Servo: لا يصل الوضع الغامر إلى 60 إطارًا في الثانية
أنا أستخدم هذا لتتبع التحقيقات في سبب انخفاض قيم FPS عند استخدام الوضع الغامر على الأجهزة.
 jdm
jdm
ال 71 كومينتر
بعض المعلومات التي تم الكشف عنها:
- هناك فترات انتظار طويلة بين xrWaitFrame و xrBeginFrame
- في التطبيق التجريبي تحدث بشكل متسلسل
- في نموذج Servo ، ننتظر إطار الجهاز ، ثم بمجرد استلامنا من سلسلة webgl ، نبدأ إطار openxr التالي
يتم استنساخ أثر للعرض التوضيحي للطلاء باستخدام علامات لواجهة برمجة تطبيقات OpenXR في هذه الأيام ، ويظهر أيضًا خلال تلك الفترة:
- يستخدم خيط webgl معظم وحدة المعالجة المركزية (يتم إنفاق الغالبية العظمى من ذلك الوقت تحت gl :: Finish ، وهو ما يسمى من جهاز Surfman's :: bind_surface_to_context)
- الخيط الرئيسي هو الثاني الأكثر ازدحامًا ، حيث تم إنفاق أعلى استخدام في eglCreatePbufferFromClientBuffer وتقريبًا نفس القدر من الوقت الذي يقضيه في الاستيلاء على كائن Egl من TLS
- يظهر عرض webrender أيضًا في هذه المجموعة
- يظهر winrt :: servo :: flush هنا أيضًا ، وليس من الواضح بالنسبة لي ما إذا كنا نحتاج بالفعل إلى تبديل مخازن GL الخاصة بالتطبيق الرئيسي بينما نحن في الوضع الغامر
- ثالث أعلى استخدام لوحدة المعالجة المركزية هو خيط البرنامج النصي ، حيث يقضي الكثير من الوقت داخل كود JIT
- بعد ذلك ، يكون استخدام وحدة المعالجة المركزية للخيط منخفضًا جدًا بشكل عام ، ولكن هناك بعض الرموز من صندوق النمط تظهر تشير إلى أن التخطيط يحدث
jdm
في ٣ يناير ٢٠٢٠
بالنظر إلى نقاط البيانات هذه ، سأحاول طريقتين للبدء:
- ابدأ إطار XR التالي في أقرب وقت ممكن بعد انتظار إطار الجهاز
- تقليل عدد المرات التي نحتاج فيها لاستدعاء gl :: Finish (موضوع webgl) ، eglCreateBufferFromClientBuffer و TLS (موضوع رئيسي)
jdm
في ٣ يناير ٢٠٢٠
https://github.com/servo/servo/pull/25343#issuecomment -567706735 لديه المزيد من التحقيق في تأثير إرسال الرسائل إلى أماكن مختلفة في المحرك. لا يشير إلى أي أصابع واضحة ، لكنه يقترح أخذ قياسات أكثر دقة.
jdm
في ٣ يناير ٢٠٢٠
يأتي استخدام gl :: Finish من https://github.com/pcwalton/surfman/blob/6705a9aaa8f33ac1324fdb1913242800e68c7720/surfman/src/platform/windows/angle/context.rs#L259 -L266.
jdm
في ٣ يناير ٢٠٢٠
يؤدي تغيير gl :: Finish إلى gl :: Flush إلى تعزيز معدل الإطارات من ~ 15-> 30 ، ولكن هناك تأخرًا ملحوظًا للغاية في محتويات الإطار يعكس في الواقع حركة رأس المستخدم ، مما يتسبب في أن يتبع الإطار الحالي رأس المستخدم في هذه الأثناء.
jdm
في ٣ يناير ٢٠٢٠
يتم تعطيل كائنات المزامنة ذات المفاتيح بشكل افتراضي في ANGLE لأسباب تراوغني ، ولكن mozangle تمكنها بشكل صريح (https://github.com/servo/mozangle/blob/706a9baaf8026c1a3cb6c67ba63aa5f4734264d0/build_data.rs#L175) ، وهذا ما يتم اختباره باستخدام . سأقوم ببناء ANGLE لتمكينهم ومعرفة ما إذا كان ذلك كافياً لتجنب مكالمات gl :: Finish.
jdm
في ٣ يناير ٢٠٢٠
مؤكد! يمنحني فرض كائنات المزامنة ذات المفاتيح في ANGLE 25-30 إطارًا في الثانية في العرض التوضيحي للطلاء دون أي مشكلات تأخر جاءت مع تغيير gl :: Finish call.
jdm
في ٣ يناير ٢٠٢٠
أوه ، ومعلومة أخرى وفقًا لتحقيقات لارس:
- تم تعيين w / dom.ion.enabled على false ، ويختفي وقت JIT. تكون الأحمال الأولية أبطأ بكثير ، ولكن بمجرد تشغيل الأشياء تكون جيدة جدًا.
- لا يزال الأمر غير رائع - استخدام الذاكرة مرتفع جدًا (أساسًا كل الذاكرة المتاحة) في مثال babylon.js هذا
- يجب أن نقوم بترقية spidermonkey أخرى لسحب التحسينات ذات الصلة بـ arm64 والتي كانت تحدث لـ FxR على أجهزة Android
jdm
في ٣ يناير ٢٠٢٠
أعتقد أنني أساءت فهم وجود std::thread::local::LocalKey<surfman::egll::Egl> في الملفات الشخصية - أنا متأكد من أن قراءة TLS ليست سوى جزء صغير جدًا من الوقت المحكوم به ، وهي الوظائف التي تسمى داخل كتلة TLS مثل eglCreatePbufferFromClientBuffer و DXGIAcquireSync التي _ في الواقع _ تأخذ الوقت.
jdm
في ٣ يناير ٢٠٢٠
للأسف ، يبدو أن تعطيل js.ion.enabled يؤذي FPS لعرض الطلاء التجريبي ، مما يؤدي إلى خفضه إلى 20-25.
jdm
في ٤ يناير ٢٠٢٠
بدلاً من استدعاء Device :: create_surface_texture_from_texture مرتين كل إطار (مرة واحدة لكل نسيج d3d لكل عين) ، قد يكون من الممكن إنشاء نسيج سطحي لجميع أنسجة swapchain عند إنشاء جهاز openxr webxr. إذا نجح ذلك ، فسيؤدي ذلك إلى إزالة ثاني أكبر مستخدم لوحدة المعالجة المركزية من الخيط الرئيسي أثناء الوضع الغامر.
jdm
في ٤ يناير ٢٠٢٠
فكرة أخرى لتقليل استخدام الذاكرة: هل هناك أي تأثير إذا قمنا بتعيين bfcache على رقم منخفض جدًا بحيث يتم إخلاء خط أنابيب الصفحة الرئيسية الأصلية لـ HL عند الانتقال إلى أحد العروض التوضيحية؟
jdm
في ٤ يناير ٢٠٢٠
لا يؤدي تصحيح webxr التالي بشكل واضح إلى تحسين FPS ، ولكنه قد يحسن استقرار الصورة. أحتاج إلى إنشاء بنائين منفصلين يمكنني تشغيلهما مرة أخرى للتحقق.
diff --git a/webxr/openxr/mod.rs b/webxr/openxr/mod.rs
index 91c78da..a6866de 100644
--- a/webxr/openxr/mod.rs
+++ b/webxr/openxr/mod.rs
@@ -416,11 +416,30 @@ impl DeviceAPI<Surface> for OpenXrDevice {
}
fn wait_for_animation_frame(&mut self) -> Option<Frame> {
- if !self.handle_openxr_events() {
- // Session is not running anymore.
- return None;
+ loop {
+ if !self.handle_openxr_events() {
+ // Session is not running anymore.
+ return None;
+ }
+ self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
+ // XXXManishearth this code should perhaps be in wait_for_animation_frame,
+ // but we then get errors that wait_image was called without a release_image()
+ self.frame_stream
+ .begin()
+ .expect("failed to start frame stream");
+
+ if self.frame_state.should_render {
+ break;
+ }
+
+ self.frame_stream.end(
+ self.frame_state.predicted_display_time,
+ EnvironmentBlendMode::ADDITIVE,
+ &[],
+ ).unwrap();
}
- self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
let time_ns = time::precise_time_ns();
// XXXManishearth should we check frame_state.should_render?
let (_view_flags, views) = self
@@ -506,12 +525,6 @@ impl DeviceAPI<Surface> for OpenXrDevice {
0,
);
- // XXXManishearth this code should perhaps be in wait_for_animation_frame,
- // but we then get errors that wait_image was called without a release_image()
- self.frame_stream
- .begin()
- .expect("failed to start frame stream");
-
self.left_image = self.left_swapchain.acquire_image().unwrap();
self.left_swapchain
.wait_image(openxr::Duration::INFINITE)
manishearth أي أفكار حول هذا؟ إنها محاولتي الاقتراب من النموذج الموضح بواسطة https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#Session.
jdm
في ٤ يناير ٢٠٢٠
أجل ، هذا يبدو جيدًا. كنت أقصد نقل begin() لأعلى إلى waf ، وأعتقد أن الخطأ المذكور في التعليق لم يعد يحدث ، ولكن لم يكن له أيضًا تأثير ملحوظ على FPS لذلك لم أتابعها كثيرا الآن. إذا كان يحسن الاستقرار فهذا أمر جيد!
 Manishearth
في ٤ يناير ٢٠٢٠
Manishearth
في ٤ يناير ٢٠٢٠
سعيد حقًا باكتشاف المفاتيح! تستهلك مكالمات Surfman بالفعل مجموعة من ميزانية الإطار ولكن من الصعب تحديد ما هو ضروري وما هو غير ضروري.
Manishearth
في ٤ يناير ٢٠٢٠
نعم ، إعادة: تعطيل js.ion.enabled ، سيكون ذلك مفيدًا فقط عندما نتضور جوعًا في ذاكرة الوصول العشوائي ونقضي معظم وقتنا في تجميع وظائف GC وإعادة تجميعها. ويجب تحسين ذلك باستخدام SM أحدث. كان لدى IIRC ، الواجهة الخلفية ARM64 التي تعود إلى 66 حقبة ، أداء ضعيف نسبيًا لخط الأساس JIT والمترجم ؛ يجب أن نرى تسريعًا في جميع المجالات مع تحديث ولكن بشكل خاص في التطبيقات كثيفة استخدام ذاكرة الوصول العشوائي.
 larsbergstrom
في ٤ يناير ٢٠٢٠
larsbergstrom
في ٤ يناير ٢٠٢٠
تم نشر حزمة ANGLE الجديدة مع تمكين كائنات المزامنة ذات المفاتيح. سأقوم بإنشاء طلب سحب لترقيته لاحقًا.
jdm
في ٦ يناير ٢٠٢٠
حاولت إنشاء نسيج السطح لجميع صور swapchain openxr أثناء تهيئة جهاز XR ، ولكن لا يزال هناك مجموعة من الوقت على مؤشر الترابط الرئيسي الذي أمضاه في استدعاء eglCreatePbufferFromClientBuffer على السطح الذي نتلقاه من خيط webgl لكل إطار. ربما هناك طريقة ما لتخزين تلك الأنسجة السطحية مؤقتًا حتى نتمكن من إعادة استخدامها إذا تلقينا نفس السطح ...
jdm
في ٦ يناير ٢٠٢٠
يأتي أكبر استخدام لوحدة المعالجة المركزية للخيط الرئيسي من Render_animation_frame ، مع وجود معظم ذلك تحت وقت تشغيل OpenXR ولكن تظهر المكالمات إلى BlitFramebuffer و FramebufferTexture2D بالتأكيد في الملف الشخصي أيضًا. أتساءل عما إذا كان من الأفضل أن تغمض كلتا العينين مرة واحدة في نسيج واحد؟ ربما يكون هذا مرتبطًا بأشياء مصفوفة النسيج التي تمت مناقشتها في https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-Text-array-and-vprt.
jdm
في ٦ يناير ٢٠٢٠
يمكننا أن نغمض كلتا العينين في وقت واحد ، ولكن ما أفهمه هو أن وقت التشغيل
قد تفعل حينها الثواب الخاص بها. مصفوفة النسيج هي أسرع طريقة. ولكن
تستحق لقطة ، واجهة برمجة تطبيقات عرض الإسقاط تدعم القيام بذلك.
أما بالنسبة لحركة مرور الخيط الرئيسي ANGLE ، فهي تقوم بإيقاف حلقة RAF من
تلطيخ قماش المساعدة؟ حتى الآن لم يفعل هذا أي شيء ولكنه يستحق
لقطة ، من الناحية المثالية لا ينبغي أن نفعل أي شيء تخطيط / عرض على الرئيسي
مسلك.
يوم الاثنين ، 6 يناير 2020 ، 11:49 مساءً Josh Matthews [email protected]
كتب:
يأتي أكبر استخدام لوحدة المعالجة المركزية للخيط الرئيسي من Render_animation_frame ، مع
معظم ذلك في ظل وقت تشغيل OpenXR ولكنه يستدعي BlitFramebuffer و
يظهر FramebufferTexture2D بالتأكيد في الملف الشخصي أيضًا. انا اتعجب
إذا كان من الأفضل إزالة كلتا العينين مرة واحدة في واحدة
الملمس؟ ربما يكون هذا مرتبطًا بأشياء مصفوفة النسيج التي تمت مناقشتها
في
https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-Text-array-and-vprt
.-
أنت تتلقى هذا لأنه تم ذكرك.
قم بالرد على هذا البريد الإلكتروني مباشرة ، وقم بعرضه على GitHub
https://github.com/servo/servo/issues/25425؟email_source=notifications&email_token=AAMK6SBRH72JGZMXTUKOXETQ4NY37A5CNFSM4KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LN
أو إلغاء الاشتراك
https://github.com/notifications/unsubscribe-auth/AAMK6SECM6MDNZZ6Y7VL7SDQ4NY37ANCNFSM4KCRI6AA
.
Manishearth
في ٦ يناير ٢٠٢٠
تؤدي إزالة تلطيخ القماش إلى تنظيف الملف الشخصي فقط ؛ لا يبدو أنها تؤدي إلى زيادة ذات مغزى في FPS.
jdm
في ٦ يناير ٢٠٢٠
حاولت إنشاء ذاكرة تخزين مؤقت لأنسجة السطح للأسطح من خيط webgl بالإضافة إلى أنسجة swapchain openxr ، وبينما اختفى وقت eglCreatePbufferFromClientBuffer تمامًا ، لم ألاحظ أي تغيير ذي معنى في FPS.
jdm
في ٦ يناير ٢٠٢٠
بعض معلومات التوقيت للعمليات المختلفة في خط الأنابيب الغامر (جميع القياسات بالمللي ثانية):
Name min max avg
raf queued 0.070833 14.010261 0.576834
<1ms: 393
<2ms: 28
<4ms: 5
<8ms: 1
<16ms: 2
<32ms: 0
32+ms: 0
raf transmitted 0.404270 33.649583 7.403302
<1ms: 123
<2ms: 43
<4ms: 48
<8ms: 48
<16ms: 95
<32ms: 69
32+ms: 3
raf wait 1.203500 191.064100 17.513593
<1ms: 0
<2ms: 17
<4ms: 98
<8ms: 95
<16ms: 48
<32ms: 69
32+ms: 101
raf execute 3.375000 128.663200 6.994588
<1ms: 0
<2ms: 0
<4ms: 5
<8ms: 351
<16ms: 70
<32ms: 1
32+ms: 2
raf receive 0.111510 8.564010 0.783503
<1ms: 353
<2ms: 52
<4ms: 18
<8ms: 4
<16ms: 1
<32ms: 0
32+ms: 0
raf render 2.372200 75.944000 4.219310
<1ms: 0
<2ms: 0
<4ms: 253
<8ms: 167
<16ms: 8
<32ms: 0
32+ms: 1
receive : الوقت من إرسال معلومات إطار XR من مؤشر ترابط XR إلى أن يتم استلامها بواسطة جهاز توجيه IPC
queued : الوقت من موجه IPC الذي يستقبل معلومات الإطار حتى XRSession :: raf_callback تم استدعاؤه
execute : الوقت من XRSession :: تم استدعاء raf_callback حتى العودة من الطريقة
transmitted : الوقت من إرسال طلب RAF جديد من مؤشر ترابط البرنامج النصي حتى استلامه بواسطة سلسلة XR
render : الوقت المستغرق لاستدعاء render_animation_frame وإعادة تدوير السطح
wait : الوقت الذي يستغرقه wait_for_animation_frame (باستخدام التصحيح السابق في هذه المشكلة والذي يتكرّر فوق الإطارات التي لا يجب عرضها)
يوجد تحت كل إدخال توزيع القيم على مدار الجلسة.
jdm
في ٧ يناير ٢٠٢٠
نقطة بيانات مثيرة للاهتمام من معلومات التوقيت تلك - فئة transmitted تبدو أعلى بكثير مما ينبغي. هذا هو التأخير بين تنفيذ رد نداء rAF وخيط XR الذي يتلقى الرسالة التي تمزج الإطار المكتمل في نسيج openxr. هناك قدر كبير من الاختلاف ، مما يشير إلى أن الخيط الرئيسي مشغول بفعل أشياء أخرى ، أو يحتاج إلى إيقاظه من أجل معالجته.
jdm
في ٧ يناير ٢٠٢٠
بالنظر إلى البيانات السابقة ، قد أحاول إحياء https://github.com/servo/webxr/issues/113 غدًا لمعرفة ما إذا كان ذلك يؤثر بشكل إيجابي على توقيت الإرسال. قد أتطرق إلى الخيط الرئيسي في ملف التعريف أولاً لمعرفة ما إذا كان بإمكاني التوصل إلى أي أفكار حول كيفية معرفة ما إذا كان الموضوع مشغولاً بمهام أخرى أو نائماً.
jdm
في ٧ يناير ٢٠٢٠
نقطة بيانات أخرى:
swap buffer 1.105938 28.193698 2.154793
<1ms: 0
<2ms: 273
<4ms: 110
<8ms: 15
<16ms: 2
<32ms: 2
32+ms: 0
swap complete 0.053802 4.337812 0.295064
<1ms: 308
<2ms: 9
<4ms: 6
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
swap request 0.003333 24033027.355364 4662890.724805
<1ms: 268
<2ms: 49
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 1
32+ms: 79
هذه هي التوقيتات المتعلقة بـ 1) التأخير من إرسال رسالة المخزن المؤقت للتبديل حتى يتم معالجتها في سلسلة webgl ، 2) الوقت المستغرق لمبادلة المخازن المؤقتة ، 3) التأخير من إرسال الرسالة التي تشير إلى اكتمال التبديل حتى استلامها في موضوع البرنامج النصي. لا يوجد شيء مثير للدهشة هنا (باستثناء تلك القيم المتطرفة الغريبة في فئة swap request ، ولكن هذه تحدث في بداية الجلسة الغامرة أثناء عملية الإعداد) ، لكن تبديل المخزن المؤقت الفعلي يستغرق باستمرار ما بين 1-4 مللي ثانية.
jdm
في ٧ يناير ٢٠٢٠
قدم رقم 117 بعد قراءة بعض نموذج كود openxr ولاحظ أن مكالمات locate_views تظهر في الملف الشخصي.
jdm
في ٧ يناير ٢٠٢٠
 asajeffrey
في ٧ يناير ٢٠٢٠
asajeffrey
في ٧ يناير ٢٠٢٠
نقطة بيانات مثيرة للاهتمام من معلومات التوقيت تلك - تبدو الفئة المرسلة أعلى بكثير مما ينبغي. هذا هو التأخير بين تنفيذ رد نداء rAF وخيط XR الذي يتلقى الرسالة التي تمزج الإطار المكتمل في نسيج openxr. هناك قدر كبير من الاختلاف ، مما يشير إلى أن الخيط الرئيسي مشغول بفعل أشياء أخرى ، أو يحتاج إلى إيقاظه من أجل معالجته.
بالنسبة إلى الاختلافات في القيمة transmitted ، فقد ترتبط بالمهلة المستخدمة كجزء من run_one_frame عندما تكون الجلسة قيد التشغيل على مؤشر الترابط الرئيسي (وهو موجود في تلك القياسات ، أليس كذلك؟) ، راجع https://github.com/servo/webxr/blob/c6abf4c60d165ffc978ad2ebd6bcddc3c21698e1/webxr-api/session.rs#L275
أظن أنه عندما يتم استلام رسالة RenderAnimationFrame msg (التي تم إرسالها بواسطة سلسلة البرنامج النصي بعد تشغيل عمليات الاسترجاعات) قبل انتهاء المهلة ، فإنك تضغط على "المسار السريع" ، وإذا ضاعت المهلة ، ينتقل Servo إلى آخر تكرار perform_updates ، و "تشغيل إطار آخر" يحدث في وقت متأخر إلى حد ما في الدورة ، كجزء من compositor.perform_updates ، وهو نفسه يسمى متأخرًا إلى حد ما كجزء من servo.handle_events .
بصرف النظر عن نقل XR إلى مؤشر ترابط خاص به ، قد يكون من المفيد معرفة ما إذا كانت القيمة الأعلى للمهلة تؤدي إلى تحسين متوسط القيمة (على الرغم من أنه قد لا يكون الحل الصحيح لأنه قد يتسبب في تجويع العناصر الضرورية الأخرى في السلسلة الرئيسية).
 gterzian
في ٨ يناير ٢٠٢٠
gterzian
في ٨ يناير ٢٠٢٠
لقد أحرزت تقدمًا في إزالة openxr من الموضوع الرئيسي في https://github.com/servo/webxr/issues/113 ، لذلك سأقوم بإجراء المزيد من القياسات بناءً على هذا العمل الأسبوع المقبل.
jdm
في ١٠ يناير ٢٠٢٠
تقنيات الحصول على ملفات تعريف مفيدة من الجهاز:
- استخدم خادمًا يتضمن
rustflags = "-C force-frame-pointers=yes" - uncomment هذه السطور
- استخدم WinXR_Perf.wprp من علامة التبويب MS team
Filesكملف تعريف تتبع مخصص ضمن "تتبع الأداء" في بوابة جهاز HL - بناء
--features profilemozjs
ستكون هذه التتبع (التي تم الحصول عليها من "Start Trace" في مدخل الجهاز) قابلة للاستخدام داخل أداة Windows Performance Analyzer. لا تعرض هذه الأداة أسماء مؤشرات الترابط ، ولكن السلاسل التي تستخدم معظم وحدة المعالجة المركزية تكون سهلة التحديد بناءً على المجموعات.
لتوصيف توزيع الوقت لإطار openxr معين:
- أضف عرض "نشاط النظام -> الأحداث العامة" في WPA
- قم بتصفية العرض لإظهار سلسلة Microsoft.Windows.WinXrContinuousProvider فقط
- قم بالتكبير لمدة قصيرة ، ثم قم بتحسين المنطقة التي تم تكبيرها بحيث يكون حدث xrBegin في الجانب الأيسر من العرض ، ويكون حدث xrEnd في الجانب الأيمن من العرض
وجهات النظر الأكثر فائدة لاستخدام وحدة المعالجة المركزية:
- استخدام وحدة المعالجة المركزية (عينات) -> الاستخدام حسب العملية ، الخيط ، المكدس (قم بتصفية العرض لإظهار المؤازرة فقط ، ثم قم بتعطيل عمود العملية)
- Flame by Process ، Stack (تصفية العرض لإظهار أجهزة مؤازرة فقط)
jdm
في ١٦ يناير ٢٠٢٠
أحد الاحتمالات للقيام بعمل أقل قليلاً في سلسلة البرنامج النصي:
- XRView :: الجديد يستهلك 0.02٪ من كل وحدات المعالجة المركزية المؤازرة
- نظرًا لأن محتويات كائنات العرض لا تتغير إلا إذا كان هناك حدث FrameUpdateEvent :: UpdateViews (والذي يأتي من Session :: update_clip_planes عبر XRSession :: UpdateRenderState) ، يمكننا تصور تخزين كائنات XRView مؤقتًا في XRSession والاستمرار في استخدامها حتى يتم تحديث حالة العرض
- يمكننا حتى الاحتفاظ بتمثيل JS لقائمة العروض المخزنة مؤقتًا في XRSession وتعيين عضو عروض الوضع ، وتجنب إعادة إنشاء كائنات XRView ، وتخصيص المتجه ، وتنفيذ تحويل قيمة JS
jdm
في ١٦ يناير ٢٠٢٠
أحد الاحتمالات للقيام بعمل أقل عند عرض إطار غامر:
- قام GL و d3d بقلب أنظمة إحداثيات Y.
- يخفي ANGLE هذا بشكل ضمني عند التقديم على الشاشة عن طريق القيام ببعض الأعمال خلف الكواليس
- بالنسبة للوضع الغامر ، نستخدم glBlitFramebuffer لإجراء انعكاس y عند مزج بيانات نسيج GL إلى d3d
- إذا تمكنا من معرفة كيفية جعل ANGLE لا يقوم بالتحويل داخليًا ، فقد يكون من الممكن عكس هذا النموذج وجعل صفحات الويب غير الغامرة تتطلب نسخة y-invert إضافية (عبر خيار webrender
surface_origin_is_top_left) بينما يمكن مسح الوضع المجسم دون أي تحول
استنادًا إلى https://bugzilla.mozilla.org/show_bug.cgi؟id=1591346 والتحدث مع jrmuizel ، إليك ما يتعين علينا القيام به:
- احصل على swapchain d3d لعنصر النافذة الذي نريد عرض صفحات غير غامرة فيه (ستكون هذه لوحة SwapChainPanel في تطبيق XAML)
- لف ذلك في صورة EGL (https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#554)
- قدم swapchain بشكل صريح عندما نريد تحديث العرض الرئيسي
- تجنب استخدام eglCreateWindowSurface و eglSwapBuffers في https://github.com/servo/servo/blob/master/support/hololens/ServoApp/ServoControl/OpenGLES.cpp#L205 -L208
كود أبو بريص ذو الصلة: https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#192
رمز ANGLE ذي الصلة: https://github.com/google/angle/blob/df0203a9ae7a285d885d7bc5c2d4754fe8a59c72/src/libANGLE/renderer/d3d/d3d11/winrt/SwapChainPanelNativeWindow.cpp#L24
jdm
في ١٦ يناير ٢٠٢٠
فروع المسح الحالية:
- https://github.com/servo/ipc-channel/tree/try-recv-error
- https://github.com/jdm/webxr/tree/oxr
- https://github.com/jdm/rust-offscreen-rendering-context/tree/angle-perf
- https://github.com/jdm/servo/tree/profile
يتضمن ذلك ميزة xr-profile التي تضيف بيانات التوقيت التي ذكرتها سابقًا ، بالإضافة إلى التنفيذ الأولي لتغييرات ANGLE لإزالة التحويل العكسي y في الوضع الغامر. يتم عرض الوضع غير المجسم بشكل صحيح ، لكن الوضع المجسم مقلوب رأسًا على عقب. أعتقد أنني بحاجة إلى إزالة رمز GL من render_animation_frame واستبداله بمكالمة CopySubresourceRegion مباشرة عن طريق استخراج مقبض المشاركة من سطح GL حتى أتمكن من الحصول على نسيج d3d.
jdm
في ١٧ يناير ٢٠٢٠
قدم https://github.com/servo/servo/issues/25582 لعمل ANGLE y-inversion ؛ سيتم إجراء مزيد من التحديثات على هذا العمل في هذه المسألة.
jdm
في ٢٣ يناير ٢٠٢٠
سيكون عنصر التذكرة الكبير التالي هو التحقيق في طرق تجنب مكالمات glBlitFramebuffer في الواجهة الخلفية لـ openxr webxr بالكامل. هذا يستلزم:
- إنشاء الإطارات المؤقتة openxr التي تتطابق مع إطارات الويب المعتمة المطلوبة بدقة
- دعم وضع webgl حيث توفر الواجهة الخلفية webxr جميع أسطح swapchain ، بدلاً من إنشائها (على سبيل المثال في https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L458 و https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L111-L118)
jdm
في ٢٣ يناير ٢٠٢٠
قد يكون ذلك صعبًا ، نظرًا لأن المتصفّح يوفر فقط وصولاً للكتابة إلى السياق الذي أنشأ السطح ، لذلك إذا تم إنشاء السطح بواسطة مؤشر ترابط openxr ، فلن يكون قابلاً للكتابة بواسطة مؤشر ترابط WebGL. https://github.com/pcwalton/surfman/blob/a515fb2f5d6b9e9b36ba4e8b498cdb4bea92d330/surfman/src/device.rs#L95 -L96
asajeffrey
في ٢٣ يناير ٢٠٢٠
يحدث ذلك بالنسبة لي - إذا قمنا بإجراء عرض openxr في خيط webgl ، فلن تكون هناك مجموعة من المشكلات المتعلقة بالترابط حول التقديم مباشرة إلى مواد openxr (على سبيل المثال ، القيود حول eglCreatePbufferFromClientBuffer التي تحظر استخدام أجهزة d3d المتعددة). يعتبر:
- لا يزال هناك مؤشر ترابط openxr مسؤول عن الاستقصاء عن أحداث openxr ، وانتظار إطار الرسوم المتحركة ، وبدء إطار جديد واسترداد حالة الإطار الحالية
- يتم إرسال حالة الإطار إلى مؤشر ترابط البرنامج النصي ، والذي يقوم بتنفيذ رد الاتصال المتحرك ثم إرسال رسالة إلى مؤشر ترابط webgl لمبادلة المخزن المؤقت لطبقة xr
- عندما يتم تلقي رسالة المبادلة هذه في خيط webgl ، نقوم بإصدار آخر صورة مبادلة تم الحصول عليها من openxr ، وإرسال رسالة إلى مؤشر ترابط openxr لإنهاء الإطار الحالي ، والحصول على صورة swapchain جديدة للإطار التالي
تقترح قراءتي لـ https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#threading -behavior أن هذا التصميم قد يكون عمليًا. الحيلة هي ما إذا كان يمكن أن يعمل مع الخلفيات الخلفية غير openxr وكذلك مع openxr.
من المواصفات: "بينما لا يلزم استدعاء xrBeginFrame و xrEndFrame في نفس مؤشر الترابط ، يجب أن يعالج التطبيق المزامنة إذا تم استدعاؤها في مؤشرات ترابط منفصلة."
jdm
في ٢٥ يناير ٢٠٢٠
في الوقت الحالي ، لا يوجد اتصال مباشر بين خيوط جهاز XR و webgl ، كل ذلك إما عبر البرنامج النصي أو عبر سلسلة المبادلة المشتركة الخاصة بهم. سأميل إلى تقديم واجهة برمجة تطبيقات سلسلة المبادلة التي تقع فوق سلسلة مقايضة متصفحي أو سلسلة مبادلة openxr ، واستخدمها للاتصال من webgl-to-openxr.
asajeffrey
في ٢٥ يناير ٢٠٢٠
ملاحظات من محادثة حول قياسات الوقت السابقة:
* concerns about wait time - why?????
* figure out time spent in JS vs. DOM logic
* when does openxr give us should render=false frames - maybe related to previous frame taking too long
* are threads being scheduled on inappropriate cpus? - on magic leap, main thread (including weber) pinned to big core.
* when one of the measured numbers is large, is there correlation with other large numbers?
* probably should pin openxr thread, running deterministic code
* consider clearing after telling script that the swap is complete - measure if clear is taking significant time in swap operation
* consider a swap chain API operation - “wait until a buffer swap occurs”
- block waiting on swapchain
- block waiting on swapchain + timeout
- async????????
- a gc would look like a spike in script execution time
قدم # 25735 لتتبع التحقيقات التي أتابعها حول التقديم مباشرة إلى مواد openxr.
jdm
في ١١ فبراير ٢٠٢٠
شيء واحد يجب علينا القيام به هو تضييق نطاق مقارنة spidermonkey على الجهاز بالمحركات الأخرى. أسهل طريقة للحصول على بعض البيانات هنا هي العثور على معيار JS بسيط يمكن لـ Servo تشغيله ، ومقارنة أداء Servo بمتصفح Edge المثبت على الجهاز. بالإضافة إلى ذلك ، يمكننا محاولة زيارة بعض عروض Babylon التجريبية المعقدة في كلا المستعرضين دون الدخول في الوضع المجسم لمعرفة ما إذا كان هناك فرق كبير في الأداء. سيعطينا هذا أيضًا معيارًا للمقارنة مع ترقية spidermonkey القادمة.
jdm
في ١٣ فبراير ٢٠٢٠
بعض البيانات الجديدة. هذا مع ترقية ANGLE ، ولكن ليس IPC.
$ python timing.py raw
Name min max mean
raf queued 0.056198 5.673125 0.694902
<1ms: 335
<2ms: 26
<4ms: 17
<8ms: 7
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.822917 36.582083 7.658619
<1ms: 1
<2ms: 4
<4ms: 31
<8ms: 181
<16ms: 158
<32ms: 8
32+ms: 1
raf wait 1.196615 39.707709 10.256875
<1ms: 0
<2ms: 32
<4ms: 93
<8ms: 67
<16ms: 107
<32ms: 68
32+ms: 17
raf execute 3.078438 532.205677 7.752839
<1ms: 0
<2ms: 0
<4ms: 37
<8ms: 290
<16ms: 52
<32ms: 2
32+ms: 3
raf receive 0.084375 9.053125 1.024403
<1ms: 276
<2ms: 71
<4ms: 27
<8ms: 9
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.004115 73.939479 0.611254
<1ms: 369
<2ms: 10
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.706198 233.459636 9.241698
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 183
<16ms: 190
<32ms: 10
32+ms: 1
run_one_frame 7.663333 2631.052969 28.035143
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 3
<16ms: 157
<32ms: 185
32+ms: 41
swap buffer 0.611927 8.521302 1.580279
<1ms: 127
<2ms: 169
<4ms: 74
<8ms: 15
<16ms: 1
<32ms: 0
32+ms: 0
swap complete 0.046511 2.446302 0.215040
<1ms: 375
<2ms: 6
<4ms: 3
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
بيانات التوقيت: https://gist.github.com/Manishearth/825799a98bf4dca0d9a7e55058574736
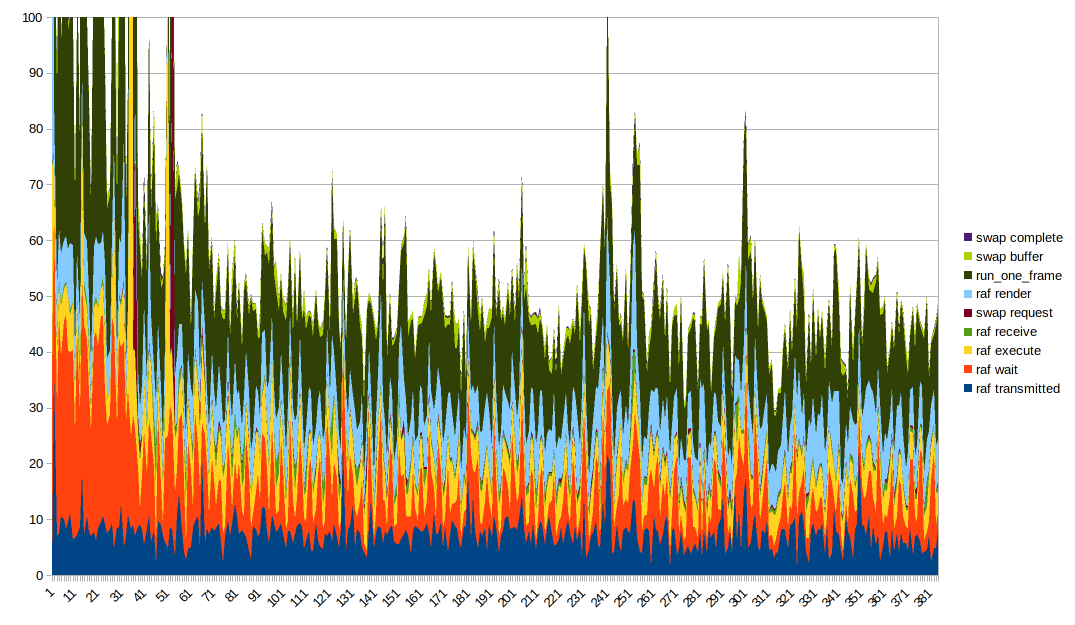
الحصول على تصور بيانات جيد لهذا أمر صعب. يبدو الرسم البياني الخطي المكدس مثاليًا ، على الرغم من أنه من الجدير بالذكر أن run_one_frame يقيس عدة توقيتات تم قياسها بالفعل. من المفيد العبث بترتيب الرسم البياني ووضع أعمدة مختلفة في الأسفل لرؤية تأثيرها بشكل أفضل. تحتاج أيضًا إلى اقتطاع المحور Y للحصول على أي شيء مفيد بسبب بعض القيم المتطرفة الكبيرة جدًا.
أشياء مثيرة للاهتمام يجب ملاحظتها:
- يبدو أن وقت العرض ووقت التنفيذ ثابتان في الغالب ولكن بهما ارتفاعات عندما تكون هناك ارتفاعات كبيرة بشكل عام. أظن أن الارتفاعات الكبيرة تأتي من تباطؤ كل شيء لأي سبب من الأسباب
- يبدو أن وقت الإرسال مرتبط جيدًا بالشكل العام
- وقت الانتظار هو أيضًا جزء من السبب في أن الشكل العام هكذا ، إنه _متموج_ جدًا
Manishearth
في ٢١ فبراير ٢٠٢٠
الحالة الحالية: مع إصلاحات IPC ، تحوم FPS الآن حول 55. إنها تهتز في بعض الأحيان ، ولكنها عادة لا تقل عن 45 ، _ باستثناء_ خلال الثواني القليلة الأولى بعد التحميل (حيث يمكن أن تنخفض إلى 30) ، وعندما يرى أولاً يد (عندما تنخفض إلى 20).
Manishearth
في ٢٥ فبراير ٢٠٢٠
أحدث رسم بياني لعرض الرسم ( بيانات أولية ):
Name min max mean
raf queued 0.113854 5.707917 0.441650
<1ms: 352
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.546667 44.954792 6.886162
<1ms: 4
<2ms: 2
<4ms: 23
<8ms: 279
<16ms: 59
<32ms: 3
32+ms: 1
raf wait 1.611667 37.913177 9.441104
<1ms: 0
<2ms: 6
<4ms: 98
<8ms: 82
<16ms: 135
<32ms: 43
32+ms: 6
raf execute 3.336562 418.198541 7.592147
<1ms: 0
<2ms: 0
<4ms: 11
<8ms: 319
<16ms: 36
<32ms: 2
32+ms: 3
raf receive 0.119323 9.804167 0.806074
<1ms: 324
<2ms: 31
<4ms: 13
<8ms: 1
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.003646 79.236354 0.761324
<1ms: 357
<2ms: 9
<4ms: 2
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 3
raf render 5.844687 172.898906 8.131682
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 283
<16ms: 86
<32ms: 1
32+ms: 1
run_one_frame 8.826198 2577.357604 25.922205
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 176
<32ms: 174
32+ms: 22
swap buffer 0.708177 12.528906 1.415950
<1ms: 164
<2ms: 161
<4ms: 38
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
swap complete 0.042917 1.554740 0.127729
<1ms: 370
<2ms: 1
<4ms: 0
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
المدى الطويل ( الخام ). صُنع لتقليل تأثير تباطؤ بدء التشغيل.
اسم الحد الأقصى يعني
raf في قائمة الانتظار 0.124896 6.356562 0.440674
<1 مللي ثانية: 629
<2 مللي ثانية: 13
<4 مللي ثانية: 5
<8 مللي ثانية: 1
<16 مللي ثانية: 0
<32 مللي ثانية: 0
32 + مللي ثانية: 0
أرسل raf 0.640677 20.275104 6.944751
<1 مللي ثانية: 2
<2 مللي ثانية: 3
<4 مللي ثانية: 29
<8 مللي ثانية: 513
<16 مللي ثانية: 99
<32 مللي ثانية: 1
32 + مللي ثانية: 0
raf انتظر 1.645886 40.955208 9.386255
<1 مللي ثانية: 0
<2 مللي ثانية: 10
<4 مللي ثانية: 207
<8 مللي ثانية: 114
<16 مللي ثانية: 236
<32 مللي ثانية: 65
32 + مللي ثانية: 15
تنفيذ raf 3.090104 526.041198 6.226997
<1 مللي ثانية: 0
<2 مللي ثانية: 0
<4 مللي ثانية: 68
<8 مللي ثانية: 546
<16 مللي ثانية: 29
<32 مللي ثانية: 1
32 + مللي ثانية: 3
raf تلقي 0.203334 6.441198 0.747615
<1 مللي ثانية: 554
<2 مللي ثانية: 84
<4 مللي ثانية: 7
<8 مللي ثانية: 2
<16 مللي ثانية: 0
<32 مللي ثانية: 0
32 + مللي ثانية: 0
طلب مبادلة 0.003490 73.644322 0.428460
<1 مللي ثانية: 627
<2 مللي ثانية: 18
<4 مللي ثانية: 1
<8 مللي ثانية: 0
<16 مللي ثانية: 0
<32 مللي ثانية: 0
32 + مللي ثانية: 2
raf تقديم 5.450312 209.662969 8.055021
<1 مللي ثانية: 0
<2 مللي ثانية: 0
<4 مللي ثانية: 0
<8 مللي ثانية: 467
<16 مللي ثانية: 176
<32 مللي ثانية: 3
32 + مللي ثانية: 1
run_one_frame 8.417291 2579.454948 22.226204
<1 مللي ثانية: 0
<2 مللي ثانية: 0
<4 مللي ثانية: 0
<8 مللي ثانية: 0
<16 مللي ثانية: 326
<32 مللي ثانية: 290
32 + مللي ثانية: 33
عازلة المبادلة 0.658125 12.179167 1.378725
<1 مللي ثانية: 260
<2 مللي ثانية: 308
<4 مللي ثانية: 72
<8 مللي ثانية: 4
<16 مللي ثانية: 4
<32 مللي ثانية: 0
32 + مللي ثانية: 0
اكتمل المبادلة 0.041562 5.161458 0.136875
<1 مللي ثانية: 642
<2 مللي ثانية: 3
<4 مللي ثانية: 1
<8 مللي ثانية: 1
<16 مللي ثانية: 0
<32 مللي ثانية: 0
32 + مللي ثانية: 0
Manishearth
في ٢٧ فبراير ٢٠٢٠
الرسوم البيانية:
المدى الأطول:

المدى القصير: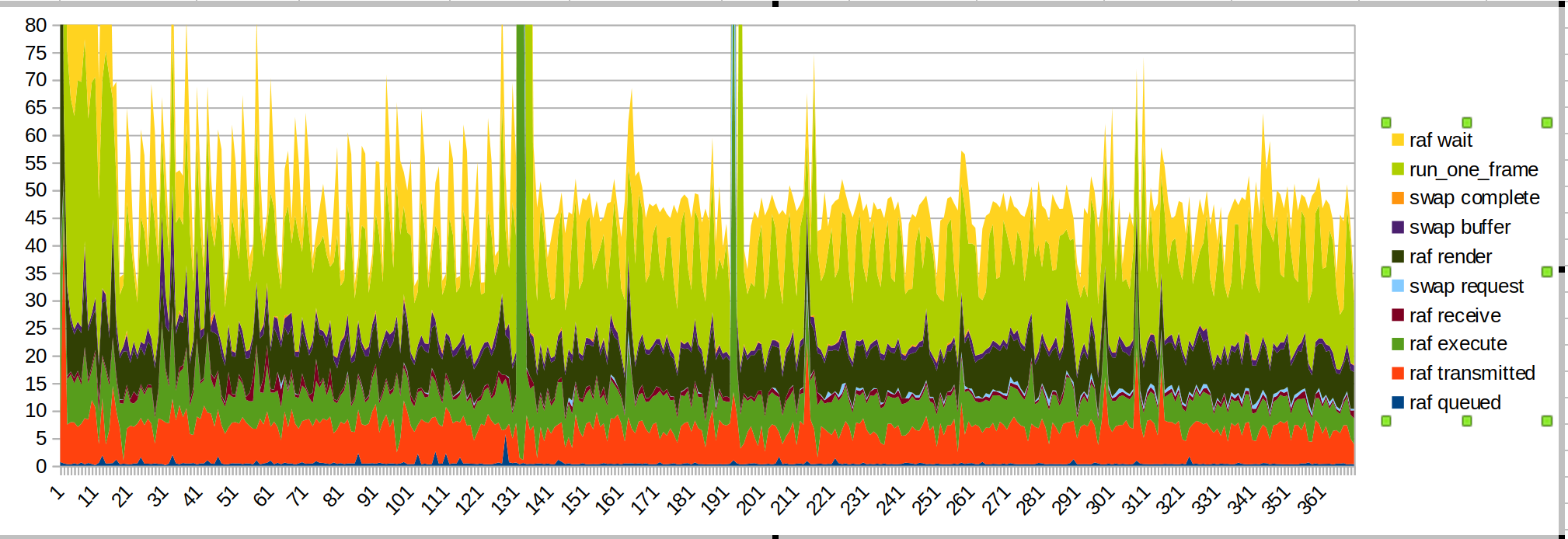
الارتفاع الكبير هو عندما أضع يدي داخل نطاق المستشعر.
هذه المرة أضع أوقات الانتظار / run_one_frame لأعلى لأن هذه هي الأكثر خشونة ، وهذا بسبب نظام التشغيل الذي يخنقنا.
زوجان الأشياء التي يجب ملاحظتها:
- سبب الارتفاع الكبير في توزيع الورق هو رمز JS (basil green، "raf render")
- أصبح وقت الإرسال أكثر سلاسة ، كما هو متوقع
- عندما أبدأ الرسم هناك ارتفاع JS آخر
- لا يزال وقت العرض والإرسال جزءًا مهمًا من الميزانية. يمكن أيضًا تحسين أداء البرنامج النصي.
- أظن أن وقت الإرسال يستغرق وقتًا طويلاً بسبب انشغال الخيط الرئيسي بأشياء أخرى. هذا https://github.com/servo/webxr/issues/113 ، jdm يبحث في الأمر
- قد تعمل تحديثات متصفّح الإنترنت على تحسين أوقات العرض. asajeffrey الصورة القياسات على surfmanup يبدو أفضل من الألغام
- قد يؤدي القيام بمشاركة السطح إلى تحسين أوقات العرض (تم حظره عند تصفح الإنترنت)
- تقترب نسبة الإطارات في الثانية التي يظهرها الجهاز إلى النصف تقريبًا عند قياسها باستخدام ملف تعريف xr. قد يكون هذا بسبب كل IO.
مكامن الخلل في الأداء بسبب رؤية اليد ثم البدء في الرسم غير موجودة في كرة الرماية. ربما يقوم العرض التوضيحي للطلاء بالكثير من العمل عندما يقرر أولاً رسم صورة اليد؟
(يمكن أن يكون هذا أيضًا العرض التوضيحي للطلاء الذي يحاول التفاعل مع مكتبة مدخلات webxr)
Manishearth
في ٢٧ فبراير ٢٠٢٠
Manishearth هل يمكنك أيضًا تراكب استخدام الذاكرة يساعد تحديث SM الخاص بـ
larsbergstrom
في ٢٧ فبراير ٢٠٢٠
ليس لدي طريقة سهلة للحصول على بيانات ملف تعريف الذاكرة بطريقة يمكن ربطها بأشياء التنميط xr.
يمكنني استخدام أدوات perf الحالية ومعرفة ما إذا كان الشكل هو نفسه.
Manishearth
في ٢٧ فبراير ٢٠٢٠
Manishearth هل تعرض عناصر التنميط xr (أو يمكن أن تظهر) أحداث JS GC؟ قد يكون ذلك وكيلًا معقولًا.
larsbergstrom
في ٢٧ فبراير ٢٠٢٠
في كلتا الحالتين ، لا تعتبر طفرات بدء التشغيل شاغلي الأساسي ، أود الحصول على كل شيء _ آخر_ بمعدل 60 إطارًا في الثانية أولاً. إذا كان الأمر صعبًا لمدة ثانية أو ثانيتين عند بدء التشغيل ، فهذا مصدر قلق أقل إلحاحًا.
Manishearth
في ٢٧ فبراير ٢٠٢٠
نعم ، يمكن أن يظهر ذلك ، سيحتاج إلى بعض التعديلات.
Manishearth
في ٢٧ فبراير ٢٠٢٠
Manishearth موافق تمامًا على الأولويات! لم أكن متأكدًا مما إذا كنت تحاول "إزالة مكامن الخلل" أو القيادة في حالة مستقرة. توافق على الأخير أكثر أهمية الآن.
larsbergstrom
في ٢٧ فبراير ٢٠٢٠
ناه ، كنت في الغالب أسجل كل التحليل الذي أستطيعه.
Manishearth
في ٢٧ فبراير ٢٠٢٠
تلك الارتفاعات بالقرب من نهاية الرسم البياني للمسار الأصغر حيث يرتفع وقت الإرسال أيضًا: كان ذلك عندما كنت أحرك رأسي وأرسم ، وكان آلان أيضًا يلاحظ انخفاضًا في FPS عند القيام بالأشياء ، وعزا ذلك إلى قيام نظام التشغيل بعمل آخر . بعد إصلاحات IPC ، حدسي عن ارتفاعات وقت الإرسال هو أنها ناتجة عن قيام نظام التشغيل بعمل آخر ، لذلك قد يكون هذا هو ما يحدث هناك. في عالم خارج الخيط الرئيسي أتوقع أن يكون أكثر سلاسة.
Manishearth
في ٢٧ فبراير ٢٠٢٠
تجاهلني إذا تم النظر في هذا بالفعل ، هل فكرت في تقسيم قياس run_one_frame على أساس معالجة كل رسالة ، وكذلك توقيت الوقت الذي يقضيه thread::sleep() -ing؟
قد يكون من المفيد إضافة ثلاث نقاط قياس:
وتغليف آخر https://github.com/servo/webxr/blob/2841497966d87bbd561f18ea66547dde9b13962f/webxr-api/lib.rs#L124 ككل ،
وأيضًا يقوم أحد الأشخاص بتغليف المكالمة بـ
thread::sleepفقط.
بالنسبة إلى recv_timeout ، فقد يكون هذا شيئًا يجب إعادة النظر فيه تمامًا.
أجد صعوبة إلى حد ما في التفكير في فائدة المهلة. نظرًا لأنك تحسب الإطار الذي تم عرضه ، راجع frame_count ، فقد يبدو أن حالة الاستخدام "ربما تتعامل مع رسالة واحدة أو عدة رسائل لا تعرض الإطار ، أولاً ، متبوعًا بعرض إطار ، مع تجنب المرور عبر الحلقة الكاملة للحدث الرئيسي للخيط الرئيسي "؟
لدي أيضًا بعض الشكوك حول الحساب الفعلي لـ delay المستخدم فيه ، حيث حاليًا:
- يبدأ من
delay = timeout / 1000، معtimeoutيتم ضبطه حاليًا على 5 مللي ثانية - ثم ينمو أضعافًا مضاعفة ، حيث يتضاعف عند كل تكرار عند
delay = delay * 2; - يتم فحصه في الجزء العلوي من الحلقة بـ
while delay < timeout.
لذا فإن تسلسل النوم ، في أسوأ الحالات ، يذهب إلى شيء مثل: 5 ميكرو -> 10 -> 20 -> 40 -> 80 -> 160 -> 320 -> 640 -> 1.28 ملي -> 2.56 ملي -> 5.12 ملي
عندما تصل إلى 5.12 مللي ثانية ، ستخرج من الحلقة (منذ delay > timeout ) ، بعد أن انتظرت ما مجموعه 5،115 ملي ثانية ، بالإضافة إلى أي وقت إضافي يقضيه في انتظار نظام التشغيل الذي يستيقظ الخيط بعد كل sleep .
لذلك أعتقد أن المشكلة هي أنك ربما تنام لأكثر من 5 مللي ثانية في المجموع ، وأعتقد أيضًا أنه ليس من الجيد أن تنام مرتين لأكثر من 1 مللي ثانية (والمرة الثانية أكثر من 2.5 مللي ثانية) منذ الرسالة خلال تلك الفترة ولن تستيقظ.
لست متأكدًا تمامًا من كيفية تحسينها ، يبدو أنك تحاول التدوير بحثًا عن رسالة محتملة ، وأخيرًا انتقل إلى التكرار التالي لحلقة الحدث الرئيسية إذا لم يكن هناك شيء متاح (لماذا لا تحظر على recv؟).
يمكنك التبديل لاستخدام https://doc.rust-lang.org/std/thread/fn.yield_now.html ، بالنظر إلى هذه المقالة حول الأقفال ، يبدو أنها تدور حوالي 40 مرة أثناء الاتصال بـ yield كل مرة ، هو الأمثل (انظر فقرة "Spinning" ، لا يمكن الارتباط بها مباشرة). بعد ذلك ، يجب عليك إما حظر جهاز الاستقبال ، أو الاستمرار في التكرار الحالي لحلقة الحدث (نظرًا لأن هذا يعمل كحلقة فرعية داخل حلقة حدث التضمين الرئيسية).
(من الواضح، إذا كنت لا قياس مع ipc تشغيل، الجزء فوق على recv_timeout لا يهم، على الرغم من أنك قد لا تزال ترغب في قياس calll إلى recv_timeout على mpsc نظرًا لأن القناة المترابطة ستؤدي بعض التدوير / العائد الداخلي الذي قد يؤثر أيضًا على النتائج. وبما أنه تم ذكر "إصلاح IPC" غير محدد في عدة مناسبات أعلاه ، أفترض أنك تقيس باستخدام IPC).
gterzian
في ٢٧ فبراير ٢٠٢٠
تجاهلني إذا تم التفكير في هذا بالفعل ، هل فكرت في تقسيم قياس run_one_frame على أساس معالجة كل رسالة ، وكذلك توقيت الوقت الذي يقضيه مؤشر الترابط :: sleep () - ing؟
لقد تم تقسيمه بالفعل ، وأوقات الانتظار / العرض هي بالضبط هذه. علامة واحدة من run_one_frame هي عرض واحد وانتظار واحد وعدد غير محدد من الأحداث التي تتم معالجتها (نادرًا).
recv_timeout فكرة جيدة للقياس
Manishearth
في ٢٧ فبراير ٢٠٢٠
للأسف ، لا يبدو أن ترقية spidermonkey في # 25678 تمثل تحسنًا كبيرًا - فقد انخفض متوسط معدل الإطارات في الثانية لكل عرض توضيحي باستثناء معظم الذاكرة المقيدة ؛ ارتفع العرض التوضيحي لـ Hill Valley قليلاً. لا يُظهر تشغيل Servo مع -Z gc-profile في وسيطات التهيئة أي اختلاف في سلوك GC بين الرئيسي وفرع ترقية spidermonkey - لم يتم الإبلاغ عن GCs بعد تحميل محتوى GL وعرضه.
jdm
في ٣ مارس ٢٠٢٠
قياسات الفروع المختلفة:
master:
- espilit: 14-16 fps
- paint: 39-45 fps
- ball shooter: 30-40 fps
- hill valley: 8 fps, 200mb free mem
- mansion: 10-14fps, 650mb free mem
master + single swapchain:
- espilit: 10-12 fps
- paint: 29-55 fps, 1.2gb free mem
- ball shooter: 25-35 fps, 1.3gb free mem
- hill valley: 6-7 fps, 200mb free mem
- mansion: 10-11 fps, 700mb free mem
texture sharing + ANGLE 2.1.19:
- espilit: 13-15 fps, 670mb free mem
- paint: 39-45 fps
- ball shooter: 30-37 fps, 1.3gb free mem
- hill valley: 9-10 fps, 188mb free mem
- mansion: 13-14 fps, 671mb free mem
smup:
- espilit: 11-13 fps, 730mb free mem
- paint: 25-42 fps, 1.1gb free mem
- ball shooter: 26-30 fps, 1.4gb free mem
- hill valley: 10-11 fps, 145mb
- mansion: 9-11fps, 680mb free mem
جعلت smup الأداء أسوأ ؟؟؟
asajeffrey
في ٣ مارس ٢٠٢٠
مع التغييرات من https://github.com/servo/servo/pull/25855#issuecomment -594203492 ، هناك نتيجة مثيرة للاهتمام وهي أن تعطيل Ion JIT يبدأ عند 12 إطارًا في الثانية ، ثم بعد ذلك بعدة ثوانٍ ، يتحول فجأة إلى 1 إطارًا في الثانية و يبقى هناك.
jdm
في ٣ مارس ٢٠٢٠
فعلت بعض القياسات مع تلك البقع.
على الرسم ، أحصل على 60 إطارًا في الثانية عندما لا يكون هناك الكثير من المحتوى في العرض ، وعند النظر إلى المحتوى المرسوم ، ينخفض إلى 50 إطارًا في الثانية (المسامير الصفراء تظهر عندما أنظر إلى المحتوى المرسوم). من الصعب معرفة السبب ، في الغالب يبدو أن وقت الانتظار يتأثر بالاختناق openxr لكن الأشياء الأخرى لا تبدو بطيئة بما يكفي لإحداث مشكلة. توقيت طلب المبادلة أبطأ قليلاً. يكون وقت تنفيذ rAF بطيئًا في البداية (هذه هي المرة الأولى التي يتم فيها مشاهدة وحدة تحكم "تباطؤًا) ولكن بعد ذلك يكون ثابتًا جدًا. يبدو أن openxr يخنقنا فقط ، ولكن لا يوجد تباطؤ مرئي في أي مكان آخر قد يتسبب في ذلك.

Manishearth
في ٧ مارس ٢٠٢٠
هذا هو ما لدي من أجل السحب التجريبي. المقياس y هو نفسه. من الواضح هنا أن وقت التنفيذ يبطئنا.

Manishearth
في ٧ مارس ٢٠٢٠
شيء واحد يجب ملاحظته هو أنني كنت أقوم بإجراء قياسات مع تطبيق # 25837 ، وقد يؤثر ذلك على الأداء.
jdm
في ٧ مارس ٢٠٢٠
لم أكن ، ولكني كنت أحصل على نتائج مماثلة لك
Manishearth
في ٧ مارس ٢٠٢٠
الرسوم البيانية لأداة الأداء في الوقت الحالي حيث تنتقل من 60 إطارًا في الثانية إلى 45 إطارًا في الثانية عند النظر إلى المحتوى:
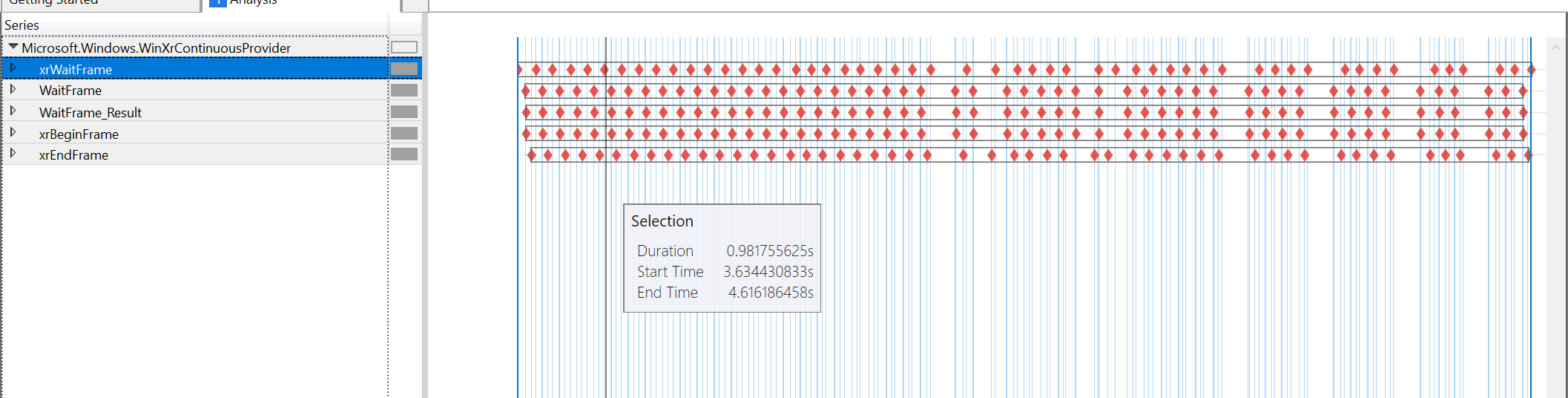
يبدو أن اللوم يقع بالكامل على xrWaitFrame ، وجميع المواعيد الأخرى قريبة جدًا من بعضها البعض. لا يزال xrBeginFrame على الفور تقريبًا بعد xrWaitFrame ، و xrEndFrame هو 4us بعد xrBeginFrame (في كلتا الحالتين). يكون xrWaitFrame التالي بعد xrEndFrame مباشرةً تقريبًا. الفجوة الوحيدة غير المحسوبة هي الفجوة التي يسببها xrWaitFrame نفسه.
Manishearth
في ١١ مارس ٢٠٢٠
مع السحب التجريبي ، أحصل على التتبع التالي:

هذا هو العرض التوضيحي للطلاء بنفس المقياس:
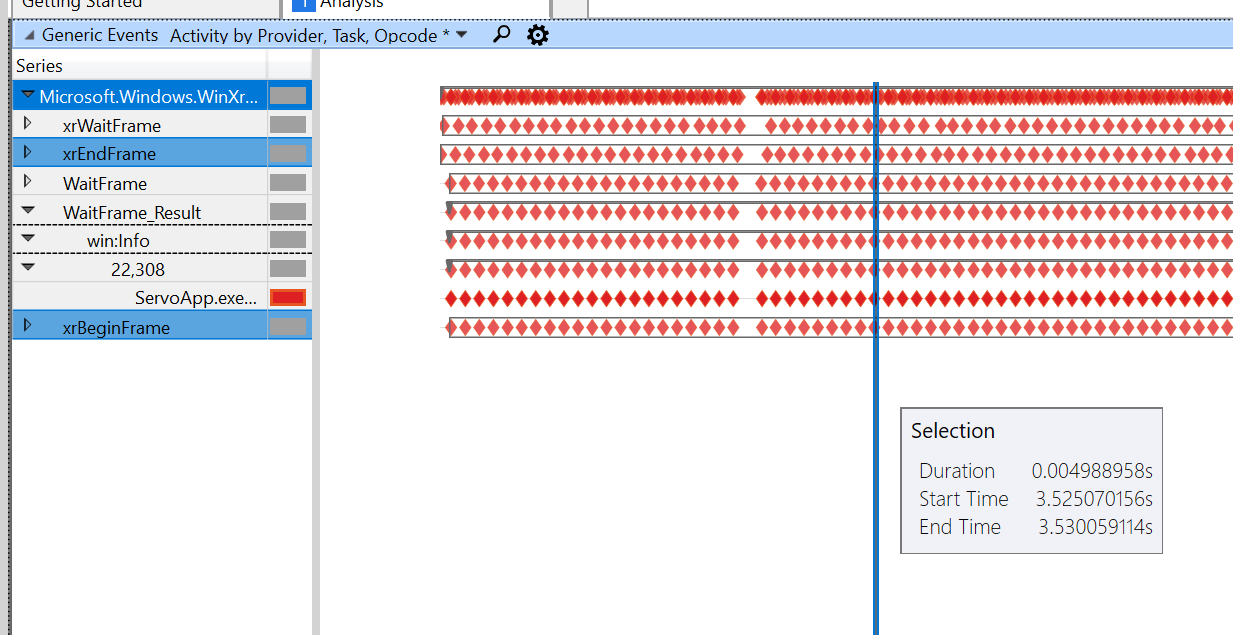
نحن بطيئون بين إطار البداية / النهاية (من 5 مللي ثانية إلى 38 مللي ثانية في أسرع وقت!) ، ثم يبدأ اختناق إطار الانتظار. لم أفهم سبب حدوث هذا بعد ، فأنا أتصفح التعليمات البرمجية لـ على حد سواء.
Manishearth
في ١٨ مارس ٢٠٢٠
يتم إبطاء عرض السحب لأن مصدر الضوء الخاص به يلقي بظلاله. تم إجراء أشياء الظل على جانب GL لذا لست متأكدًا مما إذا كان بإمكاننا تسريع ذلك بسهولة؟
Manishearth
في ١٨ مارس ٢٠٢٠
إذا تم ذلك بالكامل من خلال GLSL ، فقد نواجه صعوبات ؛ إذا تم تنفيذ كل إطار من خلال واجهات برمجة تطبيقات WebGL ، فقد تكون هناك أماكن للتحسين.
jdm
في ١٨ مارس ٢٠٢٠
نعم يبدو أن الجميع على جانب GLSL ؛ لم أتمكن من رؤية أي استدعاءات WebGL عندما يتعلق الأمر بكيفية عمل واجهات برمجة تطبيقات الظل ، فقط بعض البتات التي يتم تمريرها إلى أدوات التظليل
Manishearth
في ١٩ مارس ٢٠٢٠
أعتقد أن هذا قد تم تناوله بشكل عام. يمكننا تقديم مشكلات للعروض التوضيحية الفردية التي تحتاج إلى عمل.
jdm
في ٢٠ يوليو ٢٠٢٠
القضايا ذات الصلة
gterzian
·
3تعليقات
 pyfisch
·
4تعليقات
pyfisch
·
4تعليقات
 shinglyu
·
4تعليقات
shinglyu
·
4تعليقات
 CYBAI
·
4تعليقات
Manishearth
·
4تعليقات
CYBAI
·
4تعليقات
Manishearth
·
4تعليقات
التعليق الأكثر فائدة
الحالة الحالية: مع إصلاحات IPC ، تحوم FPS الآن حول 55. إنها تهتز في بعض الأحيان ، ولكنها عادة لا تقل عن 45 ، _ باستثناء_ خلال الثواني القليلة الأولى بعد التحميل (حيث يمكن أن تنخفض إلى 30) ، وعندما يرى أولاً يد (عندما تنخفض إلى 20).