Kubernetes: Квоты CFS могут привести к ненужному регулированию
/ добрый баг
Это не ошибка Kubernet как таковая, это скорее предупреждение.
Я прочитал этот замечательный пост в блоге:
Из сообщения в блоге я узнал, что k8s использует квоты cfs для принудительного ограничения ЦП. К сожалению, это может привести к ненужному регулированию, особенно для хорошо воспитанных арендаторов.
Посмотрите на эту нерешенную ошибку в ядре Linux, которую я зарегистрировал некоторое время назад:
Есть открытый и заблокированный патч, который решает проблему (я не проверял, работает ли он):
cc @ConnorDoyle @balajismaniam
 bobrik
bobrik
Все 142 Комментарий
/ sig узел
/ добрый баг
 neolit123
20 авг. 2018
neolit123
20 авг. 2018
это дубликат № 51135?
 liggitt
20 авг. 2018
liggitt
20 авг. 2018
Он похож по духу, но, похоже, упускает из виду тот факт, что в ядре есть реальная ошибка, а не просто некоторая компромиссная конфигурация в период квоты CFS. Мне понравился номер 51135, чтобы дать людям больше контекста.
bobrik
22 авг. 2018
Насколько я понимаю, это еще одна причина либо отключить квоту CFS ( --cpu-cfs-quota=false ), либо сделать ее настраиваемой (# 63437).
Мне также очень интересно увидеть эту суть (ссылка на патч ядра) (чтобы оценить влияние): https://gist.github.com/bobrik/2030ff040fad360327a5fab7a09c4ff1
 hjacobs
22 авг. 2018
hjacobs
22 авг. 2018
cc @adityakali
 vishh
23 авг. 2018
vishh
23 авг. 2018
Еще одна проблема с квотами заключается в том, что кубелет считает гиперпотоки как "процессоры". Когда кластер становится настолько загруженным, что два потока планируются на одном ядре и процесс имеет квоту квоты процессора, один из них будет работать только с небольшой долей доступной вычислительной мощности (он будет делать что-то только тогда, когда что-то в другом потоке киоски), но по-прежнему потребляют квоту, как если бы у нее было физическое ядро. Таким образом, он потребляет вдвое больше квоты, чем должен, без значительного увеличения объема работы.
Это приводит к тому, что на полностью загруженном узле узла с включенной гиперпоточностью производительность будет вдвое меньше, чем при отключенной гиперпоточности или квотах.
Imo, kubelet не должен рассматривать гиперпотоки как реальные процессоры, чтобы избежать этой ситуации.
 juliantaylor
30 авг. 2018
juliantaylor
30 авг. 2018
@juliantaylor Как я уже упоминал в # 51135, отключение квоты ЦП может быть лучшим подходом для большинства кластеров k8s, выполняющих надежные рабочие нагрузки.
vishh
30 авг. 2018
Считается ли это ошибкой?
Если в некоторых модулях происходит дросселирование, при этом не исчерпывается лимит процессора, для меня это звучит как ошибка.
В моем кластере большинство модулей с превышением квоты связаны с метриками (heapster, metrics-collector, node-exporter ...) или операторами, которые, очевидно, имеют ту рабочую нагрузку, которая здесь является проблемой: большую часть время и просыпаться, чтобы помириться время от времени.
Странно то, что я попытался поднять лимит, перейдя с 40m на 100m или 200m , а процессы по-прежнему тормозились.
Я не вижу других показателей, указывающих на рабочую нагрузку, которая может вызвать это регулирование.
Я снял ограничения для этих модулей на данный момент ... становится лучше, но, что ж, это действительно похоже на ошибку, и мы должны предложить лучшее решение, чем отключение Limits
 prune998
26 нояб. 2018
prune998
26 нояб. 2018
@ prune998 см. комментарий @vishh и его суть : ядро чрезмерно агрессивно дросселирует, даже если математика подсказывает, что этого не должно быть. Мы (Zalando) решили отключить квоту CFS (регулирование ЦП) в наших кластерах: https://www.slideshare.net/try_except_/optimizing-kubernetes-resource-requestslimits-for-costefficiency-and-latency-highload
hjacobs
27 нояб. 2018
Спасибо @hjacobs.
Я использую Google GKE и не вижу простого способа отключить его, но продолжаю искать ....
prune998
27 нояб. 2018
@ prune998 Насколько мне известно, Google еще не предоставил необходимые ручки. Мы подали запрос функции сразу после того, как возможность отключить CFS приземлилась в апстриме, с тех пор не слышал никаких новостей.
 timoreimann
27 нояб. 2018
timoreimann
27 нояб. 2018
Я использую Google GKE и не вижу простого способа отключить его, но продолжаю искать ....
Можете ли вы сейчас снять ограничения ЦП со своих контейнеров?
vishh
28 нояб. 2018
Согласно документации диспетчера ЦП, CFS quota is not used to bound the CPU usage of these containers as their usage is bound by the scheduling domain itself. Но мы наблюдаем дросселирование CFS.
Это делает статический диспетчер ЦП практически бессмысленным, поскольку установка предела ЦП для достижения класса гарантированного QoS сводит на нет любые преимущества, связанные с регулированием.
Это ошибка, что квоты CFS вообще устанавливаются для модулей на статическом процессоре?
 mariusgrigoriu
12 февр. 2019
mariusgrigoriu
12 февр. 2019
Для дополнительного контекста (узнал об этом вчера): @hrzbrg (MyTaxi) предоставил Kops флаг для отключения регулирования ЦП: https://github.com/kubernetes/kops/issues/5826
hjacobs
12 февр. 2019
Пожалуйста, поделитесь кратким описанием проблемы здесь. Не очень ясно, в чем проблема, и в каких сценариях это затрагивает пользователей и что именно требуется для ее устранения?
В настоящее время мы понимаем, что когда мы переступаем границы, нас наказывают и ограничивают. Скажем, у нас есть квота ЦП в 3 ядра, и в первые 5 мс мы потребляли 3 ядра, затем в 100-миллисекундном срезе мы будем дросселированы на 95 мс, и в эти 95 мс наши контейнеры ничего не могут сделать. И мы видели, как происходит троттлинг, даже когда всплески процессора не видны в показателях использования процессора. Мы предполагаем, что это связано с тем, что временное окно измерения использования процессора выражается в секундах, а регулирование происходит на уровне микросекунд, поэтому оно усредняется и не отображается. Но упомянутая здесь ошибка сбила нас с толку.
Несколько вопросов:
- Когда узел загружен на 100% ЦП? Это особый случай, когда все контейнеры блокируются независимо от их использования?
Когда это происходит, все ли контейнеры получают 100% -ное регулирование ЦП?
Что вызывает срабатывание этой ошибки в узле?
В чем разница между неиспользованием
limitsи отключениемcpu.cfs_quota?Разве отключение
limitsявляется рискованным решением, когда существует много модулей с возможностью наращивания, и один модуль может вызвать нестабильность в узле и повлиять на другие модули, выполняющие их запросы?Отдельно, согласно документу ядра, процесс может быть ограничен, когда родительская квота полностью исчерпана. Что здесь является родительским в контексте контейнера (связано ли это с этой ошибкой)? https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
There are two ways in which a group may become throttled: a. it fully consumes its own quota within a period b. a parent's quota is fully consumed within its period- Что нужно для их исправления? Обновить версию ядра?
Мы столкнулись с довольно большим отключением, и он выглядит тесно связанным (если не с основной причиной) со всеми нашими модулями, которые застревают в цикле перезапуска с регулированием скорости и не могут масштабироваться. Мы копаемся в деталях, чтобы найти реальную проблему. Я открою отдельный выпуск, в котором подробно расскажу о нашем отключении.
Любая помощь здесь приветствуется.
cc @justinsb
 alok87
14 февр. 2019
alok87
14 февр. 2019
Один из наших пользователей установил лимит ЦП и был ограничен по тайм-ауту для проверки работоспособности, что привело к отключению их службы.
Мы наблюдаем дросселирование даже при закреплении контейнеров на ЦП. Например, ограничение ЦП, равное 1, и закрепление этого контейнера для работы только на одном ЦП. Невозможно превысить квоту за любой период, если ваша квота была точно равна количеству ЦП, которое у вас есть, но мы видим дросселирование в каждом случае.
Я думал, что где-то видел, что ядро 4.18 решает проблему. Я еще не тестировал его, поэтому было бы неплохо, если бы кто-нибудь мог подтвердить.
mariusgrigoriu
15 февр. 2019
https://github.com/torvalds/linux/commit/512ac999d2755d2b7109e996a76b6fb8b888631d в 4.18 кажется подходящим патчем для этой проблемы.
 clkao
23 февр. 2019
clkao
23 февр. 2019
@mariusgrigoriu Кажется, я застрял в той же головоломке, которую вы описали здесь https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -462534360.
Мы наблюдаем дросселирование ЦП на модулях в классе гарантированного QoS с помощью статической политики CPUManager (что, кажется, не имеет никакого смысла).
Удаление limits для этих модулей поместит их в класс Burstable QoS, что не является тем, что мы хотим, поэтому единственный оставшийся вариант - отключить квоты ЦП CFS в масштабах всей системы, что мы также не можем безопасно сделать. поскольку разрешение всем модулям доступа к несвязанной мощности ЦП может привести к опасным проблемам с перегрузкой ЦП.
@vishh, учитывая вышеуказанные обстоятельства, что было бы лучше всего? похоже, обновление до ядра> 4.18 (в котором есть исправление учета cfs cpu) и (возможно) сокращение периода квоты cfs?
В общем, предложение просто удалить limits из контейнеров, которые регулируются, должно иметь четкие предупреждения:
1) Если это были модули в классе гарантированного QoS, с целым числом ядер и со статической политикой CPUMnanager - эти модули больше не будут получать выделенные ядра ЦП, поскольку они будут помещены в класс Burstable QoS (без запросов == ограничений)
2) Эти поды не будут связаны с точки зрения того, сколько ЦП они могут потреблять, и потенциально могут причинить немалый ущерб при определенных обстоятельствах.
Мы будем очень признательны за ваш отзыв / руководство.
 dannyk81
25 мар. 2019
dannyk81
25 мар. 2019
Обновление ядра определенно помогает, но поведение при применении квоты CFS по-прежнему не соответствует тому, что предлагают в документации.
mariusgrigoriu
25 мар. 2019
Я уже некоторое время исследую различные аспекты этой проблемы. Мои исследования резюмируются в моем сообщении на LKML.
https://lkml.org/lkml/2019/3/18/706
При этом я не смог воспроизвести описанную здесь проблему в ядрах до 512ac99. Однако я видел снижение производительности в ядрах после 512ac99. Так что это исправление не панацея.
 chiluk
25 мар. 2019
chiluk
25 мар. 2019
Благодаря @mariusgrigoriu, мы собираемся для ядра обновления и надеюсь , что поможет несколько, а также проверить https://github.com/kubernetes/kubernetes/issues/70585 - это , кажется , что квоты действительно установлены для гарантированных стручков с cpuset ( т.е. закрепленный процессор), поэтому мне это кажется ошибкой.
dannyk81
25 мар. 2019
@chiluk не могли бы вы немного уточнить? Вы имеете в виду, что патч, который был включен в 4.18 (упомянутый выше в https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-466609030), на самом деле не решает проблему?
dannyk81
25 мар. 2019
Патч ядра 512ac99 устраняет проблему для некоторых людей, но вызывал проблему для наших конфигураций. Патч исправил способ распределения временных интервалов между cfs_rq, теперь они корректно истекают. Раньше срок их действия не истекал.
Рабочие нагрузки Java, в частности, на машинах с большим количеством ядер, теперь подвергаются значительному регулированию при низком использовании ЦП из-за блокирующих рабочих потоков. Этим потокам назначается временной интервал, который они используют только небольшую часть, срок действия которого истекает позже. В синтетическом тесте, который я написал * (ссылка на который есть в этом потоке), мы видим снижение производительности примерно в 30 раз. В реальной жизни мы наблюдали снижение времени отклика между двумя ядрами на сотни миллисекунд из-за увеличенного троттлинга.
chiluk
25 мар. 2019
Используя ядро 4.19.30, я вижу, что поды, которые, как я надеялся, уменьшили от троттлинга, все еще регулируются, а некоторые поды, которые ранее не регулировались, теперь дросселируются довольно сильно (kube2iam сообщает о большем количестве секунд, чем был запущен экземпляр , как-то)
 willthames
27 мар. 2019
willthames
27 мар. 2019
В CoreOS 4.19.25-coreos я вижу, что Prometheus запускает предупреждение CPUThrottlingHigh почти на каждом модуле в системе.
 teralype
27 мар. 2019
teralype
27 мар. 2019
@williamsandrew @teralype, похоже, это отражает выводы @chiluk .
После различных внутренних обсуждений мы фактически решили полностью отключить квоты cfs (флаг kubelet --cpu-cfs-quota=false ), это, похоже, решает все проблемы, которые у нас были как для Burstable, так и для Гарантированных (закрепленных на ЦП или стандартных) модулей.
Здесь есть отличная колода по этой (и нескольким другим темам): https://www.slideshare.net/try_except_/ensuring-kubernetes-cost-efficiency-across-many-clusters-devops-gathering-2019
Настоятельно рекомендуется прочитать: +1:
dannyk81
27 мар. 2019
долгосрочная проблема (примечание для себя)
 dims
27 мар. 2019
dims
27 мар. 2019
@ dannyk81 просто для полноты: связанный доклад также доступен в виде записанного видео: https://www.youtube.com/watch?v=4QyecOoPsGU
hjacobs
27 мар. 2019
@hjacobs ,
Есть идеи, как применить это исправление к AKS или GKE?
благодаря
 agolomoodysaada
2 апр. 2019
agolomoodysaada
2 апр. 2019
@agolomoodysaada мы
timoreimann
2 апр. 2019
Я обратился в службу поддержки Azure, и они сказали, что она будет доступна не раньше августа 2019 года.
agolomoodysaada
4 апр. 2019

Думал, что поделюсь графиком приложения, которое постоянно дросселируется на протяжении всей его жизни.
agolomoodysaada
5 апр. 2019
На каком ядре это было?
chiluk
5 апр. 2019
" чилук " 4.15.0-1037-лазурь "
agolomoodysaada
5 апр. 2019
Так что это не содержит фиксации ядра 512ac99. Вот соответствующие
источник.
https://kernel.ubuntu.com/git/kernel-ppa/mirror/ubuntu-azure-xenial.git/tree/kernel/sched/fair.c?h=Ubuntu-azure-4.15.0-1037.39_16.04.1 & id = 19b0066cc4829f45321a52a802b640bab14d0f67
Это означает, что вы можете столкнуться с проблемой, описанной в 512ac99. Держать в
Учтите, что 512ac99 принес нам и другие регрессы.
Пятница, 5 апреля 2019 г., 12:08 Moody Saada [email protected]
написал:
@chiluk https://github.com/chiluk "4.15.0-1037-лазурный"
-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment-480350946 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ACDI05YeS6wfUE9XkiMbxrLvPllYQZ7Iks5vd4MOgaJpZM4WDUF3
.
chiluk
5 апр. 2019
Я опубликовал исправления для LKML по этому поводу.
https://lkml.org/lkml/2019/4/10/1068
Было бы очень полезно провести дополнительное тестирование.
chiluk
11 апр. 2019
Я повторно отправил эти исправления с изменениями в документации.
https://lkml.org/lkml/2019/5/17/581
Было бы действительно полезно, если бы люди могли протестировать эти исправления и прокомментировать ветку LKML. На данный момент я единственный, кто вообще упомянул об этом на LKML, и я не получил никаких комментариев от сообщества или сопровождающих. Было бы очень важно, если бы я смог получить некоторые тесты сообщества и комментарии по LKML под моим патчем.
chiluk
21 мая 2019
Как бы то ни было, эта проблема серьезно затронула этот конкретный проект https://github.com/tensorflow/serving . И это в основном приложение на C ++.
@chiluk , есть ли какие-то обходные пути, которые мы можем применить, пока патч выкатывается?
большое спасибо
agolomoodysaada
29 мая 2019
Мы должны помочь @chiluk собрать цитаты о серьезном влиянии этой ошибки ядра на Kubernetes и всех, кто использует квоты CFS.
Золандо отметил в своей презентации на прошлой неделе, что их неудачный опыт работы с текущим ядром означает, что они считают отключение квот CFS передовой практикой, поскольку считают, что это приносит больше вреда, чем пользы.
https://www.youtube.com/watch?v=6sDTB4eV4F8
 whereisaaron
29 мая 2019
whereisaaron
29 мая 2019
Все больше и больше компаний отключают троттлинг процессора, например mytaxi, Datadog, Zalando ( ветка Twitter )
hjacobs
29 мая 2019
@derekwaynecarr @ dchen1107 @ kubernetes / sig-node-feature-requests Дон, Дерек, пора ли изменить настройки по умолчанию? и / или документация?
dims
29 мая 2019
Да, @whereisaaron собирает и ограничении работы приложений,
chiluk
29 мая 2019
@agolomoodysaada обходным
Есть также лучшие практики по сокращению количества потоков приложения, что также помогает.
Для golang установите GOMAXPROCS ~ = ceil (quota)
Для java перейдите на более новые JVM, которые признают и соблюдают ограничения квот ЦП. Ранее jvms создавал потоки в зависимости от количества ядер ЦП, а не количества ядер, доступных для приложения.
И то, и другое было для нас большим преимуществом.
Отслеживайте и сообщайте о приложениях, в которых происходит регулирование, чтобы ваши разработчики могли корректировать квоты.
chiluk
29 мая 2019
К вашему сведению, после того, как я указал на эту ветку поддержки Azure AKS, мне ответили, что патч будет выпущен, когда они обновятся до ядра 5.0, в лучшем случае в конце сентября.
А пока перестаньте использовать лимиты :)
prune998
29 мая 2019
@ prune998 есть небольшая оговорка, если вы используете CPUmanager (то есть выделенное выделение ЦП для модулей в гарантированном QoS).
Удалив ограничения, вы избежите проблемы с регулированием CFS, но удалите модули из гарантированного QoS, чтобы CPUmanager больше не выделял выделенные ядра для этих модулей.
Если вы не используете CPUmanager - ничего страшного, просто к сведению всех, кто выбрал это направление.
Существует PR (https://github.com/kubernetes/kubernetes/issues/70585), чтобы полностью отключить квоты CFS для модулей с выделенными процессорами, однако он еще не был объединен.
Мы также решили отключить всю систему квот CFS, как было предложено выше, и пока никаких проблем.
dannyk81
29 мая 2019
@ dannyk81 https://github.com/kubernetes/kubernetes/issues/70585 не является PR, который можно объединить (это проблема с фрагментом кода). Не могли бы вы (или кто-то еще) написать PR?
dims
29 мая 2019
 praseodym
29 мая 2019
praseodym
29 мая 2019
@dims Я связал проблему, а не PR ... но проблема связана с PR :) действительно, это https://github.com/kubernetes/kubernetes/pull/75682, и какое-то время он там висел, Так что, если бы вы могли подтолкнуть, это было бы здорово, так как это действительно неприятная проблема.
Спасибо: +1:
dannyk81
29 мая 2019
упс! спасибо @ dannyk81, я назначил людей и добавил веху
dims
29 мая 2019
FWIW мы также столкнулись с этой проблемой и обнаружили, что снижение периода квоты CFS до 10 мс вместо 100 мс по умолчанию привело к значительному увеличению задержек в хвостовой части. Я думаю, это связано с тем, что даже если вы столкнетесь с ошибкой ядра, гораздо меньшее количество квоты будет потрачено впустую, если оно не используется, и процесс может получить большую квоту (в меньших выделениях) намного раньше. Это просто обходной путь, но для тех, кто не хочет полностью отключать квоту CFS, это может быть бандаж, пока исправление не будет реализовано. k8s поддерживает это в 1.12 с помощью шлюза функции cpuCFSQuotaPeriod и флага kubelet --cpu-cfs-quota-period.
 d-shi
30 мая 2019
d-shi
30 мая 2019
Мне пришлось бы проверить, но я думаю, что сокращение периода до такой степени может привести к его эффективному отключению, поскольку в коде есть минимумы срезов и минимумы квот. Вероятно, вам лучше отключить квоты и перейти к мягким квотам.
chiluk
30 мая 2019
@chiluk, мое непрофессиональное понимание состоит в том, что срез по умолчанию составляет 5 мс, поэтому установка этого или меньшего значения фактически отключает его, но до тех пор, пока период больше 5 мс, все равно должно быть соблюдение квоты. Обязательно дайте мне знать, если это не так.
d-shi
31 мая 2019
С --feature-gates=CustomCPUCFSQuotaPeriod=true --cpu-cfs-quota-period=10ms один из моих подов действительно не запустился. В прикрепленном графе Прометея контейнер пытается запуститься, не приближается к проверке работоспособности до тех пор, пока не будет убит (обычно контейнер запускается примерно через 5 секунд - даже увеличение liveness initialDelaySeconds до 60 не помогло) и потом заменил на новый.
Вы можете видеть, что контейнер сильно ограничен до тех пор, пока я не удалил cpu-cfs-quota-period из аргументов kubelet, после чего регулирование стало намного более плоским, и контейнер снова запускается примерно через 5 секунд.

willthames
5 июн. 2019
К вашему сведению: текущая ветка Twitter по теме отключения регулирования ЦП: https://twitter.com/it_supertramp/status/1133648291332263936
hjacobs
5 июн. 2019
Это графики дросселирования ЦП до и после того, как мы перешли на --cpu-cfs-quota-period=10ms в производстве для двух служб, чувствительных к задержкам:
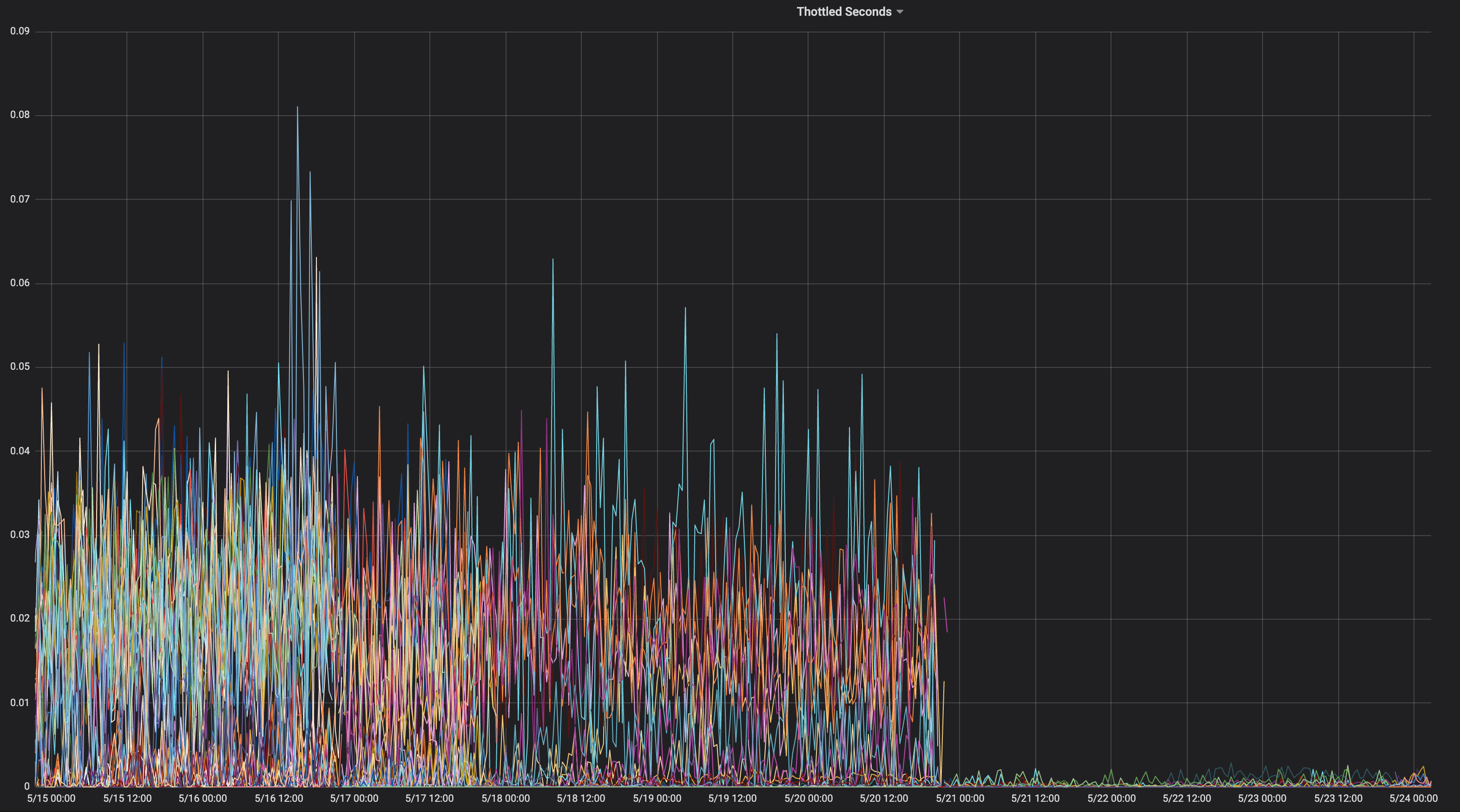

Эти службы работают на разных типах экземпляров (с разными пороками / допусками). Экземпляры 2-й службы сначала были переведены на период более низкой квоты CFS.
Результаты должны сильно зависеть от нагрузки.
d-shi
5 июн. 2019
@ d-shi что-то еще происходит на вашем графике. Я думаю, что может быть некоторая минимальная квота, которую вы сейчас используете, потому что период настолько мал. Мне нужно проверить код, чтобы быть уверенным. По сути, вы непреднамеренно увеличили квоту, доступную для приложения. Вероятно, вы могли бы добиться того же, фактически увеличив квоты.
chiluk
5 июн. 2019
Для нас было намного полезнее измерять задержку, чем регулировать. Отключение cfs-quota значительно уменьшило задержку. Я бы хотел увидеть аналогичные результаты при изменении cfs-quota-period .
 blakebarnett
6 июн. 2019
blakebarnett
6 июн. 2019
@chiluk, мы действительно пытались увеличить
@blakebarnett мы разработали программу тестирования, которая измеряла наши задержки, и они --cpu-cfs-quota-period , до диапазона 10–20 мс, со средним значением около 11 мс после этого. Задержки p99 увеличились с 98 мс до 20 мс.
РЕДАКТИРОВАНИЕ: извините за правки, которые мне пришлось вернуться и перепроверить свои числа.
d-shi
6 июн. 2019
@ d-shi, вы, вероятно, столкнулись с проблемой, решенной 512ac999.
chiluk
6 июн. 2019
@chiluk После того, как я снова и снова прочитал ваш патч, я должен признать, что мне трудно понять влияние этого кода:
if (cfs_rq->expires_seq == cfs_b->expires_seq) {
- /* extend local deadline, drift is bounded above by 2 ticks */
- cfs_rq->runtime_expires += TICK_NSEC;
- } else {
- /* global deadline is ahead, expiration has passed */
- cfs_rq->runtime_remaining = 0;
- }
В случае, когда квота истекает, даже если runtime_remaining просто заимствовал некоторое время из глобального пула. В худшем случае вы получите дросселирование на 5 мс на основе sched_cfs_bandwidth_slice_us. Не правда ли?
Я что-то упускаю?
 Mwea
6 июн. 2019
Mwea
6 июн. 2019
@chiluk да думаю правы. Наши производственные серверы все еще работают на ядре 4.4, поэтому в них нет этого исправления. Возможно, как только мы перейдем на более новое ядро, мы сможем вернуть период квот CFS к значениям по умолчанию, но на данный момент он работает над улучшением задержек в хвостовой части, и мы еще не заметили никаких побочных эффектов. Хотя в прямом эфире всего пару недель.
d-shi
6 июн. 2019
@chiluk Не могли бы резюмировать статус этой проблемы в ядре? Похоже, был патч 512ac999, но с ним были проблемы. Я где-то читал, что его отменили? Или это полностью / частично исправлено? Если да, то какой версии?
mariusgrigoriu
7 июн. 2019
@mariusgrigoriu это не исправлено, @chiluk создал патч, который должен исправить это,
См. Https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -482198124 для получения последнего статуса
willthames
7 июн. 2019
@Mwea глобальный пул хранится в cfs_b-> runtime_remaining. По мере того, как это назначается очередям выполнения для каждого процессора (cfs_rq), количество, остающееся в глобальном пуле, уменьшается. cfs_bandwidth_slice_us - это количество времени выполнения ЦП, которое передается из глобального пула в очереди выполнения для каждого ЦП. Если вы получили дросселирование, это будет означать, что вам нужно запустить и cfs_b-> runtime_remaining == 0. Вам нужно будет дождаться конца текущего периода (по умолчанию 100 мс), чтобы квота пополнилась до cfs_b, а затем распределилась по ваш cfs_rq. Недавно я обнаружил, что время выполнения с истекшим сроком действия составляет не более 1 мс на cfs_rq из-за того, что таймер резервирования восстанавливает все неиспользованные квоты на 1 мс из очередей выполнения для каждого процессора. Затем эта 1 мс теряется / истекает в конце периода. В худшем случае, когда приложение распространяется на 88 процессоров, что потенциально может составить 88 мс потраченной впустую квоты за период 100 мс. Это фактически привело к альтернативному предложению, которое заключалось в том, чтобы позволить таймеру бездействия повторно захватить всю неиспользованную квоту из простаивающих очередей выполнения для каждого процессора.
Что касается линий, которые вы особо выделяете. Мое предложение состоит в том, чтобы полностью удалить истечение времени выполнения, назначенное очередям выполнения для каждого процессора. Эти строки являются частью исправления для 512ac999. Это исправило проблему, из-за которой рассогласование часов между очередями выполнения для каждого процессора приводило к преждевременному истечению квоты, что ограничивало работу приложений, которые еще не использовали квоту (afaiu). Обычно они увеличивают expires_seq на каждой границе периода. Следовательно, expires_seq должен совпадать между каждым из cfs_rq, когда они находятся в одном периоде.
@mariusgrigoriu - если вы достигаете высокого троттлинга при низком использовании процессора и ваше ядро до 512ac999, вам, вероятно, понадобится 512ac999. Если вы отправляете сообщение 512ac999, вы, вероятно, столкнетесь с проблемой, которую я объяснил выше, которая в настоящее время обсуждается на lkml.
Есть много способов решить эту проблему.
- Закрепление процессора
- Уменьшение количества потоков, создаваемых вашим приложением
- Превышение квоты для приложений, испытывающих дросселирование.
- Отключите жесткие ограничения сейчас.
- Создайте собственное ядро с любым из предложенных изменений.
chiluk
7 июн. 2019
@chiluk есть ли шанс, что вы уже опубликовали версию этого патча, которая уже совместима с ядром 4.14? Я собираюсь протестировать его довольно активно, так как мы только что обновили несколько тысяч хостов до 4.14.121 (с 4.9.62) и видим:
- Уменьшение троттлинга для memcached, mysql, nginx и т. Д.
- Увеличение дросселирования для наших Java-приложений
Действительно хочу прокатиться вперед, чтобы получить лучшее из обоих миров. Я могу попытаться перенести его на себя на следующей неделе, но если он у вас уже есть, это было бы здорово.
 PaulFurtado
21 июн. 2019
PaulFurtado
21 июн. 2019
@PaulFurtado
Я фактически переписал патч за последние несколько дней, учитывая предложения Бена Сегулла. Новый патч ядра появится в ближайшее время, как только я смогу провести некоторое время для тестирования наших кластеров.
chiluk
24 июн. 2019
@chiluk есть ли обновления для этого патча? Не беспокойтесь, если нет, я просто удостоверяюсь, что не пропустил патч
PaulFurtado
18 июл. 2019
@PaulFurtado , патч был «одобрен» автором CFS, и я просто жду, когда разработчики планировщика интегрируют его и отправят Линусу.
chiluk
24 июл. 2019
@chiluk Спасибо!
Я только что перенес патч на ядро 4.14, которое является нашим текущим производственным ядром.
Я сделал суть с backport и некоторыми результатами вашего fibtest здесь: https://gist.github.com/PaulFurtado/ff6c67ec87416b66ba1c6fc70f7beec1
В экземплярах c5.9xlarge и m5.24xlarge ec2 текущего поколения, которые мы используем в наших кластерах kubernetes и mesos, патч удваивает производительность вашей программы fibtest. В экземпляре типа r4.16xlarge предыдущего поколения он управляет в 1,5 раза большей загрузкой ЦП, но почти не требует дополнительных итераций (что, как я предполагаю, связано только с поколением ЦП и экспоненциальным характером последовательности Фибоначчи). Все эти числа будут в значительной степени точными, если я увеличу тест до 30 секунд вместо 5 по умолчанию.
На этой неделе мы начнем внедрять это в нашу среду контроля качества, чтобы получить некоторые показатели от наших приложений, которые страдают от наиболее сильного троттлинга. Еще раз спасибо!
PaulFurtado
26 июл. 2019
@PaulFurtado прежде всего спасибо за тестирование. Я предполагаю, что вы используете kernel.org 4.14 или ubuntu 4.14, оба из которых содержат 512ac999. Что касается fibtest, то завершенные итерации не так важны, как используемое время процессора, так как на завершенные итерации может сильно повлиять частота процессора во время выполнения теста (особенно в облаке, где я не уверен, насколько вы контролируете это).
chiluk
31 июл. 2019
Я предполагаю, что вы используете kernel.org 4.14 или ubuntu 4.14, оба из которых содержат 512ac999.
Да, мы запускаем mainline 4.14 (ну, плюс набор исправлений из ядра Amazon Linux 2, но в данном случае ни один из этих исправлений не имеет значения).
512ac999 приземлился в основной версии 4.14.95, и мы заметили его влияние при обновлении с 4.14.77 до 4.14.121+. Это заставило наши контейнеры memcached (очень низкое количество потоков) перейти от необъяснимого регулирования к отсутствию регулирования, но заставило наши контейнеры golang и java (очень большое количество потоков) испытывать большее регулирование.
Что касается fibtest, то завершенные итерации не так важны, как используемое время процессора, так как на завершенные итерации может сильно повлиять частота процессора во время выполнения теста (особенно в облаке, где я не уверен, насколько вы контролируете это).
На более новых / более крупных инстансах EC2 вы действительно получаете приличный уровень контроля над состояниями процессора , поэтому мы работаем с выключенным турбонаддувом и не позволяем ядрам простаивать. Хотя на самом деле я только что понял, что мы настраиваем c-состояния, но не p-состояния, и тип экземпляра, в котором не наблюдалось увеличения количества итераций, был тем, где p-состояния можно было контролировать, так что это вполне может объяснить это.
во-первых, спасибо за тестирование
Вообще нет проблем, в нашей среде pre-qa на выходных все было стабильно, и завтра мы начнем развертывание патча в нашей основной среде QA, где мы увидим больше реальных эффектов. Учитывая, что memcached выиграл от предыдущего патча, мы действительно хотели съесть наш пирог и съесть его с обоими патчами, поэтому мы были счастливы протестировать. Еще раз спасибо за всю работу, которую вы вложили в троттлинг!
PaulFurtado
31 июл. 2019
Просто хотел оставить заметку по поводу обсуждаемого патча ядра ....
Я адаптировал его к ядру, которое мы используем в текущем тестировании, и вижу огромные выигрыши в скорости дросселирования CFS, однако я упомяну, что если вы ранее установили период cfs до 10 мс в качестве смягчения, вы хотите вернуть это значение до 100 мс, чтобы увидеть преимущества изменения.
 jhohertz
6 авг. 2019
jhohertz
6 авг. 2019
Этим утром пластырь попал на кончик.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Как только он попадет в дерево Торвальда, я отправлю его для включения в стабильную Linux, а затем и в основные дистрибутивы (Redhat / Ubuntu). Если вас волнует что-то еще, и они не используют стабильные для Linux патчи, вы можете отправить их напрямую.
chiluk
8 авг. 2019
Я протестировал патч (ubuntu 18.04, ядро 5.2.7, узел: 56-ядерный процессор E5-2660 v4 @ 2,00 ГГц) с нашим микросервисом golang для обработки изображений с большим количеством процессоров и получил довольно впечатляющие результаты. Производительность, как если бы я полностью отключил CFS на узле.
У меня на 5-35% меньше задержки и на 5-55% больше запросов в секунду в зависимости от параллелизма / использования ЦП при почти нулевой скорости дросселирования.
Спасибо, @chiluk !
Как сказал @jhohertz , квоту cfs следует вернуть на 100 мс, я тестировал с более низкими периодами и получил сильное дросселирование и снижение производительности.
 zigmund
10 авг. 2019
zigmund
10 авг. 2019
Для большей производительности с golang установите GOMAXPROCS на ceil (quota) +2. Плюс 2 - это гарантия некоторого параллелизма.
chiluk
12 авг. 2019
@chiluk тестировал с GOMAXPROCS = 8 против GOMAXPROCS = 10 с cpu.limit = 8 - небольшая разница, примерно 1-2%.
zigmund
13 авг. 2019
@zigmund , потому что ваш cpu.limit установлен на целое число 8, которое должно связывать ваши процессы с процессором из 8 процессоров. Ваша разница в 1-2% - это просто увеличение накладных расходов на переключение контекста с двумя дополнительными бегунами Goroutine в вашем наборе задач из 8 процессоров.
Я должен был сказать, что установка GOMAXPROCS = # является хорошим обходным путем для программ go до тех пор, пока исправления ядра не станут широко распространены.
chiluk
26 авг. 2019
Мы перевели наши производственные кластеры на исправленное ядро, и теперь я могу поделиться с вами некоторыми интересными моментами.
Статистика одного из наших кластеров - 4 узла по 72 ядра E5-2695 v4 @ 2.10GHz, 128Gb RAM, Debian 9, ядро 5.2.7 с патчем.
У нас смешанная загрузка состоит в основном из сервисов golang, но также есть php и python.
Голанг. Задержка ниже, установка правильного GOMAXPROCS абсолютно необходима. Вот сервис с GOMAXPROCS = 72 по умолчанию. Мы изменили ядро на ~ 16, после чего задержка уменьшилась, а загрузка ЦП сильно возросла. В 21:15 я установил правильный GOMAXPROCS и нормализовал загрузку процессора.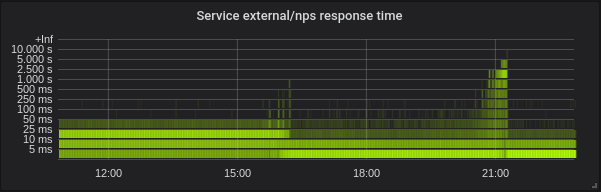

Python. С патчем все стало лучше, без лишних ходов - снизилась загрузка процессора и латентность.
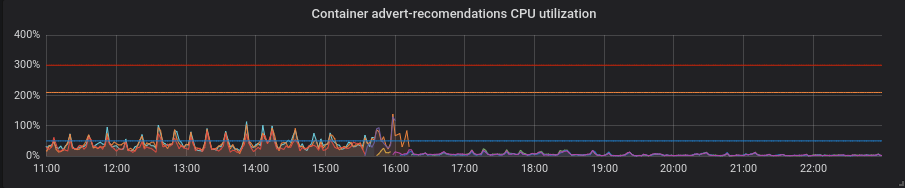
PHP. Загрузка ЦП такая же, задержки на некоторых сервисах немного уменьшились. Небольшая прибыль.
zigmund
3 сент. 2019
Спасибо @zigmund.
Я не уверен, что понимаю, когда вы говорите I setted correct GOMAXPROCS ...
Я предполагаю, что вы не запускаете только один модуль на узле с 72 ядрами, поэтому вы устанавливаете GOMAXPROCS на что-то меньшее, возможно, равное пределам ЦП модуля, верно?
prune998
3 сент. 2019
Спасибо @zigmund. Изменения в го в значительной степени соответствуют тому, что ожидалось.
Я действительно удивлен улучшениями в Python, так как ожидал, что GIL в значительной степени сведет на нет преимущества этого. Во всяком случае, этот патч должен почти полностью уменьшить время отклика, уменьшить процент дросселированных периодов и увеличить загрузку процессора. Вы уверены, что ваше приложение на Python все еще работает?
chiluk
3 сент. 2019
@ prune998 извините, возможно орфографическая
@chiluk Я не силен в python и не знаю, как патч повлиял на нижний уровень. Но приложение работает без проблем, проверял после смены ядра.
zigmund
4 сент. 2019
@chiluk Не
 Nuru
13 сент. 2019
Nuru
13 сент. 2019
@Nuru https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html?highlight=stable%20rules ... В основном я отправлю через linux-stable, как только мой патч попадет в Linus ' tree, * (может быть, раньше), и тогда все дистрибутивы должны следовать Linux-стабильному процессу и вставлять исправления, принятые разработчиками стабильной версии, для своих ядер, специфичных для их дистрибутивов. Если это не так, вам не следует запускать их дистрибутивы.
chiluk
13 сент. 2019
@chiluk Я ничего не знаю о процессе разработки Linux. Под «деревом Линуса» вы имеете в виду https://github.com/torvalds/linux ?
Nuru
14 сент. 2019
Здесь живет дерево Линуса, https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/. Мои изменения в настоящее время выполняются в linux-next, который является деревом интеграции разработки. Да, разработка ядра немного застряла в темноте, но это работает.
Скорее всего, он внесет изменения из дерева linux-next, как только выйдет 5.3 и начнет разработку 5.4-rc0. Примерно в те сроки, которые, как я ожидаю, стабильные ядра начнут извлекать из этого исправления. Остается только догадываться, когда Линус считает, что версия 5.3 стабильна.
chiluk
14 сент. 2019
[Линус], скорее всего, внесет изменения из дерева linux-next после выпуска 5.3 и начнет разработку 5.4-rc0. Примерно в те сроки, которые, как я ожидаю, стабильные ядра начнут извлекать из этого исправления. Остается только догадываться, когда Линус считает, что версия 5.3 стабильна.
@chiluk Похоже, Линус решил, что 15 сентября 2019 г. Итак, что такое «linux-next» и как мы можем отслеживать прогресс вашего патча на следующих этапах?
Nuru
20 сент. 2019
Кто-нибудь создавал пакеты debian stretch и / или образ AWS, включающий этот патч? Я собираюсь сделать это с помощью https://github.com/kubernetes-sigs/image-builder/tree/master/images/kube-deploy/imagebuilder
Просто подумал, что я избегу дублирования усилий, если он уже существует.
blakebarnett
24 сент. 2019
Теперь он был объединен с деревом Линуса и должен быть выпущен в версии 5.4. Я также только что отправил его в linux-stable, и, предполагая, что все идет гладко, все дистрибутивы, которые правильно следуют стабильному процессу, должны начать его в ближайшее время.
chiluk
25 сент. 2019
Кто-нибудь знает, как понять, как это изменение сводится к CentOS (7)? Не уверен, как работает обратное портирование и т. Д.
 till
26 сент. 2019
till
26 сент. 2019
@ по-прежнему https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -531370333
Здесь идет разговор о стабильном ядре.
https://lore.kernel.org/stable/CAC=E7cUXpUDgpvsmMaMU6sAydbfD0FEJiK25R1r=e9=YtcPjGw@mail.gmail.com/
Также для тех, кто собирается на KubeCon, я расскажу об этом здесь.
https://sched.co/Uae1
chiluk
3 окт. 2019
Есть какие-нибудь новости от разработчиков планировщика относительно подтверждения, которое Грег ХК искал, чтобы поместить его в стабильное дерево (а)?
jhohertz
18 окт. 2019
Грег К. Х. воздержался от принятия решения по поводу этого патча, потому что разработчики планировщика не отвечали (вероятно, просто пропустили почту). Будем признательны за комментарий от кого-либо, кроме меня, о LKML, который протестировал этот патч и считает, что его следует перенести.
chiluk
18 окт. 2019
Для людей, использующих CoreOS, существует нерешенная проблема , требующая резервного копирования патча @chiluk.
 evanfoster
1 нояб. 2019
evanfoster
1 нояб. 2019
Ядро CoreOS 4.19.82 содержит исправления: https://github.com/coreos/linux/pull/364
Контейнер CoreOS для Linux 2317.0.1 (альфа-канал) содержит исправления: https://github.com/coreos/coreos-overlay/pull/3796 http://coreos.com/releases/#2317.0.1
Резервные копии стабильной версии Linux кажутся остановленными, потому что исправления применяются некорректно . @chiluk Собираетесь ли вы работать над бэкпортом для стабильной версии Linux? Если да, не могли бы вы выполнить обратный перенос на 4.9, чтобы он попал в Debian "stretch" и был подхвачен kops ? Хотя я предполагаю, что на то, чтобы ввести его в "stretch", уйдет до 6 месяцев, и, возможно, к тому времени kops перейдет в "buster".
Nuru
8 нояб. 2019
@Nuru , я
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.buildinfo
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-image-4.19.67-pm-dbg_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-headers-4.19.67-pm_4.19.67-1_amd64.deb
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-4.19.67-pm_4.19.67-1_amd64.changes
https://pm-kops-dev.s3.amazonaws.com/kernel-packages/linux-libc-dev_4.19.67-1_amd64.deb
293993587779 / k8s-1.11-debian-stretch-amd64-hvm-ebs-2019-09-26
blakebarnett
8 нояб. 2019
@blakebarnett Спасибо за ваши усилия и извините за беспокойство, но я немного запутался.
- "stretch" основан на Linux 4.9, но все ваши ссылки относятся к 4.19.
- Вы говорите, что перенесли «патч», но есть 3 патча (я думаю, третий не очень важен:
- 512ac999 sched / fair: Исправить условие дрейфа таймера полосы пропускания
- de53fd7ae sched / fair: исправить низкое использование ЦП с высоким троттлингом, удалив истечение срока действия локальных срезов ЦП
- 763a9ec06 sched / fair: исправить предупреждения -Wunused-but-set-variable
Вы сделали бэкпорт всех 3 патчей на 4.9? (Я не знаю, что делать с пакетами Debian, чтобы посмотреть, есть ли там изменения, а в документе «изменения» не говорится о том, что действительно изменилось.)
Кроме того, в каких регионах доступен ваш AMI?
Nuru
8 нояб. 2019
Нет, я использовал ядро stretch-backports, которое имеет версию 4.19, поскольку в нем есть исправления, которые нам также понадобились на AWS (особенно для типов инстансов M5 / C5).
Я применил различие, включающее все исправления, которые я считаю, мне пришлось немного изменить его, чтобы удалить лишние ссылки на переменные в 4.19, которые были удалены в другом месте, я сначала применил это https://github.com/kubernetes/kubernetes/issues/67577 #issuecomment -515324561, а затем необходимо добавить:
--- kernel/sched/fair.c 2019-09-25 16:06:02.954933954 -0700
+++ kernel/sched/fair.c-b 2019-09-25 16:06:56.341615817 -0700
@@ -4928,8 +4928,6 @@
cfs_b->period_active = 1;
overrun = hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
- cfs_b->runtime_expires += (overrun + 1) * ktime_to_ns(cfs_b->period);
- cfs_b->expires_seq++;
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
--- kernel/sched/sched.h 2019-08-16 01:12:54.000000000 -0700
+++ sched.h.b 2019-09-25 13:24:00.444566284 -0700
@@ -334,8 +334,6 @@
u64 quota;
u64 runtime;
s64 hierarchical_quota;
- u64 runtime_expires;
- int expires_seq;
short idle;
short period_active;
@@ -555,8 +553,6 @@
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
- int expires_seq;
- u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock;
AMI опубликован для us-west-1
Надеюсь, это поможет!
blakebarnett
8 нояб. 2019
Я перенес эти патчи и отправил их в стабильные ядра Linux.
v4.14 https://lore.kernel.org/stable/[email protected]/
v4.19 https://lore.kernel.org/stable/[email protected]/ #t
chiluk
8 нояб. 2019
Здравствуйте,
после интеграции патча в ветку 4.19 я открыл отчет об ошибке в debian для правильного обновления kerner на buster и stretch-backport:
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=946144
не стесняйтесь добавлять новые комментарии к обновлению пакета debian.
 alexises
4 дек. 2019
alexises
4 дек. 2019
Надеюсь, это не слишком спам, но я хотел связать этот отличный доклад от @chiluk, в котором подробно рассказывается о многих подробностях, связанных с этой проблемой https://youtu.be/UE7QX98-kO0.
 bboreham
4 дек. 2019
bboreham
4 дек. 2019
Есть ли способ избежать троттлинга на GKE? У нас просто была огромная проблема, когда один метод в контейнере php занимал 120 секунд вместо обычных 0,1 секунды.
 bartoszhernas
5 дек. 2019
bartoszhernas
5 дек. 2019
удалить ограничения на ЦП
 monotek
5 дек. 2019
monotek
5 дек. 2019
Мы уже это сделали, контейнер регулируется, когда запросы ЦП слишком малы. В этом суть проблемы, отсутствие ограничений и использование только запросов ЦП все равно приведет к дросселированию :(
bartoszhernas
5 дек. 2019
@bartoszhernas Я думаю, вы здесь неправильно употребили слово. Когда люди в этом потоке ссылаются на "регулирование", они имеют в виду контроль пропускной способности cfs, nr_throttled в cpu.stat для увеличения контрольной группы. Это возможно только при включенных ограничениях ЦП. Если GKE не добавляет ограничения к вашему модулю без вашего ведома, я бы не назвал то, что вы ударяете, как регулирование.
Я бы назвал то, что вы описали, «конкуренция за процессор». Я подозреваю, что у вас, вероятно, есть несколько приложений * (запросов) неправильного размера, которые борются за процессор или другой ресурс на коробке, потому что они часто используют больше, чем они запрашивали. Это точная причина, по которой мы используем ограничения. Так что эти приложения неправильного размера могут сильно повлиять только на другие приложения на коробке.
Другая возможность заключается в том, что недостаточная сумма вашего запроса приводит к просто плохому планированию. Установка низкого уровня запросов аналогична установке положительного «хорошего» значения по отношению к приложениям с более высоким «запросом». Для получения дополнительной информации ознакомьтесь с мягкими ограничениями.
chiluk
5 дек. 2019
Проблемы становятся устаревшими после 90 дней бездействия.
Отметьте проблему как новую с помощью /remove-lifecycle stale .
Устаревшие выпуски гниют после дополнительных 30 дней бездействия и в конечном итоге закрываются.
Если сейчас можно безопасно закрыть эту проблему, сделайте это с помощью /close .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/ жизненный цикл устаревший
 fejta-bot
4 мар. 2020
fejta-bot
4 мар. 2020
/ remove-жизненный цикл устаревший
Nuru
4 мар. 2020
Насколько я понимаю, основная проблема в ядре была исправлена и сделана доступной, например, в ContainerLinux на https://github.com/coreos/bugs/issues/2623.
Кто-нибудь знает об остающихся проблемах после этого патча ядра?
 sfudeus
4 мар. 2020
sfudeus
4 мар. 2020
@sfudeus Kubernetes может быть запущен на любом варианте Linux или, AFAIK, на любом POSIT-совместимом варианте Unix. Эта ошибка никогда не была проблемой для людей, не использующих Linux, она была исправлена для некоторых производных от Linux дистрибутивов и не исправлена для других.
Основная проблема была исправлена в ядре Linux 5.4, которым на данный момент мало кто пользуется. Доступны исправления для обратного переноса на различные старые ядра и включения в новые дистрибутивы Linux, которые еще не готовы к переходу на ядро 5.4, которых много. Как видно из приведенного выше списка коммитов, относящихся к этой проблеме, исправления ошибок все еще находятся в процессе включения в бесчисленное количество дистрибутивов Linux, в которых кто-то может использовать Kubernetes.
Поэтому я хотел бы оставить этот вопрос открытым, пока он все еще видит активные ссылки на фиксацию. Я также хотел бы, чтобы он закрылся с помощью сценария или другого простого метода, который кто-то может использовать, чтобы определить, затронута ли его установка Kubernetes.
Nuru
5 мар. 2020
@Nuru Хорошо, я просто хотел убедиться, что не осталось никаких других проблем с ядром, которые уже известны. Лично я бы не стал держать это открытым дольше, чем в более крупных дистрибутивах, включивших исправление, ожидание бесконечных устройств IoT может означать бесконечное ожидание. Также можно найти закрытые выпуски. Но это всего лишь мои 2 цента.
sfudeus
5 мар. 2020
Не уверен, что это правильное место для информирования людей, но не совсем уверен, где еще поднять это:
Мы запускаем ядро Linux 5.4 на Debian Buster (с использованием ядра buster-backports) с кластером k8s 1.15.10, и мы все еще наблюдаем проблемы с этим. Особенно для модулей, которые обычно имеют очень мало дел (kube-downscaler - пример, к которому мы продолжаем возвращаться, который обычно требует около 3 м ЦП) и которым выделено очень мало ресурсов процессора (50 м в случае kube-downscaler в нашем cluster) мы по-прежнему видим очень высокое значение дросселирования. Для справки, kube-downscaler - это в основном скрипт Python, который запускает sleep течение 30 минут, прежде чем что-либо сделает. cAdvisor показывает, что увеличение container_cpu_cfs_throttled_periods_total для этого контейнера всегда более или менее похоже на значение container_cpu_cfs_periods_total этого контейнера (оба значения составляют около 250 при проверке увеличения с 5-метровыми интервалами). Мы ожидаем, что периоды дросселирования будут около 0.
Мы это неправильно измеряем? CAdvisor выводит неверные данные? Верно ли наше предположение, что мы должны увидеть сокращение периодов дросселирования? Любой совет будет оценен здесь.
После перехода на ядро 5.4 мы действительно увидели, что количество подов с этой проблемой немного уменьшилось (около 40%), но в настоящее время мы не уверены, является ли то, что мы видим, реальной проблемой или нет. В основном, глядя на приведенную выше статистику, мы не уверены, что на самом деле означает здесь «дросселирование», если мы получаем эти значения при среднем использовании ЦП 3 млн. Узел, на котором он работает, вообще не перегружен и имеет среднее использование ЦП менее 10%.
 timstoop
5 мар. 2020
timstoop
5 мар. 2020
@timstoop интервалы, о которых заботится планировщик, находятся в области микросекунд, а не в больших 30-минутных диапазонах. Если для контейнера установлено ограничение ЦП в 50 мПе, и он использует 50 мПи в течение 100 микросекунд, он будет дросселирован, независимо от того, провел ли он 30 минут в режиме ожидания. В общем, 50 милликубических единиц - это очень маленький предел ЦП. Если программа на Python даже делает один запрос HTTPS с таким низким пределом, он почти гарантированно будет задушен.
Узел, на котором он работает, вообще не перегружен и имеет среднее использование ЦП менее 10%.
Уточняю: нагрузка на узел и другие нагрузки на него не имеют никакого отношения к троттлингу. Регулирование учитывает только собственный лимит контейнера / контрольной группы.
PaulFurtado
5 мар. 2020
@PaulFurtado Спасибо за ответ! Однако сам Pod в среднем использует 3 млн ЦП во время этого сна, и он все еще дросселируется. В это время он не делает никаких запросов, он ждет сна. Я надеюсь, что он сможет это сделать, не пробивая 50 метров, верно? Или это все равно неверное предположение?
timstoop
5 мар. 2020
Я думаю, что это, вероятно, настолько мало, что возникнут проблемы с точностью. А 50 м - это настолько мало, что что угодно может споткнуть его. Среда выполнения Python также может выполнять фоновые задачи в потоках, пока вы спите.
PaulFurtado
5 мар. 2020
Вы были правы, я делал предположения, которые не соответствовали действительности. Спасибо за руководство! Теперь это имеет для меня смысл.
timstoop
5 мар. 2020
Просто хотел вмешаться и сказать, что здесь все значительно улучшилось с тех пор, как патч ядра попал в ядра 4.19 LTS и появился в CoreOS / Flatcar. Глядя на данный момент, я вижу только пару вещей, на которые мне, вероятно, следует поднять ограничения. :улыбка:
jhohertz
5 мар. 2020
@sfudeus @chiluk Есть ли какой-нибудь простой тест, чтобы узнать, исправлено ли это в вашем ядре или нет?
Я не могу сказать, исправлен ли kope.io/k8s-1.15-debian-stretch-amd64-hvm-ebs-2020-01-17 (текущее официальное изображение kops ) или нет.
Nuru
20 мар. 2020
Я согласен с @mariusgrigoriu , для модулей, которые работают на эксклюзивном процессоре в соответствии со статической политикой процессора, мы можем просто отключить ограничение квоты процессора - в любом случае он может работать только на своем эксклюзивном наборе процессоров. Вышеупомянутый патч предназначен для этой цели и только для этого типа контейнеров.
 jianzzha
6 апр. 2020
jianzzha
6 апр. 2020
@Nuru я написал https://github.com/indeedeng/fibtest
Это примерно такой же окончательный тест, который вы можете получить, но вам понадобится компилятор C.
Игнорируйте количество выполненных итераций, но сосредоточьтесь на количестве времени, затраченном на однопоточное или многопоточное выполнение.
chiluk
10 апр. 2020
Думаю, хороший способ увидеть, какие ядра были исправлены, - это один из последних слайдов с @chiluk (спасибо за это, кстати) https://www.youtube.com/watch?v=UE7QX98-kO0
Ядро 4.15.0-67, похоже, имеет патч (https://launchpad.net/ubuntu/+source/linux/4.15.0-67.76), однако мы все еще наблюдаем дросселирование в некоторых модулях, где количество запросов / лимит намного выше использование их ЦП.
Я говорю об использовании около 50 мс с запросом, установленным на 250 м и ограниченным до 500 м. Мы видим, что около 50% периодов ЦП снижается, может ли это значение быть достаточно низким, чтобы его можно было ожидать и можно ли его принять? Я бы хотел, чтобы он снизился до нуля, нас вообще не следует ограничивать, если использование даже близко не к пределу.
Кто-то, использующий новое исправленное ядро, все еще имеет какое-то регулирование?
 vgarcia-te
22 апр. 2020
vgarcia-te
22 апр. 2020
@ vgarcia-te Вокруг циркулирует слишком много ядер, чтобы узнать из списка, какие из них были исправлены, а какие нет. Просто посмотрите на все коммиты, относящиеся к этой проблеме. Несколько сотен. Мое чтение журнала изменений для Ubuntu предполагает, что 4.15 еще не исправлен (за исключением mabye для работы в Azure), а исправление, с которым вы связались, было отклонено .
Лично меня интересует серия 4.9, потому что это то, что использует kops , и хотел бы знать, когда они выпустят AMI с исправлением.
В то же время, вы можете попробовать запустить @bobrik «s тест , который выглядит довольно хорошо для меня.
wget https://gist.githubusercontent.com/bobrik/2030ff040fad360327a5fab7a09c4ff1/raw/9dcf83b821812064fa7fb056b8f22cbd5c4364f1/cfs.go
sudo docker run --rm -it --cpu-quota 20000 --cpu-period 100000 -v $(pwd):$(pwd) -w $(pwd) golang:1.9.2 go run cfs.go -iterations 15 -sleep 1000ms
При правильно функционирующем CFS время записи всегда будет 5 мс. Для затронутых ядер, которые я тестировал, используя приведенные выше числа, я часто вижу время записи 99 мс. Все, что превышает 6 мс, является проблемой.
Nuru
22 апр. 2020
@nuru благодарит за сценарий, чтобы выяснить, есть ли проблема.
@justinsb Пожалуйста, подскажите, есть ли патч для изображений kops по умолчанию
https://github.com/kubernetes/kops/blob/master/channels/stable
Открыл проблему: https://github.com/kubernetes/kops/issues/8954
https://github.com/kubernetes/kubernetes/issues/67577#issuecomment -617586330
Обновление: проведите тест в образе kops 1.15, есть ненужное регулирование https://github.com/kubernetes/kops/issues/8954#issuecomment -617673755
alok87
22 апр. 2020
@Nuru
2020/04/22 11:02:48 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 6ms
2020/04/22 11:02:49 [1] burn took 5ms, real time so far: 1012ms, cpu time so far: 12ms
2020/04/22 11:02:50 [2] burn took 5ms, real time so far: 2017ms, cpu time so far: 18ms
2020/04/22 11:02:51 [3] burn took 5ms, real time so far: 3023ms, cpu time so far: 23ms
2020/04/22 11:02:52 [4] burn took 5ms, real time so far: 4028ms, cpu time so far: 29ms
2020/04/22 11:02:53 [5] burn took 5ms, real time so far: 5033ms, cpu time so far: 35ms
2020/04/22 11:02:54 [6] burn took 5ms, real time so far: 6038ms, cpu time so far: 40ms
2020/04/22 11:02:55 [7] burn took 5ms, real time so far: 7043ms, cpu time so far: 46ms
2020/04/22 11:02:56 [8] burn took 5ms, real time so far: 8049ms, cpu time so far: 51ms
2020/04/22 11:02:57 [9] burn took 5ms, real time so far: 9054ms, cpu time so far: 57ms
2020/04/22 11:02:58 [10] burn took 5ms, real time so far: 10059ms, cpu time so far: 63ms
2020/04/22 11:02:59 [11] burn took 5ms, real time so far: 11064ms, cpu time so far: 69ms
2020/04/22 11:03:00 [12] burn took 5ms, real time so far: 12069ms, cpu time so far: 74ms
2020/04/22 11:03:01 [13] burn took 5ms, real time so far: 13074ms, cpu time so far: 80ms
2020/04/22 11:03:02 [14] burn took 5ms, real time so far: 14079ms, cpu time so far: 85ms
эти результаты взяты из
Linux <servername> 4.15.0-96-generic #97-Ubuntu SMP Wed Apr 1 03:25:46 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
Это последнее стабильное ядро ubuntu по умолчанию в ubuntu 18.04.
Таким образом, это выглядит как пятно есть.
 zerkms
22 апр. 2020
zerkms
22 апр. 2020
@zerkms Где вы запускали тесты на Ubuntu 18.04? Мне кажется, что патч, возможно, попал только в ядро для Azure. Если вы можете найти примечание к выпуску, в котором говорится, где он был применен к пакету Ubuntu linux , поделитесь. Я не могу его найти.
Также обратите внимание, что этот тест также не смог воспроизвести проблему на CoreOS. Возможно, в конфигурации по умолчанию планирование CFS было отключено глобально.
Nuru
22 апр. 2020
@Nuru
Где вы запускали тесты на Ubuntu 18.04?
Один из моих серверов.
Я не проверял примечания к выпуску, я даже не уверен, что искать, и тем не менее - это ядро по умолчанию, как и у всех. 🤷
zerkms
22 апр. 2020
патч должен быть здесь, в git ядра ubuntus:
https://kernel.ubuntu.com/git/ubuntu/ubuntu-bionic.git/commit/?id=aadd794e744086fb50cdc752d54044fbc14d4adb
и вот ошибка Ubuntu по этому поводу:
https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1832151
он должен быть выпущен в бионике.
В этом можно убедиться, запустив apt-get source linux и проверив загруженный исходный код.
juliantaylor
22 апр. 2020
@zerkms Под «где вы запускали свои тесты» я имел в виду, был ли это сервер в вашем офисе, сервер в GCP, AWS, Azure или где-то еще?
Очевидно, я многого не понимаю в том, как распространяется и поддерживается Ubuntu. Меня тоже смущает ваш вывод uname -a . В примечаниях к выпуску Ubuntu говорится:
18.04.4 поставляется с ядром Linux на основе v5.3, обновленным с ядра на основе v5.0 в 18.04.3.
а также сообщает, что 18.04.4 был выпущен 12 февраля 2020 г. В ваших выходных данных указано, что вы используете ядро v4.15, скомпилированное 1 апреля 2020 г.
@juliantaylor У меня нет сервера Ubuntu или копии aadd794e7440, превратился в опубликованное стабильное ядро. Если вы покажете мне, как это сделать, я был бы признателен.
Когда я смотрю на комментарии об ошибках на
- Эта ошибка исправлена в пакете linux-azure - 5.0.0-1027.29.
- Эта ошибка исправлена в пакете linux-azure - 5.0.0-1027.29 ~ 18.04.1
но этот конкретный патч ( sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices ) не указан в
- Эта ошибка исправлена в пакете linux - 4.15.0-69.78
Я также не вижу «1832151» в примечаниях к выпуску Ubuntu
В предыдущем комментарии говорилось, что он был пропатчен в 4.15.0-67.76, но я не вижу пакета linux-image-4.15.0-67-generic .
Я далек от эксперта по Ubuntu и считаю, что отслеживание патчей недопустимо сложно, так что это все, что я видел.
Надеюсь, теперь вы понимаете, почему я не уверен, что этот патч действительно был включен в Ubuntu 18.04.4, которая является текущей версией 18.04. Мое _ лучшее предположение_ заключается в том, что оно было выпущено как обновление ядра после выпуска 18.04.4 и, вероятно, будет включено, если ваше ядро Ubuntu сообщает о версии 4.15.0-69 или новее, но если вы просто загрузите 18.04.4 и не обновите его, у него не будет патча.
Nuru
22 апр. 2020
Я только что запустил этот тест Go (очень полезный) в ядре 4.15.0-72 на сервере baremetal в центре обработки данных, и, похоже, патч уже есть:
2020/04/22 21:24:27 [0] burn took 5ms, real time so far: 5ms, cpu time so far: 7ms
2020/04/22 21:24:28 [1] burn took 5ms, real time so far: 1010ms, cpu time so far: 13ms
2020/04/22 21:24:29 [2] burn took 5ms, real time so far: 2015ms, cpu time so far: 20ms
2020/04/22 21:24:30 [3] burn took 5ms, real time so far: 3020ms, cpu time so far: 25ms
2020/04/22 21:24:31 [4] burn took 5ms, real time so far: 4025ms, cpu time so far: 32ms
2020/04/22 21:24:32 [5] burn took 5ms, real time so far: 5030ms, cpu time so far: 38ms
2020/04/22 21:24:33 [6] burn took 5ms, real time so far: 6036ms, cpu time so far: 43ms
2020/04/22 21:24:34 [7] burn took 5ms, real time so far: 7041ms, cpu time so far: 50ms
2020/04/22 21:24:35 [8] burn took 5ms, real time so far: 8046ms, cpu time so far: 56ms
2020/04/22 21:24:36 [9] burn took 5ms, real time so far: 9051ms, cpu time so far: 63ms
2020/04/22 21:24:37 [10] burn took 5ms, real time so far: 10056ms, cpu time so far: 68ms
2020/04/22 21:24:38 [11] burn took 5ms, real time so far: 11061ms, cpu time so far: 75ms
2020/04/22 21:24:39 [12] burn took 5ms, real time so far: 12067ms, cpu time so far: 81ms
2020/04/22 21:24:40 [13] burn took 5ms, real time so far: 13072ms, cpu time so far: 86ms
2020/04/22 21:24:41 [14] burn took 5ms, real time so far: 14077ms, cpu time so far: 94ms
Я также вижу, что одно и то же выполнение в ядре 4.9.164 на том же типе сервера показывает ожоги более 5 мс:
2020/04/22 21:24:41 [0] burn took 97ms, real time so far: 97ms, cpu time so far: 8ms
2020/04/22 21:24:42 [1] burn took 5ms, real time so far: 1102ms, cpu time so far: 12ms
2020/04/22 21:24:43 [2] burn took 5ms, real time so far: 2107ms, cpu time so far: 16ms
2020/04/22 21:24:44 [3] burn took 5ms, real time so far: 3112ms, cpu time so far: 24ms
2020/04/22 21:24:45 [4] burn took 83ms, real time so far: 4197ms, cpu time so far: 28ms
2020/04/22 21:24:46 [5] burn took 5ms, real time so far: 5202ms, cpu time so far: 32ms
2020/04/22 21:24:47 [6] burn took 94ms, real time so far: 6297ms, cpu time so far: 36ms
2020/04/22 21:24:48 [7] burn took 99ms, real time so far: 7397ms, cpu time so far: 40ms
2020/04/22 21:24:49 [8] burn took 100ms, real time so far: 8497ms, cpu time so far: 44ms
2020/04/22 21:24:50 [9] burn took 5ms, real time so far: 9503ms, cpu time so far: 52ms
2020/04/22 21:24:51 [10] burn took 5ms, real time so far: 10508ms, cpu time so far: 60ms
2020/04/22 21:24:52 [11] burn took 5ms, real time so far: 11602ms, cpu time so far: 64ms
2020/04/22 21:24:53 [12] burn took 5ms, real time so far: 12607ms, cpu time so far: 72ms
2020/04/22 21:24:54 [13] burn took 5ms, real time so far: 13702ms, cpu time so far: 76ms
2020/04/22 21:24:55 [14] burn took 5ms, real time so far: 14707ms, cpu time so far: 80ms
Итак, моя проблема в том, что я все еще вижу троттлинг процессора, даже мое ядро, кажется, исправлено
vgarcia-te
22 апр. 2020
@ Нуру , извини. Это был мой голый металлический сервер, размещенный в офисе.
а также сообщает, что 18.04.4 был выпущен 12 февраля 2020 г. В ваших выходных данных указано, что вы используете ядро v4.15, скомпилированное 1 апреля 2020 г.
Это потому, что это серверный LTS: вам нужно явно указать HWE, чтобы иметь новые ядра, иначе вы просто запустите mainline.
И основные ядра, и ядра HWE выпускаются регулярно, поэтому нет ничего подозрительного в наличии недавно созданного ядра: http://changelogs.ubuntu.com/changelogs/pool/main/l/linux-meta/linux-meta_4.15.0.96.87/ журнал изменений
zerkms
22 апр. 2020
@zerkms Спасибо за информацию. Я по-прежнему сбит с толку, но это не место, чтобы меня учить.
@ vgarcia-te Если ваше ядро пропатчено, что, похоже, есть, то троттлинг не из-за этой ошибки. Я не уверен в вашей терминологии, когда вы говорите:
Я говорю об использовании около 50 мс с запросом, установленным на 250 м и ограниченным до 500 м. Мы видим, что около 50% периодов ЦП снижается, может ли это значение быть достаточно низким, чтобы его можно было ожидать и можно ли его принять?
Ресурс ЦП Kubernetes измеряется в ЦП: 1 означает 100% от 1 полного ЦП, 1 м означает 0,1% от 1 ЦП. Таким образом, ваш предел в «500 м» говорит о разрешении 0,5 ЦП.
Период планирования по умолчанию для CFS составляет 100 мс, поэтому установка предела 0,5 ЦП ограничит ваш процесс 50 мс ЦП каждые 100 мс. Если ваш процесс попытается превысить это значение, он будет задушен. Если ваш процесс обычно выполняет более 50 мсек за один проход, то да, вы ожидаете, что он будет ограничен правильно работающим планировщиком.
Nuru
23 апр. 2020
@Nuru, это имеет смысл, но позвольте мне понять это, учитывая, что период процессора по умолчанию составляет 100 мс, в случае, если процессу назначен 1 процессор, если этот процесс выполняется более 100 мс за один проход, будет ли он дросселирован?
Означает ли это, что в Linux, где период ЦП по умолчанию составляет 100 мс, любой процесс, у которого есть ограничение, которое выполняется более 100 мс за один проход, будет ограничиваться?
Какой была бы хорошая конфигурация ограничения для процесса, который занимает более 100 мс за один проход, но остальное время простаивает?
vgarcia-te
23 апр. 2020
@ vgarcia-te спросил
Учитывая, что период ЦП по умолчанию составляет 100 мс, в случае, если процессу назначен 1 ЦП, если этот процесс выполняется более 100 мс за один проход, будет ли он ограничен?
Конечно, планирование безумно сложно, поэтому я не могу дать вам идеального ответа, но упрощенный ответ - нет. Более подробные объяснения здесь и здесь .
Все процессы unix подлежат упреждающему планированию на основе временных интервалов. Во времена одноядерного одноядерного процессора у вас все еще было 30 процессов, работающих «одновременно». Что происходит, так это то, что они какое-то время бегают и либо спят, либо, в конце своего временного отрезка, задерживаются, чтобы что-то еще могло работать.
КВПБ с квотами делает еще один шаг вперед.
Однако спросите себя, когда вы говорите, что хотите, чтобы процесс использовал 50% ЦП, что вы на самом деле имеете в виду? Вы говорите, что это нормально, если он загружает 100% ЦП в течение 5 минут, если затем он вообще не работает в течение следующих 5 минут? Это будет 50% использования за 10 минут, но это неприемлемо для большинства людей из-за проблем с задержкой.
Таким образом, CFS определяет «период ЦП», то есть промежуток времени, в течение которого он применяет квоты. На машине с 4 ядрами и периодом ЦП 100 мс планировщик имеет 400 мс процессорного времени для распределения более 100 мс реального (настенные часы) времени. Если вы выполняете один поток выполнения, который нельзя распараллелить, то этот поток может использовать не более 100 мс процессорного времени за период, что составляет 100% от 1 процессора. если вы установите его квоту на 1 процессор, он никогда не должен быть ограничен.
Если вы установите квоту на 500 мс (0,5 ЦП), то процесс будет запускаться по 50 мс каждые 100 мс. Любой период 100 мс использует менее 50 мс, он не должен регулироваться. Период Ayn 100 мс, он не завершается после запуска 50 мс, он дросселируется до следующего периода 100 мс. Это поддерживает баланс между задержкой (сколько времени нужно ждать, чтобы вообще можно было запустить) и зависанием (сколько времени разрешено, чтобы другие процессы не запускались).
Nuru
23 апр. 2020
@ Нуру, мои слайды верны. Я также разработчик Ubuntu * (сейчас только в свободное время). Лучше всего прочитать исходники и проверить git blame + tag --contains, чтобы отслеживать, когда патч попадает в нужную вам версию ядра.
chiluk
26 апр. 2020
@chiluk Я твоих слайдов не видел. Для тех, кто их не видел, вот где они говорят, что патч появился некоторое время назад:
- Ubuntu 4.15.0-67 +
- Ubuntu 5.3.0-24 +
- Ядро RHEL7 3.10.0-1062.8.1.el7
и, конечно же, стабильная версия Linux v4.14.154, v4.19.84, 5.3.9. Замечу, что это также есть в Linux стабильной версии 5.4-rc1.
Я все еще изо всех сил пытаюсь разобраться в различных ошибках планировщика CFS и найти надежные, простые для интерпретации тесты, которые будут работать на небольшом сервере AWS, потому что я поддерживаю широкий спектр ядер из устаревших установок. Насколько я понимаю, в 2014 году в ядре Linux v3.16-rc1 появилась ошибка.
[51f2176d74ac](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=51f2176d74ac) sched/fair: Fix unlocked reads of some cfs_b->quota/period.
Это вызвало различные проблемы с регулированием CFS. Я думаю, что проблемы, которые я видел в кластерах kops Kubernetes, были вызваны этой ошибкой, поскольку они использовали ядра 4.9.
51f2176d74ac было исправлено в ядре 2018 v4.18-rc4 с
[512ac999](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=512ac999d2755d2b7109e996a76b6fb8b888631d) sched/fair: Fix bandwidth timer clock drift condition
но это привело к ошибке, которую
[de53fd7ae](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425) sched/fair: Fix low cpu usage with high throttling by removing expiration of cpu-local slices
Конечно, это не вина Чилука или кого-либо еще в том, что патчи ядра трудно отслеживать в разных дистрибутивах. Однако это по-прежнему расстраивает меня и способствует моему замешательству.
Например, в Debuan buster 10 (AWS AMI debian-10-amd64-20191113-76 ) версия ядра отображается как
Linux ip-172-31-41-138 4.19.0-6-cloud-amd64 #1 SMP Debian 4.19.67-2+deb10u2 (2019-11-11) x86_64 GNU/Linux
Насколько я могу судить, это ядро должно иметь 51f2176d74ac и НЕ иметь 512ac999 и, следовательно, должно провалить тест, описанный в 512ac999 , но это не так. (Я говорю, что не думаю, что у него есть 512ac999 потому что он был постепенно обновлен с ядра Linux 4.10, и в журнале изменений нет упоминания об этом патче.) Однако на 4-процессорной AWS VM он не дает сбоя Chiluk в fibtest или Бобрик в КВПБ икота тест, который показывает , что - то еще происходит.
У меня были аналогичные проблемы с воспроизведением любых проблем с расписанием в CoreOS еще до того, как он получил патч Чилука.
На данный момент я думаю, что тест Бобрика - это в основном тест для 51f2176d74ac , AMI Debian buster 10, который я использую _Does_ имеет 512ac999 , просто не вызываемый явно в журнале изменений, и fibtest не очень чувствительный тест на машине с несколькими ядрами.
Nuru
27 апр. 2020
Четырехъядерный процессор, вероятно, недостаточно велик, чтобы воспроизвести проблему, исправленную chiluk.
Он должен воспроизводиться на более крупных машинах с процессором выше 40, если я правильно понял объяснение из выступления chiluks kubecon (https://www.youtube.com/watch?v=UE7QX98-kO0).
Существует множество версий ядра, и происходит много исправлений и откатов исправлений. Журналы изменений и номера версий пока только вам помогут.
Единственный надежный способ, если у вас есть сомнения, - это загрузить исходный код и сравнить его с изменениями в патчах, ссылки на которые приведены здесь.
juliantaylor
27 апр. 2020
Проблемы становятся устаревшими после 90 дней бездействия.
Отметьте проблему как новую с помощью /remove-lifecycle stale .
Устаревшие выпуски гниют после дополнительных 30 дней бездействия и в конечном итоге закрываются.
Если сейчас можно безопасно закрыть эту проблему, сделайте это с помощью /close .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/ жизненный цикл устаревший
fejta-bot
26 июл. 2020
/ remove-жизненный цикл устаревший
 yashbhutwala
27 июл. 2020
yashbhutwala
27 июл. 2020
Тесты, упомянутые ранее в этом потоке, на самом деле не воспроизводят для меня проблему (несколько ожогов занимают более 5 мс, но это примерно 0,01% из них), но наши метрики дросселирования cfs все еще показывают умеренное количество дросселирования. У нас есть разные версии ядра в наших кластерах, но две наиболее распространенные версии:
Debian 4.19.67-2+deb10u2~bpo9+1 (2019-11-12)- ручная резервная копия
5.4.38
Я не знаю, должны ли быть исправлены обе ошибки в этих версиях, но я _ думаю_, что они должны быть исправлены, поэтому мне интересно, не так ли полезен тест. Я тестирую на машинах с 16 ядрами и с 36 ядрами, не уверен, нужно ли мне еще больше ядер, чтобы тест был действительным, но мы все еще видим дросселирование в этих кластерах, поэтому ...
 2rs2ts
18 авг. 2020
2rs2ts
18 авг. 2020
Должны ли мы закрыть эту проблему и попросить людей, столкнувшихся с проблемами, начать новые? Спам здесь, вероятно, сделает любой разговор очень трудным.
 omnibs
31 окт. 2020
omnibs
31 окт. 2020
^ Согласен. Многое было сделано для решения этой проблемы.
 sfxworks
31 окт. 2020
sfxworks
31 окт. 2020
/Закрыть
на основе комментариев выше. при необходимости открывайте новые выпуски.
dims
1 нояб. 2020
@dims : закрытие этого вопроса.
В ответ на это :
/Закрыть
на основе комментариев выше. при необходимости открывайте новые выпуски.
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
 k8s-ci-robot
1 нояб. 2020
k8s-ci-robot
1 нояб. 2020
пожалуйста, сообщите о последующих проблемах по этой проблеме, чтобы люди, подписавшиеся на проблему, могли подписаться на новые выпуски, чтобы следить
 glensc
1 нояб. 2020
glensc
1 нояб. 2020
Смежные вопросы
 ttripp
·
3Комментарии
ttripp
·
3Комментарии
 zetaab
·
3Комментарии
zetaab
·
3Комментарии
 jason-riddle
·
3Комментарии
jason-riddle
·
3Комментарии
 jadhavnitind
·
3Комментарии
jadhavnitind
·
3Комментарии
 Seb-Solon
·
3Комментарии
Seb-Solon
·
3Комментарии
Самый полезный комментарий
Этим утром пластырь попал на кончик.
https://git.kernel.org/pub/scm/linux/kernel/git/tip/tip.git/commit/?id=de53fd7aedb100f03e5d2231cfce0e4993282425
Как только он попадет в дерево Торвальда, я отправлю его для включения в стабильную Linux, а затем и в основные дистрибутивы (Redhat / Ubuntu). Если вас волнует что-то еще, и они не используют стабильные для Linux патчи, вы можете отправить их напрямую.