Kubernetes: Les quotas du CFS peuvent entraîner une limitation inutile
/ genre bug
Ce n'est pas un bogue dans Kubernets en soi, c'est plutôt un avertissement.
J'ai lu ce super article de blog:
Dans le billet de blog, j'ai appris que k8s utilise des quotas cfs pour appliquer les limites du processeur. Malheureusement, ceux-ci peuvent conduire à une limitation inutile, en particulier pour les locataires bien élevés.
Voir ce bogue non résolu dans le noyau Linux que j'ai déposé il y a quelque temps:
Il existe un correctif ouvert et bloqué qui résout le problème (je n'ai pas vérifié s'il fonctionne):
cc @ConnorDoyle @balajismaniam
 bobrik
bobrik
Tous les 142 commentaires
/ nœud sig
/ genre bug
 neolit123
le 20 août 2018
neolit123
le 20 août 2018
est-ce un duplicata de # 51135?
 liggitt
le 20 août 2018
liggitt
le 20 août 2018
C'est similaire dans l'esprit, mais il semble manquer le fait qu'il y ait un bogue réel dans le noyau plutôt que juste un compromis de configuration dans la période de quota CFS. J'ai aimé le # 51135 ici pour donner aux gens plus de contexte.
bobrik
le 22 août 2018
Autant que je sache, c'est une autre raison de désactiver le quota CFS ( --cpu-cfs-quota=false ) ou de le rendre configurable (# 63437).
Je trouve également cet essentiel (lié à partir du correctif du noyau) très intéressant à voir (pour mesurer l'impact): https://gist.github.com/bobrik/2030ff040fad360327a5fab7a09c4ff1
 hjacobs
le 22 août 2018
hjacobs
le 22 août 2018
cc @adityakali
 vishh
le 23 août 2018
vishh
le 23 août 2018
Un autre problème avec les quotas est que le kubelet compte les hyperthreads comme "cpus". Lorsqu'un cluster devient tellement chargé que deux threads sont planifiés sur le même cœur et que le processus a un quota de quota de processeur, l'un d'eux ne fonctionnera qu'avec une petite fraction de la puissance de traitement disponible (il ne fera quelque chose que lorsque quelque chose sur l'autre thread stalls) mais consomme toujours le quota comme s'il avait un cœur physique pour lui-même. Donc, il consomme le double du quota qu'il devrait sans faire beaucoup plus de travail.
Cela a pour effet que sur un nœud de nœud entièrement chargé avec l'hyperthreading activé, les performances seront la moitié de ce qu'elles seraient avec l'hyperthreading ou les quotas désactivés.
Imo le kubelet ne doit pas considérer les hyperthreads comme de vrais processeurs pour éviter cette situation.
 juliantaylor
le 30 août 2018
juliantaylor
le 30 août 2018
@juliantaylor Comme je l'ai mentionné dans # 51135, la désactivation du quota de processeur peut être la meilleure approche pour la plupart des clusters k8s exécutant des charges de travail fiables.
vishh
le 30 août 2018
Est-ce considéré comme un bug?
Si certains pods sont étranglés sans vraiment épuiser leur limite de CPU, cela me semble être un bug.
Sur mon cluster, la plupart des pods de dépassement de quota sont liés à des métriques (heapster, metrics-collector, node-export ...) ou à des opérateurs, qui ont évidemment le type de charge de travail qui pose problème ici: ne rien faire la plupart du temps l'heure et se réveiller pour se réconcilier de temps en temps.
La chose étrange ici est que j'ai essayé d'augmenter la limite, passant de 40m à 100m ou 200m , et les processus étaient toujours limités.
Je ne vois aucune autre métrique indiquant une charge de travail qui pourrait déclencher cette limitation.
J'ai supprimé les limites de ces pods pour le moment ... ça va mieux, mais bon, ça ressemble vraiment à un bug et nous devrions venir avec une meilleure solution que de désactiver le Limits
 prune998
le 26 nov. 2018
prune998
le 26 nov. 2018
@ prune998 voir le commentaire de @vishh et l'essentiel : le noyau ralentit de manière trop agressive, même si le calcul vous dit qu'il ne devrait pas. Nous (Zalando) avons décidé de désactiver le quota CFS (limitation du processeur) dans nos clusters: https://www.slideshare.net/try_except_/optimizing-kubernetes-resource-requestslimits-for-costefficiency-and-latency-highload
hjacobs
le 27 nov. 2018
Merci @hjacobs.
Je suis sur Google GKE et je ne vois pas de moyen facile de le désactiver, mais je continue à chercher ...
prune998
le 27 nov. 2018
@ prune998 AFAIK, Google n'a pas
 timoreimann
le 27 nov. 2018
timoreimann
le 27 nov. 2018
Je suis sur Google GKE et je ne vois pas de moyen facile de le désactiver, mais je continue à chercher ...
Pouvez-vous supprimer les limites de processeur de vos conteneurs pour le moment?
vishh
le 28 nov. 2018
Selon la documentation du gestionnaire de processeur, CFS quota is not used to bound the CPU usage of these containers as their usage is bound by the scheduling domain itself. Mais nous sommes confrontés à une limitation du CFS.
Cela rend le gestionnaire de CPU statique pratiquement inutile car la définition d'une limite de CPU pour atteindre la classe QoS garantie annule tout avantage dû à la limitation.
Est-ce un bogue que les quotas CFS sont définis pour les pods sur un processeur statique?
 mariusgrigoriu
le 12 févr. 2019
mariusgrigoriu
le 12 févr. 2019
Pour plus de contexte (appris cela hier): @hrzbrg (MyTaxi) a contribué un drapeau à Kops pour désactiver la régulation du processeur: https://github.com/kubernetes/kops/issues/5826
hjacobs
le 12 févr. 2019
Veuillez partager un résumé du problème ici. On ne sait pas très bien quel est le problème et dans quels scénarios les utilisateurs sont touchés et que faut-il exactement pour le résoudre?
Notre compréhension actuelle est que lorsque nous franchissons les limites, nous sommes pénalisés et étranglés. Disons que nous avons un quota de processeur de 3 cœurs et que dans les 5 premières ms, nous avons consommé 3 cœurs, puis dans la tranche de 100 ms, nous serons limités pendant 95 ms, et dans ces 95 ms, nos conteneurs ne peuvent rien faire. Et nous avons vu se ralentir même lorsque les pics de processeur ne sont pas visibles dans les métriques d'utilisation du processeur. Nous supposons que c'est parce que la fenêtre de temps de mesure de l'utilisation du processeur est en secondes et que la limitation se produit au niveau des micro secondes, de sorte qu'elle est en moyenne et n'est pas visible. Mais le bug mentionné ici nous a laissé perplexes maintenant.
Quelques questions:
- Quand le nœud est à 100% CPU? S'agit-il d'un cas particulier dans lequel tous les conteneurs sont limités indépendamment de leur utilisation?
Lorsque cela se produit, tous les conteneurs sont-ils limités à 100% par le processeur?
Qu'est-ce qui déclenche ce bogue dans le nœud?
Quelle est la différence entre ne pas utiliser
limitset désactivercpu.cfs_quota?La désactivation de
limitsn'est-elle pas une solution risquée quand il y a de nombreux pods extensibles et qu'un pod peut provoquer l'instabilité du nœud et avoir un impact sur d'autres pods qui exécutent leurs requêtes?Séparément, selon le noyau, le processus de documentation peut être limité lorsque le quota parent est entièrement utilisé. Qu'est-ce que le parent dans le contexte du conteneur ici (est-il lié à ce bogue)? https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
There are two ways in which a group may become throttled: a. it fully consumes its own quota within a period b. a parent's quota is fully consumed within its period- Que faut-il pour y remédier? Mettre à jour la version du noyau?
Nous avons été confrontés à une panne assez importante et cela semble étroitement lié (sinon la cause principale) au fait que tous nos pods sont bloqués dans une boucle de redémarrage par étranglement et ne peuvent pas évoluer. Nous fouillons dans les détails pour trouver le vrai problème. Je vais ouvrir un autre numéro expliquant en détail notre panne.
Toute aide ici est grandement appréciée.
cc @justinsb
 alok87
le 14 févr. 2019
alok87
le 14 févr. 2019
L'un de nos utilisateurs a défini une limite de processeur et a été limité dans le délai d'expiration de sa sonde de vivacité, provoquant une panne de son service.
Nous constatons une limitation même lors de l'épinglage de conteneurs à un processeur. Par exemple, une limite de processeur de 1 et épinglant ce conteneur pour qu'il ne s'exécute que sur un seul processeur. Il devrait être impossible de dépasser le quota sur une période donnée si votre quota était exactement le nombre de processeurs dont vous disposez, mais nous constatons une limitation dans tous les cas.
Je pensais avoir vu quelque part que le noyau 4.18 résout le problème. Je ne l'ai pas encore testé, donc ce serait bien si quelqu'un pouvait confirmer.
mariusgrigoriu
le 15 févr. 2019
https://github.com/torvalds/linux/commit/512ac999d2755d2b7109e996a76b6fb8b888631d dans 4.18 semble être le correctif approprié pour ce problème.
 clkao
le 23 févr. 2019
clkao
le 23 févr. 2019
@mariusgrigoriu Je semble être coincé dans la même énigme que vous avez décrite ici https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -462534360.
Nous observons la limitation du processeur sur les pods dans la classe QoS garantie avec la politique statique de CPUManager (ce qui ne semble pas avoir de sens).
La suppression des limits pour ces pods les placera dans la classe Burstable QoS, ce qui n'est pas ce que nous voulons, donc la seule option restante est de désactiver les quotas de CPU CFS à l'échelle du système, ce qui n'est pas non plus quelque chose que nous pouvons faire en toute sécurité, car autoriser tous les pods à accéder à la capacité du processeur non liée peut entraîner de dangereux problèmes de saturation du processeur.
@vishh étant donné les circonstances ci-dessus, quel serait le meilleur plan d'action? il semble que la mise à niveau vers le noyau> 4.18 (qui a le correctif de comptabilité cfs cpu) et (peut-être) réduire la période de quota cfs?
D'une manière générale, suggérer de supprimer simplement limits des conteneurs en cours de limitation devrait avoir des avertissements clairs:
1) S'il s'agissait de pods dans la classe QoS garantie, avec un nombre entier de cœurs et avec la politique statique CPUMnanager en place - ces pods
2) Ces pods ne seront pas liés en termes de quantité de CPU qu'ils peuvent consommer et peuvent potentiellement causer des dommages importants dans certaines circonstances.
Vos commentaires / conseils seraient très appréciés.
 dannyk81
le 25 mars 2019
dannyk81
le 25 mars 2019
La mise à niveau du noyau aide certainement, mais le comportement de l'application d'un quota CFS semble toujours ne pas correspondre à ce que la documentation suggère.
mariusgrigoriu
le 25 mars 2019
Je fais des recherches sur divers aspects de cette question depuis un certain temps maintenant. Mes recherches sont résumées dans mon article sur LKML.
https://lkml.org/lkml/2019/3/18/706
Cela étant dit, je n'ai pas été en mesure de reproduire le problème décrit ici dans les noyaux pré-512ac99. J'ai cependant vu une régression des performances dans les noyaux post-512ac99. Ce correctif n'est donc pas une panacée.
 chiluk
le 25 mars 2019
chiluk
le 25 mars 2019
Merci @mariusgrigoriu , nous allons pour la mise à niveau du noyau et espérons que cela vous aidera un peu, consultez également https://github.com/kubernetes/kubernetes/issues/70585 - il semble que des quotas sont effectivement fixés pour les pods garantis avec cpuset ( ie cpus épinglé), donc cela me semble être un bug.
dannyk81
le 25 mars 2019
@chiluk pourriez-vous élaborer un peu? voulez-vous dire que le correctif inclus dans la version 4.18 (mentionné ci-dessus dans https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-466609030) ne résout pas réellement le problème?
dannyk81
le 25 mars 2019
Le correctif du noyau 512ac99 corrige un problème pour certaines personnes, mais a causé un problème pour nos configurations. Le correctif a corrigé la façon dont les tranches de temps sont réparties entre cfs_rq, en ce sens qu'elles expirent désormais correctement. Auparavant, ils n'expiraient pas.
Les charges de travail Java, en particulier sur les machines à grand nombre de cœurs, subissent désormais des limitations élevées avec une faible utilisation du processeur en raison du blocage des threads de travail. Ces threads se voient attribuer une tranche de temps dont ils n'utilisent qu'une petite partie qui expire plus tard. Dans le test synthétique que j'ai écrit * (lié à ce fil), nous constatons une dégradation des performances d'environ 30x. Dans les performances du monde réel, nous avons constaté une dégradation du temps de réponse de centaines de millisecondes entre les deux noyaux en raison de la limitation accrue.
chiluk
le 25 mars 2019
En utilisant un noyau 4.19.30, je vois que les pods que j'espérais voir moins d'étranglement sont toujours étranglés et certains pods qui n'étaient pas auparavant en cours de limitation sont maintenant assez sévèrement étranglés (kube2iam rapporte plus de secondes que l'instance a été en place , en quelque sorte)
 willthames
le 27 mars 2019
willthames
le 27 mars 2019
Sur CoreOS 4.19.25-coreos, je vois Prometheus déclencher l'alerte CPUThrottlingHigh presque sur chaque pod du système.
 teralype
le 27 mars 2019
teralype
le 27 mars 2019
@williamsandrew @teralype cela semble refléter les conclusions de @chiluk .
Après diverses discussions internes, nous avons en fait décidé de désactiver complètement les quotas cfs (drapeau de kubelet --cpu-cfs-quota=false ), cela semble résoudre tous les problèmes que nous avons rencontrés pour les pods Burstable et Garanti (épinglés par le processeur ou standard).
Il y a une excellente présentation à ce sujet (et quelques autres sujets) ici: https://www.slideshare.net/try_except_/ensuring-kubernetes-cost-efficiency-across-many-clusters-devops-gathering-2019
Lecture hautement recommandée: +1:
dannyk81
le 27 mars 2019
problème à long terme (note de soi)
 dims
le 27 mars 2019
dims
le 27 mars 2019
@ dannyk81 juste pour être complet: la conférence liée est également disponible sous forme de vidéo enregistrée: https://www.youtube.com/watch?v=4QyecOoPsGU
hjacobs
le 27 mars 2019
@hjacobs ,
Une idée comment appliquer ce correctif sur AKS ou GKE?
Merci
 agolomoodysaada
le 2 avr. 2019
agolomoodysaada
le 2 avr. 2019
@agolomoodysaada, nous avons déposé une demande de fonctionnalité auprès de GKE il y a quelque temps. Je ne sais pas quel est le statut, je ne travaille plus intensivement avec GKE.
timoreimann
le 2 avr. 2019
J'ai contacté le support Azure et ils ont dit qu'il ne serait disponible que vers août 2019.
agolomoodysaada
le 4 avr. 2019

Je pensais que je partagerais un graphique d'une application constamment étranglée tout au long de sa vie.
agolomoodysaada
le 5 avr. 2019
Sur quel noyau était-ce?
chiluk
le 5 avr. 2019
" chiluk " 4.15.0-1037-azur "
agolomoodysaada
le 5 avr. 2019
Cela ne contient donc pas le commit noyau 512ac99. Voici le correspondant
la source.
https://kernel.ubuntu.com/git/kernel-ppa/mirror/ubuntu-azure-xenial.git/tree/kernel/sched/fair.c?h=Ubuntu-azure-4.15.0-1037.39_16.04.1 & id = 19b0066cc4829f45321a52a802b640bab14d0f67
Ce qui signifie que vous rencontrez peut-être le problème décrit dans 512ac99. Garder à
sachez que 512ac99 nous a apporté d'autres régressions.
Le ven 5 avril 2019 à 12 h 08 Moody Saada [email protected]
a écrit:
@chiluk https://github.com/chiluk "4.15.0-1037-azur"
-
Vous recevez cela parce que vous avez été mentionné.
Répondez directement à cet e-mail, affichez-le sur GitHub
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-480350946 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/ACDI05YeS6wfUE9XkiMbxrLvPllYQZ7Iks5vd4MOgaJpZM4WDUF3
.
chiluk
le 5 avr. 2019
J'ai maintenant posté des correctifs sur LKML à ce sujet.
https://lkml.org/lkml/2019/4/10/1068
Des tests supplémentaires seraient grandement appréciés.
chiluk
le 11 avr. 2019
J'ai resoumis ces correctifs maintenant avec des changements de documentation.
https://lkml.org/lkml/2019/5/17/581
Cela aiderait vraiment si les gens pouvaient tester ces correctifs et commenter le fil sur LKML. Pour le moment, je suis le seul à l'avoir mentionné sur LKML, et je n'ai reçu aucun commentaire de la part de la communauté ou des responsables. Ce serait vraiment très utile si je pouvais obtenir des tests de la communauté et des commentaires sur LKML sous mon patch.
chiluk
le 21 mai 2019
Pour ce que ça vaut, ce projet particulier https://github.com/tensorflow/serving semble être gravement affecté par ce problème. Et c'est surtout une application C ++.
@chiluk , Y a-t-il des solutions de contournement que nous pouvons appliquer pendant le déploiement du correctif?
Merci beaucoup
agolomoodysaada
le 29 mai 2019
Nous devrions aider @chiluk à collecter les citations de l'impact sérieux de ce bogue du noyau sur Kubernetes et quiconque utilise les quotas CFS.
Zolando a indiqué dans sa présentation la semaine dernière que ses mauvaises expériences avec le noyau actuel signifiaient qu'il considérait la désactivation des quotas CFS comme la meilleure pratique actuelle, car ils considèrent que cela fait plus de mal que de bien.
https://www.youtube.com/watch?v=6sDTB4eV4F8
 whereisaaron
le 29 mai 2019
whereisaaron
le 29 mai 2019
De plus en plus d'entreprises désactivent la limitation du processeur, par exemple mytaxi, Datadog, Zalando ( fil Twitter )
hjacobs
le 29 mai 2019
@derekwaynecarr @ dchen1107 @ kubernetes / sig-node-feature-requests Dawn, Derek, est-il temps de changer la valeur par défaut? et / ou documentation?
dims
le 29 mai 2019
Oui @whereisaaron collecter et partager des rapports sur la limitation des applications paralysantes, et / ou être désactivé en raison de son mauvais comportement serait une participation bienvenue sur le fil lkml le cas échéant. Pour le moment, il semble que je me plains principalement de ce problème à la communauté du noyau.
chiluk
le 29 mai 2019
@agolomoodysaada, la solution de contournement consiste à désactiver temporairement les quotas
Il existe également des bonnes pratiques concernant la réduction du nombre de threads d'application, ce qui aide également.
Pour golang set GOMAXPROCS ~ = ceil (quota)
Pour Java, passez aux JVM plus récents qui reconnaissent et respectent les limites de quota du processeur. Les jvms antérieurs généraient des threads en fonction du nombre de cœurs de processeur, et non du nombre de cœurs disponibles pour l'application.
Ces deux éléments ont été des atouts majeurs pour nous.
Surveillez et signalez les applications qui connaissent une limitation afin que vos développeurs puissent ajuster les quotas.
chiluk
le 29 mai 2019
Pour info, après avoir signalé ce fil au support Azure AKS, on m'a répondu que le correctif serait déployé lors de la mise à niveau vers le noyau 5.0, fin septembre, au mieux.
Jusque-là, eh bien, arrêtez d'utiliser des limites :)
prune998
le 29 mai 2019
@ prune998 il y a une petite mise en garde au cas où vous utiliseriez CPUmanager (c.-à-d. allocation de CPU dédiée aux pods dans la qualité de service garantie).
En supprimant les limites, vous éviterez le problème de limitation du CFS, mais vous supprimerez les pods de la qualité de service garantie afin que CPUmanager n'alloue plus de cœurs dédiés à ces pods.
Si vous n'utilisez pas CPUmanager - pas de mal, mais juste pour info pour quiconque opte pour cette direction.
Il existe un PR (https://github.com/kubernetes/kubernetes/issues/70585) pour désactiver entièrement les quotas CFS pour les pods avec des processeurs dédiés, mais il n'a pas encore été fusionné.
Nous avons également choisi de désactiver les quotas du CFS à l'échelle du système comme suggéré ci-dessus et aucun problème jusqu'à présent.
dannyk81
le 29 mai 2019
@ dannyk81 https://github.com/kubernetes/kubernetes/issues/70585 n'est pas un PR qui peut être fusionné (c'est un problème avec un extrait de code). Pouvez-vous (ou quelqu'un d'autre) s'il vous plaît déposer un PR?
dims
le 29 mai 2019
Il y en a déjà un: https://github.com/kubernetes/kubernetes/pull/75682
 praseodym
le 29 mai 2019
praseodym
le 29 mai 2019
@dims J'ai lié le problème, pas le PR ... mais le problème est lié au PR :) en effet, c'est https://github.com/kubernetes/kubernetes/pull/75682 et ça y est suspendu depuis un moment donc si vous pouviez pousser ce serait génial car c'est vraiment un problème ennuyeux.
Merci: +1:
dannyk81
le 29 mai 2019
oups! merci @ dannyk81 j'ai assigné des gens et ajouté un jalon
dims
le 29 mai 2019
FWIW, nous avons également rencontré ce problème et avons constaté que l'abandon de la période de quota CFS à 10 ms au lieu des 100 ms par défaut entraînait une amélioration spectaculaire de nos latences de fin de course. Je pense que c'est parce que même si vous rencontrez le bogue du noyau, une quantité beaucoup plus courte de quota est gaspillée s'il n'est pas utilisé, et le processus peut obtenir plus de quota (dans des allocations plus petites) beaucoup plus tôt. C'est juste une solution de contournement, mais pour ceux qui ne veulent pas désactiver complètement le quota CFS, cela pourrait être un pansement jusqu'à ce que le correctif soit implémenté. k8s prend en charge cette opération dans la version 1.12 avec la porte de fonctionnalité cpuCFSQuotaPeriod et l'indicateur kubelet --cpu-cfs-quota-period.
 d-shi
le 30 mai 2019
d-shi
le 30 mai 2019
Je devrais vérifier, mais je pense que réduire la période aussi loin peut avoir pour effet de la désactiver efficacement, car il y a des tranches minimales et des quotas minimums dans le code. Il vaut probablement mieux désactiver les quotas et passer à des quotas souples.
chiluk
le 30 mai 2019
@chiluk ma compréhension de profane est que la tranche par défaut est de 5 ms, donc la définir sur cette valeur ou moins la désactive effectivement, mais tant que la période est supérieure à 5 ms, il devrait toujours y avoir une application de quota. Faites-moi savoir si ce n'est pas correct.
d-shi
le 31 mai 2019
Avec --feature-gates=CustomCPUCFSQuotaPeriod=true --cpu-cfs-quota-period=10ms un de mes pods a vraiment eu du mal à démarrer. Dans le graphique prometheus ci-joint, le conteneur tente de démarrer, ne parvient pas à atteindre son test de vivacité jusqu'à ce qu'il soit tué (normalement, le conteneur démarre dans environ 5 secondes - même augmenter la vivacité initialDelaySeconds à 60s n'a pas aidé) et est puis remplacé par un nouveau.
Vous pouvez voir que le conteneur est fortement étranglé jusqu'à ce que je supprime la période cpu-cfs-quota-period des arguments kubelet, à quel point la limitation est beaucoup plus plate et le conteneur redémarre dans environ 5 secondes.

willthames
le 5 juin 2019
Pour info: fil Twitter actuel sur le sujet de la désactivation de la limitation du processeur: https://twitter.com/it_supertramp/status/1133648291332263936
hjacobs
le 5 juin 2019
Voici les graphiques de limitation du processeur avant / après le passage à --cpu-cfs-quota-period=10ms en production pour 2 services sensibles à la latence:
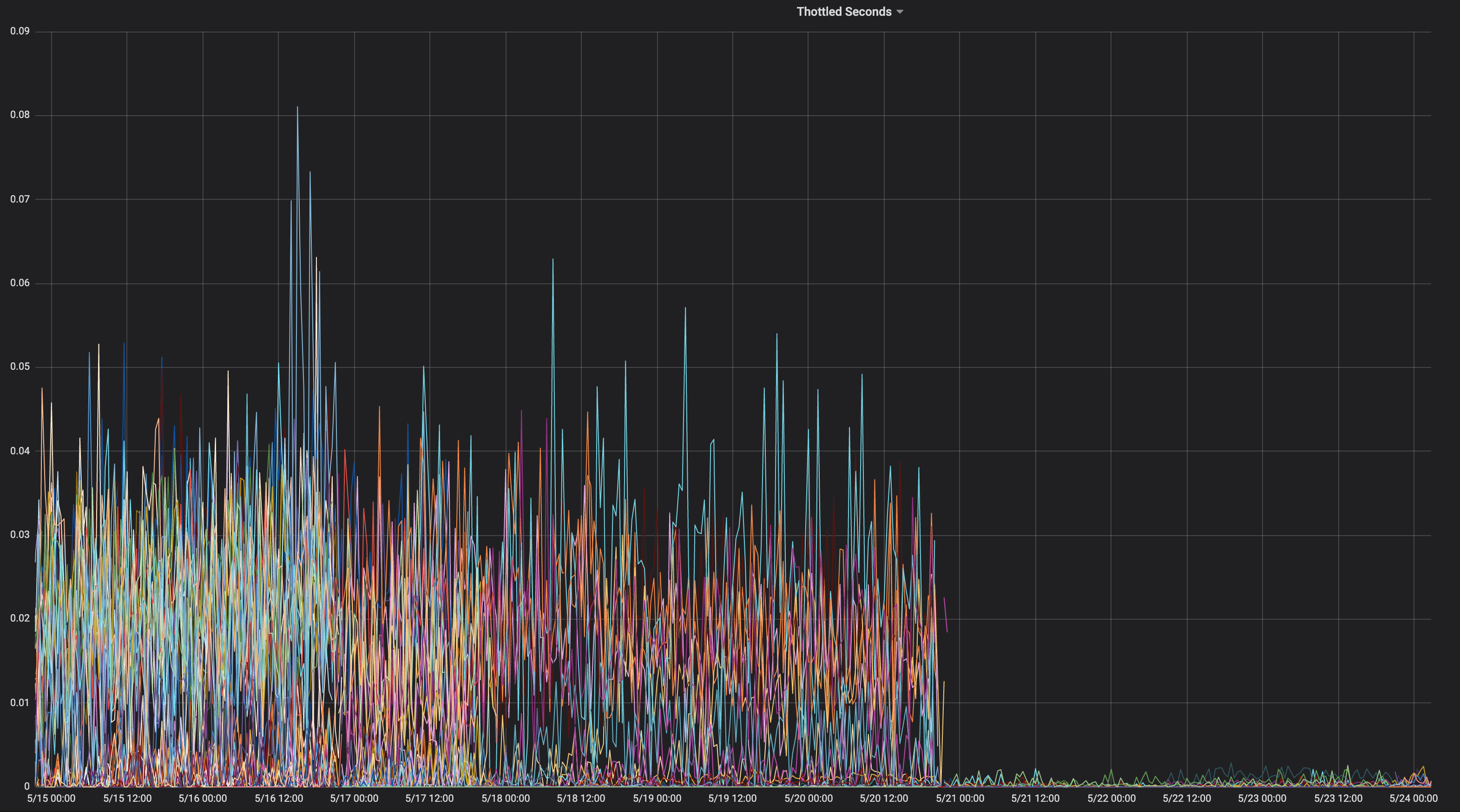

Ces services s'exécutent sur différents types d'instances (avec différentes teintes / tolérances). Les instances du 2ème service ont d'abord été déplacées vers la période de quota inférieure du CFS.
Les résultats doivent être très dépendants de la charge.
d-shi
le 5 juin 2019
@ d-shi, il se passe autre chose sur votre graphique. Je pense qu'il y a peut-être un quota minimum que vous atteignez maintenant parce que la période est si courte. Je devrais vérifier le code pour être sûr. Fondamentalement, vous avez augmenté par inadvertance la quantité de quota disponible pour l'application. Vous auriez probablement pu accomplir la même chose en augmentant les allocations de quotas.
chiluk
le 5 juin 2019
Pour nous, il était beaucoup plus utile de mesurer la latence que la limitation. La désactivation de cfs-quota considérablement amélioré la latence. J'aimerais voir des résultats similaires pour changer le cfs-quota-period .
 blakebarnett
le 6 juin 2019
blakebarnett
le 6 juin 2019
@chiluk nous avons en fait essayé d'augmenter les allocations de quotas (jusqu'au maximum pris en charge par kubernetes par pod), et en aucun cas les latences de fin de course ni la limitation n'ont été réduites de beaucoup. Les latences p99 sont passées d'environ 98 ms à une limite de 4 cœurs à 86 ms à une limite de 16 cœurs. Après avoir réduit le quota CFS à 10 ms, p99 est passé à 20 ms à 4 cœurs.
@blakebarnett nous avons développé un programme de référence qui mesurait nos latences, et ils sont passés d'une plage de 10 ms à --cpu-cfs-quota-period ms, avec une moyenne d'environ 18 ms avant la mise à jour
MODIFICATIONS: Désolé pour les modifications que j'ai dû revenir en arrière et revérifier mes numéros.
d-shi
le 6 juin 2019
@ d-shi, vous rencontriez probablement le problème résolu par 512ac999 alors.
chiluk
le 6 juin 2019
@chiluk Après avoir lu encore et encore votre patch, je dois admettre que j'ai du mal à comprendre l'impact de ce code:
if (cfs_rq->expires_seq == cfs_b->expires_seq) {
- /* extend local deadline, drift is bounded above by 2 ticks */
- cfs_rq->runtime_expires += TICK_NSEC;
- } else {
- /* global deadline is ahead, expiration has passed */
- cfs_rq->runtime_remaining = 0;
- }
Dans un cas où le quota expire même si runtime_remaining vient d'emprunter du temps au pool global. Au pire, vous serez limité pendant 5 ms en fonction de sched_cfs_bandwidth_slice_us. N'est-ce pas?
Est-ce que je rate quelque chose?
 Mwea
le 6 juin 2019
Mwea
le 6 juin 2019
@chiluk oui je pense avoir raison. Nos serveurs de production sont toujours sur le noyau 4.4, donc ne disposez pas de ce correctif. Peut-être qu'une fois que nous aurons mis à niveau vers un noyau plus récent, nous pourrons ramener la période de quota CFS à la valeur par défaut, mais pour l'instant, il travaille à améliorer nos latences d'extrémité de queue et nous n'avons pas encore remarqué d'effets secondaires indésirables. Bien qu'il ne soit en ligne que depuis quelques semaines.
d-shi
le 6 juin 2019
@chiluk Voulez- vous résumer l'état de ce problème dans le noyau? On dirait qu'il y avait un correctif, 512ac999, mais il y avait des problèmes. Ai-je lu quelque part qu'il avait été inversé? Ou est-ce totalement / partiellement corrigé? Si oui, quelle version?
mariusgrigoriu
le 7 juin 2019
@mariusgrigoriu ce n'est pas corrigé, @chiluk a créé un correctif qui devrait le corriger et qui nécessite des tests supplémentaires (je vais y consacrer une partie de mon temps dans les prochains jours)
Voir https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -482198124 pour le dernier statut
willthames
le 7 juin 2019
@Mwea le pool global est stocké dans cfs_b-> runtime_remaining. Au fur et à mesure que cela est affecté aux files d'attente d'exécution par processeur (cfs_rq), le montant restant dans le pool global est décrémenté. cfs_bandwidth_slice_us est la quantité d'exécution du processeur qui est transférée du pool global vers les files d'attente d'exécution par processeur. Si vous étiez limité, cela signifierait que vous deviez exécuter et cfs_b-> runtime_remaining == 0. Vous devrez attendre la fin de la période actuelle (par défaut 100 ms), pour que le quota soit réapprovisionné en cfs_b puis distribué à votre cfs_rq. J'ai récemment découvert que la quantité de temps d'exécution expiré est d'au plus 1 ms par cfs_rq, en raison du fait que le minuteur de relâche recapture tout par 1 ms de quota inutilisé à partir des files d'attente d'exécution par processeur. Ce 1 ms est ensuite perdu / expiré à la fin de la période. Dans le pire des cas, l'application se propage sur 88 cpus, ce qui pourrait représenter 88 ms de quota gaspillé par période de 100 ms. Cela a en fait conduit à une proposition alternative qui était de permettre au temporisateur de relance de récupérer tout le quota inutilisé des files d'attente inactives par processeur.
Quant aux lignes que vous mettez en évidence spécifiquement. Ma proposition est de supprimer complètement l'expiration du runtime qui a été attribué aux files d'attente d'exécution par processeur. Ces lignes font partie du correctif pour 512ac999. Cela a résolu un problème où le décalage d'horloge entre les files d'attente d'exécution par processeur entraînait l'expiration prématurée du quota, limitant ainsi les applications qui n'avaient pas encore utilisé le quota (afaiu). Fondamentalement, ils incrémentent expires_seq à chaque limite de période. expires_seq doit donc correspondre entre chacun des cfs_rq lorsqu'ils sont sur la même période.
@mariusgrigoriu - si vous
Il existe de nombreuses façons d'atténuer ce problème.
- Épinglage du processeur
- Diminuer le nombre de threads générés par votre application
- Surallocation de quota pour les applications confrontées à une limitation.
- Désactivez les limites strictes pour le moment.
- Créez un noyau personnalisé avec l'une des modifications proposées.
chiluk
le 7 juin 2019
@chiluk est-ce que vous avez déjà publié une version de ce patch compatible avec le noyau 4.14? Je cherche à le tester de manière assez agressive puisque nous venons de mettre à niveau quelques milliers d'hôtes vers la version 4.14.121 (à partir de 4.9.62) et que nous voyons:
- Une réduction de la limitation pour Memcached, mysql, nginx, etc.
- Une augmentation de la limitation pour nos applications Java
Je veux vraiment avancer pour tirer le meilleur parti des deux mondes ici. Je peux essayer de le porter sur moi-même la semaine prochaine, mais si vous en avez déjà un, ce serait génial.
 PaulFurtado
le 21 juin 2019
PaulFurtado
le 21 juin 2019
@PaulFurtado
J'ai réécrit le patch au cours des derniers jours compte tenu des suggestions de Ben Segull. Un nouveau correctif du noyau sera disponible dès que je pourrai le tester sur nos clusters.
chiluk
le 24 juin 2019
@chiluk une mise à jour sur ce patch? Pas de soucis sinon, je m'assure juste de ne pas manquer le patch qui passe
PaulFurtado
le 18 juil. 2019
@PaulFurtado , le patch a été "approuvé" par l'auteur du CFS, et j'attends juste que les responsables du planificateur l'intègrent et le transmettent à Linus.
chiluk
le 24 juil. 2019
@chiluk Merci!
Je viens de rétroporter le patch sur le noyau 4.14, qui est notre noyau de production actuel.
J'ai fait un résumé du backport et des résultats de votre test fibtest ici: https://gist.github.com/PaulFurtado/ff6c67ec87416b66ba1c6fc70f7beec1
Sur les instances ec2 c5.9xlarge et m5.24xlarge de la génération actuelle que nous utilisons dans nos clusters kubernetes et mesos, le patch double les performances de votre programme fibtest. Sur un type d'instance r4.16xlarge de génération précédente, il gère 1,5 fois plus d'utilisation du processeur, mais à peine des itérations supplémentaires (ce qui, je suppose, est simplement dû à la génération du processeur et à la nature exponentielle de la séquence fibonacci). Ces chiffres tiennent tous à peu près exactement si j'augmente le test à 30 secondes au lieu de la valeur par défaut de 5 secondes.
Nous commencerons à intégrer cela dans notre environnement QA cette semaine pour obtenir des métriques de nos applications qui souffrent de la pire limitation. Merci encore!
PaulFurtado
le 26 juil. 2019
@PaulFurtado tout d' abord merci pour les tests. Je suppose que vous utilisez kernel.org 4.14 ou ubuntu 4.14, qui contiennent tous deux 512ac999. En ce qui concerne les itérations de test fibtest terminées, ce n'est pas aussi important que le temps CPU utilisé, car les itérations terminées peuvent être fortement affectées par cpu mhz lors de l'exécution du test (en particulier dans le cloud où je ne suis pas sûr du contrôle que vous avez sur cela).
chiluk
le 31 juil. 2019
Je suppose que vous utilisez kernel.org 4.14 ou ubuntu 4.14, qui contiennent tous deux 512ac999.
Oui, nous exécutons mainline 4.14 (enfin, plus l'ensemble de correctifs du noyau Amazon Linux 2, mais aucun de ces correctifs n'a d'importance dans ce cas).
512ac999 a atterri dans la ligne principale 4.14.95, et nous avons observé ses effets lors de la mise à niveau de 4.14.77 à 4.14.121+. Cela a permis à nos conteneurs memcached (nombre de threads très bas) de passer d'une limitation inexplicable à aucune limitation, mais a rendu nos conteneurs golang et java (nombre de threads très élevé) plus étranglés.
En ce qui concerne les itérations de test fibtest terminées, ce n'est pas aussi important que le temps CPU utilisé, car les itérations terminées peuvent être fortement affectées par cpu mhz lors de l'exécution du test (en particulier dans le cloud où je ne suis pas sûr du contrôle que vous avez sur cela).
Sur les instances EC2 plus récentes / plus grandes, vous obtenez en fait un niveau de contrôle décent fonctionnons donc avec le turbo boost désactivé et ne permettons pas aux cœurs de rester inactifs. Cependant, je viens de réaliser que nous ajustons les états-c, mais pas les états-p et le type d'instance qui n'a pas vu d'augmentation des itérations était celui où les états-p sont contrôlables, ce qui peut très bien l'expliquer.
tout d'abord merci pour le test
Pas de problème du tout, les choses sont restées stables dans notre environnement pré-QA au cours du week-end, et nous commencerons à déployer le correctif dans notre environnement principal de QA demain où nous verrons plus d'effets dans le monde réel. Étant donné que Memcached avait bénéficié du patch précédent, nous voulions vraiment avoir notre gâteau et le manger aussi avec les deux patchs en place, donc nous étions heureux de tester. Merci encore pour tout le travail que vous avez consacré à la limitation!
PaulFurtado
le 31 juil. 2019
Je voulais juste laisser une note, concernant le correctif du noyau en cours de discussion ...
Je l'ai adapté au noyau que nous utilisons dans les tests actuels, et je constate d'énormes gains sur les taux de limitation du CFS, mais je mentionnerai que si vous avez précédemment défini la période cfs à 10 ms comme atténuation, vous allez veulent ramener cela à 100 ms pour voir les avantages du changement.
 jhohertz
le 6 août 2019
jhohertz
le 6 août 2019
Le patch a atterri sur la pointe ce matin.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Une fois qu'il aura atteint l'arborescence de Torvald, je le soumettrai pour une inclusion stable sous Linux, et par la suite des distributions majeures (Redhat / Ubuntu). Si vous vous souciez de quelque chose d'autre et qu'ils ne suivent pas les correctifs stables sous Linux, vous voudrez peut-être le soumettre directement.
chiluk
le 8 août 2019
J'ai testé le patch (ubuntu 18.04, noyau 5.2.7, nœud: CPU 56 cœurs E5-2660 v4 @ 2.00GHz) avec notre microservice golang de traitement d'image lourd en CPU et j'ai obtenu des résultats assez impressionnants. Des performances comme si je désactivais complètement CFS sur le nœud.
J'ai 5 à 35% de latence en moins et 5 à 55% de RPS en plus en fonction de la concurrence / utilisation du processeur à un taux de limitation proche de zéro.
Merci, @chiluk !
Comme dit @jhohertz , le quota rétabli à 100 ms , j'ai testé avec des périodes inférieures et j'ai obtenu une limitation élevée et une dégradation des performances.
 zigmund
le 10 août 2019
zigmund
le 10 août 2019
Pour plus de performances avec golang, réglez GOMAXPROCS sur ceil (quota) +2. Le plus 2 est de garantir une certaine concurrence.
chiluk
le 12 août 2019
@chiluk testé avec GOMAXPROCS = 8 vs GOMAXPROCS = 10 avec cpu.limit = 8 - pas une grande différence, quelque chose d'environ 1-2%.
zigmund
le 13 août 2019
@zigmund c'est parce que votre cpu.limit est défini sur le nombre entier 8 qui devrait lier vos processus à un cpuset de 8 cpus. Votre différence de 1 à 2% n'est que l'augmentation des frais généraux pour le changement de contexte avec vos 2 coureurs Goroutine supplémentaires sur votre ensemble de tâches 8 cpu.
J'aurais dû dire que définir GOMAXPROCS = # est une bonne solution de contournement pour les programmes go jusqu'à ce que les correctifs du noyau soient largement distribués.
chiluk
le 26 août 2019
Nous avons migré nos clusters de production vers un noyau patché et je peux maintenant vous partager quelques moments intéressants.
Statistiques de l'un de nos clusters - 4 nœuds de 72 cœurs E5-2695 v4 @ 2,10 GHz, 128 Go de RAM, Debian 9, noyau 5.2.7 avec patch.
Nous avons des charges mixtes composées principalement de services golang, mais aussi de php et python.
Golang. La latence est inférieure, le réglage correct de GOMAXPROCS est absolument indispensable. Voici le service avec GOMAXPROCS par défaut = 72. Nous avons changé le noyau à ~ 16 et après cette latence a diminué et l'utilisation du processeur a fortement augmenté. À 21h15, j'ai réglé le GOMAXPROCS correct et l'utilisation du processeur normalisée.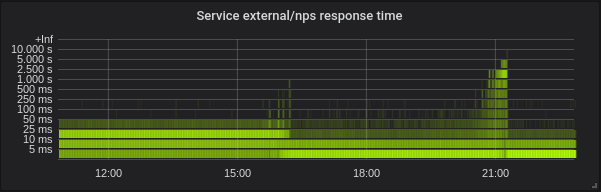

Python. Tout s'est amélioré avec le patch sans aucun mouvement supplémentaire - l'utilisation du processeur et la latence ont diminué.
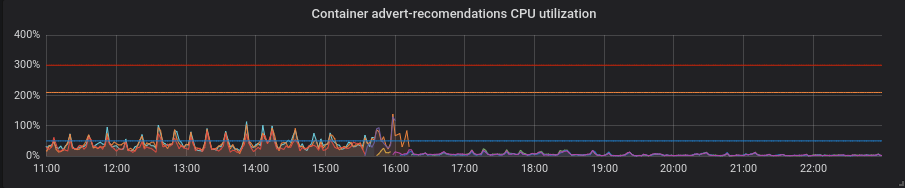
PHP. L'utilisation du processeur est la même, la latence a peu diminué sur certains services. Pas un gros profit.
zigmund
le 3 sept. 2019
Merci @zigmund.
Je ne suis pas sûr de comprendre quand vous dites I setted correct GOMAXPROCS ...
Je suppose que vous n'exécutez pas un seul pod sur le nœud à 72 cœurs, vous définissez donc GOMAXPROCS sur quelque chose de plus bas, peut-être égal aux limites de processeur du pod, n'est-ce pas?
prune998
le 3 sept. 2019
Merci @zigmund. Les changements de go correspondent à peu près à ce qui était attendu.
Je suis vraiment surpris par les améliorations de python, car je m'attendais à ce que le GIL annule largement les avantages de cela. Si quoi que ce soit, ce correctif devrait presque purement réduire le temps de réponse, diminuer le pourcentage de périodes limitées et augmenter l'utilisation du processeur. Êtes-vous sûr que votre application Python était toujours saine?
chiluk
le 3 sept. 2019
@ prune998 désolé, peut-être une faute d'orthographe. J'ai mis GOMAXPROCS = limits.cpu. Pour le moment, nous avons environ 110 pods par nœud dans ce cluster.
@chiluk Je ne suis pas fort en python et je ne sais pas comment le patch a été affecté à la couche inférieure. Mais l'application est saine et sans problème, je l'ai vérifiée après le changement du noyau.
zigmund
le 4 sept. 2019
@chiluk Pouvez -vous nous expliquer comment nous pouvons suivre la progression de votre patch dans diverses distributions Linux? Je suis particulièrement intéressé par Debian et AWS Linux, mais je pense que d'autres personnes sont intéressées par Ubuntu, etc., donc quelle que soit la lumière que vous pouvez apporter, merci.
 Nuru
le 13 sept. 2019
Nuru
le 13 sept. 2019
@Nuru https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html?highlight=stable%20rules ... Fondamentalement, je soumettrai via linux-stable une fois que mon patch aura atteint Linus ' tree, * (peut-être plus tôt), puis toutes les distributions devraient suivre un processus stable sous Linux, et extraire les correctifs acceptés par les mainteneurs stables dans leurs noyaux spécifiques à la distribution. S'ils ne le sont pas, vous ne devriez pas exécuter leurs distributions.
chiluk
le 13 sept. 2019
@chiluk Je ne connais rien au processus de développement Linux. Par «arbre de Linus», voulez-vous dire https://github.com/torvalds/linux ?
Nuru
le 14 sept. 2019
L'arbre de Linus vit ici, https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/. Mes modifications sont actuellement mises en scène sur linux-next qui est l'arborescence d'intégration de développement. Ouais, le développement du noyau est un peu coincé dans les âges sombres, mais ça marche.
Il apportera probablement les modifications de l'arborescence linux-next une fois que la version 5.3 sera publiée et qu'il commencera le développement sur la version 5.4-rc0. C'est à peu près dans le temps que je m'attends à ce que les noyaux stables commencent à intégrer ce correctif. Chaque fois que Linus estime que 5.3 est stable, tout le monde le devine.
chiluk
le 14 sept. 2019
[Linus] apportera probablement des changements à partir de l'arborescence linux-next une fois que 5.3 sera publié et qu'il commencera le développement sur 5.4-rc0. C'est à peu près dans le temps que je m'attends à ce que les noyaux stables commencent à intégrer ce correctif. Chaque fois que Linus estime que 5.3 est stable, tout le monde le devine.
@chiluk On dirait que Linus a décidé que 5.3 était stable le 15 septembre 2019 . Alors, qu'est-ce que "linux-next" et comment suivons-nous la progression de votre patch à travers les étapes suivantes?
Nuru
le 20 sept. 2019
Quelqu'un a-t-il construit des packages extensibles Debian et / ou une image AWS qui inclut ce correctif? Je suis sur le point de le faire en utilisant https://github.com/kubernetes-sigs/image-builder/tree/master/images/kube-deploy/imagebuilder
Je pensais juste que j'éviterais de dupliquer les efforts si cela existe déjà.
blakebarnett
le 24 sept. 2019
Cela a maintenant été fusionné dans l'arbre de Linus et devrait être publié avec la version 5.4. Je viens également de le soumettre à linux-stable, et en supposant que cela se passe bien, toutes les distributions qui suivent correctement le processus stable devraient commencer à le récupérer sous peu.
chiluk
le 25 sept. 2019
Quelqu'un sait-il comment suivre si / comment ce changement se résume à CentOS (7)? Je ne sais pas comment fonctionne le backporting, etc.
 till
le 26 sept. 2019
till
le 26 sept. 2019
@till https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -531370333
Pour le noyau stable, la conversation se poursuit ici.
https://lore.kernel.org/stable/CAC=E7cUXpUDgpvsmMaMU6sAydbfD0FEJiK25R1r=e9=YtcPjGw@mail.gmail.com/
Aussi pour ceux qui vont à KubeCon, je présenterai ce problème là-bas.
https://sched.co/Uae1
chiluk
le 3 oct. 2019
Un mot des responsables de l'ordonnanceur à propos de: l'ack que Greg HK recherchait pour l'introduire dans des arbres stables?
jhohertz
le 18 oct. 2019
Greg KH a tardé à prendre une décision concernant ce correctif parce que les responsables du planificateur n'ont pas répondu (ils ont probablement manqué le courrier). Un commentaire de quelqu'un d'autre que moi sur LKML qui a testé ce patch et pense qu'il devrait être rétroporté serait apprécié.
chiluk
le 18 oct. 2019
Pour les personnes utilisant CoreOS, il existe un problème ouvert demandant que le correctif de
 evanfoster
le 1 nov. 2019
evanfoster
le 1 nov. 2019
Le noyau CoreOS 4.19.82 a les correctifs: https://github.com/coreos/linux/pull/364
CoreOS Container Linux 2317.0.1 (canal alpha) a les correctifs: https://github.com/coreos/coreos-overlay/pull/3796 http://coreos.com/releases/#2317.0.1
Les backports vers Linux stable semblent être bloqués car les correctifs ne s'appliquent pas correctement . @chiluk Allez-vous travailler sur des backports pour Linux stable? Si tel est le cas, allez-vous rétroporter à 4.9 pour qu'il entre dans Debian "stretch" et soit repris par kops ? Bien que je suppose que cela va prendre jusqu'à 6 mois pour le mettre en "stretch" et peut-être que d'ici là kops aura migré vers "buster".
Nuru
le 8 nov. 2019
@Nuru , j'ai rétroporté le patch et créé des packages stretch (basés sur le noyau stretch-backports) et une AMI compatible avec kops 1.11 si vous souhaitez tester:
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.buildinfo
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm-dbg_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-headers-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.changes
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-libc-dev_4.19.67-1_amd64.deb
293993587779 / k8s-1.11-debian-stretch-amd64-hvm-ebs-2019-09-26
blakebarnett
le 8 nov. 2019
@blakebarnett Merci pour vos efforts et désolé de vous déranger, mais je suis plus qu'un peu confus.
- "stretch" est basé sur Linux 4.9, mais tous vos liens sont pour 4.19.
- Vous dites que vous avez rétroporté "le patch" mais il y a 3 patches (je suppose que le troisième n'est pas vraiment important:
- 512ac999 sched / fair: correction de la condition de dérive de l'horloge de la minuterie
- de53fd7ae sched / fair: Correction d'une faible utilisation du processeur avec une limitation élevée en supprimant l'expiration des tranches locales du processeur
- 763a9ec06 sched / fair: Correction des avertissements -Wunused-but-set-variable
Avez-vous rétroporté les 3 patchs vers 4.9? (Je ne sais pas quoi faire avec les paquets Debian pour regarder et voir si les changements sont là, et le document «changements» ne traite pas de ce qui a vraiment changé.)
De plus, dans quelles régions votre AMI est-elle disponible?
Nuru
le 8 nov. 2019
Non, j'ai utilisé le noyau stretch-backports, qui est 4.19, car il contient des correctifs dont nous avions également besoin sur AWS (en particulier pour les types d'instances M5 / C5)
J'ai appliqué un diff qui incorporait tous les correctifs que je crois, j'ai dû le modifier légèrement pour supprimer les références supplémentaires à des variables dans 4.19 qui ont été supprimées ailleurs, j'ai d'abord appliqué ceci https://github.com/kubernetes/kubernetes/issues/67577 #issuecomment -515324561 et ensuite nécessaire d'ajouter:
--- kernel/sched/fair.c 2019-09-25 16:06:02.954933954 -0700
+++ kernel/sched/fair.c-b 2019-09-25 16:06:56.341615817 -0700
@@ -4928,8 +4928,6 @@
cfs_b->period_active = 1;
overrun = hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
- cfs_b->runtime_expires += (overrun + 1) * ktime_to_ns(cfs_b->period);
- cfs_b->expires_seq++;
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
--- kernel/sched/sched.h 2019-08-16 01:12:54.000000000 -0700
+++ sched.h.b 2019-09-25 13:24:00.444566284 -0700
@@ -334,8 +334,6 @@
u64 quota;
u64 runtime;
s64 hierarchical_quota;
- u64 runtime_expires;
- int expires_seq;
short idle;
short period_active;
@@ -555,8 +553,6 @@
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
- int expires_seq;
- u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock;
L'AMI est publiée à us-west-1
J'espère que ça t'as aidé!
blakebarnett
le 8 nov. 2019
J'ai rétroporté ces correctifs et les ai soumis aux noyaux linux stables
v4.14 https://lore.kernel.org/stable/[email protected]/
v4.19 https://lore.kernel.org/stable/[email protected]/ #t
chiluk
le 8 nov. 2019
Bonjour,
suite à l'intégration du patch sur la branche 4.19, j'ai ouvert un rapport de bogue sur debian pour une mise à jour correcte de kerner sur buster et stretch-backport:
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=946144
n'hésitez pas à ajouter un nouveau commentaire pour la mise à jour du paquet debian.
 alexises
le 4 déc. 2019
alexises
le 4 déc. 2019
J'espère que ce n'est pas trop de spam, mais je voulais lier cet excellent discours de @chiluk en passant par de nombreux détails de base liés à ce problème https://youtu.be/UE7QX98-kO0
 bboreham
le 4 déc. 2019
bboreham
le 4 déc. 2019
Existe-t-il un moyen d'éviter la limitation sur GKE? Nous venons d'avoir un énorme problème où une méthode sur un conteneur php prenait 120s au lieu de 0,1 s habituels
 bartoszhernas
le 5 déc. 2019
bartoszhernas
le 5 déc. 2019
supprimer les limites du processeur
 monotek
le 5 déc. 2019
monotek
le 5 déc. 2019
Nous l'avons déjà fait, le conteneur est limité lorsque les demandes de processeur sont trop petites. C'est le cœur du problème, le manque de limites et l'utilisation seule des requêtes CPU conduira toujours à une limitation :(
bartoszhernas
le 5 déc. 2019
@bartoszhernas Je pense que vous utilisez le mauvais mot ici. Lorsque les utilisateurs de ce thread font référence à la "limitation", ils font référence au contrôle de la bande passante cfs, nr_throttled dans cpu.stat pour l'augmentation du groupe de contrôle. Cela n'est activé que lorsque les limites du processeur sont activées. À moins que GKE n'ajoute des limites à votre pod à votre insu, je n'appellerais pas ce que vous frappez comme une limitation.
J'appellerais ce que vous avez décrit "la contention pour le processeur". Je soupçonne que vous avez probablement plusieurs applications de taille incorrecte * (demandes), qui se disputent le processeur ou une autre ressource sur la boîte parce qu'elles utilisent fréquemment plus que ce qu'elles ont demandé. C'est la raison précise pour laquelle nous utilisons des limites. De sorte que ces applications de taille incorrecte ne peuvent affecter que les autres applications de la boîte.
L'autre possibilité est que le montant de votre demande insuffisant entraîne simplement un mauvais comportement de planification. La définition des demandes à un niveau bas est similaire à la définition d'une valeur «agréable» positive par rapport à des applications de «demande» supérieures. Pour plus d'informations à ce sujet, consultez les limites souples.
chiluk
le 5 déc. 2019
Les problèmes disparaissent après 90 jours d'inactivité.
Marquez le problème comme récent avec /remove-lifecycle stale .
Les problèmes périmés pourrissent après 30 jours supplémentaires d'inactivité et finissent par se fermer.
Si ce problème peut être résolu en toute sécurité maintenant, veuillez le faire avec /close .
Envoyez vos commentaires à sig-testing, kubernetes / test-infra et / ou fejta .
/ cycle de vie périmé
 fejta-bot
le 4 mars 2020
fejta-bot
le 4 mars 2020
/ remove-lifecycle obsolète
Nuru
le 4 mars 2020
D'après ce que j'ai compris, le problème sous-jacent dans le noyau a été corrigé et rendu disponible par exemple dans ContainerLinux sur https://github.com/coreos/bugs/issues/2623.
Quelqu'un est-il au courant des problèmes restants après ce correctif du noyau?
 sfudeus
le 4 mars 2020
sfudeus
le 4 mars 2020
@sfudeus Kubernetes peut être exécuté sur n'importe quelle version de Linux ou, AFAIK, sur n'importe quelle version d'Unix compatible POSIT. Ce bogue n'a jamais été un problème pour les personnes n'utilisant pas Linux, a été corrigé pour certaines distributions dérivées de Linux et non corrigé pour d'autres.
Le problème sous-jacent a été résolu dans le noyau Linux 5.4, que presque personne n'utilise à ce stade. Des correctifs ont été rendus disponibles pour le rétroportage vers divers noyaux plus anciens et y compris dans les nouvelles distributions Linux qui ne sont pas encore prêtes à passer au noyau 5.4, dont il y en a beaucoup. Comme vous pouvez le voir dans la liste ci-dessus de commits faisant référence à ce problème, les correctifs de correction de bogue sont toujours en train d'être incorporés dans la myriade de distributions Linux sur lesquelles quelqu'un pourrait utiliser Kubernetes.
Par conséquent, je voudrais garder ce problème ouvert pendant qu'il voit encore des références de commit actives. Je voudrais également le voir fermé avec un script ou une autre méthode simple que quelqu'un peut utiliser pour déterminer si son installation Kubernetes est affectée ou non.
Nuru
le 5 mars 2020
@Nuru Bien pour moi, je voulais juste m'assurer qu'aucun autre problème de noyau ne
sfudeus
le 5 mars 2020
Je ne sais pas si c'est le bon endroit pour informer les gens, mais je ne sais pas vraiment où en parler:
Nous exécutons le noyau Linux 5.4 sur Debian Buster (en utilisant le noyau buster-backports) en utilisant le cluster k8s 1.15.10 et nous rencontrons toujours des problèmes avec cela. Surtout pour les pods qui ont généralement très peu à faire (kube-downscaler est l'exemple auquel nous revenons, ce qui nécessite généralement environ 3 m de CPU) et qui n'ont que très peu de ressources cpu affectées (50 m dans le cas de kube-downscaler dans notre cluster), nous voyons toujours une valeur de limitation très élevée. Pour référence, le kube-downscaler est essentiellement un script Python qui exécute un sleep pendant 30 minutes avant de faire quoi que ce soit. cAdvisor montre que l'augmentation de container_cpu_cfs_throttled_periods_total pour ce conteneur est toujours plus ou moins similaire à la valeur container_cpu_cfs_periods_total de ce conteneur (les deux sont d'environ 250 lors de la vérification de l'augmentation à intervalles de 5 m). Nous nous attendrions à ce que les périodes d'étranglement soient proches de 0.
Est-ce que nous mesurons cela de manière incorrecte? Est-ce que cAdvisor génère des données incorrectes? Notre hypothèse est-elle correcte selon laquelle nous devrions voir une baisse des périodes de limitation? Tout conseil serait apprécié ici.
Après le passage au noyau 5.4, nous avons vu le nombre de pods avec ce problème diminuer un peu (environ 40%), mais nous ne savons actuellement pas si ce que nous voyons est un problème réel ou non. Principalement, nous ne sommes pas sûrs en regardant les statistiques ci-dessus ce que «throttling» signifie vraiment ici si nous obtenons ces valeurs avec l'utilisation moyenne du processeur de 3 m. Le nœud sur lequel il s'exécute n'est pas du tout surchargé et a une utilisation moyenne du processeur inférieure à 10%.
 timstoop
le 5 mars 2020
timstoop
le 5 mars 2020
@timstoop les intervalles qui
Le nœud sur lequel il s'exécute n'est pas du tout surchargé et a une utilisation moyenne du processeur inférieure à 10%.
Juste pour clarifier: la charge du nœud et les autres charges de travail sur celui-ci n'ont rien à voir avec la limitation. La limitation ne tient compte que de la propre limite du conteneur / groupe de contrôle.
PaulFurtado
le 5 mars 2020
@PaulFurtado Merci pour votre réponse! Cependant, le pod lui-même a une utilisation moyenne de 3 m de processeur pendant ce sommeil et il est toujours limité. Il ne fait aucune demande pendant ce temps, il attend le sommeil. J'espère qu'il pourra le faire sans atteindre le 50m, non? Ou est-ce une hypothèse incorrecte de toute façon?
timstoop
le 5 mars 2020
Je pense que ce nombre est probablement tellement faible qu'il y aura des problèmes de précision. Et 50 m est si bas que n'importe quoi pourrait le faire trébucher. Le runtime de Python peut également effectuer des tâches d'arrière-plan dans les threads pendant que vous dormez.
PaulFurtado
le 5 mars 2020
Vous aviez raison, je faisais des suppositions qui n'étaient pas vraies. Merci pour vos conseils! Cela a du sens pour moi maintenant.
timstoop
le 5 mars 2020
Je voulais juste intervenir et dire que les choses ici ont été considérablement améliorées depuis que le correctif du noyau a frappé les noyaux 4.19 LTS, et qu'il est apparu sur CoreOS / Flatcar. En regardant pour le moment, les seules choses que je vois être étranglées sont quelques choses sur lesquelles je devrais probablement augmenter les limites. :sourire:
jhohertz
le 5 mars 2020
@sfudeus @chiluk Existe-t-il un test simple pour voir si votre noyau a résolu ce problème ou non?
Je ne peux pas dire si kope.io/k8s-1.15-debian-stretch-amd64-hvm-ebs-2020-01-17 (l'image officielle actuelle kops ) a été corrigé ou non.
Nuru
le 20 mars 2020
Je suis d'accord avec @mariusgrigoriu , pour les pods qui fonctionnent sur un processeur exclusif sous une politique de processeur statique, nous pouvons simplement désactiver la limite de quota de processeur - il ne peut fonctionner que sur son ensemble de processeur exclusif de toute façon. Le patch ci-dessus est à cet effet et pour ce type de pods uniquement.
 jianzzha
le 6 avr. 2020
jianzzha
le 6 avr. 2020
@Nuru j'ai écrit https://github.com/indeedeng/fibtest
Il s'agit d'un test aussi définitif que possible, mais vous aurez besoin d'un compilateur C.
Ignorez le nombre d'itérations effectuées, mais concentrez-vous sur le temps utilisé pour l'exécution à thread unique par rapport à l'exécution multi-thread.
chiluk
le 10 avr. 2020
Je suppose qu'un bon moyen de voir quels noyaux ont été corrigés est dans l'une des dernières diapositives de @chiluk (merci pour ce btw) talk https://www.youtube.com/watch?v=UE7QX98-kO0
Le noyau 4.15.0-67 semble avoir le correctif (https://launchpad.net/ubuntu/+source/linux/4.15.0-67.76) cependant, nous constatons toujours une limitation dans certains pods où les requêtes / limite sont bien au-dessus leur utilisation du processeur.
Je parle d'une utilisation d'environ 50 ms avec une demande définie sur 250 m et une limite de 500 m. Nous constatons qu'environ 50% des périodes CPU sont limitées, cette valeur est-elle peut-être suffisamment basse pour être attendue et peut être acceptée? J'aimerais qu'il le voie à zéro, nous ne devrions pas du tout être limités si l'utilisation n'est même pas proche de la limite.
Quelqu'un qui utilise le nouveau noyau patché a-t-il encore des limitations?
 vgarcia-te
le 22 avr. 2020
vgarcia-te
le 22 avr. 2020
@ vgarcia-te Il y a beaucoup trop de noyaux qui circulent pour savoir à partir d'une liste qui ont été patchés et qui ne l'ont pas été. Regardez tous les commits faisant référence à ce problème. Plusieurs centaines. Ma lecture du journal des modifications pour Ubuntu suggère que 4.15 n'a pas encore été corrigé (sauf mabye pour fonctionner sur Azure), et le correctif auquel vous avez lié a été rejeté .
Personnellement, je suis intéressé par la série 4.9 parce que c'est ce que kops utilise, et j'aimerais savoir quand ils publient une AMI avec un correctif.
En attendant, vous pouvez essayer de lancer le test de @bobrik qui me semble plutôt bien.
wget https://gist.githubusercontent.com/bobrik/2030ff040fad360327a5fab7a09c4ff1/raw/9dcf83b821812064fa7fb056b8f22cbd5c4364f1/cfs.go
sudo docker run --rm -it --cpu-quota 20000 --cpu-period 100000 -v $(pwd):$(pwd) -w $(pwd) golang:1.9.2 go run cfs.go -iterations 15 -sleep 1000ms
Avec un CFS fonctionnant correctement, les temps de combustion seront toujours de 5 ms. Avec les noyaux affectés que j'ai testés, en utilisant les nombres ci-dessus, je vois fréquemment des temps de combustion de 99 ms. Tout ce qui dépasse 6 ms est un problème.
Nuru
le 22 avr. 2020
@nuru merci pour le script pour trouver le problème est là ou pas.
@justinsb Veuillez suggérer si les images kops par défaut ont le correctif ou non
https://github.com/kubernetes/kops/blob/master/channels/stable
Ouverture d'un problème: https://github.com/kubernetes/kops/issues/8954
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -617586330
Mise à jour: a effectué le test dans l'image kops 1.15, une limitation inutile est là https://github.com/kubernetes/kops/issues/8954#issuecomment -617673755
alok87
le 22 avr. 2020
@Nuru
2020/04/22 11:02:48 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 6ms
2020/04/22 11:02:49 [1] burn took 5ms, real time so far: 1012ms, cpu time so far: 12ms
2020/04/22 11:02:50 [2] burn took 5ms, real time so far: 2017ms, cpu time so far: 18ms
2020/04/22 11:02:51 [3] burn took 5ms, real time so far: 3023ms, cpu time so far: 23ms
2020/04/22 11:02:52 [4] burn took 5ms, real time so far: 4028ms, cpu time so far: 29ms
2020/04/22 11:02:53 [5] burn took 5ms, real time so far: 5033ms, cpu time so far: 35ms
2020/04/22 11:02:54 [6] burn took 5ms, real time so far: 6038ms, cpu time so far: 40ms
2020/04/22 11:02:55 [7] burn took 5ms, real time so far: 7043ms, cpu time so far: 46ms
2020/04/22 11:02:56 [8] burn took 5ms, real time so far: 8049ms, cpu time so far: 51ms
2020/04/22 11:02:57 [9] burn took 5ms, real time so far: 9054ms, cpu time so far: 57ms
2020/04/22 11:02:58 [10] burn took 5ms, real time so far: 10059ms, cpu time so far: 63ms
2020/04/22 11:02:59 [11] burn took 5ms, real time so far: 11064ms, cpu time so far: 69ms
2020/04/22 11:03:00 [12] burn took 5ms, real time so far: 12069ms, cpu time so far: 74ms
2020/04/22 11:03:01 [13] burn took 5ms, real time so far: 13074ms, cpu time so far: 80ms
2020/04/22 11:03:02 [14] burn took 5ms, real time so far: 14079ms, cpu time so far: 85ms
ces résultats proviennent du
Linux <servername> 4.15.0-96-generic #97-Ubuntu SMP Wed Apr 1 03:25:46 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
C'est un dernier noyau stable par défaut ubuntu dans ubuntu 18.04.
Donc, il semble que le patch soit là.
 zerkms
le 22 avr. 2020
zerkms
le 22 avr. 2020
@zerkms Où avez-vous effectué vos tests sur Ubuntu 18.04? Il me semble que le correctif ne l'a peut-être fait que dans le noyau d'Azure. Si vous pouvez trouver une note de publication indiquant où elle a été appliquée au package Ubuntu linux , veuillez la partager. Je ne peux pas le trouver.
Notez également que ce test n'a pas non plus pu reproduire le problème sur CoreOS. Il se peut que dans la configuration par défaut, la planification CFS soit globalement désactivée.
Nuru
le 22 avr. 2020
@Nuru
Où avez-vous effectué vos tests sur Ubuntu 18.04?
Un de mes serveurs.
Je n'ai pas vérifié les notes de publication, je ne suis même pas sûr de ce qu'il faut rechercher, et néanmoins - c'est un noyau par défaut comme tout le monde. 🤷
zerkms
le 22 avr. 2020
le patch devrait être ici dans le noyau ubuntus git:
https://kernel.ubuntu.com/git/ubuntu/ubuntu-bionic.git/commit/?id=aadd794e744086fb50cdc752d54044fbc14d4adb
et voici le bug ubuntu le concernant:
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1832151
il devrait être libéré dans le bionique.
Vous pouvez vous en assurer en exécutant apt-get source linux et en archivant le code source téléchargé.
juliantaylor
le 22 avr. 2020
@zerkms Par «où avez-vous effectué vos tests», je veux dire était-ce un serveur dans votre bureau, un serveur dans GCP, AWS, Azure ou ailleurs?
De toute évidence, il y a beaucoup de choses que je ne comprends pas sur la façon dont Ubuntu est distribué et maintenu. Je suis également confus par votre sortie uname -a . Les notes de publication d'Ubuntu disent:
18.04.4 est livré avec un noyau Linux basé sur la v5.3 mis à jour à partir du noyau basé sur la v5.0 dans la version 18.04.3.
et indique également que 18.04.4 a été publié le 12 février 2020. Votre sortie indique que vous exécutez un noyau v4.15 compilé le 1er avril 2020.
@juliantaylor Je n'ai pas de serveur Ubuntu ou de copie du aadd794e7440 en a fait un noyau stable publié. Si vous pouvez me montrer comment faire cela, je vous en serais reconnaissant.
Quand je regarde les commentaires de bogue du
- Ce bogue a été corrigé dans le paquet linux-azure - 5.0.0-1027.29
- Ce bogue a été corrigé dans le paquet linux-azure - 5.0.0-1027.29 ~ 18.04.1
mais ce patch spécifique ( sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices ) n'est pas répertorié sous
- Ce bogue a été corrigé dans le paquet linux - 4.15.0-69.78
Je ne vois pas non plus "1832151" répertorié dans les notes de mise à jour d' Ubuntu
Un commentaire précédent disait qu'il avait été corrigé dans 4.15.0-67.76 mais je ne vois aucun paquet linux-image-4.15.0-67-generic .
Je suis loin d'être un expert d'Ubuntu et je trouve ce suivi des correctifs inacceptablement difficile, c'est donc ce que j'ai regardé.
J'espère que vous voyez maintenant pourquoi je ne suis pas sûr que ce correctif ait été réellement inclus dans Ubuntu 18.04.4, qui est la version actuelle de 18.04. Ma meilleure supposition est qu'elle a été publiée en tant que mise à jour du noyau après la publication de 18.04.4, et est probablement incluse si votre noyau Ubuntu signale 4.15.0-69 ou version ultérieure, mais si vous téléchargez simplement 18.04.4 et ne la mettez pas à jour, il n'aura pas le patch.
Nuru
le 22 avr. 2020
Je viens de lancer ce test Go (très utile) dans le noyau 4.15.0-72 dans un serveur baremetal dans un centre de données et il semble que le correctif est là:
2020/04/22 21:24:27 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 7ms
2020/04/22 21:24:28 [1] burn took 5ms, real time so far: 1010ms, cpu time so far: 13ms
2020/04/22 21:24:29 [2] burn took 5ms, real time so far: 2015ms, cpu time so far: 20ms
2020/04/22 21:24:30 [3] burn took 5ms, real time so far: 3020ms, cpu time so far: 25ms
2020/04/22 21:24:31 [4] burn took 5ms, real time so far: 4025ms, cpu time so far: 32ms
2020/04/22 21:24:32 [5] burn took 5ms, real time so far: 5030ms, cpu time so far: 38ms
2020/04/22 21:24:33 [6] burn took 5ms, real time so far: 6036ms, cpu time so far: 43ms
2020/04/22 21:24:34 [7] burn took 5ms, real time so far: 7041ms, cpu time so far: 50ms
2020/04/22 21:24:35 [8] burn took 5ms, real time so far: 8046ms, cpu time so far: 56ms
2020/04/22 21:24:36 [9] burn took 5ms, real time so far: 9051ms, cpu time so far: 63ms
2020/04/22 21:24:37 [10] burn took 5ms, real time so far: 10056ms, cpu time so far: 68ms
2020/04/22 21:24:38 [11] burn took 5ms, real time so far: 11061ms, cpu time so far: 75ms
2020/04/22 21:24:39 [12] burn took 5ms, real time so far: 12067ms, cpu time so far: 81ms
2020/04/22 21:24:40 [13] burn took 5ms, real time so far: 13072ms, cpu time so far: 86ms
2020/04/22 21:24:41 [14] burn took 5ms, real time so far: 14077ms, cpu time so far: 94ms
Je peux également voir que la même exécution dans le noyau 4.9.164 dans le même type de serveur montre des brûlures sur 5 ms:
2020/04/22 21:24:41 [0] burn took 97ms, real time so far: 97ms, cpu time so far: 8ms
2020/04/22 21:24:42 [1] burn took 5ms, real time so far: 1102ms, cpu time so far: 12ms
2020/04/22 21:24:43 [2] burn took 5ms, real time so far: 2107ms, cpu time so far: 16ms
2020/04/22 21:24:44 [3] burn took 5ms, real time so far: 3112ms, cpu time so far: 24ms
2020/04/22 21:24:45 [4] burn took 83ms, real time so far: 4197ms, cpu time so far: 28ms
2020/04/22 21:24:46 [5] burn took 5ms, real time so far: 5202ms, cpu time so far: 32ms
2020/04/22 21:24:47 [6] burn took 94ms, real time so far: 6297ms, cpu time so far: 36ms
2020/04/22 21:24:48 [7] burn took 99ms, real time so far: 7397ms, cpu time so far: 40ms
2020/04/22 21:24:49 [8] burn took 100ms, real time so far: 8497ms, cpu time so far: 44ms
2020/04/22 21:24:50 [9] burn took 5ms, real time so far: 9503ms, cpu time so far: 52ms
2020/04/22 21:24:51 [10] burn took 5ms, real time so far: 10508ms, cpu time so far: 60ms
2020/04/22 21:24:52 [11] burn took 5ms, real time so far: 11602ms, cpu time so far: 64ms
2020/04/22 21:24:53 [12] burn took 5ms, real time so far: 12607ms, cpu time so far: 72ms
2020/04/22 21:24:54 [13] burn took 5ms, real time so far: 13702ms, cpu time so far: 76ms
2020/04/22 21:24:55 [14] burn took 5ms, real time so far: 14707ms, cpu time so far: 80ms
Donc, mon problème est que je vois toujours une limitation du processeur même si mon noyau semble être patché
vgarcia-te
le 22 avr. 2020
@Nuru a raison, désolé. C'était mon serveur bare metal hébergé dans le bureau.
et indique également que 18.04.4 a été publié le 12 février 2020. Votre sortie indique que vous exécutez un noyau v4.15 compilé le 1er avril 2020.
C'est parce que c'est un serveur LTS: vous devez activer explicitement HWE avec lui pour avoir des noyaux plus récents, sinon vous exécutez simplement mainline.
Et les noyaux Mainline et HWE sont publiés régulièrement, donc rien de suspect à avoir un noyau récemment construit: http://changelogs.ubuntu.com/changelogs/pool/main/l/linux-meta/linux-meta_4.15.0.96.87/ changelog
zerkms
le 22 avr. 2020
@zerkms Merci pour l'info. Je reste confus, mais ce n'est pas le lieu pour m'éduquer.
@ vgarcia-te Si votre noyau est patché, ce qu'il semble être, alors la limitation n'est pas due à ce bogue. Je ne suis pas sûr de votre terminologie lorsque vous dites:
Je parle d'une utilisation d'environ 50 ms avec une demande définie sur 250 m et une limite de 500 m. Nous constatons qu'environ 50% des périodes CPU sont limitées, cette valeur est-elle peut-être suffisamment basse pour être attendue et peut être acceptée?
La ressource CPU Kubernetes est mesurée en CPU, 1 signifiant 100% d'un CPU complet, 1 m signifiant 0,1% d'un CPU. Donc, votre limite de "500m" indique autoriser 0,5 CPU.
La période de planification par défaut pour CFS est de 100 ms, donc la définition de la limite à 0,5 CPU limiterait votre processus à 50 ms de CPU toutes les 100 ms. Si votre processus tente de dépasser cela, il sera limité. Si votre processus s'exécute généralement plus de 50 ms en une seule passe, alors oui, vous vous attendez à ce qu'il soit limité par un planificateur fonctionnant correctement.
Nuru
le 23 avr. 2020
@Nuru cela a du sens, mais laissez-moi comprendre cela, étant donné que la période de processeur par défaut est de 100 ms, dans le cas où un processus se voit attribuer 1 processeur, si ce processus s'exécute pendant plus de 100 ms en une seule passe, sera-t-il étranglé?
Cela signifie-t-il que sous Linux, où la période de processeur par défaut est de 100 ms, tout processus qui a une limite qui s'exécute pendant plus de 100 ms en une seule passe sera limité?
Quelle serait une bonne configuration de limite pour un processus qui prend plus de 100 ms en une seule passe mais qui reste inactif le reste de son temps?
vgarcia-te
le 23 avr. 2020
@ vgarcia-te a demandé
Étant donné que la période de processeur par défaut est de 100 ms, dans le cas où un processus se voit attribuer 1 processeur, si ce processus s'exécute pendant plus de 100 ms en une seule passe, sera-t-il limité?
Bien sûr, la planification est incroyablement compliquée, donc je ne peux pas vous donner une réponse parfaite, mais la réponse simplifiée est non. Des explications plus détaillées sont ici et ici .
Tous les processus Unix sont soumis à une planification préemptive basée sur des tranches de temps. À l'époque des processeurs mono-cœur, 30 processus fonctionnaient toujours "simultanément". Ce qui se passe, c'est qu'ils courent pendant un certain temps et dorment ou, à la fin de leur tranche horaire, se mettent en attente pour que quelque chose d'autre puisse fonctionner.
Le CSA avec quotas va encore plus loin.
Demandez-vous, cependant, lorsque vous dites que vous voulez qu'un processus utilise 50% d'un processeur, que dites-vous vraiment? Êtes-vous en train de dire que tout va bien s'il monopolise 100% du processeur pendant 5 minutes tant qu'il ne fonctionne pas du tout pendant les 5 minutes suivantes? Ce serait 50% d'utilisation sur 10 minutes, mais ce n'est pas acceptable pour la plupart des gens en raison des problèmes de latence.
Ainsi, CFS définit une «période CPU» qui est la fenêtre de temps pendant laquelle il applique les quotas. Sur une machine avec 4 cœurs et une période CPU de 100 ms, le planificateur dispose de 400 ms de temps CPU pour allouer plus de 100 ms de temps réel (horloge murale). Si vous exécutez un seul thread d'exécution qui ne peut pas être parallélisé, ce thread peut utiliser au maximum 100 ms de temps CPU par période, ce qui équivaut à 100% de 1 CPU. si vous définissez son quota sur 1 CPU, il ne devrait jamais être limité.
Si vous définissez le quota sur 500 m (0,5 CPU), le processus obtient 50 ms pour s'exécuter toutes les 100 ms. Toute période de 100 ms utilise moins de 50 ms et ne doit pas être étranglée. Pendant une période de 100 ms, il n'est pas terminé après 50 ms, il est limité jusqu'à la prochaine période de 100 ms. Cela maintient un équilibre entre la latence (combien de temps il faut attendre pour pouvoir s'exécuter du tout) et la monopolisation (combien de temps il est autorisé à empêcher les autres processus de s'exécuter).
Nuru
le 23 avr. 2020
@Nuru mes diapositives sont correctes. Je suis également un développeur Ubuntu * (uniquement dans mon temps libre maintenant). Votre meilleur pari est de lire les sources et de vérifier git blame + tag --contains pour savoir quand le patch atteint la version du noyau qui vous intéresse.
chiluk
le 26 avr. 2020
@chiluk Je n'avais pas vu vos diapositives. Pour les autres qui ne les ont pas vus, voici où ils disent que le patch a atterri il y a quelque temps:
- Ubuntu 4.15.0-67 +
- Ubuntu 5.3.0-24 +
- Noyau RHEL7 3.10.0-1062.8.1.el7
et bien sûr Linux stable v4.14.154, v4.19.84, 5.3.9. Je note qu'il est également dans Linux stable 5.4-rc1.
J'ai toujours du mal à comprendre les différents bogues du planificateur CFS et à trouver des tests fiables et faciles à interpréter qui fonctionneraient sur un petit serveur AWS, car je prends en charge une grande variété de noyaux provenant d'installations héritées. Si je comprends bien la chronologie, un bogue a été introduit dans le noyau Linux v3.16-rc1 en 2014 par
[51f2176d74ac](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=51f2176d74ac) sched/fair: Fix unlocked reads of some cfs_b->quota/period.
Cela a provoqué différents problèmes de limitation du CFS. Je pense que les problèmes que je voyais sous les clusters Kubernetes kops étaient dus à ce bogue, car ils utilisaient des noyaux 4.9.
51f2176d74ac été corrigé dans le noyau 2018 v4.18-rc4 avec
[512ac999](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) sched/fair: Fix bandwidth timer clock drift condition
mais cela a introduit le bogue @chiluk corrigé avec
[de53fd7ae](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425) sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
Ce n'est bien sûr pas la faute de Chiluk ou de toute autre personne si les correctifs du noyau sont difficiles à suivre à travers les distributions. Cela reste frustrant pour moi, cependant, et contribue à ma confusion.
Par exemple, sur Debuan buster 10 (AWS AMI debian-10-amd64-20191113-76 ), la version du noyau est signalée comme
Linux ip-172-31-41-138 4.19.0-6-cloud-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
Autant que je sache, ce noyau devrait avoir 51f2176d74ac et NE PAS avoir 512ac999 et devrait donc échouer au test décrit dans 512ac999 , mais ce n'est pas le cas. (Je dis que je ne pense pas qu'il a 512ac999 car il a été mis à niveau progressivement à partir du noyau Linux 4.10 et il n'y a aucune mention de ce correctif dans le journal des modifications.) Cependant, sur une machine virtuelle AWS à 4 cpu, il n'échoue pas Le test fibtest Chiluk ou le test de hoquet CFS de Bobrik, qui suggère qu'il se passe autre chose.
J'ai eu des problèmes similaires en reproduisant des problèmes de planification avec CoreOS avant même qu'il ne reçoive le correctif de Chiluk.
Je pense pour le moment que le test de Bobrik est principalement un test pour 51f2176d74ac , l'AMI Debian buster 10 que j'utilise _does_ a le 512ac999 , mais pas explicitement appelé dans le journal des modifications, et fibtest n'est pas un test très sensible sur une machine avec seulement quelques cœurs.
Nuru
le 27 avr. 2020
Un processeur à 4 cœurs n'est probablement pas assez grand pour reproduire le problème résolu par chiluk.
Il ne devrait être reproductible que sur des machines plus grandes avec peut-être 40 cpus si j'ai bien compris l'explication de chiluks kubecon talk (https://www.youtube.com/watch?v=UE7QX98-kO0) correctement.
Il existe de nombreuses versions de noyau et de nombreux correctifs et inversion de correctifs sont en cours. Les journaux des modifications et les numéros de version ne vous mènent pas loin.
Le seul moyen fiable si vous avez des doutes est de télécharger le code source et de le comparer avec les modifications des correctifs qui ont été liés ici.
juliantaylor
le 27 avr. 2020
Les problèmes disparaissent après 90 jours d'inactivité.
Marquez le problème comme récent avec /remove-lifecycle stale .
Les problèmes périmés pourrissent après 30 jours supplémentaires d'inactivité et finissent par se fermer.
Si ce problème peut être résolu en toute sécurité maintenant, veuillez le faire avec /close .
Envoyez vos commentaires à sig-testing, kubernetes / test-infra et / ou fejta .
/ cycle de vie périmé
fejta-bot
le 26 juil. 2020
/ remove-lifecycle obsolète
 yashbhutwala
le 27 juil. 2020
yashbhutwala
le 27 juil. 2020
Les tests mentionnés plus tôt dans ce fil ne reproduisent pas vraiment le problème pour moi (quelques brûlures prennent plus de 5 ms mais c'est comme 0,01% d'entre elles) mais nos métriques de limitation cfs montrent toujours des quantités modérées de limitation. Nous avons différentes versions de noyau dans nos clusters, mais les deux versions les plus courantes sont:
Debian 4.19.67-2+deb10u2~bpo9+1 (2019-11-12)- un backport manuel de
5.4.38
Je ne sais pas si les deux bogues sont censés être corrigés dans ces versions, mais je pense qu'ils le sont, donc je me demande si le test n'est pas si utile. Je teste sur des machines avec 16 cœurs et avec 36 cœurs, je ne sais pas si j'ai besoin d'encore plus de cœurs pour que le test soit valide, mais nous voyons toujours l'étranglement dans ces clusters donc ...
 2rs2ts
le 18 août 2020
2rs2ts
le 18 août 2020
Devrions-nous fermer ce problème et demander aux personnes confrontées à des problèmes d'en créer de nouvelles? Le spamming ici va probablement rendre toute conversation très difficile.
 omnibs
le 31 oct. 2020
omnibs
le 31 oct. 2020
^ Je suis d'accord. Beaucoup a été fait pour résoudre ce problème.
 sfxworks
le 31 oct. 2020
sfxworks
le 31 oct. 2020
/Fermer
basé sur les commentaires ci-dessus. veuillez ouvrir de nouveaux numéros si nécessaire.
dims
le 1 nov. 2020
@dims : clôture de ce numéro.
En réponse à cela :
/Fermer
basé sur les commentaires ci-dessus. veuillez ouvrir de nouveaux numéros si nécessaire.
Les instructions pour interagir avec moi en utilisant les commentaires PR sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème sur le
 k8s-ci-robot
le 1 nov. 2020
k8s-ci-robot
le 1 nov. 2020
veuillez informer les problèmes de suivi de ce problème, afin que les personnes qui y sont abonnées puissent s'abonner aux nouveaux problèmes à suivre
 glensc
le 1 nov. 2020
glensc
le 1 nov. 2020
Questions connexes
 broady
·
3Commentaires
broady
·
3Commentaires
 alexferl
·
3Commentaires
alexferl
·
3Commentaires
 chowyu08
·
3Commentaires
chowyu08
·
3Commentaires
 pwittrock
·
3Commentaires
pwittrock
·
3Commentaires
 ttripp
·
3Commentaires
ttripp
·
3Commentaires
Commentaire le plus utile
Le patch a atterri sur la pointe ce matin.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Une fois qu'il aura atteint l'arborescence de Torvald, je le soumettrai pour une inclusion stable sous Linux, et par la suite des distributions majeures (Redhat / Ubuntu). Si vous vous souciez de quelque chose d'autre et qu'ils ne suivent pas les correctifs stables sous Linux, vous voudrez peut-être le soumettre directement.