在设备上使用沉浸模式时,我正在使用它来跟踪对低 FPS 值原因的调查。
 jdm
jdm
所有71条评论
一些被发现的信息:
- xrWaitFrame 和 xrBeginFrame 之间有很长的等待
- 在演示应用程序中,这些顺序发生
- 在伺服的模型中,我们等待一个设备帧,然后一旦我们从 webgl 线程接收到渲染,我们就开始下一个 openxr 帧
这些天重现了带有 OpenXR API 标记的绘制演示的踪迹,并在此期间显示:
- webgl 线程使用最多的 CPU(大部分时间花在 gl::Finish 下,它是从 surfman 的 Device::bind_surface_to_context 调用的)
- 主线程是第二繁忙的,在 eglCreatePbufferFromClientBuffer 中使用率最高,几乎与从 TLS 获取 Egl 对象所花费的时间一样多
- webrender 的渲染也出现在这个堆栈中
- winrt::servo::flush 也出现在这里,我不清楚我们是否真的需要在沉浸模式下交换主应用程序的 GL 缓冲区
- 第三高 CPU 使用率是脚本线程,在 JIT 代码中花费大量时间
- 在该线程之后,CPU 使用率通常很低,但是样式包中的一些符号显示正在发生布局
jdm
于 2020-01-03
鉴于这些数据点,我将尝试两种方法开始:
- 等待设备帧后尽快开始下一个XR帧
- 减少我们需要调用 gl::Finish(webgl 线程)、eglCreateBufferFromClientBuffer 和 TLS(主线程)的次数
jdm
于 2020-01-03
https://github.com/servo/servo/pull/25343#issuecomment -567706735 对引擎中各个地方发送消息的影响进行了更多的调查。 它没有指向任何明确的手指,但建议应该进行更精确的测量。
jdm
于 2020-01-03
gl::Finish 用法来自https://github.com/pcwalton/surfman/blob/6705a9aaa8f33ac1324fdb1913242800e68c7720/surfman/src/platform/windows/angle/context.rs#L259 -L266。
jdm
于 2020-01-03
将 gl::Finish 更改为 gl::Flush 将帧率从 ~15->30 提升,但帧内容中存在极其明显的延迟,实际上反映了用户头部的移动,导致当前帧跟随用户的头部移动与此同时。
jdm
于 2020-01-03
由于一些我无法理解的原因,ANGLE 中默认禁用键控互斥锁,但 mozangle 明确启用它们(https://github.com/servo/mozangle/blob/706a9baaf8026c1a3cb6c67ba63aa5f4734264d0/build_data.rs#L175),并通过 surfman 进行测试. 我将构建 ANGLE 以启用它们,看看这是否足以避免 gl::Finish 调用。
jdm
于 2020-01-03
确认的! 在 ANGLE 中强制键控互斥体在绘制演示中为我提供了 25-30 FPS,而没有任何更改 gl::Finish 调用带来的延迟问题。
jdm
于 2020-01-03
哦,还有另一条根据 lars 的调查得到的信息:
- w/ dom.ion.enabled 设置为 false,JIT 时间消失。 初始加载要慢得多,但是一旦运行起来,它们就非常好。
- 它仍然不是很好 - 在那个 babylon.js 示例上的内存使用率非常高(基本上所有可用内存)
- 我们应该再做一次 Spidermonkey 升级,以引入针对 Android 设备上的 FxR 的 arm64 相关优化
jdm
于 2020-01-03
我想我误解了配置文件中std::thread::local::LocalKey<surfman::egll::Egl>的存在 - 我很确定 TLS 读取只是占用它的一小部分时间,它是 TLS 块内调用的函数,如 eglCreatePbufferFromClientBuffer 和DXGIAcquireSync _实际上_需要时间。
jdm
于 2020-01-03
可悲的是,禁用 js.ion.enabled 似乎损害了绘制演示的 FPS,将其降低到 20-25。
jdm
于 2020-01-04
与其每帧调用 Device::create_surface_texture_from_texture 两次(每只眼睛的每个 d3d 纹理一次),不如在创建 openxr webxr 设备时为所有交换链纹理创建表面纹理。 如果这可行,它将在沉浸模式期间从主线程中删除 CPU 的第二大用户。
jdm
于 2020-01-04
另一个减少内存使用的想法:如果我们将 bfcache 设置为一个非常低的数字,以便在导航到其中一个演示时驱逐原始 HL 主页管道,是否有任何影响?
jdm
于 2020-01-04
下面的 webxr 补丁并没有明显提高 FPS,但它可能会提高图像稳定性。 我需要创建两个单独的构建,我可以连续运行以进行检查。
diff --git a/webxr/openxr/mod.rs b/webxr/openxr/mod.rs
index 91c78da..a6866de 100644
--- a/webxr/openxr/mod.rs
+++ b/webxr/openxr/mod.rs
@@ -416,11 +416,30 @@ impl DeviceAPI<Surface> for OpenXrDevice {
}
fn wait_for_animation_frame(&mut self) -> Option<Frame> {
- if !self.handle_openxr_events() {
- // Session is not running anymore.
- return None;
+ loop {
+ if !self.handle_openxr_events() {
+ // Session is not running anymore.
+ return None;
+ }
+ self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
+ // XXXManishearth this code should perhaps be in wait_for_animation_frame,
+ // but we then get errors that wait_image was called without a release_image()
+ self.frame_stream
+ .begin()
+ .expect("failed to start frame stream");
+
+ if self.frame_state.should_render {
+ break;
+ }
+
+ self.frame_stream.end(
+ self.frame_state.predicted_display_time,
+ EnvironmentBlendMode::ADDITIVE,
+ &[],
+ ).unwrap();
}
- self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
let time_ns = time::precise_time_ns();
// XXXManishearth should we check frame_state.should_render?
let (_view_flags, views) = self
@@ -506,12 +525,6 @@ impl DeviceAPI<Surface> for OpenXrDevice {
0,
);
- // XXXManishearth this code should perhaps be in wait_for_animation_frame,
- // but we then get errors that wait_image was called without a release_image()
- self.frame_stream
- .begin()
- .expect("failed to start frame stream");
-
self.left_image = self.left_swapchain.acquire_image().unwrap();
self.left_swapchain
.wait_image(openxr::Duration::INFINITE)
@manishearth 对此有何想法? 我试图更接近https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#Session所描述的模型
jdm
于 2020-01-04
是的,这看起来不错。 我一直想把begin()移到waf中,我相信评论中提到的错误不再发生,但它对FPS也没有明显影响所以我没有追求它现在太多了。 如果它提高了稳定性,那就太好了!
 Manishearth
于 2020-01-04
Manishearth
于 2020-01-04
对关键发现感到非常高兴! Surfman 电话确实占用了大量的帧预算,但很难确定哪些是必要的,哪些是不必要的。
Manishearth
于 2020-01-04
是的,re:禁用js.ion.enabled ,这只会在我们内存不足并且大部分时间都花在 GC 和重新编译函数上时会有好处。 这应该用更新的 SM 改进。 IIRC,66 时代的 ARM64 后端也有相对较差的基线 JIT 和解释器性能; 我们应该会通过更新看到全面的加速,尤其是在 RAM 密集型应用程序上。
 larsbergstrom
于 2020-01-04
larsbergstrom
于 2020-01-04
发布了启用了键控互斥锁的新 ANGLE 包。 我将创建一个拉取请求以稍后升级它。
jdm
于 2020-01-06
我尝试在 XR 设备初始化期间为所有 openxr 交换链图像创建表面纹理,但主线程上仍有大量时间花在我们每帧从 webgl 线程接收的表面上调用 eglCreatePbufferFromClientBuffer 上。 也许有一些方法可以缓存这些表面纹理,这样我们就可以在收到相同的表面时重用它们......
jdm
于 2020-01-06
最大的主线程 CPU 使用来自 render_animation_frame,其中大部分在 OpenXR 运行时下,但对 BlitFramebuffer 和 FramebufferTexture2D 的调用肯定也出现在配置文件中。 我想知道将双眼同时闪烁到单个纹理是否会有所改进? 也许这与https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt 中讨论的纹理数组内容有关。
jdm
于 2020-01-06
我们可以同时点亮双眼,但是我的理解是运行时
然后可以执行自己的 blit。 纹理数组是最快的方法。 但
值得一试,投影视图 API 支持这样做。
至于主线程 ANGLE 流量,是否停止了 RAF 循环
弄脏画布有帮助吗? 到目前为止,这还没有做任何事情,但值得一试
拍摄,理想情况下我们不应该在主上做任何布局/渲染
线。
2020 年 1 月 6 日,星期一,晚上 11:49,Josh Matthews通知@ github.com
写道:
最大的主线程CPU占用来自render_animation_frame,有
大部分在 OpenXR 运行时下,但调用 BlitFramebuffer 和
FramebufferTexture2D 肯定也出现在配置文件中。 我想知道
如果将两只眼睛同时闪烁到单个眼睛会有所改善
质地? 也许这与讨论的纹理数组内容有关
在
https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt
.—
你收到这个是因为你被提到了。
直接回复本邮件,在GitHub上查看
https://github.com/servo/servo/issues/25425?email_source=notifications&email_token=AAMK6SBRH72JGZMXTUKOXETQ4NY37A5CNFSM4KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXWSZ2000MVBW63LNMVXWSZ20000000M
或取消订阅
https://github.com/notifications/unsubscribe-auth/AAMK6SECM6MDNZZ6Y7VL7SDQ4NY37ANCNFSM4KCRI6AA
.
Manishearth
于 2020-01-06
去除画布弄脏只会清理轮廓; 它似乎没有导致有意义的 FPS 增加。
jdm
于 2020-01-06
我尝试为来自 webgl 线程和 openxr 交换链纹理的表面创建表面纹理缓存,虽然 eglCreatePbufferFromClientBuffer 时间完全消失,但我没有注意到任何有意义的 FPS 变化。
jdm
于 2020-01-06
沉浸式管道中各种操作的一些计时信息(所有测量值均以毫秒为单位):
Name min max avg
raf queued 0.070833 14.010261 0.576834
<1ms: 393
<2ms: 28
<4ms: 5
<8ms: 1
<16ms: 2
<32ms: 0
32+ms: 0
raf transmitted 0.404270 33.649583 7.403302
<1ms: 123
<2ms: 43
<4ms: 48
<8ms: 48
<16ms: 95
<32ms: 69
32+ms: 3
raf wait 1.203500 191.064100 17.513593
<1ms: 0
<2ms: 17
<4ms: 98
<8ms: 95
<16ms: 48
<32ms: 69
32+ms: 101
raf execute 3.375000 128.663200 6.994588
<1ms: 0
<2ms: 0
<4ms: 5
<8ms: 351
<16ms: 70
<32ms: 1
32+ms: 2
raf receive 0.111510 8.564010 0.783503
<1ms: 353
<2ms: 52
<4ms: 18
<8ms: 4
<16ms: 1
<32ms: 0
32+ms: 0
raf render 2.372200 75.944000 4.219310
<1ms: 0
<2ms: 0
<4ms: 253
<8ms: 167
<16ms: 8
<32ms: 0
32+ms: 1
receive :从XR线程发送XR帧信息到IPC路由器接收的时间
queued : 从 IPC 路由器收到帧信息到调用 XRSession::raf_callback 的时间
execute :从调用 XRSession::raf_callback 到从方法返回的时间
transmitted :从脚本线程发送新 rAF 请求到 XR 线程接收到的时间
render :调用render_animation_frame并回收表面所
wait : wait_for_animation_frame (使用本期早些时候的补丁,在不应该渲染的帧上循环)
每个条目下是值在会话过程中的分布。
jdm
于 2020-01-07
来自该时间信息的一个有趣的数据点 - transmitted类别似乎比它应该的要高得多。 这是 rAF 回调执行与 XR 线程接收消息之间的延迟,该消息将完成的帧 blit 到 openxr 的纹理中。 有相当多的变化,表明要么主线程被占用做其他事情,要么需要被唤醒才能处理它。
jdm
于 2020-01-07
鉴于之前的数据,我明天可能会尝试重新启动https://github.com/servo/webxr/issues/113 ,看看这是否会对传输时间产生积极影响。 我可能会先在探查器中的主线程上戳一下,看看我是否能想出任何关于如何判断线程是忙于其他任务还是睡着了的想法。
jdm
于 2020-01-07
另一个数据点:
swap buffer 1.105938 28.193698 2.154793
<1ms: 0
<2ms: 273
<4ms: 110
<8ms: 15
<16ms: 2
<32ms: 2
32+ms: 0
swap complete 0.053802 4.337812 0.295064
<1ms: 308
<2ms: 9
<4ms: 6
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
swap request 0.003333 24033027.355364 4662890.724805
<1ms: 268
<2ms: 49
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 1
32+ms: 79
这些时间与 1) 从发送交换缓冲区消息到在 webgl 线程中处理它之间的延迟,2) 交换缓冲区所花费的时间,3) 从发送指示交换完成的消息到在脚本线程。 这里没有什么特别令人惊讶的(除了swap request类别中的那些奇怪的异常值,但那些发生在设置 afaict 期间沉浸式会话的最开始时),但实际的缓冲区交换始终需要 1-4 毫秒。
jdm
于 2020-01-07
在阅读了一些 openxr 示例代码并注意到 locate_views 调用出现在配置文件中后,提交了 #117。
jdm
于 2020-01-07
 asajeffrey
于 2020-01-07
asajeffrey
于 2020-01-07
来自该时间信息的一个有趣的数据点 - 传输的类别似乎比它应该的要高得多。 这是 rAF 回调执行与 XR 线程接收消息之间的延迟,该消息将完成的帧 blit 到 openxr 的纹理中。 有相当多的变化,表明要么主线程被占用做其他事情,要么需要被唤醒才能处理它。
关于transmitted值的变化,当会话在主线程上运行时,它可能与用作run_one_frame一部分的超时有关(在这些测量中,它是这样的,对吧?) ,见https://github.com/servo/webxr/blob/c6abf4c60d165ffc978ad2ebd6bcddc3c21698e1/webxr-api/session.rs#L275
我推测当RenderAnimationFrame msg(运行回调后由脚本线程发送的消息)在超时之前收到时,您会进入“快速路径”,如果超时,伺服会进入另一个perform_updates迭代和“运行另一帧”发生在周期的后期,作为compositor.perform_updates ,本身作为servo.handle_events一部分被称为相当晚。
除了将 XR 移动到它自己的线程之外,如果超时的更高值会提高平均值,可能值得一看(尽管它可能不是正确的解决方案,因为它可能会导致主线程上的其他必要内容匮乏)。
 gterzian
于 2020-01-08
gterzian
于 2020-01-08
我在https://github.com/servo/webxr/issues/113 中从主线程中移除 openxr 方面取得了进展,因此我将在下周基于该工作进行更多测量。
jdm
于 2020-01-10
从设备获取有用配置文件的技术:
- 使用包含
rustflags = "-C force-frame-pointers=yes"的 .servobuild - 取消注释这些行
- 使用来自 MS 团队 char
Files选项卡的 WinXR_Perf.wprp 作为 HL 设备门户中“性能跟踪”下的自定义跟踪配置文件 - 用
--features profilemozjs构建
这些跟踪(从设备门户中的“开始跟踪”获得)将在 Windows 性能分析器工具中可用。 此工具不显示线程名称,但使用 CPU 最多的线程可以根据堆栈直接识别。
要分析特定 openxr 帧的时间分布:
- 在 WPA 中添加“系统活动 -> 通用事件”视图
- 过滤视图以仅显示 Microsoft.Windows.WinXrContinuousProvider 系列
- 放大到很短的持续时间,然后细化放大的区域,以便 xrBegin 事件在视图的左侧,而 xrEnd 事件在视图的右侧
CPU 使用率最有用的视图:
- CPU Usage (Sampled) -> Utilization by Process, Thread, Stack(过滤视图以仅显示伺服,然后禁用进程列)
- Flame by Process, Stack(过滤视图以仅显示伺服)
jdm
于 2020-01-16
在脚本线程中稍微减少工作的一种可能性:
- XRView::new 占用所有伺服 CPU 的 0.02%
- 因为除非有 FrameUpdateEvent::UpdateViews 事件(通过 XRSession::UpdateRenderState 来自 Session::update_clip_planes),否则视图对象的内容不会改变,我们可以想象在 XRSession 上缓存 XRView 对象并继续使用它们直到渲染状态已更新
- 我们甚至可以将视图列表的 JS 表示缓存在 XRSession 中并设置姿势的视图成员,避免重新创建 XRView 对象、分配向量和执行 JS 值转换
jdm
于 2020-01-16
渲染沉浸式框架时减少工作量的一种可能性:
- GL 和 d3d 具有倒置的 Y 坐标系
- 通过在幕后做一些工作,ANGLE 在呈现给屏幕时隐含地隐藏了这一点
- 对于沉浸式模式,我们使用 glBlitFramebuffer 在将 GL 纹理数据块传输到 d3d 时执行 y 反转
- 如果我们能弄清楚如何使 ANGLE 不在内部进行转换,则可能会反转此模型并使渲染非沉浸式网页需要额外的 y-invert blit(通过 webrender 选项
surface_origin_is_top_left)而沉浸式模式可以在没有任何转换的情况下进行
基于https://bugzilla.mozilla.org/show_bug.cgi?id=1591346并与 jrmuizel 交谈,这是我们需要做的:
- 为我们想要呈现非沉浸式页面的窗口元素获取 d3d 交换链(这将是 XAML 应用程序中的 SwapChainPanel)
- 将其包装在 EGL 图像中(https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#554)
- 当我们想要更新主渲染时显式呈现交换链
- 避免在https://github.com/servo/servo/blob/master/support/hololens/ServoApp/ServoControl/OpenGLES.cpp#L205 -L208 中使用 eglCreateWindowSurface 和 eglSwapBuffers
jdm
于 2020-01-16
当前的wip分支:
- https://github.com/servo/ipc-channel/tree/try-recv-error
- https://github.com/jdm/webxr/tree/oxr
- https://github.com/jdm/rust-offscreen-rendering-context/tree/angle-perf
- https://github.com/jdm/servo/tree/profile
这包括xr-profile功能,该功能添加了我之前提到的计时数据,以及 ANGLE 更改的初始实现,以消除沉浸式模式下的 y 逆变换。 非沉浸模式渲染正确,但沉浸模式颠倒了。 我相信我需要从 render_animation_frame 中删除 GL 代码,并通过从 GL 表面提取共享句柄来将其替换为直接 CopySubresourceRegion 调用,以便我可以获得它的 d3d 纹理。
jdm
于 2020-01-17
为角度 y 反转工作提交https://github.com/servo/servo/issues/25582 ; 关于这项工作的进一步更新将在该问题上进行。
jdm
于 2020-01-23
下一个重要项目将研究在 openxr webxr 后端完全避免 glBlitFramebuffer 调用的方法。 这需要:
- 创建与所需的不透明 webgl 帧缓冲区精确匹配的 openxr 帧缓冲区
- 支持 webgl 模式,其中 webxr 后端提供所有交换链表面,而不是创建它们(例如在 https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#和 https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L111-L118)
jdm
于 2020-01-23
这可能很困难,因为 surfman 只提供对创建表面的上下文的写入访问权限,因此如果表面是由 openxr 线程创建的,则 WebGL 线程将无法写入它。 https://github.com/pcwalton/surfman/blob/a515fb2f5d6b9e9b36ba4e8b498cdb4bea92d330/surfman/src/device.rs#L95 -L96
asajeffrey
于 2020-01-23
我突然想到 - 如果我们在 webgl 线程中进行 openxr 渲染,那么围绕直接渲染到 openxr 纹理的一系列线程相关问题将不再是问题(即 eglCreatePbufferFromClientBuffer 周围的限制禁止使用多个 d3d 设备)。 考虑:
- 还有一个openxr线程负责轮询openxr事件,等待动画帧,开始新帧并检索当前帧状态
- 帧状态发送到脚本线程,脚本线程执行动画回调,然后向 webgl 线程发送消息以交换 xr 层的帧缓冲区
- 当 webgl 线程收到这个交换消息时,我们释放最后获取的 openxr 交换链图像,向 openxr 线程发送消息以结束当前帧,并为下一帧获取新的交换链图像
我对https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#threading -behavior 的阅读表明这种设计可能是可行的。 诀窍在于它是否适用于我们的非 openxr 后端以及 openxr。
来自规范:“虽然 xrBeginFrame 和 xrEndFrame 不需要在同一线程上调用,但如果在不同的线程上调用它们,应用程序必须处理同步。”
jdm
于 2020-01-25
目前,XR 设备线程和 webgl 之间没有直接通信,这一切都通过脚本或通过它们的共享交换链进行。 我很想提供一个位于 surfman 交换链或 openxr 交换链之上的交换链 API,并将其用于 webgl 到 openxr 的通信。
asajeffrey
于 2020-01-25
关于早期时间测量的对话笔记:
* concerns about wait time - why?????
* figure out time spent in JS vs. DOM logic
* when does openxr give us should render=false frames - maybe related to previous frame taking too long
* are threads being scheduled on inappropriate cpus? - on magic leap, main thread (including weber) pinned to big core.
* when one of the measured numbers is large, is there correlation with other large numbers?
* probably should pin openxr thread, running deterministic code
* consider clearing after telling script that the swap is complete - measure if clear is taking significant time in swap operation
* consider a swap chain API operation - “wait until a buffer swap occurs”
- block waiting on swapchain
- block waiting on swapchain + timeout
- async????????
- a gc would look like a spike in script execution time
已提交 #25735 以跟踪我正在进行的有关直接渲染到 openxr 纹理的调查。
jdm
于 2020-02-11
我们应该做的一件事是缩小蜘蛛猴在设备上与其他引擎的比较范围。 在这里获取一些数据的最简单方法是找到一个 Servo 可以运行的简单 JS 基准测试,并将 Servo 的性能与设备上安装的 Edge 浏览器进行比较。 此外,我们可以尝试在两种浏览器中访问一些复杂的 babylon 演示,而无需进入沉浸式模式,以查看是否存在显着的性能差异。 这也将为我们提供与即将到来的蜘蛛猴升级进行比较的基准。
jdm
于 2020-02-13
一些新数据。 这是 ANGLE 升级,而不是 IPC 升级。
$ python timing.py raw
Name min max mean
raf queued 0.056198 5.673125 0.694902
<1ms: 335
<2ms: 26
<4ms: 17
<8ms: 7
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.822917 36.582083 7.658619
<1ms: 1
<2ms: 4
<4ms: 31
<8ms: 181
<16ms: 158
<32ms: 8
32+ms: 1
raf wait 1.196615 39.707709 10.256875
<1ms: 0
<2ms: 32
<4ms: 93
<8ms: 67
<16ms: 107
<32ms: 68
32+ms: 17
raf execute 3.078438 532.205677 7.752839
<1ms: 0
<2ms: 0
<4ms: 37
<8ms: 290
<16ms: 52
<32ms: 2
32+ms: 3
raf receive 0.084375 9.053125 1.024403
<1ms: 276
<2ms: 71
<4ms: 27
<8ms: 9
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.004115 73.939479 0.611254
<1ms: 369
<2ms: 10
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.706198 233.459636 9.241698
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 183
<16ms: 190
<32ms: 10
32+ms: 1
run_one_frame 7.663333 2631.052969 28.035143
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 3
<16ms: 157
<32ms: 185
32+ms: 41
swap buffer 0.611927 8.521302 1.580279
<1ms: 127
<2ms: 169
<4ms: 74
<8ms: 15
<16ms: 1
<32ms: 0
32+ms: 0
swap complete 0.046511 2.446302 0.215040
<1ms: 375
<2ms: 6
<4ms: 3
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
时序数据: https :
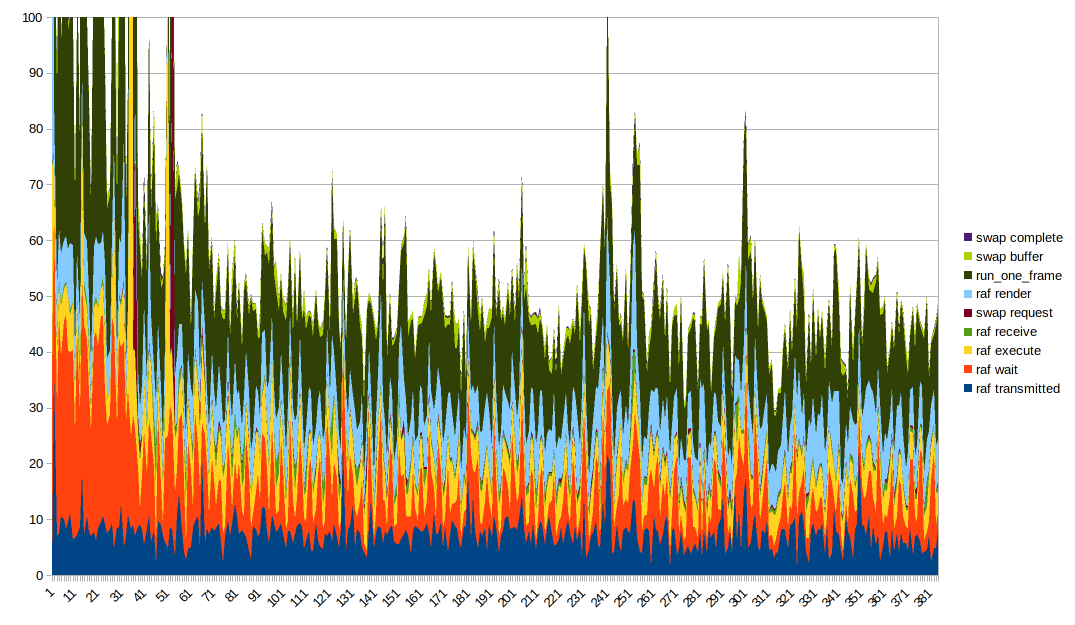
获得良好的数据可视化是很棘手的。 堆叠线图似乎很理想,但值得注意的是 run_one_frame 测量多个已经测量的时间。 摆弄图形顺序并将不同的列放在底部以更好地查看它们的效果是有帮助的。 由于一些非常大的异常值,您还需要截断 Y 轴以获得任何有用的东西。
有趣的事情要注意:
- 渲染时间和执行时间似乎大部分是稳定的,但是当整体出现大的峰值时会出现峰值。 我怀疑大尖峰来自任何原因都在放缓
- 传输时间似乎与整体形状非常相关
- 等待时间也是整体形状如此的部分原因,它_非常_波浪形
Manishearth
于 2020-02-21
当前状态:通过 IPC 修复,FPS 现在徘徊在 55 左右。它有时会摆动一堆,但通常不会低于 45,_except_ 在加载后的前几秒钟(它可以下降到 30),以及何时首先看到一手牌(当它下降到 20 时)。
Manishearth
于 2020-02-25
油漆演示的新直方图(原始数据):
Name min max mean
raf queued 0.113854 5.707917 0.441650
<1ms: 352
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.546667 44.954792 6.886162
<1ms: 4
<2ms: 2
<4ms: 23
<8ms: 279
<16ms: 59
<32ms: 3
32+ms: 1
raf wait 1.611667 37.913177 9.441104
<1ms: 0
<2ms: 6
<4ms: 98
<8ms: 82
<16ms: 135
<32ms: 43
32+ms: 6
raf execute 3.336562 418.198541 7.592147
<1ms: 0
<2ms: 0
<4ms: 11
<8ms: 319
<16ms: 36
<32ms: 2
32+ms: 3
raf receive 0.119323 9.804167 0.806074
<1ms: 324
<2ms: 31
<4ms: 13
<8ms: 1
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.003646 79.236354 0.761324
<1ms: 357
<2ms: 9
<4ms: 2
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 3
raf render 5.844687 172.898906 8.131682
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 283
<16ms: 86
<32ms: 1
32+ms: 1
run_one_frame 8.826198 2577.357604 25.922205
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 176
<32ms: 174
32+ms: 22
swap buffer 0.708177 12.528906 1.415950
<1ms: 164
<2ms: 161
<4ms: 38
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
swap complete 0.042917 1.554740 0.127729
<1ms: 370
<2ms: 1
<4ms: 0
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
更长的运行时间(原始)。 旨在减少启动减速的影响。
名称最小最大平均值
英国皇家空军排队 0.124896 6.356562 0.440674
<1 毫秒:629
<2 毫秒:13
<4 毫秒:5
<8 毫秒:1
<16ms:0
<32 毫秒:0
32+毫秒:0
raf 传输 0.640677 20.275104 6.944751
<1毫秒:2
<2毫秒:3
<4 毫秒:29
<8 毫秒:513
<16 毫秒:99
<32ms:1
32+毫秒:0
英国皇家空军等待 1.645886 40.955208 9.386255
<1毫秒:0
<2 毫秒:10
<4 毫秒:207
<8 毫秒:114
<16 毫秒:236
<32 毫秒:65
32+毫秒:15
皇家空军执行 3.090104 526.041198 6.226997
<1毫秒:0
<2毫秒:0
<4 毫秒:68
<8 毫秒:546
<16 毫秒:29
<32ms:1
32+毫秒:3
英国皇家空军接收 0.203334 6.441198 0.747615
<1 毫秒:554
<2 毫秒:84
<4 毫秒:7
<8 毫秒:2
<16ms:0
<32 毫秒:0
32+毫秒:0
交换请求 0.003490 73.644322 0.428460
<1 毫秒:627
<2 毫秒:18
<4 毫秒:1
<8 毫秒:0
<16ms:0
<32 毫秒:0
32+毫秒:2
英国皇家空军渲染 5.450312 209.662969 8.055021
<1毫秒:0
<2毫秒:0
<4 毫秒:0
<8 毫秒:467
<16 毫秒:176
<32ms:3
32+毫秒:1
run_one_frame 8.417291 2579.454948 22.226204
<1毫秒:0
<2毫秒:0
<4 毫秒:0
<8 毫秒:0
<16 毫秒:326
<32 毫秒:290
32+毫秒:33
交换缓冲区 0.658125 12.179167 1.378725
<1 毫秒:260
<2 毫秒:308
<4 毫秒:72
<8 毫秒:4
<16 毫秒:4
<32 毫秒:0
32+毫秒:0
交换完成 0.041562 5.161458 0.136875
<1 毫秒:642
<2毫秒:3
<4 毫秒:1
<8 毫秒:1
<16ms:0
<32 毫秒:0
32+毫秒:0
Manishearth
于 2020-02-27
图表:
更长的运行:

更短的运行: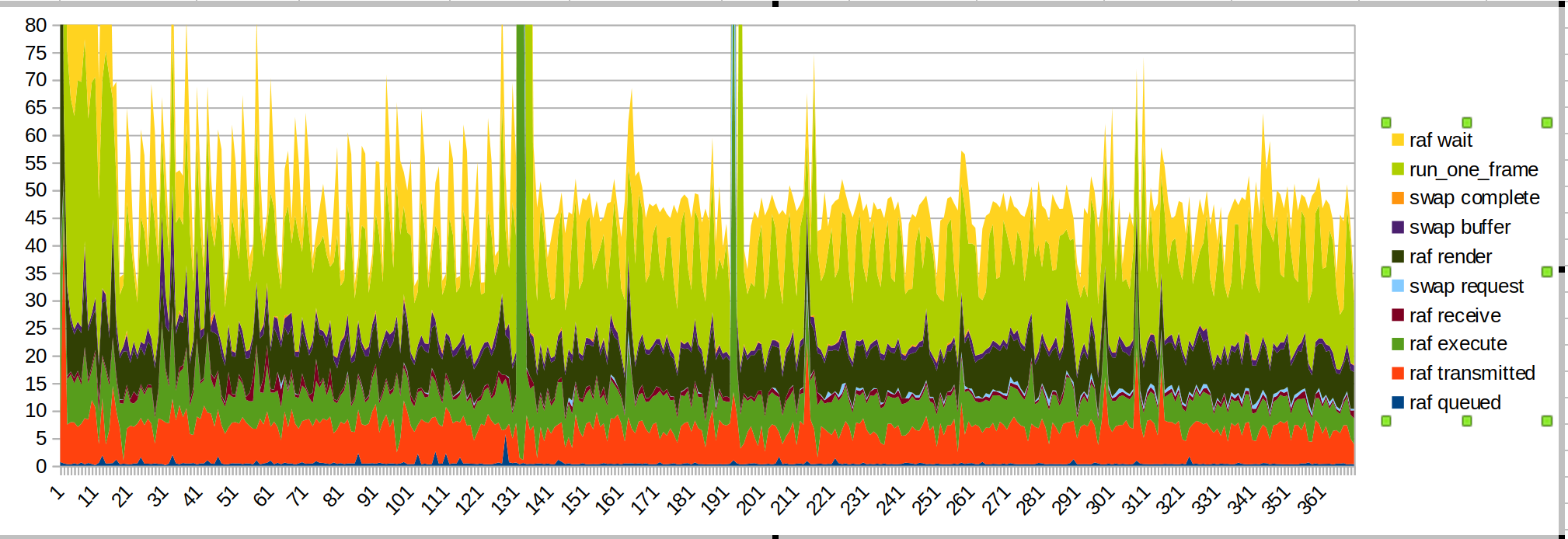
大尖峰是当我把手伸进传感器范围内时。
这次我把 wait/run_one_frame 时间放在最前面,因为它们是最参差不齐的,这是因为操作系统限制了我们。
需要注意的几点:
- 引入手的大尖峰是由 JS 代码引起的(罗勒绿色,“raf 渲染”)
- 正如预期的那样,传输时间变得更顺畅
- 当我开始画画时,还有另一个 JS 尖峰
- 渲染和传输时间仍然是预算的重要部分。 脚本性能也可以提高。
- 我怀疑传输时间太长是因为主线程忙于做其他事情。 这是https://github.com/servo/webxr/issues/113 , @jdm正在调查它
- 冲浪者更新可能会改善渲染时间。 @asajeffrey对 surfmanup 的测量似乎比我的好
- 进行表面共享可能会改善渲染时间(在 surfmanup 上被阻止)
- 使用 xr-profile 测量时,设备显示的 FPS 几乎减半。 这可能是因为所有的 IO。
球射手不存在由于看到手然后开始绘制而导致的性能问题。 也许paint demo在它第一次决定绘制手部图像时做了很多工作?
(这也可能是尝试与 webxr 输入库交互的绘制演示)
Manishearth
于 2020-02-27
@Manishearth您还可以覆盖内存使用情况并与这些事件相关联吗? 除了首次编译 JS 代码外,您可能会在大量新代码中出错,并遇到物理内存限制,并在遇到内存压力时引发一堆 GC。 我在大多数非平凡的情况下都看到了这一点。 我希望@nox的 SM 更新会有所帮助,因为这绝对是我们在 FxR Android 上的这个 SM 构建中看到的神器。
larsbergstrom
于 2020-02-27
我没有一种简单的方法可以与 xr 分析的东西相关联的方式获取内存分析数据。
我可能会使用现有的 perf 工具并确定形状是否相同。
Manishearth
于 2020-02-27
@Manishearth xr 分析的东西是否显示(或可以显示)JS GC 事件? 这可能是一个合理的代理。
larsbergstrom
于 2020-02-27
无论哪种方式,启动峰值都不是我最关心的问题,我想先以 60fps 的速度获得所有 _else_。 如果它在启动时出现一两秒钟的卡顿,那就不是那么紧迫的问题了。
Manishearth
于 2020-02-27
是的,它可以表明,需要一些调整。
Manishearth
于 2020-02-27
@Manishearth完全同意优先事项! 我不确定你是想“解决问题”还是降低稳定状态。 现在同意后者更重要。
larsbergstrom
于 2020-02-27
不,我主要只是记下我能做的所有分析。
Manishearth
于 2020-02-27
在较小运行的图表末尾附近的那些尖峰,其中传输时间也出现尖峰:那是我移动头部和绘图的时候,Alan 在做事时也注意到 FPS 下降,并将其归因于操作系统在做其他工作. 在 IPC 修复了我对传输时间峰值的预感之后,它们是由操作系统执行其他工作引起的,所以这可能就是那里发生的事情。 在非主线程世界中,我希望它会更流畅。
Manishearth
于 2020-02-27
如果已经考虑过这一点,请忽略我,你有没有想过在每条消息处理的基础上分解run_one_frame的度量,并计算花费thread::sleep() -ing 的时间?
可能值得添加三个测量点:
和另一个包装https://github.com/servo/webxr/blob/2841497966d87bbd561f18ea66547dde9b13962f/webxr-api/lib.rs#L124整体,
还有一个只将调用包装到
thread::sleep。
至于recv_timeout ,这可能需要完全重新考虑。
我发现很难推断超时的用处。 由于您正在计算渲染的帧,请参阅frame_count ,用例似乎是“可能首先处理一个或多个未渲染帧的消息,然后渲染帧,同时避免通过主线程的完整事件循环”?
此外,我对其中使用的delay的实际计算有一些疑问,目前:
- 它从
delay = timeout / 1000,timeout当前设置为 5 ms - 然后它呈指数增长,每次迭代加倍,
delay = delay * 2; - 它在循环的顶部使用
while delay < timeout。
所以在最坏的情况下,睡眠的顺序是这样的:5micro -> 10 -> 20 -> 40 -> 80 -> 160 -> 320 -> 640 -> 1.28milli -> 2.56 milli -> 5.12 milli
当它达到 5.12 毫秒时,您将退出循环(自delay > timeout ),总共等待了 5,115 毫秒,再加上等待操作系统在每次sleep后唤醒线程所花费的额外时间
所以我认为问题是你总共可能睡了 5ms 以上,而且我认为睡两次超过 1 ms(其中第二次超过 2.5 ms)不是一个好主意,因为一条消息在那段时间进来,你就不会醒来。
我不太确定如何改进它,听起来你正在尝试寻找一个潜在的消息,最后如果没有可用的东西,就转到主事件循环的下一次迭代(为什么不阻止接收?)。
您可以切换到使用https://doc.rust-lang.org/std/thread/fn.yield_now.html ,查看这篇关于锁的文章,每次调用yield时似乎旋转了大约 40 次, 是最佳的(请参阅“旋转”段落,无法直接链接到它)。 之后,您应该阻塞接收器,或者继续事件循环的当前迭代(因为它像主嵌入事件循环内的子循环一样运行)。
(显然,如果您没有在打开ipc进行测量,则上面recv_timeout上的部分是无关紧要的,尽管您可能仍想在recv_timeout上测量调用mpsc因为螺纹通道会进行一些内部旋转/屈服,这也可能会影响结果。而且由于上面多次提到了一个不明的“IPC 修复”,我假设您正在使用 IPC 进行测量)。
gterzian
于 2020-02-27
如果已经考虑过这一点,请忽略我,您是否考虑过在每个消息处理的基础上分解 run_one_frame 的度量,并且还对 thread::sleep()-ing 花费的时间进行计时?
它已经分解了,等待/渲染时间正是这样。 run_one_frame 的一个滴答是一次渲染,一次等待,以及不确定数量的正在处理的事件(罕见)。
recv_timeout 是测量的好主意
Manishearth
于 2020-02-27
可悲的是,#25678 中的 spidermonkey 升级似乎没有显着改进 - 除了最受内存限制的内存之外,每个演示的平均 FPS 都降低了; Hill Valley 演示小幅上升。 在初始化参数中使用-Z gc-profile运行 Servo 不会显示 master 和 spidermonkey upgrade 分支之间的 GC 行为有任何差异 - 在加载和显示 GL 内容后没有报告 GC。
jdm
于 2020-03-03
各种分支的测量:
master:
- espilit: 14-16 fps
- paint: 39-45 fps
- ball shooter: 30-40 fps
- hill valley: 8 fps, 200mb free mem
- mansion: 10-14fps, 650mb free mem
master + single swapchain:
- espilit: 10-12 fps
- paint: 29-55 fps, 1.2gb free mem
- ball shooter: 25-35 fps, 1.3gb free mem
- hill valley: 6-7 fps, 200mb free mem
- mansion: 10-11 fps, 700mb free mem
texture sharing + ANGLE 2.1.19:
- espilit: 13-15 fps, 670mb free mem
- paint: 39-45 fps
- ball shooter: 30-37 fps, 1.3gb free mem
- hill valley: 9-10 fps, 188mb free mem
- mansion: 13-14 fps, 671mb free mem
smup:
- espilit: 11-13 fps, 730mb free mem
- paint: 25-42 fps, 1.1gb free mem
- ball shooter: 26-30 fps, 1.4gb free mem
- hill valley: 10-11 fps, 145mb
- mansion: 9-11fps, 680mb free mem
smup 使性能变差???
asajeffrey
于 2020-03-03
随着https://github.com/servo/servo/pull/25855#issuecomment -594203492 的变化,有一个有趣的结果是禁用 Ion JIT 从 12 FPS 开始,然后几秒钟后它突然降低到 1 FPS 和留在那里。
jdm
于 2020-03-03
用这些补丁做了一些测量。
在绘画方面,当视图中的内容不多时,我得到 60fps,而在查看绘制内容时,它下降到 50ish fps(黄色尖峰是当我查看绘制内容时)。 很难说为什么,主要是等待时间似乎受到 openxr 限制的影响,但其他事情似乎并没有慢到足以引起问题。 交换请求时间有点慢。 rAF 执行时间最初很慢(这是最初的“第一次看到控制器”减速),但之后它非常稳定。 似乎 openxr 只是在限制我们,但在其他地方没有明显的放缓会导致这种情况。

Manishearth
于 2020-03-07
这就是我为拖动演示所做的。 y 尺度是相同的。 更明显的是,执行时间正在减慢我们的速度。

Manishearth
于 2020-03-07
需要注意的一件事是,我在应用#25837 的情况下进行测量,这可能会影响性能。
jdm
于 2020-03-07
我不是,但是我得到了与你相似的结果
Manishearth
于 2020-03-07
查看内容时从 60FPS 到 45FPS 的那一刻的性能工具图:
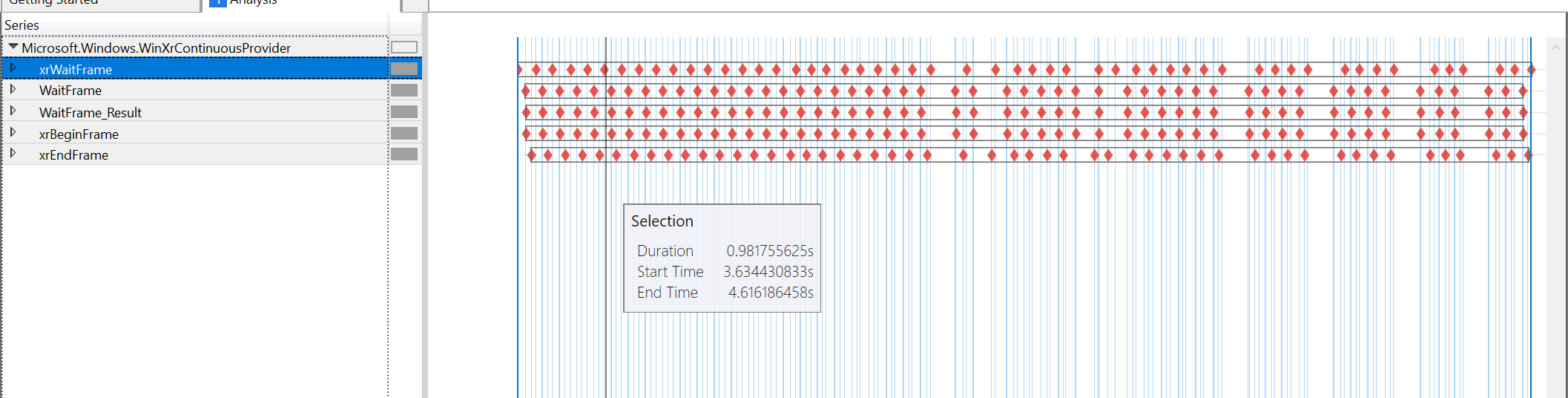
似乎责任完全在 xrWaitFrame 上,所有其他时间都非常接近。 xrBeginFrame 仍然几乎紧跟在 xrWaitFrame 之后,xrEndFrame 在 xrBeginFrame 之后 4us(在这两种情况下)。 下一个 xrWaitFrame 几乎紧跟在 xrEndFrame 之后。 唯一无法解释的差距是由 xrWaitFrame 本身引起的差距。
Manishearth
于 2020-03-11
通过拖动演示,我得到以下跟踪:

这是相同比例的绘画演示:
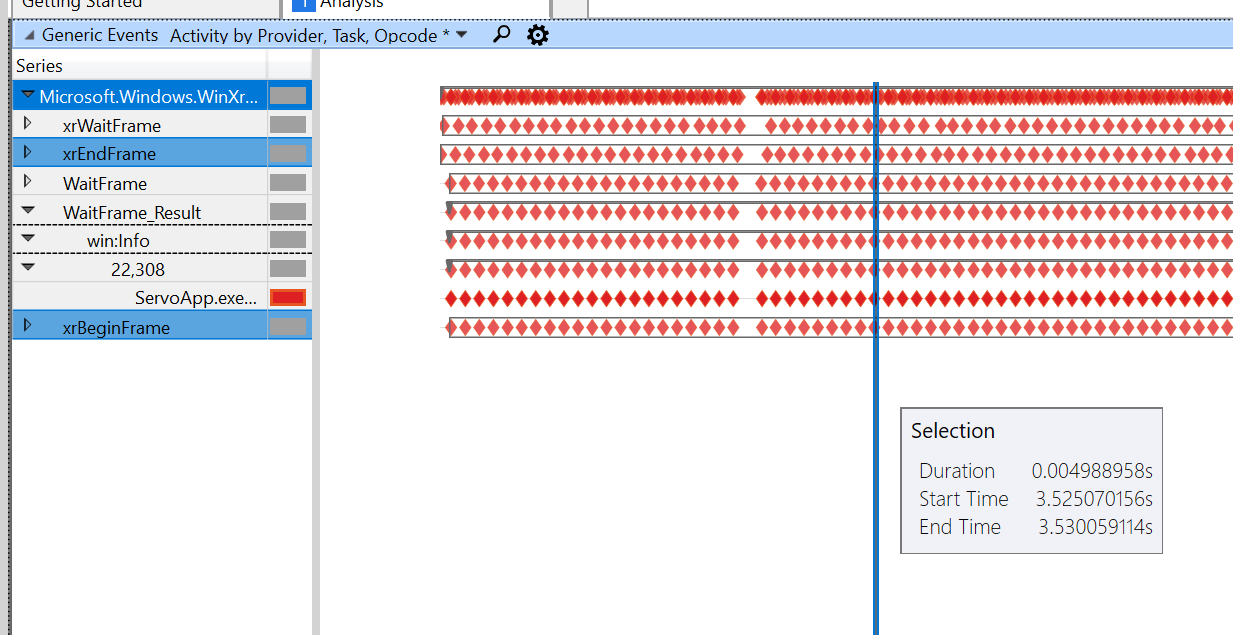
我们在开始/结束帧之间很慢(最快从 5 毫秒到 38 毫秒!),然后等待帧节流开始。我还没有弄清楚为什么会这样,我正在浏览代码两个都。
Manishearth
于 2020-03-18
拖动演示变慢了,因为它的光源投下了阴影。 阴影部分是在 GL 端完成的,所以我不确定我们是否可以轻松加快速度?
Manishearth
于 2020-03-18
如果完全通过 GLSL 完成,我们可能会遇到困难; 如果每帧都通过 WebGL API 完成,那么可能会有优化的地方。
jdm
于 2020-03-18
是的,似乎都在 GLSL 方面; 当涉及到影子 API 的工作方式时,我看不到任何 WebGL 调用,只有一些传递给着色器的位
Manishearth
于 2020-03-19
我相信这已得到普遍解决。 我们可以为需要工作的单个演示提交问题。
jdm
于 2020-07-20
相关问题
 CYBAI
·
3评论
CYBAI
·
3评论
 AgustinCB
·
4评论
AgustinCB
·
4评论
 shinglyu
·
4评论
shinglyu
·
4评论
 noisiak
·
3评论
noisiak
·
3评论
 pshaughn
·
3评论
pshaughn
·
3评论
最有用的评论
当前状态:通过 IPC 修复,FPS 现在徘徊在 55 左右。它有时会摆动一堆,但通常不会低于 45,_except_ 在加载后的前几秒钟(它可以下降到 30),以及何时首先看到一手牌(当它下降到 20 时)。