Kubernetes: CFS quotas can lead to unnecessary throttling
/kind bug
This is not a bug in Kubernets per se, it's more of a heads-up.
I've read this great blog post:
From the blog post I learned that k8s is using cfs quotas to enforce CPU limits. Unfortunately, those can lead to unnecessary throttling, especially for well behaved tenants.
See this unresolved bug in Linux kernel I filed a while back:
There's an open and stalled patch that addresses the issue (I've not verified if it works):
cc @ConnorDoyle @balajismaniam
 bobrik
bobrik
All 142 comments
/sig node
/kind bug
 neolit123
on 20 Aug 2018
neolit123
on 20 Aug 2018
is this a duplicate of #51135?
 liggitt
on 20 Aug 2018
liggitt
on 20 Aug 2018
It's similar in spirit, but it seems to miss the fact that there's an actual bug in the kernel rather than just some configuration tradeoff in CFS quota period. I've liked #51135 back here to give people there more context.
bobrik
on 22 Aug 2018
As far as I understand this is another reason to either disable CFS quota (--cpu-cfs-quota=false) or make it configurable (#63437).
I also find this gist (linked from Kernel patch) very interesting to see (to gauge the impact): https://gist.github.com/bobrik/2030ff040fad360327a5fab7a09c4ff1
 hjacobs
on 22 Aug 2018
hjacobs
on 22 Aug 2018
cc @adityakali
 vishh
on 23 Aug 2018
vishh
on 23 Aug 2018
Another issue with quotas is that the kubelet counts hyperthreads as "cpus". When a cluster becomes so loaded that two threads are scheduled on the same core and the process has a cpu quota quota one of them will only perform with a small fraction of the available processing power (it will only do something when something on the other thread stalls) but still consume quota as if it had a physical core for itself. So it consumes double the quota that it should without doing significantly more work.
This has the effect that on a fully loaded node node with hyperthreading enabled the performance will be half of what it would be with hyperthreading or quotas disabled.
Imo the kubelet should not consider hyperthreads as real cpus to avoid this situation.
 juliantaylor
on 30 Aug 2018
juliantaylor
on 30 Aug 2018
@juliantaylor As I mentioned in #51135 turning off CPU quota might be the best approach for most k8s clusters running trusted workloads.
vishh
on 30 Aug 2018
Is this considered as a bug ?
If some pods are throttled while not really exhausting their CPU limit, it sound like a bug to me.
On my cluster, most of the over-quota pods are related to metrics (heapster, metrics-collector, node-exporter...) or Operators, which obviously have the kind of workload that is in problem here : do nothing most of the time and wake up to reconcile every once and a while.
The strange thing here is that I tried to raise the limit, going from 40m to 100m or 200m, and the processes were still throttled.
I can't see any other metrics pointing out a workload that could trigger this throttling.
I've removed the limits on these pods for now... it's getting better, but, well, that really sounds like a bug and we should come with a better solution than disabling the Limits
 prune998
on 26 Nov 2018
prune998
on 26 Nov 2018
@prune998 see @vishh's comment and this gist: the Kernel over-aggressively throttles, even if the math tells you it should not. We (Zalando) decided to disable CFS quota (CPU throttling) in our clusters: https://www.slideshare.net/try_except_/optimizing-kubernetes-resource-requestslimits-for-costefficiency-and-latency-highload
hjacobs
on 27 Nov 2018
Thanks @hjacobs.
I'm on Google GKE and I see no easy way to disable it, but I keep searching....
prune998
on 27 Nov 2018
@prune998 AFAIK, Google hasn't exposed the necessary knobs yet. We filed a feature request right after the possibility to disable CFS landed in upstream, haven't heard any news since then.
 timoreimann
on 27 Nov 2018
timoreimann
on 27 Nov 2018
I'm on Google GKE and I see no easy way to disable it, but I keep searching....
Can you remove CPU limits from your containers for now?
vishh
on 28 Nov 2018
According to the CPU manager docs, CFS quota is not used to bound the CPU usage of these containers as their usage is bound by the scheduling domain itself. But we're experiencing CFS throttling.
This makes the static CPU manager mostly pointless as setting a CPU limit to achieve the Guaranteed QoS class negates any benefit due to throttling.
Is it a bug that CFS quotas are set at all for pods on static CPU?
 mariusgrigoriu
on 12 Feb 2019
mariusgrigoriu
on 12 Feb 2019
For additional context (learned this yesterday): @hrzbrg (MyTaxi) contributed a flag to Kops to disable CPU throttling: https://github.com/kubernetes/kops/issues/5826
hjacobs
on 12 Feb 2019
Please share a summary of the problem here. It is not very clear what the problem is and in what scenarios users are impacted and what exactly is required to fix it?
Our understanding at present is when we cross limits we get penaltied and throttled. So say we have a cpu quota of 3 cores and in the first 5ms we consumed 3 cores then in the 100ms slice we will get throttled for 95ms, and in this 95ms our containers cannot do anything. And we have seen to get throttled even when the cpu spikes are not visible in the cpu usage metrics. We assume that it is because the time window of measuring cpu usage is in seconds and the throttling is happening at micro seconds level, so it averages out and is not visible. But the bug mentioned here has left us confused now.
Few questions:
- When the node is at 100% cpu? Is this a special case in which all containers get throttled regardless of their usage?
When this happens does all containers get 100% cpu throttled?
What triggers this bug to get triggered in the node?
What is the difference between not using
limitsand disablingcpu.cfs_quota?Is not disabling
limitsa risky solution when there are many burstable pods and one pod can cause the instability in the node and impact other pods which are running over their requests?Separately, according to the kernel doc process may get throttled when the parent quota is fully consumed. What is parent in the container context here(is it related to this bug)? https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
There are two ways in which a group may become throttled: a. it fully consumes its own quota within a period b. a parent's quota is fully consumed within its period- What is needed to fix them? Upgrade kernel version?
We have faced a fairly big outage and it looks closely related(if not the root cause) to all our pods getting stuck in throttling restart loop and not able to scale up. We are digging into the details to find the real issue. I will be opening a separate issue explaining in details about our outage.
Any help here is greatly appreciated.
cc @justinsb
 alok87
on 14 Feb 2019
alok87
on 14 Feb 2019
One of our users set a CPU limit and got throttled into timing out their liveness probe causing an outage of their service.
We're seeing throttling even when pinning containers to a CPU. For example a CPU Limit of 1 and pinning that container to run only on the one CPU. It should be impossible to exceed the quota given any period if your quota were exactly the number of CPU you have, yet we see throttling in every case.
I thought I saw it posted somewhere that kernel 4.18 solves the problem. I haven't tested it yet, so it would be nice if someone could confirm.
mariusgrigoriu
on 15 Feb 2019
https://github.com/torvalds/linux/commit/512ac999d2755d2b7109e996a76b6fb8b888631d in 4.18 seems to be the relevant patch for this issue.
 clkao
on 23 Feb 2019
clkao
on 23 Feb 2019
@mariusgrigoriu I seem to be stuck in the same conundrum you described here https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-462534360.
We observe CPU throttling on Pods in Guaranteed QoS class with CPUManager static policy (which doesn't seem to make any sense).
Removing the limits for these Pods will put them in Burstable QoS class, which is not what we want, so the only option remaining is disable CFS cpu quotas system-wide, which is also not something we can safely do, since allowing all Pods access to unbound cpu capacity can lead to dangerous CPU saturation issues.
@vishh given the above circumstances, what would be the best course of action? it seems like upgrading to kernel >4.18 (which has the cfs cpu accounting fix) and (perhaps) reducing cfs quota period?
On a general note, suggesting we just remove limits from containers that are being throttled should have clear warnings:
1) If these were Pods in Guaranteed QoS class, with integer number of cores and with CPUMnanager static policy in place - these Pods will no longer get dedicated CPU cores since they will be put in Burstable QoS class (having no requests == limits)
2) These pods will be unbound in terms of how much CPU they can consume and potentially can cause quite a bit of damage under certain circumstances.
Your feedback/guidance would be highly appreciated.
 dannyk81
on 25 Mar 2019
dannyk81
on 25 Mar 2019
Upgrading the kernel definitely helps, but the behavior of applying a CFS quota still seems out of alignment with what the docs suggest.
mariusgrigoriu
on 25 Mar 2019
I've been researching various aspects of this issue for a while now. My research is summarized in my post to LKML.
https://lkml.org/lkml/2019/3/18/706
That being said, I have not been able to reproduce the issue as described here in the pre-512ac99 kernels. I have seen a performance regression in post-512ac99 kernels however. So that fix is not a panacea.
 chiluk
on 25 Mar 2019
chiluk
on 25 Mar 2019
Thanks @mariusgrigoriu, we are going for the kernel upgrade and hope that will help somewhat, also check out https://github.com/kubernetes/kubernetes/issues/70585 - it seems that quotas are indeed set for guaranteed pods with cpuset (i.e. pinned cpus), so this seems like a bug to me.
dannyk81
on 25 Mar 2019
@chiluk could you elaborate a bit? do you mean that the patch that was included in 4.18 (mentioned above in https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-466609030) doesn't actually solve the issue?
dannyk81
on 25 Mar 2019
The 512ac99 kernel patch fixes an issue for some people, but caused an issue for our configurations. The patch fixed the way time slices are distributed amongst cfs_rq, in that they now correctly expire. Previously they would not expire.
Java workloads in particular on high core-count machines now see high amounts of throttling with low cpu usage because of the blocking worker threads. Those threads are assigned time slice which they only use a small portion of which is later expired. In the synthetic test I wrote *(linked to on that thread), we see a performance degradation of roughly 30x. In real world performance we saw response time degradation of hundreds of milliseconds between the two kernels due to the increased throttling.
chiluk
on 25 Mar 2019
Using a 4.19.30 kernel I see pods that I'd hoped to see less throttling are still throttled and some pods that weren't previously being throttled are now being throttled quite severely (kube2iam is reporting more seconds throttled than the instance has been up, somehow)
 willthames
on 27 Mar 2019
willthames
on 27 Mar 2019
On CoreOS 4.19.25-coreos I see Prometheus triggering CPUThrottlingHigh alert almost on every single pod in the system.
 teralype
on 27 Mar 2019
teralype
on 27 Mar 2019
@williamsandrew @teralype this seems to reflect @chiluk's findings.
After various internal discussions we in fact decided to disable cfs quotas entirely (kubelet's flag --cpu-cfs-quota=false), this seems to solve all the issues we've been having for both Burstable and Guaranteed (cpu pinned or standard) Pods.
There's an excellent deck about this (and few other topics) here: https://www.slideshare.net/try_except_/ensuring-kubernetes-cost-efficiency-across-many-clusters-devops-gathering-2019
Highly recommended read :+1:
dannyk81
on 27 Mar 2019
long-term-issue (note to self)
 dims
on 27 Mar 2019
dims
on 27 Mar 2019
@dannyk81 just for completeness: the linked talk is also available as recorded video: https://www.youtube.com/watch?v=4QyecOoPsGU
hjacobs
on 27 Mar 2019
@hjacobs , loved the talk! Thanks a lot...
Any idea how to apply this fix on AKS or GKE?
Thanks
 agolomoodysaada
on 2 Apr 2019
agolomoodysaada
on 2 Apr 2019
@agolomoodysaada we filed a feature request with GKE a while back. Not sure what the status is though, I do not work intensively with GKE anymore.
timoreimann
on 2 Apr 2019
I reached out to Azure support and they said it won't be available until around August 2019.
agolomoodysaada
on 4 Apr 2019

Thought I would share a graph of an application consistently throttled throughout its lifetime.
agolomoodysaada
on 5 Apr 2019
What kernel was this on?
chiluk
on 5 Apr 2019
@chiluk "4.15.0-1037-azure"
agolomoodysaada
on 5 Apr 2019
So that doesn't contain kernel commit 512ac99. Here's the corresponding
source.
https://kernel.ubuntu.com/git/kernel-ppa/mirror/ubuntu-azure-xenial.git/tree/kernel/sched/fair.c?h=Ubuntu-azure-4.15.0-1037.39_16.04.1&id=19b0066cc4829f45321a52a802b640bab14d0f67
Which means you might be hitting the issue described in 512ac99. Keep in
mind that 512ac99 brought other regressions for us.
On Fri, Apr 5, 2019 at 12:08 PM Moody Saada notifications@github.com
wrote:
@chiluk https://github.com/chiluk "4.15.0-1037-azure"
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-480350946,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ACDI05YeS6wfUE9XkiMbxrLvPllYQZ7Iks5vd4MOgaJpZM4WDUF3
.
chiluk
on 5 Apr 2019
I have now posted patches to LKML about this.
https://lkml.org/lkml/2019/4/10/1068
Additional testing would be greatly appreciated.
chiluk
on 11 Apr 2019
I resubmitted these patches now with documentation changes.
https://lkml.org/lkml/2019/5/17/581
It would really help if people could test these patches and comment on the thread on LKML. At the moment I'm the only one to have mentioned this at all on LKML, and I have not received any comments whatsoever from the community or the maintainers. It would really go a long way if I could get some community testing and commentary on LKML under my patch.
chiluk
on 21 May 2019
For what it's worth, this particular project https://github.com/tensorflow/serving seems to be severely impacted by this issue. And it's mostly a C++ application.
@chiluk , Are there any workarounds we can apply while the patch gets rolled out?
Thank you very much
agolomoodysaada
on 29 May 2019
We should help @chiluk collect citations of serious impact of this kernel bug on Kubernetes and anyone else using CFS quotas.
Zolando included in their presentation last week that their bad experiences with the current kernel means that they consider disabling CFS quotas as current Best Practice, as they consider it does more harm than good.
https://www.youtube.com/watch?v=6sDTB4eV4F8
 whereisaaron
on 29 May 2019
whereisaaron
on 29 May 2019
More and more companies are disabling CPU throttling, e.g. mytaxi, Datadog, Zalando (Twitter thread)
hjacobs
on 29 May 2019
@derekwaynecarr @dchen1107 @kubernetes/sig-node-feature-requests Dawn, Derek, is it time to change the default? and/or documentation?
dims
on 29 May 2019
Yes @whereisaaron collecting and sharing reports of throttling crippling applications, and or being turned off because of it's bad behavior would be welcome participation on the lkml thread where appropriate. At the moment it looks like it's mostly just me complaining about this issue to the kernel community.
chiluk
on 29 May 2019
@agolomoodysaada the workaround is to temporarily disable cfs quotas or over-allocate cpu quota to affected applications *(not all applications will hit this, but the majority of multi-threaded user-interactive applications probably are).
There's also best practices around reducing application thread count which also helps.
For golang set GOMAXPROCS~=ceil(quota)
For java move to the newer JVMs that recognize and respect cpu quota limits. Earlier jvms spawned threads based on the number of CPU cores, not the number of cores available to the application.
Both of these have been major boons to performance for us.
Monitor and report applications that are hitting throttling so that your developers can adjust quotas.
chiluk
on 29 May 2019
FYI, after I pointed out this thread to the Azure AKS support, I was answered the patch will be rolled out when they upgrade to kernel 5.0, in late september, at best.
Until then, well, stop using limits :)
prune998
on 29 May 2019
@prune998 there's a small caveat there in case you are using CPUmanager (i.e. dedicated cpu allocation to pods in Guaranteed QoS).
By removing limits you will avoid the CFS throttling issue, but you will remove the pods from Guaranteed QoS so CPUmanager will not allocate dedicated cores for these pods anymore.
If you don't use CPUmanager - no harm done, but just FYI for anyone opting for this direction.
There is a PR (https://github.com/kubernetes/kubernetes/issues/70585) to disable CFS quotas entirely for Pods with dedicated CPUs however it was not merged yet.
We have also opted to disable CFS quotas system wide as suggested above and no issues so far.
dannyk81
on 29 May 2019
@dannyk81 https://github.com/kubernetes/kubernetes/issues/70585 is not a PR that can be merged (it's an issue with a code snippet). Can you (or someone else) please file a PR?
dims
on 29 May 2019
There’s one already: https://github.com/kubernetes/kubernetes/pull/75682
 praseodym
on 29 May 2019
praseodym
on 29 May 2019
@dims I linked the issue, not the PR... but the issue is linked to the PR :) indeed it is https://github.com/kubernetes/kubernetes/pull/75682 and it's been hanging there for a while, so if you could push this would be great as this is really an annoying issue.
Thanks :+1:
dannyk81
on 29 May 2019
whoops! thanks @dannyk81 i've assigned folks and added milestone
dims
on 29 May 2019
FWIW we ran into this issue as well, and found that dropping the CFS quota period to 10ms instead of the default 100ms caused our tail end latencies to improve dramatically. I think this is because even if you run into the kernel bug, a far shorter amount of quota is wasted if it is not used, and the process can get more quota (in smaller allotments) much sooner. This is just a workaround, but for those who don't want to disable CFS quota entirely, this could be a bandaid until the fix is implemented. k8s supports doing this in 1.12 with the cpuCFSQuotaPeriod feature gate and --cpu-cfs-quota-period kubelet flag.
 d-shi
on 30 May 2019
d-shi
on 30 May 2019
I'd have to check, but I think shrinking the period down that far may have the effect of effectively disabling it, as there are slice minimums and quota minimums in the code. You are probably better off turning off quotas and moving to soft quotas.
chiluk
on 30 May 2019
@chiluk my layman's understanding is that the default slice is 5ms, so setting it to that or less is effectly disabling it, but as long as the period is greater than 5ms there should still be quota enforcement. Definitely let me know if that's not correct.
d-shi
on 31 May 2019
With --feature-gates=CustomCPUCFSQuotaPeriod=true --cpu-cfs-quota-period=10ms one of my pods really struggled to start up. In the attached prometheus graph, the container attempts to start up, doesn't get anywhere near meeting its liveness check until it's killed (normally the container starts in about 5 seconds - even increasing the liveness initialDelaySeconds to 60s didn't help) and is then replaced by a new one.
You can see that the container is heavily throttled until I removed the cpu-cfs-quota-period from the kubelet args, at which point the throttling is a lot flatter and the container starts up in around 5 seconds again.

willthames
on 5 Jun 2019
FYI: current Twitter thread about the topic of disabling CPU throttling: https://twitter.com/it_supertramp/status/1133648291332263936
hjacobs
on 5 Jun 2019
These are the CPU throttling graphs from before/after we moved to --cpu-cfs-quota-period=10ms in production for 2 latency sensitive services:
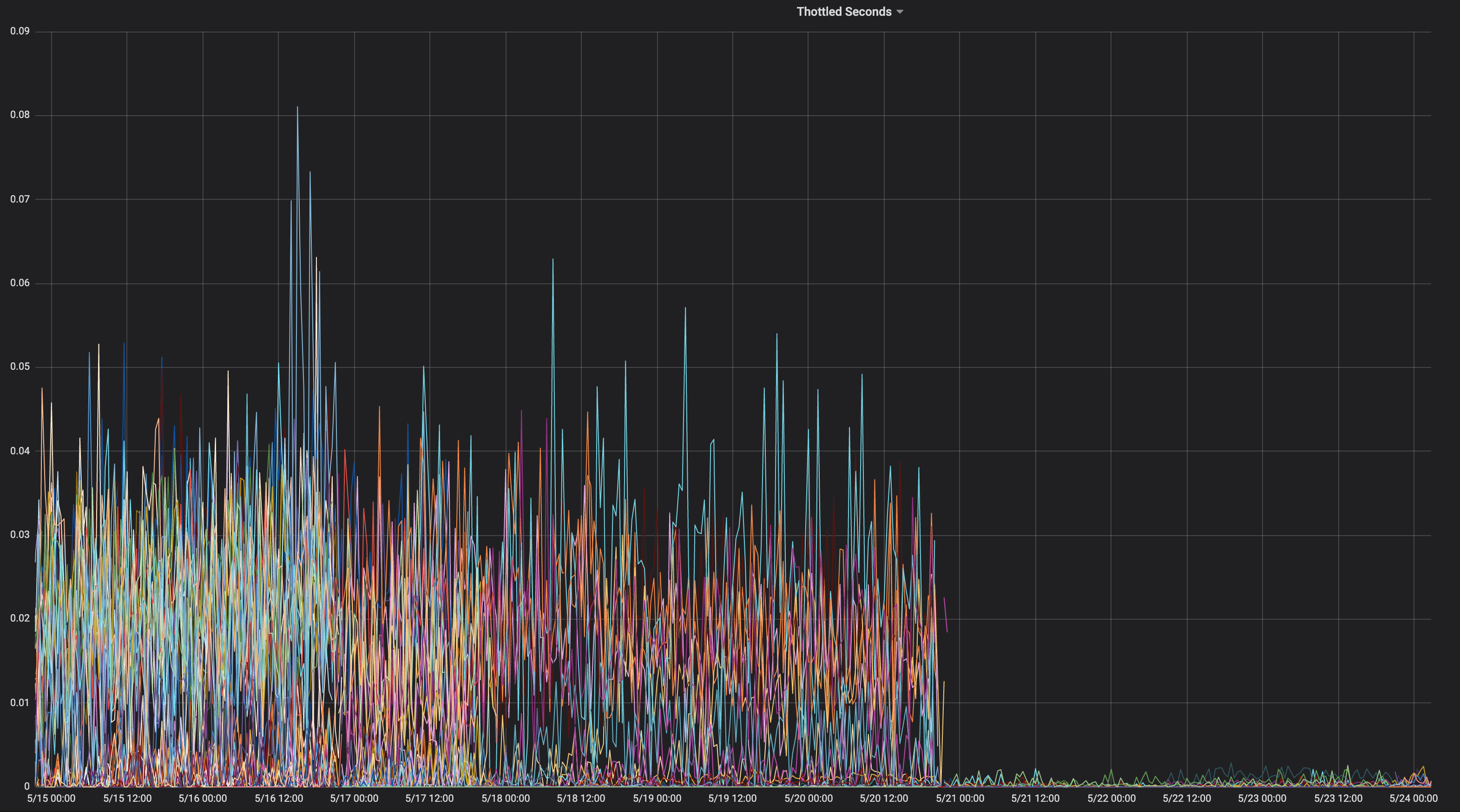

These services run on different instance types (with different taints/tolerations). The 2nd service's instances were moved to lower CFS quota period first.
Results must be very dependent on load.
d-shi
on 5 Jun 2019
@d-shi something else is going on on your graph. I think there may be some minimum quota alotment that you are now hitting because the period is so small. I'd have to check to code to be sure. Basically you inadvertently increased the amount of quota available to the application. You probably could have accomplished the same thing by actually increasing quota allotments.
chiluk
on 5 Jun 2019
For us it was a lot more useful to measure latency rather than throttling. Disabling cfs-quota dramatically improved latency. I'd like to see similar results for changing the cfs-quota-period.
 blakebarnett
on 6 Jun 2019
blakebarnett
on 6 Jun 2019
@chiluk we did actually try increasing quota allotments (up to the maximum supported by kubernetes per pod), and in no case were tail end latencies nor throttling reduced by much. p99 latencies went from about 98ms at a limit of 4 cores to 86ms at a limit of 16 cores. After reducing CFS quota to 10ms p99 went to 20ms at 4 cores.
@blakebarnett we developed a benchmark program that measured our latencies, and they went from a range of 10ms-100ms, with an average of around 18ms prior to updating --cpu-cfs-quota-period, to a range of 10ms-20ms, with an average of around 11ms afterwards. p99 latencies went from around 98ms to 20ms.
EDITS: Sorry for the edits I had to go back and doublecheck my numbers.
d-shi
on 6 Jun 2019
@d-shi, you were likely hitting the problem solved by 512ac999 then.
chiluk
on 6 Jun 2019
@chiluk After reading again and again your patch, I've to admit I struggle to understand the impact of this code :
if (cfs_rq->expires_seq == cfs_b->expires_seq) {
- /* extend local deadline, drift is bounded above by 2 ticks */
- cfs_rq->runtime_expires += TICK_NSEC;
- } else {
- /* global deadline is ahead, expiration has passed */
- cfs_rq->runtime_remaining = 0;
- }
In a case where the quota expire even if runtime_remaining just borrowed some time from the global pool. At worst you will get throttled for 5ms based on sched_cfs_bandwidth_slice_us. Isnt it?
Do I miss something ?
 Mwea
on 6 Jun 2019
Mwea
on 6 Jun 2019
@chiluk yes I think are right. Our production servers are still on kernel 4.4, so do not have that fix. Perhaps once we upgrade to a newer kernel we can move CFS quota period back to default, but for now it is working to improve our tail end latencies and we have not noticed any adverse side effects yet. Though it has only been live for a couple weeks.
d-shi
on 6 Jun 2019
@chiluk Mind summarizing the status of this issue in the kernel? Seems like there was a patch, 512ac999, but it had issues. Did I read somewhere that it got reverted? Or is this fully / partially fixed? If so, what version?
mariusgrigoriu
on 7 Jun 2019
@mariusgrigoriu it's not fixed, @chiluk has created a patch that should fix it that needs further testing (I'm going to allocate some of my time in the next few days to this)
See https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-482198124 for the latest status
willthames
on 7 Jun 2019
@Mwea the global pool is stored in cfs_b->runtime_remaining. As that gets assigned to per cpu run queues (cfs_rq), the amount remaining in the global pool gets decremented. cfs_bandwidth_slice_us is the amount of cpu runtime that gets transferred from the global pool to the per-cpu run queues. If you got throttled that would mean that you needed to run and cfs_b->runtime_remaining == 0. You would have to wait for the end of the current period (by default 100ms), for quota to be replenished to cfs_b and then distributed to your cfs_rq. I recently discovered that the amount of expired runtime is at most 1ms per cfs_rq, due to the fact the slack timer recaptures all by 1ms of unused quota from per-cpu run queues. That 1ms is then wasted/expired at the end of the period. In a worse case scenario where the application spreads accross 88 cpus that could potentially be 88ms of wasted quota per 100ms period. That actually led to an alternative proposal which was to allow the slack timer to recapture all of the unused quota from the idle per-cpu runqueues.
As for the lines you specifically highlight. My proposal is to remove expiration of runtime that has been assigned to per-cpu run-queues completely. Those lines are part of the fix for 512ac999. That fixed an issue where clock skew between per-cpu run queues caused quota to be prematurely expired thereby throttling applications that have yet to use quota (afaiu). Basically they increment expires_seq on each period boundary. expires_seq should therefore match between each of the cfs_rq when they are on the same period.
@mariusgrigoriu - if you are hitting high throttling with low cpu usage and your kernel is pre-512ac999 you probably need 512ac999. If you are post 512ac999 you are likely hitting the issue I explained above that is currently being discussed on lkml.
There are lots of ways to mitigate this issue.
- Cpu pinning
- Decreasing the number of threads your application spawn
- Over-allocate quota for applications experiencing throttling.
- Turn off hard limits for now.
- Build a custom kernel with either of the proposed changes.
chiluk
on 7 Jun 2019
@chiluk any chance you've already posted a version of this patch that is compatible with kernel 4.14 already? I'm looking to test it pretty aggressively since we've just upgraded a few thousand hosts to 4.14.121 (from 4.9.62) and are seeing:
- A reduction in throttling for memcached, mysql, nginx, etc
- An increase in throttling for our java apps
Really want to roll forward to get the best of both worlds here. I can attempt to port it over myself next week, but if you already have one, that would be awesome.
 PaulFurtado
on 21 Jun 2019
PaulFurtado
on 21 Jun 2019
@PaulFurtado
I have actually rewritten the patch over the last few days given Ben Segull's suggestions. A new kernel patch will be forthcoming as soon as I can get it some test time on our clusters.
chiluk
on 24 Jun 2019
@chiluk any update on that patch? No worries if not, I'm just making sure I didn't miss the patch going by
PaulFurtado
on 18 Jul 2019
@PaulFurtado , the patch has been "approved" by the CFS author, and I'm just waiting for the scheduler maintainers to integrate it and push it to Linus.
chiluk
on 24 Jul 2019
@chiluk Thank you!
I just backported the patch onto kernel 4.14, which is our current production kernel.
I made a gist with the backport and some results from your fibtest here: https://gist.github.com/PaulFurtado/ff6c67ec87416b66ba1c6fc70f7beec1
On current generation c5.9xlarge and m5.24xlarge ec2 instance which we use in our kubernetes and mesos clusters, the patch doubles the performance of your fibtest program. On a previous generation r4.16xlarge instance type, it manages 1.5x more CPU utilization but barely any additional iterations (which I'm assuming is just due to the CPU generation and the exponential nature of the fibonacci sequence). These numbers all hold pretty much exactly if I increase the test to 30s instead of the 5s default.
We'll start rolling this into our QA environment this week to get some metrics from our apps that are suffering from the worst throttling. Thanks again!
PaulFurtado
on 26 Jul 2019
@PaulFurtado first off thank you for the testing. I'll assume you are running kernel.org 4.14 or the ubuntu 4.14, both of which have 512ac999 in it. As for fibtest Iterations completed isn't as important as cpu time utilized, as iterations completed can be heavily affected by cpu mhz while running the test (especially in the cloud where I'm not sure how much control you have over that).
chiluk
on 31 Jul 2019
I'll assume you are running kernel.org 4.14 or the ubuntu 4.14, both of which have 512ac999 in it.
Yes, we run mainline 4.14 (well, plus the patch set from the Amazon Linux 2 kernel, but none of those patches matter in this case).
512ac999 landed in mainline 4.14.95, and we observed its affects upon upgrading from 4.14.77 to 4.14.121+. It made our memcached containers (very low thread count) go from inexplicable throttling to no throttling, but made our golang and java containers (very high thread count) experience more throttling.
As for fibtest Iterations completed isn't as important as cpu time utilized, as iterations completed can be heavily affected by cpu mhz while running the test (especially in the cloud where I'm not sure how much control you have over that).
On newer/bigger EC2 instances, you actually do get a decent level of control over processor states, so we run with turbo boost off and don't allow the cores to idle. Though, I actually just realized that we're tuning c-states, but not p-states and the instance type that didn't see any increase in iterations was one where p-states are controllable, so that may very well explain it.
first off thank you for the testing
No problem at all, things have been stable in our pre-qa environment over the weekend, and we'll begin rolling the patch out to our main QA environment tomorrow where we'll get to see more real-world effects. Given that memcached had benefited from the previous patch, we really wanted to have our cake and eat it too with both patches in place so we were happy to test. Thanks again for all the work you've been putting into throttling!
PaulFurtado
on 31 Jul 2019
Just wanted to leave a note, regarding the kernel patch being discussed....
I have adapted it to the kernel we're using in current testing, and see some huge wins on CFS throttling rates, however I will mention that if you have previously set the cfs period down to 10ms as a mitigation, you're going to want to bring that back up to 100ms to see the benefits of the change.
 jhohertz
on 6 Aug 2019
jhohertz
on 6 Aug 2019
The patch landed on tip this morning.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Once it hits Torvald's tree, I'll submit it for linux-stable inclusion, and subsequently major distros (Redhat/Ubuntu). If you care about something else, and they aren't following linux-stable patches you might want to submit it directly.
chiluk
on 8 Aug 2019
I've tested patch (ubuntu 18.04, 5.2.7 kernel, node: 56 core CPU E5-2660 v4 @ 2.00GHz) with our cpu-heavy image processing golang microservice and got pretty impressive results. Performance like if I disable CFS on node completelly.
I've got 5-35% less latency and 5-55% more RPS depending on concurrency / CPU utilization at near zero throttling rate.
Thanks, @chiluk !
As said @jhohertz , cfs quota should be reverted to 100ms, I've tested with lower periods and got high throttling and performance degradation.
 zigmund
on 10 Aug 2019
zigmund
on 10 Aug 2019
For more performance with golang set GOMAXPROCS to ceil(quota)+2. The plus 2 is to guarantee some concurrency.
chiluk
on 12 Aug 2019
@chiluk tested with GOMAXPROCS=8 vs GOMAXPROCS=10 with cpu.limit=8 - not a big difference, something about 1-2%.
zigmund
on 13 Aug 2019
@zigmund that's because your cpu.limit is set to the whole number 8 which should bind your processes to a cpuset of 8 cpus. Your 1-2% difference is just the increase in overhead for context switching with your 2 additional Goroutine runners on your 8 cpu taskset.
I should have said that setting GOMAXPROCS=# is a good workaround for go programs until the kernel patches get widely distributed.
chiluk
on 26 Aug 2019
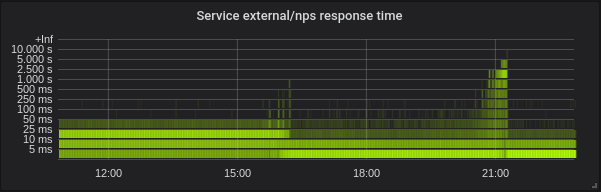
We've migrated our production clusters to patched kernel and now I can share you some interesting moments.
Statistics from one of our clusters - 4 nodes of 72 core E5-2695 v4 @ 2.10GHz, 128Gb RAM, Debian 9, 5.2.7 kernel with patch.
We have mixed loads consist mostly of golang services, but also have php and python.
Golang. Latency is lower, setting correct GOMAXPROCS is absolutely must-have. Here is service with default GOMAXPROCS=72. We've changed the kernel at ~16 and after that latency gone down and CPU utilization gone up heavily. At 21:15 I set correct GOMAXPROCS and CPU utilization normalized.

Python. Everything became better with patch without any extra movements - CPU utilization and latency gone down.

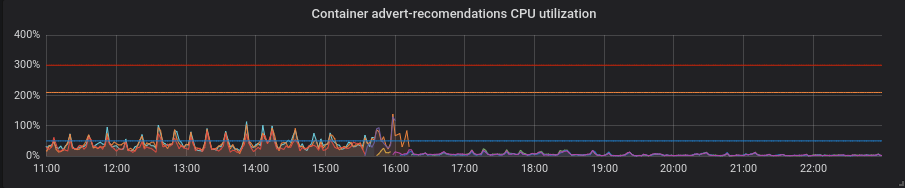
PHP. CPU utilization is the same, latency gone little down on some of services. Not a big profit.
zigmund
on 3 Sep 2019
Thanks @zigmund.
I'm not sure I get it when you say I setted correct GOMAXPROCS...
I assume you're not running only one pod on the 72 cores node, so you set GOMAXPROCS to something lower, maybe equal to the Pod's CPU Limits right ?
prune998
on 3 Sep 2019
Thanks @zigmund. The go changes are pretty much in line with what was expected.
I'm really surprised by the python improvements though as I expected the GIL to largely negate the benefits of this. If anything this patch should almost purely decrease response time, decrease percentage of periods throttled, and increase cpu utilization. Are you sure your python application was still healthy?
chiluk
on 3 Sep 2019
@prune998 sorry, maybe misspelling. I set GOMAXPROCS = limits.cpu. At the moment we have about ~110 pods per node in this cluster.
@chiluk I'm not strong in python and don't know how patch affected at lower layer. But application is healthy with no issues, I've checked it after kernel change.
zigmund
on 4 Sep 2019
@chiluk Would you please explain how we can follow the progress of your patch into various Linux distros? I'm particularly interested in debian and AWS Linux, but I expect other people are interested in Ubuntu etc., so whatever light you can shed, thank you.
 Nuru
on 13 Sep 2019
Nuru
on 13 Sep 2019
@Nuru https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html?highlight=stable%20rules ... Basically I will submit through linux-stable once my patch hit's Linus' tree, *(maybe earlier), and then all of the distros should be following linux-stable process, and be pulling in patches accepted by the stable maintainers to their distro specific kernels. If they aren't you shouldn't be running their distros.
chiluk
on 13 Sep 2019
@chiluk I know nothing about the Linux development process. By "Linus' tree" do you mean https://github.com/torvalds/linux ?
Nuru
on 14 Sep 2019
Linus's tree lives here, https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/. My changes are currently staged on linux-next which is the development integration tree. Yeah kernel development is a bit stuck in the dark ages, but it works.
He will likely pull in changes from the linux-next tree once 5.3 is released and he starts development on 5.4-rc0. That is around the time frame I expect the stable kernels to start pulling in this fix. Whenever Linus feels 5.3 is stable is anyone's guess.
chiluk
on 14 Sep 2019
[Linus] will likely pull in changes from the linux-next tree once 5.3 is released and he starts development on 5.4-rc0. That is around the time frame I expect the stable kernels to start pulling in this fix. Whenever Linus feels 5.3 is stable is anyone's guess.
@chiluk Looks like Linus decided 5.3 was stable on Sept 15, 2019. So, what is "linux-next" and how do we track the progress of your patch through the next steps?
Nuru
on 20 Sep 2019
Has anyone built debian stretch packages and/or an AWS image that includes this patch? I'm about to do so using https://github.com/kubernetes-sigs/image-builder/tree/master/images/kube-deploy/imagebuilder
Just thought I'd avoid duplicating efforts if it exists already.
blakebarnett
on 24 Sep 2019
This has now been merged into Linus' tree and should be released with 5.4. I also just submitted it to linux-stable, and assuming that goes smoothly all distros that correctly follow stable process should start picking it up shortly.
chiluk
on 25 Sep 2019
Is anyone in the know how to follow if/how this change makes it down to CentOS(7)? Not sure how backporting etc. works.
 till
on 26 Sep 2019
till
on 26 Sep 2019
@till https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-531370333
For the stable kernel conversation is going on here.
https://lore.kernel.org/stable/CAC=E7cUXpUDgpvsmMaMU6sAydbfD0FEJiK25R1r=e9=YtcPjGw@mail.gmail.com/
Also for those going to KubeCon, I'll be presenting this issue there.
https://sched.co/Uae1
chiluk
on 3 Oct 2019
Any word from the scheduler maintainers re: the ack Greg HK was looking for to get it into stable tree(s)?
jhohertz
on 18 Oct 2019
Greg KH has held off on making a decision about this patch because the scheduler maintainers have been unresponsive (the probably just missed the mail). Comment from anyone other than me on LKML that has tested this patch and thinks it should be backported would be appreciated.
chiluk
on 18 Oct 2019
For folks using CoreOS, there's an open issue requesting that @chiluk's patch be backported.
 evanfoster
on 1 Nov 2019
evanfoster
on 1 Nov 2019
CoreOS kernel 4.19.82 has the fixes: https://github.com/coreos/linux/pull/364
CoreOS Container Linux 2317.0.1 (alpha channel) has the fixes: https://github.com/coreos/coreos-overlay/pull/3796 http://coreos.com/releases/#2317.0.1
Backports to Linux stable appear to be stalled because the patches do not apply cleanly. @chiluk Are you going to work on backports for Linux stable? If so, will you please backport to 4.9 so that it gets into Debian "stretch" and is picked up by kops? Although I guess it's going to end up taking as much as 6 months to get it into "stretch" and maybe by then kops will have migrated to "buster".
Nuru
on 8 Nov 2019
@Nuru, I backported the patch and made stretch packages (based on the stretch-backports kernel) and a kops 1.11-friendly AMI if you'd like to test:
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.buildinfo
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm-dbg_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-headers-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.changes
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-libc-dev_4.19.67-1_amd64.deb
293993587779/k8s-1.11-debian-stretch-amd64-hvm-ebs-2019-09-26
blakebarnett
on 8 Nov 2019
@blakebarnett Thanks for your effort, and sorry to bother you, but I'm more than a little confused.
- "stretch" is based on Linux 4.9, but all your links are for 4.19.
- You say you backported "the patch" but there are 3 patches (I guess the third is not really important:
- 512ac999 sched/fair: Fix bandwidth timer clock drift condition
- de53fd7ae sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
- 763a9ec06 sched/fair: Fix -Wunused-but-set-variable warnings
Did you backport all 3 patches to 4.9? (I don't know what to do with the Debian packages to look and see if the changes are in there, and the "changes" document does not address what has really changed.)
Also, in what regions is your AMI available?
Nuru
on 8 Nov 2019
No I used the stretch-backports kernel, which is 4.19, as it has fixes we also needed on AWS (especially for M5/C5 instance types)
I applied a diff that incorporated all the patches I believe, I had to slightly change it to remove extra references to variables in 4.19 that were deleted elsewhere, I first applied this https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-515324561 and then needed to add:
--- kernel/sched/fair.c 2019-09-25 16:06:02.954933954 -0700
+++ kernel/sched/fair.c-b 2019-09-25 16:06:56.341615817 -0700
@@ -4928,8 +4928,6 @@
cfs_b->period_active = 1;
overrun = hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
- cfs_b->runtime_expires += (overrun + 1) * ktime_to_ns(cfs_b->period);
- cfs_b->expires_seq++;
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
--- kernel/sched/sched.h 2019-08-16 01:12:54.000000000 -0700
+++ sched.h.b 2019-09-25 13:24:00.444566284 -0700
@@ -334,8 +334,6 @@
u64 quota;
u64 runtime;
s64 hierarchical_quota;
- u64 runtime_expires;
- int expires_seq;
short idle;
short period_active;
@@ -555,8 +553,6 @@
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
- int expires_seq;
- u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock;
The AMI is published to us-west-1
Hope that helps!
blakebarnett
on 8 Nov 2019
I have backported these patches and submitted them to the linux-stable kernels
v4.14 https://lore.kernel.org/stable/[email protected]/
v4.19 https://lore.kernel.org/stable/[email protected]/#t
chiluk
on 8 Nov 2019
Hello,
following the integration of patch on 4.19 branch, I have opened a bug report on debian for a proper upgrade of kerner on buster and stretch-backport :
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=946144
don't hesitate to add new comment for the upgrade of debian package.
 alexises
on 4 Dec 2019
alexises
on 4 Dec 2019
Hope this isn't too spammy but I wanted to link this excellent talk from @chiluk going into many background details related to this issue https://youtu.be/UE7QX98-kO0.
 bboreham
on 4 Dec 2019
bboreham
on 4 Dec 2019
Is there a way to avoid throttling on GKE? We just had huge issue where one method on php container was taking 120s instead of usual 0.1 s
 bartoszhernas
on 5 Dec 2019
bartoszhernas
on 5 Dec 2019
remove cpu limits
 monotek
on 5 Dec 2019
monotek
on 5 Dec 2019
We did already, the container is being throttled when CPU requests are too small. That's the core of the issue, lack of limits and only using CPU requests will still lead to throttling :(
bartoszhernas
on 5 Dec 2019
@bartoszhernas I think you are using the wrong word here. When people on this thread refer to "throttling" they are referring to cfs bandwidth control, nr_throttled in cpu.stat for the cgroup increasing. That is only enabled when cpu limits are enabled. Unless GKE is adding limits to your pod without your knowledge I would not call what you are hitting as throttling.
I would call what you've described "contention for the processor". I suspect you probably have multiple incorrectly sized applications *(requests), that are contending for the processor or other resource on the box because they are frequently using more than what they requested. This is the precise reason we use limits. So that those improperly sized applications can only affect other applications on the box so much.
The other possibility is that your insufficient request amount is leading to simply poor scheduling behavior. Setting requests low is similar to setting a positive "nice" value relative to higher "request" applications. For more information on that check out soft limits.
chiluk
on 5 Dec 2019
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 4 Mar 2020
fejta-bot
on 4 Mar 2020
/remove-lifecycle stale
Nuru
on 4 Mar 2020
From my understanding, the underlying issue in the kernel was fixed and made available in e.g. ContainerLinux in https://github.com/coreos/bugs/issues/2623.
Anybody aware of remaining issues after this kernel patch?
 sfudeus
on 4 Mar 2020
sfudeus
on 4 Mar 2020
@sfudeus Kubernetes can be run on any flavor of Linux, or, AFAIK, any POSIT-compliant flavor of Unix. This bug was never an issue for people not using Linux, has been fixed for some Linux-derived distributions, and not fixed for others.
The underlying issue was fixed in Linux kernel 5.4, which hardly anyone is using at this point. Patches were made available for backporting to various older kernels and including in new Linux distributions that are not ready to move to the 5.4 kernel yet, of which there are many. As you can see from the above list of commits referencing this issue, the bug fix patches are still in the process of being incorporated into the myriad Linux distributions that someone might be using Kubernetes on.
Therefore, I would like to keep this issue open a while it is still seeing active commit references. I would also like to see it closed with a script or other easy method someone can use to determine whether or not their Kubernetes installation is affected.
Nuru
on 5 Mar 2020
@Nuru Fine for me, I just wanted to make sure that no other kernel issue is left, which is already known. I personally wouldn't keep this open longer than the larger distributions having incorporated the fix, waiting for endless IoT devices can mean waiting endlessly. Closed issues can be found as well. But that is only my 2 cents.
sfudeus
on 5 Mar 2020
Not sure if this is the correct place to inform people, but not really sure where else to bring this up:
We're running the 5.4 Linux kernel on Debian Buster (using the buster-backports kernel) using k8s 1.15.10 cluster and we're still seeing issues with this. Especially for Pods that usually have very little to do (kube-downscaler is the example we keep returning to, which usually requires about 3m of CPU) and that have only very few cpu resources assigned (50m in the case of kube-downscaler in our cluster) we still see a very high throttling value. For reference, the kube-downscaler is basically a Python script that runs a sleep for 30 minutes before it does anything. cAdvisor shows the increase of container_cpu_cfs_throttled_periods_total for this container to be always more or less similar to the container_cpu_cfs_periods_total value of this container (both are around 250 when checking the increase at 5m intervals). We would expect the throttled periods to be near 0.
Are we measuring this incorrectly? Is cAdvisor outputting incorrect data? Is our assumption correct that we should see a drop in the throttled periods? Any advice would be appreciated here.
After switching to the 5.4 kernel we did see the number of Pods with this problem decrease a bit (about 40%), but we are currently unsure if what we're seeing is an actual problem or not. Mainly, we're not sure when looking at the above statistics what "throttling" really means here if we get these values with the 3m average cpu usage. The node it's running on is not overcommitted at all and has an average CPU usage of less then 10%.
 timstoop
on 5 Mar 2020
timstoop
on 5 Mar 2020
@timstoop the intervals which the scheduler cares about are on the realm of microseconds, not large 30 minute ranges. If a container has a CPU limit of 50 millicpu and it uses 50 millicpu over the span of 100 microseconds, it will get throttled, regardless of whether it spend 30 minutes idle. In general, 50 millicpu is an extremely small CPU limit. If a python program even makes a single HTTPS request with that low of a limit, it's pretty much guaranteed to get throttled.
The node it's running on is not overcommitted at all and has an average CPU usage of less then 10%.
Just to clarify: the load of the node and other workloads on it have nothing to do with throttling. Throttling is only considering the container/cgroup's own limit.
PaulFurtado
on 5 Mar 2020
@PaulFurtado Thanks for your answer! However, the Pod itself has an average usage of 3m cpu during that sleep and it's still being throttled. It's not making any request during that time, it's waiting on the sleep. I'd hope it can do that while not hitting the 50m, right? Or is that an incorrect assumption anyway?
timstoop
on 5 Mar 2020
I think this is likely just such a low number that there's going to be accuracy issues. And 50m is so low that anything at all could trip it up. Python's runtime may also be performing background tasks in threads while you sleep.
PaulFurtado
on 5 Mar 2020
You were right, I was making assumptions that were not true. Thanks for your guidance! It's making sense to me now.
timstoop
on 5 Mar 2020
Just wanted to jump in and say things over here have been substantially improved since the kernel patch hit the 4.19 LTS kernels, and it showed up on CoreOS/Flatcar. Looking at the moment, the only things I see being throttled are a couple things I should probably raise limits on. :smile:
jhohertz
on 5 Mar 2020
@sfudeus @chiluk Is there any simple test to see if your kernel has this fixed or not?
I cannot tell if kope.io/k8s-1.15-debian-stretch-amd64-hvm-ebs-2020-01-17 (the current official kops image) has been patched or not.
Nuru
on 20 Mar 2020
I agree with @mariusgrigoriu , for pods that runs on exclusive cpuset under static cpu policy, we can simply disable cpu quota limit - it can only run on its exclusive cpu set anyway. The patch above is for this purpose and for this type of pods only.
 jianzzha
on 6 Apr 2020
jianzzha
on 6 Apr 2020
@Nuru I wrote https://github.com/indeedeng/fibtest
It's about as definitive of a test as you can get, but you'll need a C compiler.
Ignore the number of iterations completed, but focus on the amount of time used for the single threaded vs multi-threaded run.
chiluk
on 10 Apr 2020
I guess a good way to see what kernels have been patched is in one of the last slides from @chiluk (thanks for this btw) talk https://www.youtube.com/watch?v=UE7QX98-kO0
Kernel 4.15.0-67 seems to have the patch (https://launchpad.net/ubuntu/+source/linux/4.15.0-67.76) however, we are still seeing throttling in some Pods where requests/limit is way above their CPU usage.
I'm talking about around 50ms usage having request set to 250m and limit to 500m. We are seeing around 50% of the CPU periods being throttled, is this value maybe low enough to be expected and can be accepted? I'd like it to see it down to zero, we shouldn't be throttled at all if the usage is not even close to the limit.
Is someone using the new patched kernel still having some throttling?
 vgarcia-te
on 22 Apr 2020
vgarcia-te
on 22 Apr 2020
@vgarcia-te There are far too many kernels circulating around to know from a list which have been patched and which have not. Just look at all the commits referencing this issue. Several hundred. My reading of the changelog for Ubuntu suggests that 4.15 has not yet been patched (except mabye for running on Azure), and the patch you linked to was rejected.
Personally, I'm interested in the 4.9 series because that is what kops is using, and would like to know when they release an AMI with a fix.
Meanwhile, you can try running @bobrik's test which seems pretty good to me.
wget https://gist.githubusercontent.com/bobrik/2030ff040fad360327a5fab7a09c4ff1/raw/9dcf83b821812064fa7fb056b8f22cbd5c4364f1/cfs.go
sudo docker run --rm -it --cpu-quota 20000 --cpu-period 100000 -v $(pwd):$(pwd) -w $(pwd) golang:1.9.2 go run cfs.go -iterations 15 -sleep 1000ms
With a properly functioning CFS, burn times will always be 5ms. With the affected kernels I have tested, using the above numbers, I frequently see burn times of 99ms. Anything over 6ms is an problem.
Nuru
on 22 Apr 2020
@nuru thanks for the script to find the issue is there or not.
@justinsb Please suggest if the default kops images have the patch or not
https://github.com/kubernetes/kops/blob/master/channels/stable
Opened an issue: https://github.com/kubernetes/kops/issues/8954
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-617586330
Update: Ran the test in kops 1.15 image, un-necessary throttling is there https://github.com/kubernetes/kops/issues/8954#issuecomment-617673755
alok87
on 22 Apr 2020
@Nuru
2020/04/22 11:02:48 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 6ms
2020/04/22 11:02:49 [1] burn took 5ms, real time so far: 1012ms, cpu time so far: 12ms
2020/04/22 11:02:50 [2] burn took 5ms, real time so far: 2017ms, cpu time so far: 18ms
2020/04/22 11:02:51 [3] burn took 5ms, real time so far: 3023ms, cpu time so far: 23ms
2020/04/22 11:02:52 [4] burn took 5ms, real time so far: 4028ms, cpu time so far: 29ms
2020/04/22 11:02:53 [5] burn took 5ms, real time so far: 5033ms, cpu time so far: 35ms
2020/04/22 11:02:54 [6] burn took 5ms, real time so far: 6038ms, cpu time so far: 40ms
2020/04/22 11:02:55 [7] burn took 5ms, real time so far: 7043ms, cpu time so far: 46ms
2020/04/22 11:02:56 [8] burn took 5ms, real time so far: 8049ms, cpu time so far: 51ms
2020/04/22 11:02:57 [9] burn took 5ms, real time so far: 9054ms, cpu time so far: 57ms
2020/04/22 11:02:58 [10] burn took 5ms, real time so far: 10059ms, cpu time so far: 63ms
2020/04/22 11:02:59 [11] burn took 5ms, real time so far: 11064ms, cpu time so far: 69ms
2020/04/22 11:03:00 [12] burn took 5ms, real time so far: 12069ms, cpu time so far: 74ms
2020/04/22 11:03:01 [13] burn took 5ms, real time so far: 13074ms, cpu time so far: 80ms
2020/04/22 11:03:02 [14] burn took 5ms, real time so far: 14079ms, cpu time so far: 85ms
those results are from the
Linux <servername> 4.15.0-96-generic #97-Ubuntu SMP Wed Apr 1 03:25:46 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
It's a default latest stable ubuntu kernel in ubuntu 18.04.
So, it looks like patch is there.
 zerkms
on 22 Apr 2020
zerkms
on 22 Apr 2020
@zerkms Where did you run your tests on Ubuntu 18.04? It looks to me like the patch may have only made it into the kernel for Azure. If you can find a release note saying where it was applied to the Ubuntu linux package please share. I can't find it.
Note also that this test was not able to reproduce the problem on CoreOS, either. It could be that in the default configuration CFS scheduling was globally disabled.
Nuru
on 22 Apr 2020
@Nuru
Where did you run your tests on Ubuntu 18.04?
One one of my servers.
I did not check release notes, I'm not even sure what to look for, and nevertheless - it's a default kernel like everyone has. 🤷
zerkms
on 22 Apr 2020
the patch should be here in ubuntus kernel git:
https://kernel.ubuntu.com/git/ubuntu/ubuntu-bionic.git/commit/?id=aadd794e744086fb50cdc752d54044fbc14d4adb
and here the ubuntu bug concerning it:
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1832151
it should be released in the bionic.
You can make sure by running apt-get source linux and check in the downloaded the source code.
juliantaylor
on 22 Apr 2020
@zerkms By "where did you run your tests" I mean was it a server in your office, a server in GCP, AWS, Azure, or somewhere else?
Obviously there is a lot I do not understand about how Ubuntu is distributed and maintained. I am confused by your uname -a output, too. The Ubuntu Release Notes say:
18.04.4 ships with a v5.3 based Linux kernel updated from the v5.0 based kernel in 18.04.3.
and also says 18.04.4 was released February 12, 2020. Your output says you are running a v4.15 kernel compiled April 1, 2020.
@juliantaylor I don't have an Ubuntu server or a copy of the Git repo, and do not know how to track where a specific commit like aadd794e7440 made it into a published stable kernel. If you can show me how to do that, I would appreciate it.
When I look at the launchpad bug comments I see
- This bug was fixed in the package linux-azure - 5.0.0-1027.29
- This bug was fixed in the package linux-azure - 5.0.0-1027.29~18.04.1
but this specific patch (sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices) is not listed under
- This bug was fixed in the package linux - 4.15.0-69.78
I also do not see "1832151" listed in the Ubuntu 18.04.4 Release notes.
A previous comment said it was patched in 4.15.0-67.76 but I see no linux-image-4.15.0-67-generic package.
I am far from an expert on Ubuntu and find this patch tracking unacceptably difficult, so that is as far as I have looked.
I hope you now see why I am not confident this patch was actually included in Ubuntu 18.04.4, which is the current version of 18.04. My _best guess_ is that it was released as a kernel update after 18.04.4 was released, and is probably included if your Ubuntu kernel reports 4.15.0-69 or later, but if you just download 18.04.4 and do not update it, it will not have the patch.
Nuru
on 22 Apr 2020
I just ran that Go test (very useful) in kernel 4.15.0-72 in a baremetal server in a datacenter and it seems the patch is there:
2020/04/22 21:24:27 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 7ms
2020/04/22 21:24:28 [1] burn took 5ms, real time so far: 1010ms, cpu time so far: 13ms
2020/04/22 21:24:29 [2] burn took 5ms, real time so far: 2015ms, cpu time so far: 20ms
2020/04/22 21:24:30 [3] burn took 5ms, real time so far: 3020ms, cpu time so far: 25ms
2020/04/22 21:24:31 [4] burn took 5ms, real time so far: 4025ms, cpu time so far: 32ms
2020/04/22 21:24:32 [5] burn took 5ms, real time so far: 5030ms, cpu time so far: 38ms
2020/04/22 21:24:33 [6] burn took 5ms, real time so far: 6036ms, cpu time so far: 43ms
2020/04/22 21:24:34 [7] burn took 5ms, real time so far: 7041ms, cpu time so far: 50ms
2020/04/22 21:24:35 [8] burn took 5ms, real time so far: 8046ms, cpu time so far: 56ms
2020/04/22 21:24:36 [9] burn took 5ms, real time so far: 9051ms, cpu time so far: 63ms
2020/04/22 21:24:37 [10] burn took 5ms, real time so far: 10056ms, cpu time so far: 68ms
2020/04/22 21:24:38 [11] burn took 5ms, real time so far: 11061ms, cpu time so far: 75ms
2020/04/22 21:24:39 [12] burn took 5ms, real time so far: 12067ms, cpu time so far: 81ms
2020/04/22 21:24:40 [13] burn took 5ms, real time so far: 13072ms, cpu time so far: 86ms
2020/04/22 21:24:41 [14] burn took 5ms, real time so far: 14077ms, cpu time so far: 94ms
I can also see that the same execution in kernel 4.9.164 in the same type of server shows burns over 5ms:
2020/04/22 21:24:41 [0] burn took 97ms, real time so far: 97ms, cpu time so far: 8ms
2020/04/22 21:24:42 [1] burn took 5ms, real time so far: 1102ms, cpu time so far: 12ms
2020/04/22 21:24:43 [2] burn took 5ms, real time so far: 2107ms, cpu time so far: 16ms
2020/04/22 21:24:44 [3] burn took 5ms, real time so far: 3112ms, cpu time so far: 24ms
2020/04/22 21:24:45 [4] burn took 83ms, real time so far: 4197ms, cpu time so far: 28ms
2020/04/22 21:24:46 [5] burn took 5ms, real time so far: 5202ms, cpu time so far: 32ms
2020/04/22 21:24:47 [6] burn took 94ms, real time so far: 6297ms, cpu time so far: 36ms
2020/04/22 21:24:48 [7] burn took 99ms, real time so far: 7397ms, cpu time so far: 40ms
2020/04/22 21:24:49 [8] burn took 100ms, real time so far: 8497ms, cpu time so far: 44ms
2020/04/22 21:24:50 [9] burn took 5ms, real time so far: 9503ms, cpu time so far: 52ms
2020/04/22 21:24:51 [10] burn took 5ms, real time so far: 10508ms, cpu time so far: 60ms
2020/04/22 21:24:52 [11] burn took 5ms, real time so far: 11602ms, cpu time so far: 64ms
2020/04/22 21:24:53 [12] burn took 5ms, real time so far: 12607ms, cpu time so far: 72ms
2020/04/22 21:24:54 [13] burn took 5ms, real time so far: 13702ms, cpu time so far: 76ms
2020/04/22 21:24:55 [14] burn took 5ms, real time so far: 14707ms, cpu time so far: 80ms
So, my problem is that i still see CPU throttling even my kernel seems to be patched
vgarcia-te
on 22 Apr 2020
@Nuru right, sorry. That was my bare metal server hosted in the office.
and also says 18.04.4 was released February 12, 2020. Your output says you are running a v4.15 kernel compiled April 1, 2020.
That's because it's a server LTS: you need to opt-in HWE explicitly with it to have newer kernels, otherwise you just run mainline.
And both mainline and HWE kernels are released regularly, so nothing suspicious in having a recently built kernel: http://changelogs.ubuntu.com/changelogs/pool/main/l/linux-meta/linux-meta_4.15.0.96.87/changelog
zerkms
on 22 Apr 2020
@zerkms Thanks for the info. I remain confused, but this is not the place to educate me.
@vgarcia-te If your kernel is patched, which it seems to be, then the throttling is not due to this bug. I'm not sure of your terminology when you say:
I'm talking about around 50ms usage having request set to 250m and limit to 500m. We are seeing around 50% of the CPU periods being throttled, is this value maybe low enough to be expected and can be accepted?
Kubernetes CPU resource is measured in CPUs, 1 meaning 100% of 1 full CPU, 1m meaning 0.1% of 1 CPU. So your limit of "500m" says allow 0.5 CPUs.
The default scheduling period for CFS is 100ms, so setting the limit to 0.5 CPUs would limit your process to 50ms of CPU every 100ms. If your process tries to exceed that, it will get throttled. If your process typically runs more than 50ms in a single pass, then yes, you would expect it to get throttled by a properly working scheduler.
Nuru
on 23 Apr 2020
@Nuru that makes sense, but let me understand this, given that the default cpu period is 100ms, in the case a process gets 1 CPU assigned, if that process runs for more than 100ms in a single pass, will it be throttled?
Does this mean that in linux, where the default cpu period is 100ms, any process that has a limit that runs for more than 100ms in a single pass, is going to get throttled?
What would be a good limit configuration for a process that takes more than 100ms in a single pass but it is idle the rest of its time?
vgarcia-te
on 23 Apr 2020
@vgarcia-te asked
Given that the default cpu period is 100ms, in the case a process gets 1 CPU assigned, if that process runs for more than 100ms in a single pass, will it be throttled?
Of course scheduling is insanely complicated so I can't give you a perfect answer, but the simplified answer is no. More detailed explanations are here and here.
All unix processes are subject to preemptive scheduling based on time slices. Back in the single core single CPU days, you still had 30 processes running "simultaneously". What happens is that they run for a while and either sleep or, at the end of their time slice, get put on hold so something else can run.
The CFS with quotas takes that a step further.
Ask yourself, though, when you say you want a process to use 50% of a CPU, what are you really saying? Are you saying that it is fine if it hogs 100% of the CPU for 5 minutes as long as it then does not run at all for the following 5 minutes? That would be 50% usage over 10 minutes, but it is not acceptable to most people because of the latency issues.
So CFS defines a "CPU Period" that is the window of time over which it enforces quotas. On a machine with 4 cores and a 100ms CPU period, the scheduler has 400ms of CPU time to allocate over 100ms of real (wall clock) time. If you are running a single thread of execution that can not be parallelized, then that thread can use at most 100ms of CPU time per period, which would be 100% of 1 CPU. if you set its quota to 1 CPU, it should never get throttled.
If you set the quota to 500m (0.5 CPUs), then the process gets 50ms to run every 100ms. Any 100ms period is uses less than 50ms it should not get throttled. Ayn 100ms period it is not finished after running 50ms, it gets throttled until the next 100ms period. That maintains a balance between latency (how long it has to wait to be able to run at all) and hogging (how long it is allowed to keep other processes from running).
Nuru
on 23 Apr 2020
@Nuru my slides are correct. I'm a also an Ubuntu developer *(only in my spare time now). Your best bet is to read the sources, and check git blame +tag --contains to track when the patch hits the version of the kernel you care about.
chiluk
on 26 Apr 2020
@chiluk I had not seen your slides. For others who haven't seen them, here is where they say the patch has landed as of some time ago:
- Ubuntu 4.15.0-67+
- Ubuntu 5.3.0-24+
- RHEL7 kernel 3.10.0-1062.8.1.el7
and of course Linux stable v4.14.154 , v4.19.84, 5.3.9. I note it is also in Linux stable 5.4-rc1.
I'm still struggling to understand the various CFS scheduler bugs and find reliable, easy-to-interpret tests that would work on a small AWS server, because I am supporting a wide variety of kernels from legacy installations. As I understand the timeline, a bug was introduced in Linux kernel v3.16-rc1 in 2014 by
[51f2176d74ac](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=51f2176d74ac) sched/fair: Fix unlocked reads of some cfs_b->quota/period.
This caused different CFS throttling issues. I think the issues I was seeing under kops Kubernetes clusters were due to this bug, since they were using 4.9 kernels.
51f2176d74ac was fixed in 2018 kernel v4.18-rc4 with
[512ac999](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) sched/fair: Fix bandwidth timer clock drift condition
but that introduced the bug @chiluk fixed with
[de53fd7ae](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425) sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
It is, of course, not Chiluk's or any other one person's fault that the kernel patches are hard to track across distributions. It remains frustrating for me, though, and contributes to my confusion.
For example, on Debuan buster 10 (AWS AMI debian-10-amd64-20191113-76), the kernel version is reported as
Linux ip-172-31-41-138 4.19.0-6-cloud-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
As far as I can tell, this kernel should have 51f2176d74ac and NOT have 512ac999 and thus should fail the test described in 512ac999, but it does not. (I say I do not think it has 512ac999 because it was incrementally upgraded from Linux kernel 4.10 and there is no mention of that patch in the change log.) However, on a 4 cpu AWS VM it does not fail Chiluk's fibtest or Bobrik's CFS hiccups test, which suggests something else is going on.
I had similar problems reproducing any scheduling issues with CoreOS even before it received Chiluk's patch.
My thinking at the moment is that Bobrik's test is mainly a test for 51f2176d74ac, the Debian buster 10 AMI I am using _does_ have the 512ac999, just not explicitly called out in the change log, and fibtest is not a very sensitive test on a machine with only a few cores.
Nuru
on 27 Apr 2020
A 4 core cpu is probably not large enough to reproduce the problem chiluk fixed.
It should only be reproducible on larger machines with upward of maybe 40 cpus if I understood the explanation from chiluks kubecon talk (https://www.youtube.com/watch?v=UE7QX98-kO0) correctly.
There are a lot of kernel versions around and there is a lot of patching and reverting of patches going on. Changelogs and version numbers only get you so far.
The only reliable way if you have doubts is to download the source code and compare it with the changes in the patches which have been linked here.
juliantaylor
on 27 Apr 2020
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 26 Jul 2020
/remove-lifecycle stale
 yashbhutwala
on 27 Jul 2020
yashbhutwala
on 27 Jul 2020
The tests mentioned earlier in this thread do not really reproduce the issue for me (a few burns take more than 5ms but it's like 0.01% of them) but our cfs throttling metrics still show moderate amounts of throttling. We have different kernel versions across our clusters but the two most common versions are:
Debian 4.19.67-2+deb10u2~bpo9+1 (2019-11-12)- a manual backport of
5.4.38
I do not know if both bugs are supposed to be fixed in these versions, but I _think_ they're supposed to be, so I wonder if the test is not that useful. I am testing on machines with 16 cores and with 36 cores, not sure if I need even more cores for the test to be valid but we still see the throttling in these clusters so...
 2rs2ts
on 18 Aug 2020
2rs2ts
on 18 Aug 2020
Should we close this issue and ask for folks facing issues to start new ones? The spamming here is likely going to make any conversation very difficult.
 omnibs
on 31 Oct 2020
omnibs
on 31 Oct 2020
^I agree. A lot has been done to resolve this.
 sfxworks
on 31 Oct 2020
sfxworks
on 31 Oct 2020
/close
based on comments above. please open fresh issue(s) as needed.
dims
on 1 Nov 2020
@dims: Closing this issue.
In response to this:
/close
based on comments above. please open fresh issue(s) as needed.
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 1 Nov 2020
k8s-ci-robot
on 1 Nov 2020
please notify the followup issues to this issue, so people subscribed to the issue can subscribe to new issues to follow
 glensc
on 1 Nov 2020
glensc
on 1 Nov 2020
Related issues
 arun-gupta
·
3Comments
arun-gupta
·
3Comments
 pwittrock
·
3Comments
pwittrock
·
3Comments
 errordeveloper
·
3Comments
errordeveloper
·
3Comments
 chowyu08
·
3Comments
chowyu08
·
3Comments
 rhohubbuild
·
3Comments
rhohubbuild
·
3Comments
Most helpful comment
The patch landed on tip this morning.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Once it hits Torvald's tree, I'll submit it for linux-stable inclusion, and subsequently major distros (Redhat/Ubuntu). If you care about something else, and they aren't following linux-stable patches you might want to submit it directly.