Estou usando isso para rastrear investigações sobre a causa de baixos valores de FPS ao usar o modo imersivo em dispositivos.
 jdm
jdm
Todos 71 comentários
Algumas informações que foram descobertas:
- há longas esperas entre xrWaitFrame e xrBeginFrame
- no aplicativo de demonstração, eles ocorrem sequencialmente
- no modelo do Servo, esperamos por um frame de dispositivo , então, uma vez que recebemos o renderizado do thread webgl, começamos o próximo frame openxr
Um traço da demonstração de pintura com marcadores para as APIs OpenXR reproduz esses dias e também mostra durante esse período:
- o thread webgl usa a maior parte da CPU (a maior parte desse tempo é gasto em gl :: Finish, que é chamado de Device :: bind_surface_to_context de surfman)
- o thread principal é o segundo mais ocupado, com o maior uso gasto em eglCreatePbufferFromClientBuffer e quase o mesmo tempo gasto capturando o objeto Egl do TLS
- a renderização do webrender também aparece nesta pilha
- winrt :: servo :: flush aparece aqui também, e não está claro para mim se realmente precisamos trocar os buffers GL do aplicativo principal enquanto estamos no modo imersivo
- o terceiro maior uso da CPU é o thread de script, gastando muito tempo dentro do código JIT
- após esse thread, o uso da CPU é geralmente muito baixo, mas há alguns símbolos da caixa de estilo aparecendo, indicando que o layout está ocorrendo
jdm
em 3 jan. 2020
Considerando esses pontos de dados, vou tentar duas abordagens para começar:
- inicie o próximo quadro XR o mais rápido possível depois de esperar pelo quadro do dispositivo
- reduza o número de vezes que precisamos chamar gl :: Finish (thread webgl), eglCreateBufferFromClientBuffer e TLS (thread principal)
jdm
em 3 jan. 2020
https://github.com/servo/servo/pull/25343#issuecomment -567706735 tem mais investigação sobre o impacto do envio de mensagens para vários lugares no mecanismo. Ele não aponta nenhum dedo claro, mas sugere que medidas mais precisas devem ser tomadas.
jdm
em 3 jan. 2020
O uso de gl :: Finish vem de https://github.com/pcwalton/surfman/blob/6705a9aaa8f33ac1324fdb1913242800e68c7720/surfman/src/platform/windows/angle/context.rs#L259 -L266.
jdm
em 3 jan. 2020
Alterar gl :: Finish para gl :: Flush aumenta a taxa de quadros de ~ 15-> 30, mas há um atraso extremamente perceptível no conteúdo do quadro, refletindo realmente o movimento da cabeça do usuário, fazendo com que o quadro atual siga a cabeça do usuário enquanto isso.
jdm
em 3 jan. 2020
Mutexes com chave são desativados por padrão em ANGLE por motivos que me escapam, mas mozangle os habilita explicitamente (https://github.com/servo/mozangle/blob/706a9baaf8026c1a3cb6c67ba63aa5f4734264d0/build_data.rs#L175), e é com isso que surfman é testado . Vou fazer uma compilação do ANGLE que os habilite e ver se isso é suficiente para evitar as chamadas gl :: Finish.
jdm
em 3 jan. 2020
Confirmado! Forçar mutexes com chave no ANGLE me dá 25-30 FPS na demonstração de pintura sem nenhum dos problemas de lag que vieram com a mudança da chamada gl :: Finish.
jdm
em 3 jan. 2020
Ah, e outra informação de acordo com as investigações de Lars:
- w / dom.ion.enabled definido como false, o tempo JIT desaparece. Os carregamentos iniciais são muito mais lentos, mas uma vez que as coisas estão funcionando, eles estão muito bons.
- Ainda não é fantástico - o uso de memória é muito alto (basicamente toda a memória disponível) naquele exemplo babylon.js
- devemos fazer outra atualização do macaco-aranha para obter otimizações relacionadas ao arm64 que estão acontecendo para FxR em dispositivos Android
jdm
em 3 jan. 2020
Acho que não entendi a presença de std::thread::local::LocalKey<surfman::egll::Egl> nos perfis - tenho quase certeza de que a leitura TLS é apenas uma pequena parte do tempo cobrado dela, e são as funções chamadas dentro do bloco TLS como eglCreatePbufferFromClientBuffer e DXGIAcquireSync que _atualmente_ leva tempo.
jdm
em 3 jan. 2020
Infelizmente, desabilitar js.ion.enabled parece prejudicar o FPS da demonstração de pintura, reduzindo-o para 20-25.
jdm
em 4 jan. 2020
Em vez de chamar Device :: create_surface_texture_from_texture duas vezes a cada quadro (uma vez para cada textura d3d para cada olho), pode ser possível criar texturas de superfície para todas as texturas de swapchain quando o dispositivo openxr webxr é criado. Se isso funcionar, ele removerá o segundo maior usuário da CPU do thread principal durante o modo imersivo.
jdm
em 4 jan. 2020
Outra ideia para reduzir o uso de memória: haverá algum impacto se definirmos o bfcache para um número muito baixo, de modo que o pipeline da página inicial do HL original seja removido ao navegar para uma das demos?
jdm
em 4 jan. 2020
O seguinte patch webxr não melhora claramente o FPS, mas pode melhorar a estabilidade da imagem. Preciso criar duas compilações separadas que posso executar uma após a outra para verificar.
diff --git a/webxr/openxr/mod.rs b/webxr/openxr/mod.rs
index 91c78da..a6866de 100644
--- a/webxr/openxr/mod.rs
+++ b/webxr/openxr/mod.rs
@@ -416,11 +416,30 @@ impl DeviceAPI<Surface> for OpenXrDevice {
}
fn wait_for_animation_frame(&mut self) -> Option<Frame> {
- if !self.handle_openxr_events() {
- // Session is not running anymore.
- return None;
+ loop {
+ if !self.handle_openxr_events() {
+ // Session is not running anymore.
+ return None;
+ }
+ self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
+ // XXXManishearth this code should perhaps be in wait_for_animation_frame,
+ // but we then get errors that wait_image was called without a release_image()
+ self.frame_stream
+ .begin()
+ .expect("failed to start frame stream");
+
+ if self.frame_state.should_render {
+ break;
+ }
+
+ self.frame_stream.end(
+ self.frame_state.predicted_display_time,
+ EnvironmentBlendMode::ADDITIVE,
+ &[],
+ ).unwrap();
}
- self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
let time_ns = time::precise_time_ns();
// XXXManishearth should we check frame_state.should_render?
let (_view_flags, views) = self
@@ -506,12 +525,6 @@ impl DeviceAPI<Surface> for OpenXrDevice {
0,
);
- // XXXManishearth this code should perhaps be in wait_for_animation_frame,
- // but we then get errors that wait_image was called without a release_image()
- self.frame_stream
- .begin()
- .expect("failed to start frame stream");
-
self.left_image = self.left_swapchain.acquire_image().unwrap();
self.left_swapchain
.wait_image(openxr::Duration::INFINITE)
@manishearth alguma opinião sobre isso? É minha tentativa de me aproximar do modelo descrito por https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#Session.
jdm
em 4 jan. 2020
Sim, parece bom. Tenho pretendido mover begin() para cima no waf e acredito que o erro mencionado no comentário não ocorre mais, mas também não teve um efeito perceptível no FPS, então não o investiguei muito por agora. Se melhorar a estabilidade, isso é bom!
 Manishearth
em 4 jan. 2020
Manishearth
em 4 jan. 2020
Muito feliz com a descoberta codificada! As chamadas de Surfman realmente ocupam uma boa parte do orçamento de quadros, mas é um pouco difícil determinar o que é e o que não é necessário.
Manishearth
em 4 jan. 2020
Sim, re: desabilitar js.ion.enabled , isso só será um benefício quando estivermos com falta de RAM e nos debatendo, gastando a maior parte do nosso tempo GC'ing e recompilar funções. E isso deve ser melhorado com um SM mais recente. IIRC, o back-end do ARM64 da era 66 também apresentava JIT de linha de base e desempenho do intérprete relativamente ruins; devemos ver acelerações em toda a linha com uma atualização, mas especialmente em aplicativos com uso intensivo de RAM.
 larsbergstrom
em 4 jan. 2020
larsbergstrom
em 4 jan. 2020
Novo pacote ANGLE publicado com mutexes com chave ativados. Vou criar uma solicitação pull para atualizá-lo mais tarde.
jdm
em 6 jan. 2020
Eu tentei criar as texturas de superfície para todas as imagens da cadeia de troca openxr durante a inicialização do dispositivo XR, mas ainda há muito tempo no thread principal gasto chamando eglCreatePbufferFromClientBuffer na superfície que recebemos do thread webgl a cada frame. Talvez haja alguma maneira de armazenar em cache essas texturas de superfície para que possamos reutilizá-las se recebermos a mesma superfície ...
jdm
em 6 jan. 2020
O maior thread principal de uso da CPU vem de render_animation_frame, com a maior parte sob o tempo de execução OpenXR, mas as chamadas para BlitFramebuffer e FramebufferTexture2D definitivamente aparecem no perfil também. Eu me pergunto se seria uma melhoria transformar os dois olhos ao mesmo tempo em uma única textura? Talvez isso esteja relacionado ao material de matriz de textura que é discutido em https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt.
jdm
em 6 jan. 2020
Podemos limpar os dois olhos de uma vez, no entanto, meu entendimento é que o tempo de execução
pode então fazer seu próprio blit. A matriz de textura é o método mais rápido. Mas
vale a pena tentar, a API de visualização de projeção oferece suporte para isso.
Quanto ao tráfego ANGLE do thread principal, interrompe o loop RAF de
sujar a tela ajuda? Até agora, isso não fez nada, mas vale a pena
tiro, idealmente não deveríamos fazer nada de layout / renderização no principal
fio.
Na segunda-feira, 6 de janeiro de 2020, 23h49, Josh Matthews [email protected]
escreveu:
O maior uso de CPU de thread principal vem de render_animation_frame, com
a maior parte disso no tempo de execução OpenXR, mas chamadas para BlitFramebuffer e
FramebufferTexture2D definitivamente aparecendo no perfil também. eu me pergunto
se seria uma melhoria blit ambos os olhos de uma vez para um único
textura? Talvez isso esteja relacionado ao material de matriz de textura que é discutido
dentro
https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt
.-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/servo/servo/issues/25425?email_source=notifications&email_token=AAMK6SBRH72JGZMXTUKOXETQ4NY37A5CNFSM4KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEIGJMHA#issuecomment-571250204 ,
ou cancelar
https://github.com/notifications/unsubscribe-auth/AAMK6SECM6MDNZZ6Y7VL7SDQ4NY37ANCNFSM4KCRI6AA
.
Manishearth
em 6 jan. 2020
Remover a sujeira da lona só limpa o perfil; não pareceu levar a um aumento significativo do FPS.
jdm
em 6 jan. 2020
Eu tentei criar um cache de texturas de superfície para superfícies do thread webgl, bem como texturas de swapchain openxr, e enquanto o tempo eglCreatePbufferFromClientBuffer desapareceu completamente, não notei nenhuma mudança significativa no FPS.
jdm
em 6 jan. 2020
Algumas informações de tempo para várias operações no pipeline imersivo (todas as medições em ms):
Name min max avg
raf queued 0.070833 14.010261 0.576834
<1ms: 393
<2ms: 28
<4ms: 5
<8ms: 1
<16ms: 2
<32ms: 0
32+ms: 0
raf transmitted 0.404270 33.649583 7.403302
<1ms: 123
<2ms: 43
<4ms: 48
<8ms: 48
<16ms: 95
<32ms: 69
32+ms: 3
raf wait 1.203500 191.064100 17.513593
<1ms: 0
<2ms: 17
<4ms: 98
<8ms: 95
<16ms: 48
<32ms: 69
32+ms: 101
raf execute 3.375000 128.663200 6.994588
<1ms: 0
<2ms: 0
<4ms: 5
<8ms: 351
<16ms: 70
<32ms: 1
32+ms: 2
raf receive 0.111510 8.564010 0.783503
<1ms: 353
<2ms: 52
<4ms: 18
<8ms: 4
<16ms: 1
<32ms: 0
32+ms: 0
raf render 2.372200 75.944000 4.219310
<1ms: 0
<2ms: 0
<4ms: 253
<8ms: 167
<16ms: 8
<32ms: 0
32+ms: 1
receive : tempo desde que as informações do quadro XR estão sendo enviadas do thread XR até serem recebidas pelo roteador IPC
queued : tempo desde o roteador IPC recebendo as informações do quadro até que XRSession :: raf_callback seja invocado
execute : tempo de XRSession :: raf_callback invocado até retornar do método
transmitted : tempo desde o envio da solicitação de um novo rAF do thread do script até o recebimento pelo thread XR
render : tempo gasto para chamar render_animation_frame e reciclar a superfície
wait : tempo gasto por wait_for_animation_frame (usando o patch anterior nesta edição que faz um loop sobre os frames que não devem ser renderizados)
Abaixo de cada entrada está a distribuição dos valores ao longo da sessão.
jdm
em 7 jan. 2020
Um ponto de dados interessante dessa informação de tempo - a categoria transmitted parece muito mais alta do que deveria. Esse é o atraso entre a execução do retorno de chamada rAF e o encadeamento XR recebendo a mensagem que incorpora o quadro concluído na textura do openxr. Há muitas variações, sugerindo que o thread principal está ocupado fazendo outras coisas ou precisa ser ativado para processá-lo.
jdm
em 7 jan. 2020
Dados os dados anteriores, posso tentar ressuscitar https://github.com/servo/webxr/issues/113 amanhã para ver se isso afeta positivamente o tempo de transmissão. Posso cutucar o thread principal no criador de perfil primeiro para ver se consigo ter alguma ideia sobre como saber se o thread está ocupado com outras tarefas ou adormecido.
jdm
em 7 jan. 2020
Um outro ponto de dados:
swap buffer 1.105938 28.193698 2.154793
<1ms: 0
<2ms: 273
<4ms: 110
<8ms: 15
<16ms: 2
<32ms: 2
32+ms: 0
swap complete 0.053802 4.337812 0.295064
<1ms: 308
<2ms: 9
<4ms: 6
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
swap request 0.003333 24033027.355364 4662890.724805
<1ms: 268
<2ms: 49
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 1
32+ms: 79
Estes são tempos relacionados a 1) o atraso de envio da mensagem do buffer de troca até que ela seja processada no thread webgl, 2) o tempo gasto para trocar os buffers, 3) o atraso de envio da mensagem indicando que a troca está completa até que seja recebida em o tópico do script. Nada muito surpreendente aqui (exceto aqueles outliers estranhos na categoria swap request , mas eles acontecem bem no início da sessão imersiva durante um afaict de configuração), mas a troca real de buffer leva consistentemente entre 1-4ms.
jdm
em 7 jan. 2020
Arquivado # 117 depois de ler algum código de amostra openxr e perceber que as chamadas de locate_views aparecem no perfil.
jdm
em 7 jan. 2020
Presumivelmente https://github.com/servo/webxr/issues/117
 asajeffrey
em 7 jan. 2020
asajeffrey
em 7 jan. 2020
Um ponto de dados interessante a partir dessa informação de tempo - a categoria transmitida parece muito mais alta do que deveria ser. Esse é o atraso entre a execução do retorno de chamada rAF e o encadeamento XR recebendo a mensagem que incorpora o quadro concluído na textura do openxr. Há muitas variações, sugerindo que o thread principal está ocupado fazendo outras coisas ou precisa ser ativado para processá-lo.
Com relação às variações no transmitted , ele pode estar vinculado ao tempo limite usado como parte de run_one_frame quando a sessão está sendo executada no thread principal (que está nessas medidas, certo?) , consulte https://github.com/servo/webxr/blob/c6abf4c60d165ffc978ad2ebd6bcddc3c21698e1/webxr-api/session.rs#L275
Suponho que quando o RenderAnimationFrame msg (aquele enviado pelo script-thread após executar os callbacks) é recebido antes do tempo limite, você atinge o "caminho rápido", e se o tempo limite for perdido, o Servo vai para outro iteração de perform_updates e a "execução de outro quadro" acontecem bem tarde no ciclo, como parte de compositor.perform_updates , ele próprio chamado bem tarde como parte de servo.handle_events .
Sem mover o XR para seu próprio thread, pode valer a pena ver se um valor mais alto para o tempo limite melhora o valor médio (embora possa não ser a solução certa, pois pode privar outras coisas necessárias no thread principal).
 gterzian
em 8 jan. 2020
gterzian
em 8 jan. 2020
Fiz progresso em tirar o openxr do thread principal em https://github.com/servo/webxr/issues/113 , então farei mais medições com base nesse trabalho na próxima semana.
jdm
em 10 jan. 2020
Técnicas para obter perfis úteis do dispositivo:
- use um .servobuild que inclua
rustflags = "-C force-frame-pointers=yes" - descomente essas linhas
- use WinXR_Perf.wprp das equipes MS char
Filesguia como um perfil de rastreamento personalizado em "Rastreamento de desempenho" no portal do dispositivo HL - construir com
--features profilemozjs
Esses rastreamentos (obtidos em "Iniciar rastreamento" no portal do dispositivo) poderão ser usados na ferramenta Windows Performance Analyzer. Esta ferramenta não mostra nomes de thread, mas os threads que usam mais CPU são fáceis de identificar com base nas pilhas.
Para traçar o perfil da distribuição de tempo de um determinado frame openxr:
- adicione a visualização "Atividade do sistema -> Eventos genéricos" no WPA
- filtrar a exibição para mostrar apenas a série Microsoft.Windows.WinXrContinuousProvider
- amplie para uma curta duração e, em seguida, refine a região ampliada para que um evento xrBegin fique no lado esquerdo da visualização e um evento xrEnd no lado direito da visualização
Vistas mais úteis para o uso da CPU:
- Uso da CPU (amostrado) -> Utilização por processo, thread, pilha (filtre a visualização para mostrar apenas o servo e, em seguida, desative a coluna Processo)
- Chama por Processo, Pilha (filtre a visualização para mostrar apenas Servo)
jdm
em 16 jan. 2020
Uma possibilidade de fazer um pouco menos de trabalho no thread de script:
- XRView :: new consome 0,02% de todo o Servo CPU
- uma vez que o conteúdo dos objetos de visualização não muda a menos que haja um evento FrameUpdateEvent :: UpdateViews (que vem de Session :: update_clip_planes via XRSession :: UpdateRenderState), poderíamos concebivelmente armazenar em cache os objetos XRView no XRSession e continuar usando-os até que estado de renderização é atualizado
- poderíamos até manter a representação JS da lista de visualizações em cache no XRSession e definir o membro de visualizações da pose, evitando recriar os objetos XRView e alocar o vetor e realizar a conversão do valor JS
jdm
em 16 jan. 2020
Uma possibilidade de fazer menos trabalho ao renderizar um quadro imersivo:
- GL e d3d têm sistemas de coordenadas Y invertidos
- ANGLE oculta isso implicitamente ao apresentar na tela, fazendo algum trabalho nos bastidores
- para o modo imersivo, usamos glBlitFramebuffer para realizar uma inversão y ao enviar os dados de textura GL para d3d
- se pudermos descobrir como fazer o ANGLE não fazer a conversão internamente, pode ser possível inverter este modelo e fazer com que a renderização de páginas da web não imersivas requeira um blit de inversão de y extra (por meio da opção webrender
surface_origin_is_top_left) enquanto o modo imersivo pode ser misturado sem qualquer transformação
Com base em https://bugzilla.mozilla.org/show_bug.cgi?id=1591346 e conversando com jrmuizel, aqui está o que precisamos fazer:
- obtenha uma cadeia de troca d3d para o elemento da janela em que queremos renderizar as páginas não imersivas (será o SwapChainPanel no aplicativo XAML)
- envolva isso em uma imagem EGL (https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#554)
- Apresente explicitamente a cadeia de troca quando quisermos atualizar a renderização principal
- evite usar eglCreateWindowSurface e eglSwapBuffers em https://github.com/servo/servo/blob/master/support/hololens/ServoApp/ServoControl/OpenGLES.cpp#L205 -L208
Código Gecko relevante: https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#192
Código ANGLE relevante: https://github.com/google/angle/blob/df0203a9ae7a285d885d7bc5c2d4754fe8a59c72/src/libANGLE/renderer/d3d/d3d11/winrt/SwapChainPanelNativeWindow.cpp#L24PanelNativeWindow.cpp#L24
jdm
em 16 jan. 2020
Ramos de limpeza atuais:
- https://github.com/servo/ipc-channel/tree/try-recv-error
- https://github.com/jdm/webxr/tree/oxr
- https://github.com/jdm/rust-offscreen-rendering-context/tree/angle-perf
- https://github.com/jdm/servo/tree/profile
Isso inclui um recurso xr-profile que adiciona os dados de tempo que mencionei anteriormente, bem como uma implementação inicial das alterações ANGLE para remover a transformação y-inversa no modo imersivo. O modo não imersivo está renderizando corretamente, mas o modo imersivo está de cabeça para baixo. Acredito que preciso remover o código GL de render_animation_frame e substituí-lo por uma chamada direta de CopySubresourceRegion, extraindo o identificador de compartilhamento da superfície GL para que eu possa obter sua textura d3d.
jdm
em 17 jan. 2020
Arquivado em https://github.com/servo/servo/issues/25582 para o trabalho de inversão y do ANGLE; mais atualizações sobre esse trabalho ocorrerão nessa edição.
jdm
em 23 jan. 2020
O próximo item importante será investigar maneiras de evitar totalmente as chamadas glBlitFramebuffer no back-end openxr webxr. Isso requer:
- criando framebuffers openxr que correspondam aos framebuffers webgl opacos exigidos precisamente
- suportando um modo webgl onde o backend webxr fornece todas as superfícies de swapchain, em vez de criá-las (por exemplo, em https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L458 e https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L111-L118)
jdm
em 23 jan. 2020
Isso pode ser difícil, já que surfman só fornece acesso de gravação ao contexto que criou a superfície, portanto, se a superfície for criada pelo encadeamento openxr, não será gravável pelo encadeamento WebGL. https://github.com/pcwalton/surfman/blob/a515fb2f5d6b9e9b36ba4e8b498cdb4bea92d330/surfman/src/device.rs#L95 -L96
asajeffrey
em 23 jan. 2020
Ocorre-me - se fizéssemos a renderização openxr no webgl thread, um monte de problemas relacionados ao threading em torno da renderização direta para as texturas openxr não seriam mais problemas (ou seja, as restrições em torno de eglCreatePbufferFromClientBuffer proibindo o uso de vários dispositivos d3d). Considerar:
- ainda há um thread openxr que é responsável por pesquisar os eventos openxr, esperando por um quadro de animação, iniciando um novo quadro e recuperando o estado do quadro atual
- o estado do quadro é enviado ao thread de script, que executa o retorno de chamada da animação e, em seguida, envia uma mensagem ao thread webgl para trocar o framebuffer da camada xr
- quando essa mensagem de troca é recebida no segmento webgl, liberamos a última imagem de swapchain openxr adquirida, enviamos uma mensagem para o segmento openxr para encerrar o quadro atual e adquirimos uma nova imagem de swapchain para o próximo quadro
Minha leitura de https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#threading -behavior sugere que este design pode ser viável. O truque é saber se ele pode funcionar para nossos back-ends não openxr, bem como para o openxr.
Da especificação: "Embora xrBeginFrame e xrEndFrame não precisem ser chamados no mesmo encadeamento, o aplicativo deve lidar com a sincronização se eles forem chamados em encadeamentos separados."
jdm
em 25 jan. 2020
No momento não há comunicação direta entre os threads do dispositivo XR e o webgl, tudo passa por script ou por meio de sua cadeia de troca compartilhada. Eu ficaria tentado a fornecer uma API de cadeia de troca que fica acima de uma cadeia de troca de surfman ou uma cadeia de troca openxr e usá-la para comunicação webgl-para-openxr.
asajeffrey
em 25 jan. 2020
Notas de uma conversa sobre as medições de tempo anteriores:
* concerns about wait time - why?????
* figure out time spent in JS vs. DOM logic
* when does openxr give us should render=false frames - maybe related to previous frame taking too long
* are threads being scheduled on inappropriate cpus? - on magic leap, main thread (including weber) pinned to big core.
* when one of the measured numbers is large, is there correlation with other large numbers?
* probably should pin openxr thread, running deterministic code
* consider clearing after telling script that the swap is complete - measure if clear is taking significant time in swap operation
* consider a swap chain API operation - “wait until a buffer swap occurs”
- block waiting on swapchain
- block waiting on swapchain + timeout
- async????????
- a gc would look like a spike in script execution time
Arquivado no nº 25735 para rastrear as investigações que estou realizando sobre renderização diretamente para as texturas openxr.
jdm
em 11 fev. 2020
Uma coisa que devemos fazer é restringir a comparação do macaco-aranha no dispositivo com outros motores. A maneira mais fácil de obter alguns dados aqui é encontrar um benchmark JS simples que o Servo pode executar e comparar o desempenho do Servo com o navegador Edge instalado no dispositivo. Além disso, poderíamos tentar visitar algumas demos complexas de babylon em ambos os navegadores sem entrar no modo imersivo para ver se há uma diferença significativa de desempenho. Isso também nos dará uma referência para comparar com a atualização do macaco-aranha que está por vir.
jdm
em 13 fev. 2020
Alguns novos dados. Isso ocorre com a atualização do ANGLE, mas não com a do IPC.
$ python timing.py raw
Name min max mean
raf queued 0.056198 5.673125 0.694902
<1ms: 335
<2ms: 26
<4ms: 17
<8ms: 7
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.822917 36.582083 7.658619
<1ms: 1
<2ms: 4
<4ms: 31
<8ms: 181
<16ms: 158
<32ms: 8
32+ms: 1
raf wait 1.196615 39.707709 10.256875
<1ms: 0
<2ms: 32
<4ms: 93
<8ms: 67
<16ms: 107
<32ms: 68
32+ms: 17
raf execute 3.078438 532.205677 7.752839
<1ms: 0
<2ms: 0
<4ms: 37
<8ms: 290
<16ms: 52
<32ms: 2
32+ms: 3
raf receive 0.084375 9.053125 1.024403
<1ms: 276
<2ms: 71
<4ms: 27
<8ms: 9
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.004115 73.939479 0.611254
<1ms: 369
<2ms: 10
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.706198 233.459636 9.241698
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 183
<16ms: 190
<32ms: 10
32+ms: 1
run_one_frame 7.663333 2631.052969 28.035143
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 3
<16ms: 157
<32ms: 185
32+ms: 41
swap buffer 0.611927 8.521302 1.580279
<1ms: 127
<2ms: 169
<4ms: 74
<8ms: 15
<16ms: 1
<32ms: 0
32+ms: 0
swap complete 0.046511 2.446302 0.215040
<1ms: 375
<2ms: 6
<4ms: 3
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Dados de tempo: https://gist.github.com/Manishearth/825799a98bf4dca0d9a7e55058574736
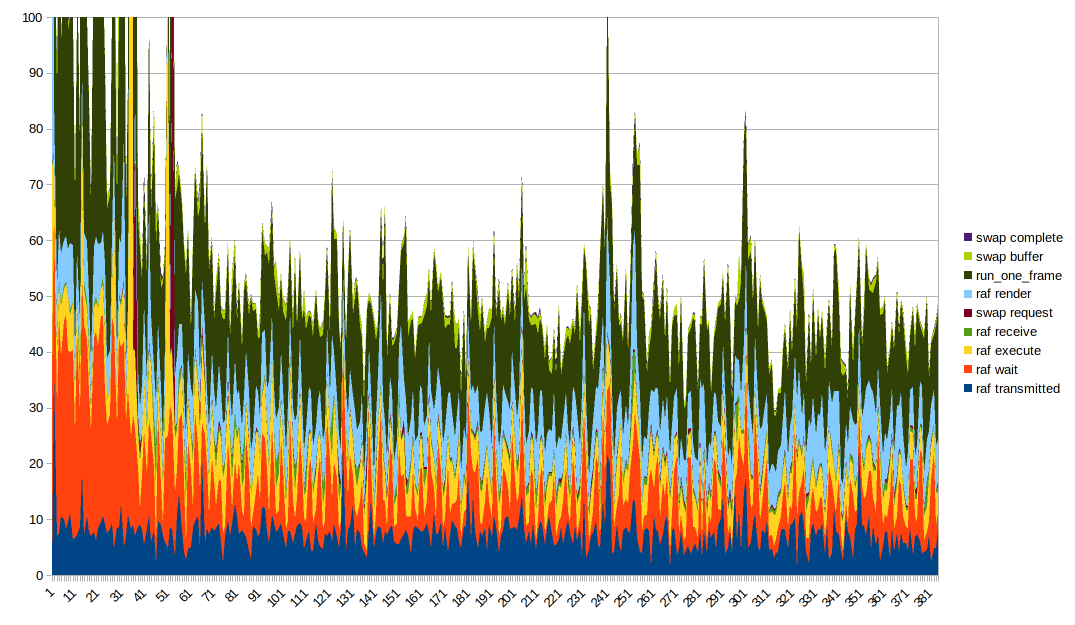
Obter uma boa visualização de dados disso é complicado. Um gráfico de linhas empilhadas parece ideal, embora seja importante notar que run_one_frame mede vários tempos já medidos. É útil mexer na ordem do gráfico e colocar colunas diferentes na parte inferior para ver melhor o efeito. Além disso, você precisa truncar o eixo Y para obter algo útil devido a alguns valores discrepantes muito grandes.
Coisas interessantes a serem observadas:
- o tempo de renderização e o tempo de execução parecem estar estáveis, mas apresentam picos quando há picos grandes em geral. Eu suspeito que os grandes picos vêm de tudo desacelerando por qualquer motivo
- O tempo de transmissão parece muito bem correlacionado com a forma geral
- o tempo de espera também é parte do motivo pelo qual a forma geral é assim, é _muito_ ondulada
Manishearth
em 21 fev. 2020
Status atual: com as correções de IPC, o FPS está agora em torno de 55. Às vezes, ele balança um bocado, mas geralmente não fica abaixo de 45, _exceto_ durante os primeiros segundos após o carregamento (onde pode cair para 30), e quando ele primeiro vê uma mão (quando cai para 20).
Manishearth
em 25 fev. 2020
Histograma mais recente para demonstração de pintura ( dados brutos ):
Name min max mean
raf queued 0.113854 5.707917 0.441650
<1ms: 352
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.546667 44.954792 6.886162
<1ms: 4
<2ms: 2
<4ms: 23
<8ms: 279
<16ms: 59
<32ms: 3
32+ms: 1
raf wait 1.611667 37.913177 9.441104
<1ms: 0
<2ms: 6
<4ms: 98
<8ms: 82
<16ms: 135
<32ms: 43
32+ms: 6
raf execute 3.336562 418.198541 7.592147
<1ms: 0
<2ms: 0
<4ms: 11
<8ms: 319
<16ms: 36
<32ms: 2
32+ms: 3
raf receive 0.119323 9.804167 0.806074
<1ms: 324
<2ms: 31
<4ms: 13
<8ms: 1
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.003646 79.236354 0.761324
<1ms: 357
<2ms: 9
<4ms: 2
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 3
raf render 5.844687 172.898906 8.131682
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 283
<16ms: 86
<32ms: 1
32+ms: 1
run_one_frame 8.826198 2577.357604 25.922205
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 176
<32ms: 174
32+ms: 22
swap buffer 0.708177 12.528906 1.415950
<1ms: 164
<2ms: 161
<4ms: 38
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
swap complete 0.042917 1.554740 0.127729
<1ms: 370
<2ms: 1
<4ms: 0
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Execução mais longa ( bruta ). Feito para reduzir o impacto de lentidão na inicialização.
Nome mín. Máx. Média
raf na fila 0,124896 6,356562 0,440674
<1ms: 629
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32 + ms: 0
raf transmitido 0,640677 20,275104 6,944751
<1ms: 2
<2ms: 3
<4ms: 29
<8ms: 513
<16ms: 99
<32ms: 1
32 + ms: 0
raf wait 1.645886 40.955208 9.386255
<1ms: 0
<2ms: 10
<4ms: 207
<8ms: 114
<16ms: 236
<32ms: 65
32 + ms: 15
raf execute 3.090104 526.041198 6.226997
<1ms: 0
<2ms: 0
<4ms: 68
<8ms: 546
<16ms: 29
<32ms: 1
32 + ms: 3
raf receber 0,203334 6,441198 0,747615
<1ms: 554
<2ms: 84
<4ms: 7
<8ms: 2
<16ms: 0
<32ms: 0
32 + ms: 0
pedido de troca 0,003490 73,644322 0,428460
<1ms: 627
<2ms: 18
<4ms: 1
<8ms: 0
<16ms: 0
<32ms: 0
32 + ms: 2
raf render 5.450312 209.662969 8.055021
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 467
<16ms: 176
<32ms: 3
32 + ms: 1
run_one_frame 8.417291 2579.454948 22.226204
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 326
<32ms: 290
32 + ms: 33
buffer de troca 0,658125 12,179167 1,378725
<1ms: 260
<2ms: 308
<4ms: 72
<8ms: 4
<16ms: 4
<32ms: 0
32 + ms: 0
troca completa 0,041562 5,161458 0,136875
<1ms: 642
<2ms: 3
<4ms: 1
<8ms: 1
<16ms: 0
<32ms: 0
32 + ms: 0
Manishearth
em 27 fev. 2020
Gráficos:
Execução mais longa:

Execução mais curta: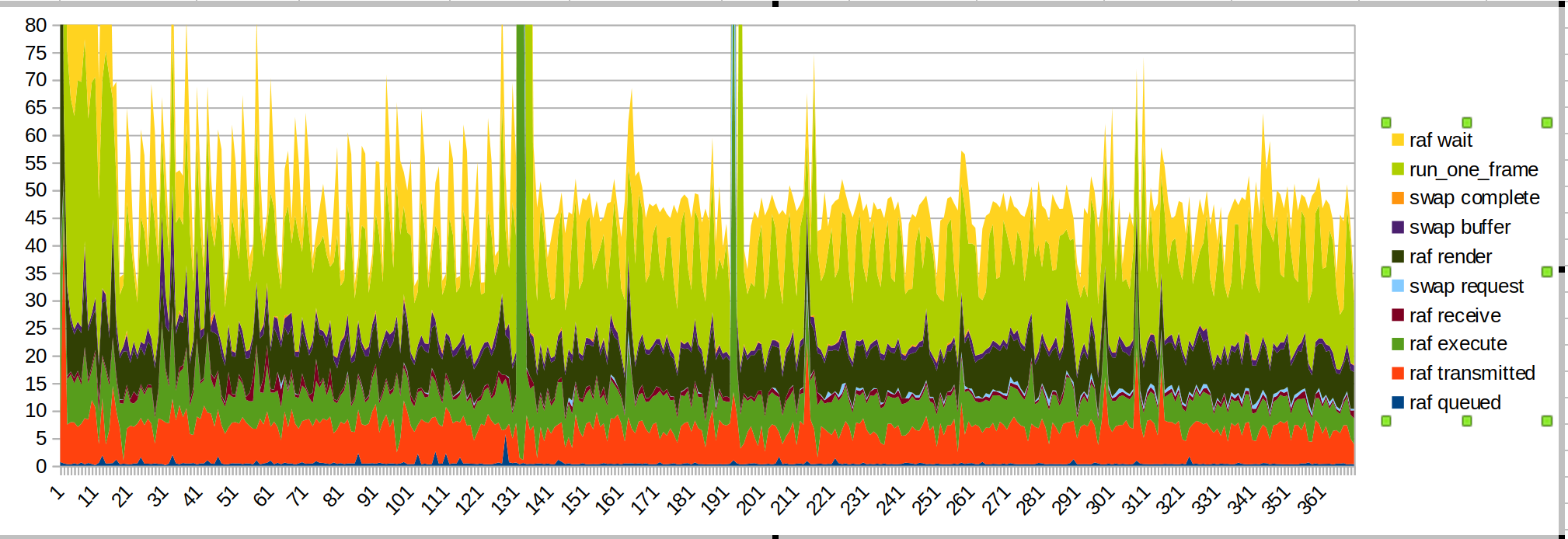
o grande pico é quando coloco minha mão dentro do alcance do sensor.
Desta vez, coloquei wait / run_one_frame times no topo porque esses são os mais irregulares, e isso é porque o sistema operacional está nos limitando.
Algumas coisas a serem observadas:
- O grande pico de mãos sendo introduzidas é causado pelo código JS (manjericão verde, "raf render")
- o tempo de transmissão ficou mais suave, como esperado
- quando eu começo a desenhar, há outro pico de JS
- o tempo de renderização e transmissão ainda são partes significativas do orçamento. O desempenho do script também pode ser melhorado.
- Suspeito que o tempo de transmissão demore muito porque o thread principal está ocupado fazendo outras coisas. Este é https://github.com/servo/webxr/issues/113 , @jdm está investigando
- As atualizações do surfman podem melhorar os tempos de renderização. As medições de @asajeffrey no surfmanup parecem melhores que as minhas
- fazer o compartilhamento de superfície pode melhorar os tempos de renderização (bloqueado no surfmanup)
- o FPS mostrado pelo dispositivo é quase reduzido pela metade quando medido com o perfil xr. Isso pode ser por causa de todo o IO.
O desempenho distorce por ver a mão e depois começar a desenhar não está presente para o lançador de bolas. Talvez a demonstração de pintura esteja fazendo muito trabalho quando decide desenhar a imagem da mão pela primeira vez?
(Isso também pode ser a demonstração de pintura tentando interagir com a biblioteca de entradas do webxr)
Manishearth
em 27 fev. 2020
@Manishearth Você também pode sobrepor o uso de memória e correlacionar a esses eventos? Além da compilação de código JS pela primeira vez, você pode estar com problemas em uma tonelada de código novo e executando contra os limites de memória física e incorrendo em um monte de GCs conforme atinge a pressão de memória. Eu estava vendo isso na maioria das situações não triviais. Tenho esperança de que a atualização do SM da @nox ajude, já que esse foi definitivamente um artefato que vimos nesta versão do SM no FxR Android.
larsbergstrom
em 27 fev. 2020
Não tenho uma maneira fácil de obter dados de perfil de memória de uma forma que possa ser correlacionada com o material de perfil xr.
Eu poderia usar as ferramentas de desempenho existentes e descobrir se a forma é a mesma.
Manishearth
em 27 fev. 2020
@Manishearth O material xr-profiling mostra (ou poderia mostrar) eventos JS GC? Isso pode ser um proxy razoável.
larsbergstrom
em 27 fev. 2020
De qualquer forma, os picos de inicialização não são minha principal preocupação, gostaria de ter tudo _mais_ a 60fps primeiro. Se estiver confuso por um ou dois segundos na inicialização, essa é uma preocupação menos urgente.
Manishearth
em 27 fev. 2020
Sim, poderia mostrar isso, precisaria de alguns ajustes.
Manishearth
em 27 fev. 2020
@Manishearth Totalmente de acordo com as prioridades! Eu não tinha certeza se você estava tentando "desvincular as torções" ou diminuir o estado estacionário. Concorde com o último mais importante agora.
larsbergstrom
em 27 fev. 2020
Nah, eu estava apenas anotando todas as análises que pude.
Manishearth
em 27 fev. 2020
Esses picos perto do final do gráfico da execução menor, onde o tempo de transmissão também aumenta: é quando eu estava movendo minha cabeça e desenhando, e Alan também estava percebendo quedas no FPS ao fazer as coisas, e atribuiu isso ao SO fazendo outro trabalho . Depois que o IPC corrige, meu palpite sobre os picos de tempo de transmissão é que eles são causados pelo sistema operacional fazendo outro trabalho, então pode ser isso que está acontecendo lá. Em um mundo fora do thread principal, eu esperaria que fosse muito mais suave.
Manishearth
em 27 fev. 2020
Ignore-me se isso já foi considerado, você já pensou em dividir a medição de run_one_frame por mensagem tratada e também cronometrar o tempo gasto thread::sleep() -ing?
Pode valer a pena adicionar três pontos de medição:
um empacotamento https://github.com/servo/webxr/blob/68b024221b8c72b5b33a63441d63803a13eadf03/webxr-api/session.rs#L364
e outro empacotamento https://github.com/servo/webxr/blob/2841497966d87bbd561f18ea66547dde9b13962f/webxr-api/lib.rs#L124 como um todo,
e também um envolvendo a chamada apenas para
thread::sleep.
Quanto aos recv_timeout , isso poderia ser algo a ser totalmente reconsiderado.
Acho um pouco difícil raciocinar sobre a utilidade do tempo limite. Já que você está contando o quadro renderizado, veja o frame_count , o caso de uso parece ser "talvez lidar com uma ou várias mensagens que não estão renderizando o quadro, primeiro, seguido pela renderização de um quadro, evitando passar por o loop de evento completo do thread principal "?
Também tenho algumas dúvidas sobre o cálculo real dos delay usados nele, onde atualmente:
- começa em
delay = timeout / 1000, comtimeoutsendo atualmente definido como 5 ms - Em seguida, ele cresce exponencialmente, dobrando a cada iteração em
delay = delay * 2; - É verificado no topo do loop com
while delay < timeout.
Então a sequência de dorme, no pior caso, é algo como: 5micro -> 10 -> 20 -> 40 -> 80 -> 160 -> 320 -> 640 -> 1,28 milli -> 2,56 milli -> 5,12 milli
Quando atingir 5,12 milissegundos, você sairá do loop (uma vez que delay > timeout ), tendo esperado um total de 5.115 milissegundos, mais o tempo adicional gasto esperando o SO ativando o thread após cada sleep .
Então, acho que o problema é que você pode estar dormindo por mais de 5 ms no total, e também acho que não é uma boa ideia dormir duas vezes por mais de 1 ms (e da segunda vez é mais de 2,5 ms) desde uma mensagem pode entrar durante esse tempo e você não vai acordar.
Não tenho certeza de como melhorá-lo, parece que você está tentando girar para uma mensagem em potencial e, finalmente, apenas passar para a próxima iteração do loop de evento principal se nada estiver disponível (por que não bloquear no recv?).
Você poderia passar a usar https://doc.rust-lang.org/std/thread/fn.yield_now.html , olhando para este artigo sobre bloqueios , ele parece girar cerca de 40 vezes enquanto chama yield cada vez , é o ideal (consulte o parágrafo "Girar", não é possível vincular diretamente a ele). Depois disso, você deve bloquear no receptor ou apenas continuar com a iteração atual do loop de evento (uma vez que ele está sendo executado como um sub-loop dentro do loop de evento de incorporação principal).
(obviamente, se você não estiver medindo com ipc ativado, a parte acima em recv_timeout é irrelevante, embora você ainda possa querer medir o calll para recv_timeout no mpsc já que o canal encadeado fará alguns giros / rendimentos internos que também podem influenciar os resultados. E como uma "correção IPC" não identificada foi mencionada várias vezes acima, presumo que você esteja medindo com ipc).
gterzian
em 27 fev. 2020
Ignore-me se isso já foi considerado, você já pensou em dividir a medição de run_one_frame por mensagem tratada e também cronometrar o tempo gasto no segmento :: sleep () - ing?
Já está quebrado, os tempos de espera / renderização são exatamente esses. Um único tique de run_one_frame é uma renderização, uma espera e um número indeterminado de eventos sendo tratados (raro).
recv_timeout é uma boa ideia para medição
Manishearth
em 27 fev. 2020
Infelizmente, a atualização do macaco-aranha em # 25678 não parece ser uma melhoria significativa - o FPS médio de cada demo, exceto o mais restrito de memória, diminuiu; a demonstração de Hill Valley subiu ligeiramente. A execução do Servo com -Z gc-profile nos argumentos de inicialização não mostra nenhuma diferença no comportamento do GC entre o master e o branch de atualização do spidermonkey - nenhum GCs é relatado após o conteúdo do GL ter sido carregado e exibido.
jdm
em 3 mar. 2020
Medições para vários ramos:
master:
- espilit: 14-16 fps
- paint: 39-45 fps
- ball shooter: 30-40 fps
- hill valley: 8 fps, 200mb free mem
- mansion: 10-14fps, 650mb free mem
master + single swapchain:
- espilit: 10-12 fps
- paint: 29-55 fps, 1.2gb free mem
- ball shooter: 25-35 fps, 1.3gb free mem
- hill valley: 6-7 fps, 200mb free mem
- mansion: 10-11 fps, 700mb free mem
texture sharing + ANGLE 2.1.19:
- espilit: 13-15 fps, 670mb free mem
- paint: 39-45 fps
- ball shooter: 30-37 fps, 1.3gb free mem
- hill valley: 9-10 fps, 188mb free mem
- mansion: 13-14 fps, 671mb free mem
smup:
- espilit: 11-13 fps, 730mb free mem
- paint: 25-42 fps, 1.1gb free mem
- ball shooter: 26-30 fps, 1.4gb free mem
- hill valley: 10-11 fps, 145mb
- mansion: 9-11fps, 680mb free mem
O smup piorou o desempenho ???
asajeffrey
em 3 mar. 2020
Com as alterações de https://github.com/servo/servo/pull/25855#issuecomment -594203492, há o resultado interessante de que a desativação do Ion JIT começa a 12 FPS e, em seguida, vários segundos depois, ele cai abruptamente para 1 FPS e fica lá.
jdm
em 3 mar. 2020
Fiz algumas medições com esses patches.
Na pintura, obtenho 60 fps quando não há muito conteúdo à vista e, quando vejo o conteúdo desenhado, cai para 50 fps (os picos amarelos ocorrem quando estou olhando o conteúdo desenhado). É difícil dizer por que, principalmente parece que o tempo de espera está sendo afetado pela limitação do openxr, mas as outras coisas não parecem lentas o suficiente para causar um problema. O tempo de solicitação de troca é um pouco mais lento. O tempo de execução do rAF é lento inicialmente (esta é a "primeira vez que um controlador é visto" lento), mas depois disso é bastante constante. Parece que o openxr está apenas nos estrangulando, mas não há nenhuma desaceleração visível em outro lugar que possa causar isso.

Manishearth
em 7 mar. 2020
Isso é o que eu tenho para a demonstração de arrastar. A escala y é a mesma. Aqui é muito mais óbvio que o tempo de execução está nos atrasando.

Manishearth
em 7 mar. 2020
Uma coisa a notar é que eu estava fazendo medições com o # 25837 aplicado e isso pode afetar o desempenho.
jdm
em 7 mar. 2020
Eu não estava, no entanto, estava obtendo resultados semelhantes aos seus
Manishearth
em 7 mar. 2020
Gráficos de ferramentas de desempenho para o momento em que vai de 60FPS a 45FPS ao olhar para o conteúdo:
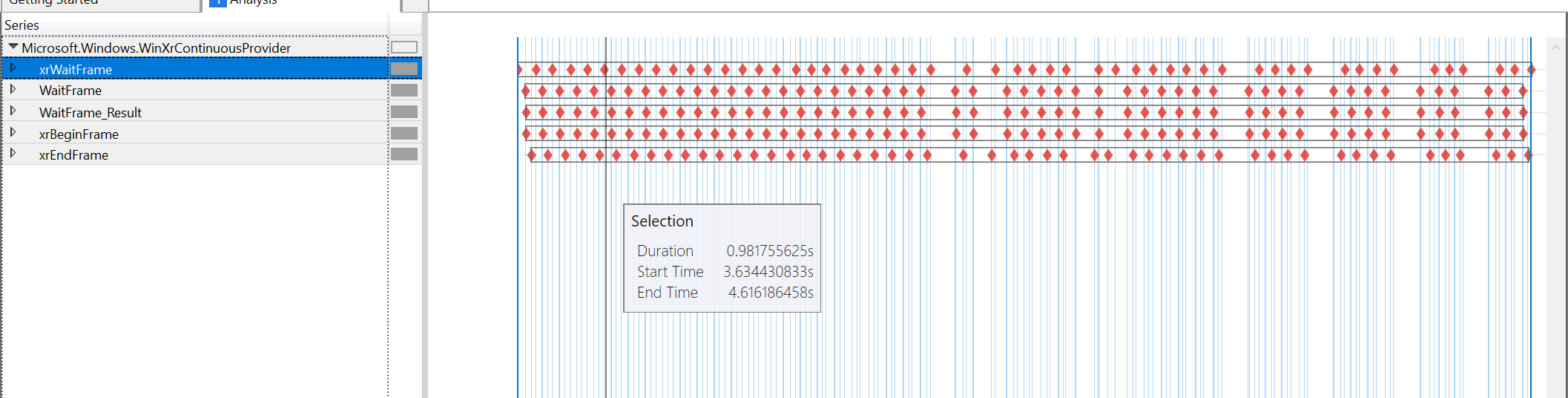
parece que a culpa é inteiramente do xrWaitFrame, todos os outros tempos estão muito próximos. O xrBeginFrame ainda está quase imediatamente após o xrWaitFrame, o xrEndFrame está 4us após o xrBeginFrame (em ambos os casos). O próximo xrWaitFrame é quase imediatamente após o xrEndFrame. A única lacuna não explicada é a causada pelo próprio xrWaitFrame.
Manishearth
em 11 mar. 2020
Com a demonstração de arrastar, obtenho o seguinte rastreamento:

Esta é a demonstração de pintura com a mesma escala:
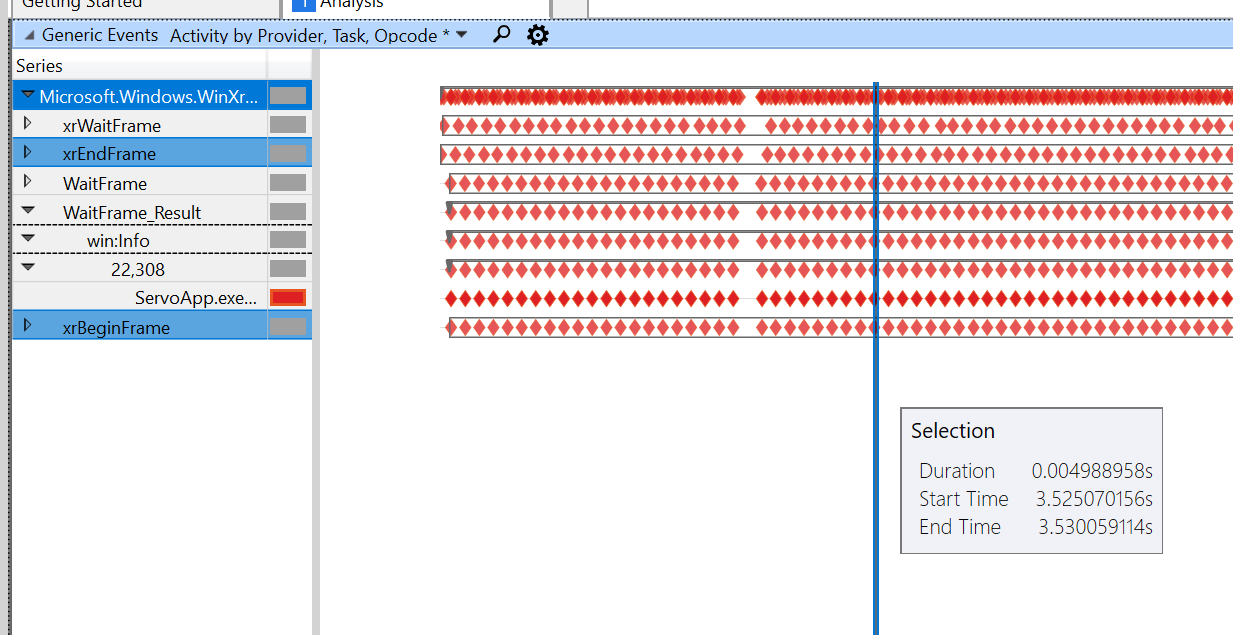
Ficamos lentos entre o início / fim do quadro (de 5ms a 38ms no mais rápido!) E, em seguida, a aceleração do quadro de espera entra em ação. Ainda não descobri por que esse é o caso, estou examinando o código para Ambas.
Manishearth
em 18 mar. 2020
A demonstração de arrastamento é desacelerada porque sua fonte de luz projeta uma sombra. O material de sombra é feito no lado do GL, então não tenho certeza se podemos acelerar isso facilmente.
Manishearth
em 18 mar. 2020
Se for feito inteiramente por meio do GLSL, podemos ter dificuldades; se for feito a cada quadro por meio de APIs WebGL, pode haver locais para otimizar.
jdm
em 18 mar. 2020
Sim, parece que todos estão do lado GLSL; Não consegui ver nenhuma chamada WebGL quando se trata de como as APIs de sombra funcionam, apenas alguns bits que são passados para os shaders
Manishearth
em 19 mar. 2020
Eu acredito que isso foi abordado em geral. Podemos registrar problemas para demonstrações individuais que precisam ser corrigidas.
jdm
em 20 jul. 2020
Questões relacionadas
 CYBAI
·
3Comentários
CYBAI
·
3Comentários
 mrobinson
·
3Comentários
mrobinson
·
3Comentários
 roberto68
·
3Comentários
roberto68
·
3Comentários
 noisiak
·
3Comentários
gterzian
·
4Comentários
noisiak
·
3Comentários
gterzian
·
4Comentários
Comentários muito úteis
Status atual: com as correções de IPC, o FPS está agora em torno de 55. Às vezes, ele balança um bocado, mas geralmente não fica abaixo de 45, _exceto_ durante os primeiros segundos após o carregamento (onde pode cair para 30), e quando ele primeiro vê uma mão (quando cai para 20).