Requests: Solicita vazamento de memória
Resumo.
resultado esperado
Programa funcionando normalmente
Resultado atual
O programa consome toda a memória RAM até parar de funcionar
Etapas de reprodução
Pseudo-código:
def function():
proxies = {
'https': proxy
}
session = requests.Session()
session.headers.update({'User-Agent': 'user - agent'})
try: #
login = session.get(url, proxies=proxies) # HERE IS WHERE MEMORY LEAKS
except: #
return -1 #
return 0
Informação do sistema
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.6"
},
"implementation": {
"name": "CPython",
"version": "3.6.3"
},
"platform": {
"release": "10",
"system": "Windows"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.18.4"
},
"system_ssl": {
"version": "100020bf"
},
"urllib3": {
"version": "1.22"
},
"using_pyopenssl": false
}
 Munroc
Munroc
Todos 22 comentários
Forneça-nos o resultado de
python -m requests.help
Se isso não estiver disponível em sua versão de Solicitações, forneça algumas informações básicas sobre seu sistema (versão Python, sistema operacional, etc).
 sigmavirus24
em 20 abr. 2018
sigmavirus24
em 20 abr. 2018
@ sigmavirus24 Feito
Munroc
em 20 abr. 2018
Ei @munroc , algumas perguntas rápidas sobre sua implementação de threading, já que ela não está incluída no pseudo código.
Você está criando uma nova sessão para cada thread e qual é o tamanho do threadpool que está usando?
Que ferramenta você está usando para determinar de onde vem o vazamento? Você se importaria de compartilhar os resultados?
Já faz algum tempo que percebemos vazamentos de memória em torno das sessões, mas não tenho certeza se encontramos uma arma fumegante ou um impacto verdadeiramente confirmado.
 nateprewitt
em 20 abr. 2018
nateprewitt
em 20 abr. 2018
@nateprewitt Olá, sim, estou criando uma nova sessão para cada tópico. O pool de threads é 30. Eu tentei com 2 - 200 threads e vazamentos de memória de qualquer maneira. Não estou usando uma ferramenta, apenas fiz estas alterações na função:
coloque return 0 antes de login = session.get e nenhum vazamento de memória. se eu colocar return 0 após login = session.get a memória começa a vazar. Se você quiser, posso enviar meu código-fonte não é muito grande.
Munroc
em 20 abr. 2018
@Munroc se tivermos o código completo, acho que seria mais fácil isolar a causa real. Mas, com base na essência do código fornecida, acho que é muito difícil concluir que há um vazamento de memória.
Como você mencionou, se você return imediatamente antes de chamar session.get , então apenas proxies e session objetos existirão na memória (simplificado demais .. mas eu espero que você tenha entendido: sorria :). No entanto, assim que você chamar session.get(url, proxies=proxies) , o HTML de url será recuperado e salvo localmente login variável session.get chamada "parecerá" que está perdendo memória, mas na verdade estão se comportando normalmente (memória) aumentando linearmente no tamanho de url resultado.
No entanto, digamos que você estava usando threads e .join() imediatamente depois. Nesse caso, acho que precisamos ver como seus threads foram gerenciados - e se eles foram fechados / limpos corretamente.
 initbar
em 21 mai. 2018
initbar
em 21 mai. 2018
@LeoSZN Acho que em seu exemplo específico, você está fechando apenas o último Process objeto após gerar vários elementos Process por urls .
Você poderia tentar daemonizá-los usando p.daemon = True e executá-los (para que, uma vez que o thread principal termine, todos os processos filhos gerados morram também)? Caso contrário, armazene os processos gerados em uma matriz separada e certifique-se de fechar todos eles usando um loop.
initbar
em 14 out. 2018
@initbar
Preciso executar p.daemon = True no loop ou fora dele antes de p.join() ? A propósito, ainda preciso de p.join() após aplicar p.daemon = True ?
 leoszn
em 15 out. 2018
leoszn
em 15 out. 2018
_Ok, fui chutado de um novo tópico para este, então deixe-me entrar no seu.
Pode ser este problema fornecer mais informações e irá acelerar a resolução do problema ..._
Estou executando o bot do Telegram e notei a degradação da memória livre ao executar o bot por um longo tempo. Em primeiro lugar, suspeito do meu código; então eu suspeito de bot e finalmente cheguei aos pedidos. :)
Eu usei len (gc.get_objects ()) para identificar que o problema existe. Localizei as rotinas de comunicação, apaguei todo o código do bot e cheguei ao exemplo que aumenta a contagem de objetos gc em cada iteração.
resultado esperado
len (gc.get_objects ()) deve dar o mesmo resultado em cada iteração de loop
Resultado atual
O valor de len (gc.get_objects ()) aumenta a cada iteração do loop.
Test N2
GetObjects len: 27959
Test N3
GetObjects len: 27960
Test N4
GetObjects len: 27961
Test N5
GetObjects len: 27962
Test N6
GetObjects len: 27963
Test N7
GetObjects len: 27964
Etapas de reprodução
token = "XXX:XXX"
chat_id = '111'
proxy = {'https':'socks5h://ZZZ'} #You may need proxy to run this in Russia
from time import sleep
import gc, requests
def garbage_info():
res = ""
res += "\nGetObjects len: " + str(len(gc.get_objects()))
return res
def tester():
count = 0
while(True):
sleep(1)
count += 1
msg = "\nTest N{0}".format(count) + garbage_info()
print(msg)
method_url = r'sendMessage'
payload = {'chat_id': str(chat_id), 'text': msg}
request_url = "https://api.telegram.org/bot{0}/{1}".format(token, method_url)
method_name = 'get'
session = requests.session()
req = requests.Request(
method=method_name.upper(),
url=request_url,
params=payload
)
prep = session.prepare_request(req)
settings = session.merge_environment_settings(
prep.url, None, None, None, None)
# prep.url, proxy, None, None, None) #Change the line to enable proxy
send_kwargs = {
'timeout': None,
'allow_redirects': None,
}
send_kwargs.update(settings)
resp = session.send(prep, **send_kwargs)
# For more clean output
gc.collect()
tester()
Informação do sistema
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "2.3.1"
},
"idna": {
"version": "2.7"
},
"implementation": {
"name": "CPython",
"version": "3.6.6"
},
"platform": {
"release": "4.15.0-36-generic",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "1010009f",
"version": "17.5.0"
},
"requests": {
"version": "2.19.1"
},
"system_ssl": {
"version": "1010007f"
},
"urllib3": {
"version": "1.23"
},
"using_pyopenssl": true
}
_O mesmo comportamento que tive no Python 3.5.3 no Windows10._
 Badiboy
em 16 out. 2018
Badiboy
em 16 out. 2018
@LeoSZN
@initbar
Preciso executar
p.daemon = Trueno loop ou fora dele antes dep.join()? A propósito, ainda preciso dep.join()após aplicarp.daemon = True?
# ..
for i in urls:
p = Process(target=main, args=(i,))
p.daemon = True # before `.start`
p.start()
# ..
Como uma observação secundária, você ainda pode .join processos daemon - mas eles são quase garantidos para serem mortos quando seu processo pai terminar (a menos que de alguma forma se tornem órfãos involuntariamente; nesse caso, por favor me avise! adoro aprender mais sobre isso).
Caso contrário, você pode armazenar os objetos Process separadamente como uma matriz e uni-los no final:
# ..
processes = [
Process(target=main, args=(i,))
for i in urls
]
# start the process activity.
resultado esperado
len (gc.get_objects ()) deve dar o mesmo resultado em cada iteração de loop
O motivo desse comportamento foi encontrado no mecanismo de cache de "solicitações".
Funciona incorretamente (suspeito): adiciona um registro de cache a cada chamada para a URL da API do Telegram (em vez de armazená-lo uma vez). Mas isso não leva ao vazamento de memória, porque o tamanho do cache é limitado a 20 e o cache é redefinido após atingir esse limite e o número crescente de objetos será reduzido de volta ao valor inicial.
Badiboy
em 26 out. 2018
Problema semelhante. Requests consome memória quando executado em thread. Código para reproduzir aqui:
import gc
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from memory_profiler import profile
def run_thread_request(sess, run):
response = sess.get('https://www.google.com')
return
<strong i="6">@profile</strong>
def main():
sess = requests.session()
with ThreadPoolExecutor(max_workers=1) as executor:
print('Starting!')
tasks = {executor.submit(run_thread_request, sess, run):
run for run in range(50)}
for _ in as_completed(tasks):
pass
print('Done!')
return
<strong i="7">@profile</strong>
def calling():
main()
gc.collect()
return
if __name__ == '__main__':
calling()
No código fornecido acima, passo um objeto de sessão, mas se eu substituí-lo apenas executando requests.get nada muda.
O resultado é:
➜ thread-test pipenv run python run.py
Starting!
Done!
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
10 23.2 MiB 23.2 MiB <strong i="13">@profile</strong>
11 def main():
12 23.2 MiB 0.0 MiB sess = requests.session()
13 23.2 MiB 0.0 MiB with ThreadPoolExecutor(max_workers=1) as executor:
14 23.2 MiB 0.0 MiB print('Starting!')
15 23.4 MiB 0.0 MiB tasks = {executor.submit(run_thread_request, sess, run):
16 23.4 MiB 0.0 MiB run for run in range(50)}
17 25.8 MiB 2.4 MiB for _ in as_completed(tasks):
18 25.8 MiB 0.0 MiB pass
19 25.8 MiB 0.0 MiB print('Done!')
20 25.8 MiB 0.0 MiB return
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
22 23.2 MiB 23.2 MiB <strong i="14">@profile</strong>
23 def calling():
24 25.8 MiB 2.6 MiB main()
25 25.8 MiB 0.0 MiB gc.collect()
26 25.8 MiB 0.0 MiB return
E o Pipfile se parece com isto:
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
[requires]
python_version = "3.6"
[packages]
requests = "==2.21.0"
memory-profiler = "==0.55.0"
 jotunskij
em 17 dez. 2018
jotunskij
em 17 dez. 2018
FWIW, também estou tendo um vazamento de memória semelhante ao @jotunskij aqui está mais informações
 pawel-lmcb
em 26 mar. 2019
pawel-lmcb
em 26 mar. 2019
Eu também tenho o mesmo problema em que o uso de requests.get com threading consome a memória em cerca de 0,1 - 0,9 por solicitação e não está "limpando" a si mesmo após as solicitações, mas a salva.
 BarryThrill
em 5 mai. 2019
BarryThrill
em 5 mai. 2019
Mesmo aqui, alguma solução?
 popjxc
em 13 jun. 2019
popjxc
em 13 jun. 2019
Editar
Meu problema parece ser devido ao uso de verify=False em solicitações, eu levantei um bug em # 5215
Tendo o mesmo problema. Eu tenho um script simples que gera um thread, este thread chama uma função que executa um loop while, este loop consulta uma API para verificar um valor de status e, em seguida, dorme por 10 segundos e, em seguida, o loop será executado novamente até que o script seja interrompido.
Ao usar a função requests.get , posso ver o uso de memória aumentando lentamente por meio do gerenciador de tarefas, observando o processo gerado.
Mas se eu remover a chamada requests.get do loop ou usar urllib3 diretamente para fazer a solicitação get, haverá muito pouco ou nenhum aumento no uso de memória.
Eu assisti isso por um período de duas horas em ambos os casos e ao usar requests.get o uso de memória é de 1 GB + após duas horas, enquanto ao usar urllib3 o uso de memória é de aprox. 20 MB após duas horas.
Python 3.7.4 e solicitações 2.22.0
 tallona
em 27 set. 2019
tallona
em 27 set. 2019
Parece que Requests ainda está em estágio beta, com vazamentos de memória como esse. Vamos, rapazes, consertem isso! 😉👍
 PedanticHacker
em 1 out. 2019
PedanticHacker
em 1 out. 2019
alguma atualização disso? A solicitação POST simples com um upload de arquivo também cria o problema semelhante de vazamento de memória.
 MuhammadAliShahzad
em 2 out. 2019
MuhammadAliShahzad
em 2 out. 2019
O mesmo para mim ... o vazamento durante a execução do threadpool também está no Windows python38.
pedidos 2.22.0
 far-rainbow
em 9 dez. 2019
far-rainbow
em 9 dez. 2019
O mesmo para mim
 sunnyjiechao
em 13 jan. 2020
sunnyjiechao
em 13 jan. 2020
Aqui está o meu problema de vazamento de memória, alguém pode ajudar? https://stackoverflow.com/questions/59746125/memory-keep-growing-when-using-mutil-thread-download-file
sunnyjiechao
em 16 jan. 2020
Call Session.close() e Response.close() pode evitar o vazamento de memória.
E o ssl consumirá mais memória, então o vazamento de memória será mais notável quando solicitar urls https.
Primeiro, faço 4 casos de teste:
- solicitações + ssl (https: //)
- solicitações + não SSL (http: //)
- aiohttp + ssl (https: //)
- aiohttp + não SSL (http: //)
Pseudo-código:
def run(url):
session = requests.session()
response = session.get(url)
while True:
for url in urls: # about 5k urls of public websites
# execute in thread pool, size=10
thread_pool.submit(run, url)
# in another thread, record memory usage every seconds
Gráfico de uso de memória (eixo y: MB, eixo x: tempo), as solicitações usam muita memória e a memória aumenta muito rápido, enquanto o uso de memória aiohttp é estável:
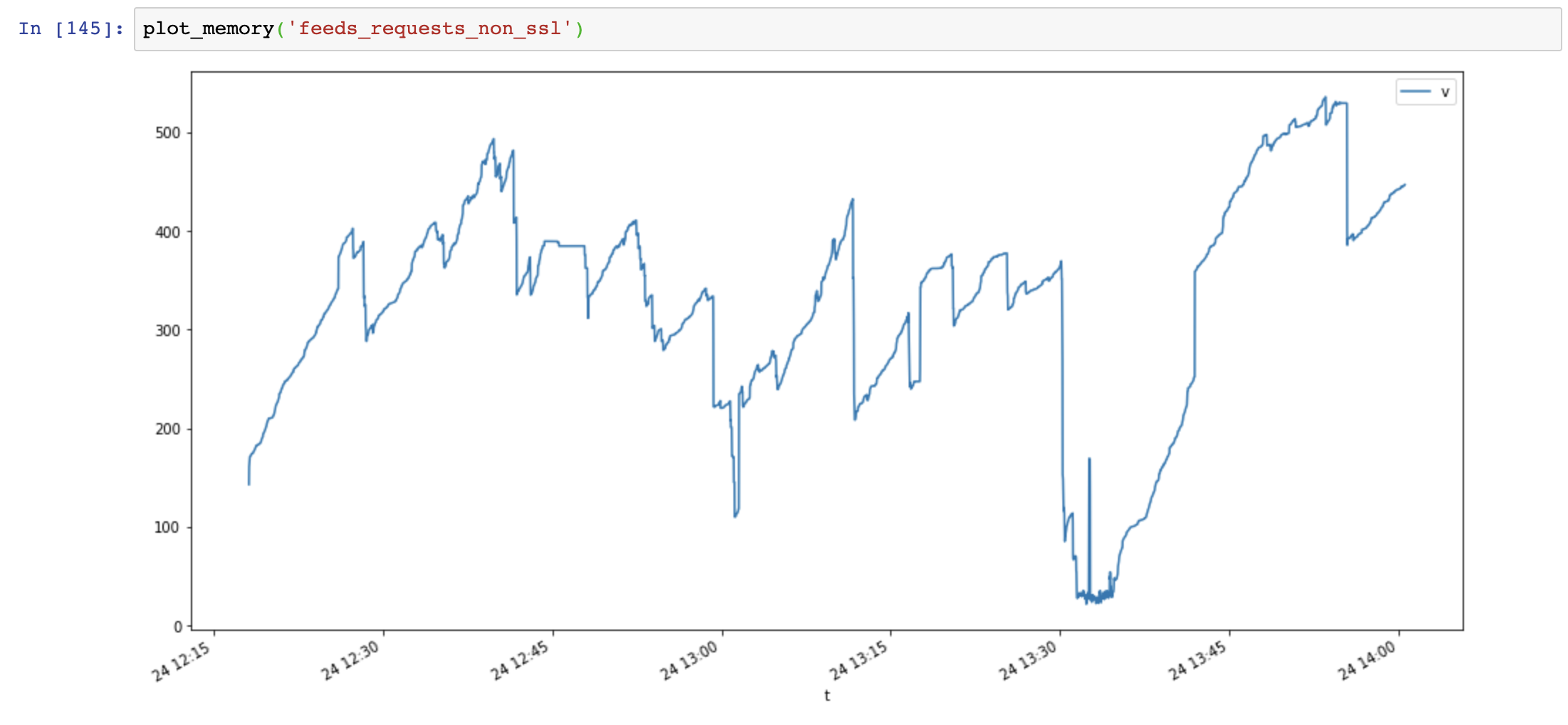



Em seguida, adiciono Session.close() e testo novamente:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
O uso de memória diminuiu significativamente, mas o uso de memória ainda aumenta com o tempo:


Finalmente adiciono Response.close() e testo novamente:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
response.close() # close response !!
O uso de memória diminuiu novamente e não aumentou com o tempo:
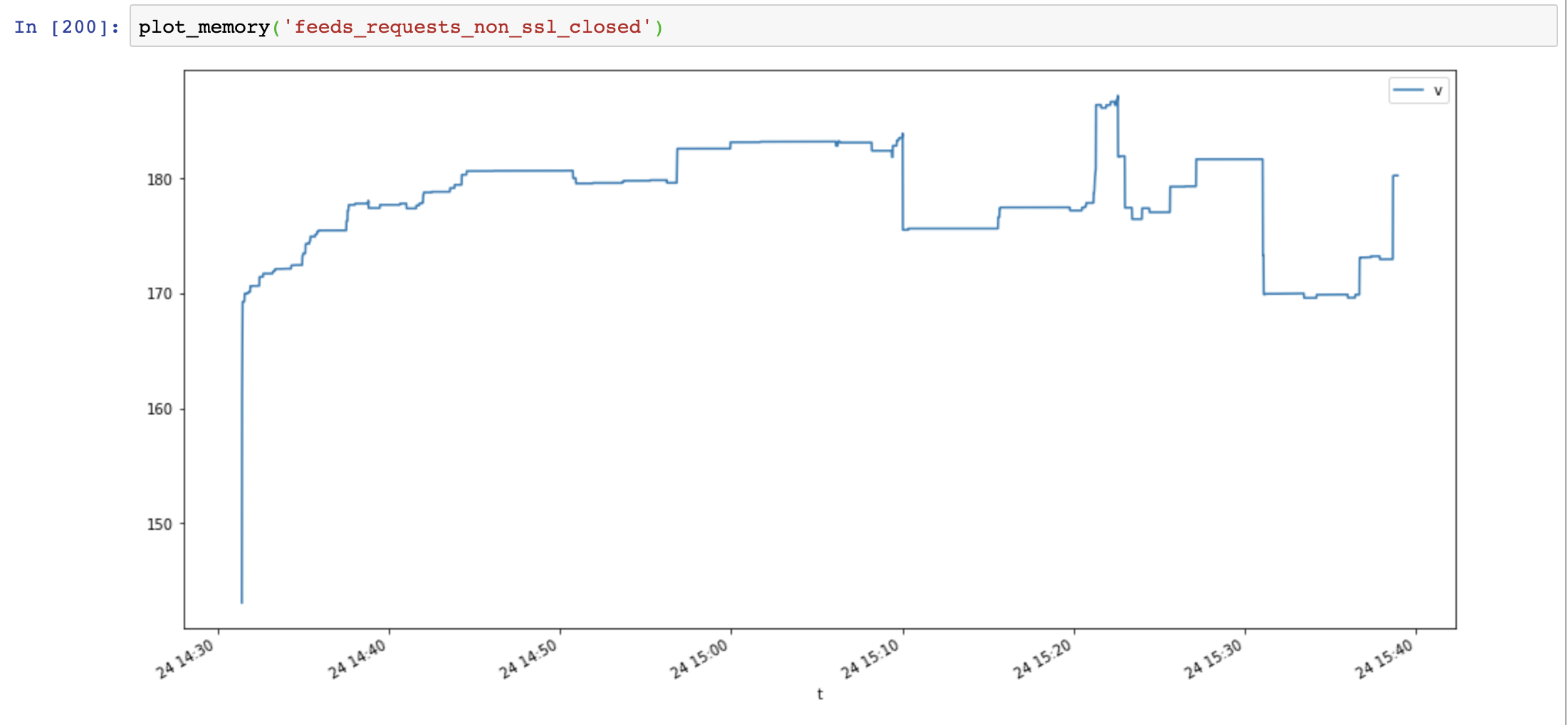

Compare aiohttp e as solicitações mostram que o vazamento de memória não é causado por SSL, mas sim por recursos de conexão não fechados.
Scripts úteis:
class MemoryReporter:
def __init__(self, name):
self.name = name
self.file = open(f'memoryleak/memory_{name}.txt', 'w')
self.thread = None
def _get_memory(self):
return psutil.Process().memory_info().rss
def main(self):
while True:
t = time.time()
v = self._get_memory()
self.file.write(f'{t},{v}\n')
self.file.flush()
time.sleep(1)
def start(self):
self.thread = Thread(target=self.main, name=self.name, daemon=True)
self.thread.start()
def plot_memory(name):
filepath = 'memoryleak/memory_{}.txt'.format(name)
df_mem = pd.read_csv(filepath, index_col=0, names=['t', 'v'])
df_mem.index = pd.to_datetime(df_mem.index, unit='s')
df_mem.v = df_mem.v / 1024 / 1024
df_mem.plot(figsize=(16, 8))
Informação do sistema:
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.8"
},
"implementation": {
"name": "CPython",
"version": "3.7.4"
},
"platform": {
"release": "18.0.0",
"system": "Darwin"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.22.0"
},
"system_ssl": {
"version": "1010104f"
},
"urllib3": {
"version": "1.25.6"
},
"using_pyopenssl": false
}
 guyskk
em 24 mar. 2020
guyskk
em 24 mar. 2020
O problema de vazamento de SSL é OpenSSL empacotado <= 3.7.4 no Windows e OSX, não está liberando a memória do contexto corretamente
https://github.com/VeNoMouS/cloudscraper/issues/143#issuecomment -613092377
 VeNoMouS
em 13 abr. 2020
VeNoMouS
em 13 abr. 2020
Questões relacionadas
 jake491
·
3Comentários
jake491
·
3Comentários
 brainwane
·
3Comentários
brainwane
·
3Comentários
 cnicodeme
·
3Comentários
cnicodeme
·
3Comentários
 ReimarBauer
·
4Comentários
ReimarBauer
·
4Comentários
 8key
·
3Comentários
8key
·
3Comentários
Comentários muito úteis
Problema semelhante. Requests consome memória quando executado em thread. Código para reproduzir aqui:
No código fornecido acima, passo um objeto de sessão, mas se eu substituí-lo apenas executando
requests.getnada muda.O resultado é:
E o Pipfile se parece com isto: