Servo: Иммерсивный режим не достигает 60 кадров в секунду
Я использую это, чтобы отслеживать расследования причин низких значений FPS при использовании иммерсивного режима на устройствах.
 jdm
jdm
Все 71 Комментарий
Некоторая информация, которая была обнаружена:
- между xrWaitFrame и xrBeginFrame долгое ожидание
- в демонстрационном приложении они происходят последовательно
- в модели Servo мы ждем кадра устройства , затем, как только мы получим визуализированный из потока webgl, мы начинаем следующий кадр openxr
След демонстрации раскраски с маркерами для API OpenXR воспроизводится в наши дни, а также показывает в течение того периода:
- поток webgl использует больше всего ЦП (большая часть этого времени тратится на gl :: Finish, которая вызывается из устройства Surfman :: bind_surface_to_context)
- основной поток является вторым по загруженности, с наибольшим использованием, затрачиваемым на eglCreatePbufferFromClientBuffer, и почти столько же времени, затрачиваемым на захват объекта Egl из TLS
- рендеринг webrender также появляется в этом стеке
- Здесь также появляется winrt :: servo :: flush, и мне не ясно, действительно ли нам нужно менять местами буферы GL основного приложения, пока мы находимся в иммерсивном режиме
- третья по величине загрузка ЦП - поток сценария, проводящий много времени внутри JIT-кода.
- после этого потока загрузка ЦП обычно довольно низка, но из ящика стилей появляются некоторые символы, указывающие на то, что происходит макет
jdm
3 янв. 2020
Учитывая эти данные, я собираюсь попробовать два подхода для начала:
- начать следующий кадр XR как можно скорее после ожидания кадра устройства
- уменьшить количество вызовов gl :: Finish (поток webgl), eglCreateBufferFromClientBuffer и TLS (основной поток)
jdm
3 янв. 2020
https://github.com/servo/servo/pull/25343#issuecomment -567706735 более подробно исследует влияние отправки сообщений в различные места в движке. Он не указывает на четкие пальцы, но предлагает более точные измерения.
jdm
3 янв. 2020
Использование gl :: Finish происходит с https://github.com/pcwalton/surfman/blob/6705a9aaa8f33ac1324fdb1913242800e68c7720/surfman/src/platform/windows/angle/context.rs#L259 -L266.
jdm
3 янв. 2020
Изменение gl :: Finish на gl :: Flush увеличивает частоту кадров с ~ 15-> 30, но есть чрезвычайно заметная задержка в содержимом кадра, фактически отражающая движение головы пользователя, в результате чего текущий кадр следует за головой пользователя в тем временем.
jdm
3 янв. 2020
Ключевые мьютексы по умолчанию отключены в ANGLE по причинам, которые ускользают от меня, но mozangle явно включает их (https://github.com/servo/mozangle/blob/706a9baaf8026c1a3cb6c67ba63aa5f4734264d0/build_data.rs#L175), и это проверяется с помощью того, что Surf . Я собираюсь сделать сборку ANGLE, которая включает их, и посмотрю, достаточно ли этого, чтобы избежать вызовов gl :: Finish.
jdm
3 янв. 2020
Подтвержденный! Принудительное включение мьютексов с ключом в ANGLE дает мне 25-30 кадров в секунду в демонстрации рисования без каких-либо проблем с задержкой, которые возникли при изменении вызова gl :: Finish.
jdm
3 янв. 2020
Да, и еще одна информация согласно расследованиям Ларса:
- если для dom.ion.enabled установлено значение false, время JIT исчезает. Начальные загрузки намного медленнее, но когда все работает, они довольно хороши.
- Это все еще не фантастика - использование памяти довольно велико (в основном вся доступная память) в этом примере babylon.js
- мы должны сделать еще одно обновление spidermonkey, чтобы задействовать связанные с arm64 оптимизации, которые происходили для FxR на устройствах Android.
jdm
3 янв. 2020
Я думаю, что неправильно понял присутствие std::thread::local::LocalKey<surfman::egll::Egl> в профилях - я почти уверен, что чтение TLS занимает лишь очень небольшую часть времени, затраченного на него, и это функции, вызываемые внутри блока TLS, такие как eglCreatePbufferFromClientBuffer и DXGIAcquireSync, который _на самом деле_ требует времени.
jdm
3 янв. 2020
К сожалению, отключение js.ion.enabled, похоже, ухудшает FPS демо-версии отрисовки, снижая его до 20-25.
jdm
4 янв. 2020
Вместо того, чтобы вызывать Device :: create_surface_texture_from_texture дважды в каждом кадре (один раз для каждой текстуры d3d для каждого глаза), можно было бы создавать текстуры поверхности для всех текстур цепочки обмена при создании устройства openxr webxr. Если это сработает, это приведет к удалению второго по величине пользователя ЦП из основного потока во время иммерсивного режима.
jdm
4 янв. 2020
Еще одна идея для уменьшения использования памяти: будет ли какое-либо влияние, если мы установим для bfcache очень низкое значение, чтобы исходный конвейер домашней страницы HL был исключен при переходе к одной из демонстраций?
jdm
4 янв. 2020
Следующий патч webxr явно не улучшает FPS, но может улучшить стабильность изображения. Мне нужно создать две отдельные сборки, которые я могу запустить один за другим, чтобы проверить.
diff --git a/webxr/openxr/mod.rs b/webxr/openxr/mod.rs
index 91c78da..a6866de 100644
--- a/webxr/openxr/mod.rs
+++ b/webxr/openxr/mod.rs
@@ -416,11 +416,30 @@ impl DeviceAPI<Surface> for OpenXrDevice {
}
fn wait_for_animation_frame(&mut self) -> Option<Frame> {
- if !self.handle_openxr_events() {
- // Session is not running anymore.
- return None;
+ loop {
+ if !self.handle_openxr_events() {
+ // Session is not running anymore.
+ return None;
+ }
+ self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
+ // XXXManishearth this code should perhaps be in wait_for_animation_frame,
+ // but we then get errors that wait_image was called without a release_image()
+ self.frame_stream
+ .begin()
+ .expect("failed to start frame stream");
+
+ if self.frame_state.should_render {
+ break;
+ }
+
+ self.frame_stream.end(
+ self.frame_state.predicted_display_time,
+ EnvironmentBlendMode::ADDITIVE,
+ &[],
+ ).unwrap();
}
- self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
let time_ns = time::precise_time_ns();
// XXXManishearth should we check frame_state.should_render?
let (_view_flags, views) = self
@@ -506,12 +525,6 @@ impl DeviceAPI<Surface> for OpenXrDevice {
0,
);
- // XXXManishearth this code should perhaps be in wait_for_animation_frame,
- // but we then get errors that wait_image was called without a release_image()
- self.frame_stream
- .begin()
- .expect("failed to start frame stream");
-
self.left_image = self.left_swapchain.acquire_image().unwrap();
self.left_swapchain
.wait_image(openxr::Duration::INFINITE)
@manishearth есть какие-нибудь мысли по этому https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#Session.
jdm
4 янв. 2020
Да, выглядит хорошо. Я имел в виду переместить begin() в waf, и я считаю, что ошибка, упомянутая в комментарии, больше не возникает, но она также не оказала заметного влияния на FPS, поэтому я не стал ее преследовать слишком много на данный момент. Если это улучшит стабильность, это хорошо!
 Manishearth
4 янв. 2020
Manishearth
4 янв. 2020
Действительно рад ключевому открытию! Звонки Surfman действительно занимают большую часть бюджета кадра, но немного сложно определить, что нужно, а что нет.
Manishearth
4 янв. 2020
Да, повторное отключение js.ion.enabled , это будет преимуществом только тогда, когда у нас не хватает оперативной памяти и мы тратим большую часть времени на сборку мусора и перекомпиляцию функций. И это должно быть улучшено с новым SM. IIRC, бэкэнд ARM64 эпохи 66, также имел относительно низкую базовую производительность JIT и интерпретатора; мы должны увидеть ускорение по всем направлениям с обновлением, но особенно для приложений с большим объемом оперативной памяти.
 larsbergstrom
4 янв. 2020
larsbergstrom
4 янв. 2020
Опубликован новый пакет ANGLE с включенными мьютексами с ключом. Я создам пул-реквест, чтобы обновить его позже.
jdm
6 янв. 2020
Я попытался создать текстуры поверхности для всех изображений swapchain openxr во время инициализации устройства XR, но в основном потоке еще много времени потрачено на вызов eglCreatePbufferFromClientBuffer на поверхности, которую мы получаем из потока webgl в каждом кадре. Может быть, есть способ кэшировать эти текстуры поверхности, чтобы мы могли повторно использовать их, если получим ту же поверхность ...
jdm
6 янв. 2020
Наибольшее использование ЦП основным потоком происходит из-за render_animation_frame, большая часть которого находится в среде выполнения OpenXR, но вызовы BlitFramebuffer и FramebufferTexture2D также определенно отображаются в профиле. Интересно, можно ли было бы улучшить одновременное преобразование обоих глаз в одну текстуру? Возможно, это связано с массивом текстур, который обсуждается в https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt.
jdm
6 янв. 2020
Мы можем приглушить оба глаза одновременно, но я понимаю, что среда выполнения
может тогда сделать свой блит. Массив текстур - самый быстрый метод. Но
Стоит попробовать, API просмотра проекции поддерживает это.
Что касается трафика ANGLE основного потока, останавливает ли цикл RAF из
пачкать холст поможет? Пока это ничего не дало, но стоит
выстрел, в идеале мы не должны ничего делать макет / рендеринг на основном
нить.
В пн, 6 января 2020 г., 23:49 Джош Мэтьюз [email protected]
написал:
Наибольшее использование ЦП основного потока происходит от render_animation_frame с
большая часть этого в среде выполнения OpenXR, но вызывает BlitFramebuffer и
FramebufferTexture2D также определенно присутствует в профиле. Я думаю
если бы было лучше, если бы оба глаза сразу обратились к одному
текстура? Возможно, это связано с обсуждаемым материалом о массиве текстур.
в
https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt
.-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/servo/servo/issues/25425?email_source=notifications&email_token=AAMK6SBRH72JGZMXTUKOXETQ4NY37A5CNFSM4KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG63LVMVB50
или отказаться от подписки
https://github.com/notifications/unsubscribe-auth/AAMK6SECM6MDNZZ6Y7VL7SDQ4NY37ANCNFSM4KCRI6AA
.
Manishearth
6 янв. 2020
Удаление загрязнения полотна только очищает профиль; похоже, что это не привело к значительному увеличению FPS.
jdm
6 янв. 2020
Я попытался создать кеш текстур поверхностей для поверхностей из потока webgl, а также текстур swapchain openxr, и хотя время eglCreatePbufferFromClientBuffer полностью исчезло, я не заметил значимого изменения FPS.
jdm
6 янв. 2020
Некоторая информация о времени для различных операций в иммерсивном конвейере (все измерения в мс):
Name min max avg
raf queued 0.070833 14.010261 0.576834
<1ms: 393
<2ms: 28
<4ms: 5
<8ms: 1
<16ms: 2
<32ms: 0
32+ms: 0
raf transmitted 0.404270 33.649583 7.403302
<1ms: 123
<2ms: 43
<4ms: 48
<8ms: 48
<16ms: 95
<32ms: 69
32+ms: 3
raf wait 1.203500 191.064100 17.513593
<1ms: 0
<2ms: 17
<4ms: 98
<8ms: 95
<16ms: 48
<32ms: 69
32+ms: 101
raf execute 3.375000 128.663200 6.994588
<1ms: 0
<2ms: 0
<4ms: 5
<8ms: 351
<16ms: 70
<32ms: 1
32+ms: 2
raf receive 0.111510 8.564010 0.783503
<1ms: 353
<2ms: 52
<4ms: 18
<8ms: 4
<16ms: 1
<32ms: 0
32+ms: 0
raf render 2.372200 75.944000 4.219310
<1ms: 0
<2ms: 0
<4ms: 253
<8ms: 167
<16ms: 8
<32ms: 0
32+ms: 1
receive : время от передачи информации кадра XR из потока XR до получения маршрутизатором IPC.
queued : время от маршрутизатора IPC, получающего информацию о кадре, до вызова XRSession :: raf_callback
execute : время от вызова XRSession :: raf_callback до возврата из метода
transmitted : время от отправки запроса на новый rAF из потока сценария до момента его получения потоком XR
render : время, затраченное на вызов render_animation_frame и переработку поверхности
wait : время, затраченное wait_for_animation_frame (с использованием патча из ранее в этом выпуске, который перебирает кадры, которые не должны отображаться)
Под каждой записью указано распределение значений в течение сеанса.
jdm
7 янв. 2020
Интересный момент из этой информации о времени - категория transmitted кажется намного выше, чем должна быть. Это задержка между выполнением обратного вызова rAF и получением потоком XR сообщения, которое переносит завершенный кадр в текстуру openxr. Существует довольно много вариантов, предполагающих, что либо основной поток занят другими делами, либо его нужно разбудить, чтобы обработать.
jdm
7 янв. 2020
Учитывая предыдущие данные, я могу попытаться воскресить https://github.com/servo/webxr/issues/113 завтра, чтобы посмотреть, повлияет ли это положительно на время передачи. Я могу сначала ткнуть основной поток в профилировщике, чтобы посмотреть, могу ли я придумать какие-либо идеи о том, как определить, занят ли поток другими задачами или спит.
jdm
7 янв. 2020
Еще одна точка данных:
swap buffer 1.105938 28.193698 2.154793
<1ms: 0
<2ms: 273
<4ms: 110
<8ms: 15
<16ms: 2
<32ms: 2
32+ms: 0
swap complete 0.053802 4.337812 0.295064
<1ms: 308
<2ms: 9
<4ms: 6
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
swap request 0.003333 24033027.355364 4662890.724805
<1ms: 268
<2ms: 49
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 1
32+ms: 79
Это время, связанное с 1) задержкой от отправки сообщения буфера подкачки до тех пор, пока оно не будет обработано в потоке webgl, 2) временем, затраченным на обмен буферами, 3) задержкой от отправки сообщения, указывающего, что подкачка завершена, до тех пор, пока оно не будет получено в поток сценария. Ничего сверхъестественного здесь нет (кроме тех странных выбросов в категории swap request , но они случаются в самом начале иммерсивного сеанса во время установки afaict), но фактическая замена буфера постоянно занимает от 1 до 4 мс.
jdm
7 янв. 2020
Файл №117 был подан после прочтения некоторого примера кода openxr и обнаружения того, что вызовы locate_views отображаются в профиле.
jdm
7 янв. 2020
Предположительно https://github.com/servo/webxr/issues/117
 asajeffrey
7 янв. 2020
asajeffrey
7 янв. 2020
Интересный момент из этой информации о времени - передаваемая категория кажется намного выше, чем должна быть. Это задержка между выполнением обратного вызова rAF и получением потоком XR сообщения, которое переносит завершенный кадр в текстуру openxr. Существует довольно много вариантов, предполагающих, что либо основной поток занят другими делами, либо его нужно разбудить, чтобы обработать.
Что касается вариаций в значении transmitted , оно может быть связано с таймаутом, используемым как часть run_one_frame когда сеанс выполняется в основном потоке (что есть в этих измерениях, верно?) см. https://github.com/servo/webxr/blob/c6abf4c60d165ffc978ad2ebd6bcddc3c21698e1/webxr-api/session.rs#L275
Я предполагаю, что когда RenderAnimationFrame msg (сообщение, отправленное потоком сценария после выполнения обратных вызовов) получено до истечения времени ожидания, вы нажимаете «быстрый путь», и если время ожидания пропущено, сервопривод переходит в другой повторение perform_updates и «запуск другого кадра» происходит довольно поздно в цикле, как часть compositor.perform_updates , которая сама вызывается довольно поздно как часть servo.handle_events .
Если не считать перемещения XR в свой собственный поток, возможно, стоит посмотреть, улучшит ли более высокое значение тайм-аута среднее значение (хотя это может быть неправильным решением, так как это может привести к нехватке других необходимых вещей в основном потоке).
 gterzian
8 янв. 2020
gterzian
8 янв. 2020
Я добился прогресса в удалении openxr из основного потока на https://github.com/servo/webxr/issues/113 , поэтому на следующей неделе я собираюсь провести дополнительные измерения на основе этой работы.
jdm
10 янв. 2020
Приемы получения полезных профилей с устройства:
- используйте .servobuild, который включает
rustflags = "-C force-frame-pointers=yes" - раскомментируйте эти строки
- используйте WinXR_Perf.wprp из вкладки MS team char
Filesв качестве настраиваемого профиля трассировки в разделе «Трассировка производительности» на портале устройств HL. - построить с помощью
--features profilemozjs
Эти трассировки (полученные из «Начать трассировку» на портале устройства) можно будет использовать в средстве Windows Performance Analyzer. Этот инструмент не показывает имена потоков, но потоки, использующие больше всего ЦП, легко идентифицировать на основе стека.
Чтобы профилировать распределение времени конкретного фрейма openxr:
- добавить представление «Системная активность -> Общие события» в WPA
- фильтровать представление, чтобы отображать только серию Microsoft.Windows.WinXrContinuousProvider
- увеличьте масштаб до короткого промежутка времени, затем уточните увеличенную область, чтобы событие xrBegin находилось в левой части представления, а событие xrEnd - в правой части представления
Наиболее полезные представления об использовании ЦП:
- Использование ЦП (выборка) -> Использование по процессам, потокам, стекам (отфильтруйте представление, чтобы отображались только сервоприводы, затем отключите столбец «Процесс»)
- Пламя по процессу, стек (отфильтруйте представление, чтобы отображались только сервоприводы)
jdm
16 янв. 2020
Одна из возможностей сделать немного меньше работы в потоке скрипта:
- XRView :: new потребляет 0,02% всего серво процессора
- поскольку содержимое объектов представления не изменяется, если не происходит событие FrameUpdateEvent :: UpdateViews (которое исходит от Session :: update_clip_planes через XRSession :: UpdateRenderState), мы могли бы предположительно кэшировать объекты XRView в сеансе XRSession и продолжать использовать их до тех пор, пока состояние рендеринга обновлено
- мы могли бы даже сохранить JS-представление списка представлений в кэше XRSession и установить элемент представлений позы, избегая как воссоздания объектов XRView, так и выделения вектора, и выполнения преобразования значений JS.
jdm
16 янв. 2020
Одна из возможностей сделать меньше работы при рендеринге иммерсивного кадра:
- GL и d3d имеют перевернутые системы координат Y
- ANGLE неявно скрывает это при выводе на экран, выполняя некоторую работу за кулисами.
- для иммерсивного режима мы используем glBlitFramebuffer для выполнения инверсии по оси Y при копировании данных текстуры GL в d3d
- если мы сможем выяснить, как заставить ANGLE не выполнять внутреннее преобразование, можно было бы инвертировать эту модель и сделать так, чтобы для рендеринга не иммерсивных веб-страниц требовался дополнительный блит-код y-инвертирования (с помощью параметра webrender
surface_origin_is_top_left) в то время как иммерсивный режим может быть перенесен без каких-либо преобразований
На основе https://bugzilla.mozilla.org/show_bug.cgi?id=1591346 и разговора с jrmuizel, вот что нам нужно сделать:
- получить цепочку подкачки d3d для элемента окна, в который мы хотим отображать неиммерсивные страницы (это будет SwapChainPanel в приложении XAML)
- оберните это в изображение EGL (https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#554)
- явным образом представлять свопчейн, когда мы хотим обновить основной рендеринг
- избегайте использования eglCreateWindowSurface и eglSwapBuffers в https://github.com/servo/servo/blob/master/support/hololens/ServoApp/ServoControl/OpenGLES.cpp#L205 -L208
Соответствующий код Gecko: https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#192
Соответствующий код ANGLE: https://github.com/google/angle/blob/df0203a9ae7a285d885d7bc5c2d4754fe8a59c72/src/libANGLE/renderer/d3d/d3d11/winrt/SwapChainPanelNativeL244
jdm
16 янв. 2020
Текущие ветки wip:
- https://github.com/servo/ipc-channel/tree/try-recv-error
- https://github.com/jdm/webxr/tree/oxr
- https://github.com/jdm/rust-offscreen-rendering-context/tree/angle-perf
- https://github.com/jdm/servo/tree/profile
Это включает в себя функцию xr-profile которая добавляет данные синхронизации, о которых я упоминал ранее, а также начальную реализацию изменений ANGLE для удаления y-инверсного преобразования в иммерсивном режиме. В неиммерсивном режиме рендеринг выполняется правильно, а в иммерсивном - наоборот. Я считаю, что мне нужно удалить код GL из render_animation_frame и заменить его прямым вызовом CopySubresourceRegion, извлекая дескриптор общего ресурса с поверхности GL, чтобы я мог получить его текстуру d3d.
jdm
17 янв. 2020
Сохранено https://github.com/servo/servo/issues/25582 для работы с Y-инверсией ANGLE; дальнейшие обновления этой работы будут опубликованы в этом выпуске.
jdm
23 янв. 2020
Следующим важным пунктом будет исследование способов полностью избежать вызовов glBlitFramebuffer в бэкэнде openxr webxr. Это требует:
- создание фреймбуферов openxr, которые точно соответствуют требуемым непрозрачным фреймбуферам webgl
- поддержка режима webgl, в котором бэкэнд webxr предоставляет все поверхности цепочки подкачки, а не создает их (например, в https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib. и https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L111-L118)
jdm
23 янв. 2020
Это может быть сложно, поскольку surfman предоставляет доступ на запись только к контексту, который создал поверхность, поэтому, если поверхность создается потоком openxr, она не будет доступна для записи потоку WebGL. https://github.com/pcwalton/surfman/blob/a515fb2f5d6b9e9b36ba4e8b498cdb4bea92d330/surfman/src/device.rs#L95 -L96
asajeffrey
23 янв. 2020
Мне пришло в голову, что если бы мы выполняли рендеринг openxr в потоке webgl, множество проблем, связанных с потоками, связанных с рендерингом непосредственно в текстуры openxr, больше не было бы проблемой (то есть ограничения вокруг eglCreatePbufferFromClientBuffer, запрещающие использование нескольких устройств d3d). Учитывать:
- есть еще поток openxr, который отвечает за опрос событий openxr, ожидание кадра анимации, начало нового кадра и получение текущего состояния кадра
- состояние кадра отправляется в поток сценария, который выполняет обратный вызов анимации, а затем отправляет сообщение потоку webgl, чтобы поменять местами буфер кадра xr-слоя
- когда это сообщение подкачки получено в потоке webgl, мы освобождаем последнее полученное изображение swapchain openxr, отправляем сообщение потоку openxr для завершения текущего кадра и получаем новое изображение swapchain для следующего кадра
Мое чтение https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#threading -behavior предполагает, что этот дизайн может быть работоспособным. Уловка заключается в том, может ли он работать для наших бэкэндов, отличных от openxr, а также для openxr.
Из спецификации: «Хотя xrBeginFrame и xrEndFrame не нужно вызывать в одном потоке, приложение должно обрабатывать синхронизацию, если они вызываются в разных потоках».
jdm
25 янв. 2020
На данный момент нет прямой связи между потоками устройства XR и webgl, все это происходит либо через скрипт, либо через их общую цепочку подкачки. У меня возникнет соблазн предоставить API цепочки подкачки, который находится над цепочкой подкачки surfman или цепочкой подкачки openxr, и использовать его для связи webgl-to-openxr.
asajeffrey
25 янв. 2020
Примечания из разговора о более ранних измерениях времени:
* concerns about wait time - why?????
* figure out time spent in JS vs. DOM logic
* when does openxr give us should render=false frames - maybe related to previous frame taking too long
* are threads being scheduled on inappropriate cpus? - on magic leap, main thread (including weber) pinned to big core.
* when one of the measured numbers is large, is there correlation with other large numbers?
* probably should pin openxr thread, running deterministic code
* consider clearing after telling script that the swap is complete - measure if clear is taking significant time in swap operation
* consider a swap chain API operation - “wait until a buffer swap occurs”
- block waiting on swapchain
- block waiting on swapchain + timeout
- async????????
- a gc would look like a spike in script execution time
Файл № 25735, чтобы отслеживать расследования, которые я веду по поводу рендеринга непосредственно в текстуры openxr.
jdm
11 февр. 2020
Одна вещь, которую мы должны сделать, - это сузить то, как Spidermonkey сравнивает устройство с другими движками. Самый простой способ получить здесь некоторые данные - найти простой тест JS, который может запустить Servo, и сравнить производительность Servo с браузером Edge, установленным на устройстве. Кроме того, мы могли бы попробовать посетить несколько сложных демонстраций Babylon в обоих браузерах, не переходя в иммерсивный режим, чтобы увидеть, есть ли существенная разница в производительности. Это также даст нам ориентир для сравнения с предстоящим обновлением Spidermonkey.
jdm
13 февр. 2020
Некоторые новые данные. Это с апгрейдом ANGLE, но не с IPC.
$ python timing.py raw
Name min max mean
raf queued 0.056198 5.673125 0.694902
<1ms: 335
<2ms: 26
<4ms: 17
<8ms: 7
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.822917 36.582083 7.658619
<1ms: 1
<2ms: 4
<4ms: 31
<8ms: 181
<16ms: 158
<32ms: 8
32+ms: 1
raf wait 1.196615 39.707709 10.256875
<1ms: 0
<2ms: 32
<4ms: 93
<8ms: 67
<16ms: 107
<32ms: 68
32+ms: 17
raf execute 3.078438 532.205677 7.752839
<1ms: 0
<2ms: 0
<4ms: 37
<8ms: 290
<16ms: 52
<32ms: 2
32+ms: 3
raf receive 0.084375 9.053125 1.024403
<1ms: 276
<2ms: 71
<4ms: 27
<8ms: 9
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.004115 73.939479 0.611254
<1ms: 369
<2ms: 10
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.706198 233.459636 9.241698
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 183
<16ms: 190
<32ms: 10
32+ms: 1
run_one_frame 7.663333 2631.052969 28.035143
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 3
<16ms: 157
<32ms: 185
32+ms: 41
swap buffer 0.611927 8.521302 1.580279
<1ms: 127
<2ms: 169
<4ms: 74
<8ms: 15
<16ms: 1
<32ms: 0
32+ms: 0
swap complete 0.046511 2.446302 0.215040
<1ms: 375
<2ms: 6
<4ms: 3
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Данные о времени: https://gist.github.com/Manishearth/825799a98bf4dca0d9a7e55058574736
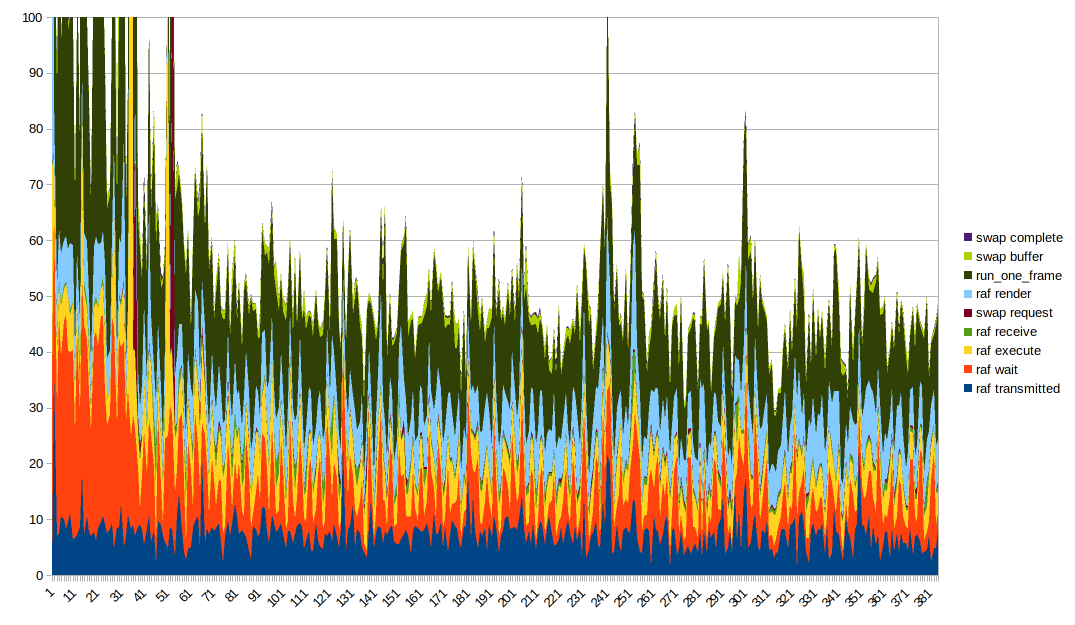
Получить хорошую визуализацию данных сложно. Сложенный линейный график кажется идеальным, хотя стоит отметить, что run_one_frame измеряет несколько уже измеренных значений времени. Полезно поиграть с упорядочиванием графиков и разместить внизу разные столбцы, чтобы лучше видеть их эффект. Также вам нужно усечь ось Y, чтобы получить что-нибудь полезное из-за очень больших выбросов.
Интересные вещи на заметку:
- Время рендеринга и время выполнения кажутся в основном стабильными, но имеют пики, когда в целом есть большие пики. Я подозреваю, что большие шипы происходят из-за того, что все замедляется по какой-то причине
- Время передачи кажется довольно хорошо коррелированным с общей формой
- время ожидания также является одной из причин, по которой общая форма такая, она _ очень_ волнистая
Manishearth
21 февр. 2020
Текущий статус: с исправлениями IPC, FPS теперь колеблется около 55. Иногда он сильно колеблется, но обычно не опускается ниже 45, _ кроме _ в течение первых нескольких секунд после загрузки (где он может опускаться до 30), и когда он впервые видит руку (когда она опускается до 20).
Manishearth
25 февр. 2020
Более новая гистограмма для демонстрации краски ( необработанные данные ):
Name min max mean
raf queued 0.113854 5.707917 0.441650
<1ms: 352
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.546667 44.954792 6.886162
<1ms: 4
<2ms: 2
<4ms: 23
<8ms: 279
<16ms: 59
<32ms: 3
32+ms: 1
raf wait 1.611667 37.913177 9.441104
<1ms: 0
<2ms: 6
<4ms: 98
<8ms: 82
<16ms: 135
<32ms: 43
32+ms: 6
raf execute 3.336562 418.198541 7.592147
<1ms: 0
<2ms: 0
<4ms: 11
<8ms: 319
<16ms: 36
<32ms: 2
32+ms: 3
raf receive 0.119323 9.804167 0.806074
<1ms: 324
<2ms: 31
<4ms: 13
<8ms: 1
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.003646 79.236354 0.761324
<1ms: 357
<2ms: 9
<4ms: 2
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 3
raf render 5.844687 172.898906 8.131682
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 283
<16ms: 86
<32ms: 1
32+ms: 1
run_one_frame 8.826198 2577.357604 25.922205
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 176
<32ms: 174
32+ms: 22
swap buffer 0.708177 12.528906 1.415950
<1ms: 164
<2ms: 161
<4ms: 38
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
swap complete 0.042917 1.554740 0.127729
<1ms: 370
<2ms: 1
<4ms: 0
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Более длинный пробег ( сырой ). Сделано, чтобы уменьшить влияние замедления запуска.
Имя мин. Макс. Среднее
raf в очереди 0,124896 6,356562 0,440674
<1 мс: 629
<2 мс: 13
<4 мс: 5
<8 мс: 1
<16 мс: 0
<32 мс: 0
32 + мс: 0
раф переданный 0,640677 20,275104 6,944751
<1 мс: 2
<2 мс: 3
<4 мс: 29
<8 мс: 513
<16 мс: 99
<32 мс: 1
32 + мс: 0
raf ждать 1.645886 40.955208 9.386255
<1 мс: 0
<2 мс: 10
<4 мс: 207
<8 мс: 114
<16 мс: 236
<32 мс: 65
32 + мс: 15
raf выполнить 3.090104 526.041198 6.226997
<1 мс: 0
<2 мс: 0
<4 мс: 68
<8 мс: 546
<16 мс: 29
<32 мс: 1
32 + мс: 3
раф получить 0,203334 6,441198 0,747615
<1 мс: 554
<2 мс: 84
<4 мс: 7
<8 мс: 2
<16 мс: 0
<32 мс: 0
32 + мс: 0
запрос на обмен 0,003490 73,644322 0,428460
<1 мс: 627
<2 мс: 18
<4 мс: 1
<8 мс: 0
<16 мс: 0
<32 мс: 0
32 + мс: 2
раф рендер 5.450312 209.662969 8.055021
<1 мс: 0
<2 мс: 0
<4 мс: 0
<8 мс: 467
<16 мс: 176
<32 мс: 3
32 + мс: 1
run_one_frame 8.417291 2579.454948 22.226204
<1 мс: 0
<2 мс: 0
<4 мс: 0
<8 мс: 0
<16 мс: 326
<32 мс: 290
32 + мс: 33
буфер подкачки 0,658125 12,179167 1,378725
<1 мс: 260
<2 мс: 308
<4 мс: 72
<8 мс: 4
<16 мс: 4
<32 мс: 0
32 + мс: 0
своп завершен 0,041562 5,161458 0,136875
<1 мс: 642
<2 мс: 3
<4 мс: 1
<8 мс: 1
<16 мс: 0
<32 мс: 0
32 + мс: 0
Manishearth
27 февр. 2020
Графики:
Более длинный пробег:

Более короткий пробег: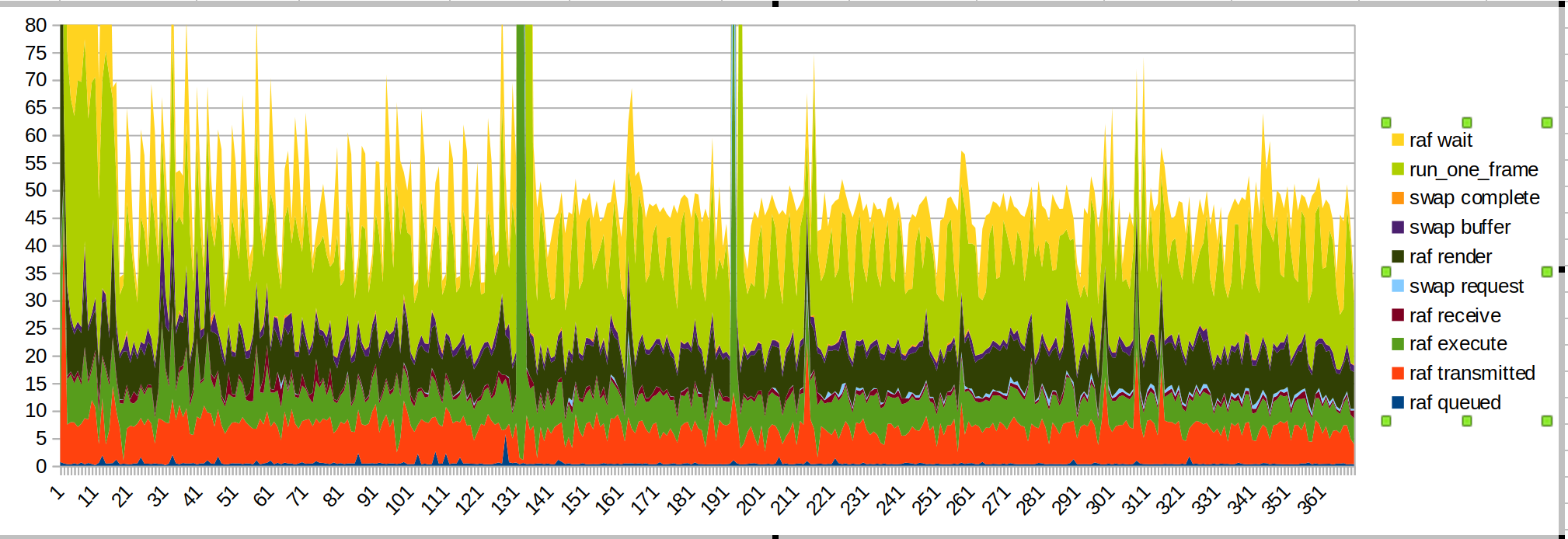
большой всплеск возникает, когда я помещаю руку в зону действия датчика.
На этот раз я поставил на первое место время ожидания / run_one_frame, потому что оно наиболее неравномерно, и это из-за того, что ОС ограничивает нас.
Пара замечаний:
- Большой всплеск от рук вызван JS-кодом (зеленый базилик, «raf render»).
- время передачи стало более плавным, как и ожидалось
- когда я начинаю рисовать, появляется еще один всплеск JS
- Время рендеринга и передачи по-прежнему составляют значительную часть бюджета. Производительность скрипта также может быть улучшена.
- Я подозреваю, что передача занимает так много времени из-за того, что основной поток занят другими делами. Это https://github.com/servo/webxr/issues/113 , @jdm изучает это
- Обновления surfman могут улучшить время рендеринга. Измерения @asajeffrey «с на surfmanup , кажется , лучше , чем у меня
- совместное использование поверхности может улучшить время рендеринга (заблокировано на surfmanup)
- FPS, показываемый устройством, уменьшается почти вдвое при измерении с помощью xr-профиля. Это могло быть из-за всего ввода-вывода.
Изгибы выступления из-за того, что увидели руку, а затем начали рисовать, не присутствуют для стрелка. Возможно, демонстрация раскраски выполняет много работы, когда впервые решает нарисовать изображение руки?
(Это также может быть демонстрация рисования, пытающаяся взаимодействовать с библиотекой входов webxr)
Manishearth
27 февр. 2020
@Manishearth Можете ли вы также накладывать данные об использовании памяти и соотносить их с этими событиями? Помимо первоначальной компиляции JS-кода, вы можете ошибиться в тонне нового кода и столкнуться с ограничениями физической памяти и вызвать кучу сборщиков мусора, когда вы столкнетесь с нехваткой памяти. Я наблюдал это в самых нетривиальных ситуациях. Я надеюсь , что @nox «s обновление SM поможет, так как это был определенно артефакт мы видели в этом SM строить на Fxr Android.
larsbergstrom
27 февр. 2020
У меня нет простого способа получить данные профилирования памяти таким образом, чтобы их можно было сопоставить с материалом для профилирования xr.
Я потенциально мог бы использовать существующие инструменты перфорации и выяснить, такая же ли форма.
Manishearth
27 февр. 2020
@Manishearth Отображает ли материал для профилирования
larsbergstrom
27 февр. 2020
В любом случае, скачки при запуске не являются моей главной заботой, я бы хотел сначала получить все _else_ со скоростью 60 кадров в секунду. Если при запуске на секунду или две он дергается, это менее насущная проблема.
Manishearth
27 февр. 2020
Да, это может показать это, потребуются некоторые настройки.
Manishearth
27 февр. 2020
@Manishearth Полностью согласен по приоритетам! Я не был уверен, пытались ли вы «избавиться от изгибов» или снизить устойчивое состояние. Согласитесь, последнее важнее прямо сейчас.
larsbergstrom
27 февр. 2020
Нет, я в основном просто записывал весь анализ, который мог.
Manishearth
27 февр. 2020
Эти всплески ближе к концу графика меньшего пробега, где также увеличивается время передачи: именно тогда я двигал головой и рисовал, и Алан также замечал падение FPS при выполнении каких-либо действий и приписывал это ОС, выполняющей другую работу. . После того, как IPC исправит, я догадываюсь о скачках времени передачи, которые вызваны тем, что ОС выполняет другую работу, так что, возможно, это именно то, что там происходит. В мире вне основного потока я ожидал, что это будет намного более плавным.
Manishearth
27 февр. 2020
Игнорируйте меня, если это уже было рассмотрено. Думали ли вы о том, чтобы разбить измерение run_one_frame по каждому сообщению, а также рассчитать время, потраченное на thread::sleep() -ing?
Возможно, стоит добавить три точки измерения:
одна упаковка https://github.com/servo/webxr/blob/68b024221b8c72b5b33a63441d63803a13eadf03/webxr-api/session.rs#L364
и еще одна упаковка https://github.com/servo/webxr/blob/2841497966d87bbd561f18ea66547dde9b13962f/webxr-api/lib.rs#L124 в целом,
а также один перенос вызова только на
thread::sleep.
Что касается recv_timeout , это может быть что-то, что нужно полностью пересмотреть.
Мне довольно сложно рассуждать о полезности тайм-аута. Поскольку вы подсчитываете отрисовку кадра, см. frame_count , вариант использования может выглядеть так: «возможно, сначала обработать одно или несколько сообщений, которые не отображают кадр, а затем следует визуализировать кадр, избегая прохождения через полный цикл событий основного потока "?
Также у меня есть некоторые сомнения относительно фактического расчета использованных в нем delay , где в настоящее время:
- он начинается с
delay = timeout / 1000, при этомtimeoutнастоящее время устанавливается на 5 мс - Затем он растет экспоненциально, удваиваясь на каждой итерации при
delay = delay * 2; - Это проверяется в верхней части цикла с помощью
while delay < timeout.
Таким образом, последовательность засыпания в худшем случае выглядит примерно так: 5 микрон -> 10 -> 20 -> 40 -> 80 -> 160 -> 320 -> 640 -> 1,28 милли -> 2,56 милли -> 5,12 милли.
Когда он достигнет 5,12 миллисекунды, вы выйдете из цикла (начиная с delay > timeout ), подождав в общей сложности 5115 миллисекунд, плюс любое дополнительное время, потраченное на ожидание, когда ОС пробуждает поток после каждого sleep .
Итак, я думаю, проблема в том, что вы можете спать более 5 мс в общей сложности, а также я думаю, что не рекомендуется спать дважды более чем на 1 мс (из которых второй раз более 2,5 мс), так как сообщение может войти в это время, и вы не проснетесь.
Я не совсем уверен, как его улучшить, похоже, вы пытаетесь найти потенциальное сообщение и, наконец, просто перейти к следующей итерации основного цикла событий, если ничего не доступно (почему бы не заблокировать recv?).
Вы можете переключиться на использование https://doc.rust-lang.org/std/thread/fn.yield_now.html , глядя на эту статью о блокировках , кажется, что она вращается примерно 40 раз при каждом вызове yield , является оптимальным (см. параграф «Вращение», ссылка на него напрямую невозможна). После этого вы должны либо заблокировать приемник, либо просто продолжить текущую итерацию цикла событий (поскольку он работает как субцикл внутри основного цикла событий внедрения).
(очевидно, что если вы не измеряете с включенным ipc , то часть выше для recv_timeout имеет значения, хотя вы все равно можете захотеть измерить вызов до recv_timeout на mpsc поскольку многопоточный канал будет выполнять некоторое внутреннее вращение / уступку, что также может повлиять на результаты. И поскольку неопознанное «исправление IPC» упоминалось несколько раз выше, я предполагаю, что вы измеряете с помощью ipc).
gterzian
27 февр. 2020
Не обращайте на меня внимания, если это уже рассматривалось, думали ли вы о разбивке измерения run_one_frame на основе каждого сообщения, а также о времени, затраченном на thread :: sleep () - ing?
Он уже сломан, время ожидания / рендеринга именно такое. Один тик run_one_frame - это один рендеринг, одно ожидание и неопределенное количество обрабатываемых событий (редко).
recv_timeout - хорошая идея для измерения
Manishearth
27 февр. 2020
К сожалению, обновление spidermonkey в # 25678 не кажется значительным улучшением - средний FPS для каждой демонстрации, кроме наиболее ограниченной памяти, уменьшился; демо Hill Valley немного выросло. Запуск Servo с -Z gc-profile в аргументах инициализации не показывает каких-либо различий в поведении GC между мастером и ветвью обновления spidermonkey - после загрузки и отображения содержимого GL не сообщается о GC.
jdm
3 мар. 2020
Измерения для различных отраслей:
master:
- espilit: 14-16 fps
- paint: 39-45 fps
- ball shooter: 30-40 fps
- hill valley: 8 fps, 200mb free mem
- mansion: 10-14fps, 650mb free mem
master + single swapchain:
- espilit: 10-12 fps
- paint: 29-55 fps, 1.2gb free mem
- ball shooter: 25-35 fps, 1.3gb free mem
- hill valley: 6-7 fps, 200mb free mem
- mansion: 10-11 fps, 700mb free mem
texture sharing + ANGLE 2.1.19:
- espilit: 13-15 fps, 670mb free mem
- paint: 39-45 fps
- ball shooter: 30-37 fps, 1.3gb free mem
- hill valley: 9-10 fps, 188mb free mem
- mansion: 13-14 fps, 671mb free mem
smup:
- espilit: 11-13 fps, 730mb free mem
- paint: 25-42 fps, 1.1gb free mem
- ball shooter: 26-30 fps, 1.4gb free mem
- hill valley: 10-11 fps, 145mb
- mansion: 9-11fps, 680mb free mem
Смап ухудшил производительность ???
asajeffrey
3 мар. 2020
С изменениями с https://github.com/servo/servo/pull/25855#issuecomment -594203492, есть интересный результат: отключение Ion JIT начинается с 12 FPS, а затем через несколько секунд резко падает до 1 FPS и остается там.
jdm
3 мар. 2020
Сделал некоторые измерения с этими заплатами.
При рисовании я получаю 60 кадров в секунду, когда в поле зрения мало контента, а при просмотре нарисованного контента оно падает до 50 кадров в секунду (желтые всплески - это когда я смотрю на нарисованный контент). Трудно сказать, почему, в основном кажется, что время ожидания зависит от троттлинга openxr, но другие вещи кажутся недостаточно медленными, чтобы вызвать проблему. Время запроса свопа немного медленнее. Время выполнения rAF изначально медленное (это начальное замедление "первый раз, когда контроллер виден"), но после этого оно остается довольно постоянным. Похоже, что openxr просто душит нас, но в другом месте нет видимого замедления, которое могло бы вызвать это.

Manishearth
7 мар. 2020
Это то, что у меня есть для демонстрации перетаскивания. Масштаб по оси Y такой же. Здесь гораздо более очевидно, что время выполнения нас замедляет.

Manishearth
7 мар. 2020
Следует отметить, что я проводил измерения с примененным # 25837, и это могло повлиять на производительность.
jdm
7 мар. 2020
Я не был, но я получал те же результаты, что и вы
Manishearth
7 мар. 2020
Графики производительности инструмента на момент изменения скорости с 60 до 45 кадров в секунду при просмотре контента:
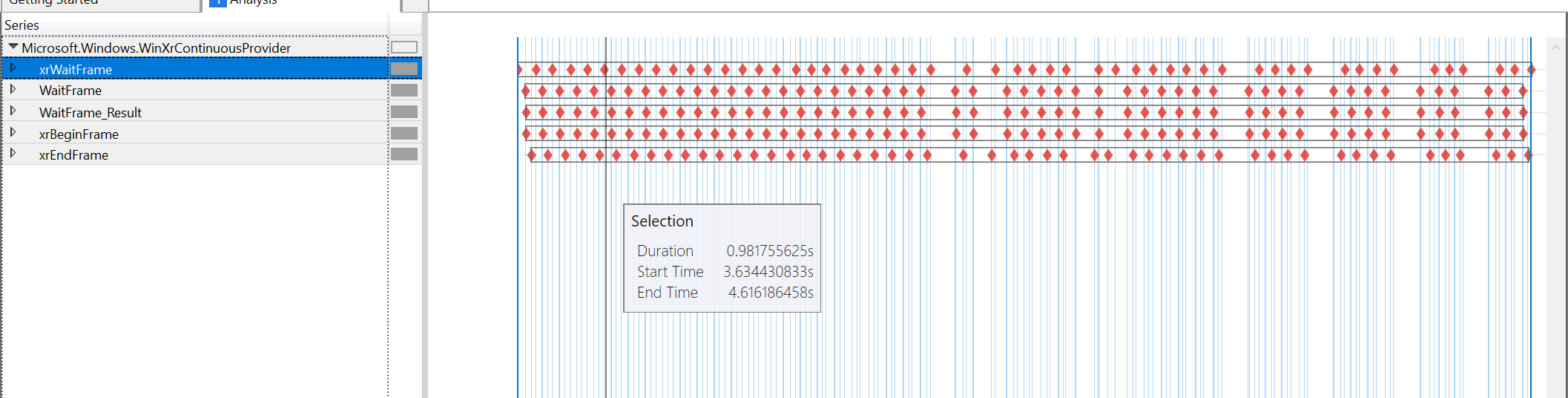
похоже, что полностью виноват xrWaitFrame, все остальные тайминги довольно близки. XrBeginFrame по-прежнему находится почти сразу после xrWaitFrame, xrEndFrame - на 4 мкс после xrBeginFrame (в обоих случаях). Следующий xrWaitFrame находится почти сразу после xrEndFrame. Единственный неучтенный пробел вызван самим xrWaitFrame.
Manishearth
11 мар. 2020
При перетаскивании демонстрации я получаю следующий след:

Это демонстрация краски с таким же масштабом:
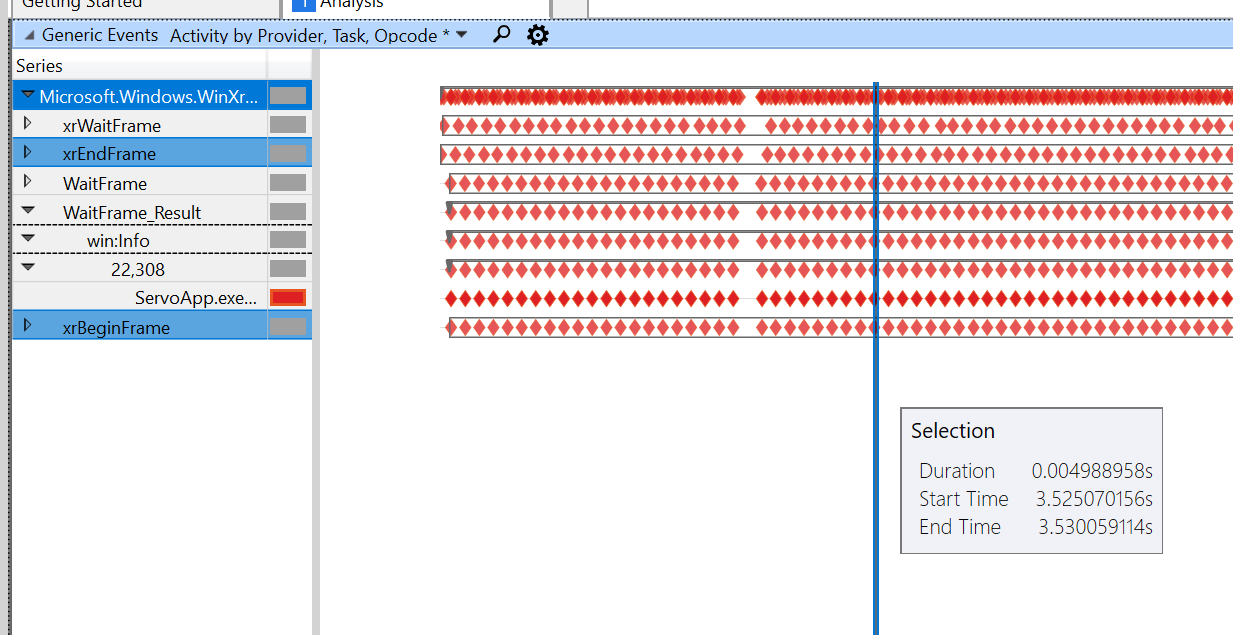
Мы медленно между началом / концом кадра (от 5 мс до 38 мс на самом быстром!), А затем срабатывает дросселирование кадра ожидания. Я еще не дразнил, почему это так, я просматриваю код для оба.
Manishearth
18 мар. 2020
Демонстрация перетаскивания замедляется, потому что ее источник света отбрасывает тень. Тень выполняется на стороне GL, так что я не уверен, сможем ли мы легко это ускорить?
Manishearth
18 мар. 2020
Если это делается полностью через GLSL, у нас могут возникнуть трудности; если это делается каждый кадр через API WebGL, то, возможно, есть места для оптимизации.
jdm
18 мар. 2020
Да, похоже, все на стороне GLSL; Я не видел никаких вызовов WebGL, когда дело дошло до того, как работают теневые API, только некоторые биты, которые передаются шейдерам.
Manishearth
19 мар. 2020
Я считаю, что это решено в целом. Мы можем зарегистрировать проблемы для отдельных демонстраций, которые требуют доработки.
jdm
20 июл. 2020
Смежные вопросы
 pyfisch
·
4Комментарии
Manishearth
·
4Комментарии
pyfisch
·
4Комментарии
Manishearth
·
4Комментарии
 SimonSapin
·
3Комментарии
jdm
·
3Комментарии
SimonSapin
·
3Комментарии
jdm
·
3Комментарии
 roberto68
·
3Комментарии
roberto68
·
3Комментарии
Самый полезный комментарий
Текущий статус: с исправлениями IPC, FPS теперь колеблется около 55. Иногда он сильно колеблется, но обычно не опускается ниже 45, _ кроме _ в течение первых нескольких секунд после загрузки (где он может опускаться до 30), и когда он впервые видит руку (когда она опускается до 20).