Data.table: 大きなcsv(44 GB)のfreadは、最新のdata.tabledevバージョンで大量のRAMを使用します
やあ、
ハードウェアとソフトウェア:
サーバー:Dell R930 4-Intel Xeon E7-8870 v3 2.1GHz、45Mキャッシュ、9.6GT / s QPI、ターボ、HT、18C / 36T、RAMに1TB
OS :Redhat 7.1
Rバージョン:3.3.2
data.tableバージョン:1.10.5ビルド2017-03-21
csvファイル(44 GB、872505行x 12785列)を読み込んでいます。 144コア(ハイパースレッディングを有効にして144コアボックスにする4つのプロセッサから72コア)を使用すると、1.30分で非常に高速にロードされます。
主な問題は、DTがロードされると、使用中のメモリの量がcsvファイルのサイズに比べて大幅に増加することです。 この場合、44 GBのcsv(fwriteで保存、saveRDSで保存、compress = FALSEで84GBのファイルを作成)は、約356GBのRAMを使用しています。
「verbose = TRUE」を使用した出力は次のとおりです。
_12785列スロットの割り当て(12785-0が削除されました)
madviseシーケンシャル:わかりました
1440ジャンプポイントと144スレッドでデータを読み取る
858881の推定行の95.7%を読み取る
43.772GBファイルから872505行x12785列を1分33.736秒の実時間で読み取ります(実行中の他のアプリの影響を受けます)
0.000s(0%)メモリマップ
0.070秒(0%)sep、ncol、およびヘッダーの検出
26.227s(28%)1440ジャンプポイントからの34832サンプル行を使用した列タイプの検出
0.614秒(1%)RAM内の3683116行x 12785列(350.838GB)の割り当て
0.000秒(0%)madviseシーケンシャル
66.825s(71%)データの読み取り
93.736秒合計_
「mclapply」などの関数を使用すると、コアごとに1つのrsessionが起動される、並列パッケージを使用するときに発生することがある同様の問題が表示されます。 このスクリーンショットで作成/リストされているRsessionsを参照してください。

「rm(DT)」を実行すると、RAMが初期状態に戻り、「Rsessions」が削除されます。
すでに「setDTthreads(20)」などを試しましたが、同じ量のRAMを使用しています。
ちなみに、ファイルに非並列バージョンの「fread」がロードされている場合、メモリ割り当ては最大106GBになります。
ギレルモ
 geponce
geponce
全てのコメント30件
これは、非並列fread実装からの出力です(data.table 1.10.5 IN DEVELOPMENT built 2017-02-09)

そして、使用されているメモリの量を再確認したところ、84GBになりました。
ギレルモ
geponce
2017年03月22日
はい、あなたが正しい。 素晴らしいレポートをありがとう。 推定されたnrowはほぼ正しいように見えますが(858,881対872,505)、割り当てはそれより4.2倍大きく(3,683,116)、かなり離れています。 計算を改善し、詳細出力に詳細を追加しました。 ただし、さらにいくつかの作業が完了するまで、再テストを保留します。
 mattdowle
2017年03月25日
mattdowle
2017年03月25日
もう一度テストしてください-今すぐ修正する必要があります。
mattdowle
2017年03月26日
data.tabledevをインストールしました。
data.table 1.10.5 IN DEVELOPMENT built 2017-03-27 02:50:31 UTC
同じ44GBのファイルを読み込もうとしたときに最初に得たのは、次のメッセージです。
DT <-fread( 'dt.daily.4km.csv')
エラー:protect():保護スタックオーバーフロー
次に、同じコマンドを再実行して、正常に動作し始めました。 ただし、このバージョンはマルチコアモードを使用していません。 fread-parallelバージョンを配置する前と同じように、ロードには約25分かかります。
ギレルモ
geponce
2017年03月27日
すべてのrセッションを閉じてテストを再実行すると、エラーが発生します。
推測された列タイプは、508列の34711745値には不十分でした。 colClassesを使用して、これらの列クラスを手動で設定します。
以下を参照してください。「推測された整数ですが、<< 0 .... >>が含まれています」に関するメッセージがいくつか表示されます。
_15:27.024の実時間で43.772GBファイルから872505行x 12785列を読み取ります(アイドル状態のように見えても、他の開いているアプリによって速度が低下する可能性があります)
列171( 'D_19810618')は 'integer'を推測しましたが、<< 2.23000001907349 >>が含まれています
列347( 'D_19811211')は 'integer'を推測しましたが、<< 1.02999997138977 >>が含まれています
列348( 'D_19811212')は 'integer'を推測しましたが、<< 3.75 >> _が含まれています
geponce
2017年03月27日
うわー-あなたのファイルは本当にエッジケースをテストしています。 素晴らしい。 将来的にはverbose=TRUE実行し、完全な出力を提供してください。 しかし、この場合にあなたが提供した情報で、私は問題が実際に何であるかを見ることができます。 スレッドごとに列ごとに作成されたバッファーがあります(この場合、12,000列を超えます)。 現在、それぞれが個別に保護されています。 それを回避する方法があります-します。 型推測に関するメッセージは正しいです。 それらの508列はあなたにとって何か意味があり、数値でなければならないことに同意しますか? 次のように、列の範囲をcolClasses渡すことができます: colClasses=list("numeric"=11:518)
このデータはどのフィールドからのものですか? ファイルを作成していますか? 通常のベストプラクティスは長いフォーマットで書き込む(そしてメモリにも保持する)ことであるワイドフォーマットにねじれているように感じます。 通常、「D_19810618」などの508列の名前は、列自体ではなく、列の値として表示されると思います。 そのため、ファイルを作成しているかどうか、長い形式で作成できるかどうかを尋ねます。 そうでない場合は、ファイルを作成している人に、ファイルをより適切に作成できることを提案します。 おそらく.SDと.SDcolsを使用して、列を介して操作を適用していると思います。 長い形式で、「D_19810618」のような値を保持する列にkeyby=の方がはるかに優れています。
ただし、 freadを、12,000列を超える非常に幅の広いファイルであっても、あらゆる入力を処理できるようにできる限り優れたものにするよう努めます。
他の人が自分のファイルをテストして問題がまったくないことを願っています!
mattdowle
2017年03月27日
_これらの508列はあなたにとって何か意味があり、数値である必要があることに同意しますか?
このテーブルには、行ごとの時系列が含まれています。 IDxに、IDY、Time1_value、Time2_value、Time3_value ...と列_valueすべての時間Nは数値のみが含まれています。 colClassesを使用する場合は、12783に対して実行する必要があります:list( "numeric" = 2:12783)。 これを試してみます。
_このデータはどのフィールドからのものですか?_
地理空間データ。 IDxとIDyを使用してDT内でユークリッド距離検索を行っています。 行が多いほど検索が遅くなると思いますよね?
現在はかなり高速です(ワイドフォーマット)。 ユーザーがエリアをクリックすると、csvファイル内で、最も近い場所(データが利用可能)から特定のクリックまでの時系列が生成されるマップがあります。 代わりに、長い形式で実装します。
いくつかの結果を返します。
geponce
2017年03月28日
いいよ。 list("numeric"=2:12783) iiucは、508列のヘルプのみが必要なため、必要ありません。 ああ-なるほど-508は私が推測する列に散らばっています(それらは連続した列のセットではありません)?
いいえ-data.tableは、幅が広い場合、ほとんど高速になりません。 ロングはほとんどの場合、より速く、より便利です。 roll="nearest"を見たり、試したりしたことがありますか? 今はどうですか? 理解できるようにコードを表示してください。 ほぼ確実に長い形式の方が優れていますが、2D最近傍の拡張が必要になる場合があります。 タイミングも教えてください。 「かなり速い」と言うと、「かなり速い」とは何かについて、人々は大きく異なる考えを持っていることがわかります。
mattdowle
2017年03月28日
このテーブルを溶かすと、2 ^ 31の制限に達します。 「負の長さのベクトルは許可されていません」というエラーが表示されます。
ソースに戻って、ロングフォーマットで生成できるかどうかを確認します。
geponce
2017年03月28日
# Read Data
DT <- fread('dt.daily.4km.csv', showProgress = FALSE)
# Add two columns with truncated values of x and y (these are geog. coords.)
DT[,y_tr:=trunc(y)]
DT[,x_tr:=trunc(x)]
# For using on plotting (x-axis values)
xaxis<-seq.Date(as.Date("1981-01-01"),as.Date("2015-12-31"), "day")
# subset by truncated coordinates to avoid full-table search. Now searches
# will happen in a smaller subset
DT2 <- DT[y_tr==trunc(y_clicked) & x_tr==trunc(x_clicked),]
# Add distance from each point in the data.table to the provided location, "gdist" is from
# Imap package for euclidean distance.
DT2[,DIST:=gdist(lat.1 = DT2$y,
lon.1 = DT2$x,
lat.2 = y_clicked,
lon.2 = x_clicked, units="miles")]
# Get the minimum distance
minDist <- min(DT2[,DIST])
# Get the y-axis values
yt <- transpose(DT2[DIST==minDist,3:(ncol(DT2)-3)])$V1`
# Ready to plot xaxis vs yt
...
...
パブリックサーバーにアプリケーションがありません。 基本的に、ユーザーは地図をクリックして、それらの座標をキャプチャし、上記の検索を実行して、時系列を取得し、プロットを作成できます。
geponce
2017年03月28日
非常に多数の列の別のスタックオーバーフローを検出して修正しました: https :
mattdowle
2017年03月28日
おお。 それがポイントです。 872505行* 12780列は110億行です。 したがって、2 ^ 31を超えるため、長い形式にするという私の提案は機能しません。 すみません-私はそれを見つけたはずです。 弾丸を噛んで> 2 ^ 31に行かなければなりません。 それまでの間、あなたが取り組んでいる幅広いフォーマットに固執しましょう。それを突き止めます。
mattdowle
2017年03月28日
もう一度やり直してください。 メモリ使用量は通常に戻り、サンプル外のタイプの例外を除いて、12,785列のうち508列を自動的に再読み取りする必要があります。 自動再実行時間を回避するために、 colClasses設定できます。
修正されていない場合は、完全な詳細出力を貼り付けてください。 成功を祈っている!
mattdowle
2017年03月29日
Ok...
最新のdata.tabledevを使用した結果の要約: data.table 1.10.5 IN DEVELOPMENT built 2017-03-29 16:17:01 UTC
言及すべき4つの主なポイント:
- freadは、ディスカッションのファイルを読んで問題なく機能しました。
- 読むのに約5.5分かかりましたが、以前のバージョンでは約1.3分かかりました。
- このバージョンは、私がテストしていた前のバージョンのようにRAM割り当てを増やしません。
- コアは「あまりアクティブではない」ようです(下のスクリーンショットを参照)。
いくつかのコメント/質問:
1.1。
コアでの使用率は以前ほどアクティブではありません。スクリーンショットを参照してください。
以前のバージョンのfreadでは、コアのアクティビティは常に約90〜80%でした。 このバージョンでは、上の画像に示すように、各コアの約2〜3%を維持しました。
freadが整数から数値へのバンプを行っている理由がわかりません。例:
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
私はそれらの行を再確認しましたが、問題ないようです。 整数として検出され、すでに数値である場合に「バンプ」して「数値」にする必要があるのはなぜですか(以下に提案する行の要約を参照)。 または私はこの行を間違って理解していますか? これは508行で発生します。 NAが問題を引き起こしていますか?
summary(DT[6041:24473,.(D_19850126)])
D_19850126
Min. :0.750
1st Qu.:0.887
Median :0.945
Mean :0.966
3rd Qu.:1.045
Max. :1.210
NA's :18393
テストからのいくつかの冗長の下。
DT<-fread('dt.daily.4km.ver032917.csv', verbose=TRUE)
出力
Parameter na.strings == <<NA>>
None of the 0 na.strings are numeric (such as '-9999').Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,D_19810113,
...
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 11 because 1281788 startSize * 10 NJUMPS * 2 = 25635760 <= -244636240 bytes from line 2 to eof
Type codes (jump 00) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 01) : 444422222222222222242444424444442222222222424444424442224424222244222222222242422222224422...4442244422 Quote rule 0
Type codes (jump 02) : 444422222222222222242444424444442422222242424444424442224424222244222222222242424222424424...4442444442 Quote rule 0
Type codes (jump 03) : 444422222222222224242444424444444422222244424444424442224424222244222222222244424442424424...4442444442 Quote rule 0
Type codes (jump 04) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 05) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 06) : 444444444422222224442444424444444444242244444444444444424444444444444244444444424442444444...4444444444 Quote rule 0
Type codes (jump 07) : 444444444422222224442444424444444444242244444444444444444444444444444244444444424444444444...4444444444 Quote rule 0
Type codes (jump 08) : 444444444442222224444444424444444444242244444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 09) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 10) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
=====
Sampled 305 rows (handled \n inside quoted fields) at 11 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=45578.20 sd=33428.37 min=12815 max=108497
Estimated nrow: 47000004016 / 45578.20 = 1031195
Initial alloc = 2062390 rows (1031195 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Type codes (drop|select): 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 44928 chunks of 0.998MB (22 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.908 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : numeric
0 : character
Rereading 508 columns due to out-of-sample type exceptions.
Column 171 ("D_19810618") bumped from 'integer' to 'numeric' due to <<2.23000001907349>> somewhere between row 6041 and row 24473
Column 347 ("D_19811211") bumped from 'integer' to 'numeric' due to <<1.02999997138977>> somewhere between row 6041 and row 24473
Column 348 ("D_19811212") bumped from 'integer' to 'numeric' due to <<3.75>> somewhere between row 6041 and row 24473
Column 643 ("D_19821003") bumped from 'integer' to 'numeric' due to <<1.04999995231628>> somewhere between row 6041 and row 24473
Column 1066 ("D_19831130") bumped from 'integer' to 'numeric' due to <<1.46000003814697>> somewhere between row 6041 and row 24473
Column 1102 ("D_19840105") bumped from 'integer' to 'numeric' due to <<0.959999978542328>> somewhere between row 6041 and row 24473
Column 1124 ("D_19840127") bumped from 'integer' to 'numeric' due to <<0.620000004768372>> somewhere between row 6041 and row 24473
Column 1130 ("D_19840202") bumped from 'integer' to 'numeric' due to <<0.540000021457672>> somewhere between row 6041 and row 24473
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
Column 1508 ("D_19850214") bumped from 'integer' to 'numeric' due to <<0.360000014305115>> somewhere between row 6041 and row 24473
...
...
Reread 872505 rows x 508 columns in 05:29.167
Read 872505 rows. Exactly what was estimated and allocated up front
Thread buffers were grown 0 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.093s ( 0%) sep, ncol and header detection
0.186s ( 0%) Column type detection using 305 sample rows from 44928 jump points
0.600s ( 0%) Allocation of 872505 rows x 12785 cols (192.552GB) plus 1.721GB of temporary buffers
326.029s ( 50%) Reading data
329.167s ( 50%) Rereading 508 columns due to out-of-sample type exceptions
656.075s Total
この最後の要約は、それを完了するのに多くの時間がかかりました(〜6分)。 この詳細な要約を数えると、全体の恐怖は約11分かかりました。 これらの508列を再読み取りしていますが、verbose = TRUEを使用せずに、「サンプル外のタイプの例外が原因で508列を再読み取りしています」というメッセージも表示されます。
「verbose = TRUE」なしでチェックしてください
ptm<-proc.time()
DT<-fread('dt.daily.4km.ver032917.csv')
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.647 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Rereading 508 columns due to out-of-sample type exceptions.
Reread 872505 rows x 508 columns in 05:30.276
proc.time() - ptm
user system elapsed
2113.100 85.919 657.870
fwriteテスト
正常に動作しています。 本当に速い。 最近は読むより書くのが遅いと思いました。
fwrite(DT,'dt.daily.4km.ver032917.csv', verbose=TRUE)
No list columns are present. Setting sep2='' otherwise quote='auto' would quote fields containing sep2.
maxLineLen=151187 from sample. Found in 1.890s
Writing column names ... done in 0.000s
Writing 872505 rows in 32315 batches of 27 rows (each buffer size 8MB, showProgress=1, nth=144) ...
done (actual nth=144, anyBufferGrown=no, maxBuffUsed=46%)
「再読」にはかなりの時間がかかります。 これは、ファイルを2回読み取るようなものです。
geponce
2017年03月30日
優秀な! すべての情報をありがとう。
- はい、あなたは正しいです、それは再読するべきではありません。
colClasses=list("numeric"=1:12785)を通過したので、Type code (colClasses)始まる出力行はすべて値4になります。欠落しているテストを修正して追加します。 - 5.5m対1.3mでは、それは興味深いことです。 各スレッドのバッファは現在1MBです。 キャッシュに収まるように小さくするという考え。 しかし、あなたの場合、1MB / 12785列= 82バイトです。 したがって、その選択ではキャッシュ効率が50倍も高くなります。 とにかく、私は推測します。 私はあなたのテストなしでそれを考えたことはありませんでした。 1.3mの速度で動作していたときは、その1MBのサイズはありませんでした。
- 305行しかサンプリングしていない理由も非常に奇妙です。 1,000をサンプリングする必要がありました。 それが修正された場合、おそらくそれはあなたがしなくても508列を検出するでしょう。 サンプルは時間がかからないため(0.186秒)、サンプルサイズを増やすことができます。
lscpu unixコマンドの出力を貼り付けてください。 これにより、キャッシュサイズがわかり、そこから考えることができます。 freadパラメーターとしてbuffMBを提供しますので、それがそれであるかどうかを確認できます。 もしそうなら、私はより良い計算を思い付くことができます。
mattdowle
2017年03月30日
以前の投稿の1つのポイントでの私の間違い。 colClasses=list("numeric"=1:12785)は正常に機能しています。 「colClasses」を指定しない場合は「再読み込み」を行います。 混乱してすみません。
私が気づいたことの1つは、「colClasses」を指定しない場合、テーブルはNAで作成され、RAMはDTが正常にロードされたかのように表示されることです(RAMで約106MB)。
lscpuの出力は次の
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 144
On-line CPU(s) list: 0-143
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 4
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E7-8870 v3 @ 2.10GHz
Stepping: 4
CPU MHz: 2898.328
BogoMIPS: 4195.66
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36,40,44,48,52,56,60,64,68,72,76,80,84,88,92,96,100,104,108,112,116,120,124,128,132,136,140
NUMA node1 CPU(s): 1,5,9,13,17,21,25,29,33,37,41,45,49,53,57,61,65,69,73,77,81,85,89,93,97,101,105,109,113,117,121,125,129,133,137,141
NUMA node2 CPU(s): 2,6,10,14,18,22,26,30,34,38,42,46,50,54,58,62,66,70,74,78,82,86,90,94,98,102,106,110,114,118,122,126,130,134,138,142
NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39,43,47,51,55,59,63,67,71,75,79,83,87,91,95,99,103,107,111,115,119,123,127,131,135,139,143
はい、わかった。 ありがとう。
最初のコメントをもう一度読んで、「整数から数値へのバンプ」ではなく、「整数から2倍へのバンプ」と言った方が理にかなっていますか?
「NAで作成された」とはどういう意味ですか? すべてのテーブルはNAでいっぱいですが、508列だけですか?
「DTは正常にロードされました(RAMに約106MB)」とは何ですか。 これは44GBのファイルですが、106MBはどのように正常なのですか?
mattdowle
2017年03月30日
さて、このファイルで私が持っているのは実数とNAだけです。 整数値がありません。 「datatypeAからdatatypeBにバンプする」というメッセージをいつスローしますか?
それがまさに私が言いたいことです。 インストールしたdata.tableの現在のバージョンでは、colClassesを省略すると、DTが読み込まれますが、NAがいっぱいになります。
DT[!is.na(D_19821001),]は0レコードを生成し、colClassesを使用してテーブルをロードし、同じフィルタリングを実行すると、実際にレコードが表示されます。さて、このファイルはディスクのcsvとして47 GBですが、Rにロードすると、RAMに2倍以上かかります...値の精度とは関係ありません。一度ロードされると、実際のメモリの割り当てが読み込まれます。数はその増加を引き起こしますか?
geponce
2017年03月30日
たぶん別のタイプミス:106MBは106GBだったはずです。
私はNAの側面に従っていません。 しかし、途中でいくつかの修正を行ってから、もう一度やり直してください...
mattdowle
2017年03月30日
わかりました-もう一度やり直してください。 推測サンプルは10,000に増加し(これにかかる時間を確認するのは興味深いでしょう)、バッファーサイズに最小値が課されるようになりました。
dratパッケージファイルがプロモートされるまで、少なくとも30分待つ必要がある場合があります。
mattdowle
2017年03月30日
申し訳ありませんが、「MB」ではなく「GB」でした。 コーヒーが足りませんでした。
アップデートを入手してテストします。
geponce
2017年03月30日
最新のdata.table開発でのテスト:
概要:
高速に動作し(csvの読み取りに1.43分)、メモリ割り当ても正常に動作しています。RAM割り当ては以前のように増加しないと思います。 ディスク上の44GBのcsvは、ロードされるとRAM内で約112(+ 37 GBの一時バッファー)GBに変換されます。 これはファイル内の値のデータ型に関連していますか?
テスト1 :
colClasses=list("numeric"=1:12785)を使用せずに
DT<-fread('dt.daily.4km.csv', verbose=TRUE)
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,
D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 47000004016 bytes from row 1 to eof / (2 * 1281788 jump0size) == 18333
Type codes (jump 000) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 001) : 444222422222222224442444444444442222444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
Type codes (jump 002) : 444222444444222244442444444444444422444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
...
Type codes (jump 034) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
Type codes (jump 100) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=79727.22 sd=32260.00 min=12804 max=153029
Estimated nrow: 47000004016 / 79727.22 = 589511
Initial alloc = 1179022 rows (589511 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Type codes (drop|select) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 02:17.726 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.099s ( 0%) sep, ncol and header detection
11.057s ( 8%) Column type detection using 10049 sample rows
0.899s ( 1%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
125.671s ( 91%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
137.726s Total
テスト2 :
現在colClasses=list("numeric"=1:12785)
タイミングが数秒改善されました...
DT<-fread('dt.daily.4km.csv', colClasses=list("numeric"=1:12785), verbose=TRUE)
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 01:43.028 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.092s ( 0%) sep, ncol and header detection
11.009s ( 11%) Column type detection using 10049 sample rows
0.332s ( 0%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
91.595s ( 89%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
103.028s Total
わかりました-私たちはそこに着きました。 修正されたサンプルサイズに加えて、100ポイントで100行(10,000サンプル行)に増やすことで、タイプを正しく推測するのに十分でした。 44GBのファイルには12,875列あり、行の長さは平均80,000文字であるため、サンプリングに11秒かかりました。 しかし、その時間はそれだけの価値がありました。それは、余分な90秒を要したであろう再読を回避したからです。 それではそれを守ります。
2回目で、オペレーティングシステムがウォームアップしてファイルをキャッシュしたからといって、2回目が速いと思います。 ボックス上で実行されている他のすべてのものは、掛け時計のタイミングに影響を与えます。 これは、最初のテストを3回連続して実行することで解決されます。 次に、1つだけ変更して、3回の同一の連続実行を再度実行します。 44GBのサイズでは、多くの自然な変動が見られます。 結論を出すには通常3回の実行で十分ですが、それはブラックアートである可能性があります。
はい、メモリ内の112GBとディスク内の44GBは、すべての列がdouble型であるため、データがメモリ内で大きいためです。 Rにはメモリ内圧縮がなく、このCSVではスペースをとらない( ",," )がメモリに8バイトを占めるNA値がかなりたくさんあります。 ただし、112GBではなく83GBにする必要があります(872505行x12785列x8バイトの倍精度/ 1024 ^ 3 = 83GB)。 その112GBは、回線長の平均と標準偏差に基づいて割り当てられたものです。 平均行長に基づいて、短すぎると思われる589,511行になると推定されました。 線の長さの変動が非常に大きかったため、クランプは+ 100%で有効になりました。 58,9511 * 2 = 1,179,022 * 12785 * 8/1024 ^ 3 = 112GB。 最終的に、872,505がファイルに含まれていることがわかりました。 しかし、それは空き領域を解放しているわけではありません。 修正します。 (TODO1)
ただし、すべての列に列タイプを指定した場合でも、サンプリングされます。 ユーザーがすべての列を指定した場合、サンプリングをスキップする必要があります。 (TODO2)
すべてのデータが2倍であるため、Cライブラリ関数strtod()に対して110億回の呼び出しが行われます。 その機能の専門化に対する長い間望まれていたことは、理論的にはこのファイルの大幅な高速化をもたらすはずです。 (終わり)
mattdowle
2017年03月31日
それをありがとう、素晴らしい説明。 このファイルで他の何かをテストしたい場合はお知らせください。 私は、約2,100万行x 1432列の、より長い形式の別のデータセットに取り組んでいます。
NAME NROW NCOL MB
[1,] DT 21,812,625 1,432 238,310
これにデータポイントを追加します。 89G .tsv 、ロード中のピークメモリ使用量は約180Gです。 NAとダブルが多いのでこれは期待できると思います。
私もこれをテストできてうれしいです。
Ubuntu 16.04 64bit / Linux 4.4.0-71-generic
R version 3.3.2 (2016-10-31)
data.table 1.10.5 IN DEVELOPMENT built 2017-04-04 14:27:46 UTC
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Stepping: 1
CPU MHz: 2699.984
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4660.70
Hypervisor vendor: Xen
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq monitor est ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt ida
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 88.603947 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<allele prediction_uuid sample_>>
Detecting sep ...
sep=='\t' with 101 lines of 76 fields using quote rule 0
Detected 76 columns on line 1. This line is either column names or first data row (first 30 chars): <<allele prediction_uuid sample_>>
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 95137762779 bytes from row 1 to eof / (2 * 24414 jump0size) == 1948426
Type codes (jump 000) : 5555542444111145424441111444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 009) : 5555542444114445424441144444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 042) : 5555542444444445424444444444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 048) : 5555544444444445444444444444225225522555545111111111111111111111111111111111 Quote rule 0
Type codes (jump 083) : 5555544444444445444444444444225225522555545254452454411154454452454411154455 Quote rule 0
Type codes (jump 085) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
Type codes (jump 100) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
=====
Sampled 10028 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 95137762779
Line length: mean=465.06 sd=250.27 min=198 max=929
Estimated nrow: 95137762779 / 465.06 = 204571280
Initial alloc = 409142560 rows (204571280 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Type codes (drop|select) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Allocating 76 column slots (76 - 0 dropped)
Reading 90752 chunks of 1.000MB (2254 rows) using 64 threads
 andrewrech
2017年04月04日
andrewrech
2017年04月04日
それが役立つ場合は、非常に長いデータベースでの結果を次に示します。419,124,196x42(〜2 ^ 34)、1つのヘッダー行とcolClassesが渡されています。
> library(data.table)
data.table 1.10.5 IN DEVELOPMENT built 2017-09-27 17:12:56 UTC; travis
The fastest way to learn (by data.table authors): https://www.datacamp.com/courses/data-analysis-the-data-table-way
Documentation: ?data.table, example(data.table) and browseVignettes("data.table")
Release notes, videos and slides: http://r-datatable.com
> CC <- c(rep('integer', 2), rep('character', 3),
+ rep('numeric', 2), rep('integer', 3),
+ rep('character', 2), 'integer', 'character', 'integer',
+ rep('character', 4), rep('numeric', 11), 'character',
+ 'numeric', 'character', rep('numeric', 2),
+ rep('integer', 3), rep('numeric', 2), 'integer',
+ 'numeric')
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXXcsv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 13:42.935 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.016s ( 0%) sep=',' ncol=42 and header detection
0.016s ( 0%) Column type detection using 10049 sample rows
188.153s ( 23%) Allocation of 419124195 rows x 42 cols (125.177GB)
634.751s ( 77%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.121s ( 0%) Finding first non-embedded \n after each jump
+ 17.036s ( 2%) Parse to row-major thread buffers
+ 616.184s ( 75%) Transpose
+ 1.410s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
822.935s Total
> memory.size()
[1] 134270.3
> rm(P)
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 585532 31.3 5489235 293.2 6461124 345.1
Vcells 1508139082 11506.2 20046000758 152938.9 25028331901 190951.1
> memory.size()
[1] 87.56
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXX.csv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 05:04.910 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.031s ( 0%) sep=',' ncol=42 and header detection
0.000s ( 0%) Column type detection using 10049 sample rows
28.437s ( 9%) Allocation of 419124195 rows x 42 cols (125.177GB)
276.442s ( 91%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.017s ( 0%) Finding first non-embedded \n after each jump
+ 12.941s ( 4%) Parse to row-major thread buffers
+ 262.989s ( 86%) Transpose
+ 0.495s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
304.910s Total
> memory.size()
[1] 157049.7
> sessionInfo()
R version 3.4.2 beta (2017-09-17 r73296)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows Server >= 2012 x64 (build 9200)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] data.table_1.10.5
loaded via a namespace (and not attached):
[1] compiler_3.4.2 tools_3.4.2
いくつかのメモ。 colClassesが渡された場合、チェックする理由がないという点で、[07]の前に[09]を置くことをお勧めします。 また、Windowsは、実行するたびに約160GBが使用されていることを示しました。 memory.size()はおそらくいくつかのクリーニングを行います。 このサーバーに532GBのRAMがある場合、メモリキャッシュは、2回目の実行での速度の向上と関係がある可能性があります。 それがお役に立てば幸いです。
 aadler
2017年09月28日
aadler
2017年09月28日
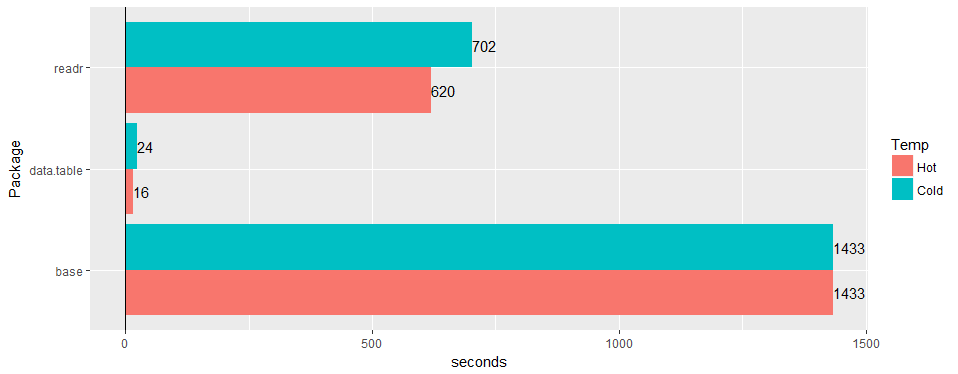
広い「実世界」のテーブル(病院データ)でテストします。3000万行×125列vリーダー「1.2.0」およびread.csv 3.4.3。
 HughParsonage
2018年01月25日
HughParsonage
2018年01月25日
問題を確認するチャンスは1.11.4でもまだ有効ですか? またはサンプルデータを生成するコード。
 jangorecki
2018年07月01日
jangorecki
2018年07月01日
私の知る限り、これはすべて解決されています。 @geponceそうでない場合は更新してください。
上記のTODO1は現在#3024として提出されています
上記のTODO2は現在#3025として提出されています
mattdowle
2018年08月31日
関連する問題
 jameslamb
·
3コメント
jameslamb
·
3コメント
 tcederquist
·
3コメント
tcederquist
·
3コメント
 rafapereirabr
·
3コメント
mattdowle
·
3コメント
rafapereirabr
·
3コメント
mattdowle
·
3コメント
 DavidArenburg
·
3コメント
DavidArenburg
·
3コメント
最も参考になるコメント
広い「実世界」のテーブル(病院データ)でテストします。3000万行×125列vリーダー「1.2.0」および
read.csv3.4.3。