概括。
预期结果
程序正常运行
实际结果
程序消耗所有内存直到停止工作
繁殖步骤
伪代码:
def function():
proxies = {
'https': proxy
}
session = requests.Session()
session.headers.update({'User-Agent': 'user - agent'})
try: #
login = session.get(url, proxies=proxies) # HERE IS WHERE MEMORY LEAKS
except: #
return -1 #
return 0
系统信息
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.6"
},
"implementation": {
"name": "CPython",
"version": "3.6.3"
},
"platform": {
"release": "10",
"system": "Windows"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.18.4"
},
"system_ssl": {
"version": "100020bf"
},
"urllib3": {
"version": "1.22"
},
"using_pyopenssl": false
}
 Munroc
Munroc
所有22条评论
请向我们提供输出
python -m requests.help
如果这在您的 Requests 版本中不可用,请提供有关您的系统的一些基本信息(Python 版本、操作系统等)。
 sigmavirus24
于 2018-04-20
sigmavirus24
于 2018-04-20
@sigmavirus24完成
Munroc
于 2018-04-20
嘿@munroc ,关于你的线程实现的几个快速问题,因为它没有包含在伪代码中。
您是否为每个线程创建一个新会话以及您使用的线程池的大小是多少?
您使用什么工具来确定泄漏的来源? 你介意分享结果吗?
一段时间以来,我们已经有关于会话内存泄漏的暗示,但我不确定我们是否找到了确凿的证据或真正确认的影响。
 nateprewitt
于 2018-04-20
nateprewitt
于 2018-04-20
@nateprewitt你好,是的,我为每个线程创建一个新会话。 线程池是 30。无论如何,我已经尝试了 2-200 个线程和内存泄漏。 我没有使用工具,我只是对功能做了以下更改:
在 login = session.get 之前放置 return 0 并且没有内存泄漏。 如果我在登录后返回 0 = session.get 内存开始泄漏。 如果你想要我可以给你我的源代码不是太大。
Munroc
于 2018-04-20
@Munroc如果我们有完整的代码,那么我认为隔离实际原因会更容易。 但是根据提供的代码要点,我认为很难断定存在内存泄漏。
正如你所提到的,如果你return立即调用之前session.get ,那么只有proxies和session对象将在内存(简单化存在..但我希望你能明白:微笑:)。 但是,一旦您调用session.get(url, proxies=proxies) , url的 HTML 将被检索并在本地保存到login变量中。 这意味着,每个session.get调用将“看起来像”它们正在泄漏内存,但实际上它们的行为正常(内存)随着url结果的大小线性增加。
但是,假设您正在使用线程,然后立即使用.join()线程。 在这种情况下,我认为我们需要查看您的线程是如何管理的 - 以及它们是否被正确关闭/清理。
 initbar
于 2018-05-21
initbar
于 2018-05-21
@LeoSZN我认为在您的具体示例中,在Process每个urls元素生成多个Process后,您只关闭了最后一个Process对象。
您能否尝试使用p.daemon = True守护它们并运行它们(这样一旦主线程终止,所有产生的子进程也会死亡)? 否则,将生成的进程存储在单独的数组中,并确保使用循环关闭所有进程。
initbar
于 2018-10-14
@initbar
我是否需要在p.join()之前在循环中或循环外运行p.daemon = True p.join() ? 顺便说一句,在申请p.daemon = True后我还需要p.join() p.daemon = True吗?
 leoszn
于 2018-10-15
leoszn
于 2018-10-15
_好吧,我被新话题踢到了这个话题,所以让我加入你的话题。
可能是这个问题提供了更多的信息,并会加紧解决问题..._
我正在运行 Telegram bot,并注意到在运行 bot 很长时间时空闲内存会下降。 首先,我怀疑我的代码; 然后我怀疑机器人,最后我来到了请求。 :)
我使用len(gc.get_objects())来确定存在的问题。 我找到了通信例程,然后清除了所有 bot 代码,然后来到了在每次迭代中增加 gc 对象计数的示例。
预期结果
len(gc.get_objects())应该在每次循环迭代中给出相同的结果
实际结果
len(gc.get_objects())的值在每次循环迭代中都会增加。
Test N2
GetObjects len: 27959
Test N3
GetObjects len: 27960
Test N4
GetObjects len: 27961
Test N5
GetObjects len: 27962
Test N6
GetObjects len: 27963
Test N7
GetObjects len: 27964
繁殖步骤
token = "XXX:XXX"
chat_id = '111'
proxy = {'https':'socks5h://ZZZ'} #You may need proxy to run this in Russia
from time import sleep
import gc, requests
def garbage_info():
res = ""
res += "\nGetObjects len: " + str(len(gc.get_objects()))
return res
def tester():
count = 0
while(True):
sleep(1)
count += 1
msg = "\nTest N{0}".format(count) + garbage_info()
print(msg)
method_url = r'sendMessage'
payload = {'chat_id': str(chat_id), 'text': msg}
request_url = "https://api.telegram.org/bot{0}/{1}".format(token, method_url)
method_name = 'get'
session = requests.session()
req = requests.Request(
method=method_name.upper(),
url=request_url,
params=payload
)
prep = session.prepare_request(req)
settings = session.merge_environment_settings(
prep.url, None, None, None, None)
# prep.url, proxy, None, None, None) #Change the line to enable proxy
send_kwargs = {
'timeout': None,
'allow_redirects': None,
}
send_kwargs.update(settings)
resp = session.send(prep, **send_kwargs)
# For more clean output
gc.collect()
tester()
系统信息
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "2.3.1"
},
"idna": {
"version": "2.7"
},
"implementation": {
"name": "CPython",
"version": "3.6.6"
},
"platform": {
"release": "4.15.0-36-generic",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "1010009f",
"version": "17.5.0"
},
"requests": {
"version": "2.19.1"
},
"system_ssl": {
"version": "1010007f"
},
"urllib3": {
"version": "1.23"
},
"using_pyopenssl": true
}
_我在 Windows10 上的 Python 3.5.3 上的行为相同。_
 Badiboy
于 2018-10-16
Badiboy
于 2018-10-16
@LeoSZN
@initbar
我是否需要在
p.join()之前在循环中或循环外运行p.daemon = Truep.join()? 顺便说一句,在申请p.daemon = True后我还需要p.join()p.daemon = True吗?
# ..
for i in urls:
p = Process(target=main, args=(i,))
p.daemon = True # before `.start`
p.start()
# ..
作为一个小提示,您仍然可以.join守护进程——但是当它们的父进程终止时,它们几乎肯定会被杀死(除非它们不知何故无意中成为孤儿;在这种情况下,请告诉我!我我很想了解更多相关信息)。
否则,您可以将Process对象单独存储为数组并在最后加入:
# ..
processes = [
Process(target=main, args=(i,))
for i in urls
]
# start the process activity.
预期结果
len(gc.get_objects())应该在每次循环迭代中给出相同的结果
这种行为的原因是在“请求”缓存机制中找到的。
它工作不正确(怀疑):它向每次调用 Telegram API URL 添加一个缓存记录(而不是缓存一次)。 但这不会导致内存泄漏,因为缓存大小限制为 20,并且缓存在达到此限制后会重置,并且不断增长的对象数量将减少回初始值。
Badiboy
于 2018-10-26
类似的问题。 请求在线程中运行时会占用内存。 在这里重现的代码:
import gc
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from memory_profiler import profile
def run_thread_request(sess, run):
response = sess.get('https://www.google.com')
return
<strong i="6">@profile</strong>
def main():
sess = requests.session()
with ThreadPoolExecutor(max_workers=1) as executor:
print('Starting!')
tasks = {executor.submit(run_thread_request, sess, run):
run for run in range(50)}
for _ in as_completed(tasks):
pass
print('Done!')
return
<strong i="7">@profile</strong>
def calling():
main()
gc.collect()
return
if __name__ == '__main__':
calling()
在上面给出的代码中,我传递了一个会话对象,但是如果我将它替换为仅运行requests.get没有任何变化。
输出是:
➜ thread-test pipenv run python run.py
Starting!
Done!
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
10 23.2 MiB 23.2 MiB <strong i="13">@profile</strong>
11 def main():
12 23.2 MiB 0.0 MiB sess = requests.session()
13 23.2 MiB 0.0 MiB with ThreadPoolExecutor(max_workers=1) as executor:
14 23.2 MiB 0.0 MiB print('Starting!')
15 23.4 MiB 0.0 MiB tasks = {executor.submit(run_thread_request, sess, run):
16 23.4 MiB 0.0 MiB run for run in range(50)}
17 25.8 MiB 2.4 MiB for _ in as_completed(tasks):
18 25.8 MiB 0.0 MiB pass
19 25.8 MiB 0.0 MiB print('Done!')
20 25.8 MiB 0.0 MiB return
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
22 23.2 MiB 23.2 MiB <strong i="14">@profile</strong>
23 def calling():
24 25.8 MiB 2.6 MiB main()
25 25.8 MiB 0.0 MiB gc.collect()
26 25.8 MiB 0.0 MiB return
Pipfile 看起来像这样:
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
[requires]
python_version = "3.6"
[packages]
requests = "==2.21.0"
memory-profiler = "==0.55.0"
 jotunskij
于 2018-12-17
jotunskij
于 2018-12-17
FWIW我也遇到了类似的内存泄漏@jotunskij这里是更多信息
 pawel-lmcb
于 2019-03-26
pawel-lmcb
于 2019-03-26
我也有同样的问题,使用带有线程的 requests.get 实际上每个请求消耗大约 0.1 - 0.9 的内存,并且在请求之后它不会“清除”自身而是保存它。
 BarryThrill
于 2019-05-05
BarryThrill
于 2019-05-05
同样在这里,有什么解决办法吗?
 popjxc
于 2019-06-13
popjxc
于 2019-06-13
编辑
我的问题似乎是由于在请求中使用了verify=False ,我在 #5215 下提出了一个错误
有同样的问题。 我有一个生成线程的简单脚本,该线程调用一个运行 while 循环的函数,该循环查询 API 以检查状态值,然后休眠 10 秒,然后循环将再次运行,直到脚本停止。
使用requests.get函数时,我可以通过任务管理器观察生成的进程,看到内存使用量慢慢增加。
但是,如果我从循环中删除requests.get调用或直接使用urllib3来发出 get 请求,则内存使用量几乎不会增加。
我在这两种情况下都看了两个多小时,当使用requests.get ,两小时后内存使用量为 1GB+,而使用urllib3内存使用量约为。 两个小时后20mb。
Python 3.7.4 和请求 2.22.0
 tallona
于 2019-09-27
tallona
于 2019-09-27
看起来 Requests 仍处于测试阶段,有这样的内存泄漏。 来吧,伙计们,修补这个! 😉👍
 PedanticHacker
于 2019-10-01
PedanticHacker
于 2019-10-01
这事有进一步更新吗? 带有文件上传的简单 POST 请求也会产生类似的内存泄漏问题。
 MuhammadAliShahzad
于 2019-10-02
MuhammadAliShahzad
于 2019-10-02
对我来说也一样......线程池执行时的泄漏也在 Windows python38 上。
请求 2.22.0
 far-rainbow
于 2019-12-09
far-rainbow
于 2019-12-09
我也是
 sunnyjiechao
于 2020-01-13
sunnyjiechao
于 2020-01-13
这是我的内存泄漏问题,有人可以帮忙吗? https://stackoverflow.com/questions/59746125/memory-keep-成长-when-using-mutil-thread-download-file
sunnyjiechao
于 2020-01-16
调用Session.close()和Response.close()可以避免内存泄漏。
并且 ssl 会消耗更多内存,因此在请求 https url 时内存泄漏会更加显着。
首先我做了4个测试用例:
- 请求 + ssl (https://)
- 请求 + 非 ssl (http://)
- aiohttp + ssl (https://)
- aiohttp + 非 ssl (http://)
伪代码:
def run(url):
session = requests.session()
response = session.get(url)
while True:
for url in urls: # about 5k urls of public websites
# execute in thread pool, size=10
thread_pool.submit(run, url)
# in another thread, record memory usage every seconds
内存使用图(y轴:MB,x轴:时间),请求使用大量内存,内存增长非常快,而aiohttp内存使用稳定:
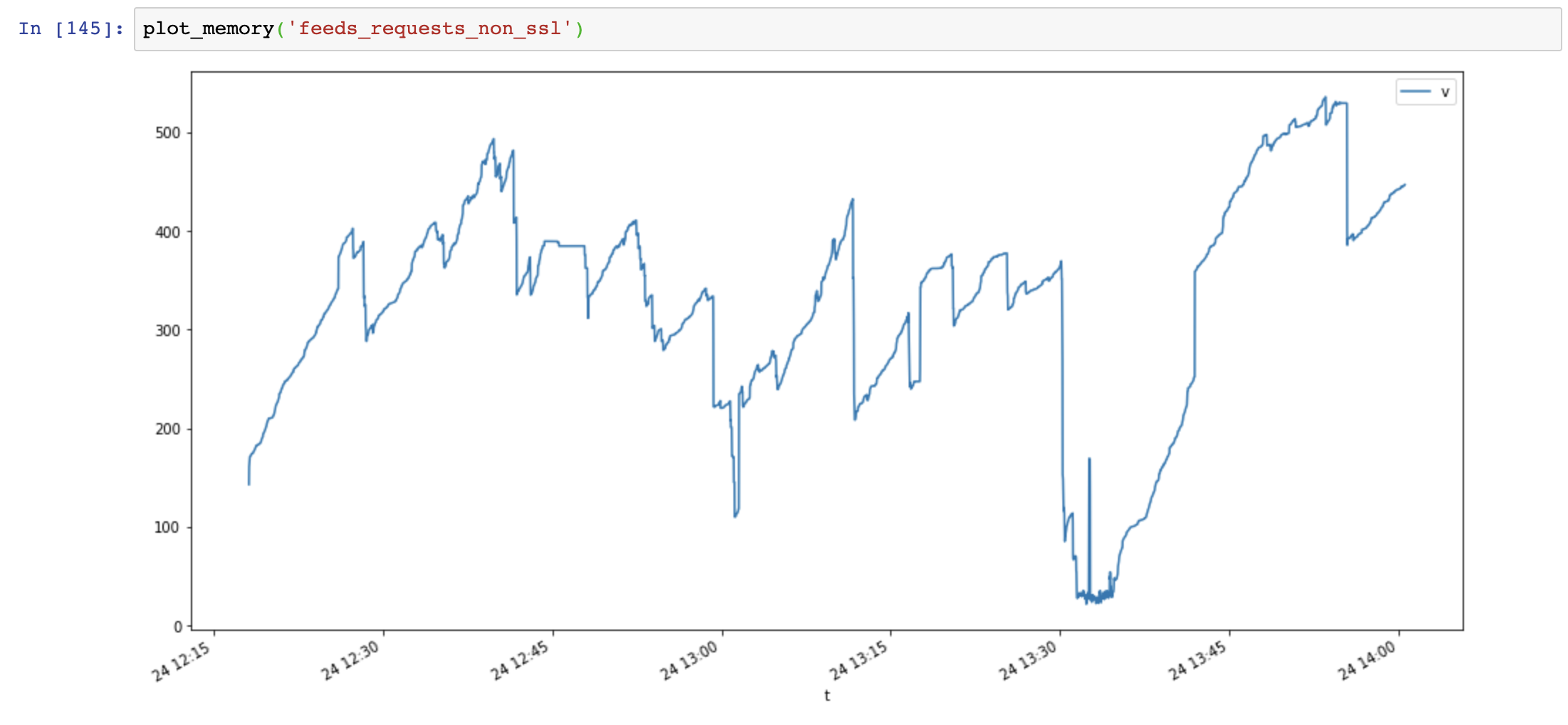



然后我添加Session.close()并再次测试:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
内存使用量显着减少,但内存使用量仍会随时间增加:


最后我添加Response.close()并再次测试:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
response.close() # close response !!
内存使用量再次减少,但不会随时间增加:
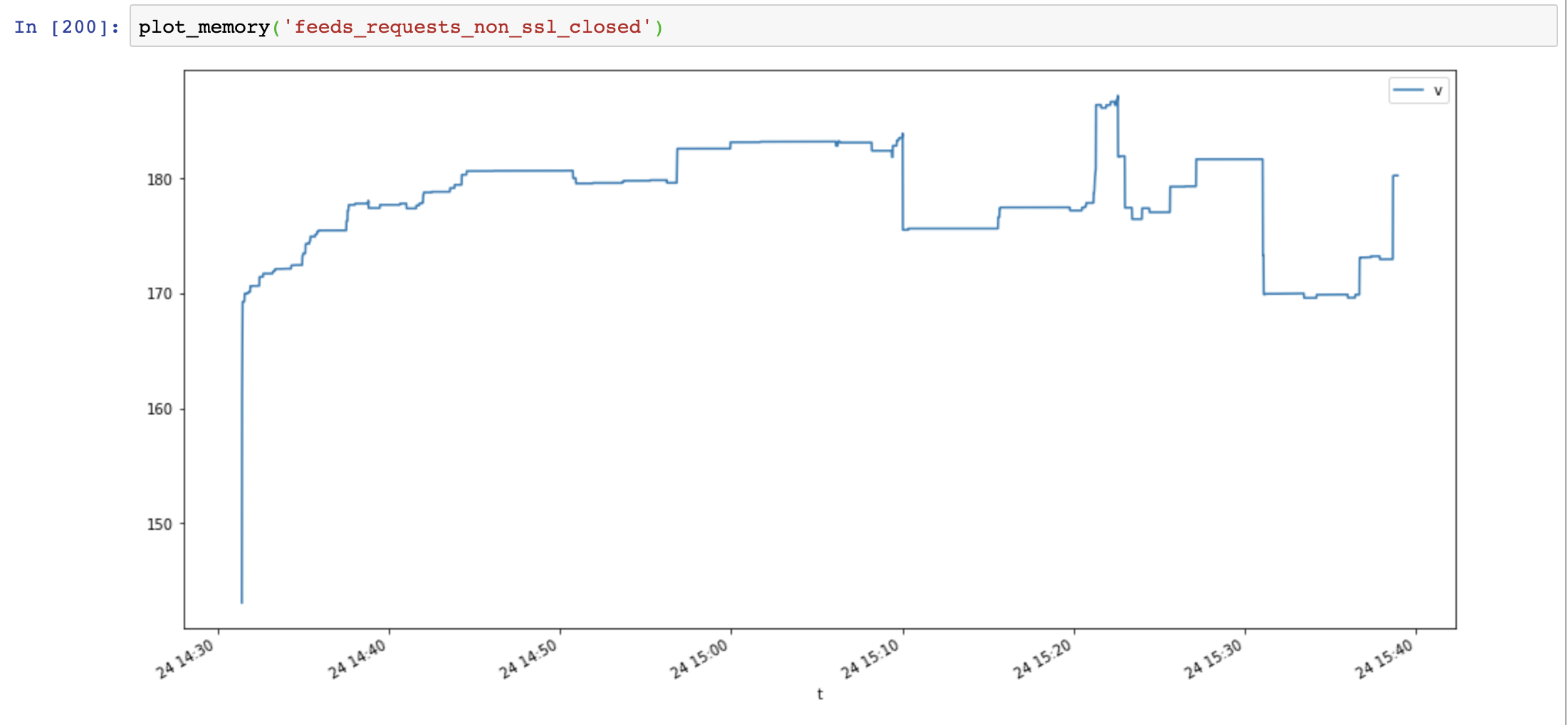

比较aiohttp和requests,内存泄漏不是ssl造成的,是连接资源没有关闭造成的。
有用的脚本:
class MemoryReporter:
def __init__(self, name):
self.name = name
self.file = open(f'memoryleak/memory_{name}.txt', 'w')
self.thread = None
def _get_memory(self):
return psutil.Process().memory_info().rss
def main(self):
while True:
t = time.time()
v = self._get_memory()
self.file.write(f'{t},{v}\n')
self.file.flush()
time.sleep(1)
def start(self):
self.thread = Thread(target=self.main, name=self.name, daemon=True)
self.thread.start()
def plot_memory(name):
filepath = 'memoryleak/memory_{}.txt'.format(name)
df_mem = pd.read_csv(filepath, index_col=0, names=['t', 'v'])
df_mem.index = pd.to_datetime(df_mem.index, unit='s')
df_mem.v = df_mem.v / 1024 / 1024
df_mem.plot(figsize=(16, 8))
系统信息:
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.8"
},
"implementation": {
"name": "CPython",
"version": "3.7.4"
},
"platform": {
"release": "18.0.0",
"system": "Darwin"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.22.0"
},
"system_ssl": {
"version": "1010104f"
},
"urllib3": {
"version": "1.25.6"
},
"using_pyopenssl": false
}
 guyskk
于 2020-03-24
guyskk
于 2020-03-24
SSL泄漏问题在Windows和OSX上打包了OpenSSL <= 3.7.4,它没有正确地从上下文中释放内存
https://github.com/VeNoMouS/cloudscraper/issues/143#issuecomment -613092377
 VeNoMouS
于 2020-04-13
VeNoMouS
于 2020-04-13
相关问题
 xsren
·
3评论
xsren
·
3评论
 Matt3o12
·
3评论
Matt3o12
·
3评论
 Gonzalliz
·
3评论
Gonzalliz
·
3评论
 tiran
·
3评论
tiran
·
3评论
 remram44
·
4评论
remram44
·
4评论
最有用的评论
类似的问题。 请求在线程中运行时会占用内存。 在这里重现的代码:
在上面给出的代码中,我传递了一个会话对象,但是如果我将它替换为仅运行
requests.get没有任何变化。输出是:
Pipfile 看起来像这样: