Data.table: 在最新的 data.table dev 版本中,带有大 csv(44 GB)的 fread 需要大量 RAM
你好,
硬件和软件:
服务器: Dell R930 4-Intel Xeon E7-8870 v3 2.1GHz,45M Cache,9.6GT/s QPI,Turbo,HT,18C/36T and 1TB in RAM
操作系统:红帽 7.1
R 版本:3.3.2
数据表版本:1.10.5 内置 2017-03-21
我正在加载一个 csv 文件(44 GB,872505 行 x 12785 列)。 它加载速度非常快,使用 144 个内核(来自 4 个处理器的 72 个内核,启用超线程使其成为 144 个内核)在 1.30 分钟内加载。
主要问题是,当加载 DT 时,正在使用的内存量相对于 csv 文件的大小显着增加。 在这种情况下,44 GB csv(使用 fwrite 保存,使用 saveRDS 保存并且 compress=FALSE 创建一个 84GB 的文件)正在使用 ~ 356 GB 的 RAM。
这是使用“verbose = TRUE”的输出
_分配 12785 个列槽(12785 - 0 丢弃)
madvise 顺序:好的
使用 1440 个跳转点和 144 个线程读取数据
读取 858881 个估计行的 95.7%
在挂钟时间的 1 分钟 33.736 秒内从 43.772GB 文件中读取 872505 行 x 12785 列(受其他正在运行的应用程序影响)
0.000s ( 0%) 内存映射
0.070s (0%) sep、ncol 和报头检测
26.227s (28%) 使用来自 1440 个跳跃点的 34832 个样本行的列类型检测
0.614s ( 1%) 在 RAM 中分配 3683116 行 x 12785 列 (350.838GB)
0.000 秒 (0%) madvise 顺序
66.825s ( 71%) 读取数据
93.736s 总计_
它显示了在使用并行包时有时会出现的类似问题,其中使用“mclapply”等功能时,每个内核启动一个 rsession。 请参阅此屏幕截图中创建/列出的 Rsessions:

如果我执行“rm(DT)”,RAM 会返回到初始状态,并且“Rsessions”将被删除。
已经尝试过例如“setDTthreads(20)”并且仍然使用相同数量的RAM。
顺便说一下,如果文件加载了非并行版本的“fread”,内存分配最多只能达到 ~106 GB。
吉列尔莫
 geponce
geponce
所有30条评论
这是非并行 fread 实现的输出(data.table 1.10.5 IN DEVELOPMENT built 2017-02-09)

我仔细检查了使用的内存量,它刚刚上升到 84GB。
吉列尔莫
geponce
于 2017-03-22
你是对的。 感谢伟大的报告。 估计的 nrow 看起来差不多(858,881 对 872,505),但分配比那个(3,683,116)大 4.2 倍,而且还差得远。 我改进了计算并在详细输出中添加了更多细节。 不过,在完成更多工作之前,暂时不要重新测试。
 mattdowle
于 2017-03-25
mattdowle
于 2017-03-25
好的,请重新测试 - 现在应该修复。
mattdowle
于 2017-03-26
我刚刚安装了 data.table dev:
data.table 1.10.5 IN DEVELOPMENT built 2017-03-27 02:50:31 UTC
当我尝试读取相同的 44 GB 文件时,我得到的第一件事是这条消息:
DT <- fread('dt.daily.4km.csv')
错误:protect():保护堆栈溢出
然后我只是重新运行相同的命令并开始正常工作。 然而,这个版本没有使用多核模式。 加载需要大约 25 分钟,与放置 fread-parallel 版本之前相同。
吉列尔莫
geponce
于 2017-03-27
我关闭了所有 r 会话并重新运行测试,但出现错误:
猜测的列类型不足以容纳 508 列中的 34711745 个值。 使用 colClasses 手动设置这些列类。
见下文,我收到几条关于“猜测的整数但包含<<0....>>”的消息
_在挂钟时间 15:27.024 从 43.772GB 文件中读取 872505 行 x 12785 列(即使看似空闲,也可能被任何其他打开的应用程序减慢速度)
第 171 列 ('D_19810618') 猜测为“整数”,但包含 <<2.23000001907349>>
第 347 列 ('D_19811211') 猜测为“整数”,但包含 <<1.02999997138977>>
第 348 列 ('D_19811212') 猜测为“整数”,但包含 <<3.75>>_
geponce
于 2017-03-27
哇 - 你的文件真的在测试边缘情况。 伟大的。 将来请使用verbose=TRUE并提供完整的输出。 但是根据您在这种情况下提供的信息,我可以看到问题实际上是什么。 为每个线程的每一列创建了一个缓冲区(在本例中,超过 12,000 列)。 目前,每一个都单独受到保护。 有一种方法可以避免这种情况 - 可以。 关于类型猜测的消息是正确的。 那些 508 列对您有意义并且您同意它们应该是数字吗? 您可以像这样将一系列列传递给colClasses : colClasses=list("numeric"=11:518)
这个数据来自哪个领域? 你在创建文件吗? 感觉它已被扭曲为宽格式,其中正常的最佳实践是以长格式写入(并将其保存在内存中)。 我通常希望将 508 列名称(例如“D_19810618”)视为列中的值,而不是列本身。 这就是为什么我问您是否正在创建文件并且您可以以长格式创建它。 如果没有,建议创建文件的人可以做得更好。 我猜您正在通过列应用操作,可能使用.SD和.SDcols 。 在长格式和keyby=列中,它确实要好得多,其中包含“D_19810618”之类的值。
但是我仍然会尝试使fread尽可能好地处理任何输入——即使是超过 12,000 列的非常宽的文件。
我希望其他人正在测试并发现他们的文件没有任何问题!
mattdowle
于 2017-03-27
_这 508 列对您有什么意义并且您同意它们应该是数字吗?
此表按行包含时间序列。 IDx、IDy、Time1_value、Time2_value、Time3_value... 以及所有 Time N _value 列仅包含数字值。 如果我使用 colClasses,我将需要为 12783 执行此操作:list("numeric"=2:12783)。 我会试试这个。
_这个数据来自哪个领域?_
地理空间数据。 我正在使用 IDx 和 IDy 在 DT 中进行欧几里德距离搜索。 我猜行数越多搜索越慢,对吧?
现在非常快(宽格式)。 我有一张地图,用户可以在其中单击一个区域,然后在 csv 文件中从最近的位置(具有可用数据)到给定的单击生成时间序列。 我会用长格式来实现它。
我会回来一些结果。
geponce
于 2017-03-28
好的。 您不需要list("numeric"=2:12783) iiuc 因为它只需要 508 列的帮助。 哦 - 我明白了 - 我猜 508 是分散在列中的(它们不是一组连续的列)?
不 - data.table 当它很宽时几乎永远不会更快! Long 几乎总是更快、更方便。 你见过并试过roll="nearest"吗? 你现在做得怎么样? 请出示代码以便我们理解。 几乎可以肯定,长格式更好,但我们可能需要对最近的 2D 进行一些增强。 请同时显示时间。 当你说“相当快”时,结果证明人们对“相当快”是什么有着截然不同的看法。
mattdowle
于 2017-03-28
熔化此表达到 2^31 限制。 我收到错误消息:“不允许使用负长度向量”。
我将回到源代码,看看我是否可以以长格式生成它。
geponce
于 2017-03-28
# Read Data
DT <- fread('dt.daily.4km.csv', showProgress = FALSE)
# Add two columns with truncated values of x and y (these are geog. coords.)
DT[,y_tr:=trunc(y)]
DT[,x_tr:=trunc(x)]
# For using on plotting (x-axis values)
xaxis<-seq.Date(as.Date("1981-01-01"),as.Date("2015-12-31"), "day")
# subset by truncated coordinates to avoid full-table search. Now searches
# will happen in a smaller subset
DT2 <- DT[y_tr==trunc(y_clicked) & x_tr==trunc(x_clicked),]
# Add distance from each point in the data.table to the provided location, "gdist" is from
# Imap package for euclidean distance.
DT2[,DIST:=gdist(lat.1 = DT2$y,
lon.1 = DT2$x,
lat.2 = y_clicked,
lon.2 = x_clicked, units="miles")]
# Get the minimum distance
minDist <- min(DT2[,DIST])
# Get the y-axis values
yt <- transpose(DT2[DIST==minDist,3:(ncol(DT2)-3)])$V1`
# Ready to plot xaxis vs yt
...
...
我在公共服务器上没有该应用程序。 本质上,用户可以单击地图,然后我捕获这些坐标并执行上面的搜索,获取时间序列并创建一个图。
geponce
于 2017-03-28
发现并修复了大量列的另一个堆栈溢出: https :
mattdowle
于 2017-03-28
哦。 这是一个重点。 872505 行 * 12780 列是 110 亿行。 所以我建议采用长格式对你不起作用,因为它大于 2^31。 对不起 - 我应该发现的。 我们只需要咬紧牙关,然后去> 2^31。 与此同时,让我们坚持使用您使用的宽幅格式,我会确定的。
mattdowle
于 2017-03-28
请再试一次。 内存使用应该会恢复正常,并且应该会自动重新读取 12,785 列中的 508 列,但存在样本外类型异常。 为避免自动重新运行时间,您可以设置colClasses 。
如果未修复,请粘贴完整的详细输出。 手指交叉!
mattdowle
于 2017-03-29
好的...
最新 data.table dev 结果汇总: data.table 1.10.5 IN DEVELOPMENT built 2017-03-29 16:17:01 UTC
主要提四点:
- fread 在讨论中阅读文件工作正常。
- 阅读大约需要 5.5 分钟,而之前的版本需要大约 1.3 分钟。
- 这个版本不会像我测试的以前的版本那样增加 RAM 分配。
- 核心似乎“不太活跃”(见下面的截图)。
一些评论/问题:
1.
内核中的使用百分比不像以前那么活跃,请看截图:
在之前版本的 fread 中,内核的活动始终为 ~ 90-80%。 在这个版本中,每个核心保持在 ~2-3% 左右,如上图所示。
我不明白为什么 fread 是从整数到数字的颠簸:例如
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
我仔细检查了这些行,看起来没问题。 为什么被检测为整数,如果已经是数字,则需要将其“碰撞”为“数字”(请参阅下面建议的行的摘要)? 还是我理解错了这条线? 这发生在 508 行。 NA 会惹麻烦吗?
summary(DT[6041:24473,.(D_19850126)])
D_19850126
Min. :0.750
1st Qu.:0.887
Median :0.945
Mean :0.966
3rd Qu.:1.045
Max. :1.210
NA's :18393
下面有些冗长出来的测试。
DT<-fread('dt.daily.4km.ver032917.csv', verbose=TRUE)
输出
Parameter na.strings == <<NA>>
None of the 0 na.strings are numeric (such as '-9999').Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,D_19810113,
...
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 11 because 1281788 startSize * 10 NJUMPS * 2 = 25635760 <= -244636240 bytes from line 2 to eof
Type codes (jump 00) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 01) : 444422222222222222242444424444442222222222424444424442224424222244222222222242422222224422...4442244422 Quote rule 0
Type codes (jump 02) : 444422222222222222242444424444442422222242424444424442224424222244222222222242424222424424...4442444442 Quote rule 0
Type codes (jump 03) : 444422222222222224242444424444444422222244424444424442224424222244222222222244424442424424...4442444442 Quote rule 0
Type codes (jump 04) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 05) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 06) : 444444444422222224442444424444444444242244444444444444424444444444444244444444424442444444...4444444444 Quote rule 0
Type codes (jump 07) : 444444444422222224442444424444444444242244444444444444444444444444444244444444424444444444...4444444444 Quote rule 0
Type codes (jump 08) : 444444444442222224444444424444444444242244444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 09) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 10) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
=====
Sampled 305 rows (handled \n inside quoted fields) at 11 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=45578.20 sd=33428.37 min=12815 max=108497
Estimated nrow: 47000004016 / 45578.20 = 1031195
Initial alloc = 2062390 rows (1031195 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Type codes (drop|select): 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 44928 chunks of 0.998MB (22 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.908 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : numeric
0 : character
Rereading 508 columns due to out-of-sample type exceptions.
Column 171 ("D_19810618") bumped from 'integer' to 'numeric' due to <<2.23000001907349>> somewhere between row 6041 and row 24473
Column 347 ("D_19811211") bumped from 'integer' to 'numeric' due to <<1.02999997138977>> somewhere between row 6041 and row 24473
Column 348 ("D_19811212") bumped from 'integer' to 'numeric' due to <<3.75>> somewhere between row 6041 and row 24473
Column 643 ("D_19821003") bumped from 'integer' to 'numeric' due to <<1.04999995231628>> somewhere between row 6041 and row 24473
Column 1066 ("D_19831130") bumped from 'integer' to 'numeric' due to <<1.46000003814697>> somewhere between row 6041 and row 24473
Column 1102 ("D_19840105") bumped from 'integer' to 'numeric' due to <<0.959999978542328>> somewhere between row 6041 and row 24473
Column 1124 ("D_19840127") bumped from 'integer' to 'numeric' due to <<0.620000004768372>> somewhere between row 6041 and row 24473
Column 1130 ("D_19840202") bumped from 'integer' to 'numeric' due to <<0.540000021457672>> somewhere between row 6041 and row 24473
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
Column 1508 ("D_19850214") bumped from 'integer' to 'numeric' due to <<0.360000014305115>> somewhere between row 6041 and row 24473
...
...
Reread 872505 rows x 508 columns in 05:29.167
Read 872505 rows. Exactly what was estimated and allocated up front
Thread buffers were grown 0 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.093s ( 0%) sep, ncol and header detection
0.186s ( 0%) Column type detection using 305 sample rows from 44928 jump points
0.600s ( 0%) Allocation of 872505 rows x 12785 cols (192.552GB) plus 1.721GB of temporary buffers
326.029s ( 50%) Reading data
329.167s ( 50%) Rereading 508 columns due to out-of-sample type exceptions
656.075s Total
最后一个总结花了很多时间来完成(~6 分钟)。 如果我们计算这个冗长的摘要,整个 fread 需要大约 11 分钟。 它正在重新读取那 508 列,我什至可以在不使用 verbose=TRUE 的情况下看到消息“由于样本外类型异常而重新读取 508 列”。
在没有“verbose = TRUE”的情况下检查它
ptm<-proc.time()
DT<-fread('dt.daily.4km.ver032917.csv')
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.647 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Rereading 508 columns due to out-of-sample type exceptions.
Reread 872505 rows x 508 columns in 05:30.276
proc.time() - ptm
user system elapsed
2113.100 85.919 657.870
写测试
它工作正常。 真的很快。 我认为这些天写作比阅读慢。
fwrite(DT,'dt.daily.4km.ver032917.csv', verbose=TRUE)
No list columns are present. Setting sep2='' otherwise quote='auto' would quote fields containing sep2.
maxLineLen=151187 from sample. Found in 1.890s
Writing column names ... done in 0.000s
Writing 872505 rows in 32315 batches of 27 rows (each buffer size 8MB, showProgress=1, nth=144) ...
done (actual nth=144, anyBufferGrown=no, maxBuffUsed=46%)
“重读”需要相当长的时间。 这就像读取文件两次。
geponce
于 2017-03-30
优秀! 感谢您提供的所有信息。
- 是的,你说得对,不应该重读。 您已经通过了
colClasses=list("numeric"=1:12785)因此从Type code (colClasses)开始的输出行应该都是值 4。将修复并添加缺少的测试。 - 在 5.5m 和 1.3m 上,这很有趣。 每个线程的缓冲区当前为 1MB。 这个想法是小到适合缓存。 但在您的情况下,1MB / 12785 cols = 82 字节。 因此,该选择使缓存效率低下 50 倍。 我想,无论如何。 如果没有你的测试,我永远不会想到这一点。 当它以 1.3m 的速度工作时,它没有 1MB 的大小。
- 为什么它只采样了 305 行也很奇怪。 它应该采样了 1,000。 如果这是固定的,它可能会检测到 508 列,而无需您这样做。 样本不需要任何时间(0.186 秒),因此可以增加样本大小。
你能粘贴lscpu unix 命令的输出吗? 这将告诉我们您的缓存大小,我可以从那里思考。 我将提供buffMB作为fread的参数,以便您查看是否是这样。 如果是的话,我可以想出一个更好的计算方法。
mattdowle
于 2017-03-30
我在上一篇文章中的一点错误。 colClasses=list("numeric"=1:12785)工作正常。 如果我不指定“colClasses”,它会执行“重读”。 很抱歉造成混乱。
我注意到的一件事是,如果我不指定“colClasses”,则该表将使用 NA 创建,并且 RAM 显示为 DT 已正常加载(RAM 中约 106MB)。
这是lscpu输出:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 144
On-line CPU(s) list: 0-143
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 4
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E7-8870 v3 @ 2.10GHz
Stepping: 4
CPU MHz: 2898.328
BogoMIPS: 4195.66
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36,40,44,48,52,56,60,64,68,72,76,80,84,88,92,96,100,104,108,112,116,120,124,128,132,136,140
NUMA node1 CPU(s): 1,5,9,13,17,21,25,29,33,37,41,45,49,53,57,61,65,69,73,77,81,85,89,93,97,101,105,109,113,117,121,125,129,133,137,141
NUMA node2 CPU(s): 2,6,10,14,18,22,26,30,34,38,42,46,50,54,58,62,66,70,74,78,82,86,90,94,98,102,106,110,114,118,122,126,130,134,138,142
NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39,43,47,51,55,59,63,67,71,75,79,83,87,91,95,99,103,107,111,115,119,123,127,131,135,139,143
好的,我知道了。 谢谢。
再次阅读您的第一条评论,如果它说“从整数跳到双倍”而不是“从整数跳到数字”会更有意义吗?
你所说的“由 NA 创造”是什么意思? 所有的表都充满了 NA,只有 508 列?
什么是“DT 加载正常(RAM 中约 106MB)”。 这是一个 44GB 的文件,所以 106MB 怎么可能是正常的?
mattdowle
于 2017-03-30
好吧,在这个文件中,我只有实数和 NA。 我没有整数值。 你什么时候抛出那个消息,“从数据类型 A 到数据类型 B”?
这正是我的意思。 在我安装的当前版本的 data.table 中,如果我省略 colClasses,它会加载 DT 但充满 NA。
DT[!is.na(D_19821001),]生成 0 条记录,如果我使用 colClasses 加载表并执行相同的过滤,它实际上会显示记录。嗯,这个文件是 47 GB 作为磁盘中的 csv,但是一旦你将它加载到 R 中,它需要两倍多的内存......与值的精度无关,一旦加载,内存分配就会真正发生数字导致增加?
geponce
于 2017-03-30
也许是另一个错字:106MB 应该是 106GB。
我没有遵循 NA 方面。 但是在途中进行了一些修复,然后再尝试新鲜...
mattdowle
于 2017-03-30
好的 - 请再试一次。 猜测样本已增加到 10,000(看看这需要多长时间会很有趣)并且缓冲区大小现在有一个最小值。
您可能需要等待至少 30 分钟才能提升 drat 包文件。
mattdowle
于 2017-03-30
抱歉,是“GB”而不是“MB”。 我没有喝足够的咖啡。
我会得到更新并测试它。
geponce
于 2017-03-30
使用最新的 data.table dev. 进行测试: data.table 1.10.5 IN DEVELOPMENT built 2017-03-30 16:31:45 UTC :
概括:
它运行速度很快(读取 csv 需要 1.43 分钟)并且内存分配也工作正常,我想,RAM 分配不会像以前那样增加。 一旦加载,磁盘上的 44 GB csv 转换为 RAM 中的 ~112(+ 37 GB 临时缓冲区)GB。 这与文件中值的数据类型有关吗?
测试 1 :
不使用colClasses=list("numeric"=1:12785)
DT<-fread('dt.daily.4km.csv', verbose=TRUE)
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,
D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 47000004016 bytes from row 1 to eof / (2 * 1281788 jump0size) == 18333
Type codes (jump 000) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 001) : 444222422222222224442444444444442222444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
Type codes (jump 002) : 444222444444222244442444444444444422444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
...
Type codes (jump 034) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
Type codes (jump 100) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=79727.22 sd=32260.00 min=12804 max=153029
Estimated nrow: 47000004016 / 79727.22 = 589511
Initial alloc = 1179022 rows (589511 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Type codes (drop|select) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 02:17.726 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.099s ( 0%) sep, ncol and header detection
11.057s ( 8%) Column type detection using 10049 sample rows
0.899s ( 1%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
125.671s ( 91%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
137.726s Total
测试 2 :
现在使用colClasses=list("numeric"=1:12785)
时间改进了几秒钟...
DT<-fread('dt.daily.4km.csv', colClasses=list("numeric"=1:12785), verbose=TRUE)
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 01:43.028 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.092s ( 0%) sep, ncol and header detection
11.009s ( 11%) Column type detection using 10049 sample rows
0.332s ( 0%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
91.595s ( 89%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
103.028s Total
好极了 - 我们快到了。 校正后的样本大小加上在 100 个点(10,000 个样本行)处增加到 100 行就足以正确猜测类型了——太好了。 由于在 44GB 的文件中有 12,875 列,行长平均为 80,000 个字符,因此采样需要 11 秒。 但那段时间是值得的,因为它避免了需要额外 90 秒的重读。 那我们就坚持下去。
我认为第二次更快,因为这是第二次并且您的操作系统已经预热并缓存了文件。 在盒子上运行的任何其他东西都会影响挂钟计时。 这可以通过运行 1 次测试的 3 次相同连续运行来解决。 然后只更改一件事并再次运行 3 次相同的连续运行。 在 44GB 大小时,您会看到很多自然差异。 3 次运行通常足以得出结论,但它可能是一种黑色艺术。
是的,内存中的 112GB 与磁盘中的 44GB 部分是因为内存中的数据更大,因为所有列都是双精度类型; R 中没有内存压缩,并且有很多 NA 值在此 CSV 中不占用空间(仅",," ),但在内存中占用 8 个字节。 但是,它应该是 83GB 而不是 112GB(872505 行 x 12785 列 x 8 字节双精度 / 1024^3 = 83GB)。 112GB 是根据行长度的平均值和标准偏差分配的。 根据平均行长度,估计为 589,511 行,这太少了。 线路长度差异如此之大,以至于钳位在 +100% 时生效。 58,9511 * 2 = 1,179,022 * 12785 * 8 / 1024^3 = 112GB。 最后发现文件中有872,505个。 但这并没有释放可用空间。 我会解决这个问题的。 (TODO1)
但是,当您为所有列指定列类型时,它仍然会进行采样。 当用户指定了每一列时,它应该跳过采样。 (TODO2)
由于您的所有数据都是双倍的,因此它对 C 库函数 strtod() 进行了 110 亿次调用。 长期以来希望对该函数进行专业化,理论上应该可以显着提高该文件的速度。 (完毕)
mattdowle
于 2017-03-31
谢谢你,很好的解释。 如果您希望我使用此文件测试其他内容,请告诉我。 我正在处理另一个更多关于长格式的数据集,大约有 2100 万行 x 1432 列。
NAME NROW NCOL MB
[1,] DT 21,812,625 1,432 238,310
为此添加一个额外的数据点。 89G .tsv ,加载期间的峰值内存使用量为~180G。 我认为这是意料之中的,因为有很多 NA 和两倍。
我也很高兴对此进行测试。
Ubuntu 16.04 64bit / Linux 4.4.0-71-generic
R version 3.3.2 (2016-10-31)
data.table 1.10.5 IN DEVELOPMENT built 2017-04-04 14:27:46 UTC
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Stepping: 1
CPU MHz: 2699.984
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4660.70
Hypervisor vendor: Xen
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq monitor est ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt ida
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 88.603947 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<allele prediction_uuid sample_>>
Detecting sep ...
sep=='\t' with 101 lines of 76 fields using quote rule 0
Detected 76 columns on line 1. This line is either column names or first data row (first 30 chars): <<allele prediction_uuid sample_>>
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 95137762779 bytes from row 1 to eof / (2 * 24414 jump0size) == 1948426
Type codes (jump 000) : 5555542444111145424441111444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 009) : 5555542444114445424441144444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 042) : 5555542444444445424444444444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 048) : 5555544444444445444444444444225225522555545111111111111111111111111111111111 Quote rule 0
Type codes (jump 083) : 5555544444444445444444444444225225522555545254452454411154454452454411154455 Quote rule 0
Type codes (jump 085) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
Type codes (jump 100) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
=====
Sampled 10028 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 95137762779
Line length: mean=465.06 sd=250.27 min=198 max=929
Estimated nrow: 95137762779 / 465.06 = 204571280
Initial alloc = 409142560 rows (204571280 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Type codes (drop|select) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Allocating 76 column slots (76 - 0 dropped)
Reading 90752 chunks of 1.000MB (2254 rows) using 64 threads
 andrewrech
于 2017-04-04
andrewrech
于 2017-04-04
如果有帮助,这里是一个很长的数据库的结果:419,124,196 x 42 (~2^34) 一个标题行和 colClasses 已通过。
> library(data.table)
data.table 1.10.5 IN DEVELOPMENT built 2017-09-27 17:12:56 UTC; travis
The fastest way to learn (by data.table authors): https://www.datacamp.com/courses/data-analysis-the-data-table-way
Documentation: ?data.table, example(data.table) and browseVignettes("data.table")
Release notes, videos and slides: http://r-datatable.com
> CC <- c(rep('integer', 2), rep('character', 3),
+ rep('numeric', 2), rep('integer', 3),
+ rep('character', 2), 'integer', 'character', 'integer',
+ rep('character', 4), rep('numeric', 11), 'character',
+ 'numeric', 'character', rep('numeric', 2),
+ rep('integer', 3), rep('numeric', 2), 'integer',
+ 'numeric')
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXXcsv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 13:42.935 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.016s ( 0%) sep=',' ncol=42 and header detection
0.016s ( 0%) Column type detection using 10049 sample rows
188.153s ( 23%) Allocation of 419124195 rows x 42 cols (125.177GB)
634.751s ( 77%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.121s ( 0%) Finding first non-embedded \n after each jump
+ 17.036s ( 2%) Parse to row-major thread buffers
+ 616.184s ( 75%) Transpose
+ 1.410s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
822.935s Total
> memory.size()
[1] 134270.3
> rm(P)
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 585532 31.3 5489235 293.2 6461124 345.1
Vcells 1508139082 11506.2 20046000758 152938.9 25028331901 190951.1
> memory.size()
[1] 87.56
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXX.csv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 05:04.910 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.031s ( 0%) sep=',' ncol=42 and header detection
0.000s ( 0%) Column type detection using 10049 sample rows
28.437s ( 9%) Allocation of 419124195 rows x 42 cols (125.177GB)
276.442s ( 91%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.017s ( 0%) Finding first non-embedded \n after each jump
+ 12.941s ( 4%) Parse to row-major thread buffers
+ 262.989s ( 86%) Transpose
+ 0.495s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
304.910s Total
> memory.size()
[1] 157049.7
> sessionInfo()
R version 3.4.2 beta (2017-09-17 r73296)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows Server >= 2012 x64 (build 9200)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] data.table_1.10.5
loaded via a namespace (and not attached):
[1] compiler_3.4.2 tools_3.4.2
一些注意事项。 我会建议将 [09] 放在 [07] 之前,因为如果 colClasses 被传递,则没有理由进行检查。 此外,每次运行后,Windows 显示大约 160GB 正在使用。 memory.size() 可能会做一些清理。 这台服务器上有 532GB 的 RAM,内存缓存可能与第二次运行的速度增加有关。 希望有帮助。
 aadler
于 2017-09-28
aadler
于 2017-09-28
在宽的“真实世界”表(医院数据)上进行测试:30M 行 × 125 列 v readr '1.2.0' 和read.csv 3.4.3。
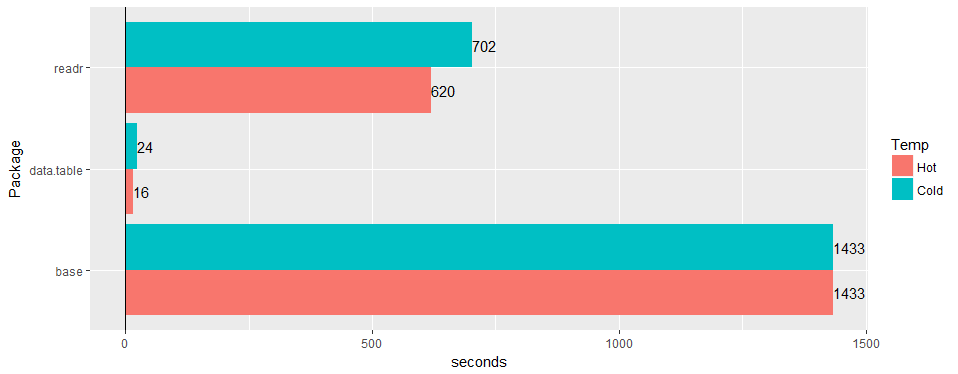
 HughParsonage
于 2018-01-25
HughParsonage
于 2018-01-25
有没有机会确认问题在 1.11.4 上仍然有效? 或生成示例数据的代码。
 jangorecki
于 2018-07-01
jangorecki
于 2018-07-01
据我所知,这一切都已解决。 @geponce如果没有请更新。
上面的 TODO1 现在已归档为 #3024
以上 TODO2 现在已归档为 #3025
mattdowle
于 2018-08-31
相关问题
 jameslamb
·
3评论
jameslamb
·
3评论
 DavidArenburg
·
3评论
DavidArenburg
·
3评论
 andschar
·
3评论
mattdowle
·
3评论
andschar
·
3评论
mattdowle
·
3评论
 franknarf1
·
3评论
franknarf1
·
3评论
最有用的评论
在宽的“真实世界”表(医院数据)上进行测试:30M 行 × 125 列 v readr '1.2.0' 和
read.csv3.4.3。