Servo: Immersiver Modus erreicht keine 60fps
Ich verwende dies, um Untersuchungen zur Ursache niedriger FPS-Werte bei Verwendung des immersiven Modus auf Geräten zu verfolgen.
 jdm
jdm
Alle 71 Kommentare
Einige Informationen, die aufgedeckt wurden:
- es gibt lange Wartezeiten zwischen xrWaitFrame und xrBeginFrame
Eine Spur der Paint-Demo mit Markern für die OpenXR-APIs reproduziert diese Tage und zeigt auch während dieser Zeit:
- der webgl-Thread verwendet die meiste CPU (ein Großteil der Zeit wird unter gl::Finish verbracht, das von Surfmans Device::bind_surface_to_context aufgerufen wird)
- der Hauptthread ist der am zweithäufigsten verwendete Thread, wobei eglCreatePbufferFromClientBuffer am meisten verwendet wird und fast genauso viel Zeit damit verbracht wird, das Egl-Objekt aus TLS zu greifen
- Das Rendering von webrender erscheint auch in diesem Stapel
- winrt::servo::flush erscheint hier auch, und es ist mir nicht klar, ob wir die GL-Puffer der Hauptanwendung tatsächlich austauschen müssen, während wir im Immersive-Modus sind
- Die dritthöchste CPU-Auslastung ist der Skript-Thread, der viel Zeit im JIT-Code verbringt
- Danach ist die CPU-Auslastung des Threads im Allgemeinen ziemlich niedrig, aber es erscheinen einige Symbole aus der Stilkiste, die darauf hinweisen, dass das Layout auftritt
jdm
am 3. Jan. 2020
Angesichts dieser Datenpunkte werde ich zwei Ansätze ausprobieren, um zu beginnen:
- Starten Sie den nächsten XR-Frame so schnell wie möglich, nachdem Sie auf den Geräte-Frame gewartet haben
- Reduzieren Sie die Anzahl der Aufrufe von gl::Finish (webgl-Thread), eglCreateBufferFromClientBuffer und TLS (Hauptthread)
jdm
am 3. Jan. 2020
https://github.com/servo/servo/pull/25343#issuecomment -567706735 hat weitere Untersuchungen zu den Auswirkungen des Sendens von Nachrichten an verschiedene Stellen in der Engine. Es zeigt keine klaren Finger, sondern schlägt vor, genauere Messungen vorzunehmen.
jdm
am 3. Jan. 2020
Die Verwendung von gl::Finish stammt von https://github.com/pcwalton/surfman/blob/6705a9aaa8f33ac1324fdb1913242800e68c7720/surfman/src/platform/windows/angle/context.rs#L259 -L266.
jdm
am 3. Jan. 2020
Das Ändern von gl::Finish zu gl::Flush erhöht die Framerate von ~15->30, aber es gibt eine extrem merkliche Verzögerung im Frame-Inhalt, die tatsächlich die Bewegung des Kopfes des Benutzers widerspiegelt, wodurch der aktuelle Frame dem Kopf des Benutzers nach innen folgt die Zwischenzeit.
jdm
am 3. Jan. 2020
Geschlüsselte Mutexe sind in ANGLE aus Gründen, die sich mir entziehen, standardmäßig deaktiviert, aber Mozangle aktiviert sie explizit (https://github.com/servo/mozangle/blob/706a9baaf8026c1a3cb6c67ba63aa5f4734264d0/build_data.rs#L175), und damit wird surfman getestet . Ich werde einen Build von ANGLE erstellen, der sie aktiviert, und sehen, ob das ausreicht, um die gl::Finish-Aufrufe zu vermeiden.
jdm
am 3. Jan. 2020
Bestätigt! Das Erzwingen von codierten Mutexes in ANGLE gibt mir 25-30 FPS in der Paint-Demo ohne die Verzögerungsprobleme, die beim Ändern des gl::Finish-Aufrufs auftreten.
jdm
am 3. Jan. 2020
Oh, und noch eine Information nach Lars' Untersuchungen:
- w/ dom.ion.enabled auf false gesetzt ist, verschwindet die JIT-Zeit. Das anfängliche Laden ist viel langsamer, aber wenn die Dinge einmal laufen, sind sie ziemlich gut.
- Es ist immer noch nicht fantastisch - die Speichernutzung ist bei diesem babylon.js-Beispiel ziemlich hoch (im Grunde der gesamte verfügbare Speicher).
- Wir sollten ein weiteres Spidermonkey-Upgrade durchführen, um arm64-bezogene Optimierungen einzubeziehen, die für FxR auf Android-Geräten durchgeführt wurden
jdm
am 3. Jan. 2020
Ich glaube, ich habe das Vorhandensein von std::thread::local::LocalKey<surfman::egll::Egl> in den Profilen falsch verstanden - ich bin mir ziemlich sicher, dass das TLS-Lesen nur ein sehr kleiner Teil der Zeit ist, die ihm in Rechnung gestellt wird, und es sind die Funktionen, die innerhalb des TLS-Blocks aufgerufen werden, wie eglCreatePbufferFromClientBuffer und DXGIAcquireSync, die _eigentlich_ die Zeit in Anspruch nehmen.
jdm
am 3. Jan. 2020
Leider scheint das Deaktivieren von js.ion.enabled die FPS der Paint-Demo zu beeinträchtigen und auf 20-25 zu reduzieren.
jdm
am 4. Jan. 2020
Anstatt Device::create_surface_texture_from_texture zweimal in jedem Frame aufzurufen (einmal für jede d3d-Textur für jedes Auge), ist es möglicherweise möglich, Oberflächentexturen für alle Swapchain-Texturen zu erstellen, wenn das openxr webxr-Gerät erstellt wird. Wenn dies funktioniert, würde es den zweitgrößten CPU-Benutzer im immersiven Modus aus dem Hauptthread entfernen.
jdm
am 4. Jan. 2020
Eine weitere Idee zur Reduzierung des Speicherverbrauchs: Hat es Auswirkungen, wenn wir den bfcache auf eine sehr niedrige Zahl setzen, damit die ursprüngliche HL-Homepage-Pipeline beim Navigieren zu einer der Demos entfernt wird?
jdm
am 4. Jan. 2020
Der folgende webxr-Patch verbessert die FPS nicht eindeutig, aber er könnte die Bildstabilität verbessern. Ich muss zwei separate Builds erstellen, die ich nacheinander ausführen kann, um sie zu überprüfen.
diff --git a/webxr/openxr/mod.rs b/webxr/openxr/mod.rs
index 91c78da..a6866de 100644
--- a/webxr/openxr/mod.rs
+++ b/webxr/openxr/mod.rs
@@ -416,11 +416,30 @@ impl DeviceAPI<Surface> for OpenXrDevice {
}
fn wait_for_animation_frame(&mut self) -> Option<Frame> {
- if !self.handle_openxr_events() {
- // Session is not running anymore.
- return None;
+ loop {
+ if !self.handle_openxr_events() {
+ // Session is not running anymore.
+ return None;
+ }
+ self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
+ // XXXManishearth this code should perhaps be in wait_for_animation_frame,
+ // but we then get errors that wait_image was called without a release_image()
+ self.frame_stream
+ .begin()
+ .expect("failed to start frame stream");
+
+ if self.frame_state.should_render {
+ break;
+ }
+
+ self.frame_stream.end(
+ self.frame_state.predicted_display_time,
+ EnvironmentBlendMode::ADDITIVE,
+ &[],
+ ).unwrap();
}
- self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
let time_ns = time::precise_time_ns();
// XXXManishearth should we check frame_state.should_render?
let (_view_flags, views) = self
@@ -506,12 +525,6 @@ impl DeviceAPI<Surface> for OpenXrDevice {
0,
);
- // XXXManishearth this code should perhaps be in wait_for_animation_frame,
- // but we then get errors that wait_image was called without a release_image()
- self.frame_stream
- .begin()
- .expect("failed to start frame stream");
-
self.left_image = self.left_swapchain.acquire_image().unwrap();
self.left_swapchain
.wait_image(openxr::Duration::INFINITE)
@manishearth irgendwelche Gedanken dazu? Es ist mein Versuch, dem von https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#Session beschriebenen Modell näher zu kommen
jdm
am 4. Jan. 2020
Ja, das sieht gut aus. Ich wollte begin() oben in waf verschieben, und ich glaube, der im Kommentar erwähnte Fehler tritt nicht mehr auf, aber er hatte auch keine merklichen Auswirkungen auf die FPS, also habe ich ihn nicht weiterverfolgt jetzt zu viel. Wenn es die Stabilität verbessert, ist das gut!
 Manishearth
am 4. Jan. 2020
Manishearth
am 4. Jan. 2020
Freue mich sehr über die Keyed Discovery! Surfman-Calls nehmen zwar einen Teil des Frame-Budgets in Anspruch, aber es ist ein bisschen schwer zu bestimmen, was notwendig ist und was nicht.
Manishearth
am 4. Jan. 2020
Ja, re: das Deaktivieren von js.ion.enabled , das wird nur ein Vorteil sein, wenn wir RAM-hungrig sind und die meiste Zeit damit verbringen, Funktionen zu GC und neu zu kompilieren. Und das sollte mit einem neueren SM verbessert werden. IIRC, das ARM64-Backend der 66-Ära, hatte auch eine relativ schlechte JIT- und Interpreter-Basisleistung; Wir sollten mit einem Update auf der ganzen Linie Beschleunigungen sehen, aber insbesondere bei RAM-intensiven Anwendungen.
 larsbergstrom
am 4. Jan. 2020
larsbergstrom
am 4. Jan. 2020
Neues ANGLE-Paket mit aktivierten verschlüsselten Mutexes veröffentlicht. Ich werde eine Pull-Anfrage erstellen, um sie später zu aktualisieren.
jdm
am 6. Jan. 2020
Ich habe versucht, die Oberflächentexturen für alle openxr-Swapchain-Images während der Initialisierung des XR-Geräts zu erstellen, aber der Hauptthread verbringt immer noch eine Menge Zeit damit, eglCreatePbufferFromClientBuffer auf der Oberfläche aufzurufen, die wir in jedem Frame vom webgl-Thread erhalten. Vielleicht gibt es eine Möglichkeit, diese Oberflächentexturen zwischenzuspeichern, damit wir sie wiederverwenden können, wenn wir dieselbe Oberfläche erhalten ...
jdm
am 6. Jan. 2020
Die größte CPU-Auslastung des Hauptthreads kommt von render_animation_frame, wobei das meiste davon unter der OpenXR-Laufzeit läuft, aber Aufrufe von BlitFramebuffer und FramebufferTexture2D erscheinen definitiv auch im Profil. Ich frage mich, ob es eine Verbesserung wäre, beide Augen gleichzeitig auf eine einzige Textur zu leuchten? Vielleicht hängt das mit dem Texturarray-Zeug zusammen, das in https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt besprochen wird.
jdm
am 6. Jan. 2020
Wir können beide Augen gleichzeitig blitzen, aber ich verstehe, dass die Laufzeit
kann dann seinen eigenen Blit machen. Das Texturarray ist die schnellste Methode. Aber
einen Versuch wert, die Projektionsansichts-API unterstützt dies.
Was den ANGLE-Verkehr des Hauptthreads betrifft, stoppt das Stoppen der RAF-Schleife von
Leinwand verschmutzen helfen? Das hat bis jetzt noch nichts gebracht aber es lohnt sich
geschossen, idealerweise sollten wir nichts Layout/Rendering am Main machen
Faden.
Am Mo, 6. Januar 2020, 23:49 Uhr Josh Matthews [email protected]
schrieb:
Die größte CPU-Auslastung des Hauptthreads kommt von render_animation_frame, mit
das meiste davon unter der OpenXR-Laufzeit, aber Aufrufe von BlitFramebuffer und
FramebufferTexture2D erscheint definitiv auch im Profil. Ich wundere mich
wenn es eine Verbesserung wäre, beide Augen gleichzeitig zu einem einzigen zu verblenden
Textur? Vielleicht hängt das mit dem besprochenen Texturarray-Zeug zusammen
in
https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt
.—
Sie erhalten dies, weil Sie erwähnt wurden.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/servo/servo/issues/25425?email_source=notifications&email_token=AAMK6SBRH72JGZMXTUKOXETQ4NY37A5CNFSM4KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMV2ZLOKTJPHA#
oder abmelden
https://github.com/notifications/unsubscribe-auth/AAMK6SECM6MDNZZ6Y7VL7SDQ4NY37ANCNFSM4KCRI6AA
.
Manishearth
am 6. Jan. 2020
Das Entfernen der Leinwandverschmutzung reinigt nur das Profil; es schien nicht zu einer nennenswerten FPS-Erhöhung zu führen.
jdm
am 6. Jan. 2020
Ich habe versucht, einen Cache mit Oberflächentexturen für Oberflächen aus dem Webgl-Thread sowie Openxr-Swapchain-Texturen zu erstellen, und während die eglCreatePbufferFromClientBuffer-Zeit vollständig verschwand, habe ich keine nennenswerten FPS-Änderungen bemerkt.
jdm
am 6. Jan. 2020
Einige Timing-Informationen für verschiedene Operationen in der immersiven Pipeline (alle Messungen in ms):
Name min max avg
raf queued 0.070833 14.010261 0.576834
<1ms: 393
<2ms: 28
<4ms: 5
<8ms: 1
<16ms: 2
<32ms: 0
32+ms: 0
raf transmitted 0.404270 33.649583 7.403302
<1ms: 123
<2ms: 43
<4ms: 48
<8ms: 48
<16ms: 95
<32ms: 69
32+ms: 3
raf wait 1.203500 191.064100 17.513593
<1ms: 0
<2ms: 17
<4ms: 98
<8ms: 95
<16ms: 48
<32ms: 69
32+ms: 101
raf execute 3.375000 128.663200 6.994588
<1ms: 0
<2ms: 0
<4ms: 5
<8ms: 351
<16ms: 70
<32ms: 1
32+ms: 2
raf receive 0.111510 8.564010 0.783503
<1ms: 353
<2ms: 52
<4ms: 18
<8ms: 4
<16ms: 1
<32ms: 0
32+ms: 0
raf render 2.372200 75.944000 4.219310
<1ms: 0
<2ms: 0
<4ms: 253
<8ms: 167
<16ms: 8
<32ms: 0
32+ms: 1
receive : Zeit vom Senden der XR-Frame-Informationen vom XR-Thread bis zum Empfang durch den IPC-Router
queued : Zeit vom Empfang der Frame-Informationen durch den IPC-Router bis zum Aufruf von XRSession::raf_callback
execute : Zeit von XRSession::raf_callback aufgerufen bis zur Rückkehr von der Methode
transmitted : Zeit vom Senden der Anforderung eines neuen rAF vom Skript-Thread bis zum Empfang durch den XR-Thread
render : Zeit, um render_animation_frame anzurufen und die Oberfläche zu recyceln
wait : Zeit von wait_for_animation_frame (mit dem Patch von vorhin in dieser Ausgabe, der über Frames wiederholt, die nicht gerendert werden sollen)
Unter jedem Eintrag befindet sich die Verteilung der Werte über den Verlauf der Sitzung.
jdm
am 7. Jan. 2020
Ein interessanter Datenpunkt aus diesen Timing-Informationen - die Kategorie transmitted scheint viel höher zu sein, als sie sein sollte. Das ist die Verzögerung zwischen der Ausführung des rAF-Callbacks und dem Empfang der Nachricht durch den XR-Thread, die den abgeschlossenen Frame in die Textur von openxr einfügt. Es gibt einige Variationen, die darauf hindeuten, dass entweder der Haupt-Thread mit anderen Dingen beschäftigt ist oder er aufgeweckt werden muss, um ihn zu verarbeiten.
jdm
am 7. Jan. 2020
Angesichts der vorherigen Daten kann ich morgen versuchen, https://github.com/servo/webxr/issues/113 wiederzubeleben, um zu sehen, ob sich dies positiv auf das Sendetiming auswirkt. Ich kann zuerst im Haupt-Thread im Profiler stöbern, um zu sehen, ob mir irgendwelche Ideen einfallen, wie ich feststellen kann, ob der Thread mit anderen Aufgaben beschäftigt ist oder schläft.
jdm
am 7. Jan. 2020
Ein weiterer Datenpunkt:
swap buffer 1.105938 28.193698 2.154793
<1ms: 0
<2ms: 273
<4ms: 110
<8ms: 15
<16ms: 2
<32ms: 2
32+ms: 0
swap complete 0.053802 4.337812 0.295064
<1ms: 308
<2ms: 9
<4ms: 6
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
swap request 0.003333 24033027.355364 4662890.724805
<1ms: 268
<2ms: 49
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 1
32+ms: 79
Dies sind Zeitpunkte im Zusammenhang mit 1) der Verzögerung vom Senden der Swap-Puffer-Nachricht bis zur Verarbeitung im Webgl-Thread, 2) der Zeit, die zum Austauschen der Puffer benötigt wird, 3) der Verzögerung vom Senden der Nachricht, die anzeigt, dass der Austausch abgeschlossen ist, bis sie in empfangen wird der Skript-Thread. Nichts Überraschendes hier (außer diesen seltsamen Ausreißern in der Kategorie swap request , die jedoch gleich zu Beginn der immersiven Sitzung während des Setups auftreten), aber der eigentliche Pufferaustausch dauert durchweg 1-4 ms.
jdm
am 7. Jan. 2020
Abgelegt Nr. 117, nachdem ich einen Openxr-Beispielcode gelesen und festgestellt habe, dass die Aufrufe von locate_views im Profil angezeigt werden.
jdm
am 7. Jan. 2020
Vermutlich https://github.com/servo/webxr/issues/117
 asajeffrey
am 7. Jan. 2020
asajeffrey
am 7. Jan. 2020
Ein interessanter Datenpunkt aus diesen Timing-Informationen - die übertragene Kategorie scheint viel höher zu sein, als sie sein sollte. Das ist die Verzögerung zwischen der Ausführung des rAF-Callbacks und dem Empfang der Nachricht durch den XR-Thread, die den abgeschlossenen Frame in die Textur von openxr einfügt. Es gibt einige Variationen, die darauf hindeuten, dass entweder der Haupt-Thread mit anderen Dingen beschäftigt ist oder er aufgeweckt werden muss, um ihn zu verarbeiten.
Bezüglich der Variationen des transmitted Werts könnte dies mit dem Timeout zusammenhängen, das als Teil von run_one_frame wenn die Sitzung auf dem Hauptthread ausgeführt wird (was es in diesen Messungen ist, oder?) , siehe https://github.com/servo/webxr/blob/c6abf4c60d165ffc978ad2ebd6bcddc3c21698e1/webxr-api/session.rs#L275
Ich vermute, dass, wenn die RenderAnimationFrame Nachricht (die vom Skript-Thread gesendet wird, nachdem die Callbacks ausgeführt wurden) vor dem Timeout empfangen wird, Sie den "schnellen Pfad" wählen und wenn der Timeout verpasst wird, geht Servo in einen anderen Iteration von perform_updates , und das "Ausführen eines anderen Frames" erfolgt ziemlich spät im Zyklus, als Teil von compositor.perform_updates , das selbst ziemlich spät als Teil von servo.handle_events aufgerufen wird.
Abgesehen davon, dass XR in einen eigenen Thread verschoben wird, kann es sich lohnen, zu sehen, ob ein höherer Wert für das Timeout den Durchschnittswert verbessert (obwohl dies möglicherweise nicht die richtige Lösung ist, da andere erforderliche Dinge im Hauptthread möglicherweise ausgehungert werden).
 gterzian
am 8. Jan. 2020
gterzian
am 8. Jan. 2020
Ich habe Fortschritte beim Entfernen von openxr aus dem Hauptthread in https://github.com/servo/webxr/issues/113 gemacht , daher werde ich nächste Woche weitere Messungen basierend auf dieser Arbeit vornehmen.
jdm
am 10. Jan. 2020
Techniken zum Abrufen nützlicher Profile vom Gerät:
- Verwenden Sie ein .servobuild, das
rustflags = "-C force-frame-pointers=yes" - entkommentiere diese Zeilen
- Verwenden Sie WinXR_Perf.wprp von der Registerkarte MS-Teams char
Filesals benutzerdefiniertes Tracing-Profil unter "Performance Tracing" im HL-Geräteportal - bauen mit
--features profilemozjs
Diese Ablaufverfolgungen (erhalten von "Trace starten" im Geräteportal) können innerhalb des Windows Performance Analyzer-Tools verwendet werden. Dieses Tool zeigt keine Thread-Namen an, aber die Threads, die die meiste CPU verbrauchen, sind anhand der Stacks einfach zu identifizieren.
So profilieren Sie die Zeitverteilung eines bestimmten openxr-Frames:
- fügen Sie die Ansicht "Systemaktivität -> Generische Ereignisse" in WPA hinzu
- Filtern Sie die Ansicht, um nur die Microsoft.Windows.WinXrContinuousProvider-Reihe anzuzeigen
- Zoomen Sie auf eine kurze Dauer heran und verfeinern Sie dann den vergrößerten Bereich, sodass sich ein xrBegin-Ereignis auf der linken Seite der Ansicht und ein xrEnd-Ereignis auf der rechten Seite der Ansicht befindet.
Die nützlichsten Ansichten für die CPU-Auslastung:
- CPU-Auslastung (abgetastet) -> Auslastung nach Prozess, Thread, Stapel (Filtern Sie die Ansicht, um nur Servo anzuzeigen, und deaktivieren Sie dann die Spalte "Prozess")
- Flamme nach Prozess, Stapel (Filtern Sie die Ansicht, um nur Servo anzuzeigen)
jdm
am 16. Jan. 2020
Eine Möglichkeit, etwas weniger Arbeit im Skriptthread zu machen:
- XRView::new verbraucht 0,02% der gesamten Servo-CPU
- Da sich der Inhalt der View-Objekte nicht ändert, es sei denn, es gibt ein FrameUpdateEvent::UpdateViews-Ereignis (das von Session::update_clip_planes über XRSession::UpdateRenderState kommt), könnten wir die XRView-Objekte möglicherweise auf der XRSession zwischenspeichern und sie bis zum Renderstatus wird aktualisiert
- Wir könnten sogar die JS-Darstellung der Ansichtsliste in XRSession zwischengespeichert halten und das Ansichtsmitglied der Pose festlegen, um sowohl die Neuerzeugung der XRView-Objekte als auch die Zuweisung des Vektors und die Durchführung der JS-Wertkonvertierung zu vermeiden
jdm
am 16. Jan. 2020
Eine Möglichkeit, beim Rendern eines immersiven Frames weniger Arbeit zu leisten:
- GL und d3d haben invertierte Y-Koordinatensysteme
- ANGLE verbirgt dies implizit bei der Präsentation auf dem Bildschirm, indem es etwas hinter den Kulissen arbeitet
- Für den immersiven Modus verwenden wir glBlitFramebuffer, um eine y-Inversion durchzuführen, wenn die GL-Texturdaten in d3d geblitet werden
- Wenn wir herausfinden können, wie ANGLE die Konvertierung nicht intern durchführt, ist es möglicherweise möglich, dieses Modell zu invertieren und das Rendern nicht immersiver Webseiten ein zusätzliches Y-Invert-Blit zu erfordern (über die Webrender-Option
surface_origin_is_top_left). während der immersive Modus ohne Transformation geblinkt werden könnte
Basierend auf https://bugzilla.mozilla.org/show_bug.cgi?id=1591346 und im Gespräch mit jrmuizel müssen wir Folgendes tun:
- Rufen Sie eine d3d-Swapchain für das Fensterelement ab, in das wir nicht immersive Seiten rendern möchten (dies ist das SwapChainPanel in der XAML-App).
- packen Sie das in ein EGL-Image (https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#554)
- Präsentieren Sie die Swapchain explizit, wenn wir das Hauptrendering aktualisieren möchten
- vermeiden Sie die Verwendung von eglCreateWindowSurface und eglSwapBuffers in https://github.com/servo/servo/blob/master/support/hololens/ServoApp/ServoControl/OpenGLES.cpp#L205 -L208
Relevanter Gecko-Code: https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#192
Relevanter ANGLE-Code: https://github.com/google/angle/blob/df0203a9ae7a285d885d7bc5c2d4754fe8a59c72/src/libANGLE/renderer/d3d/d3d11/winrt/SwapChainPanelNativeWindow.cpp#L244
jdm
am 16. Jan. 2020
Aktuelle wip-Filialen:
- https://github.com/servo/ipc-channel/tree/try-recv-error
- https://github.com/jdm/webxr/tree/oxr
- https://github.com/jdm/rust-offscreen-rendering-context/tree/angle-perf
- https://github.com/jdm/servo/tree/profile
Dazu gehört eine xr-profile Funktion, die die oben erwähnten Timing-Daten hinzufügt, sowie eine erste Implementierung der ANGLE-Änderungen, um die y-inverse Transformation im immersiven Modus zu entfernen. Der nicht immersive Modus rendert korrekt, aber der immersive Modus steht auf dem Kopf. Ich glaube, ich muss den GL-Code aus render_animation_frame entfernen und durch einen direkten CopySubresourceRegion-Aufruf ersetzen, indem ich das Share-Handle aus der GL-Oberfläche extrahiere, damit ich seine d3d-Textur erhalten kann.
jdm
am 17. Jan. 2020
Eingereicht https://github.com/servo/servo/issues/25582 für die ANGLE y-Inversionsarbeit; weitere Aktualisierungen zu dieser Arbeit werden in dieser Ausgabe erfolgen.
jdm
am 23. Jan. 2020
Der nächste große Punkt wird untersucht, wie man die glBlitFramebuffer-Aufrufe im openxr-webxr-Backend vollständig vermeiden kann. Dies erfordert:
- Openxr-Framebuffer erstellen, die genau zu den erforderlichen opaken Webgl-Framebuffern passen
- Unterstützung eines Webgl-Modus, in dem das Webxr-Backend alle Swapchain-Oberflächen bereitstellt, anstatt sie zu erstellen (z. B. in https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L458 und https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L111-L118)
jdm
am 23. Jan. 2020
Das kann schwierig sein, da surfman nur Schreibzugriff auf den Kontext bietet, der die Oberfläche erstellt hat. Wenn die Oberfläche also vom openxr-Thread erstellt wird, kann sie vom WebGL-Thread nicht geschrieben werden. https://github.com/pcwalton/surfman/blob/a515fb2f5d6b9e9b36ba4e8b498cdb4bea92d330/surfman/src/device.rs#L95 -L96
asajeffrey
am 23. Jan. 2020
Mir fällt ein - wenn wir das openxr-Rendering im webgl-Thread durchführen würden, wären eine Reihe der Threading-bezogenen Probleme beim direkten Rendern in die Texturen von openxr keine Probleme mehr (dh die Einschränkungen rund um eglCreatePbufferFromClientBuffer, die die Verwendung mehrerer d3d-Geräte verbieten). Erwägen:
- es gibt immer noch einen openxr-Thread, der dafür verantwortlich ist, nach openxr-Ereignissen abzufragen, auf einen Animationsframe zu warten, einen neuen Frame zu beginnen und den aktuellen Framestatus abzurufen
- Der Frame-Status wird an den Skript-Thread gesendet, der den Animations-Callback durchführt und dann eine Nachricht an den Webgl-Thread sendet, um den Framebuffer der xr-Ebene auszutauschen
- Wenn diese Swap-Nachricht im Webgl-Thread empfangen wird, geben wir das zuletzt erfasste openxr-Swapchain-Image frei, senden eine Nachricht an den openxr-Thread, um den aktuellen Frame zu beenden, und erfassen ein neues Swapchain-Image für den nächsten Frame
Meine Lektüre von https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#threading -behavior legt nahe, dass dieses Design praktikabel sein könnte. Der Trick ist, ob es sowohl für unsere nicht-openxr-Backends als auch für openxr funktionieren kann.
Aus der Spezifikation: "Obwohl xrBeginFrame und xrEndFrame nicht im selben Thread aufgerufen werden müssen, muss die Anwendung die Synchronisierung verarbeiten, wenn sie in separaten Threads aufgerufen werden."
jdm
am 25. Jan. 2020
Im Moment gibt es keine direkte Kommunikation zwischen den XR-Gerätethreads und webgl, alles läuft entweder über Skript oder über ihre gemeinsame Swap-Chain. Ich wäre versucht, eine Swap-Chain-API bereitzustellen, die sich entweder über einer Surfman-Swap-Chain oder einer Openxr-Swap-Chain befindet, und diese für die Webgl-to-Openxr-Kommunikation verwenden.
asajeffrey
am 25. Jan. 2020
Notizen aus einem Gespräch über die früheren Zeitmessungen:
* concerns about wait time - why?????
* figure out time spent in JS vs. DOM logic
* when does openxr give us should render=false frames - maybe related to previous frame taking too long
* are threads being scheduled on inappropriate cpus? - on magic leap, main thread (including weber) pinned to big core.
* when one of the measured numbers is large, is there correlation with other large numbers?
* probably should pin openxr thread, running deterministic code
* consider clearing after telling script that the swap is complete - measure if clear is taking significant time in swap operation
* consider a swap chain API operation - “wait until a buffer swap occurs”
- block waiting on swapchain
- block waiting on swapchain + timeout
- async????????
- a gc would look like a spike in script execution time
Eingereicht Nr. 25735, um die Untersuchungen zu verfolgen, die ich über das direkte Rendern in die Openxr-Texturen verfolge.
jdm
am 11. Feb. 2020
Eine Sache, die wir tun sollten, ist einzugrenzen, wie Spidermonkey auf dem Gerät im Vergleich zu anderen Engines abschneidet. Der einfachste Weg, hier einige Daten zu erhalten, besteht darin, einen einfachen JS-Benchmark zu finden, den Servo ausführen kann, und die Leistung von Servo mit dem auf dem Gerät installierten Edge-Browser zu vergleichen. Darüber hinaus könnten wir versuchen, einige komplexe Babylon-Demos in beiden Browsern zu besuchen, ohne in den immersiven Modus zu wechseln, um zu sehen, ob es einen signifikanten Leistungsunterschied gibt. Dies wird uns auch einen Benchmark zum Vergleich mit dem bevorstehenden Spidermonkey-Upgrade geben.
jdm
am 13. Feb. 2020
Einige neue Daten. Dies ist beim ANGLE-Upgrade der Fall, aber nicht beim IPC-Upgrade.
$ python timing.py raw
Name min max mean
raf queued 0.056198 5.673125 0.694902
<1ms: 335
<2ms: 26
<4ms: 17
<8ms: 7
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.822917 36.582083 7.658619
<1ms: 1
<2ms: 4
<4ms: 31
<8ms: 181
<16ms: 158
<32ms: 8
32+ms: 1
raf wait 1.196615 39.707709 10.256875
<1ms: 0
<2ms: 32
<4ms: 93
<8ms: 67
<16ms: 107
<32ms: 68
32+ms: 17
raf execute 3.078438 532.205677 7.752839
<1ms: 0
<2ms: 0
<4ms: 37
<8ms: 290
<16ms: 52
<32ms: 2
32+ms: 3
raf receive 0.084375 9.053125 1.024403
<1ms: 276
<2ms: 71
<4ms: 27
<8ms: 9
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.004115 73.939479 0.611254
<1ms: 369
<2ms: 10
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.706198 233.459636 9.241698
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 183
<16ms: 190
<32ms: 10
32+ms: 1
run_one_frame 7.663333 2631.052969 28.035143
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 3
<16ms: 157
<32ms: 185
32+ms: 41
swap buffer 0.611927 8.521302 1.580279
<1ms: 127
<2ms: 169
<4ms: 74
<8ms: 15
<16ms: 1
<32ms: 0
32+ms: 0
swap complete 0.046511 2.446302 0.215040
<1ms: 375
<2ms: 6
<4ms: 3
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Timing-Daten: https://gist.github.com/Manishearth/825799a98bf4dca0d9a7e55058574736
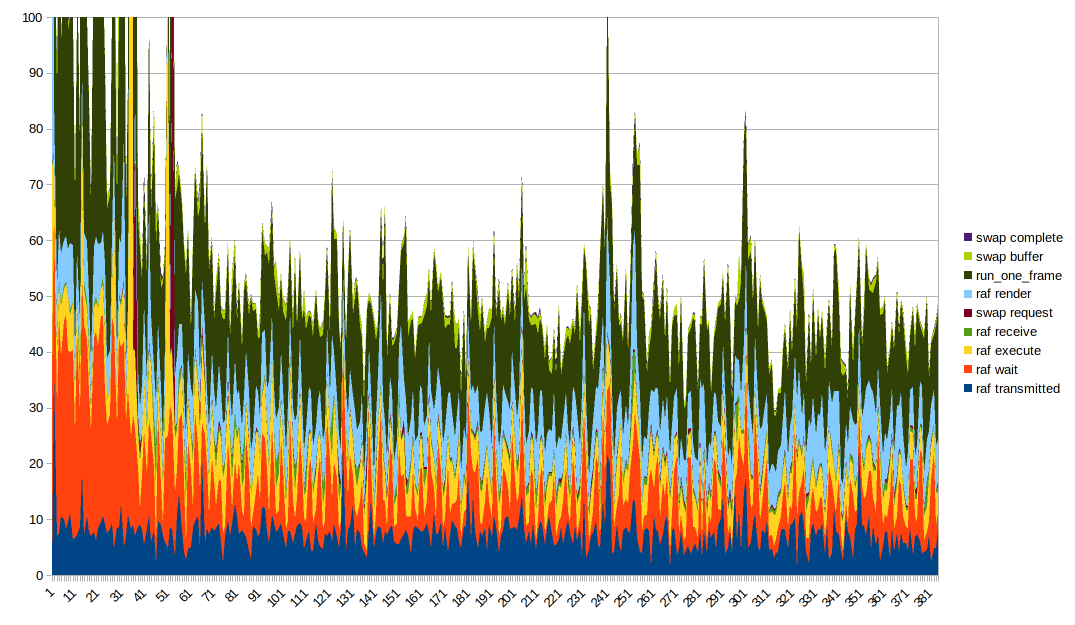
Eine gute Datenvisualisierung davon zu erhalten, ist schwierig. Ein gestapeltes Liniendiagramm scheint ideal zu sein, obwohl es erwähnenswert ist, dass run_one_frame mehrere bereits gemessene Timings misst. Es ist hilfreich, an der Reihenfolge der Diagramme herumzufummeln und verschiedene Spalten unten zu platzieren, um ihre Wirkung besser zu sehen. Außerdem müssen Sie die Y-Achse abschneiden, um aufgrund einiger sehr großer Ausreißer etwas Nützliches zu erhalten.
Interessante Dinge zu beachten:
- Renderzeit und Ausführungszeit scheinen größtenteils konstant zu sein, weisen jedoch Spitzen auf, wenn es insgesamt große Spitzen gibt. Ich vermute, dass die großen Spitzen davon kommen, dass alles aus irgendeinem Grund langsamer wird
- Die Sendezeit scheint ziemlich gut mit der Gesamtform zu korrelieren
- Die Wartezeit ist auch ein Grund dafür, dass die Gesamtform so ist, sie ist _sehr_ wellig
Manishearth
am 21. Feb. 2020
Aktueller Status: Mit IPC-Fixes schwebt die FPS jetzt bei 55. Es wackelt manchmal ein bisschen, aber normalerweise geht es nicht unter 45, _außer_ während der ersten Sekunden nach dem Laden (wo es auf 30 sinken kann) und wenn es sieht zuerst eine Hand (wenn sie auf 20 sinkt).
Manishearth
am 25. Feb. 2020
Neueres Histogramm für Lackdemo ( Rohdaten ):
Name min max mean
raf queued 0.113854 5.707917 0.441650
<1ms: 352
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.546667 44.954792 6.886162
<1ms: 4
<2ms: 2
<4ms: 23
<8ms: 279
<16ms: 59
<32ms: 3
32+ms: 1
raf wait 1.611667 37.913177 9.441104
<1ms: 0
<2ms: 6
<4ms: 98
<8ms: 82
<16ms: 135
<32ms: 43
32+ms: 6
raf execute 3.336562 418.198541 7.592147
<1ms: 0
<2ms: 0
<4ms: 11
<8ms: 319
<16ms: 36
<32ms: 2
32+ms: 3
raf receive 0.119323 9.804167 0.806074
<1ms: 324
<2ms: 31
<4ms: 13
<8ms: 1
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.003646 79.236354 0.761324
<1ms: 357
<2ms: 9
<4ms: 2
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 3
raf render 5.844687 172.898906 8.131682
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 283
<16ms: 86
<32ms: 1
32+ms: 1
run_one_frame 8.826198 2577.357604 25.922205
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 176
<32ms: 174
32+ms: 22
swap buffer 0.708177 12.528906 1.415950
<1ms: 164
<2ms: 161
<4ms: 38
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
swap complete 0.042917 1.554740 0.127729
<1ms: 370
<2ms: 1
<4ms: 0
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Längerer Lauf ( roh ). Entwickelt, um die Auswirkungen von Startverzögerungen zu reduzieren.
Name Min. Max. Mittelwert
raf in der Warteschlange 0,124896 6,356562 0,440674
<1ms: 629
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf übertragen 0.640677 20.275104 6.944751
<1ms: 2
<2ms: 3
<4ms: 29
<8ms: 513
<16ms: 99
<32ms: 1
32+ms: 0
raf warten 1.645886 40.955208 9.386255
<1ms: 0
<2ms: 10
<4ms: 207
<8ms: 114
<16ms: 236
<32ms: 65
32+ms: 15
raf ausführen 3.090104 526.041198 6.226997
<1ms: 0
<2ms: 0
<4ms: 68
<8ms: 546
<16ms: 29
<32ms: 1
32+ms: 3
raf erhalten 0.203334 6.441198 0.747615
<1ms: 554
<2ms: 84
<4ms: 7
<8ms: 2
<16ms: 0
<32ms: 0
32+ms: 0
Tauschanfrage 0,003490 73,644322 0,428460
<1ms: 627
<2ms: 18
<4ms: 1
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.450312 209.662969 8.055021
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 467
<16ms: 176
<32ms: 3
32+ms: 1
run_one_frame 8.417291 2579.454948 22.226204
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 326
<32ms: 290
32+ms: 33
Swap-Puffer 0,658125 12,179167 1,378725
<1ms: 260
<2ms: 308
<4ms: 72
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
Swap komplett 0,041562 5,161458 0,136875
<1ms: 642
<2ms: 3
<4ms: 1
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
Manishearth
am 27. Feb. 2020
Grafiken:
Längerer Lauf:

Kürzerer Lauf: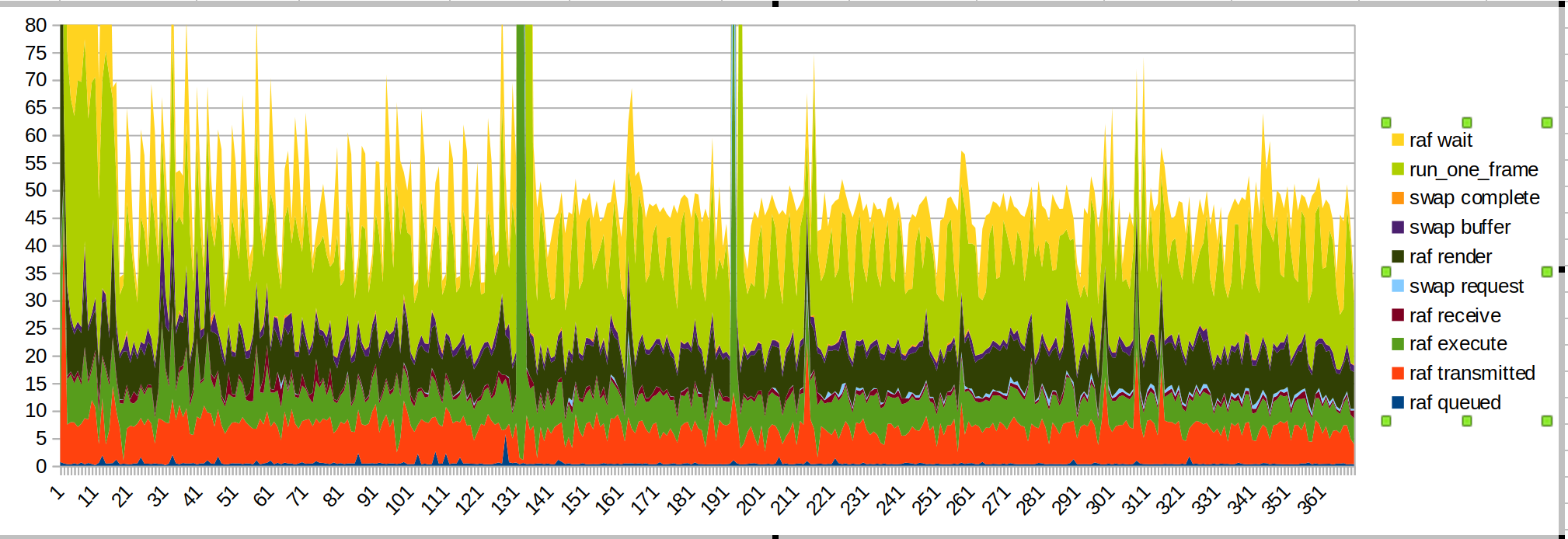
Die große Spitze ist, wenn ich meine Hand in den Sensorbereich bringe.
Diesmal habe ich die wait/run_one_frame-Zeiten nach oben gesetzt, weil diese die am meisten gezackt sind, und das liegt daran, dass uns das Betriebssystem drosselt.
Ein paar Dinge zu beachten:
- Die große Spitze durch die eingeführten Hände wird durch JS-Code verursacht (basilikumgrün, "raf render")
- Sendezeit ist wie erwartet glatter geworden
- Wenn ich mit dem Zeichnen beginne, gibt es einen weiteren JS-Spike
- Render- und Übertragungszeit sind immer noch ein erheblicher Teil des Budgets. Die Skriptleistung könnte ebenfalls verbessert werden.
- Ich vermute, dass die Übertragungszeit so lange dauert, weil der Hauptthread mit anderen Dingen beschäftigt ist. Das ist https://github.com/servo/webxr/issues/113 , @jdm schaut sich das an
- Surfman-Updates können die Renderzeiten verbessern. @asajeffreys Messungen bei Surfmanup scheinen besser zu sein als meine
- Die Oberflächenfreigabe kann die Renderzeiten verbessern (bei Surfmanup blockiert)
- Die vom Gerät angezeigte FPS wird bei der Messung mit Xr-Profil fast halbiert. Dies könnte an der ganzen IO liegen.
Die Leistungsknicke aufgrund des Sehens der Hand und dann des Beginnens des Ziehens sind für Ballschützen nicht vorhanden. Vielleicht macht die Farbdemo viel Arbeit, wenn sie sich zum ersten Mal entscheidet, das Handbild zu zeichnen?
(Dies könnte auch die Paint-Demo sein, die versucht, mit der Webxr-Eingabebibliothek zu interagieren)
Manishearth
am 27. Feb. 2020
@Manishearth Können Sie auch die Speichernutzung überlagern und mit diesen Ereignissen korrelieren? Zusätzlich zur erstmaligen Kompilierung von JS-Code können Sie bei einer Menge neuen Codes Fehler machen, an die physischen Speichergrenzen stoßen und eine Reihe von GCs verursachen, wenn Sie den Speicherdruck erreichen. Ich habe das in den meisten nicht-trivialen Situationen gesehen. Ich hoffe , dass das SM-Update von
larsbergstrom
am 27. Feb. 2020
Ich habe keine einfache Möglichkeit, Speicherprofilierungsdaten auf eine Weise zu erhalten, die mit dem xr-Profiling-Zeug korreliert werden kann.
Ich könnte möglicherweise die vorhandenen Perf-Tools verwenden und herausfinden, ob die Form gleich ist.
Manishearth
am 27. Feb. 2020
@Manishearth Zeigt das Xr-Profiling-Zeug (oder könnte es zeigen) JS GC-Ereignisse? Das könnte ein vernünftiger Proxy sein.
larsbergstrom
am 27. Feb. 2020
Wie auch immer, Startspitzen sind nicht mein Hauptanliegen, ich möchte zuerst alles _sonst_ mit 60 fps bekommen. Wenn es beim Start für ein oder zwei Sekunden ruckartig ist, ist das ein weniger dringendes Problem.
Manishearth
am 27. Feb. 2020
Ja, es könnte zeigen, dass es einige Optimierungen erfordern würde.
Manishearth
am 27. Feb. 2020
@Manishearth Übereinstimmende Prioritäten! Ich war mir nicht sicher, ob Sie versuchten, "die Knicke zu lösen" oder im Dauerzustand herunterzufahren. Stimmen Sie letzterem zu, das jetzt wichtiger ist.
larsbergstrom
am 27. Feb. 2020
Nein, ich habe meistens nur alle möglichen Analysen aufgeschrieben.
Manishearth
am 27. Feb. 2020
Diese Spitzen am Ende des Diagramms des kleineren Durchlaufs, bei denen auch die Übertragungszeit ansteigt: Das war, als ich meinen Kopf bewegte und zeichnete, und Alan bemerkte auch einen Rückgang der FPS, wenn er Dinge tat, und schrieb dies dem Betriebssystem zu, das andere Arbeiten erledigte . Nachdem der IPC meine Vermutung bezüglich Übertragungszeitspitzen behoben hat, ist, dass sie durch das Betriebssystem verursacht werden, das andere Arbeiten verrichtet, also könnte das sein, was dort vor sich geht. In einer Off-Main-Thread-Welt würde ich erwarten, dass es viel reibungsloser ist.
Manishearth
am 27. Feb. 2020
Ignorieren Sie mich, wenn dies bereits in Betracht gezogen wurde. Haben Sie daran gedacht, die Messung von run_one_frame pro Nachricht aufzuschlüsseln und auch die Zeit zu bestimmen, die thread::sleep() -ing aufgewendet wurde?
Es könnte sich lohnen, drei Messpunkte hinzuzufügen:
eine Umhüllung https://github.com/servo/webxr/blob/68b024221b8c72b5b33a63441d63803a13eadf03/webxr-api/session.rs#L364
und ein weiteres Wrapping https://github.com/servo/webxr/blob/2841497966d87bbd561f18ea66547dde9b13962f/webxr-api/lib.rs#L124 als Ganzes,
und auch eine, die den Anruf nur an
thread::sleepumschließt.
Was die recv_timeout , könnte dies etwas sein, das man komplett überdenken sollte.
Ich finde es etwas schwierig, über die Nützlichkeit des Timeouts nachzudenken. Da Sie die gerenderten Frames zählen, sehen Sie sich frame_count die komplette Event-Schleife des Main-Threads"?
Außerdem habe ich einige Zweifel an der tatsächlichen Berechnung der darin verwendeten delay , wo derzeit:
- es beginnt bei
delay = timeout / 1000, wobeitimeoutderzeit auf 5 ms eingestellt ist - Es wächst dann exponentiell und verdoppelt sich bei jeder Iteration bei
delay = delay * 2; - Es wird am Anfang der Schleife mit
while delay < timeoutüberprüft.
Die Schlafsequenz läuft also im schlimmsten Fall etwa so ab: 5micro -> 10 -> 20 -> 40 -> 80 -> 160 -> 320 -> 640 -> 1.28milli -> 2.56 milli -> 5.12 milli
Wenn es 5,12 Millisekunden erreicht, brechen Sie aus der Schleife aus (seit delay > timeout ), nachdem Sie insgesamt 5.115 Millisekunden gewartet haben, plus die zusätzliche Zeit, die Sie damit verbracht haben, auf das Betriebssystem zu warten, um den Thread nach jedem sleep .
Ich denke also, das Problem ist, dass Sie insgesamt länger als 5 ms schlafen können, und ich denke auch, dass es keine gute Idee ist, seit einer Nachricht zweimal länger als 1 ms zu schlafen (und das zweite Mal länger als 2,5 ms). könnte während dieser Zeit reinkommen und du wirst nicht aufwachen.
Ich bin mir nicht ganz sicher, wie ich es verbessern soll, es hört sich so an, als ob Sie versuchen würden, nach einer möglichen Nachricht zu suchen und schließlich einfach zur nächsten Iteration der Hauptereignisschleife überzugehen, wenn nichts verfügbar ist (warum nicht auf der recv?).
Sie könnten zu https://doc.rust-lang.org/std/thread/fn.yield_now.html wechseln. diesen Artikel über Sperren ansehen , scheint es sich ungefähr 40 Mal zu drehen, während Sie jedes Mal yield aufrufen , ist optimal (siehe den Absatz "Spinning", kann nicht direkt darauf verlinken). Danach sollten Sie entweder den Empfänger blockieren oder einfach mit der aktuellen Iteration der Ereignisschleife fortfahren (da diese wie eine Unterschleife innerhalb der Haupteinbettungs-Ereignisschleife läuft).
(natürlich, wenn Sie nicht mit Mess ipc eingeschaltet, der Teil oberhalb auf recv_timeout ist irrelevant, obwohl Sie immer noch die Calll zu wollen , könnten messen recv_timeout auf dem mpsc da der Threaded-Kanal einige interne Drehungen / Nachgiebigkeiten ausführt, die auch die Ergebnisse beeinflussen könnten.Und da oben mehrmals ein nicht identifizierter "IPC-Fix" erwähnt wurde, gehe ich davon aus, dass Sie mit ipc messen).
gterzian
am 27. Feb. 2020
Ignorieren Sie mich, wenn dies bereits in Betracht gezogen wurde, haben Sie daran gedacht, die Messung von run_one_frame auf eine pro Nachricht behandelte Basis aufzuschlüsseln und auch die Zeit zu bestimmen, die für thread::sleep()-ing aufgewendet wurde?
Es ist bereits aufgeschlüsselt, die Warte-/Renderzeiten sind genau so. Ein einzelner Tick von run_one_frame ist ein Rendern, ein Warten und eine unbestimmte Anzahl von verarbeiteten Ereignissen (selten).
recv_timeout ist eine gute Idee für die Messung
Manishearth
am 27. Feb. 2020
Leider scheint das Spidermonkey-Upgrade in #25678 keine signifikante Verbesserung zu sein - die durchschnittlichen FPS jeder Demo mit Ausnahme der am stärksten eingeschränkten Speicherkapazität sind gesunken; die Hill Valley-Demo stieg leicht an. Das Ausführen von Servo mit -Z gc-profile in den Initialisierungsargumenten zeigt keinen Unterschied im GC-Verhalten zwischen dem Master und dem Spidermonkey-Upgrade-Zweig - es werden keine GCs gemeldet, nachdem der GL-Inhalt geladen und angezeigt wurde.
jdm
am 3. März 2020
Maße für verschiedene Branchen:
master:
- espilit: 14-16 fps
- paint: 39-45 fps
- ball shooter: 30-40 fps
- hill valley: 8 fps, 200mb free mem
- mansion: 10-14fps, 650mb free mem
master + single swapchain:
- espilit: 10-12 fps
- paint: 29-55 fps, 1.2gb free mem
- ball shooter: 25-35 fps, 1.3gb free mem
- hill valley: 6-7 fps, 200mb free mem
- mansion: 10-11 fps, 700mb free mem
texture sharing + ANGLE 2.1.19:
- espilit: 13-15 fps, 670mb free mem
- paint: 39-45 fps
- ball shooter: 30-37 fps, 1.3gb free mem
- hill valley: 9-10 fps, 188mb free mem
- mansion: 13-14 fps, 671mb free mem
smup:
- espilit: 11-13 fps, 730mb free mem
- paint: 25-42 fps, 1.1gb free mem
- ball shooter: 26-30 fps, 1.4gb free mem
- hill valley: 10-11 fps, 145mb
- mansion: 9-11fps, 680mb free mem
Der Smup hat die Leistung verschlechtert???
asajeffrey
am 3. März 2020
Mit den Änderungen von https://github.com/servo/servo/pull/25855#issuecomment -594203492 gibt es das interessante Ergebnis, dass das Deaktivieren des Ion JIT bei 12 FPS beginnt und dann einige Sekunden später abrupt auf 1 FPS steigt und bleibt dort.
jdm
am 3. März 2020
Habe ein paar Messungen mit diesen Patches gemacht.
Beim Malen erhalte ich 60 fps, wenn nicht viel Inhalt zu sehen ist, und wenn ich gezeichneten Inhalt betrachte, sinkt er auf 50 fps (die gelben Spitzen sind, wenn ich gezeichneten Inhalt betrachte). Es ist schwer zu sagen, warum, meistens scheint die Wartezeit durch Openxr-Drosselung beeinflusst zu werden, aber die anderen Dinge scheinen nicht langsam genug zu sein, um ein Problem zu verursachen. Das Timing der Swap-Anforderung ist etwas langsamer. Die rAF-Ausführungszeit ist anfangs langsam (dies ist die anfängliche Verlangsamung des "ersten Mals, dass ein Controller gesehen wird"), aber danach ist sie ziemlich konstant. Es scheint, als würde uns openxr nur drosseln, aber anderswo gibt es keine sichtbare Verlangsamung, die dies verursachen würde.

Manishearth
am 7. März 2020
Das ist, was ich für die ziehende Demo habe. Die y-Skala ist die gleiche. Hier ist es viel offensichtlicher, dass uns die Ausführungszeit verlangsamt.

Manishearth
am 7. März 2020
Zu beachten ist, dass ich Messungen mit # 25837 durchgeführt habe und dies die Leistung beeinträchtigen könnte.
jdm
am 7. März 2020
Ich nicht, aber ich habe ähnliche Ergebnisse wie Sie erhalten
Manishearth
am 7. März 2020
Diagramme des Leistungstools für den Moment, in dem es beim Betrachten von Inhalten von 60 FPS auf 45 FPS geht:
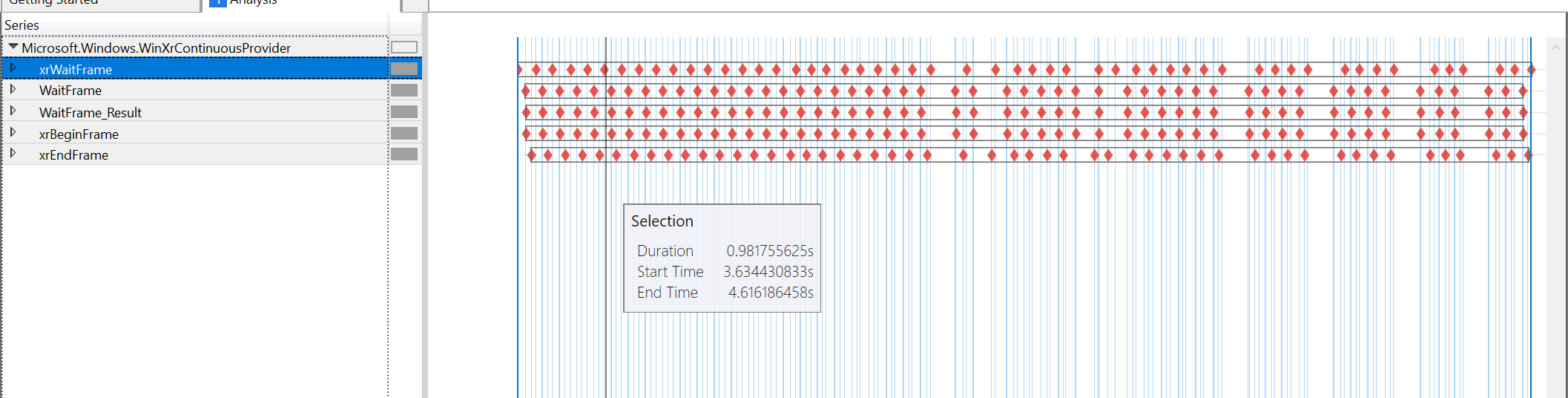
es scheint, als ob die Schuld ausschließlich bei xrWaitFrame liegt, alle anderen Timings liegen ziemlich nah beieinander. Der xrBeginFrame ist immer noch fast unmittelbar nach xrWaitFrame, der xrEndFrame ist 4us nach dem xrBeginFrame (in beiden Fällen). Der nächste xrWaitFrame ist fast unmittelbar nach dem xrEndFrame. Die einzige unberücksichtigte Lücke wird durch xrWaitFrame selbst verursacht.
Manishearth
am 11. März 2020
Bei der ziehenden Demo erhalte ich folgende Spur:

Dies ist die Farbdemo mit dem gleichen Maßstab:
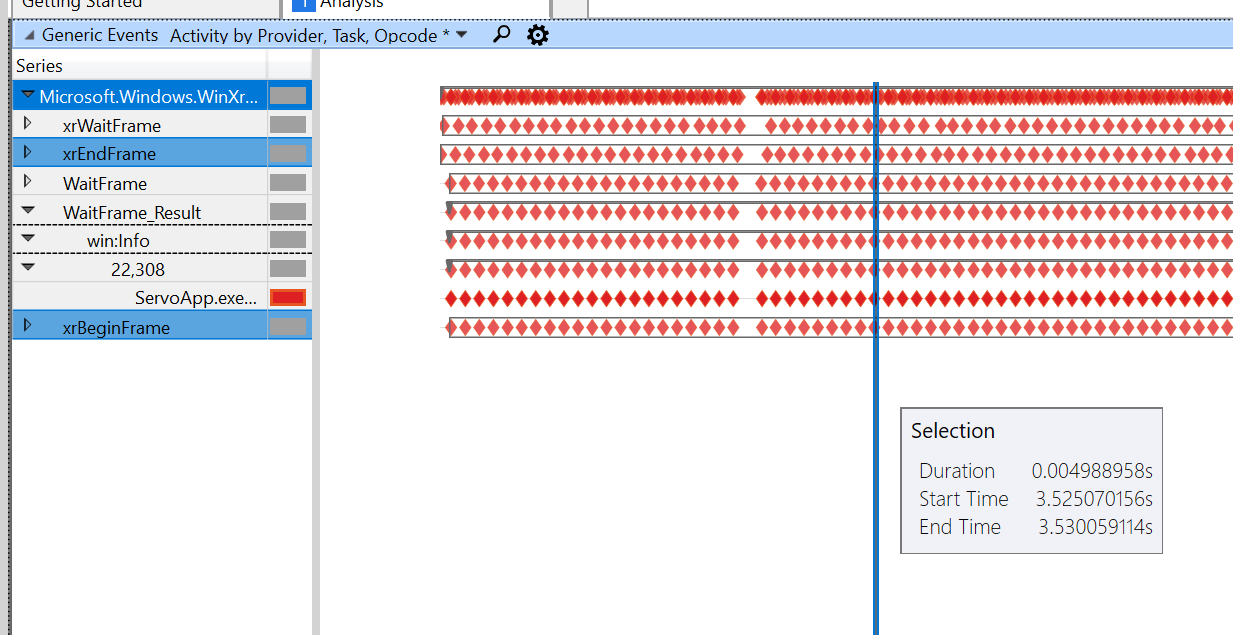
Wir sind langsam zwischen Beginn/Ende des Frames (von 5 ms bis 38 ms beim schnellsten!) beide.
Manishearth
am 18. März 2020
Die ziehende Demo wird verlangsamt, weil ihre Lichtquelle einen Schatten wirft. Das Schatten-Zeug wird auf der GL-Seite gemacht, also bin ich mir nicht sicher, ob wir das leicht beschleunigen können?
Manishearth
am 18. März 2020
Wenn dies vollständig über GLSL erfolgt, können wir Schwierigkeiten haben; Wenn dies in jedem Frame über WebGL-APIs erfolgt, gibt es möglicherweise Optimierungspunkte.
jdm
am 18. März 2020
Ja, es scheint alles auf der GLSL-Seite zu liegen; Ich konnte keine WebGL-Aufrufe sehen, wenn es um die Funktionsweise der Shadow-APIs geht, nur einige Bits, die an Shader weitergegeben werden
Manishearth
am 19. März 2020
Ich glaube, das wurde allgemein angesprochen. Wir können Probleme für einzelne Demos einreichen, die noch bearbeitet werden müssen.
jdm
am 20. Juli 2020
Verwandte Themen
 kmcallister
·
4Kommentare
kmcallister
·
4Kommentare
 CYBAI
·
3Kommentare
Manishearth
·
4Kommentare
gterzian
·
4Kommentare
gterzian
·
3Kommentare
CYBAI
·
3Kommentare
Manishearth
·
4Kommentare
gterzian
·
4Kommentare
gterzian
·
3Kommentare
Hilfreichster Kommentar
Aktueller Status: Mit IPC-Fixes schwebt die FPS jetzt bei 55. Es wackelt manchmal ein bisschen, aber normalerweise geht es nicht unter 45, _außer_ während der ersten Sekunden nach dem Laden (wo es auf 30 sinken kann) und wenn es sieht zuerst eine Hand (wenn sie auf 20 sinkt).