Kubernetes: Kuota CFS dapat menyebabkan pembatasan yang tidak perlu
/ jenis bug
Ini bukan bug di Kubernets, ini lebih merupakan pendahuluan.
Saya telah membaca entri blog yang bagus ini:
Dari posting blog saya mengetahui bahwa k8s menggunakan kuota cfs untuk menerapkan batasan CPU. Sayangnya, hal itu dapat menyebabkan pembatasan yang tidak perlu, terutama bagi penyewa yang berperilaku baik.
Lihat bug yang belum terselesaikan ini di kernel Linux yang saya ajukan beberapa waktu lalu:
Ada tambalan terbuka dan terhenti yang mengatasi masalah (saya belum memverifikasi apakah itu berfungsi):
cc @ConnorDoyle @balajismaniam
 bobrik
bobrik
Semua 142 komentar
/ sig node
/ jenis bug
 neolit123
pada 20 Agu 2018
neolit123
pada 20 Agu 2018
apakah ini duplikat dari # 51135?
 liggitt
pada 20 Agu 2018
liggitt
pada 20 Agu 2018
Semangatnya serupa, tetapi tampaknya melewatkan fakta bahwa ada bug yang sebenarnya di kernel daripada hanya beberapa pertukaran konfigurasi dalam periode kuota CFS. Saya menyukai # 51135 di sini untuk memberi lebih banyak konteks kepada orang-orang di sana.
bobrik
pada 22 Agu 2018
Sejauh yang saya pahami ini adalah alasan lain untuk menonaktifkan kuota CFS ( --cpu-cfs-quota=false ) atau membuatnya dapat dikonfigurasi (# 63437).
Saya juga menemukan inti ini (ditautkan dari patch Kernel) sangat menarik untuk dilihat (untuk mengukur dampaknya): https://gist.github.com/bobrik/2030ff040fad360327a5fab7a09c4ff1
 hjacobs
pada 22 Agu 2018
hjacobs
pada 22 Agu 2018
cc @adityakali
 vishh
pada 23 Agu 2018
vishh
pada 23 Agu 2018
Masalah lain dengan kuota adalah kubelet menghitung hyperthreads sebagai "cpus". Ketika cluster menjadi sangat dimuat sehingga dua utas dijadwalkan pada inti yang sama dan proses memiliki kuota kuota cpu, salah satunya hanya akan bekerja dengan sebagian kecil dari kekuatan pemrosesan yang tersedia (itu hanya akan melakukan sesuatu ketika sesuatu di utas lain warung) tetapi masih mengonsumsi kuota seolah-olah memiliki inti fisik untuk dirinya sendiri. Jadi itu menghabiskan dua kali lipat kuota yang seharusnya tanpa melakukan lebih banyak pekerjaan secara signifikan.
Ini memiliki efek bahwa pada node node yang dimuat penuh dengan hyperthreading diaktifkan, kinerjanya akan menjadi setengah dari apa yang akan terjadi dengan hyperthreading atau kuota dinonaktifkan.
Imo, kubelet tidak boleh menganggap hyperthreads sebagai CPU nyata untuk menghindari situasi ini.
 juliantaylor
pada 30 Agu 2018
juliantaylor
pada 30 Agu 2018
@juliantaylor Seperti yang saya sebutkan di # 51135 mematikan kuota CPU mungkin merupakan pendekatan terbaik untuk sebagian besar kluster k8s yang menjalankan beban kerja tepercaya.
vishh
pada 30 Agu 2018
Apakah ini dianggap sebagai bug?
Jika beberapa pod di-throttle namun tidak menghabiskan batas CPU-nya, ini terdengar seperti bug bagi saya.
Di cluster saya, sebagian besar pod kelebihan kuota terkait dengan metrik (heapster, metrics-collector, node-eksportir ...) atau Operator, yang jelas memiliki jenis beban kerja yang menjadi masalah di sini: tidak melakukan apa pun waktu dan bangun untuk berdamai sesekali.
Hal yang aneh di sini adalah bahwa saya mencoba menaikkan batas, dari 40m menjadi 100m atau 200m , dan prosesnya masih terhambat.
Saya tidak dapat melihat metrik lain yang menunjukkan beban kerja yang dapat memicu pelambatan ini.
Saya telah menghapus batasan pada pod ini untuk saat ini ... ini menjadi lebih baik, tetapi, yah, itu benar-benar terdengar seperti bug dan kita harus datang dengan solusi yang lebih baik daripada menonaktifkan Limits
 prune998
pada 26 Nov 2018
prune998
pada 26 Nov 2018
@ prune998 lihat komentar @vishh dan intinya : Kernel terlalu agresif mencekik, bahkan jika matematika memberitahu Anda bahwa seharusnya tidak. Kami (Zalando) memutuskan untuk menonaktifkan kuota CFS (pembatasan CPU) di cluster kami: https://www.slideshare.net/try_except_/optimizing-kubernetes-resource-requestslimits-for-costefficiency-and-latency-highload
hjacobs
pada 27 Nov 2018
Terima kasih @hjacobs.
Saya menggunakan Google GKE dan saya tidak melihat cara mudah untuk menonaktifkannya, tetapi saya terus mencari ....
prune998
pada 27 Nov 2018
@ prune998 AFAIK, Google belum membuka kenop yang diperlukan. Kami mengajukan permintaan fitur tepat setelah kemungkinan untuk menonaktifkan CFS mendarat di hulu, belum mendengar berita apa pun sejak saat itu.
 timoreimann
pada 27 Nov 2018
timoreimann
pada 27 Nov 2018
Saya menggunakan Google GKE dan saya tidak melihat cara mudah untuk menonaktifkannya, tetapi saya terus mencari ....
Bisakah Anda menghapus batas CPU dari penampung Anda untuk saat ini?
vishh
pada 28 Nov 2018
Menurut dokumen pengelola CPU, CFS quota is not used to bound the CPU usage of these containers as their usage is bound by the scheduling domain itself. Tetapi kami mengalami pelambatan CFS.
Hal ini membuat manajer CPU statis sebagian besar tidak berguna karena menetapkan batas CPU untuk mencapai kelas QoS yang Dijamin meniadakan manfaat apa pun karena pembatasan.
Apakah ini bug karena kuota CFS disetel sama sekali untuk pod pada CPU statis?
 mariusgrigoriu
pada 12 Feb 2019
mariusgrigoriu
pada 12 Feb 2019
Untuk konteks tambahan (pelajari ini kemarin): @hrzbrg (MyTaxi) menyumbangkan tanda ke Kops untuk menonaktifkan pelambatan CPU: https://github.com/kubernetes/kops/issues/5826
hjacobs
pada 12 Feb 2019
Bagikan ringkasan masalahnya di sini. Tidak begitu jelas apa masalahnya dan dalam skenario apa pengguna terkena dampak dan apa sebenarnya yang diperlukan untuk memperbaikinya?
Pemahaman kami saat ini adalah ketika kami melewati batas, kami mendapat penalti dan mencekik. Jadi katakanlah kita memiliki kuota cpu 3 core dan dalam 5ms pertama kita mengkonsumsi 3 core kemudian dalam potongan 100ms kita akan terhambat selama 95ms, dan dalam 95ms ini container kita tidak dapat melakukan apa-apa. Dan kami telah melihat terhambat bahkan ketika lonjakan cpu tidak terlihat dalam metrik penggunaan cpu. Kami berasumsi bahwa itu karena jendela waktu pengukuran penggunaan cpu dalam detik dan pelambatan terjadi pada level mikro detik, sehingga rata-rata keluar dan tidak terlihat. Tetapi bug yang disebutkan di sini membuat kami bingung sekarang.
Beberapa pertanyaan:
- Ketika node berada pada 100% cpu? Apakah ini kasus khusus di mana semua kontainer akan dibatasi terlepas dari penggunaannya?
Jika ini terjadi, apakah semua container mendapatkan 100% cpu yang dibatasi?
Apa yang memicu bug ini dipicu di node?
Apa perbedaan antara tidak menggunakan
limitsdan menonaktifkancpu.cfs_quota?Bukankah menonaktifkan
limitsmerupakan solusi yang berisiko ketika ada banyak pod yang dapat di-burst dan satu pod dapat menyebabkan ketidakstabilan di node dan memengaruhi pod lain yang menjalankan permintaan mereka?Secara terpisah, menurut kernel doc, proses mungkin akan terhambat ketika kuota induk telah digunakan sepenuhnya. Apa yang dimaksud dengan induk dalam konteks penampung di sini (apakah ini terkait dengan bug ini)? https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
There are two ways in which a group may become throttled: a. it fully consumes its own quota within a period b. a parent's quota is fully consumed within its period- Apa yang diperlukan untuk memperbaikinya? Tingkatkan versi kernel?
Kami telah menghadapi pemadaman yang cukup besar dan tampaknya terkait erat (jika bukan akar penyebab) dengan semua pod kami yang terjebak dalam loop restart pelambatan dan tidak dapat ditingkatkan. Kami sedang menggali detail untuk menemukan masalah sebenarnya. Saya akan membuka edisi terpisah yang menjelaskan secara detail tentang pemadaman kami.
Bantuan apa pun di sini sangat dihargai.
cc @b
 alok87
pada 14 Feb 2019
alok87
pada 14 Feb 2019
Salah satu pengguna kami menetapkan batas CPU dan dicekik untuk menentukan waktu pemeriksaan kehidupan mereka yang menyebabkan penghentian layanan.
Kami melihat pelambatan bahkan saat menyematkan kontainer ke CPU. Misalnya Batas CPU 1 dan menyematkan penampung itu untuk berjalan hanya di satu CPU. Seharusnya tidak mungkin untuk melebihi kuota yang diberikan periode apa pun jika kuota Anda persis dengan jumlah CPU yang Anda miliki, namun kami melihat pembatasan dalam setiap kasus.
Saya pikir saya melihatnya diposting di suatu tempat bahwa kernel 4.18 memecahkan masalah. Saya belum mengujinya, jadi alangkah baiknya jika seseorang bisa mengonfirmasi.
mariusgrigoriu
pada 15 Feb 2019
https://github.com/torvalds/linux/commit/512ac999d2755d2b7109e996a76b6fb8b888631d di 4.18 tampaknya merupakan patch yang relevan untuk masalah ini.
 clkao
pada 23 Feb 2019
clkao
pada 23 Feb 2019
@mariusgrigoriu Sepertinya saya terjebak dalam teka-teki yang sama yang Anda jelaskan di sini https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -462534360.
Kami mengamati pelambatan CPU pada Pod dalam kelas QoS Terjamin dengan kebijakan statis CPUManager (yang tampaknya tidak masuk akal).
Menghapus limits untuk Pod ini akan menempatkannya di kelas Burstable QoS, yang bukan itu yang kita inginkan, jadi satu-satunya pilihan yang tersisa adalah menonaktifkan kuota cpu CFS di seluruh sistem, yang juga bukan sesuatu yang dapat kita lakukan dengan aman, karena mengizinkan semua Pod mengakses kapasitas cpu yang tidak terikat dapat menyebabkan masalah saturasi CPU yang berbahaya.
@vishh mengingat keadaan di atas, tindakan apa yang terbaik? sepertinya mengupgrade ke kernel> 4.18 (yang memiliki perbaikan akuntansi cpu cfs) dan (mungkin) mengurangi periode kuota cfs?
Pada catatan umum, menyarankan agar kami menghapus limits dari kontainer yang sedang dibatasi seharusnya memiliki peringatan yang jelas:
1) Jika ini adalah Pod dalam kelas QoS Terjamin, dengan jumlah inti integer dan kebijakan statis pengatur CPUMnager - Pod ini tidak akan lagi mendapatkan inti CPU khusus karena mereka akan ditempatkan di kelas QoS yang Dapat Melonjak (tidak memiliki batas permintaan ==)
2) Pod-pod ini tidak akan terikat dalam hal berapa banyak CPU yang dapat mereka konsumsi dan berpotensi menyebabkan sedikit kerusakan dalam keadaan tertentu.
Umpan balik / bimbingan Anda akan sangat dihargai.
 dannyk81
pada 25 Mar 2019
dannyk81
pada 25 Mar 2019
Memutakhirkan kernel pasti membantu, tetapi perilaku penerapan kuota CFS masih tampak tidak sejalan dengan saran dokumen.
mariusgrigoriu
pada 25 Mar 2019
Saya telah meneliti berbagai aspek masalah ini untuk sementara waktu sekarang. Penelitian saya dirangkum dalam posting saya ke LKML.
https://lkml.org/lkml/2019/3/18/706
Karena itu, saya belum dapat mereproduksi masalah seperti yang dijelaskan di sini di kernel pra-512ac99. Saya telah melihat regresi kinerja di kernel pasca-512ac99. Jadi perbaikan itu bukanlah obat mujarab.
 chiluk
pada 25 Mar 2019
chiluk
pada 25 Mar 2019
Terima kasih @mariusgrigoriu, kita akan untuk kernel meng-upgrade dan harapan yang akan membantu sedikit, juga memeriksa https://github.com/kubernetes/kubernetes/issues/70585 - tampaknya bahwa kuota memang ditetapkan untuk polong dijamin dengan cpuset ( yaitu cpus yang disematkan), jadi ini tampak seperti bug bagi saya.
dannyk81
pada 25 Mar 2019
@chiluk bisakah Anda menjelaskan sedikit? maksud Anda patch yang disertakan dalam 4.18 (disebutkan di atas di https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-466609030) sebenarnya tidak menyelesaikan masalah?
dannyk81
pada 25 Mar 2019
Patch kernel 512ac99 memperbaiki masalah untuk beberapa orang, tetapi menyebabkan masalah pada konfigurasi kami. Patch memperbaiki cara pembagian waktu di antara cfs_rq, karena sekarang mereka benar-benar kedaluwarsa. Sebelumnya mereka tidak akan kedaluwarsa.
Beban kerja Java, khususnya pada mesin dengan jumlah inti tinggi, sekarang mengalami pelambatan dalam jumlah besar dengan penggunaan cpu yang rendah karena thread pekerja yang memblokir. Utas tersebut diberi potongan waktu yang hanya digunakan sebagian kecil yang kemudian kedaluwarsa. Dalam pengujian sintetis yang saya tulis * (ditautkan ke utas itu), kami melihat penurunan kinerja sekitar 30x. Dalam kinerja dunia nyata, kami melihat penurunan waktu respons ratusan milidetik antara dua kernel karena peningkatan pelambatan.
chiluk
pada 25 Mar 2019
Dengan menggunakan kernel 4.19.30, saya melihat pod yang saya harap dapat melihat lebih sedikit throttling masih dibatasi dan beberapa pod yang sebelumnya tidak di-throttling sekarang sedang di-throttling dengan cukup parah (kube2iam melaporkan lebih banyak detik di-throttling daripada instans yang telah dinaikkan , entah bagaimana)
 willthames
pada 27 Mar 2019
willthames
pada 27 Mar 2019
Pada CoreOS 4.19.25-coreos saya melihat Prometheus memicu peringatan CPUThrottlingHigh hampir di setiap pod dalam sistem.
 teralype
pada 27 Mar 2019
teralype
pada 27 Mar 2019
@williamsandrew @teralype ini sepertinya mencerminkan temuan @chiluk .
Setelah berbagai diskusi internal, kami sebenarnya memutuskan untuk menonaktifkan kuota cfs seluruhnya (tanda kubelet --cpu-cfs-quota=false ), ini sepertinya menyelesaikan semua masalah yang kami alami untuk Pod yang Burstable dan Dijamin (cpu disematkan atau standar).
Ada bahasan bagus tentang ini (dan beberapa topik lainnya) di sini: https://www.slideshare.net/try_except_/ensuring-kubernetes-cost-efficiency-across-many-clusters-devops-gathering-2019
Bacaan yang sangat direkomendasikan: +1:
dannyk81
pada 27 Mar 2019
masalah jangka panjang (catatan untuk diri sendiri)
 dims
pada 27 Mar 2019
dims
pada 27 Mar 2019
@ dannyk81 hanya untuk kelengkapan: pembicaraan terkait juga tersedia sebagai video yang direkam: https://www.youtube.com/watch?v=4QyecOoPsGU
hjacobs
pada 27 Mar 2019
@hjacobs , menyukai pembicaraannya! Terima kasih banyak...
Ada ide bagaimana menerapkan perbaikan ini pada AKS atau GKE?
Terima kasih
 agolomoodysaada
pada 2 Apr 2019
agolomoodysaada
pada 2 Apr 2019
@agolomoodysaada kami mengajukan permintaan fitur dengan GKE beberapa waktu yang lalu. Tidak yakin apa statusnya, saya tidak lagi bekerja secara intensif dengan GKE.
timoreimann
pada 2 Apr 2019
Saya menghubungi dukungan Azure dan mereka mengatakan itu tidak akan tersedia hingga sekitar Agustus 2019.
agolomoodysaada
pada 4 Apr 2019

Saya pikir saya akan membagikan grafik aplikasi yang secara konsisten dibatasi selama masa pakainya.
agolomoodysaada
pada 5 Apr 2019
Di kernel apa ini?
chiluk
pada 5 Apr 2019
" chiluk " 4.15.0-1037-azure "
agolomoodysaada
pada 5 Apr 2019
Jadi itu tidak berisi kernel commit 512ac99. Berikut korespondensinya
sumber.
https://kernel.ubuntu.com/git/kernel-ppa/mirror/ubuntu-azure-xenial.git/tree/kernel/sched/fair.c?h=Ubuntu-azure-4.15.0-1037.39_16.04.1 & id = 19b0066cc4829f45321a52a802b640bab14d0f67
Artinya, Anda mungkin mengalami masalah yang dijelaskan dalam 512ac99. Tetap
Ingat bahwa 512ac99 membawa regresi lain untuk kami.
Pada hari Jumat, 5 Apr 2019 jam 12:08 Moody Saada [email protected]
menulis:
@chiluk https://github.com/chiluk "4.15.0-1037-azure"
-
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-480350946 ,
atau nonaktifkan utasnya
https://github.com/notifications/unsubscribe-auth/ACDI05YeS6wfUE9XkiMbxrLvPllYQZ7Iks5vd4MOgaJpZM4WDUF3
.
chiluk
pada 5 Apr 2019
Sekarang saya telah memposting patch ke LKML tentang ini.
https://lkml.org/lkml/2019/4/10/1068
Pengujian tambahan akan sangat dihargai.
chiluk
pada 11 Apr 2019
Saya mengirimkan kembali tambalan ini sekarang dengan perubahan dokumentasi.
https://lkml.org/lkml/2019/5/17/581
Akan sangat membantu jika orang dapat menguji tambalan ini dan mengomentari utas pada LKML. Saat ini saya satu-satunya yang menyebutkan hal ini di LKML, dan saya belum menerima komentar apapun dari komunitas atau pengelola. Ini benar-benar akan sangat membantu jika saya bisa mendapatkan beberapa pengujian komunitas dan komentar di LKML di bawah tambalan saya.
chiluk
pada 21 Mei 2019
Untuk apa nilainya, proyek khusus ini https://github.com/tensorflow/serving tampaknya sangat terpengaruh oleh masalah ini. Dan itu sebagian besar adalah aplikasi C ++.
@chiluk , Apakah ada solusi yang dapat kami terapkan saat tambalan diluncurkan?
Terima kasih banyak
agolomoodysaada
pada 29 Mei 2019
Kami harus membantu @chiluk mengumpulkan kutipan dari dampak serius bug kernel ini pada Kubernetes dan siapa pun yang menggunakan kuota CFS.
Zolando memasukkan dalam presentasinya minggu lalu bahwa pengalaman buruk mereka dengan kernel saat ini berarti bahwa mereka menganggap menonaktifkan kuota CFS sebagai Praktik Terbaik saat ini, karena mereka menganggap hal itu lebih merugikan daripada baik.
https://www.youtube.com/watch?v=6sDTB4eV4F8
 whereisaaron
pada 29 Mei 2019
whereisaaron
pada 29 Mei 2019
Semakin banyak perusahaan yang menonaktifkan pelambatan CPU, misalnya mytaxi, Datadog, Zalando ( utas Twitter )
hjacobs
pada 29 Mei 2019
@derekwaynecarr @ dchen1107 @ kubernetes / sig-node-feature-request Dawn, Derek, apakah sudah waktunya untuk mengubah default? dan / atau dokumentasi?
dims
pada 29 Mei 2019
Ya @whereisaaron mengumpulkan dan berbagi laporan tentang aplikasi yang melumpuhkan pelambatan, dan atau dimatikan karena perilakunya yang buruk akan disambut dengan baik partisipasi di utas lkml jika sesuai. Saat ini sepertinya hanya saya yang mengeluh tentang masalah ini kepada komunitas kernel.
chiluk
pada 29 Mei 2019
@agolomoodysaada solusinya adalah menonaktifkan sementara kuota cfs atau mengalokasikan terlalu banyak kuota cpu ke aplikasi yang terpengaruh * (tidak semua aplikasi akan mencapai ini, tetapi sebagian besar aplikasi interaktif pengguna multi-utas mungkin demikian).
Ada juga praktik terbaik seputar mengurangi jumlah utas aplikasi yang juga membantu.
Untuk golang set GOMAXPROCS ~ = ceil (kuota)
Untuk java, pindah ke JVM baru yang mengenali dan menghormati batas kuota cpu. Jvms sebelumnya menghasilkan utas berdasarkan jumlah inti CPU, bukan jumlah inti yang tersedia untuk aplikasi.
Keduanya merupakan anugerah besar bagi kinerja kami.
Pantau dan laporkan aplikasi yang mengalami hambatan sehingga pengembang Anda dapat menyesuaikan kuota.
chiluk
pada 29 Mei 2019
FYI, setelah saya menunjukkan utas ini ke dukungan Azure AKS, saya dijawab bahwa patch akan diluncurkan ketika mereka memutakhirkan ke kernel 5.0, pada akhir September, paling banter.
Sampai saat itu, hentikan penggunaan batasan :)
prune998
pada 29 Mei 2019
@ prune998 ada peringatan kecil jika Anda menggunakan CPUmanager (mis. alokasi cpu khusus ke pod di QoS Terjamin).
Dengan menghapus batasan, Anda akan menghindari masalah pelambatan CFS, tetapi Anda akan menghapus pod dari Guaranteed QoS sehingga CPUmanager tidak akan mengalokasikan core khusus untuk pod ini lagi.
Jika Anda tidak menggunakan CPUmanager - tidak ada ruginya, tetapi hanya FYI untuk siapa saja yang memilih arah ini.
Ada PR (https://github.com/kubernetes/kubernetes/issues/70585) untuk menonaktifkan kuota CFS sepenuhnya untuk Pod dengan CPU khusus, namun belum digabungkan.
Kami juga memilih untuk menonaktifkan sistem kuota CFS seperti yang disarankan di atas dan sejauh ini tidak ada masalah.
dannyk81
pada 29 Mei 2019
@ dannyk81 https://github.com/kubernetes/kubernetes/issues/70585 bukanlah PR yang dapat digabungkan (ini masalah dengan potongan kode). Bisakah Anda (atau orang lain) mengajukan PR?
dims
pada 29 Mei 2019
Sudah ada satu: https://github.com/kubernetes/kubernetes/pull/75682
 praseodym
pada 29 Mei 2019
praseodym
pada 29 Mei 2019
@dims Saya menautkan masalah, bukan PR ... tetapi masalah terkait dengan PR :) memang https://github.com/kubernetes/kubernetes/pull/75682 dan telah menggantung di sana untuk sementara waktu, jadi jika Anda bisa mendorong ini akan bagus karena ini benar-benar masalah yang mengganggu.
Terima kasih: +1:
dannyk81
pada 29 Mei 2019
waduh! terima kasih @ dannyk81 saya telah menugaskan orang-orang dan menambahkan pencapaian
dims
pada 29 Mei 2019
FWIW kami mengalami masalah ini juga, dan menemukan bahwa menjatuhkan periode kuota CFS menjadi 10ms, bukan default 100ms, menyebabkan latensi tail end kami meningkat secara dramatis. Saya rasa ini karena meskipun Anda mengalami bug kernel, jumlah kuota yang jauh lebih pendek akan terbuang percuma jika tidak digunakan, dan prosesnya bisa mendapatkan lebih banyak kuota (dalam jatah yang lebih kecil) lebih cepat. Ini hanyalah solusi, tetapi bagi mereka yang tidak ingin menonaktifkan kuota CFS sepenuhnya, ini bisa menjadi bandaid hingga perbaikan diterapkan. k8s mendukung melakukan ini di 1.12 dengan gerbang fitur cpuCFSQuotaPeriod dan tanda kubelet --cpu-cfs-quota-period.
 d-shi
pada 30 Mei 2019
d-shi
pada 30 Mei 2019
Saya harus memeriksanya, tetapi saya pikir mempersingkat periode sejauh itu mungkin memiliki efek menonaktifkannya secara efektif, karena ada potongan minimum dan minimum kuota dalam kode. Anda mungkin lebih baik menonaktifkan kuota dan beralih ke kuota lunak.
chiluk
pada 30 Mei 2019
@chiluk , pemahaman awam saya adalah bahwa irisan default adalah 5ms, jadi mengaturnya ke itu atau kurang secara efektif menonaktifkannya, tetapi selama periode lebih besar dari 5ms masih harus ada penegakan kuota. Beri tahu saya jika itu tidak benar.
d-shi
pada 31 Mei 2019
Dengan --feature-gates=CustomCPUCFSQuotaPeriod=true --cpu-cfs-quota-period=10ms salah satu pod saya benar-benar kesulitan untuk memulai. Dalam grafik prometheus terlampir, kontainer mencoba untuk memulai, tidak mendekati memenuhi pemeriksaan kehidupan sampai dimatikan (biasanya kontainer mulai dalam waktu sekitar 5 detik - bahkan meningkatkan masa hidup initialDelaySeconds menjadi 60-an tidak membantu) dan lalu diganti dengan yang baru.
Anda dapat melihat bahwa container sangat dibatasi hingga saya menghapus cpu-cfs-quota-period dari kubelet args, pada titik mana throttling jauh lebih datar dan container mulai lagi dalam waktu sekitar 5 detik.

willthames
pada 5 Jun 2019
FYI: utas Twitter saat ini tentang topik menonaktifkan pelambatan CPU: https://twitter.com/it_supertramp/status/1133648291332263936
hjacobs
pada 5 Jun 2019
Ini adalah grafik pelambatan CPU dari sebelum / setelah kami pindah ke --cpu-cfs-quota-period=10ms dalam produksi untuk 2 layanan sensitif latensi:
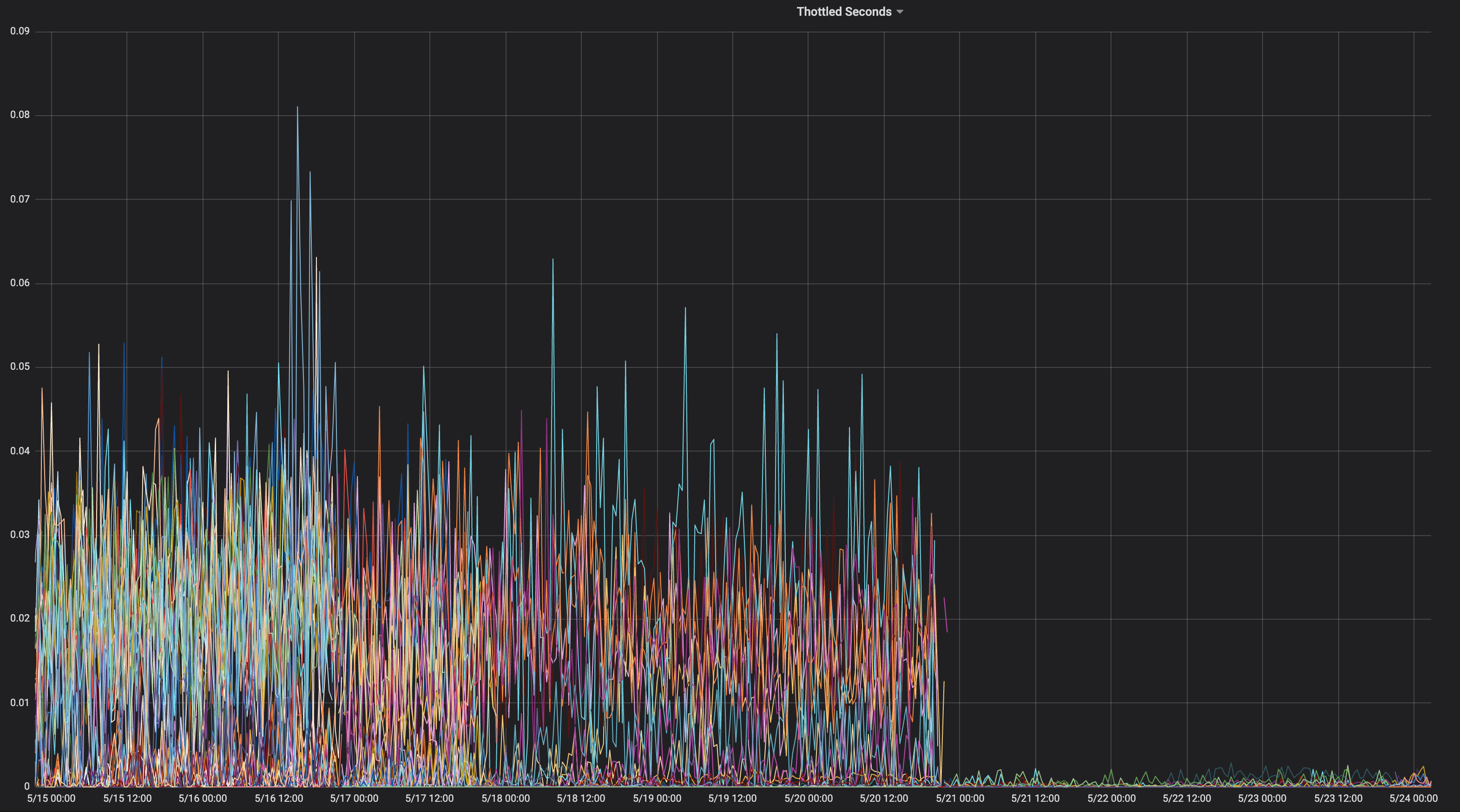

Layanan ini berjalan pada jenis instans yang berbeda (dengan taint / toleransi yang berbeda). Instans layanan kedua dipindahkan ke periode kuota CFS yang lebih rendah terlebih dahulu.
Hasil pasti sangat bergantung pada beban.
d-shi
pada 5 Jun 2019
@ d-shi ada hal lain yang terjadi di grafik Anda. Saya pikir mungkin ada alokasi kuota minimum yang sekarang Anda capai karena periode yang sangat kecil. Saya harus memeriksa kode untuk memastikan. Pada dasarnya Anda secara tidak sengaja meningkatkan jumlah kuota yang tersedia untuk aplikasi tersebut. Anda mungkin dapat mencapai hal yang sama dengan benar-benar meningkatkan jatah kuota.
chiluk
pada 5 Jun 2019
Bagi kami, mengukur latensi jauh lebih berguna daripada membatasi. Menonaktifkan cfs-quota meningkatkan latensi secara dramatis. Saya ingin melihat hasil yang serupa untuk mengubah cfs-quota-period .
 blakebarnett
pada 6 Jun 2019
blakebarnett
pada 6 Jun 2019
@chiluk kami benar-benar mencoba meningkatkan jatah kuota (hingga maksimum yang didukung oleh kubernetes per pod), dan dalam kasus apa pun latensi ujung ekor atau pembatasan berkurang banyak. latency p99 berubah dari sekitar 98ms pada batas 4 core menjadi 86ms pada batas 16 core. Setelah mengurangi kuota CFS menjadi 10ms p99 pergi ke 20ms pada 4 core.
@blakebarnett kami mengembangkan program patokan yang mengukur latensi kami, dan mereka bergerak dari kisaran 10ms-100ms, dengan rata-rata sekitar 18ms sebelum memperbarui --cpu-cfs-quota-period , ke kisaran 10ms-20ms, dengan rata-rata sekitar 11 md sesudahnya. latency p99 berubah dari sekitar 98ms menjadi 20ms.
EDIT: Maaf atas hasil edit saya harus kembali dan memeriksa ulang nomor saya.
d-shi
pada 6 Jun 2019
@ d-shi, kemungkinan besar Anda mencapai masalah yang diselesaikan dengan 512ac999.
chiluk
pada 6 Jun 2019
@chiluk Setelah membaca berulang kali tambalan Anda, saya akui saya kesulitan memahami dampak kode ini:
if (cfs_rq->expires_seq == cfs_b->expires_seq) {
- /* extend local deadline, drift is bounded above by 2 ticks */
- cfs_rq->runtime_expires += TICK_NSEC;
- } else {
- /* global deadline is ahead, expiration has passed */
- cfs_rq->runtime_remaining = 0;
- }
Dalam kasus di mana kuota kedaluwarsa meskipun runtime_remaining baru saja meminjam beberapa waktu dari kumpulan global. Paling buruk Anda akan dicekik selama 5ms berdasarkan sched_cfs_bandwidth_slice_us. Bukan?
Apakah saya melewatkan sesuatu?
 Mwea
pada 6 Jun 2019
Mwea
pada 6 Jun 2019
@ ya saya rasa sudah benar. Server produksi kami masih menggunakan kernel 4.4, jadi jangan perbaiki itu. Mungkin setelah kami meningkatkan ke kernel yang lebih baru, kami dapat mengembalikan periode kuota CFS ke default, tetapi untuk saat ini berfungsi untuk meningkatkan latensi ujung belakang kami dan kami belum melihat adanya efek samping yang merugikan. Padahal itu baru hidup beberapa minggu.
d-shi
pada 6 Jun 2019
@chiluk Pikiran meringkas status masalah ini di kernel? Sepertinya ada tambalan, 512ac999, tetapi ada masalah. Apakah saya membaca di suatu tempat yang dikembalikan? Atau apakah ini sepenuhnya / sebagian sudah diperbaiki? Jika ya, versi apa?
mariusgrigoriu
pada 7 Jun 2019
@mariusgrigoriu itu tidak diperbaiki, @chiluk telah membuat tambalan yang harus memperbaikinya yang perlu pengujian lebih lanjut (saya akan mengalokasikan sebagian waktu saya dalam beberapa hari ke depan untuk ini)
Lihat https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -482198124 untuk status terbaru
willthames
pada 7 Jun 2019
@Mwea kumpulan global disimpan di cfs_b-> runtime_remaining. Karena itu ditugaskan ke antrian per cpu run (cfs_rq), jumlah yang tersisa di kumpulan global akan berkurang. cfs_bandwidth_slice_us adalah jumlah runtime cpu yang ditransfer dari pool global ke antrian per-cpu run. Jika Anda terhambat, itu berarti Anda harus menjalankan dan cfs_b-> runtime_remaining == 0. Anda harus menunggu akhir periode saat ini (secara default 100 md), agar kuota diisi ulang ke cfs_b dan kemudian didistribusikan ke cfs_rq Anda. Saya baru-baru ini menemukan bahwa jumlah runtime yang kadaluwarsa paling banyak 1ms per cfs_rq, karena fakta pengatur waktu yang kendur menangkap kembali semua dengan 1ms kuota yang tidak terpakai dari antrian per-cpu run. 1ms itu kemudian terbuang / kedaluwarsa di akhir periode. Dalam skenario kasus yang lebih buruk di mana aplikasi menyebar di 88 cpus yang berpotensi menjadi 88ms dari kuota terbuang per 100ms periode. Itu sebenarnya mengarah pada proposal alternatif yang memungkinkan pengatur waktu kendur untuk mengambil kembali semua kuota yang tidak terpakai dari runqueue per-cpu yang menganggur.
Adapun garis yang Anda soroti secara khusus. Usulan saya adalah menghapus kedaluwarsa runtime yang telah ditetapkan ke antrian run per-cpu sepenuhnya. Baris tersebut adalah bagian dari perbaikan untuk 512ac999. Itu memperbaiki masalah di mana jam miring antara antrian yang dijalankan per-cpu menyebabkan kuota kedaluwarsa sebelum waktunya sehingga membatasi aplikasi yang belum menggunakan kuota (afaiu). Pada dasarnya mereka menambahkan expires_seq pada setiap batas periode. expires_seq karena itu harus cocok antara masing-masing cfs_rq ketika mereka berada pada periode yang sama.
@mariusgrigoriu - jika Anda mencapai pelambatan tinggi dengan penggunaan cpu rendah dan kernel Anda adalah pra-512ac999, Anda mungkin memerlukan 512ac999. Jika Anda memposting 512ac999, kemungkinan besar Anda mengalami masalah yang saya jelaskan di atas yang saat ini sedang dibahas di lkml.
Ada banyak cara untuk mengatasi masalah ini.
- Menyematkan CPU
- Mengurangi jumlah utas yang dihasilkan aplikasi Anda
- Alokasikan kuota secara berlebihan untuk aplikasi yang mengalami pembatasan.
- Matikan batas keras untuk saat ini.
- Buat kernel khusus dengan salah satu perubahan yang diusulkan.
chiluk
pada 7 Jun 2019
@chiluk, apakah Anda mungkin telah memposting versi tambalan ini yang sudah kompatibel dengan kernel 4.14? Saya ingin mengujinya dengan cukup agresif karena kami baru saja meningkatkan beberapa ribu host menjadi 4.14.121 (dari 4.9.62) dan melihat:
- Penurunan throttling untuk memcache, mysql, nginx, dll
- Peningkatan pembatasan untuk aplikasi java kami
Benar-benar ingin berguling maju untuk mendapatkan yang terbaik dari kedua dunia di sini. Saya dapat mencoba memindahkannya sendiri minggu depan, tetapi jika Anda sudah memilikinya, itu akan luar biasa.
 PaulFurtado
pada 21 Jun 2019
PaulFurtado
pada 21 Jun 2019
@Tokopedia
Saya benar-benar menulis ulang tambalan selama beberapa hari terakhir memberikan saran Ben Segull. Patch kernel baru akan segera hadir setelah saya mendapatkannya pada beberapa waktu uji coba di cluster kami.
chiluk
pada 24 Jun 2019
@chiluk pembaruan apa pun pada tambalan itu? Jangan khawatir jika tidak, saya hanya memastikan saya tidak melewatkan tambalan lewat
PaulFurtado
pada 18 Jul 2019
@PaulFurtado , tambalan telah "disetujui" oleh penulis CFS, dan saya hanya menunggu pengelola penjadwal untuk mengintegrasikannya dan mendorongnya ke Linus.
chiluk
pada 24 Jul 2019
@chiluk Terima kasih!
Saya baru saja mem-backport patch ke kernel 4.14, yang merupakan kernel produksi kami saat ini.
Saya membuat intisari dengan backport dan beberapa hasil dari fibtest Anda di sini: https://gist.github.com/PaulFurtado/ff6c67ec87416b66ba1c6fc70f7beec1
Pada instans ec2 c5.9xlarge dan m5.24xlarge generasi saat ini yang kami gunakan di cluster kubernetes dan mesos, patch tersebut menggandakan kinerja program fibtest Anda. Pada jenis instans r4.16xlarge generasi sebelumnya, ia mengelola 1,5x lebih banyak penggunaan CPU tetapi hampir tidak ada iterasi tambahan (yang saya asumsikan hanya karena generasi CPU dan sifat eksponensial dari urutan fibonacci). Angka-angka ini semuanya berlaku cukup banyak jika saya meningkatkan tes menjadi 30-an, bukan default 5-an.
Kami akan mulai meluncurkan ini ke lingkungan QA kami minggu ini untuk mendapatkan beberapa metrik dari aplikasi kami yang mengalami pelambatan terburuk. Terima kasih lagi!
PaulFurtado
pada 26 Jul 2019
@PaulFurtado pertama terima kasih atas pengujiannya. Saya akan menganggap Anda menjalankan kernel.org 4.14 atau ubuntu 4.14, keduanya memiliki 512ac999 di dalamnya. Adapun Iterasi fibtest yang diselesaikan tidak sepenting waktu cpu yang digunakan, karena iterasi yang diselesaikan dapat sangat dipengaruhi oleh cpu mhz saat menjalankan pengujian (terutama di cloud di mana saya tidak yakin berapa banyak kendali yang Anda miliki atas itu).
chiluk
pada 31 Jul 2019
Saya akan menganggap Anda menjalankan kernel.org 4.14 atau ubuntu 4.14, keduanya memiliki 512ac999 di dalamnya.
Ya, kami menjalankan mainline 4.14 (yah, ditambah set patch dari kernel Amazon Linux 2, tetapi tidak ada patch yang penting dalam kasus ini).
512ac999 mendarat di jalur utama 4.14.95, dan kami mengamati pengaruhnya saat meningkatkan dari 4.14.77 ke 4.14.121+. Hal ini membuat container memcached kami (jumlah thread yang sangat rendah) beralih dari throttling yang tidak dapat dijelaskan menjadi tanpa throttling, tetapi membuat container golang dan java kami (jumlah thread yang sangat tinggi) mengalami lebih banyak throttling.
Adapun Iterasi fibtest yang diselesaikan tidak sepenting waktu cpu yang digunakan, karena iterasi yang diselesaikan dapat sangat dipengaruhi oleh cpu mhz saat menjalankan pengujian (terutama di cloud di mana saya tidak yakin berapa banyak kendali yang Anda miliki atas itu).
Pada instans EC2 yang lebih baru / lebih besar, Anda benar-benar mendapatkan tingkat kontrol yang layak menjalankan dengan turbo boost off dan tidak membiarkan core menganggur. Padahal, saya sebenarnya baru menyadari bahwa kami menyetel status-c, tetapi bukan status-p dan jenis instans yang tidak melihat peningkatan dalam iterasi adalah di mana status-p dapat dikontrol, jadi itu mungkin menjelaskannya dengan sangat baik.
pertama terima kasih atas pengujiannya
Tidak masalah sama sekali, semuanya telah stabil di lingkungan pra-qa kami selama akhir pekan, dan kami akan mulai meluncurkan tambalan ke lingkungan QA utama kami besok di mana kami akan melihat lebih banyak efek dunia nyata. Mengingat bahwa memcache telah mendapatkan keuntungan dari tambalan sebelumnya, kami benar-benar ingin memiliki kue kami dan memakannya juga dengan kedua tambalan di tempatnya jadi kami senang untuk mengujinya. Sekali lagi terima kasih atas semua pekerjaan yang telah Anda lakukan untuk membatasi!
PaulFurtado
pada 31 Jul 2019
Hanya ingin meninggalkan catatan, tentang patch kernel yang sedang dibahas ....
Saya telah menyesuaikannya dengan kernel yang kami gunakan dalam pengujian saat ini, dan melihat beberapa kemenangan besar pada tingkat pelambatan CFS, namun saya akan menyebutkan bahwa jika Anda sebelumnya telah menetapkan periode cfs ke 10ms sebagai mitigasi, Anda akan melakukannya ingin mengembalikannya hingga 100 md untuk melihat manfaat perubahannya.
 jhohertz
pada 6 Agu 2019
jhohertz
pada 6 Agu 2019
Tambalan itu mendarat di ujungnya pagi ini.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Setelah itu mengenai pohon Torvald, saya akan mengirimkannya untuk inklusi stabil-linux, dan kemudian distro utama (Redhat / Ubuntu). Jika Anda peduli tentang hal lain, dan mereka tidak mengikuti patch linux-stable, Anda mungkin ingin mengirimkannya secara langsung.
chiluk
pada 8 Agu 2019
Saya telah menguji patch (ubuntu 18.04, 5.2.7 kernel, node: 56 core CPU E5-2660 v4 @ 2.00GHz) dengan layanan mikroservice golang pemrosesan gambar berat cpu kami dan mendapatkan hasil yang cukup mengesankan. Performa seperti jika saya menonaktifkan CFS pada node secara lengkap.
Saya mendapatkan latensi 5-35% lebih sedikit dan RPS 5-55% lebih banyak tergantung pada penggunaan konkurensi / CPU pada tingkat pelambatan hampir nol.
Terima kasih, @chiluk !
Seperti yang dikatakan @jhohertz , kuota
 zigmund
pada 10 Agu 2019
zigmund
pada 10 Agu 2019
Untuk performa lebih dengan golang, atur GOMAXPROCS ke ceil (kuota) +2. Nilai tambah 2 adalah untuk menjamin beberapa konkurensi.
chiluk
pada 12 Agu 2019
@chiluk diuji dengan GOMAXPROCS = 8 vs GOMAXPROCS = 10 dengan cpu.limit = 8 - bukan perbedaan besar, sekitar 1-2%.
zigmund
pada 13 Agu 2019
@zigmund itu karena cpu.limit Anda disetel ke bilangan bulat 8 yang seharusnya mengikat proses Anda ke cpuset 8 cpus. Perbedaan 1-2% Anda hanyalah peningkatan overhead untuk pengalihan konteks dengan 2 pelari Goroutine tambahan pada 8 set tugas cpu Anda.
Saya seharusnya mengatakan bahwa pengaturan GOMAXPROCS = # adalah solusi yang baik untuk program go sampai patch kernel didistribusikan secara luas.
chiluk
pada 26 Agu 2019
Kami telah memigrasikan cluster produksi kami ke kernel yang ditambal dan sekarang saya dapat membagikan beberapa momen menarik kepada Anda.
Statistik dari salah satu cluster kami - 4 node dari 72 core E5-2695 v4 @ 2.10GHz, RAM 128Gb, Debian 9, 5.2.7 kernel dengan patch.
Kami memiliki beban campuran yang sebagian besar terdiri dari layanan golang, tetapi juga memiliki php dan python.
Golang. Latensi lebih rendah, pengaturan GOMAXPROCS yang benar mutlak harus dimiliki. Berikut adalah layanan dengan default GOMAXPROCS = 72. Kami telah mengubah kernel pada ~ 16 dan setelah itu latensi turun dan penggunaan CPU naik drastis. Pada 21:15 saya mengatur GOMAXPROCS yang benar dan pemanfaatan CPU dinormalisasi.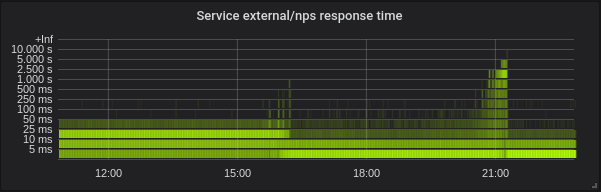

Python. Semuanya menjadi lebih baik dengan tambalan tanpa gerakan tambahan - pemanfaatan CPU dan latensi turun.
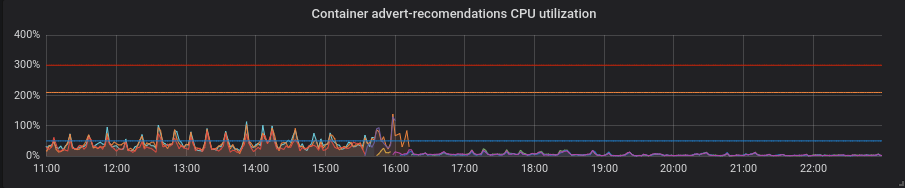
PHP. Pemakaian CPU sama, latensi berkurang sedikit pada beberapa layanan. Bukan untung besar.
zigmund
pada 3 Sep 2019
Terima kasih @zigmund.
Saya tidak yakin saya mengerti ketika Anda mengatakan I setted correct GOMAXPROCS ...
Saya berasumsi bahwa Anda tidak hanya menjalankan satu pod pada 72 core node, jadi Anda menyetel GOMAXPROCS ke sesuatu yang lebih rendah, mungkin sama dengan Batas CPU Pod kan?
prune998
pada 3 Sep 2019
Terima kasih @zigmund. Perubahan jalan cukup banyak sejalan dengan apa yang diharapkan.
Saya benar-benar terkejut dengan peningkatan python meskipun seperti yang saya harapkan GIL sebagian besar meniadakan manfaat dari ini. Jika ada, patch ini seharusnya hanya mengurangi waktu respons, mengurangi persentase periode yang dibatasi, dan meningkatkan penggunaan cpu. Apakah Anda yakin aplikasi python Anda masih sehat?
chiluk
pada 3 Sep 2019
@ prune998 maaf, mungkin salah eja. Saya mengatur GOMAXPROCS = limit.cpu. Saat ini kami memiliki sekitar ~ 110 pod per node di cluster ini.
@chiluk Saya tidak kuat di python dan tidak tahu bagaimana patch terpengaruh di lapisan bawah. Tetapi aplikasi sehat tanpa masalah, saya telah memeriksanya setelah perubahan kernel.
zigmund
pada 4 Sep 2019
@chiluk Bisakah Anda menjelaskan bagaimana kami dapat mengikuti kemajuan patch Anda ke berbagai distro Linux? Saya sangat tertarik dengan debian dan AWS Linux, tetapi saya berharap orang lain tertarik dengan Ubuntu dll., Jadi apa pun yang dapat Anda berikan, terima kasih.
 Nuru
pada 13 Sep 2019
Nuru
pada 13 Sep 2019
@Nuru https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html?highlight=stable%20rules ... Pada dasarnya saya akan mengirimkan melalui linux-stable setelah patch saya mencapai Linus ' tree, * (mungkin lebih awal), dan kemudian semua distro harus mengikuti proses stabil-linux, dan menarik patch yang diterima oleh pengelola stabil ke kernel spesifik distro mereka. Jika tidak, Anda seharusnya tidak menjalankan distro mereka.
chiluk
pada 13 Sep 2019
@chiluk Saya tidak tahu apa-apa tentang proses pengembangan Linux. Yang Anda maksud dengan "pohon Linus '" adalah https://github.com/torvalds/linux ?
Nuru
pada 14 Sep 2019
Pohon Linus ada di sini, https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/. Perubahan saya saat ini dipentaskan di linux-next yang merupakan pohon integrasi pengembangan. Ya, pengembangan kernel agak macet di zaman kegelapan, tetapi berhasil.
Dia kemungkinan akan menarik perubahan dari pohon linux-next setelah 5.3 dirilis dan dia memulai pengembangan di 5.4-rc0. Itu sekitar jangka waktu saya berharap kernel stabil mulai melakukan perbaikan ini. Kapan pun Linus merasa 5.3 stabil adalah dugaan siapa pun.
chiluk
pada 14 Sep 2019
[Linus] kemungkinan akan menarik perubahan dari pohon linux-next setelah 5.3 dirilis dan dia memulai pengembangan di 5.4-rc0. Itu sekitar jangka waktu saya berharap kernel stabil mulai melakukan perbaikan ini. Kapan pun Linus merasa 5.3 stabil adalah dugaan siapa pun.
Sepertinya Linil menganggap 5,3 stabil pada tanggal 15 Sep 2019 . Jadi, apa itu "linux-next" dan bagaimana kami melacak kemajuan tambalan Anda melalui langkah selanjutnya?
Nuru
pada 20 Sep 2019
Adakah yang pernah membuat paket peregangan debian dan / atau gambar AWS yang menyertakan tambalan ini? Saya akan melakukannya menggunakan https://github.com/kubernetes-sigs/image-builder/tree/master/images/kube-deploy/imagebuilder
Hanya berpikir saya akan menghindari upaya duplikasi jika sudah ada.
blakebarnett
pada 24 Sep 2019
Ini sekarang telah digabungkan ke dalam pohon Linus dan harus dilepaskan dengan 5.4. Saya juga baru saja mengirimkannya ke linux-stable, dan dengan asumsi itu berjalan dengan lancar semua distro yang mengikuti proses stabil dengan benar akan segera mulai mengambilnya.
chiluk
pada 25 Sep 2019
Adakah yang tahu cara mengikuti jika / bagaimana perubahan ini menurunkannya ke CentOS (7)? Tidak yakin bagaimana cara kerja backporting dll.
 till
pada 26 Sep 2019
till
pada 26 Sep 2019
@till https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -531370333
Untuk percakapan kernel stabil sedang berlangsung di sini.
https://lore.kernel.org/stable/CAC=E7cUXpUDgpvsmMaMU6sAydbfD0FEJiK25R1r=e9=YtcPjGw@mail.gmail.com/
Juga bagi mereka yang pergi ke KubeCon, saya akan mempresentasikan masalah ini di sana.
https://sched.co/Uae1
chiluk
pada 3 Okt 2019
Adakah kabar dari pengelola penjadwal tentang: ack yang dicari Greg HK untuk membuatnya menjadi pohon yang stabil?
jhohertz
pada 18 Okt 2019
Greg KH telah menunda pengambilan keputusan tentang tambalan ini karena pengelola penjadwal tidak merespons (yang mungkin baru saja melewatkan email). Komentar dari siapa pun selain saya tentang LKML yang telah menguji tambalan ini dan berpikir itu harus di-backport akan dihargai.
chiluk
pada 18 Okt 2019
Untuk orang yang menggunakan CoreOS, ada masalah terbuka yang meminta patch @chiluk di-backport.
 evanfoster
pada 1 Nov 2019
evanfoster
pada 1 Nov 2019
CoreOS kernel 4.19.82 memiliki perbaikan: https://github.com/coreos/linux/pull/364
CoreOS Container Linux 2317.0.1 (alpha channel) memiliki perbaikan: https://github.com/coreos/coreos-overlay/pull/3796 http://coreos.com/releases/#2317.0.1
Backport ke Linux stable tampaknya terhenti karena tambalan tidak diterapkan dengan bersih . @chiluk Apakah Anda akan mengerjakan backport untuk Linux stable? Jika demikian, maukah Anda mem-backport ke 4.9 agar masuk ke "rentang" Debian dan diambil oleh kops ? Meskipun saya kira itu akan memakan waktu sebanyak 6 bulan untuk membuatnya menjadi "peregangan" dan mungkin pada saat itu kops akan bermigrasi ke "buster".
Nuru
pada 8 Nov 2019
@Nuru , saya
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.buildinfo
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm-dbg_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-headers-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.changes
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-libc-dev_4.19.67-1_amd64.deb
293993587779 / k8s-1.11-debian-stretch-amd64-hvm-ebs-2019-09-26
blakebarnett
pada 8 Nov 2019
@blakebarnett Terima kasih atas usaha Anda, dan maaf mengganggu Anda, tetapi saya lebih dari sedikit bingung.
- "stretch" didasarkan pada Linux 4.9, tetapi semua tautan Anda untuk 4.19.
- Anda mengatakan Anda melakukan backport "tambalan" tetapi ada 3 tambalan (saya kira tambalan ketiga tidak terlalu penting:
- 512ac999 sched / fair: Memperbaiki kondisi penyimpangan jam pengatur waktu bandwidth
- de53fd7ae sched / fair: Perbaiki penggunaan cpu rendah dengan pelambatan tinggi dengan menghapus kedaluwarsa irisan cpu-lokal
- 763a9ec06 sched / fair: Fix -Wunused-but-set-variable warnings
Apakah Anda melakukan backport semua 3 patch ke 4.9? (Saya tidak tahu apa yang harus dilakukan dengan paket Debian untuk melihat dan melihat apakah ada perubahan di sana, dan dokumen "perubahan" tidak membahas apa yang benar-benar berubah.)
Juga, di wilayah mana AMI Anda tersedia?
Nuru
pada 8 Nov 2019
Tidak, saya menggunakan kernel stretch-backports, yaitu 4.19, karena memiliki perbaikan yang juga kami perlukan di AWS (terutama untuk jenis instans M5 / C5)
Saya menerapkan diff yang menggabungkan semua tambalan yang saya yakini, saya harus sedikit mengubahnya untuk menghapus referensi tambahan ke variabel di 4.19 yang dihapus di tempat lain, saya pertama kali menerapkan https://github.com/kubernetes/kubernetes/issues/67577 ini
--- kernel/sched/fair.c 2019-09-25 16:06:02.954933954 -0700
+++ kernel/sched/fair.c-b 2019-09-25 16:06:56.341615817 -0700
@@ -4928,8 +4928,6 @@
cfs_b->period_active = 1;
overrun = hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
- cfs_b->runtime_expires += (overrun + 1) * ktime_to_ns(cfs_b->period);
- cfs_b->expires_seq++;
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
--- kernel/sched/sched.h 2019-08-16 01:12:54.000000000 -0700
+++ sched.h.b 2019-09-25 13:24:00.444566284 -0700
@@ -334,8 +334,6 @@
u64 quota;
u64 runtime;
s64 hierarchical_quota;
- u64 runtime_expires;
- int expires_seq;
short idle;
short period_active;
@@ -555,8 +553,6 @@
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
- int expires_seq;
- u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock;
AMI dipublikasikan ke us-west-1
Semoga membantu!
blakebarnett
pada 8 Nov 2019
Saya telah mem-backport tambalan ini dan mengirimkannya ke kernel stabil-linux
v4.14 https://lore.kernel.org/stable/[email protected]/
v4.19 https://lore.kernel.org/stable/[email protected]/ #t
chiluk
pada 8 Nov 2019
Halo,
mengikuti integrasi tambalan di cabang 4.19, saya telah membuka laporan bug di debian untuk peningkatan yang tepat dari kerner pada buster dan peregangan-backport:
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=946144
jangan ragu untuk menambahkan komentar baru untuk mengupgrade paket debian.
 alexises
pada 4 Des 2019
alexises
pada 4 Des 2019
Semoga ini tidak terlalu berisi spam, tetapi saya ingin menautkan pembicaraan yang luar biasa ini dari @chiluk yang membahas banyak detail latar belakang terkait masalah ini https://youtu.be/UE7QX98-kO0.
 bboreham
pada 4 Des 2019
bboreham
pada 4 Des 2019
Apakah ada cara untuk menghindari pembatasan pada GKE? Kami baru saja mengalami masalah besar di mana satu metode pada wadah php membutuhkan waktu 120 detik, bukan biasanya 0,1 detik
 bartoszhernas
pada 5 Des 2019
bartoszhernas
pada 5 Des 2019
hapus batas cpu
 monotek
pada 5 Des 2019
monotek
pada 5 Des 2019
Kami sudah melakukannya, penampung akan dibatasi saat permintaan CPU terlalu kecil. Itulah inti masalahnya, kurangnya batasan dan hanya menggunakan permintaan CPU masih akan menyebabkan pelambatan :(
bartoszhernas
pada 5 Des 2019
@bartoszhernas Saya pikir Anda menggunakan kata yang salah di sini. Ketika orang-orang di utas ini merujuk ke "pembatasan", mereka mengacu pada kontrol bandwidth cfs, nr_throttled di cpu.stat untuk cgroup meningkat. Itu hanya diaktifkan ketika batas cpu diaktifkan. Kecuali GKE menambahkan batasan ke pod Anda tanpa sepengetahuan Anda, saya tidak akan menyebut apa yang Anda pukul sebagai throttling.
Saya akan menyebut apa yang Anda gambarkan sebagai "perselisihan untuk prosesor". Saya menduga Anda mungkin memiliki beberapa aplikasi berukuran tidak benar * (permintaan), yang bersaing untuk prosesor atau sumber daya lain di kotak karena mereka sering menggunakan lebih dari yang mereka minta. Inilah alasan tepatnya kami menggunakan batasan. Sehingga aplikasi berukuran tidak tepat tersebut hanya dapat mempengaruhi aplikasi lain di dalam kotak.
Kemungkinan lainnya adalah jumlah permintaan Anda yang tidak mencukupi menyebabkan perilaku penjadwalan yang buruk. Menetapkan permintaan rendah mirip dengan menetapkan nilai "bagus" yang relatif ke aplikasi "permintaan" yang lebih tinggi. Untuk informasi lebih lanjut tentang itu, periksa batas lunak.
chiluk
pada 5 Des 2019
Masalah menjadi basi setelah 90d tidak ada aktivitas.
Tandai terbitan sebagai baru dengan /remove-lifecycle stale .
Masalah basi membusuk setelah 30 hari tambahan tidak aktif dan akhirnya ditutup.
Jika masalah ini aman untuk ditutup sekarang, lakukan dengan /close .
Kirimkan masukan ke sig-testing, kubernetes / test-infra dan / atau fejta .
/ siklus hidup basi
 fejta-bot
pada 4 Mar 2020
fejta-bot
pada 4 Mar 2020
/ remove-lifecycle basi
Nuru
pada 4 Mar 2020
Dari pemahaman saya, masalah mendasar di kernel telah diperbaiki dan tersedia di misalnya ContainerLinux di https://github.com/coreos/bugs/issues/2623.
Adakah yang mengetahui masalah yang tersisa setelah patch kernel ini?
 sfudeus
pada 4 Mar 2020
sfudeus
pada 4 Mar 2020
@sfudeus Kubernetes dapat dijalankan di semua varian Linux, atau, AFAIK, semua rasa Unix yang sesuai dengan POSIT. Bug ini tidak pernah menjadi masalah bagi orang yang tidak menggunakan Linux, telah diperbaiki untuk beberapa distribusi turunan Linux, dan tidak diperbaiki untuk yang lain.
Masalah yang mendasarinya telah diperbaiki di Linux kernel 5.4, yang hampir tidak ada orang yang menggunakannya pada saat ini. Patch tersedia untuk melakukan backport ke berbagai kernel lama dan termasuk dalam distribusi Linux baru yang belum siap untuk dipindahkan ke kernel 5.4, yang jumlahnya banyak. Seperti yang Anda lihat dari daftar komit di atas yang merujuk pada masalah ini, tambalan perbaikan bug masih dalam proses untuk digabungkan ke dalam berbagai distribusi Linux yang mungkin digunakan oleh seseorang untuk menggunakan Kubernetes.
Oleh karena itu, saya ingin menjaga masalah ini tetap terbuka sementara masih melihat referensi komit aktif. Saya juga ingin melihatnya ditutup dengan skrip atau metode mudah lainnya yang dapat digunakan seseorang untuk menentukan apakah penginstalan Kubernetes mereka terpengaruh atau tidak.
Nuru
pada 5 Mar 2020
@Nuru Baik untuk saya, saya hanya ingin memastikan bahwa tidak ada masalah kernel lain yang tersisa, yang sudah diketahui. Saya pribadi tidak akan membiarkan ini terbuka lebih lama daripada distribusi yang lebih besar yang telah memasukkan perbaikan, menunggu perangkat IoT yang tak ada habisnya bisa berarti menunggu tanpa henti. Masalah tertutup juga dapat ditemukan. Tapi itu hanya 2 sen saya.
sfudeus
pada 5 Mar 2020
Tidak yakin apakah ini tempat yang tepat untuk memberi tahu orang, tetapi tidak yakin ke mana lagi harus mengemukakan hal ini:
Kami menjalankan kernel Linux 5.4 di Debian Buster (menggunakan kernel buster-backports) menggunakan kluster k8s 1.15.10 dan kami masih mengalami masalah dengan ini. Terutama untuk Pod yang biasanya memiliki sedikit pekerjaan (kube-downscaler adalah contoh yang selalu kami kembalikan, yang biasanya membutuhkan sekitar 3m CPU) dan yang hanya memiliki sedikit sumber daya cpu yang ditetapkan (50m dalam kasus kube-downscaler di cluster) kami masih melihat nilai throttling yang sangat tinggi. Sebagai referensi, kube-downscaler pada dasarnya adalah skrip Python yang menjalankan sleep selama 30 menit sebelum melakukan apa pun. cAdvisor menunjukkan peningkatan container_cpu_cfs_throttled_periods_total untuk penampung ini agar selalu lebih atau kurang mirip dengan nilai container_cpu_cfs_periods_total ini (keduanya sekitar 250 saat memeriksa peningkatan pada interval 5m). Kami berharap periode yang dibatasi mendekati 0.
Apakah kita mengukur ini dengan tidak benar? Apakah cAdvisor mengeluarkan data yang salah? Apakah asumsi kami benar bahwa kami akan melihat penurunan dalam periode yang dibatasi? Setiap saran akan dihargai di sini.
Setelah beralih ke kernel 5.4, kami melihat jumlah Pod dengan masalah ini sedikit berkurang (sekitar 40%), tetapi saat ini kami tidak yakin apakah yang kami lihat adalah masalah sebenarnya atau bukan. Terutama, kami tidak yakin ketika melihat statistik di atas apa arti sebenarnya "pelambatan" di sini jika kami mendapatkan nilai-nilai ini dengan penggunaan cpu rata-rata 3m. Node yang dijalankannya tidak overcommitted sama sekali dan memiliki penggunaan CPU rata-rata kurang dari 10%.
 timstoop
pada 5 Mar 2020
timstoop
pada 5 Mar 2020
@timstoop interval yang diperhatikan penjadwal berada dalam ranah mikrodetik, bukan rentang 30 menit yang besar. Jika sebuah penampung memiliki batas CPU 50 milicpu dan menggunakan 50 milicpu selama rentang 100 mikrodetik, itu akan terhambat, terlepas dari apakah itu menghabiskan 30 menit diam. Secara umum, 50 millicpu adalah batas CPU yang sangat kecil. Jika program python bahkan membuat satu permintaan HTTPS dengan batas rendah itu, itu dijamin akan terhambat.
Node yang dijalankannya tidak overcommitted sama sekali dan memiliki penggunaan CPU rata-rata kurang dari 10%.
Hanya untuk memperjelas: beban node dan beban kerja lainnya di atasnya tidak ada hubungannya dengan throttling. Throttling hanya mempertimbangkan batas container / cgroup sendiri.
PaulFurtado
pada 5 Mar 2020
@PaulFurtado Terima kasih atas jawaban Anda! Namun, Pod itu sendiri memiliki penggunaan rata-rata 3m cpu selama mode sleep itu dan masih dalam kondisi throttle. Itu tidak membuat permintaan apa pun selama waktu itu, itu menunggu saat tidur. Saya berharap itu bisa melakukan itu sementara tidak mencapai 50m, bukan? Atau apakah itu asumsi yang salah?
timstoop
pada 5 Mar 2020
Saya pikir ini kemungkinan hanya angka yang rendah sehingga akan ada masalah akurasi. Dan 50m sangat rendah sehingga apa pun bisa membuatnya tersandung. Runtime Python juga dapat melakukan tugas latar belakang di utas saat Anda tidur.
PaulFurtado
pada 5 Mar 2020
Anda benar, saya membuat asumsi yang tidak benar. Terima kasih atas bimbingan Anda! Ini masuk akal bagiku sekarang.
timstoop
pada 5 Mar 2020
Hanya ingin melompat dan mengatakan hal-hal di sini telah secara substansial ditingkatkan sejak patch kernel mencapai kernel 4,19 LTS, dan itu muncul di CoreOS / Flatcar. Melihat saat ini, satu-satunya hal yang saya lihat dicekik adalah beberapa hal yang mungkin harus saya tingkatkan. :tersenyum:
jhohertz
pada 5 Mar 2020
@sfudeus @chiluk Apakah ada tes sederhana untuk melihat apakah kernel Anda telah memperbaikinya atau belum?
Saya tidak tahu apakah kope.io/k8s-1.15-debian-stretch-amd64-hvm-ebs-2020-01-17 (gambar resmi kops ) telah ditambal atau belum.
Nuru
pada 20 Mar 2020
Saya setuju dengan @mariusgrigoriu , untuk pod yang berjalan pada cpuset eksklusif di bawah kebijakan cpu statis, kita cukup menonaktifkan batas kuota cpu - toh hanya dapat berjalan pada set cpu eksklusifnya. Patch di atas ditujukan untuk tujuan ini dan hanya untuk jenis pod ini.
 jianzzha
pada 6 Apr 2020
jianzzha
pada 6 Apr 2020
@Nuru saya menulis https://github.com/indeedeng/fibtest
Ini tentang pengujian definitif yang bisa Anda dapatkan, tetapi Anda memerlukan kompiler C.
Abaikan jumlah iterasi yang diselesaikan, tetapi fokuslah pada jumlah waktu yang digunakan untuk proses berutas tunggal vs multi-utas.
chiluk
pada 10 Apr 2020
Saya rasa cara yang baik untuk melihat kernel apa yang telah ditambal adalah di salah satu slide terakhir dari @chiluk (terima kasih untuk btw ini), bicaralah https://www.youtube.com/watch?v=UE7QX98-kO0
Kernel 4.15.0-67 tampaknya memiliki tambalan (https://launchpad.net/ubuntu/+source/linux/4.15.0-67.76) namun, kami masih melihat pelambatan di beberapa Pod di mana permintaan / batas jauh di atas penggunaan CPU mereka.
Saya berbicara tentang penggunaan sekitar 50ms dengan permintaan disetel ke 250m dan dibatasi hingga 500m. Kami melihat sekitar 50% dari periode CPU sedang dibatasi, apakah nilai ini mungkin cukup rendah untuk diharapkan dan dapat diterima? Saya ingin melihatnya turun ke nol, kita tidak boleh dicekik sama sekali jika penggunaannya bahkan tidak mendekati batas.
Apakah seseorang yang menggunakan kernel baru yang telah ditambal masih mengalami hambatan?
 vgarcia-te
pada 22 Apr 2020
vgarcia-te
pada 22 Apr 2020
@ vgarcia-te Ada terlalu banyak kernel yang beredar untuk diketahui dari daftar yang telah ditambal dan yang belum. Lihat saja semua commit yang merujuk pada masalah ini. Beberapa ratus. Saya membaca changelog untuk Ubuntu menunjukkan bahwa 4.15 belum ditambal (kecuali mabye untuk berjalan di Azure), dan tambalan yang Anda tautkan ditolak .
Secara pribadi, saya tertarik dengan seri 4.9 karena itulah yang digunakan kops , dan ingin tahu kapan mereka merilis AMI dengan perbaikan.
Sementara itu, Anda dapat mencoba menjalankan @bobrik 's tes yang tampaknya cukup baik bagi saya.
wget https://gist.githubusercontent.com/bobrik/2030ff040fad360327a5fab7a09c4ff1/raw/9dcf83b821812064fa7fb056b8f22cbd5c4364f1/cfs.go
sudo docker run --rm -it --cpu-quota 20000 --cpu-period 100000 -v $(pwd):$(pwd) -w $(pwd) golang:1.9.2 go run cfs.go -iterations 15 -sleep 1000ms
Dengan CFS yang berfungsi dengan baik, waktu pembakaran akan selalu 5ms. Dengan kernel yang terpengaruh yang telah saya uji, dengan menggunakan angka di atas, saya sering melihat waktu pembakaran 99ms. Apa pun yang lebih dari 6 md merupakan masalah.
Nuru
pada 22 Apr 2020
@nuru terima kasih atas skrip untuk menemukan masalah ada atau tidak.
@justinsb Tolong sarankan jika gambar kops default memiliki tambalan atau tidak
https://github.com/kubernetes/kops/blob/master/channels/stable
Masalah terbuka: https://github.com/kubernetes/kops/issues/8954
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -617586330
Pembaruan: Jalankan pengujian dalam gambar kops 1.15, pembatasan yang tidak perlu ada di sana https://github.com/kubernetes/kops/issues/8954#issuecomment -617673755
alok87
pada 22 Apr 2020
@Uru
2020/04/22 11:02:48 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 6ms
2020/04/22 11:02:49 [1] burn took 5ms, real time so far: 1012ms, cpu time so far: 12ms
2020/04/22 11:02:50 [2] burn took 5ms, real time so far: 2017ms, cpu time so far: 18ms
2020/04/22 11:02:51 [3] burn took 5ms, real time so far: 3023ms, cpu time so far: 23ms
2020/04/22 11:02:52 [4] burn took 5ms, real time so far: 4028ms, cpu time so far: 29ms
2020/04/22 11:02:53 [5] burn took 5ms, real time so far: 5033ms, cpu time so far: 35ms
2020/04/22 11:02:54 [6] burn took 5ms, real time so far: 6038ms, cpu time so far: 40ms
2020/04/22 11:02:55 [7] burn took 5ms, real time so far: 7043ms, cpu time so far: 46ms
2020/04/22 11:02:56 [8] burn took 5ms, real time so far: 8049ms, cpu time so far: 51ms
2020/04/22 11:02:57 [9] burn took 5ms, real time so far: 9054ms, cpu time so far: 57ms
2020/04/22 11:02:58 [10] burn took 5ms, real time so far: 10059ms, cpu time so far: 63ms
2020/04/22 11:02:59 [11] burn took 5ms, real time so far: 11064ms, cpu time so far: 69ms
2020/04/22 11:03:00 [12] burn took 5ms, real time so far: 12069ms, cpu time so far: 74ms
2020/04/22 11:03:01 [13] burn took 5ms, real time so far: 13074ms, cpu time so far: 80ms
2020/04/22 11:03:02 [14] burn took 5ms, real time so far: 14079ms, cpu time so far: 85ms
hasil tersebut berasal dari
Linux <servername> 4.15.0-96-generic #97-Ubuntu SMP Wed Apr 1 03:25:46 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
Ini adalah kernel ubuntu stabil terbaru default di ubuntu 18.04.
Jadi, sepertinya patch ada.
 zerkms
pada 22 Apr 2020
zerkms
pada 22 Apr 2020
@zerkms Di mana Anda menjalankan pengujian pada Ubuntu 18.04? Menurut saya, patch tersebut mungkin hanya berhasil masuk ke kernel untuk Azure. Jika Anda dapat menemukan catatan rilis yang mengatakan di mana itu diterapkan ke paket Ubuntu linux silakan bagikan. Saya tidak dapat menemukannya.
Perhatikan juga bahwa tes ini juga tidak dapat mereproduksi masalah pada CoreOS. Bisa jadi dalam konfigurasi default penjadwalan CFS dinonaktifkan secara global.
Nuru
pada 22 Apr 2020
@Uru
Di mana Anda menjalankan pengujian di Ubuntu 18.04?
Salah satu server saya.
Saya tidak memeriksa catatan rilis, saya bahkan tidak yakin apa yang harus dicari, dan bagaimanapun - ini adalah kernel default seperti yang dimiliki semua orang. 🤷
zerkms
pada 22 Apr 2020
tambalan harus ada di sini di ubuntus kernel git:
https://kernel.ubuntu.com/git/ubuntu/ubuntu-bionic.git/commit/?id=aadd794e744086fb50cdc752d54044fbc14d4adb
dan di sini bug ubuntu tentangnya:
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1832151
itu harus dilepaskan dalam bionik.
Anda dapat memastikan dengan menjalankan apt-get source linux dan memeriksa kode sumber yang diunduh.
juliantaylor
pada 22 Apr 2020
@zerkms Dengan "di mana Anda menjalankan pengujian" Maksud saya apakah itu server di kantor Anda, server di GCP, AWS, Azure, atau di tempat lain?
Jelas ada banyak hal yang saya tidak mengerti tentang bagaimana Ubuntu didistribusikan dan dipelihara. Saya bingung dengan keluaran uname -a juga. Catatan Rilis Ubuntu mengatakan:
18.04.4 dikirimkan dengan kernel Linux berbasis v5.3 yang diperbarui dari kernel berbasis v5.0 pada 18.04.3.
dan juga mengatakan 18.04.4 dirilis 12 Februari 2020. Output Anda mengatakan Anda menjalankan kernel v4.15 yang dikompilasi 1 April 2020.
@juliantaylor Saya tidak memiliki server Ubuntu atau salinan repo Git, dan tidak tahu cara melacak di mana komit tertentu seperti aadd794e7440 membuatnya menjadi kernel stabil yang diterbitkan. Jika Anda dapat menunjukkan kepada saya bagaimana melakukan itu, saya akan sangat menghargainya.
Ketika saya melihat komentar bug launchpad yang saya lihat
- Bug ini telah diperbaiki dalam paket linux-azure - 5.0.0-1027.29
- Bug ini telah diperbaiki dalam paket linux-azure - 5.0.0-1027.29 ~ 18.04.1
tetapi tambalan khusus ini ( sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices ) tidak terdaftar di bawah
- Bug ini telah diperbaiki di paket linux - 4.15.0-69.78
Saya juga tidak melihat "1832151" terdaftar di catatan rilis Ubuntu
Komentar sebelumnya mengatakan itu ditambal di 4.15.0-67.76 tetapi saya tidak melihat paket linux-image-4.15.0-67-generic .
Saya jauh dari pakar Ubuntu dan merasa pelacakan tambalan ini sangat sulit, jadi sejauh yang saya lihat.
Saya harap Anda sekarang melihat mengapa saya tidak yakin patch ini sebenarnya disertakan dalam Ubuntu 18.04.4, yang merupakan versi 18.04 saat ini. Dugaan terbaik_ saya adalah bahwa itu dirilis sebagai pembaruan kernel setelah 18.04.4 dirilis, dan mungkin disertakan jika kernel Ubuntu Anda melaporkan 4.15.0-69 atau lebih baru, tetapi jika Anda hanya mengunduh 18.04.4 dan tidak memperbaruinya, itu tidak akan memiliki tambalan.
Nuru
pada 22 Apr 2020
Saya baru saja menjalankan tes Go itu (sangat berguna) di kernel 4.15.0-72 di server baremetal di pusat data dan tampaknya tambalannya ada di sana:
2020/04/22 21:24:27 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 7ms
2020/04/22 21:24:28 [1] burn took 5ms, real time so far: 1010ms, cpu time so far: 13ms
2020/04/22 21:24:29 [2] burn took 5ms, real time so far: 2015ms, cpu time so far: 20ms
2020/04/22 21:24:30 [3] burn took 5ms, real time so far: 3020ms, cpu time so far: 25ms
2020/04/22 21:24:31 [4] burn took 5ms, real time so far: 4025ms, cpu time so far: 32ms
2020/04/22 21:24:32 [5] burn took 5ms, real time so far: 5030ms, cpu time so far: 38ms
2020/04/22 21:24:33 [6] burn took 5ms, real time so far: 6036ms, cpu time so far: 43ms
2020/04/22 21:24:34 [7] burn took 5ms, real time so far: 7041ms, cpu time so far: 50ms
2020/04/22 21:24:35 [8] burn took 5ms, real time so far: 8046ms, cpu time so far: 56ms
2020/04/22 21:24:36 [9] burn took 5ms, real time so far: 9051ms, cpu time so far: 63ms
2020/04/22 21:24:37 [10] burn took 5ms, real time so far: 10056ms, cpu time so far: 68ms
2020/04/22 21:24:38 [11] burn took 5ms, real time so far: 11061ms, cpu time so far: 75ms
2020/04/22 21:24:39 [12] burn took 5ms, real time so far: 12067ms, cpu time so far: 81ms
2020/04/22 21:24:40 [13] burn took 5ms, real time so far: 13072ms, cpu time so far: 86ms
2020/04/22 21:24:41 [14] burn took 5ms, real time so far: 14077ms, cpu time so far: 94ms
Saya juga dapat melihat bahwa eksekusi yang sama di kernel 4.9.164 dalam jenis server yang sama menunjukkan luka bakar selama 5ms:
2020/04/22 21:24:41 [0] burn took 97ms, real time so far: 97ms, cpu time so far: 8ms
2020/04/22 21:24:42 [1] burn took 5ms, real time so far: 1102ms, cpu time so far: 12ms
2020/04/22 21:24:43 [2] burn took 5ms, real time so far: 2107ms, cpu time so far: 16ms
2020/04/22 21:24:44 [3] burn took 5ms, real time so far: 3112ms, cpu time so far: 24ms
2020/04/22 21:24:45 [4] burn took 83ms, real time so far: 4197ms, cpu time so far: 28ms
2020/04/22 21:24:46 [5] burn took 5ms, real time so far: 5202ms, cpu time so far: 32ms
2020/04/22 21:24:47 [6] burn took 94ms, real time so far: 6297ms, cpu time so far: 36ms
2020/04/22 21:24:48 [7] burn took 99ms, real time so far: 7397ms, cpu time so far: 40ms
2020/04/22 21:24:49 [8] burn took 100ms, real time so far: 8497ms, cpu time so far: 44ms
2020/04/22 21:24:50 [9] burn took 5ms, real time so far: 9503ms, cpu time so far: 52ms
2020/04/22 21:24:51 [10] burn took 5ms, real time so far: 10508ms, cpu time so far: 60ms
2020/04/22 21:24:52 [11] burn took 5ms, real time so far: 11602ms, cpu time so far: 64ms
2020/04/22 21:24:53 [12] burn took 5ms, real time so far: 12607ms, cpu time so far: 72ms
2020/04/22 21:24:54 [13] burn took 5ms, real time so far: 13702ms, cpu time so far: 76ms
2020/04/22 21:24:55 [14] burn took 5ms, real time so far: 14707ms, cpu time so far: 80ms
Jadi, masalah saya adalah saya masih melihat pelambatan CPU bahkan kernel saya tampaknya ditambal
vgarcia-te
pada 22 Apr 2020
@Nuru benar, maaf. Itu adalah server logam saya yang dihosting di kantor.
dan juga mengatakan 18.04.4 dirilis 12 Februari 2020. Output Anda mengatakan Anda menjalankan kernel v4.15 yang dikompilasi 1 April 2020.
Itu karena ini adalah server LTS: Anda perlu mengikutsertakan HWE secara eksplisit dengannya untuk memiliki kernel yang lebih baru, jika tidak, Anda hanya menjalankan jalur utama.
Dan baik kernel mainline dan HWE dirilis secara teratur, jadi tidak ada yang mencurigakan karena memiliki kernel yang baru dibuat: http://changelogs.ubuntu.com/changelogs/pool/main/l/linux-meta/linux-meta_4.15.0.96.87/ changelog
zerkms
pada 22 Apr 2020
@zerkms Terima kasih atas infonya. Saya tetap bingung, tapi ini bukan tempat untuk mendidik saya.
@ vgarcia-te Jika kernel Anda telah di-patch, yang tampaknya memang demikian, maka pembatasan tersebut bukan karena bug ini. Saya tidak yakin dengan terminologi Anda ketika Anda mengatakan:
Saya berbicara tentang penggunaan sekitar 50ms dengan permintaan disetel ke 250m dan dibatasi hingga 500m. Kami melihat sekitar 50% dari periode CPU sedang dibatasi, apakah nilai ini mungkin cukup rendah untuk diharapkan dan dapat diterima?
Sumber daya CPU Kubernetes diukur dalam CPU, 1 berarti 100% dari 1 CPU penuh, 1m berarti 0,1% dari 1 CPU. Jadi batas Anda "500m" mengatakan izinkan 0,5 CPU.
Periode penjadwalan default untuk CFS adalah 100ms, jadi menyetel batas ke 0,5 CPU akan membatasi proses Anda menjadi 50ms CPU setiap 100ms. Jika proses Anda mencoba untuk melebihi itu, itu akan terhambat. Jika proses Anda biasanya berjalan lebih dari 50ms dalam satu lintasan, maka ya, Anda akan mengharapkannya untuk dibatasi oleh penjadwal yang berfungsi dengan baik.
Nuru
pada 23 Apr 2020
@ Nuru itu masuk akal, tapi biarkan saya mengerti ini, mengingat periode cpu default adalah 100ms, dalam kasus sebuah proses mendapat 1 CPU yang ditetapkan, jika proses itu berjalan lebih dari 100ms dalam satu lintasan, apakah itu akan dibatasi?
Apakah ini berarti bahwa di linux, di mana periode cpu default adalah 100 md, proses apa pun yang memiliki batas yang berjalan lebih dari 100 md dalam sekali lintasan, akan terhambat?
Apa yang akan menjadi konfigurasi batas yang baik untuk proses yang membutuhkan waktu lebih dari 100 md dalam sekali lintasan tetapi tetap menganggur di sisa waktunya?
vgarcia-te
pada 23 Apr 2020
@ vgarcia-te bertanya
Mengingat bahwa periode cpu default adalah 100ms, dalam kasus sebuah proses mendapatkan 1 CPU yang ditetapkan, jika proses tersebut berjalan selama lebih dari 100ms dalam satu kali lintasan, apakah itu akan dibatasi?
Tentu saja penjadwalan sangat rumit jadi saya tidak dapat memberikan jawaban yang sempurna, tetapi jawaban yang disederhanakan adalah tidak. Penjelasan lebih rinci ada di sini dan di sini .
Semua proses unix tunduk pada penjadwalan preemptive berdasarkan pembagian waktu. Kembali ke hari-hari single core CPU tunggal, Anda masih memiliki 30 proses yang berjalan "secara bersamaan". Apa yang terjadi adalah mereka berlari sebentar dan tidur atau, pada akhir waktu mereka, ditunda sehingga sesuatu yang lain dapat berjalan.
CFS dengan kuota melangkah lebih jauh.
Namun, tanyakan pada diri Anda, ketika Anda mengatakan Anda ingin suatu proses menggunakan 50% dari sebuah CPU, apa yang sebenarnya Anda katakan? Apakah Anda mengatakan bahwa tidak apa-apa jika itu memakan 100% CPU selama 5 menit selama itu tidak berjalan sama sekali selama 5 menit berikutnya? Itu akan menjadi 50% penggunaan selama 10 menit, tetapi itu tidak dapat diterima oleh kebanyakan orang karena masalah latensi.
Jadi CFS mendefinisikan "Periode CPU" yang merupakan jendela waktu di mana ia memberlakukan kuota. Pada mesin dengan 4 core dan periode CPU 100ms, penjadwal memiliki 400ms waktu CPU untuk mengalokasikan lebih dari 100ms waktu nyata (jam dinding). Jika Anda menjalankan satu thread eksekusi yang tidak dapat diparalelkan, thread tersebut dapat menggunakan paling banyak 100 md waktu CPU per periode, yang akan menjadi 100% dari 1 CPU. jika Anda menyetel kuota menjadi 1 CPU, itu tidak akan pernah dibatasi.
Jika Anda menyetel kuota menjadi 500m (0,5 CPU), maka proses akan menjalankan 50ms setiap 100ms. Periode 100ms apa pun yang menggunakan kurang dari 50ms seharusnya tidak dibatasi. Periode Ayn 100ms tidak selesai setelah berjalan 50ms, ia akan dibatasi hingga periode 100ms berikutnya. Itu menjaga keseimbangan antara latensi (berapa lama harus menunggu untuk dapat berjalan sama sekali) dan memonopoli (berapa lama diizinkan untuk mencegah proses lain berjalan).
Nuru
pada 23 Apr 2020
@Nuru slide saya benar. Saya juga seorang pengembang Ubuntu * (hanya di waktu luang saya sekarang). Taruhan terbaik Anda adalah membaca sumbernya, dan memeriksa git menyalahkan + tag - berisi untuk melacak ketika tambalan mengenai versi kernel yang Anda pedulikan.
chiluk
pada 26 Apr 2020
@chiluk Saya belum melihat slide Anda. Bagi orang lain yang belum pernah melihatnya, berikut adalah tempat mereka mengatakan tambalan telah mendarat beberapa waktu yang lalu:
- Ubuntu 4.15.0-67 +
- Ubuntu 5.3.0-24 +
- RHEL7 kernel 3.10.0-1062.8.1.el7
dan tentu saja Linux stable v4.14.154, v4.19.84, 5.3.9. Saya perhatikan itu juga di Linux stable 5.4-rc1.
Saya masih berjuang untuk memahami berbagai bug penjadwal CFS dan menemukan pengujian yang andal dan mudah diinterpretasikan yang akan bekerja di server AWS kecil, karena saya mendukung berbagai macam kernel dari penginstalan lama. Seperti yang saya pahami dari timeline, bug diperkenalkan di Linux kernel v3.16-rc1 pada tahun 2014 oleh
[51f2176d74ac](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=51f2176d74ac) sched/fair: Fix unlocked reads of some cfs_b->quota/period.
Hal ini menyebabkan masalah pelambatan CFS yang berbeda. Saya rasa masalah yang saya lihat di bawah kops Kubernetes cluster disebabkan oleh bug ini, karena mereka menggunakan 4.9 kernel.
51f2176d74ac diperbaiki pada 2018 kernel v4.18-rc4 dengan
[512ac999](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) sched/fair: Fix bandwidth timer clock drift condition
tapi itu memperkenalkan bug yang diperbaiki @chiluk
[de53fd7ae](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425) sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
Ini, tentu saja, bukan kesalahan Chiluk atau orang lain yang membuat patch kernel sulit dilacak di seluruh distribusi. Itu tetap membuat saya frustasi, dan menambah kebingungan saya.
Misalnya, pada Debuan buster 10 (AWS AMI debian-10-amd64-20191113-76 ), versi kernel dilaporkan sebagai
Linux ip-172-31-41-138 4.19.0-6-cloud-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
Sejauh yang saya tahu, kernel ini seharusnya memiliki 51f2176d74ac dan TIDAK memiliki 512ac999 dan oleh karena itu seharusnya gagal dalam pengujian yang dijelaskan dalam 512ac999 , tetapi sebenarnya tidak. (Saya katakan saya tidak berpikir itu memiliki 512ac999 karena itu secara bertahap ditingkatkan dari kernel Linux 4.10 dan tidak disebutkan tambalan itu di log perubahan.) Namun, pada VM AWS 4 cpu itu tidak gagal Chiluk fibtest atau tes cegukan CFS Bobrik, yang menunjukkan sesuatu yang lain sedang terjadi.
Saya memiliki masalah serupa saat mereproduksi masalah penjadwalan apa pun dengan CoreOS bahkan sebelum menerima tambalan Chiluk.
Pemikiran saya saat ini adalah bahwa tes Bobrik pada dasarnya adalah tes untuk 51f2176d74ac , Debian buster 10 AMI yang saya gunakan _does_ memiliki 512ac999 , hanya saja tidak secara eksplisit disebutkan di log perubahan, dan fibtest bukanlah tes yang sangat sensitif pada mesin dengan hanya beberapa inti.
Nuru
pada 27 Apr 2020
Sebuah cpu 4 inti mungkin tidak cukup besar untuk mereproduksi masalah chiluk diperbaiki.
Seharusnya hanya dapat direproduksi pada mesin yang lebih besar dengan ke atas mungkin 40 cpus jika saya memahami penjelasan dari chiluks kubecon talk (https://www.youtube.com/watch?v=UE7QX98-kO0) dengan benar.
Ada banyak versi kernel dan ada banyak tambalan dan pengembalian tambalan yang sedang berlangsung. Log perubahan dan nomor versi hanya membantu Anda sejauh ini.
Satu-satunya cara yang dapat diandalkan jika Anda ragu adalah dengan mengunduh kode sumber dan membandingkannya dengan perubahan pada tambalan yang telah ditautkan di sini.
juliantaylor
pada 27 Apr 2020
Masalah menjadi basi setelah 90d tidak ada aktivitas.
Tandai terbitan sebagai baru dengan /remove-lifecycle stale .
Masalah basi membusuk setelah 30 hari tambahan tidak aktif dan akhirnya ditutup.
Jika masalah ini aman untuk ditutup sekarang, lakukan dengan /close .
Kirimkan masukan ke sig-testing, kubernetes / test-infra dan / atau fejta .
/ siklus hidup basi
fejta-bot
pada 26 Jul 2020
/ remove-lifecycle basi
 yashbhutwala
pada 27 Jul 2020
yashbhutwala
pada 27 Jul 2020
Pengujian yang disebutkan sebelumnya di utas ini tidak benar-benar mereproduksi masalah bagi saya (beberapa luka bakar membutuhkan waktu lebih dari 5 md tetapi seperti 0,01% di antaranya) tetapi metrik pelambatan cfs kami masih menunjukkan jumlah pelambatan yang moderat. Kami memiliki versi kernel yang berbeda di seluruh cluster kami, tetapi dua versi yang paling umum adalah:
Debian 4.19.67-2+deb10u2~bpo9+1 (2019-11-12)- backport manual
5.4.38
Saya tidak tahu apakah kedua bug seharusnya diperbaiki dalam versi ini, tetapi saya _pikir_ mereka seharusnya begitu, jadi saya bertanya-tanya apakah tes ini tidak begitu berguna. Saya menguji mesin dengan 16 core dan 36 core, tidak yakin apakah saya memerlukan lebih banyak core agar pengujian valid, tetapi kami masih melihat throttling di cluster ini jadi ...
 2rs2ts
pada 18 Agu 2020
2rs2ts
pada 18 Agu 2020
Haruskah kita menutup masalah ini dan meminta orang yang menghadapi masalah untuk memulai yang baru? Spamming di sini kemungkinan besar akan membuat percakapan menjadi sangat sulit.
 omnibs
pada 31 Okt 2020
omnibs
pada 31 Okt 2020
^ Saya setuju. Banyak yang telah dilakukan untuk menyelesaikan masalah ini.
 sfxworks
pada 31 Okt 2020
sfxworks
pada 31 Okt 2020
/Menutup
berdasarkan komentar di atas. tolong buka terbitan baru seperlunya.
dims
pada 1 Nov 2020
@dims : Menutup masalah ini.
Menanggapi ini :
/Menutup
berdasarkan komentar di atas. tolong buka terbitan baru seperlunya.
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, harap ajukan masalah ke kubernetes / test-infra repository.
 k8s-ci-robot
pada 1 Nov 2020
k8s-ci-robot
pada 1 Nov 2020
harap beri tahu masalah tindak lanjut untuk masalah ini, sehingga orang yang berlangganan masalah dapat berlangganan edisi baru untuk diikuti
 glensc
pada 1 Nov 2020
glensc
pada 1 Nov 2020
Masalah terkait
 tbchj
·
3Komentar
tbchj
·
3Komentar
 alexferl
·
3Komentar
alexferl
·
3Komentar
 ttripp
·
3Komentar
ttripp
·
3Komentar
 mml
·
3Komentar
mml
·
3Komentar
 cooligc
·
3Komentar
cooligc
·
3Komentar
Komentar yang paling membantu
Tambalan itu mendarat di ujungnya pagi ini.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Setelah itu mengenai pohon Torvald, saya akan mengirimkannya untuk inklusi stabil-linux, dan kemudian distro utama (Redhat / Ubuntu). Jika Anda peduli tentang hal lain, dan mereka tidak mengikuti patch linux-stable, Anda mungkin ingin mengirimkannya secara langsung.