Kubernetes: Las cuotas de CFS pueden provocar una limitación innecesaria
/ tipo error
Esto no es un error en Kubernets per se, es más un aviso.
He leído esta gran publicación de blog:
De la publicación del blog aprendí que k8s usa cuotas de cfs para hacer cumplir los límites de la CPU. Desafortunadamente, estos pueden provocar una limitación innecesaria, especialmente para los inquilinos que se portan bien.
Vea este error no resuelto en el kernel de Linux que presenté hace un tiempo:
Hay un parche abierto y estancado que soluciona el problema (no he verificado si funciona):
cc @ConnorDoyle @balajismaniam
 bobrik
bobrik
Todos 142 comentarios
/ sig nodo
/ tipo error
 neolit123
en 20 ago. 2018
neolit123
en 20 ago. 2018
¿Es esto un duplicado de # 51135?
 liggitt
en 20 ago. 2018
liggitt
en 20 ago. 2018
Es similar en espíritu, pero parece pasar por alto el hecho de que hay un error real en el kernel en lugar de solo una compensación de configuración en el período de cuota de CFS. Me gustó el número 51135 aquí para dar a la gente más contexto.
bobrik
en 22 ago. 2018
Según tengo entendido, esta es otra razón para deshabilitar la cuota de CFS ( --cpu-cfs-quota=false ) o hacerla configurable (# 63437).
También me parece muy interesante ver esta esencia (vinculada desde el parche de Kernel) (para medir el impacto): https://gist.github.com/bobrik/2030ff040fad360327a5fab7a09c4ff1
 hjacobs
en 22 ago. 2018
hjacobs
en 22 ago. 2018
cc @adityakali
 vishh
en 23 ago. 2018
vishh
en 23 ago. 2018
Otro problema con las cuotas es que kubelet cuenta los hyperthreads como "cpus". Cuando un clúster está tan cargado que dos subprocesos están programados en el mismo núcleo y el proceso tiene una cuota de cpu, uno de ellos solo funcionará con una pequeña fracción de la potencia de procesamiento disponible (solo hará algo cuando algo en el otro subproceso se detiene) pero aún consumen cuota como si tuviera un núcleo físico para sí mismo. Por lo tanto, consume el doble de la cuota que debería sin hacer mucho más trabajo.
Esto tiene el efecto de que en un nodo de nodo completamente cargado con hyperthreading habilitado, el rendimiento será la mitad de lo que sería con hyperthreading o cuotas deshabilitadas.
Imo the kubelet no debe considerar los hyperthreads como cpus reales para evitar esta situación.
 juliantaylor
en 30 ago. 2018
juliantaylor
en 30 ago. 2018
@juliantaylor Como mencioné en # 51135, desactivar la cuota de CPU podría ser el mejor enfoque para la mayoría de los clústeres de k8s que ejecutan cargas de trabajo confiables.
vishh
en 30 ago. 2018
¿Esto se considera un error?
Si algunos pods se ralentizan sin agotar realmente su límite de CPU, me parece un error.
En mi clúster, la mayoría de los pods que superan la cuota están relacionados con métricas (heapster, metrics-collector, nodo-exporter ...) u Operadores, que obviamente tienen el tipo de carga de trabajo que está en problema aquí: no haga nada la mayoría de las tiempo y despertar para reconciliarnos de vez en cuando.
Lo extraño aquí es que traté de aumentar el límite, pasando de 40m a 100m o 200m , y los procesos aún estaban estrangulados.
No veo ninguna otra métrica que indique una carga de trabajo que podría desencadenar esta limitación.
He eliminado los límites de estos pods por ahora ... está mejorando, pero, bueno, eso realmente suena como un error y deberíamos venir con una mejor solución que deshabilitar el Limits
 prune998
en 26 nov. 2018
prune998
en 26 nov. 2018
@ prune998 vea el comentario de @vishh y esta esencia : el Kernel se acelera de manera demasiado agresiva, incluso si las matemáticas le dicen que no debería. Nosotros (Zalando) decidimos deshabilitar la cuota CFS (aceleración de CPU) en nuestros clústeres: https://www.slideshare.net/try_except_/optimizing-kubernetes-resource-requestslimits-for-costefficiency-and-latency-highload
hjacobs
en 27 nov. 2018
Gracias @hjacobs.
Estoy en Google GKE y no veo una manera fácil de desactivarlo, pero sigo buscando ...
prune998
en 27 nov. 2018
@ prune998 AFAIK, Google aún no ha expuesto las perillas necesarias. Presentamos una solicitud de función justo después de que la posibilidad de deshabilitar CFS aterrizara en upstream, no hemos escuchado ninguna noticia desde entonces.
 timoreimann
en 27 nov. 2018
timoreimann
en 27 nov. 2018
Estoy en Google GKE y no veo una manera fácil de desactivarlo, pero sigo buscando ...
¿Puedes eliminar los límites de CPU de tus contenedores por ahora?
vishh
en 28 nov. 2018
De acuerdo con los documentos del administrador de la CPU, CFS quota is not used to bound the CPU usage of these containers as their usage is bound by the scheduling domain itself. Pero estamos experimentando una limitación de CFS.
Esto hace que el administrador de CPU estático sea casi inútil, ya que establecer un límite de CPU para lograr la clase QoS garantizada niega cualquier beneficio debido a la limitación.
¿Es un error que las cuotas de CFS se establezcan para los pods en la CPU estática?
 mariusgrigoriu
en 12 feb. 2019
mariusgrigoriu
en 12 feb. 2019
Para contexto adicional (aprendí esto ayer): @hrzbrg (MyTaxi) contribuyó con una bandera a Kops para deshabilitar la aceleración de la CPU: https://github.com/kubernetes/kops/issues/5826
hjacobs
en 12 feb. 2019
Comparta un resumen del problema aquí. No está muy claro cuál es el problema y en qué escenarios los usuarios se ven afectados y qué se requiere exactamente para solucionarlo.
Lo que sabemos en la actualidad es que cuando cruzamos los límites somos sancionados y estrangulados. Entonces, digamos que tenemos una cuota de cpu de 3 núcleos y en los primeros 5 ms consumimos 3 núcleos, luego en el segmento de 100 ms obtendremos una aceleración de 95 ms, y en estos 95 ms nuestros contenedores no pueden hacer nada. Y hemos visto cómo se ralentiza incluso cuando los picos de la CPU no son visibles en las métricas de uso de la CPU. Suponemos que se debe a que la ventana de tiempo para medir el uso de la CPU está en segundos y la limitación ocurre a nivel de microsegundos, por lo que promedia y no es visible. Pero el error mencionado aquí nos ha dejado confundidos ahora.
Pocas preguntas:
- ¿Cuándo el nodo está al 100% de la CPU? ¿Es este un caso especial en el que todos los contenedores se limitan independientemente de su uso?
Cuando esto sucede, ¿todos los contenedores se aceleran al 100% de la CPU?
¿Qué provoca que este error se active en el nodo?
¿Cuál es la diferencia entre no usar
limitsy deshabilitarcpu.cfs_quota?¿No es la desactivación de
limitsuna solución arriesgada cuando hay muchos pods con ráfagas y un pod puede causar inestabilidad en el nodo y afectar a otros pods que se ejecutan sobre sus solicitudes?Por separado, de acuerdo con el proceso de documentación del kernel, el proceso puede verse limitado cuando la cuota principal se consume por completo. ¿Qué es padre en el contexto del contenedor aquí (está relacionado con este error)? https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
There are two ways in which a group may become throttled: a. it fully consumes its own quota within a period b. a parent's quota is fully consumed within its period- ¿Qué se necesita para arreglarlos? ¿Actualizar la versión del kernel?
Nos hemos enfrentado a una interrupción bastante grande y parece estar estrechamente relacionada (si no es la causa raíz) con todos nuestros pods que se atascan en el ciclo de reinicio de aceleración y no pueden escalar. Estamos investigando los detalles para encontrar el problema real. Abriré un número separado que explica en detalle nuestro corte.
Cualquier ayuda aquí es muy apreciada.
cc @justinsb
 alok87
en 14 feb. 2019
alok87
en 14 feb. 2019
Uno de nuestros usuarios estableció un límite de CPU y se aceleró para que agotara el tiempo de su prueba de vida, lo que provocó una interrupción del servicio.
Estamos viendo estrangulamientos incluso al fijar contenedores a una CPU. Por ejemplo, un límite de CPU de 1 y fijar ese contenedor para que se ejecute solo en una CPU. Debería ser imposible exceder la cuota dado cualquier período si su cuota fuera exactamente la cantidad de CPU que tiene, sin embargo, vemos limitaciones en todos los casos.
Pensé que lo vi publicado en algún lugar que el kernel 4.18 resuelve el problema. Todavía no lo he probado, por lo que sería bueno si alguien pudiera confirmarlo.
mariusgrigoriu
en 15 feb. 2019
https://github.com/torvalds/linux/commit/512ac999d2755d2b7109e996a76b6fb8b888631d en 4.18 parece ser el parche relevante para este problema.
 clkao
en 23 feb. 2019
clkao
en 23 feb. 2019
@mariusgrigoriu Parece que estoy atrapado en el mismo enigma que describiste aquí https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -462534360.
Observamos la aceleración de la CPU en los pods en la clase QoS garantizada con la política estática CPUManager (que no parece tener ningún sentido).
Eliminar el limits para estos Pods los colocará en la clase Burstable QoS, que no es lo que queremos, por lo que la única opción que queda es deshabilitar las cuotas de CPU de CFS en todo el sistema, que tampoco es algo que podamos hacer de manera segura. ya que permitir que todos los Pods accedan a la capacidad de la CPU no vinculada puede provocar problemas peligrosos de saturación de la CPU.
@vishh dadas las circunstancias anteriores, ¿cuál sería el mejor curso de acción? parece como actualizar a kernel> 4.18 (que tiene la corrección de contabilidad de cpu cfs) y (quizás) reducir el período de cuota de cfs?
En una nota general, sugerir que simplemente eliminemos limits de los contenedores que se están acelerando debería tener advertencias claras:
1) Si estos fueran pods en la clase QoS garantizada, con un número entero de núcleos y con la política estática CPUMnanager implementada, estos pods ya no obtendrán núcleos de CPU dedicados, ya que se colocarán en la clase de QoS ampliable (sin solicitudes == límites)
2) Estos pods no estarán vinculados en términos de cuánta CPU pueden consumir y potencialmente pueden causar bastante daño bajo ciertas circunstancias.
Sus comentarios / orientación serán muy apreciados.
 dannyk81
en 25 mar. 2019
dannyk81
en 25 mar. 2019
La actualización del kernel definitivamente ayuda, pero el comportamiento de aplicar una cuota CFS aún parece no estar alineado con lo que sugieren los documentos.
mariusgrigoriu
en 25 mar. 2019
He estado investigando varios aspectos de este problema durante un tiempo. Mi investigación se resume en mi publicación en LKML.
https://lkml.org/lkml/2019/3/18/706
Dicho esto, no he podido reproducir el problema como se describe aquí en los kernels anteriores a 512ac99. Sin embargo, he visto una regresión del rendimiento en los kernels posteriores a 512ac99. Entonces esa solución no es una panacea.
 chiluk
en 25 mar. 2019
chiluk
en 25 mar. 2019
Gracias @mariusgrigoriu , vamos por la actualización del kernel y esperamos que ayude un poco, también consulte https://github.com/kubernetes/kubernetes/issues/70585 ; parece que las cuotas están establecidas para los pods garantizados con cpuset ( es decir, cpus anclado), por lo que esto me parece un error.
dannyk81
en 25 mar. 2019
@chiluk, ¿ podrías explicar un poco más? ¿Quiere decir que el parche que se incluyó en 4.18 (mencionado anteriormente en https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-466609030) en realidad no resuelve el problema?
dannyk81
en 25 mar. 2019
El parche del kernel 512ac99 soluciona un problema para algunas personas, pero causó un problema en nuestras configuraciones. El parche corrigió la forma en que se distribuyen los intervalos de tiempo entre cfs_rq, ya que ahora expiran correctamente. Anteriormente no caducarían.
Las cargas de trabajo de Java, en particular en máquinas de alto número de núcleos, ahora experimentan grandes cantidades de limitación con un bajo uso de la CPU debido al bloqueo de los subprocesos de trabajo. A esos subprocesos se les asigna un intervalo de tiempo que solo usan una pequeña parte del cual caduca más tarde. En la prueba sintética que escribí * (vinculada a ese hilo), vemos una degradación del rendimiento de aproximadamente 30x. En el rendimiento del mundo real, vimos una degradación del tiempo de respuesta de cientos de milisegundos entre los dos núcleos debido al aumento de la aceleración.
chiluk
en 25 mar. 2019
Al usar un kernel 4.19.30, veo que los pods que esperaba ver menos estrangulamiento todavía están estrangulados y algunos pods que no estaban siendo estrangulados anteriormente ahora se están estrangulando de manera bastante severa (kube2iam informa más segundos estrangulados que la instancia ha estado activa , de algun modo)
 willthames
en 27 mar. 2019
willthames
en 27 mar. 2019
En CoreOS 4.19.25-coreos, veo que Prometheus activa la alerta CPUThrottlingHigh en casi todos los pod del sistema.
 teralype
en 27 mar. 2019
teralype
en 27 mar. 2019
@williamsandrew @teralype esto parece reflejar los hallazgos de @chiluk .
Después de varias discusiones internas, de hecho, decidimos deshabilitar las cuotas de cfs por completo (la marca de kubelet --cpu-cfs-quota=false ), esto parece resolver todos los problemas que hemos tenido para los pods expandibles y garantizados (cpu fijados o estándar).
Hay un excelente mazo sobre esto (y algunos otros temas) aquí: https://www.slideshare.net/try_except_/ensuring-kubernetes-cost-efficiency-across-many-clusters-devops-gathering-2019
Lectura muy recomendable: +1:
dannyk81
en 27 mar. 2019
problema a largo plazo (nota personal)
 dims
en 27 mar. 2019
dims
en 27 mar. 2019
@ dannyk81 solo para completar: la charla vinculada también está disponible como video grabado: https://www.youtube.com/watch?v=4QyecOoPsGU
hjacobs
en 27 mar. 2019
@hjacobs , ¡me encantó la charla! Muchas gracias...
¿Alguna idea de cómo aplicar esta corrección en AKS o GKE?
Gracias
 agolomoodysaada
en 2 abr. 2019
agolomoodysaada
en 2 abr. 2019
@agolomoodysaada presentamos una solicitud de función con GKE hace un tiempo. Sin embargo, no estoy seguro de cuál es el estado, ya no trabajo de forma intensiva con GKE.
timoreimann
en 2 abr. 2019
Me comuniqué con el soporte de Azure y me dijeron que no estará disponible hasta agosto de 2019.
agolomoodysaada
en 4 abr. 2019

Pensé en compartir un gráfico de una aplicación constantemente acelerada a lo largo de su vida.
agolomoodysaada
en 5 abr. 2019
¿En qué núcleo estaba esto?
chiluk
en 5 abr. 2019
" chiluk " 4.15.0-1037-azure "
agolomoodysaada
en 5 abr. 2019
Entonces eso no contiene la confirmación del kernel 512ac99. Aquí está el correspondiente
fuente.
https://kernel.ubuntu.com/git/kernel-ppa/mirror/ubuntu-azure-xenial.git/tree/kernel/sched/fair.c?h=Ubuntu-azure-4.15.0-1037.39_16.04.1 & id = 19b0066cc4829f45321a52a802b640bab14d0f67
Lo que significa que podría estar enfrentando el problema descrito en 512ac99. Mantener dentro
Tenga en cuenta que 512ac99 nos trajo otras regresiones.
El viernes 5 de abril de 2019 a las 12:08 p.m. Moody Saada [email protected]
escribió:
@chiluk https://github.com/chiluk "4.15.0-1037-azure"
-
Estás recibiendo esto porque te mencionaron.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-480350946 ,
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/ACDI05YeS6wfUE9XkiMbxrLvPllYQZ7Iks5vd4MOgaJpZM4WDUF3
.
chiluk
en 5 abr. 2019
Ahora he publicado parches en LKML sobre esto.
https://lkml.org/lkml/2019/4/10/1068
Se agradecería mucho realizar pruebas adicionales.
chiluk
en 11 abr. 2019
Volví a enviar estos parches ahora con cambios en la documentación.
https://lkml.org/lkml/2019/5/17/581
Realmente ayudaría si la gente pudiera probar estos parches y comentar sobre el hilo en LKML. Por el momento soy el único que ha mencionado esto en LKML, y no he recibido ningún comentario de la comunidad ni de los mantenedores. Realmente sería de gran ayuda si pudiera obtener algunas pruebas y comentarios de la comunidad sobre LKML en mi parche.
chiluk
en 21 may. 2019
Por lo que vale, este proyecto en particular https://github.com/tensorflow/serving parece verse gravemente afectado por este problema. Y es principalmente una aplicación C ++.
@chiluk , ¿hay alguna solución alternativa que podamos aplicar mientras se implementa el parche?
Muchas gracias
agolomoodysaada
en 29 may. 2019
Deberíamos ayudar a @chiluk a recopilar citas sobre el impacto grave de este error del kernel en Kubernetes y cualquier otra persona que utilice cuotas de CFS.
Zolando incluyó en su presentación la semana pasada que sus malas experiencias con el kernel actual significa que consideran que deshabilitar las cuotas de CFS es una Mejor Práctica actual, ya que consideran que hace más daño que bien.
https://www.youtube.com/watch?v=6sDTB4eV4F8
 whereisaaron
en 29 may. 2019
whereisaaron
en 29 may. 2019
Cada vez más empresas están desactivando la aceleración de la CPU, por ejemplo, mytaxi, Datadog, Zalando ( hilo de Twitter )
hjacobs
en 29 may. 2019
@derekwaynecarr @ dchen1107 @ kubernetes / sig-node-feature-orders Dawn, Derek, ¿es hora de cambiar el valor predeterminado? y / o documentación?
dims
en 29 may. 2019
Sí, @whereisaaron, la recopilación y el intercambio de informes sobre la limitación de aplicaciones paralizantes, o la desactivación debido a su mal comportamiento, sería una participación bienvenida en el hilo lkml cuando corresponda. Por el momento, parece que solo soy yo quejándome de este problema a la comunidad del kernel.
chiluk
en 29 may. 2019
@agolomoodysaada, la solución es deshabilitar temporalmente las cuotas de cfs o
También existen mejores prácticas para reducir el número de subprocesos de la aplicación, lo que también ayuda.
Para golang, configure GOMAXPROCS ~ = ceil (cuota)
Para Java, cambie a las JVM más nuevas que reconocen y respetan los límites de cuota de CPU. Los jvms anteriores generaban subprocesos basados en la cantidad de núcleos de CPU, no en la cantidad de núcleos disponibles para la aplicación.
Ambos han sido de gran ayuda para nuestro rendimiento.
Supervise y notifique las aplicaciones que se están acelerando para que sus desarrolladores puedan ajustar las cuotas.
chiluk
en 29 may. 2019
Para su información, después de señalar este hilo al soporte de Azure AKS, me respondieron que el parche se implementará cuando se actualicen al kernel 5.0, a fines de septiembre, en el mejor de los casos.
Hasta entonces, bueno, deja de usar límites :)
prune998
en 29 may. 2019
@ prune998 hay una pequeña advertencia en caso de que esté utilizando CPUmanager (es decir, asignación de CPU dedicada a los pods en QoS garantizada).
Al eliminar los límites, evitará el problema de aceleración de CFS, pero eliminará los pods de QoS garantizada para que CPUmanager ya no asigne núcleos dedicados para estos pods.
Si no usa CPUmanager, no se hace daño, pero solo para su información para cualquiera que opte por esta dirección.
Existe un PR (https://github.com/kubernetes/kubernetes/issues/70585) para deshabilitar las cuotas de CFS por completo para los pods con CPU dedicadas, sin embargo, aún no se fusionó.
También hemos optado por inhabilitar el sistema de cuotas del CSA en todo el sistema como se sugirió anteriormente y no hemos tenido problemas hasta ahora.
dannyk81
en 29 may. 2019
@ dannyk81 https://github.com/kubernetes/kubernetes/issues/70585 no es un PR que se pueda fusionar (es un problema con un fragmento de código). ¿Puede usted (u otra persona) presentar un PR?
dims
en 29 may. 2019
 praseodym
en 29 may. 2019
praseodym
en 29 may. 2019
@dims Vinculé el problema, no el PR ... pero el problema está vinculado al PR :) de hecho, es https://github.com/kubernetes/kubernetes/pull/75682 y ha estado ahí por un tiempo, así que si pudieras presionar esto sería genial, ya que se trata de un problema realmente molesto.
Gracias: +1:
dannyk81
en 29 may. 2019
¡Ups! gracias @ dannyk81 he asignado personas y agregado un hito
dims
en 29 may. 2019
FWIW también nos encontramos con este problema y descubrimos que reducir el período de cuota de CFS a 10 ms en lugar de los 100 ms predeterminados hizo que nuestras latencias finales mejoraran drásticamente. Creo que esto se debe a que incluso si se encuentra con el error del kernel, se desperdicia una cantidad mucho menor de cuota si no se usa, y el proceso puede obtener más cuota (en asignaciones más pequeñas) mucho antes. Esto es solo una solución alternativa, pero para aquellos que no quieran deshabilitar la cuota de CFS por completo, esto podría ser un truco hasta que se implemente la solución. k8s admite hacer esto en 1.12 con la puerta de función cpuCFSQuotaPeriod y el indicador de kubelet --cpu-cfs-quota-period.
 d-shi
en 30 may. 2019
d-shi
en 30 may. 2019
Tendría que comprobarlo, pero creo que reducir el período tan lejos puede tener el efecto de deshabilitarlo de manera efectiva, ya que hay mínimos de corte y mínimos de cuota en el código. Probablemente sea mejor desactivar las cuotas y pasar a cuotas blandas.
chiluk
en 30 may. 2019
@chiluk, mi entendimiento
d-shi
en 31 may. 2019
Con --feature-gates=CustomCPUCFSQuotaPeriod=true --cpu-cfs-quota-period=10ms uno de mis pods realmente tuvo problemas para comenzar. En el gráfico de prometheus adjunto, el contenedor intenta iniciarse, no se acerca a cumplir con su verificación de vida hasta que se mata (normalmente el contenedor comienza en aproximadamente 5 segundos; incluso aumentar la vida inicialDelaySeconds a 60 no ayudó) luego reemplazado por uno nuevo.
Puede ver que el contenedor está muy estrangulado hasta que eliminé cpu-cfs-quota-period de los argumentos de kubelet, momento en el que la regulación es mucho más plana y el contenedor se inicia nuevamente en unos 5 segundos.

willthames
en 5 jun. 2019
FYI: hilo de Twitter actual sobre el tema de la desactivación de la aceleración de la CPU: https://twitter.com/it_supertramp/status/1133648291332263936
hjacobs
en 5 jun. 2019
Estos son los gráficos de aceleración de la CPU antes / después de que nos moviéramos a --cpu-cfs-quota-period=10ms en producción para 2 servicios sensibles a la latencia:
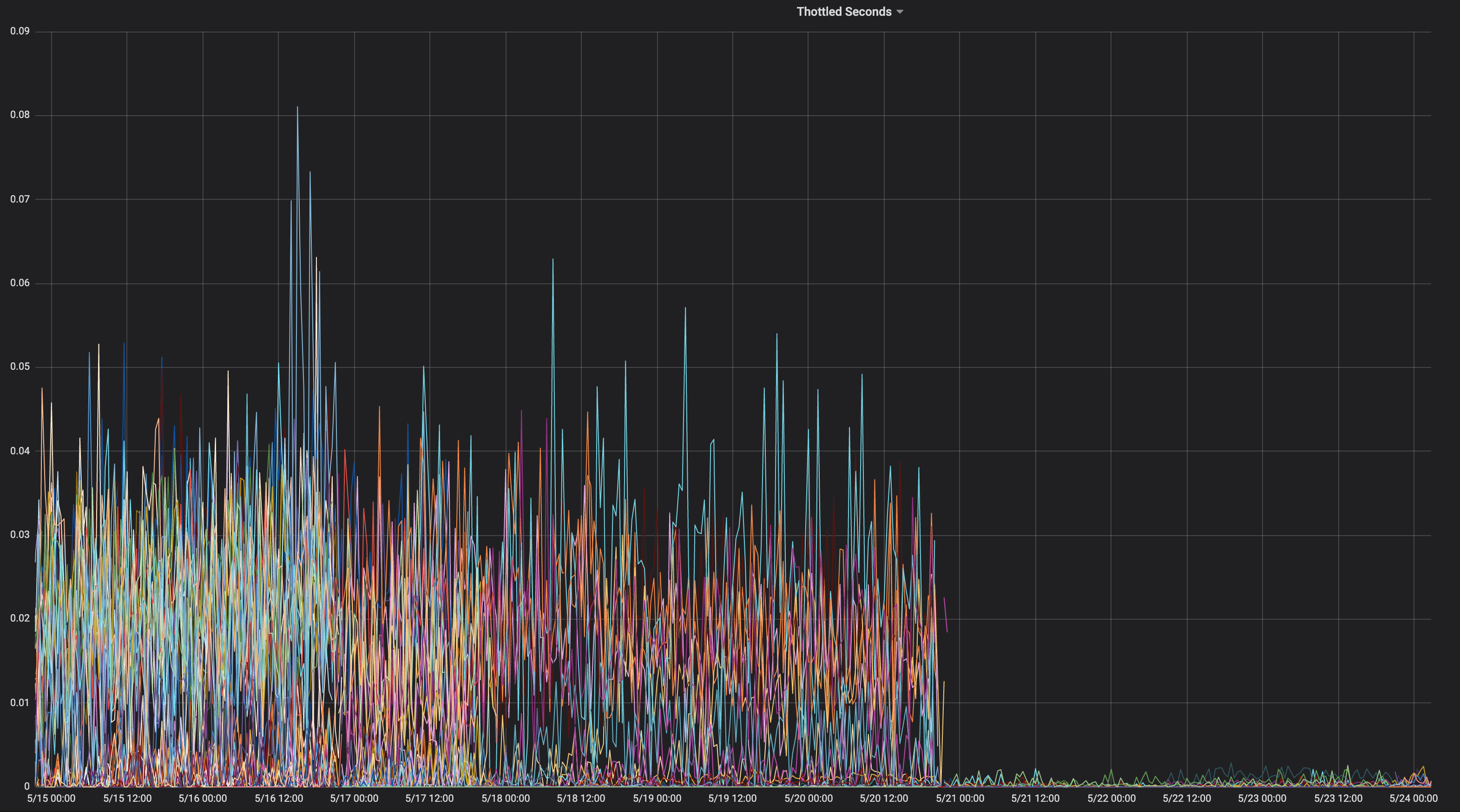

Estos servicios se ejecutan en diferentes tipos de instancias (con diferentes taints / toleraciones). Las instancias del segundo servicio se trasladaron primero a un período de cuota CFS más bajo.
Los resultados deben depender mucho de la carga.
d-shi
en 5 jun. 2019
@ d-shi, hay algo más en tu gráfico. Creo que puede haber una cuota mínima que está alcanzando ahora porque el período es muy pequeño. Tendría que verificar el código para estar seguro. Básicamente, aumentó sin darse cuenta la cantidad de cuota disponible para la aplicación. Probablemente podría haber logrado lo mismo aumentando las asignaciones de cuotas.
chiluk
en 5 jun. 2019
Para nosotros fue mucho más útil medir la latencia en lugar de la limitación. Deshabilitar cfs-quota mejoró drásticamente la latencia. Me gustaría ver resultados similares para cambiar el cfs-quota-period .
 blakebarnett
en 6 jun. 2019
blakebarnett
en 6 jun. 2019
@chiluk , de hecho, intentamos aumentar las asignaciones de cuotas (hasta el máximo admitido por kubernetes por grupo), y en ningún caso se redujeron mucho las latencias ni la aceleración al final. Las latencias de p99 pasaron de aproximadamente 98 ms con un límite de 4 núcleos a 86 ms con un límite de 16 núcleos. Después de reducir la cuota de CFS a 10 ms, p99 pasó a 20 ms en 4 núcleos.
@blakebarnett desarrollamos un programa de referencia que midió nuestras latencias, y pasaron de un rango de 10ms-100ms, con un promedio de alrededor de 18ms antes de actualizar --cpu-cfs-quota-period , a un rango de 10ms-20ms, con un promedio de alrededor de 11 ms después. Las latencias de p99 pasaron de alrededor de 98 ms a 20 ms.
EDICIONES: Perdón por las ediciones, tuve que volver y verificar mis números.
d-shi
en 6 jun. 2019
@ d-shi, entonces probablemente estabas encontrando el problema resuelto por 512ac999.
chiluk
en 6 jun. 2019
@chiluk Después de leer una y otra vez su parche, debo admitir que me cuesta entender el impacto de este código:
if (cfs_rq->expires_seq == cfs_b->expires_seq) {
- /* extend local deadline, drift is bounded above by 2 ticks */
- cfs_rq->runtime_expires += TICK_NSEC;
- } else {
- /* global deadline is ahead, expiration has passed */
- cfs_rq->runtime_remaining = 0;
- }
En un caso en el que la cuota expire incluso si runtime_remaining solo tomó prestado algo de tiempo del grupo global. En el peor de los casos, se le acelerará durante 5 ms según sched_cfs_bandwidth_slice_us. ¿No es así?
¿Me pierdo algo?
 Mwea
en 6 jun. 2019
Mwea
en 6 jun. 2019
@chiluk sí, creo que tienen razón. Nuestros servidores de producción todavía están en el kernel 4.4, así que no tenemos esa solución. Quizás una vez que actualicemos a un kernel más nuevo podamos mover el período de cuota de CFS al valor predeterminado, pero por ahora está trabajando para mejorar nuestras latencias finales y aún no hemos notado ningún efecto secundario adverso. Aunque solo ha estado en vivo durante un par de semanas.
d-shi
en 6 jun. 2019
@chiluk ¿Le importa resumir el estado de este problema en el kernel? Parece que hubo un parche, 512ac999, pero tuvo problemas. ¿Leí en alguna parte que se revirtió? ¿O es esto total o parcialmente arreglado? Si es así, ¿qué versión?
mariusgrigoriu
en 7 jun. 2019
@mariusgrigoriu no está arreglado, @chiluk ha creado un parche que debería arreglarlo y necesita más pruebas (voy a dedicar parte de mi tiempo en los próximos días a esto)
Consulte https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -482198124 para conocer el estado más reciente
willthames
en 7 jun. 2019
@Mwea el grupo global se almacena en cfs_b-> runtime_remaining. A medida que se asigna a las colas de ejecución por CPU (cfs_rq), la cantidad restante en el grupo global se reduce. cfs_bandwidth_slice_us es la cantidad de tiempo de ejecución de la CPU que se transfiere desde el grupo global a las colas de ejecución por CPU. Si se aceleró, eso significaría que necesitaba ejecutar y cfs_b-> runtime_remaining == 0. Tendría que esperar hasta el final del período actual (por defecto 100ms), para que la cuota se reponga a cfs_b y luego se distribuya a su cfs_rq. Recientemente descubrí que la cantidad de tiempo de ejecución caducado es como máximo 1 ms por cfs_rq, debido al hecho de que el temporizador de holgura recupera todo por 1 ms de cuota no utilizada de las colas de ejecución por CPU. Ese 1 ms se desperdicia / expira al final del período. En el peor de los casos, la aplicación se propaga a través de 88 cpus que podrían ser 88 ms de cuota desperdiciada por período de 100 ms. Eso en realidad condujo a una propuesta alternativa que consistía en permitir que el temporizador de holgura recuperara toda la cuota no utilizada de las colas de ejecución inactivas por CPU.
En cuanto a las líneas que resaltas específicamente. Mi propuesta es eliminar completamente la expiración del tiempo de ejecución que se ha asignado a las colas de ejecución por CPU. Esas líneas son parte de la solución para 512ac999. Eso solucionó un problema en el que la desviación del reloj entre las colas de ejecución por CPU provocaba que la cuota expirara prematuramente, lo que limitaba las aplicaciones que aún tenían que usar la cuota (afaiu). Básicamente, incrementan expires_seq en cada límite de período. expires_seq, por lo tanto, debe coincidir entre cada uno de los cfs_rq cuando están en el mismo período.
@mariusgrigoriu : si está alcanzando una aceleración alta con un uso bajo de la CPU y su kernel es anterior a 512ac999, probablemente necesite 512ac999. Si publica 512ac999, es probable que tenga el problema que expliqué anteriormente que se está discutiendo actualmente en lkml.
Hay muchas formas de mitigar este problema.
- Fijación de CPU
- Disminuir el número de subprocesos que genera su aplicación
- Asignar en exceso la cuota para las aplicaciones que experimentan limitaciones.
- Desactive los límites estrictos por ahora.
- Cree un kernel personalizado con cualquiera de los cambios propuestos.
chiluk
en 7 jun. 2019
@chiluk, ¿hay alguna posibilidad de que ya haya publicado una versión de este parche que sea compatible con el kernel 4.14? Estoy buscando probarlo de manera bastante agresiva ya que acabamos de actualizar algunos miles de hosts a 4.14.121 (desde 4.9.62) y estamos viendo:
- Una reducción en la limitación de memcached, mysql, nginx, etc.
- Un aumento en la limitación de nuestras aplicaciones java
Realmente quiero avanzar para obtener lo mejor de ambos mundos aquí. Puedo intentar portarlo yo mismo la próxima semana, pero si ya tienes uno, sería genial.
 PaulFurtado
en 21 jun. 2019
PaulFurtado
en 21 jun. 2019
@PaulFurtado
De hecho, he reescrito el parche durante los últimos días dadas las sugerencias de Ben Segull. Un nuevo parche de kernel estará disponible tan pronto como pueda obtenerlo durante algún tiempo de prueba en nuestros clústeres.
chiluk
en 24 jun. 2019
@chiluk ¿ alguna actualización de ese parche? No se preocupe si no, solo me aseguro de no perderme el parche
PaulFurtado
en 18 jul. 2019
@PaulFurtado , el parche ha sido "aprobado" por el autor de CFS, y estoy esperando a que los encargados del mantenimiento del planificador lo integren y lo envíen a Linus.
chiluk
en 24 jul. 2019
@chiluk ¡ Gracias!
Acabo de exportar el parche al kernel 4.14, que es nuestro kernel de producción actual.
Hice un resumen con el backport y algunos resultados de su fibtest aquí: https://gist.github.com/PaulFurtado/ff6c67ec87416b66ba1c6fc70f7beec1
En la instancia actual de c5.9xlarge y m5.24xlarge ec2 que usamos en nuestros clústeres de kubernetes y mesos, el parche duplica el rendimiento de su programa más fibroso. En un tipo de instancia r4.16xlarge de generación anterior, administra 1.5 veces más uso de CPU pero apenas iteraciones adicionales (que supongo que se debe solo a la generación de CPU y la naturaleza exponencial de la secuencia de fibonacci). Todos estos números se mantienen casi exactamente si aumento la prueba a 30 segundos en lugar del valor predeterminado de 5 segundos.
Comenzaremos a implementar esto en nuestro entorno de control de calidad esta semana para obtener algunas métricas de nuestras aplicaciones que están sufriendo las peores limitaciones. ¡Gracias de nuevo!
PaulFurtado
en 26 jul. 2019
@PaulFurtado en primer lugar, gracias por las pruebas. Asumiré que está ejecutando kernel.org 4.14 o ubuntu 4.14, los cuales tienen 512ac999. En cuanto a las iteraciones de fibtest completadas, no es tan importante como el tiempo de CPU utilizado, ya que las iteraciones completadas pueden verse muy afectadas por cpu mhz mientras se ejecuta la prueba (especialmente en la nube, donde no estoy seguro de cuánto control tienes sobre eso).
chiluk
en 31 jul. 2019
Asumiré que está ejecutando kernel.org 4.14 o ubuntu 4.14, los cuales tienen 512ac999.
Sí, ejecutamos mainline 4.14 (bueno, más el conjunto de parches del kernel de Amazon Linux 2, pero ninguno de esos parches importa en este caso).
512ac999 aterrizó en la línea principal 4.14.95, y observamos sus efectos al actualizar de 4.14.77 a 4.14.121+. Hizo que nuestros contenedores memcached (recuento de subprocesos muy bajo) pasaran de una limitación inexplicable a ninguna limitación, pero hizo que nuestros contenedores golang y java (recuento de subprocesos muy alto) experimentaran más limitaciones.
En cuanto a las iteraciones de fibtest completadas, no es tan importante como el tiempo de CPU utilizado, ya que las iteraciones completadas pueden verse muy afectadas por cpu mhz mientras se ejecuta la prueba (especialmente en la nube, donde no estoy seguro de cuánto control tienes sobre eso).
En instancias EC2 más nuevas / más grandes, en realidad obtienes un nivel decente de control sobre los estados del procesador , por lo que ejecutamos con turbo boost desactivado y no permitimos que los núcleos estén inactivos. Sin embargo, en realidad me acabo de dar cuenta de que estamos ajustando los estados c, pero no los estados p y el tipo de instancia que no vio ningún aumento en las iteraciones fue uno en el que los estados p son controlables, por lo que eso puede muy bien explicarlo.
en primer lugar gracias por las pruebas
No hay problema en absoluto, las cosas se han mantenido estables en nuestro entorno previo al control de calidad durante el fin de semana, y mañana comenzaremos a implementar el parche en nuestro entorno de control de calidad principal, donde veremos más efectos del mundo real. Dado que Memcached se había beneficiado del parche anterior, realmente queríamos tener nuestro pastel y comérnoslo también con ambos parches en su lugar, así que estábamos felices de probar. ¡Gracias de nuevo por todo el trabajo que ha realizado para reducir la velocidad!
PaulFurtado
en 31 jul. 2019
Solo quería dejar una nota sobre el parche del kernel que se está discutiendo ...
Lo he adaptado al kernel que estamos usando en las pruebas actuales y veo algunas ganancias enormes en las tasas de aceleración de CFS; sin embargo, mencionaré que si previamente ha establecido el período de cfs en 10 ms como mitigación, va a desea volver a subirlo a 100 ms para ver los beneficios del cambio.
 jhohertz
en 6 ago. 2019
jhohertz
en 6 ago. 2019
El parche aterrizó en la punta esta mañana.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Una vez que llegue al árbol de Torvald, lo enviaré para su inclusión estable en Linux y, posteriormente, distribuciones importantes (Redhat / Ubuntu). Si le importa otra cosa y no están siguiendo los parches estables de Linux, es posible que desee enviarlo directamente.
chiluk
en 8 ago. 2019
Probé el parche (ubuntu 18.04, 5.2.7 kernel, nodo: CPU de 56 núcleos E5-2660 v4 @ 2.00GHz) con nuestro microservicio golang de procesamiento de imágenes de alta CPU y obtuve resultados bastante impresionantes. Rendimiento como si desactivara CFS en el nodo por completo.
Tengo un 5-35% menos de latencia y un 5-55% más de RPS dependiendo de la concurrencia / utilización de la CPU a una tasa de aceleración cercana a cero.
¡Gracias, @chiluk !
Como dijo @jhohertz , la cuota de cfs debe revertirse a 100 ms, he probado con períodos más bajos y obtuve una alta aceleración y degradación del rendimiento.
 zigmund
en 10 ago. 2019
zigmund
en 10 ago. 2019
Para obtener más rendimiento con golang, configure GOMAXPROCS en ceil (quota) +2. El más 2 es para garantizar cierta concurrencia.
chiluk
en 12 ago. 2019
@chiluk probado con GOMAXPROCS = 8 vs GOMAXPROCS = 10 con cpu.limit = 8 - no es una gran diferencia, algo alrededor del 1-2%.
zigmund
en 13 ago. 2019
@zigmund, eso se debe a que su cpu.limit se establece en el número entero 8, lo que debería vincular sus procesos a un cpuset de 8 cpus. Su diferencia del 1-2% es solo el aumento en la sobrecarga para el cambio de contexto con sus 2 corredores Goroutine adicionales en su conjunto de tareas de 8 cpu.
Debería haber dicho que configurar GOMAXPROCS = # es una buena solución para los programas go hasta que los parches del kernel se distribuyan ampliamente.
chiluk
en 26 ago. 2019
Hemos migrado nuestros clústeres de producción al kernel parcheado y ahora puedo compartir algunos momentos interesantes.
Estadísticas de uno de nuestros clústeres: 4 nodos de 72 núcleos E5-2695 v4 a 2.10GHz, 128Gb de RAM, Debian 9, núcleo 5.2.7 con parche.
Tenemos cargas mixtas que consisten principalmente en servicios de golang, pero también tenemos php y python.
Golang. La latencia es menor, la configuración correcta de GOMAXPROCS es absolutamente imprescindible. Aquí está el servicio con GOMAXPROCS = 72 predeterminado. Hemos cambiado el kernel en ~ 16 y después de esa latencia disminuyó y la utilización de la CPU aumentó considerablemente. A las 21:15 configuré el GOMAXPROCS correcto y el uso de la CPU normalizado.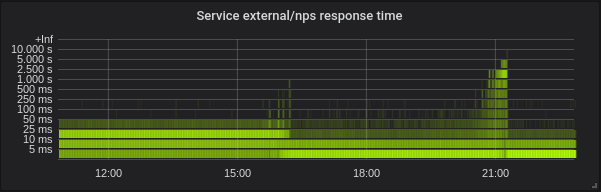

Pitón. Todo mejoró con el parche sin ningún movimiento adicional: la utilización de la CPU y la latencia disminuyeron.
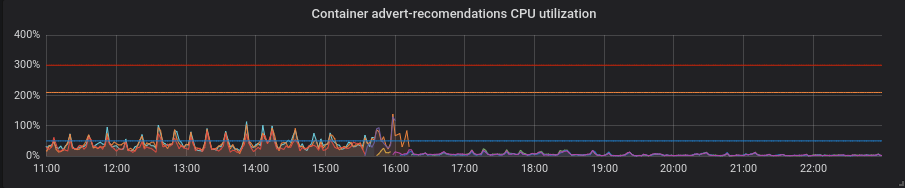
PHP. La utilización de la CPU es la misma, la latencia disminuyó poco en algunos de los servicios. No es una gran ganancia.
zigmund
en 3 sept. 2019
Gracias @zigmund.
No estoy seguro de entenderlo cuando dices I setted correct GOMAXPROCS ...
Supongo que no está ejecutando solo un pod en el nodo de 72 núcleos, por lo que establece GOMAXPROCS en algo más bajo, tal vez igual a los límites de CPU del Pod, ¿verdad?
prune998
en 3 sept. 2019
Gracias @zigmund. Los cambios de Go están bastante en línea con lo que se esperaba.
Sin embargo, estoy realmente sorprendido por las mejoras de Python, ya que esperaba que GIL anulara en gran medida los beneficios de esto. En todo caso, este parche debería reducir casi exclusivamente el tiempo de respuesta, disminuir el porcentaje de períodos limitados y aumentar la utilización de la CPU. ¿Estás seguro de que tu aplicación de Python todavía estaba en buen estado?
chiluk
en 3 sept. 2019
@ prune998 lo siento, tal vez
@chiluk No soy fuerte en Python y no sé cómo se ve afectado el parche en la capa inferior. Pero la aplicación está en buen estado sin problemas, la he comprobado después del cambio de kernel.
zigmund
en 4 sept. 2019
@chiluk ¿Podría explicar cómo podemos seguir el progreso de su parche en varias distribuciones de Linux? Estoy particularmente interesado en Debian y AWS Linux, pero espero que otras personas estén interesadas en Ubuntu, etc., así que cualquier luz que pueda arrojar, gracias.
 Nuru
en 13 sept. 2019
Nuru
en 13 sept. 2019
@Nuru https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html?highlight=stable%20rules ... Básicamente, lo enviaré a través de linux-estable una vez que mi parche llegue a Linus ' tree, * (tal vez antes), y luego todas las distribuciones deberían estar siguiendo el proceso estable de Linux, y estar incorporando parches aceptados por los mantenedores estables para sus núcleos específicos de distribución. Si no es así, no deberías ejecutar sus distribuciones.
chiluk
en 13 sept. 2019
@chiluk No sé nada sobre el proceso de desarrollo de Linux. Por "árbol de Linus" ¿te refieres a https://github.com/torvalds/linux ?
Nuru
en 14 sept. 2019
El árbol de Linus vive aquí, https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/. Actualmente, mis cambios se realizan en linux-next, que es el árbol de integración de desarrollo. Sí, el desarrollo del kernel está un poco atascado en la edad oscura, pero funciona.
Es probable que introduzca cambios en el árbol linux-next una vez que se publique 5.3 y comience el desarrollo en 5.4-rc0. Ese es el período de tiempo en el que espero que los núcleos estables comiencen a incorporar esta solución. Siempre que Linus sienta que 5.3 es estable, nadie lo sabe.
chiluk
en 14 sept. 2019
[Linus] probablemente incorporará cambios desde el árbol linux-next una vez que se publique 5.3 y comience el desarrollo en 5.4-rc0. Ese es el período de tiempo en el que espero que los núcleos estables comiencen a incorporar esta solución. Siempre que Linus sienta que 5.3 es estable, nadie lo sabe.
@chiluk Parece que Linus decidió que 5.3 era estable el 15 de septiembre de 2019 . Entonces, ¿qué es "linux-next" y cómo hacemos un seguimiento del progreso de su parche en los siguientes pasos?
Nuru
en 20 sept. 2019
¿Alguien ha creado paquetes extensibles de Debian y / o una imagen de AWS que incluya este parche? Estoy a punto de hacerlo usando https://github.com/kubernetes-sigs/image-builder/tree/master/images/kube-deploy/imagebuilder
Solo pensé que evitaría duplicar esfuerzos si ya existe.
blakebarnett
en 24 sept. 2019
Esto ahora se ha fusionado en el árbol de Linus y debería lanzarse con 5.4. También lo acabo de enviar a linux-estable, y asumiendo que todo va bien, todas las distribuciones que siguen correctamente el proceso estable deberían comenzar a recogerlo en breve.
chiluk
en 25 sept. 2019
¿Alguien sabe cómo seguir si / cómo este cambio llega a CentOS (7)? No estoy seguro de cómo funciona el backporting, etc.
 till
en 26 sept. 2019
till
en 26 sept. 2019
@till https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -531370333
Porque la conversación del kernel estable está sucediendo aquí.
https://lore.kernel.org/stable/CAC=E7cUXpUDgpvsmMaMU6sAydbfD0FEJiK25R1r=e9=YtcPjGw@mail.gmail.com/
También para aquellos que asistan a KubeCon, presentaré este tema allí.
https://sched.co/Uae1
chiluk
en 3 oct. 2019
¿Alguna palabra de los encargados del mantenimiento del planificador sobre el reconocimiento que estaba buscando Greg HK para introducirlo en los árboles estables?
jhohertz
en 18 oct. 2019
Greg KH se ha retrasado en tomar una decisión sobre este parche porque los encargados del mantenimiento del planificador no han respondido (probablemente se perdieron el correo). Se agradecería el comentario de cualquier otra persona que no sea yo sobre LKML que haya probado este parche y piense que debería ser compatible.
chiluk
en 18 oct. 2019
Para las personas que usan CoreOS, existe un problema abierto que solicita que el parche de @chiluk sea compatible.
 evanfoster
en 1 nov. 2019
evanfoster
en 1 nov. 2019
El kernel de CoreOS 4.19.82 tiene las correcciones: https://github.com/coreos/linux/pull/364
CoreOS Container Linux 2317.0.1 (canal alfa) tiene las correcciones: https://github.com/coreos/coreos-overlay/pull/3796 http://coreos.com/releases/#2317.0.1
Las versiones posteriores a Linux estable parecen estar estancadas porque los parches no se aplican correctamente . @chiluk ¿Vas a trabajar en backports para Linux estable? Si es así, ¿podría volver a la versión 4.9 para que entre en Debian "stretch" y sea recogido por kops ? Aunque supongo que va a tomar hasta 6 meses ponerlo en "estiramiento" y tal vez para entonces kops habrá migrado a "buster".
Nuru
en 8 nov. 2019
@Nuru , hice backport del parche e hice paquetes extensibles (basados en el kernel stretch-backports) y una AMI compatible con kops 1.11 si desea probar:
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.buildinfo
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm-dbg_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-headers-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.changes
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-libc-dev_4.19.67-1_amd64.deb
293993587779 / k8s-1.11-debian-stretch-amd64-hvm-ebs-2019-09-26
blakebarnett
en 8 nov. 2019
@blakebarnett Gracias por tu esfuerzo y lamento molestarte, pero estoy más que un poco confundido.
- "stretch" está basado en Linux 4.9, pero todos sus enlaces son para 4.19.
- Dices que has publicado "el parche", pero hay 3 parches (supongo que el tercero no es realmente importante:
- 512ac999 sched / fair: corrige la condición de desviación del reloj del temporizador de ancho de banda
- de53fd7ae sched / fair: corrige el uso bajo de cpu con alta aceleración eliminando la caducidad de los segmentos de cpu-local
- 763a9ec06 sched / fair: Fix -Wunused-but-set-variable warnings
¿Hiciste backport los 3 parches a 4.9? (No sé qué hacer con los paquetes de Debian para mirar y ver si los cambios están ahí, y el documento de "cambios" no aborda lo que realmente ha cambiado).
Además, ¿en qué regiones está disponible su AMI?
Nuru
en 8 nov. 2019
No, utilicé el kernel stretch-backports, que es 4.19, ya que tiene correcciones que también necesitábamos en AWS (especialmente para los tipos de instancia M5 / C5)
Apliqué una diferencia que incorporó todos los parches que creo, tuve que cambiarlo ligeramente para eliminar referencias adicionales a las variables en 4.19 que se eliminaron en otro lugar, primero apliqué esto https://github.com/kubernetes/kubernetes/issues/67577 #issuecomment -515324561 y luego necesitaba agregar:
--- kernel/sched/fair.c 2019-09-25 16:06:02.954933954 -0700
+++ kernel/sched/fair.c-b 2019-09-25 16:06:56.341615817 -0700
@@ -4928,8 +4928,6 @@
cfs_b->period_active = 1;
overrun = hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
- cfs_b->runtime_expires += (overrun + 1) * ktime_to_ns(cfs_b->period);
- cfs_b->expires_seq++;
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
--- kernel/sched/sched.h 2019-08-16 01:12:54.000000000 -0700
+++ sched.h.b 2019-09-25 13:24:00.444566284 -0700
@@ -334,8 +334,6 @@
u64 quota;
u64 runtime;
s64 hierarchical_quota;
- u64 runtime_expires;
- int expires_seq;
short idle;
short period_active;
@@ -555,8 +553,6 @@
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
- int expires_seq;
- u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock;
El AMI se publica en us-west-1
¡Espero que ayude!
blakebarnett
en 8 nov. 2019
He respaldado estos parches y los he enviado a los núcleos estables de Linux
v4.14 https://lore.kernel.org/stable/[email protected]/
v4.19 https://lore.kernel.org/stable/[email protected]/ #t
chiluk
en 8 nov. 2019
Hola,
después de la integración del parche en la rama 4.19, he abierto un informe de error en debian para una actualización adecuada de kerner en buster y stretch-backport:
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=946144
no dude en agregar un nuevo comentario para la actualización del paquete debian.
 alexises
en 4 dic. 2019
alexises
en 4 dic. 2019
Espero que esto no sea demasiado fraudulento, pero quería vincular esta excelente charla de @chiluk para https://youtu.be/UE7QX98-kO0.
 bboreham
en 4 dic. 2019
bboreham
en 4 dic. 2019
¿Hay alguna forma de evitar la limitación en GKE? Acabamos de tener un gran problema en el que un método en el contenedor php tardaba 120 segundos en lugar de los habituales 0.1
 bartoszhernas
en 5 dic. 2019
bartoszhernas
en 5 dic. 2019
eliminar los límites de la CPU
 monotek
en 5 dic. 2019
monotek
en 5 dic. 2019
Ya lo hicimos, el contenedor se ralentiza cuando las solicitudes de CPU son demasiado pequeñas. Ese es el núcleo del problema, la falta de límites y solo el uso de solicitudes de CPU aún conducirá a la aceleración :(
bartoszhernas
en 5 dic. 2019
@bartoszhernas Creo que estás usando la palabra incorrecta aquí. Cuando las personas en este hilo se refieren a "estrangulamiento", se refieren al control de ancho de banda de cfs, nr_throttled en cpu.stat para el aumento de cgroup. Eso solo está habilitado cuando los límites de CPU están habilitados. A menos que GKE esté agregando límites a su pod sin su conocimiento, no llamaría a lo que está golpeando como aceleración.
Yo llamaría a lo que ha descrito "contienda por el procesador". Sospecho que probablemente tenga varias aplicaciones * (solicitudes) de tamaño incorrecto, que compiten por el procesador u otro recurso en la caja porque con frecuencia usan más de lo que solicitaron. Esta es la razón precisa por la que usamos límites. De modo que esas aplicaciones de tamaño inadecuado solo pueden afectar mucho a otras aplicaciones en la caja.
La otra posibilidad es que la cantidad insuficiente de su solicitud esté dando lugar a un comportamiento de programación simplemente deficiente. Establecer las solicitudes en un nivel bajo es similar a establecer un valor positivo "agradable" en relación con las aplicaciones de "solicitud" superiores. Para obtener más información sobre eso, consulte los límites suaves.
chiluk
en 5 dic. 2019
Los problemas se vuelven obsoletos después de 90 días de inactividad.
Marque el problema como nuevo con /remove-lifecycle stale .
Los problemas obsoletos se pudren después de 30 días adicionales de inactividad y finalmente se cierran.
Si es seguro cerrar este problema ahora, hágalo con /close .
Envíe sus comentarios a sig-testing, kubernetes / test-infra y / o fejta .
/ ciclo de vida obsoleto
 fejta-bot
en 4 mar. 2020
fejta-bot
en 4 mar. 2020
/ remove-lifecycle stale
Nuru
en 4 mar. 2020
Según tengo entendido, el problema subyacente en el kernel se solucionó y se puso a disposición, por ejemplo, en ContainerLinux en https://github.com/coreos/bugs/issues/2623.
¿Alguien conoce los problemas restantes después de este parche del kernel?
 sfudeus
en 4 mar. 2020
sfudeus
en 4 mar. 2020
@sfudeus Kubernetes se puede ejecutar en cualquier versión de Linux o, AFAIK, en cualquier versión de Unix compatible con POSIT. Este error nunca fue un problema para las personas que no usaban Linux, se corrigió para algunas distribuciones derivadas de Linux y no se corrigió para otras.
El problema subyacente se solucionó en el kernel 5.4 de Linux, que casi nadie está usando en este momento. Se pusieron a disposición parches para su backporting a varios kernels antiguos e incluirlos en nuevas distribuciones de Linux que aún no están listas para pasar al kernel 5.4, de las cuales hay muchas. Como puede ver en la lista anterior de confirmaciones que hacen referencia a este problema, los parches de corrección de errores aún están en proceso de ser incorporados a la miríada de distribuciones de Linux en las que alguien podría estar usando Kubernetes.
Por lo tanto, me gustaría mantener este problema abierto mientras todavía ve referencias de confirmación activas. También me gustaría verlo cerrado con un script u otro método fácil que alguien pueda usar para determinar si su instalación de Kubernetes se ve afectada o no.
Nuru
en 5 mar. 2020
@Nuru Está bien para mí, solo quería asegurarme de que no quede ningún otro problema del kernel, que ya se conoce. Personalmente, no mantendría esto abierto más tiempo que las distribuciones más grandes que han incorporado la solución, esperar un sinfín de dispositivos de IoT puede significar esperar sin fin. También se pueden encontrar problemas cerrados. Pero eso es solo mis 2 centavos.
sfudeus
en 5 mar. 2020
No estoy seguro de si este es el lugar correcto para informar a las personas, pero no estoy seguro de dónde más mencionarlo:
Estamos ejecutando el kernel de Linux 5.4 en Debian Buster (usando el kernel buster-backports) usando el clúster k8s 1.15.10 y todavía estamos viendo problemas con esto. Especialmente para los Pods que generalmente tienen muy poco que hacer (kube-downscaler es el ejemplo al que seguimos volviendo, que generalmente requiere alrededor de 3 m de CPU) y que tienen muy pocos recursos de CPU asignados (50 m en el caso de kube-downscaler en nuestro cluster) todavía vemos un valor de limitación muy alto. Como referencia, el kube-downscaler es básicamente un script de Python que ejecuta un sleep durante 30 minutos antes de hacer nada. cAdvisor muestra el aumento de container_cpu_cfs_throttled_periods_total para que este contenedor sea siempre más o menos similar al valor container_cpu_cfs_periods_total de este contenedor (ambos son alrededor de 250 cuando se verifica el aumento en intervalos de 5 m). Es de esperar que los períodos de estrangulamiento estén cerca de 0.
¿Estamos midiendo esto incorrectamente? ¿CAdvisor está generando datos incorrectos? ¿Es correcta nuestra suposición de que deberíamos ver una caída en los períodos estrangulados? Cualquier consejo sería apreciado aquí.
Después de cambiar al kernel 5.4, vimos que la cantidad de Pods con este problema disminuyó un poco (alrededor del 40%), pero actualmente no estamos seguros de si lo que estamos viendo es un problema real o no. Básicamente, cuando miramos las estadísticas anteriores, no estamos seguros de qué significa realmente "estrangulamiento" si obtenemos estos valores con el uso promedio de CPU de 3 millones. El nodo en el que se ejecuta no está comprometido en exceso y tiene un uso de CPU promedio de menos del 10%.
 timstoop
en 5 mar. 2020
timstoop
en 5 mar. 2020
@timstoop los intervalos que le interesan al planificador están en el ámbito de los microsegundos, no en grandes intervalos de 30 minutos. Si un contenedor tiene un límite de CPU de 50 milicpu y usa 50 milicpu en un lapso de 100 microsegundos, se ralentizará, independientemente de si pasa 30 minutos inactivo. En general, 50 milicpu es un límite de CPU extremadamente pequeño. Si un programa de Python incluso realiza una sola solicitud HTTPS con un límite tan bajo, está prácticamente garantizado que se acelerará.
El nodo en el que se ejecuta no está comprometido en exceso y tiene un uso de CPU promedio de menos del 10%.
Solo para aclarar: la carga del nodo y otras cargas de trabajo en él no tienen nada que ver con la limitación. La limitación solo considera el límite del propio contenedor / cgroup.
PaulFurtado
en 5 mar. 2020
@PaulFurtado ¡ Gracias por tu respuesta! Sin embargo, el Pod en sí tiene un uso promedio de 3 millones de cpu durante ese período de inactividad y aún se está acelerando. No está haciendo ninguna solicitud durante ese tiempo, está esperando el sueño. Espero que pueda hacer eso sin llegar a los 50 metros, ¿verdad? ¿O es una suposición incorrecta de todos modos?
timstoop
en 5 mar. 2020
Creo que es probable que este sea un número tan bajo que habrá problemas de precisión. Y 50 m es tan bajo que cualquier cosa podría tropezarlo. El tiempo de ejecución de Python también puede realizar tareas en segundo plano en subprocesos mientras duerme.
PaulFurtado
en 5 mar. 2020
Tenías razón, estaba haciendo suposiciones que no eran ciertas. ¡Gracias por tu orientación! Tiene sentido para mí ahora.
timstoop
en 5 mar. 2020
Solo quería saltar y decir que las cosas aquí se han mejorado sustancialmente desde que el parche del kernel llegó a los kernels 4.19 LTS y apareció en CoreOS / Flatcar. Mirando el momento, las únicas cosas que veo que se están acelerando son un par de cosas en las que probablemente debería poner límites. :sonreír:
jhohertz
en 5 mar. 2020
@sfudeus @chiluk ¿Hay alguna prueba simple para ver si su kernel tiene esto arreglado o no?
No puedo decir si kope.io/k8s-1.15-debian-stretch-amd64-hvm-ebs-2020-01-17 (la imagen oficial actual kops ) ha sido parcheada o no.
Nuru
en 20 mar. 2020
Estoy de acuerdo con @mariusgrigoriu , para los pods que se ejecutan en cpuset exclusivo bajo la política de cpu estática, simplemente podemos deshabilitar el límite de cuota de cpu; de todos modos, solo se puede ejecutar en su conjunto de cpu exclusivo. El parche anterior es para este propósito y solo para este tipo de cápsulas.
 jianzzha
en 6 abr. 2020
jianzzha
en 6 abr. 2020
@Nuru escribí https://github.com/indeedeng/fibtest
Es la prueba más definitiva que puede obtener, pero necesitará un compilador de C.
Ignore el número de iteraciones completadas, pero concéntrese en la cantidad de tiempo utilizado para la ejecución de un solo subproceso frente a la de varios subprocesos.
chiluk
en 10 abr. 2020
Supongo que una buena forma de ver qué kernels se han parcheado es en una de las últimas diapositivas de @chiluk (gracias por esto) charla https://www.youtube.com/watch?v=UE7QX98-kO0
Kernel 4.15.0-67 parece tener el parche (https://launchpad.net/ubuntu/+source/linux/4.15.0-67.76) sin embargo, todavía estamos viendo estrangulamiento en algunos Pods donde las solicitudes / límite están muy por encima su uso de CPU.
Estoy hablando de un uso de alrededor de 50 ms con una solicitud establecida en 250 my un límite de 500 m. Estamos viendo que alrededor del 50% de los períodos de CPU se ralentizan, ¿es este valor tal vez lo suficientemente bajo como para esperar y ser aceptado? Me gustaría que se redujera a cero, no deberíamos estrangularnos en absoluto si el uso no está ni siquiera cerca del límite.
¿Alguien que usa el nuevo kernel parcheado todavía tiene algunas limitaciones?
 vgarcia-te
en 22 abr. 2020
vgarcia-te
en 22 abr. 2020
@ vgarcia-te Hay demasiados kernels circulando para saber de una lista cuáles han sido parcheados y cuáles no. Solo mire todas las confirmaciones que hacen referencia a este problema. Varios cientos. Mi lectura del registro de cambios para Ubuntu sugiere que 4.15 aún no ha sido parcheado (excepto mabye para ejecutarse en Azure), y el parche al que se vinculó fue rechazado .
Personalmente, estoy interesado en la serie 4.9 porque eso es lo que está usando kops y me gustaría saber cuándo lanzan una AMI con una solución.
Mientras tanto, puede intentar ejecutar @bobrik 's prueba que parece bastante bueno para mí.
wget https://gist.githubusercontent.com/bobrik/2030ff040fad360327a5fab7a09c4ff1/raw/9dcf83b821812064fa7fb056b8f22cbd5c4364f1/cfs.go
sudo docker run --rm -it --cpu-quota 20000 --cpu-period 100000 -v $(pwd):$(pwd) -w $(pwd) golang:1.9.2 go run cfs.go -iterations 15 -sleep 1000ms
Con un CFS que funcione correctamente, los tiempos de combustión siempre serán de 5 ms. Con los núcleos afectados que he probado, utilizando los números anteriores, con frecuencia veo tiempos de grabación de 99 ms. Cualquier valor superior a 6 ms es un problema.
Nuru
en 22 abr. 2020
@nuru gracias por la secuencia de comandos para encontrar el problema está ahí o no.
@justinsb Sugiera si las imágenes predeterminadas de kops tienen el parche o no
https://github.com/kubernetes/kops/blob/master/channels/stable
Problema abierto: https://github.com/kubernetes/kops/issues/8954
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -617586330
Actualización: Ejecuté la prueba en la imagen de kops 1.15, hay una limitación innecesaria https://github.com/kubernetes/kops/issues/8954#issuecomment -617673755
alok87
en 22 abr. 2020
@Nuru
2020/04/22 11:02:48 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 6ms
2020/04/22 11:02:49 [1] burn took 5ms, real time so far: 1012ms, cpu time so far: 12ms
2020/04/22 11:02:50 [2] burn took 5ms, real time so far: 2017ms, cpu time so far: 18ms
2020/04/22 11:02:51 [3] burn took 5ms, real time so far: 3023ms, cpu time so far: 23ms
2020/04/22 11:02:52 [4] burn took 5ms, real time so far: 4028ms, cpu time so far: 29ms
2020/04/22 11:02:53 [5] burn took 5ms, real time so far: 5033ms, cpu time so far: 35ms
2020/04/22 11:02:54 [6] burn took 5ms, real time so far: 6038ms, cpu time so far: 40ms
2020/04/22 11:02:55 [7] burn took 5ms, real time so far: 7043ms, cpu time so far: 46ms
2020/04/22 11:02:56 [8] burn took 5ms, real time so far: 8049ms, cpu time so far: 51ms
2020/04/22 11:02:57 [9] burn took 5ms, real time so far: 9054ms, cpu time so far: 57ms
2020/04/22 11:02:58 [10] burn took 5ms, real time so far: 10059ms, cpu time so far: 63ms
2020/04/22 11:02:59 [11] burn took 5ms, real time so far: 11064ms, cpu time so far: 69ms
2020/04/22 11:03:00 [12] burn took 5ms, real time so far: 12069ms, cpu time so far: 74ms
2020/04/22 11:03:01 [13] burn took 5ms, real time so far: 13074ms, cpu time so far: 80ms
2020/04/22 11:03:02 [14] burn took 5ms, real time so far: 14079ms, cpu time so far: 85ms
esos resultados son del
Linux <servername> 4.15.0-96-generic #97-Ubuntu SMP Wed Apr 1 03:25:46 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
Es el último kernel estable predeterminado de ubuntu en ubuntu 18.04.
Entonces, parece que el parche está ahí.
 zerkms
en 22 abr. 2020
zerkms
en 22 abr. 2020
@zerkms ¿Dónde ejecutó sus pruebas en Ubuntu 18.04? Me parece que es posible que el parche solo haya llegado al kernel de Azure. Si puede encontrar una nota de lanzamiento que diga dónde se aplicó al paquete Ubuntu linux por favor comparta. No lo encuentro.
Tenga en cuenta también que esta prueba tampoco pudo reproducir el problema en CoreOS. Podría ser que en la configuración predeterminada la programación de CFS estuviera deshabilitada globalmente.
Nuru
en 22 abr. 2020
@Nuru
¿Dónde ejecutó sus pruebas en Ubuntu 18.04?
Uno de mis servidores.
No revisé las notas de la versión, ni siquiera estoy seguro de qué buscar y, sin embargo, es un kernel predeterminado como todos. 🤷
zerkms
en 22 abr. 2020
el parche debería estar aquí en ubuntus kernel git:
https://kernel.ubuntu.com/git/ubuntu/ubuntu-bionic.git/commit/?id=aadd794e744086fb50cdc752d54044fbc14d4adb
y aquí el error de ubuntu al respecto:
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1832151
debería ser liberado en el biónico.
Puede asegurarse ejecutando apt-get source linux y verifique el código fuente descargado.
juliantaylor
en 22 abr. 2020
@zerkms Por "dónde ejecutó sus pruebas" me refiero a que era un servidor en su oficina, un servidor en GCP, AWS, Azure o en algún otro lugar?
Obviamente, hay muchas cosas que no entiendo sobre cómo se distribuye y mantiene Ubuntu. También estoy confundido por su salida uname -a . Las notas de la versión de Ubuntu dicen:
18.04.4 se envía con un kernel de Linux basado en v5.3 actualizado desde el kernel basado en v5.0 en 18.04.3.
y también dice que 18.04.4 fue lanzado el 12 de febrero de 2020. Su resultado dice que está ejecutando un kernel v4.15 compilado el 1 de abril de 2020.
@juliantaylor No tengo un servidor Ubuntu o una copia del repositorio de Git, y no sé cómo rastrear dónde una confirmación específica como aadd794e7440 se convirtió en un kernel estable publicado. Si me puede mostrar cómo hacer eso, se lo agradecería.
Cuando miro los comentarios de error de Launchpad , veo
- Este error se corrigió en el paquete linux-azure - 5.0.0-1027.29
- Este error se corrigió en el paquete linux-azure - 5.0.0-1027.29 ~ 18.04.1
pero este parche específico ( sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices ) no figura en
- Este error se corrigió en el paquete linux - 4.15.0-69.78
Tampoco veo "1832151" en las notas de la versión de Ubuntu
Un comentario anterior decía que estaba parcheado en 4.15.0-67.76 pero no veo ningún paquete linux-image-4.15.0-67-generic .
Estoy lejos de ser un experto en Ubuntu y encuentro este parche de seguimiento inaceptablemente difícil, así que eso es lo que he visto.
Espero que ahora vea por qué no estoy seguro de que este parche se haya incluido en Ubuntu 18.04.4, que es la versión actual de 18.04. Mi _mejor suposición_ es que se lanzó como una actualización del kernel después del lanzamiento de 18.04.4, y probablemente se incluya si su kernel de Ubuntu informa 4.15.0-69 o posterior, pero si solo descarga 18.04.4 y no lo actualiza, no tendrá el parche.
Nuru
en 22 abr. 2020
Acabo de ejecutar la prueba Go (muy útil) en el kernel 4.15.0-72 en un servidor baremetal en un centro de datos y parece que el parche está ahí:
2020/04/22 21:24:27 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 7ms
2020/04/22 21:24:28 [1] burn took 5ms, real time so far: 1010ms, cpu time so far: 13ms
2020/04/22 21:24:29 [2] burn took 5ms, real time so far: 2015ms, cpu time so far: 20ms
2020/04/22 21:24:30 [3] burn took 5ms, real time so far: 3020ms, cpu time so far: 25ms
2020/04/22 21:24:31 [4] burn took 5ms, real time so far: 4025ms, cpu time so far: 32ms
2020/04/22 21:24:32 [5] burn took 5ms, real time so far: 5030ms, cpu time so far: 38ms
2020/04/22 21:24:33 [6] burn took 5ms, real time so far: 6036ms, cpu time so far: 43ms
2020/04/22 21:24:34 [7] burn took 5ms, real time so far: 7041ms, cpu time so far: 50ms
2020/04/22 21:24:35 [8] burn took 5ms, real time so far: 8046ms, cpu time so far: 56ms
2020/04/22 21:24:36 [9] burn took 5ms, real time so far: 9051ms, cpu time so far: 63ms
2020/04/22 21:24:37 [10] burn took 5ms, real time so far: 10056ms, cpu time so far: 68ms
2020/04/22 21:24:38 [11] burn took 5ms, real time so far: 11061ms, cpu time so far: 75ms
2020/04/22 21:24:39 [12] burn took 5ms, real time so far: 12067ms, cpu time so far: 81ms
2020/04/22 21:24:40 [13] burn took 5ms, real time so far: 13072ms, cpu time so far: 86ms
2020/04/22 21:24:41 [14] burn took 5ms, real time so far: 14077ms, cpu time so far: 94ms
También puedo ver que la misma ejecución en el kernel 4.9.164 en el mismo tipo de servidor muestra quemaduras de más de 5ms:
2020/04/22 21:24:41 [0] burn took 97ms, real time so far: 97ms, cpu time so far: 8ms
2020/04/22 21:24:42 [1] burn took 5ms, real time so far: 1102ms, cpu time so far: 12ms
2020/04/22 21:24:43 [2] burn took 5ms, real time so far: 2107ms, cpu time so far: 16ms
2020/04/22 21:24:44 [3] burn took 5ms, real time so far: 3112ms, cpu time so far: 24ms
2020/04/22 21:24:45 [4] burn took 83ms, real time so far: 4197ms, cpu time so far: 28ms
2020/04/22 21:24:46 [5] burn took 5ms, real time so far: 5202ms, cpu time so far: 32ms
2020/04/22 21:24:47 [6] burn took 94ms, real time so far: 6297ms, cpu time so far: 36ms
2020/04/22 21:24:48 [7] burn took 99ms, real time so far: 7397ms, cpu time so far: 40ms
2020/04/22 21:24:49 [8] burn took 100ms, real time so far: 8497ms, cpu time so far: 44ms
2020/04/22 21:24:50 [9] burn took 5ms, real time so far: 9503ms, cpu time so far: 52ms
2020/04/22 21:24:51 [10] burn took 5ms, real time so far: 10508ms, cpu time so far: 60ms
2020/04/22 21:24:52 [11] burn took 5ms, real time so far: 11602ms, cpu time so far: 64ms
2020/04/22 21:24:53 [12] burn took 5ms, real time so far: 12607ms, cpu time so far: 72ms
2020/04/22 21:24:54 [13] burn took 5ms, real time so far: 13702ms, cpu time so far: 76ms
2020/04/22 21:24:55 [14] burn took 5ms, real time so far: 14707ms, cpu time so far: 80ms
Entonces, mi problema es que todavía veo la aceleración de la CPU, incluso mi kernel parece estar parcheado
vgarcia-te
en 22 abr. 2020
@Nuru , lo siento. Ese era mi servidor bare metal alojado en la oficina.
y también dice que 18.04.4 fue lanzado el 12 de febrero de 2020. Su resultado dice que está ejecutando un kernel v4.15 compilado el 1 de abril de 2020.
Eso es porque es un servidor LTS: debe optar por HWE explícitamente con él para tener kernels más nuevos, de lo contrario, simplemente ejecute la línea principal.
Y tanto los núcleos de línea principal como los de HWE se lanzan con regularidad, por lo que no hay nada sospechoso en tener un núcleo de reciente construcción: http://changelogs.ubuntu.com/changelogs/pool/main/l/linux-meta/linux-meta_4.15.0.96.87/ registro de cambios
zerkms
en 22 abr. 2020
@zerkms Gracias por la información. Sigo confundido, pero este no es el lugar para educarme.
@ vgarcia-te Si su kernel está parcheado, lo que parece ser, entonces la limitación no se debe a este error. No estoy seguro de su terminología cuando dice:
Estoy hablando de un uso de alrededor de 50 ms con una solicitud establecida en 250 my un límite de 500 m. Estamos viendo que alrededor del 50% de los períodos de CPU se ralentizan, ¿es este valor tal vez lo suficientemente bajo como para esperar y ser aceptado?
El recurso de CPU de Kubernetes se mide en CPU, 1 significa 100% de 1 CPU completa, 1 m significa 0.1% de 1 CPU. Entonces, su límite de "500 m" dice que permita 0.5 CPU.
El período de programación predeterminado para CFS es de 100 ms, por lo que establecer el límite en 0,5 CPU limitaría su proceso a 50 ms de CPU cada 100 ms. Si su proceso intenta superar eso, se ralentizará. Si su proceso generalmente se ejecuta más de 50 ms en una sola pasada, entonces sí, esperaría que un programador que funcione correctamente lo acelere.
Nuru
en 23 abr. 2020
@Nuru, eso tiene sentido, pero déjame entender esto, dado que el período predeterminado de la CPU es de 100 ms, en el caso de que un proceso obtenga 1 CPU asignada, si ese proceso se ejecuta durante más de 100 ms en una sola pasada, ¿se acelerará?
¿Significa esto que en Linux, donde el período predeterminado de la CPU es de 100 ms, cualquier proceso que tenga un límite que se ejecute durante más de 100 ms en una sola pasada, se acelerará?
¿Cuál sería una buena configuración de límite para un proceso que tarda más de 100 ms en una sola pasada pero está inactivo el resto del tiempo?
vgarcia-te
en 23 abr. 2020
@ vgarcia-te preguntó
Dado que el período predeterminado de la CPU es de 100 ms, en el caso de que a un proceso se le asigne 1 CPU, si ese proceso se ejecuta durante más de 100 ms en una sola pasada, ¿se limitará?
Por supuesto, programar es increíblemente complicado, así que no puedo darte una respuesta perfecta, pero la respuesta simplificada es no. Las explicaciones más detalladas están aquí y aquí .
Todos los procesos de Unix están sujetos a una programación preventiva basada en intervalos de tiempo. En los días de CPU única de un solo núcleo, todavía tenía 30 procesos ejecutándose "simultáneamente". Lo que sucede es que corren un rato y duermen o, al final de su intervalo de tiempo, se ponen en espera para que pueda correr otra cosa.
El CSA con cuotas va un paso más allá.
Pregúntese, sin embargo, cuando dice que quiere que un proceso use el 50% de una CPU, ¿qué está diciendo realmente? ¿Está diciendo que está bien si acapara el 100% de la CPU durante 5 minutos, siempre que no se ejecute en absoluto durante los siguientes 5 minutos? Eso sería un 50% de uso durante 10 minutos, pero no es aceptable para la mayoría de las personas debido a problemas de latencia.
Entonces, CFS define un "período de CPU" que es la ventana de tiempo durante la cual hace cumplir las cuotas. En una máquina con 4 núcleos y un período de CPU de 100 ms, el programador tiene 400 ms de tiempo de CPU para asignar más de 100 ms de tiempo real (reloj de pared). Si está ejecutando un único subproceso de ejecución que no se puede paralelizar, entonces ese subproceso puede usar como máximo 100 ms de tiempo de CPU por período, lo que sería el 100% de 1 CPU. si establece su cuota en 1 CPU, nunca debería acelerarse.
Si establece la cuota en 500 m (0,5 CPU), el proceso obtiene 50 ms para ejecutarse cada 100 ms. Cualquier período de 100 ms utiliza menos de 50 ms y no debe estrangularse. En un período de 100 ms no termina después de ejecutar 50 ms, se ralentiza hasta el siguiente período de 100 ms. Eso mantiene un equilibrio entre la latencia (cuánto tiempo debe esperar para poder ejecutarse) y acaparamiento (cuánto tiempo se permite que otros procesos no se ejecuten).
Nuru
en 23 abr. 2020
@Nuru mis diapositivas son correctas. También soy desarrollador de Ubuntu * (solo en mi tiempo libre ahora). Su mejor opción es leer las fuentes y verificar git blame + tag --contains para rastrear cuándo el parche llega a la versión del kernel que le interesa.
chiluk
en 26 abr. 2020
@chiluk No había visto tus diapositivas. Para otros que no los han visto, aquí es donde dicen que el parche aterrizó hace algún tiempo:
- Ubuntu 4.15.0-67 +
- Ubuntu 5.3.0-24 +
- Kernel RHEL7 3.10.0-1062.8.1.el7
y por supuesto Linux estable v4.14.154, v4.19.84, 5.3.9. Observo que también está en Linux estable 5.4-rc1.
Todavía estoy luchando por comprender los diversos errores del programador CFS y encontrar pruebas confiables y fáciles de interpretar que funcionen en un servidor AWS pequeño, porque soy compatible con una amplia variedad de kernels de instalaciones heredadas. Según entiendo la línea de tiempo, se introdujo un error en el kernel de Linux v3.16-rc1 en 2014 por
[51f2176d74ac](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=51f2176d74ac) sched/fair: Fix unlocked reads of some cfs_b->quota/period.
Esto provocó diferentes problemas de limitación de CFS. Creo que los problemas que estaba viendo en los clústeres de kops Kubernetes se debían a este error, ya que usaban núcleos 4.9.
51f2176d74ac se corrigió en 2018 kernel v4.18-rc4 con
[512ac999](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) sched/fair: Fix bandwidth timer clock drift condition
pero eso introdujo el error @chiluk arreglado con
[de53fd7ae](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425) sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
Por supuesto, no es culpa de Chiluk ni de ninguna otra persona que los parches del kernel sean difíciles de rastrear en las distribuciones. Sin embargo, sigue siendo frustrante para mí y contribuye a mi confusión.
Por ejemplo, en Debuan buster 10 (AWS AMI debian-10-amd64-20191113-76 ), la versión del kernel se informa como
Linux ip-172-31-41-138 4.19.0-6-cloud-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
Por lo que puedo decir, este núcleo debería tener 51f2176d74ac y NO tener 512ac999 y por lo tanto debería fallar la prueba descrita en 512ac999 , pero no es así. (Digo que no creo que tenga 512ac999 porque se actualizó gradualmente desde el kernel de Linux 4.10 y no se menciona ese parche en el registro de cambios). Sin embargo, en una VM de AWS de 4 cpu no falla fibtest Chiluk o la prueba de hipo CFS de Bobrik, que sugiere que algo más está sucediendo.
Tuve problemas similares al reproducir cualquier problema de programación con CoreOS incluso antes de que recibiera el parche de Chiluk.
Lo que pienso en este momento es que la prueba de Bobrik es principalmente una prueba para 51f2176d74ac , la AMI de Debian buster 10 que estoy usando _tiene_ 512ac999 , pero no se menciona explícitamente en el registro de cambios, y fibtest no es una prueba muy sensible en una máquina con solo unos pocos núcleos.
Nuru
en 27 abr. 2020
Una cpu de 4 núcleos probablemente no sea lo suficientemente grande para reproducir el problema que corrigió chiluk.
Solo debería ser reproducible en máquinas más grandes con más de 40 cpus si entendí correctamente la explicación de chiluks kubecon talk (https://www.youtube.com/watch?v=UE7QX98-kO0).
Hay muchas versiones del kernel y hay muchos parches y revertir parches. Los registros de cambios y los números de versión solo te llevan hasta cierto punto.
La única forma confiable si tiene dudas es descargar el código fuente y compararlo con los cambios en los parches que se han vinculado aquí.
juliantaylor
en 27 abr. 2020
Los problemas se vuelven obsoletos después de 90 días de inactividad.
Marque el problema como nuevo con /remove-lifecycle stale .
Los problemas obsoletos se pudren después de 30 días adicionales de inactividad y finalmente se cierran.
Si es seguro cerrar este problema ahora, hágalo con /close .
Envíe sus comentarios a sig-testing, kubernetes / test-infra y / o fejta .
/ ciclo de vida obsoleto
fejta-bot
en 26 jul. 2020
/ remove-lifecycle stale
 yashbhutwala
en 27 jul. 2020
yashbhutwala
en 27 jul. 2020
Las pruebas mencionadas anteriormente en este hilo no reproducen realmente el problema para mí (algunas quemaduras toman más de 5 ms, pero es como el 0.01% de ellas) pero nuestras métricas de aceleración de cfs aún muestran cantidades moderadas de aceleración. Tenemos diferentes versiones de kernel en nuestros clústeres, pero las dos versiones más comunes son:
Debian 4.19.67-2+deb10u2~bpo9+1 (2019-11-12)- un backport manual de
5.4.38
No sé si se supone que ambos errores deben corregirse en estas versiones, pero creo que se supone que deben serlo, así que me pregunto si la prueba no es tan útil. Estoy probando en máquinas con 16 núcleos y con 36 núcleos, no estoy seguro de si necesito aún más núcleos para que la prueba sea válida, pero todavía vemos la limitación en estos grupos, así que ...
 2rs2ts
en 18 ago. 2020
2rs2ts
en 18 ago. 2020
¿Deberíamos cerrar este problema y pedir a las personas que enfrentan problemas que inicien otros nuevos? El spam aquí probablemente hará que cualquier conversación sea muy difícil.
 omnibs
en 31 oct. 2020
omnibs
en 31 oct. 2020
^ Estoy de acuerdo. Se ha hecho mucho para resolver este problema.
 sfxworks
en 31 oct. 2020
sfxworks
en 31 oct. 2020
/cerca
basado en los comentarios anteriores. abra nuevos problemas según sea necesario.
dims
en 1 nov. 2020
@dims : Cerrando este problema.
En respuesta a esto :
/cerca
basado en los comentarios anteriores. abra nuevos problemas según sea necesario.
Las instrucciones para interactuar conmigo usando comentarios de relaciones públicas están disponibles aquí . Si tiene preguntas o sugerencias relacionadas con mi comportamiento, presente un problema en el repositorio de kubernetes / test-infra .
 k8s-ci-robot
en 1 nov. 2020
k8s-ci-robot
en 1 nov. 2020
notifique los problemas de seguimiento de este problema, de modo que las personas suscritas al problema puedan suscribirse a los nuevos problemas para seguir
 glensc
en 1 nov. 2020
glensc
en 1 nov. 2020
Temas relacionados
 sjenning
·
3Comentarios
sjenning
·
3Comentarios
 sanjana-bhat
·
3Comentarios
sanjana-bhat
·
3Comentarios
 Seb-Solon
·
3Comentarios
Seb-Solon
·
3Comentarios
 alexferl
·
3Comentarios
alexferl
·
3Comentarios
 mml
·
3Comentarios
mml
·
3Comentarios
Comentario más útil
El parche aterrizó en la punta esta mañana.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Una vez que llegue al árbol de Torvald, lo enviaré para su inclusión estable en Linux y, posteriormente, distribuciones importantes (Redhat / Ubuntu). Si le importa otra cosa y no están siguiendo los parches estables de Linux, es posible que desee enviarlo directamente.