Sommaire.
résultat attendu
Programme en cours d'exécution normalement
Résultat actuel
Programme consommant toute la RAM jusqu'à ce qu'il cesse de fonctionner
Étapes de reproduction
Pseudocode :
def function():
proxies = {
'https': proxy
}
session = requests.Session()
session.headers.update({'User-Agent': 'user - agent'})
try: #
login = session.get(url, proxies=proxies) # HERE IS WHERE MEMORY LEAKS
except: #
return -1 #
return 0
Informations système
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.6"
},
"implementation": {
"name": "CPython",
"version": "3.6.3"
},
"platform": {
"release": "10",
"system": "Windows"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.18.4"
},
"system_ssl": {
"version": "100020bf"
},
"urllib3": {
"version": "1.22"
},
"using_pyopenssl": false
}
 Munroc
Munroc
Tous les 22 commentaires
Veuillez nous fournir la sortie de
python -m requests.help
Si cela n'est pas disponible sur votre version de Requests, veuillez fournir des informations de base sur votre système (version Python, système d'exploitation, etc.).
 sigmavirus24
le 20 avr. 2018
sigmavirus24
le 20 avr. 2018
@sigmavirus24 Terminé
Munroc
le 20 avr. 2018
Salut @munroc , quelques questions rapides sur votre implémentation de threading car elle n'est pas incluse dans le pseudo-code.
Créez-vous une nouvelle session pour chaque thread et quelle est la taille du pool de threads que vous utilisez ?
Quel outil utilisez-vous pour déterminer d'où vient la fuite ? Cela vous dérangerait-il de partager les résultats ?
Nous avons des indices de fuites de mémoire autour des sessions depuis un certain temps maintenant, mais je ne suis pas sûr que nous ayons trouvé une arme fumante ou un impact vraiment confirmé.
 nateprewitt
le 20 avr. 2018
nateprewitt
le 20 avr. 2018
@nateprewitt Bonjour, oui je crée une nouvelle session pour chaque thread. Le pool de threads est de 30. J'ai essayé avec 2 à 200 threads et des fuites de mémoire de toute façon. Je n'utilise pas d'outil, je viens d'apporter ces modifications à la fonction :
mettre return 0 avant login = session.get et pas de fuite de mémoire. si je mets le retour 0 après la connexion = la mémoire session.get commence à fuir. Si vous voulez, je peux vous envoyer mon code source n'est pas trop volumineux.
Munroc
le 20 avr. 2018
@Munroc si nous avons le code complet, alors je pense qu'il serait plus facile d'isoler la cause réelle. Mais sur la base de l'essentiel du code qui a été fourni, je pense qu'il est très difficile de conclure qu'il y a une fuite de mémoire.
Comme vous l'avez mentionné, si vous return juste avant d'appeler session.get , alors seuls les objets proxies et session existeront dans la mémoire (simplifié.. mais je j'espère que vous avez l'idée :sourire:). Cependant, une fois que vous appelez session.get(url, proxies=proxies) , le code HTML du url sera récupéré et enregistré localement dans la variable login . Ce qui signifie que chaque appel de session.get "ressemblera" à une fuite de mémoire, mais ils se comportent en fait normalement en (mémoire) augmentant linéairement de la taille du résultat de url .
Cependant, disons que vous utilisiez des threads et que vous les .join() immédiatement après. Dans ce cas, je pense que nous devons examiner comment vos threads ont été gérés - et s'ils ont été fermés/nettoyés correctement.
 initbar
le 21 mai 2018
initbar
le 21 mai 2018
@LeoSZN Je pense que dans votre exemple spécifique, vous fermez uniquement le dernier objet Process après avoir généré plusieurs Process par urls éléments.
Pourriez-vous essayer de les démoniser en utilisant p.daemon = True et de les exécuter (de sorte qu'une fois le thread principal terminé, tous les processus enfants générés meurent également) ? Sinon, stockez les processus générés dans un tableau séparé et assurez-vous de les fermer tous à l'aide d'une boucle.
initbar
le 14 oct. 2018
@initbar
Dois-je exécuter p.daemon = True dans la boucle ou en dehors de la boucle avant p.join() ? Au fait, ai-je encore besoin de p.join() après avoir appliqué p.daemon = True ?
 leoszn
le 15 oct. 2018
leoszn
le 15 oct. 2018
_Ok, j'ai été expulsé du nouveau sujet vers celui-ci, alors laissez-moi rejoindre le vôtre.
Peut-être que ce problème fournira plus d'informations et accélérera la résolution du problème..._
J'exécute le bot Telegram et j'ai remarqué la dégradation de la mémoire libre lors de l'exécution du bot pendant une longue période. Premièrement, je suspecte mon code ; puis je soupçonne bot et enfin j'en suis venu aux requêtes. :)
J'ai utilisé len(gc.get_objects()) pour identifier que le problème existe. J'ai localisé les routines de communication, puis j'ai effacé tout le code du bot et j'en viens à l'exemple qui augmente le nombre d'objets gc à chaque itération.
résultat attendu
len(gc.get_objects()) devrait donner le même résultat à chaque itération de boucle
Résultat actuel
La valeur de len(gc.get_objects()) augmente à chaque itération de boucle.
Test N2
GetObjects len: 27959
Test N3
GetObjects len: 27960
Test N4
GetObjects len: 27961
Test N5
GetObjects len: 27962
Test N6
GetObjects len: 27963
Test N7
GetObjects len: 27964
Étapes de reproduction
token = "XXX:XXX"
chat_id = '111'
proxy = {'https':'socks5h://ZZZ'} #You may need proxy to run this in Russia
from time import sleep
import gc, requests
def garbage_info():
res = ""
res += "\nGetObjects len: " + str(len(gc.get_objects()))
return res
def tester():
count = 0
while(True):
sleep(1)
count += 1
msg = "\nTest N{0}".format(count) + garbage_info()
print(msg)
method_url = r'sendMessage'
payload = {'chat_id': str(chat_id), 'text': msg}
request_url = "https://api.telegram.org/bot{0}/{1}".format(token, method_url)
method_name = 'get'
session = requests.session()
req = requests.Request(
method=method_name.upper(),
url=request_url,
params=payload
)
prep = session.prepare_request(req)
settings = session.merge_environment_settings(
prep.url, None, None, None, None)
# prep.url, proxy, None, None, None) #Change the line to enable proxy
send_kwargs = {
'timeout': None,
'allow_redirects': None,
}
send_kwargs.update(settings)
resp = session.send(prep, **send_kwargs)
# For more clean output
gc.collect()
tester()
Informations système
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "2.3.1"
},
"idna": {
"version": "2.7"
},
"implementation": {
"name": "CPython",
"version": "3.6.6"
},
"platform": {
"release": "4.15.0-36-generic",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "1010009f",
"version": "17.5.0"
},
"requests": {
"version": "2.19.1"
},
"system_ssl": {
"version": "1010007f"
},
"urllib3": {
"version": "1.23"
},
"using_pyopenssl": true
}
_Le même comportement que j'avais sur Python 3.5.3 sur Windows10._
 Badiboy
le 16 oct. 2018
Badiboy
le 16 oct. 2018
@LeoSZN
@initbar
Dois-je exécuter
p.daemon = Truedans la boucle ou en dehors de la boucle avantp.join()? Au fait, ai-je encore besoin dep.join()après avoir appliquép.daemon = True?
# ..
for i in urls:
p = Process(target=main, args=(i,))
p.daemon = True # before `.start`
p.start()
# ..
Comme note mineure, vous pouvez toujours .join processus démons - mais ils sont presque garantis d'être tués lorsque leur processus parent se termine (à moins qu'ils ne deviennent orphelins involontairement ; dans ce cas, veuillez me le faire savoir ! Je J'adore en savoir plus).
Sinon, vous pouvez stocker les objets Process séparément sous forme de tableau et les joindre à la fin :
# ..
processes = [
Process(target=main, args=(i,))
for i in urls
]
# start the process activity.
résultat attendu
len(gc.get_objects()) devrait donner le même résultat à chaque itération de boucle
La raison de ce comportement a été trouvée dans le mécanisme de cache "demandes".
Cela fonctionne incorrectement (soupçonné): il ajoute un enregistrement de cache à chaque appel à l'URL de l'API Telegram (au lieu de le mettre en cache une fois). Mais cela n'entraîne pas de fuite de mémoire, car la taille du cache est limitée à 20 et le cache est réinitialisé après avoir atteint cette limite et le nombre croissant d'objets sera ramené à sa valeur initiale.
Badiboy
le 26 oct. 2018
Problème similaire. Les requêtes consomment de la mémoire lors de l'exécution dans le thread. Code à reproduire ici :
import gc
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from memory_profiler import profile
def run_thread_request(sess, run):
response = sess.get('https://www.google.com')
return
<strong i="6">@profile</strong>
def main():
sess = requests.session()
with ThreadPoolExecutor(max_workers=1) as executor:
print('Starting!')
tasks = {executor.submit(run_thread_request, sess, run):
run for run in range(50)}
for _ in as_completed(tasks):
pass
print('Done!')
return
<strong i="7">@profile</strong>
def calling():
main()
gc.collect()
return
if __name__ == '__main__':
calling()
Dans le code donné ci-dessus, je passe un objet de session, mais si je le remplace par l'exécution de requests.get rien ne change.
La sortie est :
➜ thread-test pipenv run python run.py
Starting!
Done!
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
10 23.2 MiB 23.2 MiB <strong i="13">@profile</strong>
11 def main():
12 23.2 MiB 0.0 MiB sess = requests.session()
13 23.2 MiB 0.0 MiB with ThreadPoolExecutor(max_workers=1) as executor:
14 23.2 MiB 0.0 MiB print('Starting!')
15 23.4 MiB 0.0 MiB tasks = {executor.submit(run_thread_request, sess, run):
16 23.4 MiB 0.0 MiB run for run in range(50)}
17 25.8 MiB 2.4 MiB for _ in as_completed(tasks):
18 25.8 MiB 0.0 MiB pass
19 25.8 MiB 0.0 MiB print('Done!')
20 25.8 MiB 0.0 MiB return
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
22 23.2 MiB 23.2 MiB <strong i="14">@profile</strong>
23 def calling():
24 25.8 MiB 2.6 MiB main()
25 25.8 MiB 0.0 MiB gc.collect()
26 25.8 MiB 0.0 MiB return
Et Pipfile ressemble à ceci :
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
[requires]
python_version = "3.6"
[packages]
requests = "==2.21.0"
memory-profiler = "==0.55.0"
 jotunskij
le 17 déc. 2018
jotunskij
le 17 déc. 2018
FWIW, je rencontre également une fuite de mémoire similaire à celle de @jotunskij, voici plus d'informations
 pawel-lmcb
le 26 mars 2019
pawel-lmcb
le 26 mars 2019
J'ai également le même problème où l'utilisation de request.get avec le threading consomme en fait de la mémoire d'environ 0,1 à 0,9 par requête et elle ne s'efface pas après les requêtes mais l'enregistre.
 BarryThrill
le 5 mai 2019
BarryThrill
le 5 mai 2019
Idem ici, un travail autour?
 popjxc
le 13 juin 2019
popjxc
le 13 juin 2019
Éditer
Mon problème semble être dû à l'utilisation de verify=False dans les requêtes, j'ai signalé un bogue sous #5215
Avoir le même problème. J'ai un script simple qui génère un thread, ce thread appelle une fonction qui exécute une boucle while, cette boucle interroge une API pour vérifier une valeur d'état, puis dort pendant 10 secondes, puis la boucle s'exécutera à nouveau jusqu'à ce que le script soit arrêté.
Lorsque vous utilisez la fonction requests.get , je peux voir l'utilisation de la mémoire augmenter lentement via le gestionnaire de tâches en observant le processus généré.
Mais si je supprime l'appel requests.get de la boucle ou que j'utilise urllib3 directement pour faire la requête get, il y a très peu ou pas de fluage de l'utilisation de la mémoire.
J'ai regardé cela sur une période de deux heures dans les deux cas et lors de l'utilisation de requests.get l'utilisation urllib3 l'utilisation
Python 3.7.4 et requêtes 2.22.0
 tallona
le 27 sept. 2019
tallona
le 27 sept. 2019
Il semble que Requests soit encore en phase bêta avec des fuites de mémoire comme celle-là. Allez, les gars, arrangez ça ! ??
 PedanticHacker
le 1 oct. 2019
PedanticHacker
le 1 oct. 2019
Une mise à jour pour ceci? Une simple requête POST avec un téléchargement de fichier crée également le même problème de fuite de mémoire.
 MuhammadAliShahzad
le 2 oct. 2019
MuhammadAliShahzad
le 2 oct. 2019
Idem pour moi... la fuite lors de l'exécution de threadpool est également sur Windows python38.
demandes 2.22.0
 far-rainbow
le 9 déc. 2019
far-rainbow
le 9 déc. 2019
Pareil pour moi
 sunnyjiechao
le 13 janv. 2020
sunnyjiechao
le 13 janv. 2020
Voici mon problème de fuite de mémoire, quelqu'un peut-il m'aider ? https://stackoverflow.com/questions/59746125/memory-keep-growing-when-using-mutil-thread-download-file
sunnyjiechao
le 16 janv. 2020
Appelez Session.close() et Response.close() peut éviter la fuite de mémoire.
Et SSL consommera plus de mémoire, donc la fuite de mémoire sera plus remarquable lors de la demande d'URL https.
Je fais d'abord 4 cas de test :
- requêtes + ssl (https://)
- requêtes + non-ssl (http://)
- aiohttp + ssl (https://)
- aiohttp + non-ssl (http://)
Pseudo-code :
def run(url):
session = requests.session()
response = session.get(url)
while True:
for url in urls: # about 5k urls of public websites
# execute in thread pool, size=10
thread_pool.submit(run, url)
# in another thread, record memory usage every seconds
Graphique d'utilisation de la mémoire (axe des y : Mo, axe des x : temps), les requêtes utilisent beaucoup de mémoire et la mémoire augmente très rapidement, tandis que l'utilisation de la mémoire aiohttp est stable :
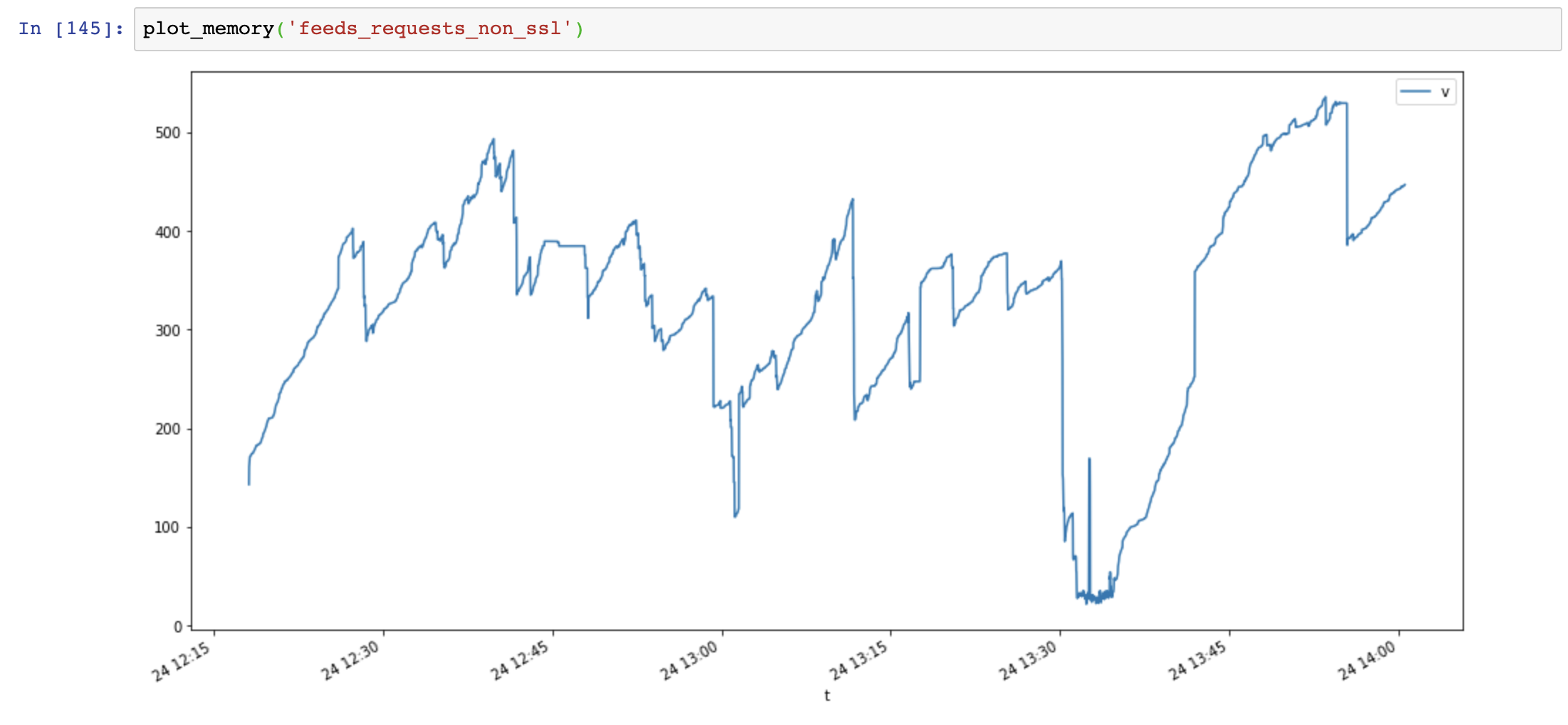



Ensuite, j'ajoute Session.close() et teste à nouveau :
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
L'utilisation de la mémoire a considérablement diminué, mais l'utilisation de la mémoire continue d'augmenter avec le temps :


Enfin, j'ajoute Response.close() et teste à nouveau :
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
response.close() # close response !!
L'utilisation de la mémoire a de nouveau diminué et n'a pas augmenté avec le temps :
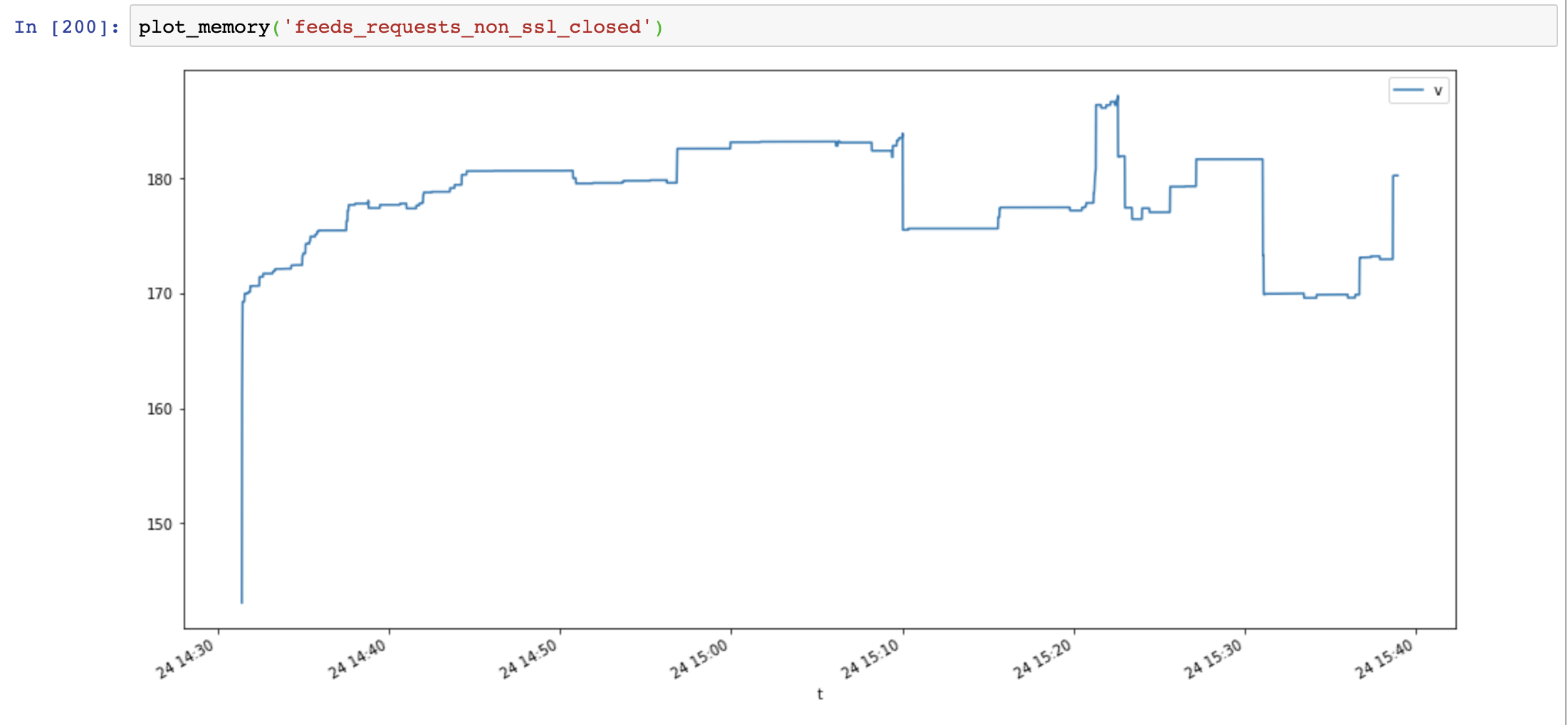

Comparez aiohttp et les requêtes montrent que la fuite de mémoire n'est pas causée par SSL, elle est causée par des ressources de connexion non fermées.
Scripts utiles :
class MemoryReporter:
def __init__(self, name):
self.name = name
self.file = open(f'memoryleak/memory_{name}.txt', 'w')
self.thread = None
def _get_memory(self):
return psutil.Process().memory_info().rss
def main(self):
while True:
t = time.time()
v = self._get_memory()
self.file.write(f'{t},{v}\n')
self.file.flush()
time.sleep(1)
def start(self):
self.thread = Thread(target=self.main, name=self.name, daemon=True)
self.thread.start()
def plot_memory(name):
filepath = 'memoryleak/memory_{}.txt'.format(name)
df_mem = pd.read_csv(filepath, index_col=0, names=['t', 'v'])
df_mem.index = pd.to_datetime(df_mem.index, unit='s')
df_mem.v = df_mem.v / 1024 / 1024
df_mem.plot(figsize=(16, 8))
Informations système :
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.8"
},
"implementation": {
"name": "CPython",
"version": "3.7.4"
},
"platform": {
"release": "18.0.0",
"system": "Darwin"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.22.0"
},
"system_ssl": {
"version": "1010104f"
},
"urllib3": {
"version": "1.25.6"
},
"using_pyopenssl": false
}
 guyskk
le 24 mars 2020
guyskk
le 24 mars 2020
Le problème de fuite SSL est empaqueté OpenSSL <= 3.7.4 sous Windows et OSX, il ne libère pas correctement la mémoire du contexte
https://github.com/VeNoMouS/cloudscraper/issues/143#issuecomment -613092377
 VeNoMouS
le 13 avr. 2020
VeNoMouS
le 13 avr. 2020
Questions connexes
 remram44
·
4Commentaires
remram44
·
4Commentaires
 ghtyrant
·
3Commentaires
ghtyrant
·
3Commentaires
 8key
·
3Commentaires
8key
·
3Commentaires
 Gonzalliz
·
3Commentaires
Gonzalliz
·
3Commentaires
 eromoe
·
3Commentaires
eromoe
·
3Commentaires
Commentaire le plus utile
Problème similaire. Les requêtes consomment de la mémoire lors de l'exécution dans le thread. Code à reproduire ici :
Dans le code donné ci-dessus, je passe un objet de session, mais si je le remplace par l'exécution de
requests.getrien ne change.La sortie est :
Et Pipfile ressemble à ceci :