概要。
期待される結果
プログラムは正常に実行されています
実結果
動作を停止するまですべてのRAMを消費するプログラム
複製手順
擬似コード:
def function():
proxies = {
'https': proxy
}
session = requests.Session()
session.headers.update({'User-Agent': 'user - agent'})
try: #
login = session.get(url, proxies=proxies) # HERE IS WHERE MEMORY LEAKS
except: #
return -1 #
return 0
システムインフォメーション
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.6"
},
"implementation": {
"name": "CPython",
"version": "3.6.3"
},
"platform": {
"release": "10",
"system": "Windows"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.18.4"
},
"system_ssl": {
"version": "100020bf"
},
"urllib3": {
"version": "1.22"
},
"using_pyopenssl": false
}
 Munroc
Munroc
全てのコメント22件
の出力を提供してください
python -m requests.help
ご使用のバージョンのリクエストでそれが利用できない場合は、システムに関する基本情報(Pythonバージョン、オペレーティングシステムなど)を入力してください。
 sigmavirus24
2018年04月20日
sigmavirus24
2018年04月20日
@ sigmavirus24完了
Munroc
2018年04月20日
@munrocさん、疑似コードに含まれていないため、スレッドの実装に関する簡単な質問がいくつかあります。
スレッドごとに新しいセッションを作成していますか?また、使用しているスレッドプールのサイズはどれくらいですか?
リークの原因を特定するためにどのツールを使用していますか? 結果を共有していただけませんか?
しばらくの間、セッションの前後でメモリリークの兆候が見られましたが、煙を吐く銃や本当に確認された影響を見つけたかどうかはわかりません。
 nateprewitt
2018年04月20日
nateprewitt
2018年04月20日
@nateprewittこんにちは、はい、すべてのスレッドに新しいセッションを作成しています。 スレッドプールは30です。2〜200のスレッドで試しましたが、とにかくメモリリークが発生しました。 私はツールを使用していません、私は関数にこの変更を加えました:
login = session.getの前にreturn0を置き、メモリリークはありません。 login = session.getメモリのリークが始まった後にreturn0を入力すると。 あなたが望むなら私はあなたに私のソースコードが大きすぎないように送ることができます。
Munroc
2018年04月20日
@Munroc完全なコードがあれば、実際の原因を
あなたが述べたように、 session.get呼び出す直前にreturnを実行すると、 proxies sessionオブジェクトとsession.get(url, proxies=proxies)を呼び出すと、 urlのHTMLが取得され、 login変数にローカルに保存されます。 つまり、各session.get呼び出しはメモリリークしているように見えますが、実際には(メモリ)がurl結果のサイズだけ直線的に増加することで正常に動作しています。
ただし、スレッドを使用していて、その直後に.join()を使用していたとします。 その場合、スレッドがどのように管理されているか、そしてスレッドが適切に閉じられているかどうかを確認する必要があると思います。
 initbar
2018年05月21日
initbar
2018年05月21日
@LeoSZNあなたの特定の例では、 urls要素ごとに複数のProcess生成した後、最後のProcessオブジェクトのみを閉じていると思います。
p.daemon = Trueを使用してそれらをデーモン化して実行してみてください(メインスレッドが終了すると、生成されたすべての子プロセスも停止します)。 それ以外の場合は、生成されたプロセスを別の配列に格納し、ループを使用してすべてを閉じるようにしてください。
initbar
2018年10月14日
@initbar
p.join()前に、ループ内またはループ外でp.daemon = Trueを実行する必要がありますか? ちなみに、 p.daemon = True適用した後もp.join()が必要ですか?
 leoszn
2018年10月15日
leoszn
2018年10月15日
_わかりました、私は新しいトピックからこのトピックに追いやられたので、あなたのトピックに参加させてください。
この問題はより多くの情報を提供し、問題解決を強化する可能性があります..._
Telegramボットを実行していますが、ボットを長時間実行すると空きメモリが低下することに気付きました。 まず、自分のコードが疑われます。 それからボットを疑って、ついにリクエストに来ました。 :)
len(gc.get_objects())を使用して、問題が存在することを確認しました。 通信ルーチンを見つけて、すべてのボットコードをクリアし、反復ごとにgcオブジェクトの数を増やす例に行き着きました。
期待される結果
len(gc.get_objects())は、すべてのループ反復で同じ結果をもたらすはずです
実結果
len(gc.get_objects())の値は、ループが繰り返されるたびに増加します。
Test N2
GetObjects len: 27959
Test N3
GetObjects len: 27960
Test N4
GetObjects len: 27961
Test N5
GetObjects len: 27962
Test N6
GetObjects len: 27963
Test N7
GetObjects len: 27964
複製手順
token = "XXX:XXX"
chat_id = '111'
proxy = {'https':'socks5h://ZZZ'} #You may need proxy to run this in Russia
from time import sleep
import gc, requests
def garbage_info():
res = ""
res += "\nGetObjects len: " + str(len(gc.get_objects()))
return res
def tester():
count = 0
while(True):
sleep(1)
count += 1
msg = "\nTest N{0}".format(count) + garbage_info()
print(msg)
method_url = r'sendMessage'
payload = {'chat_id': str(chat_id), 'text': msg}
request_url = "https://api.telegram.org/bot{0}/{1}".format(token, method_url)
method_name = 'get'
session = requests.session()
req = requests.Request(
method=method_name.upper(),
url=request_url,
params=payload
)
prep = session.prepare_request(req)
settings = session.merge_environment_settings(
prep.url, None, None, None, None)
# prep.url, proxy, None, None, None) #Change the line to enable proxy
send_kwargs = {
'timeout': None,
'allow_redirects': None,
}
send_kwargs.update(settings)
resp = session.send(prep, **send_kwargs)
# For more clean output
gc.collect()
tester()
システムインフォメーション
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "2.3.1"
},
"idna": {
"version": "2.7"
},
"implementation": {
"name": "CPython",
"version": "3.6.6"
},
"platform": {
"release": "4.15.0-36-generic",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "1010009f",
"version": "17.5.0"
},
"requests": {
"version": "2.19.1"
},
"system_ssl": {
"version": "1010007f"
},
"urllib3": {
"version": "1.23"
},
"using_pyopenssl": true
}
_Windows10のPython3.5.3で行ったのと同じ動作。_
 Badiboy
2018年10月16日
Badiboy
2018年10月16日
@LeoSZN
@initbar
p.join()前に、ループ内またはループ外でp.daemon = Trueを実行する必要がありますか? ちなみに、p.daemon = True適用した後もp.join()が必要ですか?
# ..
for i in urls:
p = Process(target=main, args=(i,))
p.daemon = True # before `.start`
p.start()
# ..
マイナーな注意として、デーモンプロセスは引き続き.joinますが、親プロセスが終了すると、ほぼ確実に強制終了されます(何らかの理由で意図せずに孤立した場合を除きます。その場合は、お知らせください。I私はそれについてもっと学ぶのが大好きです)。
それ以外の場合は、 Processオブジェクトを個別に配列として格納し、最後に結合することができます。
# ..
processes = [
Process(target=main, args=(i,))
for i in urls
]
# start the process activity.
期待される結果
len(gc.get_objects())は、すべてのループ反復で同じ結果をもたらすはずです
この動作の理由は、「リクエスト」キャッシュメカニズムにあります。
正しく機能しません(疑わしい):Telegram API URLへのすべての呼び出しにキャッシュレコードを追加します(一度キャッシュするのではなく)。 ただし、キャッシュサイズは20に制限されており、この制限に達するとキャッシュがリセットされ、オブジェクトの数が増えて初期値に戻るため、メモリリークは発生しません。
Badiboy
2018年10月26日
同様の問題。 リクエストは、スレッドで実行されているときにメモリを消費します。 ここで再現するコード:
import gc
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from memory_profiler import profile
def run_thread_request(sess, run):
response = sess.get('https://www.google.com')
return
<strong i="6">@profile</strong>
def main():
sess = requests.session()
with ThreadPoolExecutor(max_workers=1) as executor:
print('Starting!')
tasks = {executor.submit(run_thread_request, sess, run):
run for run in range(50)}
for _ in as_completed(tasks):
pass
print('Done!')
return
<strong i="7">@profile</strong>
def calling():
main()
gc.collect()
return
if __name__ == '__main__':
calling()
上記のコードでは、セッションオブジェクトを渡しますが、 requests.get実行するだけで置き換えると、何も変わりません。
出力は次のとおりです。
➜ thread-test pipenv run python run.py
Starting!
Done!
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
10 23.2 MiB 23.2 MiB <strong i="13">@profile</strong>
11 def main():
12 23.2 MiB 0.0 MiB sess = requests.session()
13 23.2 MiB 0.0 MiB with ThreadPoolExecutor(max_workers=1) as executor:
14 23.2 MiB 0.0 MiB print('Starting!')
15 23.4 MiB 0.0 MiB tasks = {executor.submit(run_thread_request, sess, run):
16 23.4 MiB 0.0 MiB run for run in range(50)}
17 25.8 MiB 2.4 MiB for _ in as_completed(tasks):
18 25.8 MiB 0.0 MiB pass
19 25.8 MiB 0.0 MiB print('Done!')
20 25.8 MiB 0.0 MiB return
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
22 23.2 MiB 23.2 MiB <strong i="14">@profile</strong>
23 def calling():
24 25.8 MiB 2.6 MiB main()
25 25.8 MiB 0.0 MiB gc.collect()
26 25.8 MiB 0.0 MiB return
そして、Pipfileは次のようになります。
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
[requires]
python_version = "3.6"
[packages]
requests = "==2.21.0"
memory-profiler = "==0.55.0"
 jotunskij
2018年12月17日
jotunskij
2018年12月17日
FWIW @ jotunskijと同様のメモリリークが発生しています。詳細はこちら
 pawel-lmcb
2019年03月26日
pawel-lmcb
2019年03月26日
また、requests.getをスレッドで使用すると、実際にはリクエストごとに約0.1〜0.9のメモリが消費され、リクエスト後にそれ自体が「クリア」されずに保存されるという同じ問題があります。
 BarryThrill
2019年05月05日
BarryThrill
2019年05月05日
ここでも同じですが、回避策はありますか?
 popjxc
2019年06月13日
popjxc
2019年06月13日
編集
私の問題はリクエストでverify=Falseを使用していることが原因のようですが、#5215でバグを発生させました
同じ問題を抱えています。 スレッドを生成する単純なスクリプトがあります。このスレッドはwhileループを実行する関数を呼び出します。このループは、APIにクエリを実行してステータス値を確認してから10秒間スリープし、スクリプトが停止するまでループを再度実行します。
requests.get関数を使用すると、生成されたプロセスを監視することで、タスクマネージャーを介してメモリ使用量がゆっくりと増加していることがわかります。
しかし、ループからrequests.get呼び出しを削除するか、 urllib3直接使用してget要求を行うと、メモリ使用量のクリープはほとんどありません。
どちらの場合も2時間にわたってこれを監視しましたが、 requests.getを使用した場合、メモリ使用量は2時間後に1GB以上になりますが、 urllib3使用した場合のメモリ使用量は約です。 2時間後に20mb。
Python3.7.4およびリクエスト2.22.0
 tallona
2019年09月27日
tallona
2019年09月27日
Requestsはまだベータ段階にあり、そのようなメモリリークが発生しているようです。 さあ、みんな、これを修正してください! 😉👍
 PedanticHacker
2019年10月01日
PedanticHacker
2019年10月01日
これに関する更新はありますか? ファイルのアップロードを伴う単純なPOSTリクエストでも、メモリリークの同様の問題が発生します。
 MuhammadAliShahzad
2019年10月02日
MuhammadAliShahzad
2019年10月02日
私も同じです...スレッドプールの実行中のリークはWindowspython38でも発生します。
リクエスト2.22.0
 far-rainbow
2019年12月09日
far-rainbow
2019年12月09日
わたしも
 sunnyjiechao
2020年01月13日
sunnyjiechao
2020年01月13日
これが私のメモリリークの問題です、誰でも助けることができますか? https://stackoverflow.com/questions/59746125/memory-keep-growing-when-using-mutil-thread-download-file
sunnyjiechao
2020年01月16日
Session.close()とResponse.close()を呼び出すと、メモリリークを回避できます。
また、SSLはより多くのメモリを消費するため、httpsURLを要求するとメモリリークがより顕著になります。
まず、4つのテストケースを作成します。
- リクエスト+ SSL(https://)
- リクエスト+非SSL(http://)
- aiohttp + ssl(https://)
- aiohttp + non-ssl(http://)
擬似コード:
def run(url):
session = requests.session()
response = session.get(url)
while True:
for url in urls: # about 5k urls of public websites
# execute in thread pool, size=10
thread_pool.submit(run, url)
# in another thread, record memory usage every seconds
メモリ使用量グラフ(y軸:MB、x軸:時間)、リクエストは大量のメモリを使用し、メモリは非常に速く増加しますが、aiohttpのメモリ使用量は安定しています。
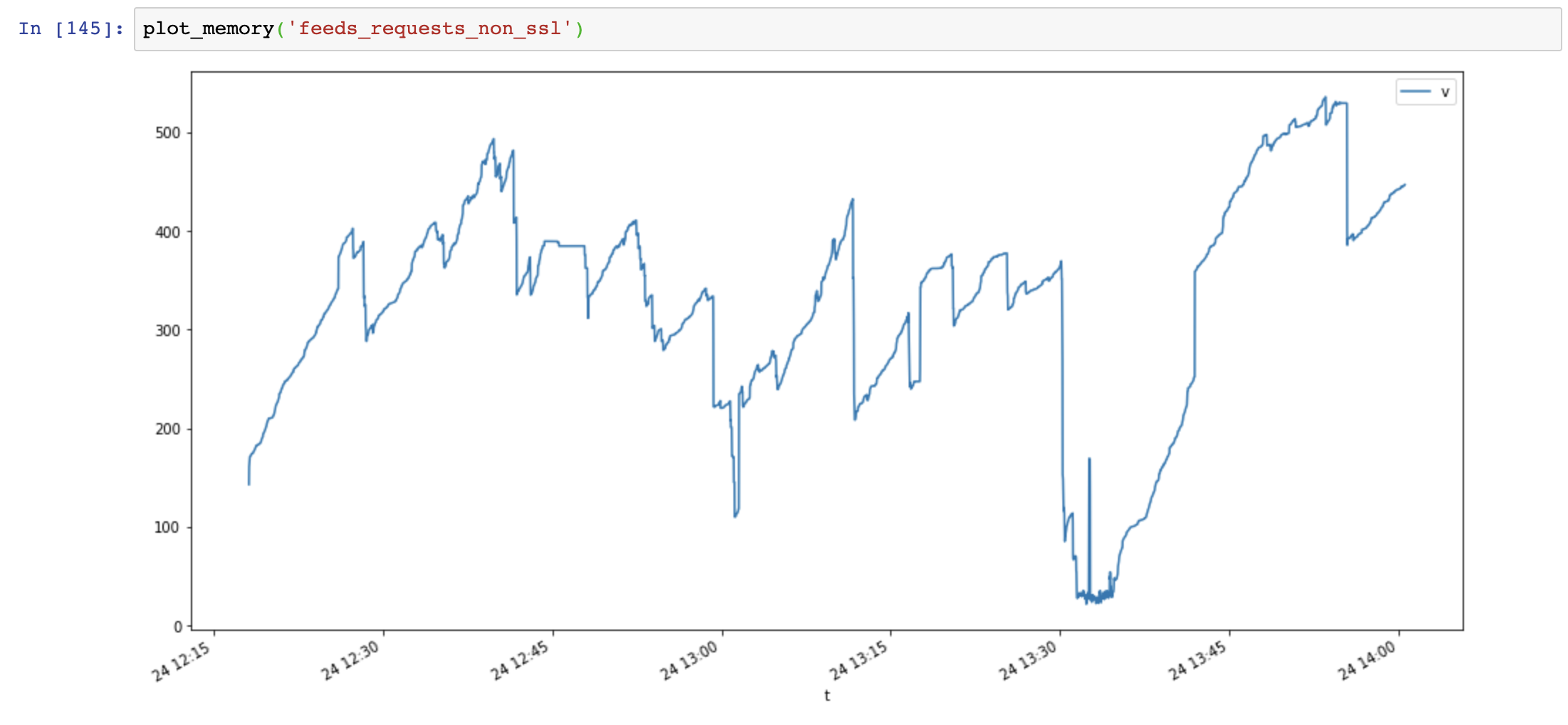



次に、 Session.close()を追加して、もう一度テストします。
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
メモリ使用量は大幅に減少しましたが、メモリ使用量は時間の経過とともに増加します。


最後に、 Response.close()を追加して、もう一度テストします。
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
response.close() # close response !!
メモリ使用量は再び減少し、時間の経過とともに増加しませんでした。
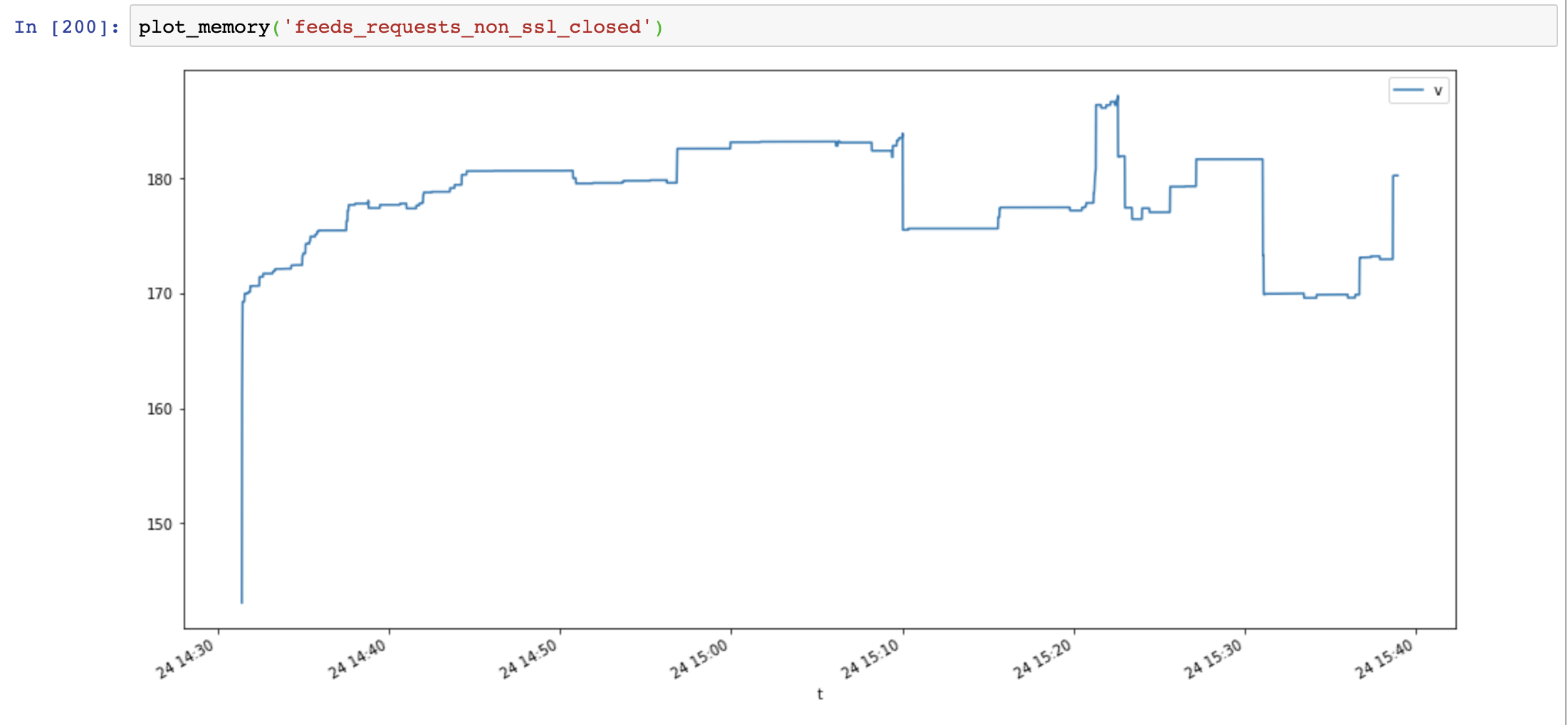

aiohttpとrequestsを比較すると、メモリリークはsslが原因ではなく、接続リソースが閉じられていないことが原因であることがわかります。
便利なスクリプト:
class MemoryReporter:
def __init__(self, name):
self.name = name
self.file = open(f'memoryleak/memory_{name}.txt', 'w')
self.thread = None
def _get_memory(self):
return psutil.Process().memory_info().rss
def main(self):
while True:
t = time.time()
v = self._get_memory()
self.file.write(f'{t},{v}\n')
self.file.flush()
time.sleep(1)
def start(self):
self.thread = Thread(target=self.main, name=self.name, daemon=True)
self.thread.start()
def plot_memory(name):
filepath = 'memoryleak/memory_{}.txt'.format(name)
df_mem = pd.read_csv(filepath, index_col=0, names=['t', 'v'])
df_mem.index = pd.to_datetime(df_mem.index, unit='s')
df_mem.v = df_mem.v / 1024 / 1024
df_mem.plot(figsize=(16, 8))
システムインフォメーション:
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.8"
},
"implementation": {
"name": "CPython",
"version": "3.7.4"
},
"platform": {
"release": "18.0.0",
"system": "Darwin"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.22.0"
},
"system_ssl": {
"version": "1010104f"
},
"urllib3": {
"version": "1.25.6"
},
"using_pyopenssl": false
}
 guyskk
2020年03月24日
guyskk
2020年03月24日
SSLリークの問題はWindowsおよびOSXでOpenSSL <= 3.7.4にパッケージ化されており、コンテキストからメモリを適切に解放しません
https://github.com/VeNoMouS/cloudscraper/issues/143#issuecomment -613092377
 VeNoMouS
2020年04月13日
VeNoMouS
2020年04月13日
関連する問題
 NoahCardoza
·
4コメント
NoahCardoza
·
4コメント
 brainwane
·
3コメント
brainwane
·
3コメント
 iLaus
·
3コメント
iLaus
·
3コメント
 avinassh
·
4コメント
avinassh
·
4コメント
 eromoe
·
3コメント
eromoe
·
3コメント
最も参考になるコメント
同様の問題。 リクエストは、スレッドで実行されているときにメモリを消費します。 ここで再現するコード:
上記のコードでは、セッションオブジェクトを渡しますが、
requests.get実行するだけで置き換えると、何も変わりません。出力は次のとおりです。
そして、Pipfileは次のようになります。