Data.table: fread com csv grande (44 GB) consome muita RAM na versão mais recente do data.table dev
Oi,
Hardware e software:
Servidor : Dell R930 4-Intel Xeon E7-8870 v3 2.1 GHz, 45M Cache, 9.6GT / s QPI, Turbo, HT, 18C / 36T e 1 TB em RAM
SO : Redhat 7.1
Versão R : 3.3.2
versão data.table : 1.10.5 construído 21-03-2017
Estou carregando um arquivo csv (44 GB, 8.72.505 linhas x 12.785 colunas). Ele carrega muito rápido, em 1,30 minutos usando 144 núcleos (72 núcleos dos 4 processadores com hyperthreading habilitado para torná-lo caixa de 144 núcleos).
O principal problema é que, quando o DT é carregado, a quantidade de memória em uso aumenta significativamente em relação ao tamanho do arquivo csv. Neste caso, o csv de 44 GB (salvo com fwrite, salvo com saveRDS e compress = FALSE cria um arquivo de 84 GB) está usando ~ 356 GB de RAM.
Aqui está a saída usando "verbose = TRUE"
_Alocando 12785 slots de coluna (12785 - 0 descartado)
madvise sequential: ok
Lendo dados com 1440 pontos de salto e 144 threads
Leia 95,7% de 858881 linhas estimadas
Ler 872505 linhas x 12785 colunas de arquivo de 43,772 GB em 1 minuto 33,736 segundos de tempo de parede (afetado por outros aplicativos em execução)
0.000s (0%) Mapa de memória
0,070s (0%) sep, ncol e detecção de cabeçalho
26,227s (28%) Detecção de tipo de coluna usando 34832 linhas de amostra de 1440 pontos de salto
0,614s (1%) Alocação de 3683116 linhas x 12785 cols (350,838 GB) na RAM
0.000s (0%) madvise sequencial
66.825s (71%) Lendo dados
93.736s Total_
Ele está mostrando um problema semelhante que às vezes surge ao trabalhar com o pacote paralelo, onde uma rsession é iniciada por núcleo ao usar funções como "mclapply". Veja as Rsessions criadas / listadas nesta captura de tela:

se eu fizer "rm (DT)", a RAM volta ao estado inicial e as "Rsessions" são removidas.
Já tentei, por exemplo, "setDTthreads (20)" e ainda usando a mesma quantidade de RAM.
A propósito, se o arquivo for carregado com a versão não paralela de "fread", a alocação de memória chega a apenas ~ 106 GB.
Guilherme
 geponce
geponce
Todos 30 comentários
Este é o resultado da implementação de fread não paralela (data.table 1.10.5 EM DESENVOLVIMENTO construído 09-02-2017)

E eu verifiquei duas vezes a quantidade de memória usada e ela só vai para 84 GB.
Guilherme
geponce
em 22 mar. 2017
Sim, você está certo. Obrigado pelo excelente relatório. O nrow estimado parece certo (858.881 vs 872.505), mas então a alocação é 4,2X maior do que isso (3.683.116) e bem distante. Eu melhorei o cálculo e adicionei mais detalhes à saída detalhada. Espere um novo teste por enquanto, até que mais algumas coisas tenham sido feitas.
 mattdowle
em 25 mar. 2017
mattdowle
em 25 mar. 2017
Ok, por favor, teste novamente - deve ser consertado agora.
mattdowle
em 26 mar. 2017
Acabei de instalar data.table dev:
data.table 1.10.5 EM DESENVOLVIMENTO criado em 2017-03-27 02:50:31 UTC
A primeira coisa que recebi quando tentei ler o mesmo arquivo de 44 GB foi esta mensagem:
DT <- fread ('dt.daily.4km.csv')
Erro: proteger (): estouro da pilha de proteção
Então, acabei de executar o mesmo comando e comecei a trabalhar bem. No entanto, esta versão não está usando um modo multi-core. Demora cerca de 25 minutos para carregar, o mesmo que antes de você colocar a versão paralela de fread.
Guilherme
geponce
em 27 mar. 2017
Fechei todas as sessões-r e executei novamente um teste e estou recebendo um erro:
O tipo de coluna adivinhado era insuficiente para 34711745 valores em 508 colunas. Use colClasses para definir essas classes de coluna manualmente.
Veja abaixo, recebo várias mensagens sobre "número inteiro adivinhado, mas contém << 0 .... >>
_Leia 872505 linhas x 12785 colunas do arquivo de 43.772 GB em 15: 27.024 relógio de parede (pode ser retardado por qualquer outro aplicativo aberto, mesmo se aparentemente inativo)
A coluna 171 ('D_19810618') deduziu 'inteiro', mas contém << 2.23000001907349 >>
A coluna 347 ('D_19811211') adivinhou 'inteiro', mas contém << 1.02999997138977 >>
A coluna 348 ('D_19811212') deduziu 'inteiro', mas contém << 3,75 >> _
geponce
em 27 mar. 2017
Uau - seu arquivo está realmente testando os casos extremos. Excelente. No futuro, execute verbose=TRUE e forneça a saída completa. Mas com as informações que você forneceu neste caso, posso ver qual é realmente o problema. Existe um buffer criado para cada coluna para cada thread (neste caso, mais de 12.000 colunas). Cada um é PROTEGIDO separadamente atualmente. Existe uma maneira de evitar isso - basta. As mensagens sobre a suposição de tipo estão corretas. Essas 508 colunas significam algo para você e você concorda que devem ser numéricas? Você pode passar um intervalo de colunas para colClasses assim: colClasses=list("numeric"=11:518)
De qual campo são esses dados? Você está criando o arquivo? Parece que foi torcido para o formato largo, onde a melhor prática normal é escrever (e mantê-lo na memória também) no formato longo. Eu normalmente esperaria ver os nomes de 508 colunas, como "D_19810618" como valores em uma coluna, não como colunas em si. É por isso que pergunto se você está criando o arquivo e pode criá-lo no formato longo. Caso contrário, sugira a quem está criando o arquivo que ele pode fazer melhor. Acho que você está aplicando operações por meio de colunas, talvez usando .SD e .SDcols . É realmente muito melhor no formato longo e keyby= a coluna que contém os valores como "D_19810618".
Mas ainda tentarei fazer fread tão bom quanto possível ao lidar com qualquer entrada - até mesmo arquivos muito largos com mais de 12.000 colunas.
Espero que outras pessoas estejam testando e não encontrando nenhum problema em seus arquivos!
mattdowle
em 27 mar. 2017
_ Essas 508 colunas significam algo para você e você concorda que deveriam ser numéricas?
Esta tabela contém séries temporais por linha. IDx, IDy, Time1_value, Time2_value, Time3_value ... e todas as colunas Time N _value contêm apenas valores numéricos. Se eu usar colClasses, vou precisar fazer isso para 12783: list ("numeric" = 2: 12783). Vou tentar isso.
_De que campo são esses dados? _
Dados geoespaciais. Estou fazendo pesquisas de distância euclidiana no DT usando IDx e IDy. Eu estou supondo que quanto mais linhas, mais lentas as pesquisas, certo?
Agora é muito rápido (formato amplo). Eu tenho um mapa, onde um usuário pode clicar em uma área e, em seguida, uma série temporal é gerada em um arquivo csv do local mais próximo (com dados disponíveis) para o clique fornecido. Vou implementá-lo com um formato longo.
Voltarei com alguns resultados.
geponce
em 28 mar. 2017
Tudo bem. Você não precisa de list("numeric"=2:12783) iiuc porque só precisa de ajuda com 508 colunas. Oh - entendo - os 508 estão espalhados pelas colunas, eu acho então (eles não são um conjunto contíguo de colunas)?
Não - data.table quase nunca é mais rápido quando é largo! Longo é quase sempre mais rápido e conveniente. Você viu e experimentou roll="nearest" ? Como você está fazendo agora? Por favor, mostre o código para que possamos entender. Quase certamente o formato longo é melhor, mas podemos precisar de alguns aprimoramentos para o 2D mais próximo. Por favor, mostre os tempos também. Quando você diz "muito rápido", as pessoas têm ideias totalmente diferentes sobre o que é "muito rápido".
mattdowle
em 28 mar. 2017
derreter esta mesa atingir o limite de 2 ^ 31. Estou recebendo o erro: "vetores de comprimento negativo não são permitidos".
Voltarei à fonte para ver se consigo gerá-lo no formato longo.
geponce
em 28 mar. 2017
# Read Data
DT <- fread('dt.daily.4km.csv', showProgress = FALSE)
# Add two columns with truncated values of x and y (these are geog. coords.)
DT[,y_tr:=trunc(y)]
DT[,x_tr:=trunc(x)]
# For using on plotting (x-axis values)
xaxis<-seq.Date(as.Date("1981-01-01"),as.Date("2015-12-31"), "day")
# subset by truncated coordinates to avoid full-table search. Now searches
# will happen in a smaller subset
DT2 <- DT[y_tr==trunc(y_clicked) & x_tr==trunc(x_clicked),]
# Add distance from each point in the data.table to the provided location, "gdist" is from
# Imap package for euclidean distance.
DT2[,DIST:=gdist(lat.1 = DT2$y,
lon.1 = DT2$x,
lat.2 = y_clicked,
lon.2 = x_clicked, units="miles")]
# Get the minimum distance
minDist <- min(DT2[,DIST])
# Get the y-axis values
yt <- transpose(DT2[DIST==minDist,3:(ncol(DT2)-3)])$V1`
# Ready to plot xaxis vs yt
...
...
Não tenho o aplicativo em um servidor público. Essencialmente, o usuário pode clicar em um mapa e, em seguida, capturar essas coordenadas e realizar a pesquisa acima, obter a série temporal e criar um gráfico.
geponce
em 28 mar. 2017
Encontrado e corrigido outro estouro de pilha para um grande número de colunas: https://github.com/Rdatatable/data.table/commit/d0469e670961dcdea115d433c0f2dce596d65906. Esqueci de marcar este número de problema na mensagem de confirmação.
mattdowle
em 28 mar. 2017
Oh. Isso é um ponto. 872505 linhas * 12780 cols é 11 bilhões de linhas. Portanto, minha sugestão de usar o formato longo não funcionará para você, pois é> 2 ^ 31. Desculpe - eu deveria ter percebido isso. Teremos apenas que morder a bala e ir> 2 ^ 31 então. Enquanto isso, vamos continuar com o formato amplo que você está trabalhando e vou acertar isso.
mattdowle
em 28 mar. 2017
Por favor, tente novamente. O uso da memória deve voltar ao normal e ele deve reler automaticamente as 508 das 12.785 colunas com exceções de tipo fora da amostra. Para evitar o tempo de reexecução automática, você pode definir colClasses .
Se não for corrigido, cole a saída detalhada completa. Dedos cruzados!
mattdowle
em 29 mar. 2017
OK...
Um resumo dos resultados com o último data.table dev: data.table 1.10.5 EM DESENVOLVIMENTO criado em 29-03-2017 16:17:01 UTC
Quatro pontos principais a serem mencionados:
- fread trabalhou bem ao ler o arquivo na discussão.
- Demorou cerca de 5,5 minutos para ler em comparação com a versão anterior, que levou cerca de 1,3 minutos.
- Esta versão não aumenta a alocação de RAM como a versão anterior que estava testando.
- Os núcleos parecem ser "menos ativos" (veja a captura de tela abaixo).
Alguns comentários / perguntas:
1
A porcentagem de uso nos núcleos não é tão ativa quanto antes, veja a captura de tela:
Na versão anterior do fread, a atividade dos núcleos sempre foi ~ 90-80%. Nesta versão ficou em torno de ~ 2-3% cada núcleo, conforme mostrado na imagem acima.
Eu não entendo por que fread está fazendo saltos de inteiro para numérico: por exemplo,
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
Verifiquei duas vezes essas linhas e parece que está tudo bem. Por que é detectado como inteiro e precisa ser 'aumentado' para 'numérico' se já for numérico (consulte o resumo das linhas sugeridas abaixo)? ou estou entendendo essa linha de forma errada? Isso acontece para 508 linhas. O NA está causando problemas?
summary(DT[6041:24473,.(D_19850126)])
D_19850126
Min. :0.750
1st Qu.:0.887
Median :0.945
Mean :0.966
3rd Qu.:1.045
Max. :1.210
NA's :18393
Abaixo algumas informações detalhadas do teste.
DT<-fread('dt.daily.4km.ver032917.csv', verbose=TRUE)
SAÍDA
Parameter na.strings == <<NA>>
None of the 0 na.strings are numeric (such as '-9999').Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,D_19810113,
...
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 11 because 1281788 startSize * 10 NJUMPS * 2 = 25635760 <= -244636240 bytes from line 2 to eof
Type codes (jump 00) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 01) : 444422222222222222242444424444442222222222424444424442224424222244222222222242422222224422...4442244422 Quote rule 0
Type codes (jump 02) : 444422222222222222242444424444442422222242424444424442224424222244222222222242424222424424...4442444442 Quote rule 0
Type codes (jump 03) : 444422222222222224242444424444444422222244424444424442224424222244222222222244424442424424...4442444442 Quote rule 0
Type codes (jump 04) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 05) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 06) : 444444444422222224442444424444444444242244444444444444424444444444444244444444424442444444...4444444444 Quote rule 0
Type codes (jump 07) : 444444444422222224442444424444444444242244444444444444444444444444444244444444424444444444...4444444444 Quote rule 0
Type codes (jump 08) : 444444444442222224444444424444444444242244444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 09) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 10) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
=====
Sampled 305 rows (handled \n inside quoted fields) at 11 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=45578.20 sd=33428.37 min=12815 max=108497
Estimated nrow: 47000004016 / 45578.20 = 1031195
Initial alloc = 2062390 rows (1031195 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Type codes (drop|select): 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 44928 chunks of 0.998MB (22 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.908 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : numeric
0 : character
Rereading 508 columns due to out-of-sample type exceptions.
Column 171 ("D_19810618") bumped from 'integer' to 'numeric' due to <<2.23000001907349>> somewhere between row 6041 and row 24473
Column 347 ("D_19811211") bumped from 'integer' to 'numeric' due to <<1.02999997138977>> somewhere between row 6041 and row 24473
Column 348 ("D_19811212") bumped from 'integer' to 'numeric' due to <<3.75>> somewhere between row 6041 and row 24473
Column 643 ("D_19821003") bumped from 'integer' to 'numeric' due to <<1.04999995231628>> somewhere between row 6041 and row 24473
Column 1066 ("D_19831130") bumped from 'integer' to 'numeric' due to <<1.46000003814697>> somewhere between row 6041 and row 24473
Column 1102 ("D_19840105") bumped from 'integer' to 'numeric' due to <<0.959999978542328>> somewhere between row 6041 and row 24473
Column 1124 ("D_19840127") bumped from 'integer' to 'numeric' due to <<0.620000004768372>> somewhere between row 6041 and row 24473
Column 1130 ("D_19840202") bumped from 'integer' to 'numeric' due to <<0.540000021457672>> somewhere between row 6041 and row 24473
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
Column 1508 ("D_19850214") bumped from 'integer' to 'numeric' due to <<0.360000014305115>> somewhere between row 6041 and row 24473
...
...
Reread 872505 rows x 508 columns in 05:29.167
Read 872505 rows. Exactly what was estimated and allocated up front
Thread buffers were grown 0 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.093s ( 0%) sep, ncol and header detection
0.186s ( 0%) Column type detection using 305 sample rows from 44928 jump points
0.600s ( 0%) Allocation of 872505 rows x 12785 cols (192.552GB) plus 1.721GB of temporary buffers
326.029s ( 50%) Reading data
329.167s ( 50%) Rereading 508 columns due to out-of-sample type exceptions
656.075s Total
Este último resumo demorou muito para ser concluído (cerca de 6 minutos). Se contarmos este resumo detalhado, toda a fread demorou cerca de 11 minutos. É reler essas 508 colunas, posso até ver a mensagem "Relendo 508 colunas devido a exceções de tipo fora da amostra" sem usar o verbose = TRUE.
Verifique sem "verbose = TRUE"
ptm<-proc.time()
DT<-fread('dt.daily.4km.ver032917.csv')
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.647 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Rereading 508 columns due to out-of-sample type exceptions.
Reread 872505 rows x 508 columns in 05:30.276
proc.time() - ptm
user system elapsed
2113.100 85.919 657.870
teste de fwrite
Está funcionando bem. Muito depressa. Achei que escrever era mais lento do que ler hoje em dia.
fwrite(DT,'dt.daily.4km.ver032917.csv', verbose=TRUE)
No list columns are present. Setting sep2='' otherwise quote='auto' would quote fields containing sep2.
maxLineLen=151187 from sample. Found in 1.890s
Writing column names ... done in 0.000s
Writing 872505 rows in 32315 batches of 27 rows (each buffer size 8MB, showProgress=1, nth=144) ...
done (actual nth=144, anyBufferGrown=no, maxBuffUsed=46%)
A "releitura" está demorando bastante. É como ler o arquivo duas vezes.
geponce
em 30 mar. 2017
Excelente! Obrigado por todas as informações.
- Sim, você está certo, não deveria ser relendo. Você passou
colClasses=list("numeric"=1:12785)portanto, a linha de saída começando comType code (colClasses)deve ter o valor 4. Corrigirá e adicionará o teste ausente. - Em 5,5m vs 1,3m, isso é interessante. O buffer de cada thread tem atualmente 1 MB. A ideia é ser pequeno para caber no cache. Mas, no seu caso, 1 MB / 12785 cols = 82 bytes. Portanto, está sendo 50x muito ineficiente em cache com essa escolha. Eu acho, de qualquer maneira. Eu nunca teria pensado nisso sem seus testes. Quando estava trabalhando com velocidade de 1,3 m, ele não tinha aquele tamanho de 1 MB.
- Por que ele amostrou apenas 305 linhas é muito estranho também. Ele deveria ter amostrado 1.000. Se isso for corrigido, talvez ele detecte as 508 colunas sem você precisar. A amostra não está demorando (0,186s), então o tamanho da amostra pode ser aumentado.
Você pode colar a saída do comando lscpu unix, por favor. Isso nos dirá o tamanho do seu cache e posso pensar a partir daí. Fornecerei buffMB como parâmetro para fread para que você possa ver se é isso. Posso fazer um cálculo melhor, se for o caso.
mattdowle
em 30 mar. 2017
Meu erro em um ponto do meu post anterior. O colClasses=list("numeric"=1:12785) está funcionando bem. Se eu não especificar "colClasses", ele faz o "Relendo". Desculpe pela confusão.
Uma coisa que notei é que se eu não especificar o "colClasses" a tabela é criada com NA's e a RAM mostra como se o DT tivesse carregado normalmente (~ 106 MB na RAM).
Aqui está a saída lscpu :
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 144
On-line CPU(s) list: 0-143
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 4
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E7-8870 v3 @ 2.10GHz
Stepping: 4
CPU MHz: 2898.328
BogoMIPS: 4195.66
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36,40,44,48,52,56,60,64,68,72,76,80,84,88,92,96,100,104,108,112,116,120,124,128,132,136,140
NUMA node1 CPU(s): 1,5,9,13,17,21,25,29,33,37,41,45,49,53,57,61,65,69,73,77,81,85,89,93,97,101,105,109,113,117,121,125,129,133,137,141
NUMA node2 CPU(s): 2,6,10,14,18,22,26,30,34,38,42,46,50,54,58,62,66,70,74,78,82,86,90,94,98,102,106,110,114,118,122,126,130,134,138,142
NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39,43,47,51,55,59,63,67,71,75,79,83,87,91,95,99,103,107,111,115,119,123,127,131,135,139,143
OK, entendi. Obrigado.
Lendo seus primeiros comentários novamente, faria mais sentido se dissesse "saltando de inteiro para duplo" em vez de "saltando de inteiro para numérico"?
O que você quer dizer com 'criado com NA'? Toda a tabela está cheia de NAs, apenas as 508 colunas?
O que é 'DT foi carregado normal (~ 106 MB na RAM)'. É um arquivo de 44 GB, então como pode 106 MB ser normal?
mattdowle
em 30 mar. 2017
Bem, neste arquivo tudo o que tenho são números reais e NA. Eu não tenho valores inteiros nele. Quando você joga essa mensagem, "pulando de datatypeA para datatypeB"?
Isso é exatamente o que quero dizer. Na versão atual do data.table que instalei, se eu omitir as colClasses, ele carrega o DT mas cheio de NA's.
DT[!is.na(D_19821001),]produz 0 registros e se eu carregar a tabela com colClasses e fizer a mesma filtragem, ela realmente mostrará os registros.Bem, este arquivo tem 47 GB como csv em disco, mas depois de carregá-lo no R demora mais que o dobro na RAM ... Não está relacionado com a precisão dos valores, uma vez que é carregada a alocação de memória real números causam esse aumento?
geponce
em 30 mar. 2017
Talvez outro erro de digitação então: 106 MB deveriam ser 106 GB.
Não estou seguindo o aspecto de NA. Mas algumas correções no caminho e tente novamente de novo ...
mattdowle
em 30 mar. 2017
Ok - por favor, tente novamente. A amostra de suposição aumentou para 10.000 (será interessante ver quanto tempo isso leva) e os tamanhos do buffer agora têm um mínimo imposto.
Pode ser necessário esperar pelo menos 30 minutos para que o arquivo do pacote drat seja promovido.
mattdowle
em 30 mar. 2017
Desculpe, era "GB" em vez de "MB". Não tomei café suficiente.
Vou pegar a atualização e testá-la.
geponce
em 30 mar. 2017
Testando com data.table dev: data.table 1.10.5 EM DESENVOLVIMENTO construído em 30-03-2017 16:31:45 UTC :
Resumo:
Ele está funcionando rápido (1,43 minutos para ler o csv) e a alocação de memória também está funcionando bem, eu acho, a alocação de RAM não aumenta como antes. Um csv de 44 GB em disco se traduz em ~ 112 (+ 37 GB de buffers temporários) GB de RAM depois de carregado. Isso está relacionado ao tipo de dados dos valores no arquivo?
Teste 1 :
Sem usar colClasses=list("numeric"=1:12785)
DT<-fread('dt.daily.4km.csv', verbose=TRUE)
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,
D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 47000004016 bytes from row 1 to eof / (2 * 1281788 jump0size) == 18333
Type codes (jump 000) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 001) : 444222422222222224442444444444442222444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
Type codes (jump 002) : 444222444444222244442444444444444422444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
...
Type codes (jump 034) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
Type codes (jump 100) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=79727.22 sd=32260.00 min=12804 max=153029
Estimated nrow: 47000004016 / 79727.22 = 589511
Initial alloc = 1179022 rows (589511 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Type codes (drop|select) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 02:17.726 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.099s ( 0%) sep, ncol and header detection
11.057s ( 8%) Column type detection using 10049 sample rows
0.899s ( 1%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
125.671s ( 91%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
137.726s Total
Teste 2 :
Agora usando colClasses=list("numeric"=1:12785)
O tempo foi melhorado em alguns segundos ...
DT<-fread('dt.daily.4km.csv', colClasses=list("numeric"=1:12785), verbose=TRUE)
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 01:43.028 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.092s ( 0%) sep, ncol and header detection
11.009s ( 11%) Column type detection using 10049 sample rows
0.332s ( 0%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
91.595s ( 89%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
103.028s Total
Ok, ótimo - estamos chegando lá. O tamanho da amostra corrigido mais o aumento para 100 linhas em 100 pontos (10.000 linhas de amostra) foi o suficiente para adivinhar os tipos corretamente - ótimo. Como existem 12.875 colunas e o comprimento da linha é em média 80.000 caracteres no arquivo de 44 GB, demorou 11s para fazer a amostra. Mas esse tempo valeu a pena porque evitou uma releitura que teria levado 90 segundos a mais. Vamos ficar com isso então.
Estou pensando que a 2ª vez é mais rápida apenas porque foi a 2ª vez e seu sistema operacional aqueceu e armazenou o arquivo em cache. Qualquer outra coisa em execução na caixa afetará os horários do relógio de parede. Isso é resolvido executando 3 execuções consecutivas idênticas do primeiro teste. Em seguida, alterando apenas uma coisa e executando 3 execuções consecutivas idênticas novamente. Com o tamanho de 44 GB, você verá muita variação natural. 3 execuções geralmente são suficientes para fazer uma conclusão, mas pode ser uma arte negra.
Sim, os 112 GB na memória vs 44 GB no disco são parcialmente porque os dados são maiores na memória porque todas as colunas são do tipo double; não há compressão na memória em R e há muitos valores NA que não ocupam espaço neste CSV (apenas ",," ), mas 8 bytes na memória. No entanto, deve ter 83 GB e não 112 GB (872505 linhas x 12785 colunas x 8 bytes duplos / 1024 ^ 3 = 83 GB). Esse 112 GB é o que foi alocado com base na média e no desvio padrão dos comprimentos de linha. Com base no comprimento médio da linha, estimou que seriam 589.511 linhas, o que seria muito baixo. A variação do comprimento da linha era tão alta que o grampo entrou em vigor a + 100%. 58,9511 * 2 = 1.179.022 * 12785 * 8/1024 ^ 3 = 112GB. No final, constatou-se que 872.505 estão no arquivo. Mas não está liberando o espaço livre. Eu vou consertar isso. (TODO1)
Porém, quando você especificou o tipo de coluna para todas as colunas, ainda é feita uma amostra. Deve pular a amostragem quando o usuário tiver especificado cada coluna. (TODO2)
Como todos os seus dados são duplos, ele está fazendo 11 bilhões de chamadas para a função strtod () da biblioteca C. A tão desejada especialização dessa função deveria, em teoria, fazer um aumento significativo para este arquivo. (FEITO)
mattdowle
em 31 mar. 2017
Obrigado por isso, ótima explicação. Avise-me se quiser que eu teste algo mais com este arquivo. Estou trabalhando em outro conjunto de dados que está mais no formato longo, com aproximadamente 21 milhões de linhas x 1432 colunas.
NAME NROW NCOL MB
[1,] DT 21,812,625 1,432 238,310
Adicionando um ponto de dados adicional a isso. 89G .tsv , o uso máximo de memória durante o carregamento é de ~ 180G. Acho que isso é esperado, pois há muitos NA e o dobro.
Também estou feliz em testar isso.
Ubuntu 16.04 64bit / Linux 4.4.0-71-generic
R version 3.3.2 (2016-10-31)
data.table 1.10.5 IN DEVELOPMENT built 2017-04-04 14:27:46 UTC
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Stepping: 1
CPU MHz: 2699.984
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4660.70
Hypervisor vendor: Xen
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq monitor est ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt ida
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 88.603947 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<allele prediction_uuid sample_>>
Detecting sep ...
sep=='\t' with 101 lines of 76 fields using quote rule 0
Detected 76 columns on line 1. This line is either column names or first data row (first 30 chars): <<allele prediction_uuid sample_>>
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 95137762779 bytes from row 1 to eof / (2 * 24414 jump0size) == 1948426
Type codes (jump 000) : 5555542444111145424441111444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 009) : 5555542444114445424441144444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 042) : 5555542444444445424444444444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 048) : 5555544444444445444444444444225225522555545111111111111111111111111111111111 Quote rule 0
Type codes (jump 083) : 5555544444444445444444444444225225522555545254452454411154454452454411154455 Quote rule 0
Type codes (jump 085) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
Type codes (jump 100) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
=====
Sampled 10028 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 95137762779
Line length: mean=465.06 sd=250.27 min=198 max=929
Estimated nrow: 95137762779 / 465.06 = 204571280
Initial alloc = 409142560 rows (204571280 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Type codes (drop|select) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Allocating 76 column slots (76 - 0 dropped)
Reading 90752 chunks of 1.000MB (2254 rows) using 64 threads
 andrewrech
em 4 abr. 2017
andrewrech
em 4 abr. 2017
Se ajudar, aqui estão os resultados em um banco de dados muito longo: 419.124.196 x 42 (~ 2 ^ 34) com uma linha de cabeçalho e colClasses passados.
> library(data.table)
data.table 1.10.5 IN DEVELOPMENT built 2017-09-27 17:12:56 UTC; travis
The fastest way to learn (by data.table authors): https://www.datacamp.com/courses/data-analysis-the-data-table-way
Documentation: ?data.table, example(data.table) and browseVignettes("data.table")
Release notes, videos and slides: http://r-datatable.com
> CC <- c(rep('integer', 2), rep('character', 3),
+ rep('numeric', 2), rep('integer', 3),
+ rep('character', 2), 'integer', 'character', 'integer',
+ rep('character', 4), rep('numeric', 11), 'character',
+ 'numeric', 'character', rep('numeric', 2),
+ rep('integer', 3), rep('numeric', 2), 'integer',
+ 'numeric')
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXXcsv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 13:42.935 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.016s ( 0%) sep=',' ncol=42 and header detection
0.016s ( 0%) Column type detection using 10049 sample rows
188.153s ( 23%) Allocation of 419124195 rows x 42 cols (125.177GB)
634.751s ( 77%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.121s ( 0%) Finding first non-embedded \n after each jump
+ 17.036s ( 2%) Parse to row-major thread buffers
+ 616.184s ( 75%) Transpose
+ 1.410s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
822.935s Total
> memory.size()
[1] 134270.3
> rm(P)
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 585532 31.3 5489235 293.2 6461124 345.1
Vcells 1508139082 11506.2 20046000758 152938.9 25028331901 190951.1
> memory.size()
[1] 87.56
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXX.csv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 05:04.910 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.031s ( 0%) sep=',' ncol=42 and header detection
0.000s ( 0%) Column type detection using 10049 sample rows
28.437s ( 9%) Allocation of 419124195 rows x 42 cols (125.177GB)
276.442s ( 91%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.017s ( 0%) Finding first non-embedded \n after each jump
+ 12.941s ( 4%) Parse to row-major thread buffers
+ 262.989s ( 86%) Transpose
+ 0.495s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
304.910s Total
> memory.size()
[1] 157049.7
> sessionInfo()
R version 3.4.2 beta (2017-09-17 r73296)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows Server >= 2012 x64 (build 9200)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] data.table_1.10.5
loaded via a namespace (and not attached):
[1] compiler_3.4.2 tools_3.4.2
Algumas notas. Eu teria sugerido colocar [09] antes de [07], pois se as colClasses forem passadas, não há razão para verificar. Além disso, o Windows mostrou cerca de 160 GB em uso após cada execução. memory.size () provavelmente faz alguma limpeza. Com 532 GB de RAM neste servidor, o cache de memória pode estar relacionado ao aumento da velocidade na segunda execução. Espero que ajude.
 aadler
em 28 set. 2017
aadler
em 28 set. 2017
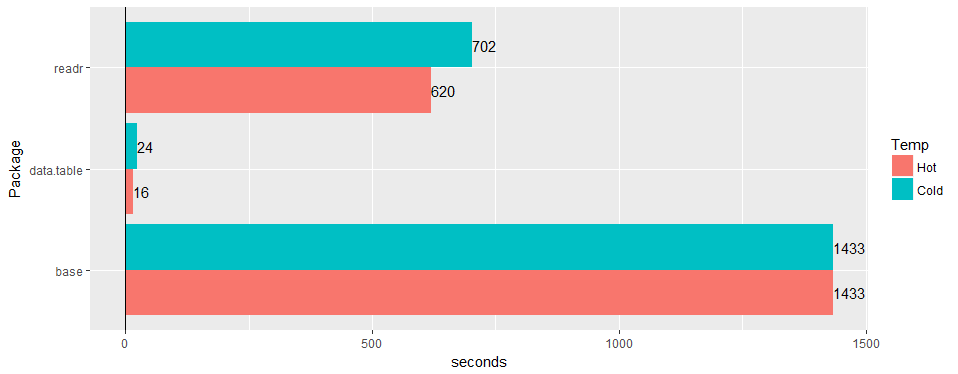
Teste em uma ampla tabela do "mundo real" (dados de hospital): 30 milhões de linhas × 125 colunas v readr '1.2.0' e read.csv 3.4.3.
 HughParsonage
em 25 jan. 2018
HughParsonage
em 25 jan. 2018
alguma chance de confirmar o problema ainda é válido em 1.11.4? ou código para produzir dados de exemplo.
 jangorecki
em 1 jul. 2018
jangorecki
em 1 jul. 2018
Este está tudo resolvido até onde eu sei. @geponce atualize se não.
TODO1 acima agora arquivado como # 3024
TODO2 acima agora arquivado como # 3025
mattdowle
em 31 ago. 2018
Questões relacionadas
 jameslamb
·
3Comentários
jameslamb
·
3Comentários
 sengoku93
·
3Comentários
sengoku93
·
3Comentários
 alex46015
·
3Comentários
alex46015
·
3Comentários
 DavidArenburg
·
3Comentários
jangorecki
·
3Comentários
DavidArenburg
·
3Comentários
jangorecki
·
3Comentários
Comentários muito úteis
Teste em uma ampla tabela do "mundo real" (dados de hospital): 30 milhões de linhas × 125 colunas v readr '1.2.0' e
read.csv3.4.3.