Resumen.
Resultado Esperado
Programa funcionando normalmente
Resultado actual
Programa que consume toda la memoria RAM hasta que deja de funcionar
Pasos de reproducción
Pseudocódigo:
def function():
proxies = {
'https': proxy
}
session = requests.Session()
session.headers.update({'User-Agent': 'user - agent'})
try: #
login = session.get(url, proxies=proxies) # HERE IS WHERE MEMORY LEAKS
except: #
return -1 #
return 0
Información del sistema
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.6"
},
"implementation": {
"name": "CPython",
"version": "3.6.3"
},
"platform": {
"release": "10",
"system": "Windows"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.18.4"
},
"system_ssl": {
"version": "100020bf"
},
"urllib3": {
"version": "1.22"
},
"using_pyopenssl": false
}
 Munroc
Munroc
Todos 22 comentarios
Por favor envíenos el resultado de
python -m requests.help
Si no está disponible en su versión de Solicitudes, proporcione información básica sobre su sistema (versión de Python, sistema operativo, etc.).
 sigmavirus24
en 20 abr. 2018
sigmavirus24
en 20 abr. 2018
@ sigmavirus24 Hecho
Munroc
en 20 abr. 2018
Hola @munroc , un par de preguntas rápidas sobre su implementación de subprocesos, ya que no está incluido en el pseudocódigo.
¿Está creando una nueva sesión para cada hilo y qué tamaño es el grupo de hilos que está usando?
¿Qué herramienta está utilizando para determinar de dónde proviene la fuga? ¿Le importaría compartir los resultados?
Hemos tenido indicios de pérdidas de memoria alrededor de las sesiones durante un tiempo, pero no estoy seguro de haber encontrado una pistola humeante o un impacto realmente confirmado.
 nateprewitt
en 20 abr. 2018
nateprewitt
en 20 abr. 2018
@nateprewitt Hola, sí, estoy creando una nueva sesión para cada hilo. El grupo de subprocesos es 30. He intentado con 2 - 200 subprocesos y pérdidas de memoria de todos modos. No estoy usando una herramienta, acabo de hacer estos cambios en la función:
poner return 0 antes de login = session.get y sin pérdida de memoria. si pongo return 0 después de iniciar sesión = session.get, la memoria comienza a gotear. Si lo desea, puedo enviarle mi código fuente no es demasiado grande.
Munroc
en 20 abr. 2018
@Munroc, si tenemos el código completo, creo que sería más fácil aislar la causa real. Pero según la esencia del código que se proporcionó, creo que es muy difícil concluir que hay una pérdida de memoria.
Como mencionaste, si return inmediatamente antes de llamar a session.get , entonces solo los objetos proxies y session existirán en la memoria (simplificado demasiado ... pero yo Espero que te hagas una idea: sonríe :). Sin embargo, una vez que llame a session.get(url, proxies=proxies) , el HTML de url se recuperará y se guardará localmente en la variable login . Lo que significa que cada llamada session.get "parecerá" que están perdiendo memoria, pero en realidad se están comportando normalmente por (memoria) aumentando linealmente en el tamaño del resultado url .
Sin embargo, digamos que estaba usando subprocesos y .join() inmediatamente después. En ese caso, creo que debemos analizar cómo se administraron sus subprocesos y si se cerraron / limpiaron correctamente.
 initbar
en 21 may. 2018
initbar
en 21 may. 2018
@LeoSZN Creo que en su ejemplo específico, está cerrando solo el último objeto Process después de generar varios elementos Process por urls .
¿Podría intentar demonizarlos usando p.daemon = True y ejecutarlos (de modo que una vez que termine el hilo principal, todos los procesos secundarios generados también mueran)? De lo contrario, almacene los procesos generados en una matriz separada y asegúrese de cerrarlos todos usando un bucle.
initbar
en 14 oct. 2018
@initbar
¿Necesito ejecutar p.daemon = True en el bucle o fuera del bucle antes de p.join() ? Por cierto, ¿todavía necesito p.join() después de aplicar p.daemon = True ?
 leoszn
en 15 oct. 2018
leoszn
en 15 oct. 2018
_Ook, fui expulsado del nuevo tema a este, así que déjame unirme al tuyo.
Puede ser que este problema brinde más información y acelere la resolución del problema ..._
Estoy ejecutando el bot de Telegram y noté la degradación de la memoria libre cuando ejecuto el bot durante mucho tiempo. En primer lugar, sospecho de mi código; luego sospecho bot y finalmente llegué a las solicitudes. :)
Usé len (gc.get_objects ()) para identificar que existe ese problema. Localicé las rutinas de comunicación, luego borré todo el código del bot y llegué al ejemplo que aumenta el recuento de objetos gc en cada iteración.
Resultado Esperado
len (gc.get_objects ()) debería dar el mismo resultado en cada iteración del ciclo
Resultado actual
El valor de len (gc.get_objects ()) aumenta en cada iteración del ciclo.
Test N2
GetObjects len: 27959
Test N3
GetObjects len: 27960
Test N4
GetObjects len: 27961
Test N5
GetObjects len: 27962
Test N6
GetObjects len: 27963
Test N7
GetObjects len: 27964
Pasos de reproducción
token = "XXX:XXX"
chat_id = '111'
proxy = {'https':'socks5h://ZZZ'} #You may need proxy to run this in Russia
from time import sleep
import gc, requests
def garbage_info():
res = ""
res += "\nGetObjects len: " + str(len(gc.get_objects()))
return res
def tester():
count = 0
while(True):
sleep(1)
count += 1
msg = "\nTest N{0}".format(count) + garbage_info()
print(msg)
method_url = r'sendMessage'
payload = {'chat_id': str(chat_id), 'text': msg}
request_url = "https://api.telegram.org/bot{0}/{1}".format(token, method_url)
method_name = 'get'
session = requests.session()
req = requests.Request(
method=method_name.upper(),
url=request_url,
params=payload
)
prep = session.prepare_request(req)
settings = session.merge_environment_settings(
prep.url, None, None, None, None)
# prep.url, proxy, None, None, None) #Change the line to enable proxy
send_kwargs = {
'timeout': None,
'allow_redirects': None,
}
send_kwargs.update(settings)
resp = session.send(prep, **send_kwargs)
# For more clean output
gc.collect()
tester()
Información del sistema
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "2.3.1"
},
"idna": {
"version": "2.7"
},
"implementation": {
"name": "CPython",
"version": "3.6.6"
},
"platform": {
"release": "4.15.0-36-generic",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "1010009f",
"version": "17.5.0"
},
"requests": {
"version": "2.19.1"
},
"system_ssl": {
"version": "1010007f"
},
"urllib3": {
"version": "1.23"
},
"using_pyopenssl": true
}
_El mismo comportamiento que tuve en Python 3.5.3 en Windows10._
 Badiboy
en 16 oct. 2018
Badiboy
en 16 oct. 2018
@LeoSZN
@initbar
¿Necesito ejecutar
p.daemon = Trueen el bucle o fuera del bucle antes dep.join()? Por cierto, ¿todavía necesitop.join()después de aplicarp.daemon = True?
# ..
for i in urls:
p = Process(target=main, args=(i,))
p.daemon = True # before `.start`
p.start()
# ..
Como nota menor, aún puede .join procesos daemon, pero es casi seguro que se eliminen cuando su proceso principal finalice (a menos que de alguna manera se queden huérfanos involuntariamente; en cuyo caso, ¡hágamelo saber! Me encanta aprender más sobre esto).
De lo contrario, puede almacenar los objetos Process separado como una matriz y unirse al final:
# ..
processes = [
Process(target=main, args=(i,))
for i in urls
]
# start the process activity.
Resultado Esperado
len (gc.get_objects ()) debería dar el mismo resultado en cada iteración del ciclo
La razón de este comportamiento se encontró en el mecanismo de caché de "solicitudes".
Funciona incorrectamente (sospechoso): agrega un registro de caché a cada llamada a la URL de la API de Telegram (en lugar de almacenarlo en caché una vez). Pero no conduce a la pérdida de memoria, porque el tamaño de la caché está limitado a 20 y la caché se reinicia después de alcanzar este límite y el número creciente de objetos se reducirá de nuevo al valor inicial.
Badiboy
en 26 oct. 2018
Problema similar. Las solicitudes se comen la memoria cuando se ejecutan en un hilo. Código para reproducir aquí:
import gc
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from memory_profiler import profile
def run_thread_request(sess, run):
response = sess.get('https://www.google.com')
return
<strong i="6">@profile</strong>
def main():
sess = requests.session()
with ThreadPoolExecutor(max_workers=1) as executor:
print('Starting!')
tasks = {executor.submit(run_thread_request, sess, run):
run for run in range(50)}
for _ in as_completed(tasks):
pass
print('Done!')
return
<strong i="7">@profile</strong>
def calling():
main()
gc.collect()
return
if __name__ == '__main__':
calling()
En el código dado arriba, paso un objeto de sesión, pero si lo reemplazo con solo ejecutar requests.get nada cambia.
La salida es:
➜ thread-test pipenv run python run.py
Starting!
Done!
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
10 23.2 MiB 23.2 MiB <strong i="13">@profile</strong>
11 def main():
12 23.2 MiB 0.0 MiB sess = requests.session()
13 23.2 MiB 0.0 MiB with ThreadPoolExecutor(max_workers=1) as executor:
14 23.2 MiB 0.0 MiB print('Starting!')
15 23.4 MiB 0.0 MiB tasks = {executor.submit(run_thread_request, sess, run):
16 23.4 MiB 0.0 MiB run for run in range(50)}
17 25.8 MiB 2.4 MiB for _ in as_completed(tasks):
18 25.8 MiB 0.0 MiB pass
19 25.8 MiB 0.0 MiB print('Done!')
20 25.8 MiB 0.0 MiB return
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
22 23.2 MiB 23.2 MiB <strong i="14">@profile</strong>
23 def calling():
24 25.8 MiB 2.6 MiB main()
25 25.8 MiB 0.0 MiB gc.collect()
26 25.8 MiB 0.0 MiB return
Y Pipfile se ve así:
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
[requires]
python_version = "3.6"
[packages]
requests = "==2.21.0"
memory-profiler = "==0.55.0"
 jotunskij
en 17 dic. 2018
jotunskij
en 17 dic. 2018
FWIW También estoy experimentando una pérdida de memoria similar a la de @jotunskij aquí hay más información
 pawel-lmcb
en 26 mar. 2019
pawel-lmcb
en 26 mar. 2019
También tengo el mismo problema en el que el uso de request.get con subprocesos consume la memoria entre 0,1 y 0,9 por solicitud y no se "borra" después de las solicitudes, sino que la guarda.
 BarryThrill
en 5 may. 2019
BarryThrill
en 5 may. 2019
Lo mismo aquí, ¿alguna solución?
 popjxc
en 13 jun. 2019
popjxc
en 13 jun. 2019
Editar
Mi problema parece deberse al uso de verify=False en las solicitudes, he presentado un error en # 5215
Tener el mismo problema. Tengo un script simple que genera un hilo, este hilo llama a una función que ejecuta un bucle while, este bucle consulta una API para verificar un valor de estado y luego duerme durante 10 segundos y luego el bucle se ejecutará nuevamente hasta que el script se detenga.
Cuando uso la función requests.get , puedo ver que el uso de la memoria aumenta lentamente a través del administrador de tareas al observar el proceso generado.
Pero si elimino la llamada requests.get del bucle o uso urllib3 directamente para realizar la solicitud de obtención, hay muy poca o ninguna alteración del uso de la memoria.
He visto esto durante un período de dos horas en ambos casos y cuando uso requests.get el uso de memoria es de 1GB + después de dos horas, mientras que al usar urllib3 el uso de memoria es de aprox. 20 mb después de dos horas.
Python 3.7.4 y solicitudes 2.22.0
 tallona
en 27 sept. 2019
tallona
en 27 sept. 2019
Parece que Requests todavía está en la etapa beta con pérdidas de memoria como esa. ¡Vamos, chicos, arreglen esto! 😉👍
 PedanticHacker
en 1 oct. 2019
PedanticHacker
en 1 oct. 2019
¿Algún avance en esto? La solicitud POST simple con la carga de un archivo también crea el problema similar de la pérdida de memoria.
 MuhammadAliShahzad
en 2 oct. 2019
MuhammadAliShahzad
en 2 oct. 2019
Lo mismo para mí ... la fuga durante la ejecución del grupo de subprocesos también está en Windows python38.
solicitudes 2.22.0
 far-rainbow
en 9 dic. 2019
far-rainbow
en 9 dic. 2019
Lo mismo para mi
 sunnyjiechao
en 13 ene. 2020
sunnyjiechao
en 13 ene. 2020
Aquí está mi problema de pérdida de memoria, ¿alguien puede ayudar? https://stackoverflow.com/questions/59746125/memory-keep-growing-when-using-mutil-thread-download-file
sunnyjiechao
en 16 ene. 2020
Llame a Session.close() y Response.close() puede evitar la pérdida de memoria.
Y ssl consumirá más memoria, por lo que la pérdida de memoria será más notable cuando se soliciten URL https.
Primero hago 4 casos de prueba:
- solicitudes + ssl (https: //)
- solicitudes + no ssl (http: //)
- aiohttp + ssl (https: //)
- aiohttp + non-ssl (http: //)
Pseudo código:
def run(url):
session = requests.session()
response = session.get(url)
while True:
for url in urls: # about 5k urls of public websites
# execute in thread pool, size=10
thread_pool.submit(run, url)
# in another thread, record memory usage every seconds
Gráfico de uso de memoria (eje y: MB, eje x: tiempo), las solicitudes usan mucha memoria y la memoria aumenta muy rápido, mientras que el uso de memoria aiohttp es estable:
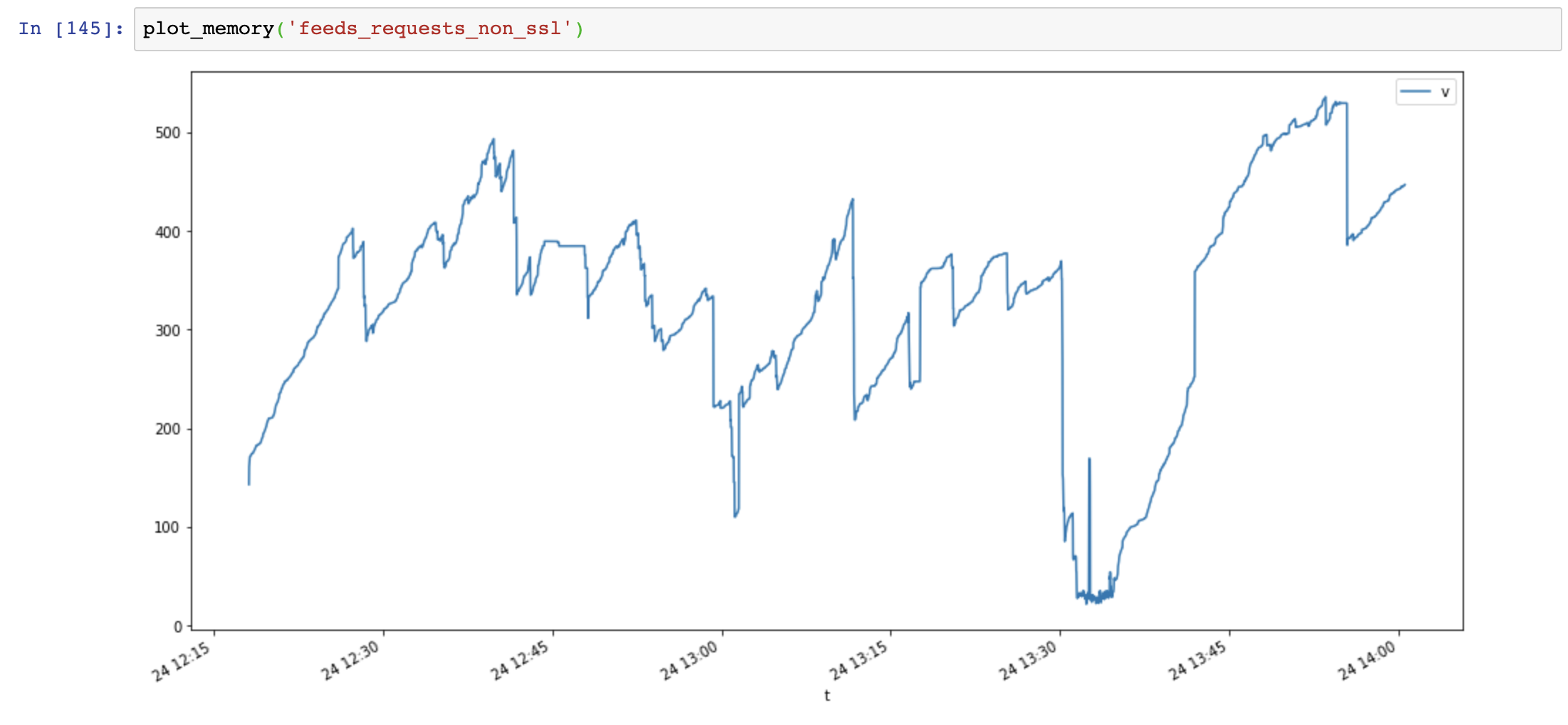



Luego agrego Session.close() y vuelvo a probar:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
El uso de memoria disminuyó significativamente, pero el uso de memoria aún aumenta con el tiempo:


Finalmente agrego Response.close() y pruebo nuevamente:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
response.close() # close response !!
El uso de memoria volvió a disminuir y no aumenta con el tiempo:
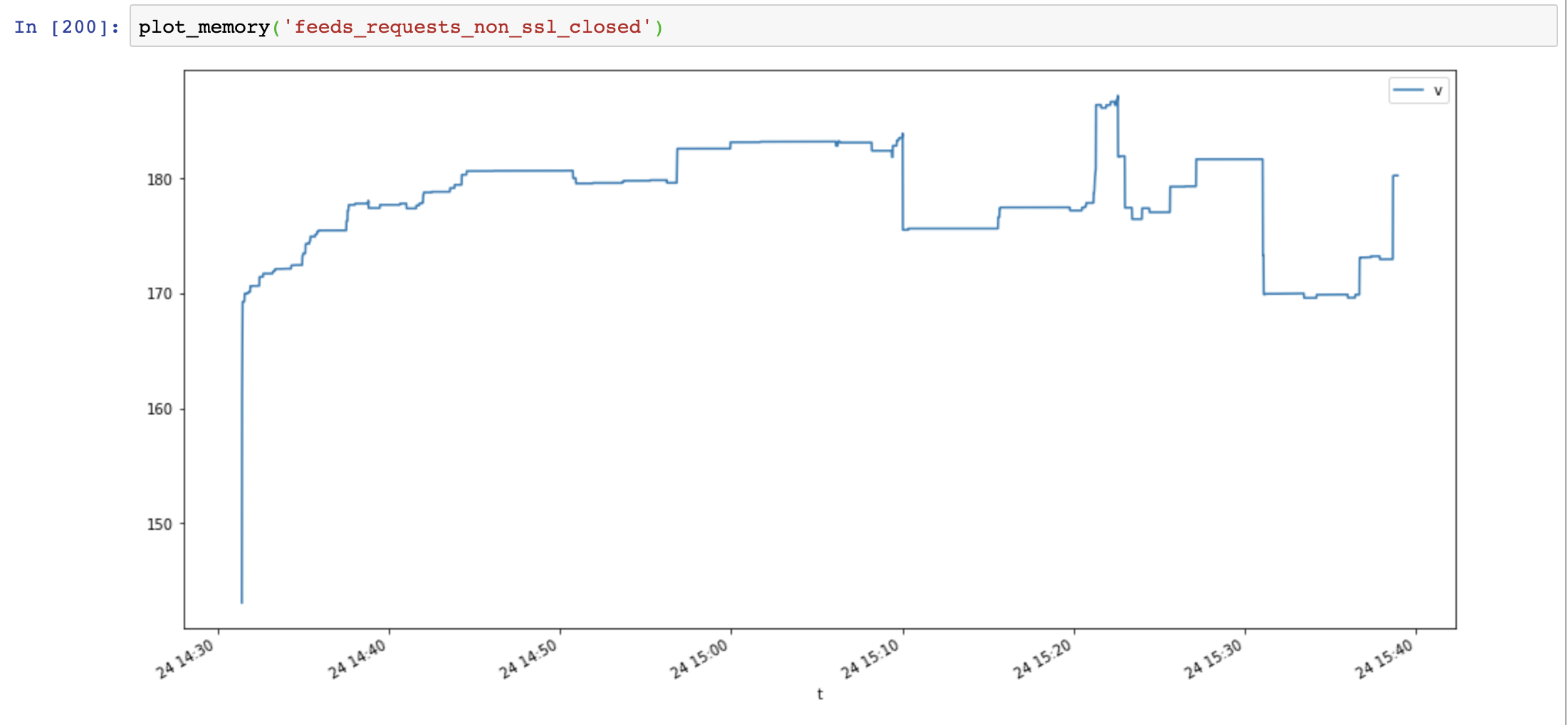

Compare aiohttp y las solicitudes muestran que la pérdida de memoria no es causada por ssl, es causada por recursos de conexión no cerrados.
Guiones útiles:
class MemoryReporter:
def __init__(self, name):
self.name = name
self.file = open(f'memoryleak/memory_{name}.txt', 'w')
self.thread = None
def _get_memory(self):
return psutil.Process().memory_info().rss
def main(self):
while True:
t = time.time()
v = self._get_memory()
self.file.write(f'{t},{v}\n')
self.file.flush()
time.sleep(1)
def start(self):
self.thread = Thread(target=self.main, name=self.name, daemon=True)
self.thread.start()
def plot_memory(name):
filepath = 'memoryleak/memory_{}.txt'.format(name)
df_mem = pd.read_csv(filepath, index_col=0, names=['t', 'v'])
df_mem.index = pd.to_datetime(df_mem.index, unit='s')
df_mem.v = df_mem.v / 1024 / 1024
df_mem.plot(figsize=(16, 8))
Información del sistema:
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.8"
},
"implementation": {
"name": "CPython",
"version": "3.7.4"
},
"platform": {
"release": "18.0.0",
"system": "Darwin"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.22.0"
},
"system_ssl": {
"version": "1010104f"
},
"urllib3": {
"version": "1.25.6"
},
"using_pyopenssl": false
}
 guyskk
en 24 mar. 2020
guyskk
en 24 mar. 2020
El problema de fuga de SSL está empaquetado OpenSSL <= 3.7.4 en Windows y OSX, no libera la memoria del contexto correctamente
https://github.com/VeNoMouS/cloudscraper/issues/143#issuecomment -613092377
 VeNoMouS
en 13 abr. 2020
VeNoMouS
en 13 abr. 2020
Temas relacionados
 cnicodeme
·
3Comentarios
cnicodeme
·
3Comentarios
 iLaus
·
3Comentarios
iLaus
·
3Comentarios
 JimHokanson
·
3Comentarios
JimHokanson
·
3Comentarios
 eromoe
·
3Comentarios
eromoe
·
3Comentarios
 mitar
·
4Comentarios
mitar
·
4Comentarios
Comentario más útil
Problema similar. Las solicitudes se comen la memoria cuando se ejecutan en un hilo. Código para reproducir aquí:
En el código dado arriba, paso un objeto de sesión, pero si lo reemplazo con solo ejecutar
requests.getnada cambia.La salida es:
Y Pipfile se ve así: