Saya menggunakan ini untuk melacak penyelidikan penyebab nilai FPS rendah saat menggunakan mode imersif pada perangkat.
 jdm
jdm
Semua 71 komentar
Beberapa informasi yang telah terbongkar:
- ada waktu tunggu yang lama antara xrWaitFrame dan xrBeginFrame
- di aplikasi demo ini terjadi secara berurutan
- dalam model Servo, kami menunggu bingkai perangkat , lalu setelah kami menerima render dari utas webgl, kami memulai bingkai openxr berikutnya
Jejak demo cat dengan spidol untuk OpenXR API direproduksi hari ini, dan juga ditampilkan selama periode itu:
- utas webgl menggunakan CPU paling banyak (sebagian besar waktu itu dihabiskan di bawah gl::Finish, yang dipanggil dari Perangkat surfman::bind_surface_to_context)
- utas utama adalah yang tersibuk kedua, dengan penggunaan tertinggi dihabiskan di eglCreatePbufferFromClientBuffer dan hampir sebanyak waktu yang dihabiskan untuk mengambil objek Egl dari TLS
- rendering webrender juga muncul di tumpukan ini
- winrt::servo::flush juga muncul di sini, dan tidak jelas bagi saya apakah kita benar-benar perlu menukar buffer GL aplikasi utama saat kita dalam mode imersif
- penggunaan CPU tertinggi ketiga adalah utas skrip, menghabiskan banyak waktu di dalam kode JIT
- setelah itu penggunaan CPU utas umumnya cukup rendah, tetapi ada beberapa simbol dari peti gaya yang muncul yang menunjukkan bahwa tata letak sedang terjadi
jdm
pada 3 Jan 2020
Mengingat titik-titik data tersebut, saya akan mencoba dua pendekatan untuk memulai:
- mulai bingkai XR berikutnya sesegera mungkin setelah menunggu bingkai perangkat
- kurangi berapa kali kita perlu memanggil gl::Finish (utas webgl), eglCreateBufferFromClientBuffer dan TLS (utas utama)
jdm
pada 3 Jan 2020
https://github.com/servo/servo/pull/25343#issuecomment -567706735 memiliki penyelidikan lebih lanjut tentang dampak pengiriman pesan ke berbagai tempat di mesin. Itu tidak menunjukkan jari yang jelas, tetapi menyarankan pengukuran yang lebih tepat harus dilakukan.
jdm
pada 3 Jan 2020
Penggunaan gl::Finish berasal dari https://github.com/pcwalton/surfman/blob/6705a9aaa8f33ac1324fdb1913242800e68c7720/surfman/src/platform/windows/angle/context.rs#L259 -L266.
jdm
pada 3 Jan 2020
Mengubah gl::Finish menjadi gl::Flush meningkatkan framerate dari ~15->30, tetapi ada jeda yang sangat mencolok dalam konten frame yang sebenarnya mencerminkan pergerakan kepala pengguna, menyebabkan frame saat ini mengikuti kepala pengguna sementara itu.
jdm
pada 3 Jan 2020
Mutex yang dikunci dinonaktifkan secara default di ANGLE karena alasan yang tidak saya ketahui, tetapi mozangle secara eksplisit mengaktifkannya (https://github.com/servo/mozangle/blob/706a9baaf8026c1a3cb6c67ba63aa5f4734264d0/build_data.rs#L175), dan itulah yang diuji oleh surfman . Saya akan membuat ANGLE yang memungkinkan mereka dan melihat apakah itu cukup untuk menghindari panggilan gl::Finish.
jdm
pada 3 Jan 2020
Dikonfirmasi! Memaksa mutex yang dikunci di ANGLE memberi saya 25-30 FPS dalam demo cat tanpa masalah lag apa pun yang muncul dengan mengubah panggilan gl::Finish.
jdm
pada 3 Jan 2020
Oh, dan informasi lain menurut penyelidikan lars:
- w/ dom.ion.enabled disetel ke false, waktu JIT menghilang. Pemuatan awal jauh lebih lambat, tetapi begitu semuanya berjalan, mereka cukup bagus.
- Itu masih belum fantastis - penggunaan memori cukup tinggi (pada dasarnya semua memori yang tersedia) pada contoh babylon.js itu
- kita harus melakukan peningkatan spidermonkey lain untuk menarik pengoptimalan terkait arm64 yang telah terjadi untuk FxR di perangkat android
jdm
pada 3 Jan 2020
Saya pikir saya salah memahami keberadaan std::thread::local::LocalKey<surfman::egll::Egl> di profil - Saya cukup yakin pembacaan TLS hanya sebagian kecil dari waktu yang dibebankan padanya, dan itu adalah fungsi yang dipanggil di dalam blok TLS seperti eglCreatePbufferFromClientBuffer dan DXGIAcquireSync yang _sebenarnya_ meluangkan waktu.
jdm
pada 3 Jan 2020
Sayangnya, menonaktifkan js.ion.enabled tampaknya merusak FPS dari demo cat, menurunkannya menjadi 20-25.
jdm
pada 4 Jan 2020
Daripada memanggil Device::create_surface_texture_from_texture dua kali setiap frame (sekali untuk setiap tekstur d3d untuk setiap mata), dimungkinkan untuk membuat tekstur permukaan untuk semua tekstur swapchain saat perangkat openxr webxr dibuat. Jika ini berhasil, itu akan menghapus pengguna CPU terbesar kedua dari utas utama selama mode imersif.
jdm
pada 4 Jan 2020
Ide lain untuk mengurangi penggunaan memori: apakah ada dampak jika kita menyetel bfcache ke angka yang sangat rendah sehingga saluran beranda HL asli dikeluarkan saat menavigasi ke salah satu demo?
jdm
pada 4 Jan 2020
Patch webxr berikut tidak secara jelas meningkatkan FPS, tetapi mungkin meningkatkan stabilitas gambar. Saya perlu membuat dua build terpisah yang dapat saya periksa secara berurutan.
diff --git a/webxr/openxr/mod.rs b/webxr/openxr/mod.rs
index 91c78da..a6866de 100644
--- a/webxr/openxr/mod.rs
+++ b/webxr/openxr/mod.rs
@@ -416,11 +416,30 @@ impl DeviceAPI<Surface> for OpenXrDevice {
}
fn wait_for_animation_frame(&mut self) -> Option<Frame> {
- if !self.handle_openxr_events() {
- // Session is not running anymore.
- return None;
+ loop {
+ if !self.handle_openxr_events() {
+ // Session is not running anymore.
+ return None;
+ }
+ self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
+ // XXXManishearth this code should perhaps be in wait_for_animation_frame,
+ // but we then get errors that wait_image was called without a release_image()
+ self.frame_stream
+ .begin()
+ .expect("failed to start frame stream");
+
+ if self.frame_state.should_render {
+ break;
+ }
+
+ self.frame_stream.end(
+ self.frame_state.predicted_display_time,
+ EnvironmentBlendMode::ADDITIVE,
+ &[],
+ ).unwrap();
}
- self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
let time_ns = time::precise_time_ns();
// XXXManishearth should we check frame_state.should_render?
let (_view_flags, views) = self
@@ -506,12 +525,6 @@ impl DeviceAPI<Surface> for OpenXrDevice {
0,
);
- // XXXManishearth this code should perhaps be in wait_for_animation_frame,
- // but we then get errors that wait_image was called without a release_image()
- self.frame_stream
- .begin()
- .expect("failed to start frame stream");
-
self.left_image = self.left_swapchain.acquire_image().unwrap();
self.left_swapchain
.wait_image(openxr::Duration::INFINITE)
@manishearth ada pemikiran tentang ini? Ini upaya saya untuk lebih dekat dengan model yang dijelaskan oleh https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#Session.
jdm
pada 4 Jan 2020
Ya, itu terlihat bagus. Saya bermaksud untuk memindahkan begin() ke waf, dan saya yakin kesalahan yang disebutkan dalam komentar tidak lagi terjadi, tetapi itu juga tidak memiliki efek nyata pada FPS jadi saya tidak mengejarnya terlalu banyak untuk saat ini. Jika itu meningkatkan stabilitas, itu bagus!
 Manishearth
pada 4 Jan 2020
Manishearth
pada 4 Jan 2020
Sangat senang dengan penemuan kunci! Panggilan Surfman memang menghabiskan banyak anggaran bingkai tetapi agak sulit untuk menentukan apa yang perlu dan tidak.
Manishearth
pada 4 Jan 2020
Ya, re: menonaktifkan js.ion.enabled , itu hanya akan bermanfaat ketika kita kekurangan RAM dan menghabiskan sebagian besar waktu kita untuk meng-GC dan mengkompilasi ulang fungsi. Dan itu harus ditingkatkan dengan SM yang lebih baru. IIRC, backend ARM64 era 66 juga memiliki JIT dasar dan kinerja interpreter yang relatif buruk; kita harus melihat percepatan di seluruh papan dengan pembaruan tetapi terutama pada aplikasi intensif RAM.
 larsbergstrom
pada 4 Jan 2020
larsbergstrom
pada 4 Jan 2020
Paket ANGLE baru yang diterbitkan dengan mutex yang diaktifkan diaktifkan. Saya akan membuat permintaan tarik untuk memutakhirkannya nanti.
jdm
pada 6 Jan 2020
Saya mencoba membuat tekstur permukaan untuk semua gambar openxr swapchain selama inisialisasi perangkat XR, tetapi masih ada banyak waktu di utas utama yang dihabiskan untuk memanggil eglCreatePbufferFromClientBuffer di permukaan yang kami terima dari utas webgl setiap bingkai. Mungkin ada cara untuk menyimpan tekstur permukaan tersebut sehingga kami dapat menggunakannya kembali jika kami menerima permukaan yang sama...
jdm
pada 6 Jan 2020
Penggunaan CPU utas utama terbesar berasal dari render_animation_frame, dengan sebagian besar di bawah runtime OpenXR tetapi panggilan ke BlitFramebuffer dan FramebufferTexture2D pasti muncul di profil juga. Saya ingin tahu apakah itu akan menjadi perbaikan untuk mengedipkan kedua mata sekaligus menjadi satu tekstur? Mungkin itu terkait dengan hal-hal array tekstur yang dibahas di https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt.
jdm
pada 6 Jan 2020
Kita bisa mengedipkan kedua mata sekaligus, namun pemahaman saya adalah bahwa runtime
kemudian dapat melakukan blit sendiri. Array tekstur adalah metode tercepat. Tetapi
layak dicoba, API tampilan proyeksi mendukung melakukan ini.
Adapun lalu lintas ANGLE utas utama, apakah menghentikan loop RAF dari
mengotori bantuan kanvas? Sejauh ini belum melakukan apa-apa tapi itu layak
bidikan, idealnya kita tidak boleh melakukan tata letak/rendering apa pun di main
benang.
Pada Senin, 6 Januari 2020, 23:49 Josh Matthews [email protected]
menulis:
Penggunaan CPU utas utama terbesar berasal dari render_animation_frame, dengan
sebagian besar di bawah runtime OpenXR tetapi panggilan ke BlitFramebuffer dan
FramebufferTexture2D pasti muncul di profil juga. aku penasaran
jika itu akan menjadi peningkatan untuk mengedipkan kedua mata sekaligus menjadi satu
tekstur? Mungkin itu terkait dengan hal-hal array tekstur yang dibahas
di
https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt
.—
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/servo/servo/issues/25425?email_source=notifications&email_token=AAMK6SBRH72JGZMXTUKOXETQ4NY37A5CNFSM4KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXH2ZLODOR5WWK3TUL52HS
atau berhenti berlangganan
https://github.com/notifications/unsubscribe-auth/AAMK6SECM6MDNZZ6Y7VL7SDQ4NY37ANCNFSM4KCRI6AA
.
Manishearth
pada 6 Jan 2020
Menghapus kanvas yang mengotori hanya membersihkan profil; tampaknya tidak mengarah pada peningkatan FPS yang berarti.
jdm
pada 6 Jan 2020
Saya mencoba membuat cache tekstur permukaan untuk permukaan dari utas webgl serta tekstur openxr swapchain, dan sementara waktu eglCreatePbufferFromClientBuffer menghilang sepenuhnya, saya tidak melihat adanya perubahan FPS yang berarti.
jdm
pada 6 Jan 2020
Beberapa informasi pengaturan waktu untuk berbagai operasi dalam pipeline imersif (semua pengukuran dalam md):
Name min max avg
raf queued 0.070833 14.010261 0.576834
<1ms: 393
<2ms: 28
<4ms: 5
<8ms: 1
<16ms: 2
<32ms: 0
32+ms: 0
raf transmitted 0.404270 33.649583 7.403302
<1ms: 123
<2ms: 43
<4ms: 48
<8ms: 48
<16ms: 95
<32ms: 69
32+ms: 3
raf wait 1.203500 191.064100 17.513593
<1ms: 0
<2ms: 17
<4ms: 98
<8ms: 95
<16ms: 48
<32ms: 69
32+ms: 101
raf execute 3.375000 128.663200 6.994588
<1ms: 0
<2ms: 0
<4ms: 5
<8ms: 351
<16ms: 70
<32ms: 1
32+ms: 2
raf receive 0.111510 8.564010 0.783503
<1ms: 353
<2ms: 52
<4ms: 18
<8ms: 4
<16ms: 1
<32ms: 0
32+ms: 0
raf render 2.372200 75.944000 4.219310
<1ms: 0
<2ms: 0
<4ms: 253
<8ms: 167
<16ms: 8
<32ms: 0
32+ms: 1
receive : waktu dari informasi bingkai XR dikirim dari utas XR hingga diterima oleh router IPC
queued : waktu dari router IPC menerima informasi frame sampai XRSession::raf_callback dipanggil
execute : waktu dari XRSession::raf_callback dipanggil hingga kembali dari metode
transmitted : waktu dari mengirim permintaan rAF baru dari utas skrip hingga diterima oleh utas XR
render : waktu yang dibutuhkan untuk memanggil render_animation_frame dan mendaur ulang permukaannya
wait : waktu yang dibutuhkan oleh wait_for_animation_frame (menggunakan tambalan dari sebelumnya dalam masalah ini yang mengulang bingkai yang seharusnya tidak dirender)
Di bawah setiap entri adalah distribusi nilai selama sesi.
jdm
pada 7 Jan 2020
Poin data yang menarik dari informasi waktu itu - kategori transmitted tampaknya jauh lebih tinggi dari yang seharusnya. Itulah penundaan antara eksekusi panggilan balik rAF dan utas XR yang menerima pesan yang memecah bingkai yang telah selesai menjadi tekstur openxr. Ada sedikit variasi, menunjukkan bahwa utas utama sedang digunakan untuk melakukan hal-hal lain, atau perlu dibangunkan untuk memprosesnya.
jdm
pada 7 Jan 2020
Mengingat data sebelumnya, saya dapat mencoba menghidupkan kembali https://github.com/servo/webxr/issues/113 besok untuk melihat apakah itu memengaruhi waktu transmisi secara positif. Saya mungkin melihat utas utama di profiler terlebih dahulu untuk melihat apakah saya dapat menemukan ide tentang cara mengetahui apakah utas sibuk dengan tugas lain atau tertidur.
jdm
pada 7 Jan 2020
Satu titik data lainnya:
swap buffer 1.105938 28.193698 2.154793
<1ms: 0
<2ms: 273
<4ms: 110
<8ms: 15
<16ms: 2
<32ms: 2
32+ms: 0
swap complete 0.053802 4.337812 0.295064
<1ms: 308
<2ms: 9
<4ms: 6
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
swap request 0.003333 24033027.355364 4662890.724805
<1ms: 268
<2ms: 49
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 1
32+ms: 79
Ini adalah pengaturan waktu yang terkait dengan 1) penundaan pengiriman pesan buffer swap hingga diproses di utas webgl, 2) waktu yang dibutuhkan untuk menukar buffer, 3) penundaan pengiriman pesan yang menunjukkan bahwa pertukaran selesai hingga diterima di benang skrip. Tidak ada yang terlalu mengejutkan di sini (kecuali outlier aneh dalam kategori swap request , tetapi itu terjadi di awal sesi imersif selama proses penyiapan), tetapi pertukaran buffer sebenarnya secara konsisten membutuhkan waktu antara 1-4 ms.
jdm
pada 7 Jan 2020
Diarsipkan #117 setelah membaca beberapa kode sampel openxr dan memperhatikan bahwa panggilan locate_views muncul di profil.
jdm
pada 7 Jan 2020
 asajeffrey
pada 7 Jan 2020
asajeffrey
pada 7 Jan 2020
Poin data yang menarik dari informasi waktu itu - kategori yang ditransmisikan tampaknya jauh lebih tinggi dari yang seharusnya. Itulah penundaan antara eksekusi panggilan balik rAF dan utas XR yang menerima pesan yang memecah bingkai yang telah selesai menjadi tekstur openxr. Ada sedikit variasi, menunjukkan bahwa utas utama sedang digunakan untuk melakukan hal-hal lain, atau perlu dibangunkan untuk memprosesnya.
Tentang variasi dalam nilai transmitted , ini mungkin terkait dengan batas waktu yang digunakan sebagai bagian dari run_one_frame saat sesi berjalan di utas utama (yang ada dalam pengukuran tersebut, bukan?) , lihat https://github.com/servo/webxr/blob/c6abf4c60d165ffc978ad2ebd6bcddc3c21698e1/webxr-api/session.rs#L275
Saya menduga bahwa ketika RenderAnimationFrame msg (yang dikirim oleh utas skrip setelah menjalankan panggilan balik) diterima sebelum batas waktu, Anda menekan "jalur cepat", dan jika batas waktu terlewatkan Servo masuk ke yang lain iterasi perform_updates , dan "menjalankan frame lain" terjadi cukup terlambat dalam siklus, sebagai bagian dari compositor.perform_updates , itu sendiri disebut cukup terlambat sebagai bagian dari servo.handle_events .
Singkat dari memindahkan XR ke utasnya sendiri, mungkin layak untuk dilihat apakah nilai batas waktu yang lebih tinggi meningkatkan nilai rata-rata (walaupun itu mungkin bukan solusi yang tepat karena mungkin membuat kelaparan hal-hal lain yang diperlukan di utas utama).
 gterzian
pada 8 Jan 2020
gterzian
pada 8 Jan 2020
Saya telah membuat kemajuan dalam mengeluarkan openxr dari utas utama di https://github.com/servo/webxr/issues/113 , jadi saya akan melakukan lebih banyak pengukuran berdasarkan pekerjaan itu minggu depan.
jdm
pada 10 Jan 2020
Teknik untuk mendapatkan profil yang berguna dari perangkat:
- gunakan .servobuild yang menyertakan
rustflags = "-C force-frame-pointers=yes" - batalkan komentar pada baris ini
- gunakan WinXR_Perf.wprp dari tim MS tab char
Filessebagai profil penelusuran kustom di bawah "Pelacakan Kinerja" di portal perangkat HL - membangun dengan
--features profilemozjs
Jejak ini (diperoleh dari "Mulai Jejak" di portal perangkat) akan dapat digunakan di dalam alat Penganalisis Kinerja Windows. Alat ini tidak menunjukkan nama utas, tetapi utas yang menggunakan sebagian besar CPU mudah diidentifikasi berdasarkan tumpukan.
Untuk membuat profil distribusi waktu dari frame openxr tertentu:
- tambahkan tampilan "Aktivitas Sistem -> Acara Umum" di WPA
- filter tampilan untuk hanya menampilkan seri Microsoft.Windows.WinXrContinuousProvider
- perbesar ke durasi yang singkat, lalu perbaiki wilayah yang diperbesar sehingga peristiwa xrBegin berada di sisi kiri tampilan, dan peristiwa xrEnd berada di sisi kanan tampilan
Tampilan paling berguna untuk penggunaan CPU:
- Penggunaan CPU (Sampel) -> Pemanfaatan oleh Proses, Utas, Tumpukan (filter tampilan untuk hanya menampilkan Servo, lalu nonaktifkan kolom Proses)
- Flame by Process, Stack (filter tampilan untuk hanya menampilkan Servo)
jdm
pada 16 Jan 2020
Satu kemungkinan untuk melakukan sedikit lebih sedikit pekerjaan di utas skrip:
- XRView::new mengkonsumsi 0,02% dari semua CPU Servo
- karena konten objek tampilan tidak berubah kecuali ada acara FrameUpdateEvent::UpdateViews (yang berasal dari Session::update_clip_planes melalui XRSession::UpdateRenderState), kita dapat menyimpan objek XRView di XRSession dan terus menggunakannya hingga status render diperbarui
- kami bahkan dapat menyimpan representasi JS dari daftar tampilan yang di-cache di XRSession dan mengatur anggota tampilan pose, menghindari pembuatan ulang objek XRView, dan mengalokasikan vektor, dan melakukan konversi nilai JS
jdm
pada 16 Jan 2020
Satu kemungkinan untuk melakukan lebih sedikit pekerjaan saat merender bingkai yang imersif:
- GL dan d3d memiliki sistem koordinat Y terbalik
- ANGLE secara implisit menyembunyikan ini saat menampilkan ke layar dengan melakukan beberapa pekerjaan di belakang layar
- untuk mode imersif, kami menggunakan glBlitFramebuffer untuk melakukan inversi y saat mem-blitting data tekstur GL ke d3d
- jika kita dapat mengetahui bagaimana membuat ANGLE tidak melakukan konversi secara internal, mungkin saja untuk membalikkan model ini dan membuat rendering halaman web non-immersive memerlukan blit y-invert tambahan (melalui opsi webrender
surface_origin_is_top_left) sementara mode imersif dapat dihancurkan tanpa transformasi apa pun
Berdasarkan https://bugzilla.mozilla.org/show_bug.cgi?id=1591346 dan berbicara dengan jrmuizel, inilah yang perlu kita lakukan:
- dapatkan d3d swapchain untuk elemen jendela tempat kita ingin merender halaman non-imersif (ini akan menjadi SwapChainPanel di aplikasi XAML)
- bungkus itu dalam gambar EGL (https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#554)
- Secara eksplisit Sajikan swapchain ketika kami ingin memperbarui rendering utama
- hindari menggunakan eglCreateWindowSurface dan eglSwapBuffers di https://github.com/servo/servo/blob/master/support/hololens/ServoApp/ServoControl/OpenGLES.cpp#L205 -L208
Kode Gecko yang relevan: https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#192
Kode ANGLE yang relevan: https://github.com/google/angle/blob/df0203a9ae7a285d885d7bc5c2d4754fe8a59c72/src/libANGLE/renderer/d3d/d3d11/winrt/SwapChainPanelNativeWindow.cpp#L244
jdm
pada 16 Jan 2020
Cabang wip saat ini:
- https://github.com/servo/ipc-channel/tree/try-recv-error
- https://github.com/jdm/webxr/tree/oxr
- https://github.com/jdm/rust-offscreen-rendering-context/tree/angle-perf
- https://github.com/jdm/servo/tree/profile
Ini termasuk fitur xr-profile yang menambahkan data waktu yang saya sebutkan sebelumnya, serta implementasi awal dari perubahan ANGLE untuk menghapus transformasi y-inverse dalam mode imersif. Mode non-imersif ditampilkan dengan benar, tetapi mode imersif terbalik. Saya yakin saya perlu menghapus kode GL dari render_animation_frame dan menggantinya dengan panggilan CopySubresourceRegion langsung dengan mengekstrak pegangan berbagi dari permukaan GL sehingga saya bisa mendapatkan tekstur d3d-nya.
jdm
pada 17 Jan 2020
Diajukan https://github.com/servo/servo/issues/25582 untuk pekerjaan ANGLE y-inversion; pembaruan lebih lanjut tentang pekerjaan itu akan dilakukan di edisi itu.
jdm
pada 23 Jan 2020
Item tiket besar berikutnya akan menyelidiki cara menghindari panggilan glBlitFramebuffer di backend openxr webxr sepenuhnya. Ini membutuhkan:
- membuat framebuffer openxr yang cocok dengan framebuffer webgl buram yang diperlukan secara tepat
- mendukung mode webgl di mana backend webxr menyediakan semua permukaan swapchain, daripada membuatnya (mis. di https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L458 dan https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L111-L118)
jdm
pada 23 Jan 2020
Itu mungkin sulit, karena surfman hanya menyediakan akses tulis ke konteks yang membuat permukaan, jadi jika permukaan dibuat oleh utas openxr, itu tidak akan dapat ditulisi oleh utas WebGL. https://github.com/pcwalton/surfman/blob/a515fb2f5d6b9e9b36ba4e8b498cdb4bea92d330/surfman/src/device.rs#L95 -L96
asajeffrey
pada 23 Jan 2020
Itu terjadi pada saya - jika kami melakukan rendering openxr di utas webgl, banyak masalah terkait threading seputar rendering langsung ke tekstur openxr tidak akan lagi menjadi masalah (mis. pembatasan di sekitar eglCreatePbufferFromClientBuffer yang melarang menggunakan beberapa perangkat d3d). Mempertimbangkan:
- masih ada utas openxr yang bertanggung jawab untuk polling untuk acara openxr, menunggu bingkai animasi, memulai bingkai baru dan mengambil status bingkai saat ini
- status bingkai dikirim ke utas skrip, yang melakukan panggilan balik animasi kemudian mengirim pesan ke utas webgl untuk menukar framebuffer lapisan xr
- ketika pesan swap ini diterima di utas webgl, kami melepaskan gambar openxr swapchain yang terakhir diperoleh, mengirim pesan ke utas openxr untuk mengakhiri frame saat ini, dan memperoleh gambar swapchain baru untuk frame berikutnya
Bacaan saya tentang https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#threading -behavior menunjukkan bahwa desain ini mungkin bisa diterapkan. Triknya adalah apakah itu dapat bekerja untuk backend non-openxr kami serta untuk openxr.
Dari spesifikasi: "Sementara xrBeginFrame dan xrEndFrame tidak perlu dipanggil di utas yang sama, aplikasi harus menangani sinkronisasi jika dipanggil di utas terpisah."
jdm
pada 25 Jan 2020
Saat ini tidak ada komunikasi langsung antara utas perangkat XR dan webgl, semuanya berjalan melalui skrip atau melalui rantai pertukaran bersama mereka. Saya akan tergoda untuk menyediakan API rantai swap yang berada di atas rantai swap surfman atau rantai swap openxr, dan menggunakannya untuk komunikasi webgl-ke-openxr.
asajeffrey
pada 25 Jan 2020
Catatan dari percakapan tentang pengukuran waktu sebelumnya:
* concerns about wait time - why?????
* figure out time spent in JS vs. DOM logic
* when does openxr give us should render=false frames - maybe related to previous frame taking too long
* are threads being scheduled on inappropriate cpus? - on magic leap, main thread (including weber) pinned to big core.
* when one of the measured numbers is large, is there correlation with other large numbers?
* probably should pin openxr thread, running deterministic code
* consider clearing after telling script that the swap is complete - measure if clear is taking significant time in swap operation
* consider a swap chain API operation - “wait until a buffer swap occurs”
- block waiting on swapchain
- block waiting on swapchain + timeout
- async????????
- a gc would look like a spike in script execution time
Mengajukan #25735 untuk melacak penyelidikan yang saya lakukan tentang rendering langsung ke tekstur openxr.
jdm
pada 11 Feb 2020
Satu hal yang harus kita lakukan adalah mempersempit perbandingan spidermonkey pada perangkat dengan mesin lain. Cara termudah untuk mendapatkan beberapa data di sini adalah dengan menemukan tolok ukur JS sederhana yang dapat dijalankan Servo, dan membandingkan kinerja Servo dengan browser Edge yang diinstal pada perangkat. Selain itu, kami dapat mencoba mengunjungi beberapa demo babylon yang kompleks di kedua browser tanpa memasuki mode imersif untuk melihat apakah ada perbedaan kinerja yang signifikan. Ini juga akan memberi kami tolok ukur untuk dibandingkan dengan peningkatan spidermonkey yang akan datang.
jdm
pada 13 Feb 2020
Beberapa data baru. Ini dengan peningkatan ANGLE, tetapi bukan yang IPC.
$ python timing.py raw
Name min max mean
raf queued 0.056198 5.673125 0.694902
<1ms: 335
<2ms: 26
<4ms: 17
<8ms: 7
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.822917 36.582083 7.658619
<1ms: 1
<2ms: 4
<4ms: 31
<8ms: 181
<16ms: 158
<32ms: 8
32+ms: 1
raf wait 1.196615 39.707709 10.256875
<1ms: 0
<2ms: 32
<4ms: 93
<8ms: 67
<16ms: 107
<32ms: 68
32+ms: 17
raf execute 3.078438 532.205677 7.752839
<1ms: 0
<2ms: 0
<4ms: 37
<8ms: 290
<16ms: 52
<32ms: 2
32+ms: 3
raf receive 0.084375 9.053125 1.024403
<1ms: 276
<2ms: 71
<4ms: 27
<8ms: 9
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.004115 73.939479 0.611254
<1ms: 369
<2ms: 10
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.706198 233.459636 9.241698
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 183
<16ms: 190
<32ms: 10
32+ms: 1
run_one_frame 7.663333 2631.052969 28.035143
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 3
<16ms: 157
<32ms: 185
32+ms: 41
swap buffer 0.611927 8.521302 1.580279
<1ms: 127
<2ms: 169
<4ms: 74
<8ms: 15
<16ms: 1
<32ms: 0
32+ms: 0
swap complete 0.046511 2.446302 0.215040
<1ms: 375
<2ms: 6
<4ms: 3
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Data waktu: https://Gist.github.com/Manisharth/825799a98bf4dca0d9a7e55058574736
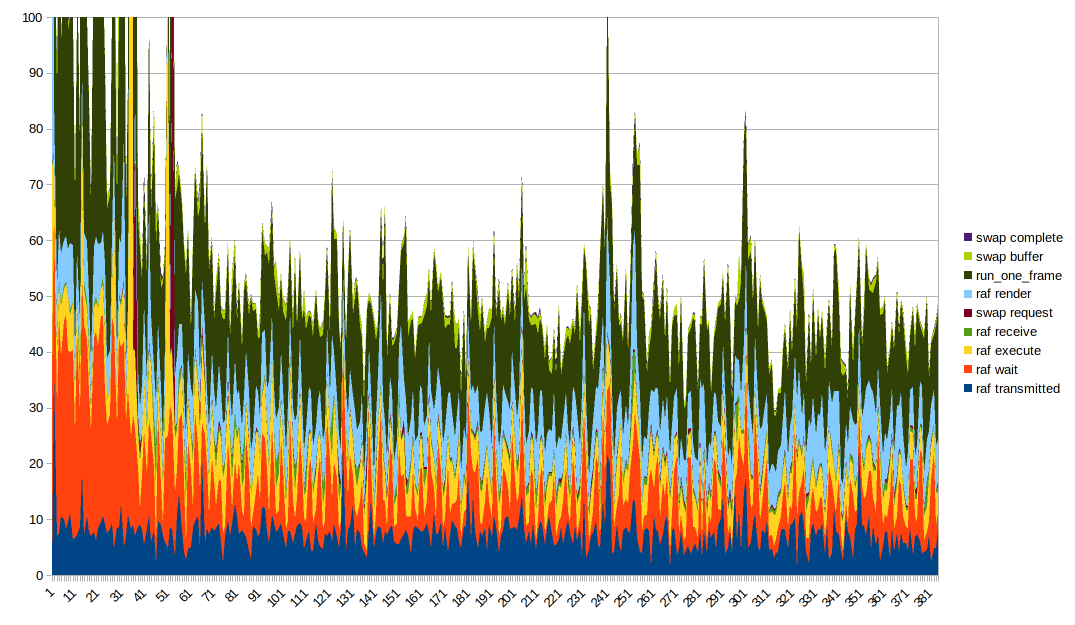
Mendapatkan visualisasi data yang baik tentang ini cukup rumit. Grafik garis bertumpuk tampaknya ideal, meskipun perlu dicatat bahwa run_one_frame mengukur beberapa pengaturan waktu yang sudah diukur. Sangat membantu untuk mengutak-atik urutan grafik dan meletakkan kolom yang berbeda di bagian bawah untuk melihat efeknya dengan lebih baik. Anda juga perlu memotong sumbu Y untuk mendapatkan sesuatu yang berguna karena beberapa outlier yang sangat besar.
Hal yang menarik untuk diperhatikan:
- waktu render dan waktu eksekusi tampaknya sebagian besar stabil tetapi memiliki lonjakan ketika ada lonjakan besar secara keseluruhan. Saya menduga paku besar datang dari segala sesuatu yang melambat karena alasan apa pun
- Waktu transmisi tampaknya berkorelasi cukup baik dengan bentuk keseluruhan
- waktu tunggu juga merupakan bagian dari alasan bentuk keseluruhannya seperti itu, _sangat_ bergelombang
Manishearth
pada 21 Feb 2020
Status saat ini: dengan perbaikan IPC, FPS sekarang berada di sekitar 55. Kadang-kadang bergoyang banyak, tetapi biasanya tidak turun di bawah 45, _kecuali_ selama beberapa detik pertama setelah memuat (di mana bisa turun ke 30), dan ketika itu pertama kali melihat tangan (ketika turun ke 20).
Manishearth
pada 25 Feb 2020
Histogram baru untuk demo cat ( data mentah ):
Name min max mean
raf queued 0.113854 5.707917 0.441650
<1ms: 352
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.546667 44.954792 6.886162
<1ms: 4
<2ms: 2
<4ms: 23
<8ms: 279
<16ms: 59
<32ms: 3
32+ms: 1
raf wait 1.611667 37.913177 9.441104
<1ms: 0
<2ms: 6
<4ms: 98
<8ms: 82
<16ms: 135
<32ms: 43
32+ms: 6
raf execute 3.336562 418.198541 7.592147
<1ms: 0
<2ms: 0
<4ms: 11
<8ms: 319
<16ms: 36
<32ms: 2
32+ms: 3
raf receive 0.119323 9.804167 0.806074
<1ms: 324
<2ms: 31
<4ms: 13
<8ms: 1
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.003646 79.236354 0.761324
<1ms: 357
<2ms: 9
<4ms: 2
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 3
raf render 5.844687 172.898906 8.131682
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 283
<16ms: 86
<32ms: 1
32+ms: 1
run_one_frame 8.826198 2577.357604 25.922205
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 176
<32ms: 174
32+ms: 22
swap buffer 0.708177 12.528906 1.415950
<1ms: 164
<2ms: 161
<4ms: 38
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
swap complete 0.042917 1.554740 0.127729
<1ms: 370
<2ms: 1
<4ms: 0
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Berjalan lebih lama ( mentah ). Dibuat untuk mengurangi dampak perlambatan startup.
Nama min maks berarti
raf antri 0.124896 6.356562 0.440674
<1ms: 629
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ md: 0
raf ditransmisikan 0.640677 20.275104 6.944751
<1ms: 2
<2ms: 3
<4ms: 29
<8ms: 513
<16ms: 99
<32ms: 1
32+ md: 0
raf tunggu 1.645886 40.955208 9.386255
<1ms: 0
<2ms: 10
<4ms: 207
<8ms: 114
<16ms: 236
<32ms: 65
32+ md: 15
raf mengeksekusi 3.090104 526.041198 6.226997
<1ms: 0
<2ms: 0
<4ms: 68
<8ms: 546
<16ms: 29
<32ms: 1
32+ md: 3
raf menerima 0.203334 6.441198 0.747615
<1ms: 554
<2ms: 84
<4ms: 7
<8ms: 2
<16ms: 0
<32ms: 0
32+ md: 0
permintaan swap 0,003490 73,644322 0,428460
<1ms: 627
<2ms: 18
<4ms: 1
<8ms: 0
<16ms: 0
<32ms: 0
32+ md: 2
raf render 5.450312 209.662969 8.055021
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 467
<16ms: 176
<32ms: 3
32+ md: 1
run_one_frame 8.417291 2579.454948 22.226204
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 326
<32ms: 290
32+ md: 33
swap buffer 0.658125 12.179167 1.378725
<1ms: 260
<2ms: 308
<4ms: 72
<8ms: 4
<16ms: 4
<32ms: 0
32+ md: 0
swap selesai 0,041562 5,161458 0,136875
<1ms: 642
<2ms: 3
<4ms: 1
<8ms: 1
<16ms: 0
<32ms: 0
32+ md: 0
Manishearth
pada 27 Feb 2020
Grafik:
Berjalan lebih lama:

Lari lebih pendek: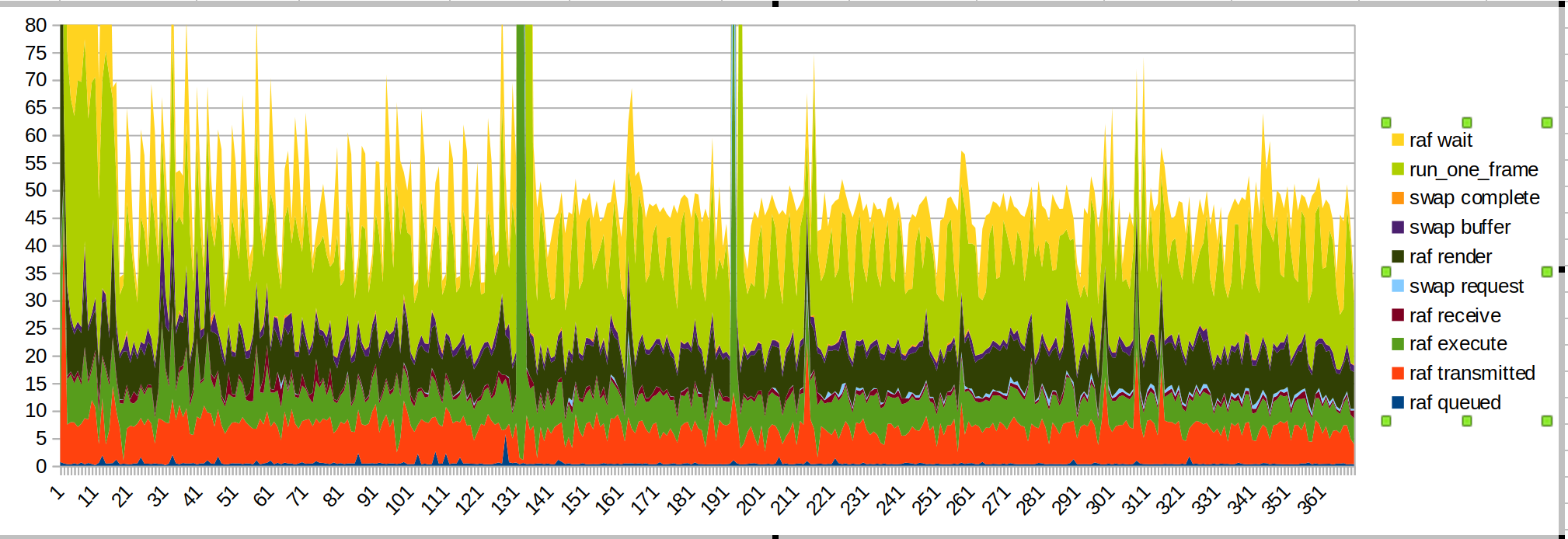
lonjakan besar adalah ketika saya meletakkan tangan saya dalam jangkauan sensor.
Kali ini saya menempatkan waktu wait/run_one_frame di atas karena itu adalah waktu yang paling bergerigi, dan itu karena OS yang membatasi kami.
Beberapa hal yang perlu diperhatikan:
- Lonjakan besar dari tangan yang diperkenalkan disebabkan oleh kode JS (hijau kemangi, "raf render")
- waktu transmisi menjadi lebih lancar, seperti yang diharapkan
- ketika saya mulai menggambar ada lonjakan JS lain
- waktu render dan transmisi masih merupakan bagian anggaran yang signifikan. Performa skrip juga dapat ditingkatkan.
- Saya menduga waktu transmisi memakan waktu lama karena utas utama sedang sibuk melakukan hal-hal lain. Ini https://github.com/servo/webxr/issues/113 , @jdm sedang menyelidikinya
- pembaruan surfman dapat meningkatkan waktu render. pengukuran @asajeffrey 's di surfmanup tampak lebih baik daripada saya
- melakukan berbagi permukaan dapat meningkatkan waktu render (diblokir saat surfmanup)
- FPS yang ditunjukkan oleh perangkat hampir setengahnya saat mengukurnya dengan xr-profile. Ini mungkin karena semua IO.
Pertunjukan tertekuk karena melihat tangan dan kemudian mulai menggambar tidak ada untuk penembak bola. Mungkin demo cat melakukan banyak pekerjaan ketika pertama kali memutuskan untuk menggambar gambar tangan?
(Ini juga bisa menjadi demo cat yang mencoba berinteraksi dengan perpustakaan input webxr)
Manishearth
pada 27 Feb 2020
@Manisharth Bisakah Anda juga melapisi penggunaan memori & berkorelasi dengan peristiwa itu? Selain kompilasi pertama kali kode JS, Anda mungkin salah dalam banyak kode baru dan berlari melawan batas memori fisik dan menimbulkan banyak GC saat Anda menekan tekanan memori. Saya melihat itu di sebagian besar situasi non-sepele. Saya berharap pembaruan SM @nox akan membantu, karena itu pasti artefak yang kami lihat di SM build di FxR Android.
larsbergstrom
pada 27 Feb 2020
Saya tidak memiliki cara mudah untuk mendapatkan data profil memori dengan cara yang dapat dikorelasikan dengan hal-hal profil xr.
Saya berpotensi menggunakan alat perf yang ada dan mencari tahu apakah bentuknya sama.
Manishearth
pada 27 Feb 2020
@Manisharth Apakah hal-hal yang membuat profil xr menunjukkan (atau dapatkah itu menunjukkan) acara JS GC? Itu mungkin proxy yang masuk akal.
larsbergstrom
pada 27 Feb 2020
Apa pun itu, lonjakan startup bukanlah perhatian utama saya, saya ingin mendapatkan semuanya _lainnya_ pada 60fps terlebih dahulu. Jika tersendat selama satu atau dua detik saat startup, itu bukan masalah yang mendesak.
Manishearth
pada 27 Feb 2020
Ya, itu bisa menunjukkan itu, perlu beberapa penyesuaian.
Manishearth
pada 27 Feb 2020
@Manisharth Sangat setuju dengan prioritas! Saya tidak yakin apakah Anda mencoba untuk "menghilangkan kekusutan" atau menurunkan kondisi mapan. Setuju yang terakhir lebih penting sekarang.
larsbergstrom
pada 27 Feb 2020
Nah, saya kebanyakan hanya mencatat semua analisis yang saya bisa.
Manishearth
pada 27 Feb 2020
Lonjakan di dekat akhir grafik run yang lebih kecil di mana waktu transmisi juga melonjak: Saat itulah saya menggerakkan kepala dan menggambar, dan Alan juga memperhatikan penurunan FPS saat melakukan sesuatu, dan menghubungkannya dengan OS yang melakukan pekerjaan lain . Setelah IPC memperbaiki firasat saya tentang lonjakan waktu transmisi adalah bahwa itu disebabkan oleh OS yang melakukan pekerjaan lain, jadi itu mungkin yang terjadi di sana. Di dunia di luar utas utama, saya berharap ini jauh lebih lancar.
Manishearth
pada 27 Feb 2020
Abaikan saya jika ini sudah dipertimbangkan, pernahkah Anda berpikir untuk membagi ukuran run_one_frame berdasarkan penanganan per-pesan, dan juga menentukan waktu yang dihabiskan thread::sleep() -ing?
Mungkin ada baiknya menambahkan tiga titik pengukuran:
satu pembungkus https://github.com/servo/webxr/blob/68b024221b8c72b5b33a63441d63803a13eadf03/webxr-api/session.rs#L364
dan pembungkus lainnya https://github.com/servo/webxr/blob/2841497966d87bbd561f18ea66547dde9b13962f/webxr-api/lib.rs#L124 secara keseluruhan,
dan juga yang membungkus panggilan ke
thread::sleepsaja.
Mengenai recv_timeout , ini bisa menjadi sesuatu untuk dipertimbangkan kembali sepenuhnya.
Saya merasa agak sulit untuk beralasan tentang kegunaan timeout. Karena Anda menghitung frame yang dirender, lihat frame_count , usecase tampaknya "mungkin menangani satu atau beberapa pesan yang tidak merender bingkai, pertama, diikuti dengan merender bingkai, sambil menghindari melalui loop acara penuh dari utas utama"?
Saya juga memiliki beberapa keraguan tentang perhitungan sebenarnya dari delay digunakan di dalamnya, di mana saat ini:
- dimulai dari
delay = timeout / 1000, dengantimeoutsaat ini disetel 5 ms - Kemudian tumbuh secara eksponensial, berlipat ganda pada setiap iterasi pada
delay = delay * 2; - Itu diperiksa di bagian atas loop dengan
while delay < timeout.
Jadi urutan tidur, dalam kasus terburuk, berjalan seperti: 5mikro -> 10 -> 20 -> 40 -> 80 -> 160 -> 320 -> 640 -> 1,28mili -> 2,56 mili -> 5,12 mili
Ketika mencapai 5,12 milidetik, Anda akan keluar dari loop (sejak delay > timeout ), setelah menunggu total 5,115 mili detik, ditambah waktu tambahan apa pun yang dihabiskan untuk menunggu OS membangunkan utas setelah setiap sleep .
Jadi saya pikir masalahnya adalah Anda mungkin tidur lebih dari 5 ms secara total, dan juga saya pikir itu bukan ide yang baik untuk tidur dua kali selama lebih dari 1 ms (dan yang kedua kalinya lebih dari 2,5 ms) sejak sebuah pesan bisa masuk selama waktu itu dan Anda tidak akan bangun.
Saya tidak yakin bagaimana cara memperbaikinya, sepertinya Anda mencoba mencari pesan potensial, dan akhirnya beralih ke iterasi berikutnya dari loop peristiwa utama jika tidak ada yang tersedia (mengapa tidak memblokir di recv?).
Anda dapat beralih menggunakan https://doc.rust-lang.org/std/thread/fn.yield_now.html , melihat artikel ini tentang kunci , sepertinya berputar sekitar 40 kali saat memanggil yield setiap kali , optimal (lihat paragraf "Pemintalan", tidak dapat menautkan langsung ke sana). Setelah itu Anda harus memblokir penerima, atau hanya melanjutkan dengan iterasi saat ini dari loop peristiwa (karena ini berjalan seperti sub-loop di dalam loop peristiwa embedding utama).
(jelas, jika Anda tidak mengukur dengan ipc diaktifkan, bagian di atas pada recv_timeout tidak relevan, meskipun Anda mungkin masih ingin mengukur panggilan ke recv_timeout pada mpsc karena saluran berulir akan melakukan beberapa putaran/penghasilan internal yang mungkin juga memengaruhi hasil. Dan karena "perbaikan IPC" yang tidak teridentifikasi telah disebutkan pada beberapa kesempatan di atas, saya berasumsi Anda mengukur dengan ipc).
gterzian
pada 27 Feb 2020
Abaikan saya jika ini sudah dipertimbangkan, pernahkah Anda berpikir untuk memecah pengukuran run_one_frame berdasarkan penanganan per-pesan, dan juga mengatur waktu yang dihabiskan untuk thread::sleep()-ing?
Sudah rusak, waktu tunggu/render persis seperti ini. Satu centang run_one_frame adalah satu render, satu tunggu, dan jumlah kejadian yang tidak ditentukan sedang ditangani (jarang).
recv_timeout adalah ide bagus untuk pengukuran
Manishearth
pada 27 Feb 2020
Sayangnya, peningkatan spidermonkey di #25678 tampaknya bukan peningkatan yang signifikan - rata-rata FPS dari setiap demo kecuali sebagian besar memori yang dibatasi mengalami penurunan; demo Hill Valley naik sedikit. Menjalankan Servo dengan -Z gc-profile dalam argumen inisialisasi tidak menunjukkan perbedaan dalam perilaku GC antara master dan cabang pemutakhiran spidermonkey - tidak ada GC yang dilaporkan setelah konten GL dimuat dan ditampilkan.
jdm
pada 3 Mar 2020
Pengukuran untuk berbagai cabang:
master:
- espilit: 14-16 fps
- paint: 39-45 fps
- ball shooter: 30-40 fps
- hill valley: 8 fps, 200mb free mem
- mansion: 10-14fps, 650mb free mem
master + single swapchain:
- espilit: 10-12 fps
- paint: 29-55 fps, 1.2gb free mem
- ball shooter: 25-35 fps, 1.3gb free mem
- hill valley: 6-7 fps, 200mb free mem
- mansion: 10-11 fps, 700mb free mem
texture sharing + ANGLE 2.1.19:
- espilit: 13-15 fps, 670mb free mem
- paint: 39-45 fps
- ball shooter: 30-37 fps, 1.3gb free mem
- hill valley: 9-10 fps, 188mb free mem
- mansion: 13-14 fps, 671mb free mem
smup:
- espilit: 11-13 fps, 730mb free mem
- paint: 25-42 fps, 1.1gb free mem
- ball shooter: 26-30 fps, 1.4gb free mem
- hill valley: 10-11 fps, 145mb
- mansion: 9-11fps, 680mb free mem
Smup membuat kinerja lebih buruk???
asajeffrey
pada 3 Mar 2020
Dengan perubahan dari https://github.com/servo/servo/pull/25855#issuecomment -594203492, ada hasil menarik bahwa menonaktifkan Ion JIT dimulai pada 12 FPS, dan kemudian beberapa detik kemudian tiba-tiba berkurang menjadi 1 FPS dan tinggal di sana.
jdm
pada 3 Mar 2020
Melakukan beberapa pengukuran dengan tambalan itu.
Pada cat, saya mendapatkan 60fps ketika tidak banyak konten yang dilihat, dan ketika melihat konten yang digambar, itu turun menjadi 50 fps (lonjakan kuning adalah ketika saya melihat konten yang digambar). Sulit untuk mengetahui alasannya, sebagian besar sepertinya waktu tunggu dipengaruhi oleh pelambatan openxr tetapi hal-hal lain tampaknya tidak cukup lambat untuk menyebabkan masalah. Waktu permintaan swap sedikit lebih lambat. waktu eksekusi rAF awalnya lambat (ini adalah perlambatan "pertama kali pengontrol terlihat") tetapi setelah itu cukup konstan. Sepertinya openxr hanya membatasi kami, tetapi tidak ada perlambatan yang terlihat di tempat lain yang akan menyebabkan itu.

Manishearth
pada 7 Mar 2020
Inilah yang saya miliki untuk demo dragging. skala y adalah sama. Di sini jauh lebih jelas bahwa waktu eksekusi memperlambat kita.

Manishearth
pada 7 Mar 2020
Satu hal yang perlu diperhatikan adalah saya melakukan pengukuran dengan menerapkan #25837, dan itu dapat memengaruhi kinerja.
jdm
pada 7 Mar 2020
Saya tidak, namun saya mendapatkan hasil yang mirip dengan Anda
Manishearth
pada 7 Mar 2020
Grafik alat kinerja saat ini berubah dari 60FPS ke 45FPS saat melihat konten:
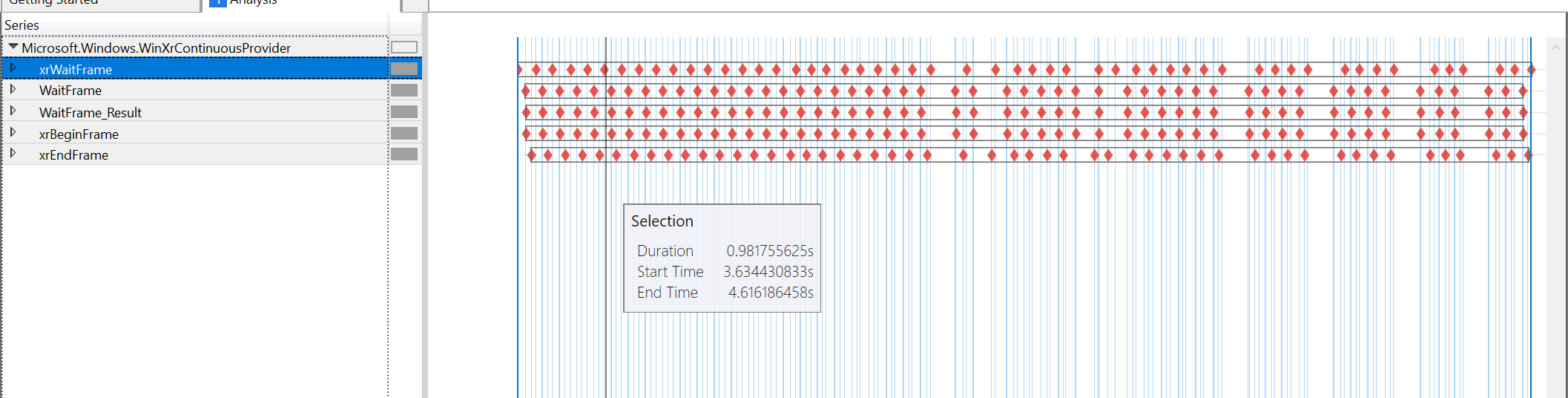
sepertinya kesalahan sepenuhnya ada pada xrWaitFrame, semua pengaturan waktu lainnya cukup berdekatan. xrBeginFrame masih segera setelah xrWaitFrame, xrEndFrame adalah 4us setelah xrBeginFrame (dalam kedua kasus). xrWaitFrame berikutnya segera setelah xrEndFrame. Satu-satunya celah yang tidak terhitung adalah yang disebabkan oleh xrWaitFrame itu sendiri.
Manishearth
pada 11 Mar 2020
Dengan demo menyeret, saya mendapatkan jejak berikut:

Ini adalah demo cat dengan skala yang sama:
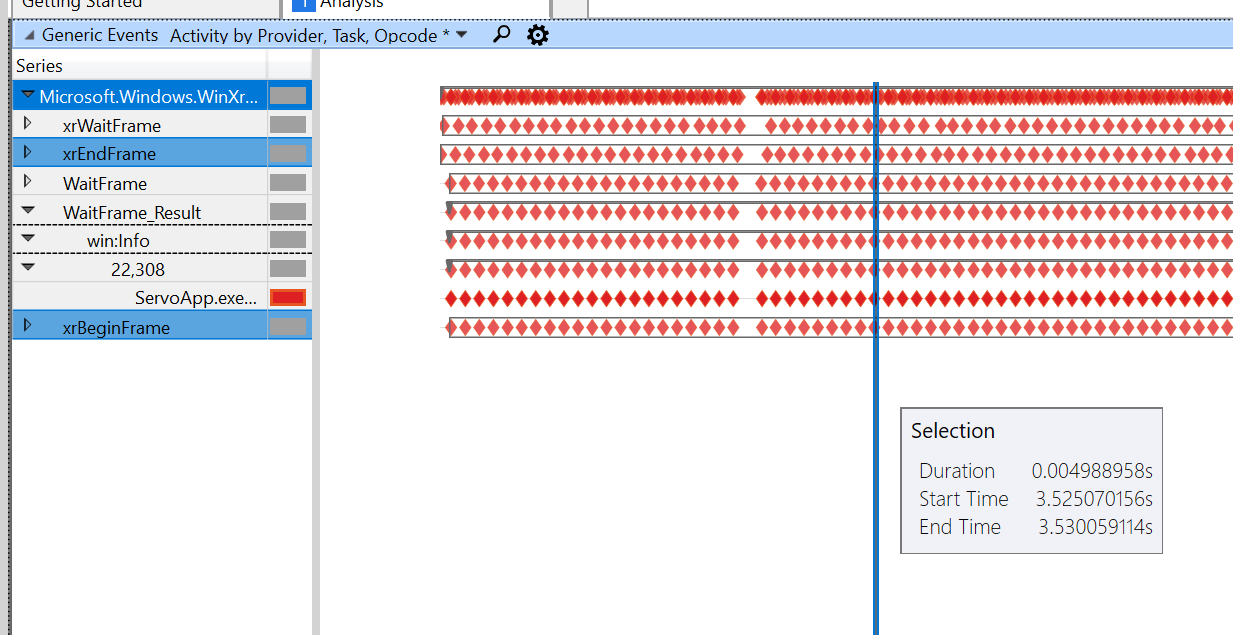
Kami lambat antara bingkai awal/akhir (dari 5 md hingga 38 md pada yang tercepat!), dan kemudian pelambatan bingkai tunggu dimulai. Saya belum menjelaskan mengapa hal ini terjadi, saya akan melalui kode untuk keduanya.
Manishearth
pada 18 Mar 2020
Demo menyeret diperlambat karena sumber cahayanya menghasilkan bayangan. Hal-hal bayangan dilakukan di sisi GL jadi saya tidak yakin apakah kita bisa mempercepatnya dengan mudah?
Manishearth
pada 18 Mar 2020
Jika dilakukan seluruhnya melalui GLSL kita mungkin mengalami kesulitan; jika dilakukan setiap frame melalui API WebGL maka mungkin ada tempat untuk dioptimalkan.
jdm
pada 18 Mar 2020
Ya tampaknya semua berada di sisi GLSL; Saya tidak dapat melihat panggilan WebGL apa pun terkait cara kerja API bayangan, hanya beberapa bit yang diteruskan ke shader
Manishearth
pada 19 Mar 2020
Saya percaya ini telah dibahas secara umum. Kami dapat mengajukan masalah untuk demo individu yang membutuhkan pekerjaan.
jdm
pada 20 Jul 2020
Masalah terkait
jdm
·
3Komentar
gterzian
·
3Komentar
 roberto68
·
3Komentar
roberto68
·
3Komentar
 CYBAI
·
4Komentar
CYBAI
·
4Komentar
 Grishy
·
3Komentar
Grishy
·
3Komentar
Komentar yang paling membantu
Status saat ini: dengan perbaikan IPC, FPS sekarang berada di sekitar 55. Kadang-kadang bergoyang banyak, tetapi biasanya tidak turun di bawah 45, _kecuali_ selama beberapa detik pertama setelah memuat (di mana bisa turun ke 30), dan ketika itu pertama kali melihat tangan (ketika turun ke 20).