Kubernetes: يمكن أن تؤدي حصص المساحات الصديقة لألطفال إلى اختناق غير ضروري
/ نوع الخطأ
هذا ليس خطأ في Kubernets في حد ذاته ، إنه أكثر من تنبيه.
لقد قرأت هذه المدونة الرائعة:
علمت من منشور المدونة أن k8s يستخدم حصص cfs لفرض حدود وحدة المعالجة المركزية. لسوء الحظ ، يمكن أن يؤدي ذلك إلى اختناق غير ضروري ، خاصة للمستأجرين حسن التصرف.
شاهد هذا الخطأ الذي لم يتم حله في Linux kernel الذي قدمته منذ فترة:
هناك تصحيح مفتوح ومتوقف يعالج المشكلة (لم أتحقق مما إذا كان يعمل):
سم مكعبConnorDoylebalajismaniam
 bobrik
bobrik
ال 142 كومينتر
/ عقدة سيج
/ نوع الخطأ
 neolit123
في ٢٠ أغسطس ٢٠١٨
neolit123
في ٢٠ أغسطس ٢٠١٨
هل هذه نسخة مكررة من # 51135؟
 liggitt
في ٢٠ أغسطس ٢٠١٨
liggitt
في ٢٠ أغسطس ٢٠١٨
إنه متشابه من حيث الروح ، ولكن يبدو أنه يفتقد حقيقة وجود خطأ فعلي في النواة بدلاً من مجرد بعض مقايضة التكوين في فترة حصة CFS. لقد أحببت # 51135 مرة أخرى هنا لمنح الناس المزيد من السياق.
bobrik
في ٢٢ أغسطس ٢٠١٨
بقدر ما أفهم أن هذا سبب آخر إما لتعطيل حصة CFS ( --cpu-cfs-quota=false ) أو جعلها قابلة للتكوين (# 63437).
أجد أيضًا هذا الجوهر (المرتبط من تصحيح Kernel) ممتعًا جدًا لرؤيته (لقياس التأثير): https://gist.github.com/bobrik/2030ff040fad360327a5fab7a09c4ff1
 hjacobs
في ٢٢ أغسطس ٢٠١٨
hjacobs
في ٢٢ أغسطس ٢٠١٨
ccadityakali
 vishh
في ٢٣ أغسطس ٢٠١٨
vishh
في ٢٣ أغسطس ٢٠١٨
مشكلة أخرى تتعلق بالحصص هي أن kubelet تحسب فرط النقاط على أنها "cpus". عندما يتم تحميل الكتلة بحيث يتم جدولة خيطين على نفس النواة والعملية لها حصة حصة وحدة المعالجة المركزية ، لن يعمل أحدهما إلا بجزء صغير من طاقة المعالجة المتاحة (لن يفعل شيئًا إلا عندما يكون هناك شيء ما على الخيط الآخر الأكشاك) لكنها لا تزال تستهلك الحصة كما لو كان لها جوهر مادي لنفسها. لذلك فهي تستهلك ضعف الحصة التي يجب أن تستهلكها دون القيام بمزيد من العمل.
هذا له تأثير على العقدة المحملة بالكامل مع تمكين مؤشر الترابط التشعبي ، سيكون الأداء نصف ما سيكون عليه مع تعطيل مؤشرات الترابط أو الحصص النسبية.
لا ينبغي أن يعتبر Imo the kubelet أن hyperthread هو cpus حقيقي لتجنب هذا الموقف.
 juliantaylor
في ٣٠ أغسطس ٢٠١٨
juliantaylor
في ٣٠ أغسطس ٢٠١٨
juliantaylor كما ذكرت في # 51135 ، قد يكون إيقاف تشغيل حصة وحدة المعالجة المركزية هو أفضل نهج لمعظم مجموعات k8s التي تشغل أحمال عمل موثوقة.
vishh
في ٣٠ أغسطس ٢٠١٨
هل هذا يعتبر خطأ؟
إذا تم خنق بعض البودات أثناء عدم استنفاد حد وحدة المعالجة المركزية (CPU) حقًا ، فهذا يبدو لي وكأنه خطأ.
في مجموعتي ، ترتبط معظم الكوات ذات الحصة الزائدة بالمقاييس (heapster ، أو metrics-Collector ، أو node-exporter ...) أو المشغلين ، الذين لديهم بوضوح نوع عبء العمل الذي يمثل مشكلة هنا: لا تفعل شيئًا معظم الوقت والاستيقاظ للتصالح بين الحين والآخر.
الشيء الغريب هنا هو أنني حاولت رفع الحد الأقصى ، من 40m إلى 100m أو 200m ، ولا تزال العمليات خنق.
لا يمكنني رؤية أي مقاييس أخرى تشير إلى عبء العمل الذي يمكن أن يؤدي إلى هذا الاختناق.
لقد قمت بإزالة القيود المفروضة على هذه الكبسولات في الوقت الحالي ... لقد تحسنت ، ولكن ، حسنًا ، هذا يبدو حقًا وكأنه خطأ ويجب أن نأتي بحل أفضل من تعطيل Limits
 prune998
في ٢٦ نوفمبر ٢٠١٨
prune998
في ٢٦ نوفمبر ٢٠١٨
رؤية @ prune998 تعليقvishh الصورة و هذا جوهر : النواة الإفراط في الصمامات الخانقة بقوة، حتى لو كانت الرياضيات يخبرك أنه لا ينبغي. قررنا (Zalando) تعطيل حصة CFS (اختناق وحدة المعالجة المركزية) في مجموعاتنا: https://www.slideshare.net/try_except_/optimizing-kubernetes-resource-requestslimits-for-costefficiency-and-latency-highload
hjacobs
في ٢٧ نوفمبر ٢٠١٨
شكرا @ hjacobs.
أنا على Google GKE ولا أرى طريقة سهلة لتعطيله ، لكنني أواصل البحث ...
prune998
في ٢٧ نوفمبر ٢٠١٨
@ prune998 AFAIK ، لم تكشف Google عن المقابض اللازمة حتى الآن. قدمنا طلب ميزة مباشرة بعد إمكانية تعطيل CFS في المنبع ، ولم نسمع أي أخبار منذ ذلك الحين.
 timoreimann
في ٢٧ نوفمبر ٢٠١٨
timoreimann
في ٢٧ نوفمبر ٢٠١٨
أنا على Google GKE ولا أرى طريقة سهلة لتعطيله ، لكنني أواصل البحث ...
هل يمكنك إزالة حدود وحدة المعالجة المركزية من حاوياتك في الوقت الحالي؟
vishh
في ٢٨ نوفمبر ٢٠١٨
وفقًا لمستندات مدير وحدة المعالجة المركزية ، CFS quota is not used to bound the CPU usage of these containers as their usage is bound by the scheduling domain itself. لكننا نواجه اختناق CFS.
هذا يجعل مدير وحدة المعالجة المركزية الثابت بلا فائدة في الغالب لأن تعيين حد وحدة المعالجة المركزية لتحقيق فئة QoS المضمونة يلغي أي فائدة بسبب الاختناق.
هل من الأخطاء أن يتم تعيين حصص CFS على الإطلاق للقرون على وحدة المعالجة المركزية الثابتة؟
 mariusgrigoriu
في ١٢ فبراير ٢٠١٩
mariusgrigoriu
في ١٢ فبراير ٢٠١٩
للحصول على سياق إضافي (تم التعرف عليه أمس): ساهمhrzbrg (MyTaxi) بعلامة إلى Kops لتعطيل التحكم في وحدة المعالجة المركزية: https://github.com/kubernetes/kops/issues/5826
hjacobs
في ١٢ فبراير ٢٠١٩
يرجى مشاركة ملخص المشكلة هنا. ليس من الواضح ما هي المشكلة وما هي السيناريوهات التي يتأثر بها المستخدمون وما هو المطلوب بالضبط لإصلاحها؟
فهمنا في الوقت الحالي هو أنه عندما نتجاوز الحدود نتعرض لعقوبات وخنق. لنفترض أن لدينا حصة وحدة المعالجة المركزية من 3 نوى وفي أول 5 مللي ثانية استهلكنا 3 مراكز ، ثم في شريحة 100 مللي ثانية ، سنخنق لمدة 95 مللي ثانية ، وفي هذه 95 مللي ثانية لا تستطيع حاوياتنا فعل أي شيء. وقد رأينا أنه يتم اختناقه حتى عندما لا تكون ارتفاعات وحدة المعالجة المركزية مرئية في مقاييس استخدام وحدة المعالجة المركزية. نحن نفترض أن السبب في ذلك هو أن النافذة الزمنية لقياس استخدام وحدة المعالجة المركزية بالثواني ويحدث الاختناق عند مستوى الثواني الدقيقة ، لذلك يتم حسابه في المتوسط ولا يكون مرئيًا. لكن الخطأ المذكور هنا جعلنا مرتبكين الآن.
بعض الأسئلة:
- عندما تكون العقدة في وحدة المعالجة المركزية بنسبة 100٪؟ هل هذه حالة خاصة يتم فيها اختناق جميع الحاويات بغض النظر عن استخدامها؟
عندما يحدث هذا ، هل يتم اختناق وحدة المعالجة المركزية بنسبة 100٪ في جميع الحاويات؟
ما الذي يؤدي إلى تشغيل هذا الخطأ في العقدة؟
ما الفرق بين عدم استخدام
limitsوتعطيلcpu.cfs_quota؟ألا يعد تعطيل
limitsحلاً محفوفًا بالمخاطر عندما يكون هناك العديد من البودات القابلة للانفجار ويمكن أن يتسبب جراب واحد في عدم الاستقرار في العقدة ويؤثر على البودات الأخرى التي تعمل على طلباتهم؟بشكل منفصل ، وفقًا لعملية مستند kernel ، قد يتم اختناق عملية مستند kernel عند استهلاك الحصة الأصلية بالكامل. ما هو الأصل في سياق الحاوية هنا (هل هو مرتبط بهذا الخطأ)؟ https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
There are two ways in which a group may become throttled: a. it fully consumes its own quota within a period b. a parent's quota is fully consumed within its period- ما هو المطلوب لإصلاحها؟ ترقية إصدار النواة؟
لقد واجهنا انقطاعًا كبيرًا إلى حد ما ويبدو أنه مرتبط ارتباطًا وثيقًا (إن لم يكن السبب الجذري) لجميع البودات التي تتعثر في حلقة إعادة التشغيل الخانقة وغير قادرة على التوسع. نحن نبحث في التفاصيل للعثور على المشكلة الحقيقية. سأقوم بفتح قضية منفصلة مع شرح تفصيلي حول انقطاع الخدمة لدينا.
أي مساعدة هنا هي موضع تقدير كبير.
cc justinsb
 alok87
في ١٤ فبراير ٢٠١٩
alok87
في ١٤ فبراير ٢٠١٩
وضع أحد مستخدمينا حدًا لوحدة المعالجة المركزية وتم خنقه في مهلة مسبار الحياة مما تسبب في انقطاع الخدمة.
نرى اختناقًا حتى عند تثبيت الحاويات في وحدة المعالجة المركزية. على سبيل المثال ، حد وحدة المعالجة المركزية 1 وتثبيت تلك الحاوية للتشغيل فقط على وحدة المعالجة المركزية واحدة. يجب أن يكون من المستحيل تجاوز الحصة المحددة لأي فترة إذا كانت حصتك هي بالضبط عدد وحدة المعالجة المركزية لديك ، ومع ذلك نرى اختناقًا في كل حالة.
اعتقدت أنني رأيت أنه تم نشره في مكان ما أن kernel 4.18 يحل المشكلة. لم أختبرها بعد ، لذا سيكون من الجيد أن يؤكد أحدهم.
mariusgrigoriu
في ١٥ فبراير ٢٠١٩
يبدو أن https://github.com/torvalds/linux/commit/512ac999d2755d2b7109e996a76b6fb8b888631d في 4.18 هو التصحيح المناسب لهذه المشكلة.
 clkao
في ٢٣ فبراير ٢٠١٩
clkao
في ٢٣ فبراير ٢٠١٩
mariusgrigoriu يبدو أنني عالق في نفس اللغز الذي وصفته هنا https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -462534360.
نلاحظ اختناق وحدة المعالجة المركزية (CPU) على Pods في فئة Guaranteed QoS مع سياسة CPUManager الثابتة (والتي لا يبدو أنها منطقية).
ستؤدي إزالة limits لهذه السنفات إلى وضعها في فئة Burstable QoS ، وهو ليس ما نريده ، لذا فإن الخيار الوحيد المتبقي هو تعطيل حصص وحدة المعالجة المركزية CFS على مستوى النظام ، وهو أيضًا شيء لا يمكننا القيام به بأمان ، نظرًا لأن السماح لجميع أجهزة Pods بالوصول إلى سعة وحدة المعالجة المركزية غير المنضمة يمكن أن يؤدي إلى مشكلات خطيرة في تشبع وحدة المعالجة المركزية.
vishh في ضوء الظروف المذكورة أعلاه ، ما هو أفضل مسار للعمل؟ يبدو أن الترقية إلى kernel> 4.18 (الذي يحتوي على إصلاح محاسبة cfs cpu) و (ربما) تقليل فترة حصة cfs؟
في ملاحظة عامة ، اقتراح إزالة limits من الحاويات التي يتم خنقها يجب أن يتضمن تحذيرات واضحة:
1) إذا كانت هذه Pods في فئة Guaranteed QoS ، مع عدد صحيح من النوى وبسياسة CPUMnanager الثابتة - فلن تحصل هذه السنفات بعد الآن على نوى مخصصة لوحدة المعالجة المركزية حيث سيتم وضعها في فئة Burstable QoS (بدون طلبات == حدود)
2) ستكون هذه الكبسولات غير مقيدة من حيث مقدار وحدة المعالجة المركزية التي يمكن أن تستهلكها ويمكن أن تسبب قدرًا كبيرًا من الضرر في ظل ظروف معينة.
ستكون ملاحظاتك / توجيهاتك محل تقدير كبير.
 dannyk81
في ٢٥ مارس ٢٠١٩
dannyk81
في ٢٥ مارس ٢٠١٩
من المؤكد أن ترقية kernel تساعد ، ولكن سلوك تطبيق حصة CFS لا يزال يبدو غير متوافق مع ما تقترحه المستندات.
mariusgrigoriu
في ٢٥ مارس ٢٠١٩
لقد كنت أبحث عن جوانب مختلفة من هذه القضية منذ فترة حتى الآن. تم تلخيص بحثي في رسالتي على LKML.
https://lkml.org/lkml/2019/3/18/706
ومع ذلك ، لم أتمكن من إعادة إنتاج المشكلة كما هو موضح هنا في نواة ما قبل 512ac99. لقد رأيت تراجعًا في الأداء في نواة ما بعد 512ac99. لذا فإن هذا الإصلاح ليس حلاً سحريًا.
 chiluk
في ٢٥ مارس ٢٠١٩
chiluk
في ٢٥ مارس ٢٠١٩
شكرًا mariusgrigoriu ، نحن بصدد ترقية kernel ونأمل أن يساعد ذلك إلى حد ما ، تحقق أيضًا من https://github.com/kubernetes/kubernetes/issues/70585 - يبدو أن الحصص محددة بالفعل للقرون المضمونة مع cpuset ( ie cpus المثبت) ، لذلك يبدو هذا خطأ بالنسبة لي.
dannyk81
في ٢٥ مارس ٢٠١٩
@ chiluk هل يمكن أن تشرح قليلاً؟ هل تقصد أن التصحيح الذي تم تضمينه في 4.18 (المذكور أعلاه في https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-466609030) لا يحل المشكلة فعليًا؟
dannyk81
في ٢٥ مارس ٢٠١٩
يعمل تصحيح kernel 512ac99 على إصلاح مشكلة لبعض الأشخاص ، ولكنه تسبب في حدوث مشكلة في التكوينات الخاصة بنا. أصلح التصحيح طريقة توزيع الشرائح الزمنية بين cfs_rq ، بحيث تنتهي صلاحيتها الآن بشكل صحيح. في السابق لن تنتهي صلاحيتها.
تشهد أحمال عمل Java على وجه الخصوص على الأجهزة ذات عدد النواة العالية الآن كميات كبيرة من الاختناق مع انخفاض استخدام وحدة المعالجة المركزية بسبب سلاسل عمليات العامل المحظورة. يتم تعيين شريحة زمنية لتلك الخيوط التي لا تستخدم سوى جزء صغير منها منتهية الصلاحية لاحقًا. في الاختبار التركيبي الذي كتبته * (مرتبط بهذا الخيط) ، نرى تدهورًا في الأداء بمقدار 30x تقريبًا. في أداء العالم الحقيقي ، رأينا تدهور وقت الاستجابة لمئات من المللي ثانية بين النواة بسبب زيادة الاختناق.
chiluk
في ٢٥ مارس ٢٠١٩
باستخدام نواة 4.19.30 ، أرى أن البودات التي كنت آمل أن أرى مقدارًا أقل من الاختناق لا تزال مخنوقة ، كما أن بعض البودات التي لم يتم خنقها سابقًا يتم الآن خنقها بشدة (يبلغ kube2iam عن المزيد من الثواني التي تم خنقها أكثر مما تم تشغيل المثيل ، بطريقة ما)
 willthames
في ٢٧ مارس ٢٠١٩
willthames
في ٢٧ مارس ٢٠١٩
في CoreOS 4.19.25-coreos ، أرى بروميثيوس يطلق CPUT تنبيهًا عاليًا تقريبًا على كل جراب واحد في النظام.
 teralype
في ٢٧ مارس ٢٠١٩
teralype
في ٢٧ مارس ٢٠١٩
williamsandrewteralype يبدو أن هذا يعكسchiluk النتائج الصورة.
بعد العديد من المناقشات الداخلية ، قررنا في الواقع تعطيل حصص cfs بالكامل (علم kubelet --cpu-cfs-quota=false ) ، يبدو أن هذا يحل جميع المشكلات التي نواجهها لكل من أجهزة Burstable و Guaranteed (وحدة المعالجة المركزية المثبتة أو القياسية).
هناك مجموعة ممتازة حول هذا (وبعض الموضوعات الأخرى) هنا: https://www.slideshare.net/try_except_/ensuring-kubernetes-cost-efficiency-across-many-clusters-devops-gathering-2019
يوصى بشدة قراءة: +1:
dannyk81
في ٢٧ مارس ٢٠١٩
قضية طويلة الأجل (ملاحظة للنفس)
 dims
في ٢٧ مارس ٢٠١٩
dims
في ٢٧ مارس ٢٠١٩
@ dannyk81 فقط من أجل الاكتمال: الحديث المرتبط متاح أيضًا كفيديو مسجل: https://www.youtube.com/watch؟v=4QyecOoPsGU
hjacobs
في ٢٧ مارس ٢٠١٩
hjacobs ، أحب الحديث! شكرا جزيلا...
هل لديك أي فكرة عن كيفية تطبيق هذا الإصلاح على AKS أو GKE؟
شكر
 agolomoodysaada
في ٢ أبريل ٢٠١٩
agolomoodysaada
في ٢ أبريل ٢٠١٩
agolomoodysaada قدمنا طلب ميزة إلى GKE منذ فترة. لست متأكدًا من الحالة ، إلا أنني لم أعد أعمل بشكل مكثف مع GKE.
timoreimann
في ٢ أبريل ٢٠١٩
لقد تواصلت مع دعم Azure وقالوا إنه لن يكون متاحًا حتى أغسطس 2019 تقريبًا.
agolomoodysaada
في ٤ أبريل ٢٠١٩

اعتقدت أنني سأشارك رسمًا بيانيًا للتطبيق الذي يتم خنقه باستمرار طوال حياته.
agolomoodysaada
في ٥ أبريل ٢٠١٩
على أي نواة كان هذا؟
chiluk
في ٥ أبريل ٢٠١٩
" شيلوك " 4.15.0-1037-أزور "
agolomoodysaada
في ٥ أبريل ٢٠١٩
بحيث لا يحتوي على kernel الالتزام 512ac99. هنا هو المقابل
مصدر.
https://kernel.ubuntu.com/git/kernel-ppa/mirror/ubuntu-azure-xenial.git/tree/kernel/sched/fair.c؟h=Ubuntu-azure-4.15.0-1037.39_16.04.1 & id = 19b0066cc4829f45321a52a802b640bab14d0f67
مما يعني أنك قد تواجه المشكلة الموضحة في 512ac99. ابق في
ضع في اعتبارك أن 512ac99 جلبت لنا انحدارات أخرى.
يوم الجمعة ، أبريل 5 ، 2019 الساعة 12:08 مساءً Moody Saada [email protected]
كتب:
chiluk https://github.com/chiluk "4.15.0-1037-azure"
-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-480350946 ،
أو كتم الخيط
https://github.com/notifications/unsubscribe-auth/ACDI05YeS6wfUE9XkiMbxrLvPllYQZ7Iks5vd4MOgaJpZM4WDUF3
.
chiluk
في ٥ أبريل ٢٠١٩
لقد قمت الآن بنشر تصحيحات إلى LKML حول هذا الموضوع.
https://lkml.org/lkml/2019/4/10/1068
سيكون موضع تقدير كبير اختبار إضافي.
chiluk
في ١١ أبريل ٢٠١٩
لقد أعدت تقديم هذه التصحيحات الآن مع تغييرات التوثيق.
https://lkml.org/lkml/2019/5/17/581
سيكون من المفيد حقًا إذا كان بإمكان الأشخاص اختبار هذه التصحيحات والتعليق على الخيط على LKML. في الوقت الحالي ، أنا الوحيد الذي ذكر هذا على الإطلاق على LKML ، ولم أتلق أي تعليقات على الإطلاق من المجتمع أو المشرفين. سأقطع شوطًا طويلاً حقًا إذا كان بإمكاني الحصول على بعض الاختبارات والتعليقات المجتمعية على LKML تحت رقعي.
chiluk
في ٢١ مايو ٢٠١٩
لما يستحق ، يبدو أن هذا المشروع المحدد https://github.com/tensorflow/serving قد تأثر بشدة بهذه المشكلة. وهو في الغالب تطبيق C ++.
chiluk ، هل هناك أي حلول يمكن تطبيقها أثناء طرح التصحيح؟
شكرا جزيلا
agolomoodysaada
في ٢٩ مايو ٢٠١٩
يجب أن نساعد chiluk في جمع الاستشهادات بالتأثير الخطير لخلل النواة هذا على Kubernetes وأي شخص آخر يستخدم حصص CFS.
أدرج Zolando في عرضه الأسبوع الماضي أن تجاربه السيئة مع النواة الحالية تعني أنهم يعتبرون تعطيل حصص CFS كأفضل ممارسة حالية ، لأنهم يرون أنها تضر أكثر مما تنفع.
https://www.youtube.com/watch؟v=6sDTB4eV4F8
 whereisaaron
في ٢٩ مايو ٢٠١٩
whereisaaron
في ٢٩ مايو ٢٠١٩
تقوم المزيد والمزيد من الشركات بتعطيل اختناق وحدة المعالجة المركزية ، مثل mytaxi و Datadog و Zalando ( مؤشر ترابط Twitter )
hjacobs
في ٢٩ مايو ٢٠١٩
derekwaynecarr @ dchen1107 @ kubernetes / sig-node-feature-طلبات Dawn ، Derek ، هل حان الوقت لتغيير الافتراضي؟ و / أو التوثيق؟
dims
في ٢٩ مايو ٢٠١٩
Yeswhereisaron أن تقوم بجمع ومشاركة تقارير الاختناق للتطبيقات
chiluk
في ٢٩ مايو ٢٠١٩
agolomoodysaada ، الحل البديل هو تعطيل حصص
هناك أيضًا أفضل الممارسات حول تقليل عدد سلاسل رسائل التطبيق والتي تساعد أيضًا.
لمجموعة جولانج GOMAXPROCS ~ = سقف (حصة)
لجافا ، انتقل إلى JVMs الأحدث التي تتعرف على حدود حصة وحدة المعالجة المركزية وتحترمها. أنتجت jvms الأقدم خيوطًا بناءً على عدد نوى وحدة المعالجة المركزية ، وليس عدد النوى المتاحة للتطبيق.
كان كلاهما نعمة كبيرة للأداء بالنسبة لنا.
راقب التطبيقات التي يتم اختناقها وأبلغ عنها بحيث يمكن للمطورين ضبط الحصص.
chiluk
في ٢٩ مايو ٢٠١٩
لمعلوماتك ، بعد أن أشرت إلى هذا الموضوع إلى دعم Azure AKS ، تم الرد على أن التصحيح سيتم طرحه عند الترقية إلى kernel 5.0 ، في أواخر سبتمبر ، في أحسن الأحوال.
حتى ذلك الحين ، توقف عن استخدام الحدود :)
prune998
في ٢٩ مايو ٢٠١٩
@ prune998 هناك تحذير صغير في حالة استخدامك CPUmanager (أي تخصيص وحدة المعالجة المركزية المخصصة للقرون في جودة الخدمة المضمونة).
عن طريق إزالة الحدود ، ستتجنب مشكلة اختناق CFS ، ولكنك ستزيل البودات من Guaranteed QoS حتى لا يقوم CPUmanager بتخصيص نوى مخصصة لهذه البودات بعد الآن.
إذا كنت لا تستخدم CPUmanager - فلا ضرر من ذلك ، ولكن لمعلوماتك فقط لأي شخص يختار هذا الاتجاه.
هناك علاقات عامة (https://github.com/kubernetes/kubernetes/issues/70585) لتعطيل حصص CFS بالكامل لأجهزة Pods المزودة بوحدات معالجة مركزية مخصصة ومع ذلك لم يتم دمجها بعد.
لقد اخترنا أيضًا تعطيل نظام حصص CFS على مستوى النظام كما هو مقترح أعلاه ولا توجد مشكلات حتى الآن.
dannyk81
في ٢٩ مايو ٢٠١٩
@ dannyk81 https://github.com/kubernetes/kubernetes/issues/70585 ليس علاقات عامة يمكن دمجها (إنها مشكلة في مقتطف الشفرة). هل يمكنك (أو أي شخص آخر) من فضلك تقديم PR؟
dims
في ٢٩ مايو ٢٠١٩
يوجد واحد بالفعل: https://github.com/kubernetes/kubernetes/pull/75682
 praseodym
في ٢٩ مايو ٢٠١٩
praseodym
في ٢٩ مايو ٢٠١٩
dims لقد ربطت المشكلة ، وليس العلاقات العامة ... ولكن المشكلة مرتبطة https://github.com/kubernetes/kubernetes/pull/75682 وهي معلقة هناك لفترة من الوقت ، لذا ، إذا كان بإمكانك الدفع ، فسيكون ذلك رائعًا لأن هذه مشكلة مزعجة حقًا.
شكر: +1:
dannyk81
في ٢٩ مايو ٢٠١٩
يصيح! شكرًا @ dannyk81 لقد خصصت
dims
في ٢٩ مايو ٢٠١٩
FWIW واجهنا هذه المشكلة أيضًا ، ووجدنا أن خفض فترة حصة CFS إلى 10 مللي ثانية بدلاً من 100 مللي ثانية الافتراضية تسبب في تحسن زمن الوصول النهائي بشكل كبير. أعتقد أن السبب في ذلك هو أنه حتى لو واجهت خطأ في النواة ، فسيتم إهدار كمية أقصر بكثير من الحصة إذا لم يتم استخدامها ، ويمكن للعملية الحصول على حصة أكبر (في تخصيصات أصغر) في وقت أقرب بكثير. هذا مجرد حل بديل ، ولكن بالنسبة لأولئك الذين لا يرغبون في تعطيل حصة CFS بالكامل ، فقد يكون هذا بمثابة حزمة حتى يتم تنفيذ الإصلاح. يدعم k8s القيام بذلك في 1.12 باستخدام بوابة ميزة cpuCFSQuotaPeriod وعلامة kubelet --cpu-cfs-quota-period.
 d-shi
في ٣٠ مايو ٢٠١٩
d-shi
في ٣٠ مايو ٢٠١٩
يجب أن أتحقق من ذلك ، لكنني أعتقد أن تقليص الفترة إلى هذا الحد قد يكون له تأثير في تعطيلها بشكل فعال ، حيث يوجد حد أدنى للشرائح وحدود دنيا في الكود. ربما يكون من الأفضل لك إيقاف تشغيل نظام الحصص والانتقال إلى نظام حصص ميسرة.
chiluk
في ٣٠ مايو ٢٠١٩
chiluk فهمي العادي هو أن الشريحة الافتراضية هي 5 مللي ثانية ، لذا فإن تعيينها على ذلك أو أقل يؤدي إلى تعطيلها فعليًا ، ولكن طالما كانت الفترة أكبر من 5 مللي ثانية ، فلا يزال هناك تطبيق للحصة. بالتأكيد اسمحوا لي أن أعرف إذا كان هذا غير صحيح.
d-shi
في ٣١ مايو ٢٠١٩
مع --feature-gates=CustomCPUCFSQuotaPeriod=true --cpu-cfs-quota-period=10ms كافح أحد قرونتي لبدء التشغيل. في الرسم البياني لبروميثيوس المرفق ، تحاول الحاوية البدء ، ولا تقترب من تلبية فحص فعاليتها حتى يتم إنهاؤها (عادةً ما تبدأ الحاوية في حوالي 5 ثوانٍ - حتى أن زيادة التأجيل الأولي من الثواني إلى 60 ثانية لم تساعد) وهي كذلك ثم استبداله بواحد جديد.
يمكنك أن ترى أن الحاوية مقيدة بشدة حتى أزلت فترة الحصة cpu-cfs-quota-period من kubelet args ، وعند هذه النقطة يكون الاختناق أكثر تسطحًا وتبدأ الحاوية في حوالي 5 ثوانٍ مرة أخرى.

willthames
في ٥ يونيو ٢٠١٩
لمعلوماتك: موضوع Twitter الحالي حول موضوع تعطيل التحكم في وحدة المعالجة المركزية: https://twitter.com/it_supertramp/status/1133648291332263936
hjacobs
في ٥ يونيو ٢٠١٩
هذه هي الرسوم البيانية الخانقة لوحدة المعالجة المركزية من قبل / بعد انتقالنا إلى --cpu-cfs-quota-period=10ms في الإنتاج لخدمتين حساستين لوقت الاستجابة:
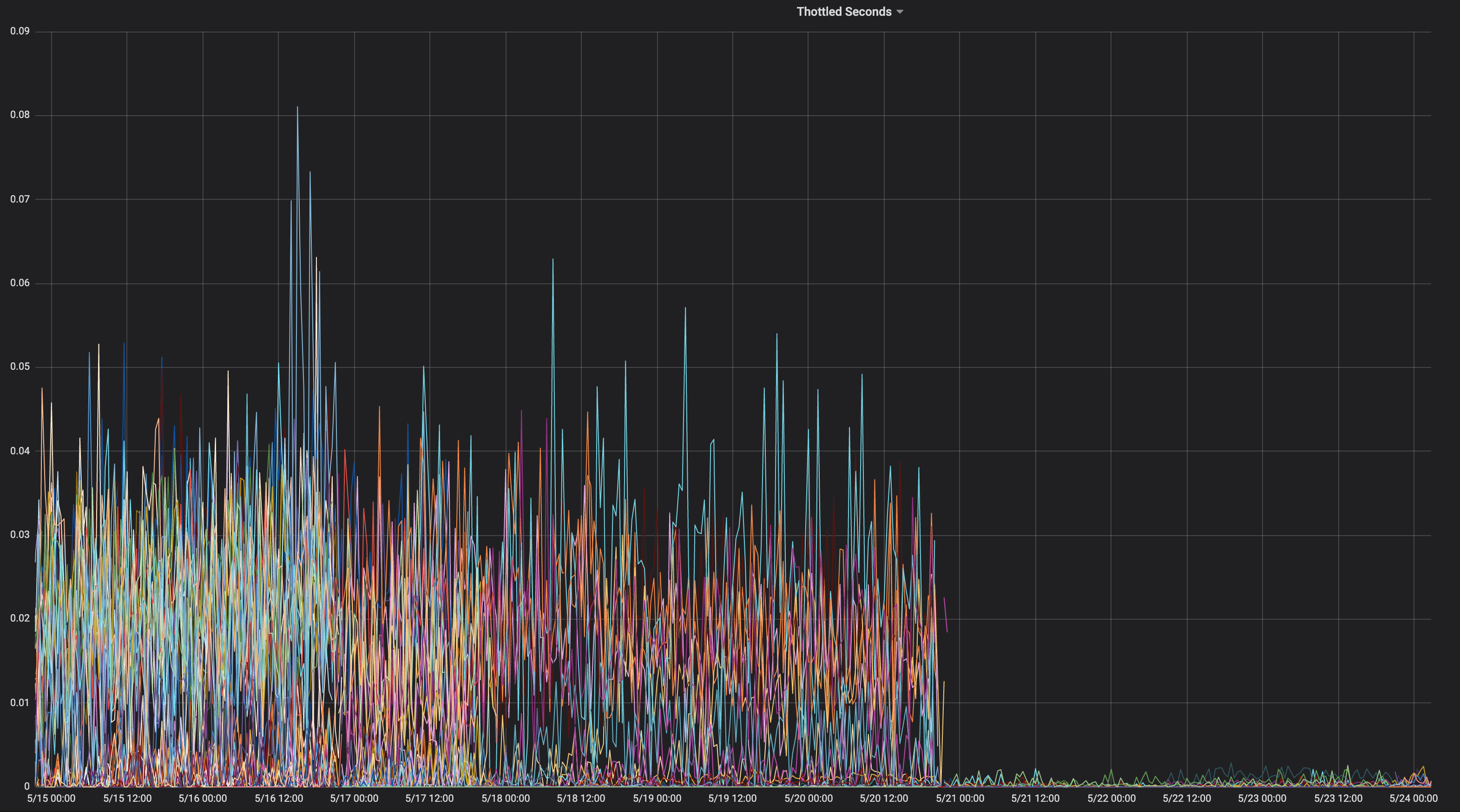

تعمل هذه الخدمات على أنواع مثيلات مختلفة (مع تلوث / تفاوتات مختلفة). تم نقل مثيلات الخدمة الثانية إلى فترة حصة CFS منخفضة أولاً.
يجب أن تعتمد النتائج بشكل كبير على الحمل.
d-shi
في ٥ يونيو ٢٠١٩
@ d-shi شيء آخر يحدث على الرسم البياني الخاص بك. أعتقد أنه قد يكون هناك بعض الحد الأدنى من حصة الحصص التي تصل إليها الآن لأن الفترة صغيرة جدًا. يجب أن أتحقق من الكود للتأكد. لقد قمت بشكل أساسي بزيادة مقدار الحصة المتاحة للتطبيق عن غير قصد. ربما كان بإمكانك تحقيق نفس الشيء من خلال زيادة مخصصات الحصص.
chiluk
في ٥ يونيو ٢٠١٩
بالنسبة لنا ، كان من المفيد جدًا قياس وقت الاستجابة بدلاً من الاختناق. أدى تعطيل cfs-quota إلى تحسين وقت الاستجابة بشكل كبير. أرغب في رؤية نتائج مماثلة لتغيير cfs-quota-period .
 blakebarnett
في ٦ يونيو ٢٠١٩
blakebarnett
في ٦ يونيو ٢٠١٩
chiluk لقد
blakebarnett لقد طورنا برنامجًا معياريًا يقيس زمن الوصول لدينا ، --cpu-cfs-quota-period ، إلى نطاق من 10 مللي ثانية -20 مللي ثانية ، بمتوسط حوالي 11 مللي ثانية بعد ذلك. انتقل زمن الانتقال p99 من حوالي 98 مللي ثانية إلى 20 مللي ثانية.
التعديلات: آسف للتعديلات التي اضطررت للعودة إليها والتحقق من أرقامي مرة أخرى.
d-shi
في ٦ يونيو ٢٠١٩
@ d-shi ، من المحتمل أن تكون قد حلّت المشكلة بواسطة 512ac999 حينها.
chiluk
في ٦ يونيو ٢٠١٩
chiluk بعد قراءة التصحيح الخاص بك مرارًا وتكرارًا ، يجب أن أعترف أنني أجد صعوبة في فهم تأثير هذا الرمز:
if (cfs_rq->expires_seq == cfs_b->expires_seq) {
- /* extend local deadline, drift is bounded above by 2 ticks */
- cfs_rq->runtime_expires += TICK_NSEC;
- } else {
- /* global deadline is ahead, expiration has passed */
- cfs_rq->runtime_remaining = 0;
- }
في حالة انتهاء صلاحية الحصة النسبية حتى لو استعار runtime_remaining بعض الوقت من المجمع العالمي. في أسوأ الأحوال ، سيتم خنقك لمدة 5 مللي ثانية بناءً على Sched_cfs_bandwidth_slice_us. أليس كذلك؟
هل افتقد شيء؟
 Mwea
في ٦ يونيو ٢٠١٩
Mwea
في ٦ يونيو ٢٠١٩
chiluk نعم أعتقد أنها على حق. لا تزال خوادم الإنتاج الخاصة بنا تعمل على kernel 4.4 ، لذلك ليس لديك هذا الإصلاح. ربما بمجرد قيامنا بالترقية إلى نواة أحدث ، يمكننا إعادة فترة حصة CFS إلى الوضع الافتراضي ، ولكن في الوقت الحالي تعمل على تحسين زمن الوصول إلى نهاية الذيل ولم نلاحظ أي آثار جانبية سلبية حتى الآن. على الرغم من أنها كانت حية لمدة أسبوعين فقط.
d-shi
في ٦ يونيو ٢٠١٩
@ chiluk عقل يلخص حالة هذه القضية في النواة؟ يبدو أنه كان هناك تصحيح ، 512ac999 ، لكن كان به مشاكل. هل قرأت في مكان ما أنه تم إرجاعه؟ أم أن هذا تم إصلاحه كليًا / جزئيًا؟ إذا كان الأمر كذلك ، فما هو الإصدار؟
mariusgrigoriu
في ٧ يونيو ٢٠١٩
mariusgrigoriu لم يتم إصلاحه ، لقد أنشأ chiluk تصحيحًا يجب أن يصلحه ويحتاج إلى مزيد من الاختبارات (
راجع https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -482198124 للحصول على أحدث حالة
willthames
في ٧ يونيو ٢٠١٩
Mwea يتم تخزين التجمع العمومي في cfs_b-> runtime_remaining. نظرًا لأنه يتم تعيين ذلك لكل قوائم انتظار تشغيل وحدة المعالجة المركزية (cfs_rq) ، يتم إنقاص المبلغ المتبقي في التجمع العالمي. cfs_bandwidth_slice_us هو مقدار وقت تشغيل وحدة المعالجة المركزية التي يتم نقلها من التجمع العالمي إلى قوائم انتظار التشغيل لكل وحدة معالجة مركزية. إذا تم خنقك ، فهذا يعني أنك بحاجة إلى التشغيل و cfs_b-> runtime_remaining == 0. سيكون عليك الانتظار حتى نهاية الفترة الحالية (افتراضيًا 100 مللي ثانية) ، حتى يتم تجديد الحصة إلى cfs_b ثم توزيعها على cfs_rq الخاص بك. لقد اكتشفت مؤخرًا أن مقدار وقت التشغيل منتهي الصلاحية هو 1 مللي ثانية على الأكثر لكل cfs_rq ، نظرًا لحقيقة أن مؤقت الركود يستعيد كل 1 مللي ثانية من الحصة غير المستخدمة من قوائم انتظار التشغيل لكل وحدة معالجة مركزية. ثم يتم إهدار / انتهاء صلاحية 1 مللي ثانية في نهاية الفترة. في سيناريو أسوأ الحالات حيث ينتشر التطبيق عبر 88 cpus والتي يمكن أن تكون 88 مللي ثانية من الحصة الضائعة لكل 100 مللي ثانية. أدى ذلك في الواقع إلى اقتراح بديل كان السماح لمؤقت فترة الركود باستعادة كل الحصة غير المستخدمة من قوائم التشغيل الخاملة لكل وحدة معالجة مركزية.
أما بالنسبة للخطوط التي تحددها على وجه التحديد. اقتراحي هو إزالة انتهاء صلاحية وقت التشغيل الذي تم تعيينه لقوائم انتظار التشغيل لكل وحدة معالجة مركزية بالكامل. هذه الأسطر جزء من الإصلاح لـ 512ac999. أدى ذلك إلى إصلاح مشكلة حيث تسبب انحراف الساعة بين قوائم انتظار التشغيل لكل وحدة معالجة مركزية في انتهاء صلاحية الحصة قبل الأوان ، مما أدى إلى تقييد التطبيقات التي لم تستخدم الحصة بعد (afaiu). يزدادون بشكل أساسي expires_seq على كل حدود فترة. لذلك يجب أن تتطابق expires_seq بين كل من cfs_rq عندما تكون في نفس الفترة.
mariusgrigoriu - إذا كنت
هناك الكثير من الطرق للتخفيف من هذه المشكلة.
- تثبيت وحدة المعالجة المركزية
- تقليل عدد سلاسل الرسائل التي ينتج عنها تطبيقك
- قم بإفراط في تخصيص الحصة للتطبيقات التي تواجه اختناق.
- قم بإيقاف تشغيل الحدود الصعبة الآن.
- قم ببناء نواة مخصصة باستخدام أي من التغييرات المقترحة.
chiluk
في ٧ يونيو ٢٠١٩
chiluk هل لديك فرصة
- تقليل الاختناق في memcached و mysql و nginx وما إلى ذلك
- زيادة في تقييد تطبيقات جافا الخاصة بنا
تريد حقًا المضي قدمًا للحصول على أفضل ما في العالمين هنا. يمكنني محاولة نقله على نفسي الأسبوع المقبل ، ولكن إذا كان لديك بالفعل ، فسيكون ذلك رائعًا.
 PaulFurtado
في ٢١ يونيو ٢٠١٩
PaulFurtado
في ٢١ يونيو ٢٠١٩
تضمين التغريدة
لقد قمت بالفعل بإعادة كتابة التصحيح خلال الأيام القليلة الماضية بناءً على اقتراحات Ben Segull. سيتم إصدار تصحيح kernel جديد بمجرد أن أحصل عليه في وقت اختبار على مجموعاتنا.
chiluk
في ٢٤ يونيو ٢٠١٩
chiluk أي تحديث على هذا التصحيح؟ لا تقلق إذا لم يكن الأمر كذلك ، فأنا فقط أتأكد من عدم تفويت التصحيح
PaulFurtado
في ١٨ يوليو ٢٠١٩
PaulFurtado ، تمت "الموافقة" على التصحيح من قِبل مؤلف CFS ، وأنا في انتظار
chiluk
في ٢٤ يوليو ٢٠١٩
@ chiluk شكرا لك!
لقد قمت للتو بنقل التصحيح على kernel 4.14 ، وهو نواة الإنتاج الحالية لدينا.
لقد قمت بعمل فكرة مع backport وبعض النتائج من fibtest الخاص بك هنا: https://gist.github.com/PaulFurtado/ff6c67ec87416b66ba1c6fc70f7beec1
في الجيل الحالي من مثيل c5.9xlarge و m5.24xlarge الذي نستخدمه في مجموعات kubernetes و mesos ، يضاعف التصحيح أداء برنامج fibtest الخاص بك. في نوع مثيل من الجيل السابق r4.16xlarge ، فإنه يدير استخدامًا أكبر بمقدار 1.5 مرة لوحدة المعالجة المركزية ولكن بالكاد أي تكرارات إضافية (والتي أفترضها فقط بسبب توليد وحدة المعالجة المركزية والطبيعة الأسية لتسلسل فيبوناتشي). كل هذه الأرقام ثابتة تمامًا إذا قمت بزيادة الاختبار إلى 30 ثانية بدلاً من 5 ثوانٍ افتراضيًا.
سنبدأ في طرح هذا في بيئة ضمان الجودة لدينا هذا الأسبوع للحصول على بعض المقاييس من تطبيقاتنا التي تعاني من أسوأ اختناق. شكرا لك مرة أخرى!
PaulFurtado
في ٢٦ يوليو ٢٠١٩
PaulFurtado أولاً أشكرك على الاختبار. سأفترض أنك تقوم بتشغيل kernel.org 4.14 أو ubuntu 4.14 ، وكلاهما يحتوي على 512ac999 فيه. بالنسبة إلى عمليات التكرار التي تم إجراؤها في fibtest ، فهي ليست بنفس أهمية وقت وحدة المعالجة المركزية المستخدمة ، حيث يمكن أن تتأثر التكرارات المكتملة بشدة بواسطة وحدة المعالجة المركزية mhz أثناء إجراء الاختبار (خاصة في السحابة حيث لست متأكدًا من مقدار التحكم الذي لديك على ذلك).
chiluk
في ٣١ يوليو ٢٠١٩
سأفترض أنك تقوم بتشغيل kernel.org 4.14 أو ubuntu 4.14 ، وكلاهما يحتوي على 512ac999 فيه.
نعم ، نقوم بتشغيل mainline 4.14 (حسنًا ، بالإضافة إلى مجموعة التصحيح من نواة Amazon Linux 2 ، ولكن لا يهم أي من هذه التصحيحات في هذه الحالة).
هبط 512ac999 في الخط الرئيسي 4.14.95 ، ولاحظنا تأثيره عند الترقية من 4.14.77 إلى 4.14.121+. لقد جعلت حاوياتنا المخزنة مؤقتًا (عدد الخيوط المنخفض جدًا) تنتقل من الاختناق الذي لا يمكن تفسيره إلى عدم الاختناق ، ولكنها جعلت حاوياتنا golang و java (عدد الخيوط العالية جدًا) أكثر اختناقًا.
بالنسبة إلى عمليات التكرار التي تم إجراؤها في fibtest ، فهي ليست بنفس أهمية وقت وحدة المعالجة المركزية المستخدمة ، حيث يمكن أن تتأثر التكرارات المكتملة بشدة بواسطة وحدة المعالجة المركزية mhz أثناء إجراء الاختبار (خاصة في السحابة حيث لست متأكدًا من مقدار التحكم الذي لديك على ذلك).
في مثيلات EC2 الأحدث / الأكبر ، تحصل في الواقع على مستوى لائق من التحكم في حالات المعالج ، لذلك نحن نعمل مع خاصية التعزيز التوربيني ولا نسمح للنواة بالتوقف عن العمل. على الرغم من ذلك ، فقد أدركت للتو أننا نضبط حالات c ، ولكن ليس حالات p وأن نوع المثيل الذي لم يشهد أي زيادة في التكرارات هو أحد الحالات التي يمكن فيها التحكم في حالات p ، لذلك قد يفسر ذلك جيدًا.
أولا شكرا لك على الاختبار
لا توجد مشكلة على الإطلاق ، فقد كانت الأمور مستقرة في بيئة ما قبل ضمان الجودة لدينا خلال عطلة نهاية الأسبوع ، وسنبدأ في طرح التصحيح على بيئة ضمان الجودة الرئيسية غدًا حيث سنرى المزيد من التأثيرات الواقعية. نظرًا لأن memcached قد استفاد من التصحيح السابق ، فقد أردنا حقًا الحصول على كعكتنا وتناولها أيضًا مع وجود كلا الرقعتين في مكانهما لذلك كنا سعداء للاختبار. شكرا مرة أخرى على كل العمل الذي كنت تقوم به في الاختناق!
PaulFurtado
في ٣١ يوليو ٢٠١٩
أردت فقط ترك ملاحظة ، بخصوص تصحيح النواة قيد المناقشة ....
لقد قمت بتكييفه مع النواة التي نستخدمها في الاختبار الحالي ، وشاهدت بعض المكاسب الضخمة على معدلات اختناق CFS ، ومع ذلك سأذكر أنه إذا كنت قد قمت مسبقًا بتعيين فترة cfs إلى 10 مللي ثانية كتخفيف ، فستذهب إلى تريد إعادة ذلك إلى 100 مللي ثانية لمعرفة فوائد التغيير.
 jhohertz
في ٦ أغسطس ٢٠١٩
jhohertz
في ٦ أغسطس ٢٠١٩
سقط التصحيح على الحافة هذا الصباح.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/؟id=de53fd7aedb100f03e5d2231cfce0e4993282425
بمجرد أن تصل إلى شجرة Torvald ، سأرسلها لإدراجها في نظام Linux المستقر ، وبعد ذلك التوزيعات الرئيسية (Redhat / Ubuntu). إذا كنت تهتم بشيء آخر ، ولا يتبعون تصحيحات Linux المستقرة ، فقد ترغب في إرسالها مباشرة.
chiluk
في ٨ أغسطس ٢٠١٩
لقد اختبرت التصحيح (ubuntu 18.04، 5.2.7 kernel، node: 56 core CPU E5-2660 v4 @ 2.00GHz) من خلال خدمة golang microservice الثقيلة لمعالجة الصور وحصلت على نتائج مبهرة. أداء مثل إذا قمت بتعطيل CFS على العقدة بشكل كامل.
لقد حصلت على زمن انتقال أقل بنسبة 5-35٪ و 5-55٪ أكثر من RPS اعتمادًا على استخدام التزامن / وحدة المعالجة المركزية بمعدل اختناق قريب من الصفر.
شكرا ، chiluk !
كما قال jhohertz ، يجب إعادة حصة
 zigmund
في ١٠ أغسطس ٢٠١٩
zigmund
في ١٠ أغسطس ٢٠١٩
لمزيد من الأداء مع golang ، اضبط GOMAXPROCS على الحد الأقصى (الحصة) +2. زائد 2 هو ضمان بعض التزامن.
chiluk
في ١٢ أغسطس ٢٠١٩
تم اختبار
zigmund
في ١٣ أغسطس ٢٠١٩
zigmund هذا بسبب تعيين حد وحدة المعالجة المركزية لديك على الرقم 8 بالكامل والذي يجب أن يربط عملياتك بـ cpuset من 8 cpus. الفرق بنسبة 1-2٪ الخاص بك هو مجرد زيادة في النفقات العامة لتبديل السياق مع عدائي Goroutine الإضافيين في مجموعة مهام وحدة المعالجة المركزية المكونة من 8 وحدات.
كان يجب أن أقول إن إعداد GOMAXPROCS = # هو حل جيد لبرامج go حتى يتم توزيع تصحيحات kernel على نطاق واسع.
chiluk
في ٢٦ أغسطس ٢٠١٩
لقد قمنا بترحيل مجموعات الإنتاج الخاصة بنا إلى نواة مصححة ويمكنني الآن مشاركة بعض اللحظات الممتعة لكم.
إحصائيات من إحدى مجموعاتنا - 4 عقد من 72 نواة E5-2695 v4 @ 2.10 جيجا هرتز ، وذاكرة وصول عشوائي 128 جيجا بايت ، و Debian 9 ، و 5.2.7 نواة مع التصحيح.
لدينا أحمال مختلطة تتكون في الغالب من خدمات golang ، ولكن لدينا أيضًا php و python.
جولانج. زمن الوصول أقل ، إعداد GOMAXPROCS الصحيح أمر لا بد منه تمامًا. هذه خدمة مع GOMAXPROCS الافتراضي = 72. لقد قمنا بتغيير النواة في 16 ~ وبعد ذلك انخفض زمن الانتقال وزاد استخدام وحدة المعالجة المركزية بشكل كبير. في الساعة 21:15 قمت بتعيين GOMAXPROCS الصحيح واستخدام وحدة المعالجة المركزية بشكل طبيعي.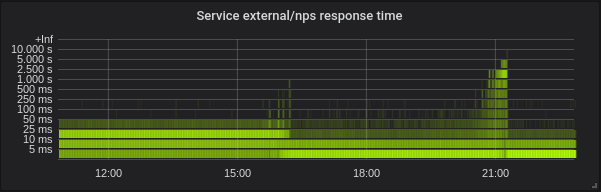

بايثون. أصبح كل شيء أفضل مع التصحيح دون أي حركات إضافية - انخفض استخدام وحدة المعالجة المركزية وزمن الوصول.
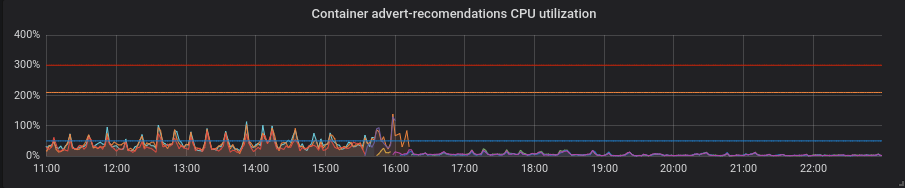
بي أتش بي. استخدام وحدة المعالجة المركزية هو نفسه ، فقد انخفض زمن الانتقال قليلاً في بعض الخدمات. ليس ربحًا كبيرًا.
zigmund
في ٣ سبتمبر ٢٠١٩
zigmund شكرا.
لست متأكدًا من أنني أحصل عليه عندما تقول I setted correct GOMAXPROCS ...
أفترض أنك لا تقوم بتشغيل جراب واحد فقط على عقدة 72 نواة ، لذا قمت بتعيين GOMAXPROCS لشيء أقل ، ربما يساوي حدود وحدة المعالجة المركزية Pod ، أليس كذلك؟
prune998
في ٣ سبتمبر ٢٠١٩
zigmund شكرا. تتوافق تغييرات go إلى حد كبير مع ما كان متوقعًا.
أنا مندهش حقًا من تحسينات الثعبان على الرغم من أنني توقعت أن ينفي GIL فوائد هذا إلى حد كبير. إذا كان أي شيء ، يجب أن يؤدي هذا التصحيح إلى تقليل وقت الاستجابة وتقليل النسبة المئوية لفترات الاختناق وزيادة استخدام وحدة المعالجة المركزية. هل أنت متأكد من أن تطبيق Python الخاص بك لا يزال سليمًا؟
chiluk
في ٣ سبتمبر ٢٠١٩
@ prune998 آسف ، ربما خطأ إملائي. لقد قمت بتعيين GOMAXPROCS = limits.cpu. في الوقت الحالي لدينا حوالي 110 كبسولات لكل عقدة في هذه المجموعة.
chiluk لست قوياً في بيثون ولا أعرف كيف تأثر التصحيح في الطبقة السفلية. لكن التطبيق سليم بدون مشاكل ، لقد تحققت منه بعد تغيير النواة.
zigmund
في ٤ سبتمبر ٢٠١٩
chiluk هل لك أن تشرح كيف يمكننا متابعة تقدم التصحيح الخاص بك في توزيعات Linux المختلفة؟ أنا مهتم بشكل خاص بـ Debian و AWS Linux ، لكنني أتوقع أن يهتم الأشخاص الآخرون بـ Ubuntu وما إلى ذلك ، لذا مهما كان الضوء الذي يمكنك تسليط الضوء عليه ، شكرًا لك.
 Nuru
في ١٣ سبتمبر ٢٠١٩
Nuru
في ١٣ سبتمبر ٢٠١٩
Nuru https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html؟highlight=stable٪20rules ... بشكل أساسي سأقدم من خلال linux- stabil بمجرد أن يصل التصحيح الخاص بي إلى Linus ' شجرة ، * (ربما قبل ذلك) ، ومن ثم يجب أن تتبع جميع التوزيعات عملية لينكس المستقرة ، وأن تسحب البقع التي يقبلها القائمون على الصيانة الثابتة إلى نواة التوزيع الخاصة بهم. إذا لم يكونوا كذلك ، فلا يجب عليك تشغيل توزيعاتهم.
chiluk
في ١٣ سبتمبر ٢٠١٩
chiluk لا أعرف شيئًا عن عملية تطوير Linux. تقصد بـ "شجرة لينوس" https://github.com/torvalds/linux ؟
Nuru
في ١٤ سبتمبر ٢٠١٩
تعيش شجرة لينوس هنا ، https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/. يتم حاليًا تنظيم تغييراتي على linux-next وهي شجرة تكامل التطوير. نعم ، إن تطوير النواة عالق بعض الشيء في العصور المظلمة ، لكنه يعمل.
من المحتمل أن يسحب التغييرات من شجرة linux-next بمجرد إصدار 5.3 ويبدأ التطوير في 5.4-rc0. هذا هو الإطار الزمني الذي أتوقعه أن تبدأ النواة المستقرة في جذب هذا الإصلاح. عندما يشعر Linus أن 5.3 مستقر ، فإن أي شخص سيخمن.
chiluk
في ١٤ سبتمبر ٢٠١٩
من المحتمل أن يسحب [Linus] التغييرات من شجرة linux-next بمجرد إصدار 5.3 ويبدأ التطوير في 5.4-rc0. هذا هو الإطار الزمني الذي أتوقعه أن تبدأ النواة المستقرة في جذب هذا الإصلاح. عندما يشعر Linus أن 5.3 مستقر ، فإن أي شخص سيخمن.
chiluk يبدو أن Linus قرر أن 5.3 كان مستقرًا في 15 سبتمبر 2019 . إذن ، ما هو "linux-next" وكيف نتتبع تقدم التصحيح الخاص بك من خلال الخطوات التالية؟
Nuru
في ٢٠ سبتمبر ٢٠١٩
هل قام أي شخص ببناء حزم امتداد دبيان و / أو صورة AWS تتضمن هذا التصحيح؟ أنا على وشك القيام بذلك باستخدام https://github.com/kubernetes-sigs/image-builder/tree/master/images/kube-deploy/imagebuilder
فقط اعتقدت أنني سأتجنب تكرار الجهود إذا كانت موجودة بالفعل.
blakebarnett
في ٢٤ سبتمبر ٢٠١٩
تم الآن دمج هذا في شجرة Linus ويجب إصداره بـ 5.4. لقد قمت أيضًا بإرسالها إلى مستقر لينكس ، وعلى افتراض أن كل التوزيعات التي تتبع عملية مستقرة بشكل صحيح يجب أن تبدأ في التقاطها قريبًا.
chiluk
في ٢٥ سبتمبر ٢٠١٩
هل يعرف أي شخص كيف يتابع ما إذا / كيف يؤدي هذا التغيير إلى CentOS (7)؟ لست متأكدًا من كيفية عمل backporting وما إلى ذلك.
 till
في ٢٦ سبتمبر ٢٠١٩
till
في ٢٦ سبتمبر ٢٠١٩
حتى https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -531370333
لمحادثة kernel المستقرة تجري هنا.
https://lore.kernel.org/stable/CAC=E7cUXpUDgpvsmMaMU6sAydbfD0FEJiK25R1r=e9=YtcPjGw@mail.gmail.com/
أيضًا لأولئك الذين يذهبون إلى KubeCon ، سأقدم هذه المشكلة هناك.
https://sched.co/Uae1
chiluk
في ٣ أكتوبر ٢٠١٩
أي كلمة من المشرفين على الجدولة تعيد: ack Greg HK الذي كان يبحث عنه لتحويله إلى شجرة (شجرات) مستقرة؟
jhohertz
في ١٨ أكتوبر ٢٠١٩
لقد أوقف Greg KH عن اتخاذ قرار بشأن هذا التصحيح لأن المشرفين على الجدولة لم يستجيبوا (ربما فاتهم البريد للتو). تعليق من أي شخص آخر غيري على LKML الذي اختبر هذا التصحيح ويعتقد أنه يجب نقله إلى الخلف سيكون موضع تقدير.
chiluk
في ١٨ أكتوبر ٢٠١٩
بالنسبة للأشخاص الذين يستخدمون CoreOS ، هناك مشكلة مفتوحة تطلب نقل تصحيح
 evanfoster
في ١ نوفمبر ٢٠١٩
evanfoster
في ١ نوفمبر ٢٠١٩
يحتوي CoreOS kernel 4.19.82 على الإصلاحات: https://github.com/coreos/linux/pull/364
يحتوي CoreOS Container Linux 2317.0.1 (قناة ألفا) على الإصلاحات: https://github.com/coreos/coreos-overlay/pull/3796 http://coreos.com/releases/#2317.0.1
يبدو أن Backports to Linux مستقرة متوقفة لأن التصحيحات لا تنطبق بشكل صحيح . chiluk هل ستعمل على Backports لـ Linux المستقر؟ إذا كان الأمر كذلك ، فهل يمكنك رجاءًا backport إلى 4.9 بحيث يصل إلى "امتداد" دبيان ويتم التقاطه بواسطة kops ؟ على الرغم من أنني اعتقد انه سيكون في نهاية المطاف أخذ بقدر 6 أشهر للحصول عليه في "امتداد" وربما في ذلك الوقت kops سوف هاجروا إلى "المغفل".
Nuru
في ٨ نوفمبر ٢٠١٩
Nuru ، لقد قمت وصنعت حزمًا قابلة للتمدد (بناءً على نواة امتداد backports) و kops 1.11-friendly AMI إذا كنت ترغب في اختبار:
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.buildinfo
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm-dbg_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-headers-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.changes
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-libc-dev_4.19.67-1_amd64.deb
293993587779 / k8s-1.11-debian-stretch-amd64-hvm-ebs-2019-09-26
blakebarnett
في ٨ نوفمبر ٢٠١٩
blakebarnett شكرًا على
- يعتمد "امتداد" على Linux 4.9 ، ولكن جميع الروابط الخاصة بك هي 4.19.
- تقول إنك قمت بنقل "التصحيح" إلى الخلف ولكن هناك 3 تصحيحات (أعتقد أن الثالثة ليست مهمة حقًا:
- جدول 512ac999 / عادل: إصلاح حالة انجراف ساعة مؤقت عرض النطاق الترددي
- de53fd7ae Sched / fair: إصلاح الاستخدام المنخفض لوحدة المعالجة المركزية مع الاختناق العالي عن طريق إزالة انتهاء صلاحية الشرائح المحلية لوحدة المعالجة المركزية
- 763a9ec06 Sched / fair: Fix -Wunused-but-set-متغير التحذيرات
هل قمت بنقل جميع التصحيحات الثلاثة إلى 4.9؟ (لا أعرف ماذا أفعل بحزم دبيان لأبحث ومعرفة ما إذا كانت التغييرات موجودة ، ولا تتناول وثيقة "التغييرات" ما الذي تغير بالفعل.)
أيضًا ، في أي مناطق يتوفر AMI الخاص بك؟
Nuru
في ٨ نوفمبر ٢٠١٩
لا ، لقد استخدمت نواة امتداد backports ، وهي 4.19 ، حيث تحتوي على إصلاحات نحتاجها أيضًا على AWS (خاصة لأنواع مثيلات M5 / C5)
لقد طبقت فرقًا يتضمن جميع التصحيحات التي أعتقد ، واضطررت إلى تغييرها قليلاً لإزالة المراجع الإضافية للمتغيرات في 4.19 التي تم حذفها في مكان آخر ، وقد قمت أولاً بتطبيق https://github.com/kubernetes/kubernetes/issues/67577 #issuecomment -515324561 ثم يلزم إضافة:
--- kernel/sched/fair.c 2019-09-25 16:06:02.954933954 -0700
+++ kernel/sched/fair.c-b 2019-09-25 16:06:56.341615817 -0700
@@ -4928,8 +4928,6 @@
cfs_b->period_active = 1;
overrun = hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
- cfs_b->runtime_expires += (overrun + 1) * ktime_to_ns(cfs_b->period);
- cfs_b->expires_seq++;
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
--- kernel/sched/sched.h 2019-08-16 01:12:54.000000000 -0700
+++ sched.h.b 2019-09-25 13:24:00.444566284 -0700
@@ -334,8 +334,6 @@
u64 quota;
u64 runtime;
s64 hierarchical_quota;
- u64 runtime_expires;
- int expires_seq;
short idle;
short period_active;
@@ -555,8 +553,6 @@
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
- int expires_seq;
- u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock;
تم نشر AMI في us-west-1
امل ان يساعد!
blakebarnett
في ٨ نوفمبر ٢٠١٩
لقد قمت بنقل هذه التصحيحات إلى الخلف وأرسلتها إلى حبات لينوكس المستقرة
الإصدار 4.14 https://lore.kernel.org/stable/[email protected]/
الإصدار 4.19 https://lore.kernel.org/stable/[email protected]/ #t
chiluk
في ٨ نوفمبر ٢٠١٩
مرحبا،
بعد تكامل التصحيح على فرع 4.19 ، فتحت تقرير خطأ على ديبيان من أجل ترقية مناسبة لـ kerner على buster و stretch-backport:
https://bugs.debian.org/cgi-bin/bugreport.cgi؟bug=946144
لا تتردد في إضافة تعليق جديد لترقية حزمة دبيان.
 alexises
في ٤ ديسمبر ٢٠١٩
alexises
في ٤ ديسمبر ٢٠١٩
آمل ألا يكون هذا غير مرغوب فيه للغاية ولكني أردت ربط هذا الحديث الممتاز من chiluk مع الدخول في العديد من تفاصيل الخلفية المتعلقة بهذه المشكلة https://youtu.be/UE7QX98-kO0.
 bboreham
في ٤ ديسمبر ٢٠١٩
bboreham
في ٤ ديسمبر ٢٠١٩
هل هناك طريقة لتجنب الاختناق على GKE؟ لقد واجهتنا مشكلة كبيرة حيث كانت إحدى طرق حاوية php تأخذ 120 ثانية بدلاً من 0.1 ثانية المعتادة
 bartoszhernas
في ٥ ديسمبر ٢٠١٩
bartoszhernas
في ٥ ديسمبر ٢٠١٩
إزالة حدود وحدة المعالجة المركزية
 monotek
في ٥ ديسمبر ٢٠١٩
monotek
في ٥ ديسمبر ٢٠١٩
لقد فعلنا ذلك بالفعل ، يتم تقييد الحاوية عندما تكون طلبات وحدة المعالجة المركزية صغيرة جدًا. هذا هو جوهر المشكلة ، وسيؤدي عدم وجود حدود واستخدام طلبات وحدة المعالجة المركزية فقط إلى الاختناق :(
bartoszhernas
في ٥ ديسمبر ٢٠١٩
bartoszhernas أعتقد أنك تستخدم كلمة خاطئة هنا. عندما يشير الأشخاص في هذا الموضوع إلى "الاختناق" ، فإنهم يشيرون إلى التحكم في عرض النطاق الترددي لـ cfs ، nr_throttled في cpu.stat لزيادة المجموعة. يتم تمكين ذلك فقط عند تمكين حدود وحدة المعالجة المركزية. ما لم تضيف GKE حدودًا إلى جرابك دون علمك ، فلن أسمي ما تضربه على أنه اختناق.
أود أن أسمي ما وصفته بـ "الخلاف على المعالج". أظن أنه من المحتمل أن يكون لديك العديد من التطبيقات * (الطلبات) ذات الحجم غير الصحيح ، والتي تتنافس على المعالج أو مورد آخر في الصندوق لأنها تستخدم في كثير من الأحيان أكثر مما طلبوه. هذا هو السبب الدقيق لاستخدامنا الحدود. بحيث لا تؤثر هذه التطبيقات ذات الحجم غير المناسب إلا على التطبيقات الأخرى الموجودة على العلبة كثيرًا.
الاحتمال الآخر هو أن مبلغ الطلب غير الكافي يؤدي إلى سلوك جدولة ضعيف. يشبه إعداد الطلبات منخفضة تعيين قيمة موجبة "لطيفة" بالنسبة إلى تطبيقات "الطلب" الأعلى. لمزيد من المعلومات حول ذلك تحقق من الحدود الناعمة.
chiluk
في ٥ ديسمبر ٢٠١٩
تصبح المشكلات قديمة بعد 90 يومًا من الخمول.
ضع علامة على المشكلة على أنها جديدة /remove-lifecycle stale .
تتعفن المشكلات التي لا معنى لها بعد 30 يومًا إضافيًا من عدم النشاط وتغلق في النهاية.
إذا كان إغلاق هذه المشكلة آمنًا الآن ، فيرجى القيام بذلك باستخدام /close .
إرسال ملاحظات إلى اختبار سيج ، kubernetes / test-infra و / أو fejta .
/ دورة الحياة التي لا معنى لها
 fejta-bot
في ٤ مارس ٢٠٢٠
fejta-bot
في ٤ مارس ٢٠٢٠
/ إزالة دورة الحياة التي لا معنى لها
Nuru
في ٤ مارس ٢٠٢٠
من وجهة نظري ، تم إصلاح المشكلة الأساسية في النواة وإتاحتها على سبيل المثال ContainerLinux في https://github.com/coreos/bugs/issues/2623.
أي شخص على علم بالمشكلات المتبقية بعد تصحيح kernel هذا؟
 sfudeus
في ٤ مارس ٢٠٢٠
sfudeus
في ٤ مارس ٢٠٢٠
يمكن تشغيل sfudeus Kubernetes على أي نكهة من Linux ، أو ، AFAIK ، أي نكهة متوافقة مع POSIT من Unix. لم يكن هذا الخطأ أبدًا مشكلة للأشخاص الذين لا يستخدمون Linux ، وقد تم إصلاحه لبعض التوزيعات المشتقة من Linux ، ولم يتم إصلاحه للآخرين.
تم إصلاح المشكلة الأساسية في Linux kernel 5.4 ، والتي بالكاد يستخدمها أي شخص في هذه المرحلة. تم توفير التصحيحات للتنقل الخلفي إلى العديد من النواة القديمة وتضمين توزيعات Linux الجديدة غير الجاهزة للانتقال إلى 5.4 kernel حتى الآن ، والتي يوجد منها الكثير. كما ترى من القائمة أعلاه للالتزامات التي تشير إلى هذه المشكلة ، لا تزال تصحيحات إصلاح الأخطاء في طور دمجها في توزيعات Linux التي لا تعد ولا تحصى والتي قد يستخدمها شخص ما Kubernetes.
لذلك ، أود أن أبقي هذه المشكلة مفتوحة لفترة ما زالت ترى مراجع الالتزام النشطة. أود أيضًا أن أراه مغلقًا بنص أو طريقة سهلة أخرى يمكن لأي شخص استخدامها لتحديد ما إذا كان تثبيت Kubernetes قد تأثر أم لا.
Nuru
في ٥ مارس ٢٠٢٠
Nuru Fine بالنسبة لي ، أردت فقط التأكد من عدم وجود مشكلة أخرى في kernel ، وهو أمر معروف بالفعل. أنا شخصياً لن أبقي هذا مفتوحًا لفترة أطول من التوزيعات الأكبر التي أدرجت الإصلاح ، فانتظار أجهزة إنترنت الأشياء التي لا نهاية لها يمكن أن يعني الانتظار إلى ما لا نهاية. يمكن العثور على القضايا المغلقة كذلك. ولكن هذا هو فقط 2 سنتي.
sfudeus
في ٥ مارس ٢٠٢٠
لست متأكدًا مما إذا كان هذا هو المكان الصحيح لإعلام الناس ، ولكن لست متأكدًا حقًا من المكان الآخر الذي يجب طرح هذا فيه:
نحن نشغل 5.4 Linux kernel على Debian Buster (باستخدام نواة buster-backports) باستخدام مجموعة k8s 1.15.10 وما زلنا نرى مشكلات في هذا الأمر. خاصة بالنسبة إلى أجهزة Pods التي عادةً ما يكون لديها القليل جدًا من المهام (kube-downscaler هو المثال الذي نستمر في العودة إليه ، والذي يتطلب عادةً حوالي 3 أمتار من وحدة المعالجة المركزية) والتي لا تحتوي إلا على عدد قليل جدًا من موارد وحدة المعالجة المركزية (50 مترًا في حالة kube-downscaler في موقعنا الكتلة) ما زلنا نرى قيمة اختناق عالية جدًا. كمرجع ، فإن kube-downscaler هو في الأساس نص برمجي Python يقوم بتشغيل sleep لمدة 30 دقيقة قبل أن يفعل أي شيء. يُظهر cAdvisor الزيادة في إجمالي container_cpu_cfs_throttled_periods_total لهذه الحاوية لتكون دائمًا أكثر أو أقل شبهاً بالقيمة الإجمالية لـ container_cpu_cfs_periods_tool لهذه الحاوية (كلاهما يبلغ حوالي 250 عند التحقق من الزيادة على فترات 5 أمتار). نتوقع أن تكون الفترات المخنوقة قريبة من 0.
هل نقيس هذا بشكل غير صحيح؟ هل يقوم cAdvisor بإخراج بيانات غير صحيحة؟ هل افتراضنا صحيح بأنه ينبغي أن نرى انخفاضًا في فترات الاختناق؟ سيكون موضع تقدير أي نصيحة هنا.
بعد التبديل إلى 5.4 kernel ، رأينا أن عدد Pods مع هذه المشكلة يتناقص قليلاً (حوالي 40٪) ، لكننا حاليًا غير متأكدين مما إذا كان ما نراه مشكلة فعلية أم لا. بشكل أساسي ، لسنا متأكدين عند النظر إلى الإحصائيات أعلاه ، ما يعنيه "الاختناق" حقًا هنا إذا حصلنا على هذه القيم باستخدام متوسط 3 أمتار من استخدام وحدة المعالجة المركزية. العقدة التي يتم تشغيلها عليها ليست مُبالغ فيها على الإطلاق ولديها متوسط استخدام وحدة المعالجة المركزية أقل من 10٪.
 timstoop
في ٥ مارس ٢٠٢٠
timstoop
في ٥ مارس ٢٠٢٠
timstoop الفواصل الزمنية التي يهتم بها المجدول هي في عالم ميكروثانية ، وليس نطاقات 30 دقيقة كبيرة. إذا كانت الحاوية تحتوي على حد وحدة المعالجة المركزية (CPU) يبلغ 50 ملي وحدة ، وتستخدم 50 ملي وحدة على مدى 100 ميكروثانية ، فسيتم اختناقها ، بغض النظر عما إذا كانت تستغرق 30 دقيقة في وضع الخمول. بشكل عام ، تعد 50 ملي بوحدة معالجة مركزية صغيرة للغاية. إذا قام برنامج python بتقديم طلب HTTPS واحد بهذا الحد الأدنى ، فمن المضمون إلى حد كبير أن يتم الاختناق.
العقدة التي يتم تشغيلها عليها ليست مُبالغ فيها على الإطلاق ولديها متوسط استخدام وحدة المعالجة المركزية أقل من 10٪.
فقط للتوضيح: حمل العقدة وأعباء العمل الأخرى عليها لا علاقة لها بالاختناق. الخنق هو فقط النظر في الحد الخاص بالحاوية / المجموعة.
PaulFurtado
في ٥ مارس ٢٠٢٠
@ PaulFurtado شكرا لإجابتك! ومع ذلك ، فإن البود نفسه لديه متوسط استخدام 3 أمتار وحدة المعالجة المركزية أثناء ذلك النوم ولا يزال يتم خنقه. إنه لا يقدم أي طلب خلال تلك الفترة ، إنه ينتظر النوم. آمل أن تتمكن من فعل ذلك دون أن تصل إلى 50 مترًا ، أليس كذلك؟ أم أن هذا افتراض غير صحيح على أي حال؟
timstoop
في ٥ مارس ٢٠٢٠
أعتقد أن هذا من المحتمل أن يكون مجرد رقم منخفض حيث ستكون هناك مشكلات تتعلق بالدقة. و 50 مترًا منخفضة جدًا لدرجة أن أي شيء على الإطلاق يمكن أن يفسدها. قد يؤدي وقت تشغيل Python أيضًا إلى أداء مهام في الخلفية في سلاسل الرسائل أثناء النوم.
PaulFurtado
في ٥ مارس ٢٠٢٠
كنت على حق ، كنت أفترض افتراضات غير صحيحة. شكرا لتوجيهاتك! من المنطقي بالنسبة لي الآن.
timstoop
في ٥ مارس ٢٠٢٠
أردت فقط القفز والقول إن الأشياء هنا قد تحسنت بشكل كبير منذ أن وصل تصحيح النواة إلى 4.19 LTS kernels ، وظهر على CoreOS / Flatcar. بالنظر إلى هذه اللحظة ، فإن الأشياء الوحيدة التي أراها يتم خنقها هي شيئان ربما يجب أن أرفع القيود عليها. :ابتسامة:
jhohertz
في ٥ مارس ٢٠٢٠
sfudeuschiluk هل هناك أي اختبار بسيط لمعرفة ما إذا النواة وهذا ثابت أم لا؟
لا يمكنني معرفة ما إذا كان kope.io/k8s-1.15-debian-stretch-amd64-hvm-ebs-2020-01-17 (الصورة الرسمية الحالية kops ) قد تم تصحيحها أم لا.
Nuru
في ٢٠ مارس ٢٠٢٠
أتفق مع mariusgrigoriu ، بالنسبة إلى السنفات التي تعمل على وحدة المعالجة المركزية الحصرية بموجب سياسة وحدة المعالجة المركزية الثابتة ، يمكننا ببساطة تعطيل حد حصة وحدة المعالجة المركزية - لا يمكن تشغيلها إلا على مجموعة وحدة المعالجة المركزية الحصرية الخاصة بها على أي حال. التصحيح أعلاه مخصص لهذا الغرض وهذا النوع من القرون فقط.
 jianzzha
في ٦ أبريل ٢٠٢٠
jianzzha
في ٦ أبريل ٢٠٢٠
Nuru كتبت https://github.com/indeedeng/fibtest
إنه أمر نهائي للاختبار كما يمكنك الحصول عليه ، لكنك ستحتاج إلى مترجم سي.
تجاهل عدد التكرارات المكتملة ، ولكن ركز على مقدار الوقت المستخدم للتشغيل الفردي المترابط مقابل التشغيل متعدد الخيوط.
chiluk
في ١٠ أبريل ٢٠٢٠
أعتقد أن هناك طريقة جيدة لمعرفة النوى التي تم تصحيحها في إحدى الشرائح الأخيرة من chiluk (شكرًا على هذا راجع للشغل) تحدث https://www.youtube.com/watch؟v=UE7QX98-kO0
يبدو أن Kernel 4.15.0-67 يحتوي على التصحيح (https://launchpad.net/ubuntu/+source/linux/4.15.0-67.76) ومع ذلك ، ما زلنا نرى الاختناق في بعض Pods حيث الطلبات / الحد أعلى بكثير استخدام وحدة المعالجة المركزية الخاصة بهم.
أنا أتحدث عن استخدام حوالي 50 مللي ثانية بعد أن تم ضبط الطلب على 250 مترًا والحد على 500 متر. نشهد اختناق حوالي 50٪ من فترات وحدة المعالجة المركزية ، فهل هذه القيمة ربما منخفضة بما يكفي لتوقعها ويمكن قبولها؟ أرغب في رؤيته وصولاً إلى الصفر ، لا ينبغي خنقنا على الإطلاق إذا لم يكن الاستخدام قريبًا من الحد الأقصى.
هل لا يزال هناك بعض الاختناق الذي يستخدمه شخص ما للنواة الجديدة المرقعة؟
 vgarcia-te
في ٢٢ أبريل ٢٠٢٠
vgarcia-te
في ٢٢ أبريل ٢٠٢٠
@ vgarcia-te هناك عدد كبير جدًا من النوى المتداولة لمعرفة من القائمة التي تم تصحيحها ولم يتم تصحيحها. ما عليك سوى إلقاء نظرة على جميع الالتزامات التي تشير إلى هذه المشكلة. عدة مئات. تشير قراءتي لسجل التغيير لـ Ubuntu إلى أنه لم يتم تصحيح 4.15 بعد (باستثناء mabye للتشغيل على Azure) ، وتم رفض التصحيح الذي قمت بربطه.
أنا شخصياً مهتم بسلسلة 4.9 لأن هذا هو ما يستخدمه kops ، وأود أن أعرف متى يصدرون AMI مع الإصلاح.
في غضون ذلك ، يمكنك محاولة إجراء اختبار bobrik الذي يبدو جيدًا بالنسبة لي.
wget https://gist.githubusercontent.com/bobrik/2030ff040fad360327a5fab7a09c4ff1/raw/9dcf83b821812064fa7fb056b8f22cbd5c4364f1/cfs.go
sudo docker run --rm -it --cpu-quota 20000 --cpu-period 100000 -v $(pwd):$(pwd) -w $(pwd) golang:1.9.2 go run cfs.go -iterations 15 -sleep 1000ms
مع CFS تعمل بشكل صحيح ، ستكون أوقات الحرق 5 مللي ثانية. مع النوى المتأثرة التي اختبرتها ، باستخدام الأرقام المذكورة أعلاه ، كثيرًا ما أرى أوقات حرق تبلغ 99 مللي ثانية. أي شيء يزيد عن 6 مللي ثانية يمثل مشكلة.
Nuru
في ٢٢ أبريل ٢٠٢٠
nuru شكرًا على البرنامج النصي للعثور على المشكلة أم لا.
justinsb يرجى اقتراح ما إذا كانت صور
https://github.com/kubernetes/kops/blob/master/channels/stable
تم فتح مشكلة: https://github.com/kubernetes/kops/issues/8954
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -617586330
تحديث: نفذ الاختبار في صورة kops 1.15 ، هناك اختناق غير ضروري https://github.com/kubernetes/kops/issues/8954#issuecomment -617673755
alok87
في ٢٢ أبريل ٢٠٢٠
تضمين التغريدة
2020/04/22 11:02:48 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 6ms
2020/04/22 11:02:49 [1] burn took 5ms, real time so far: 1012ms, cpu time so far: 12ms
2020/04/22 11:02:50 [2] burn took 5ms, real time so far: 2017ms, cpu time so far: 18ms
2020/04/22 11:02:51 [3] burn took 5ms, real time so far: 3023ms, cpu time so far: 23ms
2020/04/22 11:02:52 [4] burn took 5ms, real time so far: 4028ms, cpu time so far: 29ms
2020/04/22 11:02:53 [5] burn took 5ms, real time so far: 5033ms, cpu time so far: 35ms
2020/04/22 11:02:54 [6] burn took 5ms, real time so far: 6038ms, cpu time so far: 40ms
2020/04/22 11:02:55 [7] burn took 5ms, real time so far: 7043ms, cpu time so far: 46ms
2020/04/22 11:02:56 [8] burn took 5ms, real time so far: 8049ms, cpu time so far: 51ms
2020/04/22 11:02:57 [9] burn took 5ms, real time so far: 9054ms, cpu time so far: 57ms
2020/04/22 11:02:58 [10] burn took 5ms, real time so far: 10059ms, cpu time so far: 63ms
2020/04/22 11:02:59 [11] burn took 5ms, real time so far: 11064ms, cpu time so far: 69ms
2020/04/22 11:03:00 [12] burn took 5ms, real time so far: 12069ms, cpu time so far: 74ms
2020/04/22 11:03:01 [13] burn took 5ms, real time so far: 13074ms, cpu time so far: 80ms
2020/04/22 11:03:02 [14] burn took 5ms, real time so far: 14079ms, cpu time so far: 85ms
هذه النتائج من
Linux <servername> 4.15.0-96-generic #97-Ubuntu SMP Wed Apr 1 03:25:46 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
إنها نواة أوبونتو الافتراضية الأحدث المستقرة في أوبونتو 18.04.
لذلك ، يبدو أن التصحيح موجود .
 zerkms
في ٢٢ أبريل ٢٠٢٠
zerkms
في ٢٢ أبريل ٢٠٢٠
zerkms أين أجريت اختباراتك على Ubuntu 18.04؟ يبدو لي أن التصحيح ربما جعله فقط في نواة Azure. إذا كان بإمكانك العثور على مذكرة إصدار تفيد بمكان تطبيقها على حزمة Ubuntu linux يرجى مشاركتها. لا يمكنني العثور عليه.
لاحظ أيضًا أن هذا الاختبار لم يكن قادرًا على إعادة إنتاج المشكلة على CoreOS أيضًا. قد يكون ذلك في التكوين الافتراضي لجدولة CFS معطل عالميًا.
Nuru
في ٢٢ أبريل ٢٠٢٠
تضمين التغريدة
أين أجريت اختباراتك على Ubuntu 18.04؟
أحد خوادمي.
لم أتحقق من ملاحظات الإصدار ، ولست متأكدًا مما أبحث عنه ، ومع ذلك - إنها نواة افتراضية مثل الجميع. 🤷
zerkms
في ٢٢ أبريل ٢٠٢٠
يجب أن يكون التصحيح هنا في بوابة ubuntus kernel:
https://kernel.ubuntu.com/git/ubuntu/ubuntu-bionic.git/commit/؟id=aadd794e744086fb50cdc752d54044fbc14d4adb
وهنا علة أوبونتو بخصوصها:
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1832151
يجب أن يتم تحريرها في الكترونية.
يمكنك التأكد من تشغيل apt-get source linux وإيداع كود المصدر الذي تم تنزيله.
juliantaylor
في ٢٢ أبريل ٢٠٢٠
zerkms بواسطة "أين أجريت اختباراتك" أعني هل كان خادمًا في مكتبك أم خادمًا في GCP أو AWS أو Azure أو في أي مكان آخر؟
من الواضح أن هناك الكثير الذي لا أفهمه حول كيفية توزيع Ubuntu وصيانته. أنا في حيرة من أمري بسبب إنتاجك uname -a أيضًا. تنص ملاحظات إصدار Ubuntu على ما يلي:
يأتي الإصدار 18.04.4 مزودًا بنواة Linux مبنية على v5.3 تم تحديثها من النواة المستندة إلى v5.0 في 18.04.3.
ويقول أيضًا إن إصدار 18.04.4 تم إصداره في 12 فبراير 2020. وتشير مخرجاتك إلى أنك تقوم بتشغيل نواة v4.15 تم تجميعها في 1 أبريل 2020.
juliantaylor ليس لدي خادم Ubuntu أو نسخة من Git repo ، ولا أعرف كيفية تتبع مكان التزام معين مثل aadd794e7440 جعله في نواة مستقرة منشورة. إذا كنت تستطيع أن تريني كيفية القيام بذلك ، فسأكون ممتنا.
عندما ألقي نظرة على تعليقات علة لوحة التشغيل التي أراها
- تم إصلاح هذا الخطأ في حزمة linux-azure - 5.0.0-1027.29
- تم إصلاح هذا الخطأ في حزمة linux-azure - 5.0.0-1027.29 ~ 18.04.1
لكن هذا التصحيح المحدد ( sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices ) غير مدرج تحت
- تم إصلاح هذا الخطأ في حزمة لينكس - 4.15.0-69.78
كما أنني لا أرى "1832151" مدرجًا في ملاحظات إصدار Ubuntu
قال تعليق سابق إنه تم تصحيحه في 4.15.0-67.76 لكنني لا أرى حزمة linux-image-4.15.0-67-generic .
أنا بعيد كل البعد عن خبير في Ubuntu وأجد أن تتبع التصحيح هذا صعب بشكل غير مقبول ، لذا فإن هذا هو بقدر ما نظرت إليه.
أتمنى أن تعرف الآن سبب عدم ثقيتي في أن هذا التصحيح قد تم تضمينه بالفعل في Ubuntu 18.04.4 ، وهو الإصدار الحالي من 18.04. أفضل تخميني هو أنه تم إصداره كتحديث kernel بعد إصدار 18.04.4 ، وربما يتم تضمينه إذا كانت تقارير Ubuntu kernel الخاصة بك تبلغ 4.15.0-69 أو إصدارًا أحدث ، ولكن إذا قمت بتنزيل 18.04.4 فقط ولم تقم بتحديثه ، لن يكون لديها التصحيح.
Nuru
في ٢٢ أبريل ٢٠٢٠
لقد أجريت للتو اختبار Go هذا (مفيد جدًا) في kernel 4.15.0-72 في خادم baremetal في مركز بيانات ويبدو أن التصحيح موجود:
2020/04/22 21:24:27 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 7ms
2020/04/22 21:24:28 [1] burn took 5ms, real time so far: 1010ms, cpu time so far: 13ms
2020/04/22 21:24:29 [2] burn took 5ms, real time so far: 2015ms, cpu time so far: 20ms
2020/04/22 21:24:30 [3] burn took 5ms, real time so far: 3020ms, cpu time so far: 25ms
2020/04/22 21:24:31 [4] burn took 5ms, real time so far: 4025ms, cpu time so far: 32ms
2020/04/22 21:24:32 [5] burn took 5ms, real time so far: 5030ms, cpu time so far: 38ms
2020/04/22 21:24:33 [6] burn took 5ms, real time so far: 6036ms, cpu time so far: 43ms
2020/04/22 21:24:34 [7] burn took 5ms, real time so far: 7041ms, cpu time so far: 50ms
2020/04/22 21:24:35 [8] burn took 5ms, real time so far: 8046ms, cpu time so far: 56ms
2020/04/22 21:24:36 [9] burn took 5ms, real time so far: 9051ms, cpu time so far: 63ms
2020/04/22 21:24:37 [10] burn took 5ms, real time so far: 10056ms, cpu time so far: 68ms
2020/04/22 21:24:38 [11] burn took 5ms, real time so far: 11061ms, cpu time so far: 75ms
2020/04/22 21:24:39 [12] burn took 5ms, real time so far: 12067ms, cpu time so far: 81ms
2020/04/22 21:24:40 [13] burn took 5ms, real time so far: 13072ms, cpu time so far: 86ms
2020/04/22 21:24:41 [14] burn took 5ms, real time so far: 14077ms, cpu time so far: 94ms
أستطيع أيضًا أن أرى أن نفس التنفيذ في kernel 4.9.164 في نفس النوع من الخادم يُظهر نسخًا تزيد عن 5 مللي ثانية:
2020/04/22 21:24:41 [0] burn took 97ms, real time so far: 97ms, cpu time so far: 8ms
2020/04/22 21:24:42 [1] burn took 5ms, real time so far: 1102ms, cpu time so far: 12ms
2020/04/22 21:24:43 [2] burn took 5ms, real time so far: 2107ms, cpu time so far: 16ms
2020/04/22 21:24:44 [3] burn took 5ms, real time so far: 3112ms, cpu time so far: 24ms
2020/04/22 21:24:45 [4] burn took 83ms, real time so far: 4197ms, cpu time so far: 28ms
2020/04/22 21:24:46 [5] burn took 5ms, real time so far: 5202ms, cpu time so far: 32ms
2020/04/22 21:24:47 [6] burn took 94ms, real time so far: 6297ms, cpu time so far: 36ms
2020/04/22 21:24:48 [7] burn took 99ms, real time so far: 7397ms, cpu time so far: 40ms
2020/04/22 21:24:49 [8] burn took 100ms, real time so far: 8497ms, cpu time so far: 44ms
2020/04/22 21:24:50 [9] burn took 5ms, real time so far: 9503ms, cpu time so far: 52ms
2020/04/22 21:24:51 [10] burn took 5ms, real time so far: 10508ms, cpu time so far: 60ms
2020/04/22 21:24:52 [11] burn took 5ms, real time so far: 11602ms, cpu time so far: 64ms
2020/04/22 21:24:53 [12] burn took 5ms, real time so far: 12607ms, cpu time so far: 72ms
2020/04/22 21:24:54 [13] burn took 5ms, real time so far: 13702ms, cpu time so far: 76ms
2020/04/22 21:24:55 [14] burn took 5ms, real time so far: 14707ms, cpu time so far: 80ms
لذا ، مشكلتي هي أنني ما زلت أرى اختناق وحدة المعالجة المركزية حتى يبدو أن النواة الخاصة بي قد تم تصحيحها
vgarcia-te
في ٢٢ أبريل ٢٠٢٠
Nuru صحيح ، آسف. كان ذلك خادمًا معدنيًا مكشوفًا مستضافًا في المكتب.
ويقول أيضًا إن إصدار 18.04.4 تم إصداره في 12 فبراير 2020. وتشير مخرجاتك إلى أنك تقوم بتشغيل نواة v4.15 تم تجميعها في 1 أبريل 2020.
هذا لأنه خادم LTS: تحتاج إلى الاشتراك في HWE بشكل صريح للحصول على نواة أحدث ، وإلا فإنك تقوم بتشغيل mainline.
ويتم إصدار نواة الخط الرئيسي و HWE بانتظام ، لذلك لا يوجد شيء مريب في امتلاك نواة مبنية حديثًا: http://changelogs.ubuntu.com/changelogs/pool/main/l/linux-meta/linux-meta_4.15.0.96.87/ التغيير
zerkms
في ٢٢ أبريل ٢٠٢٠
zerkms شكرا للمعلومات. ما زلت في حيرة من أمري ، لكن هذا ليس المكان المناسب لتعليمي.
@ vgarcia-te إذا تم تصحيح النواة الخاصة بك ، كما يبدو ، فإن الاختناق لا يرجع إلى هذا الخطأ. لست متأكدًا من المصطلحات الخاصة بك عندما تقول:
أنا أتحدث عن استخدام حوالي 50 مللي ثانية بعد أن تم ضبط الطلب على 250 مترًا والحد على 500 متر. نشهد اختناق حوالي 50٪ من فترات وحدة المعالجة المركزية ، فهل هذه القيمة ربما منخفضة بما يكفي لتوقعها ويمكن قبولها؟
يتم قياس مورد وحدة المعالجة المركزية Kubernetes بوحدات المعالجة المركزية ، 1 يعني 100٪ من وحدة معالجة مركزية كاملة واحدة ، و 1 متر يعني 0.1٪ من وحدة معالجة مركزية واحدة. لذا فإن حدك البالغ "500 متر" يشير إلى السماح بـ 0.5 وحدة معالجة مركزية.
فترة الجدولة الافتراضية لـ CFS هي 100 مللي ثانية ، لذا فإن تعيين حد 0.5 وحدة معالجة مركزية سيحد من عمليتك إلى 50 مللي ثانية من وحدة المعالجة المركزية كل 100 مللي ثانية. إذا حاولت العملية الخاصة بك تجاوز ذلك ، فسيتم اختناقها. إذا كانت العملية الخاصة بك تعمل عادةً أكثر من 50 مللي ثانية في مسار واحد ، فعندئذٍ نعم ، تتوقع أن يتم اختناقها من خلال جدولة تعمل بشكل صحيح.
Nuru
في ٢٣ أبريل ٢٠٢٠
Nuru هذا منطقي ، لكن دعني أفهم هذا ، بالنظر إلى أن فترة وحدة المعالجة المركزية الافتراضية هي 100 مللي ثانية ، في حالة تعيين وحدة معالجة مركزية واحدة للعملية ، إذا تم تشغيل هذه العملية لأكثر من 100 مللي ثانية في مسار واحد ، فهل سيتم خنقها؟
هل هذا يعني أنه في نظام Linux ، حيث تكون فترة وحدة المعالجة المركزية الافتراضية هي 100 مللي ثانية ، فإن أي عملية لها حد يمتد لأكثر من 100 مللي ثانية في مسار واحد ، سيتم خنقها؟
ماذا سيكون تكوينًا جيدًا لحد العملية التي تستغرق أكثر من 100 مللي ثانية في مسار واحد ولكنها تظل خاملة بقية الوقت؟
vgarcia-te
في ٢٣ أبريل ٢٠٢٠
سأل @ vgarcia-te
بالنظر إلى أن فترة وحدة المعالجة المركزية الافتراضية هي 100 مللي ثانية ، في حالة تعيين وحدة معالجة مركزية واحدة للعملية ، إذا تم تشغيل هذه العملية لأكثر من 100 مللي ثانية في مسار واحد ، فهل سيتم اختناقها؟
بالطبع الجدولة معقدة للغاية ، لذا لا يمكنني إعطائك إجابة مثالية ، لكن الإجابة المبسطة هي لا. تفسيرات أكثر تفصيلا هنا وهنا .
تخضع جميع عمليات يونيكس لجدولة وقائية على أساس الشرائح الزمنية. مرة أخرى في أيام وحدة المعالجة المركزية أحادية النواة ، لا يزال لديك 30 عملية تعمل "في وقت واحد". ما يحدث هو أنهم يركضون لفترة وإما أن يناموا أو ، في نهاية شريحة وقتهم ، يتم تعليقهم حتى يتمكن شيء آخر من الجري.
تأخذ لجنة الأمن الغذائي العالمي ذات الحصص هذه خطوة إلى الأمام.
اسأل نفسك ، مع ذلك ، عندما تقول أنك تريد عملية تستخدم 50٪ من وحدة المعالجة المركزية ، فماذا تقول حقًا؟ هل تقول أنه لا بأس إذا كانت تستهلك 100٪ من وحدة المعالجة المركزية لمدة 5 دقائق طالما أنها لا تعمل على الإطلاق خلال الدقائق الخمس التالية؟ سيكون هذا استخدامًا بنسبة 50٪ على مدار 10 دقائق ، ولكنه غير مقبول لمعظم الأشخاص بسبب مشكلات زمن الوصول.
لذلك تحدد CFS "فترة وحدة المعالجة المركزية" وهي النافذة الزمنية التي تفرض خلالها الحصص. على جهاز به 4 مراكز وفترة وحدة معالجة مركزية تبلغ 100 مللي ثانية ، يمتلك المجدول 400 مللي ثانية من وقت وحدة المعالجة المركزية لتخصيص أكثر من 100 مللي ثانية من الوقت الحقيقي (ساعة الحائط). إذا كنت تقوم بتشغيل سلسلة تنفيذ واحدة لا يمكن أن تكون متوازية ، فيمكن أن يستخدم هذا الخيط 100 مللي ثانية على الأكثر من وقت وحدة المعالجة المركزية لكل فترة ، والتي ستكون 100٪ من وحدة المعالجة المركزية الواحدة. إذا قمت بتعيين حصتها على وحدة معالجة مركزية واحدة ، فلن يتم اختناقها مطلقًا.
إذا قمت بتعيين الحصة على 500 م (0.5 وحدة معالجة مركزية) ، فستحصل العملية على 50 مللي ثانية للتشغيل كل 100 مللي ثانية. أي فترة 100 مللي ثانية تستخدم أقل من 50 مللي ثانية يجب ألا يتم خنقها. فترة Ayn 100 مللي ثانية لم تنته بعد تشغيل 50 مللي ثانية ، يتم خنقها حتى فترة 100 مللي ثانية. هذا يحافظ على التوازن بين زمن الوصول (كم من الوقت يجب أن تنتظر حتى تتمكن من العمل على الإطلاق) والعبث (المدة المسموح بها لمنع العمليات الأخرى من العمل).
Nuru
في ٢٣ أبريل ٢٠٢٠
Nuru بلدي الشرائح صحيحة. أنا أيضًا مطور Ubuntu * (فقط في وقت فراغي الآن). أفضل رهان لك هو قراءة المصادر ، والتحقق من git blame + tag - يحتوي على تتبع عندما يصل التصحيح إلى إصدار النواة الذي يهمك.
chiluk
في ٢٦ أبريل ٢٠٢٠
chiluk لم أر الشرائح الخاصة بك. بالنسبة للآخرين الذين لم يروهم ، هنا هو المكان الذي يقولون فيه إن الرقعة قد هبطت منذ بعض الوقت:
- نظام التشغيل Ubuntu 4.15.0-67 +
- نظام التشغيل Ubuntu 5.3.0-24 +
- نواة RHEL7 3.10.0-1062.8.1.el7
وبالطبع مستقر Linux v4.14.154 ، v4.19.84 ، 5.3.9. ألاحظ أنه موجود أيضًا في Linux الثابت 5.4-rc1.
ما زلت أكافح لفهم أخطاء جدولة CFS المختلفة والعثور على اختبارات موثوقة وسهلة التفسير من شأنها أن تعمل على خادم AWS صغير ، لأنني أدعم مجموعة متنوعة من النوى من عمليات التثبيت القديمة. كما أفهم الجدول الزمني ، تم إدخال خطأ في Linux kernel v3.16-rc1 في عام 2014 بواسطة
[51f2176d74ac](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=51f2176d74ac) sched/fair: Fix unlocked reads of some cfs_b->quota/period.
وقد تسبب هذا في مشكلات مختلفة تتعلق بالاختناق في CFS. أعتقد أن المشكلات التي كنت أراها تحت مجموعات Kubernetes kops كانت بسبب هذا الخطأ ، حيث كانوا يستخدمون 4.9 نواة.
تم إصلاح 51f2176d74ac في 2018 kernel v4.18-rc4 مع
[512ac999](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) sched/fair: Fix bandwidth timer clock drift condition
ولكن هذا أدخل الخطأ chiluk الثابت بـ
[de53fd7ae](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425) sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
بالطبع ، ليس خطأ Chiluk أو أي شخص آخر هو أنه من الصعب تتبع بقع النواة عبر التوزيعات. لا يزال الأمر محبطًا بالنسبة لي ، ويساهم في ارتباكي.
على سبيل المثال ، في Debuan buster 10 (AWS AMI debian-10-amd64-20191113-76 ) ، تم الإبلاغ عن إصدار kernel على أنه
Linux ip-172-31-41-138 4.19.0-6-cloud-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
بقدر ما أستطيع أن أقول ، يجب أن يكون لهذه النواة 51f2176d74ac ولا تحتوي على 512ac999 وبالتالي يجب أن تفشل في الاختبار الموضح في 512ac999 ، لكنها لا تفعل ذلك. (أقول لا أعتقد أنه يحتوي على 512ac999 لأنه تمت ترقيته بشكل تدريجي من Linux kernel 4.10 ولا يوجد أي ذكر لهذا التصحيح في سجل التغيير.) ومع ذلك ، في وحدة المعالجة المركزية المكونة من 4 وحدات معالجة مركزية AWS VM لا تفشل Chiluk fibtest أو اختبار Bobrik's CFS hiccups ، مما يشير إلى حدوث شيء آخر.
واجهت مشكلات مماثلة في إعادة إنتاج أي مشكلات في الجدولة مع CoreOS حتى قبل أن تتلقى تصحيح Chiluk.
ما أفكر به في الوقت الحالي هو أن اختبار Bobrik هو بشكل أساسي اختبار لـ 51f2176d74ac ، و Debian buster 10 AMI الذي أستخدمه _does_ يحتوي على 512ac999 ، فقط لم يتم ذكره صراحةً في سجل التغيير ، و fibtest ليس اختبارًا حساسًا للغاية على جهاز يحتوي على عدد قليل من النوى.
Nuru
في ٢٧ أبريل ٢٠٢٠
ربما لا تكون وحدة المعالجة المركزية رباعية النوى كبيرة بما يكفي لإعادة إنتاج مشكلة chiluk الثابتة.
يجب أن يكون قابلاً للتكرار فقط على الأجهزة الكبيرة التي تزيد عن 40 cpus ربما إذا فهمت التفسير من chiluks kubecon talk (https://www.youtube.com/watch؟v=UE7QX98-kO0) بشكل صحيح.
هناك الكثير من إصدارات kernel حولها وهناك الكثير من عمليات التصحيح والعودة للتصحيحات الجارية. لا تحصل إلا على سجلات التغيير وأرقام الإصدارات حتى الآن.
الطريقة الوحيدة الموثوقة إذا كانت لديك شكوك هي تنزيل شفرة المصدر ومقارنتها بالتغييرات في التصحيحات التي تم ربطها هنا.
juliantaylor
في ٢٧ أبريل ٢٠٢٠
تصبح المشكلات قديمة بعد 90 يومًا من الخمول.
ضع علامة على المشكلة على أنها جديدة /remove-lifecycle stale .
تتعفن المشكلات التي لا معنى لها بعد 30 يومًا إضافيًا من عدم النشاط وتغلق في النهاية.
إذا كان إغلاق هذه المشكلة آمنًا الآن ، فيرجى القيام بذلك باستخدام /close .
إرسال ملاحظات إلى اختبار سيج ، kubernetes / test-infra و / أو fejta .
/ دورة الحياة التي لا معنى لها
fejta-bot
في ٢٦ يوليو ٢٠٢٠
/ إزالة دورة الحياة التي لا معنى لها
 yashbhutwala
في ٢٧ يوليو ٢٠٢٠
yashbhutwala
في ٢٧ يوليو ٢٠٢٠
الاختبارات المذكورة سابقًا في هذا الموضوع لا تعيد إنتاج المشكلة حقًا بالنسبة لي (تستغرق بعض الحروق أكثر من 5 مللي ثانية ولكنها تشبه 0.01 ٪ منها) ولكن مقاييس cfs الخانقة لا تزال تظهر كميات معتدلة من الاختناق. لدينا إصدارات مختلفة من kernel عبر مجموعاتنا ولكن الإصدارين الأكثر شيوعًا هما:
Debian 4.19.67-2+deb10u2~bpo9+1 (2019-11-12)- منفذ خلفي يدوي
5.4.38
لا أعرف ما إذا كان من المفترض أن يتم إصلاح كلا الخطأين في هذه الإصدارات ، لكنني أعتقد أنه من المفترض أن يكونا كذلك ، لذلك أتساءل ما إذا كان الاختبار غير مفيد. أقوم باختبار على أجهزة ذات 16 مركزًا وبها 36 مركزًا ، ولست متأكدًا مما إذا كنت بحاجة إلى المزيد من النوى حتى يكون الاختبار صالحًا ولكننا ما زلنا نرى الاختناق في هذه المجموعات لذا ...
 2rs2ts
في ١٨ أغسطس ٢٠٢٠
2rs2ts
في ١٨ أغسطس ٢٠٢٠
هل يجب أن نغلق هذه المشكلة ونطلب من الأشخاص الذين يواجهون مشكلات بدء مشاكل جديدة؟ من المحتمل أن يجعل البريد العشوائي هنا أي محادثة صعبة للغاية.
 omnibs
في ٣١ أكتوبر ٢٠٢٠
omnibs
في ٣١ أكتوبر ٢٠٢٠
^ أوافق. لقد تم عمل الكثير لحل هذه المشكلة.
 sfxworks
في ٣١ أكتوبر ٢٠٢٠
sfxworks
في ٣١ أكتوبر ٢٠٢٠
/أغلق
بناء على التعليقات أعلاه. الرجاء فتح عدد جديد (ق) حسب الحاجة.
dims
في ١ نوفمبر ٢٠٢٠
dims : إغلاق هذه القضية.
ردًا على هذا :
/أغلق
بناء على التعليقات أعلاه. الرجاء فتح عدد جديد (ق) حسب الحاجة.
تعليمات للتفاعل معي باستخدام تعليقات العلاقات العامة متوفرة هنا . إذا كانت لديك أسئلة أو اقتراحات تتعلق بسلوكي ، فالرجاء رفع قضية ضد
 k8s-ci-robot
في ١ نوفمبر ٢٠٢٠
k8s-ci-robot
في ١ نوفمبر ٢٠٢٠
يرجى إخطار مشكلات المتابعة لهذه المشكلة ، حتى يتمكن الأشخاص المشتركون في المشكلة من الاشتراك في الإصدارات الجديدة لمتابعة
 glensc
في ١ نوفمبر ٢٠٢٠
glensc
في ١ نوفمبر ٢٠٢٠
القضايا ذات الصلة
 theothermike
·
3تعليقات
theothermike
·
3تعليقات
 mml
·
3تعليقات
mml
·
3تعليقات
 alexferl
·
3تعليقات
alexferl
·
3تعليقات
 tbchj
·
3تعليقات
tbchj
·
3تعليقات
 rhohubbuild
·
3تعليقات
rhohubbuild
·
3تعليقات
التعليق الأكثر فائدة
سقط التصحيح على الحافة هذا الصباح.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/؟id=de53fd7aedb100f03e5d2231cfce0e4993282425
بمجرد أن تصل إلى شجرة Torvald ، سأرسلها لإدراجها في نظام Linux المستقر ، وبعد ذلك التوزيعات الرئيسية (Redhat / Ubuntu). إذا كنت تهتم بشيء آخر ، ولا يتبعون تصحيحات Linux المستقرة ، فقد ترغب في إرسالها مباشرة.