Zusammenfassung.
erwartetes Ergebnis
Programm läuft normal
Tatsächliche Ergebnis
Programm, das den gesamten RAM verbraucht, bis es nicht mehr funktioniert
Reproduktionsschritte
Pseudocode:
def function():
proxies = {
'https': proxy
}
session = requests.Session()
session.headers.update({'User-Agent': 'user - agent'})
try: #
login = session.get(url, proxies=proxies) # HERE IS WHERE MEMORY LEAKS
except: #
return -1 #
return 0
System Information
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.6"
},
"implementation": {
"name": "CPython",
"version": "3.6.3"
},
"platform": {
"release": "10",
"system": "Windows"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.18.4"
},
"system_ssl": {
"version": "100020bf"
},
"urllib3": {
"version": "1.22"
},
"using_pyopenssl": false
}
 Munroc
Munroc
Alle 22 Kommentare
Bitte geben Sie uns die Ausgabe von
python -m requests.help
Wenn dies in Ihrer Version von Requests nicht verfügbar ist, geben Sie bitte einige grundlegende Informationen zu Ihrem System an (Python-Version, Betriebssystem usw.).
 sigmavirus24
am 20. Apr. 2018
sigmavirus24
am 20. Apr. 2018
@sigmavirus24 Fertig
Munroc
am 20. Apr. 2018
Hey @munroc , ein paar
Erstellen Sie für jeden Thread eine neue Sitzung und wie groß ist der Threadpool, den Sie verwenden?
Mit welchem Tool ermitteln Sie, woher das Leck kommt? Würde es Ihnen etwas ausmachen, die Ergebnisse zu teilen?
Wir haben seit einiger Zeit Hinweise auf Speicherlecks bei Sitzungen, aber ich bin mir nicht sicher, ob wir eine rauchende Waffe oder einen wirklich bestätigten Einfluss gefunden haben.
 nateprewitt
am 20. Apr. 2018
nateprewitt
am 20. Apr. 2018
@nateprewitt Hallo, ja,
put return 0 vor login = session.get und kein Speicherverlust. wenn ich nach dem Login 0 zurückgeben = session.get Speicher beginnt undicht. Wenn Sie möchten, kann ich Ihnen meinen Quellcode senden, der nicht zu groß ist.
Munroc
am 20. Apr. 2018
@Munroc Wenn wir den vollständigen Code haben, wäre es meiner Meinung nach einfacher, die eigentliche Ursache zu isolieren. Aber basierend auf dem bereitgestellten Code ist es meiner Meinung nach sehr schwer, auf ein Speicherleck zu schließen.
Wie Sie bereits erwähnt haben, wenn Sie return direkt vor dem Aufrufen von session.get aufrufen, dann existieren nur proxies und session Objekte im Speicher (zu stark vereinfacht Ich hoffe, du verstehst die Idee :smile :). Sobald Sie jedoch session.get(url, proxies=proxies) aufrufen, wird der HTML-Code von url abgerufen und lokal in der Variablen login gespeichert. Das bedeutet, dass jeder session.get Aufruf "aussehen" wird, als würden sie Speicher verlieren, aber sie verhalten sich tatsächlich normal, indem sie (Speicher) linear um die Größe des url Ergebnisses ansteigen.
Nehmen wir jedoch an, Sie verwenden Threads und .join() sie direkt danach. In diesem Fall müssen wir meiner Meinung nach prüfen, wie Ihre Threads verwaltet wurden - und ob sie ordnungsgemäß geschlossen / bereinigt wurden.
 initbar
am 21. Mai 2018
initbar
am 21. Mai 2018
@LeoSZN Ich denke, in Ihrem spezifischen Beispiel schließen Sie nur das letzte Process Objekt, nachdem Sie mehrere Process pro urls Elemente generiert haben.
Könnten Sie versuchen, sie mit p.daemon = True dämonisieren und auszuführen (damit nach Beendigung des Hauptthreads auch alle erzeugten untergeordneten Prozesse sterben)? Andernfalls speichern Sie die erzeugten Prozesse in einem separaten Array und stellen Sie sicher, dass Sie alle mit einer Schleife schließen.
initbar
am 14. Okt. 2018
@initbar
Muss ich p.daemon = True in der Schleife oder außerhalb der Schleife vor p.join() ausführen? Durch die Art und Weise brauche ich noch p.join() nach der Anwendung von p.daemon = True ?
 leoszn
am 15. Okt. 2018
leoszn
am 15. Okt. 2018
_Ook, ich wurde vom neuen Thema zu diesem geworfen, also lass mich zu deinem kommen.
Vielleicht liefert dieses Problem weitere Informationen und wird die Lösung des Problems beschleunigen..._
Ich verwende den Telegram-Bot und habe die Verschlechterung des freien Speichers bemerkt, wenn ich den Bot längere Zeit ausgeführt habe. Erstens vermute ich meinen Code; dann vermute ich bot und schließlich kam ich zu anfragen. :)
Ich habe len(gc.get_objects()) verwendet , um dieses Problem zu identifizieren. Ich habe die Kommunikationsroutinen lokalisiert, dann den gesamten Bot-Code gelöscht und komme zu dem Beispiel, das die Anzahl der gc-Objekte bei jeder Iteration erhöht.
erwartetes Ergebnis
len(gc.get_objects()) sollte bei jeder Schleifeniteration das gleiche Ergebnis liefern
Tatsächliche Ergebnis
Der Wert von len(gc.get_objects()) erhöht sich bei jeder Schleifeniteration.
Test N2
GetObjects len: 27959
Test N3
GetObjects len: 27960
Test N4
GetObjects len: 27961
Test N5
GetObjects len: 27962
Test N6
GetObjects len: 27963
Test N7
GetObjects len: 27964
Reproduktionsschritte
token = "XXX:XXX"
chat_id = '111'
proxy = {'https':'socks5h://ZZZ'} #You may need proxy to run this in Russia
from time import sleep
import gc, requests
def garbage_info():
res = ""
res += "\nGetObjects len: " + str(len(gc.get_objects()))
return res
def tester():
count = 0
while(True):
sleep(1)
count += 1
msg = "\nTest N{0}".format(count) + garbage_info()
print(msg)
method_url = r'sendMessage'
payload = {'chat_id': str(chat_id), 'text': msg}
request_url = "https://api.telegram.org/bot{0}/{1}".format(token, method_url)
method_name = 'get'
session = requests.session()
req = requests.Request(
method=method_name.upper(),
url=request_url,
params=payload
)
prep = session.prepare_request(req)
settings = session.merge_environment_settings(
prep.url, None, None, None, None)
# prep.url, proxy, None, None, None) #Change the line to enable proxy
send_kwargs = {
'timeout': None,
'allow_redirects': None,
}
send_kwargs.update(settings)
resp = session.send(prep, **send_kwargs)
# For more clean output
gc.collect()
tester()
System Information
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "2.3.1"
},
"idna": {
"version": "2.7"
},
"implementation": {
"name": "CPython",
"version": "3.6.6"
},
"platform": {
"release": "4.15.0-36-generic",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "1010009f",
"version": "17.5.0"
},
"requests": {
"version": "2.19.1"
},
"system_ssl": {
"version": "1010007f"
},
"urllib3": {
"version": "1.23"
},
"using_pyopenssl": true
}
_Das gleiche Verhalten hatte ich bei Python 3.5.3 unter Windows10._
 Badiboy
am 16. Okt. 2018
Badiboy
am 16. Okt. 2018
@LeoSZN
@initbar
Muss ich
p.daemon = Truein der Schleife oder außerhalb der Schleife vorp.join()ausführen? Durch die Art und Weise brauche ich nochp.join()nach der Anwendung vonp.daemon = True?
# ..
for i in urls:
p = Process(target=main, args=(i,))
p.daemon = True # before `.start`
p.start()
# ..
Als kleine Anmerkung, Sie können immer noch .join Daemon-Prozesse können – aber sie werden fast garantiert beendet, wenn ihr Elternprozess beendet wird (es sei denn, sie werden irgendwie unbeabsichtigt verwaist; in diesem Fall lassen Sie es mich bitte wissen! I gerne mehr darüber erfahren).
Andernfalls können Sie die Process Objekte separat als Array speichern und am Ende verbinden:
# ..
processes = [
Process(target=main, args=(i,))
for i in urls
]
# start the process activity.
erwartetes Ergebnis
len(gc.get_objects()) sollte bei jeder Schleifeniteration das gleiche Ergebnis liefern
Der Grund für dieses Verhalten wurde im Cache-Mechanismus "Anfragen" gefunden.
Es funktioniert falsch (vermutlich): Es fügt jedem Aufruf der Telegram API-URL einen Cache-Datensatz hinzu (anstatt ihn einmal zwischenzuspeichern). Dies führt jedoch nicht zum Speicherverlust, da die Cachegröße auf 20 begrenzt ist und der Cache nach Erreichen dieser Grenze zurückgesetzt wird und die wachsende Anzahl von Objekten wieder auf den ursprünglichen Wert reduziert wird.
Badiboy
am 26. Okt. 2018
Ähnliches Problem. Anforderungen verbrauchen Speicher, wenn sie im Thread ausgeführt werden. Code zum reproduzieren hier:
import gc
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from memory_profiler import profile
def run_thread_request(sess, run):
response = sess.get('https://www.google.com')
return
<strong i="6">@profile</strong>
def main():
sess = requests.session()
with ThreadPoolExecutor(max_workers=1) as executor:
print('Starting!')
tasks = {executor.submit(run_thread_request, sess, run):
run for run in range(50)}
for _ in as_completed(tasks):
pass
print('Done!')
return
<strong i="7">@profile</strong>
def calling():
main()
gc.collect()
return
if __name__ == '__main__':
calling()
Im obigen Code gebe ich ein Sitzungsobjekt weiter, aber wenn ich es ersetze, indem ich nur requests.get ausführe, ändert sich nichts.
Ausgabe ist:
➜ thread-test pipenv run python run.py
Starting!
Done!
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
10 23.2 MiB 23.2 MiB <strong i="13">@profile</strong>
11 def main():
12 23.2 MiB 0.0 MiB sess = requests.session()
13 23.2 MiB 0.0 MiB with ThreadPoolExecutor(max_workers=1) as executor:
14 23.2 MiB 0.0 MiB print('Starting!')
15 23.4 MiB 0.0 MiB tasks = {executor.submit(run_thread_request, sess, run):
16 23.4 MiB 0.0 MiB run for run in range(50)}
17 25.8 MiB 2.4 MiB for _ in as_completed(tasks):
18 25.8 MiB 0.0 MiB pass
19 25.8 MiB 0.0 MiB print('Done!')
20 25.8 MiB 0.0 MiB return
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
22 23.2 MiB 23.2 MiB <strong i="14">@profile</strong>
23 def calling():
24 25.8 MiB 2.6 MiB main()
25 25.8 MiB 0.0 MiB gc.collect()
26 25.8 MiB 0.0 MiB return
Und Pipfile sieht so aus:
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
[requires]
python_version = "3.6"
[packages]
requests = "==2.21.0"
memory-profiler = "==0.55.0"
 jotunskij
am 17. Dez. 2018
jotunskij
am 17. Dez. 2018
FWIW Ich erlebe auch ein ähnliches Speicherleck wie @jotunskij hier gibt es mehr Infos
 pawel-lmcb
am 26. März 2019
pawel-lmcb
am 26. März 2019
Ich habe auch das gleiche Problem, bei dem die Verwendung von request.get mit Threading den Speicher tatsächlich um etwa 0,1 - 0,9 pro Anfrage auffrisst und sich nach den Anfragen nicht selbst "löscht", sondern speichert.
 BarryThrill
am 5. Mai 2019
BarryThrill
am 5. Mai 2019
Das gleiche hier, irgendeine Arbeit um?
 popjxc
am 13. Juni 2019
popjxc
am 13. Juni 2019
Bearbeiten
Mein Problem scheint auf die Verwendung von verify=False in Anfragen zurückzuführen zu sein. Ich habe einen Fehler unter #5215 gemeldet
Habe das gleiche Problem. Ich habe ein einfaches Skript, das einen Thread erzeugt, dieser Thread ruft eine Funktion auf, die eine while-Schleife ausführt, diese Schleife fragt eine API ab, um einen Statuswert zu überprüfen, und schläft dann für 10 Sekunden und dann wird die Schleife erneut ausgeführt, bis das Skript gestoppt wird.
Wenn ich die Funktion requests.get kann ich sehen, wie der Speicherverbrauch über den Task-Manager langsam ansteigt, indem ich den erzeugten Prozess beobachte.
Aber wenn ich den requests.get Aufruf aus der Schleife entferne oder urllib3 direkt verwende, um die Get-Anforderung zu stellen, gibt es sehr wenig, wenn überhaupt, den Speicherverbrauch.
Ich habe dies in beiden Fällen über einen Zeitraum von zwei Stunden beobachtet und bei Verwendung von requests.get die Speichernutzung nach zwei Stunden bei 1 GB+, während bei Verwendung von urllib3 die Speichernutzung bei ca. 20 MB nach zwei Stunden.
Python 3.7.4 und Anforderungen 2.22.0
 tallona
am 27. Sept. 2019
tallona
am 27. Sept. 2019
Es scheint, dass Requests sich noch im Beta-Stadium mit solchen Speicherlecks befindet. Kommt schon, Jungs, flickt das zusammen! 😉👍
 PedanticHacker
am 1. Okt. 2019
PedanticHacker
am 1. Okt. 2019
Gibt es hierzu Neuigkeiten? Eine einfache POST-Anfrage mit einem Datei-Upload verursacht auch das ähnliche Problem des Speicherlecks.
 MuhammadAliShahzad
am 2. Okt. 2019
MuhammadAliShahzad
am 2. Okt. 2019
Gleiches für mich ... Leckage während der Threadpool-Ausführung ist auch unter Windows python38.
Anfragen 2.22.0
 far-rainbow
am 9. Dez. 2019
far-rainbow
am 9. Dez. 2019
Gleiche für mich
 sunnyjiechao
am 13. Jan. 2020
sunnyjiechao
am 13. Jan. 2020
Hier ist mein Problem mit dem Speicherverlust, kann jemand helfen? https://stackoverflow.com/questions/59746125/memory-keep-growing-when-using-mutil-thread-download-file
sunnyjiechao
am 16. Jan. 2020
Rufen Sie Session.close() und Response.close() auf, um das Speicherleck zu vermeiden.
Und SSL verbraucht mehr Speicher, sodass das Speicherleck bei der Anforderung von https-URLs bemerkenswerter ist.
Zuerst mache ich 4 Testfälle:
- Anfragen + SSL (https://)
- Anfragen + Nicht-SSL (http://)
- aiohttp + ssl (https://)
- aiohttp + nicht-ssl (http://)
Pseudocode:
def run(url):
session = requests.session()
response = session.get(url)
while True:
for url in urls: # about 5k urls of public websites
# execute in thread pool, size=10
thread_pool.submit(run, url)
# in another thread, record memory usage every seconds
Speichernutzungsdiagramm (y-Achse: MB, x-Achse: Zeit), Anfragen verwenden viel Speicher und der Speicher nimmt sehr schnell zu, während die Speichernutzung von aiohttp stabil ist:
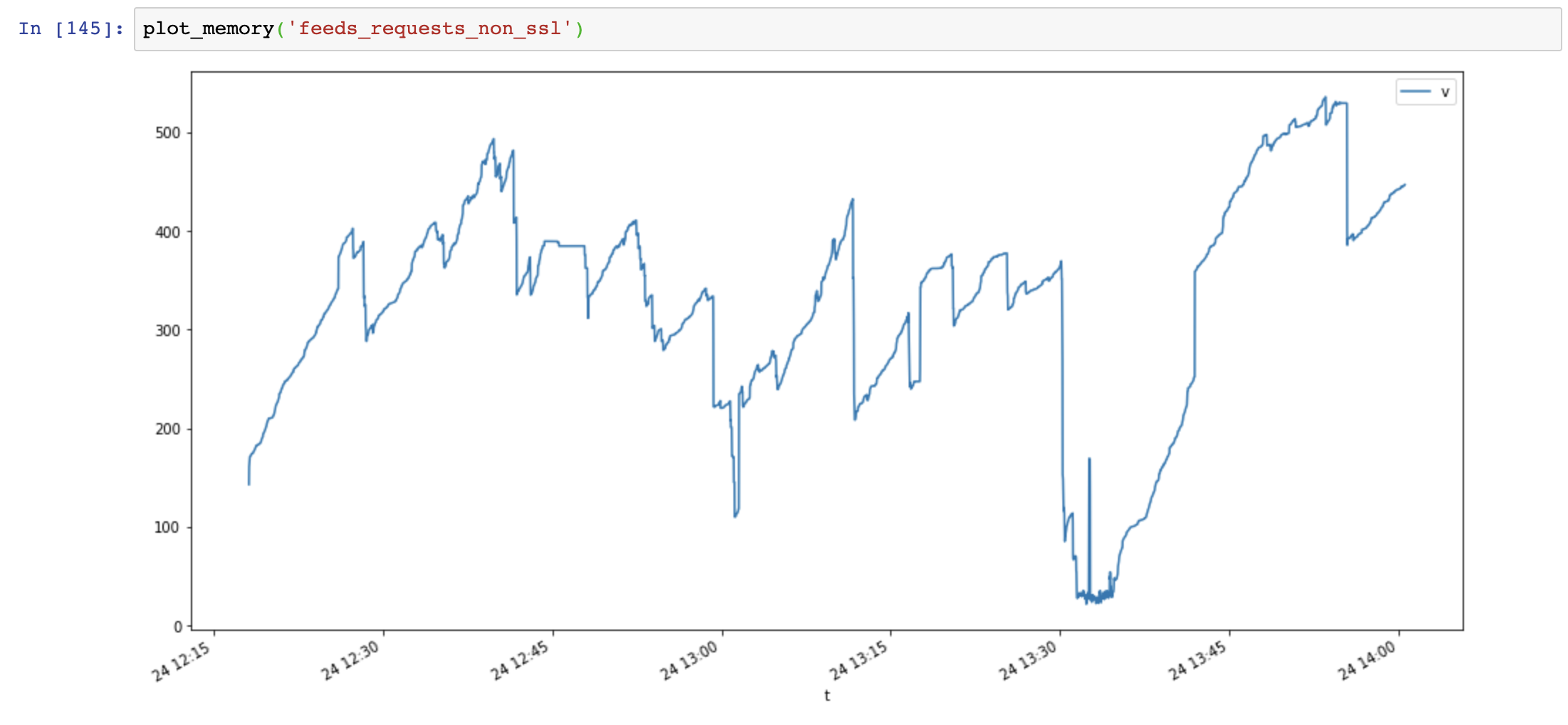



Dann füge ich Session.close() und teste erneut:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
Die Speichernutzung hat deutlich abgenommen, aber die Speichernutzung nimmt im Laufe der Zeit immer noch zu:


Schließlich füge ich Response.close() und teste erneut:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
response.close() # close response !!
Die Speicherauslastung hat wieder abgenommen und ist im Laufe der Zeit nicht gestiegen:
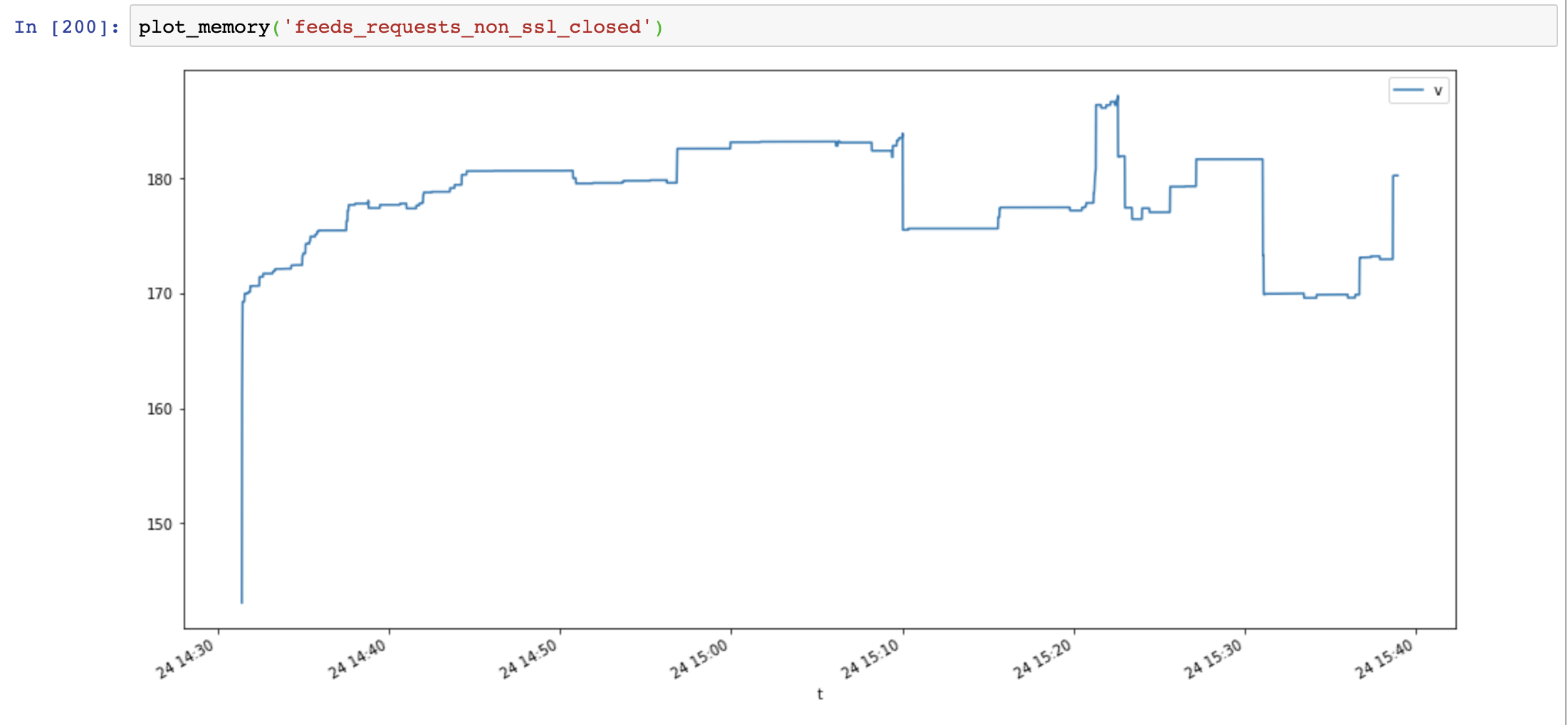

Vergleichen Sie aiohttp und Anfragen, dass das Speicherleck nicht durch SSL verursacht wird, sondern durch nicht geschlossene Verbindungsressourcen.
Nützliche Skripte:
class MemoryReporter:
def __init__(self, name):
self.name = name
self.file = open(f'memoryleak/memory_{name}.txt', 'w')
self.thread = None
def _get_memory(self):
return psutil.Process().memory_info().rss
def main(self):
while True:
t = time.time()
v = self._get_memory()
self.file.write(f'{t},{v}\n')
self.file.flush()
time.sleep(1)
def start(self):
self.thread = Thread(target=self.main, name=self.name, daemon=True)
self.thread.start()
def plot_memory(name):
filepath = 'memoryleak/memory_{}.txt'.format(name)
df_mem = pd.read_csv(filepath, index_col=0, names=['t', 'v'])
df_mem.index = pd.to_datetime(df_mem.index, unit='s')
df_mem.v = df_mem.v / 1024 / 1024
df_mem.plot(figsize=(16, 8))
System Information:
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.8"
},
"implementation": {
"name": "CPython",
"version": "3.7.4"
},
"platform": {
"release": "18.0.0",
"system": "Darwin"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.22.0"
},
"system_ssl": {
"version": "1010104f"
},
"urllib3": {
"version": "1.25.6"
},
"using_pyopenssl": false
}
 guyskk
am 24. März 2020
guyskk
am 24. März 2020
Das SSL-Leckproblem ist OpenSSL <= 3.7.4 unter Windows und OSX verpackt, es wird der Speicher nicht richtig aus dem Kontext freigegeben
https://github.com/VeNoMouS/cloudscraper/issues/143#issuecomment -613092377
 VeNoMouS
am 13. Apr. 2020
VeNoMouS
am 13. Apr. 2020
Verwandte Themen
 jakul
·
3Kommentare
jakul
·
3Kommentare
 ghtyrant
·
3Kommentare
ghtyrant
·
3Kommentare
 eromoe
·
3Kommentare
eromoe
·
3Kommentare
 jake491
·
3Kommentare
jake491
·
3Kommentare
 8key
·
3Kommentare
8key
·
3Kommentare
Hilfreichster Kommentar
Ähnliches Problem. Anforderungen verbrauchen Speicher, wenn sie im Thread ausgeführt werden. Code zum reproduzieren hier:
Im obigen Code gebe ich ein Sitzungsobjekt weiter, aber wenn ich es ersetze, indem ich nur
requests.getausführe, ändert sich nichts.Ausgabe ist:
Und Pipfile sieht so aus: