Servo: Le mode immersif n'atteint pas les 60 ips
J'utilise ceci pour suivre les enquêtes sur la cause des faibles valeurs FPS lors de l'utilisation du mode immersif sur les appareils.
 jdm
jdm
Tous les 71 commentaires
Quelques informations découvertes :
- il y a de longues attentes entre xrWaitFrame et xrBeginFrame
- dans l' application de démonstration, ceux-ci se produisent de manière séquentielle
- dans le modèle de Servo, nous attendons un cadre de périphérique , puis une fois que nous avons reçu le rendu du thread webgl, nous commençons le prochain cadre openxr
Une trace de la démonstration de peinture avec des marqueurs pour les API OpenXR se reproduit ces jours-ci et montre également pendant cette période :
- le thread webgl utilise le plus de CPU (une grande majorité de ce temps est passé sous gl::Finish, qui est appelé depuis le périphérique de surfman::bind_surface_to_context)
- le thread principal est le deuxième plus occupé, avec l'utilisation la plus élevée dépensée dans eglCreatePbufferFromClientBuffer et presque autant de temps passé à saisir l'objet Egl à partir de TLS
- le rendu de webrender apparaît également dans cette pile
- winrt::servo::flush apparaît également ici, et je ne sais pas si nous devons réellement échanger les tampons GL de l'application principale pendant que nous sommes en mode immersif
- la troisième utilisation du processeur la plus élevée est le thread de script, passant beaucoup de temps dans le code JIT
- après ce fil, l'utilisation du processeur est généralement assez faible, mais certains symboles de la caisse de style apparaissent indiquant que la mise en page est en cours
jdm
le 3 janv. 2020
Compte tenu de ces points de données, je vais essayer deux approches pour commencer :
- démarrer la prochaine trame XR dès que possible après avoir attendu la trame de l'appareil
- réduire le nombre de fois que nous devons appeler gl::Finish (fil webgl), eglCreateBufferFromClientBuffer et TLS (fil principal)
jdm
le 3 janv. 2020
https://github.com/servo/servo/pull/25343#issuecomment -567706735 a plus d'enquête sur l'impact de l'envoi de messages à divers endroits dans le moteur. Il ne pointe aucun doigt clair, mais suggère de prendre des mesures plus précises.
jdm
le 3 janv. 2020
L'utilisation de gl::Finish provient de https://github.com/pcwalton/surfman/blob/6705a9aaa8f33ac1324fdb1913242800e68c7720/surfman/src/platform/windows/angle/context.rs#L259 -L266.
jdm
le 3 janv. 2020
Changer gl::Finish en gl::Flush augmente la fréquence d'images de ~15->30, mais il y a un décalage extrêmement notable dans le contenu de l'image reflétant réellement le mouvement de la tête de l'utilisateur, faisant que l'image actuelle suive la tête de l'utilisateur dans pendant ce temps.
jdm
le 3 janv. 2020
Les mutex à clé sont désactivés par défaut dans ANGLE pour des raisons qui m'échappent, mais mozangle les active explicitement (https://github.com/servo/mozangle/blob/706a9baaf8026c1a3cb6c67ba63aa5f4734264d0/build_data.rs#L175), et c'est ce avec quoi surfman est testé . Je vais créer une version d'ANGLE qui les active et voir si cela suffit pour éviter les appels gl::Finish.
jdm
le 3 janv. 2020
Confirmé! Forcer les mutex à clé dans ANGLE me donne 25-30 FPS dans la démonstration de peinture sans aucun des problèmes de décalage liés au changement de l'appel gl::Finish.
jdm
le 3 janv. 2020
Oh, et une autre information selon les investigations de Lars :
- avec dom.ion.enabled défini sur false, le temps JIT disparaît. Les charges initiales sont beaucoup plus lentes, mais une fois que les choses fonctionnent, elles sont plutôt bonnes.
- Ce n'est toujours pas fantastique - l'utilisation de la mémoire est assez élevée (essentiellement toute la mémoire disponible) sur cet exemple babylon.js
- nous devrions faire une autre mise à niveau de spidermonkey pour intégrer les optimisations liées à arm64 qui se sont produites pour FxR sur les appareils Android
jdm
le 3 janv. 2020
Je pense que j'ai mal compris la présence de std::thread::local::LocalKey<surfman::egll::Egl> dans les profils - je suis presque sûr que la lecture TLS n'est qu'une très petite partie du temps qui lui est facturé, et ce sont les fonctions appelées à l'intérieur du bloc TLS comme eglCreatePbufferFromClientBuffer et DXGIAcquireSync qui prend _réellement_ le temps.
jdm
le 3 janv. 2020
Malheureusement, la désactivation de js.ion.enabled semble nuire au FPS de la démo de peinture, le réduisant à 20-25.
jdm
le 4 janv. 2020
Plutôt que d'appeler Device::create_surface_texture_from_texture deux fois par image (une fois pour chaque texture d3d pour chaque œil), il pourrait être possible de créer des textures de surface pour toutes les textures de la chaîne d'échange lorsque le périphérique openxr webxr est créé. Si cela fonctionne, cela supprimerait le deuxième plus grand utilisateur de CPU du thread principal en mode immersif.
jdm
le 4 janv. 2020
Une autre idée pour réduire l'utilisation de la mémoire : y a-t-il un impact si nous définissons le bfcache sur un nombre très bas afin que le pipeline de la page d'accueil HL d'origine soit expulsé lors de la navigation vers l'une des démos ?
jdm
le 4 janv. 2020
Le correctif webxr suivant n'améliore pas clairement les FPS, mais il pourrait améliorer la stabilité de l'image. Je dois créer deux versions distinctes que je peux exécuter dos à dos pour vérifier.
diff --git a/webxr/openxr/mod.rs b/webxr/openxr/mod.rs
index 91c78da..a6866de 100644
--- a/webxr/openxr/mod.rs
+++ b/webxr/openxr/mod.rs
@@ -416,11 +416,30 @@ impl DeviceAPI<Surface> for OpenXrDevice {
}
fn wait_for_animation_frame(&mut self) -> Option<Frame> {
- if !self.handle_openxr_events() {
- // Session is not running anymore.
- return None;
+ loop {
+ if !self.handle_openxr_events() {
+ // Session is not running anymore.
+ return None;
+ }
+ self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
+ // XXXManishearth this code should perhaps be in wait_for_animation_frame,
+ // but we then get errors that wait_image was called without a release_image()
+ self.frame_stream
+ .begin()
+ .expect("failed to start frame stream");
+
+ if self.frame_state.should_render {
+ break;
+ }
+
+ self.frame_stream.end(
+ self.frame_state.predicted_display_time,
+ EnvironmentBlendMode::ADDITIVE,
+ &[],
+ ).unwrap();
}
- self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
let time_ns = time::precise_time_ns();
// XXXManishearth should we check frame_state.should_render?
let (_view_flags, views) = self
@@ -506,12 +525,6 @@ impl DeviceAPI<Surface> for OpenXrDevice {
0,
);
- // XXXManishearth this code should perhaps be in wait_for_animation_frame,
- // but we then get errors that wait_image was called without a release_image()
- self.frame_stream
- .begin()
- .expect("failed to start frame stream");
-
self.left_image = self.left_swapchain.acquire_image().unwrap();
self.left_swapchain
.wait_image(openxr::Duration::INFINITE)
@manishearth des réflexions à ce sujet ? C'est ma tentative de me rapprocher du modèle décrit par https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#Session.
jdm
le 4 janv. 2020
Ouais, ça a l'air bien. J'avais l'intention de déplacer le begin() vers le haut dans waf, et je pense que l'erreur mentionnée dans le commentaire ne se produit plus, mais cela n'a pas non plus eu d'effet notable sur le FPS, donc je ne l'ai pas poursuivi trop pour l'instant. Si ça améliore la stabilité c'est tant mieux !
 Manishearth
le 4 janv. 2020
Manishearth
le 4 janv. 2020
Vraiment heureux de la découverte clé! Les appels de Surfman occupent en effet une grande partie du budget du cadre, mais il est un peu difficile de déterminer ce qui est nécessaire et ce qui n'est pas nécessaire.
Manishearth
le 4 janv. 2020
Oui, re: désactiver js.ion.enabled , cela ne sera un avantage que lorsque nous serons affamés de RAM et que nous passerons la plupart de notre temps à GC et à recompiler des fonctions. Et cela devrait être amélioré avec un SM plus récent. IIRC, le backend ARM64 de l'ère 66, avait également des performances JIT et d'interprétation de base relativement médiocres ; nous devrions voir des accélérations à tous les niveaux avec une mise à jour mais surtout sur les applications gourmandes en RAM.
 larsbergstrom
le 4 janv. 2020
larsbergstrom
le 4 janv. 2020
Nouveau package ANGLE publié avec les mutex à clé activés. Je créerai une pull request pour la mettre à jour plus tard.
jdm
le 6 janv. 2020
J'ai essayé de créer les textures de surface pour toutes les images swapchain openxr lors de l'initialisation du périphérique XR, mais il reste encore beaucoup de temps sur le thread principal passé à appeler eglCreatePbufferFromClientBuffer sur la surface que nous recevons du thread webgl à chaque image. Il existe peut-être un moyen de mettre en cache ces textures de surface afin que nous puissions les réutiliser si nous recevons la même surface...
jdm
le 6 janv. 2020
La plus grande utilisation du processeur du thread principal provient de render_animation_frame, la plupart sous l'environnement d'exécution OpenXR, mais les appels à BlitFramebuffer et FramebufferTexture2D apparaissent également dans le profil. Je me demande si ce serait une amélioration d'éclaircir les deux yeux à la fois en une seule texture ? Cela est peut-être lié aux éléments du tableau de textures qui sont discutés dans https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt.
jdm
le 6 janv. 2020
Nous pouvons exploser les deux yeux à la fois, mais je crois comprendre que le runtime
peut alors faire son propre blit. Le tableau de textures est la méthode la plus rapide. Mais
vaut le détour, l'API de vue de projection prend en charge cette opération.
En ce qui concerne le trafic ANGLE du thread principal, l'arrêt de la boucle RAF de
salir la toile aide? Jusqu'à présent, cela n'a rien fait mais ça vaut le coup
tourné, idéalement nous ne devrions rien faire de mise en page/rendu sur le principal
fil.
Le lundi 6 janvier 2020, 23:49 Josh Matthews [email protected]
a écrit:
La plus grande utilisation du processeur du thread principal vient de render_animation_frame, avec
la plupart de cela sous l'environnement d'exécution OpenXR mais les appels à BlitFramebuffer et
FramebufferTexture2D apparaît également dans le profil. je me demande
si ce serait une amélioration d'exploser les deux yeux à la fois sur un seul
texture? Peut-être que c'est lié aux trucs de tableau de texture qui sont discutés
dans
https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt
.-
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/servo/servo/issues/25425?email_source=notifications&email_token=AAMK6SBRH72JGZMXTUKOXETQ4NY37A5CNFSM4KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKLOBE
ou se désinscrire
https://github.com/notifications/unsubscribe-auth/AAMK6SECM6MDNZZ6Y7VL7SDQ4NY37ANCNFSM4KCRI6AA
.
Manishearth
le 6 janv. 2020
Retirer la toile salissante ne fait que nettoyer le profil; il n'a pas semblé conduire à une augmentation significative du FPS.
jdm
le 6 janv. 2020
J'ai essayé de créer un cache de textures de surface pour les surfaces à partir du thread webgl ainsi que des textures de swapchain openxr, et bien que le temps eglCreatePbufferFromClientBuffer ait complètement disparu, je n'ai remarqué aucun changement FPS significatif.
jdm
le 6 janv. 2020
Quelques informations de synchronisation pour diverses opérations dans le pipeline immersif (toutes les mesures en ms) :
Name min max avg
raf queued 0.070833 14.010261 0.576834
<1ms: 393
<2ms: 28
<4ms: 5
<8ms: 1
<16ms: 2
<32ms: 0
32+ms: 0
raf transmitted 0.404270 33.649583 7.403302
<1ms: 123
<2ms: 43
<4ms: 48
<8ms: 48
<16ms: 95
<32ms: 69
32+ms: 3
raf wait 1.203500 191.064100 17.513593
<1ms: 0
<2ms: 17
<4ms: 98
<8ms: 95
<16ms: 48
<32ms: 69
32+ms: 101
raf execute 3.375000 128.663200 6.994588
<1ms: 0
<2ms: 0
<4ms: 5
<8ms: 351
<16ms: 70
<32ms: 1
32+ms: 2
raf receive 0.111510 8.564010 0.783503
<1ms: 353
<2ms: 52
<4ms: 18
<8ms: 4
<16ms: 1
<32ms: 0
32+ms: 0
raf render 2.372200 75.944000 4.219310
<1ms: 0
<2ms: 0
<4ms: 253
<8ms: 167
<16ms: 8
<32ms: 0
32+ms: 1
receive : temps écoulé entre l'envoi des informations de trame XR par le thread XR et leur réception par le routeur IPC
queued : temps depuis le routeur IPC recevant les informations de trame jusqu'à ce que XRSession::raf_callback soit invoqué
execute : temps depuis XRSession::raf_callback invoqué jusqu'au retour de la méthode
transmitted : temps entre l'envoi de la demande d'un nouveau rAF depuis le thread de script jusqu'à sa réception par le thread XR
render : temps pris pour appeler render_animation_frame et recycler la surface
wait : temps pris par wait_for_animation_frame (en utilisant le correctif de plus tôt dans ce numéro qui boucle sur les images qui ne devraient pas être rendues)
Sous chaque entrée se trouve la répartition des valeurs au cours de la session.
jdm
le 7 janv. 2020
Un point de données intéressant à partir de ces informations de synchronisation - la catégorie transmitted semble bien plus élevée qu'elle ne devrait l'être. C'est le délai entre l'exécution du rappel rAF et le thread XR recevant le message qui transforme l'image terminée en texture openxr. Il y a pas mal de variations, ce qui suggère que soit le thread principal est occupé à faire autre chose, soit il doit être réveillé pour le traiter.
jdm
le 7 janv. 2020
Compte tenu des données précédentes, je peux essayer de ressusciter https://github.com/servo/webxr/issues/113 demain pour voir si cela affecte positivement la synchronisation de transmission. Je peux d'abord fouiller le fil principal dans le profileur pour voir si je peux trouver des idées sur la façon de savoir si le fil est occupé par d'autres tâches ou endormi.
jdm
le 7 janv. 2020
Un autre point de données :
swap buffer 1.105938 28.193698 2.154793
<1ms: 0
<2ms: 273
<4ms: 110
<8ms: 15
<16ms: 2
<32ms: 2
32+ms: 0
swap complete 0.053802 4.337812 0.295064
<1ms: 308
<2ms: 9
<4ms: 6
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
swap request 0.003333 24033027.355364 4662890.724805
<1ms: 268
<2ms: 49
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 1
32+ms: 79
Ce sont des délais liés à 1) le délai entre l'envoi du message de tampon d'échange jusqu'à ce qu'il soit traité dans le thread webgl, 2) le temps nécessaire pour échanger les tampons, 3) le délai entre l'envoi du message indiquant que l'échange est terminé jusqu'à sa réception dans le fil de script. Rien de très surprenant ici (sauf ces valeurs aberrantes étranges dans la catégorie swap request , mais celles-ci se produisent au tout début de la session immersive lors de la configuration), mais l'échange de tampon réel prend systématiquement entre 1 et 4 ms.
jdm
le 7 janv. 2020
Classé n°117 après avoir lu un exemple de code openxr et remarqué que les appels locate_views s'affichent dans le profil.
jdm
le 7 janv. 2020
Vraisemblablement https://github.com/servo/webxr/issues/117
 asajeffrey
le 7 janv. 2020
asajeffrey
le 7 janv. 2020
Un point de données intéressant à partir de ces informations de synchronisation - la catégorie transmise semble bien plus élevée qu'elle ne devrait l'être. C'est le délai entre l'exécution du rappel rAF et le thread XR recevant le message qui transforme la trame terminée dans la texture d'openxr. Il y a pas mal de variations, ce qui suggère que soit le thread principal est occupé à faire autre chose, soit il doit être réveillé pour le traiter.
Concernant les variations de la transmitted , cela peut être lié au délai d'attente utilisé dans le cadre de run_one_frame lorsque la session s'exécute sur le thread principal (ce qui est le cas dans ces mesures, non ?) , voir https://github.com/servo/webxr/blob/c6abf4c60d165ffc978ad2ebd6bcddc3c21698e1/webxr-api/session.rs#L275
Je suppose que lorsque le message RenderAnimationFrame (celui envoyé par le script-thread après avoir exécuté les rappels) est reçu avant le délai d'attente, vous appuyez sur le "chemin rapide", et si le délai d'attente est manqué, le servo passe dans un autre l'itération de perform_updates , et "l'exécution d'une autre image" se produit assez tard dans le cycle, dans le cadre de compositor.perform_updates , lui-même appelé assez tard dans le cadre de servo.handle_events .
À moins de déplacer XR vers son propre thread, cela pourrait valoir la peine de voir si une valeur plus élevée pour le délai d'attente améliore la valeur moyenne (bien que ce ne soit peut-être pas la bonne solution car cela pourrait affamer d'autres éléments nécessaires sur le thread principal).
 gterzian
le 8 janv. 2020
gterzian
le 8 janv. 2020
J'ai progressé dans la suppression d'openxr du fil principal dans https://github.com/servo/webxr/issues/113 , je vais donc prendre plus de mesures sur la base de ce travail la semaine prochaine.
jdm
le 10 janv. 2020
Techniques pour obtenir des profils utiles à partir de l'appareil :
- utilisez un .servobuild qui inclut
rustflags = "-C force-frame-pointers=yes" - décommenter ces lignes
- utilisez WinXR_Perf.wprp à partir de l'onglet MS teams char
Filescomme profil de traçage personnalisé sous "Performance Tracing" dans le portail des appareils HL - construire avec
--features profilemozjs
Ces traces (obtenues à partir de "Démarrer la trace" dans le portail de l'appareil) seront utilisables dans l'outil Windows Performance Analyzer. Cet outil n'affiche pas les noms de threads, mais les threads utilisant le plus de CPU sont faciles à identifier en fonction des piles.
Pour profiler la distribution temporelle d'une trame openxr particulière :
- ajouter la vue "System Activity -> Generic Events" dans WPA
- filtrer la vue pour afficher uniquement la série Microsoft.Windows.WinXrContinuousProvider
- zoomer sur une courte durée, puis affiner la région zoomée de sorte qu'un événement xrBegin soit sur le côté gauche de la vue et un événement xrEnd sur le côté droit de la vue
Vues les plus utiles pour l'utilisation du processeur :
- Utilisation du processeur (échantillonné) -> Utilisation par processus, thread, pile (filtrez la vue pour afficher uniquement Servo, puis désactivez la colonne Processus)
- Flamme par processus, pile (filtrez la vue pour afficher uniquement le servo)
jdm
le 16 janv. 2020
Une possibilité pour faire un peu moins de travail dans le fil de script :
- XRView::new consomme 0,02% de tous les processeurs Servo
- étant donné que le contenu des objets de vue ne change pas à moins qu'il n'y ait un événement FrameUpdateEvent::UpdateViews (qui vient de Session::update_clip_planes via XRSession::UpdateRenderState), nous pourrions éventuellement mettre en cache les objets XRView sur la XRSession et continuer à les utiliser jusqu'à ce que l'état de rendu est mis à jour
- nous pourrions même garder la représentation JS de la liste des vues en cache dans XRSession et définir le membre des vues de la pose, en évitant à la fois de recréer les objets XRView, d'allouer le vecteur et d'effectuer la conversion de valeur JS
jdm
le 16 janv. 2020
Une possibilité pour faire moins de travail lors du rendu d'un cadre immersif :
- GL et d3d ont des systèmes de coordonnées Y inversés
- ANGLE cache implicitement cela lors de la présentation à l'écran en effectuant un travail dans les coulisses
- pour le mode immersif, nous utilisons glBlitFramebuffer pour effectuer une inversion y lors de la conversion des données de texture GL en d3d
- si nous pouvons comprendre comment faire en sorte qu'ANGLE ne fasse pas la conversion en interne, il serait possible d'inverser ce modèle et de faire en sorte que le rendu des pages Web non immersives nécessite un blit d'inversion y supplémentaire (via l'option webrender
surface_origin_is_top_left) tandis que le mode immersif pourrait être supprimé sans aucune transformation
Basé sur https://bugzilla.mozilla.org/show_bug.cgi?id=1591346 et en discutant avec jrmuizel, voici ce que nous devrons faire :
- obtenir une chaîne d'échange d3d pour l'élément de fenêtre dans lequel nous voulons rendre les pages non immersives (ce sera le SwapChainPanel dans l'application XAML)
- enveloppez cela dans une image EGL (https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#554)
- Présenter explicitement la swapchain quand on veut mettre à jour le rendu principal
- évitez d'utiliser eglCreateWindowSurface et eglSwapBuffers dans https://github.com/servo/servo/blob/master/support/hololens/ServoApp/ServoControl/OpenGLES.cpp#L205 -L208
Code Gecko pertinent : https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#192
Code ANGLE pertinent : https://github.com/google/angle/blob/df0203a9ae7a285d885d7bc5c2d4754fe8a59c72/src/libANGLE/renderer/d3d/d3d11/winrt/SwapChainPanelNativeWindow.cpp#L244
jdm
le 16 janv. 2020
Branches wip actuelles :
- https://github.com/servo/ipc-channel/tree/try-recv-error
- https://github.com/jdm/webxr/tree/oxr
- https://github.com/jdm/rust-offscreen-rendering-context/tree/angle-perf
- https://github.com/jdm/servo/tree/profile
Cela inclut une fonctionnalité xr-profile qui ajoute les données de synchronisation que j'ai mentionnées précédemment, ainsi qu'une implémentation initiale des changements d'ANGLE pour supprimer la transformation y-inverse en mode immersif. Le mode non immersif est rendu correctement, mais le mode immersif est à l'envers. Je pense que je dois supprimer le code GL de render_animation_frame et le remplacer par un appel direct CopySubresourceRegion en extrayant la poignée de partage de la surface GL afin que je puisse obtenir sa texture d3d.
jdm
le 17 janv. 2020
Classé https://github.com/servo/servo/issues/25582 pour le travail d'inversion y ANGLE ; d'autres mises à jour sur ce travail auront lieu dans ce numéro.
jdm
le 23 janv. 2020
Le prochain élément important consistera à rechercher des moyens d'éviter entièrement les appels glBlitFramebuffer dans le backend openxr webxr. Cela nécessite :
- créer des framebuffers openxr qui correspondent précisément aux framebuffers opaques webgl requis
- prenant en charge un mode webgl où le backend webxr fournit toutes les surfaces de swapchain, plutôt que de les créer (par exemple dans https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L458 et https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L111-L118)
jdm
le 23 janv. 2020
Cela peut être difficile, car surfman ne fournit qu'un accès en écriture au contexte qui a créé la surface, donc si la surface est créée par le thread openxr, elle ne sera pas accessible en écriture par le thread WebGL. https://github.com/pcwalton/surfman/blob/a515fb2f5d6b9e9b36ba4e8b498cdb4bea92d330/surfman/src/device.rs#L95 -L96
asajeffrey
le 23 janv. 2020
Cela me vient à l'esprit - si nous faisions le rendu openxr dans le thread webgl, un tas de problèmes liés au threading autour du rendu directement aux textures d'openxr ne seraient plus des problèmes (c'est-à-dire les restrictions autour de eglCreatePbufferFromClientBuffer interdisant l'utilisation de plusieurs périphériques d3d). Envisager:
- il y a toujours un thread openxr qui est chargé d'interroger les événements openxr, d'attendre une image d'animation, de commencer une nouvelle image et de récupérer l'état actuel de l'image
- l'état du cadre est envoyé au fil de script, qui effectue le rappel d'animation puis envoie un message au fil webgl pour échanger le tampon d'images de la couche xr
- lorsque ce message d'échange est reçu dans le thread webgl, nous publions la dernière image swapchain openxr acquise, envoyons un message au thread openxr pour terminer la trame actuelle et acquérons une nouvelle image swapchain pour la trame suivante
Ma lecture de https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#threading -behavior suggère que cette conception pourrait être réalisable. L'astuce est de savoir si cela peut fonctionner pour nos backends non openxr ainsi que pour openxr.
D'après la spécification : « Bien que xrBeginFrame et xrEndFrame n'aient pas besoin d'être appelés sur le même thread, l'application doit gérer la synchronisation s'ils sont appelés sur des threads distincts. »
jdm
le 25 janv. 2020
Pour le moment, il n'y a pas de communication directe entre les threads du périphérique XR et webgl, tout se passe soit via un script, soit via leur chaîne d'échange partagée. Je serais tenté de fournir une API de chaîne d'échange qui se situe au-dessus d'une chaîne d'échange surfman ou d'une chaîne d'échange openxr, et de l'utiliser pour la communication webgl-to-openxr.
asajeffrey
le 25 janv. 2020
Notes d'une conversation sur les mesures de temps antérieures :
* concerns about wait time - why?????
* figure out time spent in JS vs. DOM logic
* when does openxr give us should render=false frames - maybe related to previous frame taking too long
* are threads being scheduled on inappropriate cpus? - on magic leap, main thread (including weber) pinned to big core.
* when one of the measured numbers is large, is there correlation with other large numbers?
* probably should pin openxr thread, running deterministic code
* consider clearing after telling script that the swap is complete - measure if clear is taking significant time in swap operation
* consider a swap chain API operation - “wait until a buffer swap occurs”
- block waiting on swapchain
- block waiting on swapchain + timeout
- async????????
- a gc would look like a spike in script execution time
Classé #25735 pour suivre les investigations que je poursuis sur le rendu directement dans les textures openxr.
jdm
le 11 févr. 2020
Une chose que nous devrions faire est de déterminer comment spidermonkey se compare sur l'appareil aux autres moteurs. Le moyen le plus simple d'obtenir des données ici est de trouver une référence JS simple que Servo peut exécuter et de comparer les performances de Servo au navigateur Edge installé sur l'appareil. De plus, nous pourrions essayer de visiter certaines démos complexes de babylon dans les deux navigateurs sans entrer en mode immersif pour voir s'il y a une différence de performances significative. Cela nous donnera également une référence à comparer avec la prochaine mise à niveau de spidermonkey.
jdm
le 13 févr. 2020
Quelques nouvelles données. C'est avec la mise à niveau ANGLE, mais pas celle de l'IPC.
$ python timing.py raw
Name min max mean
raf queued 0.056198 5.673125 0.694902
<1ms: 335
<2ms: 26
<4ms: 17
<8ms: 7
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.822917 36.582083 7.658619
<1ms: 1
<2ms: 4
<4ms: 31
<8ms: 181
<16ms: 158
<32ms: 8
32+ms: 1
raf wait 1.196615 39.707709 10.256875
<1ms: 0
<2ms: 32
<4ms: 93
<8ms: 67
<16ms: 107
<32ms: 68
32+ms: 17
raf execute 3.078438 532.205677 7.752839
<1ms: 0
<2ms: 0
<4ms: 37
<8ms: 290
<16ms: 52
<32ms: 2
32+ms: 3
raf receive 0.084375 9.053125 1.024403
<1ms: 276
<2ms: 71
<4ms: 27
<8ms: 9
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.004115 73.939479 0.611254
<1ms: 369
<2ms: 10
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.706198 233.459636 9.241698
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 183
<16ms: 190
<32ms: 10
32+ms: 1
run_one_frame 7.663333 2631.052969 28.035143
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 3
<16ms: 157
<32ms: 185
32+ms: 41
swap buffer 0.611927 8.521302 1.580279
<1ms: 127
<2ms: 169
<4ms: 74
<8ms: 15
<16ms: 1
<32ms: 0
32+ms: 0
swap complete 0.046511 2.446302 0.215040
<1ms: 375
<2ms: 6
<4ms: 3
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Données de synchronisation : https://gist.github.com/Manishearth/825799a98bf4dca0d9a7e55058574736
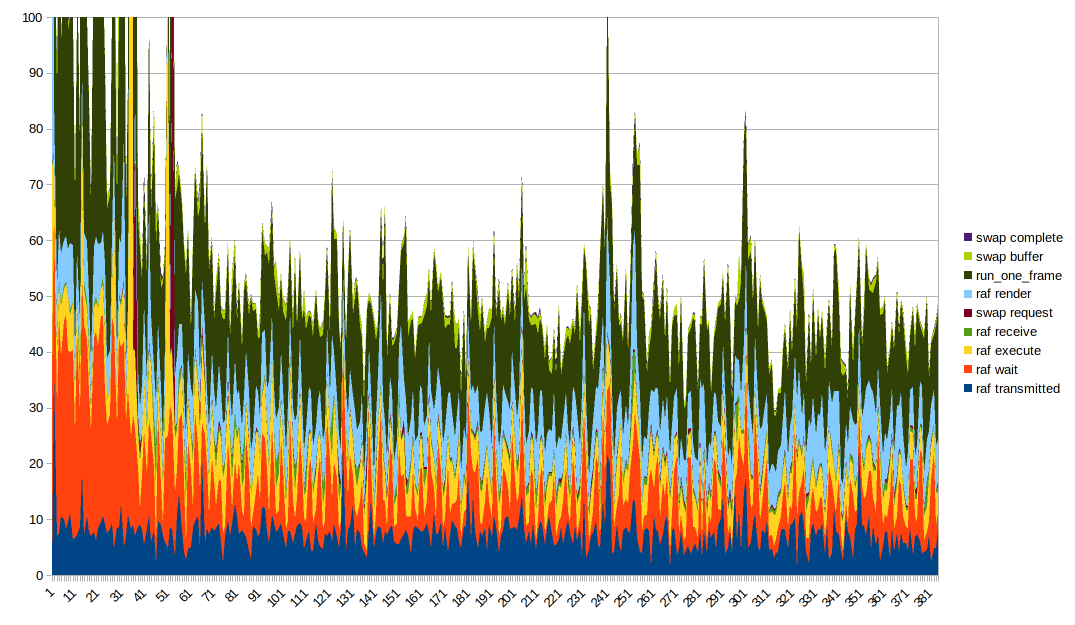
Il est difficile d'obtenir une bonne visualisation des données. Un graphique à lignes empilées semble idéal, même s'il convient de noter que run_one_frame mesure plusieurs timings déjà mesurés. Il est utile de manipuler l'ordre des graphiques et de placer différentes colonnes en bas pour mieux voir leur effet. Vous devez également tronquer l'axe Y pour obtenir quelque chose d'utile en raison de très grandes valeurs aberrantes.
A noter :
- le temps de rendu et le temps d'exécution semblent être pour la plupart stables, mais ont des pics lorsqu'il y a de gros pics dans l'ensemble. Je soupçonne que les gros pics proviennent de tout ce qui ralentit pour une raison quelconque
- Le temps de transmission semble assez bien corrélé à la forme globale
- le temps d'attente fait également partie de la raison pour laquelle la forme générale est comme ça, c'est _très_ ondulé
Manishearth
le 21 févr. 2020
Statut actuel : avec les correctifs IPC, le FPS oscille maintenant autour de 55. Il bouge parfois beaucoup, mais ne descend généralement pas en dessous de 45, _sauf_ pendant les premières secondes après le chargement (où il peut descendre à 30), et quand il voit d'abord une main (quand elle descend à 20).
Manishearth
le 25 févr. 2020
Histogramme plus récent pour la démonstration de peinture ( données brutes ) :
Name min max mean
raf queued 0.113854 5.707917 0.441650
<1ms: 352
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.546667 44.954792 6.886162
<1ms: 4
<2ms: 2
<4ms: 23
<8ms: 279
<16ms: 59
<32ms: 3
32+ms: 1
raf wait 1.611667 37.913177 9.441104
<1ms: 0
<2ms: 6
<4ms: 98
<8ms: 82
<16ms: 135
<32ms: 43
32+ms: 6
raf execute 3.336562 418.198541 7.592147
<1ms: 0
<2ms: 0
<4ms: 11
<8ms: 319
<16ms: 36
<32ms: 2
32+ms: 3
raf receive 0.119323 9.804167 0.806074
<1ms: 324
<2ms: 31
<4ms: 13
<8ms: 1
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.003646 79.236354 0.761324
<1ms: 357
<2ms: 9
<4ms: 2
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 3
raf render 5.844687 172.898906 8.131682
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 283
<16ms: 86
<32ms: 1
32+ms: 1
run_one_frame 8.826198 2577.357604 25.922205
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 176
<32ms: 174
32+ms: 22
swap buffer 0.708177 12.528906 1.415950
<1ms: 164
<2ms: 161
<4ms: 38
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
swap complete 0.042917 1.554740 0.127729
<1ms: 370
<2ms: 1
<4ms: 0
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Plus long terme ( brut ). Conçu pour réduire l'impact des ralentissements de démarrage.
Nom min max moyenne
raf en file d'attente 0,124896 6,356562 0,440674
<1ms : 629
<2ms : 13
<4ms : 5
<8ms : 1
<16ms : 0
<32ms : 0
32+ms : 0
raf transmis 0,640677 20,275104 6,944751
<1ms : 2
<2ms : 3
<4ms : 29
<8ms : 513
<16ms : 99
<32ms : 1
32+ms : 0
raf attendre 1.645886 40.955208 9.386255
<1ms : 0
<2ms : 10
<4ms : 207
<8ms : 114
<16ms : 236
<32ms : 65
32+ms : 15
raf exécuter 3.090104 526.041198 6.226997
<1ms : 0
<2ms : 0
<4ms : 68
<8ms : 546
<16ms : 29
<32ms : 1
32+ms : 3
raf reçoit 0,203334 6,441198 0,747615
<1ms : 554
<2ms : 84
<4ms : 7
<8ms : 2
<16ms : 0
<32ms : 0
32+ms : 0
demande d'échange 0,003490 73,644322 0,428460
<1ms : 627
<2ms : 18
<4ms : 1
<8ms : 0
<16ms : 0
<32ms : 0
32+ms : 2
rendu raf 5.450312 209.662969 8.055021
<1ms : 0
<2ms : 0
<4ms : 0
<8ms : 467
<16ms : 176
<32ms : 3
32+ms : 1
run_one_frame 8.417291 2579.454948 22.226204
<1ms : 0
<2ms : 0
<4ms : 0
<8ms : 0
<16ms : 326
<32ms : 290
32+ms : 33
coussin de swap 0,658125 12,179167 1,378725
<1ms : 260
<2ms : 308
<4ms : 72
<8ms : 4
<16ms : 4
<32ms : 0
32+ms : 0
swap terminé 0,041562 5,161458 0,136875
<1ms : 642
<2ms : 3
<4ms : 1
<8ms : 1
<16ms : 0
<32ms : 0
32+ms : 0
Manishearth
le 27 févr. 2020
Graphiques :
Course plus longue :

Course plus courte :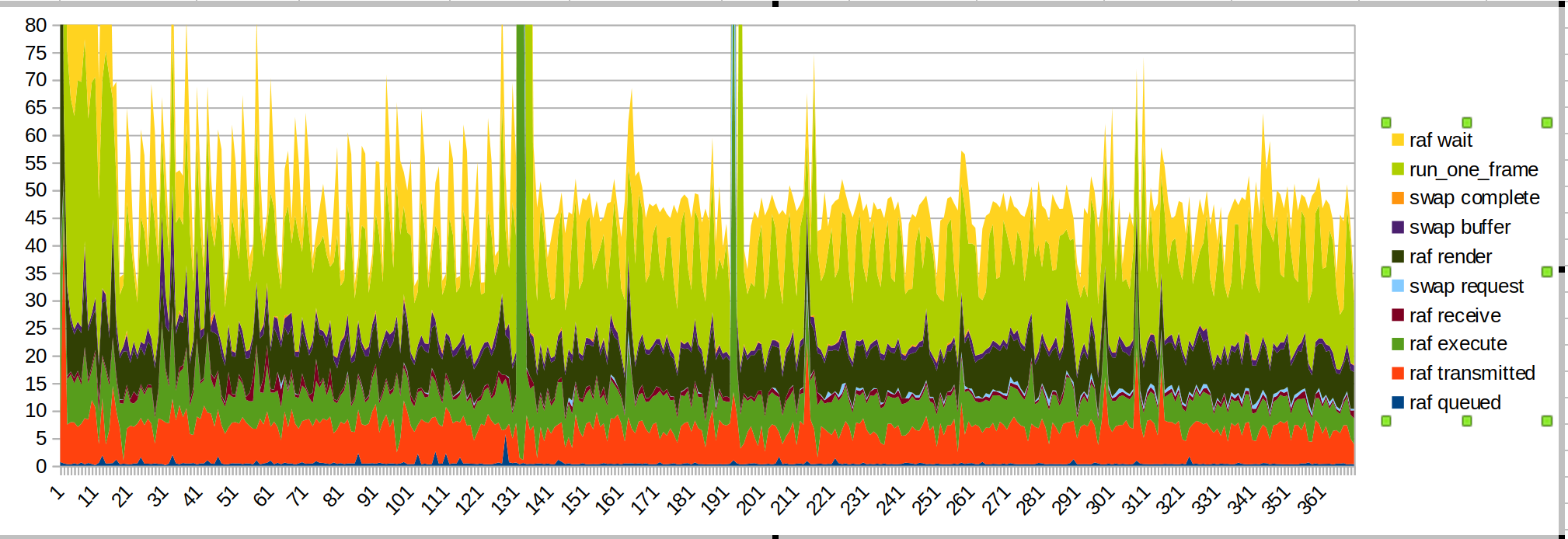
le gros pic, c'est quand je mets ma main à portée du capteur.
Cette fois, j'ai mis les temps wait/run_one_frame en haut car ce sont les plus irréguliers, et c'est à cause du système d'exploitation qui nous étouffe.
Quelques points à noter :
- Le gros pic des mains introduit est causé par le code JS (basil green, "raf render")
- le temps de transmission est devenu plus fluide, comme prévu
- quand je commence à dessiner, il y a un autre pic JS
- le rendu et le temps de transmission sont encore des morceaux importants du budget. Les performances du script pourraient également être améliorées.
- Je soupçonne que le temps de transmission prend si longtemps à cause du fil principal étant occupé à faire d'autres choses. Ceci est https://github.com/servo/webxr/issues/113 , @jdm l' examine
- Les mises à jour de surfman peuvent améliorer les temps de rendu. Les mesures de » @asajeffrey sur surfmanup semblent mieux que le mien
- faire le partage de surface peut améliorer les temps de rendu (bloqué sur surfmanup)
- le FPS affiché par l'appareil est presque réduit de moitié lors de la mesure avec le profil xr. C'est peut-être à cause de tous les IO.
Les problèmes de performance à cause de la vue de la main et du fait de commencer à dessiner ne sont pas présents pour le tireur de balle. Peut-être que la démonstration de peinture fait beaucoup de travail lorsqu'elle décide pour la première fois de dessiner l'image de la main ?
(Cela pourrait également être la démonstration de peinture tentant d'interagir avec la bibliothèque d'entrées webxr)
Manishearth
le 27 févr. 2020
@Manishearth Pouvez-vous également superposer l'utilisation de la mémoire et établir une corrélation avec ces événements ? En plus de la compilation initiale du code JS, vous pouvez être en faute avec une tonne de nouveau code et vous heurter aux limites de la mémoire physique et encourir un tas de GC lorsque vous atteignez la pression de la mémoire. Je voyais cela dans la plupart des situations non triviales. J'espère que la mise à jour SM de @nox aidera, car c'était certainement un artefact que nous avons vu dans cette version SM sur FxR Android.
larsbergstrom
le 27 févr. 2020
Je n'ai pas de moyen facile d'obtenir des données de profilage de mémoire d'une manière qui puisse être corrélée avec les trucs de profilage xr.
Je pourrais potentiellement utiliser les outils de perf existants et déterminer si la forme est la même.
Manishearth
le 27 févr. 2020
@Manishearth Est-ce que les trucs de profilage xr montrent (ou pourraient-ils montrer) les événements JS GC? Cela pourrait être une procuration raisonnable.
larsbergstrom
le 27 févr. 2020
Quoi qu'il en soit, les pics de démarrage ne sont pas ma principale préoccupation, j'aimerais d'abord obtenir tout le reste à 60 images par seconde. Si c'est janky pendant une seconde ou deux au démarrage, c'est une préoccupation moins urgente.
Manishearth
le 27 févr. 2020
Oui, cela pourrait montrer cela, aurait besoin de quelques ajustements.
Manishearth
le 27 févr. 2020
@Manishearth Totalement d'accord sur les priorités ! Je n'étais pas sûr si vous essayiez de « dénouer les nœuds » ou de descendre en régime permanent. D'accord, ce dernier est plus important en ce moment.
larsbergstrom
le 27 févr. 2020
Non, je notais surtout toutes les analyses que je pouvais.
Manishearth
le 27 févr. 2020
Ces pics vers la fin du graphique de la plus petite course où le temps de transmission augmente également : c'est à ce moment-là que je bougeais la tête et que je dessinais, et Alan remarquait également des baisses de FPS en faisant les choses, et l'attribuait au système d'exploitation effectuant d'autres travaux . Une fois que l'IPC a corrigé mon intuition sur les pics de temps de transmission, c'est qu'ils sont causés par le système d'exploitation effectuant d'autres travaux, c'est donc peut-être ce qui se passe là-bas. Dans un monde hors fil principal, je m'attendrais à ce que ce soit beaucoup plus fluide.
Manishearth
le 27 févr. 2020
Ignorez-moi si cela a déjà été pris en compte, avez-vous pensé à décomposer la mesure de run_one_frame sur une base par message géré, et également à chronométrer le temps passé thread::sleep() -ing ?
Il peut être intéressant d'ajouter trois points de mesure :
un emballage https://github.com/servo/webxr/blob/68b024221b8c72b5b33a63441d63803a13eadf03/webxr-api/session.rs#L364
et un autre emballage https://github.com/servo/webxr/blob/2841497966d87bbd561f18ea66547dde9b13962f/webxr-api/lib.rs#L124 dans son ensemble,
et aussi un enveloppant l'appel à
thread::sleepuniquement.
Quant au recv_timeout , cela pourrait être quelque chose à reconsidérer entièrement.
J'ai du mal à raisonner sur l'utilité du timeout. Puisque vous comptez l'image rendue, voir le frame_count , le cas d'utilisation semblerait être "peut-être gérer un ou plusieurs messages qui ne rendent pas l'image, d'abord, suivi du rendu d'une image, tout en évitant de passer par la boucle d'événement complète du thread principal" ?
J'ai également quelques doutes sur le calcul réel du delay utilisé, où actuellement :
- il commence à
delay = timeout / 1000, avectimeoutétant actuellement défini sur 5 ms - Il croît ensuite de façon exponentielle, doublant à chaque itération à
delay = delay * 2; - Il est vérifié en haut de la boucle avec
while delay < timeout.
Donc, la séquence de sommeils, dans le pire des cas, va quelque chose comme : 5micro -> 10 -> 20 -> 40 -> 80 -> 160 -> 320 -> 640 -> 1,28milli -> 2,56 milli -> 5,12 milli
Lorsqu'il atteint 5,12 millisecondes, vous sortirez de la boucle (depuis delay > timeout ), après avoir attendu un total de 5 115 millisecondes, plus le temps supplémentaire passé à attendre que le système d'exploitation réveille le thread après chaque sleep .
Donc je pense que le problème est que vous pourriez dormir pendant plus de 5 ms au total, et aussi je pense que ce n'est pas une bonne idée de dormir deux fois pendant plus de 1 ms (et dont la deuxième fois est plus de 2,5 ms) depuis un message pourrait entrer pendant ce temps et vous ne vous réveillerez pas.
Je ne sais pas trop comment l'améliorer, on dirait que vous essayez de faire tourner un message potentiel, et finalement passez simplement à la prochaine itération de la boucle d'événement principale si rien n'est disponible (pourquoi ne pas bloquer sur le reçu ?).
Vous pouvez passer à https://doc.rust-lang.org/std/thread/fn.yield_now.html , en regardant cet article sur les verrous , il semble tourner environ 40 fois tout en appelant yield chaque fois , est optimal (voir le paragraphe "Spinning", ne peut pas y être lié directement). Après cela, vous devez soit bloquer sur le récepteur, soit continuer avec l'itération actuelle de la boucle d'événement (puisqu'elle s'exécute comme une sous-boucle à l'intérieur de la boucle d'événement d'intégration principale).
(évidemment, si vous ne mesurez pas avec ipc activé, la partie ci-dessus sur recv_timeout n'est pas pertinente, bien que vous souhaitiez toujours mesurer l'appel à recv_timeout sur le mpsc puisque le canal fileté effectuera une rotation/rendement interne qui pourrait également influencer les résultats. Et comme un "correctif IPC" non identifié a été mentionné à plusieurs reprises ci-dessus, je suppose que vous mesurez avec ipc).
gterzian
le 27 févr. 2020
Ignorez-moi si cela a déjà été pris en compte, avez-vous pensé à décomposer la mesure de run_one_frame sur une base gérée par message, et également à chronométrer le temps passé thread::sleep()-ing ?
C'est déjà décomposé, les temps d'attente/rendu sont justement ça. Un seul tick de run_one_frame correspond à un rendu, une attente et un nombre indéterminé d'événements en cours de traitement (rare).
recv_timeout est une bonne idée pour la mesure
Manishearth
le 27 févr. 2020
Malheureusement, la mise à niveau de spidermonkey dans #25678 ne semble pas être une amélioration significative - le FPS moyen de chaque démo, à l'exception de la mémoire la plus limitée, a diminué ; la démo de Hill Valley a légèrement augmenté. L'exécution de Servo avec -Z gc-profile dans les arguments d'initialisation ne montre aucune différence de comportement GC entre le maître et la branche de mise à niveau spidermonkey - aucun GC n'est signalé après le chargement et l'affichage du contenu GL.
jdm
le 3 mars 2020
Mesures pour diverses branches :
master:
- espilit: 14-16 fps
- paint: 39-45 fps
- ball shooter: 30-40 fps
- hill valley: 8 fps, 200mb free mem
- mansion: 10-14fps, 650mb free mem
master + single swapchain:
- espilit: 10-12 fps
- paint: 29-55 fps, 1.2gb free mem
- ball shooter: 25-35 fps, 1.3gb free mem
- hill valley: 6-7 fps, 200mb free mem
- mansion: 10-11 fps, 700mb free mem
texture sharing + ANGLE 2.1.19:
- espilit: 13-15 fps, 670mb free mem
- paint: 39-45 fps
- ball shooter: 30-37 fps, 1.3gb free mem
- hill valley: 9-10 fps, 188mb free mem
- mansion: 13-14 fps, 671mb free mem
smup:
- espilit: 11-13 fps, 730mb free mem
- paint: 25-42 fps, 1.1gb free mem
- ball shooter: 26-30 fps, 1.4gb free mem
- hill valley: 10-11 fps, 145mb
- mansion: 9-11fps, 680mb free mem
Le smup a aggravé les performances ???
asajeffrey
le 3 mars 2020
Avec les changements de https://github.com/servo/servo/pull/25855#issuecomment -594203492, il y a le résultat intéressant que la désactivation de l'Ion JIT commence à 12 FPS, puis quelques secondes plus tard, il atteint brusquement 1 FPS et y reste.
jdm
le 3 mars 2020
J'ai fait quelques mesures avec ces patchs.
Sur la peinture, j'obtiens 60 ips lorsqu'il n'y a pas beaucoup de contenu en vue, et lorsque je regarde le contenu dessiné, il tombe à 50 ips (les pointes jaunes sont lorsque je regarde le contenu dessiné). Il est difficile de dire pourquoi, la plupart du temps, il semble que le temps d'attente soit affecté par la limitation d'openxr, mais les autres choses ne semblent pas assez lentes pour causer un problème. Le délai de demande d'échange est un peu plus lent. Le temps d'exécution de rAF est lent au départ (il s'agit du ralentissement initial de la « première fois qu'un contrôleur est vu »), mais après cela, il est assez constant. Il semble qu'openxr ne fasse que nous ralentir, mais il n'y a aucun ralentissement visible ailleurs qui causerait cela.

Manishearth
le 7 mars 2020
C'est ce que j'ai pour la démo de draging. L'échelle y est la même. Ici, il est beaucoup plus évident que le temps d'exécution nous ralentit.

Manishearth
le 7 mars 2020
Une chose à noter est que je prenais des mesures avec #25837 appliqué, et cela pourrait affecter les performances.
jdm
le 7 mars 2020
Je ne l'étais pas, mais j'obtenais des résultats similaires à vous
Manishearth
le 7 mars 2020
Graphiques de l'outil de performance pour le moment où il passe de 60FPS à 45FPS en regardant le contenu :
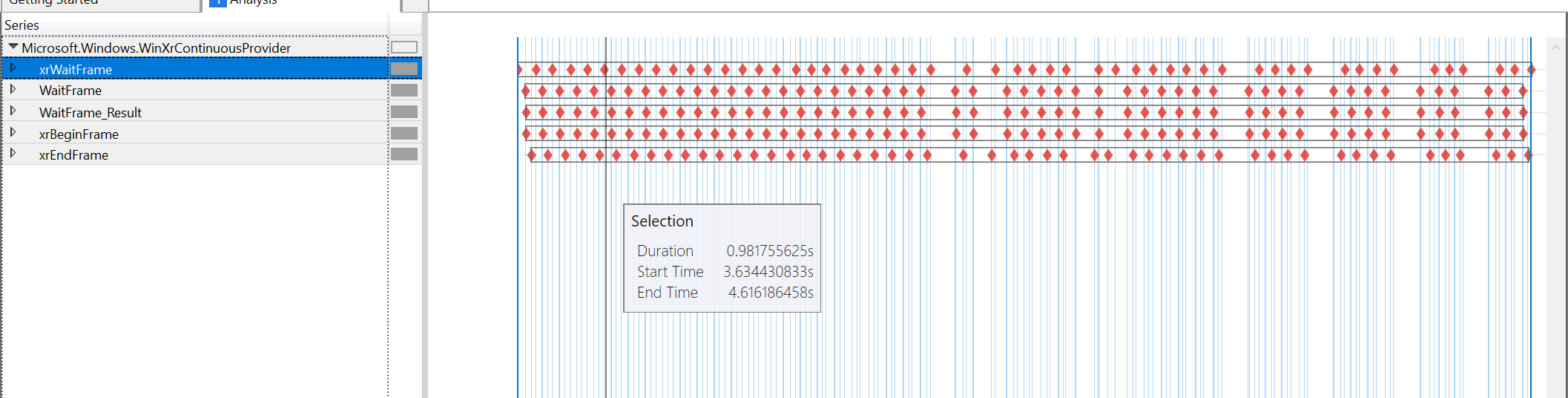
il semble que le blâme soit entièrement sur xrWaitFrame, tous les autres timings sont assez proches les uns des autres. Le xrBeginFrame est toujours presque immédiatement après xrWaitFrame, le xrEndFrame est 4us après le xrBeginFrame (dans les deux cas). Le prochain xrWaitFrame est presque immédiatement après le xrEndFrame. Le seul écart non pris en compte est celui causé par xrWaitFrame lui-même.
Manishearth
le 11 mars 2020
Avec la démo en glissant, j'obtiens la trace suivante :

Voici la démo de peinture à la même échelle :
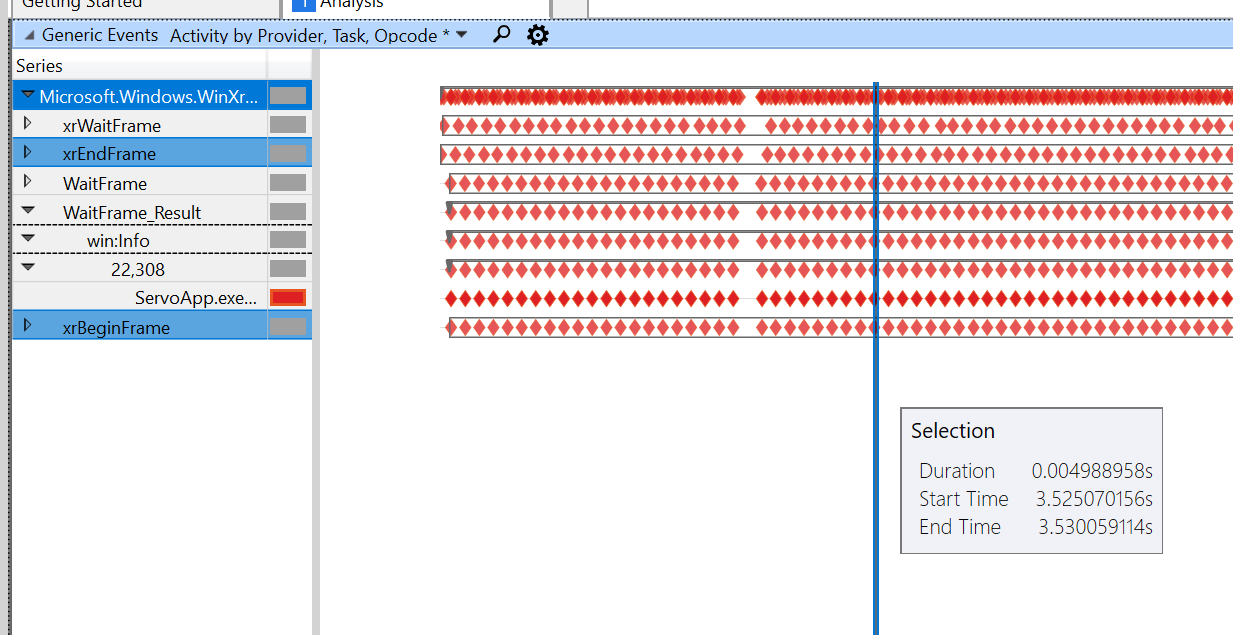
Nous sommes lents entre le début/la fin de l'image (de 5 ms à 38 ms sur le plus rapide !), puis la limitation de l'image d'attente entre en jeu. Je n'ai pas encore expliqué pourquoi c'est le cas, je suis en train de parcourir le code pour les deux.
Manishearth
le 18 mars 2020
La démo en traînant est ralentie car sa source lumineuse projette une ombre. Le truc de l'ombre est fait du côté de GL donc je ne suis pas sûr si nous pouvons accélérer cela facilement ?
Manishearth
le 18 mars 2020
Si cela se fait entièrement via GLSL, nous pouvons avoir des difficultés ; si cela est fait à chaque image via les API WebGL, il peut y avoir des endroits à optimiser.
jdm
le 18 mars 2020
Oui, tout semble être du côté de GLSL ; Je ne pouvais voir aucun appel WebGL en ce qui concerne le fonctionnement des API fantômes, juste quelques éléments qui sont transmis aux shaders
Manishearth
le 19 mars 2020
Je pense que cela a été traité en général. Nous pouvons déposer des problèmes pour des démos individuelles qui ont besoin de travail.
jdm
le 20 juil. 2020
Questions connexes
 CYBAI
·
4Commentaires
CYBAI
·
4Commentaires
 AgustinCB
·
4Commentaires
AgustinCB
·
4Commentaires
 ferjm
·
3Commentaires
jdm
·
3Commentaires
ferjm
·
3Commentaires
jdm
·
3Commentaires
 roberto68
·
3Commentaires
roberto68
·
3Commentaires
Commentaire le plus utile
Statut actuel : avec les correctifs IPC, le FPS oscille maintenant autour de 55. Il bouge parfois beaucoup, mais ne descend généralement pas en dessous de 45, _sauf_ pendant les premières secondes après le chargement (où il peut descendre à 30), et quand il voit d'abord une main (quand elle descend à 20).