Requests: Запрашивает утечку памяти
Резюме.
ожидаемый результат
Программа работает нормально
Фактический результат
Программа потребляет весь барабан до тех пор, пока не перестанет работать
Шаги размножения
Псевдокод:
def function():
proxies = {
'https': proxy
}
session = requests.Session()
session.headers.update({'User-Agent': 'user - agent'})
try: #
login = session.get(url, proxies=proxies) # HERE IS WHERE MEMORY LEAKS
except: #
return -1 #
return 0
Системная информация
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.6"
},
"implementation": {
"name": "CPython",
"version": "3.6.3"
},
"platform": {
"release": "10",
"system": "Windows"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.18.4"
},
"system_ssl": {
"version": "100020bf"
},
"urllib3": {
"version": "1.22"
},
"using_pyopenssl": false
}
 Munroc
Munroc
Все 22 Комментарий
Пожалуйста, предоставьте нам результат
python -m requests.help
Если это недоступно в вашей версии запросов, предоставьте основную информацию о вашей системе (версия Python, операционная система и т. Д.).
 sigmavirus24
20 апр. 2018
sigmavirus24
20 апр. 2018
@ sigmavirus24 Готово
Munroc
20 апр. 2018
Привет, @munroc , пара передачи , поскольку она не включена в псевдокод.
Вы создаете новый сеанс для каждого потока и какого размера пул потоков вы используете?
Какой инструмент вы используете, чтобы определить источник утечки? Не могли бы вы поделиться результатами?
Некоторое время у нас были намеки на утечки памяти во время сеансов, но я не уверен, что мы нашли дымящийся пистолет или действительно подтвержденный удар.
 nateprewitt
20 апр. 2018
nateprewitt
20 апр. 2018
@nateprewitt Привет, да, я создаю новый сеанс для каждого потока. Пул потоков - 30. Я все равно пробовал с 2-200 потоками и утечками памяти. Я не использую инструмент, я просто внес следующие изменения в функцию:
поставьте return 0 перед login = session.get и никакой утечки памяти. если я поставлю return 0 после входа в систему = session.get, память начнет протекать. Если вы хотите, я могу отправить вам мой исходный код не слишком большой.
Munroc
20 апр. 2018
@Munroc, если бы у нас был полный код, я думаю, было бы легче изолировать настоящую причину. Но, исходя из предоставленного кода, я думаю, что очень трудно сделать вывод об утечке памяти.
Как вы упомянули, если вы return непосредственно перед вызовом session.get , тогда в памяти будут существовать только объекты proxies и session (упрощенно ... но я надеюсь, вы поняли: smile :). Однако после вызова session.get(url, proxies=proxies) HTML-код url будет извлечен и локально сохранен в переменной login . Это означает, что каждый вызов session.get будет "выглядеть" как утечка памяти, но на самом деле они ведут себя нормально, линейно увеличивая (память) на размер url result.
Однако предположим, что вы использовали потоки и сразу после этого .join() их. В этом случае, я думаю, нам нужно посмотреть, как управлялись ваши потоки - и были ли они закрыты / очищены должным образом.
 initbar
21 мая 2018
initbar
21 мая 2018
@LeoSZN Я думаю, что в вашем конкретном примере вы закрываете только последний объект Process после создания нескольких элементов Process на urls элементов.
Не могли бы вы попробовать демонизировать их с помощью p.daemon = True и запустить их (чтобы после завершения основного потока все порожденные дочерние процессы также умерли)? В противном случае сохраните порожденные процессы в отдельном массиве и обязательно закройте их все с помощью цикла.
initbar
14 окт. 2018
@initbar
Нужно ли мне запускать p.daemon = True в цикле или вне цикла перед p.join() ? Кстати, мне все еще нужно p.join() после применения p.daemon = True ?
 leoszn
15 окт. 2018
leoszn
15 окт. 2018
_Ook, меня выгнали из новой темы в эту, так что позвольте мне присоединиться к вашей.
Возможно, эта проблема предоставит дополнительную информацию и ускорит ее решение ..._
Я запускаю бота Telegram и заметил ухудшение свободной памяти при длительном запуске бота. Во-первых, я подозреваю свой код; потом подозреваю бота и наконец пришел к запросам. :)
Я использовал len (gc.get_objects ()), чтобы определить, что проблема существует. Я обнаружил процедуры связи, затем очистил весь код бота и перешел к примеру, который увеличивает количество объектов gc на каждой итерации.
ожидаемый результат
len (gc.get_objects ()) должен давать одинаковый результат на каждой итерации цикла.
Фактический результат
Значение len (gc.get_objects ()) увеличивается на каждой итерации цикла.
Test N2
GetObjects len: 27959
Test N3
GetObjects len: 27960
Test N4
GetObjects len: 27961
Test N5
GetObjects len: 27962
Test N6
GetObjects len: 27963
Test N7
GetObjects len: 27964
Шаги размножения
token = "XXX:XXX"
chat_id = '111'
proxy = {'https':'socks5h://ZZZ'} #You may need proxy to run this in Russia
from time import sleep
import gc, requests
def garbage_info():
res = ""
res += "\nGetObjects len: " + str(len(gc.get_objects()))
return res
def tester():
count = 0
while(True):
sleep(1)
count += 1
msg = "\nTest N{0}".format(count) + garbage_info()
print(msg)
method_url = r'sendMessage'
payload = {'chat_id': str(chat_id), 'text': msg}
request_url = "https://api.telegram.org/bot{0}/{1}".format(token, method_url)
method_name = 'get'
session = requests.session()
req = requests.Request(
method=method_name.upper(),
url=request_url,
params=payload
)
prep = session.prepare_request(req)
settings = session.merge_environment_settings(
prep.url, None, None, None, None)
# prep.url, proxy, None, None, None) #Change the line to enable proxy
send_kwargs = {
'timeout': None,
'allow_redirects': None,
}
send_kwargs.update(settings)
resp = session.send(prep, **send_kwargs)
# For more clean output
gc.collect()
tester()
Системная информация
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "2.3.1"
},
"idna": {
"version": "2.7"
},
"implementation": {
"name": "CPython",
"version": "3.6.6"
},
"platform": {
"release": "4.15.0-36-generic",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "1010009f",
"version": "17.5.0"
},
"requests": {
"version": "2.19.1"
},
"system_ssl": {
"version": "1010007f"
},
"urllib3": {
"version": "1.23"
},
"using_pyopenssl": true
}
_ То же поведение, что и на Python 3.5.3 в Windows10. _
 Badiboy
16 окт. 2018
Badiboy
16 окт. 2018
@LeoSZN
@initbar
Нужно ли мне запускать
p.daemon = Trueв цикле или вне цикла передp.join()? Кстати, мне все еще нужноp.join()после примененияp.daemon = True?
# ..
for i in urls:
p = Process(target=main, args=(i,))
p.daemon = True # before `.start`
p.start()
# ..
В качестве небольшого примечания, вы все еще .join , но они почти гарантированно будут убиты, когда их родительский процесс завершится (если они каким-то образом не станут случайно осиротевшими; в этом случае, пожалуйста, дайте мне знать! I Люблю узнавать об этом побольше).
В противном случае вы можете сохранить объекты Process отдельно как массив и в конце присоединиться:
# ..
processes = [
Process(target=main, args=(i,))
for i in urls
]
# start the process activity.
ожидаемый результат
len (gc.get_objects ()) должен давать одинаковый результат на каждой итерации цикла.
Причина такого поведения была обнаружена в механизме кеширования «запросов».
Он работает некорректно (подозревается): добавляет запись в кеш при каждом вызове URL-адреса Telegram API (вместо того, чтобы кэшировать ее один раз). Но это не приводит к утечке памяти, потому что размер кеша ограничен 20, и кеш сбрасывается после достижения этого лимита, и растущее количество объектов будет уменьшено до исходного значения.
Badiboy
26 окт. 2018
Похожая проблема. Запросы съедают память при работе в потоке. Код для воспроизведения здесь:
import gc
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from memory_profiler import profile
def run_thread_request(sess, run):
response = sess.get('https://www.google.com')
return
<strong i="6">@profile</strong>
def main():
sess = requests.session()
with ThreadPoolExecutor(max_workers=1) as executor:
print('Starting!')
tasks = {executor.submit(run_thread_request, sess, run):
run for run in range(50)}
for _ in as_completed(tasks):
pass
print('Done!')
return
<strong i="7">@profile</strong>
def calling():
main()
gc.collect()
return
if __name__ == '__main__':
calling()
В приведенном выше коде я передаю объект сеанса, но если я заменю его просто запущенным requests.get ничего не изменится.
Выход:
➜ thread-test pipenv run python run.py
Starting!
Done!
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
10 23.2 MiB 23.2 MiB <strong i="13">@profile</strong>
11 def main():
12 23.2 MiB 0.0 MiB sess = requests.session()
13 23.2 MiB 0.0 MiB with ThreadPoolExecutor(max_workers=1) as executor:
14 23.2 MiB 0.0 MiB print('Starting!')
15 23.4 MiB 0.0 MiB tasks = {executor.submit(run_thread_request, sess, run):
16 23.4 MiB 0.0 MiB run for run in range(50)}
17 25.8 MiB 2.4 MiB for _ in as_completed(tasks):
18 25.8 MiB 0.0 MiB pass
19 25.8 MiB 0.0 MiB print('Done!')
20 25.8 MiB 0.0 MiB return
Filename: run.py
Line # Mem usage Increment Line Contents
================================================
22 23.2 MiB 23.2 MiB <strong i="14">@profile</strong>
23 def calling():
24 25.8 MiB 2.6 MiB main()
25 25.8 MiB 0.0 MiB gc.collect()
26 25.8 MiB 0.0 MiB return
А Pipfile выглядит так:
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
[requires]
python_version = "3.6"
[packages]
requests = "==2.21.0"
memory-profiler = "==0.55.0"
 jotunskij
17 дек. 2018
jotunskij
17 дек. 2018
FWIW Я также испытываю аналогичную утечку памяти, как @jotunskij, здесь больше информации
 pawel-lmcb
26 мар. 2019
pawel-lmcb
26 мар. 2019
У меня также есть такая же проблема, когда использование request.get с потоковой передачей фактически съедает память примерно на 0,1–0,9 за запрос и не «очищает» себя после запросов, а сохраняет ее.
 BarryThrill
5 мая 2019
BarryThrill
5 мая 2019
То же самое здесь, любая работа?
 popjxc
13 июн. 2019
popjxc
13 июн. 2019
Редактировать
Моя проблема, похоже, связана с использованием verify=False в запросах, я обнаружил ошибку под # 5215
Имея ту же проблему. У меня есть простой скрипт, который порождает поток, этот поток вызывает функцию, которая запускает цикл while, этот цикл запрашивает API, чтобы проверить значение статуса, а затем засыпает в течение 10 секунд, а затем цикл будет выполняться снова, пока скрипт не будет остановлен.
При использовании функции requests.get я вижу, как использование памяти медленно увеличивается через диспетчер задач, наблюдая за порожденным процессом.
Но если я удалю вызов requests.get из цикла или использую urllib3 напрямую для выполнения запроса на получение, будет очень мало, если вообще вообще, снижение использования памяти.
Я наблюдал это в течение двухчасового периода в обоих случаях, и при использовании requests.get использование памяти составляет 1 ГБ + через два часа, тогда как при использовании urllib3 использование памяти составляет прибл. 20мб через два часа.
Python 3.7.4 и запросы 2.22.0
 tallona
27 сент. 2019
tallona
27 сент. 2019
Похоже, что Requests все еще находится в стадии бета-тестирования с подобными утечками памяти. Давайте, ребята, исправьте это! 😉👍
 PedanticHacker
1 окт. 2019
PedanticHacker
1 окт. 2019
Есть новости по этому поводу? Простой запрос POST с загрузкой файла также создает аналогичную проблему с утечкой памяти.
 MuhammadAliShahzad
2 окт. 2019
MuhammadAliShahzad
2 окт. 2019
То же самое для меня ... утечка при выполнении пула потоков тоже есть на Windows python38.
запросы 2.22.0
 far-rainbow
9 дек. 2019
far-rainbow
9 дек. 2019
Мне то же
 sunnyjiechao
13 янв. 2020
sunnyjiechao
13 янв. 2020
Вот моя проблема с утечкой памяти, кто-нибудь может помочь? https://stackoverflow.com/questions/59746125/memory-keep-growing-when-using-mutil-thread-download-file
sunnyjiechao
16 янв. 2020
Вызов Session.close() и Response.close() может избежать утечки памяти.
И ssl будет потреблять больше памяти, поэтому утечка памяти будет более заметной при запросе URL-адресов https.
Сначала я делаю 4 тестовых случая:
- запросы + ssl (https: //)
- запросы + не-SSL (http: //)
- aiohttp + ssl (https: //)
- aiohttp + без SSL (http: //)
Псевдокод:
def run(url):
session = requests.session()
response = session.get(url)
while True:
for url in urls: # about 5k urls of public websites
# execute in thread pool, size=10
thread_pool.submit(run, url)
# in another thread, record memory usage every seconds
График использования памяти (ось y: МБ, ось x: время), запросы используют много памяти, и память увеличивается очень быстро, в то время как использование памяти aiohttp стабильно:
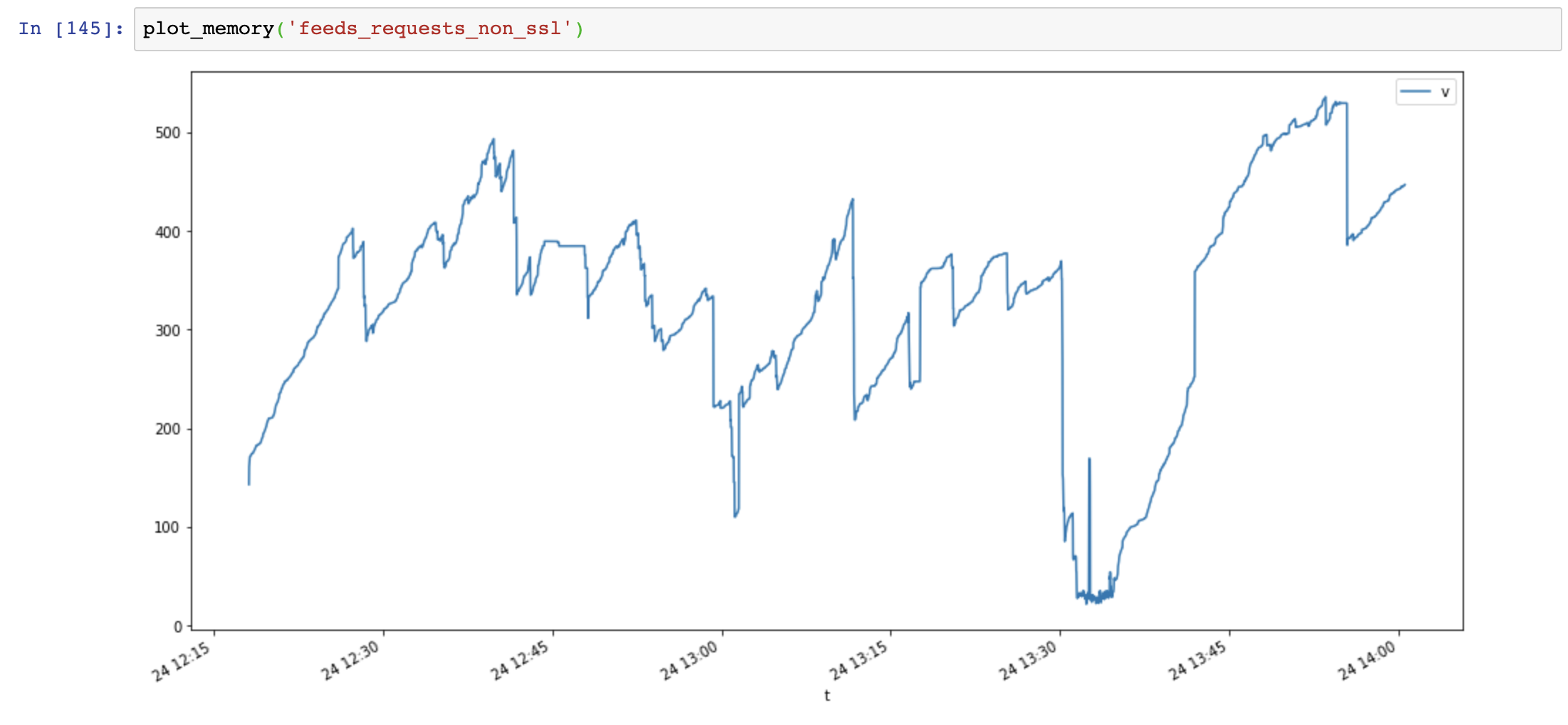



Затем я добавляю Session.close() и снова тестирую:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
Использование памяти значительно уменьшилось, но со временем использование памяти все равно увеличивается:


Наконец, я добавляю Response.close() и снова тестирую:
def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
response.close() # close response !!
Использование памяти снова уменьшилось, а не увеличилось со временем:
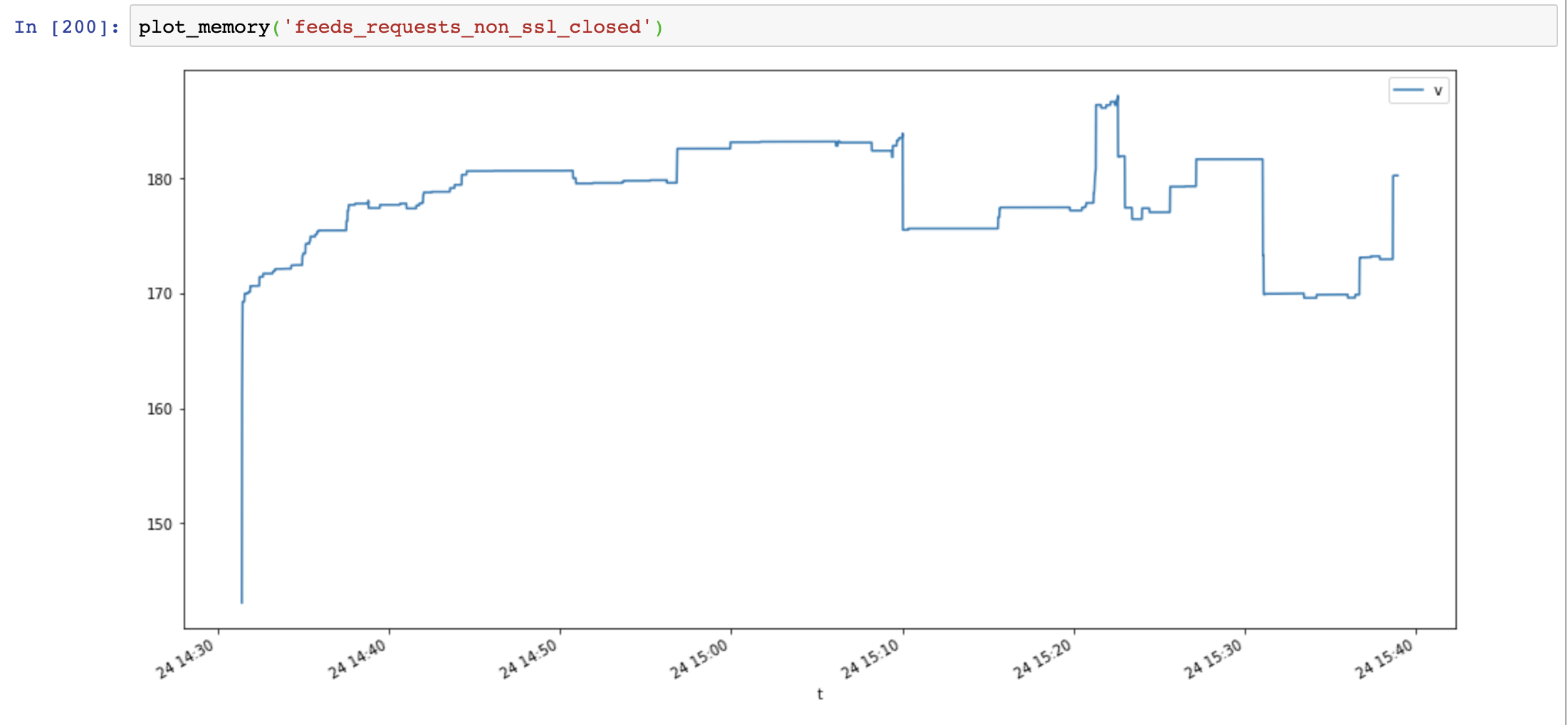

Сравнение aiohttp и запросов показывает, что утечка памяти вызвана не ssl, а тем, что ресурсы соединения не закрыты.
Полезные скрипты:
class MemoryReporter:
def __init__(self, name):
self.name = name
self.file = open(f'memoryleak/memory_{name}.txt', 'w')
self.thread = None
def _get_memory(self):
return psutil.Process().memory_info().rss
def main(self):
while True:
t = time.time()
v = self._get_memory()
self.file.write(f'{t},{v}\n')
self.file.flush()
time.sleep(1)
def start(self):
self.thread = Thread(target=self.main, name=self.name, daemon=True)
self.thread.start()
def plot_memory(name):
filepath = 'memoryleak/memory_{}.txt'.format(name)
df_mem = pd.read_csv(filepath, index_col=0, names=['t', 'v'])
df_mem.index = pd.to_datetime(df_mem.index, unit='s')
df_mem.v = df_mem.v / 1024 / 1024
df_mem.plot(figsize=(16, 8))
Системная информация:
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": ""
},
"idna": {
"version": "2.8"
},
"implementation": {
"name": "CPython",
"version": "3.7.4"
},
"platform": {
"release": "18.0.0",
"system": "Darwin"
},
"pyOpenSSL": {
"openssl_version": "",
"version": null
},
"requests": {
"version": "2.22.0"
},
"system_ssl": {
"version": "1010104f"
},
"urllib3": {
"version": "1.25.6"
},
"using_pyopenssl": false
}
 guyskk
24 мар. 2020
guyskk
24 мар. 2020
Проблема утечки SSL упакована OpenSSL <= 3.7.4 в Windows и OSX, она не освобождает память из контекста должным образом
https://github.com/VeNoMouS/cloudscraper/issues/143#issuecomment -613092377
 VeNoMouS
13 апр. 2020
VeNoMouS
13 апр. 2020
Смежные вопросы
 remram44
·
4Комментарии
remram44
·
4Комментарии
 Gonzalliz
·
3Комментарии
Gonzalliz
·
3Комментарии
 jake491
·
3Комментарии
jake491
·
3Комментарии
 thadeusb
·
3Комментарии
thadeusb
·
3Комментарии
 jakul
·
3Комментарии
jakul
·
3Комментарии
Самый полезный комментарий
Похожая проблема. Запросы съедают память при работе в потоке. Код для воспроизведения здесь:
В приведенном выше коде я передаю объект сеанса, но если я заменю его просто запущенным
requests.getничего не изменится.Выход:
А Pipfile выглядит так: