これを使用して、デバイスでイマーシブモードを使用しているときにFPS値が低くなる原因の調査を追跡しています。
 jdm
jdm
全てのコメント71件
明らかにされたいくつかの情報:
- xrWaitFrameとxrBeginFrameの間には長い待機があります
- デモアプリでは、これらは順番に発生します
- Servoのモデルでは、デバイスフレームをすると、次のopenxrフレームを
OpenXR APIのマーカーを使用したペイントデモのトレースは、最近再現されており、その期間中も表示されます。
- webglスレッドは最も多くのCPUを使用します(その時間の大部分は、surfmanのDevice :: bind_surface_to_contextから呼び出されるgl :: Finishの下で費やされます)
- メインスレッドは2番目にビジーで、eglCreatePbufferFromClientBufferで最も多く使用され、TLSからEglオブジェクトを取得するのにほぼ同じ時間が費やされます。
- webrenderのレンダリングもこのスタックに表示されます
- winrt ::サーボ::フラッシュもここに表示されますが、イマーシブモードでメインアプリケーションのGLバッファーを実際に交換する必要があるかどうかはわかりません。
- 3番目に高いCPU使用率はスクリプトスレッドであり、JITコード内で多くの時間を費やしています
- その後、スレッドのCPU使用率は一般的にかなり低くなりますが、レイアウトが発生していることを示すスタイルクレートからのいくつかのシンボルが表示されます
jdm
2020年01月03日
これらのデータポイントを前提として、次の2つのアプローチを試してみます。
- デバイスフレームを待った後、できるだけ早く次のXRフレームを開始します
- gl :: Finish(webglスレッド)、eglCreateBufferFromClientBufferおよびTLS(メインスレッド)を呼び出す必要がある回数を減らします
jdm
2020年01月03日
https://github.com/servo/servo/pull/25343#issuecomment -567706735には、エンジン内のさまざまな場所にメッセージを送信することの影響に関する詳細な調査があります。 明確な指を指しているわけではありませんが、より正確な測定を行う必要があることを示しています。
jdm
2020年01月03日
gl :: Finishの使用法は、 https: //github.com/pcwalton/surfman/blob/6705a9aaa8f33ac1324fdb1913242800e68c7720/surfman/src/platform/windows/angle/context.rs#L259-L266から取得され
jdm
2020年01月03日
gl :: Finishをgl :: Flushに変更すると、フレームレートが〜15-> 30に上がりますが、実際にはユーザーの頭の動きを反映してフレームコンテンツに非常に顕著なラグがあり、現在のフレームがユーザーの頭に追従します。その間。
jdm
2020年01月03日
キー付きミューテックスは、私が理解できない理由でANGLEでデフォルトで無効になっていますが、mozangleは明示的に有効にしています(https://github.com/servo/mozangle/blob/706a9baaf8026c1a3cb6c67ba63aa5f4734264d0/build_data.rs#L175)。 。 それらを可能にするANGLEのビルドを作成し、gl :: Finish呼び出しを回避するのに十分かどうかを確認します。
jdm
2020年01月03日
確認済み! ANGLEでキー付きミューテックスを強制的にオンにすると、ペイントデモで25〜30 FPSが得られ、gl :: Finish呼び出しの変更に伴うラグの問題は発生しません。
jdm
2020年01月03日
ああ、そしてラールの調査による別の情報:
- dom.ion.enabledをfalseに設定すると、JIT時間が消えます。 初期ロードははるかに遅いですが、物事が実行されると、それらはかなり良好です。
- それはまだ素晴らしいことではありません-そのbabylon.jsの例では、メモリ使用量はかなり高いです(基本的にすべての利用可能なメモリ)
- AndroidデバイスのFxRで行われているarm64関連の最適化を取り込むために、別のスパイダーモンキーのアップグレードを行う必要があります
jdm
2020年01月03日
プロファイルにstd::thread::local::LocalKey<surfman::egll::Egl>が存在することを誤解したと思います-TLS読み取りは、それに請求される時間のごく一部にすぎないと確信しています。これは、eglCreatePbufferFromClientBufferや_実際に_時間がかかるDXGIAcquireSync。
jdm
2020年01月03日
残念ながら、js.ion.enabledを無効にすると、ペイントデモのFPSが低下し、20〜25に低下するようです。
jdm
2020年01月04日
Device :: create_surface_texture_from_textureをフレームごとに2回(各目のd3dテクスチャごとに1回)呼び出すのではなく、openxrwebxrデバイスの作成時にすべてのスワップチェーンテクスチャのサーフェステクスチャを作成できる場合があります。 これが機能する場合、イマーシブモード中にメインスレッドからCPUの2番目に大きいユーザーを削除します。
jdm
2020年01月04日
メモリ使用量を削減するための別のアイデア:bfcacheを非常に低い数値に設定して、デモの1つに移動するときに、元のHLホームページパイプラインが削除された場合、影響はありますか?
jdm
2020年01月04日
次のwebxrパッチは、FPSを明確に改善しませんが、画像の安定性を改善する可能性があります。 連続して実行して確認できる2つの別々のビルドを作成する必要があります。
diff --git a/webxr/openxr/mod.rs b/webxr/openxr/mod.rs
index 91c78da..a6866de 100644
--- a/webxr/openxr/mod.rs
+++ b/webxr/openxr/mod.rs
@@ -416,11 +416,30 @@ impl DeviceAPI<Surface> for OpenXrDevice {
}
fn wait_for_animation_frame(&mut self) -> Option<Frame> {
- if !self.handle_openxr_events() {
- // Session is not running anymore.
- return None;
+ loop {
+ if !self.handle_openxr_events() {
+ // Session is not running anymore.
+ return None;
+ }
+ self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
+ // XXXManishearth this code should perhaps be in wait_for_animation_frame,
+ // but we then get errors that wait_image was called without a release_image()
+ self.frame_stream
+ .begin()
+ .expect("failed to start frame stream");
+
+ if self.frame_state.should_render {
+ break;
+ }
+
+ self.frame_stream.end(
+ self.frame_state.predicted_display_time,
+ EnvironmentBlendMode::ADDITIVE,
+ &[],
+ ).unwrap();
}
- self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
let time_ns = time::precise_time_ns();
// XXXManishearth should we check frame_state.should_render?
let (_view_flags, views) = self
@@ -506,12 +525,6 @@ impl DeviceAPI<Surface> for OpenXrDevice {
0,
);
- // XXXManishearth this code should perhaps be in wait_for_animation_frame,
- // but we then get errors that wait_image was called without a release_image()
- self.frame_stream
- .begin()
- .expect("failed to start frame stream");
-
self.left_image = self.left_swapchain.acquire_image().unwrap();
self.left_swapchain
.wait_image(openxr::Duration::INFINITE)
@manishearthこれについて何か考えはありますか? https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#Sessionで説明されているモデルに近づくための私の試み
jdm
2020年01月04日
ええ、それはよさそうだ。 私はbegin()をwafに移動するつもり
 Manishearth
2020年01月04日
Manishearth
2020年01月04日
キー付きの発見に本当に満足しています! サーフマンコールは確かにフレームバジェットの多くを占めますが、何が必要で何が必要でないかを判断するのは少し難しいです。
Manishearth
2020年01月04日
はい、再: js.ion.enabled無効にします。これは、RAMが不足していて、ほとんどの時間をGCと関数の再コンパイルに費やしている場合にのみメリットになります。 そして、それは新しいSMで改善されるべきです。 66時代のARM64バックエンドであるIIRCも、ベースラインJITとインタープリターのパフォーマンスが比較的低かった。 アップデートにより、特にRAMを大量に消費するアプリケーションでは、全体的にスピードアップが見られるはずです。
 larsbergstrom
2020年01月04日
larsbergstrom
2020年01月04日
キー付きミューテックスが有効になっている新しいANGLEパッケージを公開しました。 後でアップグレードするためのプルリクエストを作成します。
jdm
2020年01月06日
XRデバイスの初期化中にすべてのopenxrスワップチェーンイメージのサーフェステクスチャを作成しようとしましたが、メインスレッドで、各フレームのwebglスレッドから受け取るサーフェスでeglCreatePbufferFromClientBufferの呼び出しに費やされる時間がまだあります。 同じサーフェスを受け取った場合に再利用できるように、これらのサーフェステクスチャをキャッシュする方法があるかもしれません...
jdm
2020年01月06日
メインスレッドのCPU使用率の最大値は、render_animation_frameによるもので、そのほとんどはOpenXRランタイムで発生しますが、BlitFramebufferとFramebufferTexture2Dの呼び出しもプロファイルに確実に表示されます。 両方の目を一度に1つのテクスチャにブリットするのが改善されるのではないかと思います。 たぶん、それはhttps://github.com/microsoft/OpenXR-SDK-VisualStudio/#render-with-texture-array-and-vprtで説明されているテクスチャ配列のものに関連してい
jdm
2020年01月06日
一度に両方の目を輝かせることができますが、私の理解では、ランタイムは
その後、独自のブリットを行うことができます。 テクスチャ配列は最速の方法です。 しかし
一見の価値がありますが、プロジェクションビューAPIはこれをサポートしています。
メインスレッドのANGLEトラフィックに関しては、RAFループを停止しますか
キャンバスのヘルプを汚しますか? これまでのところ、これは何もしていませんが、価値があります
ショット、理想的にはメインでレイアウト/レンダリングを行うべきではありません
糸。
月、2020年1月6日には、午前11時49分PMジョシュ・マシューズ[email protected]
書きました:
メインスレッドの最大のCPU使用率は、render_animation_frameから発生します。
そのほとんどはOpenXRランタイムの下にありますが、BlitFramebufferと
FramebufferTexture2Dは、プロファイルにも確実に表示されます。 私は疑問に思う
両方の目を一度に1つにブリットすることが改善される場合
テクスチャ? 多分それは議論されているテクスチャ配列のものに関連しています
の
https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt
。—
あなたが言及されたので、あなたはこれを受け取っています。
このメールに直接返信し、GitHubで表示してください
https://github.com/servo/servo/issues/25425?email_source=notifications&email_token=AAMK6SBRH72JGZMXTUKOXETQ4NY37A5CNFSM4KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW
または購読を解除する
https://github.com/notifications/unsubscribe-auth/AAMK6SECM6MDNZZ6Y7VL7SDQ4NY37ANCNFSM4KCRI6AA
。
Manishearth
2020年01月06日
キャンバスの汚れを取り除くと、プロファイルがクリーンアップされるだけです。 意味のあるFPSの増加につながるようには見えませんでした。
jdm
2020年01月06日
webglスレッドとopenxrスワップチェーンテクスチャからサーフェスのサーフェステクスチャのキャッシュを作成しようとしましたが、eglCreatePbufferFromClientBufferの時間が完全に消えましたが、意味のあるFPSの変更には気づきませんでした。
jdm
2020年01月06日
没入型パイプラインでのさまざまな操作のタイミング情報(すべての測定値はミリ秒):
Name min max avg
raf queued 0.070833 14.010261 0.576834
<1ms: 393
<2ms: 28
<4ms: 5
<8ms: 1
<16ms: 2
<32ms: 0
32+ms: 0
raf transmitted 0.404270 33.649583 7.403302
<1ms: 123
<2ms: 43
<4ms: 48
<8ms: 48
<16ms: 95
<32ms: 69
32+ms: 3
raf wait 1.203500 191.064100 17.513593
<1ms: 0
<2ms: 17
<4ms: 98
<8ms: 95
<16ms: 48
<32ms: 69
32+ms: 101
raf execute 3.375000 128.663200 6.994588
<1ms: 0
<2ms: 0
<4ms: 5
<8ms: 351
<16ms: 70
<32ms: 1
32+ms: 2
raf receive 0.111510 8.564010 0.783503
<1ms: 353
<2ms: 52
<4ms: 18
<8ms: 4
<16ms: 1
<32ms: 0
32+ms: 0
raf render 2.372200 75.944000 4.219310
<1ms: 0
<2ms: 0
<4ms: 253
<8ms: 167
<16ms: 8
<32ms: 0
32+ms: 1
receive :XRフレーム情報がXRスレッドから送信されてからIPCルーターで受信されるまでの時間
queued :IPCルーターがフレーム情報を受信してからXRSession :: raf_callbackが呼び出されるまでの時間
execute :XRSession :: raf_callbackが呼び出されてからメソッドから戻るまでの時間
transmitted :スクリプトスレッドから新しいrAFのリクエストを送信してから、XRスレッドが受信するまでの時間
render : render_animation_frameを呼び出して表面をリサイクルするのにかかる時間
wait : wait_for_animation_frameかかる時間(レンダリングされるべきではないフレームをループするこの問題の前半のパッチを使用)
各エントリの下には、セッション中の値の分布があります。
jdm
2020年01月07日
そのタイミング情報からの興味深いデータポイント- transmittedカテゴリは、本来よりもはるかに高いようです。 これは、rAFコールバックが実行されてから、完成したフレームをopenxrのテクスチャにブリットするメッセージをXRスレッドが受信するまでの遅延です。 かなりのバリエーションがあり、メインスレッドが他のことを行うために占有されているか、メインスレッドを処理するためにウェイクアップする必要があることを示唆しています。
jdm
2020年01月07日
以前のデータを踏まえて、明日https://github.com/servo/webxr/issues/113を復活させて、送信タイミングにプラスの影響があるかどうかを確認する場合があります。 最初にプロファイラーのメインスレッドを調べて、スレッドが他のタスクでビジーであるかスリープ状態であるかを判断する方法についてアイデアを思いつくことができるかどうかを確認します。
jdm
2020年01月07日
もう1つのデータポイント:
swap buffer 1.105938 28.193698 2.154793
<1ms: 0
<2ms: 273
<4ms: 110
<8ms: 15
<16ms: 2
<32ms: 2
32+ms: 0
swap complete 0.053802 4.337812 0.295064
<1ms: 308
<2ms: 9
<4ms: 6
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
swap request 0.003333 24033027.355364 4662890.724805
<1ms: 268
<2ms: 49
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 1
32+ms: 79
これらは、1)スワップバッファメッセージを送信してからwebglスレッドで処理されるまでの遅延、2)バッファをスワップするのにかかる時間、3)スワッピングが完了したことを示すメッセージを送信してからで受信されるまでの遅延に関連するタイミングです。スクリプトスレッド。 ここでは驚くべきことは何もありませんが( swap requestカテゴリの奇妙な外れ値を除いて、セットアップの失敗中の没入型セッションの開始時に発生します)、実際のバッファスワッピングには一貫して1〜4ミリ秒かかります。
jdm
2020年01月07日
いくつかのopenxrサンプルコードを読み、locate_views呼び出しがプロファイルに表示されることに気付いた後、#117を提出しました。
jdm
2020年01月07日
 asajeffrey
2020年01月07日
asajeffrey
2020年01月07日
そのタイミング情報からの興味深いデータポイント-送信されたカテゴリは、本来よりもはるかに高いようです。 これは、rAFコールバックが実行されてから、完成したフレームをopenxrのテクスチャにブリットするメッセージをXRスレッドが受信するまでの遅延です。 かなりのバリエーションがあり、メインスレッドが他のことを行うために占有されているか、メインスレッドを処理するためにウェイクアップする必要があることを示唆しています。
transmitted値の変動については、セッションがメインスレッドで実行されているときにrun_one_frame一部として使用されるタイムアウトに結びつく可能性があります(これらの測定値に含まれていますか?) 、 https://github.com/servo/webxr/blob/c6abf4c60d165ffc978ad2ebd6bcddc3c21698e1/webxr-api/session.rs#L275を参照して
RenderAnimationFrame msg(コールバックの実行後にスクリプトスレッドによって送信されたもの)がタイムアウトの前に受信された場合、「高速パス」に到達し、タイムアウトを逃した場合、サーボは別のパスに入ると推測します。 perform_updates反復、および「別のフレームの実行」は、 compositor.perform_updates一部として、サイクルのかなり遅い段階で発生します。これ自体は、 servo.handle_events一部としてかなり遅く呼び出されます。
XRを独自のスレッドに移動する以外に、タイムアウトの値を大きくすると平均値が改善されるかどうかを確認する価値があるかもしれません(ただし、メインスレッドで他の必要なものが不足する可能性があるため、適切な解決策ではない可能性があります)。
 gterzian
2020年01月08日
gterzian
2020年01月08日
https://github.com/servo/webxr/issues/113のメインスレッドからopenxrを削除する作業が進んだので、来週はその作業に基づいてさらに測定を行う予定です。
jdm
2020年01月10日
デバイスから有用なプロファイルを取得するための手法:
rustflags = "-C force-frame-pointers=yes"を含む.servobuildを使用します- これらの行のコメントを解除し
- HLデバイスポータルの[パフォーマンストレース]の下にあるカスタムトレースプロファイルとして、MSチームのchar
FilesタブのWinXR_Perf.wprpを使用します --features profilemozjsビルドする
これらのトレース(デバイスポータルの[トレースの開始]から取得)は、Windowsパフォーマンスアナライザツール内で使用できます。 このツールはスレッド名を表示しませんが、CPUを最も多く使用しているスレッドは、スタックに基づいて簡単に識別できます。
特定のopenxrフレームの時間分布をプロファイリングするには:
- WPAに「システムアクティビティ->一般的なイベント」ビューを追加します
- ビューをフィルター処理して、Microsoft.Windows.WinXrContinuousProviderシリーズのみを表示します
- 短時間にズームインしてから、ズームインした領域を調整して、xrBeginイベントがビューの左側に表示され、xrEndイベントがビューの右側に表示されるようにします。
CPU使用率に関する最も有用なビュー:
- CPU使用率(サンプル)->プロセス、スレッド、スタックごとの使用率(ビューをフィルタリングしてサーボのみを表示し、[プロセス]列を無効にします)
- プロセスごとのフレーム、スタック(ビューをフィルタリングしてサーボのみを表示)
jdm
2020年01月16日
スクリプトスレッドでの作業をわずかに減らすための1つの可能性:
- XRView :: newはすべてのサーボCPUの0.02%を消費します
- FrameUpdateEvent :: UpdateViewsイベント(XRSession :: UpdateRenderStateを介してSession :: update_clip_planesから発生)がない限り、ビューオブジェクトの内容は変更されないため、XRSessionにXRViewオブジェクトをキャッシュし、レンダリング状態が更新されます
- XRSessionにキャッシュされたビューリストのJS表現を保持し、ポーズのビューメンバーを設定して、XRViewオブジェクトの再作成とベクトルの割り当て、およびJS値変換の実行の両方を回避することもできます。
jdm
2020年01月16日
没入型フレームをレンダリングするときに作業を減らすための1つの可能性:
- GLとd3dはY座標系が逆になっています
- ANGLEは、舞台裏でいくつかの作業を行うことにより、画面に表示するときにこれを暗黙的に非表示にします
- イマーシブモードの場合、GLテクスチャデータをd3dにブリットするときに、glBlitFramebufferを使用してy反転を実行します。
- ANGLEが内部で変換を行わないようにする方法を理解できれば、このモデルを反転して、非没入型Webページのレンダリングに追加のy反転ブリットを必要とする可能性があります(webrenderオプション
surface_origin_is_top_left)没入型モードは変換せずにブリットすることができますが
https://bugzilla.mozilla.org/show_bug.cgi?id=1591346に基づいて、jrmuizelと話している場合、次のことを行う必要があります。
- 非没入型ページをレンダリングするウィンドウ要素のd3dスワップチェーンを取得します(これはXAMLアプリのSwapChainPanelになります)
- それをEGLイメージでラップします(https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#554)
- メインレンダリングを更新する場合は、スワップチェーンを明示的に提示します
- https://github.com/servo/servo/blob/master/support/hololens/ServoApp/ServoControl/OpenGLES.cpp#L205-L208でeglCreateWindowSurfaceとeglSwapBuffersを使用しないで
jdm
2020年01月16日
現在の仕掛品ブランチ:
- https://github.com/servo/ipc-channel/tree/try-recv-error
- https://github.com/jdm/webxr/tree/oxr
- https://github.com/jdm/rust-offscreen-rendering-context/tree/angle-perf
- https://github.com/jdm/servo/tree/profile
これには、前述のタイミングデータを追加するxr-profile機能と、イマーシブモードでのy逆変換を削除するためのANGLE変更の初期実装が含まれます。 非没入型モードは正しくレンダリングされていますが、没入型モードは上下逆になっています。 GLコードをrender_animation_frameから削除し、GLサーフェスから共有ハンドルを抽出してd3dテクスチャを取得できるようにすることで、直接のCopySubresourceRegion呼び出しに置き換える必要があると思います。
jdm
2020年01月17日
ANGLE y-inversion作業について、 https://github.com/servo/servo/issues/25582に提出。 その作業に関するさらなる更新は、その号で行われます。
jdm
2020年01月23日
次の大きなチケット項目は、openxrwebxrバックエンドでのglBlitFramebuffer呼び出しを完全に回避する方法を調査することです。 これには以下が必要です。
- 必要な不透明なwebglフレームバッファと正確に一致するopenxrフレームバッファを作成する
- webxrバックエンドがすべてのスワップチェーンサーフェスを作成するのではなく提供するwebglモードをサポートします(例:https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L458およびhttps://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L111-L118)
jdm
2020年01月23日
surfmanはサーフェスを作成したコンテキストへの書き込みアクセスしか提供しないため、これは難しい場合があります。したがって、サーフェスがopenxrスレッドによって作成された場合、WebGLスレッドでは書き込みできません。 https://github.com/pcwalton/surfman/blob/a515fb2f5d6b9e9b36ba4e8b498cdb4bea92d330/surfman/src/device.rs#L95 -L96
asajeffrey
2020年01月23日
それは私に起こります-webglスレッドでopenxrレンダリングを行った場合、openxrのテクスチャへの直接レンダリングに関するスレッド関連の問題の束はもはや問題ではなくなります(つまり、複数のd3dデバイスの使用を禁止するeglCreatePbufferFromClientBufferに関する制限)。 検討:
- openxrイベントのポーリング、アニメーションフレームの待機、新しいフレームの開始、現在のフレーム状態の取得を担当するopenxrスレッドがまだあります。
- フレームの状態がスクリプトスレッドに送信され、スクリプトスレッドがアニメーションのコールバックを実行してから、メッセージをwebglスレッドに送信して、xrレイヤーのフレームバッファーを交換します。
- このスワップメッセージがwebglスレッドで受信されると、最後に取得したopenxrスワップチェーンイメージを解放し、メッセージをopenxrスレッドに送信して現在のフレームを終了し、次のフレームの新しいスワップチェーンイメージを取得します。
https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#threading -behaviorを読んだところ、この設計が機能する可能性があることがわかりました。 秘訣は、openxr以外のバックエンドとopenxrで機能するかどうかです。
仕様から:「xrBeginFrameとxrEndFrameは同じスレッドで呼び出す必要はありませんが、別々のスレッドで呼び出される場合は、アプリケーションが同期を処理する必要があります。」
jdm
2020年01月25日
現時点では、XRデバイススレッドとwebglの間に直接通信はありません。すべて、スクリプトまたは共有スワップチェーンを介して行われます。 サーフマンスワップチェーンまたはopenxrスワップチェーンのいずれかの上にあるスワップチェーンAPIを提供し、それをwebglからopenxrへの通信に使用したいと思います。
asajeffrey
2020年01月25日
以前の時間測定についての会話からのメモ:
* concerns about wait time - why?????
* figure out time spent in JS vs. DOM logic
* when does openxr give us should render=false frames - maybe related to previous frame taking too long
* are threads being scheduled on inappropriate cpus? - on magic leap, main thread (including weber) pinned to big core.
* when one of the measured numbers is large, is there correlation with other large numbers?
* probably should pin openxr thread, running deterministic code
* consider clearing after telling script that the swap is complete - measure if clear is taking significant time in swap operation
* consider a swap chain API operation - “wait until a buffer swap occurs”
- block waiting on swapchain
- block waiting on swapchain + timeout
- async????????
- a gc would look like a spike in script execution time
openxrテクスチャに直接レンダリングすることについて私が追求している調査を追跡するために#25735を提出しました。
jdm
2020年02月11日
私たちがすべきことの1つは、スパイダーモンキーがデバイス上で他のエンジンと比較する方法を絞り込むことです。 ここでデータを取得する最も簡単な方法は、Servoが実行できる単純なJSベンチマークを見つけて、ServoのパフォーマンスをデバイスにインストールされているEdgeブラウザーと比較することです。 さらに、没入型モードに入らずに、両方のブラウザーでいくつかの複雑なバビロンデモにアクセスして、パフォーマンスに大きな違いがあるかどうかを確認することもできます。 これにより、今後のスパイダーモンキーのアップグレードと比較するためのベンチマークも提供されます。
jdm
2020年02月13日
いくつかの新しいデータ。 これはANGLEアップグレードによるものですが、IPCアップグレードによるものではありません。
$ python timing.py raw
Name min max mean
raf queued 0.056198 5.673125 0.694902
<1ms: 335
<2ms: 26
<4ms: 17
<8ms: 7
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.822917 36.582083 7.658619
<1ms: 1
<2ms: 4
<4ms: 31
<8ms: 181
<16ms: 158
<32ms: 8
32+ms: 1
raf wait 1.196615 39.707709 10.256875
<1ms: 0
<2ms: 32
<4ms: 93
<8ms: 67
<16ms: 107
<32ms: 68
32+ms: 17
raf execute 3.078438 532.205677 7.752839
<1ms: 0
<2ms: 0
<4ms: 37
<8ms: 290
<16ms: 52
<32ms: 2
32+ms: 3
raf receive 0.084375 9.053125 1.024403
<1ms: 276
<2ms: 71
<4ms: 27
<8ms: 9
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.004115 73.939479 0.611254
<1ms: 369
<2ms: 10
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.706198 233.459636 9.241698
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 183
<16ms: 190
<32ms: 10
32+ms: 1
run_one_frame 7.663333 2631.052969 28.035143
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 3
<16ms: 157
<32ms: 185
32+ms: 41
swap buffer 0.611927 8.521302 1.580279
<1ms: 127
<2ms: 169
<4ms: 74
<8ms: 15
<16ms: 1
<32ms: 0
32+ms: 0
swap complete 0.046511 2.446302 0.215040
<1ms: 375
<2ms: 6
<4ms: 3
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
タイミングデータ: https :
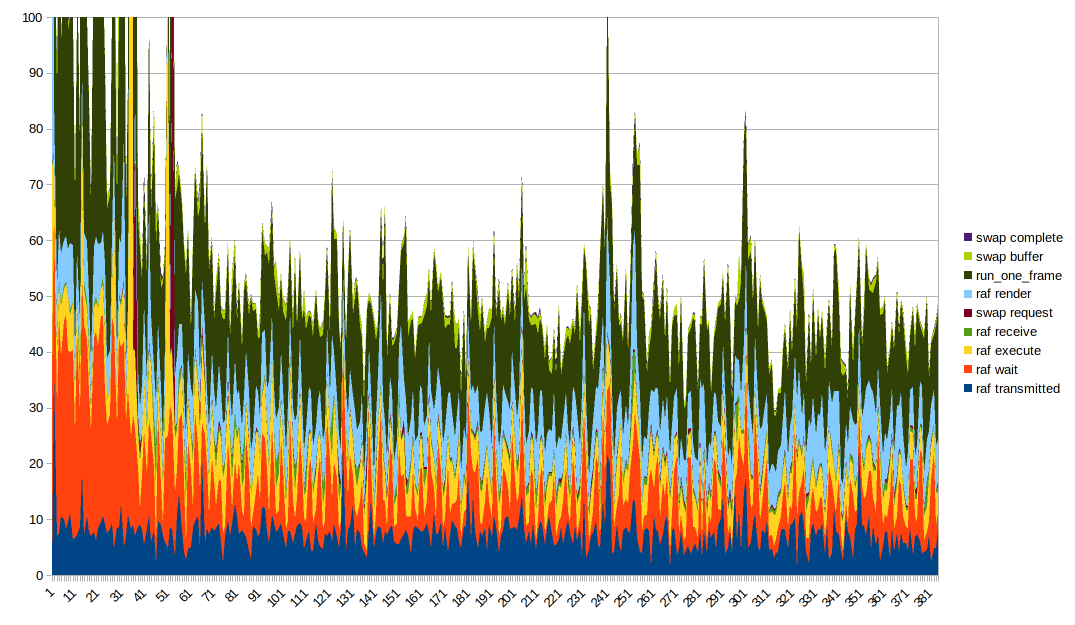
これを適切にデータで視覚化するのは難しいことです。 積み上げ折れ線グラフは理想的なようですが、run_one_frameがすでに測定された複数のタイミングを測定することは注目に値します。 グラフの順序をいじって、その効果をよく確認するために下部にさまざまな列を配置すると便利です。 また、非常に大きな外れ値があるため、有用なものを取得するには、Y軸を切り捨てる必要があります。
注意すべき興味深い点:
- レンダリング時間と実行時間はほぼ安定しているように見えますが、全体的に大きなスパイクがある場合はスパイクがあります。 大きなスパイクは、何らかの理由で減速するすべてのものから来ていると思います
- 送信時間は全体的な形状とかなりよく相関しているようです
- 待ち時間も全体的な形がそのような理由の一部であり、それは_非常に_波状です
Manishearth
2020年02月21日
現在のステータス:IPCの修正により、FPSは55前後でホバリングしています。ときどき小刻みに動くことがありますが、通常は45を下回りません。ただし、ロード後の最初の数秒間(30まで下がる可能性があります)、およびそれが発生したときは例外です。最初に手が見えます(20に下がったとき)。
Manishearth
2020年02月25日
ペイントデモの新しいヒストグラム(生データ):
Name min max mean
raf queued 0.113854 5.707917 0.441650
<1ms: 352
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.546667 44.954792 6.886162
<1ms: 4
<2ms: 2
<4ms: 23
<8ms: 279
<16ms: 59
<32ms: 3
32+ms: 1
raf wait 1.611667 37.913177 9.441104
<1ms: 0
<2ms: 6
<4ms: 98
<8ms: 82
<16ms: 135
<32ms: 43
32+ms: 6
raf execute 3.336562 418.198541 7.592147
<1ms: 0
<2ms: 0
<4ms: 11
<8ms: 319
<16ms: 36
<32ms: 2
32+ms: 3
raf receive 0.119323 9.804167 0.806074
<1ms: 324
<2ms: 31
<4ms: 13
<8ms: 1
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.003646 79.236354 0.761324
<1ms: 357
<2ms: 9
<4ms: 2
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 3
raf render 5.844687 172.898906 8.131682
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 283
<16ms: 86
<32ms: 1
32+ms: 1
run_one_frame 8.826198 2577.357604 25.922205
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 176
<32ms: 174
32+ms: 22
swap buffer 0.708177 12.528906 1.415950
<1ms: 164
<2ms: 161
<4ms: 38
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
swap complete 0.042917 1.554740 0.127729
<1ms: 370
<2ms: 1
<4ms: 0
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
長期実行( raw )。 起動速度の低下の影響を減らすために作られました。
名前最小最大平均
rafキュー0.1248966.356562 0.440674
<1ms:629
<2ms:13
<4ms:5
<8ms:1
<16ms:0
<32ms:0
32 + ms:0
送信されたraf0.640677 20.275104 6.944751
<1ms:2
<2ms:3
<4ms:29
<8ms:513
<16ms:99
<32ms:1
32 + ms:0
raf wait 1.645886 40.955208 9.386255
<1ms:0
<2ms:10
<4ms:207
<8ms:114
<16ms:236
<32ms:65
32 + ms:15
raf execute 3.090104 526.041198 6.226997
<1ms:0
<2ms:0
<4ms:68
<8ms:546
<16ms:29
<32ms:1
32 + ms:3
raf receive 0.203334 6.441198 0.747615
<1ms:554
<2ms:84
<4ms:7
<8ms:2
<16ms:0
<32ms:0
32 + ms:0
スワップリクエスト0.00349073.6443220.428460
<1ms:627
<2ms:18
<4ms:1
<8ms:0
<16ms:0
<32ms:0
32 + ms:2
raf render 5.450312 209.662969 8.055021
<1ms:0
<2ms:0
<4ms:0
<8ms:467
<16ms:176
<32ms:3
32 + ms:1
run_one_frame 8.417291 2579.454948 22.226204
<1ms:0
<2ms:0
<4ms:0
<8ms:0
<16ms:326
<32ms:290
32 + ms:33
スワップバッファ0.65812512.179167 1.378725
<1ms:260
<2ms:308
<4ms:72
<8ms:4
<16ms:4
<32ms:0
32 + ms:0
スワップ完了0.0415625.161458 0.136875
<1ms:642
<2ms:3
<4ms:1
<8ms:1
<16ms:0
<32ms:0
32 + ms:0
Manishearth
2020年02月27日
グラフ:
長期実行:

短期間の実行: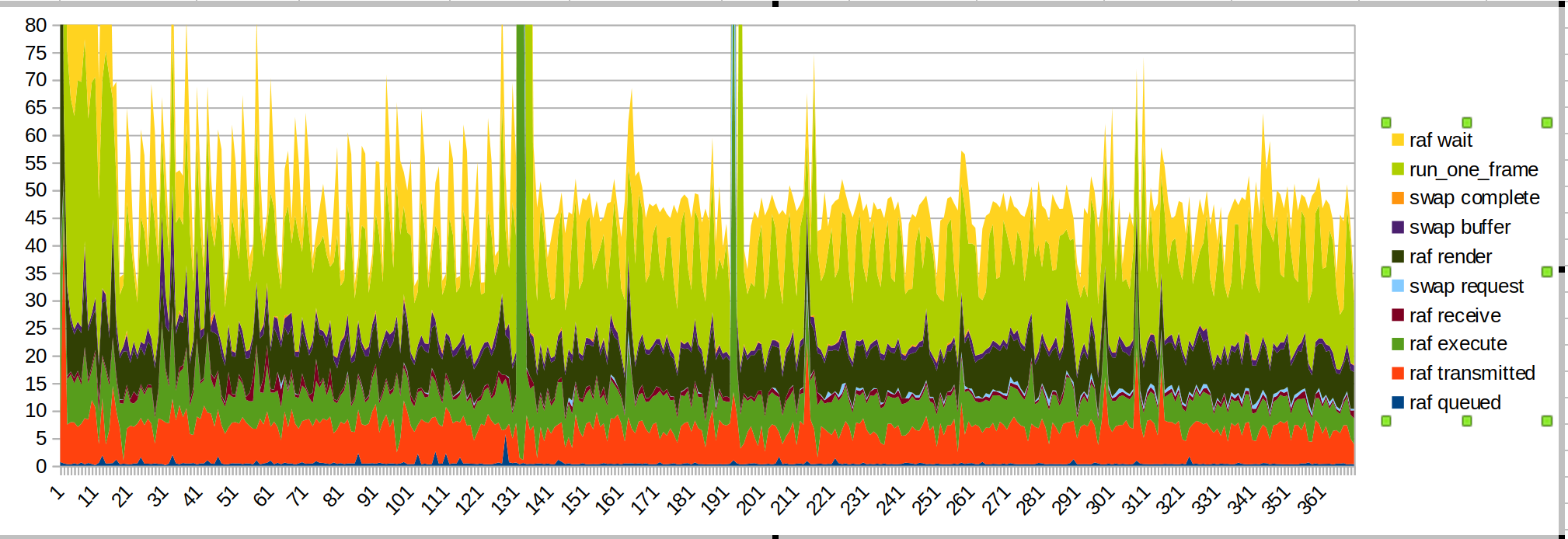
大きなスパイクは、センサーの範囲内に手を置いたときです。
今回は、wait / run_one_frameの時間を一番上に置きました。これは、それらが最もギザギザになっているためです。これは、OSが私たちを抑制しているためです。
注意すべきいくつかの事柄:
- 導入された手からの大きなスパイクは、JSコード(バジルグリーン、「rafrender」)によって引き起こされます
- 予想通り、送信時間がスムーズになりました
- 描画を開始すると、別のJSスパイクがあります
- レンダリングと送信時間は依然として予算のかなりの部分です。 スクリプトのパフォーマンスも改善される可能性があります。
- メインスレッドが他のことをするのに忙しいので、送信時間がとても長くかかるのではないかと思います。 これはhttps://github.com/servo/webxr/issues/113です、 @ jdmはそれを調べています
- サーフマンの更新により、レンダリング時間が改善される場合があります。 surfmanupでの@asajeffreyの測定値は私のものよりも優れているようです
- サーフェス共有を行うと、レンダリング時間が改善される可能性があります(surfmanupでブロックされます)
- xr-profileで測定すると、デバイスに表示されるFPSはほぼ半分になります。 これは、すべてのIOが原因である可能性があります。
ボールシューターには、手を見てから描き始めたためにパフォーマンスがねじれることはありません。 おそらく、ペイントデモは、最初に手の画像を描画することを決定したときに多くの作業を行っていますか?
(これは、webxr入力ライブラリと対話しようとするペイントデモである可能性もあります)
Manishearth
2020年02月27日
@Manishearthメモリ使用量をオーバーレイして、それらのイベントに関連付けることもできますか? JSコードの初回コンパイルに加えて、大量の新しいコードで障害が発生し、物理メモリの制限に達して、メモリの負荷に達すると大量のGCが発生する可能性があります。 私はそれをほとんどの重要な状況で見ていました。 @noxのSMアップデートがお役に立てば幸いです。これは、FxRAndroidでのこのSMビルドで見られたアーティファクトであったためです。
larsbergstrom
2020年02月27日
xrプロファイリングのものと相関させることができる方法でメモリプロファイリングデータを取得する簡単な方法がありません。
既存のperfツールを使用して、形状が同じかどうかを判断できる可能性があります。
Manishearth
2020年02月27日
@Manishearth xr-profilingのものは
larsbergstrom
2020年02月27日
いずれにせよ、スタートアップの急上昇は私の主な関心事ではありません。最初にすべてを60fpsで取得したいと思います。 起動時に1、2秒間ぎくしゃくしている場合は、それほど差し迫った問題ではありません。
Manishearth
2020年02月27日
はい、それはそれを示すことができます、いくつかの微調整が必要になるでしょう。
Manishearth
2020年02月27日
@Manishearth優先順位について完全に合意しました! あなたが「よじれを解き放つ」ことを試みているのか、それとも定常状態を運転しようとしているのかはわかりませんでした。 後者の方が今より重要であることに同意します。
larsbergstrom
2020年02月27日
いや、私はほとんどの場合、私ができるすべての分析を書き留めていました。
Manishearth
2020年02月27日
送信時間も急上昇する小さな実行のグラフの終わり近くのこれらの急上昇:それは私が頭を動かして描いていたときであり、アランは物事をしているときにFPSの低下に気づいていて、それをOSが他の仕事をしていることに起因していました。 IPCが送信時間の急上昇についての私の予感を修正した後、それらはOSが他の作業を行っていることが原因であるため、そこで起こっている可能性があります。 オフメインスレッドの世界では、はるかにスムーズになると思います。
Manishearth
2020年02月27日
これがすでに考慮されている場合は無視してください。メッセージ処理ごとにrun_one_frameの測定値を分解し、 thread::sleep() -ingに費やした時間のタイミングを計ることを考えましたか?
3つの測定ポイントを追加する価値があるかもしれません:
そして別のラッピングhttps://github.com/servo/webxr/blob/2841497966d87bbd561f18ea66547dde9b13962f/webxr-api/lib.rs#L124全体として
また、
thread::sleepのみへの呼び出しをラップします。
recv_timeout 、これは完全に再考するものかもしれません。
タイムアウトの有用性について推論するのは少し難しいと思います。 レンダリングされたフレームをカウントしているので、 frame_count参照してください。ユースケースは、「最初にフレームをレンダリングしていない1つまたは複数のメッセージを処理し、次にフレームをレンダリングしますが、通過しないようにします。メインスレッドの完全なイベントループ」?
また、現在使用されているdelayの実際の計算について疑問があります。
delay = timeout / 1000から始まり、timeoutは現在5ミリ秒に設定されています- その後、指数関数的に成長し、各反復で
delay = delay * 2;で2倍になります。 - ループの先頭で
while delay < timeoutチェックされます。
したがって、スリープのシーケンスは、最悪の場合、次のようになります。5micro-> 10-> 20-> 40-> 80-> 160-> 320-> 640-> 1.28milli-> 2.56 mill-> 5.12 mill
5.12ミリ秒にdelay > timeoutと、ループから抜け出し( sleep後にOSがスレッドをウェイクアップするのを待機するために追加の時間を費やします。
ですから、問題は合計で5ミリ秒以上寝ている可能性があることだと思います。また、メッセージが表示されてから1ミリ秒以上(2回目は2.5ミリ秒以上)2回寝ることはお勧めできません。その間に入る可能性があり、あなたは目を覚ましません。
改善方法がよくわかりません。潜在的なメッセージを探してスピンしようとしているようです。最後に、利用できるものがない場合は、メインイベントループの次の反復に進んでください(ブロックしないのはなぜですか)。 recv?)。
https://doc.rust-lang.org/std/thread/fn.yield_now.htmlを使用するように切り替えることができますロックに関するこの記事を見ると、毎回yieldを呼び出している間、約40回回転しているようです。 、最適です(「回転」の段落を参照してください。直接リンクすることはできません)。 その後、レシーバーでブロックするか、イベントループの現在の反復を続行する必要があります(これは、メインの埋め込みイベントループ内のサブループのように実行されているため)。
(もちろん、あなたが測定していない場合はipc側の上に、オンrecv_timeoutあなたはまだにcalll測定したいかもしれませんが、無関係であるrecv_timeout上をmpscスレッド化されたチャネルは、結果に影響を与える可能性のある内部スピニング/イールドを実行するためです。また、未確認の「IPC修正」が上記で何度か言及されているため、ipcで測定していると思います)。
gterzian
2020年02月27日
これがすでに考慮されている場合は無視してください。メッセージ処理ごとにrun_one_frameの測定値を分解し、thread :: sleep()-ingに費やした時間のタイミングを計ることを考えましたか?
すでに分解されており、待機/レンダリング時間はまさにこれです。 run_one_frameの1ティックは、1回のレンダリング、1回の待機、および処理されるイベントの数が不確定です(まれです)。
recv_timeoutは測定に適しています
Manishearth
2020年02月27日
残念ながら、#25678でのスパイダーモンキーのアップグレードは、大幅な改善ではないようです。メモリの制約が最も大きいものを除いて、すべてのデモの平均FPSが低下しました。 ヒルバレーのデモはわずかに上昇しました。 初期化引数に-Z gc-profileを指定してServoを実行しても、マスターとスパイダーモンキーアップグレードブランチの間でGCの動作に違いはありません。GLコンテンツが読み込まれて表示された後、GCは報告されません。
jdm
2020年03月03日
さまざまなブランチの測定:
master:
- espilit: 14-16 fps
- paint: 39-45 fps
- ball shooter: 30-40 fps
- hill valley: 8 fps, 200mb free mem
- mansion: 10-14fps, 650mb free mem
master + single swapchain:
- espilit: 10-12 fps
- paint: 29-55 fps, 1.2gb free mem
- ball shooter: 25-35 fps, 1.3gb free mem
- hill valley: 6-7 fps, 200mb free mem
- mansion: 10-11 fps, 700mb free mem
texture sharing + ANGLE 2.1.19:
- espilit: 13-15 fps, 670mb free mem
- paint: 39-45 fps
- ball shooter: 30-37 fps, 1.3gb free mem
- hill valley: 9-10 fps, 188mb free mem
- mansion: 13-14 fps, 671mb free mem
smup:
- espilit: 11-13 fps, 730mb free mem
- paint: 25-42 fps, 1.1gb free mem
- ball shooter: 26-30 fps, 1.4gb free mem
- hill valley: 10-11 fps, 145mb
- mansion: 9-11fps, 680mb free mem
smupはパフォーマンスを悪化させました???
asajeffrey
2020年03月03日
https://github.com/servo/servo/pull/25855#issuecomment -594203492からの変更により、IonJITの無効化が12FPSで開始され、数秒後に突然1FPSにタンクされてそこにとどまります。
jdm
2020年03月03日
それらのパッチでいくつかの測定を行いました。
ペイントでは、表示されているコンテンツが少ないときに60 fpsを取得し、描画されたコンテンツを表示すると50 fpsに低下します(黄色のスパイクは描画されたコンテンツを表示しているときです)。 理由を理解するのは難しいです。ほとんどの場合、待機時間はopenxrスロットリングの影響を受けているようですが、他のことは問題を引き起こすほど遅くはないようです。 スワップ要求のタイミングは少し遅くなります。 rAFの実行時間は最初は遅いですが(これは最初の「コントローラーが最初に見られる」速度低下です)、その後はかなり一定です。 openxrが私たちを抑制しているように見えますが、それを引き起こすような目に見える減速は他にありません。

Manishearth
2020年03月07日
これは私がドラッグデモのために持っているものです。 yスケールは同じです。 ここでは、実行時間が遅くなっていることがはるかに明白です。

Manishearth
2020年03月07日
注意すべき点の1つは、#25837を適用して測定を行っていたため、パフォーマンスに影響を与える可能性があることです。
jdm
2020年03月07日
私はそうではありませんでしたが、私はあなたと同様の結果を得ていました
Manishearth
2020年03月07日
コンテンツを見ると、60FPSから45FPSに変化する瞬間のパフォーマンスツールのグラフ:
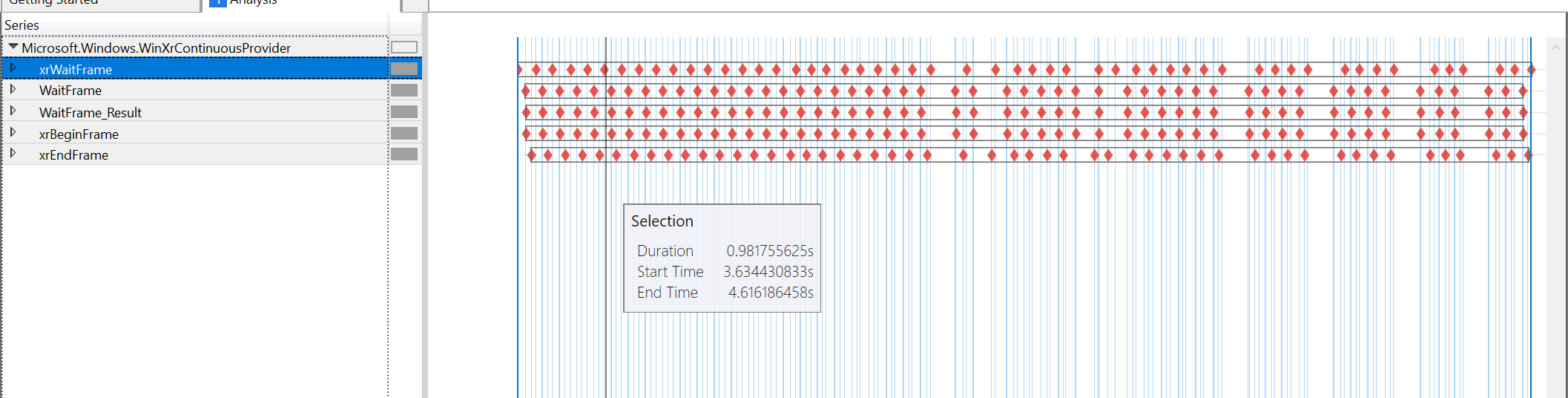
責任は完全にxrWaitFrameにあるようで、他のすべてのタイミングは非常に接近しています。 xrBeginFrameはまだxrWaitFrameのほぼ直後にあり、xrEndFrameはxrBeginFrameの4us後です(どちらの場合も)。 次のxrWaitFrameは、xrEndFrameのほぼ直後にあります。 考慮されていない唯一のギャップは、xrWaitFrame自体によって引き起こされたものです。
Manishearth
2020年03月11日
ドラッグデモを使用すると、次のトレースが得られます。

これは同じスケールのペイントデモです:
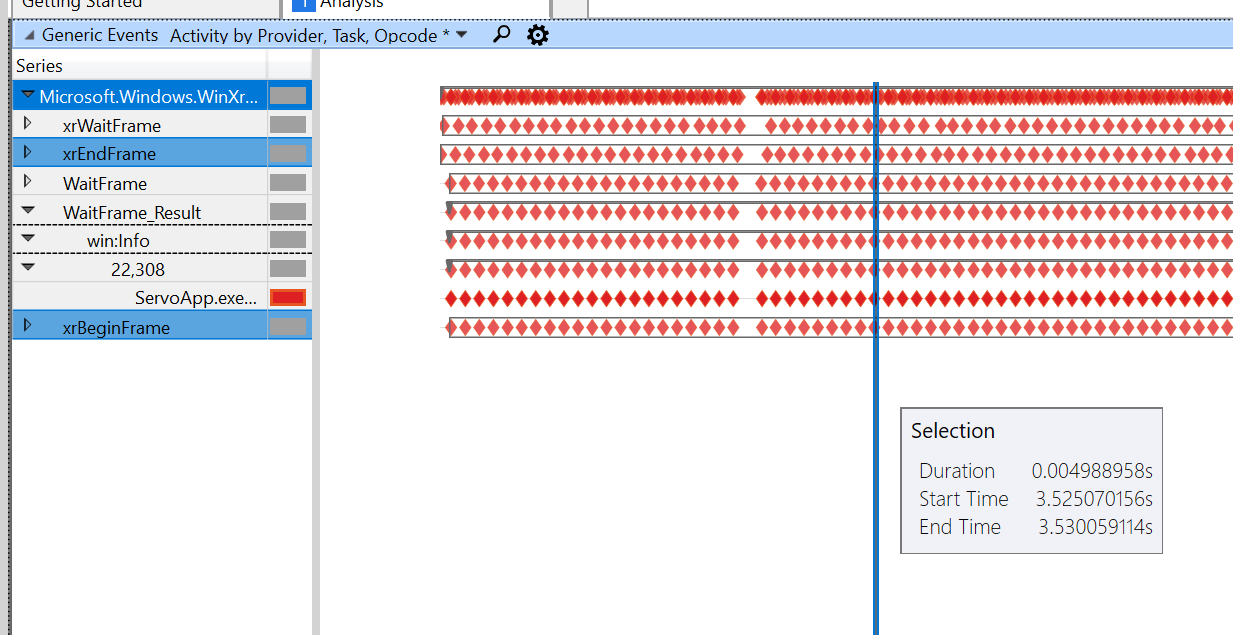
開始フレームと終了フレームの間で速度が遅くなり(最速で5ミリ秒から38ミリ秒になります!)、待機フレームのスロットルが開始されます。これが当てはまる理由はまだわかりません。次のコードを確認します。どちらも。
Manishearth
2020年03月18日
光源が影を落とすため、ドラッグデモの速度が低下します。 シャドウはGL側で行われるので、簡単にスピードアップできるかどうかわかりません。
Manishearth
2020年03月18日
それが完全にGLSLを介して行われる場合、問題が発生する可能性があります。 WebGL APIを介してすべてのフレームで実行される場合は、最適化する場所がある可能性があります。
jdm
2020年03月18日
ええ、それはすべてGLSL側にあるようです。 シャドウAPIの動作に関しては、WebGL呼び出しを確認できませんでした。シェーダーに渡されるビットは、ほんの一部です。
Manishearth
2020年03月19日
これは一般的に対処されていると思います。 作業が必要な個々のデモの問題を提出できます。
jdm
2020年07月20日
関連する問題
 noisiak
·
3コメント
noisiak
·
3コメント
 ayelen912
·
3コメント
larsbergstrom
·
3コメント
Manishearth
·
4コメント
ayelen912
·
3コメント
larsbergstrom
·
3コメント
Manishearth
·
4コメント
 pyfisch
·
4コメント
pyfisch
·
4コメント
最も参考になるコメント
現在のステータス:IPCの修正により、FPSは55前後でホバリングしています。ときどき小刻みに動くことがありますが、通常は45を下回りません。ただし、ロード後の最初の数秒間(30まで下がる可能性があります)、およびそれが発生したときは例外です。最初に手が見えます(20に下がったとき)。