Kubernetes: [test flakes] мастер-наборы масштабируемости
Неудачные наборы для блокировки выпуска:
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correness
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
все три люкса в последнее время сильно ломаются, сортировка мыслей?
/ sig масштабируемость
/ приоритет сбой-тест
/ добрый баг
/ статус утвержден для контрольной точки
Копия @jdumars @jberkus
/ назначить @shyamjvs @ wojtek-t
 krzyzacy
krzyzacy
Все 164 Комментарий
- Работа по обеспечению корректности не выполняется в основном из-за тайм-аута (необходимо соответственно скорректировать наше расписание), поскольку недавно в пакет были добавлены несколько e2es (например, https://github.com/kubernetes/kubernetes/pull/59391)
- Для хлопьев со 100 узлами у нас есть https://github.com/kubernetes/kubernetes/issues/60500 (и я считаю, что это связано ... необходимо проверить).
- Что касается работы с производительностью, я считаю, что есть регресс (судя по последним нескольким запускам, как будто это связано с задержкой запуска пода). Может быть, что-то еще.
Я постараюсь добраться до них когда-нибудь на этой неделе (из-за нехватки свободных циклов в банкомате).
 shyamjvs
28 февр. 2018
shyamjvs
28 февр. 2018
@shyamjvs есть ли какие-нибудь обновления для этой проблемы?
krzyzacy
2 мар. 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correness
Я вкратце изучил это. И либо некоторые тесты работают очень медленно, либо что-то зависает. Количество журналов с последнего запуска:
62571 I0301 23:01:31.360] Mar 1 23:01:31.348: INFO: Running AfterSuite actions on all node
62572 I0301 23:01:31.360]
62573 W0302 07:32:00.441] 2018/03/02 07:32:00 process.go:191: Abort after 9h30m0s timeout during ./hack/ginkgo-e2e.sh --ginkgo.flakeAttempts=2 --ginkgo.skip=\[Serial\]|\[Disruptive \]|\[Flaky\]|\[Feature:.+\]|\[DisabledForLargeClusters\] --allowed-not-ready-nodes=50 --node-schedulable-timeout=90m --minStartupPods=8 --gather-resource-usage=master --gathe r-metrics-at-teardown=master --logexporter-gcs-path=gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-correctness/80/artifacts --report-dir=/workspace/_artifacts --dis able-log-dump=true --cluster-ip-range=10.64.0.0/11. Will terminate in another 15m
62574 W0302 07:32:00.445] SIGABRT: abort
Ни один тест не завершился в течение 8:30 мин.
 wojtek-t
2 мар. 2018
wojtek-t
2 мар. 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
Действительно похоже на регресс. Я думаю, что регресс произошел где-то между прогонами:
105 (все еще нормально)
108 (у которых было заметно более высокое время запуска)
Мы можем попробовать заглянуть в kubemark-5000, чтобы увидеть, виден ли он и там.
wojtek-t
2 мар. 2018
Кубемарк-5000 работает довольно стабильно. 99-й процентиль на этом графике (возможно, регресс случился даже раньше, но я думаю, что это где-то между 105 и 108):

wojtek-t
2 мар. 2018
Что касается тестов на корректность - gce-large-правильность также не работает.
Может быть, в то время добавили какой-то очень длинный тест?
wojtek-t
2 мар. 2018
Большое спасибо, что посмотрели @ wojtek-t. Что касается работы с производительностью - я тоже сильно чувствую, что есть регресс (хотя я не мог должным образом разобраться в них).
Может быть, в то время добавили какой-то очень длинный тест?
Я изучал это некоторое время назад. И я обнаружил 2 подозрительных изменения:
- # 59391 - Это добавило кучу тестов для локального хранилища (запуски после этого изменения начинали с таймаутом)
- StatefulSet с антиаффинностью пода должен использовать тома, распределенные по узлам (этот тест, похоже, выполняется в течение 3,5-5 часов) - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e -gce-scale-правильность / 79
shyamjvs
2 мар. 2018
cc @ kubernetes / сиг-хранилища-ошибки
shyamjvs
2 мар. 2018
/ назначить
Некоторые тесты локального хранилища будут пытаться использовать каждый узел в кластере, полагая, что размеры кластера не такие уж большие. Я добавлю исправление, чтобы ограничить максимальное количество узлов.
 msau42
2 мар. 2018
msau42
2 мар. 2018
Некоторые тесты локального хранилища будут пытаться использовать каждый узел в кластере, полагая, что размеры кластера не такие уж большие. Я добавлю исправление, чтобы ограничить максимальное количество узлов.
Спасибо @ msau42 - было бы здорово.
wojtek-t
2 мар. 2018
Возвращаясь к https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance suite
Я внимательно изучил пробеги до 105, 108 и после этого.
Самая большая разница во времени запуска пода, похоже, проявляется на этапе:
10% worst watch latencies:
[название вводит в заблуждение - поясню ниже]
До 105 пробега это вообще выглядело так:
I0129 21:17:43.450] Jan 29 21:17:43.356: INFO: perc50: 1.041233793s, perc90: 1.685463015s, perc99: 2.350747103s
Начиная с 108 пробега, это больше похоже на:
Feb 12 10:08:57.123: INFO: perc50: 1.122693874s, perc90: 1.934670461s, perc99: 3.195883331s
Это в основном означает увеличение на ~ 0,85 с, и это примерно то, что мы наблюдаем в конечном результате.
Теперь - что это за "отставание часов".
По сути, это время между «Kubelet заметил, что модуль работает» и «когда тестовое наблюдаемое обновление модуля установило его состояние на выполнение».
Есть пара возможностей, по которым мы могли бы регрессировать:
- kubelet замедляется в состоянии отчета
- kubelet не хватает qps (и, следовательно, медленнее сообщает статус)
- apiserver работает медленнее (например, не хватает процессора) и, следовательно, обрабатывает запросы медленнее (либо запись, либо наблюдение, либо и то, и другое)
- test не хватает процессора и поэтому обрабатывает входящие события медленнее
Поскольку на самом деле мы не наблюдаем разницы между «расписание -> начало» пода, это говорит о том, что он, скорее всего, не apiserver (потому что обработка запросов и часы также находятся на этом пути), и, скорее всего, это не медленный kubelet тоже (потому что запускает стручок).
Поэтому я думаю, что наиболее вероятная гипотеза:
- kubelet не хватает qps (или sth, что мешает ему быстро отправлять обновление статуса)
- тест не хватает процессора (или что-то в этом роде)
Тесты в то время вообще не изменились. Так что я думаю, что это, скорее всего, первый.
Тем не менее, я прошел через PR, объединенные между 105 и 108 прогонами, и пока не нашел ничего полезного.
wojtek-t
2 мар. 2018
Я думаю, что следующим шагом будет:
- посмотрите на самые медленные модули (кажется, разница между самыми медленными тоже составляет O (1 с)) и посмотрите, является ли разница «до» или «после» отправки запроса статуса обновления
wojtek-t
2 мар. 2018
Итак, я рассмотрел примеры модулей. И я уже это вижу:
I0209 10:01:19.960823 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.615907ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
...
I0209 10:01:22.464046 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (279.153µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:23.468353 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (218.216µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:24.470944 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.42987ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 09:57:01.559125 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (1.836423ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
...
I0209 09:57:04.452830 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (231.2µs) 429 [[kubelet/v1.10.0 (linu x/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:05.454274 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (213.872µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:06.458831 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (2.13295ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 10:01:53.063575 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (1.410064ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:3391
...
I0209 10:01:55.259949 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (10.4894ms) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:56.266377 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (233.931µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:57.269427 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (182.035µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:58.290456 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (13.44863ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
Таким образом, кажется довольно очевидным, что проблема связана с «429».
wojtek-t
2 мар. 2018
Эти ограниченные вызовы API связаны с квотой в учетной записи владельца?
 jdumars
2 мар. 2018
jdumars
2 мар. 2018
Эти ограниченные вызовы API связаны с квотой в учетной записи владельца?
Это не троттлинг, как я думал изначально. Это 429 на apiserver (причина может быть либо в более медленном apiserver по какой-то причине, либо в большем количестве запросов, поступающих в apiserver).
wojtek-t
2 мар. 2018
Ну ладно. Это не хорошие новости.
jdumars
2 мар. 2018
/ этап очищен
krzyzacy
2 мар. 2018
/ milestone v1.10
krzyzacy
2 мар. 2018
/ этап очищен
 cjwagner
2 мар. 2018
cjwagner
2 мар. 2018
@cjwagner : Вы должны быть членом команды github kubernetes-milestone- mainers, чтобы установить веху.
В ответ на это :
/ этап очищен
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, сообщите о проблеме в репозиторий kubernetes / test-infra .
 k8s-ci-robot
2 мар. 2018
k8s-ci-robot
2 мар. 2018
/ milestone v1.9
cjwagner
2 мар. 2018
@cjwagner : Вы должны быть членом команды github kubernetes-milestone- mainers, чтобы установить веху.
В ответ на это :
/ milestone v1.9
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, сообщите о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
2 мар. 2018
Похоже, PR https://github.com/kubernetes/kubernetes/pull/60740 исправил проблемы с тайм-аутом - спасибо @ msau42 за быстрый ответ.
Наши задания на правильность (как 2k, так и 5k) вернулись к зеленому цвету:
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -large-правильность
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -scale-correness
Так что мои подозрения насчет этих объемных тестов действительно оправдались :)
shyamjvs
5 мар. 2018
ACK. В ходе выполнения
Расчетное время прибытия: 03.09.2018
Риски: возможное влияние на производительность k8s
shyamjvs
5 мар. 2018
Итак, я немного покопался в этом, и из графика задержки запуска пода для нашего теста с 5 тыс. Узлов у меня возникло ощущение, что регресс также может быть в ч / б прогонах 108 и 109 (см. 99% файлов):

shyamjvs
5 мар. 2018
Я быстро просмотрел различие, и следующее изменение показалось мне подозрительным:
"Разрешить передачу тайм-аута запроса от NewRequest полностью вниз" # 51042
Этот PR позволяет распространять тайм-аут клиента в качестве параметра запроса для вызова API. И я действительно вижу следующую разницу в вызовах PATCH node/status в этих двух прогонах (из журналов apiserver):
пробег-108:
I0207 22:01:06.450385 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-2rn2/status: (11.81392ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.227.96.23:47270]
I0207 22:01:03.857892 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-9659/status: (8.570809ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.196.85.108:43532]
I0207 22:01:03.857972 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc4w/status: (8.287643ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.229.110.22:50530]
пробег-109:
I0209 21:01:08.551289 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-89f2/status?timeout=10s: (71.351634ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.229.77.215:51070]
I0209 21:01:08.551310 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-3ms3/status?timeout=10s: (70.705466ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.227.84.87:49936]
I0209 21:01:08.551394 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc02/status?timeout=10s: (70.847605ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.196.125.143:53662]
Моя гипотеза заключается в том, что из-за того, что для вызовов PATCH добавлен тайм-аут в 10 секунд, эти вызовы теперь длятся дольше на стороне сервера (IIUC этот комментарий правильно). Это означает, что они теперь находятся в очереди на борт на более длительный срок. Это, в сочетании с тем фактом, что эти вызовы PATCH происходят в огромных количествах в таких больших кластерах, приводит к тому, что вызовы PUT pod/status не могут получить достаточную пропускную способность в бортовой очереди и, следовательно, возвращаются с 429s. В результате задержка обновления статуса пода на стороне кублета увеличилась. Эта история также хорошо согласуется с наблюдениями @ wojtek-t выше.
Я постараюсь собрать больше доказательств, чтобы проверить эту гипотезу.
shyamjvs
5 мар. 2018
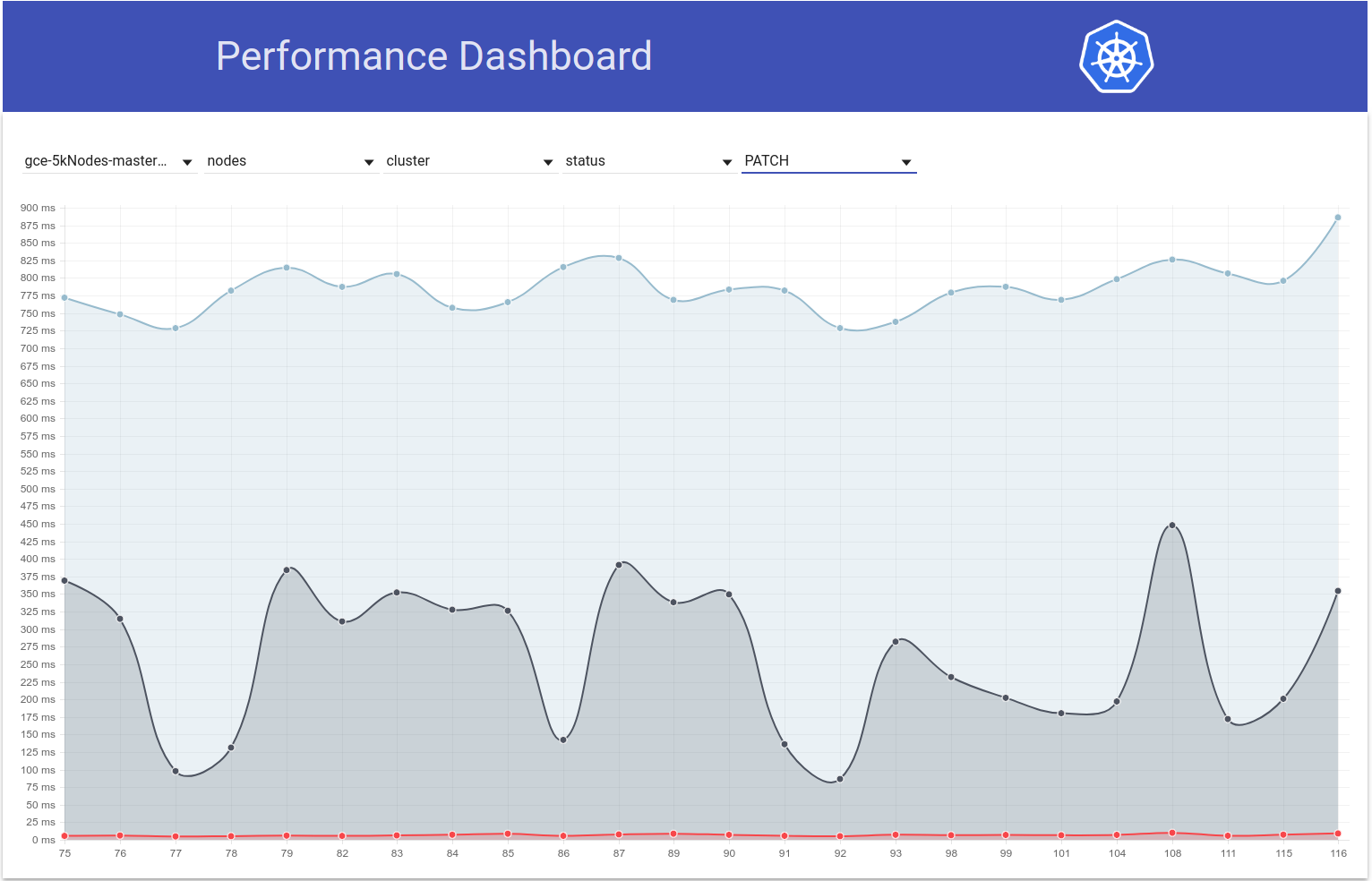
Итак, я проверил, как задержка PATCH node-status меняется во время тестовых прогонов, и действительно кажется, что примерно в это время наблюдается рост 99-го процентиля (см. Верхнюю строку). Однако не совсем ясно, что это произошло, ч / б прогоны 108 и 109 (хотя я считаю, что это так):
shyamjvs
5 мар. 2018
[РЕДАКТИРОВАТЬ: в моем предыдущем комментарии ошибочно упоминалось количество этих 429 (клиентом был npd, а не kubelet)]
Теперь у меня есть больше подтверждающих доказательств:
в run-108 у нас было ~ 479k PATCH node/status вызовов, которые получили 429:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"479181"
]
},
а в run-109 их ~ 757k:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"757318"
]
},
И ... Посмотрите на это:
в пробеге-108:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"28594"
]
},
и в пробеге-109:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"33224"
]
},
Я проверил номер для нескольких соседних прогонов:
- для пробега-104 это 21187
- для пробега-105 это 22003
- для пробега-108 это 28594
- этот PR слился -
- для пробега-109 это 33224
- для пробега-110 это 30977
- для пробега-111 это 25615
Хотя это кажется немного разным, в целом похоже, что нет. 429-х увеличилось примерно на 25%.
shyamjvs
5 мар. 2018
А для PATCH node-status полученного от kubelets, получившего 429, вот как выглядят числа:
- пробег-104 = 313348
- пробег-105 = 309136
- пробег-108 = 479181
- этот PR слился -
- пробег-109 = 757318
- пробег-110 = 752062
- пробег-111 = 296368
Этот показатель тоже варьируется, но в целом кажется, что он увеличивается.
shyamjvs
5 мар. 2018
99-й процент задержки вызовов PATCH node-status также, похоже, в целом увеличился (как я и предсказывал в https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370573938):
run-104 (798ms), run-105 (783ms), run-108 (826ms)
run-109 (878ms), run-110 (869ms), run-111 (806ms)
Кстати - по всем вышеперечисленным показателям, 108 кажется хуже, чем обычно, а 111 - лучше, чем обычно.
shyamjvs
5 мар. 2018
Попробую проверить это завтра, запустив вручную большой кластер 5k.
shyamjvs
5 мар. 2018
спасибо за сортировку @shyamjvs
krzyzacy
5 мар. 2018
Итак, я дважды провел тест плотности для кластера 5k против ~ HEAD, и оба раза тест неожиданно прошел с 99% задержкой запуска модуля ile как 4.510015461s и 4.623276837s . Тем не менее, «задержки при просмотре» действительно показали увеличение, которое @ wojtek-t указал в https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -369951288
В первом прогоне это было:
INFO: perc50: 1.123056294s, perc90: 1.932503347s, perc99: 3.061238209s
а второй прогон был:
INFO: perc50: 1.121218293s, perc90: 1.996638787s, perc99: 3.137325187s
Сейчас попробую проверить, что было раньше.
shyamjvs
6 мар. 2018
https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 - Я не уверен, что следую этому Да - мы добавили тайм-аут, но таймаут по умолчанию больше 10 секунд IIRC - так что это должно только помочь не усугублять ситуацию.
Я думаю, мы до сих пор не понимаем, почему мы наблюдаем больше 429-х (тот факт, что это как-то связано с 429-м, я уже упоминал в https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370036377)
wojtek-t
6 мар. 2018
Что касается ваших чисел - я не уверен, что регрессия была в диапазоне 109 - возможно, было две регрессии - одна где-то между 105 и 108, а другая - в 109.
wojtek-t
6 мар. 2018
Хм ... Я не отрицаю возможности, о которых вы упомянули (это всего лишь моя гипотеза).
Я сейчас делаю деление пополам (прямо сейчас против коммита 108) для проверки.
shyamjvs
6 мар. 2018
Мое ощущение, что регресс до 108 забега все сильнее и сильнее.
Например, задержки вызовов API уже увеличены в 108 запусках.
статус патч-узла:
90%: 198 мс (105) 447 мс (108) 444 мс (109)
поставить статус стручка:
99%: 83 мс (105) 657 мс (108) 728 мс (109)
wojtek-t
6 мар. 2018
Думаю, я пытаюсь сказать:
- число 429 является следствием, и мы не должны тратить на это слишком много времени
- основная причина - либо более медленные вызовы API, либо их большее количество
Мы явно видим более медленные вызовы API в 108. Вопрос в том, видим ли мы и большее их количество.
wojtek-t
6 мар. 2018
Итак, я думаю, почему запросы заметно медленнее - есть три основных возможности
запросов значительно больше (на первый взгляд это не так)
мы добавили что-то на пути обработки (например, дополнительная обработка) или сами объекты стали больше
что-то еще на главной машине (например, планировщик) потребляет больше процессора и, таким образом, лишает apiserver больше
wojtek-t
6 мар. 2018
Итак, я и @ wojtek-t обсуждали офлайн, и теперь мы оба согласны с тем, что вполне вероятно регресс до 108. Добавляем некоторые моменты:
запросов значительно больше (на первый взгляд это не так)
Мне тоже не кажется
мы добавили что-то на пути обработки (например, дополнительная обработка) или сами объекты стали больше
Мне кажется, что это более вероятно в kubelet, чем в apiserver (поскольку мы не видим никаких видимых изменений в задержках патча / вставки на kubemark-5000)
что-то еще на главной машине (например, планировщик) потребляет больше процессора и, таким образом, лишает apiserver больше
ИМО, это не тот случай, так как у нас есть некоторая нехватка процессора / памяти на нашем главном устройстве. Также perf-dash не предполагает значительного увеличения использования основных компонентов.
Тем не менее, я немного покопался, и «к счастью» кажется, что мы замечаем это увеличение задержек при просмотре даже для кластеров из 2k узлов:
INFO: perc50: 1.024377533s, perc90: 1.589770858s, perc99: 1.934099611s
INFO: perc50: 1.03503718s, perc90: 1.624451701s, perc99: 2.348645755s
Должно сделать пополам немного проще.
shyamjvs
6 мар. 2018
К сожалению, разница в задержках этих часов кажется одноразовой (в остальном это примерно то же самое). К счастью, у нас есть задержка PUT pod-status как надежный индикатор регрессии. Вчера я провел 2 раунда деления пополам и сузился до этой разницы (~ 80 коммитов). Я пролистал их и подозреваю:
- # 58990 - добавляет новое поле в pod-status (хотя я не уверен, будет ли оно заполнено в наших тестах, где прерывания IIUC не происходят - но нужно проверить)
- # 58645 - обновляет версию сервера etcd до 3.2.14
shyamjvs
7 мар. 2018
Я действительно сомневаюсь, что # 58990 здесь связан - NominatedNodeName - это строка, содержащая одно имя узла. Даже если он будет заполняться все время, изменение размера объекта должно быть незначительным.
wojtek-t
7 мар. 2018
@ wojtek-t - Как вы предлагали в автономном режиме, похоже, что мы используем другую версию (3.2.16) в kubemark (https://github.com/kubernetes/kubernetes/blob/master/test/kubemark/ start-kubemark.sh # L62), что является потенциальной причиной того, что здесь нет этой регрессии :)
cc @jpbetz
shyamjvs
7 мар. 2018
Сейчас мы везде используем 3.2.16.
wojtek-t
7 мар. 2018
Упс .. Извините за ретроспективу - я смотрел на неправильную комбинацию коммитов.
shyamjvs
7 мар. 2018
Кстати, это увеличение задержки PUT-модулей / статуса видно также в нагрузочном тесте в больших реальных кластерах.
wojtek-t
7 мар. 2018
Итак, я откопал немного больше и, похоже, мы начали наблюдать большие задержки примерно в это время для запросов на запись в целом (что заставляет меня подозревать, что etcd изменится еще больше):
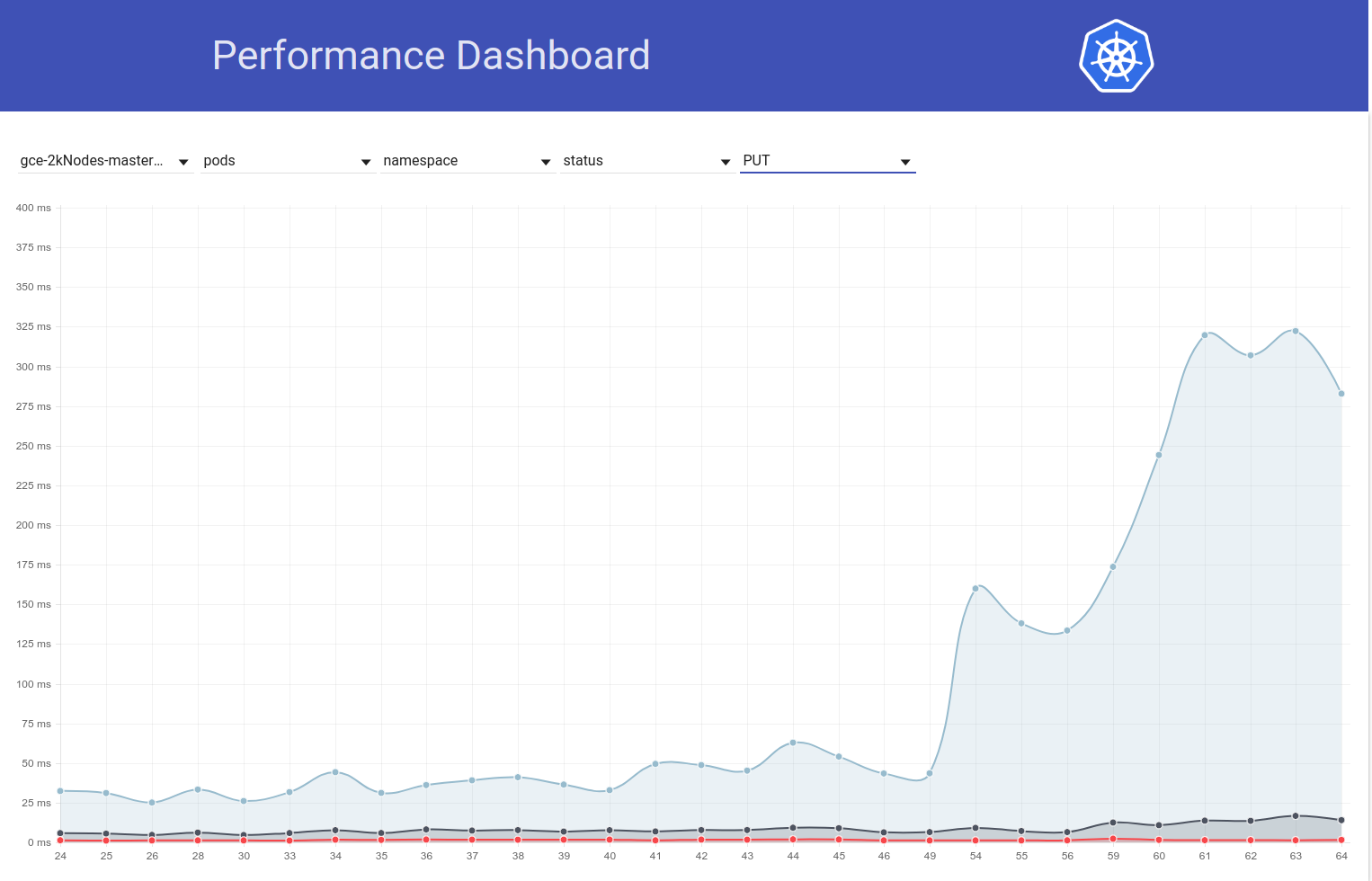
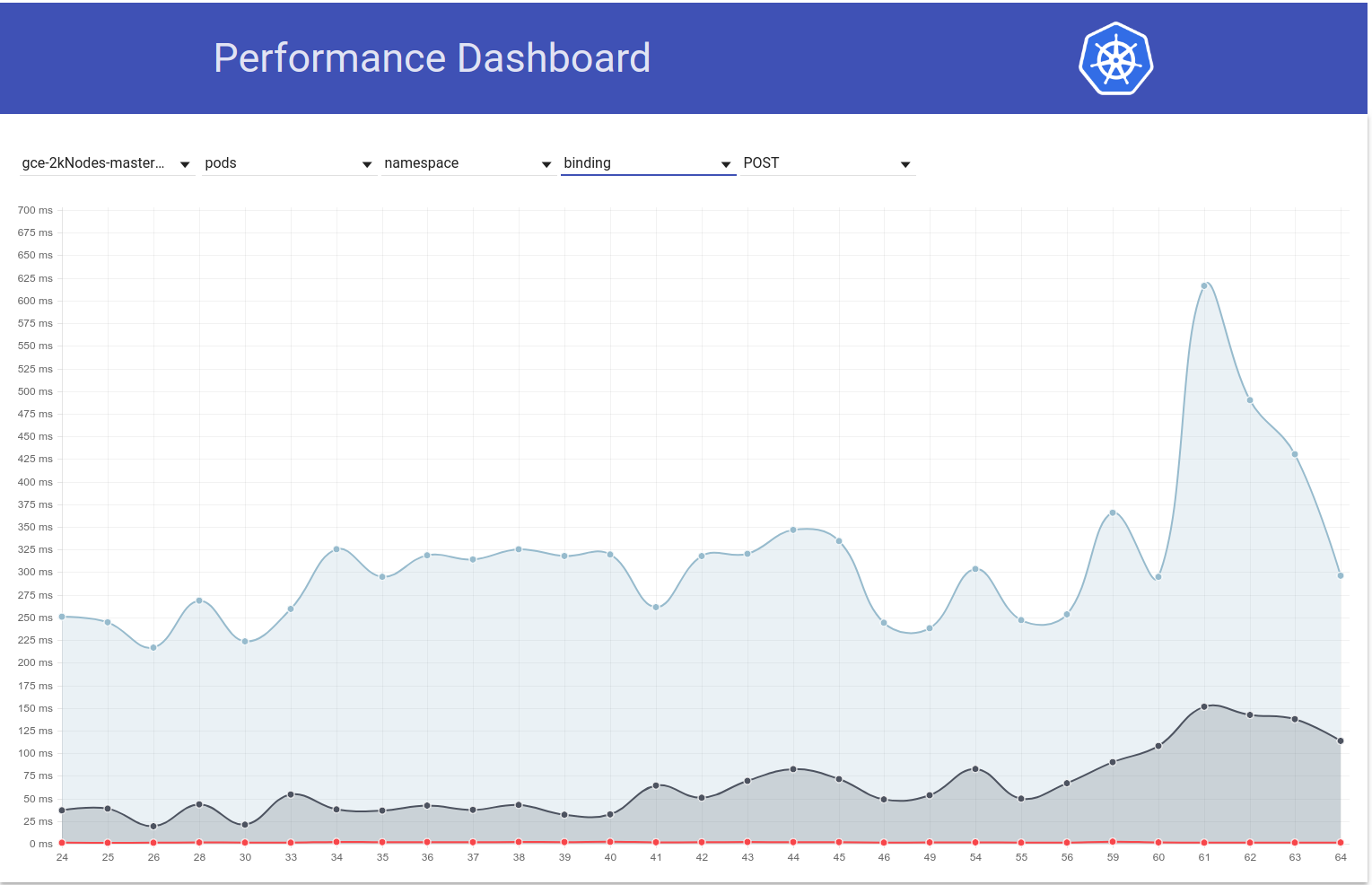

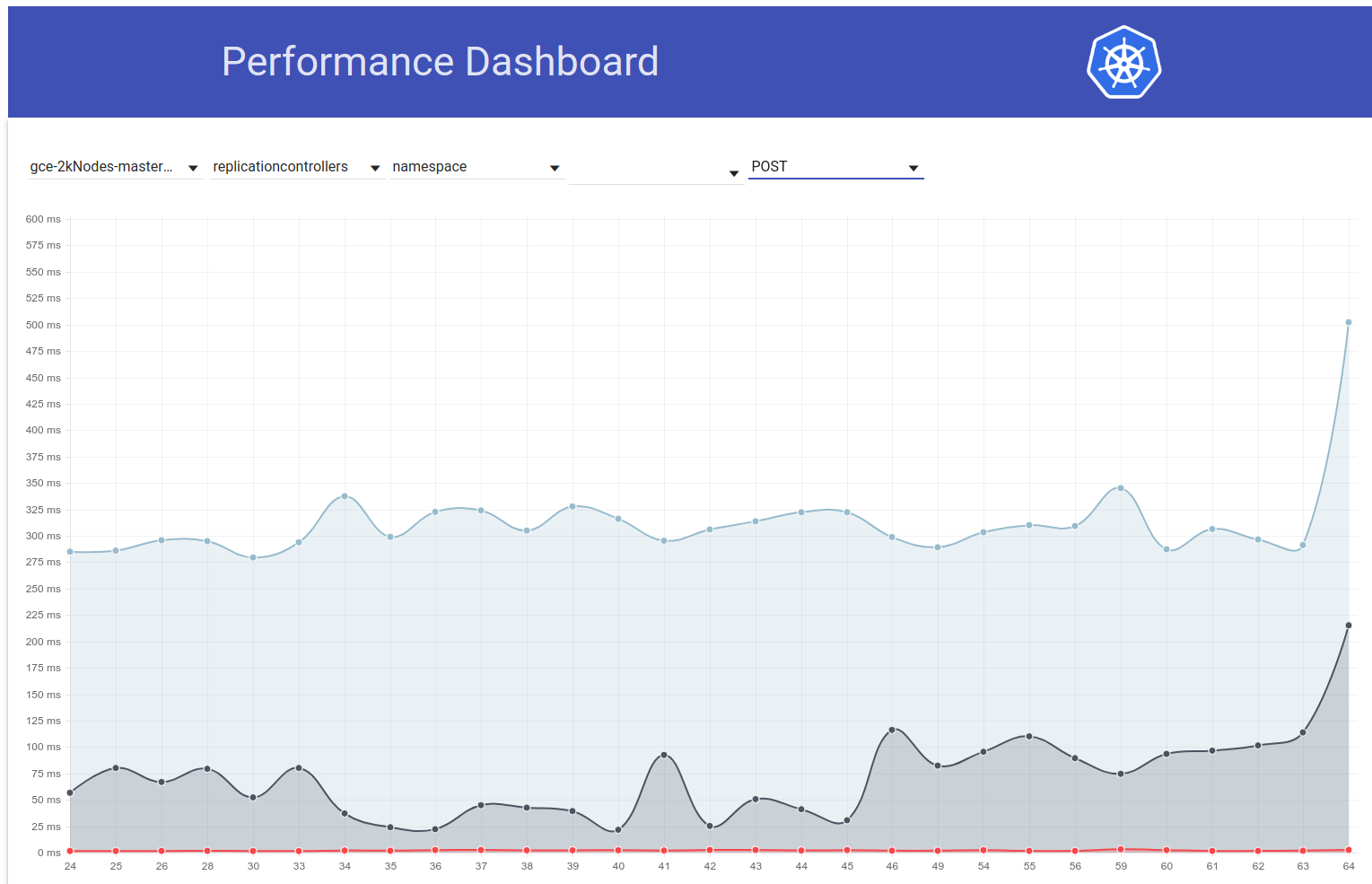
shyamjvs
7 мар. 2018
Собственно, я голосую за то, что по крайней мере часть проблемы здесь:
https://github.com/kubernetes/kubernetes/pull/58990/commit/384a86caa92bdb7cf9ac96b10a6ef333d2d60519#diff -c73f80ad83608f18657d22a06950d929R240
Я был бы удивлен, если бы это была вся проблема, но это может способствовать ей.
Отправлю PR, который изменит это за секунду.
wojtek-t
7 мар. 2018
К вашему сведению. Когда я столкнулся с фиксацией, которая была до изменения etcd 3.2.14, но после изменения API-интерфейса pod-status, задержка put-состояния узла казалась полностью нормальной (т.е. 99% ile = 39 мс).
shyamjvs
7 мар. 2018
Итак, я подтвердил, что это действительно вызвано скачком etcd до 3.2.14. Вот как выглядит задержка размещения пода:
против этого пиара :
{
"data": {
"Perc50": 1.479,
"Perc90": 10.959,
"Perc99": 163.095
},
"unit": "ms",
"labels": {
"Count": "344494",
"Resource": "pods",
"Scope": "namespace",
"Subresource": "status",
"Verb": "PUT"
}
},
против ~ HEAD (от 5 марта) с этим PR отменен (тест все еще продолжается, но скоро закончится):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.5"} 1669
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.9"} 9597
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.99"} 63392
63 мс кажется очень похожим на то, что было раньше .
Мы должны вернуть версию и попытаться понять:
- Почему мы наблюдаем такое увеличение в etcd 3.2.14?
- Почему мы не поймали это в кубемарке?
Копия @jpbetz @ kubernetes / sig-api-machinery-bugs
shyamjvs
7 мар. 2018
Одна из гипотез (почему мы не уловили это в kubemark - хотя это все еще предположение) заключается в том, что мы, возможно, изменили там сертификаты.
Когда я сравниваю журнал etcd из kubemark и реального кластера, только в последнем я вижу следующую строку:
2018-03-05 08:06:56.389648 I | embed: peerTLS: cert = /etc/srv/kubernetes/etcd-peer.crt, key = /etc/srv/kubernetes/etcd-peer.key, ca = , trusted-ca = /etc/srv/kubernetes/etcd-ca.crt, client-cert-auth = true
Глядя на сам PR, я не вижу никаких изменений вокруг этого, но я также не знаю, почему мы должны видеть эту линию только в реальных кластерах ...
@jpbetz за мысли
wojtek-t
7 мар. 2018
ACK. В ходе выполнения
Расчетное время прибытия: 03.09.2018
Риски: проблема, вызванная первопричиной (в основном)
shyamjvs
7 мар. 2018
Re peerTLS - похоже, так было и раньше (с 3.1.11), поэтому я думаю, что это отвлекающий маневр.
wojtek-t
7 мар. 2018
cc @gyuho @wenjiaswe
 jpbetz
7 мар. 2018
jpbetz
7 мар. 2018
63 мс кажется очень похожим на то, что
Откуда у нас эти числа? Действительно ли apiserver_request_latencies_summary измеряет задержку записи etcd? Также помогут метрики из etcd.
 gyuho
7 мар. 2018
gyuho
7 мар. 2018
встроить: peerTLS: сертификат ...
Это печатает, если настроен одноранговый TLS (то же самое в 3.1).
gyuho
7 мар. 2018
Откуда у нас эти числа? Действительно ли apiserver_request_latencies_summary измеряет задержки записи etcd? Также помогут метрики из etcd.
Это измеряет апикальную задержку, которая (по крайней мере, в случае вызовов записи) включает задержку etcd.
Мы по-прежнему не совсем понимаем, что происходит, но возврат к предыдущей версии etcd (3.1) исправляет регресс. Итак, ясно, что проблема где-то в etcd.
wojtek-t
7 мар. 2018
@shyamjvs
Какие версии Kubemark и Kubernetes вы используете? Мы тестировали Kubemark 1.10 против etcd 3.2 vs 3.3 (рабочие нагрузки с 500 узлами) и не наблюдали этого. Сколько узлов нужно, чтобы это воспроизвести?
gyuho
7 мар. 2018
Какие версии Kubemark и Kubernetes вы используете? Мы тестировали Kubemark 1.10 против etcd 3.2 vs 3.3 (рабочие нагрузки с 500 узлами) и не наблюдали этого. Сколько узлов нужно, чтобы это воспроизвести?
Мы не можем воспроизвести его с помощью kubemark, даже с 5k-узловым - см. Внизу https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -371171837
Похоже, это проблема только в реальных кластерах.
Почему это так, это открытый вопрос.
wojtek-t
7 мар. 2018
Поскольку мы откатились на etcd 3.1. для кубернетов. Мы также выпустили etcd 3.1.12 с единственным критическим исправлением для kubernetes: "несинхронизированная" операция восстановления наблюдателя mvcc . Найдя и исправив основную причину снижения производительности, обнаруженную в этой проблеме, мы можем набросать план обновления сервера etcd, используемого kubernetes, до версии 3.2.
jpbetz
8 мар. 2018
похоже, что https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100 постоянно выходит из строя с сегодняшнего утра
krzyzacy
9 мар. 2018
Из сравнения , единственное изменение - https://github.com/kubernetes/kubernetes/pull/60421, которое по умолчанию включает квоты в наших тестах производительности. Мы видим следующую ошибку:
Container kube-controller-manager-e2e-big-master/kube-controller-manager is using 0.531144723/0.5 CPU
not to have occurred
@gmarek - Похоже, включение квот влияет на нашу масштабируемость :) Не могли бы вы разобраться в этом подробнее - может быть, что-то серьезно?
Позвольте мне подать еще одну проблему, чтобы держать ее в курсе.
shyamjvs
9 мар. 2018
@ wojtek-t @jpbetz @gyuho @timothysc Я нашел кое-что действительно интересное в изменении версии etcd, предполагающее значительный эффект перехода с etcd 3.1.11 на 3.2.16.
Посмотрите на следующий график использования памяти etcd в нашем 100-узловом кластере (он увеличился примерно в 2 раза), когда задание было перемещено с k8s версии 1.9 на 1.10:
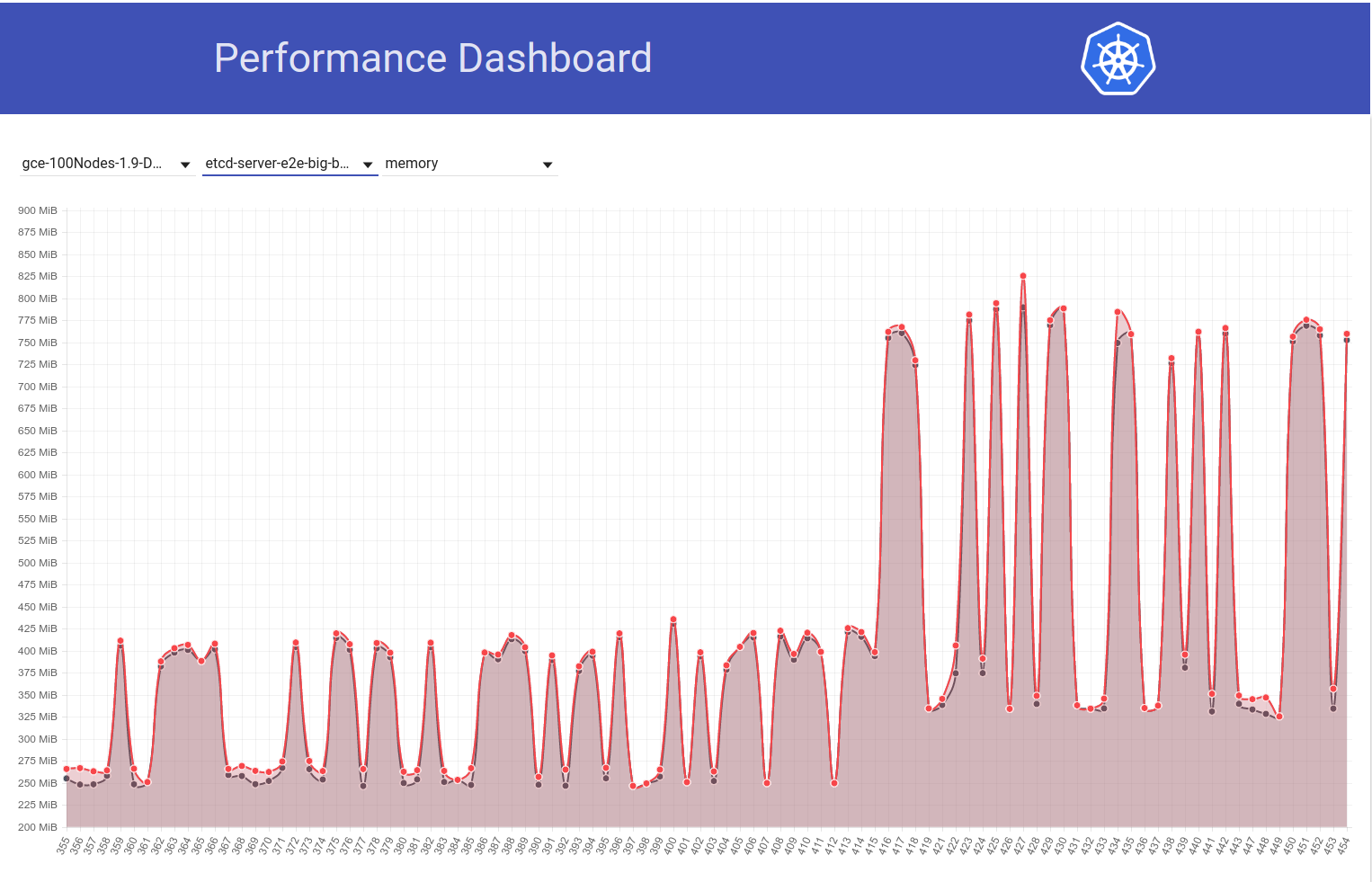
А теперь посмотрим, как наше 100-узловое задание (работающее с HEAD) видит падение использования памяти до половины сразу после того, как я вернулся с etcd 3.2.16 -> 3.1.11:
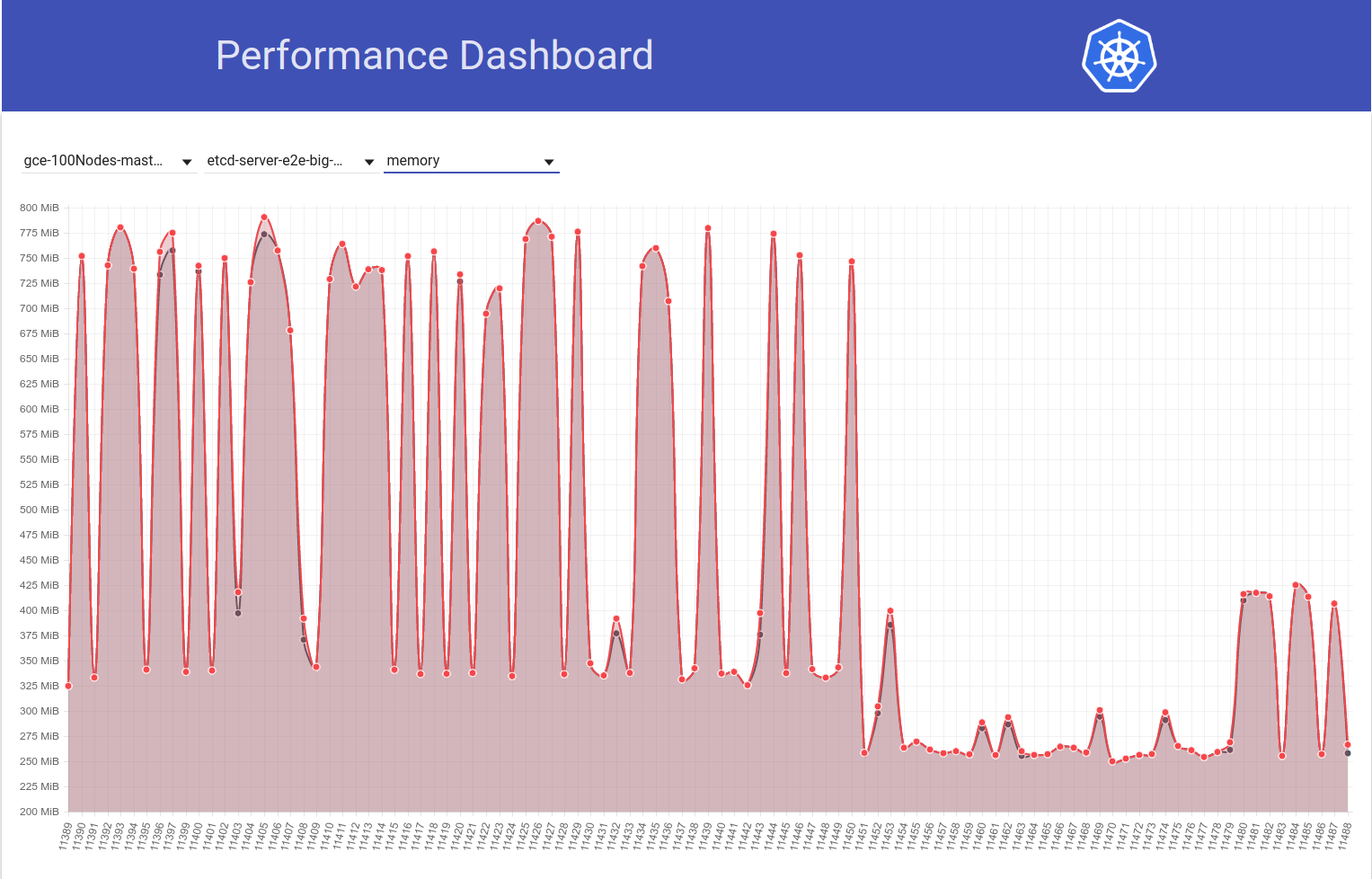
Таким образом, версия сервера etcd 3.2 ЯСНО демонстрирует снижение производительности (при сохранении всех остальных переменных) :)
shyamjvs
10 мар. 2018
мой откат от etcd 3.2.16 -> 3.2.11:
Мы имели ввиду 3.1.11?
gyuho
10 мар. 2018
Правильно .. извините. Отредактировал свой комментарий.
shyamjvs
10 мар. 2018
@shyamjvs Как настроен etcd? Мы увеличили значение по умолчанию --snapshot-count с 10000 до 100000 в версии 3.2. Таким образом, если количество снимков отличается, тот с большим количеством снимков хранит записи Raft дольше, что требует большего количества резидентной памяти, прежде чем отбрасывать старые журналы.
gyuho
10 мар. 2018
Ааа! Это действительно кажется подозрительным изменением. Wrt flags, я не думаю, что что-то изменится со стороны k8s. Потому что, как вы можете видеть на моем втором графике выше, diff b / w запускает 11450, а 11451 - это в основном мое изменение возврата etcd (которое, похоже, не затрагивает никаких флагов).
Мы увеличили значение по умолчанию --snapshot-count с 10000 до 100000.
Не могли бы вы подтвердить, является ли это основной причиной увеличения использования памяти? Если да, мы можем захотеть:
- исправить etcd обратно с исходным значением, или
- установите его на 10000 в k8s
прежде чем вернуться на 3.2
shyamjvs
10 мар. 2018
Ааа! Это действительно кажется подозрительным изменением.
Да, это изменение должно было быть выделено со стороны etcd (улучшит наши журналы изменений и руководства по обновлению).
Не могли бы вы подтвердить, является ли это основной причиной увеличения использования памяти?
Я не уверен, что это основная причина. Меньшее количество снимков определенно поможет уменьшить чрезмерное использование памяти. Если обе версии etcd используют одинаковое количество снимков, но одна etcd по-прежнему показывает гораздо большее использование памяти, должно быть что-то еще.
gyuho
10 мар. 2018
Обновление: я подтвердил, что увеличение использования памяти etcd действительно вызвано более высоким значением по умолчанию --snapshot-count. Подробнее здесь - https://github.com/kubernetes/kubernetes/pull/61037#issuecomment -372457843
Если мы не хотим увеличивать использование памяти, нам следует подумать о том, чтобы установить его на 10,000, когда мы переходим к etcd 3.2.16.
Копия @gyuho @ xiang90 @jpbetz
shyamjvs
12 мар. 2018
Обновление: с исправлением etcd задержка запуска модуля на 99% все еще кажется близкой к нарушению SLO 5s. Есть по крайней мере еще одна регрессия, и я собрал доказательства того, что она, скорее всего, связана с черно-белыми прогонами 111 и 112 нашего задания производительности с 5 тыс. Узлов (см. Ч / б этих прогонов на графике, который я вставил в https: / /github.com/kubernetes/kubernetes/issues/60589#issuecomment-370568929). В настоящее время я рассекает диф (который имеет около 50 фиксаций) и тест занимает ~ 4-5 часов на итерацию.
Доказательства, о которых я говорил выше, следующие:
Задержки просмотра на 111 были:
Feb 14 21:36:05.531: INFO: perc50: 1.070980786s, perc90: 1.743347483s, perc99: 2.629721166s
И общие задержки при запуске пода на уровне 111 были:
Feb 14 21:36:05.671: INFO: perc50: 2.416307575s, perc90: 3.24553118s, perc99: 4.092430858s
Тогда же на 112 были:
Feb 16 10:07:43.222: INFO: perc50: 1.131108849s, perc90: 2.18487651s, perc99: 3.570548412s
и
Feb 16 10:07:43.353: INFO: perc50: 2.56160248s, perc90: 3.754024568s, perc99: 4.967573867s
Между тем, если кто-то готов к игре со ставками - вы можете взглянуть на разницу фиксации, о которой я упоминал выше, и угадать неисправную :)
shyamjvs
12 мар. 2018
ACK. В ходе выполнения
ETA: 13/03/2018
Риски: может подтолкнуть дату выпуска, если до этого не было отлажено
shyamjvs
12 мар. 2018
@shyamjvs toooooooo многие делают ставки :)
 dims
13 мар. 2018
dims
13 мар. 2018
@dims Думаю, это
Обновление: я выполнил несколько итераций деления пополам, и вот как соответствующие метрики выглядят по коммитам (в хронологическом порядке). Обратите внимание, что для тех, которые я запускал вручную, я запускал их с возвратом более ранней регрессии (т.е. 3.2. -> 3.1.11).
| Зафиксировать | 99% задержки просмотра | 99% задержки при запуске пода | Хорошо плохо? |
| ------------- | ------------- | ----- | ------- |
| a042ecde36 (из ран-111) | 2.629721166s | 4.092430858s | Хорошо (повторное подтверждение вручную) |
| 5f7b530d87 (руководство) | 3.150616856s | 4.683392706s | Плохо (вероятно) |
| a8060ab0a1 (руководство) | 3.11319985s | 4.710277511s | Плохо (вероятно) |
| 430c1a68c8 (из ран-112) | 3.570548412s | 4.967573867s | Плохо |
| 430c1a68c8 (руководство) | 3.63505091s | 4.96697776s | Плохо |
Из вышесказанного кажется, что здесь может быть 2 регресса (поскольку это не прямой скачок с 2,6 с -> 3,6 с) - одно ч / б «a042ecde36 - 5f7b530d87» и другое ч / б «a8060ab0a1 - 430c1a68c8». Вздох!
shyamjvs
13 мар. 2018
выражая как диапазоны для получения ссылок сравнения:
a042ecde36 ... 5f7b530
a8060ab0a1 ... 430c1a6
 liggitt
13 мар. 2018
liggitt
13 мар. 2018
Только что получил результаты для ручного запуска против a042ecde36, и это только усложняет жизнь:
3.269330734s (watch), 4.939237532s (pod-startup)
поскольку это, вероятно, означает, что это может быть ненадежный регресс.
shyamjvs
13 мар. 2018
В настоящее время я провожу тест с a042ecde36 еще раз, чтобы проверить возможность того, что регрессия произошла еще до нее.
shyamjvs
13 мар. 2018
Итак, вот результат повторной работы с a042ecd:
2.645592996s (watch), 5.026010032s (pod-startup)
Это, вероятно, означает, что регрессия вошла еще до запуска 111 (хорошая новость, что теперь у нас правильный конец деления пополам).
Теперь я попытаюсь продолжить поиск по левому краю. Run-108 (commit 11104d75f) является потенциальным кандидатом, который дал следующие результаты, когда я ранее запускал его (с etcd 3.1.11):
2.593628224s (watch), 4.321942836s (pod-startup)
Мой повторный запуск против фиксации 11104d7, похоже, говорит, что он хороший:
2.663456162s (watch), 4.288927203s (pod-startup)
Я сделаю удар по делению пополам в диапазоне 11104d7 ... a042ecd
shyamjvs
13 мар. 2018
Обновление: мне нужно было трижды протестировать фиксацию 097efb71a315, чтобы обрести уверенность. Он показывает некоторые отклонения, но похоже на хороший коммит:
2.578970061s (watch), 4.129003596s (pod-startup)
2.315561531s (watch), 4.70792639s (pod-startup)
2.303510957s (watch), 3.88150234s (pod-startup)
Я продолжу делить пополам дальше.
Тем не менее, всего пару дней назад, похоже, произошел еще один всплеск (~ 1 с) задержки запуска pod. А этот увеличивает с 99% почти до 6:
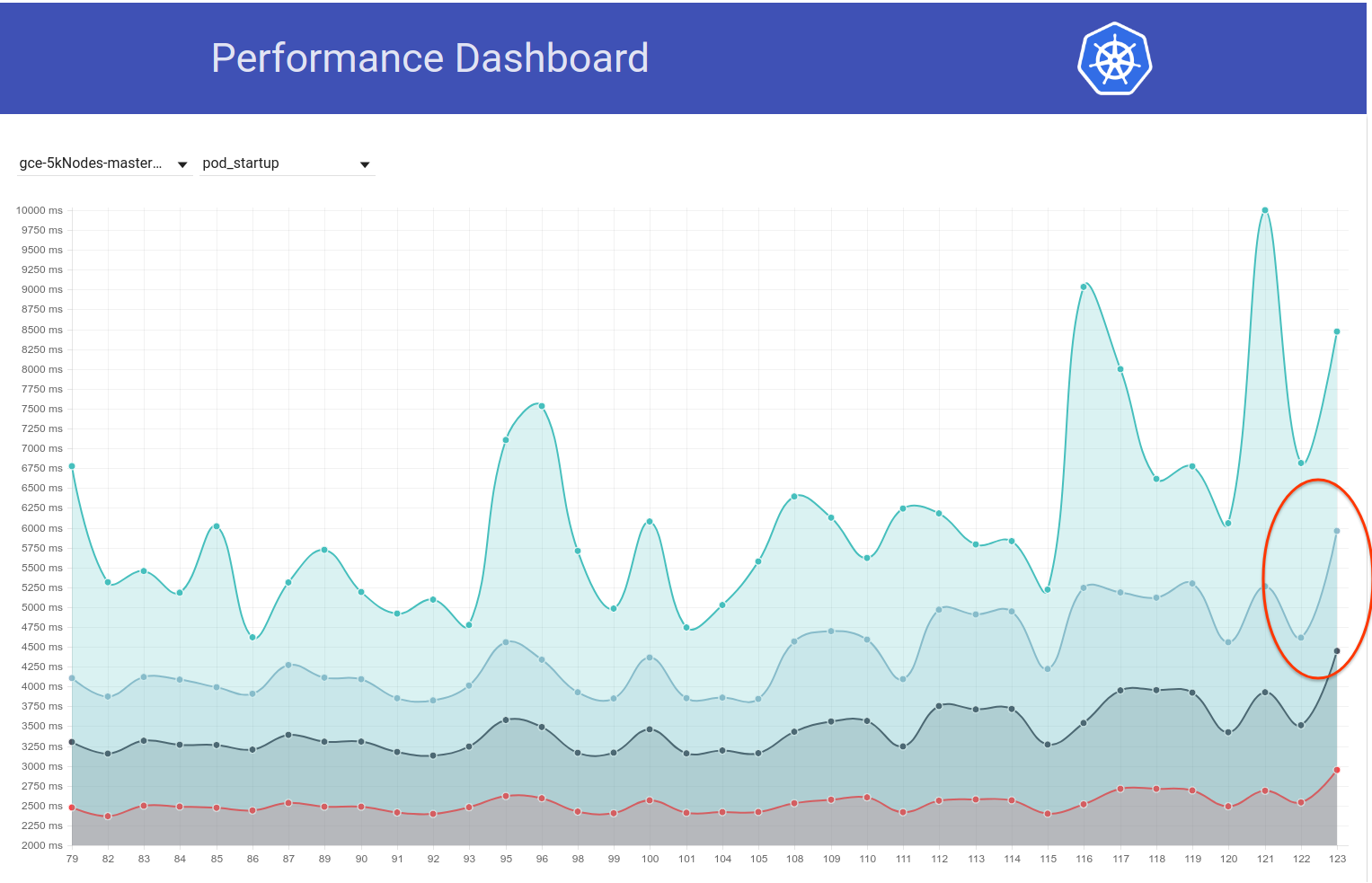
Моим основным подозреваемым из-за разницы коммитов является изменение etcd с 3.1.11 на 3.1.12 (https://github.com/kubernetes/kubernetes/pull/60998). Я бы дождался следующего прогона (который в настоящее время выполняется), чтобы подтвердить, что это не разовый случай, но нам действительно нужно это понять.
коп @jpbetz @gyuho
shyamjvs
14 мар. 2018
Поскольку на этой неделе я буду в отпуске с четверга по пятницу, я вставляю инструкции по запуску теста плотности для кластера из 5k узлов (чтобы кто-то, имеющий доступ к проекту, мог продолжить деление пополам):
# Start with a clean shell.
# Checkout to the right commit.
make quick-release
# Set the project:
gcloud config set project k8s-scale-testing
# Set some configs for creating/testing 5k-node cluster:
export CLOUDSDK_CORE_PRINT_UNHANDLED_TRACEBACKS=1
export KUBE_GCE_ZONE=us-east1-a
export NUM_NODES=5000
export NODE_SIZE=n1-standard-1
export NODE_DISK_SIZE=50GB
export MASTER_MIN_CPU_ARCHITECTURE=Intel\ Broadwell
export ENABLE_BIG_CLUSTER_SUBNETS=true
export LOGROTATE_MAX_SIZE=5G
export KUBE_ENABLE_CLUSTER_MONITORING=none
export ALLOWED_NOTREADY_NODES=50
export KUBE_GCE_ENABLE_IP_ALIASES=true
export TEST_CLUSTER_LOG_LEVEL=--v=1
export SCHEDULER_TEST_ARGS=--kube-api-qps=100
export CONTROLLER_MANAGER_TEST_ARGS=--kube-api-qps=100\ --kube-api-burst=100
export APISERVER_TEST_ARGS=--max-requests-inflight=3000\ --max-mutating-requests-inflight=1000
export TEST_CLUSTER_RESYNC_PERIOD=--min-resync-period=12h
export TEST_CLUSTER_DELETE_COLLECTION_WORKERS=--delete-collection-workers=16
export PREPULL_E2E_IMAGES=false
export ENABLE_APISERVER_ADVANCED_AUDIT=false
# Bring up the cluster (this brings down pre-existing one if present, so you don't have to explicitly '--down' the previous one) and run density test:
go run hack/e2e.go \
--up \
--test \
--test_args='--ginkgo.focus=\[sig\-scalability\]\sDensity\s\[Feature\:Performance\]\sshould\sallow\sstarting\s30\spods\sper\snode\susing\s\{\sReplicationController\}\swith\s0\ssecrets\,\s0\sconfigmaps\sand\s0\sdaemons$ --allowed-not-ready-nodes=30 --node-schedulable-timeout=30m --minStartupPods=8 --gather-resource-usage=master --gather-metrics-at-teardown=master' \
> somepath/build-log.txt 2>&1
# To re-run the test on same cluster (without re-creating) just omit '--up' in the above.
ВАЖНЫЕ ЗАМЕТКИ:
- Предполагаемый текущий диапазон фиксации - ff7918d ... a042ecde3 (давайте обновим его, поскольку мы делим пополам)
- Нам нужно использовать etcd-3.1.11 вместо 3.2.14 (чтобы избежать ранней регрессии). Измените версию в следующих файлах, чтобы добиться этого минимально:
- кластер / gce / манифесты / etcd.manifest
- кластер / изображения / etcd / Makefile
- взломать / lib / etcd.sh
shyamjvs
14 мар. 2018
Копия: @ wojtek-t
jdumars
14 мар. 2018
etcd v3.1.12 исправляет пропуски событий при восстановлении. И это единственное изменение, которое мы сделали по сравнению с v3.1.11. Включает ли тест производительности что-либо с перезапуском etcd или многоузловой системой, что может вызвать снимок от лидера?
gyuho
14 мар. 2018
Включает ли тест производительности что-либо с перезапуском etcd
Судя по журналам etcd , перезапуска не было.
многоузловой
В нашей настройке мы используем только одноузловой etcd (при условии, что вы об этом просили).
shyamjvs
14 мар. 2018
Понимаю. Тогда v3.1.11 и v3.1.12 не должны отличаться: 0
Посмотрим еще раз, если второй прогон также покажет более высокие задержки.
gyuho
14 мар. 2018
Копия: @jpbetz
jdumars
14 мар. 2018
Согласитесь с @gyuho, что мы должны попытаться получить более сильный сигнал по этому поводу, учитывая, что единственное изменение кода для etcd изолировано для перезапуска / восстановления кода.
Единственное другое изменение - это обновление etcd с go1.8.5 до go1.8.7, но я сомневаюсь, что при этом мы увидим значительное снижение производительности.
jpbetz
14 мар. 2018
Итак, продолжая деление пополам, ff7918d1f кажется хорошим:
2.246719086s (watch), 3.916350274s (pod-startup)
Я обновлю диапазон фиксации в https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -373051051 соответственно.
shyamjvs
14 мар. 2018
Далее, commit aa19a1726 кажется хорошим вариантом, хотя я бы посоветовал повторить попытку еще раз, чтобы подтвердить:
2.715156606s (watch), 4.382527095s (pod-startup)
На этом я собираюсь приостановить деление пополам и начать отпуск :)
Я отключил свой кластер, чтобы освободить место для следующего запуска.
shyamjvs
15 мар. 2018
Спасибо, Шьям. Я пытаюсь повторить попытку aa19a172693a4ad60d5a08e9b93557267d259c37.
 wasylkowski-a
15 мар. 2018
wasylkowski-a
15 мар. 2018
Для фиксации aa19a172693a4ad60d5a08e9b93557267d259c37 я получил следующие результаты:
2.47655243s (watch), 4.174016696s (pod-startup)
Так что это выглядит хорошо. Продолжаем деление пополам.
Предполагаемый текущий диапазон фиксации: aa19a172693a4ad60d5a08e9b93557267d259c37 ... a042ecde362000e51f1e7bdbbda5bf9d81116f84
wasylkowski-a
15 мар. 2018
@ wasylkowski-a, не могли бы вы присутствовать на нашем выпускном собрании в 17:00 UTC / 13:00 по восточному времени / 10:00 по тихоокеанскому времени? Встреча Zoom: https://zoom.us/j/2018742972
jdumars
15 мар. 2018
Я буду присутствовать.
wasylkowski-a
15 мар. 2018
Коммит cca7ccbff161255292f72c2d18459cdface62122 выглядит нечетко со следующими результатами:
2.984185673s (watch), 4.568914929s (pod-startup)
Я повторю это еще раз, чтобы убедиться, что я не ввожу неправильную половину деления пополам.
wasylkowski-a
15 мар. 2018
Хорошо, теперь я вполне уверен, что cca7ccbff161255292f72c2d18459cdface62122 - это плохо:
3.285168535s (watch), 4.783986141s (pod-startup)
Обрезка диапазона до aa19a172693a4ad60d5a08e9b93557267d259c37 ... cca7ccbff161255292f72c2d18459cdface62122 и проба 92e4d3da0076f923a45d54d69c84e91ac6a61a55.
wasylkowski-a
16 мар. 2018
Commit 92e4d3da0076f923a45d54d69c84e91ac6a61a55 выглядит хорошо:
2.522438984s (watch), 4.21739985s (pod-startup)
Новый диапазон подозрительной фиксации: 92e4d3da0076f923a45d54d69c84e91ac6a61a55 ... cca7ccbff161255292f72c2d18459cdface62122, пробуем 603ebe466d335a37392315d491782ed18d1bae11
wasylkowski-a
16 мар. 2018
@wasylkowski, обратите внимание, что один из https://github.com/kubernetes/kubernetes/commit/4c289014a05669c376994868d8d91f7565a204b5, был отменен в https://github.com/kubernetes/kubernetesf3c5358493b3c8b3c8c8c08c8c8c8c8c8c8c8
dims
16 мар. 2018
Повторяя комментарий
Можем ли мы назначить приоритет повторному тестированию один раз против главы ветки 1.10, а не продолжать деление пополам?
 tpepper
16 мар. 2018
tpepper
16 мар. 2018
@wasylkowski / @ wasylkowski-a ^^^^
tpepper
16 мар. 2018
@ wojtek-t PTAL как можно скорее
jdumars
16 мар. 2018
Спасибо @dims и @tpepper. Позвольте мне попробовать против 1.10 ветки head и посмотреть, что произойдет.
wasylkowski-a
16 мар. 2018
спасибо @wasylkowski в худшем случае мы вернемся к тому, что мы
dims
16 мар. 2018
1.10 голова имеет регресс:
3.522924087s (watch), 4.946431238s (pod-startup)
Это на etcd 3.1.12, а не на etcd 3.1.11, но, если я правильно понимаю, это не должно иметь большого значения.
Также неплохо выглядит 603ebe466d335a37392315d491782ed18d1bae11:
2.744654024s (watch), 4.284582476s (pod-startup)
2.76287483s (watch), 4.326409841s (pod-startup)
2.560703844s (watch), 4.213785531s (pod-startup)
Это оставляет нам диапазон 603ebe466d335a37392315d491782ed18d1bae11 ... cca7ccbff161255292f72c2d18459cdface62122, и там всего 3 коммита. Дай мне посмотреть, что я узнаю.
Также возможно, что действительно виноват 4c289014a05669c376994868d8d91f7565a204b5, но тогда это означает, что у нас есть еще одна регрессия, которая проявляется на голове.
wasylkowski-a
16 мар. 2018
Хорошо, очевидно, что commit 6590ea6d5d50700d34255b1e037b2702ad26b7fc хорош:
2.553170576s (watch), 4.22516704s (pod-startup)
в то время как коммит 7b678dc4035c61a1991b5e1442edb13f40deae72 - это плохо:
3.498855918s (watch), 4.886599251s (pod-startup)
Плохая фиксация - это слияние отмененной фиксации, упомянутой
Позвольте мне попробовать перезапустить head на etcd 3.1.11 вместо 3.1.12 и посмотреть, что произойдет.
wasylkowski-a
17 мар. 2018
@ wasylkowski-а классические хорошие новости плохие новости :) Спасибо, что продолжаете.
@ wojtek-t есть другие предложения?
dims
17 мар. 2018
Голова на etcd 3.1.11 тоже плохо; Моя следующая попытка будет состоять в том, чтобы попробовать сразу после отката (так, при фиксации cdecea545553eff09e280d389a3aef69e2f32bf1), но с etcd 3.1.11 вместо 3.2.14.
wasylkowski-a
17 мар. 2018
Звучит хорошо Анджей
- тускнеет
17 марта 2018 г. в 13:19 Анджей Василковский [email protected] написал:
Голова на etcd 3.1.11 тоже плохо; Моя следующая попытка будет состоять в том, чтобы попробовать сразу после отката (так, при фиксации cdecea5), но с etcd 3.1.11 вместо 3.2.14.
-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub или отключите обсуждение.
dims
17 мар. 2018
Коммит cdecea545553eff09e280d389a3aef69e2f32bf1 - это хорошо, поэтому у нас есть более поздняя регрессия:
2.66454307s (watch), 4.308091589s (pod-startup)
Commit 2a373ace6eda6a9cf050ce70a6cf99183c5e5b37 явно плохой:
3.656979569s (watch), 6.746987916s (pod-startup)
@ wasylkowski-a Итак, мы в основном смотрим на коммиты в диапазоне https://github.com/kubernetes/kubernetes/compare/cdecea5...2a373ac, чтобы понять, что же не так? (разделите эти два)?
dims
17 мар. 2018
Да. К сожалению, это огромный диапазон. Я сейчас исследую aded0d922592fdff0137c70443caf2a9502c7580.
wasylkowski-a
17 мар. 2018
Спасибо @wasylkowski, какой сейчас диапазон? (так что я могу пойти посмотреть PR).
dims
18 мар. 2018
Коммит aded0d922592fdff0137c70443caf2a9502c7580 - это плохо:
3.626257043s (watch), 5.00754503s (pod-startup)
Коммит f8298702ffe644a4f021e23a616ad6a8790a5537 тоже плохо:
3.747051371s (watch), 6.126914967s (pod-startup)
Итак, совершаем 20a6749c3f86c7cb9e98442046532380fb5f6e36:
3.641172882s (watch), 5.100922237s (pod-startup)
А также 0e81651e77e0be7e75179e5986ef2c76601f4bd6:
3.687028394s (watch), 5.208157763s (pod-startup)
Текущий диапазон: cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6. Мы (я, @ wojtek-t, @shyamjvs) начинаем подозревать, что передача cdecea545553eff09e280d389a3aef69e2f32bf1 на самом деле нестабильная, поэтому нам нужен другой левый конец.
wasylkowski-a
19 мар. 2018
/ me делает ставку на https://github.com/kubernetes/kubernetes/commit/b259543985b10875f4a010ed0285ac43e335c8e0 как на виновника
cc @ wasylkowski-a
dims
19 мар. 2018
0e81651e77e0be7e75179e5986ef2c76601f4bd6 это, оказывается, плохо, так b259543985b10875f4a010ed0285ac43e335c8e0 (объединившиеся 244549f02afabc5be23fc56e86a60e5b36838828, после 0e81651e77e0be7e75179e5986ef2c76601f4bd6) не может быть самым ранним виновником (хотя не исключено, что он ввел еще одну регрессии мы будем наблюдать, как только мы вытряхнуть эту)
wasylkowski-a
19 мар. 2018
Per @ wojtek-t и @shyamjvs Я повторно запускаю cdecea545553eff09e280d389a3aef69e2f32bf1, потому что мы подозреваем, что это могло быть "ненормальное"
wasylkowski-a
19 мар. 2018
Я предполагаю, что cdecea545553eff09e280d389a3aef69e2f32bf1 действительно хорош, основываясь на следующих результатах, которые я наблюдал:
2.66454307s (watch), 4.308091589s (pod-startup)
2.695629257s (watch), 4.194027608s (pod-startup)
2.660956347s (watch), 3m36.62259323s (pod-startup) <-- looks like an outlier
2.865445137s (watch), 4.594671099s (pod-startup)
2.412093606s (watch), 4.070130529s (pod-startup)
Предполагаемый диапазон в настоящее время: cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6
В настоящее время тестируется 99c87cf679e9cbd9647786bf7e81f0a2d771084f
wasylkowski-a
20 мар. 2018
Спасибо @wasylkowski за продолжение этой работы.
jdumars
20 мар. 2018
на сегодняшнее обсуждение: у fluentd-scaler все еще есть проблемы: https://github.com/kubernetes/kubernetes/issues/61190 , которые не были исправлены PR. Возможно ли, что эта регрессия вызвана fluentd?
 jberkus
20 мар. 2018
jberkus
20 мар. 2018
один из PR, касающихся fluentd https://github.com/kubernetes/kubernetes/commit/a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2, находится в последнем диапазоне
dims
20 мар. 2018
на сегодняшнее обсуждение: у fluentd-scaler все еще есть проблемы: # 61190, которые не были исправлены PR. Возможно ли, что эта регрессия вызвана fluentd?
ТБХ, я был бы очень удивлен, если бы это произошло из-за проблем с беглым языком. Но я не могу точно исключить эту гипотезу.
По моему личному мнению, в Kubelet были бы некоторые изменения, но я также посмотрел на PR в этом диапазоне, и ничего не показалось действительно подозрительным ...
Надеюсь, что завтра диапазон будет в 4 раза меньше, что будет означать всего пару PR.
wojtek-t
20 мар. 2018
Хорошо, итак, 99c87cf679e9cbd9647786bf7e81f0a2d771084f выглядит хорошо, но мне потребовалось три прогона, чтобы убедиться, что это не хлопья:
2.901624657s (watch), 4.418169754s (pod-startup)
2.938653965s (watch), 4.423465198s (pod-startup)
3.047455619s (watch), 4.455485098s (pod-startup)
Далее, a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 - это плохо:
3.769747695s (watch), 5.338517616s (pod-startup)
Текущий диапазон: 99c87cf679e9cbd9647786bf7e81f0a2d771084f ... a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2. Анализируя c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd.
wasylkowski-a
20 мар. 2018
Заглянул в упомянутый выше диапазон - там всего 9 PR.
https://github.com/kubernetes/kubernetes/pull/59944 - 100% НЕ - изменяет только файл владельцев
https://github.com/kubernetes/kubernetes/pull/59953 - потенциально
https://github.com/kubernetes/kubernetes/pull/59809 - касается только кода kubectl, поэтому в данном случае это не имеет значения
https://github.com/kubernetes/kubernetes/pull/59955 - 100% НЕ - только касание несвязанных тестов e2e
https://github.com/kubernetes/kubernetes/pull/59808 - потенциально (меняет настройку кластера)
https://github.com/kubernetes/kubernetes/pull/59913 - 100% НЕ - только касание несвязанных тестов e2e
https://github.com/kubernetes/kubernetes/pull/59917 - он меняет тест, но не включает изменения, поэтому маловероятно
https://github.com/kubernetes/kubernetes/pull/59668 - 100% НЕ - только касание кода AWS
https://github.com/kubernetes/kubernetes/pull/59909 - 100% НЕ - только касание файлов владельцев
Итак, я думаю, у нас здесь два кандидата: https://github.com/kubernetes/kubernetes/pull/59953 и https://github.com/kubernetes/kubernetes/pull/59808.
Я попытаюсь изучить их глубже, чтобы понять их.
wojtek-t
21 мар. 2018
c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd выглядит довольно плохо:
3.428891786s (watch), 4.909251611s (pod-startup)
Учитывая, что это слияние # 59953, одного из подозреваемых Войтека, теперь я буду запускать один коммит перед этим, поэтому f60083549a43f152b3142e01756e25611d911770.
Однако эта фиксация представляет собой изменение OWNERS_ALIASES, и в этом диапазоне до него ничего не осталось, поэтому проблема должна быть c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd. В любом случае, я проведу тест из соображений безопасности.
wasylkowski-a
21 мар. 2018
Обсуждается в автономном режиме - вместо этого мы будем запускать тесты с локальным откатом этой фиксации.
wojtek-t
21 мар. 2018
Вот Это Да! один лайнер вызывает столько проблем. спасибо @wasylkowski @ wojtek-t
dims
21 мар. 2018
@dims Однострочники действительно могут вызвать разрушение масштабируемости. Еще один пример из прошлого - https://github.com/kubernetes/kubernetes/pull/53720#issue-145949976
В общем, вы можете захотеть просмотреть https://github.com/kubernetes/community/blob/master/sig-scalability/blogs/scalability-regressions-case-studies.md для хорошего чтения :)
shyamjvs
21 мар. 2018
Обновить re. тест в голове: первый запуск с локальным откатом фиксации пройден. Однако это может быть хлопья, поэтому я запускаю его повторно.
wasylkowski-a
21 мар. 2018
Глядя на фиксацию на https: //github.com/kubernetes/kubernetes/pull/59953 ... разве это не исправляет ошибку? Похоже, он исправлял ошибку, при которой статус "запланирован" был помещен не в тот объект. Основываясь на упомянутой проблеме в этом PR, похоже, что кубелет мог пропустить сообщение о том, что под был запланирован без этого исправления?
liggitt
21 мар. 2018
@ Random-Liu Кто может лучше объяснить нам, каков эффект этого изменения :)
shyamjvs
21 мар. 2018
Глядя на коммит в # 59953 ... разве это не исправляет ошибку? Похоже, он исправлял ошибку, при которой статус "запланирован" был помещен не в тот объект. Мог ли kubelet сообщать, что модуль был запланирован слишком рано до этого исправления?
Да - я знаю, что это была ошибка. Я просто не совсем понимаю это.
Кажется, это решило проблему с отчетами о пакете как о «По расписанию». Но мы не видим проблемы даже до тех пор, пока kubelet не укажет время "StartedAt".
Проблема в том, что мы видим значительное увеличение времени, которое Kubelet сообщает как «StartedAt» и когда тестирует и отслеживает обновление статуса модуля.
Так что я думаю, что фрагмент «Запланированный» здесь отвлекает.
Мое предположение (но это все еще только предположение) заключается в том, что из-за этого изменения мы отправляем больше обновлений статуса Pod, что, в свою очередь, приводит к большему количеству 429 или или чего-то подобного. И, в конце концов, Kubelet требуется больше времени, чтобы сообщить о статусе модуля. Но нам все еще нужно подтвердить это.
wojtek-t
21 мар. 2018
После двух прогонов я почти уверен, что возврат # 59953 решит проблему:
3.052567319s (watch), 4.489142104s (pod-startup)
2.799364978s (watch), 4.385999497s (pod-startup)
мы рассылаем больше обновлений статуса Pod, что, в свою очередь, приводит к увеличению количества сообщений 429 или чего-то подобного. И, в конце концов, Kubelet требуется больше времени, чтобы сообщить о статусе модуля.
Это в значительной степени эффект, который я предполагал в https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 (хотя причина, которую я предположил, была неправильной) :)
Кроме того, мы, IIRC, похоже, увидели увеличение # 429 для коллов пут (см. Мой https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370582634), но я думаю, это было из более раннего диапазона вокруг etcd change).
shyamjvs
21 мар. 2018
После двух прогонов я почти уверен, что возврат # 59953 решит проблему:
Моя интуиция (https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370874602) о том, что проблема на стороне kubelet довольно рано в потоке, была правильной :)
shyamjvs
21 мар. 2018
/ sig узел
@ kubernetes / sig-node-bugs, команда релиза действительно могла бы использовать обзор коммита # 59953 по сравнению с откатом и проблемы с производительностью здесь
tpepper
21 мар. 2018
Глядя на коммит в # 59953 ... разве это не исправляет ошибку? Похоже, он исправлял ошибку, при которой статус "запланирован" был помещен не в тот объект. Основываясь на упомянутой проблеме в этом PR, похоже, что кубелет мог пропустить сообщение о том, что под был запланирован без этого исправления?
@liggitt Спасибо, что объяснили мне это. Да, этот PR исправляет ошибку. Раньше kubelet не всегда устанавливал PodScheduled . С # 59953 kubelet будет делать это правильно.
@shyamjvs Я не уверен, может ли он представить больше обновлений статуса модуля.
Если я правильно понимаю, условие PodScheduled будет установлено при первом обновлении статуса, и тогда оно всегда будет там и никогда не изменится. Я не понимаю, почему он генерирует больше обновлений статуса.
Если он действительно вводит дополнительные обновления статуса, это проблема, появившаяся 2 года назад https://github.com/kubernetes/kubernetes/pull/24459, но покрытая ошибкой, и # 59953 просто исправьте ошибку ...
@ wasylkowski-a Есть ли у вас журналы для 2-х тестовых прогонов в https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -374982422 и https://github.com/kubernetes/kubernetes/issues/60589# комментарий -374871490? В основном хороший и плохой. Будет очень полезен журнал kubelet.log.
 Random-Liu
21 мар. 2018
Random-Liu
21 мар. 2018
@yujuhong и я обнаружили, что # 59953 выявил проблему, из-за которой состояние PodScheduled статического модуля будет постоянно обновляться.
Kubelet генерирует новое условие PodScheduled для модуля, в котором его нет. Статический модуль не имеет его, и его статус никогда не обновляется (ожидаемое поведение). Таким образом, kubelet будет продолжать генерировать новое условие PodScheduled для статического модуля.
Проблема была представлена в # 24459, но покрыта ошибкой. # 59953 исправлена ошибка и выявлена исходная проблема.
Есть 2 варианта, как быстро это исправить:
- Вариант 1: не позволяйте kubelet добавлять условие
PodScheduled, kubelet должен просто сохранять условиеPodScheduledустановленное планировщиком.- Плюсы: просто.
- Минусы: статические модули и модули, которые обходят планировщик (напрямую назначают имя узла), не будут иметь условия
PodScheduled. На самом деле без # 59953, хотя kubelet в конечном итоге установит это условие для этих подов, но это может занять очень много времени из-за ошибки.
- Вариант 2: сгенерировать условие
PodScheduledдля статического модуля, когда kubelet изначально его видит.
Вариант 2 может внести меньше изменений, с которыми сталкивается пользователь.
Но мы хотим спросить, что PodScheduled означает для пакетов, которые не запланированы планировщиком? Действительно ли нам нужно это условие для этих стручков? / cc @ kubernetes / sig-autoscaling-bugs Потому что @yujuhong сказал мне, что теперь для автомасштабирования используется PodScheduled .
/ cc @ kubernetes / sig-node-bugs @ kubernetes / sig-scheduling-bugs
Random-Liu
21 мар. 2018
@ Random-Liu Каков эффект very long time for kubelet to eventually set this condition ? С какой проблемой конечный пользователь заметит / столкнется (за исключением нестабильности тестовой привязи)? (из Варианта №1)
dims
21 мар. 2018
@dims Пользователь долго не будет видеть условие PodScheduled .
Random-Liu
21 мар. 2018
У меня есть исправление № 61504, которое реализует вариант 2 в https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979.
Я могу изменить его на вариант 1, если люди думают, что это лучшее решение. :)
Random-Liu
21 мар. 2018
Вы лучше спросите людей, которые знают это наизнанку! (НЕ выпускающая команда 😄!)
пинг @dashpole @ dchen1107 @derekwaynecarr
dims
21 мар. 2018
@ Random-Liu IIRC единственный статический модуль, работающий на узлах в наших тестах, - это kube-proxy. Не могли бы вы сказать, как часто kubelet делает эти «непрерывные обновления»? (спрашивается, чтобы оценить дополнительные qps, вызванные ошибкой)
shyamjvs
21 мар. 2018
@ Random-Liu IIRC единственный статический модуль, работающий на узлах в наших тестах, - это kube-proxy. Не могли бы вы сказать, как часто kubelet делает эти «непрерывные обновления»? (спрашивается, чтобы оценить дополнительные qps, вызванные ошибкой)
@shyamjvs Да, сейчас kube-proxy единственный на узле.
Я думаю, это зависит от частоты синхронизации подов https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/kubeletconfig/v1beta1/defaults.go#L47 , что составляет 1 минуту. Таким образом, kubelet генерирует одно дополнительное обновление статуса модуля каждые 1 минуту.
Random-Liu
22 мар. 2018
Благодарю. Это означает, что 5000/60 = ~ 83 qps добавлено дополнительно из-за вызовов put pod-status. Кажется, это объясняет увеличение числа 429, отмеченное ранее в ошибке.
shyamjvs
22 мар. 2018
@ Random-Liu большое спасибо за то, что помогли нам разобраться.
jdumars
22 мар. 2018
@jdumars np ~ @yujuhong мне очень помог!
Random-Liu
22 мар. 2018
Но мы хотим спросить, что PodScheduled означает для модулей, которые не запланированы планировщиком? Действительно ли нам нужно это условие для этих стручков? / cc @ kubernetes / sig-autoscaling-bugs Потому что @yujuhong сказал мне, что PodScheduled теперь используется для автомасштабирования.
Я все еще думаю, что разрешение kubelet устанавливать условие PodScheduled несколько странно (как я отмечал в исходном PR). Даже если kubelet не устанавливает это условие, это не повлияет на автомасштабирование кластера, поскольку автомасштабирование игнорирует поды без определенного условия. В любом случае исправление, которое мы в конечном итоге придумали, имеет очень незначительные последствия и будет поддерживать текущее поведение (то есть всегда устанавливать условие PodScheduled), поэтому мы будем придерживаться этого.
 yujuhong
22 мар. 2018
yujuhong
22 мар. 2018
Кроме того, восстановлена действительно старая проблема для добавления тестов для постоянной частоты обновления модуля # 14391.
yujuhong
22 мар. 2018
В любом случае исправление, которое мы в конечном итоге придумали, имеет очень незначительные последствия и будет поддерживать текущее поведение (то есть всегда устанавливать условие PodScheduled), поэтому мы будем придерживаться этого.
@yujuhong - ты про этот: # 61504 (или я неправильно его понял)?
@wasylkowski @shyamjvs - не могли бы вы запустить тесты на 5000 узлов с этим PR, исправленным локально (до того, как мы его объединим), чтобы убедиться, что это действительно помогает?
wojtek-t
22 мар. 2018
Я провел тест против 1.10 HEAD + # 61504, и задержка при запуске пода кажется нормальной:
INFO: perc50: 2.594635536s, perc90: 3.483550118s, perc99: 4.327417676s
Повторно запустится еще раз для подтверждения.
shyamjvs
22 мар. 2018
@shyamjvs - большое спасибо!
wojtek-t
22 мар. 2018
Второй прогон тоже кажется неплохим:
INFO: perc50: 2.583489146s, perc90: 3.466873901s, perc99: 4.380595534s
Довольно уверенно, теперь исправление сделало свое дело. Давайте как можно скорее переведем его в 1.10.
shyamjvs
22 мар. 2018
Спасибо @shyamjvs
Когда мы говорили оффлайн - я думаю, что за последний месяц у нас был еще один регресс, но он не должен блокировать выпуск.
wojtek-t
22 мар. 2018
@yujuhong - ты про этот: # 61504 (или я неправильно его понял)?
Ага. Текущее исправление в этом PR отсутствует в вариантах, изначально предложенных в https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979
yujuhong
22 мар. 2018
повторно открывать до тех пор, пока у нас не будет хорошего результата теста производительности.
jberkus
25 мар. 2018
@yujuhong @krzyzacy @shyamjvs @ wojtek-t @ Random-Liu @ wasylkowski-a есть новости по этому поводу? На данный момент это все еще блокирует 1.10.
jdumars
26 мар. 2018
Таким образом, единственная часть этой ошибки, которая блокировала выпуск, - это задание производительности 5k-узлов. К сожалению, с сегодняшнего дня мы проиграли по другой причине (см. Https://github.com/kubernetes/kubernetes/issues/61190#issuecomment-376150569)
Тем не менее, мы вполне уверены, что исправление работает на основе моих ручных запусков (результаты вставлены в https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-375350217). Так что IMHO нам не нужно блокировать релиз на нем (следующий запуск будет в среду).
shyamjvs
26 мар. 2018
+1
@jdumars - я думаю, мы можем рассматривать это как
wojtek-t
26 мар. 2018
Извините, я отредактировал свой пост выше. Я имел в виду, что мы должны относиться к нему как к «неблокирующему».
wojtek-t
26 мар. 2018
Хорошо, большое спасибо. Этот вывод представляет собой огромное количество потраченных вами часов, и я не могу отблагодарить вас всех за проделанную вами работу. Пока мы абстрактно говорим о «сообществе» и «участниках», вы и другие, кто работал над этой проблемой, представляете ее в конкретных терминах. Вы являетесь сердцем и душой этого проекта, и я знаю, что говорю от имени всех участников, когда говорю, что для меня большая честь работать вместе с таким энтузиазмом, целеустремленностью и профессионализмом.
jdumars
26 мар. 2018
[MILESTONENOTIFIER] Контрольная проблема: актуальность для процесса
@krzyzacy @ msau42 @shyamjvs @ wojtek-t
Ярлыки выпуска
sig/api-machinerysig/autoscalingsig/nodesig/scalabilitysig/schedulingsig/storage: При необходимости проблема будет передана этим SIG.priority/critical-urgent: Никогда автоматически не переносить задачу из этапа выпуска; постоянно сообщать участникам и SIG по всем доступным каналам.kind/bug: исправляет ошибку, обнаруженную в текущем выпуске.Помогите
 k8s-github-robot
11 апр. 2018
k8s-github-robot
11 апр. 2018
Эта проблема была решена с помощью соответствующих исправлений в версии 1.10.
В версии 1.11 мы отслеживаем сбои по адресу -
/Закрыть
shyamjvs
25 мая 2018
Смежные вопросы
 broady
·
3Комментарии
broady
·
3Комментарии
 arun-gupta
·
3Комментарии
arun-gupta
·
3Комментарии
 sanjana-bhat
·
3Комментарии
sanjana-bhat
·
3Комментарии
 zetaab
·
3Комментарии
zetaab
·
3Комментарии
 tbchj
·
3Комментарии
tbchj
·
3Комментарии
Самый полезный комментарий
Я провел тест против 1.10 HEAD + # 61504, и задержка при запуске пода кажется нормальной:
Повторно запустится еще раз для подтверждения.