Kubernetes: [test flakes] suites d'évolutivité maître
Échec des suites de blocage des versions:
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100
- [x] https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
les trois suites s'écaillent beaucoup récemment, triage mental?
Évolutivité / sig
/ priorité échec-test
/ genre bug
/ statut approuvé-pour-jalon
cc @jdumars @jberkus
/ assign @shyamjvs @ wojtek-t
 krzyzacy
krzyzacy
Tous les 164 commentaires
- Le travail de correction échoue principalement en raison du délai d'expiration (besoin d'ajuster notre calendrier en conséquence) car il y a eu un tas d'e2es qui ont été ajoutés récemment à la suite (par exemple https://github.com/kubernetes/kubernetes/pull/59391)
- Pour les flocons de 100 nœuds, nous avons https://github.com/kubernetes/kubernetes/issues/60500 (et je crois que c'est lié .. besoin de vérifier).
- Pour le travail de performance, je pense qu'il y a une régression (il semble que, d'après les dernières exécutions, il y ait une latence au démarrage du pod). Peut-être qch plus aussi.
J'essaierai de m'y rendre à un moment donné au cours de cette semaine (ayant la rareté des cycles gratuits atm).
 shyamjvs
le 28 févr. 2018
shyamjvs
le 28 févr. 2018
@shyamjvs existe-t-il une mise à jour pour ce problème?
krzyzacy
le 2 mars 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-correctness
J'ai jeté un bref coup d'œil là-dessus. Et soit certains tests sont extrêmement lents, soit quelque chose se bloque quelque part. Par des journaux de la dernière exécution:
62571 I0301 23:01:31.360] Mar 1 23:01:31.348: INFO: Running AfterSuite actions on all node
62572 I0301 23:01:31.360]
62573 W0302 07:32:00.441] 2018/03/02 07:32:00 process.go:191: Abort after 9h30m0s timeout during ./hack/ginkgo-e2e.sh --ginkgo.flakeAttempts=2 --ginkgo.skip=\[Serial\]|\[Disruptive \]|\[Flaky\]|\[Feature:.+\]|\[DisabledForLargeClusters\] --allowed-not-ready-nodes=50 --node-schedulable-timeout=90m --minStartupPods=8 --gather-resource-usage=master --gathe r-metrics-at-teardown=master --logexporter-gcs-path=gs://kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-correctness/80/artifacts --report-dir=/workspace/_artifacts --dis able-log-dump=true --cluster-ip-range=10.64.0.0/11. Will terminate in another 15m
62574 W0302 07:32:00.445] SIGABRT: abort
Aucun test terminé dans les 8h30
 wojtek-t
le 2 mars 2018
wojtek-t
le 2 mars 2018
https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance
En effet, cela ressemble à une régression. Je pense que la régression s'est produite quelque part entre les exécutions:
105 (ce qui était toujours ok)
108 (qui avait un temps de démarrage visiblement plus élevé)
Nous pouvons essayer de regarder dans kubemark-5000 pour voir s'il y est également visible.
wojtek-t
le 2 mars 2018
Kubemark-5000 est assez stable. 99e centile sur ce graphique (peut-être que la régression s'est produite avant même, mais je pense qu'elle se situe entre 105 et 108):

wojtek-t
le 2 mars 2018
En ce qui concerne les tests de correction, la correction gce-large échoue également.
Peut-être qu'un test extrêmement long a été ajouté à ce moment-là?
wojtek-t
le 2 mars 2018
Merci beaucoup d'avoir regardé @ wojtek-t. Travail de performance Wrt - Moi aussi, je suis convaincu qu'il y a une régression (même si je n'ai pas pu les examiner correctement).
Peut-être qu'un test extrêmement long a été ajouté à ce moment-là?
J'ai étudié cela il y a quelque temps. Et il y a eu 2 changements suspects que j'ai trouvés:
- # 59391 - Cela a ajouté un tas de tests autour du stockage local (les exécutions après ce changement ont commencé à expirer)
- StatefulSet avec anti-affinité de pod devrait utiliser des volumes répartis sur les nœuds (ce test semble s'exécuter pendant 3,5 à 5 heures) - https://k8s-gubernator.appspot.com/build/kubernetes-jenkins/logs/ci-kubernetes-e2e -gce-scale-correctness / 79
shyamjvs
le 2 mars 2018
cc @ kubernetes / sig-storage-bugs
shyamjvs
le 2 mars 2018
/attribuer
Certains des tests de stockage local essaieront d'utiliser chaque nœud du cluster, pensant que les tailles de cluster ne sont pas si grandes. Je vais ajouter un correctif pour limiter le nombre maximum de nœuds.
 msau42
le 2 mars 2018
msau42
le 2 mars 2018
Certains des tests de stockage local essaieront d'utiliser chaque nœud du cluster, pensant que les tailles de cluster ne sont pas si grandes. Je vais ajouter un correctif pour limiter le nombre maximum de nœuds.
Merci @ msau42 - ce serait génial.
wojtek-t
le 2 mars 2018
Revenant à https://k8s-testgrid.appspot.com/sig-release-master-blocking#gce -scale-performance suite
J'ai examiné de plus près les courses jusqu'à 105 et 108 et après.
La plus grande différence par rapport au temps de démarrage du pod semble apparaître à l'étape:
10% worst watch latencies:
[son nom est trompeur - vous l'expliquerez ci-dessous]
Jusqu'à 105 exécutions, cela ressemblait généralement à ceci:
I0129 21:17:43.450] Jan 29 21:17:43.356: INFO: perc50: 1.041233793s, perc90: 1.685463015s, perc99: 2.350747103s
À partir de 108 run, cela ressemble plus à:
Feb 12 10:08:57.123: INFO: perc50: 1.122693874s, perc90: 1.934670461s, perc99: 3.195883331s
Cela signifie essentiellement une augmentation d'environ 0,85 s et c'est à peu près ce que nous observons dans le résultat final.
Maintenant - quel est ce «décalage de la montre».
Il s'agit essentiellement d'un temps entre "Kubelet a observé que le pod est en cours d'exécution" et "lorsque le test a observé la mise à jour du pod mettant son état en cours d'exécution".
Il y a quelques possibilités où nous aurions pu régresser:
- kubelet est ralenti dans la génération de rapports
- kubelet est affamé de qps (et donc plus lent dans le statut de rapport)
- apiserver est plus lent (par exemple, le processeur est affamé) et donc le traitement des requêtes plus lentement (soit écrire, regarder, ou les deux)
- le test est privé de processeur et traite donc les événements entrants plus lentement
Comme nous n'observons pas vraiment de différence entre "planifier -> démarrer" d'un pod, cela suggère que ce n'est probablement pas un apiserver (car le traitement des requêtes et de la surveillance se fait également sur ce chemin), et ce n'est probablement pas un kubelet lent aussi (car il démarre le pod).
Je pense donc que l'hypothèse la plus probable est:
- kubelet est affamé de qps (ou qps qui l'empêche d'envoyer rapidement une mise à jour de statut)
- le test manque de CPU (ou qch comme ça)
Le test n'a pas du tout changé à cette époque. Je pense donc que c'est probablement le premier.
Cela dit, je suis passé par des PR fusionnés entre 105 et 108 courses et je n'ai rien trouvé d'utile jusqu'à présent.
wojtek-t
le 2 mars 2018
Je pense que la prochaine étape consiste à:
- examinez les pods les plus lents (il semble y avoir une différence de O (1s) entre les plus lents aussi) et voyez si la différence est "avant" ou "après" la demande de statut de mise à jour a été envoyée
wojtek-t
le 2 mars 2018
J'ai donc examiné des exemples de pods. Et je vois déjà ceci:
I0209 10:01:19.960823 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.615907ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
...
I0209 10:01:22.464046 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (279.153µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:23.468353 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (218.216µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 10:01:24.470944 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-16-5pl6z/pods/density-latency-pod-3115-fh7hl/status: (1.42987ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.200.5:37414]
I0209 09:57:01.559125 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (1.836423ms) 200 [[kubelet/v1.10.0 (l inux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
...
I0209 09:57:04.452830 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (231.2µs) 429 [[kubelet/v1.10.0 (linu x/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:05.454274 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (213.872µs) 429 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 09:57:06.458831 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-35-gjzmd/pods/density-latency-pod-2034-t7c7h/status: (2.13295ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.229.43.12:37782]
I0209 10:01:53.063575 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (1.410064ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:3391
...
I0209 10:01:55.259949 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (10.4894ms) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:56.266377 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (233.931µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:57.269427 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (182.035µs) 429 [[kubelet/v1.10.0 (lin ux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
I0209 10:01:58.290456 1 wrap.go:42] PUT /api/v1/namespaces/e2e-tests-density-30-5-6w4kv/pods/density-latency-pod-3254-586j7/status: (13.44863ms) 200 [[kubelet/v1.10.0 (li nux/amd64) kubernetes/05944b1] 35.196.212.60:33916]
Il semble donc assez clair que le problème est lié aux «429».
wojtek-t
le 2 mars 2018
Ces appels d'API limités sont-ils dus à un quota sur le compte propriétaire?
 jdumars
le 2 mars 2018
jdumars
le 2 mars 2018
Ces appels d'API limités sont-ils dus à un quota sur le compte propriétaire?
Ce n'est pas un étranglement comme je le pensais au départ. Ce sont des 429 sur apiserver (la raison peut être soit un apiserver plus lent pour une raison quelconque, soit plus de demandes venant à apiserver).
wojtek-t
le 2 mars 2018
Ah d'accord. Ce n'est pas une bonne nouvelle.
jdumars
le 2 mars 2018
/ jalon effacé
krzyzacy
le 2 mars 2018
/ jalon v1.10
krzyzacy
le 2 mars 2018
/ jalon effacé
 cjwagner
le 2 mars 2018
cjwagner
le 2 mars 2018
@cjwagner : vous devez être membre de l'équipe github kubernetes-milestone-mainters pour définir le jalon.
En réponse à cela :
/ jalon effacé
Les instructions pour interagir avec moi en utilisant les commentaires PR sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème avec le
 k8s-ci-robot
le 2 mars 2018
k8s-ci-robot
le 2 mars 2018
/ jalon v1.9
cjwagner
le 2 mars 2018
@cjwagner : vous devez être membre de l'équipe github kubernetes-milestone-mainters pour définir le jalon.
En réponse à cela :
/ jalon v1.9
Les instructions pour interagir avec moi en utilisant les commentaires PR sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème avec le
k8s-ci-robot
le 2 mars 2018
On dirait que PR https://github.com/kubernetes/kubernetes/pull/60740 a corrigé les problèmes de délai d'expiration - merci @ msau42 pour une réponse rapide.
Nos travaux de correction (2k et 5k) sont de retour au vert maintenant:
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -large-correctness
- https://k8s-testgrid.appspot.com/sig-scalability-gce#gce -scale-correctness
Donc, mes soupçons concernant ces tests de volume étaient en effet justes :)
shyamjvs
le 5 mars 2018
ACK. En cours
ETA: 03/09/2018
Risques: impact potentiel sur les performances du k8s
shyamjvs
le 5 mars 2018
J'ai donc creusé un peu là-dedans et à partir du graphique de latence de démarrage du pod pour notre test de 5k nœuds, j'ai le sentiment que la régression pourrait également être en n / b exécute 108 et 109 (voir 99% ile):

shyamjvs
le 5 mars 2018
J'ai balayé rapidement le diff et le changement suivant me semble suspect:
"Autoriser le dépassement du délai de demande depuis NewRequest jusqu'au bout" # 51042
Ce PR active la propagation du délai d'expiration du client en tant que paramètre de requête vers l'appel d'API. Et je vois en effet la différence suivante dans les appels PATCH node/status entre ces 2 exécutions (à partir des journaux apiserver):
course 108:
I0207 22:01:06.450385 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-1-2rn2/status: (11.81392ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.227.96.23:47270]
I0207 22:01:03.857892 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-9659/status: (8.570809ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.196.85.108:43532]
I0207 22:01:03.857972 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc4w/status: (8.287643ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7] 35.229.110.22:50530]
run-109:
I0209 21:01:08.551289 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-89f2/status?timeout=10s: (71.351634ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.229.77.215:51070]
I0209 21:01:08.551310 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-2-3ms3/status?timeout=10s: (70.705466ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.227.84.87:49936]
I0209 21:01:08.551394 1 wrap.go:42] PATCH /api/v1/nodes/gce-scale-cluster-minion-group-3-wc02/status?timeout=10s: (70.847605ms) 200 [[kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1] 35.196.125.143:53662]
Mon hypothèse est que, en raison de ce délai supplémentaire de 10 secondes pour les appels PATCH, ces appels durent maintenant plus longtemps côté serveur (IIUC ce commentaire correctement). Cela signifie qu'ils sont maintenant dans la file d'attente en vol pour une durée plus longue. Cela, combiné au fait que ces appels PATCH se produisent en quantités énormes dans de si grands clusters, conduit à des appels PUT pod/status incapables d'obtenir suffisamment de bande passante dans la file d'attente en vol et sont donc renvoyés avec 429s. En conséquence, le délai côté kubelet dans la mise à jour de l'état du pod a augmenté. Cette histoire correspond également bien aux observations de @ wojtek-t ci-dessus.
Je vais essayer de rassembler plus de preuves pour vérifier cette hypothèse.
shyamjvs
le 5 mars 2018
J'ai donc vérifié comment les latences de PATCH node-status varient au cours des tests, et il semble en effet qu'il y ait une augmentation du 99e centile (voir la ligne du haut) à cette époque. Cependant, il n'est pas très clair que cela se soit produit b / w exécute 108 et 109 (même si je pense que c'est le cas):
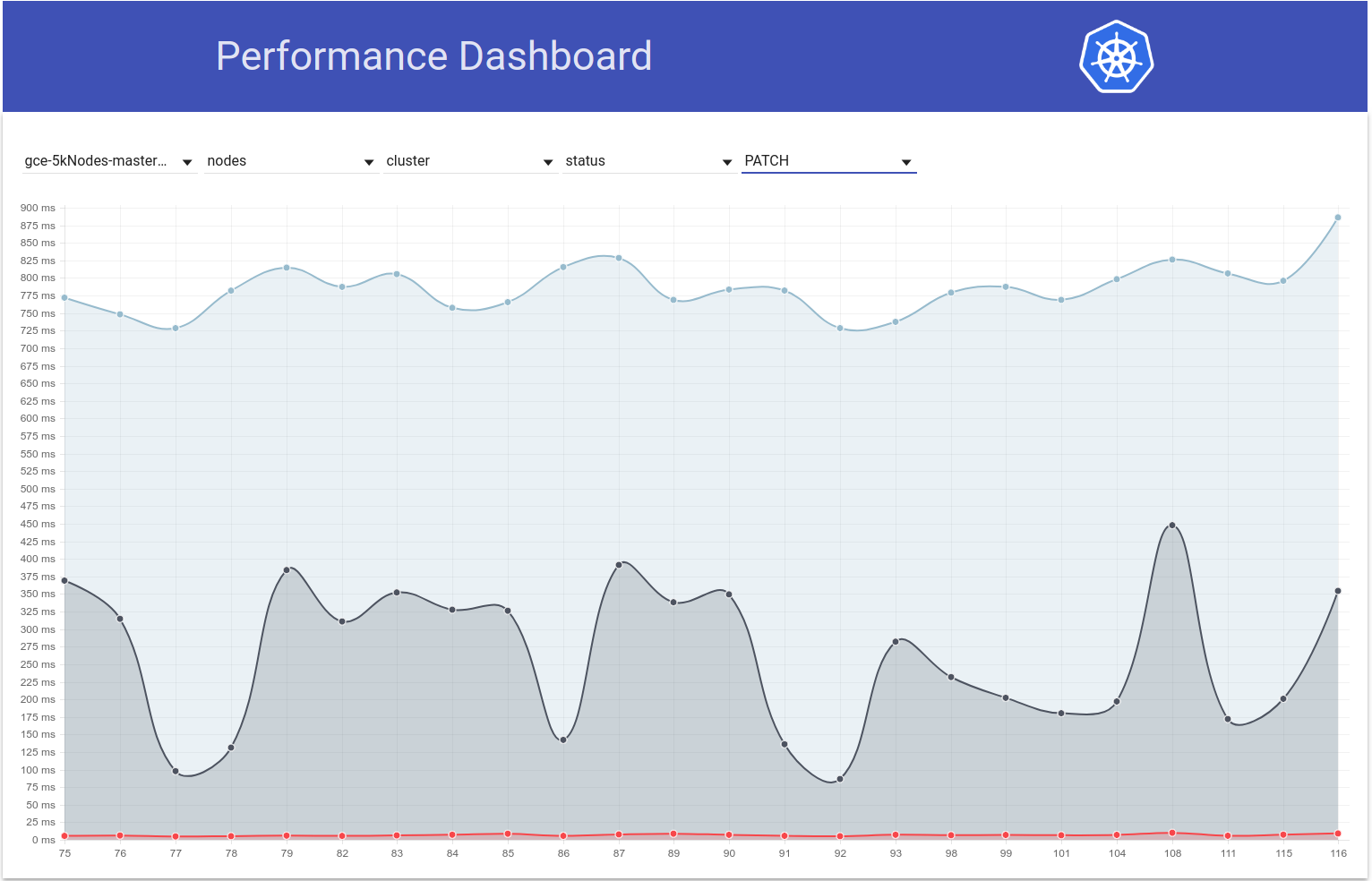
shyamjvs
le 5 mars 2018
[EDIT: Mon commentaire précédent mentionnait à tort le décompte de ces 429 (le client était npd, pas kubelet)]
J'ai plus de preuves à l'appui maintenant:
dans run-108 , nous avons eu ~ 479k PATCH node/status appels qui ont obtenu un 429:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"479181"
]
},
et dans run-109 , nous avons ~ 757k de ceux-ci:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "resource",
"resource": "nodes",
"scope": "",
"subresource": "status",
"verb": "PATCH"
},
"value": [
0,
"757318"
]
},
Et ... Regardez ceci:
en run-108:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/11104d7",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"28594"
]
},
et en run-109:
{
"metric": {
"__name__": "apiserver_request_count",
"client": "kubelet/v1.10.0 (linux/amd64) kubernetes/05944b1",
"code": "429",
"contentType": "namespace",
"resource": "pods",
"scope": "",
"subresource": "status",
"verb": "UPDATE"
},
"value": [
0,
"33224"
]
},
J'ai vérifié le nombre de quelques autres pistes adjacentes:
- que PR a fusionné -
Bien que cela semble un peu différent, dans l'ensemble, cela ressemble au non. des 429 ont augmenté d'environ 25%.
shyamjvs
le 5 mars 2018
Et pour PATCH node-status provenant de kubelets qui ont reçu 429s, voici à quoi ressemblent les nombres:
- run-104 = 313348
- course-105 = 309136
- course-108 = 479181
- que PR a fusionné -
- course-109 = 757318
- course-110 = 752062
- course-111 = 296368
Cela varie également, mais il semble généralement augmenter.
shyamjvs
le 5 mars 2018
Le 99e% ile des latences d'appels PATCH node-status semble également avoir généralement augmenté (comme je le prédisais dans https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370573938):
run-104 (798ms), run-105 (783ms), run-108 (826ms)
run-109 (878ms), run-110 (869ms), run-111 (806ms)
Btw - Avec toutes les métriques ci-dessus, 108 semble être une course pire que la normale et 111 semble être une course meilleure que la normale.
shyamjvs
le 5 mars 2018
J'essaierai de vérifier cela demain en exécutant manuellement un grand cluster 5k.
shyamjvs
le 5 mars 2018
merci pour le triage @shyamjvs
krzyzacy
le 5 mars 2018
J'ai donc exécuté un test de densité deux fois contre un cluster 5k contre ~ HEAD, et le test a étonnamment réussi les deux fois avec une latence de démarrage du pod de 99% comme 4.510015461s et 4.623276837s . Cependant, les `` latences de la montre '' ont montré l'augmentation indiquée par @ wojtek-t dans https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -369951288
Dans la première manche, c'était:
INFO: perc50: 1.123056294s, perc90: 1.932503347s, perc99: 3.061238209s
et la deuxième manche c'était:
INFO: perc50: 1.121218293s, perc90: 1.996638787s, perc99: 3.137325187s
Je vais maintenant essayer de vérifier ce qui était le cas plus tôt.
shyamjvs
le 6 mars 2018
https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 - Je ne suis pas sûr de suivre ceci Oui - nous avons ajouté un délai d'expiration, mais le délai d'expiration par défaut est supérieur à 10 s IIRC - cela ne devrait donc aider ne pas aggraver les choses.
Je pense que nous ne comprenons toujours pas pourquoi nous observons plus de 429 (le fait que cela soit en quelque sorte lié aux 429 que j'ai déjà mentionné dans https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370036377)
wojtek-t
le 6 mars 2018
Et en ce qui concerne vos chiffres - je ne suis pas convaincu que la régression était en cours 109 - il aurait pu y avoir deux régressions - une entre 105 et 108 et l'autre en 109.
wojtek-t
le 6 mars 2018
Hmm ... Je ne nie pas les possibilités que vous avez mentionnées (ce qui précède n'était que mon hypothèse).
Je fais actuellement une bissection (en ce moment contre le commit de 108) pour vérifier.
shyamjvs
le 6 mars 2018
Mon sentiment que la régression est avant la course 108 est de plus en plus fort.
Par exemple, les latences des appels d'API sont déjà augmentées en 108 exécutions.
état du nœud de patch:
90%: 198 ms (105) 447 ms (108) 444 ms (109)
mettre le statut du pod:
99%: 83 ms (105) 657 ms (108) 728 ms (109)
wojtek-t
le 6 mars 2018
Je suppose que ce que j'essaie de dire, c'est:
- le nombre de 429 est une conséquence et il ne faut pas y passer trop de temps
- la cause première est soit des appels API plus lents, soit un plus grand nombre de ceux-ci
Nous semblons clairement voir des appels API plus lents dans 108. La question est de savoir si nous en voyons également un plus grand nombre.
wojtek-t
le 6 mars 2018
Je pense donc pourquoi les demandes sont visiblement plus lentes - il y a trois possibilités principales
il y a beaucoup plus de demandes (à première vue, cela ne semble pas être le cas)
nous avons ajouté quelque chose sur le chemin du traitement (par exemple, traitement supplémentaire) ou les objets eux-mêmes sont plus gros
quelque chose d'autre sur la machine maître (par exemple le planificateur) consomme plus de processeur et donc affamé plus apiserver
wojtek-t
le 6 mars 2018
Donc, @ wojtek-t et moi avons discuté hors ligne et nous sommes tous les deux d'accord maintenant qu'il y a très probablement une régression avant 108. Ajout de quelques points:
il y a beaucoup plus de demandes (à première vue, cela ne semble pas être le cas)
Cela ne me semble pas non plus le cas
nous avons ajouté quelque chose sur le chemin du traitement (par exemple, traitement supplémentaire) ou les objets eux-mêmes sont plus gros
Mon sentiment est que c'est plus probable dans kubelet par opposition à apiserver (car nous ne voyons aucun changement visible dans les latences de patch / put sur kubemark-5000)
quelque chose d'autre sur la machine maître (par exemple le planificateur) consomme plus de processeur et donc affamé plus apiserver
IMO ce n'est pas le cas car nous avons un peu de relâchement CPU / mémoire sur notre maître. De plus, perf-dash ne suggère aucune augmentation considérable des utilisations des composants principaux.
Cela dit, j'ai creusé un peu et "heureusement", il semble que nous remarquons cette augmentation des latences de la montre, même pour les clusters à 2k nœuds:
INFO: perc50: 1.024377533s, perc90: 1.589770858s, perc99: 1.934099611s
INFO: perc50: 1.03503718s, perc90: 1.624451701s, perc99: 2.348645755s
Cela devrait faciliter la coupe en deux.
shyamjvs
le 6 mars 2018
Malheureusement, la variation de ces latences de montre semble être ponctuelle (c'est à peu près la même chose). Heureusement, nous avons la latence PUT pod-status comme indicateur fiable de la régression. J'ai couru 2 tours de bissection hier et je me suis réduit à ce diff (~ 80 commits). Je les ai parcourus et j'ai de fortes soupçons sur:
- # 58990 - Ajoute un nouveau champ au statut du pod (même si je ne suis pas sûr que cela soit rempli dans nos tests, où les préemptions IIUC ne se produisent pas - mais doivent vérifier)
- # 58645 - Met à jour la version du serveur etcd à 3.2.14
shyamjvs
le 7 mars 2018
Je doute vraiment que le # 58990 soit lié ici - NominatedNodeName est une chaîne qui contient un seul nom de nœud. Même s'il était rempli tout le temps, le changement de taille de l'objet devrait être négligeable.
wojtek-t
le 7 mars 2018
@ wojtek-t - Comme vous le suggériez hors ligne, il semble en effet que nous utilisons une version différente (3.2.16) dans kubemark (https://github.com/kubernetes/kubernetes/blob/master/test/kubemark/ start-kubemark.sh # L62) qui est la raison potentielle pour ne pas voir cette régression là :)
cc @jpbetz
shyamjvs
le 7 mars 2018
Nous utilisons maintenant 3.2.16 partout.
wojtek-t
le 7 mars 2018
Oups ... Désolé pour le recul - je recherchais une mauvaise combinaison de commits.
shyamjvs
le 7 mars 2018
BTW - cette augmentation des pods PUT / latence d'état est également visible dans les tests de charge dans de grands clusters réels.
wojtek-t
le 7 mars 2018
J'ai donc creusé un peu plus et il semble que nous avons commencé à observer des latences plus importantes à cette époque pour les demandes d'écriture en général (ce qui me fait suspecter encore plus le changement d'etcd):
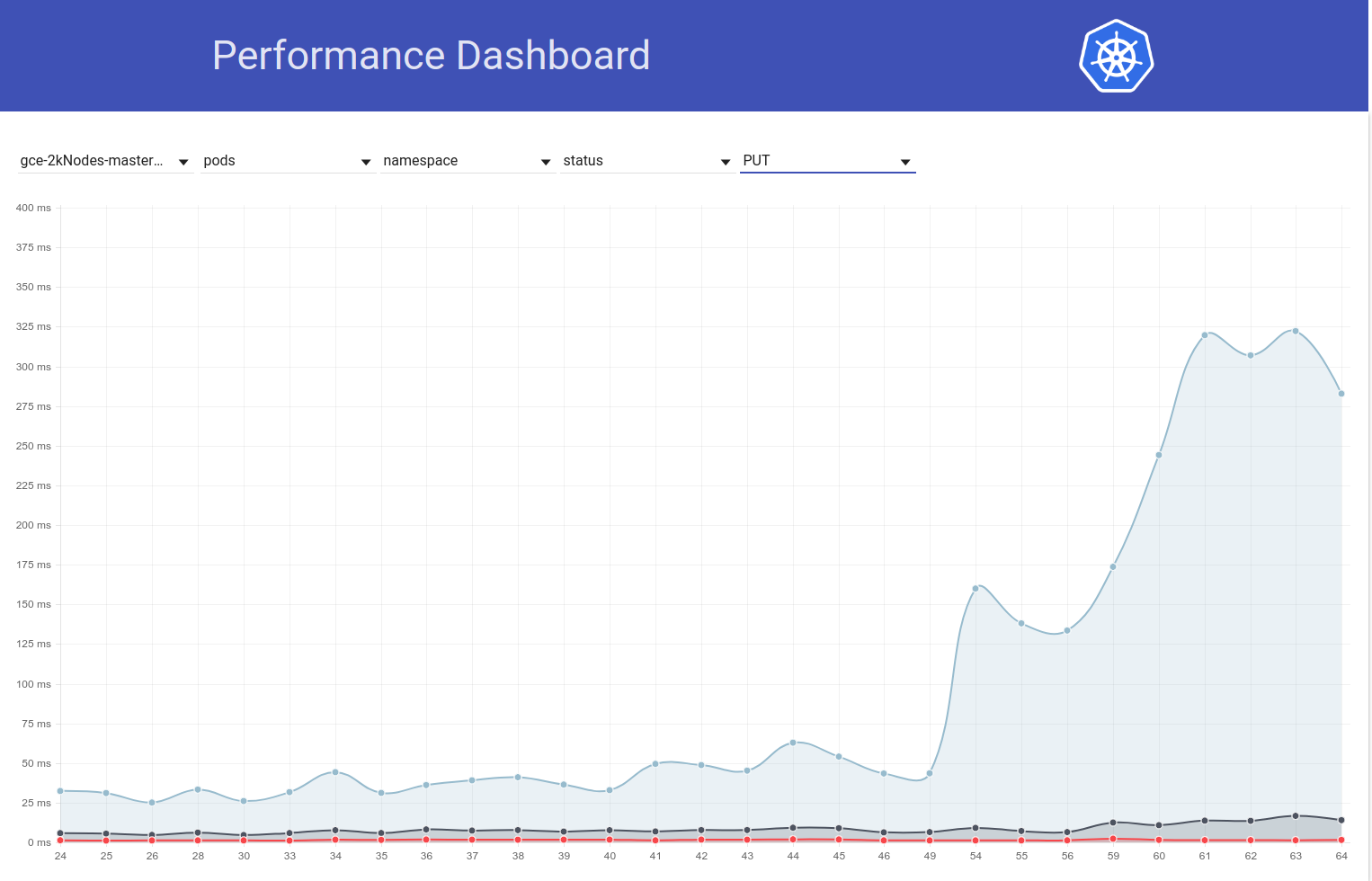
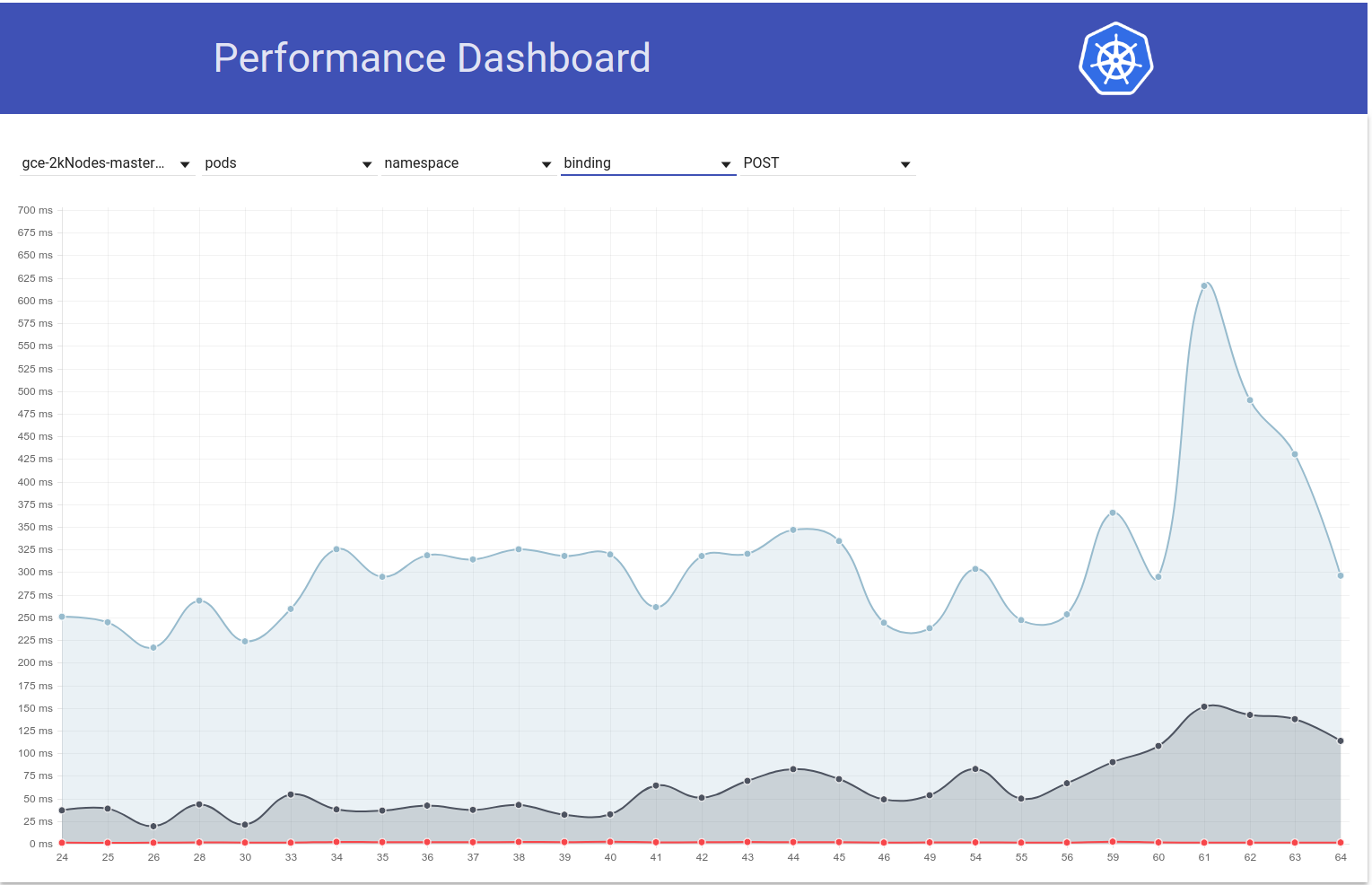

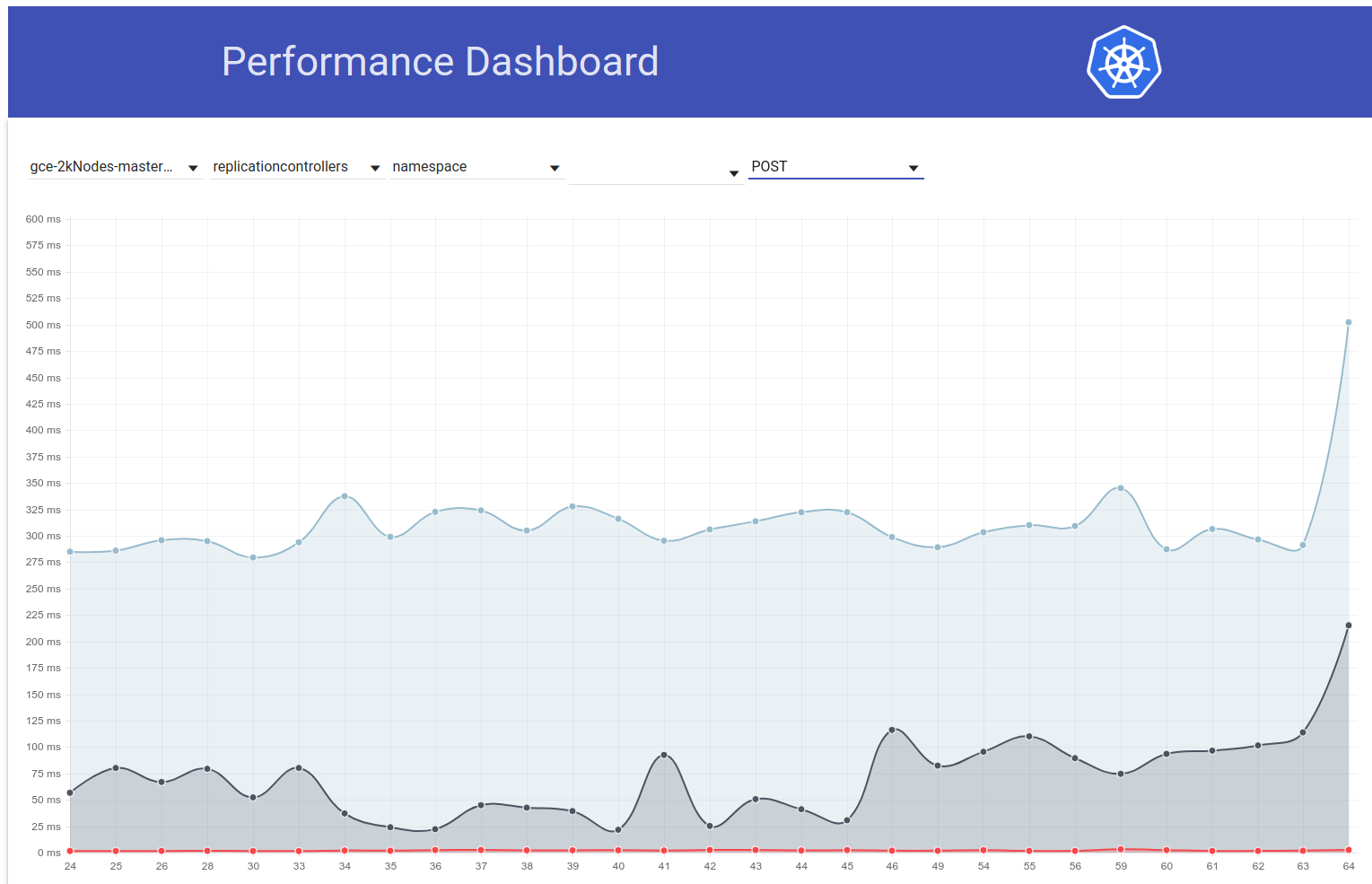
shyamjvs
le 7 mars 2018
En fait, je vote qu'au moins une partie du problème est ici:
https://github.com/kubernetes/kubernetes/pull/58990/commits/384a86caa92bdb7cf9ac96b10a6ef333d2d60519#diff -c73f80ad83608f18657d22a06950d929R240
Je serais surpris que ce soit tout le problème, mais cela peut y contribuer.
Va envoyer un PR changer cela dans une seconde.
wojtek-t
le 7 mars 2018
FYI - Quand j'ai couru contre un commit qui est avant le changement etcd 3.2.14 mais après le changement de l'API pod-status, la latence put node-status semble tout à fait correcte (c'est-à-dire 99% ile = 39ms).
shyamjvs
le 7 mars 2018
J'ai donc vérifié que cela était bien causé par le passage d'etcd à 3.2.14. Voici à quoi ressemble la latence de l'état du pod put:
contre ce PR :
{
"data": {
"Perc50": 1.479,
"Perc90": 10.959,
"Perc99": 163.095
},
"unit": "ms",
"labels": {
"Count": "344494",
"Resource": "pods",
"Scope": "namespace",
"Subresource": "status",
"Verb": "PUT"
}
},
contre ~ HEAD (à partir du 5 mars) avec ce PR annulé (le test est toujours en cours, mais sur le point de se terminer bientôt):
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.5"} 1669
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.9"} 9597
apiserver_request_latencies_summary{resource="pods",scope="namespace",subresource="status",verb="PUT",quantile="0.99"} 63392
63ms semble assez similaire à ce qu'il était avant .
Nous devrions revenir sur la version et essayer de comprendre:
- Pourquoi voyons-nous cette augmentation dans etcd 3.2.14?
- Pourquoi n'avons-nous pas attrapé ça dans kubemark?
cc @jpbetz @ kubernetes / sig-api-machines-bugs
shyamjvs
le 7 mars 2018
Une hypothèse (pourquoi nous n'avons pas compris cela dans kubemark - bien que ce soit toujours une supposition) est que nous avons peut-être changé qc en certificats là-bas.
Lorsque je compare le journal etcd de kubemark et du cluster réel, seulement dans ce dernier, je vois la ligne suivante:
2018-03-05 08:06:56.389648 I | embed: peerTLS: cert = /etc/srv/kubernetes/etcd-peer.crt, key = /etc/srv/kubernetes/etcd-peer.key, ca = , trusted-ca = /etc/srv/kubernetes/etcd-ca.crt, client-cert-auth = true
En regardant dans le PR lui-même, je ne vois aucun changement à ce sujet, mais je ne sais pas non plus pourquoi nous aurions dû voir cette ligne uniquement dans de vrais clusters ...
@jpbetz pour des pensées
wojtek-t
le 7 mars 2018
ACK. En cours
ETA: 03/09/2018
Risques: Problème d'origine (principalement)
shyamjvs
le 7 mars 2018
Re peerTLS - cela semble être le cas aussi avant (avec 3.1.11) donc je pense que c'est un hareng rouge
wojtek-t
le 7 mars 2018
cc @gyuho @wenjiaswe
 jpbetz
le 7 mars 2018
jpbetz
le 7 mars 2018
63ms semble assez similaire à ce que
D'où obtenons-nous ces chiffres? Est-ce que apiserver_request_latencies_summary mesure réellement les latences des écritures etcd? De plus, les métriques d'etcd seraient utiles.
 gyuho
le 7 mars 2018
gyuho
le 7 mars 2018
embed: peerTLS: cert ...
Cela s'imprime, si le TLS homologue est configuré (idem en 3.1).
gyuho
le 7 mars 2018
D'où obtenons-nous ces chiffres? Apiserver_request_latencies_summary mesure-t-il réellement les latences des écritures etcd? De plus, les métriques d'etcd seraient utiles.
Cela mesure la latence apicalls qui (au moins en cas d'appels d'écriture) inclut la latence de etcd.
Nous ne comprenons toujours pas vraiment ce qui se passe, mais le retour à la version précédente d'etcd (3.1) corrige la régression. Il est donc clair que le problème se situe quelque part dans etcd.
wojtek-t
le 7 mars 2018
@shyamjvs
Quelles versions de Kubemark et Kubernetes utilisez-vous? Nous avons testé Kubemark 1.10 contre etcd 3.2 vs 3.3 (charges de travail à 500 nœuds) et n'avons pas observé cela. Combien de nœuds sont nécessaires pour reproduire cela?
gyuho
le 7 mars 2018
Quelles versions de Kubemark et Kubernetes utilisez-vous? Nous avons testé Kubemark 1.10 contre etcd 3.2 vs 3.3 (charges de travail à 500 nœuds) et n'avons pas observé cela. Combien de nœuds sont nécessaires pour reproduire cela?
Nous ne pouvons pas le reproduire avec kubemark, même avec un nœud de 5k - voir en bas de https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -371171837
Cela semble être un problème uniquement dans les grappes réelles.
C'est une question ouverte pourquoi est-ce le cas.
wojtek-t
le 7 mars 2018
Depuis que nous sommes revenus à etcd 3.1. pour kubernetes. Nous avons également publié etcd 3.1.12 avec le seul correctif critique exceptionnel pour kubernetes: l' opération de restauration de l'observateur "unsynced" mvcc . Une fois que nous avons trouvé et corrigé la cause première de la régression des performances trouvée dans ce problème, nous pouvons esquisser un plan pour mettre à niveau le serveur etcd utilisé par kubernetes vers la version 3.2.
jpbetz
le 8 mars 2018
ressemble à https://k8s-testgrid.appspot.com/sig-release-master-blocking#gci -gce-100 commence à échouer régulièrement depuis ce matin
krzyzacy
le 9 mars 2018
Depuis le diff , le seul changement est https://github.com/kubernetes/kubernetes/pull/60421 qui active les quotas dans nos tests de performances par défaut. L'erreur que nous voyons est:
Container kube-controller-manager-e2e-big-master/kube-controller-manager is using 0.531144723/0.5 CPU
not to have occurred
@gmarek - On dirait que l'activation des quotas affecte notre évolutivité :) Pourriez-vous approfondir cette question - peut-être que c'est sérieux?
Permettez-moi de déposer un autre problème pour garder celui-ci sur la bonne voie.
shyamjvs
le 9 mars 2018
@ wojtek-t @jpbetz @gyuho @timothysc J'ai trouvé quelque chose de vraiment intéressant avec le changement de version d'etcd, suggérant un effet significatif du passage d'etcd 3.1.11 à 3.2.16.
Regardez le graphique suivant de l'utilisation de la mémoire etcd dans notre cluster de 100 nœuds (il a augmenté ~ 2x) lorsque le travail a été déplacé de la version k8 1.9 à 1.10:
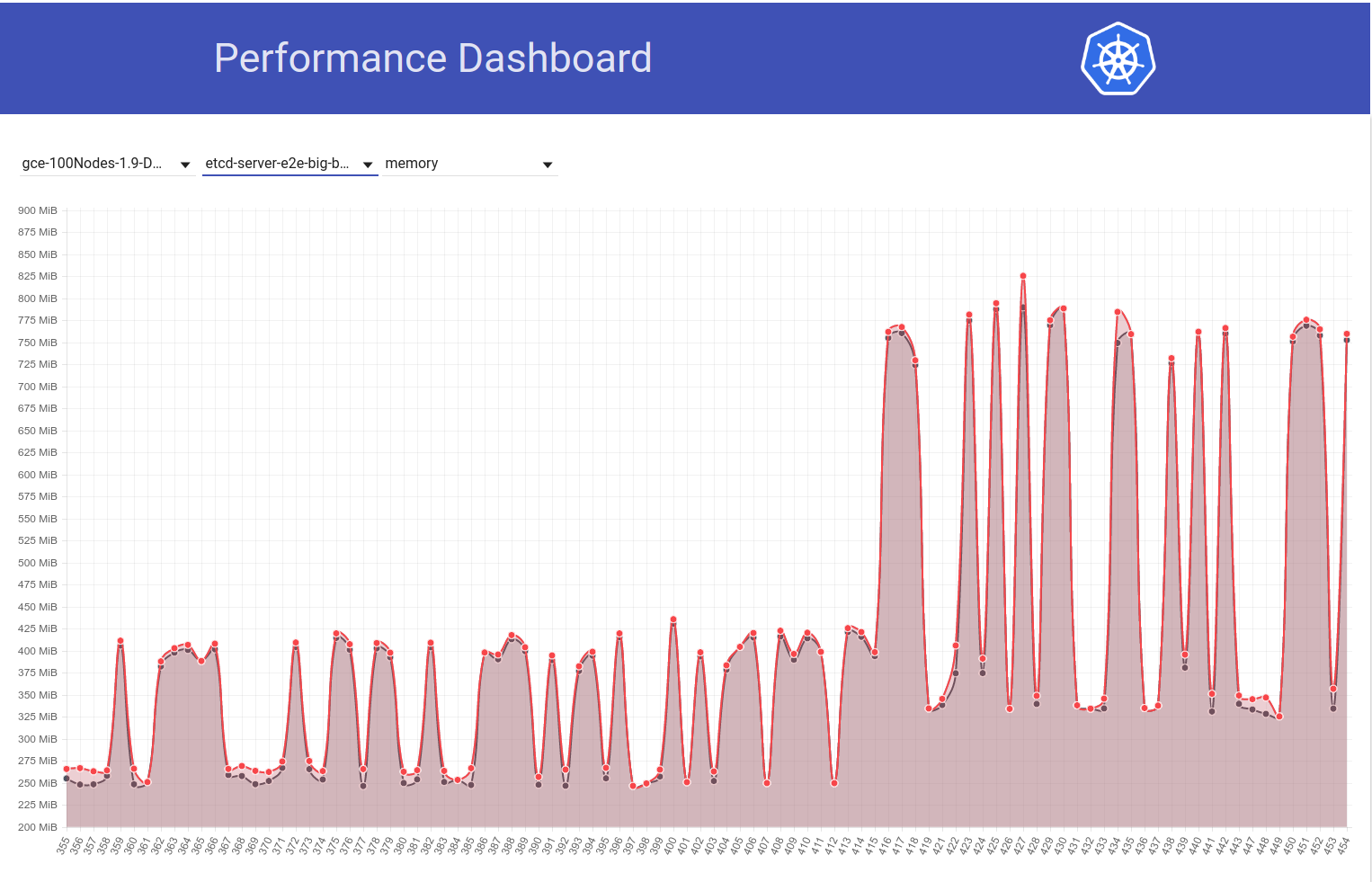
Et regardez ensuite comment notre travail à 100 nœuds (fonctionnant contre HEAD) voit une baisse de l'utilisation de la mémoire de moitié juste après mon retour d'etcd 3.2.16 -> 3.1.11:
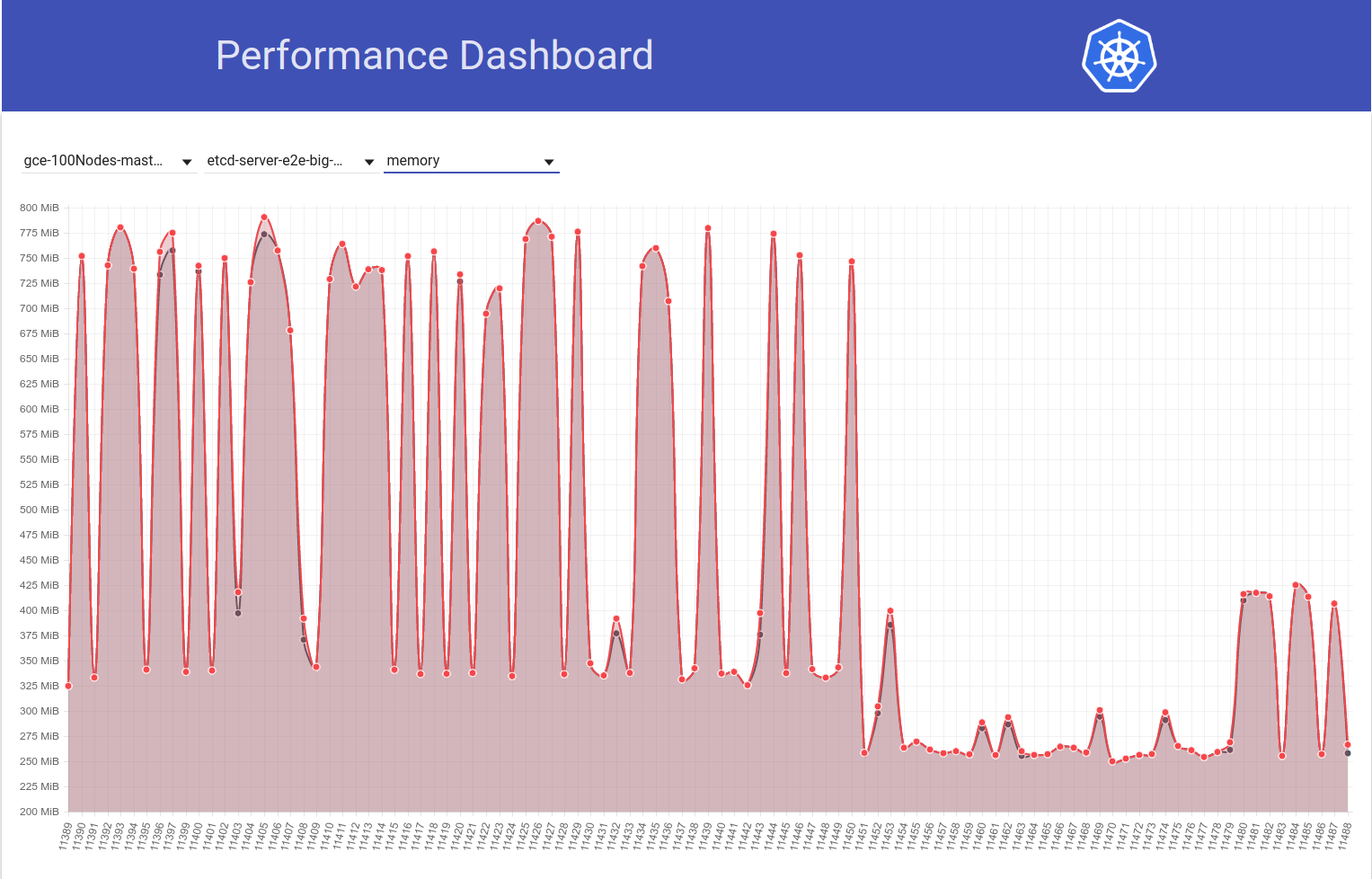
Ainsi, la version du serveur etcd 3.2 montre CLAIREMENT les performances affectées (avec toutes les autres variables gardées les mêmes) :)
shyamjvs
le 10 mars 2018
mon retour d'etcd 3.2.16 -> 3.2.11:
Voulons-nous dire 3.1.11?
gyuho
le 10 mars 2018
C'est vrai ... désolé. J'ai édité mon commentaire.
shyamjvs
le 10 mars 2018
@shyamjvs Comment etcd est-il configuré? Nous avons augmenté la valeur par défaut --snapshot-count de 10000 à 100000 , dans la v3.2. Ainsi, si le nombre de clichés est différent, celui avec le plus grand nombre de clichés conserve les entrées du Raft plus longtemps, nécessite donc plus de mémoire résidente, avant de supprimer les anciens journaux.
gyuho
le 10 mars 2018
Aah! Cela semble en effet être un changement suspect. Wrt flags, je ne pense pas qu'il y ait de changement dans ceux du côté k8. Parce que, comme vous pouvez le voir dans mon deuxième graphique ci-dessus, le diff b / w court 11450 et 11451 est principalement juste mon changement de retour etcd (qui ne semble toucher aucun indicateur).
Nous avons augmenté la valeur par défaut --snapshot-count de 10000 à 100000
Pourriez-vous confirmer si c'est la cause première de cette utilisation accrue des mémoires? Si tel est le cas, nous pouvons souhaiter:
- patch etcd avec la valeur d'origine, ou
- réglez-le à 10000 en k8s
avant de revenir à 3.2
shyamjvs
le 10 mars 2018
Aah! Cela semble en effet être un changement suspect.
Ouais, ce changement aurait dû être mis en évidence du côté d'etcd (améliorera nos journaux de modifications et nos guides de mise à niveau).
Pourriez-vous confirmer si c'est la cause première de cette utilisation accrue des mémoires?
Je ne sais pas si ce serait la cause profonde. Un nombre d'instantanés inférieur aidera certainement à réduire l'utilisation de la mémoire en pointe. Si les deux versions d'etcd utilisent le même nombre d'instantanés, mais qu'un etcd montre toujours une utilisation de la mémoire beaucoup plus élevée, il devrait y avoir autre chose.
gyuho
le 10 mars 2018
Mise à jour: J'ai vérifié que l'augmentation de l'utilisation de la mémoire etcd est effectivement due à une valeur par défaut plus élevée --snapshot-count. Plus de détails ici - https://github.com/kubernetes/kubernetes/pull/61037#issuecomment -372457843
Nous devrions envisager de le mettre à 10 000 lorsque nous passons à etcd 3.2.16, si nous ne voulons pas l'augmentation de l'utilisation de mem.
cc @gyuho @ xiang90 @jpbetz
shyamjvs
le 12 mars 2018
Mise à jour: avec le correctif etcd, la latence de démarrage du pod à 99% semble toujours proche de la violation du SLO 5s. Il y a au moins une autre régression et j'ai rassemblé des preuves que c'est très probablement dans les exécutions n / b 111 et 112 de notre travail de performance de 5k nœuds (voir la bosse b / w ces exécutions dans le graphique que j'ai collé en https: / /github.com/kubernetes/kubernetes/issues/60589#issuecomment-370568929). Actuellement, je divise en deux le diff (qui a environ 50 commits) et le test prend ~ 4-5 heures par itération.
Les preuves auxquelles je faisais référence ci-dessus sont les suivantes:
Les latences de la montre à 111 étaient:
Feb 14 21:36:05.531: INFO: perc50: 1.070980786s, perc90: 1.743347483s, perc99: 2.629721166s
Et les latences globales de démarrage des pods à 111 étaient:
Feb 14 21:36:05.671: INFO: perc50: 2.416307575s, perc90: 3.24553118s, perc99: 4.092430858s
Alors que les mêmes à 112 étaient:
Feb 16 10:07:43.222: INFO: perc50: 1.131108849s, perc90: 2.18487651s, perc99: 3.570548412s
et
Feb 16 10:07:43.353: INFO: perc50: 2.56160248s, perc90: 3.754024568s, perc99: 4.967573867s
En attendant, si quelqu'un est prêt pour le jeu de pari, vous pouvez jeter un œil au différentiel de commit que j'ai mentionné ci-dessus et deviner celui qui est défectueux :)
shyamjvs
le 12 mars 2018
ACK. En cours
ETA: 13/03/2018
Risques: Peut repousser la date de sortie s'il n'a pas été débogué avant
shyamjvs
le 12 mars 2018
@shyamjvs toooooooo beaucoup s'engage à placer des paris :)
 dims
le 13 mars 2018
dims
le 13 mars 2018
@dims Cela ajouterait plus de plaisir je suppose;)
Mise à jour: J'ai donc exécuté quelques itérations de la bissection et voici à quoi ressemblaient les métriques pertinentes à travers les commits (classés par ordre chronologique). Notez que pour ceux que j'ai exécutés manuellement, je les ai exécutés avec la régression précédente inversée (ie 3.2. -> 3.1.11).
| Commit | 99% de latence de la montre | 99% de latence au démarrage du pod | Bon mauvais? |
| ------------- | ------------- | ----- | ------- |
| a042ecde36 (à partir de la course 111) | 2.629721166s | 4.092430858s | Bon (confirmation à nouveau manuellement) |
| 5f7b530d87 (manuel) | 3.150616856s | 4.683392706s | Mauvais (probable) |
| a8060ab0a1 (manuel) | 3.11319985s | 4.710277511s | Mauvais (probable) |
| 430c1a68c8 (à partir de la série 112) | 3.570548412s | 4.967573867s | Mauvais |
| 430c1a68c8 (manuel) | 3.63505091s | 4.96697776s | Mauvais |
De ce qui précède, il semble qu'il puisse y avoir 2 régressions ici (car ce n'est pas un saut direct de 2.6s -> 3.6s) - un b / w "a042ecde36 - 5f7b530d87" et un autre b / w "a8060ab0a1 - 430c1a68c8". Soupir!
shyamjvs
le 13 mars 2018
exprimer sous forme de plages pour obtenir des liens de comparaison:
a042ecde36 ... 5f7b530
a8060ab0a1 ... 430c1a6
 liggitt
le 13 mars 2018
liggitt
le 13 mars 2018
Je viens d'obtenir les résultats de l'exécution manuelle contre a042ecde36 et cela ne fait que rendre la vie plus difficile:
3.269330734s (watch), 4.939237532s (pod-startup)
car cela signifie probablement qu'il pourrait s'agir d'une régression floconneuse.
shyamjvs
le 13 mars 2018
J'exécute actuellement le test contre a042ecde36 une fois de plus pour vérifier la possibilité que la régression soit arrivée avant même.
shyamjvs
le 13 mars 2018
Alors, voici le résultat de courir à nouveau contre a042ecd:
2.645592996s (watch), 5.026010032s (pod-startup)
Cela signifie probablement que la régression est entrée avant même l'exécution 111 (bonne nouvelle que nous avons maintenant une bonne extrémité pour la bissection).
Je vais maintenant essayer de poursuivre pour une extrémité gauche. Run-108 (commit 11104d75f) est un candidat potentiel, qui a eu les résultats suivants lorsque je l'ai exécuté plus tôt (avec etcd 3.1.11):
2.593628224s (watch), 4.321942836s (pod-startup)
Ma nouvelle exécution contre le commit 11104d7 semble dire que c'est une bonne:
2.663456162s (watch), 4.288927203s (pod-startup)
Je vais essayer ici de couper en deux dans la plage 11104d7 ... a042ecd
shyamjvs
le 13 mars 2018
Mise à jour: j'avais besoin de tester le commit 097efb71a315 trois fois pour gagner en confiance. Cela montre une certaine variance, mais semble être un bon commit:
2.578970061s (watch), 4.129003596s (pod-startup)
2.315561531s (watch), 4.70792639s (pod-startup)
2.303510957s (watch), 3.88150234s (pod-startup)
Je vais continuer à couper en deux.
Cela dit, il semble y avoir eu un autre pic (d'environ 1s) dans la latence de démarrage des pods il y a quelques jours à peine. Et celui-ci pousse les 99% à presque 6s:
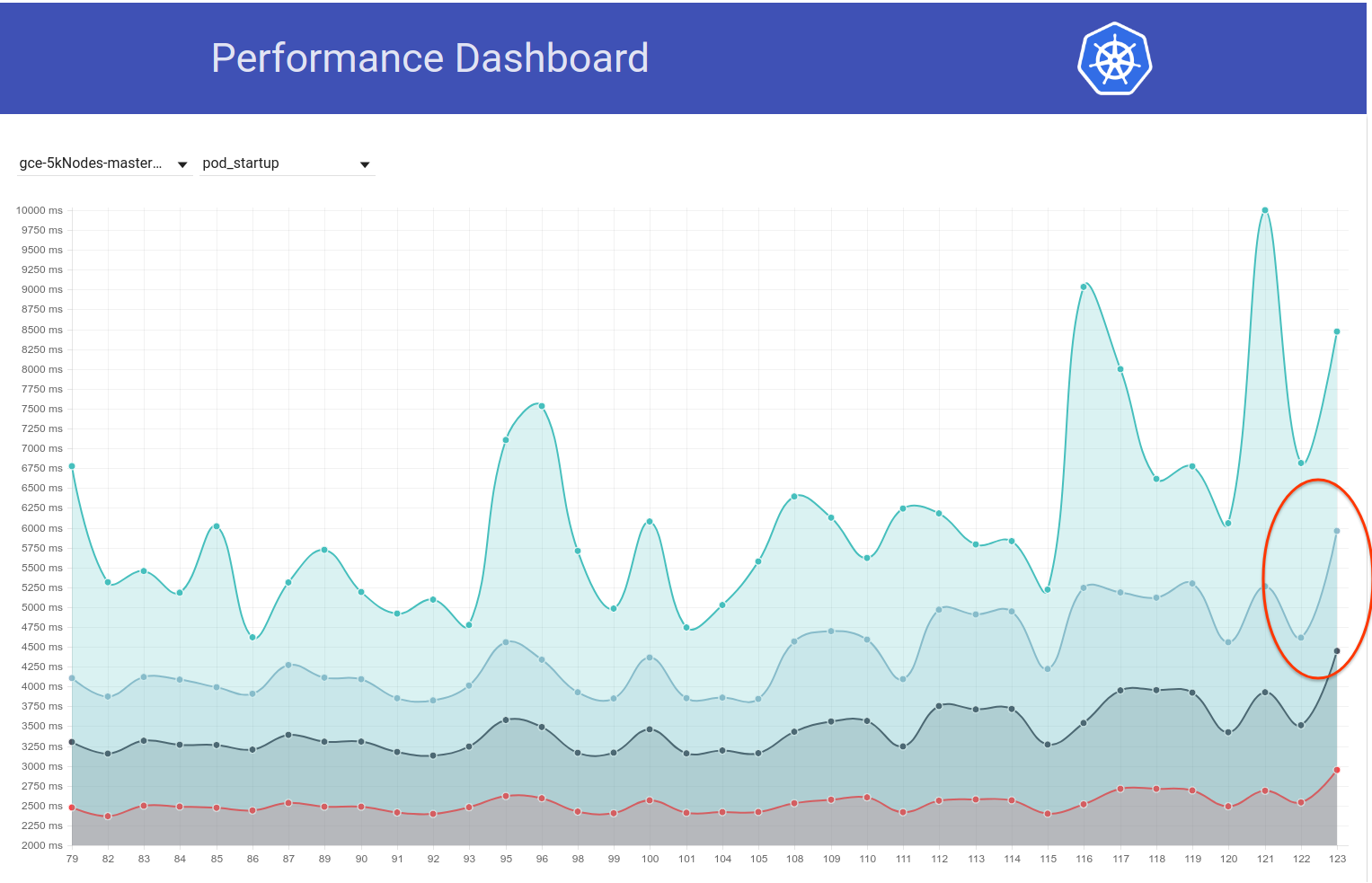
Mon principal suspect de la différence de validation est le changement etcd de 3.1.11 -> 3.1.12 (https://github.com/kubernetes/kubernetes/pull/60998). J'attendrais la prochaine exécution (actuellement en cours) pour confirmer que ce n'était pas une opération ponctuelle - mais nous devons vraiment comprendre cela.
cc @jpbetz @gyuho
shyamjvs
le 14 mars 2018
Puisque je serais en vacances jeudi-vendredi cette semaine, je colle des instructions pour exécuter un test de densité sur un cluster de 5 000 nœuds (afin que quelqu'un ayant accès au projet puisse continuer la bissection):
# Start with a clean shell.
# Checkout to the right commit.
make quick-release
# Set the project:
gcloud config set project k8s-scale-testing
# Set some configs for creating/testing 5k-node cluster:
export CLOUDSDK_CORE_PRINT_UNHANDLED_TRACEBACKS=1
export KUBE_GCE_ZONE=us-east1-a
export NUM_NODES=5000
export NODE_SIZE=n1-standard-1
export NODE_DISK_SIZE=50GB
export MASTER_MIN_CPU_ARCHITECTURE=Intel\ Broadwell
export ENABLE_BIG_CLUSTER_SUBNETS=true
export LOGROTATE_MAX_SIZE=5G
export KUBE_ENABLE_CLUSTER_MONITORING=none
export ALLOWED_NOTREADY_NODES=50
export KUBE_GCE_ENABLE_IP_ALIASES=true
export TEST_CLUSTER_LOG_LEVEL=--v=1
export SCHEDULER_TEST_ARGS=--kube-api-qps=100
export CONTROLLER_MANAGER_TEST_ARGS=--kube-api-qps=100\ --kube-api-burst=100
export APISERVER_TEST_ARGS=--max-requests-inflight=3000\ --max-mutating-requests-inflight=1000
export TEST_CLUSTER_RESYNC_PERIOD=--min-resync-period=12h
export TEST_CLUSTER_DELETE_COLLECTION_WORKERS=--delete-collection-workers=16
export PREPULL_E2E_IMAGES=false
export ENABLE_APISERVER_ADVANCED_AUDIT=false
# Bring up the cluster (this brings down pre-existing one if present, so you don't have to explicitly '--down' the previous one) and run density test:
go run hack/e2e.go \
--up \
--test \
--test_args='--ginkgo.focus=\[sig\-scalability\]\sDensity\s\[Feature\:Performance\]\sshould\sallow\sstarting\s30\spods\sper\snode\susing\s\{\sReplicationController\}\swith\s0\ssecrets\,\s0\sconfigmaps\sand\s0\sdaemons$ --allowed-not-ready-nodes=30 --node-schedulable-timeout=30m --minStartupPods=8 --gather-resource-usage=master --gather-metrics-at-teardown=master' \
> somepath/build-log.txt 2>&1
# To re-run the test on same cluster (without re-creating) just omit '--up' in the above.
NOTES IMPORTANTES:
- La plage de commit actuelle suspectée est ff7918d ... a042ecde3 (gardons ceci à jour pendant que nous coupons en deux)
- Nous devons utiliser etcd-3.1.11 au lieu de 3.2.14 (pour éviter d'inclure une régression antérieure). Modifiez la version dans les fichiers suivants pour y parvenir au minimum:
- cluster / gce / manifestests / etcd.manifest
- cluster / images / etcd / Makefile
- pirater / lib / etcd.sh
shyamjvs
le 14 mars 2018
cc: @ wojtek-t
jdumars
le 14 mars 2018
etcd v3.1.12 corrige les événements de surveillance manqués lors de la restauration. Et c'est le seul changement que nous avons apporté à partir de la v3.1.11. Le test de performance implique-t-il quelque chose avec le redémarrage etcd ou multi-nœud qui peut déclencher un instantané du leader?
gyuho
le 14 mars 2018
Le test de performance implique-t-il quelque chose avec le redémarrage etcd
À partir des journaux etcd , il ne semble pas qu'il y ait eu de redémarrage.
multi-nœuds
Nous utilisons uniquement etcd à nœud unique dans notre configuration (en supposant que c'est ce que vous avez demandé).
shyamjvs
le 14 mars 2018
Je vois. Ensuite, v3.1.11 et v3.1.12 ne devraient pas être différents: 0
Jettera un autre coup d'œil si la deuxième exécution montre également des latences plus élevées.
gyuho
le 14 mars 2018
cc: @jpbetz
jdumars
le 14 mars 2018
D'accord avec @gyuho que nous devrions essayer d'obtenir un signal plus fort sur celui-ci étant donné que le seul changement de code vers etcd est isolé pour redémarrer / récupérer le code.
Le seul autre changement est la mise à niveau d'etcd de go1.8.5 à go1.8.7, mais je doute que nous voyions une régression de performances significative avec cela.
jpbetz
le 14 mars 2018
Continuant donc avec la bissection, ff7918d1f semble être bon:
2.246719086s (watch), 3.916350274s (pod-startup)
Je mettrai à jour la plage de commit dans https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -373051051 en conséquence.
shyamjvs
le 14 mars 2018
Ensuite, le commit aa19a1726 semble être un bon, bien que je suggère de réessayer une fois de plus pour confirmer:
2.715156606s (watch), 4.382527095s (pod-startup)
À ce stade, je vais mettre en pause la bissection et commencer mes vacances :)
J'ai abattu mon cluster pour faire de la place pour la prochaine exécution.
shyamjvs
le 15 mars 2018
Merci Shyam. Je réessaye aa19a172693a4ad60d5a08e9b93557267d259c37.
 wasylkowski-a
le 15 mars 2018
wasylkowski-a
le 15 mars 2018
Pour commettre aa19a172693a4ad60d5a08e9b93557267d259c37, j'ai obtenu les résultats suivants:
2.47655243s (watch), 4.174016696s (pod-startup)
Donc ça a l'air bien. Bissection continue.
Plage de validation actuelle suspectée: aa19a172693a4ad60d5a08e9b93557267d259c37 ... a042ecde362000e51f1e7bdbbda5bf9d81116f84
wasylkowski-a
le 15 mars 2018
@ wasylkowski-a pourriez-vous assister à notre réunion de publication à 17h00 UTC / 13h00 Est / 10h00 Pacifique? C'est une réunion Zoom: https://zoom.us/j/2018742972
jdumars
le 15 mars 2018
Je participerai.
wasylkowski-a
le 15 mars 2018
Commit cca7ccbff161255292f72c2d18459cdface62122 ne semble pas clair avec les résultats suivants:
2.984185673s (watch), 4.568914929s (pod-startup)
Je vais lancer celui-ci une fois de plus pour avoir confiance que je n'entre pas dans la mauvaise moitié de la bissection.
wasylkowski-a
le 15 mars 2018
OK, donc je suis assez confiant maintenant que cca7ccbff161255292f72c2d18459cdface62122 est mauvais:
3.285168535s (watch), 4.783986141s (pod-startup)
Réduire la plage jusqu'à aa19a172693a4ad60d5a08e9b93557267d259c37 ... cca7ccbff161255292f72c2d18459cdface62122 et essayer 92e4d3da0076f923a45d54d69c84e91ac6a61a55.
wasylkowski-a
le 16 mars 2018
Commit 92e4d3da0076f923a45d54d69c84e91ac6a61a55 semble bon:
2.522438984s (watch), 4.21739985s (pod-startup)
La nouvelle plage de validation suspecte est 92e4d3da0076f923a45d54d69c84e91ac6a61a55 ... cca7ccbff161255292f72c2d18459cdface62122, en essayant 603ebe466d335a37392315d491782ed18d1bae11
wasylkowski-a
le 16 mars 2018
@wasylkowski veuillez noter que l'un des commits à savoir https://github.com/kubernetes/kubernetes/commit/4c289014a05669c376994868d8d91f7565a204b5 a été annulé dans https://github.com/kubernetes/kubernetes/commit/30883b8b3b3
dims
le 16 mars 2018
En reformulant le commentaire de
Pouvons-nous donner la priorité à un nouveau test une fois contre la tête de branche 1.10, plutôt que de continuer la bissection?
 tpepper
le 16 mars 2018
tpepper
le 16 mars 2018
@wasylkowski / @ wasylkowski-a ^^^^
tpepper
le 16 mars 2018
@ wojtek-t PTAL ASAP
jdumars
le 16 mars 2018
Merci @dims et @tpepper. Laissez mon essai contre la tête de branche 1.10 et voyez ce qui se passe.
wasylkowski-a
le 16 mars 2018
Merci @wasylkowski dans le pire des cas, nous revenons à ce que nous divisions auparavant. droite?
dims
le 16 mars 2018
1.10 tête a une régression:
3.522924087s (watch), 4.946431238s (pod-startup)
C'est sur etcd 3.1.12, pas sur etcd 3.1.11, mais si je comprends bien cela ne devrait pas faire beaucoup de différence.
En outre, 603ebe466d335a37392315d491782ed18d1bae11 semble bon:
2.744654024s (watch), 4.284582476s (pod-startup)
2.76287483s (watch), 4.326409841s (pod-startup)
2.560703844s (watch), 4.213785531s (pod-startup)
Cela nous laisse avec la plage 603ebe466d335a37392315d491782ed18d1bae11 ... cca7ccbff161255292f72c2d18459cdface62122 et il n'y a que 3 commits. Laissez-moi voir ce que je découvre.
Il est également possible qu'en effet 4c289014a05669c376994868d8d91f7565a204b5 soit le coupable ici, mais cela signifie alors que nous avons une autre régression qui se manifeste sur la tête.
wasylkowski-a
le 16 mars 2018
OK, donc évidemment commettre 6590ea6d5d50700d34255b1e037b2702ad26b7fc est bon:
2.553170576s (watch), 4.22516704s (pod-startup)
tandis que le commit 7b678dc4035c61a1991b5e1442edb13f40deae72 est incorrect:
3.498855918s (watch), 4.886599251s (pod-startup)
Le mauvais commit est la fusion du commit retourné mentionné par @dims , nous devons donc observer une autre régression en tête.
Laissez-moi essayer de relancer head sur etcd 3.1.11 au lieu de 3.1.12 et voir ce qui se passe.
wasylkowski-a
le 17 mars 2018
@ wasylkowski-ah classique bonnes nouvelles mauvaises nouvelles :) merci de continuer.
@ wojtek-t d'autres suggestions?
dims
le 17 mars 2018
La tête sur etcd 3.1.11 est également mauvaise; mon prochain essai sera d'essayer directement après le retour (donc, au commit cdecea545553eff09e280d389a3aef69e2f32bf1), mais avec etcd 3.1.11 au lieu de 3.2.14.
wasylkowski-a
le 17 mars 2018
Ça sonne bien Andrzej
- s'assombrit
Le 17 mars 2018, à 13 h 19, Andrzej Wasylkowski [email protected] a écrit:
La tête sur etcd 3.1.11 est également mauvaise; mon prochain essai sera d'essayer directement après le retour (donc, au commit cdecea5), mais avec etcd 3.1.11 au lieu de 3.2.14.
-
Vous recevez cela parce que vous avez été mentionné.
Répondez directement à cet e-mail, affichez-le sur GitHub ou désactivez le fil de discussion.
dims
le 17 mars 2018
Commit cdecea545553eff09e280d389a3aef69e2f32bf1 est bon, nous avons donc une régression ultérieure:
2.66454307s (watch), 4.308091589s (pod-startup)
Commit 2a373ace6eda6a9cf050ce70a6cf99183c5e5b37 est clairement mauvais:
3.656979569s (watch), 6.746987916s (pod-startup)
@ wasylkowski-a Donc, nous examinons essentiellement les commits dans la gamme https://github.com/kubernetes/kubernetes/compare/cdecea5...2a373ac pour voir ce qui ne va pas alors? (courir en deux entre ces deux)?
dims
le 17 mars 2018
Oui. C'est une gamme énorme, malheureusement. J'enquête actuellement sur aded0d922592fdff0137c70443caf2a9502c7580.
wasylkowski-a
le 17 mars 2018
Merci @wasylkowski quelle est la gamme actuelle? (pour que je puisse aller voir les PR).
dims
le 18 mars 2018
La validation aded0d922592fdff0137c70443caf2a9502c7580 est mauvaise:
3.626257043s (watch), 5.00754503s (pod-startup)
Commit f8298702ffe644a4f021e23a616ad6a8790a5537 est également mauvais:
3.747051371s (watch), 6.126914967s (pod-startup)
Il en va de même pour le commit 20a6749c3f86c7cb9e98442046532380fb5f6e36:
3.641172882s (watch), 5.100922237s (pod-startup)
Et il en va de même pour 0e81651e77e0be7e75179e5986ef2c76601f4bd6:
3.687028394s (watch), 5.208157763s (pod-startup)
La plage actuelle est cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6. Nous (moi, @ wojtek-t, @shyamjvs) commençons à soupçonner que cdecea545553eff09e280d389a3aef69e2f32bf1 est en fait une passe irrégulière, nous avons donc besoin d'une extrémité gauche différente.
wasylkowski-a
le 19 mars 2018
/ me place un pari sur https://github.com/kubernetes/kubernetes/commit/b259543985b10875f4a010ed0285ac43e335c8e0 en tant que coupable
cc @ wasylkowski-a
dims
le 19 mars 2018
0e81651e77e0be7e75179e5986ef2c76601f4bd6 est, se révèle, mauvais, donc b259543985b10875f4a010ed0285ac43e335c8e0 (fusionné comme 244549f02afabc5be23fc56e86a60e5b36838828, après 0e81651e77e0be7e75179e5986ef2c76601f4bd6) ne peut pas être le premier coupable (mais il est impossible qu'il a introduit une nouvelle régression, nous allons observer une fois que nous secouer celui-ci)
wasylkowski-a
le 19 mars 2018
Pour @ wojtek-t et @shyamjvs, je suis en train de relancer cdecea545553eff09e280d389a3aef69e2f32bf1, car nous soupçonnons que cela aurait pu être un "bon floconneux"
wasylkowski-a
le 19 mars 2018
Je suppose que cdecea545553eff09e280d389a3aef69e2f32bf1 est en fait bon sur la base des résultats suivants que j'ai observés:
2.66454307s (watch), 4.308091589s (pod-startup)
2.695629257s (watch), 4.194027608s (pod-startup)
2.660956347s (watch), 3m36.62259323s (pod-startup) <-- looks like an outlier
2.865445137s (watch), 4.594671099s (pod-startup)
2.412093606s (watch), 4.070130529s (pod-startup)
Plage actuellement suspectée: cdecea545553eff09e280d389a3aef69e2f32bf1 ... 0e81651e77e0be7e75179e5986ef2c76601f4bd6
Teste actuellement 99c87cf679e9cbd9647786bf7e81f0a2d771084f
wasylkowski-a
le 20 mars 2018
Merci @wasylkowski pour continuer ce travail.
jdumars
le 20 mars 2018
par discussion aujourd'hui: fluentd-scaler a toujours des problèmes: https://github.com/kubernetes/kubernetes/issues/61190 , qui n'ont pas été corrigés par les PR. Est-il possible que cette régression soit causée par fluentd?
 jberkus
le 20 mars 2018
jberkus
le 20 mars 2018
l'un des PR relatifs à fluentd https://github.com/kubernetes/kubernetes/commit/a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 est dans la dernière gamme
dims
le 20 mars 2018
par discussion aujourd'hui: fluentd-scaler a toujours des problèmes: # 61190, qui n'ont pas été résolus par les PR. Est-il possible que cette régression soit causée par fluentd?
TBH, je serais vraiment surpris si cela était dû à des problèmes de fluence. Mais je ne peux pas exclure cette hypothèse avec certitude.
Mon sentiment personnel serait un changement dans Kubelet, mais j'ai aussi examiné les PR dans cette gamme et rien ne semble vraiment suspect ...
Espérons que la fourchette sera 4 fois plus petite demain, ce qui ne signifierait que quelques PR.
wojtek-t
le 20 mars 2018
OK, donc 99c87cf679e9cbd9647786bf7e81f0a2d771084f semble bon, mais j'avais besoin de trois essais pour m'assurer que ce n'est pas un flocon:
2.901624657s (watch), 4.418169754s (pod-startup)
2.938653965s (watch), 4.423465198s (pod-startup)
3.047455619s (watch), 4.455485098s (pod-startup)
Ensuite, a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2 est mauvais:
3.769747695s (watch), 5.338517616s (pod-startup)
La plage actuelle est 99c87cf679e9cbd9647786bf7e81f0a2d771084f ... a88ddac1e47e0bc4b43bfa1b0df2f19aea4455f2. Analyse de c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd.
wasylkowski-a
le 20 mars 2018
J'ai regardé dans la gamme mentionnée ci-dessus - il n'y a que 9 PR là-bas.
https://github.com/kubernetes/kubernetes/pull/59944 - 100% PAS - ne change que le fichier des propriétaires
https://github.com/kubernetes/kubernetes/pull/59953 - potentiellement
https://github.com/kubernetes/kubernetes/pull/59809 - toucher uniquement le code kubectl, cela ne devrait donc pas avoir d'importance dans ce cas
https://github.com/kubernetes/kubernetes/pull/59955 - 100% PAS - ne touchant que des tests e2e non liés
https://github.com/kubernetes/kubernetes/pull/59808 - potentiellement (cela change la configuration du cluster)
https://github.com/kubernetes/kubernetes/pull/59913 - 100% PAS - ne touchant que des tests e2e non liés
https://github.com/kubernetes/kubernetes/pull/59917 - cela change le test, mais n'active pas les changements, donc peu probable
https://github.com/kubernetes/kubernetes/pull/59668 - 100% PAS - ne touchant que le code AWS
https://github.com/kubernetes/kubernetes/pull/59909 - 100% PAS - ne touchant que les fichiers des propriétaires
Je pense donc que nous avons deux candidats ici: https://github.com/kubernetes/kubernetes/pull/59953 et https://github.com/kubernetes/kubernetes/pull/59808
J'essaierai de creuser plus profondément ces derniers pour les comprendre.
wojtek-t
le 21 mars 2018
c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd semble plutôt mauvais:
3.428891786s (watch), 4.909251611s (pod-startup)
Étant donné qu'il s'agit de la fusion de # 59953, l'un des suspects de Wojtek, je vais maintenant exécuter sur un commit avant cela, donc f60083549a43f152b3142e01756e25611d911770.
Ce commit, cependant, est un changement OWNERS_ALIASES, et il ne reste plus rien dans cette plage avant, donc c105796e4ba7fc9cfafc2e7a3cc4a556d7d9defd doit être le problème. Je vais exécuter le test juste pour la sécurité, de toute façon.
wasylkowski-a
le 21 mars 2018
Discuté hors ligne - nous exécuterons des tests en tête avec ce commit localement annulé à la place.
wojtek-t
le 21 mars 2018
Hou la la! une seule doublure causant tant de problèmes. merci @wasylkowski @ wojtek-t
dims
le 21 mars 2018
@dims One-liners peut en effet causer des ravages avec l'évolutivité. Un autre par exemple du passé - https://github.com/kubernetes/kubernetes/pull/53720#issue-145949976
En général, vous voudrez peut-être voir https://github.com/kubernetes/community/blob/master/sig-scalability/blogs/scalability-regressions-case-studies.md pour une bonne lecture :)
shyamjvs
le 21 mars 2018
Mettre à jour re. test en tête: première exécution avec le commit localement rétabli passé. Cela pourrait être un flocon, cependant, alors je le réexécute.
wasylkowski-a
le 21 mars 2018
En regardant le commit dans https: //github.com/kubernetes/kubernetes/pull/59953 ... n'était-ce pas en
liggitt
le 21 mars 2018
@ Random-Liu Qui pourra peut-être mieux nous expliquer quel est l'effet de ce changement :)
shyamjvs
le 21 mars 2018
En regardant le commit dans # 59953 ... ne corrigeait-il pas un bogue? Il semble avoir corrigé un bogue plaçant le statut «programmé» dans le mauvais objet. Le kubelet aurait-il pu signaler qu'un pod était planifié trop tôt avant ce correctif?
Ouais - je sais que c'était une correction de bogue. Je ne comprends tout simplement pas cela.
Il semble résoudre le problème des rapports de pod en tant que "programmé". Mais nous ne voyons pas le problème même jusqu'à ce que le temps soit signalé par kubelet comme "StartedAt".
Le problème est que nous constatons une augmentation significative entre le temps signalé comme "StartedAt" par Kubelet et le moment où la mise à jour de l'état du pod est rapportée et surveillée par le test.
Je pense donc que le bit «programmé» est un hareng rouge ici.
Ma conjecture (mais ce n'est encore qu'une supposition) est qu'en raison de ce changement, nous envoyons plus de mises à jour de l'état des pods, ce qui à son tour entraîne plus de 429 ou autre chose comme ça. Et à la fin, il faut plus de temps à un Kubelet pour signaler l'état du pod. Mais c'est quelque chose que nous devons encore confirmer.
wojtek-t
le 21 mars 2018
Après deux essais, je suis convaincu que le fait de revenir au # 59953 résout le problème:
3.052567319s (watch), 4.489142104s (pod-startup)
2.799364978s (watch), 4.385999497s (pod-startup)
nous envoyons plus de mises à jour de l'état des pods, ce qui à son tour entraîne plus de 429 ou de qch comme ça. Et à la fin, il faut plus de temps à un Kubelet pour signaler l'état du pod.
C'est à peu près l'effet que je supposais dans https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -370573938 (bien que la cause que je suppose était fausse) :)
De plus, l'IIRC a semblé voir une augmentation du nombre de 429 pour les appels put (voir mon https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370582634) mais cela provenait d'une gamme antérieure, je pense ( autour du changement etcd).
shyamjvs
le 21 mars 2018
Après deux essais, je suis convaincu que le fait de revenir au # 59953 résout le problème:
Mon intuition (https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-370874602) à propos du problème d'être assez tôt côté kubelet dans le fil était correcte après tout :)
shyamjvs
le 21 mars 2018
/ nœud sig
@ kubernetes / sig-node-bugs l'équipe de publication pourrait vraiment utiliser la révision sur # 59953 commit contre revert et le problème de performance ici
tpepper
le 21 mars 2018
En regardant le commit dans # 59953 ... ne corrigeait-il pas un bogue? Il semble avoir corrigé un bogue plaçant le statut «programmé» dans le mauvais objet. Sur la base du problème référencé dans ce PR, il semble que le kubelet pourrait manquer de signaler qu'un pod a été planifié sans ce correctif?
@liggitt Merci de PodScheduled . Avec # 59953, kubelet le fera correctement.
@shyamjvs Je ne sais pas si cela pourrait introduire plus de mise à jour de l'état des pods.
Si je comprends bien, la condition PodScheduled sera définie dans la première mise à jour de statut, puis elle sera toujours là et jamais modifiée. Je ne comprends pas pourquoi il génère plus de mise à jour de statut.
S'il introduit vraiment plus de mise à jour de statut, c'est un problème introduit il y a 2 ans https://github.com/kubernetes/kubernetes/pull/24459 mais couvert par un bug, et # 59953 vient de corriger le bug ...
@ wasylkowski-a Avez-vous des journaux pour le 2 test exécuté dans https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -374982422 et https://github.com/kubernetes/kubernetes/issues/60589# issueecomment -374871490? Fondamentalement, un bon et un mauvais. Le kubelet.log sera très utile.
 Random-Liu
le 21 mars 2018
Random-Liu
le 21 mars 2018
@yujuhong et moi avons découvert que # 59953 exposait un problème selon lequel la condition PodScheduled du pod statique continuera à être mise à jour.
Kubelet génère une nouvelle condition PodScheduled pour le pod qui ne l'a pas. Le pod statique ne l'a pas et son statut n'est jamais mis à jour (comportement attendu). Ainsi, kubelet continuera à générer une nouvelle condition PodScheduled pour le pod statique.
Le problème a été introduit dans # 24459, mais couvert par un bogue. # 59953 a corrigé le bogue et exposé le problème d'origine.
Il existe 2 options pour résoudre rapidement ce problème:
- Option 1: Ne laissez pas kubelet ajouter la condition
PodScheduled, kubelet devrait juste préserver la conditionPodScheduleddéfinie par le planificateur.- Avantages: Simple.
- Inconvénients: Le pod statique et le pod qui contourne le programmateur (attribuez directement le nom du nœud) n'auront pas de condition
PodScheduled. En fait, sans # 59953, bien que kubelet finisse par définir cette condition pour ces pods, mais cela peut prendre très longtemps à cause d'un bogue.
- Option 2: Générer une condition
PodScheduledpour le pod statique lorsque kubelet le voit initialement.
L'option 2 pourrait introduire moins de changement face aux utilisateurs.
Mais nous voulons demander ce que signifie PodScheduled pour les pods qui ne sont pas planifiés par le planificateur? Avons-nous vraiment besoin de cette condition pour ces pods? / cc @ kubernetes / sig-autoscaling-bugs Parce que @yujuhong m'a dit que PodScheduled est maintenant utilisé par l'autoscaling.
/ cc @ kubernetes / sig-node-bugs @ kubernetes / sig-scheduling-bugs
Random-Liu
le 21 mars 2018
@ Random-Liu Quel est l'effet du very long time for kubelet to eventually set this condition ? Quel problème un utilisateur final remarquera-t-il / rencontrera-t-il (en dehors de la desquamation du faisceau d'essai)? (à partir de l'option 1)
dims
le 21 mars 2018
@dims L' utilisateur ne verra pas la condition PodScheduled pendant longtemps.
Random-Liu
le 21 mars 2018
J'ai un correctif # 61504 qui implémente l'option 2 dans https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979.
Je peux le changer en option 1 si les gens pensent que c'est une meilleure solution. :)
Random-Liu
le 21 mars 2018
vous feriez mieux de demander à des gens qui le savent à fond! (PAS l'équipe de publication 😄!)
ping @dashpole @ dchen1107 @derekwaynecarr
dims
le 21 mars 2018
@ Random-Liu IIRC le seul pod statique fonctionnant sur les nœuds dans nos tests est kube-proxy. Pourriez-vous dire à quelle fréquence ces «mises à jour continues» sont effectuées par kubelet? (demander afin d'estimer les qps supplémentaires introduits par le bogue)
shyamjvs
le 21 mars 2018
@ Random-Liu IIRC le seul pod statique fonctionnant sur les nœuds dans nos tests est kube-proxy. Pourriez-vous dire à quelle fréquence ces «mises à jour continues» sont effectuées par kubelet? (demander afin d'estimer les qps supplémentaires introduits par le bogue)
@shyamjvs Ouais, kube-proxy est le seul sur le nœud maintenant.
Je pense que cela dépend de la fréquence de synchronisation du pod https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/kubeletconfig/v1beta1/defaults.go#L47 , soit 1 minute. Ainsi, kubelet génère une mise à jour supplémentaire du statut du pod toutes les 1 minute.
Random-Liu
le 22 mars 2018
Merci. Cela signifie donc 5000/60 = ~ 83 qps supplémentaires en raison de ces appels de statut de pod. Cela semble expliquer l'augmentation des 429 notés plus tôt dans le bogue.
shyamjvs
le 22 mars 2018
@ Random-Liu merci beaucoup de nous aider à faire ce tri.
jdumars
le 22 mars 2018
@jdumars np ~ @yujuhong m'a beaucoup aidé!
Random-Liu
le 22 mars 2018
Mais nous voulons nous demander ce que signifie PodScheduled pour les pods qui ne sont pas planifiés par le planificateur? Avons-nous vraiment besoin de cette condition pour ces pods? / cc @ kubernetes / sig-autoscaling-bugs Parce que @yujuhong m'a dit que PodScheduled est maintenant utilisé par l'autoscaling.
Je pense toujours que laisser kubelet définir la condition PodScheduled est quelque peu étrange (comme je l'ai noté dans le PR original). Même si kubelet ne définit pas cette condition, cela n'affectera pas l'autoscaler du cluster puisque l'autoscaler ignore les pods sans la condition spécifique. Quoi qu'il en soit, le correctif que nous avons finalement proposé a une empreinte très mineure, et conserverait le comportement actuel (c'est-à-dire toujours définir la condition PodScheduled), nous allons donc continuer avec cela.
 yujuhong
le 22 mars 2018
yujuhong
le 22 mars 2018
En outre, ravivé le très vieux problème d'ajout de tests pour le taux de mise à jour des pods en état stable
yujuhong
le 22 mars 2018
Quoi qu'il en soit, le correctif que nous avons finalement proposé a une empreinte très mineure, et conserverait le comportement actuel (c'est-à-dire toujours définir la condition PodScheduled), nous allons donc continuer avec cela.
@yujuhong - parlez-vous de celui-ci: # 61504 (ou ai-je mal compris)?
@wasylkowski @shyamjvs - pouvez-vous s'il vous plaît exécuter des tests de 5000 nœuds avec ce PR corrigé localement (avant de le fusionner) pour vous assurer que cela aide vraiment?
wojtek-t
le 22 mars 2018
J'ai exécuté le test contre 1.10 HEAD + # 61504, et la latence de démarrage du pod semble bien:
INFO: perc50: 2.594635536s, perc90: 3.483550118s, perc99: 4.327417676s
Sera réexécuté une fois de plus pour confirmer.
shyamjvs
le 22 mars 2018
@shyamjvs - merci beaucoup!
wojtek-t
le 22 mars 2018
La deuxième manche semble également bonne:
INFO: perc50: 2.583489146s, perc90: 3.466873901s, perc99: 4.380595534s
Assez confiant maintenant, le correctif a fait l'affaire. Allons-y dès que possible 1.10.
shyamjvs
le 22 mars 2018
Merci @shyamjvs
Pendant que nous parlions hors ligne, je pense que nous avons eu une autre régression au cours du dernier mois, mais celle-ci ne devrait pas bloquer la publication.
wojtek-t
le 22 mars 2018
@yujuhong - parlez-vous de celui-ci: # 61504 (ou ai-je mal compris)?
Oui. Le correctif actuel dans ce PR ne figure pas dans les options proposées initialement dans https://github.com/kubernetes/kubernetes/issues/60589#issuecomment -375103979
yujuhong
le 22 mars 2018
réouverture jusqu'à ce que nous ayons un bon résultat de test de performance.
jberkus
le 25 mars 2018
@yujuhong @krzyzacy @shyamjvs @ wojtek-t @ Random-Liu @ wasylkowski-a des mises à jour à ce sujet? Cela bloque toujours 1.10 pour le moment.
jdumars
le 26 mars 2018
Donc, la seule partie de ce bogue qui bloquait la publication est le travail de performance de 5k nœuds. Malheureusement, nous avons perdu notre course d'aujourd'hui pour une raison différente (réf: https://github.com/kubernetes/kubernetes/issues/61190#issuecomment-376150569)
Cela dit, nous sommes assez confiants que le correctif fonctionne sur la base de mes exécutions manuelles (résultats collés dans https://github.com/kubernetes/kubernetes/issues/60589#issuecomment-375350217). Donc, à mon humble avis, nous n'avons pas besoin de bloquer la publication sur celui-ci (la prochaine exécution aura lieu mercredi).
shyamjvs
le 26 mars 2018
+1
@jdumars - Je pense que nous pouvons traiter cela comme un non-bloquant.
wojtek-t
le 26 mars 2018
Désolé, j'ai modifié mon message ci-dessus. Je voulais dire que nous devrions le traiter comme "non bloquant".
wojtek-t
le 26 mars 2018
D'accord, merci beaucoup. Cette conclusion représente un nombre considérable d'heures que vous avez investies, et je ne saurais trop vous remercier pour le travail que vous avez accompli. Alors que nous parlons dans l'abstrait de «communauté» et de «contributeurs», vous et les autres qui ont travaillé sur cette question le représentez en termes concrets. Vous êtes le cœur et l'âme de ce projet, et je sais que je parle au nom de toutes les personnes impliquées lorsque je dis que c'est un honneur de travailler aux côtés d'une telle passion, engagement et professionnalisme.
jdumars
le 26 mars 2018
[MILESTONENOTIFIER] Problème de jalon: à jour pour le processus
@krzyzacy @ msau42 @shyamjvs @ wojtek-t
Étiquettes de problème
sig/api-machinerysig/autoscalingsig/nodesig/scalabilitysig/schedulingsig/storage: le problème sera transmis à ces SIG si nécessaire.priority/critical-urgent: ne déplacez jamais automatiquement le problème hors d'un jalon de publication; escaladez continuellement vers le contributeur et SIG via tous les canaux disponibles.kind/bug: Corrige un bogue découvert lors de la version actuelle.Aidez-moi
 k8s-github-robot
le 11 avr. 2018
k8s-github-robot
le 11 avr. 2018
Ce problème a été résolu avec les correctifs appropriés dans la version 1.10.
Pour la version 1.11, nous suivons les échecs sous - https://github.com/kubernetes/kubernetes/issues/63030.
/Fermer
shyamjvs
le 25 mai 2018
Questions connexes
 theothermike
·
3Commentaires
theothermike
·
3Commentaires
 ddysher
·
3Commentaires
ddysher
·
3Commentaires
 ttripp
·
3Commentaires
ttripp
·
3Commentaires
 jason-riddle
·
3Commentaires
jason-riddle
·
3Commentaires
 sanjana-bhat
·
3Commentaires
sanjana-bhat
·
3Commentaires
Commentaire le plus utile
J'ai exécuté le test contre 1.10 HEAD + # 61504, et la latence de démarrage du pod semble bien:
Sera réexécuté une fois de plus pour confirmer.