Data.table: fread dengan csv besar (44 GB) membutuhkan banyak RAM dalam versi dev data.table terbaru
Hai,
Perangkat keras dan perangkat lunak:
Server : Dell R930 4-Intel Xeon E7-8870 v3 2.1GHz,45M Cache,9.6GT/s QPI,Turbo,HT,18C/36T dan RAM 1TB
OS : Redhat 7.1
R-versi : 3.3.2
versi data.table : 1.10.5 dibuat 21-03-2017
Saya sedang memuat file csv (44 GB, 872505 baris x 12785 cols). Ini memuat sangat cepat, dalam 1,30 menit menggunakan 144 core (72 core dari 4 prosesor dengan hyperthreading diaktifkan untuk menjadikannya 144 core box).
Masalah utamanya adalah ketika DT dimuat, jumlah memori yang digunakan meningkat secara signifikan dalam kaitannya dengan ukuran file csv. Dalam hal ini csv 44 GB (disimpan dengan fwrite, disimpan dengan saveRDS dan kompres=FALSE membuat file 84GB) menggunakan ~ 356 GB RAM.
Berikut adalah output menggunakan "verbose=TRUE"
_Mengalokasikan 12785 slot kolom (12785 - 0 dijatuhkan)
sekuensial madvise: ok
Membaca data dengan 1440 titik lompatan dan 144 utas
Baca 95,7% dari 858881 perkiraan baris
Membaca 872505 baris x 12785 kolom dari file 43.772GB dalam 1 menit 33.736 detik waktu jam dinding (dipengaruhi oleh aplikasi lain yang berjalan)
0,000s ( 0%) Peta memori
0.070s (0%) sep, ncol dan deteksi header
26.227 detik (28%) Deteksi tipe kolom menggunakan 34832 baris sampel dari 1440 titik lompatan
0,614s ( 1%) Alokasi 3683116 baris x 12785 cols (350.838GB) dalam RAM
0,000s ( 0%) madvise sekuensial
66.825s (71%) Membaca data
93.736s Total_
Ini menunjukkan masalah serupa yang terkadang muncul saat bekerja dengan paket paralel, di mana satu sesi diluncurkan per inti saat menggunakan fungsi seperti "mclapply". Lihat Rsessions yang dibuat/tercantum di tangkapan layar ini:

jika saya melakukan "rm(DT)" RAM kembali ke keadaan awal dan "Rsessions" dihapus.
Sudah mencoba misalnya "setDTthreads(20)" dan masih menggunakan jumlah RAM yang sama.
Omong-omong, jika file dimuat dengan "fread" versi non-paralel, alokasi memori hanya mencapai ~106 GB.
Guillermo
 geponce
geponce
Semua 30 komentar
Ini adalah output dari implementasi non-parallel fread (data.table 1.10.5 IN DEVELOPMENT dibangun 2017-02-09)

Dan saya memeriksa ulang jumlah memori yang digunakan dan hanya mencapai 84GB.
Guillermo
geponce
pada 22 Mar 2017
Ya kau benar. Terima kasih atas laporan yang bagus. Estimasi sempit terlihat tepat (858.881 vs 872.505) tapi kemudian alokasinya 4,2X lebih besar dari itu (3.683.116) dan jauh. Saya telah meningkatkan perhitungan dan menambahkan lebih banyak detail ke output verbose. Tunda pengujian ulang untuk saat ini sampai beberapa hal lagi telah dilakukan.
 mattdowle
pada 25 Mar 2017
mattdowle
pada 25 Mar 2017
Ok silakan tes ulang - harus diperbaiki sekarang.
mattdowle
pada 26 Mar 2017
Saya baru saja menginstal data.table dev:
data.table 1.10.5 DALAM PEMBANGUNAN dibangun 27-03-2017 02:50:31 UTC
Hal pertama yang saya dapatkan ketika mencoba membaca file 44 GB yang sama adalah pesan ini:
DT <- fread('dt.daily.4km.csv')
Kesalahan: protect(): proteksi stack overflow
Kemudian saya menjalankan kembali perintah yang sama dan mulai berfungsi dengan baik. Namun, versi ini tidak menggunakan mode multi-core. Dibutuhkan ~ 25 menit untuk memuat, sama seperti sebelum Anda meletakkan versi paralel-fread.
Guillermo
geponce
pada 27 Mar 2017
Saya menutup semua sesi-r dan menjalankan kembali tes dan saya mendapatkan kesalahan:
Jenis kolom yang ditebak tidak cukup untuk 34711745 nilai dalam 508 kolom. Gunakan colClasses untuk mengatur kelas kolom ini secara manual.
Lihat di bawah, saya mendapatkan beberapa pesan tentang "tebakan bilangan bulat tetapi mengandung <<0....>>
_Baca 872505 baris x 12785 kolom dari file 43.772GB dalam waktu 15:27.024 jam dinding (dapat diperlambat oleh aplikasi terbuka lainnya bahkan jika tampaknya menganggur)
Kolom 171 ('D_19810618') menebak 'bilangan bulat' tetapi berisi <<2.23000001907349>>
Kolom 347 ('D_19811211') menebak 'bilangan bulat' tetapi berisi <<1.02999997138977>>
Kolom 348 ('D_19811212') menebak 'bilangan bulat' tetapi berisi <<3.75>>_
geponce
pada 27 Mar 2017
Wow - file Anda benar-benar menguji kasus Edge. Besar. Di masa mendatang, jalankan dengan verbose=TRUE dan berikan output lengkapnya. Tetapi dengan informasi yang Anda berikan dalam kasus ini saya dapat melihat apa masalahnya sebenarnya. Ada buffer yang dibuat untuk setiap kolom untuk setiap utas (dalam hal ini, lebih dari 12.000 kolom). Masing-masing secara terpisah DILINDUNGI saat ini. Ada cara untuk menghindari itu - akan dilakukan. Pesan tentang tipe menebak benar. Apakah 508 kolom itu berarti bagi Anda dan Anda setuju bahwa kolom itu harus berupa angka? Anda dapat meneruskan rentang kolom ke colClasses seperti ini: colClasses=list("numeric"=11:518)
Data ini dari bidang apa? Apakah Anda membuat file? Rasanya seperti telah dipelintir ke format lebar di mana praktik terbaik yang normal adalah menulis (dan menyimpannya juga dalam memori) dalam format panjang. Saya biasanya berharap untuk melihat 508 nama kolom seperti "D_19810618" sebagai nilai dalam kolom, bukan sebagai kolom itu sendiri. Itulah sebabnya saya bertanya apakah Anda membuat file dan dapatkah Anda membuatnya dalam format panjang. Jika tidak, sarankan kepada siapa pun yang membuat file agar mereka dapat melakukannya dengan lebih baik. Saya kira Anda menerapkan operasi melalui kolom mungkin menggunakan .SD dan .SDcols . Ini benar-benar jauh lebih baik dalam format panjang dan keyby= kolom yang menyimpan nilai seperti "D_19810618".
Tetapi saya akan tetap mencoba dan membuat fread sebaik mungkin dalam menangani input apa pun -- bahkan file yang sangat lebar dengan lebih dari 12.000 kolom.
Saya berharap orang lain sedang menguji dan tidak menemukan masalah sama sekali pada file mereka!
mattdowle
pada 27 Mar 2017
_ Apakah 508 kolom itu berarti bagi Anda dan Anda setuju bahwa kolom itu harus berupa angka?
Tabel ini berisi deret waktu demi baris. IDx,IDy, Time1_value, Time2_value, Time3_value... dan semua kolom Time N _value hanya berisi nilai numerik. Jika saya menggunakan colClasses, saya harus melakukannya untuk 12783: list("numeric"=2:12783). Saya akan mencoba ini.
_Data ini dari bidang apa?_
data geospasial. Saya melakukan pencarian euclidean-distance dalam DT menggunakan IDx & IDy. Saya menduga semakin banyak baris semakin lambat pencarian, bukan?
Saat ini cukup cepat (format lebar). Saya memiliki peta, di mana pengguna dapat mengklik suatu area dan kemudian deret waktu dihasilkan dalam file csv dari lokasi terdekat (dengan data tersedia) ke klik yang diberikan. Saya akan menerapkannya dengan format panjang sebagai gantinya.
Saya akan kembali dengan beberapa hasil.
geponce
pada 28 Mar 2017
Oke bagus. Anda tidak perlu list("numeric"=2:12783) iiuc karena hanya membutuhkan bantuan dengan 508 kolom. Oh - saya mengerti - 508 tersebar melalui kolom, saya kira itu (mereka bukan kumpulan kolom yang berdekatan)?
Tidak - data.table hampir tidak pernah lebih cepat jika lebar! Panjang hampir selalu lebih cepat dan lebih nyaman. Pernahkah Anda melihat dan mencoba roll="nearest" ? Bagaimana Anda melakukannya sekarang? Tolong tunjukkan kodenya agar kami bisa mengerti. Hampir pasti format panjang lebih baik tetapi kita mungkin memerlukan beberapa peningkatan untuk 2D terdekat. Tolong tunjukkan waktunya juga. Ketika Anda mengatakan "cukup cepat" ternyata orang memiliki gagasan yang sangat berbeda tentang apa itu "cukup cepat".
mattdowle
pada 28 Mar 2017
melelehkan meja ini mencapai batas 2^31. Saya mendapatkan kesalahan: "vektor panjang negatif tidak diizinkan".
Saya akan kembali ke sumbernya untuk melihat apakah saya dapat membuatnya dalam format panjang.
geponce
pada 28 Mar 2017
# Read Data
DT <- fread('dt.daily.4km.csv', showProgress = FALSE)
# Add two columns with truncated values of x and y (these are geog. coords.)
DT[,y_tr:=trunc(y)]
DT[,x_tr:=trunc(x)]
# For using on plotting (x-axis values)
xaxis<-seq.Date(as.Date("1981-01-01"),as.Date("2015-12-31"), "day")
# subset by truncated coordinates to avoid full-table search. Now searches
# will happen in a smaller subset
DT2 <- DT[y_tr==trunc(y_clicked) & x_tr==trunc(x_clicked),]
# Add distance from each point in the data.table to the provided location, "gdist" is from
# Imap package for euclidean distance.
DT2[,DIST:=gdist(lat.1 = DT2$y,
lon.1 = DT2$x,
lat.2 = y_clicked,
lon.2 = x_clicked, units="miles")]
# Get the minimum distance
minDist <- min(DT2[,DIST])
# Get the y-axis values
yt <- transpose(DT2[DIST==minDist,3:(ncol(DT2)-3)])$V1`
# Ready to plot xaxis vs yt
...
...
Saya tidak memiliki aplikasi di server publik. Pada dasarnya, pengguna dapat mengklik peta dan kemudian saya menangkap koordinat tersebut dan melakukan pencarian di atas, mendapatkan deret waktu, dan membuat plot.
geponce
pada 28 Mar 2017
Menemukan dan memperbaiki stack overflow lain untuk jumlah kolom yang sangat besar: https://github.com/Rdatatable/data.table/commit/d0469e670961dcdea115d433c0f2dce596d65906. Lupa memberi tag nomor masalah ini di pesan komit.
mattdowle
pada 28 Mar 2017
Oh. Itu poin. 872505 baris * 12780 cols adalah 11 miliar baris. Jadi saran saya untuk menggunakan format panjang tidak akan berhasil untuk Anda karena itu > 2^31. Maaf - saya seharusnya melihat itu. Kita hanya perlu gigit peluru dan pergi > 2^31. Sementara itu, mari kita tetap menggunakan format lebar yang telah Anda kerjakan dan saya akan menyelesaikannya.
mattdowle
pada 28 Mar 2017
Silakan coba lagi. Penggunaan memori harus kembali normal dan secara otomatis harus membaca ulang 508 dari 12.785 kolom dengan pengecualian jenis di luar sampel. Untuk menghindari waktu pemutaran ulang otomatis, Anda dapat mengatur colClasses .
Jika tidak diperbaiki, silakan tempel keluaran verbose lengkap. Semoga saja!
mattdowle
pada 29 Mar 2017
Oke...
Ringkasan hasil dengan data.table dev terbaru: data.table 1.10.5 DALAM PENGEMBANGAN dibangun 29-03-2017 16:17:01 UTC
Empat poin utama untuk disebutkan:
- fread bekerja dengan baik membaca file dalam diskusi.
- Butuh ~ 5,5 menit untuk membaca vs. versi sebelumnya yang membutuhkan ~ 1,3 menit.
- Versi ini tidak menambah alokasi RAM seperti versi sebelumnya yang saya uji.
- Core tampaknya "kurang aktif" (lihat tangkapan layar di bawah).
Beberapa komentar/pertanyaan:
1.
Persentase penggunaan di core tidak seaktif sebelumnya, lihat tangkapan layar:
Di versi fread sebelumnya, aktivitas inti selalu ~ 90-80%. Dalam versi ini tinggal sekitar ~2-3% setiap inti seperti yang ditunjukkan pada gambar di atas.
Saya tidak mengerti mengapa fread melakukan benjolan dari bilangan bulat ke numerik: misalnya
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
Saya memeriksa ulang baris-baris itu dan sepertinya ok. Mengapa terdeteksi sebagai bilangan bulat dan perlu 'bertemu' ke 'numerik' jika sudah numerik (lihat ringkasan untuk baris yang disarankan di bawah)? atau apakah saya salah memahami baris ini? Ini terjadi untuk 508 baris. Apakah NA menyebabkan masalah?
summary(DT[6041:24473,.(D_19850126)])
D_19850126
Min. :0.750
1st Qu.:0.887
Median :0.945
Mean :0.966
3rd Qu.:1.045
Max. :1.210
NA's :18393
Di bawah ini beberapa verbose dari tes.
DT<-fread('dt.daily.4km.ver032917.csv', verbose=TRUE)
KELUARAN
Parameter na.strings == <<NA>>
None of the 0 na.strings are numeric (such as '-9999').Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,D_19810113,
...
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 11 because 1281788 startSize * 10 NJUMPS * 2 = 25635760 <= -244636240 bytes from line 2 to eof
Type codes (jump 00) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 01) : 444422222222222222242444424444442222222222424444424442224424222244222222222242422222224422...4442244422 Quote rule 0
Type codes (jump 02) : 444422222222222222242444424444442422222242424444424442224424222244222222222242424222424424...4442444442 Quote rule 0
Type codes (jump 03) : 444422222222222224242444424444444422222244424444424442224424222244222222222244424442424424...4442444442 Quote rule 0
Type codes (jump 04) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 05) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 06) : 444444444422222224442444424444444444242244444444444444424444444444444244444444424442444444...4444444444 Quote rule 0
Type codes (jump 07) : 444444444422222224442444424444444444242244444444444444444444444444444244444444424444444444...4444444444 Quote rule 0
Type codes (jump 08) : 444444444442222224444444424444444444242244444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 09) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 10) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
=====
Sampled 305 rows (handled \n inside quoted fields) at 11 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=45578.20 sd=33428.37 min=12815 max=108497
Estimated nrow: 47000004016 / 45578.20 = 1031195
Initial alloc = 2062390 rows (1031195 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Type codes (drop|select): 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 44928 chunks of 0.998MB (22 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.908 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : numeric
0 : character
Rereading 508 columns due to out-of-sample type exceptions.
Column 171 ("D_19810618") bumped from 'integer' to 'numeric' due to <<2.23000001907349>> somewhere between row 6041 and row 24473
Column 347 ("D_19811211") bumped from 'integer' to 'numeric' due to <<1.02999997138977>> somewhere between row 6041 and row 24473
Column 348 ("D_19811212") bumped from 'integer' to 'numeric' due to <<3.75>> somewhere between row 6041 and row 24473
Column 643 ("D_19821003") bumped from 'integer' to 'numeric' due to <<1.04999995231628>> somewhere between row 6041 and row 24473
Column 1066 ("D_19831130") bumped from 'integer' to 'numeric' due to <<1.46000003814697>> somewhere between row 6041 and row 24473
Column 1102 ("D_19840105") bumped from 'integer' to 'numeric' due to <<0.959999978542328>> somewhere between row 6041 and row 24473
Column 1124 ("D_19840127") bumped from 'integer' to 'numeric' due to <<0.620000004768372>> somewhere between row 6041 and row 24473
Column 1130 ("D_19840202") bumped from 'integer' to 'numeric' due to <<0.540000021457672>> somewhere between row 6041 and row 24473
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
Column 1508 ("D_19850214") bumped from 'integer' to 'numeric' due to <<0.360000014305115>> somewhere between row 6041 and row 24473
...
...
Reread 872505 rows x 508 columns in 05:29.167
Read 872505 rows. Exactly what was estimated and allocated up front
Thread buffers were grown 0 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.093s ( 0%) sep, ncol and header detection
0.186s ( 0%) Column type detection using 305 sample rows from 44928 jump points
0.600s ( 0%) Allocation of 872505 rows x 12785 cols (192.552GB) plus 1.721GB of temporary buffers
326.029s ( 50%) Reading data
329.167s ( 50%) Rereading 508 columns due to out-of-sample type exceptions
656.075s Total
Ringkasan terakhir ini membutuhkan banyak waktu untuk menyelesaikannya (~6 menit). Jika kita menghitung ringkasan verbose ini seluruh fread memakan waktu ~ 11 menit. Itu membaca ulang 508 kolom itu, saya bahkan dapat melihat pesan "Membaca ulang 508 kolom karena pengecualian tipe di luar sampel" tanpa menggunakan verbose=TRUE.
Lihat tanpa "verbose=TRUE"
ptm<-proc.time()
DT<-fread('dt.daily.4km.ver032917.csv')
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.647 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Rereading 508 columns due to out-of-sample type exceptions.
Reread 872505 rows x 508 columns in 05:30.276
proc.time() - ptm
user system elapsed
2113.100 85.919 657.870
tes tulis
Ini bekerja dengan baik. Sangat cepat. Saya pikir menulis lebih lambat daripada membaca hari ini.
fwrite(DT,'dt.daily.4km.ver032917.csv', verbose=TRUE)
No list columns are present. Setting sep2='' otherwise quote='auto' would quote fields containing sep2.
maxLineLen=151187 from sample. Found in 1.890s
Writing column names ... done in 0.000s
Writing 872505 rows in 32315 batches of 27 rows (each buffer size 8MB, showProgress=1, nth=144) ...
done (actual nth=144, anyBufferGrown=no, maxBuffUsed=46%)
"Baca ulang" memakan waktu cukup lama. Ini seperti membaca file dua kali.
geponce
pada 30 Mar 2017
Bagus sekali! Terima kasih untuk semua infonya.
- Ya Anda benar seharusnya tidak membaca ulang. Anda telah melewati
colClasses=list("numeric"=1:12785)sehingga baris keluaran mulaiType code (colClasses)harus semua nilai 4. Akan memperbaiki dan menambahkan tes yang hilang. - Pada 5,5m vs 1,3m, itu menarik. Buffer setiap utas saat ini berukuran 1MB. Idenya adalah menjadi kecil agar muat di cache. Tetapi dalam kasus Anda 1MB / 12785 cols = 82 byte. Jadi itu menjadi 50x terlalu cache tidak efisien dengan pilihan itu. Saya kira, bagaimanapun. Saya tidak akan pernah memikirkan itu tanpa pengujian Anda. Ketika bekerja pada kecepatan 1,3m, tidak ada ukuran 1MB di sana.
- Mengapa hanya mengambil sampel 305 baris juga sangat aneh. Seharusnya sampel 1.000. Jika itu diperbaiki, mungkin itu akan mendeteksi 508 kolom tanpa Anda harus melakukannya. Sampel tidak membutuhkan waktu (0,186 detik) sehingga ukuran sampel dapat ditingkatkan.
Bisakah Anda menempelkan output dari perintah unix lscpu . Ini akan memberi tahu kami ukuran cache Anda dan saya dapat memikirkannya dari sana. Saya akan memberikan buffMB sebagai parameter ke fread sehingga Anda dapat melihat apakah itu benar. Saya bisa datang dengan perhitungan yang lebih baik jika itu.
mattdowle
pada 30 Mar 2017
Kesalahan saya di satu poin dari posting saya sebelumnya. colClasses=list("numeric"=1:12785) berfungsi dengan baik. Jika saya tidak menentukan "colClasses" itu melakukan "Membaca ulang". Maaf tentang kebingungan.
Satu hal yang saya perhatikan adalah bahwa jika saya tidak menentukan "colClasses" tabel dibuat dengan NA dan RAM menunjukkan seolah-olah DT dimuat secara normal (~106MB dalam RAM).
Berikut adalah output lscpu :
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 144
On-line CPU(s) list: 0-143
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 4
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E7-8870 v3 @ 2.10GHz
Stepping: 4
CPU MHz: 2898.328
BogoMIPS: 4195.66
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36,40,44,48,52,56,60,64,68,72,76,80,84,88,92,96,100,104,108,112,116,120,124,128,132,136,140
NUMA node1 CPU(s): 1,5,9,13,17,21,25,29,33,37,41,45,49,53,57,61,65,69,73,77,81,85,89,93,97,101,105,109,113,117,121,125,129,133,137,141
NUMA node2 CPU(s): 2,6,10,14,18,22,26,30,34,38,42,46,50,54,58,62,66,70,74,78,82,86,90,94,98,102,106,110,114,118,122,126,130,134,138,142
NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39,43,47,51,55,59,63,67,71,75,79,83,87,91,95,99,103,107,111,115,119,123,127,131,135,139,143
OK mengerti. Terima kasih.
Membaca komentar pertama Anda lagi, apakah akan lebih masuk akal jika dikatakan "menabrak dari bilangan bulat ke ganda" daripada "menabrak dari bilangan bulat ke numerik"?
Apa yang Anda maksud dengan 'dibuat dengan NA'? Semua tabel penuh dengan NA, hanya 508 kolom?
Apa itu 'DT dimuat normal (~106MB dalam RAM)'. Ini file 44GB jadi bagaimana 106MB bisa normal?
mattdowle
pada 30 Mar 2017
Nah, dalam file ini yang saya miliki hanyalah bilangan real dan NA. Saya tidak memiliki nilai integer di dalamnya. Kapan Anda melempar pesan itu, "menabrak dari datatypeA ke datatypeB"?
Itulah yang saya maksud. Dalam versi data.table saat ini yang saya instal, jika saya menghilangkan colClasses itu memuat DT tetapi penuh dengan NA.
DT[!is.na(D_19821001),]menghasilkan 0 catatan dan jika saya memuat tabel dengan colClasses dan melakukan pemfilteran yang sama, itu benar-benar menampilkan catatan.Nah, file ini 47 GB sebagai csv dalam disk, tetapi setelah Anda memuatnya ke R, dibutuhkan lebih dari dua kali lipat dalam RAM ... Tidak terkait dengan ketepatan nilai, sekali dimuat alokasi memori secara nyata angka menyebabkan peningkatan itu?
geponce
pada 30 Mar 2017
Mungkin salah ketik lagi: 106MB seharusnya 106GB.
Saya tidak mengikuti aspek NA. Tapi beberapa perbaikan di jalan dan kemudian coba lagi segar...
mattdowle
pada 30 Mar 2017
Oke - silakan coba lagi. Sampel tebakan telah meningkat menjadi 10.000 (akan menarik untuk melihat berapa lama waktu yang dibutuhkan) dan ukuran buffer sekarang memiliki minimum yang dikenakan.
Anda mungkin perlu menunggu setidaknya 30 menit agar file paket drat dipromosikan.
mattdowle
pada 30 Mar 2017
Maaf, itu "GB" bukan "MB". Saya tidak punya cukup kopi.
Saya akan mendapatkan pembaruan dan mengujinya.
geponce
pada 30 Mar 2017
Pengujian dengan data.table dev. terbaru: data.table 1.10.5 DALAM PENGEMBANGAN dibangun 30-03-2017 16:31:45 UTC :
Ringkasan:
Ini bekerja cepat (1,43 menit untuk membaca csv) dan alokasi memori juga berfungsi dengan baik, saya kira, alokasi RAM tidak meningkat seperti sebelumnya. Csv 44 GB pada disk diterjemahkan menjadi ~112 (+ 37 GB buffer temp.) GB dalam RAM setelah dimuat. Apakah ini terkait dengan tipe data nilai dalam file?
Tes 1 :
Tanpa menggunakan colClasses=list("numeric"=1:12785)
DT<-fread('dt.daily.4km.csv', verbose=TRUE)
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,
D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 47000004016 bytes from row 1 to eof / (2 * 1281788 jump0size) == 18333
Type codes (jump 000) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 001) : 444222422222222224442444444444442222444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
Type codes (jump 002) : 444222444444222244442444444444444422444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
...
Type codes (jump 034) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
Type codes (jump 100) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=79727.22 sd=32260.00 min=12804 max=153029
Estimated nrow: 47000004016 / 79727.22 = 589511
Initial alloc = 1179022 rows (589511 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Type codes (drop|select) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 02:17.726 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.099s ( 0%) sep, ncol and header detection
11.057s ( 8%) Column type detection using 10049 sample rows
0.899s ( 1%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
125.671s ( 91%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
137.726s Total
Tes 2 :
Sekarang menggunakan colClasses=list("numeric"=1:12785)
Pengaturan waktu ditingkatkan beberapa detik ...
DT<-fread('dt.daily.4km.csv', colClasses=list("numeric"=1:12785), verbose=TRUE)
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 01:43.028 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.092s ( 0%) sep, ncol and header detection
11.009s ( 11%) Column type detection using 10049 sample rows
0.332s ( 0%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
91.595s ( 89%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
103.028s Total
Oke bagus - kita sampai di sana. Ukuran sampel yang dikoreksi ditambah meningkatkannya menjadi 100 baris pada 100 titik (10.000 baris sampel) sudah cukup untuk menebak jenisnya dengan benar saat itu - bagus. Karena ada 12.875 kolom dan panjang baris rata-rata 80.000 karakter dalam file 44GB, dibutuhkan waktu 11 detik untuk mengambil sampel. Tapi waktu itu tidak sia-sia karena menghindari pembacaan ulang yang akan memakan waktu 90-an ekstra. Kami akan tetap dengan itu.
Saya pikir yang ke-2 lebih cepat hanya karena ini adalah yang ke-2 dan sistem operasi Anda telah melakukan pemanasan dan cache file. Apa pun yang berjalan di kotak akan memengaruhi pengaturan waktu jam dinding. Itu diatasi dengan menjalankan 3 kali berturut-turut yang identik dari tes pertama. Kemudian ubah satu hal saja dan jalankan 3 kali berturut-turut yang identik lagi. Pada ukuran 44GB Anda akan melihat banyak variasi alami. 3 run biasanya cukup untuk membuat kesimpulan tetapi bisa menjadi seni hitam.
Ya, 112GB di memori vs 44GB di disk sebagian karena data lebih besar di memori karena semua kolom bertipe double; tidak ada kompresi dalam memori di R dan ada cukup banyak nilai NA yang tidak memakan tempat di CSV ini (hanya ",," ) tetapi 8 byte dalam memori. Namun, itu harus 83GB bukan 112GB (872505 baris x 12785 cols x 8 byte ganda / 1024^3 = 83GB). Itu 112GB adalah apa yang dialokasikan berdasarkan rata-rata dan standar deviasi dari panjang garis. Berdasarkan panjang garis rata-rata, diperkirakan akan menjadi 589.511 baris yang akan terlalu rendah. Varians panjang garis sangat tinggi sehingga klem mulai berlaku pada +100%. 58.9511 * 2 = 1.179.022 * 12785 * 8 / 1024^3 = 112GB. Pada akhirnya ditemukan bahwa 872.505 ada di dalam file. Tapi itu tidak membebaskan ruang kosong. Aku akan memperbaikinya. (TODO1)
Saat Anda menentukan jenis kolom untuk semua kolom, itu masih sampel. Itu harus melewati pengambilan sampel ketika pengguna telah menentukan setiap kolom. (TODO2)
Karena semua data Anda berlipat ganda, itu membuat 11 miliar panggilan ke fungsi pustaka C strtod(). Keinginan lama untuk spesialisasi fungsi itu secara teori harus membuat percepatan yang signifikan untuk file ini. (SELESAI)
mattdowle
pada 31 Mar 2017
Terima kasih untuk itu, penjelasan yang bagus. Beri tahu saya jika Anda ingin saya menguji sesuatu yang lain dengan file ini. Saya sedang mengerjakan kumpulan data lain yang lebih pada format panjang, dengan ~ 21 juta baris x 1432 kolom.
NAME NROW NCOL MB
[1,] DT 21,812,625 1,432 238,310
Menambahkan titik data tambahan untuk ini. 89G .tsv , penggunaan memori puncak selama pemuatan adalah ~180G. Saya pikir ini diharapkan karena ada banyak NA dan ganda.
Saya juga senang untuk menguji ini.
Ubuntu 16.04 64bit / Linux 4.4.0-71-generic
R version 3.3.2 (2016-10-31)
data.table 1.10.5 IN DEVELOPMENT built 2017-04-04 14:27:46 UTC
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Stepping: 1
CPU MHz: 2699.984
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4660.70
Hypervisor vendor: Xen
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq monitor est ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt ida
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 88.603947 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<allele prediction_uuid sample_>>
Detecting sep ...
sep=='\t' with 101 lines of 76 fields using quote rule 0
Detected 76 columns on line 1. This line is either column names or first data row (first 30 chars): <<allele prediction_uuid sample_>>
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 95137762779 bytes from row 1 to eof / (2 * 24414 jump0size) == 1948426
Type codes (jump 000) : 5555542444111145424441111444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 009) : 5555542444114445424441144444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 042) : 5555542444444445424444444444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 048) : 5555544444444445444444444444225225522555545111111111111111111111111111111111 Quote rule 0
Type codes (jump 083) : 5555544444444445444444444444225225522555545254452454411154454452454411154455 Quote rule 0
Type codes (jump 085) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
Type codes (jump 100) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
=====
Sampled 10028 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 95137762779
Line length: mean=465.06 sd=250.27 min=198 max=929
Estimated nrow: 95137762779 / 465.06 = 204571280
Initial alloc = 409142560 rows (204571280 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Type codes (drop|select) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Allocating 76 column slots (76 - 0 dropped)
Reading 90752 chunks of 1.000MB (2254 rows) using 64 threads
 andrewrech
pada 4 Apr 2017
andrewrech
pada 4 Apr 2017
Jika membantu, berikut adalah hasil pada database yang sangat panjang: 419.124.196 x 42 (~2^34) dengan satu baris header dan colClasses lulus.
> library(data.table)
data.table 1.10.5 IN DEVELOPMENT built 2017-09-27 17:12:56 UTC; travis
The fastest way to learn (by data.table authors): https://www.datacamp.com/courses/data-analysis-the-data-table-way
Documentation: ?data.table, example(data.table) and browseVignettes("data.table")
Release notes, videos and slides: http://r-datatable.com
> CC <- c(rep('integer', 2), rep('character', 3),
+ rep('numeric', 2), rep('integer', 3),
+ rep('character', 2), 'integer', 'character', 'integer',
+ rep('character', 4), rep('numeric', 11), 'character',
+ 'numeric', 'character', rep('numeric', 2),
+ rep('integer', 3), rep('numeric', 2), 'integer',
+ 'numeric')
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXXcsv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 13:42.935 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.016s ( 0%) sep=',' ncol=42 and header detection
0.016s ( 0%) Column type detection using 10049 sample rows
188.153s ( 23%) Allocation of 419124195 rows x 42 cols (125.177GB)
634.751s ( 77%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.121s ( 0%) Finding first non-embedded \n after each jump
+ 17.036s ( 2%) Parse to row-major thread buffers
+ 616.184s ( 75%) Transpose
+ 1.410s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
822.935s Total
> memory.size()
[1] 134270.3
> rm(P)
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 585532 31.3 5489235 293.2 6461124 345.1
Vcells 1508139082 11506.2 20046000758 152938.9 25028331901 190951.1
> memory.size()
[1] 87.56
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXX.csv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 05:04.910 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.031s ( 0%) sep=',' ncol=42 and header detection
0.000s ( 0%) Column type detection using 10049 sample rows
28.437s ( 9%) Allocation of 419124195 rows x 42 cols (125.177GB)
276.442s ( 91%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.017s ( 0%) Finding first non-embedded \n after each jump
+ 12.941s ( 4%) Parse to row-major thread buffers
+ 262.989s ( 86%) Transpose
+ 0.495s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
304.910s Total
> memory.size()
[1] 157049.7
> sessionInfo()
R version 3.4.2 beta (2017-09-17 r73296)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows Server >= 2012 x64 (build 9200)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] data.table_1.10.5
loaded via a namespace (and not attached):
[1] compiler_3.4.2 tools_3.4.2
Beberapa catatan. Saya akan menyarankan untuk meletakkan [09] sebelum [07] di dalamnya jika colClasses dilewatkan, tidak ada alasan untuk memeriksanya. Juga, Windows menunjukkan sekitar 160GB digunakan setelah setiap kali dijalankan. memory.size() mungkin melakukan pembersihan. Dengan RAM 532GB di server ini, cache memori mungkin ada hubungannya dengan peningkatan kecepatan pada putaran kedua. Semoga membantu.
 aadler
pada 28 Sep 2017
aadler
pada 28 Sep 2017
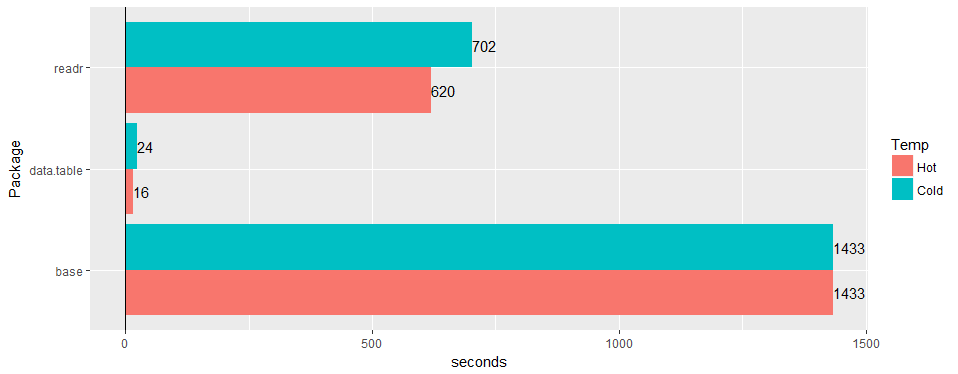
Uji pada tabel lebar "dunia nyata" (data rumah sakit): 30 juta baris × 125 kolom v readr '1.2.0' dan read.csv 3.4.3.
 HughParsonage
pada 25 Jan 2018
HughParsonage
pada 25 Jan 2018
adakah kesempatan untuk mengkonfirmasi masalah masih berlaku pada 1.11.4? atau kode untuk menghasilkan contoh data.
 jangorecki
pada 1 Jul 2018
jangorecki
pada 1 Jul 2018
Yang ini semua diselesaikan sejauh yang saya tahu. @geponce tolong perbarui jika tidak.
TODO1 di atas sekarang diajukan sebagai #3024
TODO2 di atas sekarang diajukan sebagai #3025
mattdowle
pada 31 Agu 2018
Masalah terkait
 st-pasha
·
3Komentar
st-pasha
·
3Komentar
st-pasha
·
3Komentar
st-pasha
·
3Komentar
 lux5
·
3Komentar
lux5
·
3Komentar
 symbalex
·
3Komentar
symbalex
·
3Komentar
 arunsrinivasan
·
3Komentar
arunsrinivasan
·
3Komentar
Komentar yang paling membantu
Uji pada tabel lebar "dunia nyata" (data rumah sakit): 30 juta baris × 125 kolom v readr '1.2.0' dan
read.csv3.4.3.