ملخص.
نتيجة متوقعة
البرنامج يعمل بشكل طبيعي
نتيجة فعلية
برنامج يستهلك كل ذاكرة الوصول العشوائي حتى يتوقف عن العمل
خطوات التكاثر
كود مزيف:
def function():
proxies = {
'https': proxy
}
session = requests.Session()
session.headers.update({'User-Agent': 'user - agent'})
try: #
login = session.get(url, proxies=proxies) # HERE IS WHERE MEMORY LEAKS
except: #
return -1 #
return 0
معلومات النظام
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.6"
},
"implementation": {
"name": "CPython",
"version": "3.6.3"
},
"platform": {
"release": "10",
"system": "Windows"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.18.4"
},
"system_ssl": {
"version": "100020bf"
},
"urllib3": {
"version": "1.22"
},
"using_pyopenssl": false
}
 Munroc
Munroc
ال 22 كومينتر
يرجى تزويدنا بإخراج
python -m requests.help
إذا لم يكن ذلك متاحًا في إصدار الطلبات الخاص بك ، فيرجى تقديم بعض المعلومات الأساسية حول نظامك (إصدار Python ، ونظام التشغيل ، وما إلى ذلك).
 sigmavirus24
في ٢٠ أبريل ٢٠١٨
sigmavirus24
في ٢٠ أبريل ٢٠١٨
@ sigmavirus24 تم
Munroc
في ٢٠ أبريل ٢٠١٨
مرحبًا unroc ،
هل تقوم بإنشاء جلسة جديدة لكل موضوع وما هو حجم مجموعة مؤشرات الترابط التي تستخدمها؟
ما الأداة التي تستخدمها لتحديد مصدر التسريب؟ هل تمانع في مشاركة النتائج؟
لقد تلقينا تلميحات عن تسرب للذاكرة حول الجلسات لفترة من الوقت الآن ، لكنني لست متأكدًا من أننا وجدنا مسدسًا قويًا أو تأثيرًا مؤكدًا حقًا.
 nateprewitt
في ٢٠ أبريل ٢٠١٨
nateprewitt
في ٢٠ أبريل ٢٠١٨
nateprewitt مرحبًا ، نعم ،
ضع الإرجاع 0 قبل تسجيل الدخول = session.get ولا يوجد تسرب للذاكرة. إذا وضعت العودة 0 بعد تسجيل الدخول = جلسة.تبدأ الذاكرة تتسرب. إذا كنت تريد ، يمكنني أن أرسل لك شفرة المصدر الخاصة بي ليست كبيرة جدًا.
Munroc
في ٢٠ أبريل ٢٠١٨
Munroc إذا كان لدينا الكود الكامل ، فأعتقد أنه سيكون من الأسهل عزل السبب الفعلي. ولكن استنادًا إلى جوهر الكود الذي تم توفيره ، أعتقد أنه من الصعب جدًا استنتاج وجود تسرب للذاكرة.
كما ذكرت ، إذا كنت return مباشرة قبل الاتصال بـ session.get ، فعندئذٍ فقط proxies و session ستكون موجودة في الذاكرة (مفرط التبسيط .. لكن أنا أتمنى أن تحصل على الفكرة: ابتسم :). ومع ذلك ، بمجرد استدعاء session.get(url, proxies=proxies) ، سيتم استرداد HTML الخاص بـ url وحفظه محليًا في المتغير login . مما يعني أن كل مكالمة session.get ستبدو "مثل" أنها تسريب للذاكرة ، لكنها في الواقع تتصرف بشكل طبيعي عن طريق زيادة (الذاكرة) خطيًا بحجم url نتيجة.
ومع ذلك ، لنفترض أنك كنت تستخدم المواضيع و .join() لها بعد ذلك مباشرة. في هذه الحالة ، أعتقد أننا بحاجة إلى النظر في كيفية إدارة سلاسل الرسائل الخاصة بك - وما إذا تم إغلاقها / تنظيفها بشكل صحيح.
 initbar
في ٢١ مايو ٢٠١٨
initbar
في ٢١ مايو ٢٠١٨
LeoSZN أعتقد في Process بعد إنشاء عدة عناصر Process لكل urls .
هل يمكنك محاولة إضفاء الطابع الخفي عليها باستخدام p.daemon = True وتشغيلها (بحيث أنه بمجرد انتهاء الخيط الرئيسي ، تموت جميع العمليات الفرعية الناتجة أيضًا)؟ خلاف ذلك ، قم بتخزين العمليات التي تم إنتاجها في مصفوفة منفصلة وتأكد من إغلاقها جميعًا باستخدام حلقة.
initbar
في ١٤ أكتوبر ٢٠١٨
initbar
هل أحتاج إلى تشغيل p.daemon = True في الحلقة أو خارج الحلقة قبل p.join() ؟ بالمناسبة ، ما زلت بحاجة إلى p.join() بعد تطبيق p.daemon = True ؟
 leoszn
في ١٥ أكتوبر ٢٠١٨
leoszn
في ١٥ أكتوبر ٢٠١٨
_Ook ، لقد طردت من الموضوع الجديد إلى هذا الموضوع ، لذا دعني أنضم إلى موضوعك.
قد تكون هذه المشكلة توفر مزيدًا من المعلومات وستزيد من حل المشكلة ..._
أنا أقوم بتشغيل Telegram bot ولاحظت تدهور الذاكرة المجانية عند تشغيل الروبوت لفترة طويلة. أولاً ، أشك في الكود الخاص بي ؛ ثم أشك في أن بوت وأخيرًا جئت إلى الطلبات. :)
لقد استخدمت len (gc.get_objects ()) لتحديد وجود هذه المشكلة. لقد حددت إجراءات الاتصال ، ثم قمت بمسح جميع أكواد البوت وأتيت إلى المثال الذي يرفع عدد كائنات gc في كل تكرار.
نتيجة متوقعة
يجب أن يعطي len (gc.get_objects ()) نفس النتيجة في كل تكرار حلقي
نتيجة فعلية
تزداد قيمة
Test N2
GetObjects len: 27959
Test N3
GetObjects len: 27960
Test N4
GetObjects len: 27961
Test N5
GetObjects len: 27962
Test N6
GetObjects len: 27963
Test N7
GetObjects len: 27964
خطوات التكاثر
token = "XXX:XXX"
chat_id = '111'
proxy = {'https':'socks5h://ZZZ'} #You may need proxy to run this in Russia
from time import sleep
import gc, requests
def garbage_info():
res = ""
res += "\nGetObjects len: " + str(len(gc.get_objects()))
return res
def tester():
count = 0
while(True):
sleep(1)
count += 1
msg = "\nTest N{0}".format(count) + garbage_info()
print(msg)
method_url = r'sendMessage'
payload = {'chat_id': str(chat_id), 'text': msg}
request_url = "https://api.telegram.org/bot{0}/{1}".format(token, method_url)
method_name = 'get'
session = requests.session()
req = requests.Request(
method=method_name.upper(),
url=request_url,
params=payload
)
prep = session.prepare_request(req)
settings = session.merge_environment_settings(
prep.url, None, None, None, None)
# prep.url, proxy, None, None, None) #Change the line to enable proxy
send_kwargs = {
'timeout': None,
'allow_redirects': None,
}
send_kwargs.update(settings)
resp = session.send(prep, **send_kwargs)
# For more clean output
gc.collect()
tester()
معلومات النظام
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "2.3.1"
},
"idna": {
"version": "2.7"
},
"implementation": {
"name": "CPython",
"version": "3.6.6"
},
"platform": {
"release": "4.15.0-36-generic",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "1010009f",
"version": "17.5.0"
},
"requests": {
"version": "2.19.1"
},
"system_ssl": {
"version": "1010007f"
},
"urllib3": {
"version": "1.23"
},
"using_pyopenssl": true
}
_نفس السلوك الذي كنت أتبعه في Python 3.5.3 على نظام التشغيل Windows10._
 Badiboy
في ١٦ أكتوبر ٢٠١٨
Badiboy
في ١٦ أكتوبر ٢٠١٨
تضمين التغريدة
initbar
هل أحتاج إلى تشغيل
p.daemon = Trueفي الحلقة أو خارج الحلقة قبلp.join()؟ بالمناسبة ، ما زلت بحاجة إلىp.join()بعد تطبيقp.daemon = True؟
# ..
for i in urls:
p = Process(target=main, args=(i,))
p.daemon = True # before `.start`
p.start()
# ..
كملاحظة ثانوية ، لا يزال .join - لكن من شبه المؤكد أن يتم قتلهم عند انتهاء عملية الوالدين (ما لم يصبحوا أيتامًا بطريقة ما عن غير قصد ؛ في هذه الحالة ، يرجى إعلامي! أحب معرفة المزيد عنها).
بخلاف ذلك ، يمكنك تخزين العناصر Process بشكل منفصل كمصفوفة والانضمام في النهاية:
# ..
processes = [
Process(target=main, args=(i,))
for i in urls
]
# start the process activity.
نتيجة متوقعة
يجب أن يعطي len (gc.get_objects ()) نفس النتيجة في كل تكرار حلقي
تم العثور على سبب هذا السلوك في آلية ذاكرة التخزين المؤقت "الطلبات".
يعمل بشكل غير صحيح (مشتبه به): يضيف سجل ذاكرة التخزين المؤقت إلى كل استدعاء إلى عنوان URL لواجهة برمجة تطبيقات Telegram (بدلاً من تخزينه مؤقتًا مرة واحدة). لكنه لا يؤدي إلى تسرب الذاكرة ، لأن حجم ذاكرة التخزين المؤقت يقتصر على 20 ويتم إعادة تعيين ذاكرة التخزين المؤقت بعد الوصول إلى هذا الحد وسيتم تقليل العدد المتزايد من الكائنات إلى القيمة الأولية.
Badiboy
في ٢٦ أكتوبر ٢٠١٨
قضية مماثلة. الطلبات تأكل الذاكرة عند تشغيلها في الخيط. رمز لإعادة إنتاجه هنا:
import gc
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from memory_profiler import profile
def run_thread_request(sess, run):
response = sess.get('https://www.google.com')
return
<strong i="6">@profile</strong>
def main():
sess = requests.session()
with ThreadPoolExecutor(max_workers=1) as executor:
print('Starting!')
tasks = {executor.submit(run_thread_request, sess, run):
run for run in range(50)}
for _ in as_completed(tasks):
pass
print('Done!')
return
<strong i="7">@profile</strong>
def calling():
main()
gc.collect()
return
if __name__ == '__main__':
calling()
في الكود الموضح أعلاه ، قمت بتمرير كائن جلسة ، ولكن إذا استبدله بمجرد تشغيل requests.get فلن يتغير شيء.
الإخراج هو:
➜ thread-test pipenv run python run.py
Starting!
Done!
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
10 23.2 MiB 23.2 MiB <strong i="13">@profile</strong>
11 def main():
12 23.2 MiB 0.0 MiB sess = requests.session()
13 23.2 MiB 0.0 MiB with ThreadPoolExecutor(max_workers=1) as executor:
14 23.2 MiB 0.0 MiB print('Starting!')
15 23.4 MiB 0.0 MiB tasks = {executor.submit(run_thread_request, sess, run):
16 23.4 MiB 0.0 MiB run for run in range(50)}
17 25.8 MiB 2.4 MiB for _ in as_completed(tasks):
18 25.8 MiB 0.0 MiB pass
19 25.8 MiB 0.0 MiB print('Done!')
20 25.8 MiB 0.0 MiB return
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
22 23.2 MiB 23.2 MiB <strong i="14">@profile</strong>
23 def calling():
24 25.8 MiB 2.6 MiB main()
25 25.8 MiB 0.0 MiB gc.collect()
26 25.8 MiB 0.0 MiB return
ويبدو Pipfile كما يلي:
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
[requires]
python_version = "3.6"
[packages]
requests = "==2.21.0"
memory-profiler = "==0.55.0"
 jotunskij
في ١٧ ديسمبر ٢٠١٨
jotunskij
في ١٧ ديسمبر ٢٠١٨
FWIW أواجه أيضًا تسربًا مشابهًا للذاكرة مثل jotunskij هنا مزيد من المعلومات
 pawel-lmcb
في ٢٦ مارس ٢٠١٩
pawel-lmcb
في ٢٦ مارس ٢٠١٩
لدي أيضًا نفس المشكلة حيث يؤدي استخدام طلبات الحصول على خيوط المعالجة في الواقع إلى استهلاك الذاكرة بحوالي 0.1 - 0.9 لكل طلب ولا "يمسح" نفسه بعد الطلبات ولكنه يحفظها.
 BarryThrill
في ٥ مايو ٢٠١٩
BarryThrill
في ٥ مايو ٢٠١٩
بالمثل هنا ، أي عمل بالجوار؟
 popjxc
في ١٣ يونيو ٢٠١٩
popjxc
في ١٣ يونيو ٢٠١٩
يحرر
يبدو أن مشكلتي ناتجة عن استخدام verify=False في الطلبات ، لقد أثرت خطأ تحت رقم 5215
وجود نفس المشكلة. لدي برنامج نصي بسيط يولد سلسلة رسائل ، هذا الخيط يستدعي وظيفة تعمل في حلقة while ، تستعلم هذه الحلقة عن واجهة برمجة تطبيقات للتحقق من قيمة الحالة ثم تنام لمدة 10 ثوانٍ ، ثم ستعمل الحلقة مرة أخرى حتى يتم إيقاف البرنامج النصي.
عند استخدام الوظيفة requests.get أستطيع أن أرى استخدام الذاكرة يزحف ببطء عبر مدير المهام من خلال مشاهدة العملية الناتجة.
ولكن إذا قمت بإزالة المكالمة requests.get من الحلقة أو استخدمت urllib3 مباشرة لتقديم طلب الاستلام ، فلن يكون هناك سوى القليل جدًا من استخدام الذاكرة.
لقد شاهدت هذا على مدار ساعتين في كلتا الحالتين ، وعند استخدام requests.get يكون استخدام الذاكرة 1GB + بعد ساعتين حيث يكون استخدام الذاكرة تقريبًا عند استخدام urllib3 . 20 ميغا بايت بعد ساعتين.
Python 3.7.4 ويطلب 2.22.0
 tallona
في ٢٧ سبتمبر ٢٠١٩
tallona
في ٢٧ سبتمبر ٢٠١٩
يبدو أن الطلبات لا تزال في المرحلة التجريبية بها تسرب للذاكرة من هذا القبيل. تعال يا رفاق ، تصحيح هذا الأمر! 😉👍
 PedanticHacker
في ١ أكتوبر ٢٠١٩
PedanticHacker
في ١ أكتوبر ٢٠١٩
أي تحديث على هذا؟ يؤدي طلب POST البسيط مع تحميل ملف أيضًا إلى إنشاء مشكلة مماثلة تتعلق بتسرب الذاكرة.
 MuhammadAliShahzad
في ٢ أكتوبر ٢٠١٩
MuhammadAliShahzad
في ٢ أكتوبر ٢٠١٩
نفس الشيء بالنسبة لي ... التسرب أثناء تنفيذ threadpool على Windows python38 أيضًا.
يطلب 2.22.0
 far-rainbow
في ٩ ديسمبر ٢٠١٩
far-rainbow
في ٩ ديسمبر ٢٠١٩
نفس الشيء بالنسبة لي
 sunnyjiechao
في ١٣ يناير ٢٠٢٠
sunnyjiechao
في ١٣ يناير ٢٠٢٠
ها هي مشكلة تسريب ذاكرتي ، أي شخص يمكنه المساعدة؟ https://stackoverflow.com/questions/59746125/memory-keep-growing-when-using-mutil-thread-download-file
sunnyjiechao
في ١٦ يناير ٢٠٢٠
استدعاء Session.close() و Response.close() يمكن أن يتجنب تسرب الذاكرة.
وسوف تستهلك ssl المزيد من الذاكرة لذا فإن تسرب الذاكرة سيكون أكثر وضوحًا عند طلب عناوين url الخاصة بـ https.
أولاً أقوم بإجراء 4 حالات اختبار:
- الطلبات + SSL (https: //)
- الطلبات + non-ssl (http: //)
- aiohttp + ssl (https: //)
- aiohttp + non-ssl (http: //)
كود مزيف:
def run(url):
session = requests.session()
response = session.get(url)
while True:
for url in urls: # about 5k urls of public websites
# execute in thread pool, size=10
thread_pool.submit(run, url)
# in another thread, record memory usage every seconds
الرسم البياني لاستخدام الذاكرة (المحور ص: ميجابايت ، المحور السيني: الوقت) ، تستخدم الطلبات الكثير من الذاكرة وتزداد الذاكرة بسرعة كبيرة ، بينما يكون استخدام ذاكرة aiohttp مستقرًا:
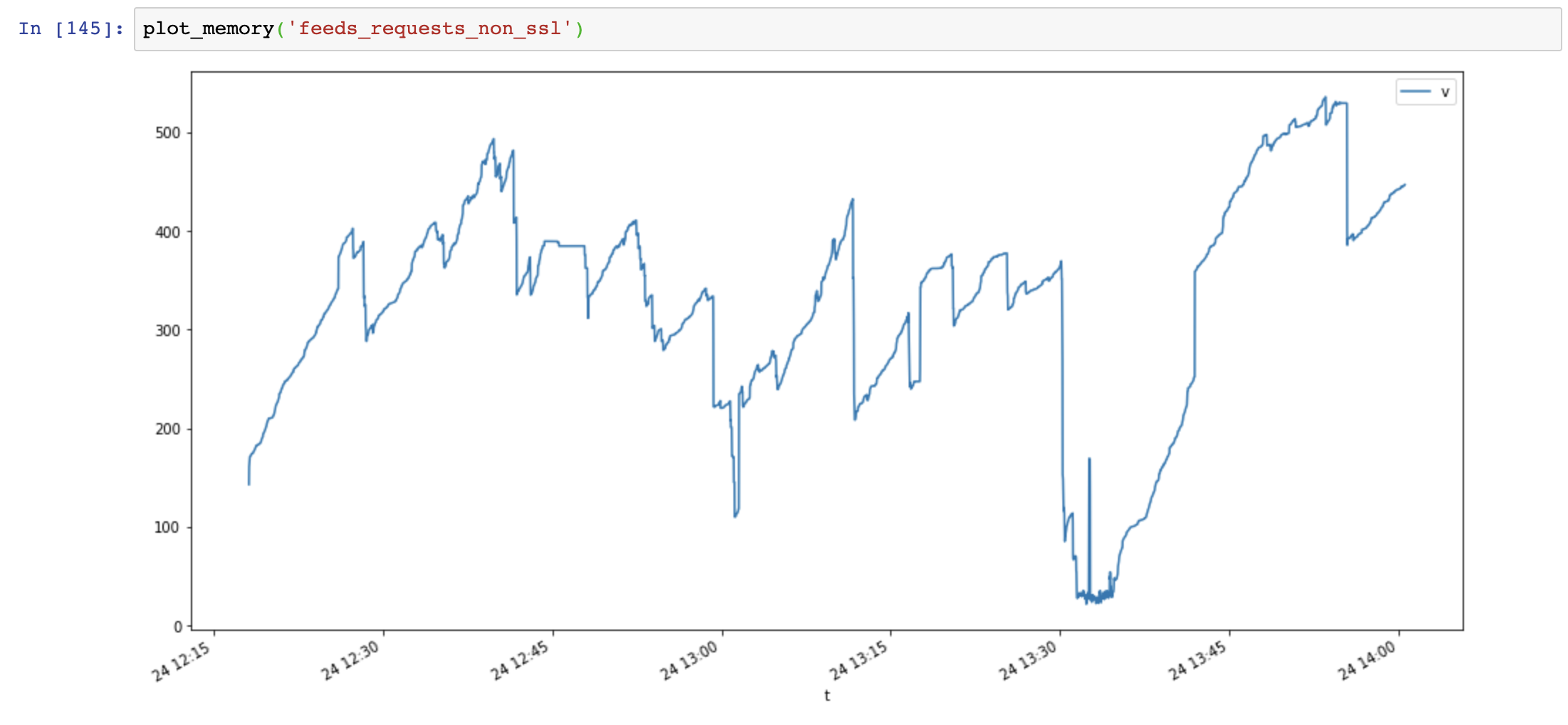



ثم أضفت Session.close() واختبر مرة أخرى:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
انخفض استخدام الذاكرة بشكل كبير ، لكن استخدام الذاكرة لا يزال يزداد بمرور الوقت:


أخيرًا ، أضفت Response.close() واختبر مرة أخرى:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
response.close() # close response !!
انخفض استخدام الذاكرة مرة أخرى ، ولم يزداد بمرور الوقت:
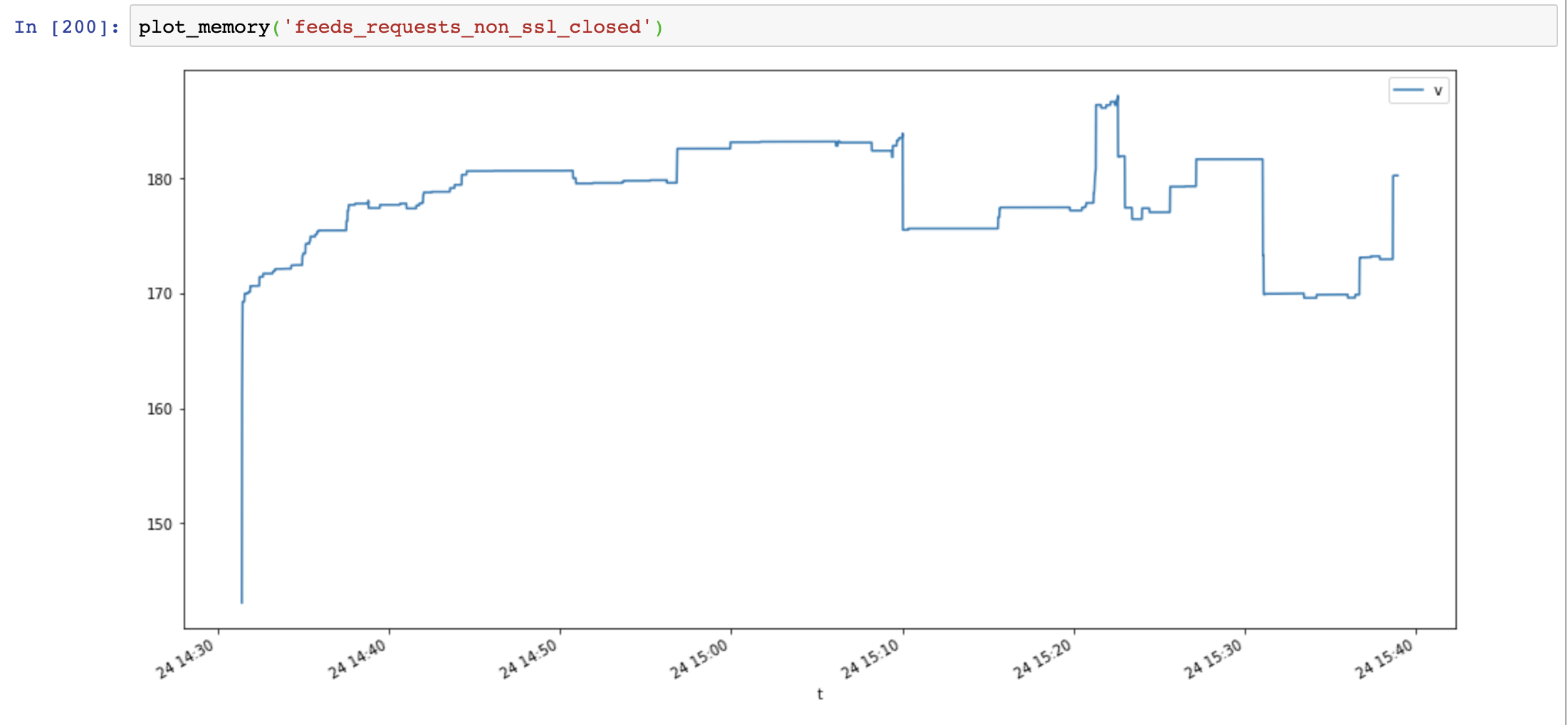

قارن aiohttp والطلبات تظهر أن تسرب الذاكرة لا ينتج عن SSL ، إنه ناتج عن عدم إغلاق موارد الاتصال.
نصوص مفيدة:
class MemoryReporter:
def __init__(self, name):
self.name = name
self.file = open(f'memoryleak/memory_{name}.txt', 'w')
self.thread = None
def _get_memory(self):
return psutil.Process().memory_info().rss
def main(self):
while True:
t = time.time()
v = self._get_memory()
self.file.write(f'{t},{v}\n')
self.file.flush()
time.sleep(1)
def start(self):
self.thread = Thread(target=self.main, name=self.name, daemon=True)
self.thread.start()
def plot_memory(name):
filepath = 'memoryleak/memory_{}.txt'.format(name)
df_mem = pd.read_csv(filepath, index_col=0, names=['t', 'v'])
df_mem.index = pd.to_datetime(df_mem.index, unit='s')
df_mem.v = df_mem.v / 1024 / 1024
df_mem.plot(figsize=(16, 8))
معلومات النظام:
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.8"
},
"implementation": {
"name": "CPython",
"version": "3.7.4"
},
"platform": {
"release": "18.0.0",
"system": "Darwin"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.22.0"
},
"system_ssl": {
"version": "1010104f"
},
"urllib3": {
"version": "1.25.6"
},
"using_pyopenssl": false
}
 guyskk
في ٢٤ مارس ٢٠٢٠
guyskk
في ٢٤ مارس ٢٠٢٠
مشكلة تسرب SSL هي حزمة OpenSSL <= 3.7.4 على Windows و OSX ، فهي لا تحرر الذاكرة من السياق بشكل صحيح
https://github.com/VeNoMouS/cloudscraper/issues/143#issuecomment -613092377
 VeNoMouS
في ١٣ أبريل ٢٠٢٠
VeNoMouS
في ١٣ أبريل ٢٠٢٠
القضايا ذات الصلة
 mitar
·
4تعليقات
mitar
·
4تعليقات
 NoahCardoza
·
4تعليقات
NoahCardoza
·
4تعليقات
 ghtyrant
·
3تعليقات
ghtyrant
·
3تعليقات
 cnicodeme
·
3تعليقات
cnicodeme
·
3تعليقات
 eromoe
·
3تعليقات
eromoe
·
3تعليقات
التعليق الأكثر فائدة
قضية مماثلة. الطلبات تأكل الذاكرة عند تشغيلها في الخيط. رمز لإعادة إنتاجه هنا:
في الكود الموضح أعلاه ، قمت بتمرير كائن جلسة ، ولكن إذا استبدله بمجرد تشغيل
requests.getفلن يتغير شيء.الإخراج هو:
ويبدو Pipfile كما يلي: