 16 10:07:43.222: INFO: perc50: 1.131108849s, perc90: 2.18487651s, perc99: 3.570548412s
e
Feb 16 10:07:43.353: INFO: perc50: 2.56160248s, perc90: 3.754024568s, perc99: 4.967573867s
Enquanto isso, se alguém está interessado no jogo de apostas - você pode dar uma olhada no diff do commit que mencionei acima e adivinhar o que está com defeito :)
shyamjvs
em 12 mar. 2018
ACK. Em progresso
ETA: 13/03/2018
Riscos: pode empurrar a data de lançamento se não for depurado antes disso
shyamjvs
em 12 mar. 2018
@shyamjvs toooooooo many commits para fazer apostas :)
 dims
em 13 mar. 2018
dims
em 13 mar. 2018
@dims Isso acrescentaria mais diversão, eu acho;)
Update: Então, eu executei algumas iterações da bissecção e aqui está como as métricas relevantes aparecem nos commits (ordenados cronologicamente). Observe que para os que executei manualmente, executei-os com a regressão anterior revertida (ou seja, 3.2. -> 3.1.11).
| Commit | 99% de latência do relógio | 99% de latência de inicialização do pod | Bom mau? |
| ------------- | ------------- | ----- | ------- |
| a042ecde36 (de run-111) | 2.629721166s | 4.092430858s | Bom (confirmando novamente manualmente) |
| 5f7b530d87 (manual) | 3.150616856s | 4.683392706s | Ruim (provável) |
| a8060ab0a1 (manual) | 3.11319985s | 4.710277511s | Ruim (provável) |
| 430c1a68c8 (da execução-112) | 3.570548412s | 4,967573867s | Bad |
| 430c1a68c8 (manual) | 3.63505091s | 4.96697776s | Bad |
Do exposto acima, parece que pode haver 2 regressões aqui (já que não é um salto direto de 2.6s -> 3.6s) - um b / w "a042ecde36 - 5f7b530d87" e outro b / w "a8060ab0a1 - 430c1a68c8". Suspiro!
shyamjvs
em 13 mar. 2018
expressando como intervalos para obter links de comparação:
a042ecde36 ... 5f7b530
a8060ab0a1 ... 430c1a6
 liggitt
em 13 mar. 2018
liggitt
em 13 mar. 2018
Acabei de obter os resultados da corrida manual contra a042ecde36 e isso só torna a vida mais difícil:
3.269330734s (watch), 4.939237532s (pod-startup)
porque isso provavelmente significa que pode ser uma regressão fragmentada.
shyamjvs
em 13 mar. 2018
No momento, estou executando o teste contra a042ecde36 mais uma vez para verificar a possibilidade de que a regressão tenha ocorrido antes mesmo.
shyamjvs
em 13 mar. 2018
Então aqui está o resultado de correr contra a042ecd novamente:
2.645592996s (watch), 5.026010032s (pod-startup)
Isso provavelmente significa que a regressão foi inserida antes mesmo da execução 111 (boas notícias de que agora temos o fim certo para a bissecção).
Agora vou tentar perseguir uma extremidade esquerda. Run-108 (commit 11104d75f) é um candidato potencial, que teve os seguintes resultados quando eu o executei anteriormente (com etcd 3.1.11):
2.593628224s (watch), 4.321942836s (pod-startup)
Minha nova corrida contra o commit 11104d7 parece dizer que é uma boa:
2.663456162s (watch), 4.288927203s (pod-startup)
Vou tentar aqui dividir o intervalo de 11104d7 ... a042ecd
shyamjvs
em 13 mar. 2018
Atualização: eu precisei testar o commit 097efb71a315 três vezes para ganhar confiança. Mostra alguma variação, mas parece um bom commit:
2.578970061s (watch), 4.129003596s (pod-startup)
2.315561531s (watch), 4.70792639s (pod-startup)
2.303510957s (watch), 3.88150234s (pod-startup)
Eu vou continuar dividindo mais.
Dito isso, parece ter ocorrido outro pico (de ~ 1s) na latência de inicialização do pod apenas alguns dias atrás. E este está empurrando os 99% para quase 6 segundos:
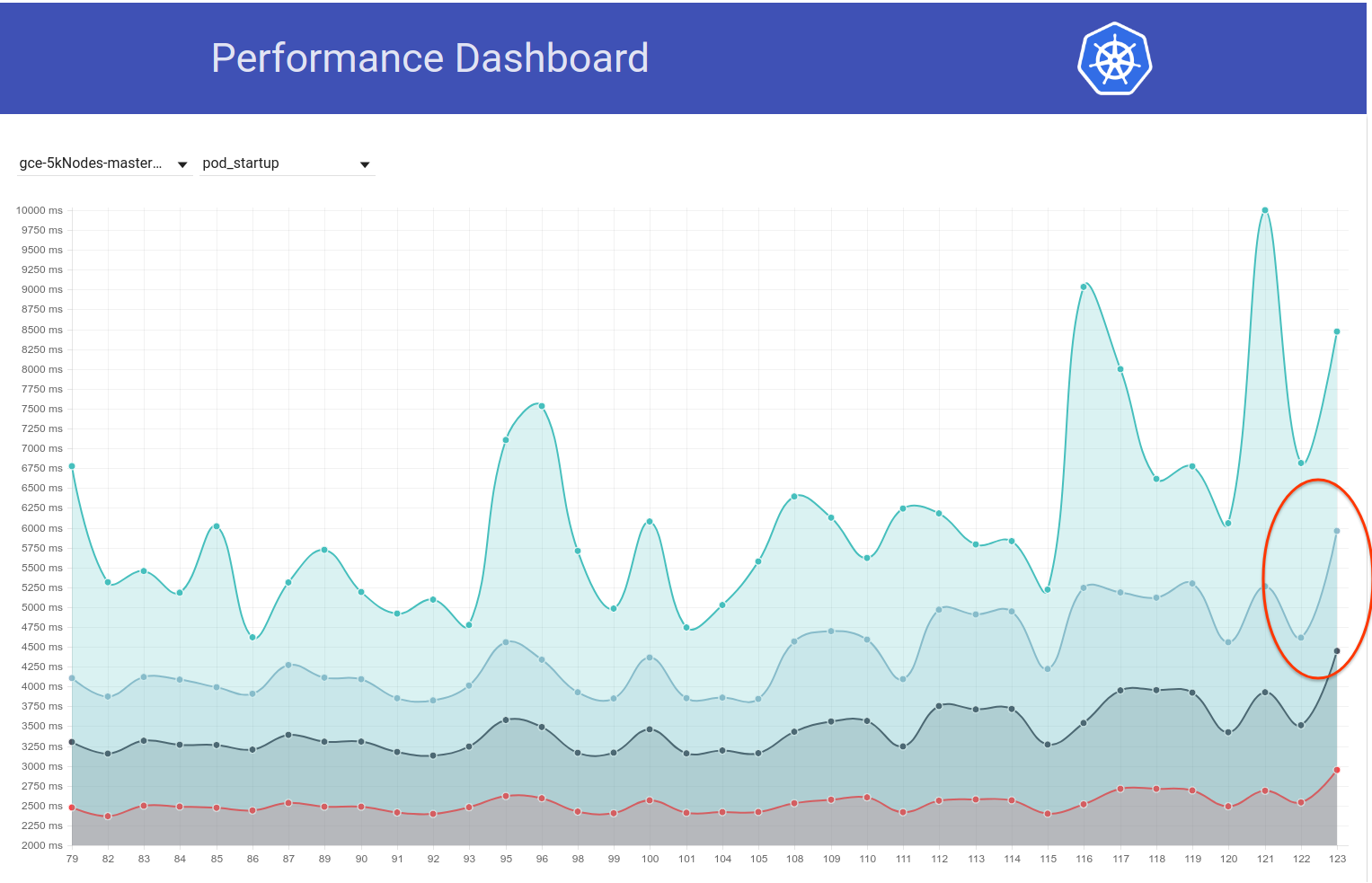
Meu principal suspeito do diff do
cc @jpbetz @gyuho
shyamjvs
em 14 mar. 2018
Como eu estaria de férias qui-sex esta semana, estou colando instruções para executar o teste de densidade em um cluster de 5k nós (para que alguém com acesso ao projeto possa continuar a bissecção):
# Start with a clean shell.
# Checkout to the right commit.
make quick-release
# Set the project:
gcloud config set project k8s-scale-testing
# Set some configs for creating/testing 5k-node cluster:
export CLOUDSDK_CORE_PRINT_UNHANDLED_TRACEBACKS=1
export KUBE_GCE_ZONE=us-east1-a
export NUM_NODES=5000
export NODE_SIZE=n1-standard-1
export NODE_DISK_SIZE=50GB
export MASTER_MIN_CPU_ARCHITECTURE=Intel\ Broadwell
export ENABLE_BIG_CLUSTER_SUBNETS=true
export LOGROTATE_MAX_SIZE=5G
export KUBE_ENABLE_CLUSTER_MONITORING=none
export ALLOWED_NOTREADY_NODES=50
export KUBE_GCE_ENABLE_IP_ALIASES=true
export TEST_CLUSTER_LOG_LEVEL=--v=1
export SCHEDULER_TEST_ARGS=--kube-api-qps=100
export CONTROLLER_MANAGER_TEST_ARGS=--kube-api-qps=100\ --kube-api-burst=100
export APISERVER_TEST_ARGS=--max-requests-inflight=3000\ --max-mutating-requests-inflight=1000
export TEST_CLUSTER_RESYNC_PERIOD=--min-resync-period=12h
export TEST_CLUSTER_DELETE_COLLECTION_WORKERS=--delete-collection-workers=16
export PREPULL_E2E_IMAGES=false
export ENABLE_APISERVER_ADVANCED_AUDIT=false
# Bring up the cluster (this brings down pre-existing one if present, so you don't have to explicitly '--down' the previous one) and run density test:
go run hack/e2e.go \
--up \
--test \
--test_args='--ginkgo.focus=\[sig\-scalability\]\sDensity\s\[Feature\:Performance\]\sshould\sallow\sstarting\s30\spods\sper\snode\susing\s\{\sReplicationController\}\swith\s0\ssecrets\,\s0\sconfigmaps\sand\s0\sdaemons$ --allowed-not-ready-nodes=30 --node-schedulable-timeout=30m --minStartupPods=8 --gather-resource-usage=master --gather-metrics-at-teardown=master' \
> somepath/build-log.txt 2>&1
# To re-run the test on same cluster (without re-creating) just omit '--up' in the above.
ANOTAÇÕES IMPORTANTES:
- O intervalo de confirmação atual suspeito é ff7918d ... a042ecde3 (vamos manter isso atualizado enquanto dividimos)
- Precisamos usar etcd-3.1.11 em vez de 3.2.14 (para evitar a inclusão de regressão anterior). Altere a versão nos seguintes arquivos para conseguir isso no mínimo:
- cluster / gce / manifests / etcd.manifest
- cluster / images / etcd / Makefile
- hack / lib / etcd.sh
shyamjvs
em 14 mar. 2018
cc: @ wojtek-t
jdumars
em 14 mar. 2018
etcd v3.1.12 corrige a perda de eventos de relógio na restauração. E esta é a única mudança que fizemos na v3.1.11. O teste de desempenho envolve algo com reinicialização de etcd ou vários nós que pode disparar um instantâneo do líder?
gyuho
em 14 mar. 2018
O teste de desempenho envolve algo com o etcd restart
A partir dos logs do
multi-nó
Estamos usando apenas o etcd de nó único em nossa configuração (presumindo que seja o que você pediu).
shyamjvs
em 14 mar. 2018
Eu vejo. Então, v3.1.11 e v3.1.12 não devem ser diferentes: 0
Analisará novamente se a segunda execução também mostra latências mais altas.
gyuho
em 14 mar. 2018
cc: @jpbetz
jdumars
em 14 mar. 2018
Concorde com @gyuho que devemos tentar obter um sinal mais forte neste, visto que a única alteração de código para o etcd é isolada para reiniciar / recuperar o código.
A única outra mudança é a atualização do etcd de go1.8.5 para go1.8.7, mas tenho dúvidas de que veríamos uma regressão de desempenho significativa com isso.
jpbetz
em 14 mar. 2018
Continuando com a bissecção, ff7918d1f parece ser bom:
2.246719086s (watch), 3.916350274s (pod-startup)
Vou atualizar o intervalo de confirmação em https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -373051051 de acordo.
shyamjvs
em 14 mar. 2018
Em seguida, o commit aa19a1726 parece bom, embora eu sugira que você tente novamente para confirmar:
2.715156606s (watch), 4.382527095s (pod-startup)
Neste ponto, vou pausar a bissecção e começar minhas férias :)
Eu abaixei meu cluster para abrir espaço para a próxima execução.
shyamjvs
em 15 mar. 2018
Obrigado Shyam. Estou tentando novamente aa19a172693a4ad60d5a08e9b93557267d259c37.
 wasylkowski-a
em 15 mar. 2018
wasylkowski-a
em 15 mar. 2018
Para o commit aa19a172693a4ad60d5a08e9b93557267d259c37, obtive os seguintes resultados:
2.47655243s (watch), 4.174016696s (pod-startup)
Então isso parece bom. Bissecção contínua.
Intervalo de confirmação atual suspeito: aa19a172693a4ad60d5a08e9b93557267d259c37 ... a042ecde362000e51f1e7bdbbda5bf9d81116f84
wasylkowski-a
em 15 mar. 2018
@ wasylkowski-a, você poderia participar de nossa reunião de lançamento às 17h UTC / 13h Leste / 10h do Pacífico? É uma reunião do Zoom: https://zoom.us/j/2018742972
jdumars
em 15 mar. 2018
Eu irei comparecer.
wasylkowski-a
em 15 mar. 2018
Commit cca7ccbff161255292f72c2d18459cdface62122 parece pouco claro com os seguintes resultados:
2.984185673s (watch), 4.568914929s (pod-startup)
Vou executar mais uma vez para ter confiança de que não entro na metade errada da bissecção.
wasylkowski-a
em 15 mar. 2018
OK, estou bastante confiante agora de que cca7ccbff161255292f72c2d18459cdface62122 é ruim:
3.285168535s (watch), 4.783986141s (pod-startup)
Cortando o intervalo para aa19a172693a4ad60d5a08e9b93557267d259c37 ... cca7ccbff161255292f72c2d18459cdface62122 e experimentando 92e4d3da0076f923a45d54d69c84e91ac6a61a55.
wasylkowski-a
em 16 mar. 2018
O commit 92e4d3da0076f923a45d54d69c84e91ac6a61a55 parece bom:
2.522438984s (watch), 4.21739985s (pod-startup)
O novo intervalo de confirmação suspeito é 92e4d3da0076f923a45d54d69c84e91ac6a61a55 ... cca7ccbff161255292f72c2d18459cdface62122, testando 603ebe466d335a37392315d491782ed18d1bae11
wasylkowski-a
em 16 mar. 2018
@wasylkowski , observe que um dos commits, nomeadamente https://github.com/kubernetes/kubernetes/commit/4c289014a05669c376994868d8d91f7565a204b5 foi revertido em https://github.com/kubernetes/kubernetes/commit/4c289014a05669c376994868d8d91f7565a204b5 foi revertido em
dims
em 16 mar. 2018
Repetindo o comentário @dims de forma mais clara, podemos estar perseguindo um sinal fantasma aqui na bissecção. Se 4c28901 for o problema, e ele já foi revertido em 493f335 por razões aparentemente não relacionadas, um teste de escalabilidade contra 1,10 branch head mostra um sinal verde?
Podemos priorizar o reteste uma vez contra 1,10 cabeça de ramificação, em vez de continuar a bissecção?
 tpepper
em 16 mar. 2018
tpepper
em 16 mar. 2018
@wasylkowski / @ wasylkowski-a ^^^^
tpepper
em 16 mar. 2018
@ wojtek-t PTAL ASAP
jdumars
em 16 mar. 2018
Obrigado @dims e @tpepper. Deixe minha tentativa contra 1.10 branch head e veja o que acontece.
wasylkowski-a
em 16 mar. 2018
obrigado @wasylkowski pior caso, voltamos ao que estávamos dividindo antes. direito?
dims
em 16 mar. 2018
1.10 cabeça tem uma regressão:
3.522924087s (watch), 4.946431238s (pod-startup)
Isso está no etcd 3.1.12, não no etcd 3.1.11, mas se eu entendi corretamente, isso não deve fazer muita diferença.
Além disso, 603ebe466d335a37392315d491782ed18d1bae11 parece bom:
2.744654024s (watch), 4.284582476s (pod-startup)
2.76287483s (watch), 4.326409841s (pod-startup)
2.560703844s (watch), 4.213785531s (pod-startup)
Isso nos deixa com o intervalo 603ebe466d335a37392315d491782ed18d1bae11 ... cca7ccbff161255292f72c2d18459cdface62122 e há apenas 3 commits lá. Deixe-me ver o que descobri.
Também é possível que de fato 4c289014a05669c376994868d8d91f7565a204b5 seja o culpado aqui, mas então isso significa que temos outra regressão que se manifesta na cabeça.
wasylkowski-a
em 16 mar. 2018
OK, então, evidentemente, comprometer 6590ea6d5d50700d34255b1e037b2702ad26b7fc é bom:
2.553170576s (watch), 4.22516704s (pod-startup)
enquanto o commit 7b678dc4035c61a1991b5e1442edb13f40deae72 é ruim:
3.498855918s (watch), 4.886599251s (pod-startup)
O commit ruim é a fusão do commit revertido mencionado por @dims , então devemos observar outra regressão inicial.
Deixe-me tentar executar novamente o head no etcd 3.1.11 em vez do 3.1.12 e ver o que acontece.
wasylkowski-a
em 17 mar. 2018
@ wasylkowski-a ah clássico boas notícias más notícias :) obrigado por continuar assim.
@ wojtek-t alguma outra sugestão?
dims
em 17 mar. 2018
Direcionar no etcd 3.1.11 também é ruim; minha próxima tentativa será tentar diretamente após a reversão (então, em commit cdecea545553eff09e280d389a3aef69e2f32bf1), mas com etcd 3.1.11 em vez de 3.2.14.
wasylkowski-a
em 17 mar. 2018
Parece bom Andrzej
- escurece
Em 17 de março de 2018, às 13h19, Andrzej Wasylkowski [email protected] escreveu:
Direcionar no etcd 3.1.11 também é ruim; minha próxima tentativa será tentar diretamente após a reversão (então, no commit cdecea5), mas com etcd 3.1.11 em vez de 3.2.14.
-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente, visualize-o no GitHub ou ignore a conversa.
dims
em 17 mar. 2018
Commit cdecea545553eff09e280d389a3aef69e2f32bf1 é bom, então temos uma regressão posterior:
2.66454307s (watch), 4.308091589s (pod-startup)
A confirmação 2a373ace6eda6a9cf050ce70a6cf99183c5e5b37 é claramente ruim:
3.656979569s (watch), 6.746987916s (pod-startup)
@ wasylkowski-a Então, estamos basicamente olhando para commits no intervalo https://github.com/kubernetes/kubernetes/compare/cdecea5...2a373ac para ver o que há de errado então? (execute a bifurcação entre os dois)?
dims
em 17 mar. 2018
Sim. Esta é uma gama enorme, infelizmente. No momento, estou investigando aded0d922592fdff0137c70443caf2a9502c7580.
wasylkowski-a
em 17 mar. 2018
Obrigado @wasylkowski qual é a faixa atual? (para que eu possa dar uma olhada no PR).
dims
em 18 mar. 2018
O compromisso aded0d922592fdff0137c70443caf2a9502c7580 é ruim:
3.626257043s (watch), 5.00754503s (pod-startup)
Commit f8298702ffe644a4f021e23a616ad6a8790a5537 também é ruim:
3.747051371s (watch), 6.126914967s (pod-startup)
Assim como o commit 20a6749c3f86c7cb9e98442046532380fb5f6e36:
3.641172882s (watch), 5.100922237s (pod-startup)
E 0e81651e77e0be7e75179e5986ef2c76601f4bd6 também:
3.687028394s (watch), 5.208157763s (pod-startup)
O intervalo atual é cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6. Nós (eu, @ wojtek-t, @shyamjvs) estamos começando a suspeitar que cdecea545553eff09e280d389a3aef69e2f32bf1 é na verdade uma passagem instável, então precisamos de uma extremidade esquerda diferente.
wasylkowski-a
em 19 mar. 2018
/ me faz uma aposta em https://github.com/kubernetes/kubernetes/commit/b259543985b10875f4a010ed0285ac43e335c8e0 como o culpado
cc @ wasylkowski-a
dims
em 19 mar. 2018
0e81651e77e0be7e75179e5986ef2c76601f4bd6 é, parece, ruim, então b259543985b10875f4a010ed0285ac43e335c8e0 (incorporada como 244549f02afabc5be23fc56e86a60e5b36838828, após 0e81651e77e0be7e75179e5986ef2c76601f4bd6) não pode ser o mais antigo culpado (embora não seja impossível que introduziu ainda uma outra regressão observaremos uma vez que sacudir este)
wasylkowski-a
em 19 mar. 2018
Por @ wojtek-t e @shyamjvs , estou executando novamente cdecea545553eff09e280d389a3aef69e2f32bf1, porque suspeitamos que isso pode ter sido um "instável bom"
wasylkowski-a
em 19 mar. 2018
Assumirei que cdecea545553eff09e280d389a3aef69e2f32bf1 é realmente bom com base nos seguintes resultados que observei:
2.66454307s (watch), 4.308091589s (pod-startup)
2.695629257s (watch), 4.194027608s (pod-startup)
2.660956347s (watch), 3m36.62259323s (pod-startup) <-- looks like an outlier
2.865445137s (watch), 4.594671099s (pod-startup)
2.412093606s (watch), 4.070130529s (pod-startup)
Intervalo atualmente suspeito: cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6
Atualmente testando 99c87cf679e9cbd9647786bf7e81f0a2d771084f
wasylkowski-a
em 20 mar. 2018
Obrigado @wasylkowski por continuar este trabalho.
jdumars
em 20 mar. 2018
por discussão hoje: fluentd-scaler ainda tem problemas: https://github.com/kubernetes/kubernetes/issues/61190 , que não foram corrigidos pelos PRs. É possível que essa regressão seja causada por fluentd?
 jberkus
em 20 mar. 2018
jberkus
em 20 mar. 2018
um dos PRs relacionados ao fluentd https://github.com/kubernetes/kubernetes/commit/a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 está na faixa mais recente
dims
em 20 mar. 2018
por discussão hoje: fluentd-scaler ainda tem problemas: # 61190, que não foram corrigidos pelos PRs. É possível que essa regressão seja causada por fluentd?
TBH, eu ficaria realmente surpreso se fosse devido a problemas de fluência. Mas não posso excluir essa hipótese com certeza.
Meu sentimento pessoal seria alguma mudança em Kubelet, mas também pesquisei PRs nessa faixa e nada parece realmente suspeito ...
Esperançosamente, o intervalo será 4x menor amanhã, o que significaria apenas alguns PRs.
wojtek-t
em 20 mar. 2018
OK, então 99c87cf679e9cbd9647786bf7e81f0a2d771084f parece bom, mas precisei de três execuções para garantir que não seja um floco:
2.901624657s (watch), 4.418169754s (pod-startup)
2.938653965s (watch), 4.423465198s (pod-startup)
3.047455619s (watch), 4.455485098s (pod-startup)
Em seguida, a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 é ruim:
3.769747695s (watch), 5.338517616s (pod-startup)
O intervalo atual é 99c87cf679e9cbd9647786bf7e81f0a2d771084f ... a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2. Analisando c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd.
wasylkowski-a
em 20 mar. 2018
Eu olhei para a faixa mencionada acima - existem apenas 9 PRs lá.
https://github.com/kubernetes/kubernetes/pull/59944 - 100% NÃO - apenas altera o arquivo de proprietários
https://github.com/kubernetes/kubernetes/pull/59953 - potencialmente
https://github.com/kubernetes/kubernetes/pull/59809 - tocar apenas no código kubectl, portanto, não importa neste caso
https://github.com/kubernetes/kubernetes/pull/59955 - 100% NÃO - apenas tocando em testes e2e não relacionados
https://github.com/kubernetes/kubernetes/pull/59808 - potencialmente (altera a configuração do cluster)
https://github.com/kubernetes/kubernetes/pull/59913 - 100% NÃO - apenas tocando em testes e2e não relacionados
https://github.com/kubernetes/kubernetes/pull/59917 - está mudando o teste, mas não ligando as mudanças, então improvável
https://github.com/kubernetes/kubernetes/pull/59668 - 100% NÃO - apenas tocando no código AWS
https://github.com/kubernetes/kubernetes/pull/59909 - 100% NÃO - apenas tocando nos arquivos dos proprietários
Portanto, acho que temos dois candidatos aqui: https://github.com/kubernetes/kubernetes/pull/59953 e https://github.com/kubernetes/kubernetes/pull/59808
Vou tentar me aprofundar neles para entendê-los.
wojtek-t
em 21 mar. 2018
c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd parece bastante ruim:
3.428891786s (watch), 4.909251611s (pod-startup)
Dado que esta é a fusão de # 59953, um dos suspeitos de Wojtek, irei agora executar um commit antes disso, então f60083549a43f152b3142e01756e25611d911770.
Esse commit, entretanto, é uma alteração de OWNERS_ALIASES, e não há mais nada nesse intervalo antes dele, então c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd deve ser o problema. Vou fazer o teste apenas por segurança, de qualquer maneira.
wasylkowski-a
em 21 mar. 2018
Discutido offline - executaremos testes iniciais com este commit revertido localmente.
wojtek-t
em 21 mar. 2018
Uau! um forro causando tantos problemas. obrigado @wasylkowski @ wojtek-t
dims
em 21 mar. 2018
@dims One-liners pode realmente causar devastação com escalabilidade. Outro exemplo do passado - https://github.com/kubernetes/kubernetes/pull/53720#issue-145949976
Em geral, você pode querer ver https://github.com/kubernetes/community/blob/master/sig-scalability/blogs/scalability-regressions-case-studies.md para uma boa leitura :)
shyamjvs
em 21 mar. 2018
Atualizar re. teste na cabeça: primeira execução com o commit revertido localmente aprovado. Isso pode ser um floco, entretanto, então estou executando novamente.
wasylkowski-a
em 21 mar. 2018
Olhando para o commit em https: //github.com/kubernetes/kubernetes/pull/59953 ... não estava corrigindo um bug? Parece ter corrigido um bug ao colocar o status "programado" no objeto errado. Com base no problema mencionado nesse PR, parece que o kubelet pode deixar de relatar que um pod foi agendado sem essa correção.
liggitt
em 21 mar. 2018
@ Random-Liu Quem pode nos explicar melhor qual é o efeito dessa mudança :)
shyamjvs
em 21 mar. 2018
Olhando para o commit em # 59953 ... não estava corrigindo um bug? Parece ter corrigido um bug ao colocar o status "programado" no objeto errado. O kubelet estava relatando que um pod foi agendado muito cedo antes dessa correção?
Sim - eu sei que foi uma correção de bug. Eu simplesmente não entendo isso completamente.
Parece corrigir o problema de relatório do pod como "Programado". Mas não vemos o problema até o momento em que é relatado pelo kubelet como "StartedAt".
O problema é que vemos um aumento significativo entre o tempo relatado como "StartedAt" por Kubelet e quando a atualização do status do pod está sendo relatada e observada pelo teste.
Portanto, acho que o bit "Programado" é uma pista falsa aqui.
Meu palpite (mas isso ainda é apenas um palpite) é que, devido a essa mudança, estamos enviando mais atualizações de status do pod, o que por sua vez está resultando em mais 429s ou ou sth como esse. E, no final, leva mais tempo para um Kubelet relatar o status do pod. Mas isso é algo que ainda precisamos confirmar.
wojtek-t
em 21 mar. 2018
Depois de duas execuções, estou bastante confiante de que a reversão do número 59953 corrige o problema:
3.052567319s (watch), 4.489142104s (pod-startup)
2.799364978s (watch), 4.385999497s (pod-startup)
estamos enviando mais atualizações de status de pod, o que por sua vez está resultando em mais 429s ou ou sth como esse. E, no final, leva mais tempo para um Kubelet relatar o status do pod.
Este é basicamente o efeito que eu estava hipotetizando em https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 (embora a causa que eu imaginei estivesse errada) :)
Além disso, nós, IIRC, parecemos ver um aumento no número de 429s para chamadas put (consulte meu https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370582634), mas acho que foi de uma faixa anterior ( em torno da mudança do etcd).
shyamjvs
em 21 mar. 2018
Depois de duas execuções, estou bastante confiante de que a reversão do número 59953 corrige o problema:
Minha intuição (https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370874602) sobre o problema de estar do lado do kubelet bem no início da discussão estava correta, afinal :)
shyamjvs
em 21 mar. 2018
nó / sig
@ kubernetes / sig-node-bugs a equipe de lançamento poderia realmente usar a revisão em # 59953 commit versus revert e o problema de desempenho aqui
tpepper
em 21 mar. 2018
Olhando para o commit em # 59953 ... não estava corrigindo um bug? Parece ter corrigido um bug ao colocar o status "programado" no objeto errado. Com base no problema mencionado nesse PR, parece que o kubelet pode deixar de relatar que um pod foi agendado sem essa correção.
@liggitt Obrigado por explicar isso para mim. Sim, aquele PR está corrigindo um bug. Anteriormente, kubelet nem sempre definia PodScheduled . Com o # 59953, o kubelet fará isso corretamente.
@shyamjvs Não tenho certeza se isso poderia introduzir mais atualização de status do pod.
Se bem entendi, a condição PodScheduled será definida na primeira atualização de status e, em seguida, estará sempre lá e nunca será alterada. Não entendo por que gera mais atualização de status.
Se realmente introduzir mais atualização de status, é um problema introduzido 2 anos atrás https://github.com/kubernetes/kubernetes/pull/24459, mas coberto por um bug, e # 59953 apenas consertar o bug ...
@ wasylkowski-a Você tem logs para os 2 testes executados em https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -374982422 e https://github.com/kubernetes/kubernetes/issues/60589# issuecomment -374871490? Basicamente, um bom e um mau. O kubelet.log será muito útil.
 Random-Liu
em 21 mar. 2018
Random-Liu
em 21 mar. 2018
@yujuhong e eu descobrimos que # 59953 expôs um problema de que a condição PodScheduled do pod estático continuará sendo atualizada.
Kubelet gera uma nova condição PodScheduled para o pod que não a possui. O pod estático não o tem e seu status nunca é atualizado (comportamento esperado). Assim, o kubelet continuará gerando uma nova condição PodScheduled para o pod estático.
O problema foi introduzido em # 24459, mas foi coberto por um bug. # 59953 corrigiu o bug e expôs o problema original.
Existem 2 opções para corrigir isso rapidamente:
- Opção 1: não deixe que o kubelet adicione
PodScheduledcondition, o kubelet deve apenas preservar aPodScheduledcondição definida pelo programador.- Prós: simples.
- Contras: pod estático e pod que ignora o programador (atribui o nome do nó diretamente) não terá a condição
PodScheduled. Na verdade, sem o # 59953, embora o kubelet acabe definindo essa condição para esses pods, isso pode levar muito tempo devido a um bug.
- Opção 2: gere uma condição
PodScheduledpara o pod estático quando o kubelet o vê inicialmente.
A opção 2 pode apresentar menos mudanças voltadas para o usuário.
Mas queremos perguntar o que PodScheduled significa para pods que não são programados pelo planejador? Precisamos realmente dessa condição para esses pods? / cc @ kubernetes / sig-autoscaling-bugs Porque @yujuhong me disse que PodScheduled é usado por escalonamento automático agora.
/ cc @ kubernetes / sig-node-bugs @ kubernetes / sig-scheduling-bugs
Random-Liu
em 21 mar. 2018
@ Random-Liu Qual é o efeito de very long time for kubelet to eventually set this condition ? Que problema um usuário final notará / enfrentará (fora da estrutura de teste)? (da Opção nº 1)
dims
em 21 mar. 2018
@dims O usuário não verá a condição PodScheduled por muito tempo.
Random-Liu
em 21 mar. 2018
Eu tenho uma correção # 61504 que implementa a opção 2 em https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979.
Posso mudar para a opção 1 se as pessoas acharem que é uma solução melhor. :)
Random-Liu
em 21 mar. 2018
é melhor você perguntar às pessoas que sabem disso por dentro! (NÃO a equipe de lançamento 😄!)
ping @dashpole @ dchen1107 @derekwaynecarr
dims
em 21 mar. 2018
@ Random-Liu IIRC, o único pod estático em execução nos nós em nossos testes é o kube-proxy. Você poderia dizer com que frequência essas 'atualizações contínuas' são feitas pelo kubelet? (perguntando para estimar qps extras introduzidos pelo bug)
shyamjvs
em 21 mar. 2018
@ Random-Liu IIRC, o único pod estático em execução nos nós em nossos testes é o kube-proxy. Você poderia dizer com que frequência essas 'atualizações contínuas' são feitas pelo kubelet? (perguntando para estimar qps extras introduzidos pelo bug)
@shyamjvs Sim, kube-proxy é o único no nó agora.
Acho que depende da frequência de sincronização do pod https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/kubeletconfig/v1beta1/defaults.go#L47 , que é de 1 minuto. Portanto, o kubelet gera uma atualização de status de pod extra a cada 1 minuto.
Random-Liu
em 22 mar. 2018
Obrigado. Isso significa que 5000/60 = ~ 83 qps extra adicionado devido a essas chamadas put pod-status. Parece explicar o aumento de 429s observado anteriormente no bug.
shyamjvs
em 22 mar. 2018
@ Random-Liu muito obrigado por nos ajudar a resolver isso.
jdumars
em 22 mar. 2018
@jdumars np ~ @yujuhong me ajudou muito!
Random-Liu
em 22 mar. 2018
Mas queremos perguntar o que PodScheduled significa para pods que não são programados pelo planejador? Precisamos realmente dessa condição para esses pods? / cc @ kubernetes / sig-autoscaling-bugs Porque @yujuhong me disse que PodScheduled é usado por escalonamento automático agora.
Eu ainda acho que deixar o kubelet definir a condição PodScheduled é um tanto estranho (como eu observei no PR original). Mesmo se o kubelet não definir essa condição, isso não afetará o autoescalador do cluster, pois o autoescalador ignora os pods sem a condição específica. De qualquer forma, a correção que eventualmente encontramos tem uma pegada muito pequena e manteria o comportamento atual (ou seja, sempre configurando a condição PodScheduled), então continuaremos com isso.
 yujuhong
em 22 mar. 2018
yujuhong
em 22 mar. 2018
Além disso, reviveu o problema realmente antigo de adicionar testes para taxa de atualização de pod de estado estacionário # 14391
yujuhong
em 22 mar. 2018
De qualquer forma, a correção que eventualmente encontramos tem uma pegada muito pequena e manteria o comportamento atual (ou seja, sempre configurando a condição PodScheduled), então continuaremos com isso.
@yujuhong - você está falando sobre este: # 61504 (ou eu não entendi bem)?
@wasylkowski @shyamjvs - você pode executar testes de 5.000 nós com esse PR corrigido localmente (antes de mesclá-lo) para garantir que isso realmente ajude?
wojtek-t
em 22 mar. 2018
Eu executei o teste em 1.10 HEAD + # 61504, e a latência de inicialização do pod parece estar bem:
INFO: perc50: 2.594635536s, perc90: 3.483550118s, perc99: 4.327417676s
Será executado novamente para confirmar.
shyamjvs
em 22 mar. 2018
@shyamjvs - muito obrigado!
wojtek-t
em 22 mar. 2018
A segunda execução também parece boa:
INFO: perc50: 2.583489146s, perc90: 3.466873901s, perc99: 4.380595534s
Bastante confiante agora que a correção funcionou. Vamos colocá-lo em 1.10 o mais rápido possível.
shyamjvs
em 22 mar. 2018
Obrigado @shyamjvs
Enquanto conversamos offline - acho que tivemos mais uma regressão no último mês ou assim, mas essa não deve bloquear o lançamento.
wojtek-t
em 22 mar. 2018
@yujuhong - você está falando sobre este: # 61504 (ou eu não entendi bem)?
Sim. A correção atual nesse PR não está nas opções propostas inicialmente em https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979
yujuhong
em 22 mar. 2018
reabrindo até termos um bom resultado de teste de desempenho.
jberkus
em 25 mar. 2018
@yujuhong @krzyzacy @shyamjvs @ wojtek-t @ Random-Liu @ wasylkowski-a alguma atualização sobre isso? Isso ainda está bloqueando 1,10 no momento.
jdumars
em 26 mar. 2018
Portanto, a única parte desse bug que estava bloqueando o lançamento é o trabalho de desempenho de 5k nós. Infelizmente, perdemos nossa corrida de hoje devido a um motivo diferente (ref: https://github.com/kubernetes/kubernetes/issues/61190#issuecomment-376150569)
Dito isso, estamos bastante confiantes de que a correção funciona com base em minhas execuções manuais (resultados colados em https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-375350217). Então, IMHO, não precisamos bloquear a liberação dele (a próxima execução será no casamento).
shyamjvs
em 26 mar. 2018
+1
@jdumars - Acho que podemos tratar isso como não bloqueador.
wojtek-t
em 26 mar. 2018
Desculpe, eu editei minha postagem acima. Eu quis dizer que devemos tratá-lo como "não bloqueador".
wojtek-t
em 26 mar. 2018
Ok, muito obrigado. Esta conclusão representa uma tremenda quantidade de horas que você investiu e não posso agradecer o suficiente pelo trabalho que você fez. Enquanto falamos em abstrato sobre "comunidade" e "contribuidores", você e os outros que trabalharam nesta questão representam em termos concretos. Você é o coração e a alma deste projeto, e sei que falo por todos os envolvidos quando digo que é uma honra trabalhar ao lado de tanta paixão, comprometimento e profissionalismo.
jdumars
em 26 mar. 2018
[MILESTONENOTIFIER] Problema de marco: atualizado para o processo
@krzyzacy @ msau42 @shyamjvs @ wojtek-t
Etiquetas de problemas
sig/api-machinerysig/autoscalingsig/nodesig/scalabilitysig/schedulingsig/storage: O problema será escalado para esses SIGs se necessário.priority/critical-urgent: Nunca mova automaticamente a questão de um marco de lançamento; escalar continuamente para o contribuidor e SIG por meio de todos os canais disponíveis.kind/bug: corrige um bug descoberto durante a versão atual.Socorro
 k8s-github-robot
em 11 abr. 2018
k8s-github-robot
em 11 abr. 2018
Este problema foi resolvido com as correções relevantes no 1.10.
Para 1.11, estamos rastreando as falhas em - https://github.com/kubernetes/kubernetes/issues/63030.
/Fechar
shyamjvs
em 25 mai. 2018
Questões relacionadas
 arun-gupta
·
3Comentários
arun-gupta
·
3Comentários
 chowyu08
·
3Comentários
chowyu08
·
3Comentários
 rhohubbuild
·
3Comentários
rhohubbuild
·
3Comentários
 cooligc
·
3Comentários
cooligc
·
3Comentários
 montanaflynn
·
3Comentários
montanaflynn
·
3Comentários
Comentários muito úteis
Eu executei o teste em 1.10 HEAD + # 61504, e a latência de inicialização do pod parece estar bem:
Será executado novamente para confirmar.