/种类错误
这并不是Kubernets本身的错误,更像是单挑。
我读了这篇很棒的博客文章:
从博客文章中,我了解到k8s正在使用cfs配额来强制执行CPU限制。 不幸的是,这些措施可能导致不必要的节流,特别是对于表现良好的租户而言。
在我提起的Linux内核中看到这个未解决的错误:
有一个开放且停滞的补丁程序可以解决该问题(我尚未验证它是否有效):
抄送@ConnorDoyle @balajismaniam
 bobrik
bobrik
所有142条评论
/ sig节点
/种类错误
 neolit123
于 2018-08-20
neolit123
于 2018-08-20
这是#51135的副本吗?
 liggitt
于 2018-08-20
liggitt
于 2018-08-20
这在本质上是相似的,但是似乎错过了一个事实,那就是内核中存在一个实际的错误,而不是在CFS配额期间进行一些配置折衷。 我喜欢#51135回到这里给人们更多的上下文。
bobrik
于 2018-08-22
据我了解,这是禁用CFS配额( --cpu-cfs-quota=false )或使其可配置(#63437)的另一个原因。
我还发现这个要点(链接到内核补丁)非常有趣,可以观察(以评估影响): https :
 hjacobs
于 2018-08-22
hjacobs
于 2018-08-22
cc @adityakali
 vishh
于 2018-08-23
vishh
于 2018-08-23
配额的另一个问题是kubelet将超线程计为“ cpus”。 当群集变得如此负载以至于两个线程被调度在同一个内核上并且该进程具有cpu配额配额时,其中一个将仅以可用处理能力的一小部分执行(仅当另一个线程上有某些操作时才会执行某些操作)档),但仍会消耗配额,就好像它本身具有物理核心一样。 因此,它消耗的配额是其应有的两倍,而不需要做更多的工作。
这样的结果是,在启用了超线程的完全加载的节点上,性能将是禁用超线程或配额的情况的一半。
Imo kubelet不应将超线程视为真正的CPU,以避免这种情况。
 juliantaylor
于 2018-08-30
juliantaylor
于 2018-08-30
@juliantaylor正如我在#51135中提到的那样,对于大多数运行受信任的工作负载的k8s集群,关闭CPU配额可能是最好的方法。
vishh
于 2018-08-30
这被视为错误吗?
如果某些Pod在没有真正耗尽其CPU限制的情况下受到限制,这对我来说似乎是一个错误。
在我的集群上,大多数超额配额吊舱都与度量标准(堆,度量标准收集器,节点导出器...)或运算符有关,这些运算符显然具有此处遇到的工作量:大部分不执行时间和醒来,每隔一段时间调和一次。
奇怪的是,我试图提高限制,从40m变为100m或200m ,并且流程仍然受到限制。
我看不到其他指标指出可能触发此限制的工作负载。
我现在已经取消了对这些Pod的限制...越来越好了,但是,听起来确实像个bug,我们应该提供比禁用Limits更好的解决方案
 prune998
于 2018-11-26
hjacobs
于 2018-11-27
prune998
于 2018-11-26
hjacobs
于 2018-11-27
谢谢@hjacobs。
我正在使用Google GKE,但看不到禁用它的简便方法,但我一直在搜索...。
prune998
于 2018-11-27
@ prune998 AFAIK,Google尚未公开必要的旋钮。 在可能禁用上游CFS的可能性之后,我们立即提出了功能请求,此后没有再听到任何消息。
 timoreimann
于 2018-11-27
timoreimann
于 2018-11-27
我正在使用Google GKE,但看不到禁用它的简便方法,但我一直在搜索...。
您现在可以从容器中删除CPU限制吗?
vishh
于 2018-11-28
根据CPU管理器文档, CFS quota is not used to bound the CPU usage of these containers as their usage is bound by the scheduling domain itself.但是我们正在经历CFS限制。
这使静态CPU管理器几乎毫无意义,因为设置CPU限制以实现“保证的QoS”类将抵消节流带来的任何好处。
静态CPU上的Pod完全设置了CFS配额是否是一个错误?
 mariusgrigoriu
于 2019-02-12
mariusgrigoriu
于 2019-02-12
对于其他上下文(昨天了解到): @hrzbrg (MyTaxi)向Kops提供了一个标志以禁用CPU节流: https :
hjacobs
于 2019-02-12
请在这里分享问题摘要。 目前尚不清楚问题是什么,在什么情况下用户受到影响,以及确切需要解决什么问题?
目前我们的理解是,当我们越过极限时,我们会受到惩罚和限制。 假设我们有3个核心的cpu配额,在开始的5毫秒内我们消耗了3个核心,然后在100毫秒的片中我们将节流95毫秒,在这95毫秒内我们的容器无法执行任何操作。 而且我们已经看到,即使在CPU使用率指标中看不到CPU峰值时,也会受到限制。 我们假设这是因为测量CPU使用率的时间窗口以秒为单位,并且节流发生在微秒级,所以它的平均值是不可见的。 但是这里提到的错误现在让我们感到困惑。
几个问题:
- 当节点处于100%cpu时? 这是否是一种特殊情况,即所有容器无论其用途如何都受到限制?
发生这种情况时,所有容器的CPU利用率是否都会达到100%?
是什么导致此错误在节点中触发的?
不使用
limits和禁用cpu.cfs_quota什么区别?当有许多易爆Pod且一个Pod会导致节点不稳定并影响正在运行其请求的其他Pod时,禁用
limits是否不是一个冒险的解决方案?另外,根据内核文档,当父配额完全用尽时,进程可能会受到限制。 容器上下文中的父级是什么(与该错误有关)? https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
There are two ways in which a group may become throttled: a. it fully consumes its own quota within a period b. a parent's quota is fully consumed within its period- 需要什么来修复它们? 升级内核版本?
我们已经面临了相当大的停机,它看起来与我们所有的pod陷入节流重启循环中并且无法扩大规模密切相关(如果不是根本原因)。 我们正在研究细节以找到真正的问题。 我将打开一个单独的问题,详细说明我们的停机情况。
在这里的任何帮助,我们将不胜感激。
cc @justinsb
 alok87
于 2019-02-14
alok87
于 2019-02-14
我们的一位用户设置了CPU限制,并因超时而无法进行活动性探测,从而导致服务中断。
即使将容器固定到CPU,我们也看到节流。 例如,CPU限制为1并将该容器固定为仅在一个CPU上运行。 如果您的配额恰好是您拥有的CPU数量,那么在任何时期都不可能超过配额,但是在每种情况下我们都会看到节流。
我以为我看到它发布在内核4.18解决了该问题的某个地方。 我还没有测试过,所以如果有人可以确认会很好。
mariusgrigoriu
于 2019-02-15
 clkao
于 2019-02-23
clkao
于 2019-02-23
@mariusgrigoriu我似乎陷入了您在这里描述的同一难题中https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -462534360。
我们观察到使用CPUManager静态策略在“保证的QoS”类中的Pod上进行的CPU节流(这似乎没有任何意义)。
删除这些Pod的limits会将它们放入Burstable QoS类,这不是我们想要的,因此剩下的唯一选择是在系统范围内禁用CFS cpu配额,这也不是我们可以安全地做的,因为允许所有Pod访问未绑定的CPU容量会导致危险的CPU饱和问题。
鉴于上述情况, @ vishh的最佳做法是什么? 似乎升级到内核> 4.18(具有cfs cpu帐户修复程序)并且(也许)减少cfs配额期限?
总的来说,建议我们只从受限制的容器中删除limits应该有明确的警告:
1)如果这些是具有保证的QoS类的Pod,具有整数个内核并且具有CPUMnanager静态策略-这些Pod
2)这些Pod在消耗多少CPU方面是不受限制的,在某些情况下可能会造成相当大的损害。
您的反馈/指导将不胜感激。
 dannyk81
于 2019-03-25
dannyk81
于 2019-03-25
升级内核绝对有帮助,但是应用CFS配额的行为似乎仍然与文档建议的不一致。
mariusgrigoriu
于 2019-03-25
我一直在研究这个问题的各个方面。 我在LKML的帖子中总结了我的研究。
https://lkml.org/lkml/2019/3/18/706
话虽如此,但我无法重现512ac99之前的内核中所述的问题。 但是,我在512ac99之后的内核中看到了性能下降。 因此,解决办法不是万灵药。
 chiluk
于 2019-03-25
chiluk
于 2019-03-25
谢谢@mariusgrigoriu,我们将执行内核升级,并希望将有所帮助,还检查了https://github.com/kubernetes/kubernetes/issues/70585 -似乎配额确实与cpuset保证吊舱(组即固定的CPU),所以这对我来说似乎是一个错误。
dannyk81
于 2019-03-25
@chiluk您能详细说明一下吗? 您是说4.18(上面在https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-466609030中提到)中包含的补丁实际上并不能解决问题?
dannyk81
于 2019-03-25
512ac99内核补丁为某些人解决了一个问题,但导致我们的配置出现问题。 该补丁修复了时间片在cfs_rq之间的分配方式,因为它们现在正确到期了。 以前它们不会过期。
现在,由于阻塞了工作线程,特别是在高核数计算机上的Java工作负载会出现大量的节流情况,而CPU使用率却很低。 那些线程被分配了时间片,它们仅使用一小部分,该部分随后过期。 在我编写的*(在该线程上链接到)上的综合测试中,我们发现性能下降了大约30倍。 在现实世界中,由于节流增加,我们看到两个内核之间的响应时间下降了数百毫秒。
chiluk
于 2019-03-25
使用4.19.30内核,我看到希望减少油门的Pod仍处于节流状态,一些以前没有被节流的Pod现在正被严重节流(kube2iam报告的节流秒数比实例启动的时间更长) , 不知何故)
 willthames
于 2019-03-27
willthames
于 2019-03-27
在CoreOS 4.19.25-coreos上,我看到Prometheus几乎在系统中的每个Pod上都触发CPUThrottlingHigh警报。
 teralype
于 2019-03-27
teralype
于 2019-03-27
@williamsandrew @teralype,这似乎反映了@chiluk的发现。
经过各种内部讨论,我们实际上决定完全禁用cfs配额(kubelet标志--cpu-cfs-quota=false ),这似乎解决了我们对于Burstable和Guaranteed(固定或标准的CPU)Pod一直遇到的所有问题。
这里有一个很好的平台(以及其他一些主题): https :
强烈建议阅读:+1:
dannyk81
于 2019-03-27
长期发行(自我注释)
 dims
于 2019-03-27
dims
于 2019-03-27
@hjacobs ,喜欢这个话题! 非常感谢...
知道如何在AKS或GKE上应用此修复程序吗?
谢谢
 agolomoodysaada
于 2019-04-02
agolomoodysaada
于 2019-04-02
@agolomoodysaada我们
timoreimann
于 2019-04-02
我联系了Azure支持人员,他们说它将直到2019年8月左右才可用。
agolomoodysaada
于 2019-04-04

我以为我会分享一个应用程序在整个生命周期中一直受到限制的图表。
agolomoodysaada
于 2019-04-05
这是什么内核?
chiluk
于 2019-04-05
“ chiluk ” 4.15.0-1037-azure“
agolomoodysaada
于 2019-04-05
因此,其中不包含内核提交512ac99。 这是对应的
资源。
https://kernel.ubuntu.com/git/kernel-ppa/mirror/ubuntu-azure-xenial.git/tree/kernel/sched/fair.c?h=Ubuntu-azure-4.15.0-1037.39_16.04.1 &id = 19b0066cc4829f45321a52a802b640bab14d0f67
这意味着您可能遇到了512ac99中描述的问题。 保持在
请注意,512ac99为我们带来了其他回归。
2019年4月5日星期五,下午12:08穆迪(Moody Saada) [email protected]
写道:
@chiluk https://github.com/chiluk “ 4.15.0-1037-azure”
—
您收到此邮件是因为有人提到您。
直接回复此电子邮件,在GitHub上查看
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-480350946 ,
或使线程静音
https://github.com/notifications/unsubscribe-auth/ACDI05YeS6wfUE9XkiMbxrLvPllYQZ7Iks5vd4MOgaJpZM4WDUF3
。
chiluk
于 2019-04-05
我现在已经将有关此问题的补丁发布到LKML。
https://lkml.org/lkml/2019/4/10/1068
附加的测试将不胜感激。
chiluk
于 2019-04-11
我现在通过文档更改重新提交了这些补丁。
https://lkml.org/lkml/2019/5/17/581
如果人们可以测试这些补丁并对LKML上的线程发表评论,那将真的有帮助。 目前,我是唯一在LKML上完全提到这一点的人,而且我还没有收到社区或维护者的任何评论。 如果我可以在补丁程序下获得一些有关LKML的社区测试和评论,那将真的很长。
chiluk
于 2019-05-21
对于它的价值,这个特定项目https://github.com/tensorflow/serving似乎受到此问题的严重影响。 它主要是一个C ++应用程序。
@chiluk ,在补丁发布期间,我们可以应用任何替代方法吗?
非常感谢你
agolomoodysaada
于 2019-05-29
我们应该帮助@chiluk收集此内核错误对Kubernetes以及使用CFS配额的其他人的严重影响的引用。
Zolando在上周的演讲中表示,他们对当前内核的不良经验意味着他们认为禁用CFS配额是当前的最佳实践,因为他们认为弊大于利。
https://www.youtube.com/watch?v=6sDTB4eV4F8
 whereisaaron
于 2019-05-29
whereisaaron
于 2019-05-29
越来越多的公司正在禁用CPU节流,例如mytaxi,Datadog,Zalando( Twitter线程)
hjacobs
于 2019-05-29
@derekwaynecarr @ dchen1107 @ kubernetes / sig-node-feature-requests黎明,Derek,现在是时候更改默认值了吗? 和/或文档?
dims
于 2019-05-29
是的, @ whereisaaron收集和共享限制应用程序的报告,或者由于行为不良而被关闭,欢迎在适当的情况下加入lkml线程。 目前看来,主要是我向内核社区抱怨此问题。
chiluk
于 2019-05-29
@agolomoodysaada的解决方法是暂时禁用cfs配额或将cpu配额过度分配给受影响的应用程序*(并非所有应用程序都可以实现这一目标,但是大多数多线程用户交互应用程序都可以使用)。
围绕减少应用程序线程数的最佳实践也有帮助。
对于golang设置GOMAXPROCS〜= ceil(quota)
对于Java,请迁移到识别并遵守cpu配额限制的较新JVM。 早期的jvm根据CPU核心数(而不是应用程序可用的核心数)生成线程。
这两方面对我们来说都是极大的收益。
监视和报告遇到问题的应用程序,以便您的开发人员可以调整配额。
chiluk
于 2019-05-29
仅供参考,在我指出了该线程对Azure AKS支持后,我得到回答,最多在9月下旬,补丁将在升级到内核5.0时推出。
在此之前,请停止使用限制:)
prune998
于 2019-05-29
@ prune998在使用CPUmanager的情况下有一个小警告(即,在保证QoS中将专用cpu分配给pod)。
通过消除限制,您可以避免CFS限制问题,但是您可以从保证的QoS中删除Pod,因此CPUmanager将不再为这些Pod分配专用的内核。
如果您不使用CPUmanager,则不会造成任何伤害,而对于任何选择此方向的人来说,仅供参考。
有一个PR(https://github.com/kubernetes/kubernetes/issues/70585)可以完全禁用具有专用CPU的Pod的CFS配额,但是尚未合并。
我们还选择了如上所述禁用整个CFS配额系统,到目前为止没有任何问题。
dannyk81
于 2019-05-29
@ dannyk81 https://github.com/kubernetes/kubernetes/issues/70585不是可以合并的PR(这是代码段的问题)。 您(或其他人)可以提交PR吗?
dims
于 2019-05-29
已经有一个了: https :
 praseodym
于 2019-05-29
praseodym
于 2019-05-29
@dims我链接了该问题,而不是PR ...,但该问题与PR链接了:)确实是https://github.com/kubernetes/kubernetes/pull/75682 ,它已经挂了一段时间了,因此,如果您可以推动,那就太好了,因为这确实是一个令人讨厌的问题。
谢谢:+1
dannyk81
于 2019-05-29
哎呀! 感谢@ dannyk81我已经分配了乡亲并添加了里程碑
dims
于 2019-05-29
FWIW我们也遇到了这个问题,发现将CFS配额期限降低到10ms而不是默认的100ms会导致我们的后端延迟显着提高。 我认为这是因为,即使您遇到了内核错误,如果不使用配额,也会浪费更少的配额,并且该过程可以更快地获得更多的配额(以较小的分配)。 这只是一种解决方法,但对于不想完全禁用CFS配额的用户,在实施此修复程序之前,这可能是一个临时方案。 k8s在1.12中通过cpuCFSQuotaPeriod功能门和--cpu-cfs-quota-period kubelet标志支持此操作。
 d-shi
于 2019-05-30
d-shi
于 2019-05-30
我必须检查一下,但是我认为将周期缩短得这么远可能会有效地禁用它,因为代码中有切片最小值和配额最小值。 您最好关闭配额并转到软配额。
chiluk
于 2019-05-30
我的外行人@chiluk的理解是,默认分片为5ms,因此将其设置为5ms或更小会有效地禁用它,但是只要时间段大于5ms,仍然应该执行配额。 绝对让我知道是否不正确。
d-shi
于 2019-05-31
有了--feature-gates=CustomCPUCFSQuotaPeriod=true --cpu-cfs-quota-period=10ms ,我的一个吊舱真的很难启动。 在所附的普罗米修斯图中,容器尝试启动,直到被杀死之前,它几乎无法满足其活动性检查(通常容器会在大约5秒内启动-甚至将活动性initialDelaySeconds增加到60s都无济于事),并且然后换成新的
您可以看到,在我从kubelet args中删除了cpu-cfs-quota-period之前,该容器已被严重限制,此时节流变得更加平坦,并且该容器在大约5秒钟后再次启动。

willthames
于 2019-06-05
仅供参考:有关禁用CPU节流的主题的当前Twitter线程: https :
hjacobs
于 2019-06-05
以下是我们移至生产中的--cpu-cfs-quota-period=10ms之前/之后的2种延迟敏感服务的CPU节流图:
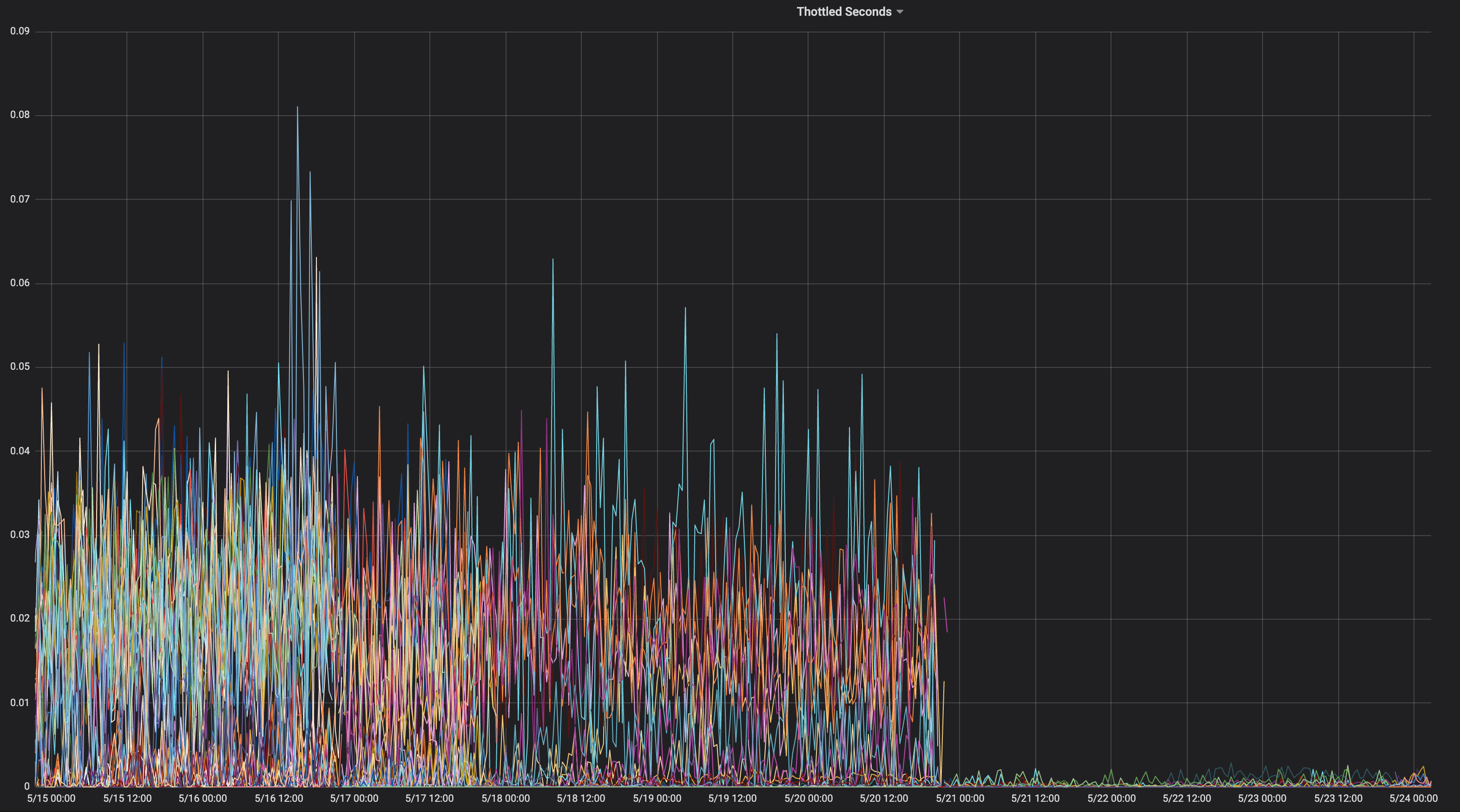

这些服务在不同的实例类型上运行(具有不同的污点/容差)。 首先将第二个服务的实例移至较低的CFS配额期限。
结果必须非常取决于负载。
d-shi
于 2019-06-05
@ d-shi您的图形上还有其他情况。 我认为您可能正在达到一些最低配额配额,因为期限太短了。 我必须检查一下代码才能确定。 基本上,您无意中增加了该应用程序可用的配额数量。 您实际上可以通过增加配额分配来完成同一件事。
chiluk
于 2019-06-05
对我们来说,衡量延迟而不是节流更为有用。 禁用cfs-quota大大改善延迟。 我希望看到类似的更改cfs-quota-period 。
 blakebarnett
于 2019-06-06
blakebarnett
于 2019-06-06
@chiluk实际上我们确实尝试增加配额分配(达到每个Pod kubernetes支持的最大限额),并且在任何情况下,尾部延迟和节流都不会减少太多。 p99延迟从限制为4个核心的约98ms变为限制为16个核心的86ms。 将CFS配额减少到10ms之后,p99在4个内核时达到了20ms。
@blakebarnett我们开发了一个基准程序来测量我们的延迟,在更新--cpu-cfs-quota-period之前,它们从10ms-100ms的范围(平均大约18ms)变为10ms-20ms的范围,平均之后大约11毫秒。 p99延迟从大约98ms变为20ms。
编辑:对不起,我不得不回去仔细检查我的电话号码。
d-shi
于 2019-06-06
@ d-shi,您可能当时遇到了512ac999解决的问题。
chiluk
于 2019-06-06
@chiluk一遍
if (cfs_rq->expires_seq == cfs_b->expires_seq) {
- /* extend local deadline, drift is bounded above by 2 ticks */
- cfs_rq->runtime_expires += TICK_NSEC;
- } else {
- /* global deadline is ahead, expiration has passed */
- cfs_rq->runtime_remaining = 0;
- }
在配额过期的情况下,即使runtime_remaining刚刚从全局池中借了一些时间。 在最坏的情况下,您将基于sched_cfs_bandwidth_slice_us被限制5ms。 是不是
我想念什么吗?
 Mwea
于 2019-06-06
Mwea
于 2019-06-06
@chiluk是的,我认为是正确的。 我们的生产服务器仍在内核4.4上,因此没有该修补程序。 也许一旦我们升级到更新的内核,就可以将CFS配额期限重新设置为默认期限,但是目前它正在努力改善后端延迟,并且我们尚未注意到任何不利的副作用。 虽然它只启用了几个星期。
d-shi
于 2019-06-06
@chiluk介意此问题在内核中的状态吗? 似乎有一个512ac999补丁,但是有问题。 我在某处读到它被还原了吗? 还是这是完全/部分固定的? 如果是这样,什么版本?
mariusgrigoriu
于 2019-06-07
@mariusgrigoriu,它不是固定的, @ chiluk已经创建了一个补丁,应该对其进行修复,需要进一步的测试(我将在接下来的几天中为此花一些时间)
有关最新状态,请参见https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -482198124
willthames
于 2019-06-07
@Mwea全局池存储在cfs_b-> runtime_remaining中。 随着分配给每个cpu运行队列(cfs_rq),全局池中剩余的数量将减少。 cfs_bandwidth_slice_us是从全局池转移到每个cpu运行队列的cpu运行时数量。 如果受到限制,那意味着您需要运行并且cfs_b-> runtime_remaining ==0。您必须等待当前时间段结束(默认为100ms),才能将配额补充到cfs_b,然后分配给您的cfs_rq。 我最近发现,每个cfs_rq的到期运行时间最多为1ms,这是由于松弛计时器从每个cpu运行队列中重新捕获了1ms的未使用配额。 然后在该周期结束时浪费/过期了那1ms。 在更糟的情况下,应用程序跨88 cpus传播,每100毫秒周期可能浪费88毫秒配额。 这实际上导致了另一种建议,该建议允许松弛计时器从空闲的每CPU运行队列中重新捕获所有未使用的配额。
至于您特别强调的线条。 我的建议是完全删除已分配给每个CPU运行队列的运行时到期。 这些行是512ac999修复程序的一部分。 修复了以下问题:每个cpu运行队列之间的时钟偏斜导致配额过早过期,从而限制了尚未使用配额的应用程序(afaiu)。 基本上,它们在每个周期边界上递增expires_seq。 因此,当每个cfs_rq处于同一时间段时,expires_seq应该匹配。
@mariusgrigoriu-如果您正在以较低的cpu使用率达到高限制,并且您的内核是512ac999之前的版本,则可能需要512ac999。 如果您发布的是512ac999,则可能是我在lkml上正在讨论的上述问题。
有很多方法可以缓解此问题。
- CPU固定
- 减少应用程序产生的线程数
- 遇到节流的应用程序的过度分配配额。
- 现在关闭硬限制。
- 使用任何建议的更改构建自定义内核。
chiluk
于 2019-06-07
@chiluk,您有可能已经发布了与内核4.14兼容的此修补程序的版本吗? 由于我们刚刚将几千台主机从4.9.62升级到4.14.121(从4.9.62开始),因此我希望能对其进行积极的测试:
- 减少对memcached,mysql,nginx等的限制
- Java应用程序的节流增加
真的很想向前发展,以便在这里两全其美。 下周我可以尝试将其移植到我自己身上,但是如果您已经拥有它,那将非常棒。
 PaulFurtado
于 2019-06-21
PaulFurtado
于 2019-06-21
@PaulFurtado
实际上,根据Ben Segull的建议,最近几天我实际上已经重写了补丁。 我可以在集群上获得一些测试时间后,将立即发布新的内核补丁。
chiluk
于 2019-06-24
@chiluk该补丁有更新吗? 如果没有的话,请不要担心,我只是确保我不会错过补丁程序
PaulFurtado
于 2019-07-18
@PaulFurtado ,该补丁已由CFS作者“批准”,我只是在等待调度程序维护人员对其进行集成并将其推送到Linus。
chiluk
于 2019-07-24
@chiluk谢谢!
我只是将该修补程序反向移植到了内核4.14,这是我们当前的生产内核。
我对反向端口和您的fibtest的一些结果做了一个总结: https ://gist.github.com/PaulFurtado/ff6c67ec87416b66ba1c6fc70f7beec1
在我们在kubernetes和mesos集群中使用的最新c5.9xlarge和m5.24xlarge ec2实例上,此补丁使您的fibtest程序的性能提高了一倍。 在上一代r4.16xlarge实例类型上,它管理的CPU利用率提高了1.5倍,但几乎没有任何其他迭代(我认为这仅仅是由于CPU生成和斐波那契数列的指数性质)。 如果我将测试增加到30秒而不是默认的5秒,那么这些数字几乎完全成立。
我们将在本周开始将其应用到我们的质量检查环境中,以从我们的应用程序中获得一些指标,这些指标正面临着最严峻的考验。 再次感谢!
PaulFurtado
于 2019-07-26
@PaulFurtado首先感谢您的测试。 我假设您正在运行kernel.org 4.14或ubuntu 4.14,两者都具有512ac999。 至于fibtest,完成的迭代并不像使用的cpu时间那么重要,因为完成的迭代在运行测试时会受到cpu mhz的严重影响(尤其是在云中,我不确定您对此有多少控制权)。
chiluk
于 2019-07-31
我假设您正在运行kernel.org 4.14或ubuntu 4.14,两者都具有512ac999。
是的,我们运行主线4.14(好吧,再加上Amazon Linux 2内核的补丁集,但是在这种情况下,这些补丁都不重要)。
512ac999进入主线4.14.95,我们观察到它对从4.14.77升级到4.14.121+的影响。 它使我们的memcached容器(线程数非常低)从无法解释的限制变为没有限制,但使golang和java容器(线程数非常高)经历了更多的限制。
至于fibtest,完成的迭代并不像使用的cpu时间那么重要,因为完成的迭代在运行测试时会受到cpu mhz的严重影响(尤其是在云中,我不确定您对此有多少控制权)。
在更新/更大的EC2实例上,您实际上确实获得了对处理器状态的良好在关闭涡轮增压的情况下运行并且不允许内核闲置。 虽然,我实际上只是意识到我们正在调整c状态,而不是p状态,并且在迭代中没有看到任何增加的实例类型是p状态是可控的,因此可以很好地解释它。
首先,谢谢您的测试
完全没问题,周末的质量检查前环境一直稳定,我们将在明天开始将补丁发布到主要的质量检查环境中,在那里我们将看到更多实际效果。 鉴于memcached已从先前的补丁程序中受益,我们真的很想拥有我们的蛋糕,并且在两个补丁程序都就绪的情况下也可以食用它,因此我们很乐意进行测试。 再次感谢您为节流所做的所有工作!
PaulFurtado
于 2019-07-31
只是想留下一个注释,关于正在讨论的内核补丁。
我已经将其调整为当前测试中使用的内核,并看到了CFS节流率方面的巨大成功,但是我要提到的是,如果您以前将cfs周期设置为10ms作为缓解措施,那么您将希望将其恢复到100ms以查看更改的好处。
 jhohertz
于 2019-08-06
jhohertz
于 2019-08-06
补丁今天早上降落在尖端。
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
一旦它到达了Torvald的树上,我将其提交给linux稳定的包容,然后提交主要发行版(Redhat / Ubuntu)。 如果您关心其他事情,并且他们没有遵循linux稳定的补丁程序,则可能需要直接提交。
chiluk
于 2019-08-08
我已经使用我们的CPU大量图像处理golang微服务测试了补丁(ubuntu 18.04、5.2.7内核,节点:56核CPU E5-2660 v4 @ 2.00GHz),并获得了相当不错的结果。 性能就像我完全禁用节点上的CFS一样。
根据并发性/ CPU利用率,在接近零节流率的情况下,我的延迟减少了5-35%,RPS增加了5-55%。
谢谢@chiluk !
正如@jhohertz所说,cfs配额应恢复为100ms,我用较低的周期进行了测试,并且节流和性能下降都很高。
 zigmund
于 2019-08-10
zigmund
于 2019-08-10
要使用golang获得更高的性能,请将GOMAXPROCS设置为ceil(quota)+2。 加号2是为了保证一定的并发性。
chiluk
于 2019-08-12
@chiluk在GOMAXPROCS = 8的
zigmund
于 2019-08-13
@zigmund ,因为您的cpu.limit设置为整数8,这会将您的进程绑定到8 cpu的cpuset。 1-2%的差异只是在8个cpu任务集上使用2个额外的Goroutine运行程序进行上下文切换的开销增加。
我应该说过,对于GO程序,设置GOMAXPROCS =#是一个不错的解决方法,直到内核补丁广泛分发为止。
chiluk
于 2019-08-26
我们已经将生产集群迁移到补丁内核中,现在我可以与您分享一些有趣的时刻。
来自我们群集之一的统计信息-72个核心E5-2695 v4 @ 2.10GHz,4个节点,128Gb RAM,Debian 9、5.2.7内核(带补丁)。
我们的混合负载主要由golang服务组成,但也有php和python。
高朗延迟较低,绝对必须设置正确的GOMAXPROCS。 这是默认GOMAXPROCS = 72的服务。 我们将内核更改为大约16,之后延迟降低,CPU利用率大幅提高。 在21:15,我设置了正确的GOMAXPROCS并标准化了CPU使用率。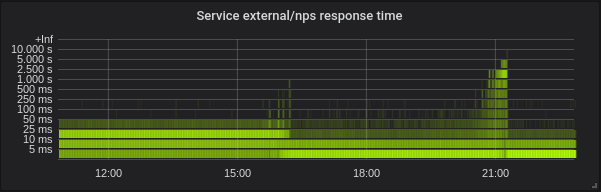

蟒蛇。 补丁程序使一切变得更好,而没有任何额外的动作-CPU利用率和等待时间下降了。
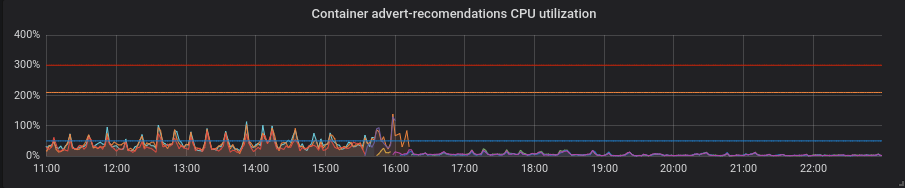
PHP。 CPU利用率相同,某些服务的延迟几乎没有下降。 利润不大。
zigmund
于 2019-09-03
谢谢@zigmund。
当您说I setted correct GOMAXPROCS时,我不确定是否能收到...
我假设您不是在72核节点上仅运行一个Pod,因此将GOMAXPROCS为更低的值,也许等于Pod的CPU限制吧?
prune998
于 2019-09-03
谢谢@zigmund。 更改行事方式与预期相符。
我对python的改进感到非常惊讶,尽管我希望GIL在很大程度上抵消它的好处。 如果有此补丁,几乎可以纯粹减少响应时间,减少节流周期的百分比,并提高CPU利用率。 您确定您的python应用程序仍然健康吗?
chiluk
于 2019-09-03
@ prune998对不起,也许拼写错误。 我设置GOMAXPROCS = limits.cpu。 目前,该集群中每个节点大约有110个吊舱。
@chiluk我不
zigmund
于 2019-09-04
@chiluk您能否解释一下我们如何将补丁的进度跟踪到各种Linux发行版中? 我对debian和AWS Linux特别感兴趣,但是我希望其他人也对Ubuntu等感兴趣,所以无论您能摆脱什么,谢谢。
 Nuru
于 2019-09-13
Nuru
于 2019-09-13
@Nuru https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html?highlight=stable%20rules ...基本上,一旦我的补丁打上Linus,我将通过linux-stable提交树,*(可能更早),然后所有发行版都应遵循linux稳定的过程,并将稳定的维护者接受的补丁引入其发行版特定的内核。 如果不是,那么您不应该运行他们的发行版。
chiluk
于 2019-09-13
@chiluk我对Linux开发过程一无所知。 “ Linus的树”是指https://github.com/torvalds/linux吗?
Nuru
于 2019-09-14
Linus的树住在这里, https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/。 我的更改当前在开发集成树linux-next上进行。 是的,内核开发在黑暗时代中有些停滞,但它确实有效。
一旦5.3发布,他可能会从linux-next树中获取更改,并开始在5.4-rc0上进行开发。 大约在这个时间范围内,我希望稳定的内核可以开始进行此修复。 每当Linus觉得5.3稳定时,任何人都在猜测。
chiluk
于 2019-09-14
[Linus]可能会在5.3发布并从5.4-rc0开始开发后,从linux-next树中引入更改。 大约在这个时间范围内,我希望稳定的内核可以开始进行此修复。 每当Linus觉得5.3稳定时,任何人都在猜测。
@chiluk看起来Linus决定5.3在2019年
Nuru
于 2019-09-20
是否有人构建了debian Stretch软件包和/或包含此补丁的AWS映像? 我将使用https://github.com/kubernetes-sigs/image-builder/tree/master/images/kube-deploy/imagebuilder进行操作
只是认为我会避免重复工作(如果已经存在)。
blakebarnett
于 2019-09-24
现在,它已合并到Linus的树中,应随5.4一起发布。 我还刚刚将其提交给linux-stable,并且假设一切顺利,只要遵循稳定的过程,发行版都应该会很快开始使用。
chiluk
于 2019-09-25
是否有人知道如何/如果这种改变使它变成CentOS(7)? 不确定反向移植等如何工作。
 till
于 2019-09-26
till
于 2019-09-26
@till https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -531370333
为了稳定的内核对话在这里进行。
https://lore.kernel.org/stable/CAC=E7cUXpUDgpvsmMaMU6sAydbfD0FEJiK25R1r=e9=YtcPjGw@mail.gmail.com/
另外,对于那些去KubeCon的人,我将在此处介绍此问题。
https://sched.co/Uae1
chiluk
于 2019-10-03
调度程序维护人员有任何话要说:ack Greg HK正在寻找将其放入稳定的树中的方法?
jhohertz
于 2019-10-18
Greg KH推迟做出有关此修补程序的决定,因为调度程序维护人员一直没有响应(可能只是错过了邮件)。 除了我以外,其他人对于已经测试了此补丁并认为应该反向移植的LKML都将发表评论。
chiluk
于 2019-10-18
对于使用CoreOS的人员,存在一个开放问题,要求将@chiluk的补丁回传。
 evanfoster
于 2019-11-01
evanfoster
于 2019-11-01
CoreOS内核4.19.82具有修复程序: https :
CoreOS容器Linux 2317.0.1(Alpha通道)已修复: https : http://coreos.com/releases/#2317.0.1
到Linux稳定版的反向移植似乎停滞了,因为这些补丁不能很好地应用。 @chiluk您是否打算在Linux稳定版的kops拾取? 尽管我猜想它最终将花费多达6个月才能进入“拉伸”状态,然后也许kops会迁移到“破坏者”中。
Nuru
于 2019-11-08
@Nuru ,我向后移植了补丁,并制作了拉伸包(基于Stretch-backports内核)和kops 1.11友好的AMI(如果要测试):
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.buildinfo
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm-dbg_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-headers-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.changes
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-libc-dev_4.19.67-1_amd64.deb
293993587779 / k8s-1.11-debian-stretch-amd64-hvm-ebs-2019-09-26
blakebarnett
于 2019-11-08
@blakebarnett感谢您的努力,很抱歉打扰您,但我不只感到困惑。
- “ stretch”基于Linux 4.9,但是所有链接均适用于4.19。
- 您说您向后移植了“补丁程序”,但有3个补丁程序(我想第三个补丁程序并不重要:
- 512ac999预定/正常:修复带宽计时器时钟漂移条件
- de53fd7ae sched / fair:通过消除cpu本地片的过期来修复具有高限制的低cpu使用
- 763a9ec06预定/正常:修复了-奇怪但已设置变量的警告
您是否将所有3个补丁都反向移植到4.9? (我不知道如何使用Debian软件包来查看和查看其中是否存在更改,并且“更改”文档无法解决真正更改的内容。)
另外,您的AMI在哪些地区可用?
Nuru
于 2019-11-08
不,我使用的是4.19的stretch-backports内核,因为它具有我们在AWS上也需要的修复程序(尤其是对于M5 / C5实例类型)
我应用了一个diff,其中包含了我相信的所有补丁,我必须对其稍作更改,以删除对在其他地方删除的4.19中变量的额外引用,我首先应用了此https://github.com/kubernetes/kubernetes/issues/67577 #issuecomment -515324561,然后需要添加:
--- kernel/sched/fair.c 2019-09-25 16:06:02.954933954 -0700
+++ kernel/sched/fair.c-b 2019-09-25 16:06:56.341615817 -0700
@@ -4928,8 +4928,6 @@
cfs_b->period_active = 1;
overrun = hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
- cfs_b->runtime_expires += (overrun + 1) * ktime_to_ns(cfs_b->period);
- cfs_b->expires_seq++;
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
--- kernel/sched/sched.h 2019-08-16 01:12:54.000000000 -0700
+++ sched.h.b 2019-09-25 13:24:00.444566284 -0700
@@ -334,8 +334,6 @@
u64 quota;
u64 runtime;
s64 hierarchical_quota;
- u64 runtime_expires;
- int expires_seq;
short idle;
short period_active;
@@ -555,8 +553,6 @@
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
- int expires_seq;
- u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock;
AMI已发布到us-west-1
希望有帮助!
blakebarnett
于 2019-11-08
我已经向后移植了这些补丁并将它们提交给了Linux稳定的内核
v4.14 https://lore.kernel.org/stable/[email protected]/
v4.19 https://lore.kernel.org/stable/[email protected]/ #t
chiluk
于 2019-11-08
你好,
在4.19分支上集成了补丁之后,我已经打开了一个关于debian的错误报告,目的是在buster和Stretch-backport上正确升级kerner:
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=946144
不要犹豫,为升级debian软件包添加新评论。
 alexises
于 2019-12-04
alexises
于 2019-12-04
希望这不是垃圾邮件,但我想将@chiluk的精彩演讲链接到与该问题相关的许多背景详细信息https://youtu.be/UE7QX98-kO0。
 bboreham
于 2019-12-04
bboreham
于 2019-12-04
有没有办法避免限制GKE? 我们只是遇到了一个巨大的问题,在php容器上的一种方法需要120秒而不是通常的0.1秒
 bartoszhernas
于 2019-12-05
bartoszhernas
于 2019-12-05
删除CPU限制
 monotek
于 2019-12-05
monotek
于 2019-12-05
我们已经做到了,当CPU请求太小时,容器就会受到限制。 这是问题的核心,没有限制,仅使用CPU请求仍然会导致节流:(
bartoszhernas
于 2019-12-05
@bartoszhernas我认为您在这里使用了错误的单词。 当这个线程上的人指“限制”时,他们指的是cfs带宽控制,cpu.stat中的nr_throttled用于cgroup的增加。 仅在启用cpu限制时启用。 除非GKE在您不知情的情况下为您的广告连播添加限制,否则我不会称您为节流。
我将您所说的称为“处理器争用”。 我怀疑您可能有多个大小不正确的应用程序*(请求),它们正在争夺包装盒上的处理器或其他资源,因为它们经常使用比他们所请求的更多的资源。 这就是我们使用限制的确切原因。 因此,那些大小不正确的应用程序只能对包装盒上的其他应用程序造成很大影响。
另一种可能性是您的请求量不足导致简单的调度行为。 相对于较高的“请求”应用程序,将请求设置为低类似于将“ nice”值设置为正。 有关该信息的更多信息,请查看软限制。
chiluk
于 2019-12-05
闲置90天后问题变得陈旧。
使用/remove-lifecycle stale将问题标记为新问题。
再过30天不活动后,陈旧的问题就会消失,并最终关闭。
如果现在可以安全解决此问题,请使用/close进行关闭。
将反馈发送到sig-testing,kubernetes / test-infra和/或fejta 。
/ lifecycle stale
 fejta-bot
于 2020-03-04
fejta-bot
于 2020-03-04
/删除生命周期过时
Nuru
于 2020-03-04
据我了解,内核中的基本问题已修复,并且可以在https://github.com/coreos/bugs/issues/2623中的ContainerLinux中使用
有人知道这个内核补丁之后还有其他问题吗?
 sfudeus
于 2020-03-04
sfudeus
于 2020-03-04
@sfudeus Kubernetes可以在任何版本的Linux或AFAIK,任何符合POSIT的版本的Unix上运行。 对于不使用Linux的人来说,此错误从来都不是问题,对于某些Linux发行版来说,该错误已得到修复,而对于其他发行版,则未解决。
潜在的问题已在Linux内核5.4中修复,目前几乎没有人在使用。 修补程序可用于向后移植到各种较旧的内核,包括尚未准备好迁移到5.4内核的新Linux发行版,其中有很多。 从上面提到该问题的提交列表中可以看到,错误修复补丁仍在整合到可能有人在使用Kubernetes的各种Linux发行版中。
因此,我希望在仍然看到活动提交引用的同时让这个问题保持打开状态。 我还希望看到它已被脚本或其他易于使用的方法关闭,从而可以用来确定他们的Kubernetes安装是否受到影响。
Nuru
于 2020-03-05
@Nuru对我来说很好,我只是想确保没有其他内核问题,这是已知的。 我个人不会将此开放时间长于合并了此修复程序的较大发行版,等待无尽的IoT设备可能意味着无休止的等待。 也可以找到已解决的问题。 但这只是我的2美分。
sfudeus
于 2020-03-05
不知道这是否是通知人们的正确位置,但不确定是否还有其他地方可以提出:
我们正在使用k8s 1.15.10集群在Debian Buster上运行5.4 Linux内核(使用buster-backports内核),并且仍然遇到问题。 特别是对于通常无事可做的Pod(我们不断返回的例子是kube-downscaler,通常需要大约3m CPU)并且分配的CPU资源很少(在我们的kube-downscaler中为50m)群集),我们仍然看到很高的节流值。 作为参考,kube-downscaler基本上是一个Python脚本,在执行任何操作之前先运行sleep 30分钟。 cAdvisor显示此容器的container_cpu_cfs_throttled_periods_total的增加总是与该容器的container_cpu_cfs_periods_total的值大致相似(当以5m的间隔检查增加时,两者均为250左右)。 我们希望节流周期接近于0。
我们测量不正确吗? cAdvisor输出的数据不正确吗? 我们的假设是正确的,我们应该看到节流期有所减少吗? 任何建议,将不胜感激。
切换到5.4内核后,我们确实看到出现此问题的Pods的数量有所减少(大约40%),但是目前我们不确定所看到的是否是实际问题。 主要是,在查看上述统计信息时,如果在平均CPU使用量为3m的情况下获得这些值,我们不确定“限制”在这里真正意味着什么。 它所运行的节点完全没有超负荷使用,平均CPU使用率不到10%。
 timstoop
于 2020-03-05
timstoop
于 2020-03-05
@timstoop调度程序关心的间隔是微秒级的范围,而不是30分钟的大范围。 如果容器的CPU限制为50毫秒,并且在100微秒的跨度内使用50毫秒,则无论是否闲置30分钟,容器都会受到限制。 通常,50 millicpu是一个非常小的CPU限制。 如果python程序甚至发出一个低限制的HTTPS请求,则几乎可以保证它受到限制。
它所运行的节点完全没有超负荷使用,平均CPU使用率不到10%。
只是要澄清一下:节点的负载和节点上的其他工作负载与节流无关。 节流仅考虑容器/ cgroup自身的限制。
PaulFurtado
于 2020-03-05
@PaulFurtado感谢您的回答! 但是,该Pod本身在该睡眠期间的平均使用量为3m cpu,并且仍然受到限制。 在此期间它没有发出任何请求,正在等待睡眠。 我希望它可以做到这一点,而不会达到50m,对吗? 还是那是一个错误的假设?
timstoop
于 2020-03-05
我认为这可能只是一个很小的数字,以至于会出现准确性问题。 50m太低了,根本没有任何东西可以绊倒它。 睡眠时,Python的运行时可能还在线程中执行后台任务。
PaulFurtado
于 2020-03-05
您说得对,我所做的假设是不正确的。 感谢您的指导! 现在对我来说很有意义。
timstoop
于 2020-03-05
只是想跳进来,说自从内核补丁打到4.19 LTS内核以来,这里的情况已经得到了很大的改善,并且它出现在了CoreOS / Flatcar上。 从目前来看,我看到的唯一受限制的事情是我可能应该限制的几件事。 :微笑:
jhohertz
于 2020-03-05
@sfudeus @chiluk是否有任何简单的测试来查看您的内核是否已解决此问题?
我无法确定是否已修补kope.io/k8s-1.15-debian-stretch-amd64-hvm-ebs-2020-01-17(当前官方kops映像)。
Nuru
于 2020-03-20
我同意@mariusgrigoriu ,对于在静态cpu策略下在独占cpuset上运行的pod,我们可以简单地禁用cpu配额限制-无论如何它只能在其独占cpu集合上运行。 上面的补丁程序仅用于此目的,并且仅用于此类型的Pod。
 jianzzha
于 2020-04-06
jianzzha
于 2020-04-06
@努鲁我写了https://github.com/indeedeng/fibtest
它是对测试的最终确定,但是您需要C编译器。
忽略已完成的迭代次数,而是关注单线程与多线程运行所用的时间。
chiluk
于 2020-04-10
我猜想查看补丁的内核的一种好方法是@chiluk的最后一张幻灯片(感谢此举) https://www.youtube.com/watch?v=UE7QX98-kO0
内核4.15.0-67似乎已经安装了补丁(https://launchpad.net/ubuntu/+source/linux/4.15.0-67.76),但是,我们仍然在某些Pod中限制了请求/限制,他们的CPU使用率。
我说的是大约50ms的使用,请求设置为250m,限制为500m。 我们看到大约有50%的CPU周期受到限制,这个值是否可能足够低以至于可以预期并可以接受? 我希望将其降低到零,如果使用量甚至没有接近极限,我们也不应受到任何限制。
使用新的修补内核的人是否仍有节流能力?
 vgarcia-te
于 2020-04-22
vgarcia-te
于 2020-04-22
@ vgarcia-te列表中有太多的内核在循环,无法知道哪些补丁已被修补,哪些还没有被修补。 只需查看所有引用此问题的提交即可。 几百。 我对Ubuntu的变更日志的阅读表明,尚未对4.15进行修补(在Azure上运行的mabye除外),并且链接到的修补已被拒绝。
我个人对4.9系列感兴趣,因为这是kops所使用的,并且想知道他们何时发布带有修复程序的AMI。
同时,您可以尝试运行@bobrik的测试,这对我来说似乎很好。
wget https://gist.githubusercontent.com/bobrik/2030ff040fad360327a5fab7a09c4ff1/raw/9dcf83b821812064fa7fb056b8f22cbd5c4364f1/cfs.go
sudo docker run --rm -it --cpu-quota 20000 --cpu-period 100000 -v $(pwd):$(pwd) -w $(pwd) golang:1.9.2 go run cfs.go -iterations 15 -sleep 1000ms
如果CFS正常运行,则刻录时间将始终为5ms。 使用上面的数字,在测试了受影响的内核后,我经常看到刻录时间为99ms。 任何超过6ms的问题。
Nuru
于 2020-04-22
@nuru感谢脚本查找问题是否存在。
@justinsb请建议默认的kops图像是否有补丁
https://github.com/kubernetes/kops/blob/master/channels/stable
打开了一个问题: https :
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -617586330
更新:在kops 1.15图像中进行测试,那里没有不必要的限制https://github.com/kubernetes/kops/issues/8954#issuecomment -617673755
alok87
于 2020-04-22
@努鲁
2020/04/22 11:02:48 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 6ms
2020/04/22 11:02:49 [1] burn took 5ms, real time so far: 1012ms, cpu time so far: 12ms
2020/04/22 11:02:50 [2] burn took 5ms, real time so far: 2017ms, cpu time so far: 18ms
2020/04/22 11:02:51 [3] burn took 5ms, real time so far: 3023ms, cpu time so far: 23ms
2020/04/22 11:02:52 [4] burn took 5ms, real time so far: 4028ms, cpu time so far: 29ms
2020/04/22 11:02:53 [5] burn took 5ms, real time so far: 5033ms, cpu time so far: 35ms
2020/04/22 11:02:54 [6] burn took 5ms, real time so far: 6038ms, cpu time so far: 40ms
2020/04/22 11:02:55 [7] burn took 5ms, real time so far: 7043ms, cpu time so far: 46ms
2020/04/22 11:02:56 [8] burn took 5ms, real time so far: 8049ms, cpu time so far: 51ms
2020/04/22 11:02:57 [9] burn took 5ms, real time so far: 9054ms, cpu time so far: 57ms
2020/04/22 11:02:58 [10] burn took 5ms, real time so far: 10059ms, cpu time so far: 63ms
2020/04/22 11:02:59 [11] burn took 5ms, real time so far: 11064ms, cpu time so far: 69ms
2020/04/22 11:03:00 [12] burn took 5ms, real time so far: 12069ms, cpu time so far: 74ms
2020/04/22 11:03:01 [13] burn took 5ms, real time so far: 13074ms, cpu time so far: 80ms
2020/04/22 11:03:02 [14] burn took 5ms, real time so far: 14079ms, cpu time so far: 85ms
这些结果来自
Linux <servername> 4.15.0-96-generic #97-Ubuntu SMP Wed Apr 1 03:25:46 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
它是ubuntu 18.04中默认的最新稳定ubuntu内核。
因此,它看起来像补丁是存在
 zerkms
于 2020-04-22
zerkms
于 2020-04-22
@zerkms在Ubuntu 18.04上的哪里运行测试? 在我看来,该补丁可能只是将其添加到Azure的内核中。 如果您可以找到发行说明,说明将其应用于Ubuntu linux软件包的位置,请共享。 我找不到
还请注意,该测试也无法在CoreOS上重现该问题。 可能是在默认配置下,全局禁用了CFS调度。
Nuru
于 2020-04-22
@努鲁
您在Ubuntu 18.04的哪里运行测试?
我的一台服务器。
我没有检查发行说明,我什至不知道要寻找什么,尽管如此-它是每个人都拥有的默认内核。 🤷
zerkms
于 2020-04-22
该补丁应该在ubuntus内核git中:
https://kernel.ubuntu.com/git/ubuntu/ubuntu-bionic.git/commit/?id=aadd794e744086fb50cdc752d54044fbc14d4adb
这里是与它有关的ubuntu错误:
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1832151
它应该在仿生中释放。
您可以通过运行apt-get source linux并检入下载的源代码。
juliantaylor
于 2020-04-22
@zerkms “您在哪里运行测试”是指您办公室中的服务器,GCP,AWS,Azure中的服务器还是其他地方?
显然,我对Ubuntu的分发和维护方式有很多不了解。 我也对您的uname -a输出感到困惑。 Ubuntu发行说明说:
18.04.4随附了一个基于v5.3的Linux内核,该内核已从18.04.3。中的基于v5.0的内核进行了更新。
并且还说2020年2月12日发布了18.04.4。您的输出显示您正在运行2020年4月1日编译的v4.15内核。
@juliantaylor我没有Ubuntu服务器或Git存储库的副本,并且不知道如何跟踪像aadd794e7440这样的特定提交在哪里发布到稳定的内核中。 如果您能告诉我如何做,我将不胜感激。
当我查看启动板的错误注释时,我看到了
- 此错误已在软件包linux-azure-5.0.0-1027.29中修复
- 此错误已在软件包linux-azure-5.0.0-1027.29〜18.04.1中修复
但是此特定补丁( sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices )未在下面列出
- 此错误已在软件包linux中修复-4.15.0-69.78
我也没有在Ubuntu 18.04.4发行说明中看到“ 1832151”。
先前的评论说它已在4.15.0-67.76中进行了修补,但我看不到linux-image-4.15.0-67-generic软件包。
我离Ubuntu专家还很远,并且发现此补丁跟踪非常困难,所以就我所知。
我希望您现在明白为什么我不确定该补丁实际上是否包含在当前版本的18.04中的Ubuntu 18.04.4中。 我的最佳猜测是,它是在18.04.4发布之后作为内核更新发布的,如果您的Ubuntu内核报告的是4.15.0-69或更高版本,则可能包含在内,但是如果您只是下载18.04.4而未更新,它不会有补丁。
Nuru
于 2020-04-22
我只是在数据中心的裸机服务器中的内核4.15.0-72中运行了Go测试(非常有用),似乎有补丁了:
2020/04/22 21:24:27 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 7ms
2020/04/22 21:24:28 [1] burn took 5ms, real time so far: 1010ms, cpu time so far: 13ms
2020/04/22 21:24:29 [2] burn took 5ms, real time so far: 2015ms, cpu time so far: 20ms
2020/04/22 21:24:30 [3] burn took 5ms, real time so far: 3020ms, cpu time so far: 25ms
2020/04/22 21:24:31 [4] burn took 5ms, real time so far: 4025ms, cpu time so far: 32ms
2020/04/22 21:24:32 [5] burn took 5ms, real time so far: 5030ms, cpu time so far: 38ms
2020/04/22 21:24:33 [6] burn took 5ms, real time so far: 6036ms, cpu time so far: 43ms
2020/04/22 21:24:34 [7] burn took 5ms, real time so far: 7041ms, cpu time so far: 50ms
2020/04/22 21:24:35 [8] burn took 5ms, real time so far: 8046ms, cpu time so far: 56ms
2020/04/22 21:24:36 [9] burn took 5ms, real time so far: 9051ms, cpu time so far: 63ms
2020/04/22 21:24:37 [10] burn took 5ms, real time so far: 10056ms, cpu time so far: 68ms
2020/04/22 21:24:38 [11] burn took 5ms, real time so far: 11061ms, cpu time so far: 75ms
2020/04/22 21:24:39 [12] burn took 5ms, real time so far: 12067ms, cpu time so far: 81ms
2020/04/22 21:24:40 [13] burn took 5ms, real time so far: 13072ms, cpu time so far: 86ms
2020/04/22 21:24:41 [14] burn took 5ms, real time so far: 14077ms, cpu time so far: 94ms
我还可以看到,在相同类型的服务器中,内核4.9.164中的相同执行显示了超过5ms的刻录:
2020/04/22 21:24:41 [0] burn took 97ms, real time so far: 97ms, cpu time so far: 8ms
2020/04/22 21:24:42 [1] burn took 5ms, real time so far: 1102ms, cpu time so far: 12ms
2020/04/22 21:24:43 [2] burn took 5ms, real time so far: 2107ms, cpu time so far: 16ms
2020/04/22 21:24:44 [3] burn took 5ms, real time so far: 3112ms, cpu time so far: 24ms
2020/04/22 21:24:45 [4] burn took 83ms, real time so far: 4197ms, cpu time so far: 28ms
2020/04/22 21:24:46 [5] burn took 5ms, real time so far: 5202ms, cpu time so far: 32ms
2020/04/22 21:24:47 [6] burn took 94ms, real time so far: 6297ms, cpu time so far: 36ms
2020/04/22 21:24:48 [7] burn took 99ms, real time so far: 7397ms, cpu time so far: 40ms
2020/04/22 21:24:49 [8] burn took 100ms, real time so far: 8497ms, cpu time so far: 44ms
2020/04/22 21:24:50 [9] burn took 5ms, real time so far: 9503ms, cpu time so far: 52ms
2020/04/22 21:24:51 [10] burn took 5ms, real time so far: 10508ms, cpu time so far: 60ms
2020/04/22 21:24:52 [11] burn took 5ms, real time so far: 11602ms, cpu time so far: 64ms
2020/04/22 21:24:53 [12] burn took 5ms, real time so far: 12607ms, cpu time so far: 72ms
2020/04/22 21:24:54 [13] burn took 5ms, real time so far: 13702ms, cpu time so far: 76ms
2020/04/22 21:24:55 [14] burn took 5ms, real time so far: 14707ms, cpu time so far: 80ms
所以,我的问题是,即使我的内核似乎已打补丁,我仍然看到CPU节流
vgarcia-te
于 2020-04-22
@努鲁,对,对不起。 那是我在办公室托管的裸机服务器。
并且还说2020年2月12日发布了18.04.4。您的输出显示您正在运行2020年4月1日编译的v4.15内核。
这是因为它是服务器LTS:您需要显式选择加入HWE以拥有更新的内核,否则,您只需运行mainline。
而且主线和HWE内核都定期发布,因此拥有最新构建的内核毫无疑问: http :
zerkms
于 2020-04-22
@zerkms感谢您的信息。 我仍然感到困惑,但这不是教育我的地方。
@ vgarcia-te如果您的内核已打补丁(似乎已打补丁),则限制不是由于此错误引起的。 当您说以下内容时,我不确定您的用语:
我说的是大约50ms的使用,请求设置为250m,限制为500m。 我们看到大约有50%的CPU周期受到限制,这个值是否可能足够低以至于可以预期并可以接受?
Kubernetes CPU资源以CPU为单位进行度量,1表示1个完整CPU的100%,1m表示1个CPU的0.1%。 因此,您的“ 500m”限制表示允许0.5个CPU。
CFS的默认调度周期为100毫秒,因此将限制设置为0.5 CPU将使您的进程每100毫秒将CPU限制为50毫秒。 如果您的过程试图超过该限制,它将受到限制。 如果您的进程通常单次运行超过50毫秒,那么可以,您希望它能被正常工作的调度程序限制。
Nuru
于 2020-04-23
@Nuru很有意义,但是让我理解这一点,因为默认的cpu周期是100ms,如果一个进程分配了1个CPU,如果该进程一次运行超过100ms,会受到限制吗?
这是否意味着在默认cpu周期为100ms的linux中,任何进程的限制一次运行超过100ms的进程都会受到限制?
对于一个过程,如果一次通过耗时超过100毫秒,但在其余时间都处于闲置状态,那么什么样的极限配置才是一个好的极限配置呢?
vgarcia-te
于 2020-04-23
@ vgarcia-te问
假设默认的cpu周期为100ms,在一个进程分配了1个CPU的情况下,如果该进程一次运行超过100ms,是否会受到限制?
当然,日程安排非常复杂,因此我无法为您提供完美的答案,但是简化的答案是“否”。 更详细的解释在这里和这里。
所有的UNIX进程都根据时间片进行抢占式调度。 在单核单CPU的日子里,您仍然有30个进程“同时”运行。 发生的情况是它们运行了一段时间,然后进入睡眠状态,或者在时间片结束时被搁置,以便其他运行。
具有配额的CFS向前迈了一步。
问自己,但是,当您说要一个进程使用50%的CPU时,您实际上是在说什么? 您是说,如果它占用100%的CPU 5分钟,然后在接下来的5分钟内完全不运行,那是可以的吗? 那将是10分钟内50%的使用率,但是由于延迟问题,这对于大多数人来说是不可接受的。
因此,CFS定义了一个“ CPU周期”,它是强制执行配额的时间窗口。 在具有4个内核和100ms CPU周期的机器上,调度程序具有400ms CPU时间,以分配超过100ms的实际(挂钟)时间。 如果您正在运行一个无法并行执行的执行线程,则该线程每个周期最多可以使用100ms CPU时间,这将是1个CPU的100%。 如果将其配额设置为1个CPU,则永远不要限制它。
如果将配额设置为500m(0.5个CPU),则该进程将获得50ms的运行时间,即每100ms运行一次。 任何100毫秒周期的使用时间少于50毫秒,则不应受到限制。 在100毫秒周期内运行50毫秒后仍未完成,直到下一个100毫秒周期它都会受到限制。 这样可以在等待时间(必须等待多长时间才能运行)与占用(允许其他进程保持运行多长时间)之间保持平衡。
Nuru
于 2020-04-23
@努鲁,我的幻灯片是正确的。 我也是Ubuntu开发人员*(仅在我的业余时间)。 最好的选择是阅读源代码,并检查git blame + tag-包含跟踪补丁何时到达您关心的内核版本的信息。
chiluk
于 2020-04-26
@chiluk我没看过你的幻灯片。 对于尚未见过他们的其他人,这是他们说补丁已于一段时间前登陆的地方:
- Ubuntu 4.15.0-67 +
- Ubuntu 5.3.0-24以上
- RHEL7内核3.10.0-1062.8.1.el7
当然是Linux稳定的v4.14.154,v4.19.84、5.3.9。 我注意到在Linux稳定版5.4-rc1中也是如此。
我仍在努力理解各种CFS调度程序错误,并找到可在小型AWS服务器上运行的可靠,易于理解的测试,因为我支持旧版安装中的各种内核。 据我了解时间表,2014年Linux内核v3.16-rc1中引入了一个错误
[51f2176d74ac](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=51f2176d74ac) sched/fair: Fix unlocked reads of some cfs_b->quota/period。
这导致了不同的CFS节流问题。 我认为在kops Kubernetes集群下看到的问题是由于此错误所致,因为它们使用的是4.9内核。
51f2176d74ac已在2018内核v4.18-rc4中修复,其中
[512ac999](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) sched/fair: Fix bandwidth timer clock drift condition
但这引入了错误@chiluk修复
[de53fd7ae](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425) sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
当然,很难在分布之间跟踪内核补丁不是Chiluk或任何其他人的过错。 但是,这仍然让我感到沮丧,并加剧了我的困惑。
例如,在Debuan buster 10(AWS AMI debian-10-amd64-20191113-76 )上,内核版本报告为
Linux ip-172-31-41-138 4.19.0-6-cloud-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
据我所知,该内核应具有51f2176d74ac而不应具有512ac999 ,因此应未通过512ac999描述的测试,但事实并非如此。 (我说我不认为它具有512ac999因为它是从Linux内核4.10逐步升级的,并且更改日志中没有提及该补丁。)但是,在4 cpu的AWS VM上,它不会失败Chiluk的fibtest或Bobrik的CFS打h测试表明存在其他情况。
在CoreOS收到Chiluk的补丁之前,我也遇到了类似的问题,无法重现CoreOS的任何调度问题。
目前我的想法是Bobrik的测试主要是51f2176d74ac的测试,我正在使用_does_的Debian buster 10 AMI拥有512ac999 ,只是没有在更改日志中明确指出,并且fibtest在只有几个内核的机器上不是一个非常敏感的测试。
Nuru
于 2020-04-27
4核CPU可能不够大,无法重现已修复的问题。
如果我正确理解了chiluks kubecon演讲(https://www.youtube.com/watch?v=UE7QX98-kO0)的解释,则只能在大约40 cpus以上的大型计算机上重现它。
周围有很多内核版本,并且有很多补丁程序和还原补丁程序。 变更日志和版本号仅能使您到目前为止。
如有疑问,唯一可靠的方法是下载源代码,并将其与此处链接的补丁程序中的更改进行比较。
juliantaylor
于 2020-04-27
闲置90天后问题变得陈旧。
使用/remove-lifecycle stale将问题标记为新问题。
再过30天不活动后,陈旧的问题就会消失,并最终关闭。
如果现在可以安全解决此问题,请使用/close进行关闭。
将反馈发送到sig-testing,kubernetes / test-infra和/或fejta 。
/ lifecycle stale
fejta-bot
于 2020-07-26
/删除生命周期过时
 yashbhutwala
于 2020-07-27
yashbhutwala
于 2020-07-27
此线程前面提到的测试对我而言并没有真正重现该问题(一些刻录耗时超过5毫秒,但大约占其中的0.01%),但我们的cfs节流指标仍然显示出适度的节流。 我们在集群中拥有不同的内核版本,但是两个最常见的版本是:
Debian 4.19.67-2+deb10u2~bpo9+1 (2019-11-12)- 手动向后移植
5.4.38
我不知道这两个错误是否都应该在这些版本中修复,但是我认为它们应该是,所以我想知道测试是否没有那么有用。 我正在16核和36核的机器上进行测试,不确定是否需要更多核才能使测试有效,但是我们仍然看到这些集群的节流能力……
 2rs2ts
于 2020-08-18
2rs2ts
于 2020-08-18
我们是否应该关闭此问题并要求面临问题的人们重新开始? 此处的垃圾邮件可能会使任何对话变得非常困难。
 omnibs
于 2020-10-31
omnibs
于 2020-10-31
^我同意。 解决该问题已经做了很多工作。
 sfxworks
于 2020-10-31
sfxworks
于 2020-10-31
/关
根据以上评论。 请根据需要打开新的问题。
dims
于 2020-11-01
@dims :关闭此问题。
针对此:
/关
根据以上评论。 请根据需要打开新的问题。
可在此处获得使用PR注释与我互动的说明。 如果您对我的行为有任何疑问或建议,请针对kubernetes / test-infra存储库提出问题。
 k8s-ci-robot
于 2020-11-01
k8s-ci-robot
于 2020-11-01
请将此问题通知后续问题,以便订阅此问题的人可以订阅新问题以关注
 glensc
于 2020-11-01
glensc
于 2020-11-01
相关问题
 jason-riddle
·
3评论
jason-riddle
·
3评论
 sanjana-bhat
·
3评论
sanjana-bhat
·
3评论
 pwittrock
·
3评论
pwittrock
·
3评论
 jadhavnitind
·
3评论
jadhavnitind
·
3评论
 alexferl
·
3评论
alexferl
·
3评论
最有用的评论
补丁今天早上降落在尖端。
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
一旦它到达了Torvald的树上,我将其提交给linux稳定的包容,然后提交主要发行版(Redhat / Ubuntu)。 如果您关心其他事情,并且他们没有遵循linux稳定的补丁程序,则可能需要直接提交。