Data.table: fread с большим csv (44 ГБ) занимает много оперативной памяти в последней версии data.table dev
Привет,
Железо и софт:
Сервер : Dell R930 4-Intel Xeon E7-8870 v3 2,1 ГГц, 45 МБ кэш-памяти, 9,6 ГТ / с QPI, Turbo, HT, 18C / 36T и 1 ТБ ОЗУ
ОС : Redhat 7.1
R-версия : 3.3.2
data.table версия : 1.10.5 построен 21.03.2017
Я загружаю файл csv (44 ГБ, 872505 строк x 12785 столбцов). Он загружается очень быстро, за 1,30 минуты, используя 144 ядра (72 ядра из 4 процессоров с включенной гиперпоточностью, чтобы сделать его 144 ядра).
Основная проблема заключается в том, что при загрузке DT объем используемой памяти значительно увеличивается по сравнению с размером файла csv. В этом случае csv размером 44 ГБ (сохраненное с помощью fwrite, сохраненное с помощью saveRDS и compress = FALSE создает файл размером 84 ГБ) использует ~ 356 ГБ ОЗУ.
Вот результат с использованием "verbose = TRUE"
_Выделение 12785 слотов для столбцов (12785 - 0 отброшено)
madvise последовательный: хорошо
Чтение данных с 1440 точками перехода и 144 потоками
Прочитать 95,7% из 858881 оценочных строк
Чтение 872505 строк x 12785 столбцов из файла размером 43,772 ГБ за 1 минуту 33,736 секунд времени настенных часов (зависит от запущенных других приложений)
0,000 с (0%) Карта памяти
0,070 с (0%) sep, ncol и определение заголовка
26,227 с (28%) Определение типа столбца с использованием 34832 строк выборки из 1440 точек перехода
0,614 с (1%) Выделение 3683116 строк x 12785 столбцов (350,838 ГБ) в ОЗУ
0,000 с (0%) последовательный
66,825 с (71%) Чтение данных
93,736 с Всего_
Это показывает аналогичную проблему, которая иногда возникает при работе с параллельным пакетом, когда одна сессия запускается на каждое ядро при использовании таких функций, как «mclapply». См. Созданные сеансы / перечисленные на этом снимке экрана:

если я сделаю «rm (DT)», ОЗУ вернется в исходное состояние, и «сеансы» будут удалены.
Уже пробовал, например, "setDTthreads (20)" и все еще использовал тот же объем ОЗУ.
Кстати, если файл загружается непараллельной версией "fread", выделенная память достигает ~ 106 ГБ.
Гильермо
 geponce
geponce
Все 30 Комментарий
Это результат непараллельной реализации fread (таблица data.table 1.10.5 В РАЗРАБОТКЕ, построенная 09.02.2017)

Я дважды проверил объем используемой памяти, и он вырос до 84 ГБ.
Гильермо
geponce
22 мар. 2017
Да, ты прав. Спасибо за отличный отчет. Предполагаемый nrow выглядит примерно правильно (858 881 против 872 505), но тогда выделение в 4,2 раза больше, чем это (3 683 116), и далеко. Я улучшил расчет и добавил больше деталей в подробный вывод. Но пока отложите повторное тестирование, пока не будет сделано еще несколько вещей.
 mattdowle
25 мар. 2017
mattdowle
25 мар. 2017
Хорошо, пожалуйста, повторите попытку - теперь это должно быть исправлено.
mattdowle
26 мар. 2017
Я только что установил data.table dev:
data.table 1.10.5 В РАЗРАБОТКЕ построен 2017-03-27 02:50:31 UTC
Первое, что я получил, когда попытался прочитать тот же файл размером 44 ГБ, было это сообщение:
DT <- fread ('dt.daily.4km.csv')
Ошибка: protect (): переполнение стека защиты
Затем я просто повторно запустил ту же команду и начал нормально работать. Однако в этой версии не используется многоядерный режим. Загрузка занимает ~ 25 минут, как и до того, как вы установили параллельную версию fread.
Гильермо
geponce
27 мар. 2017
Я закрыл все r-сессии и повторно запустил тест, но получаю сообщение об ошибке:
Предполагаемого типа столбца было недостаточно для 34711745 значений в 508 столбцах. Используйте colClasses, чтобы установить эти классы столбцов вручную.
См. Ниже, я получаю несколько сообщений о «угаданном целом числе, но содержит << 0 .... >>
_Чтение 872505 строк x 12785 столбцов из файла размером 43,772 ГБ за время настенных часов 15: 27.024 (может быть замедлено любыми другими открытыми приложениями, даже если они кажутся простаивающими)
В столбце 171 ('D_19810618') угадано целое число, но содержится << 2,23000001907349 >>
В столбце 347 ('D_19811211') угадано целое число, но содержится << 1.02999997138977 >>
В столбце 348 ('D_19811212') угадано целое число, но содержится << 3,75 >> _
geponce
27 мар. 2017
Вау - ваш файл действительно проверяет крайние случаи. Большой. В будущем, пожалуйста, запустите verbose=TRUE и предоставьте полный вывод. Но с информацией, которую вы предоставили в этом случае, я могу понять, в чем проблема на самом деле. Для каждого столбца каждого потока создается буфер (в данном случае более 12 000 столбцов). В настоящее время каждый из них отдельно ЗАЩИЩЕН. Есть способ этого избежать - подойдет. Сообщения о угадывании типа верны. Эти 508 столбцов что-то значат для вас, и вы согласны с тем, что они должны быть числовыми? Вы можете передать диапазон столбцов в colClasses следующим образом: colClasses=list("numeric"=11:518)
Из какого поля эти данные? Вы создаете файл? Такое ощущение, что он был преобразован в широкий формат, где лучше всего писать (и хранить его в памяти) в длинном формате. Обычно я ожидаю увидеть имена 508 столбцов, такие как «D_19810618», как значения в столбце, а не как сами столбцы. Вот почему я спрашиваю, создаете ли вы файл, и можете ли вы создать его в длинном формате. Если нет, предложите тем, кто создает файл, что они могут сделать это лучше. Я предполагаю, что вы применяете операции через столбцы, возможно, используя .SD и .SDcols . Это действительно намного лучше в длинном формате и keyby= столбец, содержащий значения типа "D_19810618".
Но я все равно постараюсь сделать fread настолько хорошо, насколько это возможно при работе с любым вводом - даже с очень широкими файлами, содержащими более 12000 столбцов.
Я надеюсь, что другие люди тестируют и не находят никаких проблем в своих файлах!
mattdowle
27 мар. 2017
_ Эти 508 столбцов что-то значат для вас, и вы согласны, что они должны быть числовыми?
Эта таблица содержит временные ряды по строкам. IDx, IDy, Time1_value, Time2_value, Time3_value ... и все столбцы Time N _value содержат только числовые значения. Если я использую colClasses, мне нужно будет сделать это для 12783: list ("numeric" = 2: 12783). Я попробую это.
_ Из какого поля взяты эти данные? _
Геопространственные данные. Я выполняю поиск на евклидовом расстоянии в DT, используя IDx и IDy. Я предполагаю, что чем больше строк, тем медленнее поиск, верно?
Сейчас довольно быстро (широкий формат). У меня есть карта, на которой пользователь может щелкнуть область, а затем в файле csv создается временной ряд из ближайшего местоположения (с доступными данными) до данного щелчка. Вместо этого я использую длинный формат.
Я вернусь с некоторыми результатами.
geponce
28 мар. 2017
Хорошо. Вам не нужно list("numeric"=2:12783) iiuc, потому что ему нужна помощь только с 508 столбцами. О, я понимаю - 508 разбросаны по столбцам, как я полагаю (они не являются непрерывным набором столбцов)?
Нет - data.table почти никогда не будет быстрее, когда он большой! Long почти всегда быстрее и удобнее. Вы видели и пробовали ли вы roll="nearest" ? Как у тебя дела сейчас? Пожалуйста, покажите код, чтобы мы могли понять. Почти наверняка длинный формат лучше, но нам могут потребоваться некоторые улучшения для ближайшего 2D. Пожалуйста, покажите также время. Когда вы говорите «довольно быстро», оказывается, что люди имеют совершенно разные представления о том, что такое «довольно быстро».
mattdowle
28 мар. 2017
таяние этой таблицы достигнет предела 2 ^ 31. Получаю сообщение об ошибке: «Векторы отрицательной длины не допускаются».
Я вернусь к источнику, чтобы посмотреть, смогу ли я сгенерировать его в длинном формате.
geponce
28 мар. 2017
# Read Data
DT <- fread('dt.daily.4km.csv', showProgress = FALSE)
# Add two columns with truncated values of x and y (these are geog. coords.)
DT[,y_tr:=trunc(y)]
DT[,x_tr:=trunc(x)]
# For using on plotting (x-axis values)
xaxis<-seq.Date(as.Date("1981-01-01"),as.Date("2015-12-31"), "day")
# subset by truncated coordinates to avoid full-table search. Now searches
# will happen in a smaller subset
DT2 <- DT[y_tr==trunc(y_clicked) & x_tr==trunc(x_clicked),]
# Add distance from each point in the data.table to the provided location, "gdist" is from
# Imap package for euclidean distance.
DT2[,DIST:=gdist(lat.1 = DT2$y,
lon.1 = DT2$x,
lat.2 = y_clicked,
lon.2 = x_clicked, units="miles")]
# Get the minimum distance
minDist <- min(DT2[,DIST])
# Get the y-axis values
yt <- transpose(DT2[DIST==minDist,3:(ncol(DT2)-3)])$V1`
# Ready to plot xaxis vs yt
...
...
У меня нет приложения на общедоступном сервере. По сути, пользователь может щелкнуть карту, а затем я фиксирую эти координаты и выполняю поиск, указанный выше, получаю временные ряды и создаю график.
geponce
28 мар. 2017
Обнаружено и исправлено еще одно переполнение стека для очень большого количества столбцов: https://github.com/Rdatatable/data.table/commit/d0469e670961dcdea115d433c0f2dce596d65906. Забыл пометить этот номер проблемы в сообщении фиксации.
mattdowle
28 мар. 2017
Ой. Это точка. 872505 строк * 12780 столбцов - это 11 миллиардов строк. Поэтому мое предложение использовать длинный формат не сработает, так как это> 2 ^ 31. Извини, я должен был это заметить. Нам просто нужно укусить пулю и тогда перейти> 2 ^ 31. А пока давайте придерживаться широкого формата, который у вас уже есть, и я решу это.
mattdowle
28 мар. 2017
Пожалуйста, попробуйте еще раз. Использование памяти должно вернуться в норму, и он должен автоматически перечитать 508 из 12785 столбцов с исключениями типа вне выборки. Чтобы избежать автоматического повторного запуска, вы можете установить colClasses .
Если проблема не устранена, вставьте полный подробный вывод. Скрещенные пальцы!
mattdowle
29 мар. 2017
Ok...
Сводка результатов с последними данными data.table dev: data.table 1.10.5 В РАЗРАБОТКЕ построено 2017-03-29 16:17:01 UTC
Следует упомянуть четыре основных момента:
- fread работал нормально читая файл в обсуждении.
- Чтение заняло ~ 5,5 минут, тогда как предыдущая версия занимала ~ 1,3 минуты.
- Эта версия не увеличивает объем оперативной памяти, как предыдущая версия, которую я тестировал.
- Ядра кажутся «менее активными» (см. Снимок экрана ниже).
Некоторые комментарии / вопросы:
1.
Процент использования ядер уже не так активен, как раньше, см. Снимок экрана:
В предыдущей версии fread активность ядер всегда была ~ 90-80%. В этой версии оставалось около 2-3% на каждое ядро, как показано на изображении выше.
Я не понимаю, почему fread делает переход от целого к числовому: например,
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
Я дважды проверил эти строки, и все в порядке. Почему определяется как целое число, и его нужно «перенастроить» на «числовой», если он уже числовой (см. Сводку для строк, предложенных ниже)? или я неправильно понимаю эту строку? Это происходит для 508 строк. Доставляет ли АН проблемы?
summary(DT[6041:24473,.(D_19850126)])
D_19850126
Min. :0.750
1st Qu.:0.887
Median :0.945
Mean :0.966
3rd Qu.:1.045
Max. :1.210
NA's :18393
Ниже немного подробностей из теста.
DT<-fread('dt.daily.4km.ver032917.csv', verbose=TRUE)
ВЫХОД
Parameter na.strings == <<NA>>
None of the 0 na.strings are numeric (such as '-9999').Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,D_19810113,
...
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 11 because 1281788 startSize * 10 NJUMPS * 2 = 25635760 <= -244636240 bytes from line 2 to eof
Type codes (jump 00) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 01) : 444422222222222222242444424444442222222222424444424442224424222244222222222242422222224422...4442244422 Quote rule 0
Type codes (jump 02) : 444422222222222222242444424444442422222242424444424442224424222244222222222242424222424424...4442444442 Quote rule 0
Type codes (jump 03) : 444422222222222224242444424444444422222244424444424442224424222244222222222244424442424424...4442444442 Quote rule 0
Type codes (jump 04) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 05) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 06) : 444444444422222224442444424444444444242244444444444444424444444444444244444444424442444444...4444444444 Quote rule 0
Type codes (jump 07) : 444444444422222224442444424444444444242244444444444444444444444444444244444444424444444444...4444444444 Quote rule 0
Type codes (jump 08) : 444444444442222224444444424444444444242244444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 09) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 10) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
=====
Sampled 305 rows (handled \n inside quoted fields) at 11 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=45578.20 sd=33428.37 min=12815 max=108497
Estimated nrow: 47000004016 / 45578.20 = 1031195
Initial alloc = 2062390 rows (1031195 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Type codes (drop|select): 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 44928 chunks of 0.998MB (22 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.908 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : numeric
0 : character
Rereading 508 columns due to out-of-sample type exceptions.
Column 171 ("D_19810618") bumped from 'integer' to 'numeric' due to <<2.23000001907349>> somewhere between row 6041 and row 24473
Column 347 ("D_19811211") bumped from 'integer' to 'numeric' due to <<1.02999997138977>> somewhere between row 6041 and row 24473
Column 348 ("D_19811212") bumped from 'integer' to 'numeric' due to <<3.75>> somewhere between row 6041 and row 24473
Column 643 ("D_19821003") bumped from 'integer' to 'numeric' due to <<1.04999995231628>> somewhere between row 6041 and row 24473
Column 1066 ("D_19831130") bumped from 'integer' to 'numeric' due to <<1.46000003814697>> somewhere between row 6041 and row 24473
Column 1102 ("D_19840105") bumped from 'integer' to 'numeric' due to <<0.959999978542328>> somewhere between row 6041 and row 24473
Column 1124 ("D_19840127") bumped from 'integer' to 'numeric' due to <<0.620000004768372>> somewhere between row 6041 and row 24473
Column 1130 ("D_19840202") bumped from 'integer' to 'numeric' due to <<0.540000021457672>> somewhere between row 6041 and row 24473
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
Column 1508 ("D_19850214") bumped from 'integer' to 'numeric' due to <<0.360000014305115>> somewhere between row 6041 and row 24473
...
...
Reread 872505 rows x 508 columns in 05:29.167
Read 872505 rows. Exactly what was estimated and allocated up front
Thread buffers were grown 0 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.093s ( 0%) sep, ncol and header detection
0.186s ( 0%) Column type detection using 305 sample rows from 44928 jump points
0.600s ( 0%) Allocation of 872505 rows x 12785 cols (192.552GB) plus 1.721GB of temporary buffers
326.029s ( 50%) Reading data
329.167s ( 50%) Rereading 508 columns due to out-of-sample type exceptions
656.075s Total
Это последнее резюме заняло много времени (~ 6 минут). Если считать это подробное резюме, то чтение заняло ~ 11 минут. Он перечитывает эти 508 столбцов, я даже могу видеть сообщение «Повторное чтение 508 столбцов из-за исключений типа вне выборки» без использования verbose = TRUE.
Проверить это без "verbose = TRUE"
ptm<-proc.time()
DT<-fread('dt.daily.4km.ver032917.csv')
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.647 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Rereading 508 columns due to out-of-sample type exceptions.
Reread 872505 rows x 508 columns in 05:30.276
proc.time() - ptm
user system elapsed
2113.100 85.919 657.870
fwrite test
Работает нормально. Действительно быстро. Я думал, что в наши дни письмо было медленнее, чем чтение.
fwrite(DT,'dt.daily.4km.ver032917.csv', verbose=TRUE)
No list columns are present. Setting sep2='' otherwise quote='auto' would quote fields containing sep2.
maxLineLen=151187 from sample. Found in 1.890s
Writing column names ... done in 0.000s
Writing 872505 rows in 32315 batches of 27 rows (each buffer size 8MB, showProgress=1, nth=144) ...
done (actual nth=144, anyBufferGrown=no, maxBuffUsed=46%)
На «Перечитать» уходит немало времени. Это как дважды прочитать файл.
geponce
30 мар. 2017
Превосходно! Спасибо за всю информацию.
- Да вы правы, это не стоит перечитывать. Вы передали
colClasses=list("numeric"=1:12785)поэтому строка вывода, начинающаяся сType code (colClasses)должна иметь значение 4. Исправит и добавит отсутствующий тест. - На 5,5 м против 1,3 м это интересно. Буфер каждого потока в настоящее время составляет 1 МБ. Идея в том, чтобы быть маленьким, чтобы поместиться в кеш. Но в вашем случае 1 МБ / 12785 столбцов = 82 байта. Таким образом, при таком выборе неэффективность кеша будет в 50 раз больше. Во всяком случае, я думаю. Я бы никогда не подумал об этом без вашего тестирования. Когда он работал на скорости 1,3 м, у него не было такого размера 1 МБ.
- Также очень странно, почему он выбрал всего 305 строк. Он должен был набрать 1000. Если это будет исправлено, возможно, он обнаружит 508 столбцов без необходимости. Выборка не занимает времени (0,186 с), поэтому размер выборки можно увеличить.
Не могли бы вы вставить вывод команды lscpu unix, пожалуйста. Это сообщит нам размер вашего кеша, и я смогу думать оттуда. Я предоставлю buffMB в качестве параметра для fread чтобы вы могли увидеть, так ли это. Если это так, я могу придумать более точный расчет.
mattdowle
30 мар. 2017
Моя ошибка в одном пункте моего предыдущего поста. colClasses=list("numeric"=1:12785) работает нормально. Если я не укажу «colClasses», будет выполнено «перечитывание». Извините за путаницу.
Одна вещь, которую я заметил, заключается в том, что если я не укажу "colClasses", таблица будет создана с NA, и RAM будет отображаться так, как если бы DT был загружен нормально (~ 106MB в RAM).
Вот результат lscpu :
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 144
On-line CPU(s) list: 0-143
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 4
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E7-8870 v3 @ 2.10GHz
Stepping: 4
CPU MHz: 2898.328
BogoMIPS: 4195.66
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36,40,44,48,52,56,60,64,68,72,76,80,84,88,92,96,100,104,108,112,116,120,124,128,132,136,140
NUMA node1 CPU(s): 1,5,9,13,17,21,25,29,33,37,41,45,49,53,57,61,65,69,73,77,81,85,89,93,97,101,105,109,113,117,121,125,129,133,137,141
NUMA node2 CPU(s): 2,6,10,14,18,22,26,30,34,38,42,46,50,54,58,62,66,70,74,78,82,86,90,94,98,102,106,110,114,118,122,126,130,134,138,142
NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39,43,47,51,55,59,63,67,71,75,79,83,87,91,95,99,103,107,111,115,119,123,127,131,135,139,143
Хорошо понял. Спасибо.
Если еще раз перечитать ваши первые комментарии, было бы больше смысла, если бы он сказал «переход от целого числа к двойному», а не «переход от целого числа к числовому»?
Что вы имеете в виду под «созданным с помощью АН»? Вся таблица заполнена НА, только 508 столбцов?
Что такое «DT был загружен нормально (~ 106 МБ ОЗУ)». Это файл размером 44 ГБ, так как же 106 МБ может быть нормальным?
mattdowle
30 мар. 2017
Что ж, в этом файле все, что у меня есть, - это действительные числа и NA. У меня нет целочисленных значений. Когда вы выдаете сообщение «переход от типа данных A к типу данных B»?
Вот именно то, что я имею в виду. В текущей версии data.table, которую я установил, если я опущу colClasses, она загрузит DT, но заполнит NA.
DT[!is.na(D_19821001),]создает 0 записей, и если я загружаю таблицу с помощью colClasses и выполняю ту же фильтрацию, она фактически отображает записи.Что ж, этот файл имеет размер 47 ГБ как csv на диске, но как только вы загружаете его в R, он занимает более чем вдвое больше ОЗУ ... Не имеет отношения к точности значений, после загрузки выделение памяти для реального числа вызывают это увеличение?
geponce
30 мар. 2017
Может быть, еще одна опечатка: 106 МБ должно было быть 106 ГБ.
Я не слежу за аспектом АН. Но несколько исправлений в пути, а затем попробуйте еще раз ...
mattdowle
30 мар. 2017
Хорошо - попробуйте еще раз. Предполагаемая выборка увеличилась до 10 000 (будет интересно посмотреть, сколько времени это займет), а размеры буфера теперь установлены минимально.
Возможно, вам придется подождать не менее 30 минут, пока файл пакета drat будет повышен.
mattdowle
30 мар. 2017
К сожалению, это был «ГБ» вместо «МБ». Мне не хватило кофе.
Получу обновление и протестирую.
geponce
30 мар. 2017
Тестирование с последними данными data.table dev: data.table 1.10.5 В РАЗРАБОТКЕ построено 2017-03-30 16:31:45 UTC :
Резюме:
Он работает быстро (1,43 минуты для чтения csv), и распределение памяти тоже работает нормально, я думаю, выделение RAM не увеличивается, как раньше. CSV объемом 44 ГБ на диске преобразуется в ~ 112 (+ 37 ГБ временных буферов) ГБ в ОЗУ после загрузки. Связано ли это с типом данных значений в файле?
Тест 1 :
Без использования colClasses=list("numeric"=1:12785)
DT<-fread('dt.daily.4km.csv', verbose=TRUE)
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,
D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 47000004016 bytes from row 1 to eof / (2 * 1281788 jump0size) == 18333
Type codes (jump 000) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 001) : 444222422222222224442444444444442222444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
Type codes (jump 002) : 444222444444222244442444444444444422444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
...
Type codes (jump 034) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
Type codes (jump 100) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=79727.22 sd=32260.00 min=12804 max=153029
Estimated nrow: 47000004016 / 79727.22 = 589511
Initial alloc = 1179022 rows (589511 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Type codes (drop|select) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 02:17.726 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.099s ( 0%) sep, ncol and header detection
11.057s ( 8%) Column type detection using 10049 sample rows
0.899s ( 1%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
125.671s ( 91%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
137.726s Total
Тест 2 :
Теперь с помощью colClasses=list("numeric"=1:12785)
Тайминг был улучшен на несколько секунд ...
DT<-fread('dt.daily.4km.csv', colClasses=list("numeric"=1:12785), verbose=TRUE)
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 01:43.028 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.092s ( 0%) sep, ncol and header detection
11.009s ( 11%) Column type detection using 10049 sample rows
0.332s ( 0%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
91.595s ( 89%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
103.028s Total
Хорошо, отлично - мы к цели. Скорректированного размера выборки плюс увеличение его до 100 строк в 100 точках (10 000 строк выборки) было достаточно, чтобы правильно угадать типы - отлично. Поскольку в файле размером 44 ГБ 12 875 столбцов, а длина строки составляет в среднем 80 000 символов, для выборки потребовалось 11 секунд. Но это время того стоило, потому что его удалось избежать повторного прочтения, на которое потребовалось бы лишние 90 секунд. Тогда мы будем придерживаться этого.
Я думаю, что второй раз быстрее, потому что это был второй раз, и ваша операционная система нагрелась и кэшировала файл. Все остальное, что запущено на коробке, повлияет на тайминги настенных часов. Это решается путем выполнения 3 идентичных последовательных прогонов 1-го теста. Затем меняем только одну вещь и снова выполняем 3 идентичных последовательных прогона. При размере 44 ГБ вы увидите много естественных отклонений. Для вывода обычно достаточно трех прогонов, но это может быть и черное искусство.
Да, 112 ГБ в памяти против 44 ГБ на диске отчасти потому, что данных больше в памяти, потому что все столбцы имеют тип double; в R нет сжатия в памяти, и существует довольно много значений NA, которые не занимают места в этом CSV (просто ",," ), но 8 байтов в памяти. Однако он должен быть 83 ГБ, а не 112 ГБ (872505 строк x 12785 столбцов x 8 байтов удвоения / 1024 ^ 3 = 83 ГБ). Эти 112 ГБ - это то, что было выделено на основе среднего и стандартного отклонения длин строк. Исходя из средней длины строки, он оценил, что это будет 589 511 строк, что было бы слишком мало. Разброс длины линии был настолько велик, что ограничение вступило в силу при + 100%. 58,9511 * 2 = 1,179,022 * 12785 * 8/1024 ^ 3 = 112 ГБ. В итоге выяснилось, что в файле находится 872 505 человек. Но это не освобождает свободное место. Я исправлю это. (TODO1)
Тем не менее, когда вы указали тип столбца для всех столбцов, он все равно будет выбран. Он должен пропускать выборку, когда пользователь указал каждый столбец. (TODO2)
Поскольку все ваши данные удваиваются, он выполняет 11 миллиардов вызовов библиотечной функции C strtod (). Давно желанная специализация этой функции теоретически должна значительно ускорить этот файл. (СДЕЛАНО)
mattdowle
31 мар. 2017
Спасибо за это, отличное объяснение. Дайте мне знать, если вы хотите, чтобы я протестировал что-то еще с этим файлом. Я работаю над другим набором данных, который больше относится к длинному формату, с ~ 21 миллионами строк на 1432 столбца.
NAME NROW NCOL MB
[1,] DT 21,812,625 1,432 238,310
Добавление к этому дополнительной точки данных. 89G .tsv , пиковое использование памяти во время загрузки составляет ~ 180G. Я думаю, что это ожидаемо, так как есть много НС и двойников.
Я также счастлив проверить это.
Ubuntu 16.04 64bit / Linux 4.4.0-71-generic
R version 3.3.2 (2016-10-31)
data.table 1.10.5 IN DEVELOPMENT built 2017-04-04 14:27:46 UTC
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Stepping: 1
CPU MHz: 2699.984
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4660.70
Hypervisor vendor: Xen
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq monitor est ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt ida
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 88.603947 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<allele prediction_uuid sample_>>
Detecting sep ...
sep=='\t' with 101 lines of 76 fields using quote rule 0
Detected 76 columns on line 1. This line is either column names or first data row (first 30 chars): <<allele prediction_uuid sample_>>
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 95137762779 bytes from row 1 to eof / (2 * 24414 jump0size) == 1948426
Type codes (jump 000) : 5555542444111145424441111444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 009) : 5555542444114445424441144444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 042) : 5555542444444445424444444444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 048) : 5555544444444445444444444444225225522555545111111111111111111111111111111111 Quote rule 0
Type codes (jump 083) : 5555544444444445444444444444225225522555545254452454411154454452454411154455 Quote rule 0
Type codes (jump 085) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
Type codes (jump 100) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
=====
Sampled 10028 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 95137762779
Line length: mean=465.06 sd=250.27 min=198 max=929
Estimated nrow: 95137762779 / 465.06 = 204571280
Initial alloc = 409142560 rows (204571280 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Type codes (drop|select) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Allocating 76 column slots (76 - 0 dropped)
Reading 90752 chunks of 1.000MB (2254 rows) using 64 threads
 andrewrech
4 апр. 2017
andrewrech
4 апр. 2017
Если это поможет, вот результаты для очень длинной базы данных: 419,124,196 x 42 (~ 2 ^ 34) с одной строкой заголовка и переданными colClasses.
> library(data.table)
data.table 1.10.5 IN DEVELOPMENT built 2017-09-27 17:12:56 UTC; travis
The fastest way to learn (by data.table authors): https://www.datacamp.com/courses/data-analysis-the-data-table-way
Documentation: ?data.table, example(data.table) and browseVignettes("data.table")
Release notes, videos and slides: http://r-datatable.com
> CC <- c(rep('integer', 2), rep('character', 3),
+ rep('numeric', 2), rep('integer', 3),
+ rep('character', 2), 'integer', 'character', 'integer',
+ rep('character', 4), rep('numeric', 11), 'character',
+ 'numeric', 'character', rep('numeric', 2),
+ rep('integer', 3), rep('numeric', 2), 'integer',
+ 'numeric')
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXXcsv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 13:42.935 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.016s ( 0%) sep=',' ncol=42 and header detection
0.016s ( 0%) Column type detection using 10049 sample rows
188.153s ( 23%) Allocation of 419124195 rows x 42 cols (125.177GB)
634.751s ( 77%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.121s ( 0%) Finding first non-embedded \n after each jump
+ 17.036s ( 2%) Parse to row-major thread buffers
+ 616.184s ( 75%) Transpose
+ 1.410s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
822.935s Total
> memory.size()
[1] 134270.3
> rm(P)
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 585532 31.3 5489235 293.2 6461124 345.1
Vcells 1508139082 11506.2 20046000758 152938.9 25028331901 190951.1
> memory.size()
[1] 87.56
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXX.csv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 05:04.910 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.031s ( 0%) sep=',' ncol=42 and header detection
0.000s ( 0%) Column type detection using 10049 sample rows
28.437s ( 9%) Allocation of 419124195 rows x 42 cols (125.177GB)
276.442s ( 91%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.017s ( 0%) Finding first non-embedded \n after each jump
+ 12.941s ( 4%) Parse to row-major thread buffers
+ 262.989s ( 86%) Transpose
+ 0.495s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
304.910s Total
> memory.size()
[1] 157049.7
> sessionInfo()
R version 3.4.2 beta (2017-09-17 r73296)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows Server >= 2012 x64 (build 9200)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] data.table_1.10.5
loaded via a namespace (and not attached):
[1] compiler_3.4.2 tools_3.4.2
Пара замечаний. Я бы посоветовал поставить [09] перед [07], так как если colClasses переданы, нет причин для проверки. Кроме того, после каждого запуска Windows показывала, что используется около 160 ГБ. memory.size (), вероятно, выполняет некоторую очистку. При 532 ГБ ОЗУ на этом сервере кэширование памяти может иметь отношение к увеличению скорости при втором запуске. Надеюсь, это поможет.
 aadler
28 сент. 2017
aadler
28 сент. 2017
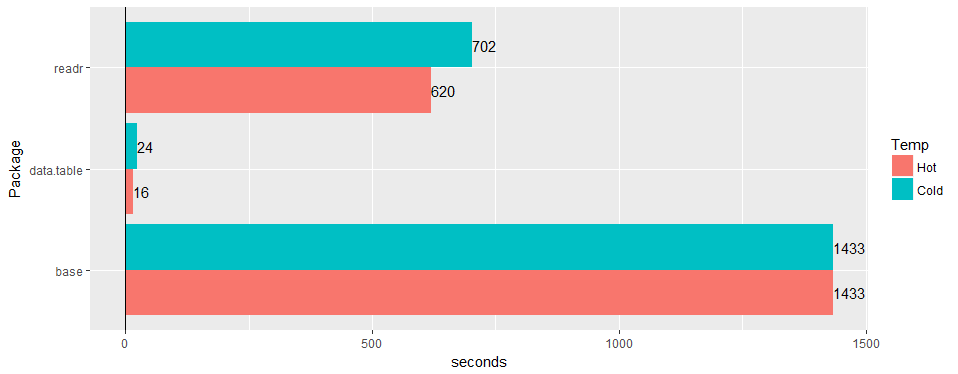
Тестируйте на широкой «реальной» таблице (данные больницы): 30 миллионов строк × 125 столбцов v readr '1.2.0' и read.csv 3.4.3.
 HughParsonage
25 янв. 2018
HughParsonage
25 янв. 2018
есть ли шанс подтвердить, что проблема все еще актуальна до 1.11.4? или код для создания примеров данных.
 jangorecki
1 июл. 2018
jangorecki
1 июл. 2018
Насколько я знаю, это все решено. @geponce, пожалуйста, обновите, если нет.
TODO1 выше теперь зарегистрирован как # 3024
TODO2 выше теперь зарегистрирован как # 3025
mattdowle
31 авг. 2018
Смежные вопросы
 jameslamb
·
3Комментарии
jameslamb
·
3Комментарии
 pannnda
·
3Комментарии
pannnda
·
3Комментарии
 lux5
·
3Комментарии
mattdowle
·
3Комментарии
lux5
·
3Комментарии
mattdowle
·
3Комментарии
 alex46015
·
3Комментарии
alex46015
·
3Комментарии
Самый полезный комментарий
Тестируйте на широкой «реальной» таблице (данные больницы): 30 миллионов строк × 125 столбцов v readr '1.2.0' и
read.csv3.4.3.