Kubernetes: Cotas CFS podem levar a limitação desnecessária
/ tipo bug
Este não é um bug no Kubernets em si, é mais um aviso.
Eu li esta ótima postagem no blog:
Na postagem do blog, aprendi que k8s está usando cotas cfs para impor limites de CPU. Infelizmente, isso pode levar a restrições desnecessárias, especialmente para inquilinos bem comportados.
Veja este bug não resolvido no kernel do Linux que anunciei há algum tempo:
Há um patch aberto e bloqueado que soluciona o problema (não verifiquei se funciona):
cc @ConnorDoyle @balajismaniam
 bobrik
bobrik
Todos 142 comentários
nó / sig
/ tipo bug
 neolit123
em 20 ago. 2018
neolit123
em 20 ago. 2018
esta é uma duplicata de # 51135?
 liggitt
em 20 ago. 2018
liggitt
em 20 ago. 2018
É semelhante em espírito, mas parece ignorar o fato de que há um bug real no kernel em vez de apenas alguma compensação de configuração no período de cota do CFS. Eu gostei do # 51135 aqui atrás para dar às pessoas lá mais contexto.
bobrik
em 22 ago. 2018
Pelo que entendi, este é outro motivo para desabilitar a cota CFS ( --cpu-cfs-quota=false ) ou torná-la configurável (# 63437).
Também acho esta essência ( link do patch do Kernel) muito interessante de ver (para avaliar o impacto):
 hjacobs
em 22 ago. 2018
hjacobs
em 22 ago. 2018
cc @adityakali
 vishh
em 23 ago. 2018
vishh
em 23 ago. 2018
Outro problema com cotas é que o kubelet conta hyperthreads como "cpus". Quando um cluster fica tão carregado que duas threads estão agendadas no mesmo núcleo e o processo tem uma cota de cpu, um deles só irá funcionar com uma pequena fração do poder de processamento disponível (ele só fará algo quando algo na outra thread paralisa), mas ainda consome cota como se tivesse um núcleo físico para si. Portanto, ele consome o dobro da cota que deveria, sem fazer muito mais trabalho.
Isso tem o efeito de que em um nó de nó totalmente carregado com hyperthreading habilitado, o desempenho será a metade do que seria com hyperthreading ou cotas desabilitadas.
Imo, o kubelet, não deve considerar hyperthreads como cpus reais para evitar essa situação.
 juliantaylor
em 30 ago. 2018
juliantaylor
em 30 ago. 2018
@juliantaylor Como mencionei em # 51135, desligar a cota de CPU pode ser a melhor abordagem para a maioria dos clusters k8s executando cargas de trabalho confiáveis.
vishh
em 30 ago. 2018
Isso é considerado um bug?
Se alguns pods são controlados sem realmente esgotar seu limite de CPU, isso soa como um bug para mim.
No meu cluster, a maioria dos pods acima da cota estão relacionados a métricas (heapster, metrics-collector, node-exporter ...) ou Operators, que obviamente têm o tipo de carga de trabalho que está em problema aqui: não faça mais nada hora e acordar para reconciliar de vez em quando.
O estranho aqui é que tentei aumentar o limite, indo de 40m para 100m ou 200m , e os processos ainda estavam estrangulados.
Não consigo ver nenhuma outra métrica apontando para uma carga de trabalho que poderia desencadear esse estrangulamento.
Eu removi os limites desses pods por enquanto ... está ficando melhor, mas, bem, isso realmente parece um bug e devemos encontrar uma solução melhor do que desativar o Limits
 prune998
em 26 nov. 2018
prune998
em 26 nov. 2018
@ prune998 veja o comentário de @vishh e esta essência : o Kernel sofre um estrangulamento excessivamente agressivo, mesmo que a matemática diga que não. Nós (Zalando) decidimos desabilitar a cota CFS (CPU throttling) em nossos clusters: https://www.slideshare.net/try_except_/optimizing-kubernetes-resource-requestslimits-for-costefficiency-and-latency-highload
hjacobs
em 27 nov. 2018
Obrigado @hjacobs.
Estou no Google GKE e não vejo uma maneira fácil de desativá-lo, mas continuo pesquisando ...
prune998
em 27 nov. 2018
@ prune998 AFAIK, o Google ainda não expôs os botões necessários. Entramos com uma solicitação de recurso logo após a possibilidade de desativar o CFS no upstream, não recebemos nenhuma notícia desde então.
 timoreimann
em 27 nov. 2018
timoreimann
em 27 nov. 2018
Estou no Google GKE e não vejo uma maneira fácil de desativá-lo, mas continuo pesquisando ...
Você pode remover os limites de CPU de seus contêineres por enquanto?
vishh
em 28 nov. 2018
De acordo com os documentos do gerenciador de CPU, CFS quota is not used to bound the CPU usage of these containers as their usage is bound by the scheduling domain itself. Mas estamos enfrentando limitação de CFS.
Isso torna o gerenciador de CPU estático praticamente inútil, pois definir um limite de CPU para atingir a classe QoS garantida nega qualquer benefício devido ao afogamento.
É um bug que as cotas CFS sejam definidas para pods na CPU estática?
 mariusgrigoriu
em 12 fev. 2019
mariusgrigoriu
em 12 fev. 2019
Para contexto adicional (aprendi isso ontem): @hrzbrg (MyTaxi) contribuiu com uma sinalização para Kops para desativar a aceleração de CPU: https://github.com/kubernetes/kops/issues/5826
hjacobs
em 12 fev. 2019
Compartilhe um resumo do problema aqui. Não está muito claro qual é o problema e em que cenários os usuários são afetados e o que exatamente é necessário para corrigi-lo?
Nosso entendimento no momento é que quando cruzamos os limites, somos penalizados e estrangulados. Digamos que tenhamos uma cota de CPU de 3 núcleos e nos primeiros 5 ms consumimos 3 núcleos, então, na fatia de 100 ms, seremos limitados por 95 ms, e nesses 95 ms nossos contêineres não podem fazer nada. E vimos que fica estrangulado mesmo quando os picos de CPU não são visíveis nas métricas de uso da CPU. Presumimos que seja porque a janela de tempo de medição do uso da CPU está em segundos e o afogamento está ocorrendo no nível de microssegundos, então a média é reduzida e não é visível. Mas o bug mencionado aqui nos deixou confusos agora.
Algumas perguntas:
- Quando o nó está em 100% da CPU? Este é um caso especial em que todos os contêineres são limitados, independentemente de seu uso?
Quando isso acontece, todos os contêineres são 100% controlados pela CPU?
O que aciona esse bug para ser acionado no nó?
Qual é a diferença entre não usar
limitse desativarcpu.cfs_quota?Desativar
limitsuma solução arriscada quando há muitos pods com capacidade de explosão e um pod pode causar instabilidade no nó e afetar outros pods que estão executando suas solicitações?Separadamente, de acordo com o kernel doc, o processo pode ser acelerado quando a cota pai é totalmente consumida. O que é pai no contexto do contêiner aqui (está relacionado a esse bug)? https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
There are two ways in which a group may become throttled: a. it fully consumes its own quota within a period b. a parent's quota is fully consumed within its period- O que é necessário para corrigi-los? Atualizar a versão do kernel?
Enfrentamos uma indisponibilidade razoavelmente grande e ela parece intimamente relacionada (se não a causa raiz) a todos os nossos pods ficarem presos no loop de reinicialização de aceleração e não conseguirem aumentar a escala. Estamos investigando os detalhes para encontrar o verdadeiro problema. Abrirei uma edição separada explicando em detalhes sobre nossa interrupção.
Qualquer ajuda aqui é muito apreciada.
cc @justinsb
 alok87
em 14 fev. 2019
alok87
em 14 fev. 2019
Um de nossos usuários definiu um limite de CPU e foi forçado a cronometrar sua sondagem de atividade, causando uma interrupção do serviço.
Estamos vendo uma limitação mesmo ao fixar contêineres em uma CPU. Por exemplo, um limite de CPU de 1 e fixar esse contêiner para ser executado apenas em uma CPU. Deveria ser impossível exceder a cota dado qualquer período se sua cota fosse exatamente o número de CPU que você tem, mas vemos uma limitação em cada caso.
Eu pensei ter visto postado em algum lugar que o kernel 4.18 resolve o problema. Eu não testei ainda, então seria bom se alguém pudesse confirmar.
mariusgrigoriu
em 15 fev. 2019
https://github.com/torvalds/linux/commit/512ac999d2755d2b7109e996a76b6fb8b888631d em 4.18 parece ser o patch relevante para esse problema.
 clkao
em 23 fev. 2019
clkao
em 23 fev. 2019
@mariusgrigoriu Parece que estou preso no mesmo enigma que você descreveu aqui https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -462534360.
Observamos a limitação da CPU em pods na classe de QoS garantida com política estática CPUManager (o que não parece fazer sentido).
Remover limits para esses pods irá colocá-los na classe Burstable QoS, o que não é o que queremos, então a única opção restante é desativar as cotas de CPU CFS em todo o sistema, o que também não é algo que podemos fazer com segurança, já que permitir o acesso de todos os pods à capacidade de CPU não vinculada pode levar a problemas perigosos de saturação da CPU.
@vishh dadas as circunstâncias acima, qual seria o melhor curso de ação? parece que está atualizando para o kernel> 4.18 (que tem a correção de contabilidade cfs cpu) e (talvez) reduzindo o período de quota cfs?
Em uma observação geral, sugerir que apenas removamos limits dos contêineres que estão sendo limitados deve ter avisos claros:
1) Se esses fossem pods na classe de QoS garantida, com número inteiro de núcleos e com política estática CPUMnanager em vigor - esses pods não terão mais núcleos de CPU dedicados, pois serão colocados na classe de QoS em burst (sem solicitações == limites)
2) Esses pods serão desvinculados em termos de quanta CPU eles podem consumir e, potencialmente, podem causar muitos danos em certas circunstâncias.
Seu feedback / orientação seria muito apreciado.
 dannyk81
em 25 mar. 2019
dannyk81
em 25 mar. 2019
Atualizar o kernel definitivamente ajuda, mas o comportamento de aplicar uma cota CFS ainda parece desalinhado com o que a documentação sugere.
mariusgrigoriu
em 25 mar. 2019
Tenho pesquisado vários aspectos desse problema há algum tempo. Minha pesquisa está resumida em minha postagem no LKML.
https://lkml.org/lkml/2019/3/18/706
Dito isso, não consegui reproduzir o problema conforme descrito aqui nos kernels pré-512ac99. No entanto, tenho visto uma regressão de desempenho em kernels pós-512ac99. Portanto, essa correção não é uma panacéia.
 chiluk
em 25 mar. 2019
chiluk
em 25 mar. 2019
Obrigado @mariusgrigoriu , estamos indo para a atualização do kernel e esperamos que ajude um pouco, também verifique https://github.com/kubernetes/kubernetes/issues/70585 - parece que as cotas estão realmente definidas para pods garantidos com cpuset ( ou seja, cpus fixados), então isso me parece um bug.
dannyk81
em 25 mar. 2019
@chiluk você poderia elaborar um pouco? você quer dizer que o patch incluído no 4.18 (mencionado acima em https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-466609030) não resolve realmente o problema?
dannyk81
em 25 mar. 2019
O patch do kernel 512ac99 corrige um problema para algumas pessoas, mas causou um problema em nossas configurações. O patch corrigiu a maneira como as fatias de tempo são distribuídas entre cfs_rq, de forma que agora expiram corretamente. Anteriormente, eles não expirariam.
Cargas de trabalho Java, em particular em máquinas com alta contagem de núcleos, agora apresentam grandes quantidades de limitação com baixo uso de CPU por causa dos threads de trabalho de bloqueio. Esses encadeamentos são atribuídos a uma fração de tempo que eles usam apenas uma pequena parte da qual é expirada posteriormente. No teste sintético que escrevi * (vinculado a esse tópico), vemos uma degradação de desempenho de cerca de 30x. No desempenho do mundo real, vimos a degradação do tempo de resposta de centenas de milissegundos entre os dois kernels devido ao aumento do estrangulamento.
chiluk
em 25 mar. 2019
Usando um kernel 4.19.30, vejo pods que esperava ver menos limitação ainda estão estrangulados e alguns pods que não estavam sendo estrangulados anteriormente agora estão sendo estrangulados de forma bastante severa (kube2iam está relatando mais segundos de limitação do que a instância foi ativada , de alguma forma)
 willthames
em 27 mar. 2019
willthames
em 27 mar. 2019
No CoreOS 4.19.25-coreos, vejo o Prometheus acionando o alerta CPUThrottlingHigh quase em todos os pods do sistema.
 teralype
em 27 mar. 2019
teralype
em 27 mar. 2019
@williamsandrew @teralype isso parece refletir as descobertas de @chiluk .
Após várias discussões internas, na verdade decidimos desabilitar as cotas cfs completamente (sinalizador do kubelet --cpu-cfs-quota=false ), isso parece resolver todos os problemas que temos tido para os Pods Burstable e Garantidos (cpu fixada ou padrão).
Há uma excelente apresentação sobre isso (e alguns outros tópicos) aqui: https://www.slideshare.net/try_except_/ensuring-kubernetes-cost-efficiency-across-many-clusters-devops-gathering-2019
Leitura altamente recomendada: +1:
dannyk81
em 27 mar. 2019
problema de longo prazo (nota para mim)
 dims
em 27 mar. 2019
dims
em 27 mar. 2019
@ dannyk81 apenas para completar: a palestra vinculada também está disponível como vídeo gravado: https://www.youtube.com/watch?v=4QyecOoPsGU
hjacobs
em 27 mar. 2019
@hjacobs , adorei a conversa! Muito obrigado...
Alguma ideia de como aplicar essa correção no AKS ou GKE?
obrigado
 agolomoodysaada
em 2 abr. 2019
agolomoodysaada
em 2 abr. 2019
@agolomoodysaada , apresentamos uma solicitação de recurso ao GKE há algum tempo. Não tenho certeza de qual é o status, não trabalho mais intensamente com o GKE.
timoreimann
em 2 abr. 2019
Entrei em contato com o suporte do Azure e eles disseram que não estará disponível até agosto de 2019.
agolomoodysaada
em 4 abr. 2019

Pensei em compartilhar um gráfico de um aplicativo consistentemente limitado ao longo de sua vida útil.
agolomoodysaada
em 5 abr. 2019
Em que kernel estava isso?
chiluk
em 5 abr. 2019
" chiluk " 4.15.0-1037-azure "
agolomoodysaada
em 5 abr. 2019
Então isso não contém o commit do kernel 512ac99. Aqui está o correspondente
fonte.
https://kernel.ubuntu.com/git/kernel-ppa/mirror/ubuntu-azure-xenial.git/tree/kernel/sched/fair.c?h=Ubuntu-azure-4.15.0-1037.39_16.04.1 & id = 19b0066cc4829f45321a52a802b640bab14d0f67
O que significa que você pode estar enfrentando o problema descrito em 512ac99. Mantenha
lembre-se que 512ac99 trouxe outras regressões para nós.
Na sexta-feira, 5 de abril de 2019 às 12h08 Moody Saada [email protected]
escrevi:
@chiluk https://github.com/chiluk "4.15.0-1037-azure"
-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-480350946 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/ACDI05YeS6wfUE9XkiMbxrLvPllYQZ7Iks5vd4MOgaJpZM4WDUF3
.
chiluk
em 5 abr. 2019
Eu já postei patches para LKML sobre isso.
https://lkml.org/lkml/2019/4/10/1068
Testes adicionais seriam muito apreciados.
chiluk
em 11 abr. 2019
Reenviei esses patches agora com alterações na documentação.
https://lkml.org/lkml/2019/5/17/581
Realmente ajudaria se as pessoas pudessem testar esses patches e comentar sobre o tópico no LKML. No momento, sou o único a ter mencionado isso no LKML, e não recebi nenhum comentário da comunidade ou dos mantenedores. Iria realmente percorrer um longo caminho se eu pudesse obter alguns testes da comunidade e comentários sobre LKML em meu patch.
chiluk
em 21 mai. 2019
Pelo que vale a pena, este projeto específico https://github.com/tensorflow/serving parece ser severamente afetado por este problema. E é principalmente um aplicativo C ++.
@chiluk , há alguma solução alternativa que possamos aplicar enquanto o patch é lançado?
Muito obrigado
agolomoodysaada
em 29 mai. 2019
Devemos ajudar o @chiluk a coletar citações do sério impacto desse bug do kernel no Kubernetes e em qualquer pessoa que use cotas CFS.
Zolando incluiu em sua apresentação na semana passada que suas experiências ruins com o kernel atual significam que eles consideram a desativação das cotas CFS como a melhor prática atual, pois consideram que isso faz mais mal do que bem.
https://www.youtube.com/watch?v=6sDTB4eV4F8
 whereisaaron
em 29 mai. 2019
whereisaaron
em 29 mai. 2019
Mais e mais empresas estão desativando a limitação de CPU, por exemplo, mytaxi, Datadog, Zalando ( tópico do Twitter )
hjacobs
em 29 mai. 2019
@derekwaynecarr @ dchen1107 @ kubernetes / sig-node-feature-requests Dawn, Derek, é hora de mudar o padrão? e / ou documentação?
dims
em 29 mai. 2019
Sim @whereisaaron coletando e compartilhando relatórios de aplicativos de limitação de limitação e / ou sendo desativado por causa de seu mau comportamento seria uma participação bem-vinda no thread lkml quando apropriado. No momento, parece que sou apenas eu reclamando desse problema para a comunidade do kernel.
chiluk
em 29 mai. 2019
@agolomoodysaada, a solução alternativa é desabilitar temporariamente as cotas cfs ou
Também existem práticas recomendadas para reduzir a contagem de threads do aplicativo, o que também ajuda.
Para golang, defina GOMAXPROCS ~ = ceil (quota)
Para java, mude para as JVMs mais novas que reconhecem e respeitam os limites de cpu da CPU. O jvms anterior gerou threads com base no número de núcleos da CPU, não no número de núcleos disponíveis para o aplicativo.
Ambos foram grandes benefícios para o nosso desempenho.
Monitore e relate aplicativos que estão atingindo o limite para que seus desenvolvedores possam ajustar as cotas.
chiluk
em 29 mai. 2019
Para sua informação, depois de apontar este segmento para o suporte do Azure AKS, fui respondido que o patch será lançado quando eles atualizarem para o kernel 5.0, no final de setembro, na melhor das hipóteses.
Até então, pare de usar limites :)
prune998
em 29 mai. 2019
@ prune998 há uma pequena ressalva no caso de você estar usando CPUmanager (isto é, alocação de CPU dedicada para pods em QoS Garantido).
Ao remover os limites, você evitará o problema de limitação do CFS, mas removerá os pods do QoS garantido para que o CPUmanager não aloque mais núcleos dedicados para esses pods.
Se você não usa CPUmanager - nenhum dano causado, mas apenas FYI para quem optar por esta direção.
Existe um PR (https://github.com/kubernetes/kubernetes/issues/70585) para desabilitar as cotas CFS inteiramente para Pods com CPUs dedicadas, no entanto, ainda não foi fundido.
Também optamos por desativar o sistema de cotas CFS como sugerido acima e nenhum problema até agora.
dannyk81
em 29 mai. 2019
@ dannyk81 https://github.com/kubernetes/kubernetes/issues/70585 não é um PR que pode ser mesclado (é um problema com um snippet de código). Você (ou outra pessoa) pode registrar uma RP?
dims
em 29 mai. 2019
Já existe um: https://github.com/kubernetes/kubernetes/pull/75682
 praseodym
em 29 mai. 2019
praseodym
em 29 mai. 2019
@dims Eu https://github.com/kubernetes/kubernetes/pull/75682 e está pendurado lá por um tempo, então, se você pudesse empurrar isso, seria ótimo, pois esse é um problema realmente irritante.
Obrigado: +1:
dannyk81
em 29 mai. 2019
opa! obrigado @ dannyk81, atribuí pessoal e adicionei um marco
dims
em 29 mai. 2019
Na FWIW, também encontramos esse problema e descobrimos que reduzir o período de cota CFS para 10 ms em vez dos 100 ms padrão fez com que nossas latências de cauda aumentassem drasticamente. Acho que isso ocorre porque, mesmo se você encontrar o bug do kernel, uma quantidade muito menor de cota será desperdiçada se não for usada, e o processo pode obter mais cota (em parcelas menores) muito mais cedo. Esta é apenas uma solução alternativa, mas para aqueles que não desejam desativar totalmente a cota CFS, isso pode ser um bandaid até que a correção seja implementada. O k8s oferece suporte para fazer isso em 1.12 com o portão de recursos cpuCFSQuotaPeriod e a sinalização kubelet --cpu-cfs-quota-period.
 d-shi
em 30 mai. 2019
d-shi
em 30 mai. 2019
Eu teria que verificar, mas acho que reduzir tanto o período pode ter o efeito de desabilitá-lo efetivamente, já que há mínimos de fatia e de cota no código. Provavelmente, é melhor desativar as cotas e passar para as cotas flexíveis.
chiluk
em 30 mai. 2019
@chiluk, meu entendimento leigo é que o slice padrão é 5ms, então defini-lo para isso ou menos está desabilitando-o, mas enquanto o período for maior que 5ms ainda deve haver aplicação de cota. Definitivamente, deixe-me saber se isso não estiver correto.
d-shi
em 31 mai. 2019
Com --feature-gates=CustomCPUCFSQuotaPeriod=true --cpu-cfs-quota-period=10ms one de meus pods realmente teve dificuldade para inicializar. No gráfico prometheus anexado, o contêiner tenta iniciar, não chega nem perto de cumprir sua verificação de atividade até que seja eliminado (normalmente o contêiner inicia em cerca de 5 segundos - mesmo aumentar a atividade initialDelaySeconds para 60s não ajudou) e é em seguida, substituído por um novo.
Você pode ver que o contêiner está fortemente estrangulado até que eu remova o cpu-cfs-quota-period dos argumentos do kubelet, ponto em que o estrangulamento é muito mais plano e o contêiner inicia em cerca de 5 segundos novamente.

willthames
em 5 jun. 2019
Para sua informação: tópico atual do Twitter sobre o tópico de desabilitação de limitação de CPU: https://twitter.com/it_supertramp/status/1133648291332263936
hjacobs
em 5 jun. 2019
Estes são os gráficos de limitação de CPU de antes / depois de mudarmos para --cpu-cfs-quota-period=10ms em produção para 2 serviços sensíveis à latência:
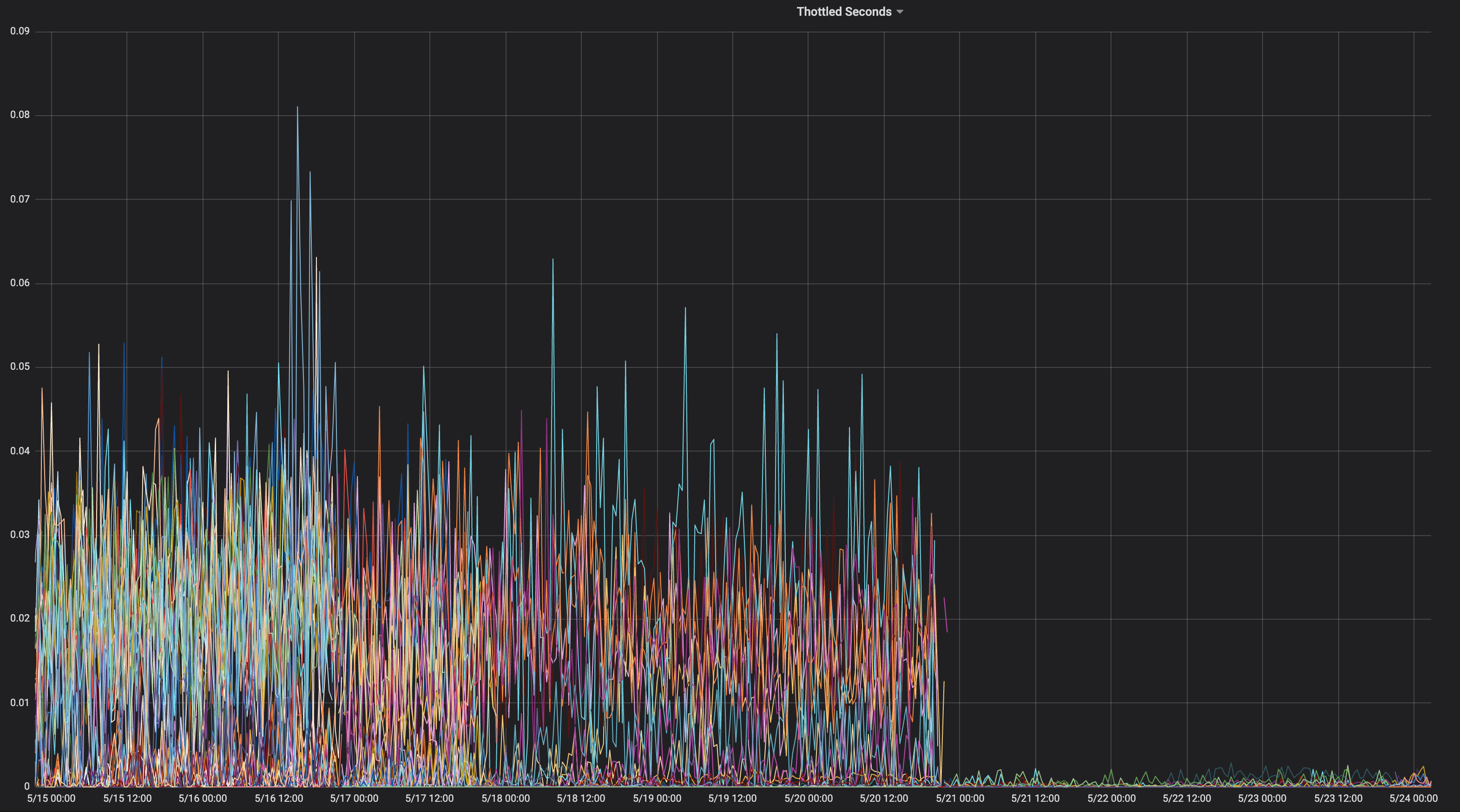

Esses serviços são executados em diferentes tipos de instância (com diferentes manchas / tolerâncias). As instâncias do segundo serviço foram movidas primeiro para o período de cota inferior do CFS.
Os resultados devem ser muito dependentes da carga.
d-shi
em 5 jun. 2019
@ d-shi algo mais está acontecendo em seu gráfico. Acho que pode haver alguma cota mínima que vocês estão atingindo agora porque o período é muito pequeno. Eu teria que verificar o código para ter certeza. Basicamente, você aumentou inadvertidamente a quantidade de cota disponível para o aplicativo. Você provavelmente poderia ter realizado a mesma coisa aumentando, de fato, as cotas de cota.
chiluk
em 5 jun. 2019
Para nós, era muito mais útil medir a latência do que o afogamento. Desativar cfs-quota melhorou drasticamente a latência. Gostaria de ver resultados semelhantes para alterar o cfs-quota-period .
 blakebarnett
em 6 jun. 2019
blakebarnett
em 6 jun. 2019
@chiluk , na verdade, tentamos aumentar as cotas de cota (até o máximo suportado por kubernetes por pod) e, em nenhum caso, as latências de cauda nem a limitação foram reduzidas muito. As latências do p99 foram de cerca de 98 ms em um limite de 4 núcleos para 86 ms em um limite de 16 núcleos. Depois de reduzir a cota CFS para 10 ms, o p99 foi para 20 ms em 4 núcleos.
@blakebarnett , desenvolvemos um programa de benchmark que mede nossas latências, e elas vão de um intervalo de 10ms-100ms, com uma média de cerca de 18ms antes da atualização --cpu-cfs-quota-period , para um intervalo de 10ms-20ms, com uma média de cerca de 11ms depois. as latências do p99 variaram de cerca de 98 ms para 20 ms.
EDITES: Desculpe pelas edições que tive que voltar e verificar novamente meus números.
d-shi
em 6 jun. 2019
@ d-shi, você provavelmente estava encontrando o problema resolvido por 512ac999 então.
chiluk
em 6 jun. 2019
@chiluk Depois de ler repetidamente seu patch, devo admitir que tenho dificuldade em entender o impacto desse código:
if (cfs_rq->expires_seq == cfs_b->expires_seq) {
- /* extend local deadline, drift is bounded above by 2 ticks */
- cfs_rq->runtime_expires += TICK_NSEC;
- } else {
- /* global deadline is ahead, expiration has passed */
- cfs_rq->runtime_remaining = 0;
- }
Em um caso em que a cota expira mesmo que runtime_remaining apenas tenha emprestado algum tempo do pool global. Na pior das hipóteses, você será acelerado por 5ms com base em sched_cfs_bandwidth_slice_us. Não é?
Eu sinto falta de alguma coisa?
 Mwea
em 6 jun. 2019
Mwea
em 6 jun. 2019
@chiluk sim eu acho que está certo. Nossos servidores de produção ainda estão no kernel 4.4, então não temos essa correção. Talvez, depois de atualizar para um kernel mais recente, possamos mover o período de cota CFS de volta ao padrão, mas por enquanto ele está trabalhando para melhorar nossas latências de cauda e não notamos nenhum efeito colateral adverso ainda. Embora só esteja no ar há algumas semanas.
d-shi
em 6 jun. 2019
@chiluk Se importa em resumir o status desse problema no kernel? Parece que houve um patch, 512ac999, mas teve problemas. Eu li em algum lugar que foi revertido? Ou isso está total / parcialmente corrigido? Se sim, qual versão?
mariusgrigoriu
em 7 jun. 2019
@mariusgrigoriu não foi consertado, @chiluk criou um patch que deve consertar e precisa de mais testes (vou alocar parte do meu tempo nos próximos dias para isso)
Consulte https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -482198124 para obter o status mais recente
willthames
em 7 jun. 2019
@Mwea o pool global é armazenado em cfs_b-> runtime_remaining. À medida que isso é atribuído a filas de execução por CPU (cfs_rq), a quantidade restante no pool global diminui. cfs_bandwidth_slice_us é a quantidade de tempo de execução da CPU que é transferida do conjunto global para as filas de execução por CPU. Se você foi estrangulado, isso significaria que você precisava executar e cfs_b-> runtime_remaining == 0. Você teria que esperar pelo final do período atual (por padrão 100ms), para que a cota fosse reabastecida para cfs_b e depois distribuída para seu cfs_rq. Recentemente, descobri que a quantidade de tempo de execução expirado é de no máximo 1 ms por cfs_rq, devido ao fato de que o temporizador de folga recaptura 1 ms de cota não utilizada de filas de execução por CPU. Esse 1ms é então desperdiçado / expirado no final do período. Em um cenário de pior caso, em que o aplicativo se espalha por 88 cpus que poderiam ser 88 ms de cota desperdiçada por período de 100 ms. Na verdade, isso levou a uma proposta alternativa que era permitir que o temporizador de folga recapturasse toda a cota não utilizada das filas de execução por CPU inativas.
Quanto às linhas que você destaca especificamente. Minha proposta é remover a expiração do tempo de execução que foi atribuído a filas de execução por CPU completamente. Essas linhas fazem parte da correção para 512ac999. Isso corrigiu um problema em que a distorção do relógio entre as filas de execução por CPU fazia com que a cota expirasse prematuramente, limitando assim os aplicativos que ainda não usavam a cota (afaiu). Basicamente, eles incrementam expires_seq em cada limite de período. expires_seq deve, portanto, corresponder entre cada um dos cfs_rq quando eles estão no mesmo período.
@mariusgrigoriu - se você está atingindo alta limitação com baixo uso de CPU e seu kernel é pré-512ac999, você provavelmente precisará de 512ac999. Se você está postando 512ac999, provavelmente está encontrando o problema que expliquei acima, que está sendo discutido no lkml.
Existem várias maneiras de atenuar esse problema.
- Fixação de CPU
- Diminuindo o número de threads que seu aplicativo gera
- Alocar cota em excesso para aplicativos que estão passando por limitação.
- Desative os limites rígidos por enquanto.
- Crie um kernel personalizado com qualquer uma das alterações propostas.
chiluk
em 7 jun. 2019
@chiluk alguma chance de você já postar uma versão desse patch que já seja compatível com o kernel 4.14? Estou tentando testá-lo de forma bastante agressiva, já que acabamos de atualizar alguns milhares de hosts para 4.14.121 (de 4.9.62) e estamos vendo:
- Uma redução na limitação de memcached, mysql, nginx, etc.
- Um aumento na limitação de nossos aplicativos Java
Realmente quero avançar para obter o melhor dos dois mundos aqui. Posso tentar transportá-lo sozinho na próxima semana, mas se você já tiver um, seria incrível.
 PaulFurtado
em 21 jun. 2019
PaulFurtado
em 21 jun. 2019
@PaulFurtado
Na verdade, reescrevi o patch nos últimos dias, de acordo com as sugestões de Ben Segull. Um novo patch do kernel estará disponível assim que eu puder testá-lo em nossos clusters.
chiluk
em 24 jun. 2019
@chiluk alguma atualização nesse patch? Não se preocupe se não, só estou garantindo que não perdi o patch passando
PaulFurtado
em 18 jul. 2019
@PaulFurtado , o patch foi "aprovado" pelo autor do CFS, e estou apenas esperando os mantenedores do planejador integrá-lo e enviá-lo ao Linus.
chiluk
em 24 jul. 2019
@chiluk Obrigado!
Acabei de fazer o backport do patch para o kernel 4.14, que é o nosso kernel de produção atual.
Fiz uma ideia geral com o backport e alguns resultados do seu fibtest aqui: https://gist.github.com/PaulFurtado/ff6c67ec87416b66ba1c6fc70f7beec1
Nas instâncias c5.9xlarge e m5.24xlarge ec2 da geração atual, que usamos em nossos clusters de kubernetes e mesos, o patch dobra o desempenho de seu programa fibtest. Em um tipo de instância r4.16xlarge da geração anterior, ele gerencia 1,5x mais utilização da CPU, mas quase nenhuma iteração adicional (que estou assumindo é apenas devido à geração da CPU e à natureza exponencial da sequência de fibonacci). Todos esses números se mantêm exatamente exatamente se eu aumentar o teste para 30s em vez do padrão de 5s.
Vamos começar a implantar isso em nosso ambiente de controle de qualidade esta semana para obter algumas métricas de nossos aplicativos que estão sofrendo com o pior estrangulamento. Obrigado novamente!
PaulFurtado
em 26 jul. 2019
@PaulFurtado primeiro, obrigado pelo teste. Vou assumir que você está executando o kernel.org 4.14 ou o ubuntu 4.14, ambos com 512ac999. Quanto ao fibtest, as iterações concluídas não são tão importantes quanto o tempo de CPU utilizado, pois as iterações concluídas podem ser fortemente afetadas por cpu mhz durante a execução do teste (especialmente na nuvem, onde não tenho certeza de quanto controle você tem sobre isso).
chiluk
em 31 jul. 2019
Vou assumir que você está executando o kernel.org 4.14 ou o ubuntu 4.14, ambos com 512ac999.
Sim, executamos o mainline 4.14 (bem, mais o conjunto de patches do kernel do Amazon Linux 2, mas nenhum desses patches importa neste caso).
512ac999 pousou na linha principal 4.14.95, e observamos seus efeitos na atualização de 4.14.77 para 4.14.121+. Isso fez com que nossos contêineres memcached (contagem de threads muito baixa) passassem de uma limitação inexplicável para nenhuma limitação, mas fez com que nossos contêineres golang e java (contagem de threads muito alta) experimentassem mais limitação.
Quanto ao fibtest, as iterações concluídas não são tão importantes quanto o tempo de CPU utilizado, pois as iterações concluídas podem ser fortemente afetadas por cpu mhz durante a execução do teste (especialmente na nuvem, onde não tenho certeza de quanto controle você tem sobre isso).
Em instâncias do EC2 mais novas / maiores, você realmente obtém um nível decente de controle sobre os estados do processador , então rodamos com turbo boost desligado e não permitimos que os núcleos
em primeiro lugar, obrigado pelo teste
Sem problemas, as coisas ficaram estáveis em nosso ambiente pré-controle de qualidade durante o fim de semana e começaremos a lançar o patch para nosso ambiente de controle de qualidade principal amanhã, onde veremos mais efeitos do mundo real. Dado que o memcached se beneficiou do patch anterior, nós realmente queríamos ter nosso bolo e comê-lo com os dois patches no lugar, então ficamos felizes em testar. Obrigado novamente por todo o trabalho que você tem feito para controlar o fluxo!
PaulFurtado
em 31 jul. 2019
Só queria deixar uma nota sobre o patch do kernel que está sendo discutido ....
Eu o adaptei ao kernel que estamos usando nos testes atuais e vejo alguns ganhos enormes nas taxas de limitação de CFS, no entanto, vou mencionar que se você definiu anteriormente o período de cfs para 10 ms como uma mitigação, você vai deseja trazer de volta para 100 ms para ver os benefícios da mudança.
 jhohertz
em 6 ago. 2019
jhohertz
em 6 ago. 2019
O patch caiu na ponta esta manhã.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Assim que chegar à árvore de Torvald, irei submetê-lo para inclusão estável no Linux e, subsequentemente, para distros principais (Redhat / Ubuntu). Se você se preocupa com outra coisa e eles não estão seguindo os patches estáveis para Linux, você pode enviar diretamente.
chiluk
em 8 ago. 2019
Eu testei o patch (ubuntu 18.04, 5.2.7 kernel, node: 56 core CPU E5-2660 v4 @ 2.00GHz) com nosso microsserviço golang de processamento de imagem pesado de CPU e obtive resultados bastante impressionantes. Desempenho como se eu desabilitasse o CFS no nó completamente.
Eu tenho 5-35% menos latência e 5-55% mais RPS dependendo da simultaneidade / utilização da CPU em uma taxa de limitação quase zero.
Obrigado, @chiluk !
Como disse @jhohertz , a cota do cfs deve ser revertida para 100 ms, testei com períodos mais baixos e obtive alta limitação e degradação de desempenho.
 zigmund
em 10 ago. 2019
zigmund
em 10 ago. 2019
Para obter mais desempenho com golang, defina GOMAXPROCS para ceil (quota) +2. O mais 2 é para garantir alguma simultaneidade.
chiluk
em 12 ago. 2019
@chiluk testado com GOMAXPROCS = 8 vs GOMAXPROCS = 10 com cpu.limit = 8 - não é uma grande diferença, algo em torno de 1-2%.
zigmund
em 13 ago. 2019
@zigmund isso
Eu deveria ter dito que definir GOMAXPROCS = # é uma boa solução alternativa para programas go até que os patches do kernel sejam amplamente distribuídos.
chiluk
em 26 ago. 2019
Migramos nossos clusters de produção para o kernel com patch e agora posso compartilhar alguns momentos interessantes.
Estatísticas de um de nossos clusters - 4 nós de 72 núcleos E5-2695 v4 @ 2.10 GHz, 128 Gb de RAM, Debian 9, kernel 5.2.7 com patch.
Temos cargas mistas que consistem principalmente de serviços golang, mas também temos php e python.
Golang. A latência é mais baixa, configurar o GOMAXPROCS correto é absolutamente obrigatório. Aqui está o serviço com GOMAXPROCS = 72 padrão. Mudamos o kernel em ~ 16 e depois que a latência caiu e a utilização da CPU aumentou muito. Às 21:15 eu defini GOMAXPROCS correto e a utilização da CPU normalizada.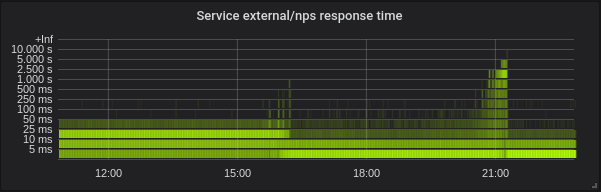

Pitão. Tudo ficou melhor com o patch sem nenhum movimento extra - a utilização da CPU e a latência diminuíram.
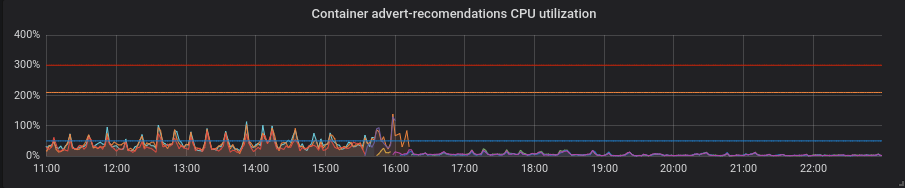
PHP. A utilização da CPU é a mesma, a latência diminuiu um pouco em alguns serviços. Não é um grande lucro.
zigmund
em 3 set. 2019
Obrigado @zigmund.
Não tenho certeza se entendi quando você diz I setted correct GOMAXPROCS ...
Presumo que você não esteja executando apenas um pod no nó de 72 núcleos, então você definiu GOMAXPROCS para algo menor, talvez igual aos limites de CPU do pod, certo?
prune998
em 3 set. 2019
Obrigado @zigmund. As mudanças go estão praticamente em linha com o que era esperado.
Estou realmente surpreso com as melhorias do python, pois esperava que o GIL negasse em grande parte os benefícios disso. No mínimo, esse patch deve diminuir quase que puramente o tempo de resposta, diminuir a porcentagem de períodos estrangulados e aumentar a utilização da CPU. Tem certeza de que seu aplicativo Python ainda estava íntegro?
chiluk
em 3 set. 2019
@ prune998 desculpe, talvez com erro de ortografia. Eu defino GOMAXPROCS = limits.cpu. No momento, temos cerca de 110 pods por nó neste cluster.
@chiluk Não sou forte em python e não sei como o patch afetou na camada inferior. Mas a aplicação está íntegra sem problemas, verifiquei após a mudança do kernel.
zigmund
em 4 set. 2019
@chiluk Você poderia explicar como podemos acompanhar o progresso de seu patch em várias distros Linux? Estou particularmente interessado em debian e AWS Linux, mas espero que outras pessoas estejam interessadas no Ubuntu etc., então, qualquer luz que você possa lançar, obrigado.
 Nuru
em 13 set. 2019
Nuru
em 13 set. 2019
@Nuru https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html?highlight=stable%20rules ... Basicamente, enviarei através do linux-stable assim que meu patch atingir o Linus ' tree, * (talvez anterior), e então todas as distros devem seguir o processo linux-stable e puxar os patches aceitos pelos mantenedores estáveis para seus kernels específicos da distro. Se eles não forem, você não deve administrar suas distros.
chiluk
em 13 set. 2019
@chiluk Não sei nada sobre o processo de desenvolvimento do Linux. Por "árvore de Linus" você quer dizer https://github.com/torvalds/linux ?
Nuru
em 14 set. 2019
A árvore de Linus mora aqui, https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/. Minhas mudanças estão atualmente em teste no linux-next, que é a árvore de integração de desenvolvimento. Sim, o desenvolvimento do kernel está um pouco preso na era das trevas, mas funciona.
Ele provavelmente puxará as alterações da árvore linux-next assim que o 5.3 for lançado e ele iniciar o desenvolvimento no 5.4-rc0. Esse é o período de tempo que espero que os kernels estáveis comecem a puxar nesta correção. Sempre que Linus sente que 5.3 está estável, ninguém sabe.
chiluk
em 14 set. 2019
[Linus] provavelmente irá puxar as mudanças da árvore linux-next assim que o 5.3 for lançado e ele iniciar o desenvolvimento no 5.4-rc0. Esse é o período de tempo que espero que os kernels estáveis comecem a puxar nesta correção. Sempre que Linus sente que 5.3 está estável, ninguém sabe.
@chiluk Parece que o Linus decidiu que o 5.3 era estável em 15 de setembro de 2019 . Então, o que é "linux-next" e como rastreamos o progresso de seu patch nas próximas etapas?
Nuru
em 20 set. 2019
Alguém construiu pacotes de extensão debian e / ou uma imagem AWS que inclui este patch? Estou prestes a fazer isso usando https://github.com/kubernetes-sigs/image-builder/tree/master/images/kube-deploy/imagebuilder
Apenas pensei em evitar a duplicação de esforços, se já existir.
blakebarnett
em 24 set. 2019
Isso agora foi incorporado à árvore do Linus e deve ser lançado com o 5.4. Eu também acabei de enviá-lo para a versão estável do Linux e, presumindo que tudo corra bem, todas as distros que seguem o processo estável corretamente devem começar a adotá-lo em breve.
chiluk
em 25 set. 2019
Alguém sabe como seguir se / como essa mudança chega ao CentOS (7)? Não tenho certeza de como funciona o backporting etc.
 till
em 26 set. 2019
till
em 26 set. 2019
@till https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -531370333
Para o kernel estável, a conversa está acontecendo aqui.
https://lore.kernel.org/stable/CAC=E7cUXpUDgpvsmMaMU6sAydbfD0FEJiK25R1r=e9=YtcPjGw@mail.gmail.com/
Também para aqueles que vão ao KubeCon, apresentarei esse problema lá.
https://sched.co/Uae1
chiluk
em 3 out. 2019
Alguma palavra dos mantenedores do planejador sobre: o ack que Greg HK estava procurando para colocá-lo nas árvores estáveis?
jhohertz
em 18 out. 2019
Greg KH adiou a decisão sobre este patch porque os mantenedores do agendador não responderam (provavelmente perderam o e-mail). Agradecemos o comentário de qualquer pessoa além de mim sobre o LKML que testou este patch e acha que deveria ser feito backport.
chiluk
em 18 out. 2019
Para quem usa CoreOS, há um problema aberto solicitando que o patch do @chiluk seja portado para
 evanfoster
em 1 nov. 2019
evanfoster
em 1 nov. 2019
CoreOS kernel 4.19.82 tem as correções: https://github.com/coreos/linux/pull/364
CoreOS Container Linux 2317.0.1 (canal alfa) tem as correções: https://github.com/coreos/coreos-overlay/pull/3796 http://coreos.com/releases/#2317.0.1
Os backports para o Linux estável parecem estar travados porque os patches não se aplicam corretamente . @chiluk Você vai trabalhar em backports para Linux estável? Em caso afirmativo, você poderia retroceder para o 4.9 para que ele "estique" o Debian e seja retomado por kops ? Embora eu ache que vai demorar até 6 meses para colocá-lo em "alongamento" e talvez até então kops terá migrado para "buster".
Nuru
em 8 nov. 2019
@Nuru , fiz backport do patch e fiz pacotes stretch (com base no kernel stretch-backports) e um AMI compatível com kops 1.11 se você quiser testar:
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.buildinfo
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm-dbg_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-headers-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.changes
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-libc-dev_4.19.67-1_amd64.deb
293993587779 / k8s-1.11-debian-stretch-amd64-hvm-ebs-2019-09-26
blakebarnett
em 8 nov. 2019
@blakebarnett Obrigado pelo seu esforço e desculpe incomodá-lo, mas estou mais do que um pouco confuso.
- "stretch" é baseado no Linux 4.9, mas todos os seus links são para 4.19.
- Você diz que fez o backport "do patch", mas há 3 patches (acho que o terceiro não é muito importante:
- 512ac999 sched / fair: corrigir condição de desvio do relógio do temporizador de largura de banda
- de53fd7ae sched / fair: Corrija o baixo uso de cpu com alta limitação removendo a expiração de fatias de CPU-local
- 763a9ec06 sched / fair: corrigir avisos -Wunused-but-set-variable
Você fez backport de todos os 3 patches para o 4.9? (Não sei o que fazer com os pacotes Debian para olhar e ver se as mudanças estão lá, e o documento "mudanças" não aborda o que realmente mudou.)
Além disso, em quais regiões seu AMI está disponível?
Nuru
em 8 nov. 2019
Não, eu usei o kernel stretch-backports, que é 4.19, pois ele tem correções que também precisávamos no AWS (especialmente para tipos de instância M5 / C5)
Eu apliquei um diff que incorporava todos os patches que acredito, tive que alterá-lo ligeiramente para remover referências extras a variáveis em 4.19 que foram excluídas em outro lugar, primeiro apliquei isso https://github.com/kubernetes/kubernetes/issues/67577 #issuecomment -515324561 e precisava adicionar:
--- kernel/sched/fair.c 2019-09-25 16:06:02.954933954 -0700
+++ kernel/sched/fair.c-b 2019-09-25 16:06:56.341615817 -0700
@@ -4928,8 +4928,6 @@
cfs_b->period_active = 1;
overrun = hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
- cfs_b->runtime_expires += (overrun + 1) * ktime_to_ns(cfs_b->period);
- cfs_b->expires_seq++;
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
--- kernel/sched/sched.h 2019-08-16 01:12:54.000000000 -0700
+++ sched.h.b 2019-09-25 13:24:00.444566284 -0700
@@ -334,8 +334,6 @@
u64 quota;
u64 runtime;
s64 hierarchical_quota;
- u64 runtime_expires;
- int expires_seq;
short idle;
short period_active;
@@ -555,8 +553,6 @@
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
- int expires_seq;
- u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock;
O AMI é publicado para us-west-1
Espero que ajude!
blakebarnett
em 8 nov. 2019
Eu fiz backport desses patches e os enviei para os kernels estáveis do Linux
v4.14 https://lore.kernel.org/stable/[email protected]/
v4.19 https://lore.kernel.org/stable/[email protected]/ #t
chiluk
em 8 nov. 2019
Olá,
seguindo a integração do patch no branch 4.19, abri um relatório de bug no debian para uma atualização adequada do kerner no buster e stretch-backport:
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=946144
não hesite em adicionar um novo comentário para a atualização do pacote debian.
 alexises
em 4 dez. 2019
alexises
em 4 dez. 2019
Espero que isso não seja muito spam, mas eu queria vincular esta excelente palestra de @chiluk abordando muitos detalhes de fundo relacionados a esse problema https://youtu.be/UE7QX98-kO0.
 bboreham
em 4 dez. 2019
bboreham
em 4 dez. 2019
Existe uma maneira de evitar a limitação do GKE? Nós acabamos de ter um grande problema onde um método no contêiner php demorava 120 segundos em vez do usual 0,1 s
 bartoszhernas
em 5 dez. 2019
bartoszhernas
em 5 dez. 2019
remover limites de CPU
 monotek
em 5 dez. 2019
monotek
em 5 dez. 2019
Já fizemos isso, o contêiner está sendo limitado quando as solicitações da CPU são muito pequenas. Esse é o cerne do problema, a falta de limites e apenas o uso de solicitações de CPU ainda levará ao estrangulamento :(
bartoszhernas
em 5 dez. 2019
@bartoszhernas Acho que você está usando a palavra errada aqui. Quando as pessoas neste tópico referem-se a "limitação", elas estão se referindo ao controle de largura de banda cfs, nr_throttled em cpu.stat para o aumento do cgroup. Isso só é habilitado quando os limites da CPU estão habilitados. A menos que o GKE esteja adicionando limites ao seu pod sem seu conhecimento, eu não chamaria o que você está atingindo de limitação.
Eu chamaria o que você descreveu de "contenção para o processador". Suspeito que você provavelmente tenha vários aplicativos de tamanho incorreto * (solicitações), que estão disputando o processador ou outro recurso na caixa porque estão frequentemente usando mais do que o que solicitaram. Esta é a razão exata pela qual usamos limites. De forma que esses aplicativos de tamanho inadequado só afetem outros aplicativos na caixa.
A outra possibilidade é que a quantidade insuficiente de solicitações esteja levando a um comportamento de programação simplesmente insatisfatório. Definir um valor baixo de solicitações é semelhante a definir um valor "agradável" positivo em relação a aplicativos de "solicitação" mais altos. Para obter mais informações sobre isso, consulte os limites flexíveis.
chiluk
em 5 dez. 2019
Os problemas ficam obsoletos após 90 dias de inatividade.
Marque o problema como novo com /remove-lifecycle stale .
Problemas obsoletos apodrecem após 30 dias adicionais de inatividade e, eventualmente, fecham.
Se for seguro encerrar este problema agora, faça-o com /close .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/ lifecycle stale
 fejta-bot
em 4 mar. 2020
fejta-bot
em 4 mar. 2020
/ remove-lifecycle stale
Nuru
em 4 mar. 2020
Do meu entendimento, o problema subjacente no kernel foi corrigido e disponibilizado, por exemplo, no ContainerLinux em https://github.com/coreos/bugs/issues/2623.
Alguém sabe dos problemas restantes após este patch do kernel?
 sfudeus
em 4 mar. 2020
sfudeus
em 4 mar. 2020
@sfudeus Kubernetes pode ser executado em qualquer versão do Linux ou, AFAIK, qualquer versão compatível com POSIT do Unix. Este bug nunca foi um problema para pessoas que não usam Linux, foi corrigido para algumas distribuições derivadas do Linux e não foi corrigido para outras.
O problema subjacente foi corrigido no kernel Linux 5.4, que quase ninguém está usando neste momento. Patches foram disponibilizados para backporting para vários kernels mais antigos e inclusive em novas distribuições Linux que ainda não estão prontas para migrar para o kernel 5.4, que são muitos. Como você pode ver na lista acima de commits que fazem referência a esse problema, os patches de correção de bug ainda estão em processo de incorporação nas inúmeras distribuições do Linux em que alguém pode estar usando o Kubernetes.
Portanto, eu gostaria de manter esse problema aberto por um tempo, ele ainda está vendo referências de commit ativas. Também gostaria de vê-lo fechado com um script ou outro método fácil que alguém possa usar para determinar se a instalação do Kubernetes foi afetada ou não.
Nuru
em 5 mar. 2020
@Nuru Tudo bem para mim, eu só queria ter certeza de que nenhum outro problema de kernel sobrou, que já é conhecido. Eu pessoalmente não manteria isso aberto por mais tempo do que as distribuições maiores que incorporaram a correção, esperar por dispositivos de IoT intermináveis pode significar uma espera interminável. Problemas fechados também podem ser encontrados. Mas isso é apenas meus 2 centavos.
sfudeus
em 5 mar. 2020
Não tenho certeza se este é o lugar correto para informar as pessoas, mas não tenho certeza de onde mais falar sobre isso:
Estamos executando o kernel Linux 5.4 no Debian Buster (usando o kernel buster-backports) usando o cluster k8s 1.15.10 e ainda estamos vendo problemas com isso. Especialmente para pods que geralmente têm muito pouco a fazer (kube-downscaler é o exemplo ao qual continuamos retornando, o que geralmente requer cerca de 3m de CPU) e que têm apenas poucos recursos de CPU atribuídos (50m no caso do kube-downscaler em nosso cluster) ainda vemos um valor de limitação muito alto. Para referência, o kube-downscaler é basicamente um script Python que executa sleep por 30 minutos antes de fazer qualquer coisa. O cAdvisor mostra que o aumento de container_cpu_cfs_throttled_periods_total para este contêiner ser sempre mais ou menos semelhante ao valor container_cpu_cfs_periods_total deste contêiner (ambos são cerca de 250 ao verificar o aumento em intervalos de 5m). Esperamos que os períodos de limitação sejam próximos a 0.
Estamos medindo isso incorretamente? O cAdvisor está gerando dados incorretos? Nossa suposição está correta de que devemos ver uma queda nos períodos estrangulados? Qualquer conselho seria apreciado aqui.
Depois de mudar para o kernel 5.4, vimos o número de pods com esse problema diminuir um pouco (cerca de 40%), mas atualmente não temos certeza se o que estamos vendo é um problema real ou não. Principalmente, não temos certeza, ao examinar as estatísticas acima, o que "limitação" realmente significa aqui se obtivermos esses valores com o uso médio de CPU de 3 m. O nó em que está sendo executado não está supercomprometido e tem um uso médio da CPU de menos de 10%.
 timstoop
em 5 mar. 2020
timstoop
em 5 mar. 2020
@timstoop os intervalos com os quais o planejador se preocupa estão no reino de microssegundos, não em grandes intervalos de 30 minutos. Se um contêiner tiver um limite de CPU de 50 milicpu e usar 50 milicpu no intervalo de 100 microssegundos, ele será estrangulado, independentemente de ficar 30 minutos ocioso. Em geral, 50 milicpu é um limite de CPU extremamente pequeno. Se um programa Python fizer uma única solicitação HTTPS com esse limite, é quase certo que será estrangulado.
O nó em que está sendo executado não está supercomprometido e tem um uso médio da CPU de menos de 10%.
Apenas para esclarecer: a carga do nó e outras cargas de trabalho sobre ele não têm nada a ver com limitação. O throttling considera apenas o próprio limite do container / cgroup.
PaulFurtado
em 5 mar. 2020
@PaulFurtado Obrigado pela sua resposta! No entanto, o Pod em si tem um uso médio de 3 m de CPU durante a suspensão e ainda está sendo regulado. Não está fazendo nenhum pedido durante esse tempo, está esperando o sono. Eu espero que ele possa fazer isso enquanto não atinge os 50m, certo? Ou isso é uma suposição incorreta de qualquer maneira?
timstoop
em 5 mar. 2020
Acho que esse é provavelmente um número tão baixo que haverá problemas de precisão. E 50m é tão baixo que qualquer coisa poderia tropeçar. O tempo de execução do Python também pode realizar tarefas em segundo plano em threads enquanto você dorme.
PaulFurtado
em 5 mar. 2020
Você estava certo, eu estava fazendo suposições que não eram verdade. Obrigado pela sua orientação! Faz sentido para mim agora.
timstoop
em 5 mar. 2020
Só queria pular e dizer que as coisas aqui foram substancialmente melhoradas desde que o patch do kernel atingiu os kernels 4.19 LTS e apareceu no CoreOS / Flatcar. Olhando para o momento, as únicas coisas que vejo sendo estranguladas são algumas coisas nas quais provavelmente deveria aumentar os limites. :sorriso:
jhohertz
em 5 mar. 2020
@sfudeus @chiluk Existe algum teste simples para ver se seu kernel corrigiu isso ou não?
Não posso dizer se kope.io/k8s-1.15-debian-stretch-amd64-hvm-ebs-2020-01-17 (a imagem oficial atual kops ) foi corrigida ou não.
Nuru
em 20 mar. 2020
Concordo com @mariusgrigoriu , para pods executados em cpuset exclusivo sob política de cpu estática, podemos simplesmente desabilitar o limite de cota de cpu - ele só pode ser executado em seu conjunto de cpu exclusivo. O patch acima é para essa finalidade e apenas para este tipo de pods.
 jianzzha
em 6 abr. 2020
jianzzha
em 6 abr. 2020
@Nuru eu escrevi https://github.com/indeedeng/fibtest
É o teste mais definitivo que você pode obter, mas você precisará de um compilador C.
Ignore o número de iterações concluídas, mas concentre-se na quantidade de tempo usada para a execução de thread único vs multi-thread.
chiluk
em 10 abr. 2020
Acho que uma boa maneira de ver quais kernels foram corrigidos é em um dos últimos slides da conversa de https://www.youtube.com/watch?v=UE7QX98-kO0
Kernel 4.15.0-67 parece ter o patch (https://launchpad.net/ubuntu/+source/linux/4.15.0-67.76), no entanto, ainda estamos vendo o afogamento em alguns pods onde as solicitações / limite estão muito acima seu uso de CPU.
Estou falando sobre o uso de cerca de 50ms com solicitação definida para 250m e limite de 500m. Estamos vendo cerca de 50% dos períodos de CPU sendo limitados. Esse valor é baixo o suficiente para ser esperado e pode ser aceito? Eu gostaria que chegasse a zero, não deveríamos ser estrangulados se o uso não estiver nem perto do limite.
Alguém está usando o novo kernel corrigido e ainda apresenta alguma limitação?
 vgarcia-te
em 22 abr. 2020
vgarcia-te
em 22 abr. 2020
@ vgarcia-te Existem muitos kernels circulando para saber de uma lista que foi corrigida e quais não foram. Basta olhar para todos os commits que fazem referência a esse problema. Várias centenas. Minha leitura do changelog do Ubuntu sugere que o 4.15 ainda não foi corrigido (exceto o mabye para execução no Azure) e o patch ao qual você vinculou foi rejeitado .
Pessoalmente, estou interessado na série 4.9 porque é isso que kops está usando e gostaria de saber quando eles lançarão um AMI com uma correção.
Enquanto isso, você pode tentar executar o teste de @bobrik , que parece muito bom para mim.
wget https://gist.githubusercontent.com/bobrik/2030ff040fad360327a5fab7a09c4ff1/raw/9dcf83b821812064fa7fb056b8f22cbd5c4364f1/cfs.go
sudo docker run --rm -it --cpu-quota 20000 --cpu-period 100000 -v $(pwd):$(pwd) -w $(pwd) golang:1.9.2 go run cfs.go -iterations 15 -sleep 1000ms
Com um CFS funcionando corretamente, os tempos de gravação serão sempre de 5 ms. Com os kernels afetados que testei, usando os números acima, frequentemente vejo tempos de queima de 99 ms. Qualquer coisa acima de 6 ms é um problema.
Nuru
em 22 abr. 2020
@nuru obrigado pelo script para descobrir que o problema está lá ou não.
@justinsb Por favor, sugira se as imagens kops padrão têm o patch ou não
https://github.com/kubernetes/kops/blob/master/channels/stable
Abriu um problema: https://github.com/kubernetes/kops/issues/8954
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -617586330
Atualização: executou o teste na imagem kops 1.15, há limitação desnecessária https://github.com/kubernetes/kops/issues/8954#issuecomment -617673755
alok87
em 22 abr. 2020
@Nuru
2020/04/22 11:02:48 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 6ms
2020/04/22 11:02:49 [1] burn took 5ms, real time so far: 1012ms, cpu time so far: 12ms
2020/04/22 11:02:50 [2] burn took 5ms, real time so far: 2017ms, cpu time so far: 18ms
2020/04/22 11:02:51 [3] burn took 5ms, real time so far: 3023ms, cpu time so far: 23ms
2020/04/22 11:02:52 [4] burn took 5ms, real time so far: 4028ms, cpu time so far: 29ms
2020/04/22 11:02:53 [5] burn took 5ms, real time so far: 5033ms, cpu time so far: 35ms
2020/04/22 11:02:54 [6] burn took 5ms, real time so far: 6038ms, cpu time so far: 40ms
2020/04/22 11:02:55 [7] burn took 5ms, real time so far: 7043ms, cpu time so far: 46ms
2020/04/22 11:02:56 [8] burn took 5ms, real time so far: 8049ms, cpu time so far: 51ms
2020/04/22 11:02:57 [9] burn took 5ms, real time so far: 9054ms, cpu time so far: 57ms
2020/04/22 11:02:58 [10] burn took 5ms, real time so far: 10059ms, cpu time so far: 63ms
2020/04/22 11:02:59 [11] burn took 5ms, real time so far: 11064ms, cpu time so far: 69ms
2020/04/22 11:03:00 [12] burn took 5ms, real time so far: 12069ms, cpu time so far: 74ms
2020/04/22 11:03:01 [13] burn took 5ms, real time so far: 13074ms, cpu time so far: 80ms
2020/04/22 11:03:02 [14] burn took 5ms, real time so far: 14079ms, cpu time so far: 85ms
esses resultados são do
Linux <servername> 4.15.0-96-generic #97-Ubuntu SMP Wed Apr 1 03:25:46 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
É um kernel ubuntu estável mais recente padrão no ubuntu 18.04.
Então, parece que o patch está lá.
 zerkms
em 22 abr. 2020
zerkms
em 22 abr. 2020
@zerkms Onde você executou seus testes no Ubuntu 18.04? Parece-me que o patch pode ter chegado apenas no kernel para o Azure. Se você encontrar uma nota de lançamento dizendo onde ela foi aplicada ao pacote Ubuntu linux , compartilhe. Eu não consigo encontrar.
Observe também que este teste também não foi capaz de reproduzir o problema no CoreOS. Pode ser que na configuração padrão o agendamento CFS tenha sido desabilitado globalmente.
Nuru
em 22 abr. 2020
@Nuru
Onde você executou seus testes no Ubuntu 18.04?
Um de meus servidores.
Não verifiquei as notas de lançamento, nem tenho certeza do que procurar e, no entanto - é um kernel padrão como todo mundo tem. 🤷
zerkms
em 22 abr. 2020
o patch deve estar aqui no kernel ubuntus git:
https://kernel.ubuntu.com/git/ubuntu/ubuntu-bionic.git/commit/?id=aadd794e744086fb50cdc752d54044fbc14d4adb
e aqui o bug do Ubuntu a respeito disso:
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1832151
ele deve ser lançado no biônico.
Você pode ter certeza executando apt-get source linux e verificar o download do código-fonte.
juliantaylor
em 22 abr. 2020
@zerkms Por "onde você executou seus testes", quero dizer era um servidor em seu escritório, um servidor no GCP, AWS, Azure ou em outro lugar?
Obviamente, há muita coisa que eu não entendo sobre como o Ubuntu é distribuído e mantido. Também estou confuso com sua saída de uname -a . As notas de versão do Ubuntu dizem:
18.04.4 vem com um kernel Linux baseado em v5.3 atualizado do kernel baseado em v5.0 em 18.04.3.
e também diz que 18.04.4 foi lançado em 12 de fevereiro de 2020. Sua saída diz que você está executando um kernel v4.15 compilado em 1 de abril de 2020.
@juliantaylor Eu não tenho um servidor Ubuntu ou uma cópia do aadd794e7440 o tornou em um kernel estável publicado. Se você puder me mostrar como fazer isso, eu agradeceria.
Quando eu olho para os comentários de bug do
- Este bug foi corrigido no pacote linux-azure - 5.0.0-1027.29
- Este bug foi corrigido no pacote linux-azure - 5.0.0-1027.29 ~ 18.04.1
mas este patch específico ( sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices ) não está listado em
- Este bug foi corrigido no pacote linux - 4.15.0-69.78
Também não vejo "1832151" listado nas notas de versão do Ubuntu
Um comentário anterior disse que foi corrigido em 4.15.0-67.76, mas não vejo nenhum pacote linux-image-4.15.0-67-generic .
Estou longe de ser um especialista em Ubuntu e acho esse rastreamento de patch inaceitavelmente difícil, pelo que pude observar.
Espero que você veja agora por que não tenho certeza de que esse patch foi realmente incluído no Ubuntu 18.04.4, que é a versão atual do 18.04. Minha _melhor suposição_ é que ele foi lançado como uma atualização do kernel após o lançamento de 18.04.4 e provavelmente está incluído se o kernel do Ubuntu relatar 4.15.0-69 ou posterior, mas se você apenas baixar 18.04.4 e não atualizá-lo não terá o patch.
Nuru
em 22 abr. 2020
Acabei de executar aquele teste Go (muito útil) no kernel 4.15.0-72 em um servidor baremetal em um datacenter e parece que o patch está lá:
2020/04/22 21:24:27 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 7ms
2020/04/22 21:24:28 [1] burn took 5ms, real time so far: 1010ms, cpu time so far: 13ms
2020/04/22 21:24:29 [2] burn took 5ms, real time so far: 2015ms, cpu time so far: 20ms
2020/04/22 21:24:30 [3] burn took 5ms, real time so far: 3020ms, cpu time so far: 25ms
2020/04/22 21:24:31 [4] burn took 5ms, real time so far: 4025ms, cpu time so far: 32ms
2020/04/22 21:24:32 [5] burn took 5ms, real time so far: 5030ms, cpu time so far: 38ms
2020/04/22 21:24:33 [6] burn took 5ms, real time so far: 6036ms, cpu time so far: 43ms
2020/04/22 21:24:34 [7] burn took 5ms, real time so far: 7041ms, cpu time so far: 50ms
2020/04/22 21:24:35 [8] burn took 5ms, real time so far: 8046ms, cpu time so far: 56ms
2020/04/22 21:24:36 [9] burn took 5ms, real time so far: 9051ms, cpu time so far: 63ms
2020/04/22 21:24:37 [10] burn took 5ms, real time so far: 10056ms, cpu time so far: 68ms
2020/04/22 21:24:38 [11] burn took 5ms, real time so far: 11061ms, cpu time so far: 75ms
2020/04/22 21:24:39 [12] burn took 5ms, real time so far: 12067ms, cpu time so far: 81ms
2020/04/22 21:24:40 [13] burn took 5ms, real time so far: 13072ms, cpu time so far: 86ms
2020/04/22 21:24:41 [14] burn took 5ms, real time so far: 14077ms, cpu time so far: 94ms
Também posso ver que a mesma execução no kernel 4.9.164 no mesmo tipo de servidor mostra queimaduras em 5ms:
2020/04/22 21:24:41 [0] burn took 97ms, real time so far: 97ms, cpu time so far: 8ms
2020/04/22 21:24:42 [1] burn took 5ms, real time so far: 1102ms, cpu time so far: 12ms
2020/04/22 21:24:43 [2] burn took 5ms, real time so far: 2107ms, cpu time so far: 16ms
2020/04/22 21:24:44 [3] burn took 5ms, real time so far: 3112ms, cpu time so far: 24ms
2020/04/22 21:24:45 [4] burn took 83ms, real time so far: 4197ms, cpu time so far: 28ms
2020/04/22 21:24:46 [5] burn took 5ms, real time so far: 5202ms, cpu time so far: 32ms
2020/04/22 21:24:47 [6] burn took 94ms, real time so far: 6297ms, cpu time so far: 36ms
2020/04/22 21:24:48 [7] burn took 99ms, real time so far: 7397ms, cpu time so far: 40ms
2020/04/22 21:24:49 [8] burn took 100ms, real time so far: 8497ms, cpu time so far: 44ms
2020/04/22 21:24:50 [9] burn took 5ms, real time so far: 9503ms, cpu time so far: 52ms
2020/04/22 21:24:51 [10] burn took 5ms, real time so far: 10508ms, cpu time so far: 60ms
2020/04/22 21:24:52 [11] burn took 5ms, real time so far: 11602ms, cpu time so far: 64ms
2020/04/22 21:24:53 [12] burn took 5ms, real time so far: 12607ms, cpu time so far: 72ms
2020/04/22 21:24:54 [13] burn took 5ms, real time so far: 13702ms, cpu time so far: 76ms
2020/04/22 21:24:55 [14] burn took 5ms, real time so far: 14707ms, cpu time so far: 80ms
Então, meu problema é que eu ainda vejo o afogamento da CPU, mesmo meu kernel parece ter sido corrigido
vgarcia-te
em 22 abr. 2020
@Nuru certo, desculpe. Esse era o meu servidor bare metal hospedado no escritório.
e também diz que 18.04.4 foi lançado em 12 de fevereiro de 2020. Sua saída diz que você está executando um kernel v4.15 compilado em 1 de abril de 2020.
Isso porque é um LTS de servidor: você precisa ativar o HWE explicitamente com ele para ter kernels mais novos, caso contrário, basta executar o mainline.
E os kernels mainline e HWE são lançados regularmente, então nada de suspeito em ter um kernel construído recentemente: http://changelogs.ubuntu.com/changelogs/pool/main/l/linux-meta/linux-meta_4.15.0.96.87/ changelog
zerkms
em 22 abr. 2020
@zerkms Obrigado pela informação. Continuo confuso, mas este não é o lugar para me educar.
@ vgarcia-te Se o seu kernel foi corrigido, o que parece ser, então o afogamento não é devido a este bug. Não tenho certeza da sua terminologia quando você diz:
Estou falando sobre o uso de cerca de 50ms com solicitação definida para 250m e limite de 500m. Estamos vendo cerca de 50% dos períodos de CPU sendo limitados. Esse valor é baixo o suficiente para ser esperado e pode ser aceito?
O recurso de CPU do Kubernetes é medido em CPUs, 1 significando 100% de 1 CPU cheia, 1m significando 0,1% de 1 CPU. Portanto, seu limite de "500 m" permite 0,5 CPUs.
O período de agendamento padrão para CFS é de 100 ms, portanto, definir o limite para 0,5 CPUs limitaria seu processo a 50 ms de CPU a cada 100 ms. Se o seu processo tentar ultrapassar isso, ele ficará estrangulado. Se o seu processo normalmente executa mais de 50 ms em uma única passagem, sim, você esperaria que ele fosse estrangulado por um planejador funcionando corretamente.
Nuru
em 23 abr. 2020
@Nuru isso faz sentido, mas deixe-me entender isso, dado que o período de cpu padrão é 100ms, no caso de um processo receber 1 CPU atribuída, se esse processo rodar por mais de 100ms em uma única passagem, ele será acelerado?
Isso significa que no Linux, onde o período de CPU padrão é 100 ms, qualquer processo que tenha um limite de execução de mais de 100 ms em uma única passagem, será estrangulado?
Qual seria uma boa configuração de limite para um processo que leva mais de 100 ms em uma única passagem, mas fica ocioso o resto do tempo?
vgarcia-te
em 23 abr. 2020
@vgarcia-te perguntou
Dado que o período de CPU padrão é 100 ms, no caso de um processo receber 1 CPU atribuída, se esse processo for executado por mais de 100 ms em uma única passagem, ele será acelerado?
Claro que o agendamento é extremamente complicado, então não posso dar uma resposta perfeita, mas a resposta simplificada é não. Explicações mais detalhadas estão aqui e aqui .
Todos os processos unix estão sujeitos a agendamento preventivo baseado em fatias de tempo. Na época da CPU com um único núcleo, você ainda tinha 30 processos em execução "simultaneamente". O que acontece é que eles correm um pouco e dormem ou, no final de sua fatia de tempo, são colocados em espera para que outra coisa possa correr.
O CFS com cotas leva isso um passo adiante.
Porém, pergunte a si mesmo, quando você diz que deseja que um processo use 50% da CPU, o que você está realmente dizendo? Você está dizendo que não há problema em consumir 100% da CPU por 5 minutos, desde que não funcione nos próximos 5 minutos? Isso seria 50% do uso em 10 minutos, mas não é aceitável para a maioria das pessoas por causa dos problemas de latência.
Portanto, o CFS define um "período de CPU" que é a janela de tempo durante a qual ele aplica cotas. Em uma máquina com 4 núcleos e um período de CPU de 100 ms, o agendador tem 400 ms de tempo de CPU para alocar mais de 100 ms de tempo real (clock de parede). Se você estiver executando um único thread de execução que não pode ser paralelizado, esse thread pode usar no máximo 100 ms de tempo de CPU por período, o que seria 100% de 1 CPU. se você definir sua cota para 1 CPU, ela nunca deve ser estrangulada.
Se você definir a cota para 500 m (0,5 CPUs), o processo terá 50 ms para ser executado a cada 100 ms. Qualquer período de 100 ms usa menos de 50 ms e não deve ser acelerado. O período de 100ms do Ayn não termina após a execução de 50ms, é estrangulado até o próximo período de 100ms. Isso mantém um equilíbrio entre a latência (quanto tempo ele tem que esperar para ser capaz de executar) e monopolização (quanto tempo é permitido evitar que outros processos sejam executados).
Nuru
em 23 abr. 2020
@Nuru meus slides estão corretos. Eu também sou um desenvolvedor Ubuntu * (agora apenas nas minhas horas vagas). Sua melhor aposta é ler as fontes e verificar git blame + tag --contains para rastrear quando o patch atinge a versão do kernel que você deseja.
chiluk
em 26 abr. 2020
@chiluk Eu não tinha visto seus slides. Para outras pessoas que não os viram, aqui é onde dizem que o patch caiu há algum tempo:
- Ubuntu 4.15.0-67 +
- Ubuntu 5.3.0-24 +
- Kernel RHEL7 3.10.0-1062.8.1.el7
e, claro, Linux estável v4.14.154, v4.19.84, 5.3.9. Observo que também está no Linux 5.4-rc1 estável.
Ainda estou lutando para entender os vários bugs do planejador CFS e encontrar testes confiáveis e fáceis de interpretar que funcionariam em um pequeno servidor AWS, porque estou oferecendo suporte a uma grande variedade de kernels de instalações legadas. Pelo que entendi a linha do tempo, um bug foi introduzido no kernel Linux v3.16-rc1 em 2014 por
[51f2176d74ac](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=51f2176d74ac) sched/fair: Fix unlocked reads of some cfs_b->quota/period.
Isso causou diferentes problemas de limitação do CFS. Acho que os problemas que eu estava vendo nos clusters kops Kubernetes se deviam a esse bug, já que eles estavam usando kernels 4.9.
51f2176d74ac foi corrigido no kernel de 2018 v4.18-rc4 com
[512ac999](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) sched/fair: Fix bandwidth timer clock drift condition
mas isso introduziu o bug @chiluk corrigido com
[de53fd7ae](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425) sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
Obviamente, não é culpa de Chiluk ou de qualquer outra pessoa que os patches do kernel sejam difíceis de rastrear nas distribuições. No entanto, continua sendo frustrante para mim e contribui para minha confusão.
Por exemplo, no Debuan buster 10 (AWS AMI debian-10-amd64-20191113-76 ), a versão do kernel é relatada como
Linux ip-172-31-41-138 4.19.0-6-cloud-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
Pelo que eu posso dizer, este kernel deveria ter 51f2176d74ac e NÃO 512ac999 e, portanto, deveria falhar no teste descrito em 512ac999 , mas não tem. (Eu digo que não acho que ele tenha 512ac999 porque ele foi atualizado incrementalmente do kernel Linux 4.10 e não há menção desse patch no log de alterações.) No entanto, em uma VM AWS de 4 cpu ele não falha fibtest Chiluk ou teste de soluços de CFS de Bobrik, o que sugere que algo mais está acontecendo.
Tive problemas semelhantes ao reproduzir quaisquer problemas de agendamento com o CoreOS mesmo antes de receber o patch do Chiluk.
Meu pensamento no momento é que o teste de Bobrik é principalmente um teste para 51f2176d74ac , o Debian buster 10 AMI que estou usando _tem o 512ac999 , apenas não explicitamente chamado no log de alterações, e fibtest não é um teste muito sensível em uma máquina com apenas alguns núcleos.
Nuru
em 27 abr. 2020
Uma cpu de 4 núcleos provavelmente não é grande o suficiente para reproduzir o problema corrigido por chiluk.
Ele só deve ser reproduzível em máquinas maiores com mais de talvez 40 cpus se eu entendi a explicação do chiluks kubecon talk (https://www.youtube.com/watch?v=UE7QX98-kO0) corretamente.
Existem muitas versões de kernel por aí e muitos patches e reversões de patches acontecendo. Os registros de alterações e os números de versão só levam você até aí.
Se você tiver dúvidas, a única maneira confiável é baixar o código-fonte e compará-lo com as alterações nos patches que foram vinculados aqui.
juliantaylor
em 27 abr. 2020
Os problemas ficam obsoletos após 90 dias de inatividade.
Marque o problema como novo com /remove-lifecycle stale .
Problemas obsoletos apodrecem após 30 dias adicionais de inatividade e, eventualmente, fecham.
Se for seguro encerrar este problema agora, faça-o com /close .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/ lifecycle stale
fejta-bot
em 26 jul. 2020
/ remove-lifecycle stale
 yashbhutwala
em 27 jul. 2020
yashbhutwala
em 27 jul. 2020
Os testes mencionados anteriormente neste tópico não reproduzem realmente o problema para mim (algumas queimaduras levam mais de 5 ms, mas são como 0,01% deles), mas nossas métricas de limitação de cfs ainda mostram quantidades moderadas de limitação. Temos diferentes versões do kernel em nossos clusters, mas as duas versões mais comuns são:
Debian 4.19.67-2+deb10u2~bpo9+1 (2019-11-12)- um backport manual de
5.4.38
Não sei se ambos os bugs devem ser corrigidos nessas versões, mas _cheio_ que devem ser, então me pergunto se o teste não é tão útil. Estou testando em máquinas com 16 núcleos e com 36 núcleos, não tenho certeza se preciso de ainda mais núcleos para o teste ser válido, mas ainda vemos o afogamento nesses clusters então ...
 2rs2ts
em 18 ago. 2020
2rs2ts
em 18 ago. 2020
Devemos encerrar esta edição e pedir às pessoas que estão enfrentando problemas que comecem novos? O spamming aqui provavelmente tornará qualquer conversa muito difícil.
 omnibs
em 31 out. 2020
omnibs
em 31 out. 2020
^ Eu concordo. Muito foi feito para resolver isso.
 sfxworks
em 31 out. 2020
sfxworks
em 31 out. 2020
/Fechar
com base nos comentários acima. por favor, abra novos problemas conforme necessário.
dims
em 1 nov. 2020
@dims : Fechando este problema.
Em resposta a isso :
/Fechar
com base nos comentários acima. por favor, abra novos problemas conforme necessário.
As instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
 k8s-ci-robot
em 1 nov. 2020
k8s-ci-robot
em 1 nov. 2020
notifique os problemas de acompanhamento deste problema, para que as pessoas inscritas no problema possam se inscrever em novos problemas a seguir
 glensc
em 1 nov. 2020
glensc
em 1 nov. 2020
Questões relacionadas
 mml
·
3Comentários
mml
·
3Comentários
 rhohubbuild
·
3Comentários
rhohubbuild
·
3Comentários
 chowyu08
·
3Comentários
chowyu08
·
3Comentários
 cooligc
·
3Comentários
cooligc
·
3Comentários
 zetaab
·
3Comentários
zetaab
·
3Comentários
Comentários muito úteis
O patch caiu na ponta esta manhã.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Assim que chegar à árvore de Torvald, irei submetê-lo para inclusão estável no Linux e, subsequentemente, para distros principais (Redhat / Ubuntu). Se você se preocupa com outra coisa e eles não estão seguindo os patches estáveis para Linux, você pode enviar diretamente.