Kubernetes: CFS-Quoten können zu unnötiger Drosselung führen
/ Art Bug
Dies ist kein Fehler in Kubernets an sich, sondern eher ein Heads-up.
Ich habe diesen großartigen Blog-Beitrag gelesen:
Aus dem Blog-Beitrag habe ich erfahren, dass k8s cfs-Kontingente verwendet, um CPU-Limits durchzusetzen. Leider können diese zu unnötiger Drosselung führen, insbesondere bei gut erzogenen Mietern.
Sehen Sie diesen ungelösten Fehler im Linux-Kernel, den ich vor einiger Zeit eingereicht habe:
Es gibt einen offenen und blockierten Patch, der das Problem behebt (ich habe nicht überprüft, ob es funktioniert):
cc @ConnorDoyle @balajismaniam
 bobrik
bobrik
Alle 142 Kommentare
/ sig Knoten
/ Art Bug
 neolit123
am 20. Aug. 2018
neolit123
am 20. Aug. 2018
Ist das ein Duplikat von # 51135?
 liggitt
am 20. Aug. 2018
liggitt
am 20. Aug. 2018
Es ist im Geiste ähnlich, aber es scheint die Tatsache zu übersehen, dass es einen tatsächlichen Fehler im Kernel gibt und nicht nur einen Kompromiss bei der Konfiguration in der CFS-Quotenperiode. Ich mochte # 51135 hier zurück, um den Leuten dort mehr Kontext zu geben.
bobrik
am 22. Aug. 2018
Soweit ich weiß, ist dies ein weiterer Grund, entweder das CFS-Kontingent zu deaktivieren ( --cpu-cfs-quota=false ) oder es konfigurierbar zu machen (# 63437).
Ich finde diesen Kern (verlinkt vom Kernel-Patch) auch sehr interessant (um die Auswirkungen abzuschätzen): https://gist.github.com/bobrik/2030ff040fad360327a5fab7a09c4ff1
 hjacobs
am 22. Aug. 2018
hjacobs
am 22. Aug. 2018
cc @adityakali
 vishh
am 23. Aug. 2018
vishh
am 23. Aug. 2018
Ein weiteres Problem bei Quoten ist, dass das Kubelet Hyperthreads als "cpus" zählt. Wenn ein Cluster so geladen wird, dass zwei Threads auf demselben Kern geplant sind und der Prozess ein CPU-Kontingent hat, wird einer von ihnen nur mit einem kleinen Bruchteil der verfügbaren Verarbeitungsleistung ausgeführt (er wird nur etwas tun, wenn sich etwas auf dem anderen Thread befindet Stände) verbrauchen aber immer noch eine Quote, als ob sie einen physischen Kern für sich hätte. Es verbraucht also doppelt so viel, wie es sollte, ohne wesentlich mehr Arbeit zu leisten.
Dies hat zur Folge, dass auf einem vollständig geladenen Knoten mit aktiviertem Hyperthreading die Leistung halb so hoch ist wie bei deaktiviertem Hyperthreading oder deaktivierten Kontingenten.
Imo sollte das Kubelet Hyperthreads nicht als echten CPU betrachten, um diese Situation zu vermeiden.
 juliantaylor
am 30. Aug. 2018
juliantaylor
am 30. Aug. 2018
@juliantaylor Wie ich in # 51135 erwähnt habe, ist das Deaktivieren des CPU-Kontingents möglicherweise der beste Ansatz für die meisten k8s-Cluster, auf denen vertrauenswürdige Workloads ausgeführt werden.
vishh
am 30. Aug. 2018
Wird dies als Fehler angesehen?
Wenn einige Pods gedrosselt werden, ohne das CPU-Limit wirklich zu erschöpfen, klingt das für mich nach einem Fehler.
In meinem Cluster beziehen sich die meisten Pods mit Überquoten auf Metriken (Heapster, Metrics-Collector, Node-Exporter ...) oder Operatoren, die offensichtlich die Art von Workload haben, die hier problematisch ist: Tun Sie die meisten nicht Zeit und wach auf, um dich hin und wieder zu versöhnen.
Das Seltsame hier ist, dass ich versucht habe, das Limit von 40m auf 100m oder 200m zu erhöhen, und die Prozesse wurden immer noch gedrosselt.
Ich kann keine anderen Metriken sehen, die auf eine Arbeitslast hinweisen, die diese Drosselung auslösen könnte.
Ich habe die Beschränkungen für diese Pods vorerst aufgehoben ... es wird besser, aber das klingt wirklich nach einem Fehler und wir sollten eine bessere Lösung finden, als die Limits deaktivieren
 prune998
am 26. Nov. 2018
prune998
am 26. Nov. 2018
@ prune998 siehe @vishhs Kommentar und diesen Kern : Der Kernel drosselt Fall sein sollte. Wir (Zalando) haben beschlossen, das CFS-Kontingent (CPU-Drosselung) in unseren Clustern zu deaktivieren: https://www.slideshare.net/try_except_/optimizing-kubernetes-resource-requestslimits-for-costefficiency-and-latency-highload
hjacobs
am 27. Nov. 2018
Danke @hjacobs.
Ich bin bei Google GKE und sehe keine einfache Möglichkeit, es zu deaktivieren, aber ich suche weiter ...
prune998
am 27. Nov. 2018
@ prune998 AFAIK , Google hat die erforderlichen Knöpfe noch nicht freigelegt. Wir haben direkt nach der Möglichkeit, CFS zu deaktivieren, das im Upstream gelandet ist, eine Feature-Anfrage eingereicht. Seitdem haben wir keine Neuigkeiten mehr gehört.
 timoreimann
am 27. Nov. 2018
timoreimann
am 27. Nov. 2018
Ich bin bei Google GKE und sehe keine einfache Möglichkeit, es zu deaktivieren, aber ich suche weiter ...
Können Sie vorerst CPU-Limits aus Ihren Containern entfernen?
vishh
am 28. Nov. 2018
Laut den CPU-Manager-Dokumenten CFS quota is not used to bound the CPU usage of these containers as their usage is bound by the scheduling domain itself. Aber wir erleben eine CFS-Drosselung.
Dies macht den statischen CPU-Manager größtenteils sinnlos, da das Festlegen eines CPU-Limits zum Erreichen der garantierten QoS-Klasse jeglichen Vorteil aufgrund von Drosselung zunichte macht.
Ist es ein Fehler, dass CFS-Kontingente für Pods auf statischer CPU überhaupt festgelegt werden?
 mariusgrigoriu
am 12. Feb. 2019
mariusgrigoriu
am 12. Feb. 2019
Für zusätzlichen Kontext (gestern erfahren): @hrzbrg (MyTaxi) hat Kops ein Flag zur Deaktivierung der CPU-Drosselung https://github.com/kubernetes/kops/issues/5826
hjacobs
am 12. Feb. 2019
Bitte teilen Sie hier eine Zusammenfassung des Problems. Es ist nicht sehr klar, wo das Problem liegt und in welchen Szenarien die Benutzer betroffen sind und was genau erforderlich ist, um es zu beheben.
Unser derzeitiges Verständnis ist, wenn wir Grenzen überschreiten, werden wir bestraft und gedrosselt. Nehmen wir also an, wir haben eine CPU-Quote von 3 Kernen und in den ersten 5 ms haben wir 3 Kerne verbraucht, dann werden wir in der 100-ms-Schicht 95 ms lang gedrosselt, und in diesen 95 ms können unsere Container nichts tun. Und wir haben gesehen, dass wir gedrosselt werden, selbst wenn die CPU-Spitzen in den CPU-Nutzungsmetriken nicht sichtbar sind. Wir gehen davon aus, dass das Zeitfenster für die Messung der CPU-Auslastung in Sekunden angegeben ist und die Drosselung auf Mikrosekunden-Ebene erfolgt, sodass der Durchschnitt ermittelt wird und nicht sichtbar ist. Aber der hier erwähnte Fehler hat uns jetzt verwirrt.
Einige Fragen:
- Wenn der Knoten bei 100% CPU ist? Ist dies ein Sonderfall, in dem alle Container unabhängig von ihrer Verwendung gedrosselt werden?
Wenn dies passiert, werden alle Container zu 100% mit CPU gedrosselt?
Was löst diesen Fehler aus, um im Knoten ausgelöst zu werden?
Was ist der Unterschied zwischen der Nichtverwendung von
limitsund der Deaktivierung voncpu.cfs_quota?Ist das Deaktivieren von
limitseine riskante Lösung, wenn es viele platzbare Pods gibt und ein Pod die Instabilität im Knoten verursachen und sich auf andere Pods auswirken kann, die über ihre Anforderungen laufen?Unabhängig davon kann der Prozess des Kernel-Dokuments gedrosselt werden, wenn das übergeordnete Kontingent vollständig belegt ist. Was ist hier im Containerkontext übergeordnet (hängt es mit diesem Fehler zusammen)? https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
There are two ways in which a group may become throttled: a. it fully consumes its own quota within a period b. a parent's quota is fully consumed within its period- Was wird benötigt, um sie zu beheben? Kernel-Version aktualisieren?
Wir hatten einen ziemlich großen Ausfall und es scheint eng damit verbunden zu sein (wenn nicht die Hauptursache), dass alle unsere Pods in einer Drosselungs-Neustartschleife stecken bleiben und nicht in der Lage sind, zu skalieren. Wir beschäftigen uns mit den Details, um das eigentliche Problem zu finden. Ich werde eine separate Ausgabe eröffnen, in der Einzelheiten zu unserem Ausfall erläutert werden.
Jede Hilfe hier wird sehr geschätzt.
cc @justinsb
 alok87
am 14. Feb. 2019
alok87
am 14. Feb. 2019
Einer unserer Benutzer hat ein CPU-Limit festgelegt und wurde gedrosselt, um die Lebendigkeitsprüfung zu beenden, was zu einem Ausfall seines Dienstes führte.
Wir sehen eine Drosselung, selbst wenn Container an eine CPU angeheftet werden. Zum Beispiel ein CPU-Limit von 1 und das Fixieren dieses Containers, um nur auf der einen CPU ausgeführt zu werden. Es sollte unmöglich sein, das Kontingent in einem bestimmten Zeitraum zu überschreiten, wenn Ihr Kontingent genau der Anzahl der CPUs entspricht, die Sie haben. Wir sehen jedoch in jedem Fall eine Drosselung.
Ich dachte, ich hätte irgendwo gesehen, dass Kernel 4.18 das Problem löst. Ich habe es noch nicht getestet, daher wäre es schön, wenn jemand dies bestätigen könnte.
mariusgrigoriu
am 15. Feb. 2019
https://github.com/torvalds/linux/commit/512ac999d2755d2b7109e996a76b6fb8b888631d in 4.18 scheint der relevante Patch für dieses Problem zu sein.
 clkao
am 23. Feb. 2019
clkao
am 23. Feb. 2019
@mariusgrigoriu Ich scheine in dem gleichen Rätsel zu stecken, das Sie hier beschrieben haben: https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -462534360.
Wir beobachten eine CPU-Drosselung auf Pods in der Klasse "Garantierte QoS" mit der statischen CPUManager-Richtlinie (was keinen Sinn ergibt).
Wenn Sie die limits für diese Pods entfernen, werden sie in die Burstable QoS-Klasse eingeordnet. Dies ist nicht das, was wir wollen. Die einzige verbleibende Option ist die systemweite Deaktivierung der CFS-CPU-Kontingente, was wir auch nicht sicher tun können. Da der Zugriff aller Pods auf ungebundene CPU-Kapazität zu gefährlichen Problemen mit der CPU-Sättigung führen kann.
@vishh , was wäre unter den oben genannten Umständen die beste Vorgehensweise? Es scheint, als würde ein Upgrade auf Kernel> 4.18 (bei dem die CPU-CPU-Kontoführung behoben wurde) durchgeführt und (möglicherweise) die CSF-Quotenperiode verkürzt.
Allgemein sollte der Hinweis, dass wir nur limits aus Containern entfernen, die gedrosselt werden, klare Warnungen enthalten:
1) Wenn dies Pods in der Klasse "Garantierte QoS" mit einer ganzzahligen Anzahl von Kernen und einer statischen CPUMnanager-Richtlinie wären, erhalten diese Pods keine dedizierten CPU-Kerne mehr, da sie in die Klasse "Burstable QoS" (ohne Anforderungen == Limits) gestellt werden.
2) Diese Pods sind in Bezug auf den CPU-Verbrauch ungebunden und können unter bestimmten Umständen erhebliche Schäden verursachen.
Ihr Feedback / Ihre Anleitung wäre sehr dankbar.
 dannyk81
am 25. März 2019
dannyk81
am 25. März 2019
Ein Upgrade des Kernels hilft auf jeden Fall, aber das Verhalten beim Anwenden eines CFS-Kontingents scheint immer noch nicht mit den Vorschlägen in den Dokumenten übereinzustimmen.
mariusgrigoriu
am 25. März 2019
Ich habe jetzt eine Weile verschiedene Aspekte dieses Problems untersucht. Meine Forschung ist in meinem Beitrag zu LKML zusammengefasst.
https://lkml.org/lkml/2019/3/18/706
Davon abgesehen konnte ich das hier in den Kerneln vor 512ac99 beschriebene Problem nicht reproduzieren. Ich habe jedoch eine Leistungsregression in Kerneln nach 512ac99 gesehen. Diese Lösung ist also kein Allheilmittel.
 chiluk
am 25. März 2019
chiluk
am 25. März 2019
Dank @mariusgrigoriu, werden wir für den Kernel und die Hoffnung aktualisieren , die etwas helfen wird, überprüfen Sie auch heraus https://github.com/kubernetes/kubernetes/issues/70585 - es scheint , dass die Quoten sind in der Tat für garantierte Hülsen mit CPU - Satz festgelegt ( dh angeheftete CPU), so scheint mir das ein Fehler zu sein.
dannyk81
am 25. März 2019
@chiluk könntest du etwas
dannyk81
am 25. März 2019
Der Kernel-Patch 512ac99 behebt ein Problem für einige Benutzer, verursacht jedoch ein Problem für unsere Konfigurationen. Der Patch hat die Verteilung von Zeitscheiben auf cfs_rq dahingehend festgelegt, dass sie jetzt korrekt ablaufen. Zuvor liefen sie nicht ab.
Java-Workloads, insbesondere auf Computern mit hoher Kernanzahl, werden aufgrund der blockierenden Worker-Threads jetzt bei geringer CPU-Auslastung stark gedrosselt. Diesen Threads wird eine Zeitscheibe zugewiesen, von der sie nur einen kleinen Teil verwenden, der später abgelaufen ist. In dem synthetischen Test, den ich * geschrieben habe (der mit diesem Thread verknüpft ist), sehen wir eine Leistungsverschlechterung von ungefähr 30x. In der realen Welt wurde die Reaktionszeit zwischen den beiden Kerneln aufgrund der erhöhten Drosselung um Hunderte von Millisekunden verschlechtert.
chiluk
am 25. März 2019
Bei Verwendung eines 4.19.30-Kernels werden Pods, von denen ich gehofft hatte, dass sie weniger gedrosselt werden, immer noch gedrosselt, und einige Pods, die zuvor nicht gedrosselt wurden, werden jetzt ziemlich stark gedrosselt (kube2iam meldet, dass mehr Sekunden gedrosselt wurden, als die Instanz aktiv war , irgendwie)
 willthames
am 27. März 2019
willthames
am 27. März 2019
Unter CoreOS 4.19.25-coreos sehe ich, dass Prometheus fast auf jedem einzelnen Pod im System einen CPUThrottlingHigh-Alarm auslöst.
 teralype
am 27. März 2019
teralype
am 27. März 2019
@williamsandrew @teralype dies scheint die Ergebnisse von @chiluk widerzuspiegeln .
Nach verschiedenen internen Diskussionen haben wir uns tatsächlich entschlossen, die cfs-Quoten vollständig zu deaktivieren (Kubelets Flag --cpu-cfs-quota=false ). Dies scheint alle Probleme zu lösen, die wir sowohl für Burstable- als auch für garantierte (CPU-fixierte oder Standard-) Pods hatten.
Es gibt ein exzellentes Deck zu diesem (und einigen anderen) Themen hier: https://www.slideshare.net/try_except_/ensuring-kubernetes-cost-efficiency-across-many-clusters-devops-gathering-2019
Sehr empfehlenswerte Lektüre: +1:
dannyk81
am 27. März 2019
Langzeitproblem (Hinweis für sich selbst)
 dims
am 27. März 2019
dims
am 27. März 2019
@ dannyk81 nur der Vollständigkeit verknüpfte Vortrag ist auch als aufgezeichnetes Video verfügbar: https://www.youtube.com/watch?v=4QyecOoPsGU
hjacobs
am 27. März 2019
@hjacobs , liebte das Gespräch! Vielen Dank...
Haben Sie eine Idee, wie Sie dieses Update auf AKS oder GKE anwenden können?
Vielen Dank
 agolomoodysaada
am 2. Apr. 2019
agolomoodysaada
am 2. Apr. 2019
@agolomoodysaada Wir haben vor
timoreimann
am 2. Apr. 2019
Ich habe mich an den Azure-Support gewandt und er sagte, dass er erst im August 2019 verfügbar sein wird.
agolomoodysaada
am 4. Apr. 2019

Ich dachte, ich würde ein Diagramm einer Anwendung teilen, die während ihrer gesamten Lebensdauer konstant gedrosselt wurde.
agolomoodysaada
am 5. Apr. 2019
Auf welchem Kernel war das?
chiluk
am 5. Apr. 2019
" chiluk " 4.15.0-1037-azure "
agolomoodysaada
am 5. Apr. 2019
Das enthält also kein Kernel-Commit 512ac99. Hier ist das entsprechende
Quelle.
https://kernel.ubuntu.com/git/kernel-ppa/mirror/ubuntu-azure-xenial.git/tree/kernel/sched/fair.c?h=Ubuntu-azure-4.15.0-1037.39_16.04.1 & id = 19b0066cc4829f45321a52a802b640bab14d0f67
Dies bedeutet, dass Sie möglicherweise auf das in 512ac99 beschriebene Problem stoßen. Bleib drin
Denken Sie daran, dass 512ac99 andere Regressionen für uns gebracht hat.
Am Fr, 5. April 2019 um 12:08 Uhr Moody Saada [email protected]
schrieb:
@chiluk https://github.com/chiluk "4.15.0-1037-azure"
- -
Sie erhalten dies, weil Sie erwähnt wurden.
Antworte direkt auf diese E-Mail und sieh sie dir auf GitHub an
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-480350946 ,
oder schalten Sie den Thread stumm
https://github.com/notifications/unsubscribe-auth/ACDI05YeS6wfUE9XkiMbxrLvPllYQZ7Iks5vd4MOgaJpZM4WDUF3
.
chiluk
am 5. Apr. 2019
Ich habe jetzt Patches zu LKML darüber gepostet.
https://lkml.org/lkml/2019/4/10/1068
Zusätzliche Tests wären sehr dankbar.
chiluk
am 11. Apr. 2019
Ich habe diese Patches jetzt mit Dokumentationsänderungen erneut eingereicht.
https://lkml.org/lkml/2019/5/17/581
Es wäre wirklich hilfreich, wenn die Leute diese Patches testen und den Thread zu LKML kommentieren könnten. Im Moment bin ich der einzige, der dies überhaupt auf LKML erwähnt hat, und ich habe keinerlei Kommentare von der Community oder den Betreuern erhalten. Es wäre wirklich ein langer Weg, wenn ich unter meinem Patch einige Community-Tests und Kommentare zu LKML erhalten könnte.
chiluk
am 21. Mai 2019
Für das, was es wert ist, scheint dieses spezielle Projekt https://github.com/tensorflow/serving von diesem Problem stark betroffen zu sein. Und es ist meistens eine C ++ - Anwendung.
@chiluk , Gibt es
Vielen Dank
agolomoodysaada
am 29. Mai 2019
Wir sollten @chiluk dabei helfen, Zitate über schwerwiegende Auswirkungen dieses Kernel-Fehlers auf Kubernetes und alle anderen
Zolando hat letzte Woche in ihre Präsentation aufgenommen, dass ihre schlechten Erfahrungen mit dem aktuellen Kernel dazu führen, dass sie das Deaktivieren von CFS-Quoten als aktuelle Best Practice betrachten, da sie der Meinung sind, dass dies mehr schadet als nützt.
https://www.youtube.com/watch?v=6sDTB4eV4F8
 whereisaaron
am 29. Mai 2019
whereisaaron
am 29. Mai 2019
Immer mehr Unternehmen deaktivieren die CPU-Drosselung, z. B. mytaxi, Datadog, Zalando ( Twitter-Thread )
hjacobs
am 29. Mai 2019
@derekwaynecarr @ dchen1107 @ kubernetes / sig-node-feature-request Dawn, Derek, ist es Zeit, die Standardeinstellung zu ändern? und / oder Dokumentation?
dims
am 29. Mai 2019
Ja @whereisaaron Das Sammeln und Weitergeben von Berichten über das Drosseln von lähmenden Anwendungen und das Deaktivieren aufgrund seines schlechten Verhaltens wäre gegebenenfalls eine willkommene Teilnahme am lkml-Thread. Im Moment sieht es so aus, als würde ich mich hauptsächlich bei der Kernel-Community über dieses Problem beschweren.
chiluk
am 29. Mai 2019
@agolomoodysaada Die
Es gibt auch bewährte Methoden zum Reduzieren der Anzahl der Anwendungsthreads, was ebenfalls hilfreich ist.
Für Golang setzen Sie GOMAXPROCS ~ = Ceil (Quote)
Wechseln Sie für Java zu den neueren JVMs, die CPU-Kontingentgrenzen erkennen und einhalten. Frühere JVMS haben Threads basierend auf der Anzahl der CPU-Kerne erzeugt, nicht auf der Anzahl der Kerne, die der Anwendung zur Verfügung stehen.
Beide waren für uns ein großer Segen für die Leistung.
Überwachen und melden Sie Anwendungen, die auf Drosselung stoßen, damit Ihre Entwickler die Kontingente anpassen können.
chiluk
am 29. Mai 2019
Zu Ihrer Information, nachdem ich die Azure AKS-Unterstützung auf diesen Thread hingewiesen hatte, wurde mir geantwortet, dass der Patch eingeführt wird, wenn sie bestenfalls Ende September auf Kernel 5.0 aktualisiert werden.
Bis dahin hör auf, Limits zu benutzen :)
prune998
am 29. Mai 2019
@ prune998 gibt es eine kleine Einschränkung, falls Sie CPUmanager verwenden (dh dedizierte CPU-Zuordnung zu Pods in garantierter QoS).
Durch das Entfernen von Grenzwerten vermeiden Sie das Problem der CFS-Drosselung, aber Sie entfernen die Pods aus der garantierten QoS, sodass CPUmanager diesen Pods keine dedizierten Kerne mehr zuweist.
Wenn Sie keinen CPU-Manager verwenden - kein Schaden angerichtet, sondern nur zu Ihrer Information für alle, die sich für diese Richtung entscheiden.
Es gibt eine PR (https://github.com/kubernetes/kubernetes/issues/70585), mit der CFS-Kontingente für Pods mit dedizierten CPUs vollständig deaktiviert werden können. Diese wurden jedoch noch nicht zusammengeführt.
Wir haben uns auch dafür entschieden, CFS-Quoten systemweit zu deaktivieren, wie oben vorgeschlagen, und bisher keine Probleme.
dannyk81
am 29. Mai 2019
@ dannyk81 https://github.com/kubernetes/kubernetes/issues/70585 ist keine PR, die zusammengeführt werden kann (es handelt sich um ein Problem mit einem Code-Snippet). Können Sie (oder jemand anderes) bitte eine PR einreichen?
dims
am 29. Mai 2019
Es gibt bereits eine: https://github.com/kubernetes/kubernetes/pull/75682
 praseodym
am 29. Mai 2019
praseodym
am 29. Mai 2019
@dims Ich habe das Problem verlinkt, nicht die PR ... aber das Problem ist mit der PR verknüpft :) In der Tat ist es https://github.com/kubernetes/kubernetes/pull/75682 und es hängt schon eine Weile dort. Wenn Sie also Druck machen könnten, wäre dies großartig, da dies wirklich ein ärgerliches Problem ist.
Danke: +1:
dannyk81
am 29. Mai 2019
Hoppla! danke @ dannyk81 Ich habe Leute zugewiesen und Meilenstein hinzugefügt
dims
am 29. Mai 2019
FWIW sind wir ebenfalls auf dieses Problem gestoßen und haben festgestellt, dass das Verringern des CFS-Kontingentzeitraums auf 10 ms anstelle der Standard-100 ms zu einer dramatischen Verbesserung unserer End-End-Latenzen führte. Ich denke, das liegt daran, dass selbst wenn Sie auf den Kernel-Fehler stoßen, eine viel kürzere Menge an Kontingent verschwendet wird, wenn es nicht verwendet wird, und der Prozess viel früher mehr Kontingent (in kleineren Kontingenten) erhalten kann. Dies ist nur eine Problemumgehung, aber für diejenigen, die das CFS-Kontingent nicht vollständig deaktivieren möchten, kann dies ein Bandaid sein, bis das Update implementiert ist. k8s unterstützt dies in 1.12 mit dem Feature-Gate cpuCFSQuotaPeriod und dem Kubelet-Flag --cpu-cfs-quota-period.
 d-shi
am 30. Mai 2019
d-shi
am 30. Mai 2019
Ich müsste das überprüfen, aber ich denke, dass eine Verkürzung des Zeitraums den Effekt haben kann, ihn effektiv zu deaktivieren, da der Code Slice-Minimums und Quoten-Minimums enthält. Sie sind wahrscheinlich besser dran, Quoten auszuschalten und zu weichen Quoten zu wechseln.
chiluk
am 30. Mai 2019
@chiluk Mein Laie versteht, dass das Standard-Slice 5 ms beträgt. Wenn Sie es also auf dieses oder weniger festlegen, wird es effektiv deaktiviert. Solange der Zeitraum jedoch länger als 5 ms ist, sollte die Quoten-Durchsetzung weiterhin erfolgen. Lassen Sie mich auf jeden Fall wissen, wenn das nicht stimmt.
d-shi
am 31. Mai 2019
Mit --feature-gates=CustomCPUCFSQuotaPeriod=true --cpu-cfs-quota-period=10ms einer meiner Pods wirklich Probleme beim Start. In der beigefügten Prometheus-Grafik versucht der Container zu starten, erreicht seine Lebendigkeitsprüfung erst annähernd, wenn er beendet ist (normalerweise startet der Container in etwa 5 Sekunden - selbst das Erhöhen der Lebendigkeit initialDelaySeconds auf 60s hat nicht geholfen) und ist es auch dann durch einen neuen ersetzt.
Sie können sehen, dass der Container stark gedrosselt ist, bis ich die CPU-CFS-Quoten-Periode aus den Kubelet-Argumenten entfernt habe. Zu diesem Zeitpunkt ist die Drosselung viel flacher und der Container startet in etwa 5 Sekunden erneut.

willthames
am 5. Juni 2019
Zu Ihrer Information: aktueller Twitter-Thread zum Thema Deaktivieren der CPU-Drosselung: https://twitter.com/it_supertramp/status/1133648291332263936
hjacobs
am 5. Juni 2019
Dies sind die CPU-Drosselungsdiagramme von vor / nach dem Wechsel zu --cpu-cfs-quota-period=10ms in der Produktion für 2 latenzempfindliche Dienste:
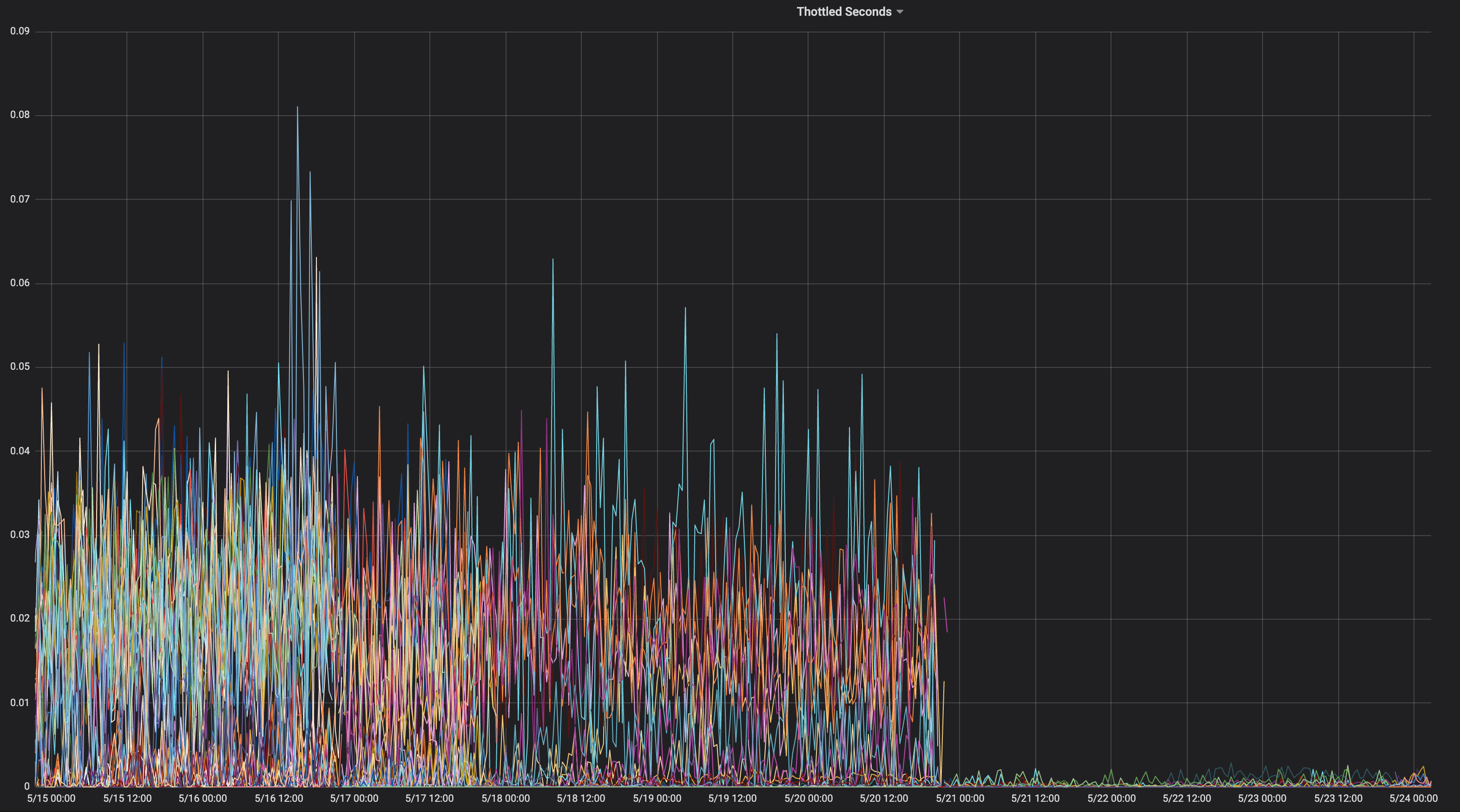

Diese Dienste werden auf verschiedenen Instanztypen ausgeführt (mit unterschiedlichen Taints / Toleranzen). Die Instanzen des 2. Dienstes wurden zuerst in einen niedrigeren CFS-Kontingentzeitraum verschoben.
Die Ergebnisse müssen stark von der Belastung abhängen.
d-shi
am 5. Juni 2019
@ d-shi In Ihrem Diagramm ist noch etwas anderes los. Ich denke, es gibt möglicherweise eine Mindestquote, die Sie jetzt erreichen, weil der Zeitraum so kurz ist. Ich müsste nach Code suchen, um sicherzugehen. Grundsätzlich haben Sie versehentlich das für die Anwendung verfügbare Kontingent erhöht. Sie hätten wahrscheinlich das Gleiche erreichen können, indem Sie die Kontingentzuteilungen tatsächlich erhöht hätten.
chiluk
am 5. Juni 2019
Für uns war es viel nützlicher, die Latenz zu messen, als zu drosseln. Durch Deaktivieren von cfs-quota die Latenz erheblich verbessert. Ich würde gerne ähnliche Ergebnisse für das Ändern von cfs-quota-period .
 blakebarnett
am 6. Juni 2019
blakebarnett
am 6. Juni 2019
@chiluk Wir haben tatsächlich versucht, die Kontingentzuteilungen zu erhöhen (bis zu dem von Kubernetes pro Pod unterstützten Maximum), und in keinem Fall wurden die Latenzen am Ende des Endes oder die Drosselung erheblich reduziert. Die p99-Latenzen gingen von etwa 98 ms bei einer Grenze von 4 Kernen auf 86 ms bei einer Grenze von 16 Kernen. Nach der Reduzierung der CFS-Quote auf 10 ms ging p99 bei 4 Kernen auf 20 ms.
@blakebarnett Wir haben ein Benchmark-Programm entwickelt, mit dem unsere Latenzen gemessen wurden. Sie gingen von einem Bereich von 10 ms bis 100 ms mit einem Durchschnitt von etwa 18 ms vor der Aktualisierung von --cpu-cfs-quota-period auf einen Bereich von 10 ms bis 20 ms mit einem Durchschnitt von ca. 11ms danach. Die p99-Latenzen gingen von etwa 98 ms auf 20 ms.
EDITS: Entschuldigung für die Änderungen, die ich zurückgehen musste, um meine Nummern zu überprüfen.
d-shi
am 6. Juni 2019
@ d-shi, Sie haben wahrscheinlich das von 512ac999 gelöste Problem getroffen.
chiluk
am 6. Juni 2019
@chiluk Nachdem ich Ihren Patch immer wieder gelesen habe, muss ich zugeben, dass ich
if (cfs_rq->expires_seq == cfs_b->expires_seq) {
- /* extend local deadline, drift is bounded above by 2 ticks */
- cfs_rq->runtime_expires += TICK_NSEC;
- } else {
- /* global deadline is ahead, expiration has passed */
- cfs_rq->runtime_remaining = 0;
- }
In einem Fall, in dem das Kontingent abläuft, auch wenn runtime_remaining nur einige Zeit aus dem globalen Pool ausgeliehen hat. Im schlimmsten Fall werden Sie basierend auf sched_cfs_bandwidth_slice_us für 5 ms gedrosselt. Ist es nicht?
Vermisse ich etwas
 Mwea
am 6. Juni 2019
Mwea
am 6. Juni 2019
@chiluk ja ich denke sind richtig. Unsere Produktionsserver befinden sich immer noch auf Kernel 4.4, daher haben Sie diesen Fix nicht. Vielleicht können wir nach dem Upgrade auf einen neueren Kernel den CFS-Kontingentzeitraum wieder auf den Standardwert zurücksetzen, aber im Moment arbeitet es daran, unsere Endlatenzen zu verbessern, und wir haben noch keine nachteiligen Nebenwirkungen festgestellt. Obwohl es erst seit ein paar Wochen live ist.
d-shi
am 6. Juni 2019
@chiluk Hast du Lust , den Status dieses Problems im Kernel zusammenzufassen? Es scheint, als gäbe es einen Patch, 512ac999, aber er hatte Probleme. Habe ich irgendwo gelesen, dass es zurückgesetzt wurde? Oder ist das ganz / teilweise behoben? Wenn ja, welche Version?
mariusgrigoriu
am 7. Juni 2019
@mariusgrigoriu es ist nicht behoben, @chiluk hat einen Patch erstellt, der es beheben sollte, der weitere Tests benötigt (ich werde in den nächsten Tagen einen Teil meiner Zeit darauf verwenden).
Den aktuellen Status finden Sie unter https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -482198124
willthames
am 7. Juni 2019
@Mwea Der globale Pool wird in cfs_b-> runtime_remaining gespeichert. Da dies den Warteschlangen pro CPU-Lauf (cfs_rq) zugewiesen wird, wird der im globalen Pool verbleibende Betrag dekrementiert. cfs_bandwidth_slice_us ist die Menge an CPU-Laufzeit, die vom globalen Pool in die Warteschlangen pro CPU übertragen wird. Wenn Sie gedrosselt würden, müssten Sie ausführen und cfs_b-> runtime_remaining == 0. Sie müssten auf das Ende des aktuellen Zeitraums (standardmäßig 100 ms) warten, bis das Kontingent auf cfs_b aufgefüllt und dann an verteilt wird Ihr cfs_rq. Ich habe kürzlich festgestellt, dass die abgelaufene Laufzeit höchstens 1 ms pro cfs_rq beträgt, da der Slack-Timer alle nicht verwendeten Quoten von 1 ms aus den Warteschlangen pro CPU wiedererlangt. Diese 1 ms werden dann am Ende des Zeitraums verschwendet / abgelaufen. In einem schlimmeren Fall, in dem sich die Anwendung auf 88 CPU verteilt, kann dies möglicherweise 88 ms verschwendetes Kontingent pro 100 ms Zeitraum sein. Dies führte tatsächlich zu einem alternativen Vorschlag, der es dem Slack-Timer ermöglichen sollte, das gesamte nicht verwendete Kontingent aus den Leerlauf-Runqueues pro CPU wieder zu erfassen.
Was die Linien betrifft, die Sie speziell hervorheben. Mein Vorschlag ist, den Ablauf der Laufzeit, der den CPU-Ausführungswarteschlangen zugewiesen wurde, vollständig zu entfernen. Diese Zeilen sind Teil des Fixes für 512ac999. Dadurch wurde ein Problem behoben, bei dem ein Zeitversatz zwischen den Warteschlangen pro CPU dazu führte, dass das Kontingent vorzeitig abgelaufen war, wodurch Anwendungen gedrosselt wurden, die das Kontingent noch nicht verwendet haben (afaiu). Grundsätzlich erhöhen sie expires_seq an jeder Periodengrenze. expires_seq sollte daher zwischen den einzelnen cfs_rq übereinstimmen, wenn sie sich im selben Zeitraum befinden.
@mariusgrigoriu - Wenn Sie eine hohe Drosselung bei geringer CPU-Auslastung erreichen und Ihr Kernel vor 512ac999 liegt, benötigen Sie wahrscheinlich 512ac999. Wenn Sie nach 512ac999 sind, stoßen Sie wahrscheinlich auf das oben erläuterte Problem, das derzeit auf lkml diskutiert wird.
Es gibt viele Möglichkeiten, dieses Problem zu beheben.
- CPU-Pinning
- Verringern der Anzahl der Threads, die Ihre Anwendung erzeugt
- Zu viel Kontingent für Anwendungen mit Drosselung.
- Schalten Sie vorerst harte Limits aus.
- Erstellen Sie einen benutzerdefinierten Kernel mit einer der vorgeschlagenen Änderungen.
chiluk
am 7. Juni 2019
@chiluk Gibt es eine Chance, dass Sie bereits eine Version dieses Patches veröffentlicht haben, die bereits mit Kernel 4.14 kompatibel ist? Ich möchte es ziemlich aggressiv testen, da wir gerade ein paar tausend Hosts auf 4.14.121 (von 4.9.62) aktualisiert haben und sehen:
- Eine Reduzierung der Drosselung für Memcached, MySQL, Nginx usw.
- Eine Erhöhung der Drosselung für unsere Java-Apps
Ich möchte wirklich vorwärts rollen, um hier das Beste aus beiden Welten zu bekommen. Ich kann versuchen, es nächste Woche über mich selbst zu portieren, aber wenn Sie bereits eines haben, wäre das großartig.
 PaulFurtado
am 21. Juni 2019
PaulFurtado
am 21. Juni 2019
@ PaulFurtado
Ich habe den Patch in den letzten Tagen aufgrund der Vorschläge von Ben Segull tatsächlich umgeschrieben. Ein neuer Kernel-Patch wird veröffentlicht, sobald ich einige Testzeit für unsere Cluster habe.
chiluk
am 24. Juni 2019
@chiluk irgendein Update zu diesem Patch? Keine Sorge, wenn nicht, ich stelle nur sicher, dass ich den Patch nicht verpasst habe
PaulFurtado
am 18. Juli 2019
@PaulFurtado , der Patch wurde vom CFS-Autor "genehmigt", und ich warte nur darauf, dass die Scheduler-Betreuer ihn integrieren und an Linus senden.
chiluk
am 24. Juli 2019
@chiluk Danke!
Ich habe den Patch gerade auf Kernel 4.14 zurückportiert, der unser aktueller Produktionskernel ist.
Ich habe einen Überblick über den Backport und einige Ergebnisse Ihres Fibtests hier gegeben: https://gist.github.com/PaulFurtado/ff6c67ec87416b66ba1c6fc70f7beec1
In der aktuellen Generation c5.9xlarge und m5.24xlarge ec2, die wir in unseren Kubernet- und Mesos-Clustern verwenden, verdoppelt der Patch die Leistung Ihres Fibtest-Programms. Bei einem Instanztyp der vorherigen Generation r4.16xlarge wird eine 1,5-mal höhere CPU-Auslastung verwaltet, jedoch kaum zusätzliche Iterationen (was meiner Meinung nach nur auf die CPU-Generierung und die exponentielle Natur der Fibonacci-Sequenz zurückzuführen ist). Diese Zahlen gelten alle ziemlich genau, wenn ich den Test auf 30 Sekunden anstatt auf den Standardwert von 5 Sekunden erhöhe.
Wir werden diese Woche damit beginnen, dies in unsere QS-Umgebung zu integrieren, um einige Messdaten aus unseren Apps zu erhalten, die unter der schlimmsten Drosselung leiden. Danke noch einmal!
PaulFurtado
am 26. Juli 2019
@ PaulFurtado Zunächst einmal danke für die Tests. Ich gehe davon aus, dass Sie kernel.org 4.14 oder Ubuntu 4.14 ausführen, die beide 512ac999 enthalten. Was die abgeschlossenen Fibtest-Iterationen betrifft, ist dies nicht so wichtig wie die verwendete CPU-Zeit, da abgeschlossene Iterationen während der Ausführung des Tests stark von der CPU-MHz beeinflusst werden können (insbesondere in der Cloud, in der ich nicht sicher bin, wie viel Kontrolle Sie darüber haben).
chiluk
am 31. Juli 2019
Ich gehe davon aus, dass Sie kernel.org 4.14 oder Ubuntu 4.14 ausführen, die beide 512ac999 enthalten.
Ja, wir führen Mainline 4.14 aus (plus dem Patch-Set aus dem Amazon Linux 2-Kernel, aber in diesem Fall ist keiner dieser Patches von Bedeutung).
512ac999 landete in der Hauptlinie 4.14.95, und wir beobachteten seine Auswirkungen beim Upgrade von 4.14.77 auf 4.14.121+. Dadurch wurden unsere zwischengespeicherten Container (sehr niedrige Thread-Anzahl) von unerklärlicher Drosselung zu keiner Drosselung übergegangen, aber unsere Golang- und Java-Container (sehr hohe Thread-Anzahl) wurden stärker gedrosselt.
Was die abgeschlossenen Fibtest-Iterationen betrifft, ist dies nicht so wichtig wie die verwendete CPU-Zeit, da abgeschlossene Iterationen während der Ausführung des Tests stark von der CPU-MHz beeinflusst werden können (insbesondere in der Cloud, in der ich nicht sicher bin, wie viel Kontrolle Sie darüber haben).
Bei neueren / größeren EC2-Instanzen erhalten Sie tatsächlich ein angemessenes Maß an Kontrolle über die Prozessorzustände , sodass wir mit ausgeschaltetem Turbo-Boost arbeiten und die Kerne nicht im Leerlauf
Zunächst einmal vielen Dank für die Prüfung
Kein Problem, die Dinge in unserer Pre-Qa-Umgebung waren über das Wochenende stabil, und wir werden morgen damit beginnen, den Patch auf unsere Haupt-QS-Umgebung auszudehnen, wo wir mehr reale Effekte sehen werden. Angesichts der Tatsache, dass memcached vom vorherigen Patch profitiert hatte, wollten wir unbedingt unseren Kuchen haben und ihn auch mit beiden Patches essen, damit wir gerne testen konnten. Nochmals vielen Dank für all die Arbeit, die Sie in die Drosselung gesteckt haben!
PaulFurtado
am 31. Juli 2019
Ich wollte nur eine Notiz über den Kernel-Patch hinterlassen, der gerade besprochen wird.
Ich habe es an den Kernel angepasst, den wir in aktuellen Tests verwenden, und sehe einige große Gewinne bei den CFS-Drosselungsraten. Ich werde jedoch erwähnen, dass Sie dies tun werden, wenn Sie zuvor die cfs-Periode als Abschwächung auf 10 ms festgelegt haben Ich möchte das auf 100 ms zurückbringen, um die Vorteile der Änderung zu sehen.
 jhohertz
am 6. Aug. 2019
jhohertz
am 6. Aug. 2019
Der Patch ist heute Morgen auf der Spitze gelandet.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Sobald es auf Torvalds Baum trifft, werde ich es zur Linux-stabilen Aufnahme und anschließend zu wichtigen Distributionen (Redhat / Ubuntu) einreichen. Wenn Sie sich für etwas anderes interessieren und diese nicht Linux-stabilen Patches folgen, möchten Sie es möglicherweise direkt einreichen.
chiluk
am 8. Aug. 2019
Ich habe den Patch (Ubuntu 18.04, 5.2.7 Kernel, Knoten: 56 Core CPU E5-2660 v4 bei 2.00 GHz) mit unserem cpu-schweren Bildverarbeitungs-Golang-Microservice getestet und ziemlich beeindruckende Ergebnisse erzielt. Leistung wie wenn ich CFS auf dem Knoten vollständig deaktiviere.
Ich habe 5-35% weniger Latenz und 5-55% mehr RPS, abhängig von der Parallelität / CPU-Auslastung bei einer Drosselungsrate nahe Null.
Danke, @chiluk !
Wie @jhohertz sagte, sollte das cfs-Kontingent auf 100 ms zurückgesetzt werden. Ich habe mit niedrigeren Perioden getestet und eine hohe Drosselung und Leistungsverschlechterung festgestellt.
 zigmund
am 10. Aug. 2019
zigmund
am 10. Aug. 2019
Für mehr Leistung mit Golang setzen Sie GOMAXPROCS auf Ceil (Quote) +2. Das Plus 2 soll eine gewisse Parallelität garantieren.
chiluk
am 12. Aug. 2019
@chiluk getestet mit GOMAXPROCS = 8 vs GOMAXPROCS = 10 mit cpu.limit = 8 - kein großer Unterschied, etwas über 1-2%.
zigmund
am 13. Aug. 2019
@zigmund , das liegt daran, dass Ihre cpu.limit auf die ganze Zahl 8 gesetzt ist, die Ihre Prozesse an eine cpuset von 8 cpus binden soll. Ihr Unterschied von 1-2% ist nur die Erhöhung des Overheads für den Kontextwechsel mit Ihren 2 zusätzlichen Goroutine-Läufern auf Ihrem 8-CPU-Task-Set.
Ich hätte sagen sollen, dass das Setzen von GOMAXPROCS = # eine gute Problemumgehung für Go-Programme ist, bis die Kernel-Patches weit verbreitet sind.
chiluk
am 26. Aug. 2019
Wir haben unsere Produktionscluster auf einen gepatchten Kernel migriert und jetzt kann ich Ihnen einige interessante Momente mitteilen.
Statistiken von einem unserer Cluster - 4 Knoten mit 72 Core E5-2695 v4 bei 2,10 GHz, 128 GB RAM, Debian 9, 5.2.7 Kernel mit Patch.
Wir haben gemischte Lasten, die hauptsächlich aus Golang-Diensten bestehen, aber auch PHP und Python.
Golang. Die Latenz ist geringer, die Einstellung der richtigen GOMAXPROCS ist ein absolutes Muss. Hier ist Service mit Standard GOMAXPROCS = 72. Wir haben den Kernel bei ~ 16 geändert und danach ist die Latenz gesunken und die CPU-Auslastung stark gestiegen. Um 21:15 Uhr habe ich korrekte GOMAXPROCS eingestellt und die CPU-Auslastung normalisiert.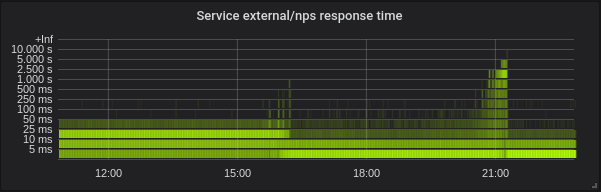

Python. Mit Patches ohne zusätzliche Bewegungen wurde alles besser - CPU-Auslastung und Latenz gingen zurück.
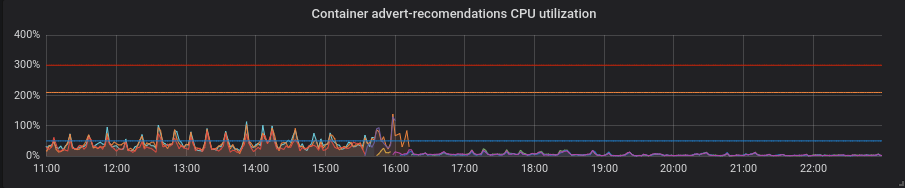
PHP. Die CPU-Auslastung ist die gleiche, da die Latenz bei einigen Diensten nur geringfügig gesunken ist. Kein großer Gewinn.
zigmund
am 3. Sept. 2019
Danke @zigmund.
Ich bin mir nicht sicher, ob ich es verstehe, wenn du I setted correct GOMAXPROCS sagst ...
Ich gehe davon aus, dass Sie nicht nur einen Pod auf dem 72-Kerne-Knoten ausführen, also setzen Sie GOMAXPROCS auf einen niedrigeren
prune998
am 3. Sept. 2019
Danke @zigmund. Die Go-Änderungen entsprechen weitgehend den Erwartungen.
Ich bin wirklich überrascht von den Python-Verbesserungen, da ich erwartet hatte, dass die GIL die Vorteile davon weitgehend zunichte macht. Wenn überhaupt, sollte dieser Patch die Reaktionszeit fast nur verkürzen, den Prozentsatz der gedrosselten Perioden verringern und die CPU-Auslastung erhöhen. Sind Sie sicher, dass Ihre Python-Anwendung noch fehlerfrei war?
chiluk
am 3. Sept. 2019
@ prune998 sorry, vielleicht falsch geschrieben. Ich setze GOMAXPROCS = limit.cpu. Im Moment haben wir ungefähr ~ 110 Pods pro Knoten in diesem Cluster.
@chiluk Ich bin nicht stark in Python und weiß nicht, wie Patch auf der unteren Ebene beeinflusst. Aber die Anwendung ist ohne Probleme fehlerfrei. Ich habe sie nach dem Kernelwechsel überprüft.
zigmund
am 4. Sept. 2019
@chiluk Würden Sie bitte erklären, wie wir den Fortschritt Ihres Patches in verschiedenen Linux-Distributionen verfolgen können? Ich interessiere mich besonders für Debian und AWS Linux, aber ich gehe davon aus, dass andere Leute an Ubuntu usw. interessiert sind. Was auch immer Sie für Licht ins Dunkel bringen können, danke.
 Nuru
am 13. Sept. 2019
Nuru
am 13. Sept. 2019
@Nuru https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html?highlight=stable%20rules ... Grundsätzlich werde ich über Linux-Stable einreichen, sobald mein Patch Linus 'erreicht hat. tree, * (möglicherweise früher), und dann sollten alle Distributionen dem Linux-stabilen Prozess folgen und Patches, die von den stabilen Betreuern akzeptiert wurden, in ihre distro-spezifischen Kernel ziehen. Wenn nicht, sollten Sie ihre Distributionen nicht betreiben.
chiluk
am 13. Sept. 2019
@chiluk Ich weiß nichts über den Linux-Entwicklungsprozess. Mit "Linus 'Baum" meinen Sie https://github.com/torvalds/linux ?
Nuru
am 14. Sept. 2019
Linus 'Baum lebt hier, https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/. Meine Änderungen werden derzeit unter Linux-Next bereitgestellt, dem Entwicklungsintegrationsbaum. Ja, die Kernel-Entwicklung steckt ein bisschen im dunklen Zeitalter fest, aber es funktioniert.
Er wird wahrscheinlich Änderungen aus dem Linux-Next-Baum übernehmen, sobald 5.3 veröffentlicht ist, und er beginnt mit der Entwicklung auf 5.4-rc0. Das ist ungefähr der Zeitrahmen, in dem ich erwarte, dass die stabilen Kernel anfangen, diesen Fix einzubringen. Wann immer Linus glaubt, dass 5.3 stabil ist, kann man nur raten.
chiluk
am 14. Sept. 2019
[Linus] wird wahrscheinlich Änderungen aus dem Linux-Next-Baum übernehmen, sobald 5.3 veröffentlicht ist und er mit der Entwicklung auf 5.4-rc0 beginnt. Das ist ungefähr der Zeitrahmen, in dem ich erwarte, dass die stabilen Kernel anfangen, diesen Fix einzubringen. Wann immer Linus glaubt, dass 5.3 stabil ist, kann man nur raten.
@chiluk Linus hat 15. September 2019 stabil
Nuru
am 20. Sept. 2019
Hat jemand Debian-Stretch-Pakete und / oder ein AWS-Image erstellt, das diesen Patch enthält? Ich bin dabei, https://github.com/kubernetes-sigs/image-builder/tree/master/images/kube-deploy/imagebuilder zu verwenden
Ich dachte nur, ich würde Doppelarbeit vermeiden, wenn es bereits existiert.
blakebarnett
am 24. Sept. 2019
Dies wurde nun in Linus 'Baum zusammengeführt und sollte mit 5.4 veröffentlicht werden. Ich habe es auch gerade bei Linux-Stable eingereicht, und unter der Annahme, dass alle Distributionen, die dem stabilen Prozess korrekt folgen, reibungslos funktionieren, sollte es in Kürze aufgenommen werden.
chiluk
am 25. Sept. 2019
Kann jemand folgen, ob / wie diese Änderung zu CentOS (7) führt? Ich bin mir nicht sicher, wie Backporting usw. funktioniert.
 till
am 26. Sept. 2019
till
am 26. Sept. 2019
@till https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -531370333
Für den stabilen Kernel wird hier ein Gespräch geführt.
https://lore.kernel.org/stable/CAC=E7cUXpUDgpvsmMaMU6sAydbfD0FEJiK25R1r=e9=YtcPjGw@mail.gmail.com/
Auch für diejenigen, die zur KubeCon gehen, werde ich diese Ausgabe dort vorstellen.
https://sched.co/Uae1
chiluk
am 3. Okt. 2019
Irgendein Wort von den Scheduler-Betreuern bezüglich: Die Bestätigung, nach der Greg HK suchte, um es in stabile Bäume zu bringen?
jhohertz
am 18. Okt. 2019
Greg KH hat sich zurückgehalten, um eine Entscheidung über diesen Patch zu treffen, da die Scheduler-Betreuer nicht reagiert haben (die haben wahrscheinlich gerade die Mail verpasst). Ein Kommentar von jemand anderem als mir zu LKML, der diesen Patch getestet hat und der Meinung ist, dass er zurückportiert werden sollte, wäre willkommen.
chiluk
am 18. Okt. 2019
Für Leute, die CoreOS verwenden, gibt es ein offenes Problem , bei dem der Patch von @chiluk zurückportiert werden muss.
 evanfoster
am 1. Nov. 2019
evanfoster
am 1. Nov. 2019
Der CoreOS-Kernel 4.19.82 enthält die folgenden Korrekturen: https://github.com/coreos/linux/pull/364
CoreOS Container Linux 2317.0.1 (Alpha-Kanal) enthält die folgenden Korrekturen: https://github.com/coreos/coreos-overlay/pull/3796 http://coreos.com/releases/#2317.0.1
Backports zu Linux Stable scheinen blockiert zu sein, da die Patches nicht sauber angewendet werden. @chiluk Wirst du an Backports für Linux Stable arbeiten? Wenn ja, werden Sie bitte auf 4.9 zurückportieren, damit es in Debian "Stretch" gelangt und von kops abgeholt wird? Obwohl ich denke, dass es bis zu 6 Monate dauern wird, bis es "dehnbar" ist und vielleicht bis dahin kops zu "buster" migriert ist.
Nuru
am 8. Nov. 2019
@Nuru , ich habe den Patch
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.buildinfo
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm-dbg_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-headers-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.changes
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-libc-dev_4.19.67-1_amd64.deb
293993587779 / k8s-1.11-debian-strip-amd64-hvm-ebs-2019-09-26
blakebarnett
am 8. Nov. 2019
@blakebarnett Danke für deine Mühe und tut mir leid, dass ich dich
- "Strecken" basiert auf Linux 4.9, aber alle Ihre Links sind für 4.19.
- Sie sagen, Sie haben "den Patch" zurückportiert, aber es gibt 3 Patches (ich denke, der dritte ist nicht wirklich wichtig:
- 512ac999 sched / fair: Die Driftbedingung des Bandbreitentimers wurde behoben
- de53fd7ae sched / fair: Korrigieren Sie die niedrige CPU-Auslastung mit hoher Drosselung, indem Sie das Ablaufen von CPU-lokalen Slices entfernen
- 763a9ec06 sched / fair: Korrigieren Sie Warnungen zu nicht verwendeten, aber festgelegten Variablen
Haben Sie alle 3 Patches auf 4.9 zurückportiert? (Ich weiß nicht, was ich mit den Debian-Paketen tun soll, um zu prüfen, ob die Änderungen vorhanden sind, und das Dokument "Änderungen" behandelt nicht, was sich wirklich geändert hat.)
In welchen Regionen ist Ihr AMI verfügbar?
Nuru
am 8. Nov. 2019
Nein, ich habe den Stretch-Backports-Kernel 4.19 verwendet, da er Korrekturen enthält, die wir auch für AWS benötigen (insbesondere für M5 / C5-Instanztypen).
Ich habe ein Diff angewendet, das alle Patches enthält, von denen ich glaube, dass ich es leicht ändern musste, um zusätzliche Verweise auf Variablen in 4.19 zu entfernen, die an anderer Stelle gelöscht wurden. Ich habe zuerst dieses https://github.com/kubernetes/kubernetes/issues/67577 angewendet
--- kernel/sched/fair.c 2019-09-25 16:06:02.954933954 -0700
+++ kernel/sched/fair.c-b 2019-09-25 16:06:56.341615817 -0700
@@ -4928,8 +4928,6 @@
cfs_b->period_active = 1;
overrun = hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
- cfs_b->runtime_expires += (overrun + 1) * ktime_to_ns(cfs_b->period);
- cfs_b->expires_seq++;
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
--- kernel/sched/sched.h 2019-08-16 01:12:54.000000000 -0700
+++ sched.h.b 2019-09-25 13:24:00.444566284 -0700
@@ -334,8 +334,6 @@
u64 quota;
u64 runtime;
s64 hierarchical_quota;
- u64 runtime_expires;
- int expires_seq;
short idle;
short period_active;
@@ -555,8 +553,6 @@
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
- int expires_seq;
- u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock;
Das AMI wird in us-west-1 veröffentlicht
Hoffentlich hilft das!
blakebarnett
am 8. Nov. 2019
Ich habe diese Patches zurückportiert und an die Linux-stabilen Kernel gesendet
v4.14 https://lore.kernel.org/stable/[email protected]/
v4.19 https://lore.kernel.org/stable/[email protected]/ #t
chiluk
am 8. Nov. 2019
Hallo,
Nach der Integration des Patches in 4.19 habe ich einen Fehlerbericht über Debian für ein ordnungsgemäßes Upgrade des Kerners auf Buster und Stretch-Backport geöffnet:
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=946144
Zögern Sie nicht, einen neuen Kommentar für das Upgrade des Debian-Pakets hinzuzufügen.
 alexises
am 4. Dez. 2019
alexises
am 4. Dez. 2019
Ich hoffe, das ist nicht zu spammig, aber ich wollte diesen ausgezeichneten Vortrag von @chiluk mit vielen Hintergrunddetails zu diesem Problem verknüpfen: https://youtu.be/UE7QX98-kO0.
 bboreham
am 4. Dez. 2019
bboreham
am 4. Dez. 2019
Gibt es eine Möglichkeit, eine Drosselung der GKE zu vermeiden? Wir hatten gerade ein großes Problem, bei dem eine Methode für PHP-Container 120 Sekunden statt der üblichen 0,1 Sekunden dauerte
 bartoszhernas
am 5. Dez. 2019
bartoszhernas
am 5. Dez. 2019
CPU-Grenzwerte entfernen
 monotek
am 5. Dez. 2019
monotek
am 5. Dez. 2019
Wir haben es bereits getan, der Container wird gedrosselt, wenn die CPU-Anforderungen zu klein sind. Das ist der Kern des Problems, mangelnde Grenzen und nur die Verwendung von CPU-Anforderungen führt immer noch zu einer Drosselung :(
bartoszhernas
am 5. Dez. 2019
@bartoszhernas Ich denke, Sie verwenden hier das falsche Wort. Wenn sich Personen in diesem Thread auf "Drosselung" beziehen, beziehen sie sich auf die cfs-Bandbreitensteuerung, nr_throttled in cpu.stat, damit die cgroup zunimmt. Dies ist nur aktiviert, wenn die CPU-Grenzwerte aktiviert sind. Wenn GKE Ihrem Pod ohne Ihr Wissen keine Grenzen setzt, würde ich das, was Sie treffen, nicht als Drosselung bezeichnen.
Ich würde das, was Sie beschrieben haben, als "Streit um den Prozessor" bezeichnen. Ich vermute, Sie haben wahrscheinlich mehrere Anwendungen * (Anfragen) mit falscher Größe, die um den Prozessor oder eine andere Ressource auf der Box kämpfen, weil sie häufig mehr als das verwenden, was sie angefordert haben. Dies ist der genaue Grund, warum wir Grenzwerte verwenden. Damit diese Anwendungen mit falscher Größe nur andere Anwendungen auf der Box so stark beeinflussen können.
Die andere Möglichkeit besteht darin, dass Ihr unzureichender Anforderungsbetrag zu einem einfach schlechten Planungsverhalten führt. Das Setzen von Anforderungen ist ähnlich wie das Festlegen eines positiven "netten" Werts im Vergleich zu höheren "Anforderungs" -Anwendungen. Weitere Informationen hierzu finden Sie unter Soft Limits.
chiluk
am 5. Dez. 2019
Probleme sind nach 90 Tagen Inaktivität veraltet.
Markieren Sie das Problem mit /remove-lifecycle stale als frisch.
Veraltete Probleme verrotten nach weiteren 30 Tagen Inaktivität und schließen schließlich.
Wenn dieses Problem jetzt sicher geschlossen werden kann, tun Sie dies bitte mit /close .
Senden Sie Feedback an sig-testing, kubernetes / test-infra und / oder fejta .
/ Lebenszyklus abgestanden
 fejta-bot
am 4. März 2020
fejta-bot
am 4. März 2020
/ remove-lifecycle veraltet
Nuru
am 4. März 2020
Nach meinem Verständnis wurde das zugrunde liegende Problem im Kernel behoben und zB in ContainerLinux unter https://github.com/coreos/bugs/issues/2623 verfügbar gemacht
Kennt jemand die verbleibenden Probleme nach diesem Kernel-Patch?
 sfudeus
am 4. März 2020
sfudeus
am 4. März 2020
@sfudeus Kubernetes kann auf jeder Linux- Version ausgeführt werden. Dieser Fehler war nie ein Problem für Benutzer von Linux, wurde für einige von Linux abgeleitete Distributionen behoben und für andere nicht behoben.
Das zugrunde liegende Problem wurde im Linux-Kernel 5.4 behoben, den derzeit kaum jemand verwendet. Patches wurden für das Backporting auf verschiedene ältere Kernel zur Verfügung gestellt und in neue Linux-Distributionen aufgenommen, die noch nicht bereit sind, auf den 5.4-Kernel zu wechseln, von denen es viele gibt. Wie Sie der obigen Liste von Commits entnehmen können, die auf dieses Problem verweisen, werden die Bugfix-Patches noch in die unzähligen Linux-Distributionen integriert, auf denen möglicherweise jemand Kubernetes verwendet.
Daher möchte ich dieses Problem eine Weile offen halten, da noch aktive Commit-Referenzen angezeigt werden. Ich würde es auch gerne mit einem Skript oder einer anderen einfachen Methode schließen sehen, mit der jemand feststellen kann, ob die Installation von Kubernetes betroffen ist oder nicht.
Nuru
am 5. März 2020
@Nuru Gut für mich, ich wollte nur sicherstellen, dass kein anderes
sfudeus
am 5. März 2020
Ich bin mir nicht sicher, ob dies der richtige Ort ist, um Leute zu informieren, aber ich bin mir nicht sicher, wo ich das sonst noch ansprechen soll:
Wir führen den 5.4 Linux-Kernel auf Debian Buster (unter Verwendung des Buster-Backports-Kernels) unter Verwendung des k8s 1.15.10-Clusters aus und sehen immer noch Probleme damit. Insbesondere für Pods, die normalerweise sehr wenig zu tun haben (kube-downscaler ist das Beispiel, auf das wir immer wieder zurückkommen, für das normalerweise etwa 3 m CPU erforderlich sind) und denen nur sehr wenige CPU-Ressourcen zugewiesen sind (50 m bei kube-downscaler in unserem Cluster) sehen wir immer noch einen sehr hohen Drosselungswert. Als Referenz ist der Kube-Downscaler im Grunde ein Python-Skript, das 30 Minuten lang ein sleep ausführt, bevor es etwas tut. cAdvisor zeigt an, dass die Zunahme von container_cpu_cfs_throttled_periods_total für diesen Container immer mehr oder weniger dem container_cpu_cfs_periods_total-Wert dieses Containers ähnlich ist (beide liegen bei 250, wenn die Zunahme in Intervallen von 5 m überprüft wird). Wir würden erwarten, dass die gedrosselten Perioden nahe 0 liegen.
Messen wir das falsch? Gibt cAdvisor falsche Daten aus? Ist unsere Annahme richtig, dass wir einen Rückgang der gedrosselten Perioden sehen sollten? Jeder Rat wäre hier dankbar.
Nach dem Wechsel zum 5.4-Kernel hat sich die Anzahl der Pods mit diesem Problem etwas verringert (ca. 40%), aber wir sind uns derzeit nicht sicher, ob das, was wir sehen, ein tatsächliches Problem ist oder nicht. Hauptsächlich sind wir uns bei der Betrachtung der obigen Statistiken nicht sicher, was "Drosselung" hier wirklich bedeutet, wenn wir diese Werte mit der durchschnittlichen CPU-Auslastung von 3 m erhalten. Der Knoten, auf dem er ausgeführt wird, ist überhaupt nicht überlastet und hat eine durchschnittliche CPU-Auslastung von weniger als 10%.
 timstoop
am 5. März 2020
timstoop
am 5. März 2020
@timstoop Die Intervalle, um die sich der Scheduler kümmert, liegen im Bereich von Mikrosekunden, nicht in großen 30-Minuten-Bereichen. Wenn ein Container ein CPU-Limit von 50 Millicpu hat und über einen Zeitraum von 100 Mikrosekunden 50 Millicpu verbraucht, wird er gedrosselt, unabhängig davon, ob er 30 Minuten im Leerlauf ist. Im Allgemeinen ist 50 Millicpu eine extrem kleine CPU-Grenze. Wenn ein Python-Programm sogar eine einzelne HTTPS-Anfrage mit einem so niedrigen Limit erstellt, wird es garantiert gedrosselt.
Der Knoten, auf dem er ausgeführt wird, ist überhaupt nicht überlastet und hat eine durchschnittliche CPU-Auslastung von weniger als 10%.
Nur zur Verdeutlichung: Die Belastung des Knotens und andere Workloads haben nichts mit Drosselung zu tun. Bei der Drosselung wird nur das eigene Limit des Containers / der Gruppe berücksichtigt.
PaulFurtado
am 5. März 2020
@PaulFurtado Danke für deine Antwort! Der Pod selbst verbraucht im Schlaf durchschnittlich 3 m CPU und wird immer noch gedrosselt. Während dieser Zeit macht es keine Anfrage, es wartet auf den Schlaf. Ich würde hoffen, dass es das kann, ohne die 50m zu erreichen, oder? Oder ist das überhaupt eine falsche Annahme?
timstoop
am 5. März 2020
Ich denke, dies ist wahrscheinlich eine so niedrige Zahl, dass es Genauigkeitsprobleme geben wird. Und 50 m sind so niedrig, dass alles darüber stolpern könnte. Die Laufzeit von Python führt möglicherweise auch Hintergrundaufgaben in Threads aus, während Sie schlafen.
PaulFurtado
am 5. März 2020
Sie hatten Recht, ich machte Annahmen, die nicht wahr waren. Vielen Dank für Ihre Anleitung! Es macht jetzt Sinn für mich.
timstoop
am 5. März 2020
Ich wollte nur einspringen und sagen, dass die Dinge hier wesentlich verbessert wurden, seit der Kernel-Patch die 4.19 LTS-Kernel erreicht hat und auf CoreOS / Flatcar angezeigt wurde. Im Moment sehe ich nur ein paar Dinge, bei denen ich wahrscheinlich Grenzen setzen sollte. :Lächeln:
jhohertz
am 5. März 2020
@sfudeus @chiluk Gibt es einen einfachen Test, um
Ich kann nicht sagen, ob kope.io/k8s-1.15-debian-stretch-amd64-hvm-ebs-2020-01-17 (das aktuelle offizielle kops Image) gepatcht wurde oder nicht.
Nuru
am 20. März 2020
Ich stimme @mariusgrigoriu zu . Für Pods, die auf exklusivem CPU unter statischer CPU-Richtlinie ausgeführt werden, können wir das CPU-Kontingentlimit einfach deaktivieren - es kann ohnehin nur auf seinem exklusiven CPU-Satz ausgeführt werden. Der obige Patch ist für diesen Zweck und nur für diese Art von Pods vorgesehen.
 jianzzha
am 6. Apr. 2020
jianzzha
am 6. Apr. 2020
@Nuru Ich schrieb https://github.com/indeedeng/fibtest
Es ist ungefähr so endgültig wie möglich für einen Test, aber Sie benötigen einen C-Compiler.
Ignorieren Sie die Anzahl der abgeschlossenen Iterationen, konzentrieren Sie sich jedoch auf die Zeit, die für den Lauf mit einem oder mehreren Threads benötigt wird.
chiluk
am 10. Apr. 2020
Ich denke, ein guter Weg, um zu sehen, welche Kernel gepatcht wurden, ist eine der letzten Folien von @chiluk (danke übrigens). Talk https://www.youtube.com/watch?v=UE7QX98-kO0
Kernel 4.15.0-67 scheint den Patch zu haben (https://launchpad.net/ubuntu/+source/linux/4.15.0-67.76), aber wir sehen immer noch Drosselung in einigen Pods, in denen Anforderungen / Limits weit darüber liegen ihre CPU-Auslastung.
Ich spreche von einer Nutzungsdauer von ca. 50 ms, wobei die Anforderung auf 250 m und das Limit auf 500 m festgelegt ist. Wir sehen, dass ungefähr 50% der CPU-Perioden gedrosselt werden. Ist dieser Wert möglicherweise niedrig genug, um erwartet zu werden und kann akzeptiert werden? Ich möchte, dass es auf Null sinkt. Wir sollten überhaupt nicht gedrosselt werden, wenn die Nutzung nicht einmal nahe am Limit liegt.
Hat jemand, der den neuen gepatchten Kernel verwendet, noch etwas Drosselung?
 vgarcia-te
am 22. Apr. 2020
vgarcia-te
am 22. Apr. 2020
@ vgarcia-te Es sind viel zu viele Kernel im Umlauf, um aus einer Liste zu wissen, welche gepatcht wurden und welche nicht. Schauen Sie sich einfach alle Commits an, die auf dieses Problem verweisen. Einige Hundert. Meine Lektüre des Änderungsprotokolls für Ubuntu legt nahe, dass 4.15 noch nicht gepatcht wurde (außer Mabye für die Ausführung unter Azure) und der von Ihnen verknüpfte Patch abgelehnt wurde .
Persönlich interessiere ich mich für die 4.9-Serie, weil dies das ist, was kops verwendet, und ich würde gerne wissen, wann sie ein AMI mit einem Fix veröffentlichen.
In der Zwischenzeit können Sie versuchen, den @ Bobrik - Test auszuführen , der mir ziemlich gut erscheint.
wget https://gist.githubusercontent.com/bobrik/2030ff040fad360327a5fab7a09c4ff1/raw/9dcf83b821812064fa7fb056b8f22cbd5c4364f1/cfs.go
sudo docker run --rm -it --cpu-quota 20000 --cpu-period 100000 -v $(pwd):$(pwd) -w $(pwd) golang:1.9.2 go run cfs.go -iterations 15 -sleep 1000ms
Bei einem ordnungsgemäß funktionierenden CFS betragen die Brennzeiten immer 5 ms. Bei den betroffenen Kerneln, die ich anhand der oben genannten Zahlen getestet habe, werden häufig Brennzeiten von 99 ms angezeigt. Alles über 6 ms ist ein Problem.
Nuru
am 22. Apr. 2020
@nuru danke für das Skript, um herauszufinden, vorliegt oder nicht.
@justinsb Bitte schlagen Sie vor, ob die Standard-Kops-Images den Patch haben oder nicht
https://github.com/kubernetes/kops/blob/master/channels/stable
Es wurde ein Problem geöffnet :
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -617586330
Update: Test in Kops 1.15 Image durchgeführt, unnötige Drosselung gibt es https://github.com/kubernetes/kops/issues/8954#issuecomment -617673755
alok87
am 22. Apr. 2020
@Nuru
2020/04/22 11:02:48 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 6ms
2020/04/22 11:02:49 [1] burn took 5ms, real time so far: 1012ms, cpu time so far: 12ms
2020/04/22 11:02:50 [2] burn took 5ms, real time so far: 2017ms, cpu time so far: 18ms
2020/04/22 11:02:51 [3] burn took 5ms, real time so far: 3023ms, cpu time so far: 23ms
2020/04/22 11:02:52 [4] burn took 5ms, real time so far: 4028ms, cpu time so far: 29ms
2020/04/22 11:02:53 [5] burn took 5ms, real time so far: 5033ms, cpu time so far: 35ms
2020/04/22 11:02:54 [6] burn took 5ms, real time so far: 6038ms, cpu time so far: 40ms
2020/04/22 11:02:55 [7] burn took 5ms, real time so far: 7043ms, cpu time so far: 46ms
2020/04/22 11:02:56 [8] burn took 5ms, real time so far: 8049ms, cpu time so far: 51ms
2020/04/22 11:02:57 [9] burn took 5ms, real time so far: 9054ms, cpu time so far: 57ms
2020/04/22 11:02:58 [10] burn took 5ms, real time so far: 10059ms, cpu time so far: 63ms
2020/04/22 11:02:59 [11] burn took 5ms, real time so far: 11064ms, cpu time so far: 69ms
2020/04/22 11:03:00 [12] burn took 5ms, real time so far: 12069ms, cpu time so far: 74ms
2020/04/22 11:03:01 [13] burn took 5ms, real time so far: 13074ms, cpu time so far: 80ms
2020/04/22 11:03:02 [14] burn took 5ms, real time so far: 14079ms, cpu time so far: 85ms
Diese Ergebnisse stammen aus dem
Linux <servername> 4.15.0-96-generic #97-Ubuntu SMP Wed Apr 1 03:25:46 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
Es ist der neueste stabile Ubuntu-Kernel in Ubuntu 18.04.
So sieht es aus wie Patch gibt.
 zerkms
am 22. Apr. 2020
zerkms
am 22. Apr. 2020
@zerkms Wo hast du deine Tests unter Ubuntu 18.04 durchgeführt? Mir scheint, der Patch hat es möglicherweise nur in den Kernel für Azure geschafft. Wenn Sie einen Versionshinweis finden, der besagt, wo er auf das Ubuntu linux -Paket angewendet wurde, teilen Sie ihn bitte mit. Ich kann es nicht finden.
Beachten Sie auch, dass dieser Test das Problem auch unter CoreOS nicht reproduzieren konnte. Möglicherweise war die CFS-Planung in der Standardkonfiguration global deaktiviert.
Nuru
am 22. Apr. 2020
@Nuru
Wo haben Sie Ihre Tests unter Ubuntu 18.04 durchgeführt?
Einer meiner Server.
Ich habe die Versionshinweise nicht überprüft, bin mir nicht einmal sicher, wonach ich suchen soll, und trotzdem - es ist ein Standardkernel, wie ihn jeder hat. 🤷
zerkms
am 22. Apr. 2020
Der Patch sollte hier in Ubuntus Kernel Git sein:
https://kernel.ubuntu.com/git/ubuntu/ubuntu-bionic.git/commit/?id=aadd794e744086fb50cdc752d54044fbc14d4adb
und hier der Ubuntu-Bug dazu:
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1832151
es sollte in der bionischen freigesetzt werden.
Sie können dies sicherstellen, indem Sie apt-get source linux ausführen und den heruntergeladenen Quellcode einchecken.
juliantaylor
am 22. Apr. 2020
@zerkms Mit "Wo haben Sie Ihre Tests durchgeführt?" meine ich, war es ein Server in Ihrem Büro, ein Server in GCP, AWS, Azure oder woanders?
Offensichtlich gibt es eine Menge, die ich nicht verstehe, wie Ubuntu verteilt und gewartet wird. Ich bin auch verwirrt über Ihre Ausgabe von uname -a . In den Ubuntu-Versionshinweisen heißt es:
18.04.4 wird mit einem v5.3-basierten Linux-Kernel ausgeliefert, der in 18.04.3 vom v5.0-basierten Kernel aktualisiert wurde.
und sagt auch, dass 18.04.4 am 12. Februar 2020 veröffentlicht wurde. Ihre Ausgabe besagt, dass Sie einen Kernel der Version 4.15 ausführen, der am 1. April 2020 kompiliert wurde.
@ juliantaylor Ich habe keinen Ubuntu-Server oder eine Kopie des Git-Repos und weiß nicht, wie ich verfolgen soll, wo ein bestimmtes Commit wie aadd794e7440 es in einen veröffentlichten stabilen Kernel geschafft hat. Wenn Sie mir zeigen können, wie das geht, würde ich es begrüßen.
Wenn ich mir die Kommentare zum Launchpad-Fehler ansehe, sehe ich
- Dieser Fehler wurde im Paket linux-azure - 5.0.0-1027.29 behoben
- Dieser Fehler wurde im Paket linux-azure - 5.0.0-1027.29 ~ 18.04.1 behoben
Dieser spezielle Patch ( sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices ) ist jedoch nicht unter aufgeführt
- Dieser Fehler wurde im Paket Linux - 4.15.0-69.78 behoben
Ich sehe auch nicht "1832151" in den Versionshinweisen zu Ubuntu
Ein vorheriger Kommentar sagte, dass es in 4.15.0-67.76 gepatcht wurde, aber ich sehe kein linux-image-4.15.0-67-generic -Paket.
Ich bin weit entfernt von einem Ubuntu-Experten und finde dieses Patch-Tracking inakzeptabel schwierig, so weit ich es mir angesehen habe.
Ich hoffe, Sie sehen jetzt, warum ich nicht sicher bin, ob dieser Patch tatsächlich in Ubuntu 18.04.4 enthalten ist, der aktuellen Version von 18.04. Meine beste Vermutung ist, dass es als Kernel-Update nach dem 18.04.4 veröffentlicht wurde und wahrscheinlich enthalten ist, wenn Ihr Ubuntu-Kernel 4.15.0-69 oder höher meldet, aber wenn Sie nur 18.04.4 herunterladen und es nicht aktualisieren, Der Patch wird nicht angezeigt.
Nuru
am 22. Apr. 2020
Ich habe gerade diesen Go-Test (sehr nützlich) im Kernel 4.15.0-72 auf einem Baremetal-Server in einem Rechenzentrum ausgeführt und es scheint, dass der Patch da ist:
2020/04/22 21:24:27 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 7ms
2020/04/22 21:24:28 [1] burn took 5ms, real time so far: 1010ms, cpu time so far: 13ms
2020/04/22 21:24:29 [2] burn took 5ms, real time so far: 2015ms, cpu time so far: 20ms
2020/04/22 21:24:30 [3] burn took 5ms, real time so far: 3020ms, cpu time so far: 25ms
2020/04/22 21:24:31 [4] burn took 5ms, real time so far: 4025ms, cpu time so far: 32ms
2020/04/22 21:24:32 [5] burn took 5ms, real time so far: 5030ms, cpu time so far: 38ms
2020/04/22 21:24:33 [6] burn took 5ms, real time so far: 6036ms, cpu time so far: 43ms
2020/04/22 21:24:34 [7] burn took 5ms, real time so far: 7041ms, cpu time so far: 50ms
2020/04/22 21:24:35 [8] burn took 5ms, real time so far: 8046ms, cpu time so far: 56ms
2020/04/22 21:24:36 [9] burn took 5ms, real time so far: 9051ms, cpu time so far: 63ms
2020/04/22 21:24:37 [10] burn took 5ms, real time so far: 10056ms, cpu time so far: 68ms
2020/04/22 21:24:38 [11] burn took 5ms, real time so far: 11061ms, cpu time so far: 75ms
2020/04/22 21:24:39 [12] burn took 5ms, real time so far: 12067ms, cpu time so far: 81ms
2020/04/22 21:24:40 [13] burn took 5ms, real time so far: 13072ms, cpu time so far: 86ms
2020/04/22 21:24:41 [14] burn took 5ms, real time so far: 14077ms, cpu time so far: 94ms
Ich kann auch sehen, dass dieselbe Ausführung im Kernel 4.9.164 auf demselben Servertyp Verbrennungen über 5 ms zeigt:
2020/04/22 21:24:41 [0] burn took 97ms, real time so far: 97ms, cpu time so far: 8ms
2020/04/22 21:24:42 [1] burn took 5ms, real time so far: 1102ms, cpu time so far: 12ms
2020/04/22 21:24:43 [2] burn took 5ms, real time so far: 2107ms, cpu time so far: 16ms
2020/04/22 21:24:44 [3] burn took 5ms, real time so far: 3112ms, cpu time so far: 24ms
2020/04/22 21:24:45 [4] burn took 83ms, real time so far: 4197ms, cpu time so far: 28ms
2020/04/22 21:24:46 [5] burn took 5ms, real time so far: 5202ms, cpu time so far: 32ms
2020/04/22 21:24:47 [6] burn took 94ms, real time so far: 6297ms, cpu time so far: 36ms
2020/04/22 21:24:48 [7] burn took 99ms, real time so far: 7397ms, cpu time so far: 40ms
2020/04/22 21:24:49 [8] burn took 100ms, real time so far: 8497ms, cpu time so far: 44ms
2020/04/22 21:24:50 [9] burn took 5ms, real time so far: 9503ms, cpu time so far: 52ms
2020/04/22 21:24:51 [10] burn took 5ms, real time so far: 10508ms, cpu time so far: 60ms
2020/04/22 21:24:52 [11] burn took 5ms, real time so far: 11602ms, cpu time so far: 64ms
2020/04/22 21:24:53 [12] burn took 5ms, real time so far: 12607ms, cpu time so far: 72ms
2020/04/22 21:24:54 [13] burn took 5ms, real time so far: 13702ms, cpu time so far: 76ms
2020/04/22 21:24:55 [14] burn took 5ms, real time so far: 14707ms, cpu time so far: 80ms
Mein Problem ist also, dass ich immer noch eine CPU-Drosselung sehe, selbst wenn mein Kernel gepatcht zu sein scheint
vgarcia-te
am 22. Apr. 2020
@Nuru richtig, sorry. Das war mein Bare-Metal-Server, der im Büro gehostet wurde.
und sagt auch, dass 18.04.4 am 12. Februar 2020 veröffentlicht wurde. Ihre Ausgabe besagt, dass Sie einen Kernel der Version 4.15 ausführen, der am 1. April 2020 kompiliert wurde.
Das liegt daran, dass es sich um ein Server-LTS handelt: Sie müssen HWE explizit damit aktivieren, um neuere Kernel zu erhalten, andernfalls führen Sie nur mainline aus.
Und sowohl Mainline- als auch HWE-Kernel werden regelmäßig veröffentlicht, sodass kein Verdacht besteht, einen kürzlich erstellten Kernel zu haben: http://changelogs.ubuntu.com/changelogs/pool/main/l/linux-meta/linux-meta_4.15.0.96.87/ Änderungsprotokoll
zerkms
am 22. Apr. 2020
@zerkms Danke für die Info. Ich bleibe verwirrt, aber dies ist nicht der Ort, um mich zu erziehen.
@ vgarcia-te Wenn dein Kernel gepatcht ist, was es zu sein scheint, dann ist die Drosselung nicht auf diesen Fehler zurückzuführen. Ich bin mir Ihrer Terminologie nicht sicher, wenn Sie sagen:
Ich spreche von einer Nutzungsdauer von ca. 50 ms, wobei die Anforderung auf 250 m und das Limit auf 500 m festgelegt ist. Wir sehen, dass ungefähr 50% der CPU-Perioden gedrosselt werden. Ist dieser Wert möglicherweise niedrig genug, um erwartet zu werden und kann akzeptiert werden?
Die Kubernetes-CPU-Ressource wird in CPUs gemessen, wobei 1 100% von 1 vollen CPU und 1 m 0,1% von 1 CPU bedeutet. Ihr Limit von "500m" besagt also, dass 0,5 CPUs zulässig sind.
Der Standardplanungszeitraum für CFS beträgt 100 ms. Wenn Sie also das Limit auf 0,5 CPUs festlegen, wird Ihr Prozess alle 100 ms auf 50 ms CPU begrenzt. Wenn Ihr Prozess versucht, diesen Wert zu überschreiten, wird er gedrosselt. Wenn Ihr Prozess in der Regel mehr als 50 ms in einem Durchgang ausführt, ist zu erwarten, dass er von einem ordnungsgemäß funktionierenden Scheduler gedrosselt wird.
Nuru
am 23. Apr. 2020
@Nuru das macht Sinn, aber lassen Sie mich das verstehen, da die Standard-CPU-Periode 100 ms beträgt. Wenn einem Prozess 1 CPU zugewiesen wird und dieser Prozess mehr als 100 ms in einem Durchgang ausgeführt wird, wird er dann gedrosselt?
Bedeutet dies, dass unter Linux, wo die Standard-CPU-Periode 100 ms beträgt, jeder Prozess, dessen Limit in einem einzigen Durchgang mehr als 100 ms beträgt, gedrosselt wird?
Was wäre eine gute Grenzwertkonfiguration für einen Prozess, der in einem Durchgang mehr als 100 ms dauert, aber den Rest seiner Zeit im Leerlauf ist?
vgarcia-te
am 23. Apr. 2020
@ vgarcia-te fragte
Angesichts der Tatsache, dass die Standard-CPU-Periode 100 ms beträgt, wird der Prozess gedrosselt, wenn einem Prozess 1 CPU zugewiesen wird. Wenn dieser Prozess in einem einzigen Durchgang mehr als 100 ms lang ausgeführt wird, wird er gedrosselt?
Natürlich ist die Planung wahnsinnig kompliziert, daher kann ich Ihnen keine perfekte Antwort geben, aber die vereinfachte Antwort lautet Nein. Detailliertere Erklärungen finden Sie hier und hier .
Alle Unix-Prozesse unterliegen einer vorbeugenden Planung basierend auf Zeitscheiben. In den Tagen der Single-Core-Single-CPU liefen noch 30 Prozesse "gleichzeitig". Was passiert ist, dass sie eine Weile rennen und entweder schlafen oder am Ende ihrer Zeitscheibe in die Warteschleife gelegt werden, damit etwas anderes laufen kann.
Das CFS mit Quoten geht noch einen Schritt weiter.
Fragen Sie sich jedoch, was Sie wirklich sagen, wenn Sie sagen, dass ein Prozess 50% einer CPU nutzen soll? Wollen Sie damit sagen, dass es in Ordnung ist, wenn es 5 Minuten lang 100% der CPU beansprucht, solange es dann die folgenden 5 Minuten überhaupt nicht läuft? Das wäre eine 50% ige Auslastung über 10 Minuten, aber für die meisten Menschen aufgrund der Latenzprobleme nicht akzeptabel.
Daher definiert CFS einen "CPU-Zeitraum", der das Zeitfenster darstellt, über das Kontingente erzwungen werden. Auf einem Computer mit 4 Kernen und einer CPU-Periode von 100 ms verfügt der Scheduler über eine CPU-Zeit von 400 ms, um mehr als 100 ms Echtzeit (Wanduhr) zuzuweisen. Wenn Sie einen einzelnen Ausführungsthread ausführen, der nicht parallelisiert werden kann, kann dieser Thread höchstens 100 ms CPU-Zeit pro Periode verwenden, was 100% von 1 CPU entspricht. Wenn Sie das Kontingent auf 1 CPU festlegen, sollte es niemals gedrosselt werden.
Wenn Sie das Kontingent auf 500 m (0,5 CPUs) festlegen, werden alle 100 ms 50 ms ausgeführt. Jeder Zeitraum von 100 ms verwendet weniger als 50 ms und sollte nicht gedrosselt werden. Nach 100 ms wird es nach 50 ms nicht beendet, sondern bis zur nächsten 100 ms gedrosselt. Dadurch wird ein Gleichgewicht zwischen Latenz (wie lange es warten muss, bis es überhaupt ausgeführt werden kann) und Hogging (wie lange es erlaubt ist, andere Prozesse am Laufen zu halten) aufrechterhalten.
Nuru
am 23. Apr. 2020
@Nuru meine Folien sind korrekt. Ich bin auch ein Ubuntu-Entwickler * (jetzt nur in meiner Freizeit). Am besten lesen Sie die Quellen und überprüfen Sie git tad + tag --contains, um zu verfolgen, wann der Patch die Version des Kernels erreicht, die Sie interessiert.
chiluk
am 26. Apr. 2020
@chiluk Ich hatte deine Folien nicht gesehen. Für andere, die sie nicht gesehen haben, heißt es hier, dass der Patch seit einiger Zeit gelandet ist:
- Ubuntu 4.15.0-67 +
- Ubuntu 5.3.0-24 +
- RHEL7-Kernel 3.10.0-1062.8.1.el7
und natürlich Linux Stable v4.14.154, v4.19.84, 5.3.9. Ich stelle fest, es ist auch in Linux stabil 5.4-rc1.
Ich habe immer noch Probleme, die verschiedenen CFS-Scheduler-Fehler zu verstehen und zuverlässige, einfach zu interpretierende Tests zu finden, die auf einem kleinen AWS-Server funktionieren würden, da ich eine Vielzahl von Kerneln aus älteren Installationen unterstütze. Soweit ich die Zeitleiste verstehe, wurde 2014 von ein Fehler im Linux-Kernel v3.16-rc1 eingeführt
[51f2176d74ac](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=51f2176d74ac) sched/fair: Fix unlocked reads of some cfs_b->quota/period.
Dies verursachte verschiedene CFS-Drosselungsprobleme. Ich denke, die Probleme, die ich unter kops Kubernetes-Clustern sah, waren auf diesen Fehler zurückzuführen, da sie 4.9-Kernel verwendeten.
51f2176d74ac wurde im Kernel v4.18-rc4 von 2018 mit behoben
[512ac999](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) sched/fair: Fix bandwidth timer clock drift condition
aber das führte den Fehler @chiluk ein, der mit behoben wurde
[de53fd7ae](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425) sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
Es ist natürlich nicht die Schuld von Chiluk oder einer anderen Person, dass die Kernel-Patches über Distributionen hinweg schwer zu verfolgen sind. Es bleibt jedoch für mich frustrierend und trägt zu meiner Verwirrung bei.
Beispielsweise wird auf Debuan Buster 10 (AWS AMI debian-10-amd64-20191113-76 ) die Kernel-Version als gemeldet
Linux ip-172-31-41-138 4.19.0-6-cloud-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
Soweit ich das beurteilen kann, sollte dieser Kernel 51f2176d74ac und NICHT 512ac999 und daher den in 512ac999 beschriebenen Test nicht bestehen, aber nicht. (Ich glaube nicht, dass es 512ac999 da es schrittweise von Linux Kernel 4.10 aktualisiert wurde und dieser Patch im Änderungsprotokoll nicht erwähnt wird.) Auf einer 4-CPU-AWS-VM schlägt dies jedoch nicht fehl Chiluks fibtest oder Bobriks CFS-Schluckauf- Test, der darauf hindeutet, dass etwas anderes vor sich geht.
Ich hatte ähnliche Probleme beim Reproduzieren von Planungsproblemen mit CoreOS, noch bevor es Chiluks Patch erhielt.
Ich denke im Moment, dass Bobriks Test hauptsächlich ein Test für 51f2176d74ac , der Debian Buster 10 AMI, den ich benutze, hat die 512ac999 , die im Änderungsprotokoll nur nicht explizit angegeben sind, und fibtest ist kein sehr empfindlicher Test auf einer Maschine mit nur wenigen Kernen.
Nuru
am 27. Apr. 2020
Eine 4-Kern-CPU ist wahrscheinlich nicht groß genug, um das Problem zu reproduzieren, das Chiluk behoben hat.
Es sollte nur auf größeren Maschinen mit mehr als 40 cpus reproduzierbar sein, wenn ich die Erklärung von chiluks kubecon talk (https://www.youtube.com/watch?v=UE7QX98-kO0) richtig verstanden habe.
Es gibt viele Kernel-Versionen und es wird viel gepatcht und zurückgesetzt. Änderungsprotokolle und Versionsnummern bringen Sie nur so weit.
Wenn Sie Zweifel haben, können Sie den Quellcode nur zuverlässig herunterladen und mit den Änderungen in den hier verlinkten Patches vergleichen.
juliantaylor
am 27. Apr. 2020
Probleme sind nach 90 Tagen Inaktivität veraltet.
Markieren Sie das Problem mit /remove-lifecycle stale als frisch.
Veraltete Probleme verrotten nach weiteren 30 Tagen Inaktivität und schließen schließlich.
Wenn dieses Problem jetzt sicher geschlossen werden kann, tun Sie dies bitte mit /close .
Senden Sie Feedback an sig-testing, kubernetes / test-infra und / oder fejta .
/ Lebenszyklus abgestanden
fejta-bot
am 26. Juli 2020
/ remove-lifecycle veraltet
 yashbhutwala
am 27. Juli 2020
yashbhutwala
am 27. Juli 2020
Die zuvor in diesem Thread erwähnten Tests reproduzieren das Problem für mich nicht wirklich (einige Verbrennungen dauern mehr als 5 ms, aber es sind etwa 0,01% von ihnen), aber unsere cfs-Drosselungsmetriken zeigen immer noch mäßige Drosselungsbeträge. Wir haben verschiedene Kernelversionen in unseren Clustern, aber die beiden häufigsten Versionen sind:
Debian 4.19.67-2+deb10u2~bpo9+1 (2019-11-12)- ein manueller Backport von
5.4.38
Ich weiß nicht, ob beide Fehler in diesen Versionen behoben werden sollen, aber ich denke, dass sie behoben sein sollen, also frage ich mich, ob der Test nicht so nützlich ist. Ich teste auf Maschinen mit 16 Kernen und mit 36 Kernen. Ich bin mir nicht sicher, ob ich noch mehr Kerne benötige, damit der Test gültig ist, aber wir sehen immer noch die Drosselung in diesen Clustern, also ...
 2rs2ts
am 18. Aug. 2020
2rs2ts
am 18. Aug. 2020
Sollten wir dieses Problem schließen und nach Leuten fragen, die Probleme haben, um neue zu beginnen? Das Spammen hier wird wahrscheinlich jedes Gespräch sehr schwierig machen.
 omnibs
am 31. Okt. 2020
omnibs
am 31. Okt. 2020
^ Ich stimme zu. Es wurde viel getan, um dieses Problem zu lösen.
 sfxworks
am 31. Okt. 2020
sfxworks
am 31. Okt. 2020
/schließen
basierend auf den obigen Kommentaren. Bitte öffnen Sie nach Bedarf neue Ausgaben.
dims
am 1. Nov. 2020
@dims : Dieses Problem wird geschlossen.
Als Antwort darauf :
/schließen
basierend auf den obigen Kommentaren. Bitte öffnen Sie nach Bedarf neue Ausgaben.
Anweisungen zur Interaktion mit mir mithilfe von PR-Kommentaren finden Sie hier . Wenn Sie Fragen oder Anregungen zu meinem Verhalten haben, reichen Sie bitte ein Problem mit dem Repository
 k8s-ci-robot
am 1. Nov. 2020
k8s-ci-robot
am 1. Nov. 2020
Bitte benachrichtigen Sie die Folgeprobleme zu diesem Problem, damit Personen, die das Problem abonniert haben, neue Probleme abonnieren können, die folgen sollen
 glensc
am 1. Nov. 2020
glensc
am 1. Nov. 2020
Verwandte Themen
 mml
·
3Kommentare
mml
·
3Kommentare
 zetaab
·
3Kommentare
zetaab
·
3Kommentare
 broady
·
3Kommentare
broady
·
3Kommentare
 pwittrock
·
3Kommentare
pwittrock
·
3Kommentare
 montanaflynn
·
3Kommentare
montanaflynn
·
3Kommentare
Hilfreichster Kommentar
Der Patch ist heute Morgen auf der Spitze gelandet.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Sobald es auf Torvalds Baum trifft, werde ich es zur Linux-stabilen Aufnahme und anschließend zu wichtigen Distributionen (Redhat / Ubuntu) einreichen. Wenn Sie sich für etwas anderes interessieren und diese nicht Linux-stabilen Patches folgen, möchten Sie es möglicherweise direkt einreichen.