Data.table: يأخذ fread مع csv كبير (44 جيجابايت) الكثير من ذاكرة الوصول العشوائي في أحدث إصدار data.table dev
أهلا،
الأجهزة والبرامج:
الخادم : Dell R930 4-Intel Xeon E7-8870 v3 2.1 جيجاهرتز و 45 م كاش و 9.6 جيجابت / ثانية QPI و Turbo و HT و 18C / 36T و 1 تيرابايت في ذاكرة الوصول العشوائي
نظام التشغيل : Redhat 7.1
الإصدار R : 3.3.2
إصدار جدول data :
أقوم بتحميل ملف CSV (44 جيجابايت ، 872505 صفًا × 12785 عمودًا). يتم تحميله بسرعة كبيرة ، في 1.30 دقيقة باستخدام 144 نواة (72 نواة من 4 معالجات مع إمكانية تشغيل مؤشر الترابط لجعله مربع 144 نواة).
تكمن المشكلة الرئيسية في أنه عندما يتم تحميل DT ، تزداد كمية الذاكرة عند الاستخدام بشكل ملحوظ بالنسبة إلى حجم ملف csv. في هذه الحالة ، فإن 44 جيجا بايت csv (المحفوظة مع fwrite ، المحفوظة مع saveRDS والضغط = FALSE تنشئ ملفًا بحجم 84 جيجا بايت) تستخدم ~ 356 جيجا بايت من ذاكرة الوصول العشوائي.
هذا هو الإخراج باستخدام "مطول = TRUE"
_ تخصيص 12785 خانة عمود (12785 - 0 مسقطة)
متسلسل madvise: طيب
قراءة البيانات مع 1440 نقطة قفز و 144 موضوع
اقرأ 95.7٪ من 858881 من الصفوف المقدرة
قراءة 872505 صفًا × 12785 عمودًا من ملف 43.772 جيجابايت في دقيقة واحدة 33.736 ثانية من وقت ساعة الحائط (متأثرًا بتشغيل التطبيقات الأخرى)
0.000 ثانية (0٪) خريطة الذاكرة
0.070 ثانية (0٪) كشف sep و ncol والرأس
26.227 ثانية (28٪) الكشف عن نوع العمود باستخدام 34832 نموذج صف من 1440 نقطة قفزة
0.614 ثانية (1٪) تخصيص 3683116 صفًا × 12785 عمودًا (350.838 جيجابايت) في ذاكرة الوصول العشوائي
0.000 ثانية (0٪) madvise متسلسل
66.825 ثانية (71٪) قراءة البيانات
93.736s المجموع_
إنها تظهر مشكلة مماثلة تظهر أحيانًا عند العمل مع الحزمة المتوازية ، حيث يتم تشغيل جلسة واحدة لكل نواة عند استخدام وظائف مثل "mclapply". شاهد الجلسات التي تم إنشاؤها / إدراجها في لقطة الشاشة هذه:

إذا فعلت ذلك ، فإن ذاكرة الوصول العشوائي "rm (DT)" تعود إلى الحالة الأولية وتتم إزالة "Rsessions".
جربت بالفعل على سبيل المثال "setDTthreads (20)" ولا تزال تستخدم نفس المقدار من ذاكرة الوصول العشوائي.
بالمناسبة ، إذا تم تحميل الملف بإصدار غير متوازي من "fread" ، فإن تخصيص الذاكرة يصل فقط إلى ~ 106 جيجابايت.
غييرمو
 geponce
geponce
ال 30 كومينتر
هذا هو الناتج من تنفيذ fread غير المتوازي (data.table 1.10.5 in DEVELOPMENT built 2017-02-09)

وقمت بمضاعفة حجم الذاكرة المستخدمة وترتفع لتصل إلى 84 جيجابايت.
غييرمو
geponce
في ٢٢ مارس ٢٠١٧
نعم انت على حق. شكرا على التقرير العظيم. يبدو السهم المقدّر صحيحًا (858،881 مقابل 872،505) ولكن بعد ذلك يكون التخصيص أكبر بـ 4.2X من ذلك (3،683،116) وبعيدًا. لقد قمت بتحسين الحساب وإضافة المزيد من التفاصيل إلى الإخراج المطول. توقف عن إعادة الاختبار في الوقت الحالي حتى يتم الانتهاء من بعض الأشياء الأخرى.
 mattdowle
في ٢٥ مارس ٢٠١٧
mattdowle
في ٢٥ مارس ٢٠١٧
حسنًا ، يرجى إعادة الاختبار - يجب إصلاحه الآن.
mattdowle
في ٢٦ مارس ٢٠١٧
لقد قمت للتو بتثبيت data.table dev:
جدول البيانات 1.10.5 في التنمية المبنية 2017-03-27 02:50:31 بالتوقيت العالمي
أول شيء حصلت عليه عندما حاولت قراءة نفس الملف 44 جيجا بايت كانت هذه الرسالة:
DT <- fread ("dt.daily.4km.csv")
خطأ: حماية (): تجاوز مكدس الحماية
ثم أعدت تشغيل نفس الأمر وبدأت في العمل بشكل جيد. ومع ذلك ، لا يستخدم هذا الإصدار وضعًا متعدد النواة. يستغرق التحميل حوالي 25 دقيقة ، تمامًا كما كان قبل وضع الإصدار الموازي.
غييرمو
geponce
في ٢٧ مارس ٢٠١٧
لقد أغلقت جميع جلسات r وأعدت إجراء اختبار ويظهر لي خطأ:
كان نوع العمود الذي تم تخمينه غير كافٍ لقيم 34711745 في 508 عمودًا. استخدم colClasses لتعيين فئات الأعمدة هذه يدويًا.
انظر أدناه ، تلقيت عدة رسائل بخصوص "عدد صحيح مخمن ولكنه يحتوي على << 0 .... >>
_اقرأ 872505 صفًا × 12785 عمودًا من ملف 43.772 جيجا بايت في وقت ساعة الحائط 15: 27.024 (يمكن إبطاء سرعة أي تطبيقات أخرى مفتوحة حتى لو كانت تبدو خاملة)
العمود 171 ('D_19810618') تم تخمينه "عدد صحيح" ولكنه يحتوي على << 2.23000001907349 >>
العمود 347 ('D_19811211') خمّن 'عددًا صحيحًا' ولكنه يحتوي على << 1.02999997138977 >>
العمود 348 ('D_19811212') تم تخمينه "عدد صحيح" ولكنه يحتوي على << 3.75 >> _
geponce
في ٢٧ مارس ٢٠١٧
رائع - يختبر ملفك بالفعل حالات الحافة. رائعة. في المستقبل ، يرجى تشغيل verbose=TRUE وتقديم الناتج الكامل. ولكن مع المعلومات التي قدمتها في هذه الحالة ، يمكنني أن أرى ما هي المشكلة في الواقع. يوجد مخزن مؤقت تم إنشاؤه لكل عمود لكل مؤشر ترابط (في هذه الحالة ، أكثر من 12000 عمود). كل واحد محمي بشكل منفصل حاليا. هناك طريقة لتجنب ذلك - سوف تفعل. الرسائل المتعلقة بنوع التخمين صحيحة. هل هذه الأعمدة الـ 508 تعني لك شيئًا وتوافق على أنها يجب أن تكون رقمية؟ يمكنك تمرير نطاق من الأعمدة إلى colClasses مثل هذا: colClasses=list("numeric"=11:518)
ما المجال من هذه البيانات؟ هل تقوم بإنشاء الملف؟ يبدو أنه قد تم تحريفه إلى تنسيق عريض حيث تكون أفضل الممارسات العادية هي الكتابة (والاحتفاظ بها في الذاكرة أيضًا) بتنسيق طويل. أتوقع عادةً أن أرى أسماء الأعمدة البالغ عددها 508 مثل "D_19810618" كقيم في عمود ، وليس كأعمدة بحد ذاتها. وهذا هو سبب سؤالي عما إذا كنت تقوم بإنشاء الملف وهل يمكنك إنشاؤه بتنسيق طويل. إذا لم يكن الأمر كذلك ، فاقترح على الشخص الذي ينشئ الملف أنه يمكنه القيام بذلك بشكل أفضل. أعتقد أنك تقوم بتطبيق العمليات من خلال الأعمدة ربما باستخدام .SD و .SDcols . إنه حقًا أفضل بكثير في التنسيق الطويل و keyby= العمود الذي يحتوي على قيم مثل "D_19810618".
لكنني ما زلت أحاول جعل fread جيدًا بقدر ما يمكن أن يكون في التعامل مع أي مدخلات - حتى الملفات الكبيرة جدًا التي تزيد عن 12000 عمود.
آمل أن يختبر أشخاص آخرون ملفاتهم ولا يجدون أي مشاكل على الإطلاق!
mattdowle
في ٢٧ مارس ٢٠١٧
_ هل هذه الأعمدة الـ 508 تعني لك شيئًا وتوافق على أنها يجب أن تكون رقمية؟
يحتوي هذا الجدول على سلسلة زمنية بصف. IDx و IDy و Time1_value و Time2_value و Time3_value ... وجميع أعمدة Time N _value تحتوي على قيم رقمية فقط. إذا كنت أستخدم colClasses ، فسوف أحتاج إلى القيام بذلك لـ 12783: list ("numeric" = 2: 12783). سأحاول هذا.
_ما هو المجال الذي تأتي منه هذه البيانات؟ _
البيانات الجغرافية المكانية. أقوم بإجراء عمليات بحث عن المسافات الإقليدية داخل DT باستخدام IDx & IDy. أظن أنه كلما زاد عدد الصفوف كلما كانت عمليات البحث أبطأ ، أليس كذلك؟
الآن سريع جدًا (تنسيق واسع). لدي خريطة ، حيث يمكن للمستخدم النقر فوق منطقة ثم يتم إنشاء سلسلة زمنية داخل ملف csv من أقرب موقع (مع توفر البيانات) إلى النقرة المحددة. سأقوم بتنفيذه بتنسيق طويل بدلاً من ذلك.
سأعود ببعض النتائج.
geponce
في ٢٨ مارس ٢٠١٧
حسنا جيد. لست بحاجة إلى list("numeric"=2:12783) iiuc لأنه يحتاج فقط إلى مساعدة مع 508 أعمدة. أوه - أرى - 508 مبعثرة عبر الأعمدة التي أعتقد أنها ثم (ليست مجموعة متجاورة من الأعمدة)؟
لا - لا يكون جدول البيانات أسرع من أي وقت مضى عندما يكون عريضًا! دائمًا ما تكون فترة طويلة أسرع وأكثر ملاءمة. هل رأيت وجربت roll="nearest" ؟ كيف حالك الان يرجى إظهار الكود حتى نتمكن من فهمه. من المؤكد تقريبًا أن التنسيق الطويل أفضل ولكن قد نحتاج إلى بعض التحسينات للأقرب ثنائي الأبعاد. يرجى إظهار التوقيت كذلك. عندما تقول "سريعًا جدًا" ، يتضح أن لدى الناس أفكارًا مختلفة تمامًا حول معنى "سريع جدًا".
mattdowle
في ٢٨ مارس ٢٠١٧
يصل ذوبان هذا الجدول إلى حد 2 ^ 31. أتلقى الخطأ: "غير مسموح بموجهات الطول السالب".
سأعود إلى المصدر لمعرفة ما إذا كان بإمكاني إنشائه بالتنسيق الطويل.
geponce
في ٢٨ مارس ٢٠١٧
# Read Data
DT <- fread('dt.daily.4km.csv', showProgress = FALSE)
# Add two columns with truncated values of x and y (these are geog. coords.)
DT[,y_tr:=trunc(y)]
DT[,x_tr:=trunc(x)]
# For using on plotting (x-axis values)
xaxis<-seq.Date(as.Date("1981-01-01"),as.Date("2015-12-31"), "day")
# subset by truncated coordinates to avoid full-table search. Now searches
# will happen in a smaller subset
DT2 <- DT[y_tr==trunc(y_clicked) & x_tr==trunc(x_clicked),]
# Add distance from each point in the data.table to the provided location, "gdist" is from
# Imap package for euclidean distance.
DT2[,DIST:=gdist(lat.1 = DT2$y,
lon.1 = DT2$x,
lat.2 = y_clicked,
lon.2 = x_clicked, units="miles")]
# Get the minimum distance
minDist <- min(DT2[,DIST])
# Get the y-axis values
yt <- transpose(DT2[DIST==minDist,3:(ncol(DT2)-3)])$V1`
# Ready to plot xaxis vs yt
...
...
ليس لدي التطبيق على خادم عام. بشكل أساسي ، يمكن للمستخدم النقر فوق الخريطة ثم التقاط هذه الإحداثيات وإجراء البحث أعلاه والحصول على السلاسل الزمنية وإنشاء مخطط.
geponce
في ٢٨ مارس ٢٠١٧
تم العثور على تجاوز سعة مكدس آخر وإصلاحه لعدد كبير جدًا من الأعمدة: https://github.com/Rdatatable/data.table/commit/d0469e670961dcdea115d433c0f2dce596d65906. نسيت وضع علامة على رقم هذا الإصدار في رسالة الالتزام.
mattdowle
في ٢٨ مارس ٢٠١٧
أوه. هذا هو نقطة. 872505 صفًا * 12780 عمودًا هو 11 مليار صف. لذا فإن اقتراحي بالانتقال إلى التنسيق الطويل لن يعمل معك لأن ذلك> 2 ^ 31. آسف - كان علي أن ألاحظ ذلك. سيتعين علينا فقط أن نعض الرصاصة ونذهب> 2 ^ 31 بعد ذلك. في غضون ذلك ، دعنا نلتزم بالتنسيق الواسع الذي تعمل به وسأقوم بتدوين ذلك.
mattdowle
في ٢٨ مارس ٢٠١٧
حاول مرة اخرى. يجب أن يعود استخدام الذاكرة إلى الوضع الطبيعي ويجب إعادة قراءة 508 عمودًا من أصل 12785 عمودًا مع استثناءات نوع خارج العينة تلقائيًا. لتجنب وقت إعادة التشغيل التلقائي ، يمكنك تعيين colClasses .
إذا لم يتم إصلاحه ، يرجى لصق الإخراج المطول الكامل. تشابك الاصابع!
mattdowle
في ٢٩ مارس ٢٠١٧
نعم...
ملخص النتائج بأحدث data.table dev: data.table 1.10.5 in DEVELOPMENT build 2017-03-29 16:17:01 UTC
أربع نقاط رئيسية يجب ذكرها:
- عمل fread بشكل جيد في قراءة الملف في المناقشة.
- استغرق الأمر 5.5 دقيقة تقريبًا للقراءة مقابل الإصدار السابق الذي استغرق 1.3 دقيقة تقريبًا.
- لا يزيد هذا الإصدار من تخصيص ذاكرة الوصول العشوائي مثل الإصدار السابق الذي كنت أختبره.
- يبدو أن النوى "أقل نشاطًا" (انظر لقطة الشاشة أدناه).
بعض التعليقات / الأسئلة:
1.
نسبة الاستخدام في النوى ليست نشطة كما كانت من قبل ، انظر لقطة الشاشة:
في الإصدار السابق من fread ، كان نشاط النوى دائمًا ~ 90-80٪. في هذا الإصدار بقي حوالي 2-3٪ لكل نواة كما هو موضح في الصورة أعلاه.
لا أفهم لماذا يقوم fread بعمل ارتفاعات من عدد صحيح إلى رقم: على سبيل المثال
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
لقد راجعت هذه الصفوف مرتين ويبدو أنها لا بأس بها. لماذا يتم الكشف عن عدد صحيح وتحتاج إلى "ارتطام" بـ "رقمية" إذا كانت رقمية بالفعل (انظر ملخص الصفوف المقترحة أدناه)؟ أم أنني أفهم هذا الخط بشكل خاطئ؟ يحدث هذا لـ 508 سطور. هل يسبب زمالة المدمنين المجهولين مشكلة؟
summary(DT[6041:24473,.(D_19850126)])
D_19850126
Min. :0.750
1st Qu.:0.887
Median :0.945
Mean :0.966
3rd Qu.:1.045
Max. :1.210
NA's :18393
أدناه بعض مطول خارج الاختبار.
DT<-fread('dt.daily.4km.ver032917.csv', verbose=TRUE)
انتاج
Parameter na.strings == <<NA>>
None of the 0 na.strings are numeric (such as '-9999').Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,D_19810113,
...
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 11 because 1281788 startSize * 10 NJUMPS * 2 = 25635760 <= -244636240 bytes from line 2 to eof
Type codes (jump 00) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 01) : 444422222222222222242444424444442222222222424444424442224424222244222222222242422222224422...4442244422 Quote rule 0
Type codes (jump 02) : 444422222222222222242444424444442422222242424444424442224424222244222222222242424222424424...4442444442 Quote rule 0
Type codes (jump 03) : 444422222222222224242444424444444422222244424444424442224424222244222222222244424442424424...4442444442 Quote rule 0
Type codes (jump 04) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 05) : 444444244422222224442444424444444444242244444444444444424444442244444222222244424442444444...4444444444 Quote rule 0
Type codes (jump 06) : 444444444422222224442444424444444444242244444444444444424444444444444244444444424442444444...4444444444 Quote rule 0
Type codes (jump 07) : 444444444422222224442444424444444444242244444444444444444444444444444244444444424444444444...4444444444 Quote rule 0
Type codes (jump 08) : 444444444442222224444444424444444444242244444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 09) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
Type codes (jump 10) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444 Quote rule 0
=====
Sampled 305 rows (handled \n inside quoted fields) at 11 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=45578.20 sd=33428.37 min=12815 max=108497
Estimated nrow: 47000004016 / 45578.20 = 1031195
Initial alloc = 2062390 rows (1031195 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Type codes (drop|select): 444444444442222424444444424444444444244444444444444444444444444444444444444444424444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 44928 chunks of 0.998MB (22 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.908 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : numeric
0 : character
Rereading 508 columns due to out-of-sample type exceptions.
Column 171 ("D_19810618") bumped from 'integer' to 'numeric' due to <<2.23000001907349>> somewhere between row 6041 and row 24473
Column 347 ("D_19811211") bumped from 'integer' to 'numeric' due to <<1.02999997138977>> somewhere between row 6041 and row 24473
Column 348 ("D_19811212") bumped from 'integer' to 'numeric' due to <<3.75>> somewhere between row 6041 and row 24473
Column 643 ("D_19821003") bumped from 'integer' to 'numeric' due to <<1.04999995231628>> somewhere between row 6041 and row 24473
Column 1066 ("D_19831130") bumped from 'integer' to 'numeric' due to <<1.46000003814697>> somewhere between row 6041 and row 24473
Column 1102 ("D_19840105") bumped from 'integer' to 'numeric' due to <<0.959999978542328>> somewhere between row 6041 and row 24473
Column 1124 ("D_19840127") bumped from 'integer' to 'numeric' due to <<0.620000004768372>> somewhere between row 6041 and row 24473
Column 1130 ("D_19840202") bumped from 'integer' to 'numeric' due to <<0.540000021457672>> somewhere between row 6041 and row 24473
Column 1489 ("D_19850126") bumped from 'integer' to 'numeric' due to <<0.949999988079071>> somewhere between row 6041 and row 24473
Column 1508 ("D_19850214") bumped from 'integer' to 'numeric' due to <<0.360000014305115>> somewhere between row 6041 and row 24473
...
...
Reread 872505 rows x 508 columns in 05:29.167
Read 872505 rows. Exactly what was estimated and allocated up front
Thread buffers were grown 0 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.093s ( 0%) sep, ncol and header detection
0.186s ( 0%) Column type detection using 305 sample rows from 44928 jump points
0.600s ( 0%) Allocation of 872505 rows x 12785 cols (192.552GB) plus 1.721GB of temporary buffers
326.029s ( 50%) Reading data
329.167s ( 50%) Rereading 508 columns due to out-of-sample type exceptions
656.075s Total
استغرق هذا الملخص الأخير الكثير من الوقت لإنهائه (حوالي 6 دقائق). إذا احتسبنا هذا الملخص المطول ، فقد استغرق الأمر حوالي 11 دقيقة. إنها تعيد قراءة تلك الأعمدة البالغ عددها 508 ، ويمكنني حتى رؤية الرسالة "إعادة قراءة 508 أعمدة بسبب استثناءات نوع خارج العينة" دون استخدام مطول = TRUE.
تحقق من ذلك بدون "مطول = TRUE"
ptm<-proc.time()
DT<-fread('dt.daily.4km.ver032917.csv')
Read 872505 rows x 12785 columns from 43.772GB file in 05:26.647 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Rereading 508 columns due to out-of-sample type exceptions.
Reread 872505 rows x 508 columns in 05:30.276
proc.time() - ptm
user system elapsed
2113.100 85.919 657.870
اختبار fwrite
إنها تعمل بشكل جيد. سريع حقا. اعتقدت أن الكتابة كانت أبطأ من القراءة هذه الأيام.
fwrite(DT,'dt.daily.4km.ver032917.csv', verbose=TRUE)
No list columns are present. Setting sep2='' otherwise quote='auto' would quote fields containing sep2.
maxLineLen=151187 from sample. Found in 1.890s
Writing column names ... done in 0.000s
Writing 872505 rows in 32315 batches of 27 rows (each buffer size 8MB, showProgress=1, nth=144) ...
done (actual nth=144, anyBufferGrown=no, maxBuffUsed=46%)
"إعادة القراءة" تستغرق وقتًا طويلاً. إنه مثل قراءة الملف مرتين.
geponce
في ٣٠ مارس ٢٠١٧
ممتاز! شكرا على كل المعلومات.
- نعم أنت محق في أنه لا ينبغي إعادة القراءة. لقد اجتزت
colClasses=list("numeric"=1:12785)لذا يجب أن يكون سطر الإخراج الذي يبدأType code (colClasses)كله قيمة 4. سيتم إصلاحه وإضافة الاختبار المفقود. - 5.5 م مقابل 1.3 م ، هذا مثير للاهتمام. يبلغ حجم المخزن المؤقت لكل مؤشر ترابط حاليًا 1 ميغا بايت. الفكرة هي أن تكون صغيرة لتناسب ذاكرة التخزين المؤقت. ولكن في حالتك ، 1 ميجابايت / 12785 عمودًا = 82 بايت. لذا ، فإن ذاكرة التخزين المؤقت 50 مرة غير فعالة مع هذا الاختيار. أعتقد ، على أي حال. لم أفكر في ذلك أبدًا بدون اختباراتك. عندما كان يعمل بسرعة 1.3 متر ، لم يكن حجمه 1 ميغا بايت.
- لماذا اختبرت 305 سطرًا فقط هو أمر غريب جدًا أيضًا. يجب أن يكون قد أخذ عينة من 1000. إذا تم إصلاح ذلك ، فربما يكتشف 508 أعمدة دون الحاجة إلى ذلك. لا تستغرق العينة أي وقت (0.186 ثانية) لذا يمكن زيادة حجم العينة.
هل يمكنك لصق إخراج الأمر lscpu unix من فضلك. سيخبرنا هذا بأحجام ذاكرة التخزين المؤقت الخاصة بك ويمكنني التفكير من هناك. سأقدم buffMB كمعامل لـ fread حتى تتمكن من معرفة ما إذا كان الأمر كذلك. يمكنني التوصل إلى حساب أفضل إذا كان كذلك.
mattdowle
في ٣٠ مارس ٢٠١٧
خطأي في نقطة واحدة من رسالتي السابقة. colClasses=list("numeric"=1:12785) يعمل بشكل جيد. إذا لم أحدد "colClasses" فإنها تقوم بـ "إعادة القراءة". آسف على الارتباك.
أحد الأشياء التي لاحظتها هو أنه إذا لم أحدد "colClasses" ، فسيتم إنشاء الجدول باستخدام NA و RAM يظهر كما لو تم تحميل DT بشكل عادي (~ 106 ميجابايت في ذاكرة الوصول العشوائي).
هنا هو إخراج lscpu :
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 144
On-line CPU(s) list: 0-143
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 4
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E7-8870 v3 @ 2.10GHz
Stepping: 4
CPU MHz: 2898.328
BogoMIPS: 4195.66
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36,40,44,48,52,56,60,64,68,72,76,80,84,88,92,96,100,104,108,112,116,120,124,128,132,136,140
NUMA node1 CPU(s): 1,5,9,13,17,21,25,29,33,37,41,45,49,53,57,61,65,69,73,77,81,85,89,93,97,101,105,109,113,117,121,125,129,133,137,141
NUMA node2 CPU(s): 2,6,10,14,18,22,26,30,34,38,42,46,50,54,58,62,66,70,74,78,82,86,90,94,98,102,106,110,114,118,122,126,130,134,138,142
NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39,43,47,51,55,59,63,67,71,75,79,83,87,91,95,99,103,107,111,115,119,123,127,131,135,139,143
حسنًا ، حسنًا. شكرا.
عند قراءة تعليقاتك الأولى مرة أخرى ، هل سيكون من المنطقي أن تقول "الارتداد من عدد صحيح إلى مزدوج" بدلاً من "الارتداد من عدد صحيح إلى رقم"؟
ماذا تقصد بعبارة "تم إنشاؤها باستخدام زمالة المدمنين المجهولين"؟ كل الجدول مليء بـ NAs ، فقط 508 أعمدة؟
ما هو "تم تحميل DT بشكل عادي (~ 106 ميجابايت في ذاكرة الوصول العشوائي)". إنه ملف بسعة 44 جيجابايت ، فكيف يمكن أن يكون حجم 106 ميجابايت عاديًا؟
mattdowle
في ٣٠ مارس ٢٠١٧
حسنًا ، كل ما لدي في هذا الملف هو أرقام حقيقية و NA's. ليس لدي قيم عدد صحيح فيه. متى ترسل هذه الرسالة ، "الانتقال من نوع البيانات أ إلى نوع البيانات ب"؟
هذا بالضبط ما أعنيه. في الإصدار الحالي من data.table الذي قمت بتثبيته ، إذا حذفت colClasses ، فإنه يقوم بتحميل DT ولكنه مليء بـ NA's. ينتج
DT[!is.na(D_19821001),]0 تسجيلات وإذا قمت بتحميل الجدول باستخدام colClasses وقمت بنفس التصفية فإنه يعرض السجلات بالفعل.حسنًا ، يبلغ حجم هذا الملف 47 جيجا بايت كملف csv بالقرص ، ولكن بمجرد تحميله في R ، فإنه يأخذ أكثر من ضعف ذاكرة الوصول العشوائي ... لا يتعلق بدقة القيم ، بمجرد تحميل تخصيص الذاكرة بشكل حقيقي الأرقام تسبب تلك الزيادة؟
geponce
في ٣٠ مارس ٢٠١٧
ربما خطأ مطبعي آخر: 106 ميغابايت كان يجب أن يكون 106 غيغابايت.
أنا لا أتبع جانب زمالة المدمنين المجهولين. لكن بعض الإصلاحات في الطريق ثم حاول مرة أخرى جديدة ...
mattdowle
في ٣٠ مارس ٢٠١٧
حسنًا - يرجى المحاولة مرة أخرى. زادت عينة التخمين إلى 10000 (سيكون من المثير للاهتمام معرفة المدة التي يستغرقها ذلك) وأصبحت أحجام المخزن المؤقت الآن مفروضة على الحد الأدنى.
قد تحتاج إلى الانتظار لمدة 30 دقيقة على الأقل حتى تتم ترقية ملف حزمة drat.
mattdowle
في ٣٠ مارس ٢٠١٧
عذرًا ، كانت "GB" بدلاً من "MB". لم يكن لدي ما يكفي من القهوة.
سأحصل على التحديث واختبره.
geponce
في ٣٠ مارس ٢٠١٧
الاختبار باستخدام أحدث إصدار من data.table: data.table 1.10.5 in DEVELOPMENT المبني 2017-03-30 16:31:45 بالتوقيت العالمي المنسق :
ملخص:
إنه يعمل بسرعة (1.43 دقيقة لقراءة ملف csv) وتخصيص الذاكرة يعمل بشكل جيد أيضًا ، على ما أعتقد ، لا يزيد تخصيص ذاكرة الوصول العشوائي كما كان من قبل. يتم ترجمة 44 جيجا بايت csv على القرص إلى 112 (+ 37 جيجا بايت مؤقتًا مؤقتًا) جيجا بايت في ذاكرة الوصول العشوائي مرة واحدة يتم تحميلها. هل هذا متعلق بنوع بيانات القيم الموجودة في الملف؟
اختبار 1 :
بدون استخدام colClasses=list("numeric"=1:12785)
DT<-fread('dt.daily.4km.csv', verbose=TRUE)
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 43.772296 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<x,y,D_19810101,D_19810102,D_19810103,D_19810104,D_19810105,D_19810106,D_19810107,
D_19810108,D_19810109,D_19810110,D_19810111,D_19810112,
...
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 47000004016 bytes from row 1 to eof / (2 * 1281788 jump0size) == 18333
Type codes (jump 000) : 441111111111111111111111111111111111111111111111111111111111111111111111111111111111111111...1111111111 Quote rule 0
Type codes (jump 001) : 444222422222222224442444444444442222444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
Type codes (jump 002) : 444222444444222244442444444444444422444444444444444444442444444444444222224444444444444444...4444444442 Quote rule 0
...
Type codes (jump 034) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
Type codes (jump 100) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 47000004016
Line length: mean=79727.22 sd=32260.00 min=12804 max=153029
Estimated nrow: 47000004016 / 79727.22 = 589511
Initial alloc = 1179022 rows (589511 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Type codes (drop|select) : 444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444...4444444444
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 02:17.726 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.099s ( 0%) sep, ncol and header detection
11.057s ( 8%) Column type detection using 10049 sample rows
0.899s ( 1%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
125.671s ( 91%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
137.726s Total
اختبار 2 :
الآن باستخدام colClasses=list("numeric"=1:12785)
تم تحسين التوقيت ببضع ثوان ...
DT<-fread('dt.daily.4km.csv', colClasses=list("numeric"=1:12785), verbose=TRUE)
Allocating 12785 column slots (12785 - 0 dropped)
Reading 432 chunks of 103.756MB (1364 rows) using 144 threads
Read 872505 rows x 12785 columns from 43.772GB file in 01:43.028 wall clock time (can be slowed down by any other open apps even if seemingly idle)
Final type counts
0 : drop
0 : logical
0 : integer
0 : integer64
12785 : double
0 : character
Thread buffers were grown 67 times (if all 144 threads each grew once, this figure would be 144)
=============================
0.000s ( 0%) Memory map
0.092s ( 0%) sep, ncol and header detection
11.009s ( 11%) Column type detection using 10049 sample rows
0.332s ( 0%) Allocation of 872505 rows x 12785 cols (112.309GB) plus 37.433GB of temporary buffers
91.595s ( 89%) Reading data
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
103.028s Total
حسنًا ، لقد وصلنا إلى هناك. كان حجم العينة المصحح بالإضافة إلى زيادته إلى 100 سطر عند 100 نقطة (10000 سطر عينة) كافياً لتخمين الأنواع بشكل صحيح في ذلك الوقت - رائع. نظرًا لوجود 12875 عمودًا ويبلغ متوسط طول السطر 80000 حرف في ملف 44 جيجابايت ، فقد استغرق الأمر 11 ثانية لأخذ عينة. لكن ذلك الوقت كان يستحق العناء لأنه تجنب إعادة القراءة التي كانت ستستغرق تسعينيات إضافية. سوف نتمسك بذلك بعد ذلك.
أعتقد أن المرة الثانية تكون أسرع لمجرد أنها كانت المرة الثانية وقام نظام التشغيل لديك بتسخين الملف وتخزينه مؤقتًا. سيؤثر أي شيء آخر يعمل على الصندوق على توقيت ساعة الحائط. تتم معالجة ذلك من خلال تشغيل 3 عمليات تشغيل متطابقة متتالية للاختبار الأول. ثم تغيير شيء واحد فقط وتشغيل 3 مرات متتالية متتالية مرة أخرى. بحجم 44 غيغابايت ، سترى الكثير من التباين الطبيعي. عادة ما تكون 3 أشواط كافية للتوصل إلى استنتاج ولكن يمكن أن يكون فنًا أسود.
نعم ، فإن ذاكرة 112 جيجابايت مقابل 44 جيجابايت في القرص يرجع جزئيًا إلى أن البيانات أكبر في الذاكرة لأن جميع الأعمدة من النوع المزدوج ؛ لا يوجد ضغط في الذاكرة في R وهناك الكثير من قيم NA التي لا تأخذ مساحة في ملف CSV هذا (فقط ",," ) ولكن 8 بايت في الذاكرة. ومع ذلك ، يجب أن يكون 83 جيجابايت وليس 112 جيجابايت (872505 صفًا × 12785 عمودًا × 8 بايت مزدوجًا / 1024 ^ 3 = 83 جيجابايت). 112 جيجا بايت هو ما تم تخصيصه بناءً على المتوسط والانحراف المعياري لأطوال الخطوط. بناءً على متوسط طول السطر ، قدّر أنه سيكون 589،511 صفاً كان من الممكن أن يكون منخفضاً للغاية. كان تباين طول الخط مرتفعًا جدًا لدرجة أن المشبك دخل حيز التنفيذ عند + 100٪. 589511 * 2 = 1179022 * 12785 * 8/1024 ^ 3 = 112 جيجابايت. في النهاية وجد أن 872505 موجودًا في الملف. لكنها لا تحرر المساحة الحرة. سوف أصلح ذلك. (TODO1)
عند تحديد نوع العمود لجميع الأعمدة ، لا يزال يتم أخذ عينات منه ، على الرغم من ذلك. يجب أن يتخطى أخذ العينات عندما يحدد المستخدم كل عمود. (TODO2)
نظرًا لأن جميع بياناتك مضاعفة ، فإنها تجري 11 مليار استدعاء لوظيفة مكتبة C strtod (). إن الرغبة الطويلة في التخصص في هذه الوظيفة يجب أن تؤدي نظريًا إلى تسريع كبير لهذا الملف. (انتهى)
mattdowle
في ٣١ مارس ٢٠١٧
شكرا على هذا الشرح العظيم. اسمحوا لي أن أعرف إذا كنت تريد مني اختبار شيء آخر مع هذا الملف. أنا أعمل على مجموعة بيانات أخرى ذات تنسيق طويل ، مع حوالي 21 مليون صف × 1432 عمودًا.
NAME NROW NCOL MB
[1,] DT 21,812,625 1,432 238,310
إضافة نقطة بيانات إضافية إلى هذا. 89 جرام .tsv ، أقصى استخدام للذاكرة أثناء التحميل هو 180 جيجا تقريبًا. أعتقد أن هذا متوقع لأن هناك العديد من زمالة المدمنين المجهولين ومضاعفة.
أنا سعيد أيضًا باختبار هذا.
Ubuntu 16.04 64bit / Linux 4.4.0-71-generic
R version 3.3.2 (2016-10-31)
data.table 1.10.5 IN DEVELOPMENT built 2017-04-04 14:27:46 UTC
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Stepping: 1
CPU MHz: 2699.984
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4660.70
Hypervisor vendor: Xen
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 46080K
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq monitor est ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm xsaveopt ida
Parameter na.strings == <<NA>>
None of the 1 na.strings are numeric (such as '-9999').
Input contains no \n. Taking this to be a filename to open
File opened, filesize is 88.603947 GB.
Memory mapping ... ok
Detected eol as \n only (no \r afterwards), the UNIX and Mac standard.
Positioned on line 1 starting: <<allele prediction_uuid sample_>>
Detecting sep ...
sep=='\t' with 101 lines of 76 fields using quote rule 0
Detected 76 columns on line 1. This line is either column names or first data row (first 30 chars): <<allele prediction_uuid sample_>>
All the fields on line 1 are character fields. Treating as the column names.
Number of sampling jump points = 101 because 95137762779 bytes from row 1 to eof / (2 * 24414 jump0size) == 1948426
Type codes (jump 000) : 5555542444111145424441111444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 009) : 5555542444114445424441144444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 042) : 5555542444444445424444444444111111111111111111111111111111111111111111111111 Quote rule 0
Type codes (jump 048) : 5555544444444445444444444444225225522555545111111111111111111111111111111111 Quote rule 0
Type codes (jump 083) : 5555544444444445444444444444225225522555545254452454411154454452454411154455 Quote rule 0
Type codes (jump 085) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
Type codes (jump 100) : 5555544444444445444444444444225225522555545254452454454454454452454454454455 Quote rule 0
=====
Sampled 10028 rows (handled \n inside quoted fields) at 101 jump points including middle and very end
Bytes from first data row on line 2 to the end of last row: 95137762779
Line length: mean=465.06 sd=250.27 min=198 max=929
Estimated nrow: 95137762779 / 465.06 = 204571280
Initial alloc = 409142560 rows (204571280 + 100%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
Type codes (colClasses) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Type codes (drop|select) : 5555544444444445444444444444225225522555545254452454454454454452454454454455
Allocating 76 column slots (76 - 0 dropped)
Reading 90752 chunks of 1.000MB (2254 rows) using 64 threads
 andrewrech
في ٤ أبريل ٢٠١٧
andrewrech
في ٤ أبريل ٢٠١٧
إذا كان ذلك مفيدًا ، فإليك النتائج في قاعدة بيانات طويلة جدًا : 419124196 × 42 (~ 2 ^ 34) مع تمرير صف رئيسي واحد و colClasses.
> library(data.table)
data.table 1.10.5 IN DEVELOPMENT built 2017-09-27 17:12:56 UTC; travis
The fastest way to learn (by data.table authors): https://www.datacamp.com/courses/data-analysis-the-data-table-way
Documentation: ?data.table, example(data.table) and browseVignettes("data.table")
Release notes, videos and slides: http://r-datatable.com
> CC <- c(rep('integer', 2), rep('character', 3),
+ rep('numeric', 2), rep('integer', 3),
+ rep('character', 2), 'integer', 'character', 'integer',
+ rep('character', 4), rep('numeric', 11), 'character',
+ 'numeric', 'character', rep('numeric', 2),
+ rep('integer', 3), rep('numeric', 2), 'integer',
+ 'numeric')
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXXcsv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 13:42.935 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.016s ( 0%) sep=',' ncol=42 and header detection
0.016s ( 0%) Column type detection using 10049 sample rows
188.153s ( 23%) Allocation of 419124195 rows x 42 cols (125.177GB)
634.751s ( 77%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.121s ( 0%) Finding first non-embedded \n after each jump
+ 17.036s ( 2%) Parse to row-major thread buffers
+ 616.184s ( 75%) Transpose
+ 1.410s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
822.935s Total
> memory.size()
[1] 134270.3
> rm(P)
> gc()
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 585532 31.3 5489235 293.2 6461124 345.1
Vcells 1508139082 11506.2 20046000758 152938.9 25028331901 190951.1
> memory.size()
[1] 87.56
> P <- fread('XXXX.csv', colClasses = CC, header = TRUE, verbose = TRUE)
Input contains no \n. Taking this to be a filename to open
[01] Check arguments
Using 40 threads (omp_get_max_threads()=40, nth=40)
NAstrings = [<<NA>>]
None of the NAstrings look like numbers.
show progress = 1
0/1 column will be read as boolean
[02] Opening the file
Opening file XXXX.csv
File opened, size = 51.71GB (55521868868 bytes).
Memory mapping ... ok
[03] Detect and skip BOM
[04] Arrange mmap to be \0 terminated
\r-only line endings are not allowed because \n is found in the data
[05] Skipping initial rows if needed
Positioned on line 1 starting: <<X,X,X,X>>
[06] Detect separator, quoting rule, and ncolumns
Detecting sep ...
sep=',' with 100 lines of 42 fields using quote rule 0
Detected 42 columns on line 1. This line is either column names or first data row. Line starts as: <<X,X,X,X>>
Quote rule picked = 0
fill=false and the most number of columns found is 42
[07] Detect column types, good nrow estimate and whether first row is column names
'header' changed by user from 'auto' to true
Number of sampling jump points = 101 because (55521868866 bytes from row 1 to eof) / (2 * 13006 jump0size) == 2134471
Type codes (jump 000) : 5161010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 022) : 5561010775551055105101111111111111110110771117717 Quote rule 0
Type codes (jump 030) : 5561010775551055105101010107517171151110110771117717 Quote rule 0
Type codes (jump 037) : 5561010775551055105101010107517771171110110771117717 Quote rule 0
Type codes (jump 073) : 5561010775551055105101010107517771177110110771117717 Quote rule 0
Type codes (jump 093) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
Type codes (jump 100) : 5561010775551055105101010107717771177110110771117717 Quote rule 0
=====
Sampled 10049 rows (handled \n inside quoted fields) at 101 jump points
Bytes from first data row on line 1 to the end of last row: 55521868866
Line length: mean=132.68 sd=6.00 min=118 max=425
Estimated number of rows: 55521868866 / 132.68 = 418453923
Initial alloc = 460299315 rows (418453923 + 9%) using bytes/max(mean-2*sd,min) clamped between [1.1*estn, 2.0*estn]
=====
[08] Assign column names
[09] Apply user overrides on column types
After 11 type and 0 drop user overrides : 551010107755510105105101010107777777777710710775557757
[10] Allocate memory for the datatable
Allocating 42 column slots (42 - 0 dropped) with 460299315 rows
[11] Read the data
jumps=[0..52960), chunk_size=1048373, total_size=55521868441
Read 98%. ETA 00:00
[12] Finalizing the datatable
Read 419124195 rows x 42 columns from 51.71GB (55521868868 bytes) file in 05:04.910 wall clock time
Thread buffers were grown 0 times (if all 40 threads each grew once, this figure would be 40)
Final type counts
0 : drop
0 : bool8
0 : bool8
0 : bool8
0 : bool8
11 : int32
0 : int64
19 : float64
0 : float64
0 : float64
12 : string
=============================
0.000s ( 0%) Memory map 51.709GB file
0.031s ( 0%) sep=',' ncol=42 and header detection
0.000s ( 0%) Column type detection using 10049 sample rows
28.437s ( 9%) Allocation of 419124195 rows x 42 cols (125.177GB)
276.442s ( 91%) Reading 52960 chunks of 1.000MB (7901 rows) using 40 threads
= 0.017s ( 0%) Finding first non-embedded \n after each jump
+ 12.941s ( 4%) Parse to row-major thread buffers
+ 262.989s ( 86%) Transpose
+ 0.495s ( 0%) Waiting
0.000s ( 0%) Rereading 0 columns due to out-of-sample type exceptions
304.910s Total
> memory.size()
[1] 157049.7
> sessionInfo()
R version 3.4.2 beta (2017-09-17 r73296)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows Server >= 2012 x64 (build 9200)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] data.table_1.10.5
loaded via a namespace (and not attached):
[1] compiler_3.4.2 tools_3.4.2
بضع ملاحظات. كنت قد اقترحت وضع [09] قبل [07] في ذلك إذا تم تمرير colClasses فليس هناك سبب للتحقق. أيضًا ، أظهر Windows حوالي 160 جيجابايت قيد الاستخدام بعد كل تشغيل. memory.size () ربما يقوم ببعض التنظيف. مع 532 جيجابايت من ذاكرة الوصول العشوائي على هذا الخادم ، قد يكون للتخزين المؤقت للذاكرة ما يجب فعله مع زيادة السرعة في التشغيل الثاني. امل ان يساعد.
 aadler
في ٢٨ سبتمبر ٢٠١٧
aadler
في ٢٨ سبتمبر ٢٠١٧
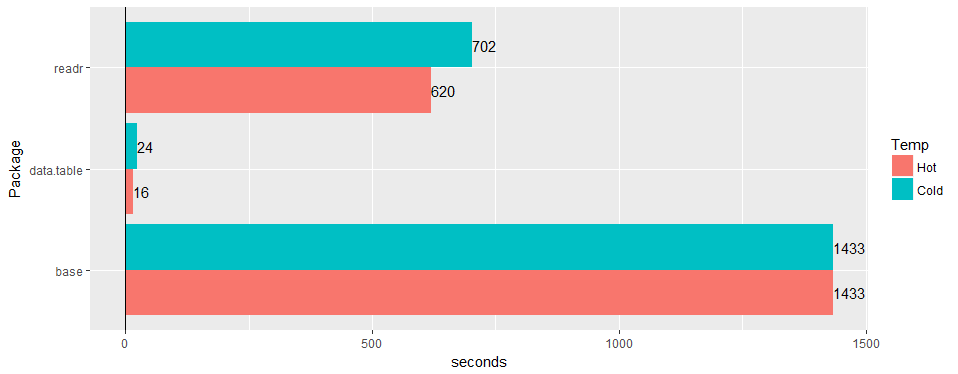
اختبار على جدول "العالم الحقيقي" الواسع (بيانات المستشفى): 30 مليون صف × 125 عمودًا مقابل قراءة '1.2.0' و read.csv 3.4.3
 HughParsonage
في ٢٥ يناير ٢٠١٨
HughParsonage
في ٢٥ يناير ٢٠١٨
أي فرصة لتأكيد الإصدار ما زالت سارية على 1.11.4؟ أو رمز لإنتاج بيانات نموذجية.
 jangorecki
في ١ يوليو ٢٠١٨
jangorecki
في ١ يوليو ٢٠١٨
تم حل هذا كله بقدر ما أعرف. geponce يرجى التحديث إذا لم يكن كذلك.
تم تقديم TODO1 أعلاه الآن كـ # 3024
تم تقديم TODO2 أعلاه الآن كـ # 3025
mattdowle
في ٣١ أغسطس ٢٠١٨
القضايا ذات الصلة
 tcederquist
·
3تعليقات
tcederquist
·
3تعليقات
 st-pasha
·
3تعليقات
st-pasha
·
3تعليقات
 rafapereirabr
·
3تعليقات
rafapereirabr
·
3تعليقات
 DavidArenburg
·
3تعليقات
jangorecki
·
3تعليقات
DavidArenburg
·
3تعليقات
jangorecki
·
3تعليقات
التعليق الأكثر فائدة
اختبار على جدول "العالم الحقيقي" الواسع (بيانات المستشفى): 30 مليون صف × 125 عمودًا مقابل قراءة '1.2.0' و
read.csv3.4.3